Redis 基准测试
在Redis服务器上使用redis-benchmark工具
Redis有多快?
Redis 包含了 redis-benchmark 工具,该工具模拟了由 N 个客户端同时发送 M 个总查询的运行命令(类似于 Apache 的 ab 工具)。下面你将看到一个针对 Linux 系统执行的基准测试的完整输出。
支持以下选项:
Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>]
-h <hostname> Server hostname (default 127.0.0.1)
-p <port> Server port (default 6379)
-s <socket> Server socket (overrides host and port)
-a <password> Password for Redis Auth
--user <username> Used to send ACL style 'AUTH username pass'. Needs -a.
-c <clients> Number of parallel connections (default 50)
-n <requests> Total number of requests (default 100000)
-d <size> Data size of SET/GET value in bytes (default 3)
--dbnum <db> SELECT the specified db number (default 0)
--threads <num> Enable multi-thread mode.
--cluster Enable cluster mode.
--enable-tracking Send CLIENT TRACKING on before starting benchmark.
-k <boolean> 1=keep alive 0=reconnect (default 1)
-r <keyspacelen> Use random keys for SET/GET/INCR, random values for
SADD, random members and scores for ZADD.
Using this option the benchmark will expand the string
__rand_int__ inside an argument with a 12 digits number
in the specified range from 0 to keyspacelen-1. The
substitution changes every time a command is executed.
Default tests use this to hit random keys in the
specified range.
-P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline).
-e If server replies with errors, show them on stdout.
(No more than 1 error per second is displayed.)
-q Quiet. Just show query/sec values
--precision Number of decimal places to display in latency output (default 0)
--csv Output in CSV format
-l Loop. Run the tests forever
-t <tests> Only run the comma separated list of tests. The test
names are the same as the ones produced as output.
-I Idle mode. Just open N idle connections and wait.
--help Output this help and exit.
--version Output version and exit.
在启动基准测试之前,您需要有一个正在运行的 Redis 实例。 一个典型的例子是:
redis-benchmark -q -n 100000
使用这个工具非常简单,你也可以编写自己的基准测试, 但就像任何基准测试活动一样,有一些陷阱需要避免。
仅运行部分测试
你不需要每次执行redis-benchmark时都运行所有默认测试。
选择只运行一部分测试的最简单方法是使用-t选项,
如下例所示:
$ redis-benchmark -t set,lpush -n 100000 -q
SET: 180180.17 requests per second, p50=0.143 msec
LPUSH: 188323.91 requests per second, p50=0.135 msec
在上面的例子中,我们要求只运行测试SET和LPUSH命令,在安静模式下(参见-q开关)。
也可以直接指定要基准测试的命令,如下例所示:
$ redis-benchmark -n 100000 -q script load "redis.call('set','foo','bar')"
script load redis.call('set','foo','bar'): 69881.20 requests per second
选择密钥空间的大小
默认情况下,基准测试针对单个键运行。在Redis中,这种合成基准测试与真实基准测试之间的差异并不大,因为它是一个内存系统,但是通过使用较大的键空间,可以强调缓存未命中的情况,并通常模拟更真实的工作负载。
这是通过使用-r开关获得的。例如,如果我想运行一百万次SET操作,每次操作使用100k个可能键中的一个随机键,我将使用以下命令行:
$ redis-cli flushall
OK
$ redis-benchmark -t set -r 100000 -n 1000000
====== SET ======
1000000 requests completed in 13.86 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.76% `<=` 1 milliseconds
99.98% `<=` 2 milliseconds
100.00% `<=` 3 milliseconds
100.00% `<=` 3 milliseconds
72144.87 requests per second
$ redis-cli dbsize
(integer) 99993
使用管道
默认情况下,每个客户端(如果未使用-c指定,基准测试模拟50个客户端)只有在接收到前一个命令的回复后才会发送下一个命令,这意味着服务器可能需要一个读取调用来从每个客户端读取每个命令。此外,还需要支付往返时间(RTT)。
Redis 支持 pipelining,因此可以一次性发送多个命令,这一特性常被实际应用所利用。Redis 的 pipelining 能够显著提高服务器每秒能够执行的操作数量。
这是在MacBook Air 11英寸上运行基准测试的示例,使用了16个命令的流水线:
$ redis-benchmark -n 1000000 -t set,get -P 16 -q
SET: 1536098.25 requests per second, p50=0.479 msec
GET: 1811594.25 requests per second, p50=0.391 msec
使用管道可以显著提高性能。
陷阱和误解
第一点很明显:一个有用的基准测试的黄金法则是只比较同类事物。例如,可以在相同的工作负载下比较不同版本的Redis。或者比较相同版本的Redis,但使用不同的选项。如果你计划将Redis与其他东西进行比较,那么评估功能和技术差异并加以考虑是很重要的。
- Redis 是一个服务器:所有命令都涉及网络或IPC往返。将其与嵌入式数据存储(如SQLite、Berkeley DB、Tokyo/Kyoto Cabinet等)进行比较是没有意义的,因为大多数操作的成本主要在于网络/协议管理。
- Redis 命令对所有常规命令返回确认。其他一些数据存储则不这样做。将 Redis 与涉及单向查询的存储进行比较只有轻微的用处。
- 简单地迭代同步的Redis命令并不能对Redis本身进行基准测试,而是测量你的网络(或IPC)延迟和客户端库的固有延迟。要真正测试Redis,你需要多个连接(如redis-benchmark)和/或使用管道来聚合多个命令和/或多个线程或进程。
- Redis 是一个内存数据存储,具有一些可选的持久化选项。如果你计划将其与事务性服务器(MySQL、PostgreSQL 等)进行比较,那么你应该考虑激活 AOF 并决定一个合适的 fsync 策略。
- Redis 主要是一个单线程的服务器,从命令执行的角度来看(实际上现代版本的 Redis 使用线程来处理不同的事情)。它并不是为了从多个 CPU 核心中受益而设计的。如果需要,人们应该启动多个 Redis 实例以在多个核心上进行扩展。将单个 Redis 实例与多线程数据存储进行比较并不公平。
一个常见的误解是,redis-benchmark 旨在使 Redis 的性能看起来非常出色,redis-benchmark 实现的吞吐量有些人为,真实应用程序无法实现。实际上,这并不是真的。
redis-benchmark 程序是一种快速且有用的方式,可以在给定硬件上获取一些数据并评估 Redis 实例的性能。然而,默认情况下,它并不代表 Redis 实例可以维持的最大吞吐量。实际上,通过使用流水线和一个快速的客户端(hiredis),编写一个生成比 redis-benchmark 更多吞吐量的程序是相当容易的。redis-benchmark 的默认行为是通过仅利用并发性来实现吞吐量(即它创建多个连接到服务器)。它不使用流水线或任何并行性(每个连接最多只有一个待处理的查询,并且没有多线程),除非通过 -P 参数明确启用。因此,在某些情况下,使用 redis-benchmark 并同时触发例如后台的 BGSAVE 操作,将向用户提供更接近 最坏情况 而不是最佳情况的数字。
要使用流水线模式运行基准测试(并实现更高的吞吐量), 您需要显式使用-P选项。请注意,这仍然是 一种现实的行为,因为许多基于Redis的应用程序积极使用 流水线来提高性能。然而,您应该使用一个大致相当于 您应用程序中能够使用的平均流水线长度的流水线大小, 以便获得现实的数字。
最后,基准测试应该应用相同的操作,并以相同的方式与您想要比较的多个数据存储一起工作。将redis-benchmark的结果与另一个基准测试程序的结果进行比较并推断是完全没有意义的。
例如,可以在GET/SET操作上比较单线程模式下的Redis和memcached。两者都是内存数据存储,在协议级别上工作方式基本相同。如果它们各自的基准测试应用程序以相同的方式(管道化)聚合查询并使用相似数量的连接,那么比较实际上是有意义的。
这个完美的例子通过Redis(antirez)和memcached(dormando)开发者之间的对话得到了说明。
antirez 1 - 关于Redis、Memcached、速度、基准测试和厕所
dormando - Redis VS Memcached (稍微更好的基准测试)
antirez 2 - Memcached/Redis 基准测试的更新
你可以看到,最终,一旦考虑了所有技术方面,两种解决方案之间的差异并不那么惊人。请注意,Redis和memcached在这些基准测试之后都得到了进一步的优化。
最后,当对非常高效的服务器进行基准测试时(像Redis或memcached这样的存储系统肯定属于这一类),可能很难使服务器达到饱和。有时,性能瓶颈出现在客户端,而不是服务器端。在这种情况下,必须修复客户端(即基准测试程序本身),或者可能需要扩展,以达到最大吞吐量。
影响Redis性能的因素
有多个因素直接影响Redis的性能。我们在这里提到它们,因为它们可能会改变任何基准测试的结果。然而,请注意,通常运行在低端、未调优的机器上的典型Redis实例通常能为大多数应用程序提供足够好的性能。
- 网络带宽和延迟通常对性能有直接影响。在启动基准测试之前,使用ping程序快速检查客户端和服务器主机之间的延迟是否正常是一个好习惯。关于带宽,通常有用的是以Gbit/s为单位估算吞吐量,并将其与网络的理论带宽进行比较。例如,一个在Redis中以100000 q/s设置4 KB字符串的基准测试,实际上会消耗3.2 Gbit/s的带宽,可能适合10 Gbit/s的链路,但不适合1 Gbit/s的链路。在许多实际场景中,Redis的吞吐量在网络限制之前就已经受到CPU的限制。为了在单个服务器上整合多个高吞吐量的Redis实例,值得考虑使用10 Gbit/s的网卡或多个1 Gbit/s的网卡与TCP/IP绑定。
- CPU 是另一个非常重要的因素。由于 Redis 是单线程的,它更倾向于具有大缓存且核心数不多的快速 CPU。在这方面,Intel CPU 目前是赢家。与类似的 Nehalem EP/Westmere EP/Sandy Bridge Intel CPU 相比,在 AMD Opteron CPU 上使用 Redis 时,性能只有一半的情况并不少见。当客户端和服务器在同一台机器上运行时,CPU 是 redis-benchmark 的限制因素。
- RAM的速度和内存带宽对整体性能的影响似乎较小,尤其是对于小对象。对于大对象(>10 KB),可能会变得明显。通常,购买昂贵的高速内存模块来优化Redis并不是非常划算。
- 与在没有虚拟化的相同硬件上运行相比,Redis在虚拟机上的运行速度较慢。如果你有机会在物理机上运行Redis,这是首选。然而,这并不意味着Redis在虚拟化环境中运行缓慢,其提供的性能仍然非常好,并且你在虚拟化环境中可能遇到的大多数严重性能问题是由于过度配置、高延迟的非本地磁盘或具有缓慢
fork系统调用实现的旧版管理程序软件。 - 当服务器和客户端基准测试程序在同一台机器上运行时,可以使用TCP/IP回环和Unix域套接字。根据平台的不同,Unix域套接字的吞吐量可以比TCP/IP回环高出约50%(例如在Linux上)。redis-benchmark的默认行为是使用TCP/IP回环。
- 当大量使用流水线时(即长流水线),Unix域套接字与TCP/IP环回相比的性能优势往往会减少。
- 当使用以太网访问Redis时,如果数据大小保持在以太网数据包大小(约1500字节)以下,使用管道聚合命令尤其高效。实际上,处理10字节、100字节或1000字节的查询几乎会产生相同的吞吐量。请参见下图。

- 在多CPU插槽服务器上,Redis的性能取决于NUMA配置和进程位置。最明显的影响是redis-benchmark结果似乎是非确定性的,因为客户端和服务器进程随机分布在核心上。为了获得确定性的结果,需要使用进程放置工具(在Linux上:taskset或numactl)。最有效的组合总是将客户端和服务器放在同一CPU的两个不同核心上,以从L3缓存中受益。以下是针对3种服务器CPU(AMD Istanbul、Intel Nehalem EX和Intel Westmere)在不同相对位置下的4 KB SET基准测试的一些结果。请注意,此基准测试不用于比较CPU型号本身(因此未披露CPU的确切型号和频率)。

- 在高配置下,客户端连接的数量也是一个重要因素。基于epoll/kqueue的Redis事件循环具有很高的可扩展性。Redis已经在超过60000个连接的情况下进行了基准测试,并且在这些条件下仍然能够维持50000 q/s的吞吐量。根据经验,一个具有30000个连接的实例只能处理100个连接时可达到吞吐量的一半。以下是一个展示Redis实例在不同连接数下的吞吐量的示例:

- 通过高端配置,可以通过调整网卡(NIC)配置和相关中断来实现更高的吞吐量。最佳吞吐量是通过设置Rx/Tx网卡队列与CPU核心之间的关联性,并激活RPS(接收包导向)支持来实现的。更多信息请参见此线程。 当使用大对象时,巨型帧也可能提供性能提升。
- 根据平台的不同,Redis 可以针对不同的内存分配器(libc malloc、jemalloc、tcmalloc)进行编译,这些分配器在原始速度、内部和外部碎片方面可能具有不同的行为。
如果您没有自己编译 Redis,可以使用 INFO 命令检查
mem_allocator字段。请注意,大多数基准测试运行时间不够长,无法产生显著的外部碎片(与生产环境中的 Redis 实例相反)。
其他需要考虑的事项
任何基准测试的一个重要目标是获得可重复的结果,以便它们可以与其他测试的结果进行比较。
- 一个好的做法是尽可能在隔离的硬件上运行测试。 如果不可能,那么必须监控系统以检查基准测试是否受到某些外部活动的影响。
- 一些配置(台式机和笔记本电脑肯定有,一些服务器也有)具有可变的CPU核心频率机制。控制此机制的策略可以在操作系统级别设置。一些CPU模型比其他模型更积极地根据工作负载调整CPU核心的频率。为了获得可重复的结果,最好为参与基准测试的所有CPU核心设置尽可能高的固定频率。
- 一个重要点是根据基准测试来调整系统的大小。
系统必须有足够的RAM,并且不能进行交换。在Linux上,不要忘记正确设置
overcommit_memory参数。请注意,32位和64位的Redis实例占用的内存不同。 - 如果您计划在基准测试中使用RDB或AOF,请确保系统中没有其他I/O活动。避免将RDB或AOF文件放在NAS或NFS共享上,或任何可能影响网络带宽和/或延迟的设备上(例如,Amazon EC2上的EBS)。
- 将Redis日志级别(loglevel参数)设置为warning或notice。避免将生成的日志文件放在远程文件系统上。
- 避免使用可能改变基准测试结果的监控工具。例如,定期使用INFO来收集统计数据可能是可以的,但使用MONITOR会显著影响测量的性能。
在不同Redis版本上的裸金属服务器基准测试结果
确保Redis性能在每个发布版本中无缝保留或改进是至关重要的。
为了评估它,我们对Redis的发布版本(从v2.6.0开始)进行了基准测试,使用redis-benchmark在一系列命令类型上对独立的redis-server进行测试,重复相同的基准测试多次,确保其统计显著性,并测量运行间的差异。
使用的硬件平台是一个稳定的裸金属HPE ProLiant DL380 Gen10服务器,配备一个Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz,禁用Intel HT技术,禁用CPU频率缩放,所有可配置的BIOS和CPU系统设置均设置为性能模式。
该机器运行的是Ubuntu 18.04 Linux版本4.15.0-123,Redis是用gcc 7.5.0编译的。
使用的基准测试客户端(redis-benchmark)在所有测试中保持稳定,版本为redis-benchmark 6.2.0 (git:445aa844)。
redis-server和redis-benchmark进程都被固定到特定的物理核心上。
以下基准选项在所有测试中使用:
- 测试是在50个同时进行的客户端执行500万次请求的情况下完成的。
- 测试是使用回环接口执行的。
- 测试是在没有使用管道的情况下执行的。
- 使用的有效载荷大小为256字节。
- 对于每个redis-benchmark进程,使用了2个线程以确保基准测试客户端不是瓶颈。
- 对字符串、哈希、集合和有序集合数据类型进行了基准测试。
下面我们展示了按数据类型分类的获得结果。
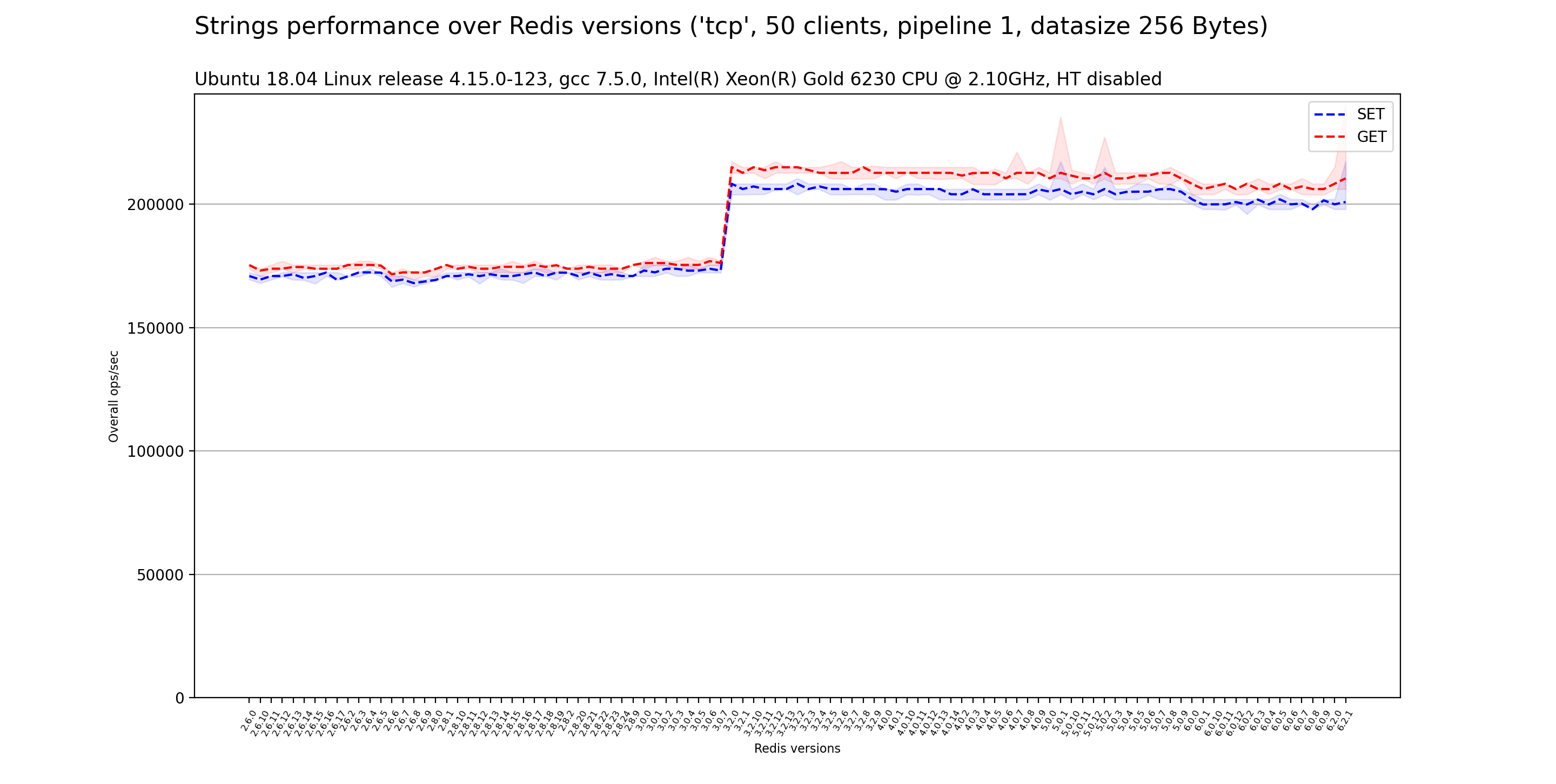


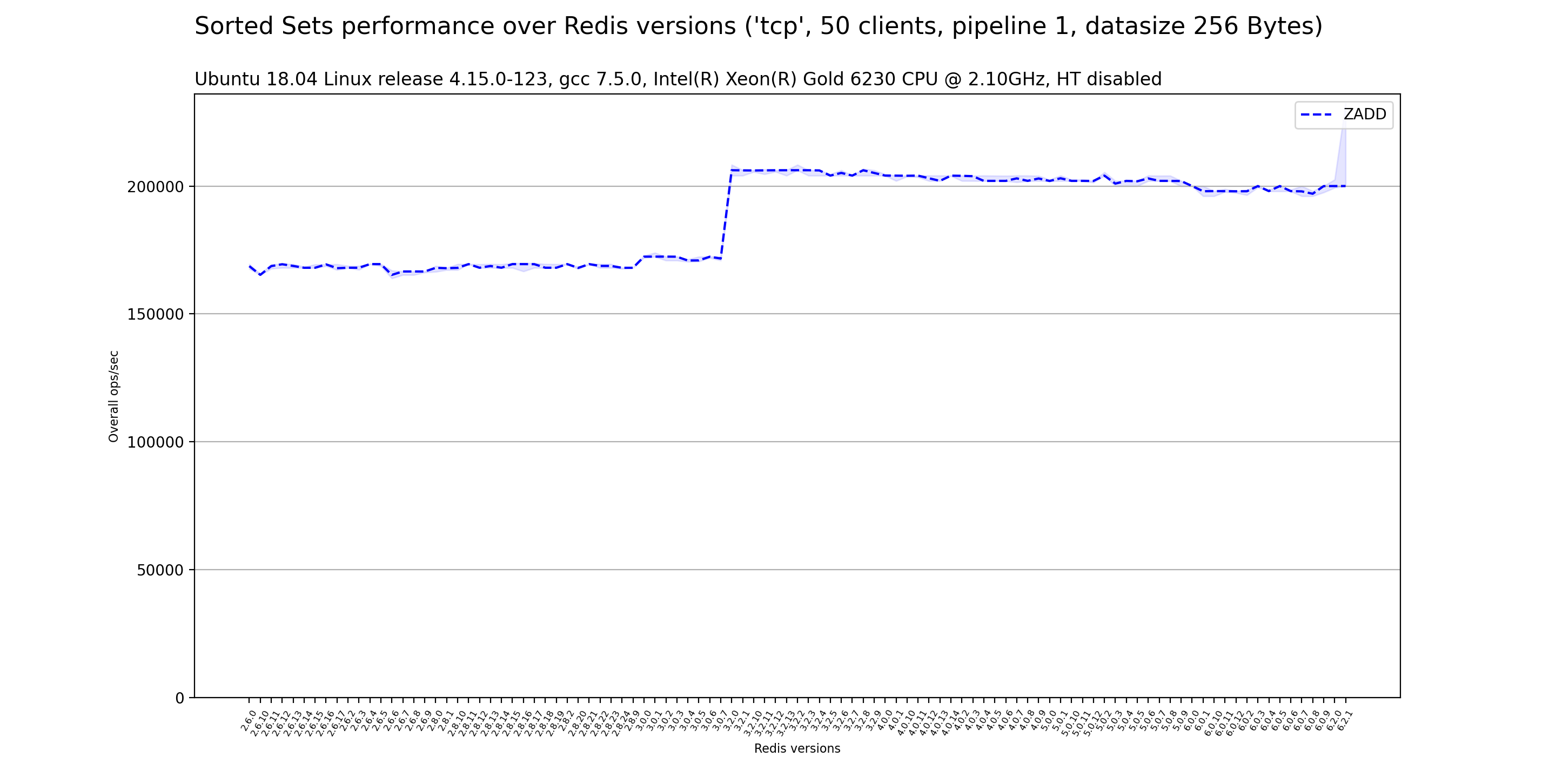
其他 Redis 基准测试工具
有几种第三方工具可以用于对Redis进行基准测试。有关每个工具的目标和功能的更多信息,请参考其文档。
- memtier_benchmark 来自 Redis Labs 是一个用于 NoSQL Redis 和 Memcache 的流量生成和基准测试工具。
- rpc-perf 来自 Twitter 是一个用于基准测试 RPC 服务的工具,支持 Redis 和 Memcache。
- YCSB 来自 Yahoo @Yahoo 是一个基准测试框架,支持多种数据库的客户端,包括 Redis。