任务¶
任务(Task)是Airflow中的基本执行单元。任务被组织到DAGs中,然后通过设置上下游依赖关系来定义它们的执行顺序。
有三种基本类型的任务:
Operators,预定义的任务模板,您可以快速将它们串联起来构建DAG的大部分内容。
Sensors,一种特殊的Operator子类,专门用于等待外部事件发生。
一个经过TaskFlow装饰的
@task,这是一个打包成任务的自定义Python函数。
在内部,这些实际上都是Airflow的BaseOperator的子类,任务(Task)和操作符(Operator)的概念在某种程度上可以互换,但将它们视为独立的概念更有帮助 - 本质上,操作符和传感器是模板,当你在DAG文件中调用它们时,就是在创建一个任务。
关系¶
使用任务的关键部分在于定义它们之间的关系——它们的依赖关系,或者用Airflow中的术语来说,它们的上游和下游任务。你需要先声明任务,然后再声明它们之间的依赖关系。
注意
我们将直接位于另一个任务之前的任务称为上游任务。过去我们曾称其为父任务。 请注意,这个概念并不描述任务层次结构中更高层的任务(即它们不是该任务的直接父任务)。 同样的定义适用于下游任务,它必须是另一个任务的直接子任务。
有两种声明依赖关系的方式 - 使用 >> 和 << (位移)操作符:
first_task >> second_task >> [third_task, fourth_task]
或者更明确的 set_upstream 和 set_downstream 方法:
first_task.set_downstream(second_task)
third_task.set_upstream(second_task)
这两种方式实现的功能完全相同,但通常我们推荐使用位移运算符,因为在大多数情况下它们更易于阅读。
默认情况下,当任务的所有上游(父级)任务都成功时,该任务才会运行。但可以通过多种方式修改此行为,例如添加分支、仅等待部分上游任务,或根据当前运行在历史中的位置改变行为。更多信息请参阅控制流。
默认情况下,任务之间不会传递信息,且完全独立运行。如果您想要在任务间传递信息,应该使用XComs。
任务实例¶
就像每次运行时DAG会被实例化为DAG Run一样,DAG下的任务也会被实例化为任务实例。
任务实例是针对给定DAG(以及给定的数据间隔)运行该任务的具体实例。它们也是具有状态的任务表示,代表其处于生命周期的哪个阶段。
任务实例的可能状态包括:
none: 任务尚未进入执行队列(其依赖条件尚未满足)scheduled: 调度器已确定该任务的依赖条件满足,应该运行queued: 任务已分配给执行器,正在等待工作节点running: 任务正在worker上运行(或在本地/同步执行器上运行)success: 任务运行完成,没有错误restarting: 任务在运行时被外部请求重新启动failed: 任务在执行过程中出现错误,未能成功运行skipped: 任务由于分支、LatestOnly或类似原因被跳过。upstream_failed: 上游任务失败,且触发规则表明我们需要该任务up_for_retry: 任务失败,但仍有重试次数,将被重新调度。up_for_reschedule: 该任务是一个处于reschedule模式的Sensordeferred: 任务已被延迟到触发器removed: 自运行开始以来,该任务已从DAG中消失
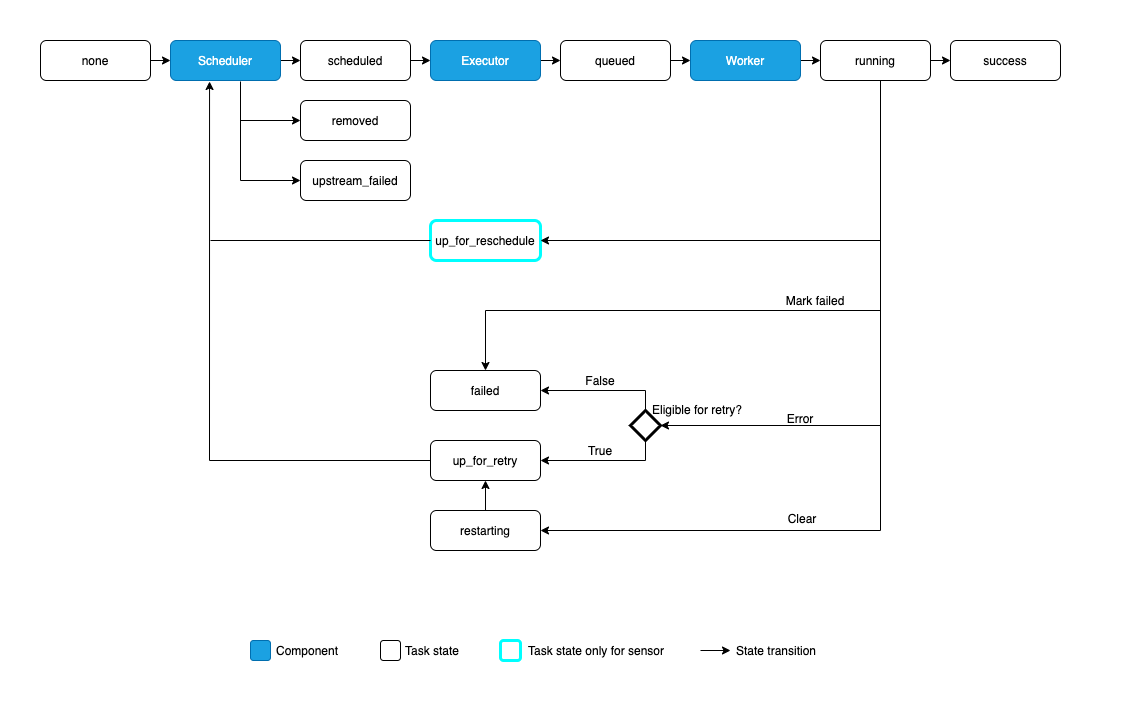
理想情况下,一个任务应该从none状态流转到scheduled,再到queued,然后进入running,最终达到success状态。
当任何自定义任务(Operator)运行时,它将获得传递给它的任务实例副本;除了能够检查任务元数据外,它还包含诸如XComs等功能的方法。
关系术语¶
对于任何给定的任务实例,它与其他实例之间存在两种类型的关系。
首先,它可以有上游和下游任务:
task1 >> task2 >> task3
当DAG运行时,它会为这些相互上下游但具有相同数据间隔的任务创建实例。
也可能存在相同任务的实例,但针对不同的数据区间 - 来自同一DAG的其他运行。我们称这些为前驱和后继 - 这与上游和下游是不同的关系!
注意
一些较旧的Airflow文档可能仍使用"previous"表示"upstream"。如果您发现这种情况,请帮助我们修正它!
超时设置¶
如果想要为任务设置最大运行时间,请将其execution_timeout属性设为datetime.timedelta值作为允许的最长运行时间。这适用于所有Airflow任务,包括传感器。execution_timeout控制每次执行允许的最大时间。如果超过execution_timeout限制,任务将超时并引发AirflowTaskTimeout异常。
此外,传感器有一个timeout参数。这仅对处于reschedule模式的传感器有意义。timeout控制传感器成功运行的最大允许时间。如果超过timeout,将引发AirflowSensorTimeout异常,传感器会立即失败且不会重试。
以下SFTPSensor示例说明了这一点。该sensor处于reschedule模式,意味着它会定期执行并重新调度,直到成功为止。
每次传感器探测SFTP服务器时,允许的最长时间为60秒,由
execution_timeout定义。如果传感器探测SFTP服务器的时间超过60秒,将会引发
AirflowTaskTimeout错误。 当这种情况发生时,传感器允许重试。根据retries参数的定义,最多可以重试2次。从第一次执行开始,直到最终成功(即文件'root/test'出现),传感器允许的最大时间为3600秒,如
timeout所定义。换句话说,如果文件在3600秒内未出现在SFTP服务器上,传感器将抛出AirflowSensorTimeout。当此错误抛出时,不会进行重试。如果传感器在3600秒间隔期间因网络中断等其他原因失败,它可以按照
retries定义最多重试2次。重试不会重置timeout。它仍然总共有最多3600秒的时间来成功。
sensor = SFTPSensor(
task_id="sensor",
path="/root/test",
execution_timeout=timedelta(seconds=60),
timeout=3600,
retries=2,
mode="reschedule",
)
如果您只想在任务超时运行时收到通知但仍允许其完成运行,您需要的是SLAs。
服务级别协议(SLAs)¶
SLA(服务等级协议)是指相对于Dag运行开始时间,任务应完成的最长预期时间。如果任务运行时间超过此限制,则会在用户界面的“SLA未达标”部分显示,同时会发送包含所有未达标任务的电子邮件通知。
超过SLA的任务不会被取消,而是允许其运行完成。如果您想在任务运行达到一定时间后取消它,您需要的是超时设置。
要为任务设置SLA,请将datetime.timedelta对象传递给任务/操作器的sla参数。您还可以提供sla_miss_callback,当SLA未达标时将调用此回调函数以执行自定义逻辑。
如果想完全禁用SLA检查,可以在Airflow的[core]配置中设置check_slas = False。
要了解更多关于邮件配置的信息,请参阅Email Configuration。
注意
手动触发的任务和事件驱动DAG中的任务不会检查是否违反SLA。有关DAGschedule值的更多信息,请参阅DAG Run。
sla_miss_callback¶
你也可以提供一个sla_miss_callback,当SLA未达标时会调用它,以便运行你自己的逻辑。
sla_miss_callback的函数签名需要5个参数。
dagtask_list自上次
sla_miss_callback运行以来,所有错过SLA的任务的字符串列表(以换行符\n分隔)。
blocking_task_listslas与
task_list参数中任务相关联的SlaMiss对象列表。
blocking_tis与
blocking_task_list参数中任务相关联的TaskInstance对象列表。
sla_miss_callback 函数签名的示例:
def my_sla_miss_callback(dag, task_list, blocking_task_list, slas, blocking_tis): ...
def my_sla_miss_callback(*args): ...
示例DAG:
def sla_callback(dag, task_list, blocking_task_list, slas, blocking_tis):
print(
"The callback arguments are: ",
{
"dag": dag,
"task_list": task_list,
"blocking_task_list": blocking_task_list,
"slas": slas,
"blocking_tis": blocking_tis,
},
)
@dag(
schedule="*/2 * * * *",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
sla_miss_callback=sla_callback,
default_args={"email": "email@example.com"},
)
def example_sla_dag():
@task(sla=datetime.timedelta(seconds=10))
def sleep_20():
"""Sleep for 20 seconds"""
time.sleep(20)
@task
def sleep_30():
"""Sleep for 30 seconds"""
time.sleep(30)
sleep_20() >> sleep_30()
example_dag = example_sla_dag()
特殊异常¶
如果你想在自定义任务/操作器代码中控制任务状态,Airflow提供了两个可以抛出的特殊异常:
AirflowSkipException会将当前任务标记为已跳过AirflowFailException会将当前任务标记为失败 忽略任何剩余的重试尝试
当您的代码对其运行环境有额外了解并希望更快地失败/跳过时,这些功能会很有用 - 例如,当知道没有可用数据时跳过,或者在检测到API密钥无效时快速失败(因为重试无法解决此问题)。
僵尸/未完成任务¶
没有任何系统能完美运行,任务实例偶尔会失败是正常现象。Airflow 能检测到两种任务/进程不匹配的情况:
僵尸任务是指那些
TaskInstances处于running状态,但其关联作业已不活跃的情况 (例如,进程因被终止或机器宕机而未能发送最近的心跳信号)。Airflow会定期发现这些任务, 清理它们,并根据设置决定是让任务失败还是重试。任务变成僵尸的原因有很多,包括:Airflow工作进程内存耗尽并被OOMKilled终止。
Airflow worker 未能通过存活探针检测,因此系统(例如 Kubernetes)重启了该 worker。
系统(例如Kubernetes)进行了缩减操作,并将一个Airflow worker从一个节点迁移到了另一个节点。
僵尸任务是指那些不应该在运行但实际上仍在运行的任务,通常是由于通过用户界面手动编辑任务实例导致的。Airflow会定期发现并终止这些任务。
以下是来自Airflow调度器的代码片段,它会定期运行以检测僵尸/未终止任务。
def _find_and_purge_zombies(self) -> None:
"""
Find and purge zombie task instances.
Zombie instances are tasks that failed to heartbeat for too long, or
have a no-longer-running LocalTaskJob.
A TaskCallbackRequest is also created for the killed zombie to be
handled by the DAG processor, and the executor is informed to no longer
count the zombie as running when it calculates parallelism.
"""
with create_session() as session:
if zombies := self._find_zombies(session=session):
self._purge_zombies(zombies, session=session)
def _find_zombies(self, *, session: Session) -> list[tuple[TI, str, str]]:
from airflow.jobs.job import Job
self.log.debug("Finding 'running' jobs without a recent heartbeat")
limit_dttm = timezone.utcnow() - timedelta(seconds=self._zombie_threshold_secs)
zombies = (
session.execute(
select(TI, DM.fileloc, DM.processor_subdir)
.with_hint(TI, "USE INDEX (ti_state)", dialect_name="mysql")
.join(Job, TI.job_id == Job.id)
.join(DM, TI.dag_id == DM.dag_id)
.where(TI.state == TaskInstanceState.RUNNING)
.where(or_(Job.state != JobState.RUNNING, Job.latest_heartbeat < limit_dttm))
.where(Job.job_type == "LocalTaskJob")
.where(TI.queued_by_job_id == self.job.id)
)
.unique()
.all()
)
if zombies:
self.log.warning("Failing (%s) jobs without heartbeat after %s", len(zombies), limit_dttm)
return zombies
def _purge_zombies(self, zombies: list[tuple[TI, str, str]], *, session: Session) -> None:
for ti, file_loc, processor_subdir in zombies:
zombie_message_details = self._generate_zombie_message_details(ti)
request = TaskCallbackRequest(
full_filepath=file_loc,
processor_subdir=processor_subdir,
simple_task_instance=SimpleTaskInstance.from_ti(ti),
msg=str(zombie_message_details),
)
session.add(
Log(
event="heartbeat timeout",
task_instance=ti.key,
extra=(
f"Task did not emit heartbeat within time limit ({self._zombie_threshold_secs} "
"seconds) and will be terminated. "
"See https://airflow.apache.org/docs/apache-airflow/"
"stable/core-concepts/tasks.html#zombie-undead-tasks"
),
)
)
self.log.error(
"Detected zombie job: %s "
"(See https://airflow.apache.org/docs/apache-airflow/"
"stable/core-concepts/tasks.html#zombie-undead-tasks)",
request,
)
self.job.executor.send_callback(request)
if (executor := self._try_to_load_executor(ti.executor)) is None:
self.log.warning("Cannot clean up zombie %r with non-existent executor %s", ti, ti.executor)
continue
executor.change_state(ti.key, TaskInstanceState.FAILED, remove_running=True)
Stats.incr("zombies_killed", tags={"dag_id": ti.dag_id, "task_id": ti.task_id})
上述代码片段中用于检测僵尸任务的标准解释如下:
任务实例状态
只有处于运行状态的任务实例才会被视为潜在的僵尸任务。
作业状态与心跳检查
当关联作业未处于运行状态,或作业的最新心跳时间早于计算的时间阈值(limit_dttm)时,系统会判定存在僵尸任务。心跳机制用于指示任务或作业仍然存活并运行中。
任务类型
与任务关联的作业必须是
LocalTaskJob类型。按作业ID排队
仅考虑由当前正在处理的同一作业排队的任务。
这些条件共同帮助识别运行中的任务是否可能成为僵尸任务,依据其状态、关联作业状态、心跳状态、作业类型以及排队它们的特定作业。如果任务符合这些标准,则被视为潜在的僵尸任务,并采取进一步操作,例如记录日志和发送回调请求。
在本地重现僵尸任务¶
如果您希望在开发/测试过程中重现僵尸任务,请按照以下步骤操作:
为您的本地Airflow设置配置以下环境变量(或者您也可以调整airflow.cfg中对应的配置值)
export AIRFLOW__SCHEDULER__LOCAL_TASK_JOB_HEARTBEAT_SEC=600
export AIRFLOW__SCHEDULER__SCHEDULER_ZOMBIE_TASK_THRESHOLD=2
export AIRFLOW__SCHEDULER__ZOMBIE_DETECTION_INTERVAL=5
拥有一个包含耗时约10分钟完成的任务的DAG(即长时间运行的任务)。例如,您可以使用以下DAG:
from airflow.decorators import dag
from airflow.operators.bash import BashOperator
from datetime import datetime
@dag(start_date=datetime(2021, 1, 1), schedule="@once", catchup=False)
def sleep_dag():
t1 = BashOperator(
task_id="sleep_10_minutes",
bash_command="sleep 600",
)
sleep_dag()
运行上述DAG并等待一段时间。您应该会看到任务实例变成僵尸任务,然后被调度器终止。
执行器配置¶
部分Executors允许可选的每任务配置 - 例如KubernetesExecutor,它允许您设置运行任务的镜像。
这是通过任务或操作器的executor_config参数实现的。以下是一个为将在KubernetesExecutor上运行的任务设置Docker镜像的示例:
MyOperator(...,
executor_config={
"KubernetesExecutor":
{"image": "myCustomDockerImage"}
}
)
你可以传入executor_config的设置因执行器而异,因此请阅读individual executor documentation以了解可以设置的内容。