![]()
设置说明: 本笔记本提供了由 sktime 支持的预测学习任务的教程。在binder上,这应该可以直接运行。
要按预期运行此笔记本,请确保在您的 Python 环境中安装了带有基本依赖项要求的 sktime。
要在本地开发版本的 sktime 上运行此笔记本,建议使用可编辑的开发者安装,参见 sktime 开发者安装指南 获取说明。
使用 sktime 进行预测#
在预测中,过去的数据用于对时间序列进行时间上的前向预测。这与 scikit-learn 和类似库支持的表格预测任务有显著不同。
sktime 提供了一个通用的、类似于 scikit-learn 的接口,用于多种经典和机器学习风格的预测算法,以及用于构建管道和复合机器学习模型的工具,包括时间调优方案,或如 scikit-learn 回归器的逐步应用等简化方法。
第1节 提供了 sktime 支持的常见预测工作流程的概述。
第2节 讨论了 sktime 中可用的预测器系列。
第3节 讨论了高级组合模式,包括管道构建、简化、调优、集成和自动机器学习。
第4节 介绍了如何编写符合 sktime 接口的自定义估计器。
进一步参考:
目录#
1. 基本预测工作流程
1.1 数据容器格式
1.2 基本部署工作流程 - 批量拟合和预测
1.2.1 基本部署工作流程概述
1.2.2 在拟合时需要预测范围的预测器
1.2.3 可以使用外部数据的预测器
1.2.4 多元预测器
1.2.5 预测区间和分位数预测
1.2.6 面板预测和层次预测
1.3 基本评估工作流程 - 根据地面实况观测评估一批预测
1.3.1 基本批量预测评估工作流程概述 - 函数度量接口
1.3.2 基本批量预测评估工作流程概述 - 指标类接口
1.4 高级部署工作流程:滚动更新与预测
1.4.1 使用 update 方法更新预测器
1.4.2 在不更新模型的情况下移动“现在”状态
1.4.3 对一批数据的向前预测
1.5 高级评估工作流程:滚动重采样和聚合误差,滚动回测
2. sktime 中的预测器 - 搜索、标签、常见家族
2.1 预测器查找 - 注册表
2.2 预测器标签
2.2.1 能力标签:多变量、概率性、层次性
2.2.2 按标签查找和列出预测器
2.2.3 列出所有预测器标签
2.3 常见的预测器类型
2.3.1 指数平滑,theta预测器,statsmodels中的autoETS
2.3.2 ARIMA 和 autoARIMA
2.3.3 BATS 和 TBATS
2.3.4 Facebook prophet
2.3.5 状态空间模型(结构时间序列)
2.3.6 StatsForecast 中的 AutoArima
3. 高级组合模式 - 管道、归约、自动机器学习等
3.1 简化:从预测到回归
3.2 流水线处理、去趋势化和去季节化
3.2.1 基本预测流程
3.2.2 作为管道组件的去趋势器
3.2.3 复杂管道组合与参数检查
3.3 参数调整
3.3.1 使用 ForecastingGridSearchCV 进行基本调优
3.3.2 复杂复合材料的调谐
3.3.3 选择指标并获取分数
3.4 自动机器学习(autoML),即自动模型选择、集成和对冲
3.4.1 autoML 即自动模型选择,使用调优加多路复用器
3.4.2 autoML: 通过OptimalPassthrough选择转换器组合
3.4.3 简单的集成策略
3.4.4 预测加权集成和套期集成
4. 扩展指南 - 实现你自己的预测器
5. 总结
包导入#
[1]:
import warnings
import numpy as np
import pandas as pd
# hide warnings
warnings.filterwarnings("ignore")
1. 基本预测工作流程#
本节解释了基本的预测工作流程,以及其关键的接口点。
我们涵盖以下四个工作流程:
基本部署工作流程:批量拟合和预测
基本评估工作流程:将一批预测与地面真值观测进行比较
高级部署工作流程:拟合和滚动更新/预测
高级评估工作流程:使用滚动预测分割和计算分割误差及总体误差,包括常见的回测方案
所有工作流程对输入数据的格式都有共同的假设。
sktime 使用 pandas 来表示时间序列:
pd.DataFrame主要用于时间序列和序列。行表示时间索引,列表示变量。pd.Series也可以用于单变量时间序列和序列numpy数组(1D 和 2D)也可以传递,但鼓励使用pandas。
Series.index 和 DataFrame.index 用于表示时间序列或序列索引。sktime 支持 pandas 的整数、周期和时间戳索引用于简单时间序列。
sktime 支持面板和层次时间序列的进一步、额外的容器格式,这些在第1.6节中讨论。
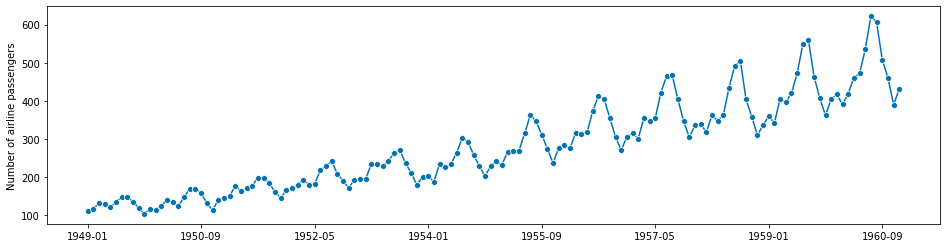
示例: 在本教程中,我们使用一个教科书数据集,即 Box-Jenkins 航空公司数据集,该数据集包含 1949 年至 1960 年国际航空公司每月乘客总数的数量。数值以千为单位。参见“Makridakis, Wheelwright 和 Hyndman (1998) 预测:方法和应用”,练习部分 2 和 3。
[2]:
from sktime.datasets import load_airline
from sktime.utils.plotting import plot_series
[3]:
y = load_airline()
# plotting for visualization
plot_series(y)
[3]:
(<Figure size 1152x288 with 1 Axes>,
<AxesSubplot:ylabel='Number of airline passengers'>)

[4]:
y.index
[4]:
PeriodIndex(['1949-01', '1949-02', '1949-03', '1949-04', '1949-05', '1949-06',
'1949-07', '1949-08', '1949-09', '1949-10',
...
'1960-03', '1960-04', '1960-05', '1960-06', '1960-07', '1960-08',
'1960-09', '1960-10', '1960-11', '1960-12'],
dtype='period[M]', length=144)
通常,用户应使用 pandas 及其兼容包的内置加载功能来加载用于预测的数据集,例如 read_csv 或 Series 或 DataFrame 构造函数(如果数据以另一种内存格式(如 numpy.array)可用)。
sktime 预测器可能接受 pandas 相邻格式的输入,但将产生输出,并尝试将输入强制转换为 pandas 格式。
注意:如果你的首选格式没有被正确转换或强制转换,请考虑为 sktime 贡献该功能。
最简单的使用案例工作流程是批量拟合和预测,即,将预测模型拟合到一批历史数据,然后请求未来时间点的预测。
此工作流程的步骤如下:
数据准备
指定请求预测的时间点。这使用
numpy.array或ForecastingHorizon对象。预测器的规范和实例化。这遵循类似
scikit-learn的语法;预测器对象遵循熟悉的scikit-learnBaseEstimator接口。使用预测器的
fit方法将预测器拟合到数据上使用预测器的
predict方法进行预测
下面首先概述了基本部署工作流程的原始版本,一步一步地进行。
最后,提供了一细胞工作流程,以及与模式常见的偏差(第1.2.1节及后续)。
步骤 1 - 数据准备#
如第1.1节所述,数据假定为 pd.Series 或 pd.DataFrame 格式。
[5]:
from sktime.datasets import load_airline
from sktime.utils.plotting import plot_series
[6]:
# in the example, we use the airline data set.
y = load_airline()
plot_series(y)
[6]:
(<Figure size 1152x288 with 1 Axes>,
<AxesSubplot:ylabel='Number of airline passengers'>)
步骤 2 - 指定预测范围#
现在我们需要指定预测范围,并将其传递给我们的预测算法。
有两种主要方式:
使用一个
numpy.array的整数。这假设时间序列中要么是整数索引,要么是周期索引(PeriodIndex);整数表示我们想要进行预测的时间点或周期的数量。例如,1表示预测下一个周期,2表示预测第二个下一个周期,依此类推。使用
ForecastingHorizon对象。这可以用来定义预测范围,使用任何支持的索引类型作为参数。不假设周期性索引。
预测范围可以是绝对的,即引用未来特定的时点,或者是相对的,即引用相对于当前的时间差异。默认情况下,当前时间点是传递给预测器的任何 y 中看到的最新时间点。
基于 numpy.array 的预测范围总是相对的;ForecastingHorizon 对象可以是相对的,也可以是绝对的。特别是,绝对预测范围只能使用 ForecastingHorizon 来指定。
使用 numpy 预测范围#
[7]:
fh = np.arange(1, 37)
fh
[7]:
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36])
这将要求未来三年的每月预测,因为原始序列的周期是1个月。在另一个例子中,要仅预测未来第二和第五个月,可以这样写:
import numpy as np
fh = np.array([2, 5]) # 2nd and 5th step ahead
使用基于 ForecastingHorizon 的预测范围#
ForecastingHorizon 对象接受绝对索引作为输入,但根据 is_relative 标志考虑输入是绝对的还是相对的。
ForecastingHorizon 如果传入 pandas 的时间差类型,将自动假设一个相对时间范围;如果传入 pandas 的值类型,将假设一个绝对时间范围。
在我们的示例中定义一个绝对 ForecastingHorizon:
[8]:
from sktime.forecasting.base import ForecastingHorizon
[9]:
fh = ForecastingHorizon(
pd.PeriodIndex(pd.date_range("1961-01", periods=36, freq="M")), is_relative=False
)
fh
[9]:
ForecastingHorizon(['1961-01', '1961-02', '1961-03', '1961-04', '1961-05', '1961-06',
'1961-07', '1961-08', '1961-09', '1961-10', '1961-11', '1961-12',
'1962-01', '1962-02', '1962-03', '1962-04', '1962-05', '1962-06',
'1962-07', '1962-08', '1962-09', '1962-10', '1962-11', '1962-12',
'1963-01', '1963-02', '1963-03', '1963-04', '1963-05', '1963-06',
'1963-07', '1963-08', '1963-09', '1963-10', '1963-11', '1963-12'],
dtype='period[M]', is_relative=False)
ForecastingHorizon 可以通过 to_relative 和 to_absolute 方法从相对转换为绝对,反之亦然。这两种转换都需要传递一个兼容的 cutoff:
[10]:
cutoff = pd.Period("1960-12", freq="M")
[11]:
fh.to_relative(cutoff)
[11]:
ForecastingHorizon([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36],
dtype='int64', is_relative=True)
[12]:
fh.to_absolute(cutoff)
[12]:
ForecastingHorizon(['1961-01', '1961-02', '1961-03', '1961-04', '1961-05', '1961-06',
'1961-07', '1961-08', '1961-09', '1961-10', '1961-11', '1961-12',
'1962-01', '1962-02', '1962-03', '1962-04', '1962-05', '1962-06',
'1962-07', '1962-08', '1962-09', '1962-10', '1962-11', '1962-12',
'1963-01', '1963-02', '1963-03', '1963-04', '1963-05', '1963-06',
'1963-07', '1963-08', '1963-09', '1963-10', '1963-11', '1963-12'],
dtype='period[M]', is_relative=False)
步骤 3 - 指定预测算法#
要进行预测,需要指定一个预测算法。这是通过类似 scikit-learn 的接口完成的。最重要的是,所有 sktime 预测器都遵循相同的接口,因此无论选择哪个预测器,前面的步骤和剩余的步骤都是相同的。
在这个例子中,我们选择预测最后一个观测值的朴素预测方法。使用管道和简化构造语法可以实现更复杂的规范;这将在第2节中介绍。
[13]:
from sktime.forecasting.naive import NaiveForecaster
[14]:
forecaster = NaiveForecaster(strategy="last")
步骤 4 - 将预测器拟合到已见数据#
现在,预测器需要拟合已见数据:
[15]:
forecaster.fit(y)
[15]:
NaiveForecaster()
步骤 5 - 请求预测#
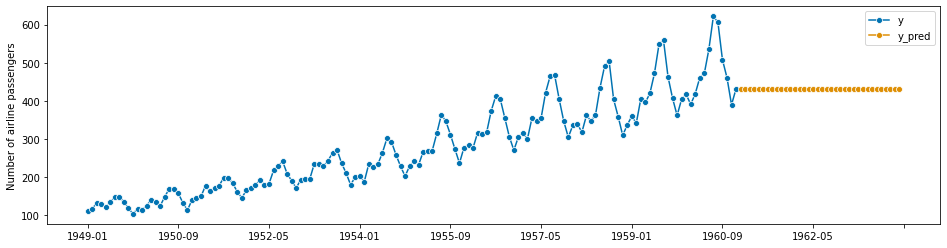
最后,我们请求对指定的预测范围进行预测。这需要在拟合预测器之后完成:
[16]:
y_pred = forecaster.predict(fh)
[17]:
# plotting predictions and past data
plot_series(y, y_pred, labels=["y", "y_pred"])
[17]:
(<Figure size 1152x288 with 1 Axes>,
<AxesSubplot:ylabel='Number of airline passengers'>)
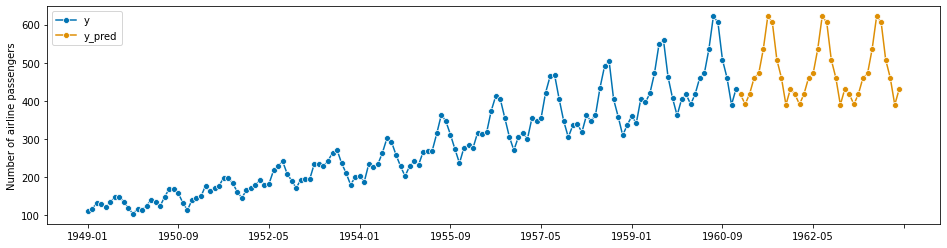
1.2.1 基本部署工作流程概述#
为了方便,我们在一个单元格中展示了基本的部署工作流程。这里使用了相同的数据,但不同的预测器:预测同一个月中观察到的最新值。
[18]:
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.naive import NaiveForecaster
[19]:
# step 1: data specification
y = load_airline()
# step 2: specifying forecasting horizon
fh = np.arange(1, 37)
# step 3: specifying the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 4: fitting the forecaster
forecaster.fit(y)
# step 5: querying predictions
y_pred = forecaster.predict(fh)
[20]:
# optional: plotting predictions and past data
plot_series(y, y_pred, labels=["y", "y_pred"])
[20]:
(<Figure size 1152x288 with 1 Axes>,
<AxesSubplot:ylabel='Number of airline passengers'>)
1.2.2 需要在 fit 中已经包含预测范围的预测器#
一些预测器需要在 fit 中提供预测范围。当未在 fit 中传递时,这些预测器将生成信息性错误消息。所有预测器在 fit 中传递时都会记住预测范围以用于预测。为了允许此类预测器,修改后的工作流程如下:
[21]:
# step 1: data specification
y = load_airline()
# step 2: specifying forecasting horizon
fh = np.arange(1, 37)
# step 3: specifying the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 4: fitting the forecaster
forecaster.fit(y, fh=fh)
# step 5: querying predictions
y_pred = forecaster.predict()
1.2.3 能够利用外生数据的预测器#
许多预测器可以利用外生时间序列,即那些不是预测对象但有助于预测 y 的其他时间序列。外生时间序列总是作为 X 参数传递,在 fit、predict 和其他方法中(见下文)。外生时间序列应始终作为 pandas.DataFrames 传递。大多数能够处理外生时间序列的预测器会假设传递给 fit 的 X 的时间索引是传递给 fit 的 y 的时间索引的超集;并且传递给 predict 的 X 的时间索引是 fh 中的时间索引的超集,尽管这不是一个普遍的接口限制。不使用外生时间序列的预测器仍然接受该参数(并且在内部不使用它)。
传递外生数据的常规工作流程如下:
[22]:
# step 1: data specification
y = load_airline()
# we create some dummy exogeneous data
X = pd.DataFrame(index=y.index)
# step 2: specifying forecasting horizon
fh = np.arange(1, 37)
# step 3: specifying the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 4: fitting the forecaster
forecaster.fit(y, X=X, fh=fh)
# step 5: querying predictions
y_pred = forecaster.predict(X=X)
注意:如同在工作流 1.2.1 和 1.2.2 中,一些使用外生变量的预测器可能也只需要在 predict 中提供预测范围。这些预测器在步骤 4 和 5 中也可以被调用。
forecaster.fit(y, X=X)
y_pred = forecaster.predict(fh=fh, X=X)
1.2.4. 多元预测#
sktime 中的所有预测器都支持多变量预测 - 一些预测器是“真正的”多变量,其他则是“按列应用”。
以下是使用 VAR``(向量自回归)预测器在 ``sktime.datasets 中的 Longley 数据集上进行多元预测工作流程的示例。该工作流程与单变量预测器相同,但输入具有多个变量(列)。
[23]:
from sktime.datasets import load_longley
from sktime.forecasting.var import VAR
_, y = load_longley()
y = y.drop(columns=["UNEMP", "ARMED", "POP"])
forecaster = VAR()
forecaster.fit(y, fh=[1, 2, 3])
y_pred = forecaster.predict()
多元预测器 y 的输入是一个 pandas.DataFrame,其中每一列是一个变量。
[24]:
y
[24]:
| GNPDEFL | GNP | |
|---|---|---|
| Period | ||
| 1947 | 83.0 | 234289.0 |
| 1948 | 88.5 | 259426.0 |
| 1949 | 88.2 | 258054.0 |
| 1950 | 89.5 | 284599.0 |
| 1951 | 96.2 | 328975.0 |
| 1952 | 98.1 | 346999.0 |
| 1953 | 99.0 | 365385.0 |
| 1954 | 100.0 | 363112.0 |
| 1955 | 101.2 | 397469.0 |
| 1956 | 104.6 | 419180.0 |
| 1957 | 108.4 | 442769.0 |
| 1958 | 110.8 | 444546.0 |
| 1959 | 112.6 | 482704.0 |
| 1960 | 114.2 | 502601.0 |
| 1961 | 115.7 | 518173.0 |
| 1962 | 116.9 | 554894.0 |
多变量预测器 y_pred 的结果是一个 pandas.DataFrame,其中列是每个变量的预测值。y_pred 中的变量与多变量预测器的输入 y 中的变量相同。
[25]:
y_pred
[25]:
| GNPDEFL | GNP | |
|---|---|---|
| 1963 | 121.688295 | 578514.398653 |
| 1964 | 124.353664 | 601873.015890 |
| 1965 | 126.847886 | 625411.588754 |
如上所述,所有预测器都接受多变量输入并会产生多变量预测。有两种类别:
真正多变量的预测模型,如
VAR。一个内生 (y) 变量的预测将依赖于其他变量的值。单变量预测模型,如
ARIMA。预测将由内生变量 (y) 进行,不会受到其他变量的影响。
要显示完整的多变量预测器列表,请搜索带有 'multivariate' 或 'both' 标签值的预测器,标签为 'scitype:y',如下所示:
[26]:
from sktime.registry import all_estimators
for forecaster in all_estimators(filter_tags={"scitype:y": ["multivariate", "both"]}):
print(forecaster[0])
单变量预测器具有标签值 'univariate',并且将为每一列拟合一个模型。要访问按列的模型,请访问 forecasters_ 参数,该参数将拟合的预测器存储在 pandas.DataFrame 中,拟合的预测器位于包含预测变量的列中:
[27]:
from sktime.datasets import load_longley
from sktime.forecasting.arima import ARIMA
_, y = load_longley()
y = y.drop(columns=["UNEMP", "ARMED", "POP"])
forecaster = ARIMA()
forecaster.fit(y, fh=[1, 2, 3])
forecaster.forecasters_
[27]:
| GNPDEFL | GNP | |
|---|---|---|
| forecasters | ARIMA() | ARIMA() |
1.2.5 概率预测:预测区间、分位数、方差和分布预测#
sktime 提供了一个统一的接口来进行概率预测。以下方法可能适用于概率预测:
predict_interval生成区间预测。除了任何predict参数外,还必须提供一个coverage参数(名义区间覆盖率)。predict_quantiles生成分位数预测。除了任何predict参数外,还必须提供一个alpha参数(分位数值)。predict_var生成方差预测。它的参数与predict相同。predict_proba生成完整的分布预测。这与predict具有相同的参数。
并非所有预测器都能返回概率预测,但如果一个预测器提供了一种概率预测,它也能返回其他类型的概率预测。可以通过 registry.all_estimators 查询具有此能力的预测器列表,查找那些 capability:pred_int 标签值为 True 的预测器。
概率预测的基本工作流程与基本预测工作流程相似,不同之处在于,不是使用 predict,而是使用其中一种概率预测方法:
[28]:
import numpy as np
from sktime.datasets import load_airline
from sktime.forecasting.theta import ThetaForecaster
# until fit, identical with the simple workflow
y = load_airline()
fh = np.arange(1, 13)
forecaster = ThetaForecaster(sp=12)
forecaster.fit(y, fh=fh)
[28]:
ThetaForecaster(sp=12)
现在我们介绍不同的概率预测方法。
predict_interval - 区间预测#
predict_interval 接受一个参数 coverage,这是一个浮点数(或浮点数列表),表示查询的预测区间(s)的名义覆盖率。predict_interval 生成对称的预测区间,例如,覆盖率为 0.9 时,返回在分位数 0.5 - coverage/2 = 0.05 处的“下限”预测,以及在分位数 0.5 + coverage/2 = 0.95 处的“上限”预测。
[29]:
coverage = 0.9
y_pred_ints = forecaster.predict_interval(coverage=coverage)
y_pred_ints
[29]:
| Coverage | ||
|---|---|---|
| 0.9 | ||
| lower | upper | |
| 1961-01 | 418.280122 | 464.281951 |
| 1961-02 | 402.215882 | 456.888054 |
| 1961-03 | 459.966115 | 522.110499 |
| 1961-04 | 442.589311 | 511.399213 |
| 1961-05 | 443.525029 | 518.409479 |
| 1961-06 | 506.585817 | 587.087736 |
| 1961-07 | 561.496771 | 647.248955 |
| 1961-08 | 557.363325 | 648.062362 |
| 1961-09 | 477.658059 | 573.047750 |
| 1961-10 | 407.915093 | 507.775353 |
| 1961-11 | 346.942927 | 451.082014 |
| 1961-12 | 394.708224 | 502.957139 |
返回的 y_pred_ints 是一个 pandas.DataFrame ,具有一个列多重索引:第一级是来自 y 的变量名(如果没有变量名,则为 Coverage ),第二级是计算区间的覆盖分数,顺序与输入的 coverage 相同;第三级列是 lower 和 upper 。行是进行预测的索引(与 y_pred 或 fh 相同)。条目是同一行索引的名义覆盖预测区间的下限/上限(根据列名)。
美化预测区间预测的绘图:
[30]:
from sktime.utils import plotting
# also requires predictions
y_pred = forecaster.predict()
fig, ax = plotting.plot_series(
y, y_pred, labels=["y", "y_pred"], pred_interval=y_pred_ints
)

predict_quantiles - 分位数预测#
sktime 提供了 predict_quantiles 作为一个统一的接口,用于返回预测的分位数值。类似于 predict_interval。
predict_quantiles 有一个参数 alpha,包含被查询的分位数值。类似于 predict_interval 的情况,alpha 可以是一个 float,或者是一个 list of floats。
[31]:
y_pred_quantiles = forecaster.predict_quantiles(alpha=[0.275, 0.975])
y_pred_quantiles
[31]:
| Quantiles | ||
|---|---|---|
| 0.275 | 0.975 | |
| 1961-01 | 432.922220 | 468.688317 |
| 1961-02 | 419.617697 | 462.124924 |
| 1961-03 | 479.746288 | 528.063108 |
| 1961-04 | 464.491078 | 517.990290 |
| 1961-05 | 467.360287 | 525.582417 |
| 1961-06 | 532.209080 | 594.798752 |
| 1961-07 | 588.791161 | 655.462877 |
| 1961-08 | 586.232268 | 656.750127 |
| 1961-09 | 508.020008 | 582.184819 |
| 1961-10 | 439.699997 | 517.340642 |
| 1961-11 | 380.089755 | 461.057159 |
| 1961-12 | 429.163185 | 513.325951 |
y_pred_quantiles,即 predict_quantiles 的输出,是一个具有两级列多索引的 pandas.DataFrame。第一级是来自 fit 中 y 的变量名(如果没有变量名,则为 Quantiles),第二级是查询的分位数值(来自 alpha)。行是进行预测的索引(与 y_pred 或 fh 中的相同)。条目是该变量、该分位数值以及同一行中时间索引的分位数预测。
备注:为了清晰起见:分位数预测和(对称)区间预测可以相互转换,如下所示。
alpha < 0.5: alpha-分位数预测等于覆盖率为(0.5 - alpha) * 2的预测区间的下限
alpha > 0.5: alpha分位数预测等于覆盖率为(alpha - 0.5) * 2的预测区间的上界
predict_var - 方差预测#
predict_var 生成方差预测:
[32]:
y_pred_var = forecaster.predict_var()
y_pred_var
[32]:
| 0 | |
|---|---|
| 1961-01 | 195.540039 |
| 1961-02 | 276.196489 |
| 1961-03 | 356.852939 |
| 1961-04 | 437.509389 |
| 1961-05 | 518.165839 |
| 1961-06 | 598.822289 |
| 1961-07 | 679.478739 |
| 1961-08 | 760.135189 |
| 1961-09 | 840.791639 |
| 1961-10 | 921.448089 |
| 1961-11 | 1002.104539 |
| 1961-12 | 1082.760989 |
输出 y_pred_var 的格式与 predict 相同,除了这总是被强制转换为 pandas.DataFrame,并且条目不是点预测而是方差预测。
predict_proba - 分布预测#
要预测完整的预测分布,可以使用 predict_proba。由于这返回 tensorflow 的 Distribution 对象,因此必须安装 sktime 的深度学习依赖集 dl``(其中包括 ``tensorflow 和 tensorflow-probability 依赖)。
[33]:
y_pred_proba = forecaster.predict_proba()
y_pred_proba
[33]:
<tfp.distributions.Normal 'Normal' batch_shape=[12, 1] event_shape=[] dtype=float32>
predict_proba 返回的分布默认是时间点上的边际分布,而不是时间点上的联合分布。更准确地说,返回的 Distribution 对象的格式和解释如下:
要返回联合预测分布,可以将 marginal 参数设置为 False``(目前正在开发中)。在这种情况下,将返回一个具有 2D 事件形状 ``(len(fh), len(y)) 的 Distribution。
1.2.6 面板预测与层次预测#
sktime 提供了一个统一的接口来制作面板和层次预测。
所有 sktime 预测器都可以应用于面板和层次数据,这些数据需要以特定的输入格式呈现。不是真正的面板或层次预测器的预测器将按实例应用。
推荐的(不是唯一的)传递面板和层次数据格式是带有 MultiIndex 行的 pandas.DataFrame。在这个 MultiIndex 中,最后一级必须是 sktime 兼容的时间索引格式,其余级别是面板或层次节点。
示例数据:
[34]:
from sktime.utils._testing.hierarchical import _bottom_hier_datagen
y = _bottom_hier_datagen(no_levels=2)
y
[34]:
| passengers | |||
|---|---|---|---|
| l2_agg | l1_agg | timepoints | |
| l2_node01 | l1_node04 | 1949-01 | 1751.046693 |
| 1949-02 | 1847.272729 | ||
| 1949-03 | 2072.660808 | ||
| 1949-04 | 2024.264252 | ||
| 1949-05 | 1895.470000 | ||
| ... | ... | ... | ... |
| l2_node03 | l1_node05 | 1960-08 | 7843.728855 |
| 1960-09 | 6557.204770 | ||
| 1960-10 | 5942.431795 | ||
| 1960-11 | 5016.687658 | ||
| 1960-12 | 5563.869028 |
864 rows × 1 columns
如前所述,所有预测者,无论是真正的层次结构与否,都可以应用,所有在本节中描述的工作流程,以产生层次结构的预测。
语法与普通时间序列完全相同,除了输入和输出数据中的层次级别:
[35]:
from sktime.forecasting.arima import ARIMA
fh = [1, 2, 3]
forecaster = ARIMA()
forecaster.fit(y, fh=fh)
forecaster.predict()
[35]:
| passengers | |||
|---|---|---|---|
| l2_agg | l1_agg | timepoints | |
| l2_node01 | l1_node04 | 1961-01 | 7025.301868 |
| 1961-02 | 6932.869186 | ||
| 1961-03 | 6843.846928 | ||
| l2_node02 | l1_node01 | 1961-01 | 426.544850 |
| 1961-02 | 421.282983 | ||
| 1961-03 | 416.207550 | ||
| l1_node02 | 1961-01 | 2831.238136 | |
| 1961-02 | 2796.463164 | ||
| 1961-03 | 2762.919857 | ||
| l1_node03 | 1961-01 | 3281.334598 | |
| 1961-02 | 3235.589398 | ||
| 1961-03 | 3191.591150 | ||
| l1_node06 | 1961-01 | 699.784723 | |
| 1961-02 | 687.976011 | ||
| 1961-03 | 676.678320 | ||
| l2_node03 | l1_node05 | 1961-01 | 5492.522368 |
| 1961-02 | 5423.732250 | ||
| 1961-03 | 5357.407064 |
类似于多变量预测,那些不是真正分层的预测器通过实例进行拟合。通过实例拟合的预测器可以通过 forecasters_ 参数访问,这是一个 pandas.DataFrame,其中给定实例的预测器位于索引为该实例的行中,它们为该实例进行预测:
[36]:
forecaster.forecasters_
[36]:
| forecasters | ||
|---|---|---|
| l2_agg | l1_agg | |
| l2_node01 | l1_node04 | ARIMA() |
| l2_node02 | l1_node01 | ARIMA() |
| l1_node02 | ARIMA() | |
| l1_node03 | ARIMA() | |
| l1_node06 | ARIMA() | |
| l2_node03 | l1_node05 | ARIMA() |
如果数据既是层次化的又是多变量的,并且预测器无法真正处理其中任何一个,那么 forecasters_ 属性将同时具有列索引(用于变量)和行索引(用于实例),每个实例和变量都拟合了预测器:
[37]:
from sktime.forecasting.arima import ARIMA
from sktime.utils._testing.hierarchical import _make_hierarchical
y = _make_hierarchical(n_columns=2)
fh = [1, 2, 3]
forecaster = ARIMA()
forecaster.fit(y, fh=fh)
forecaster.forecasters_
[37]:
| c0 | c1 | ||
|---|---|---|---|
| h0 | h1 | ||
| h0_0 | h1_0 | ARIMA() | ARIMA() |
| h1_1 | ARIMA() | ARIMA() | |
| h1_2 | ARIMA() | ARIMA() | |
| h1_3 | ARIMA() | ARIMA() | |
| h0_1 | h1_0 | ARIMA() | ARIMA() |
| h1_1 | ARIMA() | ARIMA() | |
| h1_2 | ARIMA() | ARIMA() | |
| h1_3 | ARIMA() | ARIMA() |
关于分层预测的更多细节,包括简化、聚合、协调,将在“分层预测”教程中介绍。
在部署预测器之前评估其统计性能,并在持续部署中定期重新评估性能,这是一种良好的做法。对于第1.2节中解决的基本批量预测任务的评估工作流程,包括将批量预测与实际结果进行比较。这有时被称为(批量)回测。
基本的评估工作流程如下:
将一个具有代表性的历史序列划分为时间上的训练集和测试集。测试集应在训练集的时间之后。
如第1.2节所述,通过将预测器拟合到训练集,并查询测试集的预测结果,获取批量预测。
指定一个定量性能指标来比较实际测试集与预测结果
计算测试集上的定量性能
测试此性能是否在统计上优于选定的基线性能
注意:步骤 5(测试)目前在 sktime 中尚不支持,但已列入开发路线图。目前建议使用适当方法的自定义实现(例如,Diebold-Mariano 测试;平稳置信区间)。
注意:请注意,此评估设置决定了给定算法在过去的数据显示中的表现如何。结果仅在未来的表现可以假设为反映过去表现的情况下具有代表性。这在某些假设(例如,平稳性)下可以争论,但在一般情况下将是错误的。因此,建议在多次应用算法时监控预测性能。
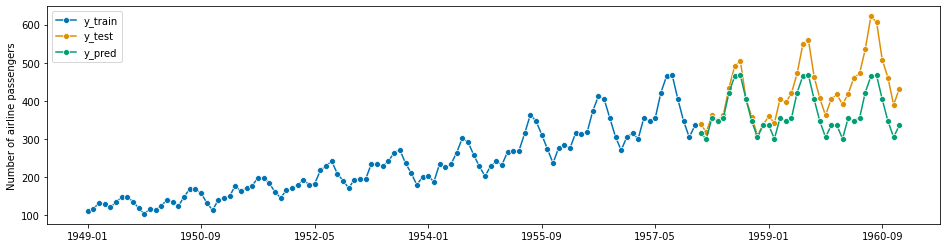
示例: 在这个示例中,我们将使用与第1.2节相同的航空公司数据。但是,我们不预测接下来的3年,而是保留航空公司数据的最后3年(如下:y_test),并看看预测者在三年前被要求预测最近3年(如下:y_pred)时的表现,这些预测基于之前的年份(如下:y_train)。“如何”是通过定量性能指标(如下:mean_absolute_percentage_error)来衡量的。然后,这被视为预测者在接下来的3年中表现如何的指示(如第1.2节所做)。这可能取决于统计假设和数据属性,可能会有所夸大(注意:通常会有所夸大——过去的表现通常不能预示未来的表现)。
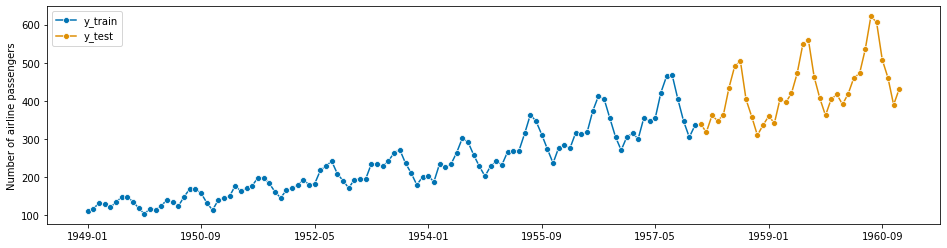
步骤 1 - 将历史数据集分割为时间序列的训练和测试批次#
[38]:
from sktime.split import temporal_train_test_split
[39]:
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
# we will try to forecast y_test from y_train
[40]:
# plotting for illustration
plot_series(y_train, y_test, labels=["y_train", "y_test"])
print(y_train.shape[0], y_test.shape[0])
步骤 2 - 从 y_train 对 y_test 进行预测#
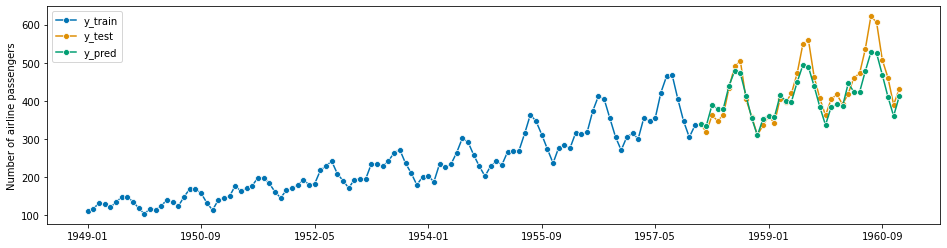
这几乎与第1.2节中的工作流程完全一致,使用 y_train 来预测 y_test 的索引。
[41]:
# we can simply take the indices from `y_test` where they already are stored
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = NaiveForecaster(strategy="last", sp=12)
forecaster.fit(y_train)
# y_pred will contain the predictions
y_pred = forecaster.predict(fh)
[42]:
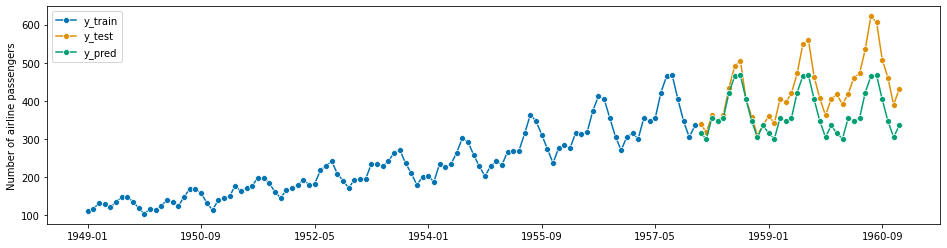
# plotting for illustration
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
[42]:
(<Figure size 1152x288 with 1 Axes>,
<AxesSubplot:ylabel='Number of airline passengers'>)
步骤 3 和 4 - 指定预测指标,在测试集上进行评估#
下一步是指定一个预测指标。这些函数在输入预测和实际序列时返回一个数值。它们与 sklearn 指标不同,因为它们接受带有索引的序列,而不是 np.array。预测指标可以通过两种方式调用:
使用精简的函数接口,例如
mean_absolute_percentage_error,这是一个 Python 函数(y_true : pd.Series, y_pred : pd.Series) -> float使用可组合的类接口,例如
MeanAbsolutePercentageError,这是一个具有相同签名的 Python 类,可以调用。
普通用户可以选择使用函数接口。类接口支持高级用例,例如参数修改、自定义指标组合、指标参数调优(本教程未涵盖)
[43]:
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
[44]:
# option 1: using the lean function interface
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
# note: the FIRST argument is the ground truth, the SECOND argument are the forecasts
# the order matters for most metrics in general
[44]:
0.13189432350948402
要正确解释这样的数字,了解相关度量的属性(例如,越低越好)是有用的,并且与合适的基线和竞争算法进行比较(见步骤5)。
[45]:
from sktime.performance_metrics.forecasting import MeanAbsolutePercentageError
[46]:
# option 2: using the composable class interface
mape = MeanAbsolutePercentageError(symmetric=False)
# the class interface allows to easily construct variants of the MAPE
# e.g., the non-symmetric version
# it also allows for inspection of metric properties
# e.g., are higher values better (answer: no)?
mape.get_tag("lower_is_better")
[46]:
True
[47]:
# evaluation works exactly like in option 2, but with the instantiated object
mape(y_test, y_pred)
[47]:
0.13189432350948402
注意:某些指标,如 mean_absolute_scaled_error,还需要训练集进行评估。在这种情况下,训练集应作为 y_train 参数传递。请参阅各个指标的API参考。
注意:对于使用外生数据进行预测的工作流程是相同的 - 不会将 X 传递给指标。
步骤 5 - 根据基准测试性能#
一般来说,预测性能应与基准性能进行定量测试。
目前(sktime v0.12.x),这是一个路线图开发项目。非常欢迎贡献。
1.3.1 基本批量预测评估工作流程简述 - 函数度量接口#
为了方便,我们在一个单元格中展示了基本的批量预测评估工作流程。此单元格使用了精简的函数度量接口。
[48]:
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.naive import NaiveForecaster
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
from sktime.split import temporal_train_test_split
[49]:
# step 1: splitting historical data
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
# step 2: running the basic forecasting workflow
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = NaiveForecaster(strategy="last", sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
# step 3: specifying the evaluation metric and
# step 4: computing the forecast performance
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
# step 5: testing forecast performance against baseline
# under development
[49]:
0.13189432350948402
1.3.2 基本批量预测评估工作流程概述 - 指标类接口#
为了方便,我们在一个单元格中展示了基本的批量预测评估工作流程。这个单元格使用了高级的类规范接口来处理指标。
[50]:
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.naive import NaiveForecaster
from sktime.performance_metrics.forecasting import MeanAbsolutePercentageError
from sktime.split import temporal_train_test_split
[51]:
# step 1: splitting historical data
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
# step 2: running the basic forecasting workflow
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = NaiveForecaster(strategy="last", sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
# step 3: specifying the evaluation metric
mape = MeanAbsolutePercentageError(symmetric=False)
# if function interface is used, just use the function directly in step 4
# step 4: computing the forecast performance
mape(y_test, y_pred)
# step 5: testing forecast performance against baseline
# under development
[51]:
0.13189432350948402
一个常见的用例要求预测者定期用新数据更新并进行滚动预测。如果必须在固定的时间点进行相同类型的预测,例如每天或每周,这尤其有用。sktime 预测者通过 update 和 update_predict 方法支持这种部署工作流程。
update 方法可以在一个预测器已经拟合后调用,以摄取新数据并进行更新预测——这被称为“更新步骤”。
更新后,预测器的内部“当前”状态(cutoff)被设置为更新批次中看到的最新时间戳(假设比之前看到的数据更晚)。
一般模式如下:
指定一个预测策略
指定一个相对的预测时间范围
使用
fit将预测器拟合到初始批次的数据使用
predict对相对预测时间范围进行预测获取新数据;使用
update来摄取新数据使用
predict对更新后的数据进行预测根据需要重复5和6
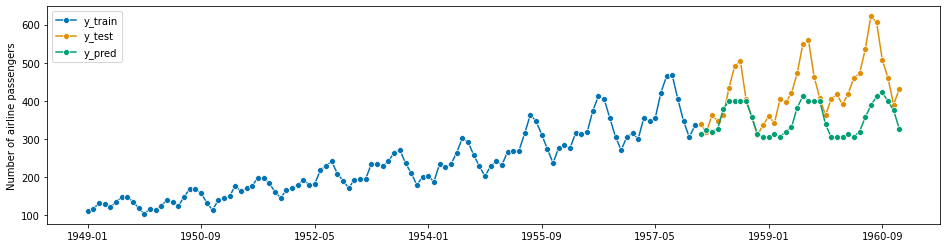
示例:假设在航空公司示例中,我们希望从1957年12月开始,每个月提前一年进行预测。前几个月的预测将如下进行:
[52]:
from sktime.datasets import load_airline
from sktime.forecasting.ets import AutoETS
from sktime.utils.plotting import plot_series
[53]:
# we prepare the full data set for convenience
# note that in the scenario we will "know" only part of this at certain time points
y = load_airline()
[54]:
# December 1957
# this is the data known in December 1957
y_1957Dec = y[:-36]
# step 1: specifying the forecasting strategy
forecaster = AutoETS(auto=True, sp=12, n_jobs=-1)
# step 2: specifying the forecasting horizon: one year ahead, all months
fh = np.arange(1, 13)
# step 3: this is the first time we use the model, so we fit it
forecaster.fit(y_1957Dec)
# step 4: obtaining the first batch of forecasts for Jan 1958 - Dec 1958
y_pred_1957Dec = forecaster.predict(fh)
[55]:
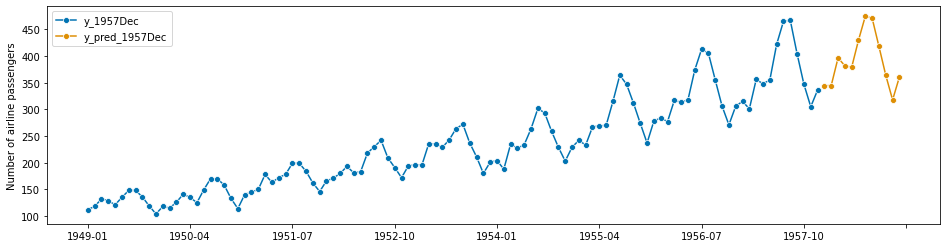
# plotting predictions and past data
plot_series(y_1957Dec, y_pred_1957Dec, labels=["y_1957Dec", "y_pred_1957Dec"])
[55]:
(<Figure size 1152x288 with 1 Axes>,
<AxesSubplot:ylabel='Number of airline passengers'>)
[56]:
# January 1958
# new data is observed:
y_1958Jan = y[[-36]]
# step 5: we update the forecaster with the new data
forecaster.update(y_1958Jan)
# step 6: making forecasts with the updated data
y_pred_1958Jan = forecaster.predict(fh)
[57]:
# note that the fh is relative, so forecasts are automatically for 1 month later
# i.e., from Feb 1958 to Jan 1959
y_pred_1958Jan
[57]:
1958-02 341.514630
1958-03 392.849241
1958-04 378.518543
1958-05 375.658188
1958-06 426.006944
1958-07 470.569699
1958-08 467.100443
1958-09 414.450926
1958-10 360.957054
1958-11 315.202860
1958-12 357.898458
1959-01 363.036833
Freq: M, dtype: float64
[58]:
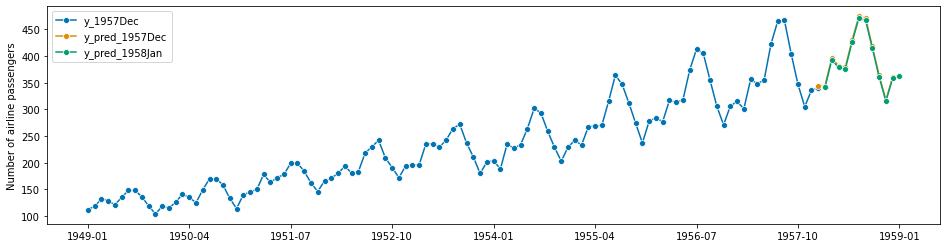
# plotting predictions and past data
plot_series(
y[:-35],
y_pred_1957Dec,
y_pred_1958Jan,
labels=["y_1957Dec", "y_pred_1957Dec", "y_pred_1958Jan"],
)
[58]:
(<Figure size 1152x288 with 1 Axes>,
<AxesSubplot:ylabel='Number of airline passengers'>)
[59]:
# February 1958
# new data is observed:
y_1958Feb = y[[-35]]
# step 5: we update the forecaster with the new data
forecaster.update(y_1958Feb)
# step 6: making forecasts with the updated data
y_pred_1958Feb = forecaster.predict(fh)
[60]:
# plotting predictions and past data
plot_series(
y[:-35],
y_pred_1957Dec,
y_pred_1958Jan,
y_pred_1958Feb,
labels=["y_1957Dec", "y_pred_1957Dec", "y_pred_1958Jan", "y_pred_1958Feb"],
)
[60]:
(<Figure size 1152x288 with 1 Axes>,
<AxesSubplot:ylabel='Number of airline passengers'>)
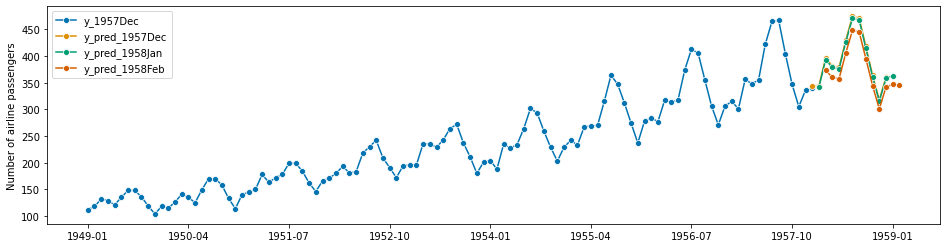
… 等等。
运行 update 然后 predict 的简写是 update_predict_single - 对于某些算法,这可能比分别调用 update 和 predict 更高效:
[61]:
# March 1958
# new data is observed:
y_1958Mar = y[[-34]]
# step 5&6: update/predict in one step
forecaster.update_predict_single(y_1958Mar, fh=fh)
[61]:
1958-04 349.161935
1958-05 346.920065
1958-06 394.051656
1958-07 435.839910
1958-08 433.316755
1958-09 384.841740
1958-10 335.535138
1958-11 293.171527
1958-12 333.275492
1959-01 338.595127
1959-02 336.983070
1959-03 388.121198
Freq: M, dtype: float64
在滚动部署模式中,可能需要将估计器的“当前”状态(即 cutoff)向后移动,例如在没有新数据观察到但时间已经推进的情况下;或者,如果计算时间过长,且需要查询预测时。
update 接口通过 update 和其他更新函数的 update_params 参数提供了此选项。
如果 update_params 设置为 False,则不会执行模型更新计算;仅存储数据,并将内部“当前”状态(cutoff)设置为最近日期。
[62]:
# April 1958
# new data is observed:
y_1958Apr = y[[-33]]
# step 5: perform an update without re-computing the model parameters
forecaster.update(y_1958Apr, update_params=False)
[62]:
AutoETS(auto=True, n_jobs=-1, sp=12)
sktime 也可以通过一批完整的数据来模拟更新/预测部署模式。
这在部署中没有用处,因为它要求所有数据都预先可用;然而,它在回放中很有用,例如用于模拟或模型评估。
更新/预测回放模式可以通过 update_predict 调用,并使用一个重新采样的构造函数,该构造函数编码了精确的向前走方案。
[63]:
# from sktime.datasets import load_airline
# from sktime.forecasting.ets import AutoETS
# from sktime.split import ExpandingWindowSplitter
# from sktime.utils.plotting import plot_series
注意:已注释 - 此接口部分目前正在进行重新设计。欢迎贡献和PR。
[64]:
# for playback, the full data needs to be loaded in advance
# y = load_airline()
[65]:
# step 1: specifying the forecasting strategy
# forecaster = AutoETS(auto=True, sp=12, n_jobs=-1)
# step 2: specifying the forecasting horizon
# fh - np.arange(1, 13)
# step 3: specifying the cross-validation scheme
# cv = ExpandingWindowSplitter()
# step 4: fitting the forecaster - fh should be passed here
# forecaster.fit(y[:-36], fh=fh)
# step 5: rollback
# y_preds = forecaster.update_predict(y, cv)
为了评估预测者在滚动预测中的表现,需要在模拟滚动预测的环境中测试预测者,通常使用过去的数据。请注意,如第1.3节中的批量回测并不适合作为滚动部署的评估设置,因为那只测试了单一的预测批次。
高级评估工作流程可以通过 evaluate 基准测试函数来执行。evaluate 接受以下参数:- 一个 forecaster 进行评估 - 一个 scikit-learn 时间分割的重采样策略(如下 cv),例如 ExpandingWindowSplitter 或 SlidingWindowSplitter - 一个 ``strategy``(字符串):是否应始终重新拟合 forecaster,或者只拟合一次然后更新
[66]:
from sktime.forecasting.arima import AutoARIMA
from sktime.forecasting.model_evaluation import evaluate
from sktime.split import ExpandingWindowSplitter
[67]:
forecaster = AutoARIMA(sp=12, suppress_warnings=True)
cv = ExpandingWindowSplitter(
step_length=12, fh=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], initial_window=72
)
df = evaluate(forecaster=forecaster, y=y, cv=cv, strategy="refit", return_data=True)
df.iloc[:, :5]
[67]:
| test_MeanAbsolutePercentageError | fit_time | pred_time | len_train_window | cutoff | |
|---|---|---|---|---|---|
| 0 | 0.061710 | 4.026436 | 0.006171 | 72 | 1954-12 |
| 1 | 0.050042 | 5.211994 | 0.006386 | 84 | 1955-12 |
| 2 | 0.029802 | 8.024385 | 0.005885 | 96 | 1956-12 |
| 3 | 0.053773 | 4.231226 | 0.005654 | 108 | 1957-12 |
| 4 | 0.073820 | 5.250797 | 0.006525 | 120 | 1958-12 |
| 5 | 0.030976 | 11.651850 | 0.006294 | 132 | 1959-12 |
[68]:
# visualization of a forecaster evaluation
fig, ax = plot_series(
y,
df["y_pred"].iloc[0],
df["y_pred"].iloc[1],
df["y_pred"].iloc[2],
df["y_pred"].iloc[3],
df["y_pred"].iloc[4],
df["y_pred"].iloc[5],
markers=["o", "", "", "", "", "", ""],
labels=["y_true"] + ["y_pred (Backtest " + str(x) + ")" for x in range(6)],
)
ax.legend();

待办事项:性能指标、平均值和测试 - 欢迎为 sktime 和教程做出贡献。
2. sktime 中的预测器 - 查找、属性、主要家族#
本节总结了如何:
在 sktime 中搜索预测器
预测器的属性,相应的搜索选项和标签
sktime中常用的预测器类型
通常,sktime 中所有可用的预测器都可以通过 all_estimators 命令列出。
这将列出 sktime 中的所有预测器,即使其软依赖项未安装。
[69]:
from sktime.registry import all_estimators
all_estimators("forecaster", as_dataframe=True)
[69]:
| name | estimator | |
|---|---|---|
| 0 | ARIMA | <class 'sktime.forecasting.arima.ARIMA'> |
| 1 | AutoARIMA | <class 'sktime.forecasting.arima.AutoARIMA'> |
| 2 | AutoETS | <class 'sktime.forecasting.ets.AutoETS'> |
| 3 | AutoEnsembleForecaster | <class 'sktime.forecasting.compose._ensemble.A... |
| 4 | BATS | <class 'sktime.forecasting.bats.BATS'> |
| 5 | BaggingForecaster | <class 'sktime.forecasting.compose._bagging.Ba... |
| 6 | ColumnEnsembleForecaster | <class 'sktime.forecasting.compose._column_ens... |
| 7 | ConformalIntervals | <class 'sktime.forecasting.conformal.Conformal... |
| 8 | Croston | <class 'sktime.forecasting.croston.Croston'> |
| 9 | DirRecTabularRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Dir... |
| 10 | DirRecTimeSeriesRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Dir... |
| 11 | DirectTabularRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Dir... |
| 12 | DirectTimeSeriesRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Dir... |
| 13 | DontUpdate | <class 'sktime.forecasting.stream._update.Dont... |
| 14 | DynamicFactor | <class 'sktime.forecasting.dynamic_factor.Dyna... |
| 15 | EnsembleForecaster | <class 'sktime.forecasting.compose._ensemble.E... |
| 16 | ExponentialSmoothing | <class 'sktime.forecasting.exp_smoothing.Expon... |
| 17 | ForecastX | <class 'sktime.forecasting.compose._pipeline.F... |
| 18 | ForecastingGridSearchCV | <class 'sktime.forecasting.model_selection._tu... |
| 19 | ForecastingPipeline | <class 'sktime.forecasting.compose._pipeline.F... |
| 20 | ForecastingRandomizedSearchCV | <class 'sktime.forecasting.model_selection._tu... |
| 21 | MultioutputTabularRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Mul... |
| 22 | MultioutputTimeSeriesRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Mul... |
| 23 | MultiplexForecaster | <class 'sktime.forecasting.compose._multiplexe... |
| 24 | NaiveForecaster | <class 'sktime.forecasting.naive.NaiveForecast... |
| 25 | NaiveVariance | <class 'sktime.forecasting.naive.NaiveVariance'> |
| 26 | OnlineEnsembleForecaster | <class 'sktime.forecasting.online_learning._on... |
| 27 | PolynomialTrendForecaster | <class 'sktime.forecasting.trend.PolynomialTre... |
| 28 | Prophet | <class 'sktime.forecasting.fbprophet.Prophet'> |
| 29 | ReconcilerForecaster | <class 'sktime.forecasting.reconcile.Reconcile... |
| 30 | RecursiveTabularRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Rec... |
| 31 | RecursiveTimeSeriesRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Rec... |
| 32 | SARIMAX | <class 'sktime.forecasting.sarimax.SARIMAX'> |
| 33 | STLForecaster | <class 'sktime.forecasting.trend.STLForecaster'> |
| 34 | StackingForecaster | <class 'sktime.forecasting.compose._stack.Stac... |
| 35 | StatsForecastAutoARIMA | <class 'sktime.forecasting.statsforecast.Stats... |
| 36 | TBATS | <class 'sktime.forecasting.tbats.TBATS'> |
| 37 | ThetaForecaster | <class 'sktime.forecasting.theta.ThetaForecast... |
| 38 | TransformedTargetForecaster | <class 'sktime.forecasting.compose._pipeline.T... |
| 39 | TrendForecaster | <class 'sktime.forecasting.trend.TrendForecast... |
| 40 | UnobservedComponents | <class 'sktime.forecasting.structural.Unobserv... |
| 41 | UpdateEvery | <class 'sktime.forecasting.stream._update.Upda... |
| 42 | UpdateRefitsEvery | <class 'sktime.forecasting.stream._update.Upda... |
| 43 | VAR | <class 'sktime.forecasting.var.VAR'> |
| 44 | VARMAX | <class 'sktime.forecasting.varmax.VARMAX'> |
| 45 | VECM | <class 'sktime.forecasting.vecm.VECM'> |
结果数据框最后一列的条目是可直接用于构造的类,或简单地检查以获取正确的导入路径。
对于循环遍历预测器的逻辑,默认的输出格式可能更为方便:
[70]:
forecaster_list = all_estimators("forecaster", as_dataframe=False)
# this returns a list of (name, estimator) tuples
forecaster_list[0]
[70]:
('ARIMA', sktime.forecasting.arima.ARIMA)
所有 sktime 的预测器都有所谓的标签,这些标签描述了估计器的属性,例如,它是否是多元的、概率性的,或者不是。本节将描述标签的使用、检查和检索。
每个预测器都有标签,这些标签是键值对,可以描述能力或内部实现细节。
最重要的“能力”样式标签如下:
requires-fh-in-fit - 一个布尔值。预测器是否需要在 fit 中已经包含预测范围 fh (True),或者是否可以在 predict 中稍后传递 (False)。
scitype:y - 一个字符串。预测器是单变量 ("univariate"),严格多变量 ("multivariate"),还是可以处理任意数量的变量 ("both")。
capability:pred_int - 一个布尔值。预测器是否可以通过 predict_interval 等返回概率预测,参见第1.5节。
ignores-exogeneous-X - 一个布尔值。预测器是否使用外生变量 X``(``False)或不使用(True)。如果预测器不使用 X,它仍然可以为了接口一致性而被传递,并且将被忽略。
handles-missing-data - 一个布尔值。预测器是否可以处理输入 X 或 y 中的缺失数据。
预报器实例的标签可以通过 ``get_tags``(列出所有标签)和 ``get_tag``(获取一个标签的值)方法进行检查。
标签值可能取决于超参数的选择。
[71]:
from sktime.forecasting.arima import ARIMA
ARIMA().get_tags()
[71]:
{'scitype:y': 'univariate',
'ignores-exogeneous-X': False,
'capability:pred_int': True,
'handles-missing-data': True,
'y_inner_mtype': 'pd.Series',
'X_inner_mtype': 'pd.DataFrame',
'requires-fh-in-fit': False,
'X-y-must-have-same-index': True,
'enforce_index_type': None,
'fit_is_empty': False,
'python_version': None,
'python_dependencies': 'pmdarima'}
y_inner_mtype 和 X_inner_mtype 指示预测器是否能够原生处理面板或分层数据 - 如果此处出现面板或分层数据类型,则可以处理(参见数据类型教程)。
所有标签的解释可以通过 all_tags 工具获得,参见第2.2.3节。
要列出带有标签的预测器,可以使用 all_estimators 工具及其 return_tags 参数。
生成的数据框随后可用于表格查询或子集操作。
[72]:
from sktime.registry import all_estimators
all_estimators(
"forecaster", as_dataframe=True, return_tags=["scitype:y", "requires-fh-in-fit"]
)
[72]:
| name | estimator | scitype:y | requires-fh-in-fit | |
|---|---|---|---|---|
| 0 | ARIMA | <class 'sktime.forecasting.arima.ARIMA'> | univariate | False |
| 1 | AutoARIMA | <class 'sktime.forecasting.arima.AutoARIMA'> | univariate | False |
| 2 | AutoETS | <class 'sktime.forecasting.ets.AutoETS'> | univariate | False |
| 3 | AutoEnsembleForecaster | <class 'sktime.forecasting.compose._ensemble.A... | univariate | False |
| 4 | BATS | <class 'sktime.forecasting.bats.BATS'> | univariate | False |
| 5 | BaggingForecaster | <class 'sktime.forecasting.compose._bagging.Ba... | univariate | False |
| 6 | ColumnEnsembleForecaster | <class 'sktime.forecasting.compose._column_ens... | both | False |
| 7 | ConformalIntervals | <class 'sktime.forecasting.conformal.Conformal... | univariate | False |
| 8 | Croston | <class 'sktime.forecasting.croston.Croston'> | univariate | False |
| 9 | DirRecTabularRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Dir... | univariate | True |
| 10 | DirRecTimeSeriesRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Dir... | univariate | True |
| 11 | DirectTabularRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Dir... | univariate | True |
| 12 | DirectTimeSeriesRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Dir... | univariate | True |
| 13 | DontUpdate | <class 'sktime.forecasting.stream._update.Dont... | univariate | False |
| 14 | DynamicFactor | <class 'sktime.forecasting.dynamic_factor.Dyna... | multivariate | False |
| 15 | EnsembleForecaster | <class 'sktime.forecasting.compose._ensemble.E... | univariate | False |
| 16 | ExponentialSmoothing | <class 'sktime.forecasting.exp_smoothing.Expon... | univariate | False |
| 17 | ForecastX | <class 'sktime.forecasting.compose._pipeline.F... | univariate | True |
| 18 | ForecastingGridSearchCV | <class 'sktime.forecasting.model_selection._tu... | both | False |
| 19 | ForecastingPipeline | <class 'sktime.forecasting.compose._pipeline.F... | both | False |
| 20 | ForecastingRandomizedSearchCV | <class 'sktime.forecasting.model_selection._tu... | both | False |
| 21 | MultioutputTabularRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Mul... | univariate | True |
| 22 | MultioutputTimeSeriesRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Mul... | univariate | True |
| 23 | MultiplexForecaster | <class 'sktime.forecasting.compose._multiplexe... | both | False |
| 24 | NaiveForecaster | <class 'sktime.forecasting.naive.NaiveForecast... | univariate | False |
| 25 | NaiveVariance | <class 'sktime.forecasting.naive.NaiveVariance'> | univariate | False |
| 26 | OnlineEnsembleForecaster | <class 'sktime.forecasting.online_learning._on... | univariate | False |
| 27 | PolynomialTrendForecaster | <class 'sktime.forecasting.trend.PolynomialTre... | univariate | False |
| 28 | Prophet | <class 'sktime.forecasting.fbprophet.Prophet'> | univariate | False |
| 29 | ReconcilerForecaster | <class 'sktime.forecasting.reconcile.Reconcile... | univariate | False |
| 30 | RecursiveTabularRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Rec... | univariate | False |
| 31 | RecursiveTimeSeriesRegressionForecaster | <class 'sktime.forecasting.compose._reduce.Rec... | univariate | False |
| 32 | SARIMAX | <class 'sktime.forecasting.sarimax.SARIMAX'> | univariate | False |
| 33 | STLForecaster | <class 'sktime.forecasting.trend.STLForecaster'> | univariate | False |
| 34 | StackingForecaster | <class 'sktime.forecasting.compose._stack.Stac... | univariate | True |
| 35 | StatsForecastAutoARIMA | <class 'sktime.forecasting.statsforecast.Stats... | univariate | False |
| 36 | TBATS | <class 'sktime.forecasting.tbats.TBATS'> | univariate | False |
| 37 | ThetaForecaster | <class 'sktime.forecasting.theta.ThetaForecast... | univariate | False |
| 38 | TransformedTargetForecaster | <class 'sktime.forecasting.compose._pipeline.T... | both | False |
| 39 | TrendForecaster | <class 'sktime.forecasting.trend.TrendForecast... | univariate | False |
| 40 | UnobservedComponents | <class 'sktime.forecasting.structural.Unobserv... | univariate | False |
| 41 | UpdateEvery | <class 'sktime.forecasting.stream._update.Upda... | univariate | False |
| 42 | UpdateRefitsEvery | <class 'sktime.forecasting.stream._update.Upda... | univariate | False |
| 43 | VAR | <class 'sktime.forecasting.var.VAR'> | multivariate | False |
| 44 | VARMAX | <class 'sktime.forecasting.varmax.VARMAX'> | multivariate | False |
| 45 | VECM | <class 'sktime.forecasting.vecm.VECM'> | multivariate | False |
要在某些标签和标签值上预先过滤,可以使用 filter_tags 参数:
[73]:
# this lists all forecasters that can deal with multivariate data
all_estimators(
"forecaster", as_dataframe=True, filter_tags={"scitype:y": ["multivariate", "both"]}
)
[73]:
| name | estimator | |
|---|---|---|
| 0 | ColumnEnsembleForecaster | <class 'sktime.forecasting.compose._column_ens... |
| 1 | DynamicFactor | <class 'sktime.forecasting.dynamic_factor.Dyna... |
| 2 | ForecastingGridSearchCV | <class 'sktime.forecasting.model_selection._tu... |
| 3 | ForecastingPipeline | <class 'sktime.forecasting.compose._pipeline.F... |
| 4 | ForecastingRandomizedSearchCV | <class 'sktime.forecasting.model_selection._tu... |
| 5 | MultiplexForecaster | <class 'sktime.forecasting.compose._multiplexe... |
| 6 | TransformedTargetForecaster | <class 'sktime.forecasting.compose._pipeline.T... |
| 7 | VAR | <class 'sktime.forecasting.var.VAR'> |
| 8 | VARMAX | <class 'sktime.forecasting.varmax.VARMAX'> |
| 9 | VECM | <class 'sktime.forecasting.vecm.VECM'> |
重要提示:如上所述,标签值可能取决于超参数设置,例如,ForecastingPipeline 只能处理多元数据,前提是其中的预测器能够处理多元数据。
在上述检索中,类的标签通常设置为表示最一般的潜在值,例如,如果对于某些参数选择,估计器可以处理多元情况,它将出现在列表中。
要列出所有预测器标签及其解释,可以使用 all_tags 工具:
[74]:
import pandas as pd
from sktime.registry import all_tags
# wrapping this in a pandas DataFrame for pretty display
pd.DataFrame(all_tags(estimator_types="forecaster"))[[0, 3]]
[74]:
| 0 | 3 | |
|---|---|---|
| 0 | X-y-must-have-same-index | do X/y in fit/update and X/fh in predict have ... |
| 1 | X_inner_mtype | which machine type(s) is the internal _fit/_pr... |
| 2 | capability:pred_int | does the forecaster implement predict_interval... |
| 3 | capability:pred_var | does the forecaster implement predict_variance? |
| 4 | enforce_index_type | passed to input checks, input conversion index... |
| 5 | ignores-exogeneous-X | does forecaster ignore exogeneous data (X)? |
| 6 | requires-fh-in-fit | does forecaster require fh passed already in f... |
| 7 | scitype:y | which series type does the forecaster support?... |
| 8 | y_inner_mtype | which machine type(s) is the internal _fit/_pr... |
sktime 支持多种常用的预测器,其中许多是从最先进的预测包中接口的。所有预测器都可以通过统一的 sktime 接口访问。
目前稳定支持的一些类包括:
ExponentialSmoothing、ThetaForecaster和autoETS来自statsmodelspmdarima中的ARIMA和AutoARIMAstatsforecast中的AutoARIMABATS和TBATS来自tbatsPolynomialTrend用于预测多项式趋势Prophet接口 Facebook 的prophet
这不是完整的列表,请参考第2.1和2.2节中展示的 all_estimators 来获取完整列表。
为了说明,下面所有的估计器都将展示在基本的预测工作流程中——尽管它们也支持在统一的 sktime 接口下的高级预测和评估工作流程(见第1节)。
在其他工作流程中使用时,只需将“预测器规范块”(“forecaster=”)替换为下面示例中提供的预测器规范块。
[75]:
# imports necessary for this chapter
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
from sktime.split import temporal_train_test_split
from sktime.utils.plotting import plot_series
# data loading for illustration (see section 1 for explanation)
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
fh = ForecastingHorizon(y_test.index, is_relative=False)
sktime 接口了来自 statsmodels 的多种统计预测算法:指数平滑、theta 和自动 ETS。
例如,要在航空数据集上使用具有加性趋势分量和乘性季节性的指数平滑法,我们可以编写如下代码。请注意,由于这是月度数据,季节性周期(sp)的一个好选择是12(=假设的一年周期)。
[76]:
from sktime.forecasting.exp_smoothing import ExponentialSmoothing
[77]:
forecaster = ExponentialSmoothing(trend="add", seasonal="additive", sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[77]:
0.05114163237371178

状态空间模型的指数平滑也可以像 R 中的 ets 函数一样自动化。这在 AutoETS 预测器中实现。
[78]:
from sktime.forecasting.ets import AutoETS
[79]:
forecaster = AutoETS(auto=True, sp=12, n_jobs=-1)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[79]:
0.06186318537056982

[80]:
# todo: explain Theta; explain how to get theta-lines
sktime 为它的 ARIMA 类模型接口了 pmdarima。对于一个带有设定参数的经典 ARIMA 模型,使用 ARIMA 预测器:
[81]:
from sktime.forecasting.arima import ARIMA
[82]:
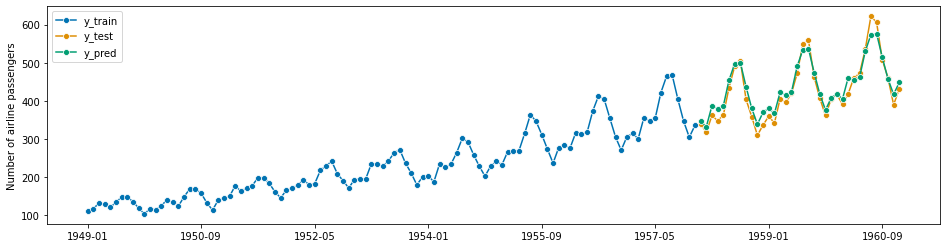
forecaster = ARIMA(
order=(1, 1, 0), seasonal_order=(0, 1, 0, 12), suppress_warnings=True
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[82]:
0.04356744885278522
AutoARIMA 是一个自动调优的 ARIMA 变体,它能自动获取最优的 pdq 参数:
[83]:
from sktime.forecasting.arima import AutoARIMA
[84]:
forecaster = AutoARIMA(sp=12, suppress_warnings=True)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[84]:
0.041489714388809135

[85]:
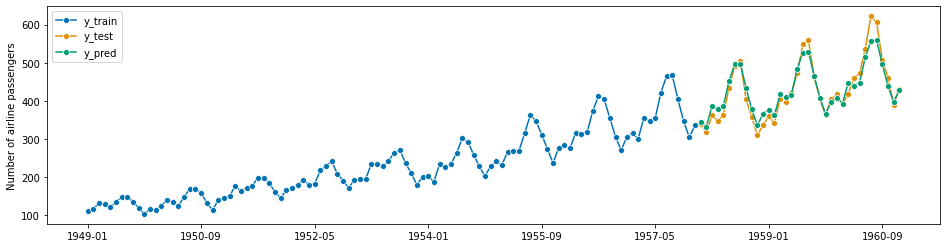
forecaster = AutoARIMA(sp=12, suppress_warnings=True)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
[85]:
0.040936759322166255
[86]:
# to obtain the fitted parameters, run
forecaster.get_fitted_params()
# should these not include pdq?
[86]:
{'ar.L1': -0.24111779230017605,
'sigma2': 92.74986650446229,
'order': (1, 1, 0),
'seasonal_order': (0, 1, 0, 12),
'aic': 704.0011679023331,
'aicc': 704.1316026849419,
'bic': 709.1089216855343,
'hqic': 706.0650836393346}
sktime 接口 BATS 和 TBATS 来自 `tbats <intive-DataScience/tbats>`__ 包。
[87]:
from sktime.forecasting.bats import BATS
[88]:
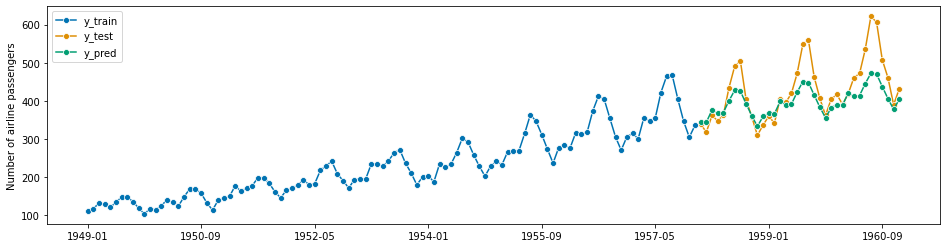
forecaster = BATS(sp=12, use_trend=True, use_box_cox=False)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[88]:
0.08185558959286515
[89]:
from sktime.forecasting.tbats import TBATS
[90]:
forecaster = TBATS(sp=12, use_trend=True, use_box_cox=False)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[90]:
0.08024090844021753
sktime 提供了对 Facebook 的 `fbprophet <facebook/prophet>`__ 的接口。
[91]:
from sktime.forecasting.fbprophet import Prophet
当前接口不支持周期索引,仅支持 pd.DatetimeIndex。考虑通过贡献 sktime 来改进这一点。
[92]:
# Convert index to pd.DatetimeIndex
z = y.copy()
z = z.to_timestamp(freq="M")
z_train, z_test = temporal_train_test_split(z, test_size=36)
[93]:
forecaster = Prophet(
seasonality_mode="multiplicative",
n_changepoints=int(len(y_train) / 12),
add_country_holidays={"country_name": "Germany"},
yearly_seasonality=True,
weekly_seasonality=False,
daily_seasonality=False,
)
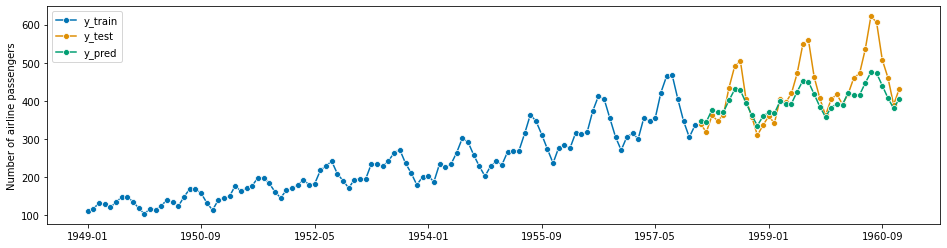
forecaster.fit(z_train)
y_pred = forecaster.predict(fh.to_relative(cutoff=y_train.index[-1]))
y_pred.index = y_test.index
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[93]:
0.07276862950407971
我们还可以使用 `statsmodels <https://www.statsmodels.org/stable/index.html>`__ 中的 `UnobservedComponents <https://www.statsmodels.org/stable/generated/statsmodels.tsa.statespace.structural.UnobservedComponents.html>`__ 类,通过状态空间模型生成预测。
[94]:
from sktime.forecasting.structural import UnobservedComponents
[95]:
# We can model seasonality using Fourier modes as in the Prophet model.
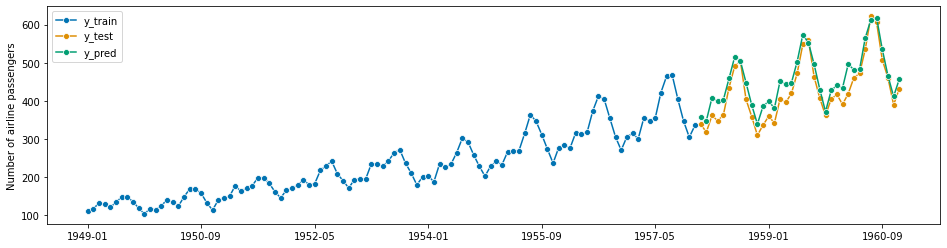
forecaster = UnobservedComponents(
level="local linear trend", freq_seasonal=[{"period": 12, "harmonics": 10}]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[95]:
0.0497366365924174
sktime 为 AutoARIMA 类模型接口了 StatsForecast。AutoARIMA 是一个自动调优的 ARIMA 变体,能够自动获取最佳的 pdq 参数:
[96]:
from sktime.forecasting.statsforecast import StatsForecastAutoARIMA
[97]:
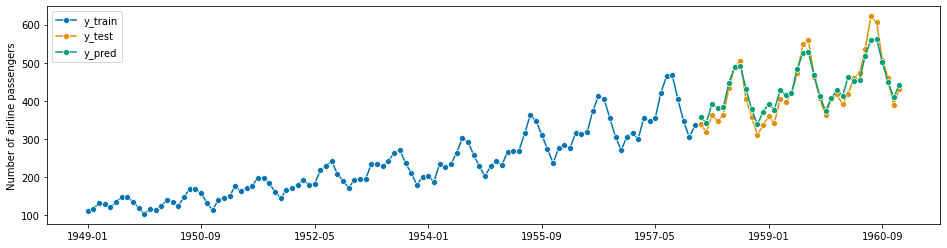
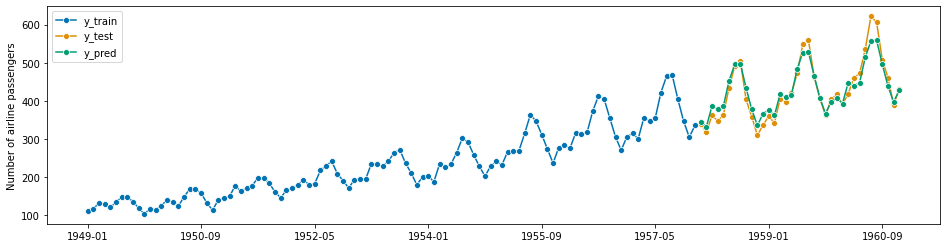
forecaster = StatsForecastAutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
[97]:
0.04093539044441262
3. 高级组合模式 - 管道、归约、自动机器学习等#
sktime 支持多种高级组合模式,以从更简单的组件创建预测器:
简化 - 从“更简单”的科学类型估计器构建预测器,如
scikit-learn回归器。一个常见的例子是通过滚动窗口进行特征/标签制表,即所谓的“直接简化策略”。调优 - 以数据驱动的方式确定预测器的超参数值。一个常见的例子是对训练/测试分割的时间滚动重采样进行网格搜索。
流水线 - 将转换器与预测器连接以获得一个预测器。一个常见的例子是去趋势化和去季节化然后进行预测,这种情况的一个实例是常见的“STL 预测器”。
AutoML,也称为自动化模型选择——使用自动化调优策略来选择不仅包括超参数,还包括整个预测策略。一个常见的例子是线上多路复用器调优。
为了说明,下面所有的估计器都将展示在基本的预测工作流程中——尽管它们也支持在统一的 sktime 接口下的高级预测和评估工作流程(见第1节)。
在其他工作流程中使用时,只需将“预测器规范块”(“forecaster=”)替换为下面示例中提供的预测器规范块。
[98]:
# imports necessary for this chapter
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
from sktime.split import temporal_train_test_split
from sktime.utils.plotting import plot_series
# data loading for illustration (see section 1 for explanation)
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
fh = ForecastingHorizon(y_test.index, is_relative=False)
sktime 提供了一个元估计器,允许使用任何 scikit-learn 估计器进行预测。
模块化 且 与 scikit-learn 兼容,因此我们可以轻松地将任何 scikit-learn 回归器应用于解决我们的预测问题,
参数化 和 可调的,使我们能够调整超参数,如窗口长度或生成预测的策略
自适应,意味着它将 scikit-learn 的估计器接口适配为预测器的接口,确保我们可以调整和正确评估我们的模型
示例:我们将定义一个表格化缩减策略,以将 k-近邻回归器(sklearn 的 KNeighborsRegressor)转换为预测器。复合算法是一个符合 sktime 预测器接口的对象(图片:大机器人),并且包含回归器作为可访问参数组件(图片:小机器人)。在 fit 中,复合算法使用滑动窗口策略来表格化数据,并将回归器拟合到表格化数据(图片:左半部分)。在 predict 中,复合算法向回归器展示最后一个观察到的窗口以获取预测(图片:右半部分)。

下面,复合模型是使用简写函数 make_reduction 构建的,该函数生成一个 sktime 预测器类型的估计器。它使用一个构建的 scikit-learn 回归器 regressor 调用,并带有可以稍后调优为超参数的附加参数。
[99]:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
[100]:
regressor = KNeighborsRegressor(n_neighbors=1)
forecaster = make_reduction(regressor, window_length=15, strategy="recursive")
[101]:
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[101]:
0.12887507224382988
在上面的例子中,我们使用了“递归”归约策略。其他已实现的策略包括:* “直接”,* “目录递归”,* “多输出”。
可以使用与 scikit-learn 兼容的 get_params 功能(以及使用 set_params 设置)来检查参数。这提供了对 KNeighborsRegressor 参数(如 estimator_etc)和简化策略的 window_length 的可调用和嵌套访问。请注意,strategy 是不可访问的,因为在实用函数下,这是映射到单独的算法类上的。有关算法调优,请参见下面的“autoML”部分。
[102]:
forecaster.get_params()
[102]:
{'estimator__algorithm': 'auto',
'estimator__leaf_size': 30,
'estimator__metric': 'minkowski',
'estimator__metric_params': None,
'estimator__n_jobs': None,
'estimator__n_neighbors': 1,
'estimator__p': 2,
'estimator__weights': 'uniform',
'estimator': KNeighborsRegressor(n_neighbors=1),
'transformers': None,
'window_length': 15}
常见的组合模式是流水线处理:例如,首先对数据进行去季节性或去趋势处理,然后对去趋势/去季节性后的序列进行预测。在预测时,需要将趋势和季节性成分重新加回到数据中。
3.2.1 基本预测流程#
sktime 提供了一个通用的管道对象用于这种复合建模,即 TransformedTargetForecaster。它将任意数量的转换与一个预测器连接起来。这些转换可以是预处理转换或后处理转换。下面是一个带有预处理转换的预测器示例。
[103]:
from sktime.forecasting.arima import ARIMA
from sktime.forecasting.compose import TransformedTargetForecaster
from sktime.transformations.series.detrend import Deseasonalizer
[104]:
forecaster = TransformedTargetForecaster(
[
("deseasonalize", Deseasonalizer(model="multiplicative", sp=12)),
("forecast", ARIMA()),
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[104]:
0.13969973496344534

在上面的例子中,TransformedTargetForecaster 是使用一系列步骤构建的,每个步骤都是一个名称和估计器的配对,其中最后一个估计器是一个预测器类型。预处理变换器应该是具有 transform 和 inverse_transform 方法的序列到序列变换器。生成的估计器是预测器类型,并且具有所有定义接口的方法。在 fit 中,所有变换器对数据应用 fit_transforms,然后是预测器的 fit;在 predict 中,首先应用预测器的 predict,然后按相反顺序应用变换器的 inverse_transform。
与上述相同的管道也可以通过乘法 dunder 方法 * 来构建。
这将创建一个 TransformedTargetForecaster ,如上所述,组件使用默认名称。
[105]:
forecaster = Deseasonalizer(model="multiplicative", sp=12) * ARIMA()
forecaster
[105]:
TransformedTargetForecaster(steps=[Deseasonalizer(model='multiplicative',
sp=12),
ARIMA()])
在双下划线构建的管道中,名称会根据情况进行唯一化处理,例如,如果使用了两个去季节化器。
多季节性模型的示例:
[106]:
forecaster = (
Deseasonalizer(model="multiplicative", sp=12)
* Deseasonalizer(model="multiplicative", sp=3)
* ARIMA()
)
forecaster.get_params()
[106]:
{'steps': [Deseasonalizer(model='multiplicative', sp=12),
Deseasonalizer(model='multiplicative', sp=3),
ARIMA()],
'Deseasonalizer_1': Deseasonalizer(model='multiplicative', sp=12),
'Deseasonalizer_2': Deseasonalizer(model='multiplicative', sp=3),
'ARIMA': ARIMA(),
'Deseasonalizer_1__model': 'multiplicative',
'Deseasonalizer_1__sp': 12,
'Deseasonalizer_2__model': 'multiplicative',
'Deseasonalizer_2__sp': 3,
'ARIMA__concentrate_scale': False,
'ARIMA__enforce_invertibility': True,
'ARIMA__enforce_stationarity': True,
'ARIMA__hamilton_representation': False,
'ARIMA__maxiter': 50,
'ARIMA__measurement_error': False,
'ARIMA__method': 'lbfgs',
'ARIMA__mle_regression': True,
'ARIMA__order': (1, 0, 0),
'ARIMA__out_of_sample_size': 0,
'ARIMA__scoring': 'mse',
'ARIMA__scoring_args': None,
'ARIMA__seasonal_order': (0, 0, 0, 0),
'ARIMA__simple_differencing': False,
'ARIMA__start_params': None,
'ARIMA__suppress_warnings': False,
'ARIMA__time_varying_regression': False,
'ARIMA__trend': None,
'ARIMA__with_intercept': True}
我们还可以创建一个包含后处理转换的管道,这些转换是在预测器之后进行的,可以在一个双下划线管道或 TransformedTargetForecaster 中进行。
以下是一个具有整数舍入后处理的多个季节性模型的示例:
[107]:
from sktime.transformations.series.func_transform import FunctionTransformer
forecaster = ARIMA() * FunctionTransformer(lambda y: y.round())
forecaster.fit_predict(y, fh=fh).head(3)
[107]:
1958-01 334.0
1958-02 338.0
1958-03 317.0
Freq: M, dtype: float64
预处理和后处理转换器都可以存在,在这种情况下,后处理转换将在预处理转换的 inverse-transform 之后应用。
[108]:
forecaster = (
Deseasonalizer(model="multiplicative", sp=12)
* Deseasonalizer(model="multiplicative", sp=3)
* ARIMA()
* FunctionTransformer(lambda y: y.round())
)
forecaster.fit_predict(y_train, fh=fh).head(3)
[108]:
1958-01 339.0
1958-02 334.0
1958-03 381.0
Freq: M, dtype: float64
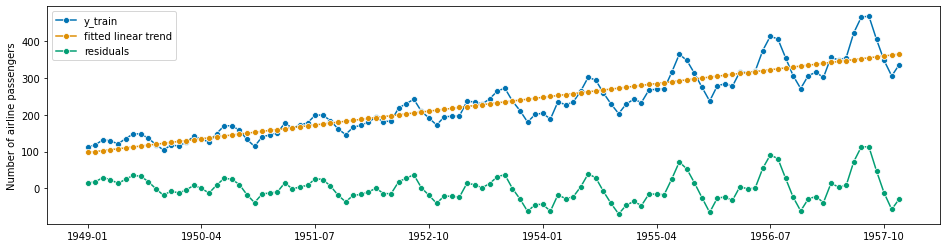
3.2.2 Detrender 作为管道组件#
对于去趋势化,我们可以使用 Detrender。这是一个序列到变换器类型的估计器,它包装了一个任意的预测器。例如,对于线性去趋势化,我们可以使用 PolynomialTrendForecaster 来拟合线性趋势,然后使用 TransformedTargetForecaster 内部的 Detrender 变换器来减去/加上它。
为了更好地理解发生了什么,我们首先单独检查去趋势器:
[109]:
from sktime.forecasting.trend import PolynomialTrendForecaster
from sktime.transformations.series.detrend import Detrender
[110]:
# linear detrending
forecaster = PolynomialTrendForecaster(degree=1)
transformer = Detrender(forecaster=forecaster)
yt = transformer.fit_transform(y_train)
# internally, the Detrender uses the in-sample predictions
# of the PolynomialTrendForecaster
forecaster = PolynomialTrendForecaster(degree=1)
fh_ins = -np.arange(len(y_train)) # in-sample forecasting horizon
y_pred = forecaster.fit(y_train).predict(fh=fh_ins)
plot_series(
y_train, y_pred, yt, labels=["y_train", "fitted linear trend", "residuals"]
);
由于 Detrender 是 scitype 序列到序列转换器,因此它可以用于 TransformedTargetForecaster 中,以对任何预测器进行去趋势处理:
[111]:
forecaster = TransformedTargetForecaster(
[
("deseasonalize", Deseasonalizer(model="multiplicative", sp=12)),
("detrend", Detrender(forecaster=PolynomialTrendForecaster(degree=1))),
("forecast", ARIMA()),
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[111]:
0.05610168219854761

3.2.3 复杂管道组合与参数检查#
sktime 遵循 scikit-learn 的组合性和嵌套参数检查的哲学。只要一个估计器具有正确的科学类型,它就可以作为任何需要该科学类型的组合原则的一部分使用。上面,我们已经看到了一个预测器在 Detrender 中的例子,这是一个科学类型为序列到序列转换器的估计器,其中一个组件是预测器科学类型。类似地,在 TransformedTargetForecaster 中,我们可以使用第3.1节中的减少组合作为管道中的最后一个预测器元素,其中包含一个科学类型为表格回归器的估计器,即 KNeighborsRegressor:
[112]:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
[113]:
forecaster = TransformedTargetForecaster(
[
("deseasonalize", Deseasonalizer(model="multiplicative", sp=12)),
("detrend", Detrender(forecaster=PolynomialTrendForecaster(degree=1))),
(
"forecast",
make_reduction(
KNeighborsRegressor(),
window_length=15,
strategy="recursive",
),
),
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[113]:
0.058708387889316475
与 scikit-learn 模型一样,我们可以通过 get_params 和 set_params 检查和访问任何组件的参数:
[114]:
forecaster.get_params()
[114]:
{'steps': [('deseasonalize', Deseasonalizer(model='multiplicative', sp=12)),
('detrend', Detrender(forecaster=PolynomialTrendForecaster())),
('forecast',
RecursiveTabularRegressionForecaster(estimator=KNeighborsRegressor(),
window_length=15))],
'deseasonalize': Deseasonalizer(model='multiplicative', sp=12),
'detrend': Detrender(forecaster=PolynomialTrendForecaster()),
'forecast': RecursiveTabularRegressionForecaster(estimator=KNeighborsRegressor(),
window_length=15),
'deseasonalize__model': 'multiplicative',
'deseasonalize__sp': 12,
'detrend__forecaster__degree': 1,
'detrend__forecaster__regressor': None,
'detrend__forecaster__with_intercept': True,
'detrend__forecaster': PolynomialTrendForecaster(),
'forecast__estimator__algorithm': 'auto',
'forecast__estimator__leaf_size': 30,
'forecast__estimator__metric': 'minkowski',
'forecast__estimator__metric_params': None,
'forecast__estimator__n_jobs': None,
'forecast__estimator__n_neighbors': 5,
'forecast__estimator__p': 2,
'forecast__estimator__weights': 'uniform',
'forecast__estimator': KNeighborsRegressor(),
'forecast__transformers': None,
'forecast__window_length': 15}
sktime 提供了作为预测器科学类型的组合器的参数调优策略,类似于 scikit-learn 的 GridSearchCV。
合成器 ForecastingGridSearchCV``(和其他调优器)是通过一个要调优的预测器、一个交叉验证构造器、一个 ``scikit-learn 参数网格以及特定于调优策略的参数构建的。交叉验证构造器遵循 scikit-learn 的重采样器接口,并且可以互换插入。
作为一个例子,我们展示了在第3.1节中,使用时间滑动窗口调谐来调整减少合成器的窗口长度:
[115]:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
from sktime.forecasting.model_selection import ForecastingGridSearchCV
from sktime.split import SlidingWindowSplitter
[116]:
regressor = KNeighborsRegressor()
forecaster = make_reduction(regressor, window_length=15, strategy="recursive")
param_grid = {"window_length": [7, 12, 15]}
# We fit the forecaster on an initial window which is 80% of the historical data
# then use temporal sliding window cross-validation to find the optimal hyper-parameters
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=20)
gscv = ForecastingGridSearchCV(
forecaster, strategy="refit", cv=cv, param_grid=param_grid
)
与其他复合模型一样,生成的预测器提供了 sktime 预测器的统一接口 - 窗口分割、调优等无需手动操作,这些都在统一接口背后完成:
[117]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[117]:
0.16607972017556033
调优后的参数可以通过 best_params_ 属性访问:
[118]:
gscv.best_params_
[118]:
{'window_length': 7}
通过访问 best_forecaster_ 属性,可以获取设置了超参数的最佳预测器实例:
[119]:
gscv.best_forecaster_
[119]:
RecursiveTabularRegressionForecaster(estimator=KNeighborsRegressor(),
window_length=7)
与 scikit-learn 中一样,可以通过访问其 get_params 键来调整嵌套组件的参数 - 默认情况下,如果 [estimatorname] 是组件的名称,而 [parametername] 是估计器 [estimatorname] 中的参数名称,则为 [estimatorname]__[parametername]。
例如,下面我们调整 KNeighborsRegressor 组件的 n_neighbors,此外还调整 window_length。可调参数可以通过 forecaster.get_params() 轻松查询。
[120]:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
from sktime.forecasting.model_selection import ForecastingGridSearchCV
from sktime.split import SlidingWindowSplitter
[121]:
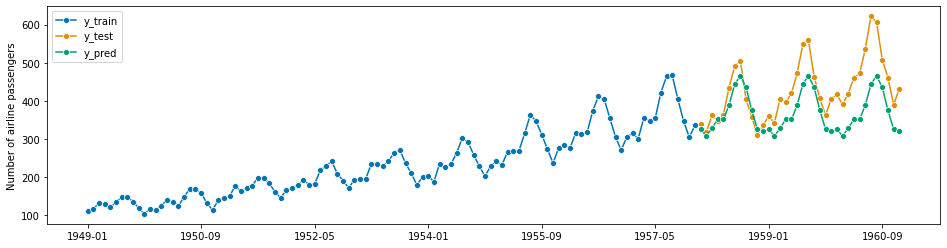
param_grid = {"window_length": [7, 12, 15], "estimator__n_neighbors": np.arange(1, 10)}
regressor = KNeighborsRegressor()
forecaster = make_reduction(regressor, strategy="recursive")
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=30)
gscv = ForecastingGridSearchCV(forecaster, cv=cv, param_grid=param_grid)
[122]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[122]:
0.13988948769413537
[123]:
gscv.best_params_
[123]:
{'estimator__n_neighbors': 2, 'window_length': 12}
另一种方法是单独调整回归器,使用 scikit-learn 的 GridSearchCV 和单独的参数网格。由于这不会使用“整体”性能指标来调整内部回归器,因此复合预测器的性能可能会有所不同。
[124]:
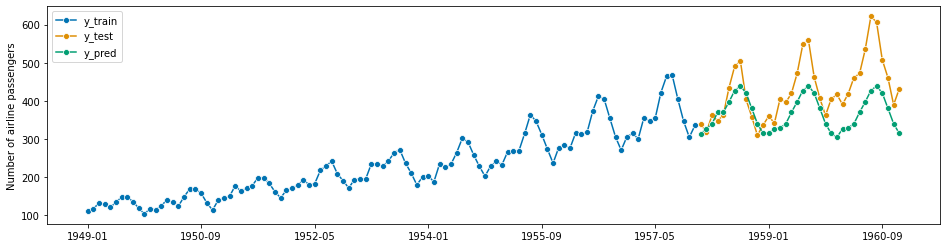
from sklearn.model_selection import GridSearchCV
# tuning the 'n_estimator' hyperparameter of RandomForestRegressor from scikit-learn
regressor_param_grid = {"n_neighbors": np.arange(1, 10)}
forecaster_param_grid = {"window_length": [7, 12, 15]}
# create a tunnable regressor with GridSearchCV
regressor = GridSearchCV(KNeighborsRegressor(), param_grid=regressor_param_grid)
forecaster = make_reduction(regressor, strategy="recursive")
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=30)
gscv = ForecastingGridSearchCV(forecaster, cv=cv, param_grid=forecaster_param_grid)
[125]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[125]:
0.14493362646957736
注意:一个智能的实现会使用缓存来保存内部调优的部分结果,从而大幅减少运行时间——目前 sktime 不支持这一点。考虑帮助改进 sktime。
sktime 中的所有调优算法都允许用户设置一个评分;对于预测,默认是平均绝对百分比误差。可以使用 score 参数设置评分,可以是任何评分函数或类,如第1.3节所述。
重采样调优器保留了在各个预测重采样折叠上的性能,这些性能可以在调用 fit 方法拟合预测器后,通过 cv_results_ 参数获取。
在上面的例子中,使用均方误差而不是平均绝对百分比误差进行调优可以通过如下定义预测器来实现:
[126]:
from sktime.performance_metrics.forecasting import MeanSquaredError
[127]:
mse = MeanSquaredError()
param_grid = {"window_length": [7, 12, 15]}
regressor = KNeighborsRegressor()
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=30)
gscv = ForecastingGridSearchCV(forecaster, cv=cv, param_grid=param_grid, scoring=mse)
在拟合之后,可以按如下方式访问各个折叠的性能:
[128]:
gscv.fit(y_train)
gscv.cv_results_
[128]:
| mean_test_MeanSquaredError | mean_fit_time | mean_pred_time | params | rank_test_MeanSquaredError | |
|---|---|---|---|---|---|
| 0 | 2600.750255 | 0.051403 | 0.002837 | {'window_length': 7} | 3.0 |
| 1 | 1134.999053 | 0.051353 | 0.002975 | {'window_length': 12} | 1.0 |
| 2 | 1285.133614 | 0.050748 | 0.003272 | {'window_length': 15} | 2.0 |
sktime 提供了多种集成和自动化模型选择的组合器。与使用数据驱动策略为固定预测器寻找最佳超参数的调优不同,本节中的策略在估计器级别进行组合或选择,使用一组预测器进行组合或选择。
本节讨论的策略包括:* 自动化机器学习(autoML),即自动模型选择 * 简单集成 * 带权重更新的预测加权集成,以及对冲策略
在预测器上执行模型选择的最灵活方式是使用 MultiplexForecaster ,它将从一个列表中选择预测器作为超参数,该超参数可以通过第3.3节中的通用超参数调整策略进行调整。
单独来看, MultiplexForecaster 是通过一个命名的列表 forecasters 构建的,其中包含预测器。它有一个超参数 selected_forecaster ,可以设置为 forecasters 中任何预测器的名称,并且其行为与 forecasters 中由 selected_forecaster 键指定的预测器完全相同。
[129]:
from sktime.forecasting.compose import MultiplexForecaster
from sktime.forecasting.exp_smoothing import ExponentialSmoothing
from sktime.forecasting.naive import NaiveForecaster
[130]:
forecaster = MultiplexForecaster(
forecasters=[
("naive", NaiveForecaster(strategy="last")),
("ets", ExponentialSmoothing(trend="add", sp=12)),
],
)
[131]:
forecaster.set_params(**{"selected_forecaster": "naive"})
# now forecaster behaves like NaiveForecaster(strategy="last")
[131]:
MultiplexForecaster(forecasters=[('naive', NaiveForecaster()),
('ets',
ExponentialSmoothing(sp=12, trend='add'))],
selected_forecaster='naive')
[132]:
forecaster.set_params(**{"selected_forecaster": "ets"})
# now forecaster behaves like ExponentialSmoothing(trend="add", sp=12))
[132]:
MultiplexForecaster(forecasters=[('naive', NaiveForecaster()),
('ets',
ExponentialSmoothing(sp=12, trend='add'))],
selected_forecaster='ets')
MultiplexForecaster 单独使用时用处不大,但与调优包装器结合时允许灵活的自动机器学习。以下定义了一个预测器,通过滑动窗口调优选择 NaiveForecaster 和 ExponentialSmoothing 中的一种,如第3.3节所述。
结合通过 update 功能(见第1.4节)对预测器的滚动使用,经过调优的复用器可以根据性能随时间推移在 NaiveForecaster 和 ExponentialSmoothing 之间来回切换。
[133]:
from sktime.forecasting.model_selection import ForecastingGridSearchCV
from sktime.split import SlidingWindowSplitter
[134]:
forecaster = MultiplexForecaster(
forecasters=[
("naive", NaiveForecaster(strategy="last")),
("ets", ExponentialSmoothing(trend="add", sp=12)),
]
)
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.5), window_length=30)
forecaster_param_grid = {"selected_forecaster": ["ets", "naive"]}
gscv = ForecastingGridSearchCV(forecaster, cv=cv, param_grid=forecaster_param_grid)
[135]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[135]:
0.19886711926999853

与任何经过调优的预测器一样,可以使用 best_params_ 和 best_forecaster_ 检索最佳参数和经过调优的预测器实例:
[136]:
gscv.best_params_
[136]:
{'selected_forecaster': 'naive'}
[137]:
gscv.best_forecaster_
[137]:
MultiplexForecaster(forecasters=[('naive', NaiveForecaster()),
('ets',
ExponentialSmoothing(sp=12, trend='add'))],
selected_forecaster='naive')
sktime 还提供了在管道 内部 自动选择管道组件的能力,即管道结构。这是通过 OptionalPassthrough 转换器实现的。
OptionalPassthrough 转换器允许调整管道内的转换器是否应用于数据。例如,如果我们想调整 sklearn.StandardScaler 是否对预测有帮助,我们可以将其包装在 OptionalPassthrough 中。在内部,OptionalPassthrough 有一个可调的超参数 passthrough: bool;当 False 时,复合体的行为类似于包装的转换器,当 True 时,它会忽略内部的转换器。
要有效使用 OptionalPasstrhough,请使用 __``(双下划线)符号定义一个合适的参数集,该符号在 ``scikit-learn 中很常见。这允许访问和调整嵌套对象的属性,如 TabularToSeriesAdaptor(StandardScaler())。如果我们有多于两层的嵌套,我们可以多次使用 __。
在以下示例中,我们采用一个去季节性/缩放管道,并调整四种可能的组合,即去季节性器和缩放器是否包含在管道中(2乘以2等于4);以及预测器和缩放器的参数。
注意:这可以与 MultiplexForecaster 任意组合,如第3.4.1节所述,以选择管道架构以及管道结构。
注意:scikit-learn 和 sktime 目前不支持条件参数集(与 mlr3 包不同)。这意味着即使跳过 scaler ,网格搜索仍会优化其参数。设计/实现这一功能将是一个有趣的贡献或研究领域。
[138]:
from sklearn.preprocessing import StandardScaler
from sktime.datasets import load_airline
from sktime.forecasting.compose import TransformedTargetForecaster
from sktime.forecasting.model_selection import ForecastingGridSearchCV
from sktime.forecasting.naive import NaiveForecaster
from sktime.split import SlidingWindowSplitter
from sktime.transformations.compose import OptionalPassthrough
from sktime.transformations.series.adapt import TabularToSeriesAdaptor
from sktime.transformations.series.detrend import Deseasonalizer
[139]:
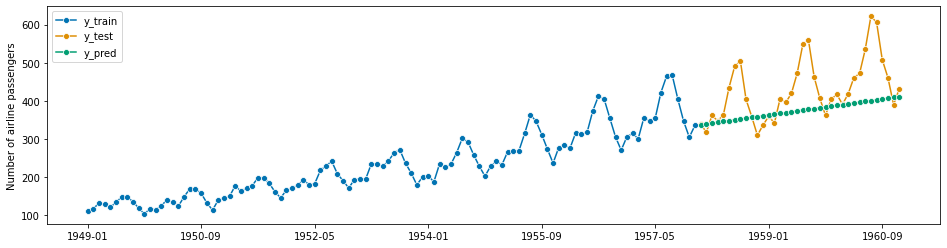
# create pipeline
pipe = TransformedTargetForecaster(
steps=[
("deseasonalizer", OptionalPassthrough(Deseasonalizer())),
("scaler", OptionalPassthrough(TabularToSeriesAdaptor(StandardScaler()))),
("forecaster", NaiveForecaster()),
]
)
# putting it all together in a grid search
cv = SlidingWindowSplitter(
initial_window=60, window_length=24, start_with_window=True, step_length=24
)
param_grid = {
"deseasonalizer__passthrough": [True, False],
"scaler__transformer__transformer__with_mean": [True, False],
"scaler__passthrough": [True, False],
"forecaster__strategy": ["drift", "mean", "last"],
}
gscv = ForecastingGridSearchCV(forecaster=pipe, param_grid=param_grid, cv=cv)
[140]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[140]:
0.1299046419013891
TODO - 本部分的贡献受到欢迎
[141]:
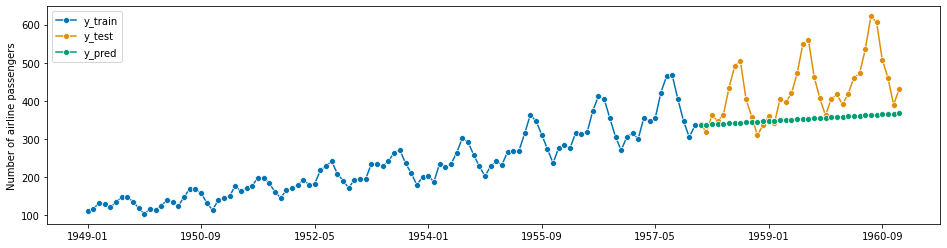
from sktime.forecasting.compose import EnsembleForecaster
[142]:
ses = ExponentialSmoothing(sp=12)
holt = ExponentialSmoothing(trend="add", damped_trend=False, sp=12)
damped = ExponentialSmoothing(trend="add", damped_trend=True, sp=12)
forecaster = EnsembleForecaster(
[
("ses", ses),
("holt", holt),
("damped", damped),
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[142]:
0.16617968035655875
对于模型评估,我们有时希望使用滑动窗口对测试数据进行时间交叉验证来评估多个预测。为此,我们可以利用 online_forecasting 模块中的预测器,这些预测器使用复合预测器 PredictionWeightedEnsemble,来跟踪每个预测器累积的损失,并根据最“准确”的预测器的预测结果创建加权预测。
注意预测任务发生了变化:我们进行35次预测,因为我们需要第一次预测来帮助更新权重,我们不会提前预测36步。
[143]:
from sktime.forecasting.all import mean_squared_error
from sktime.forecasting.online_learning import (
NormalHedgeEnsemble,
OnlineEnsembleForecaster,
)
首先,我们需要初始化一个 PredictionWeightedEnsembler,它将跟踪每个预测器的累积损失,并定义我们希望使用的损失函数。
[144]:
hedge_expert = NormalHedgeEnsemble(n_estimators=3, loss_func=mean_squared_error)
然后,我们可以通过定义各个预测器并指定我们使用的 PredictionWeightedEnsembler 来创建预测器。然后通过拟合我们的预测器并使用 update_predict 函数执行更新和预测,我们得到:
[145]:
forecaster = OnlineEnsembleForecaster(
[
("ses", ses),
("holt", holt),
("damped", damped),
],
ensemble_algorithm=hedge_expert,
)
forecaster.fit(y=y_train, fh=fh)
y_pred = forecaster.update_predict_single(y_test)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[145]:
0.0978975689038194

4. 扩展指南 - 实现你自己的预测器#
sktime 旨在易于扩展,既可以直接为 sktime 贡献,也可以通过自定义方法进行本地/私有扩展。
开始使用:
阅读 forecasting 扩展模板 - 这是一个包含
todo块的python文件,这些块标记了需要添加更改的位置。可选地,如果你计划对界面进行任何重大手术:查看 基类架构 - 请注意,“普通”扩展(例如,新算法)应该可以轻松完成,无需此操作。
将预测扩展模板复制到您自己仓库的本地文件夹(本地/私有扩展),或者复制到您克隆的
sktime或相关仓库的合适位置(如果是贡献的扩展),位于sktime.forecasting内;重命名文件并适当更新文件文档字符串。处理“待办”部分。通常,这意味着:更改类的名称,设置标签值,指定超参数,填写
__init__、_fit、_predict,以及可选的方法如_update(详情见扩展模板)。你可以添加私有方法,只要它们不覆盖默认的公共接口。更多详情,请参阅扩展模板。要手动测试您的估计器:导入您的估计器并在第1节的工作流中运行它;然后在第3节的合成器中使用它。
要自动测试您的估计器:请在您的估计器上调用
sktime.utils.estimator_checks.check_estimator。您可以在类或对象实例上调用此方法。确保您已在get_test_params方法中指定了测试参数,根据扩展模板。
在直接贡献给 sktime 或其附属包的情况下,另外:
5. 总结#
sktime提供了几种预测算法(或预测器),它们都共享一个通用接口。该接口与scikit-learn接口完全兼容,并为批处理和滚动模式下的预测提供了专门的接口点。sktime提供了丰富的组合功能,可以轻松构建复杂的管道,并轻松连接到开源生态系统的其他部分,例如scikit-learn和各个算法库。sktime易于扩展,并提供了用户友好的工具来方便实现和测试您自己的预测器和组合原则。
有用的资源#
更多详情,请参阅 我们在sktime上进行预测的论文 ,我们在其中更详细地讨论了预测API,并使用它来复制和扩展M4研究。
关于预测的良好介绍,请参阅 Hyndman, Rob J., 和 George Athanasopoulos. 预测:原理与实践. OTexts, 2018.
sktime: sktime/sktime
使用 nbsphinx 生成。Jupyter 笔记本可以在这里找到。