Apache Zeppelin 的 Flink 解释器
概述
Apache Flink 是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态的计算。 Flink 被设计为在所有常见的集群环境中运行,以内存速度执行计算,并且可以扩展到任何规模。
在 Zeppelin 0.9 中,我们重构了 Zeppelin 中的 Flink 解释器以支持最新版本的 Flink。目前,仅支持 Flink 1.15+,旧版本的 Flink 将无法使用。 Apache Flink 在 Zeppelin 中通过 Flink 解释器组得到支持,该组由下面列出的五个解释器组成。
| 名称 | 类别 | 描述 |
|---|---|---|
| %flink | FlinkInterpreter | 创建 ExecutionEnvironment/StreamExecutionEnvironment/BatchTableEnvironment/StreamTableEnvironment 并提供 Scala 环境 |
| %flink.pyflink | PyFlinkInterpreter | 提供一个Python环境 |
| %flink.ipyflink | IPyFlinkInterpreter | 提供一个ipython环境 |
| %flink.ssql | FlinkStreamSqlInterpreter | 提供一个流式SQL环境 |
| %flink.bsql | FlinkBatchSqlInterpreter | 提供一个批处理SQL环境 |
主要功能
| 功能 | 描述 |
|---|---|
| 支持多个版本的Flink | 您可以在一个Zeppelin实例中运行不同版本的Flink |
| 支持多种语言 | 支持Scala、Python、SQL,除此之外,您还可以跨语言协作,例如,您可以编写Scala UDF并在PyFlink中使用它 |
| 支持多种执行模式 | Local | Remote | Yarn | Yarn Application |
| 支持Hive | 支持Hive目录 |
| 交互式开发 | 交互式开发用户体验提高您的生产力 |
| Flink SQL 的增强 | * 在一个笔记本中同时支持流式 SQL 和批处理 SQL * 支持 SQL 注释(单行注释/多行注释) * 支持高级配置(jobName, parallelism) * 支持多个插入语句 |
Multi-tenancy | Multiple user can work in one Zeppelin instance without affecting each other. | Rest API Support | You can not only submit Flink job via Zeppelin notebook UI, but also can do that via its rest api (You can use Zeppelin as Flink job server). |
在 Zeppelin docker 中玩 Flink
对于初学者,我们建议您在Zeppelin docker中运行Flink。
首先,您需要下载Flink,因为Zeppelin没有附带Flink的二进制发行版。
例如,这里我们下载Flink 1.12.2到/mnt/disk1/flink-1.12.2,
并将其挂载到Zeppelin docker容器中,并运行以下命令来启动Zeppelin docker。
docker run -u $(id -u) -p 8080:8080 -p 8081:8081 --rm -v /mnt/disk1/flink-1.12.2:/opt/flink -e FLINK_HOME=/opt/flink --name zeppelin apache/zeppelin:0.11.2
运行上述命令后,您可以打开http://localhost:8080在Zeppelin中玩Flink。我们只在Zeppelin docker中验证了flink本地模式,其他模式可能由于网络问题无法使用。
-p 8081:8081是为了暴露Flink web ui,这样您可以通过http://localhost:8081访问Flink web ui。
这是运行笔记Flink Tutorial/5. Streaming Data Analytics的截图

你也可以挂载笔记本文件夹来替换内置的Zeppelin教程笔记本。 例如,这里有一个在Zeppelin上的Flink SQL食谱的仓库:https://github.com/zjffdu/flink-sql-cookbook-on-zeppelin/
你可以克隆这个仓库并将其挂载到docker上,
docker run -u $(id -u) -p 8080:8080 --rm -v /mnt/disk1/flink-sql-cookbook-on-zeppelin:/notebook -v /mnt/disk1/flink-1.12.2:/opt/flink -e FLINK_HOME=/opt/flink -e ZEPPELIN_NOTEBOOK_DIR='/notebook' --name zeppelin apache/zeppelin:0.11.2
先决条件
下载 Flink 1.15 或更高版本(仅支持 Scala 2.12)
Flink 版本特定说明
Flink 1.15 不再包含 Scala 并且改变了其二进制分发方式,需要以下额外步骤。 * 将 FLINKHOME/opt/flink-table-planner2.12-1.15.0.jar 移动到 FLINKHOME/lib * 将 FLINKHOME/lib/flink-table-planner-loader-1.15.0.jar 移动到 FLINKHOME/opt * 下载 flink-table-api-scala-bridge2.12-1.15.0.jar 和 flink-table-api-scala2.12-1.15.0.jar 到 FLINKHOME/lib
Flink 1.16 引入了新的 ClientResourceManager 用于 SQL 客户端,你需要将 FLINK_HOME/opt/flink-sql-client-1.16.0.jar 移动到 FLINK_HOME/lib
Flink on Zeppelin 架构

上图是Zeppelin上Flink的架构。左侧的Flink解释器实际上是一个Flink客户端,负责编译和管理Flink作业的生命周期,例如提交、取消作业、监控作业进度等。右侧的Flink集群是执行Flink作业的地方。它可以是MiniCluster(本地模式)、Standalone集群(远程模式)、Yarn会话集群(yarn模式)或Yarn应用程序会话集群(yarn-application模式)。
Flink 解释器中有两个重要组件:Scala shell 和 Python shell
- Scala shell 是 Flink 解释器的入口点,它将创建 Flink 程序的所有入口点,例如 ExecutionEnvironment、StreamExecutionEnvironment 和 TableEnvironment。Scala shell 负责编译和运行 Scala 代码和 SQL。
- Python shell 是 PyFlink 的入口点,它负责编译和运行 Python 代码。
配置
The Flink interpreter can be configured with properties provided by Zeppelin (as following table). You can also add and set other Flink properties which are not listed in the table. For a list of additional properties, refer to Flink Available Properties.
| Property | Default | Description |
|---|---|---|
FLINK_HOME |
Location of Flink installation. It is must be specified, otherwise you can not use Flink in Zeppelin | |
HADOOP_CONF_DIR |
Location of hadoop conf, this is must be set if running in yarn mode | |
HIVE_CONF_DIR |
Location of hive conf, this is must be set if you want to connect to hive metastore | |
| flink.execution.mode | local | Execution mode of Flink, e.g. local | remote | yarn | yarn-application |
| flink.execution.remote.host | Host name of running JobManager. Only used for remote mode | |
| flink.execution.remote.port | Port of running JobManager. Only used for remote mode | |
| jobmanager.memory.process.size | 1024m | Total memory size of JobManager, e.g. 1024m. It is official Flink property |
| taskmanager.memory.process.size | 1024m | Total memory size of TaskManager, e.g. 1024m. It is official Flink property |
| taskmanager.numberOfTaskSlots | 1 | Number of slot per TaskManager |
| local.number-taskmanager | 4 | Total number of TaskManagers in local mode |
| yarn.application.name | Zeppelin Flink Session | Yarn app name |
| yarn.application.queue | default | queue name of yarn app |
| zeppelin.flink.uiWebUrl | User specified Flink JobManager url, it could be used in remote mode where Flink cluster is already started, or could be used as url template, e.g. https://knox-server:8443/gateway/cluster-topo/yarn/proxy/{{applicationId}}/ where {{applicationId}} is placeholder of yarn app id | |
| zeppelin.flink.run.asLoginUser | true | Whether run Flink job as the Zeppelin login user, it is only applied when running Flink job in hadoop yarn cluster and shiro is enabled |
| flink.udf.jars | Flink udf jars (comma separated), Zeppelin will register udf in these jars automatically for user. These udf jars could be either local files or hdfs files if you have hadoop installed. The udf name is the class name. | |
| flink.udf.jars.packages | Packages (comma separated) that would be searched for the udf defined in flink.udf.jars. Specifying this can reduce the number of classes to scan, otherwise all the classes in udf jar will be scanned. |
|
| flink.execution.jars | Additional user jars (comma separated), these jars could be either local files or hdfs files if you have hadoop installed. It can be used to specify Flink connector jars or udf jars (no udf class auto-registration like flink.udf.jars) |
|
| flink.execution.packages | Additional user packages (comma separated), e.g. org.apache.flink:flink-json:1.10.0 |
|
| zeppelin.flink.concurrentBatchSql.max | 10 | Max concurrent sql of Batch Sql (%flink.bsql) |
| zeppelin.flink.concurrentStreamSql.max | 10 | Max concurrent sql of Stream Sql (%flink.ssql) |
| zeppelin.pyflink.python | python | Python binary executable for PyFlink |
| table.exec.resource.default-parallelism | 1 | Default parallelism for Flink sql job |
| zeppelin.flink.scala.color | true | Whether display Scala shell output in colorful format |
| zeppelin.flink.scala.shell.tmp_dir | Temp folder for storing scala shell compiled jar | |
| zeppelin.flink.enableHive | false | Whether enable hive |
| zeppelin.flink.hive.version | 2.3.4 | Hive version that you would like to connect |
| zeppelin.flink.module.enableHive | false | Whether enable hive module, hive udf take precedence over Flink udf if hive module is enabled. |
| zeppelin.flink.maxResult | 1000 | max number of row returned by sql interpreter |
zeppelin.flink.job.check_interval |
1000 | Check interval (in milliseconds) to check Flink job progress |
flink.interpreter.close.shutdown_cluster |
true | Whether shutdown Flink cluster when closing interpreter |
zeppelin.interpreter.close.cancel_job |
true | Whether cancel Flink job when closing interpreter |
解释器绑定模式
默认的解释器绑定模式是globally shared。这意味着所有笔记共享同一个Flink解释器,即它们共享同一个Flink集群。
在实际应用中,我们建议您使用isolated per note,这意味着每个笔记都有自己的Flink解释器,互不影响(每个都有自己的Flink集群)。
执行模式
Flink 在 Zeppelin 中支持 4 种执行模式 (flink.execution.mode):
- 本地
- 远程
- Yarn
- Yarn 应用程序
本地模式
在本地模式下运行Flink将在本地JVM中启动一个MiniCluster。默认情况下,本地MiniCluster使用端口8081,因此请确保此端口在您的机器上可用,否则您可以配置rest.port来指定另一个端口。您还可以指定local.number-taskmanager和flink.tm.slot来自定义TM的数量和每个TM的插槽数量。因为默认情况下,此MiniCluster中只有4个TM,每个TM有1个插槽,这可能在某些情况下不够用。
远程模式
在远程模式下运行Flink将连接到一个现有的Flink集群,该集群可以是独立集群或yarn会话集群。除了指定flink.execution.mode为remote外,您还需要指定flink.execution.remote.host和flink.execution.remote.port以指向Flink作业管理器的rest api地址。
Yarn 模式
为了在Yarn模式下运行Flink,您需要进行以下设置:
- 将
flink.execution.mode设置为yarn - 在Flink的解释器设置或
zeppelin-env.sh中设置HADOOP_CONF_DIR。 - 确保
hadoop命令在你的PATH中。因为Flink内部会调用命令hadoop classpath并在Flink解释器进程中加载所有与hadoop相关的jar包
在这种模式下,Zeppelin 会为你启动一个 Flink yarn 会话集群,并在你关闭 Flink 解释器时销毁它。
Yarn 应用模式
在上述的yarn模式下,Zeppelin服务器主机上会有一个独立的Flink解释器进程。然而,当有太多解释器进程时,这可能会耗尽资源。 因此,在实践中,如果您使用的是Flink 1.11或更高版本(yarn应用程序模式仅在Flink 1.11之后支持),我们建议您使用yarn应用程序模式。 在此模式下,Flink解释器在yarn容器中的JobManager中运行。 为了在yarn应用程序模式下运行Flink,您需要进行以下设置:
- 将
flink.execution.mode设置为yarn-application - 在Flink的解释器设置或
zeppelin-env.sh中设置HADOOP_CONF_DIR。 - 确保
hadoop命令在您的PATH中。因为Flink内部会调用hadoop classpath命令,并在Flink解释器进程中加载所有与Hadoop相关的jar包。
Flink Scala
Scala 是 Flink 在 Zeppelin 上的默认语言(%flink),它也是 Flink 解释器的入口。在 Flink 解释器下会创建一个 Scala shell,该 shell 会创建几个内置变量,包括 ExecutionEnvironment、StreamExecutionEnvironment 等。因此,不要再次创建这些 Flink 环境变量,否则可能会遇到奇怪的问题。你在 Zeppelin 中编写的 Scala 代码将被提交到这个 Scala shell。
以下是 Flink Scala shell 中创建的内置变量。
- senv (StreamExecutionEnvironment),
- benv (ExecutionEnvironment)
- stenv (用于blink planner的StreamTableEnvironment(即新planner))
- btenv (用于blink planner的BatchTableEnvironment(即新planner))
- z (ZeppelinContext)
Blink/Flink 规划器
在 Zeppelin 0.11 之后,我们移除了对 flink planner(即旧计划器)的支持,该计划器在 Flink 1.14 之后也被移除了。
流式单词计数示例
你可以在Zeppelin中编写任何Scala代码。
例如,在下面的例子中,我们编写了一个经典的流式单词计数示例。

代码补全
你可以输入 tab 键进行代码补全。

Zeppelin上下文
ZeppelinContext 提供了一些额外的功能和实用工具。
详情请参见 Zeppelin-Context。
对于 Flink 解释器,您可以使用 z 来显示 Flink 的 Dataset/Table。
例如,你可以使用 z.show 来显示数据集、批处理表、流表。
- z.show(DataSet)

- z.show(批量表)
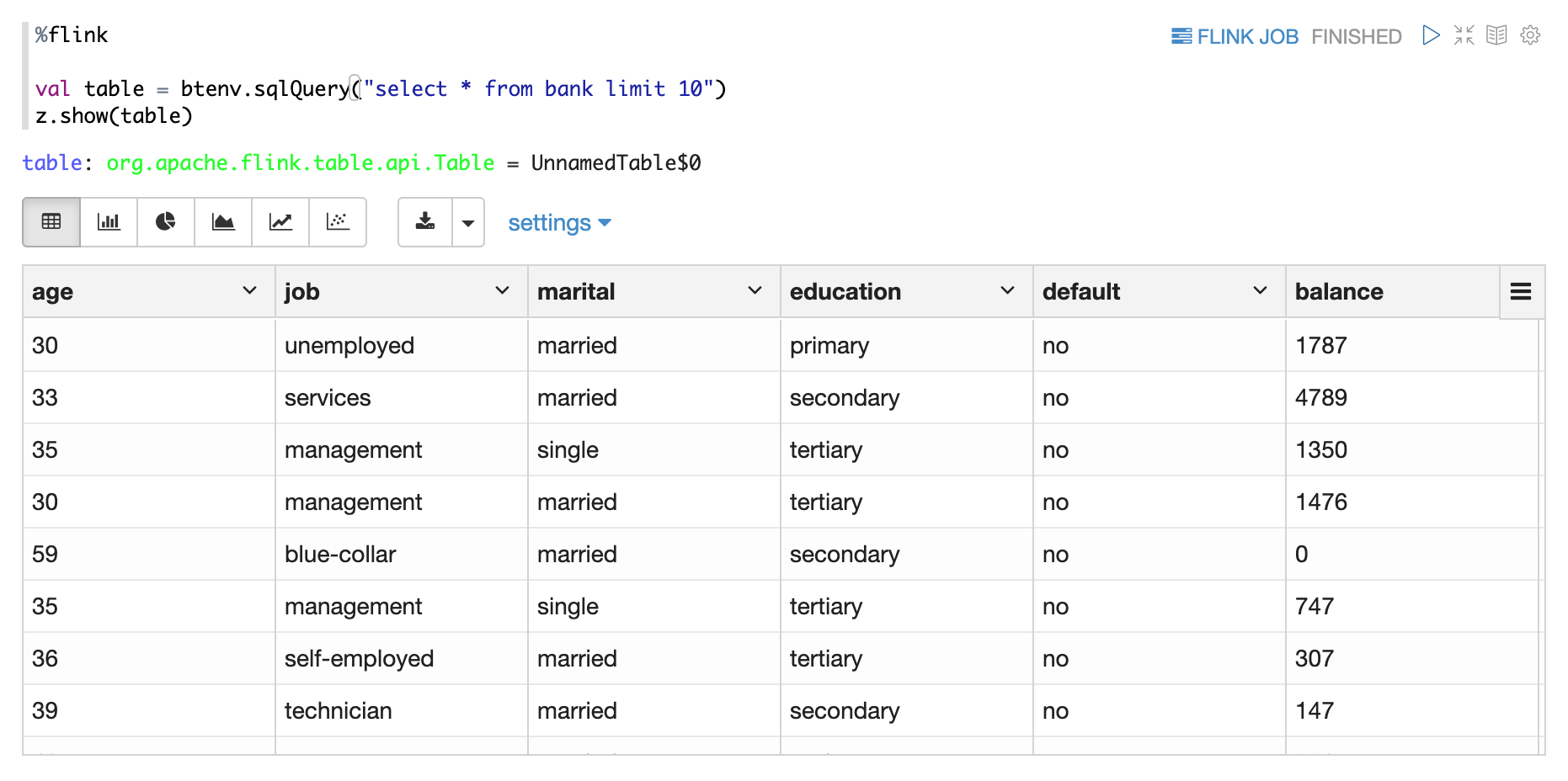
- z.show(流表)

Flink SQL
在Zeppelin中,有两种Flink SQL解释器可以使用
%flink.ssql流式SQL解释器,通过StreamTableEnvironment启动Flink流式作业%flink.bsql批处理SQL解释器,通过BatchTableEnvironment启动Flink批处理作业
Zeppelin中的Flink Sql解释器等同于Flink Sql-client加上许多其他增强功能。
增强SQL功能
支持批处理SQL和流式SQL一起使用。
在 Flink Sql-client 中,您可以在一个会话中运行流式 SQL 或批处理 SQL,但不能同时运行它们。
但在 Zeppelin 中,您可以做到这一点。%flink.ssql 用于运行流式 SQL,而 %flink.bsql 用于运行批处理 SQL。
批处理/流式 Flink 作业在同一个 Flink 会话集群中运行。
支持多语句
你可以在一个段落中编写多个SQL语句,每个SQL语句用分号分隔。
评论支持
Zeppelin 支持两种 SQL 注释:
- 单行注释以
--开始 - 多行注释使用
/* */包围

作业并行度设置
您可以通过段落本地属性设置SQL并行度:parallelism

支持多次插入
有时你有多个插入语句,它们读取相同的源,但写入不同的接收器。默认情况下,每个插入语句都会启动一个独立的Flink作业,但你可以设置段落本地属性:runAsOne为true,以便在单个Flink作业中运行它们。

设置作业名称
您可以通过设置段落本地属性为插入语句设置Flink作业名称:jobName。需要注意的是,您只能为插入语句设置作业名称。目前还不支持为选择语句设置。而且这种设置仅适用于单个插入语句。对于我们上面提到的多个插入语句,它不起作用。

流数据可视化
Zeppelin 可以可视化 Flink 流处理作业的 select sql 结果。总体而言,它支持 3 种模式:
- 单身的
- 更新
- 追加
单模式
单行模式适用于SQL语句的结果始终为一行的场景,例如以下示例。输出格式为HTML,并且可以为最终输出内容模板指定段落本地属性template。您可以使用{i}作为结果第i列的占位符。

更新模式
更新模式适用于输出多于一行并且需要持续更新的情况。这里有一个我们使用 group by 的例子。

追加模式
追加模式适用于输出数据总是追加的场景。例如,以下使用滚动窗口的示例。

PyFlink
PyFlink 是 Flink 在 Zeppelin 上的 Python 入口点,内部 Flink 解释器将创建一个 Python shell,该 shell 将创建 Flink 的环境变量(包括 ExecutionEnvironment、StreamExecutionEnvironment 等)。需要注意的是,Pyflink 背后的 Java 环境是在 Scala shell 中创建的。这意味着底层的 Scala shell 和 Python shell 共享相同的环境。这些是在 Python shell 中创建的变量。
s_env(StreamExecutionEnvironment),b_env(执行环境)st_env(用于blink planner的StreamTableEnvironment(即新planner))bt_env(用于blink planner的BatchTableEnvironment(即新planner))
配置 PyFlink
有3件事你需要配置以使Pyflink在Zeppelin中工作。
- 安装 pyflink 例如 ( pip install apache-flink==1.11.1 ). 如果您需要使用 Pyflink udf,那么您需要在所有任务管理器节点上安装 pyflink。这意味着如果您使用 yarn,那么所有 yarn 节点都需要安装 pyflink。
- 将
${FLINK_HOME}/opt下的python文件夹复制到${FLINK_HOME/lib。 - 将
zeppelin.pyflink.python设置为python可执行路径。默认情况下,它是PATH中的python。如果您安装了多个版本的python,您需要将zeppelin.pyflink.python配置为您想要使用的python版本。
如何使用 PyFlink
在Zeppelin中使用PyFlink有2种方式
%flink.pyflink%flink.ipyflink
%flink.pyflink 非常简单易用,除了上述设置外,您不需要做任何事情,但其功能也有限。我们建议您使用 %flink.ipyflink,它提供了几乎与 jupyter 相同的用户体验。
配置IPyFlink
如果您没有安装anaconda,那么您需要安装以下3个库。
pip install jupyter
pip install grpcio
pip install protobuf
如果你已经安装了anaconda,那么你只需要安装以下2个库。
pip install grpcio
pip install protobuf
ZeppelinContext 在 PyFlink 中也可用,你可以像在 Flink Scala 中一样使用它。
查看Python 文档以获取更多关于 IPython 的功能。
第三方依赖
在使用任何语言(Scala、Python、Sql)编写Flink作业时,拥有第三方依赖是非常常见的。 在IDE中添加依赖非常容易(例如在pom.xml中添加依赖), 但是在Zeppelin中如何做到这一点呢?主要有两种设置可以用来添加第三方依赖
- flink.execution.packages
- flink.execution.jars
flink.execution.packages
这是推荐的添加依赖项的方式。它的实现方式与在pom.xml中添加依赖项相同。在底层,它会从Maven仓库下载所有包及其传递依赖项,然后将它们放在类路径上。这里有一个示例,展示了如何通过内联配置添加Flink 1.10的Kafka连接器。
%flink.conf
flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.10.0,org.apache.flink:flink-connector-kafka-base_2.11:1.10.0,org.apache.flink:flink-json:1.10.0
格式为artifactGroup:artifactId:version,如果您有多个包,请用逗号分隔。flink.execution.packages需要可以访问互联网。因此,如果您无法访问互联网,则需要使用flink.execution.jars代替。
flink.execution.jars
如果您的Zeppelin机器无法访问互联网,或者您的依赖项未部署到maven仓库,
那么您可以使用flink.execution.jars来指定您依赖的jar文件(每个jar文件用逗号分隔)
这是一个如何通过flink.execution.jars添加kafka依赖项(包括kafka连接器及其传递依赖项)的示例。
%flink.conf
flink.execution.jars /usr/lib/flink-kafka/target/flink-kafka-1.0-SNAPSHOT.jar
Flink 用户定义函数
在Zeppelin中有4种方式可以定义UDF。
- 编写Scala UDF
- 编写 PyFlink UDF
- 通过SQL创建UDF
- 通过 flink.udf.jars 配置 udf jar
Scala 用户定义函数
%flink
class ScalaUpper extends ScalarFunction {
def eval(str: String) = str.toUpperCase
}
btenv.registerFunction("scala_upper", new ScalaUpper())
定义scala udf非常简单,几乎与在IDE中操作相同。
创建udf类后,您需要通过btenv注册它。
您也可以通过stenv注册它,它与btenv共享相同的Catalog。
Python 用户定义函数
%flink.pyflink
class PythonUpper(ScalarFunction):
def eval(self, s):
return s.upper()
bt_env.register_function("python_upper", udf(PythonUpper(), DataTypes.STRING(), DataTypes.STRING()))
定义Python udf也非常直接,几乎与在IDE中操作相同。
创建udf类后,您需要通过bt_env注册它。
您也可以通过st_env注册它,它与bt_env共享相同的Catalog。
通过SQL使用UDF
一些简单的用户定义函数(udf)可以在Zeppelin中编写。但如果udf逻辑非常复杂,那么最好在IDE中编写,然后在Zeppelin中注册,如下所示
%flink.ssql
CREATE FUNCTION myupper AS 'org.apache.zeppelin.flink.udf.JavaUpper';
但是这种方法要求udf jar必须在CLASSPATH上,
因此你需要配置flink.execution.jars以在CLASSPATH上包含这个udf jar,如下所示:
%flink.conf
flink.execution.jars /usr/lib/flink-udf-1.0-SNAPSHOT.jar
flink.udf.jars
上述三种方法都有一些局限性:
- 在Zeppelin中编写简单的Scala udf或Python udf是合适的,但不适合在Zeppelin中编写非常复杂的udf。因为与IDE相比,notebook不提供高级功能,例如包管理、代码导航等。
- 在笔记或用户之间共享udf并不容易,你必须在每个flink解释器中运行定义udf的段落。
所以当你有很多用户定义函数(udfs)或者udf逻辑非常复杂,并且你不想每次都自己注册它们时,你可以使用flink.udf.jars
- 步骤1. 在您的IDE中创建一个udf项目,在那里编写您的udf。
- 步骤 2. 设置
flink.udf.jars指向你从 udf 项目构建的 udf jar
例如,
%flink.conf
flink.execution.jars /usr/lib/flink-udf-1.0-SNAPSHOT.jar
Zeppelin 会扫描这个 jar 文件,找出所有的 udf 类,然后自动为你注册它们。
udf 的名称就是类名。例如,在 flink.udf.jars 中指定上述 udf jar 文件后,以下是 show functions 的输出。

默认情况下,Zeppelin会扫描此jar包中的所有类,因此如果您的jar包非常大,特别是当您的udf jar包有其他依赖项时,速度会非常慢。因此,在这种情况下,我们建议您指定flink.udf.jars.packages来指定要扫描的包,这可以减少要扫描的类的数量,并使udf检测更快。
如何使用Hive
为了在Flink中使用Hive,您必须进行以下设置。
- 将
zeppelin.flink.enableHive设置为 true - 将
zeppelin.flink.hive.version设置为您正在使用的 Hive 版本。 - 将
HIVE_CONF_DIR设置为hive-site.xml所在的位置。确保hive元数据存储已启动,并且您已在hive-site.xml中配置了hive.metastore.uris - 将以下依赖项复制到flink安装的lib文件夹中。
- flink-connector-hive_2.11–*.jar
- flink-hadoop-compatibility_2.11–*.jar
- hive-exec-2.x.jar (对于hive 1.x,您需要复制hive-exec-1.x.jar, hive-metastore-1.x.jar, libfb303–0.9.2.jar 和 libthrift-0.9.2.jar)
段落本地属性
在Streaming Data Visualization部分,我们通过段落本地属性type展示了不同的可视化类型。
在本节中,我们将列出并解释Flink解释器中支持的所有本地属性。
| 属性 | 默认值 | 描述 |
|---|---|---|
| type | 用于 %flink.ssql 来指定流式可视化类型(single, update, append) | |
| refreshInterval | 3000 | 用于 `%flink.ssql` 中指定流数据可视化的前端刷新间隔。 |
| template | {0} | 在`%flink.ssql`中使用,用于指定`single`类型的流数据可视化的html模板,并且你可以使用`{i}`作为结果中第{i}列的占位符。 |
| parallelism | 用于 %flink.ssql 和 %flink.bsql 来指定 Flink SQL 作业的并行度 | |
| maxParallelism | 用于 %flink.ssql 和 %flink.bsql 以指定 Flink SQL 作业的最大并行度,以防您以后想要更改并行度。有关更多详细信息,请参阅此 [链接](https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/parallel.html#setting-the-maximum-parallelism) | |
| savepointDir | 如果指定了该目录,那么当你在Zeppelin中取消你的flink作业时,它也会进行保存点并将状态存储在此目录中。当你恢复作业时,它将从此保存点恢复。 | |
| execution.savepoint.path | 当你恢复你的作业时,它将从这个保存点路径恢复。 | |
| resumeFromSavepoint | 如果指定了savepointDir,则从保存点恢复flink作业。 | |
| resumeFromLatestCheckpoint | 如果启用了检查点,则从最新的检查点恢复flink作业。 | |
| runAsOne | false | 如果为true,所有插入SQL将在单个flink作业中运行。 |
教程笔记
Zeppelin 附带了几篇 Flink 教程笔记,这些笔记可能对您有所帮助。您可以在教程笔记中查看更多功能。
社区
Join our community 与其他人讨论。