入门指南¶
这个非常简单的案例研究旨在帮助您快速上手使用
statsmodels。从原始数据开始,我们将展示估计统计模型和绘制诊断图所需的步骤。我们将仅使用
statsmodels 或其 pandas 和 patsy
依赖项提供的函数。
加载模块和函数¶
在 安装 statsmodels 及其依赖项 之后,我们加载一些模块和函数:
In [1]: import statsmodels.api as sm
In [2]: import pandas
In [3]: from patsy import dmatrices
pandas 建立在 numpy 数组之上,提供了丰富的数据结构和数据分析工具。pandas.DataFrame 函数提供了带有标签的(可能是异构的)数据数组,类似于 R 中的“data.frame”。pandas.read_csv 函数可以用于将逗号分隔值文件转换为 DataFrame 对象。
patsy 是一个用于描述统计模型并使用类似于 R 公式的 Python 库,用于构建 设计矩阵。
注意
此示例使用API接口。 有关导入API接口(statsmodels.api 和
statsmodels.tsa.api)与直接从定义模型的模块导入之间的区别,请参阅
导入路径和结构。
数据¶
我们下载了Guerry数据集,这是一个用于支持André-Michel Guerry 1833年著作《法国道德统计论文》的历史数据集合。该数据集以逗号分隔值格式(CSV)在线托管于Rdatasets仓库中。我们可以将文件下载到本地,然后使用read_csv加载它,但pandas会自动为我们处理所有这些:
In [4]: df = sm.datasets.get_rdataset("Guerry", "HistData").data
The 输入/输出文档页面展示了如何从其他各种格式导入数据。
我们选择感兴趣的变量并查看最后5行:
In [5]: vars = ['Department', 'Lottery', 'Literacy', 'Wealth', 'Region']
In [6]: df = df[vars]
In [7]: df[-5:]
Out[7]:
Department Lottery Literacy Wealth Region
81 Vienne 40 25 68 W
82 Haute-Vienne 55 13 67 C
83 Vosges 14 62 82 E
84 Yonne 51 47 30 C
85 Corse 83 49 37 NaN
请注意,区域列中有一个缺失的观测值。我们使用pandas提供的DataFrame方法来消除它:
In [8]: df = df.dropna()
In [9]: df[-5:]
Out[9]:
Department Lottery Literacy Wealth Region
80 Vendee 68 28 56 W
81 Vienne 40 25 68 W
82 Haute-Vienne 55 13 67 C
83 Vosges 14 62 82 E
84 Yonne 51 47 30 C
实质动机与模型¶
我们想要了解1820年代法国86个部门的识字率是否与人均皇家彩票投注额相关。我们需要控制每个部门的财富水平,并且我们还希望在回归方程的右侧包括一系列虚拟变量,以控制由于地区效应引起的未观察到的异质性。该模型使用普通最小二乘回归(OLS)进行估计。
设计矩阵(endog 和 exog)¶
要拟合由 statsmodels 涵盖的大多数模型,您需要创建两个设计矩阵。第一个是内生变量(即因变量、响应变量、回归变量等)的矩阵。第二个是外生变量(即自变量、预测变量、回归变量等)的矩阵。OLS 系数估计值按常规计算:
其中 \(y\) 是关于人均彩票投注数据的 \(N \times 1\) 列(彩票)。\(X\) 是 \(N \times 7\),包含一个截距项、识字率和财富变量,以及4个地区二元变量。
The patsy 模块提供了一个方便的函数,用于使用类似于 R 的公式准备设计矩阵。你可以在这里找到更多信息。
我们使用 patsy 的 dmatrices 函数来创建设计矩阵:
In [10]: y, X = dmatrices('Lottery ~ Literacy + Wealth + Region', data=df, return_type='dataframe')
生成的矩阵/数据框如下所示:
In [11]: y[:3]
Out[11]:
Lottery
0 41.0
1 38.0
2 66.0
In [12]: X[:3]
Out[12]:
Intercept Region[T.E] Region[T.N] Region[T.S] Region[T.W] Literacy Wealth
0 1.0 1.0 0.0 0.0 0.0 37.0 73.0
1 1.0 0.0 1.0 0.0 0.0 51.0 22.0
2 1.0 0.0 0.0 0.0 0.0 13.0 61.0
请注意,dmatrices 具有
将分类变量区域拆分为一组指示变量。
为外生回归变量矩阵添加了一个常数。
返回的是
pandasDataFrame 而不是简单的 numpy 数组。这是有用的,因为 DataFrame 允许statsmodels在报告结果时保留元数据(例如变量名称)。
上述行为当然可以被改变。请参阅patsy文档页面。
模型拟合与总结¶
在 statsmodels 中拟合模型通常涉及 3 个简单的步骤:
使用模型类来描述模型
使用类方法拟合模型
使用摘要方法检查结果
对于OLS,这是通过以下方式实现的:
In [13]: mod = sm.OLS(y, X) # Describe model
In [14]: res = mod.fit() # Fit model
In [15]: print(res.summary()) # Summarize model
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.338
Model: OLS Adj. R-squared: 0.287
Method: Least Squares F-statistic: 6.636
Date: 三, 16 10 2024 Prob (F-statistic): 1.07e-05
Time: 18:43:04 Log-Likelihood: -375.30
No. Observations: 85 AIC: 764.6
Df Residuals: 78 BIC: 781.7
Df Model: 6
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 38.6517 9.456 4.087 0.000 19.826 57.478
Region[T.E] -15.4278 9.727 -1.586 0.117 -34.793 3.938
Region[T.N] -10.0170 9.260 -1.082 0.283 -28.453 8.419
Region[T.S] -4.5483 7.279 -0.625 0.534 -19.039 9.943
Region[T.W] -10.0913 7.196 -1.402 0.165 -24.418 4.235
Literacy -0.1858 0.210 -0.886 0.378 -0.603 0.232
Wealth 0.4515 0.103 4.390 0.000 0.247 0.656
==============================================================================
Omnibus: 3.049 Durbin-Watson: 1.785
Prob(Omnibus): 0.218 Jarque-Bera (JB): 2.694
Skew: -0.340 Prob(JB): 0.260
Kurtosis: 2.454 Cond. No. 371.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
对象 res 有许多有用的属性。例如,我们可以通过输入以下内容来提取参数估计值和决定系数:
In [16]: res.params
Out[16]:
Intercept 38.651655
Region[T.E] -15.427785
Region[T.N] -10.016961
Region[T.S] -4.548257
Region[T.W] -10.091276
Literacy -0.185819
Wealth 0.451475
dtype: float64
In [17]: res.rsquared
Out[17]: np.float64(0.3379508691928822)
输入 dir(res) 以获取完整的属性列表。
更多信息和示例,请参阅回归文档页面
诊断和规范测试¶
statsmodels 允许您进行一系列有用的 回归诊断和规范测试。例如,
应用Rainbow测试线性性(原假设是关系被正确地建模为线性):
In [18]: sm.stats.linear_rainbow(res)
Out[18]: (np.float64(0.847233997615691), np.float64(0.6997965543621644))
诚然,上面生成的输出并不十分详细,但通过阅读文档字符串
(同样,print(sm.stats.linear_rainbow.__doc__)),我们知道第一个数字是F统计量,第二个是p值。
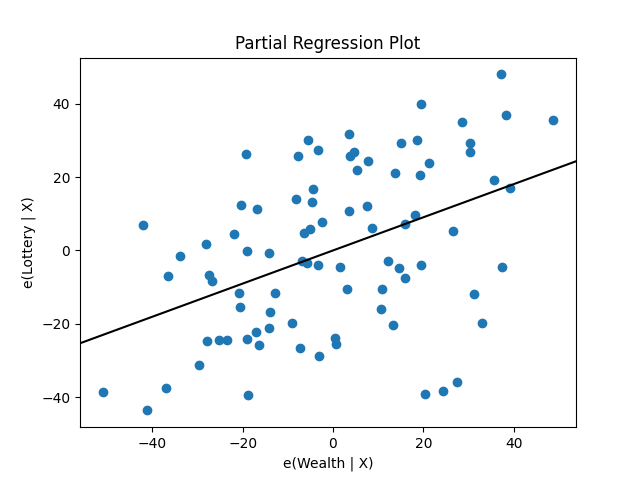
statsmodels 还提供了图形功能。例如,我们可以通过以下方式绘制一组回归变量的偏回归图:
In [19]: sm.graphics.plot_partregress('Lottery', 'Wealth', ['Region', 'Literacy'],
....: data=df, obs_labels=False)
....:
Out[19]: <Figure size 640x480 with 1 Axes>
文档¶
可以通过 IPython 会话访问文档,使用 webdoc。
打开浏览器并显示在线文档 |
更多¶
恭喜!您已准备好继续学习目录中的其他主题。