注意
Go to the end to download the full example code
图的生成模型
作者: Mufei Li, Lingfan Yu, Zheng Zhang
警告
本教程旨在通过代码作为解释手段,深入理解论文内容。因此,实现并未针对运行效率进行优化。如需推荐的实现,请参考官方示例。
在本教程中,您将学习如何一次训练和生成一个图。您还将探索图嵌入操作中的并行性,这是一个基本的构建块。教程最后介绍了一个简单的优化方法,通过跨图批处理,速度提高了一倍。
早期的教程展示了如何通过嵌入图或节点来执行任务,例如节点的半监督分类或情感分析。预测图的未来演变并迭代执行分析,这不是很有趣吗?
为了解决图的演化问题,你需要生成各种图样本。换句话说,你需要图的生成模型。除了学习节点和边的特征外,你还需要对任意图的分布进行建模。虽然一般的生成模型可以显式或隐式地建模密度函数,并一次性或顺序生成样本,但在这里我们只关注用于顺序生成的显式生成模型。典型的应用包括药物或材料发现、化学过程或蛋白质组学。
介绍
在深度图库(DGL)中,改变图的基本操作无非是add_nodes和add_edges。也就是说,如果你要画一个由三个节点组成的圆,

你可以按照以下方式编写代码。
import os
os.environ["DGLBACKEND"] = "pytorch"
import dgl
g = dgl.DGLGraph()
g.add_nodes(1) # Add node 0
g.add_nodes(1) # Add node 1
# Edges in DGLGraph are directed by default.
# For undirected edges, add edges for both directions.
g.add_edges([1, 0], [0, 1]) # Add edges (1, 0), (0, 1)
g.add_nodes(1) # Add node 2
g.add_edges([2, 1], [1, 2]) # Add edges (2, 1), (1, 2)
g.add_edges([2, 0], [0, 2]) # Add edges (2, 0), (0, 2)
/home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/checkouts/latest/python/dgl/heterograph.py:92: DGLWarning: Recommend creating graphs by `dgl.graph(data)` instead of `dgl.DGLGraph(data)`.
dgl_warning(
现实世界中的图要复杂得多。有许多不同大小、拓扑结构、节点类型、边类型的图族,以及多重图的可能性。此外,同一个图可以以许多不同的顺序生成。无论如何,生成过程都包含几个步骤。
编码一个变化的图形。
随机执行操作。
如果您正在训练,请收集错误信号并优化模型参数。
在实现方面,另一个重要的方面是速度。考虑到生成图本质上是一个顺序过程,你如何并行化计算?
注意
可以肯定的是,这不一定是一个硬性约束。子图可以并行构建,然后进行组装。但在本教程中,我们将限制自己使用顺序过程。
DGMG: 主要流程
在本教程中,您将使用 Deep Generative Models of Graphs ) (DGMG) 来实现一个使用DGL的图生成模型。其算法框架是通用的,但也具有并行化的挑战性。
注意
虽然DGMG能够处理具有类型节点、类型边和多图的复杂图,但在这里您使用其简化版本来生成图拓扑。
DGMG通过遵循一个状态机生成图,这基本上是一个两级循环。一次生成一个节点,并将其连接到现有节点的一个子集,一次一个。这与语言建模类似。生成过程是一个迭代过程,一次发出一个单词、字符或句子,基于到目前为止生成的序列。
- At each time step, you either:
向图中添加一个新节点
选择两个现有节点并在它们之间添加一条边
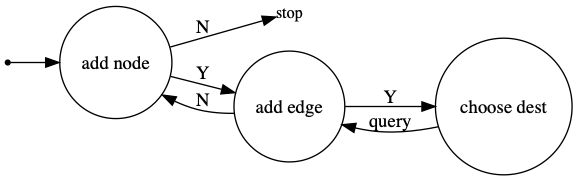
Python代码将如下所示。实际上,这正是DGL中实现DGMG推理的方式。
def forward_inference(self):
stop = self.add_node_and_update()
while (not stop) and (self.g.num_nodes() < self.v_max + 1):
num_trials = 0
to_add_edge = self.add_edge_or_not()
while to_add_edge and (num_trials < self.g.num_nodes() - 1):
self.choose_dest_and_update()
num_trials += 1
to_add_edge = self.add_edge_or_not()
stop = self.add_node_and_update()
return self.g
假设你有一个预训练的模型用于生成节点10-20的循环。 在推理过程中,它如何即时生成一个循环?使用下面的代码 用你自己的模型创建一个动画。
import torch
import matplotlib.animation as animation
import matplotlib.pyplot as plt
import networkx as nx
from copy import deepcopy
if __name__ == '__main__':
# pre-trained model saved with path ./model.pth
model = torch.load('./model.pth')
model.eval()
g = model()
src_list = g.edges()[1]
dest_list = g.edges()[0]
evolution = []
nx_g = nx.Graph()
evolution.append(deepcopy(nx_g))
for i in range(0, len(src_list), 2):
src = src_list[i].item()
dest = dest_list[i].item()
if src not in nx_g.nodes():
nx_g.add_node(src)
evolution.append(deepcopy(nx_g))
if dest not in nx_g.nodes():
nx_g.add_node(dest)
evolution.append(deepcopy(nx_g))
nx_g.add_edges_from([(src, dest), (dest, src)])
evolution.append(deepcopy(nx_g))
def animate(i):
ax.cla()
g_t = evolution[i]
nx.draw_circular(g_t, with_labels=True, ax=ax,
node_color=['#FEBD69'] * g_t.num_nodes())
fig, ax = plt.subplots()
ani = animation.FuncAnimation(fig, animate,
frames=len(evolution),
interval=600)

DGMG: 优化目标
与语言建模类似,DGMG 使用行为克隆或教师强制来训练模型。假设每个图都存在一个生成它的预言动作序列 \(a_{1},\cdots,a_{T}\)。模型的作用是遵循这些动作,计算这些动作序列的联合概率,并最大化它们。
根据链式法则,取\(a_{1},\cdots,a_{T}\)的概率为:
优化目标就是典型的MLE损失:
def forward_train(self, actions):
"""
- actions: list
- Contains a_1, ..., a_T described above
- self.prepare_for_train()
- Initializes self.action_step to be 0, which will get
incremented by 1 every time it is called.
- Initializes objects recording log p(a_t|a_1,...a_{t-1})
Returns
-------
- self.get_log_prob(): log p(a_1, ..., a_T)
"""
self.prepare_for_train()
stop = self.add_node_and_update(a=actions[self.action_step])
while not stop:
to_add_edge = self.add_edge_or_not(a=actions[self.action_step])
while to_add_edge:
self.choose_dest_and_update(a=actions[self.action_step])
to_add_edge = self.add_edge_or_not(a=actions[self.action_step])
stop = self.add_node_and_update(a=actions[self.action_step])
return self.get_log_prob()
forward_train 和 forward_inference 之间的主要区别在于训练过程将oracle动作作为输入,并返回用于评估损失的log概率。
DGMG: 实现
DGMG 类
下面你可以找到模型的骨架代码。你将逐步填写每个函数的细节。
import torch.nn as nn
class DGMGSkeleton(nn.Module):
def __init__(self, v_max):
"""
Parameters
----------
v_max: int
Max number of nodes considered
"""
super(DGMGSkeleton, self).__init__()
# Graph configuration
self.v_max = v_max
def add_node_and_update(self, a=None):
"""Decide if to add a new node.
If a new node should be added, update the graph."""
return NotImplementedError
def add_edge_or_not(self, a=None):
"""Decide if a new edge should be added."""
return NotImplementedError
def choose_dest_and_update(self, a=None):
"""Choose destination and connect it to the latest node.
Add edges for both directions and update the graph."""
return NotImplementedError
def forward_train(self, actions):
"""Forward at training time. It records the probability
of generating a ground truth graph following the actions."""
return NotImplementedError
def forward_inference(self):
"""Forward at inference time.
It generates graphs on the fly."""
return NotImplementedError
def forward(self, actions=None):
# The graph you will work on
self.g = dgl.DGLGraph()
# If there are some features for nodes and edges,
# zero tensors will be set for those of new nodes and edges.
self.g.set_n_initializer(dgl.frame.zero_initializer)
self.g.set_e_initializer(dgl.frame.zero_initializer)
if self.training:
return self.forward_train(actions=actions)
else:
return self.forward_inference()
编码动态图
所有生成图的操作都是从概率分布中采样的。为了做到这一点,你需要将结构化数据,即图,投影到欧几里得空间中。挑战在于,这个过程,称为嵌入,需要在图发生变化时重复进行。
图嵌入
设 \(G=(V,E)\) 为任意图。每个节点 \(v\) 都有一个嵌入向量 \(\textbf{h}_{v} \in \mathbb{R}^{n}\)。同样,图也有一个嵌入向量 \(\textbf{h}_{G} \in \mathbb{R}^{k}\)。通常,\(k > n\),因为图包含的信息比单个节点更多。
图嵌入是节点嵌入在线性变换下的加权和:
第一项,\(\text{Sigmoid}(g_m(\textbf{h}_{v}))\),计算一个门控函数,可以被视为整体图嵌入对每个节点的关注程度。第二项\(f_{m}:\mathbb{R}^{n}\rightarrow\mathbb{R}^{k}\)将节点嵌入映射到图嵌入的空间。
将图嵌入实现为GraphEmbed类。
import torch
class GraphEmbed(nn.Module):
def __init__(self, node_hidden_size):
super(GraphEmbed, self).__init__()
# Setting from the paper
self.graph_hidden_size = 2 * node_hidden_size
# Embed graphs
self.node_gating = nn.Sequential(
nn.Linear(node_hidden_size, 1), nn.Sigmoid()
)
self.node_to_graph = nn.Linear(node_hidden_size, self.graph_hidden_size)
def forward(self, g):
if g.num_nodes() == 0:
return torch.zeros(1, self.graph_hidden_size)
else:
# Node features are stored as hv in ndata.
hvs = g.ndata["hv"]
return (self.node_gating(hvs) * self.node_to_graph(hvs)).sum(
0, keepdim=True
)
通过图传播更新节点嵌入
DGMG中更新节点嵌入的机制与图卷积网络类似。对于图中的节点\(v\),其邻居\(u\)会向其发送消息。
其中 \(\textbf{x}_{u,v}\) 是 \(u\) 和 \(v\) 之间边的嵌入。
在接收到所有邻居的消息后,\(v\) 使用节点激活向量对它们进行总结
并使用此信息更新其自身功能:
对所有节点同步执行上述所有操作称为一轮图传播。执行的图传播轮数越多,消息在整个图中传播的距离就越长。
使用DGL,您可以通过g.update_all实现图传播。
这里的消息符号可能有点令人困惑。研究人员可以将
\(\textbf{m}_{u\rightarrow v}\)称为消息,然而下面的消息函数
只传递\(\text{concat}([\textbf{h}_{u}, \textbf{x}_{u, v}])\)。
然后,为了效率考虑,操作\(\textbf{W}_{m}\text{concat}([\textbf{h}_{v}, \textbf{h}_{u}, \textbf{x}_{u, v}]) + \textbf{b}_{m}\)
会一次性在所有边上执行。
from functools import partial
class GraphProp(nn.Module):
def __init__(self, num_prop_rounds, node_hidden_size):
super(GraphProp, self).__init__()
self.num_prop_rounds = num_prop_rounds
# Setting from the paper
self.node_activation_hidden_size = 2 * node_hidden_size
message_funcs = []
node_update_funcs = []
self.reduce_funcs = []
for t in range(num_prop_rounds):
# input being [hv, hu, xuv]
message_funcs.append(
nn.Linear(
2 * node_hidden_size + 1, self.node_activation_hidden_size
)
)
self.reduce_funcs.append(partial(self.dgmg_reduce, round=t))
node_update_funcs.append(
nn.GRUCell(self.node_activation_hidden_size, node_hidden_size)
)
self.message_funcs = nn.ModuleList(message_funcs)
self.node_update_funcs = nn.ModuleList(node_update_funcs)
def dgmg_msg(self, edges):
"""For an edge u->v, return concat([h_u, x_uv])"""
return {"m": torch.cat([edges.src["hv"], edges.data["he"]], dim=1)}
def dgmg_reduce(self, nodes, round):
hv_old = nodes.data["hv"]
m = nodes.mailbox["m"]
message = torch.cat(
[hv_old.unsqueeze(1).expand(-1, m.size(1), -1), m], dim=2
)
node_activation = (self.message_funcs[round](message)).sum(1)
return {"a": node_activation}
def forward(self, g):
if g.num_edges() > 0:
for t in range(self.num_prop_rounds):
g.update_all(
message_func=self.dgmg_msg, reduce_func=self.reduce_funcs[t]
)
g.ndata["hv"] = self.node_update_funcs[t](
g.ndata["a"], g.ndata["hv"]
)
操作
所有动作都是从使用神经网络参数化的分布中采样的,这里依次展示。
操作 1: 添加节点
给定图嵌入向量 \(\textbf{h}_{G}\),评估
然后用于参数化一个伯努利分布,以决定是否添加一个新节点。
如果要添加一个新节点,请使用以下方式初始化其特征
其中 \(\textbf{h}_{\text{init}}\) 是一个可学习的嵌入模块,用于无类型节点。
import torch.nn.functional as F
from torch.distributions import Bernoulli
def bernoulli_action_log_prob(logit, action):
"""Calculate the log p of an action with respect to a Bernoulli
distribution. Use logit rather than prob for numerical stability."""
if action == 0:
return F.logsigmoid(-logit)
else:
return F.logsigmoid(logit)
class AddNode(nn.Module):
def __init__(self, graph_embed_func, node_hidden_size):
super(AddNode, self).__init__()
self.graph_op = {"embed": graph_embed_func}
self.stop = 1
self.add_node = nn.Linear(graph_embed_func.graph_hidden_size, 1)
# If to add a node, initialize its hv
self.node_type_embed = nn.Embedding(1, node_hidden_size)
self.initialize_hv = nn.Linear(
node_hidden_size + graph_embed_func.graph_hidden_size,
node_hidden_size,
)
self.init_node_activation = torch.zeros(1, 2 * node_hidden_size)
def _initialize_node_repr(self, g, node_type, graph_embed):
"""Whenver a node is added, initialize its representation."""
num_nodes = g.num_nodes()
hv_init = self.initialize_hv(
torch.cat(
[
self.node_type_embed(torch.LongTensor([node_type])),
graph_embed,
],
dim=1,
)
)
g.nodes[num_nodes - 1].data["hv"] = hv_init
g.nodes[num_nodes - 1].data["a"] = self.init_node_activation
def prepare_training(self):
self.log_prob = []
def forward(self, g, action=None):
graph_embed = self.graph_op["embed"](g)
logit = self.add_node(graph_embed)
prob = torch.sigmoid(logit)
if not self.training:
action = Bernoulli(prob).sample().item()
stop = bool(action == self.stop)
if not stop:
g.add_nodes(1)
self._initialize_node_repr(g, action, graph_embed)
if self.training:
sample_log_prob = bernoulli_action_log_prob(logit, action)
self.log_prob.append(sample_log_prob)
return stop
操作2:添加边
给定图嵌入向量 \(\textbf{h}_{G}\) 和最新节点 \(v\) 的节点嵌入向量 \(\textbf{h}_{v}\),您进行评估
然后用于参数化一个伯努利分布,以决定是否从\(v\)开始添加一条新边。
class AddEdge(nn.Module):
def __init__(self, graph_embed_func, node_hidden_size):
super(AddEdge, self).__init__()
self.graph_op = {"embed": graph_embed_func}
self.add_edge = nn.Linear(
graph_embed_func.graph_hidden_size + node_hidden_size, 1
)
def prepare_training(self):
self.log_prob = []
def forward(self, g, action=None):
graph_embed = self.graph_op["embed"](g)
src_embed = g.nodes[g.num_nodes() - 1].data["hv"]
logit = self.add_edge(torch.cat([graph_embed, src_embed], dim=1))
prob = torch.sigmoid(logit)
if self.training:
sample_log_prob = bernoulli_action_log_prob(logit, action)
self.log_prob.append(sample_log_prob)
else:
action = Bernoulli(prob).sample().item()
to_add_edge = bool(action == 0)
return to_add_edge
操作3:选择一个目的地
当动作2返回True时,为最新节点\(v\)选择一个目的地。
对于每个可能的目的地 \(u\in\{0, \cdots, v-1\}\),选择它的概率由以下公式给出:
from torch.distributions import Categorical
class ChooseDestAndUpdate(nn.Module):
def __init__(self, graph_prop_func, node_hidden_size):
super(ChooseDestAndUpdate, self).__init__()
self.graph_op = {"prop": graph_prop_func}
self.choose_dest = nn.Linear(2 * node_hidden_size, 1)
def _initialize_edge_repr(self, g, src_list, dest_list):
# For untyped edges, only add 1 to indicate its existence.
# For multiple edge types, use a one-hot representation
# or an embedding module.
edge_repr = torch.ones(len(src_list), 1)
g.edges[src_list, dest_list].data["he"] = edge_repr
def prepare_training(self):
self.log_prob = []
def forward(self, g, dest):
src = g.num_nodes() - 1
possible_dests = range(src)
src_embed_expand = g.nodes[src].data["hv"].expand(src, -1)
possible_dests_embed = g.nodes[possible_dests].data["hv"]
dests_scores = self.choose_dest(
torch.cat([possible_dests_embed, src_embed_expand], dim=1)
).view(1, -1)
dests_probs = F.softmax(dests_scores, dim=1)
if not self.training:
dest = Categorical(dests_probs).sample().item()
if not g.has_edges_between(src, dest):
# For undirected graphs, add edges for both directions
# so that you can perform graph propagation.
src_list = [src, dest]
dest_list = [dest, src]
g.add_edges(src_list, dest_list)
self._initialize_edge_repr(g, src_list, dest_list)
self.graph_op["prop"](g)
if self.training:
if dests_probs.nelement() > 1:
self.log_prob.append(
F.log_softmax(dests_scores, dim=1)[:, dest : dest + 1]
)
Putting it together
你现在已经准备好实现模型类的完整实现。
class DGMG(DGMGSkeleton):
def __init__(self, v_max, node_hidden_size, num_prop_rounds):
super(DGMG, self).__init__(v_max)
# Graph embedding module
self.graph_embed = GraphEmbed(node_hidden_size)
# Graph propagation module
self.graph_prop = GraphProp(num_prop_rounds, node_hidden_size)
# Actions
self.add_node_agent = AddNode(self.graph_embed, node_hidden_size)
self.add_edge_agent = AddEdge(self.graph_embed, node_hidden_size)
self.choose_dest_agent = ChooseDestAndUpdate(
self.graph_prop, node_hidden_size
)
# Forward functions
self.forward_train = partial(forward_train, self=self)
self.forward_inference = partial(forward_inference, self=self)
@property
def action_step(self):
old_step_count = self.step_count
self.step_count += 1
return old_step_count
def prepare_for_train(self):
self.step_count = 0
self.add_node_agent.prepare_training()
self.add_edge_agent.prepare_training()
self.choose_dest_agent.prepare_training()
def add_node_and_update(self, a=None):
"""Decide if to add a new node.
If a new node should be added, update the graph."""
return self.add_node_agent(self.g, a)
def add_edge_or_not(self, a=None):
"""Decide if a new edge should be added."""
return self.add_edge_agent(self.g, a)
def choose_dest_and_update(self, a=None):
"""Choose destination and connect it to the latest node.
Add edges for both directions and update the graph."""
self.choose_dest_agent(self.g, a)
def get_log_prob(self):
add_node_log_p = torch.cat(self.add_node_agent.log_prob).sum()
add_edge_log_p = torch.cat(self.add_edge_agent.log_prob).sum()
choose_dest_log_p = torch.cat(self.choose_dest_agent.log_prob).sum()
return add_node_log_p + add_edge_log_p + choose_dest_log_p
下面是一个动画,其中在前400个批次中,每训练10个批次后就会动态生成一个图表。你可以看到模型如何随着时间的推移而改进,并开始生成周期。
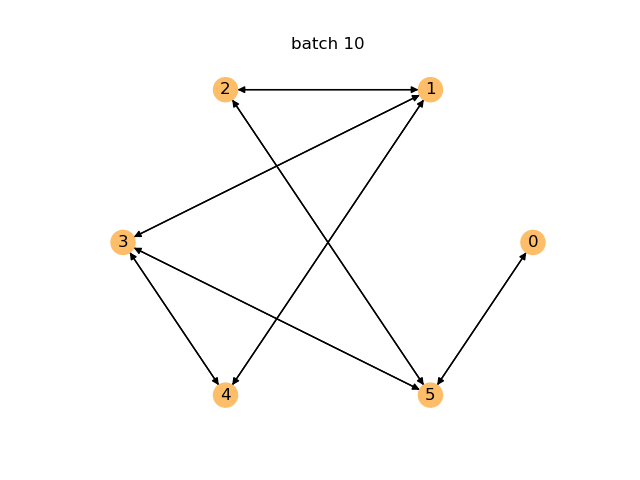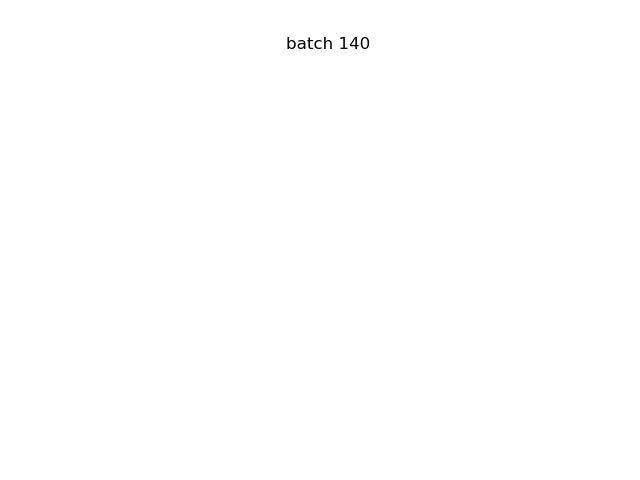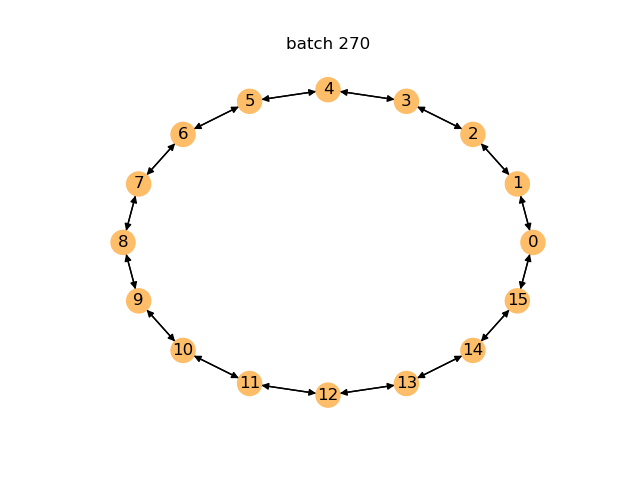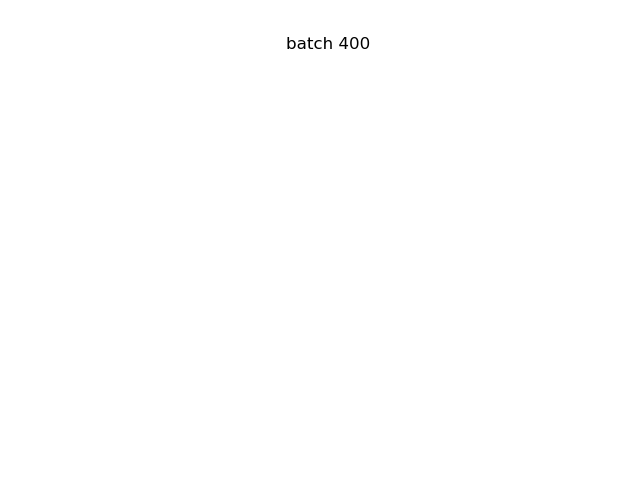
对于生成模型,您可以通过检查其即时生成的图中有效图的比例来评估性能。
import torch.utils.model_zoo as model_zoo
# Download a pre-trained model state dict for generating cycles with 10-20 nodes.
state_dict = model_zoo.load_url(
"https://data.dgl.ai/model/dgmg_cycles-5a0c40be.pth"
)
model = DGMG(v_max=20, node_hidden_size=16, num_prop_rounds=2)
model.load_state_dict(state_dict)
model.eval()
def is_valid(g):
# Check if g is a cycle having 10-20 nodes.
def _get_previous(i, v_max):
if i == 0:
return v_max
else:
return i - 1
def _get_next(i, v_max):
if i == v_max:
return 0
else:
return i + 1
size = g.num_nodes()
if size < 10 or size > 20:
return False
for node in range(size):
neighbors = g.successors(node)
if len(neighbors) != 2:
return False
if _get_previous(node, size - 1) not in neighbors:
return False
if _get_next(node, size - 1) not in neighbors:
return False
return True
num_valid = 0
for i in range(100):
g = model()
num_valid += is_valid(g)
del model
print("Among 100 graphs generated, {}% are valid.".format(num_valid))
/home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/checkouts/latest/tutorials/models/3_generative_model/5_dgmg.py:521: DeprecationWarning: an integer is required (got type float). Implicit conversion to integers using __int__ is deprecated, and may be removed in a future version of Python.
self.node_type_embed(torch.LongTensor([node_type])),
Among 100 graphs generated, 93% are valid.
有关完整实现,请参见DGL DGMG示例。
脚本的总运行时间: (0 分钟 17.501 秒)