构建运行中的管道¶
让我们看另一个例子:我们需要从在线托管的文件中获取一些数据,并将其插入到本地数据库中。在插入时还需要考虑去除重复行。
请注意: 本教程中使用的操作符已弃用。 其推荐的替代方案SQLExecuteQueryOperator功能类似。 您可能会发现此指南有所帮助。
初始设置¶
我们需要安装Docker,因为本示例将使用在Docker中运行Airflow的流程。 以下步骤应该足够,但完整说明请参阅快速入门文档。
# Download the docker-compose.yaml file
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/stable/docker-compose.yaml'
# Make expected directories and set an expected environment variable
mkdir -p ./dags ./logs ./plugins
echo -e "AIRFLOW_UID=$(id -u)" > .env
# Initialize the database
docker compose up airflow-init
# Start up all services
docker compose up
所有服务启动后,可以通过以下地址访问web界面:http://localhost:8080。默认账户的用户名是airflow,密码为airflow。
我们还需要创建一个到postgres数据库的连接。要通过网页界面创建连接,请从"Admin"菜单中选择"Connections",然后点击加号"Add a new record"来向连接列表中添加新记录。
按如下所示填写字段。注意Connection Id值,我们将把它作为postgres_conn_id参数的参数值传递。
连接ID: tutorial_pg_conn
连接类型: postgres
主机: postgres
Schema: airflow
登录: airflow
密码: airflow
端口: 5432
测试您的连接,如果测试成功,请保存您的连接。
数据表创建任务¶
我们可以使用PostgresOperator来定义在Postgres数据库中创建表的任务。
我们将创建一个表来简化数据清洗步骤(employees_temp),另一个表用于存储清洗后的数据(employees)。
from airflow.providers.postgres.operators.postgres import PostgresOperator
create_employees_table = PostgresOperator(
task_id="create_employees_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
CREATE TABLE IF NOT EXISTS employees (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
create_employees_temp_table = PostgresOperator(
task_id="create_employees_temp_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
DROP TABLE IF EXISTS employees_temp;
CREATE TABLE employees_temp (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
可选:使用文件中的SQL¶
如果您希望将这些SQL语句从DAG中抽象出来,可以将这些SQL语句文件移动到dags/目录下的某个位置,并将sql文件路径(相对于dags/)传递给sql关键字参数。例如对于employees,可以在dags/中创建一个sql目录,将employees的DDL放入dags/sql/employees_schema.sql,然后将PostgresOperator()修改为:
create_employees_table = PostgresOperator(
task_id="create_employees_table",
postgres_conn_id="tutorial_pg_conn",
sql="sql/employees_schema.sql",
)
并对 employees_temp 表重复此操作。
数据检索任务¶
在这里我们获取数据,将其保存到Airflow实例上的一个文件中,然后将数据从该文件加载到一个中间表,以便执行数据清洗步骤。
import os
import requests
from airflow.decorators import task
from airflow.providers.postgres.hooks.postgres import PostgresHook
@task
def get_data():
# NOTE: configure this as appropriate for your airflow environment
data_path = "/opt/airflow/dags/files/employees.csv"
os.makedirs(os.path.dirname(data_path), exist_ok=True)
url = "https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/tutorial/pipeline_example.csv"
response = requests.request("GET", url)
with open(data_path, "w") as file:
file.write(response.text)
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
with open(data_path, "r") as file:
cur.copy_expert(
"COPY employees_temp FROM STDIN WITH CSV HEADER DELIMITER AS ',' QUOTE '\"'",
file,
)
conn.commit()
数据合并任务¶
这里我们从检索到的数据中选择完全唯一的记录,然后检查是否有任何员工的序列号已存在于数据库中(如果存在,则用新数据更新这些记录)。
from airflow.decorators import task
from airflow.providers.postgres.hooks.postgres import PostgresHook
@task
def merge_data():
query = """
INSERT INTO employees
SELECT *
FROM (
SELECT DISTINCT *
FROM employees_temp
) t
ON CONFLICT ("Serial Number") DO UPDATE
SET
"Employee Markme" = excluded."Employee Markme",
"Description" = excluded."Description",
"Leave" = excluded."Leave";
"""
try:
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
cur.execute(query)
conn.commit()
return 0
except Exception as e:
return 1
完成我们的DAG¶
我们已经开发了任务,现在需要将它们封装在一个DAG中,这使我们能够定义任务的运行时间和方式,并声明任务之间的依赖关系。下面的DAG配置用于:
从2021年1月1日开始,每天午夜运行
仅在遗漏天数的情况下运行一次,并且
60分钟后超时
从process_employees DAG定义的最后一行我们可以看到:
[create_employees_table, create_employees_temp_table] >> get_data() >> merge_data()
merge_data()任务依赖于get_data()任务get_data()依赖于create_employees_table和create_employees_temp_table两个任务,并且create_employees_table和create_employees_temp_table任务可以独立运行。
将所有部分整合在一起,我们就完成了DAG的构建。
import datetime
import pendulum
import os
import requests
from airflow.decorators import dag, task
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.providers.postgres.operators.postgres import PostgresOperator
@dag(
dag_id="process_employees",
schedule_interval="0 0 * * *",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
dagrun_timeout=datetime.timedelta(minutes=60),
)
def ProcessEmployees():
create_employees_table = PostgresOperator(
task_id="create_employees_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
CREATE TABLE IF NOT EXISTS employees (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
create_employees_temp_table = PostgresOperator(
task_id="create_employees_temp_table",
postgres_conn_id="tutorial_pg_conn",
sql="""
DROP TABLE IF EXISTS employees_temp;
CREATE TABLE employees_temp (
"Serial Number" NUMERIC PRIMARY KEY,
"Company Name" TEXT,
"Employee Markme" TEXT,
"Description" TEXT,
"Leave" INTEGER
);""",
)
@task
def get_data():
# NOTE: configure this as appropriate for your airflow environment
data_path = "/opt/airflow/dags/files/employees.csv"
os.makedirs(os.path.dirname(data_path), exist_ok=True)
url = "https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/tutorial/pipeline_example.csv"
response = requests.request("GET", url)
with open(data_path, "w") as file:
file.write(response.text)
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
with open(data_path, "r") as file:
cur.copy_expert(
"COPY employees_temp FROM STDIN WITH CSV HEADER DELIMITER AS ',' QUOTE '\"'",
file,
)
conn.commit()
@task
def merge_data():
query = """
INSERT INTO employees
SELECT *
FROM (
SELECT DISTINCT *
FROM employees_temp
) t
ON CONFLICT ("Serial Number") DO UPDATE
SET
"Employee Markme" = excluded."Employee Markme",
"Description" = excluded."Description",
"Leave" = excluded."Leave";
"""
try:
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
cur.execute(query)
conn.commit()
return 0
except Exception as e:
return 1
[create_employees_table, create_employees_temp_table] >> get_data() >> merge_data()
dag = ProcessEmployees()
将此代码保存到/dags文件夹中的python文件(例如dags/process_employees.py),(经过短暂延迟后),process_employees DAG将会出现在web界面的可用DAG列表中。
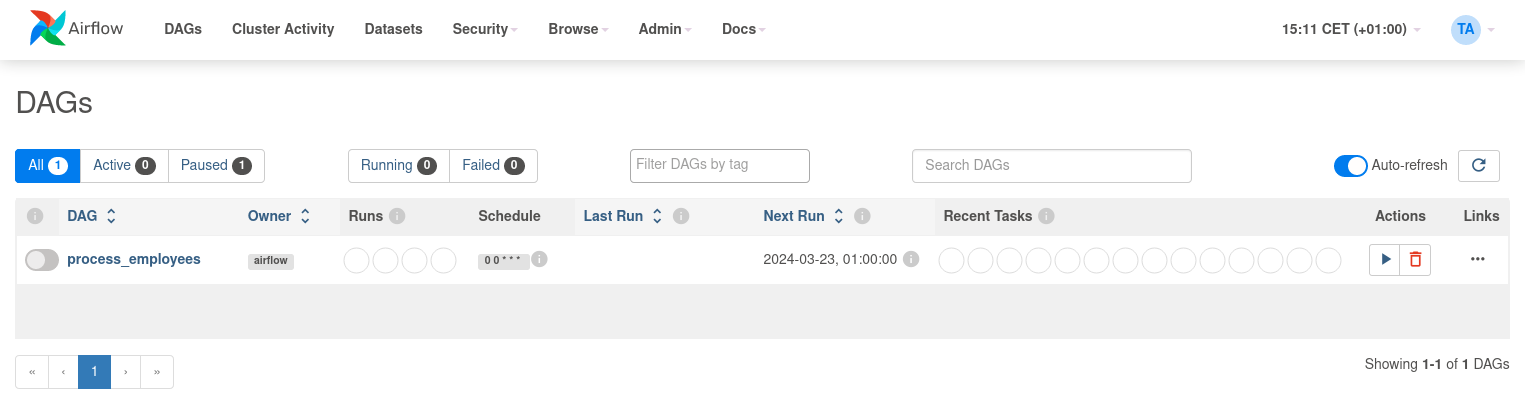
你可以通过取消暂停(通过左侧的滑块)并运行(通过操作下的运行按钮)来触发process_employees DAG。
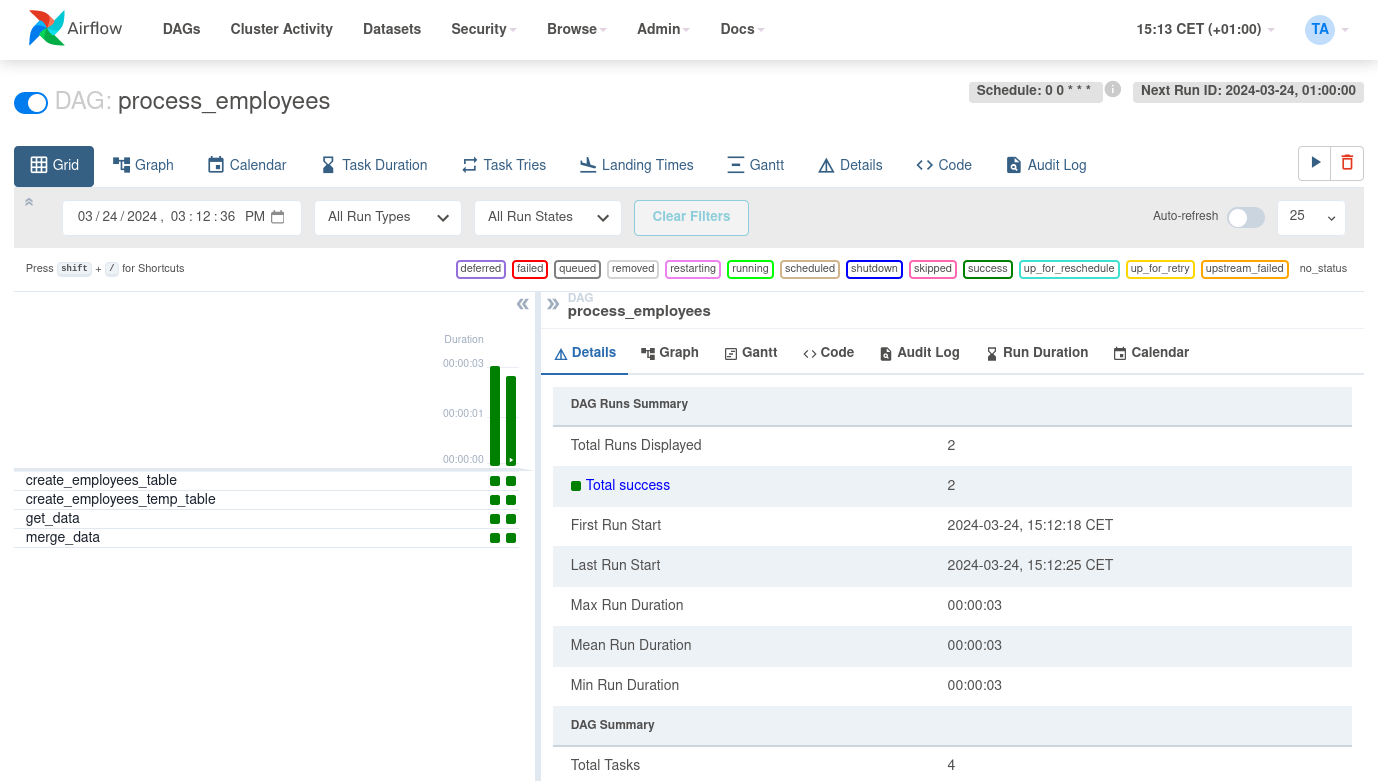
在process_employees DAG的网格视图中,我们可以看到所有任务在所有执行运行中都成功运行。成功!
下一步是什么?¶
您现在已经在使用Docker Compose在Airflow中运行了一个管道。以下是您接下来可能想做的几件事: