注意
Go to the end to download the full example code
单机多GPU小批量图分类
在本教程中,您将学习如何在训练图神经网络(GNN)进行图分类时使用多个GPU。本教程假设您已经具备图分类的GNN知识,如果您不熟悉,我们建议您查看Training a GNN for Graph Classification。
(预计时间:8分钟)
在训练GNN时使用单个GPU,我们需要将模型、图和其他张量(例如标签)放在同一个GPU上:
import torch
# Use the first GPU
device = torch.device("cuda:0")
model = model.to(device)
graph = graph.to(device)
labels = labels.to(device)
图中的节点和边特征(如果有的话)也会在GPU上。之后,前向计算、反向计算和参数更新将在GPU上进行。对于图分类,这会在每个小批量梯度下降中重复进行。
使用多个GPU可以在单位时间内执行更多的计算。这就像有一个团队一起工作,每个GPU都是团队成员。我们需要将计算工作负载分配到各个GPU上,并让它们定期同步工作。PyTorch为此任务提供了方便的API,每个GPU对应一个进程,我们可以将它们与DGL结合使用。
直观上,我们可以沿着数据的维度分配工作负载。这使得多个GPU能够并行执行多个梯度下降的前向和反向计算。为了在多个GPU之间分配数据集,我们需要将其划分为多个大小相似的互斥子集,每个GPU一个。我们需要在每个epoch重复随机划分以保证随机性。我们可以使用GraphDataLoader(),它封装了一些PyTorch API并在数据加载中完成图分类的工作。
一旦所有GPU完成其小批量的反向计算,我们需要在它们之间同步模型参数更新。具体来说,这包括从所有GPU收集梯度,对它们进行平均,并在每个GPU上更新模型参数。我们可以使用DistributedDataParallel()包装一个PyTorch模型,以便模型参数更新将在底层首先调用梯度同步。
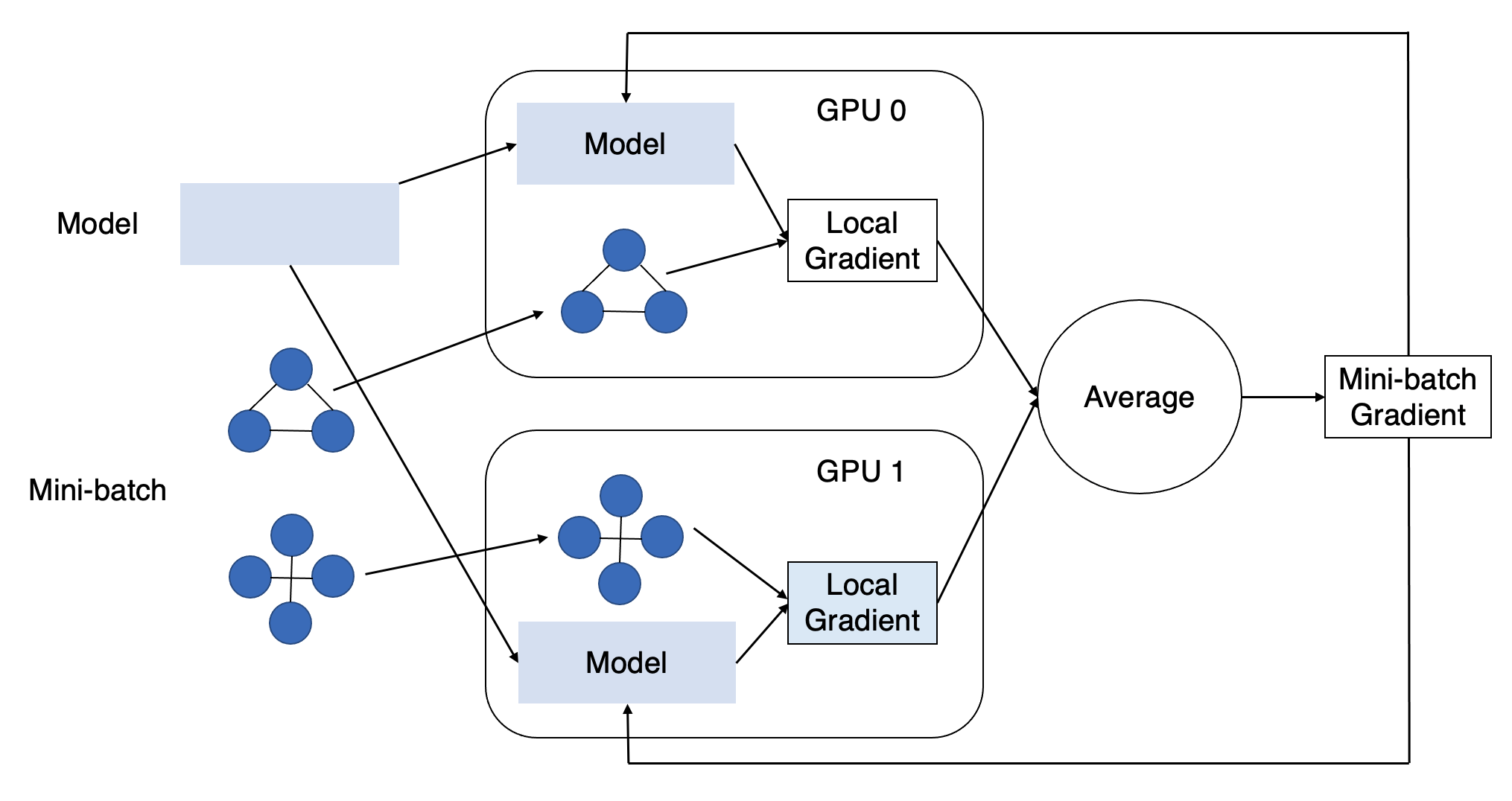
这是本教程的核心内容。我们将在下面通过一个完整的示例更详细地探讨它。
注意
请参阅此教程
来自PyTorch,了解使用DistributedDataParallel进行通用多GPU训练的信息。
分布式进程组初始化
为了在多GPU训练中的多个进程之间进行通信,我们需要在每个进程开始时启动分布式后端。我们使用world_size来指代进程的数量,使用rank来指代进程ID,它应该是一个从0到world_size - 1的整数。
import os
os.environ["DGLBACKEND"] = "pytorch"
import torch.distributed as dist
def init_process_group(world_size, rank):
dist.init_process_group(
backend="gloo", # change to 'nccl' for multiple GPUs
init_method="tcp://127.0.0.1:12345",
world_size=world_size,
rank=rank,
)
数据加载器准备
我们将数据集分为训练、验证和测试子集。在数据集分割过程中,我们需要在所有进程中使用相同的随机种子,以确保分割结果一致。我们遵循常见的做法,使用多个GPU进行训练,并使用单个GPU进行评估,因此仅在训练集的GraphDataLoader()中将use_ddp设置为True,其中ddp代表DistributedDataParallel()。
from dgl.data import split_dataset
from dgl.dataloading import GraphDataLoader
def get_dataloaders(dataset, seed, batch_size=32):
# Use a 80:10:10 train-val-test split
train_set, val_set, test_set = split_dataset(
dataset, frac_list=[0.8, 0.1, 0.1], shuffle=True, random_state=seed
)
train_loader = GraphDataLoader(
train_set, use_ddp=True, batch_size=batch_size, shuffle=True
)
val_loader = GraphDataLoader(val_set, batch_size=batch_size)
test_loader = GraphDataLoader(test_set, batch_size=batch_size)
return train_loader, val_loader, test_loader
模型初始化
在本教程中,我们使用了一个简化的图同构网络(GIN)。
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GINConv, SumPooling
class GIN(nn.Module):
def __init__(self, input_size=1, num_classes=2):
super(GIN, self).__init__()
self.conv1 = GINConv(
nn.Linear(input_size, num_classes), aggregator_type="sum"
)
self.conv2 = GINConv(
nn.Linear(num_classes, num_classes), aggregator_type="sum"
)
self.pool = SumPooling()
def forward(self, g, feats):
feats = self.conv1(g, feats)
feats = F.relu(feats)
feats = self.conv2(g, feats)
return self.pool(g, feats)
为了确保跨进程的初始模型参数相同,我们需要在模型初始化之前设置相同的随机种子。一旦我们构建了一个模型实例,我们就用DistributedDataParallel()来包装它。
import torch
from torch.nn.parallel import DistributedDataParallel
def init_model(seed, device):
torch.manual_seed(seed)
model = GIN().to(device)
if device.type == "cpu":
model = DistributedDataParallel(model)
else:
model = DistributedDataParallel(
model, device_ids=[device], output_device=device
)
return model
每个进程的主函数
定义模型评估函数,如同在单GPU设置中一样。
def evaluate(model, dataloader, device):
model.eval()
total = 0
total_correct = 0
for bg, labels in dataloader:
bg = bg.to(device)
labels = labels.to(device)
# Get input node features
feats = bg.ndata.pop("attr")
with torch.no_grad():
pred = model(bg, feats)
_, pred = torch.max(pred, 1)
total += len(labels)
total_correct += (pred == labels).sum().cpu().item()
return 1.0 * total_correct / total
为每个进程定义运行函数。
from torch.optim import Adam
def run(rank, world_size, dataset, seed=0):
init_process_group(world_size, rank)
if torch.cuda.is_available():
device = torch.device("cuda:{:d}".format(rank))
torch.cuda.set_device(device)
else:
device = torch.device("cpu")
model = init_model(seed, device)
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.01)
train_loader, val_loader, test_loader = get_dataloaders(dataset, seed)
for epoch in range(5):
model.train()
# The line below ensures all processes use a different
# random ordering in data loading for each epoch.
train_loader.set_epoch(epoch)
total_loss = 0
for bg, labels in train_loader:
bg = bg.to(device)
labels = labels.to(device)
feats = bg.ndata.pop("attr")
pred = model(bg, feats)
loss = criterion(pred, labels)
total_loss += loss.cpu().item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss = total_loss
print("Loss: {:.4f}".format(loss))
val_acc = evaluate(model, val_loader, device)
print("Val acc: {:.4f}".format(val_acc))
test_acc = evaluate(model, test_loader, device)
print("Test acc: {:.4f}".format(test_acc))
dist.destroy_process_group()
最后我们加载数据集并启动进程。
import torch.multiprocessing as mp
from dgl.data import GINDataset
def main():
if not torch.cuda.is_available():
print("No GPU found!")
return
num_gpus = torch.cuda.device_count()
dataset = GINDataset(name="IMDBBINARY", self_loop=False)
mp.spawn(run, args=(num_gpus, dataset), nprocs=num_gpus)
if __name__ == "__main__":
main()
No GPU found!
脚本的总运行时间: (0 分钟 0.005 秒)