ES|QL 参考
editES|QL 参考
editES|QL 语言的详细参考文档:
ES|QL 语法参考
edit基本语法
edit一个ES|QL查询由一个源命令组成,
后面跟着一个可选的处理命令系列,
用管道字符分隔:|。例如:
source-command | processing-command1 | processing-command2
查询的结果是由最终处理命令生成的表。
有关所有支持的命令、函数和操作符的概述,请参阅命令和函数和操作符。
为了提高可读性,本文档将每个处理命令放在新的一行。然而,您可以将ES|QL查询写成一行。以下查询与前一个查询相同:
source-command | processing-command1 | processing-command2
标识符
edit标识符需要用反引号(`)括起来,如果:
-
它们不以字母、
_或@开头 -
其他任何字符不是字母、数字或
_
例如:
FROM index | KEEP `1.field`
当引用一个本身使用带引号的标识符的函数别名时,带引号的标识符的反引号需要用另一个反引号进行转义。例如:
FROM index | STATS COUNT(`1.field`) | EVAL my_count = `COUNT(``1.field``)`
字面量
editES|QL 目前支持数字和字符串字面量。
字符串字面量
edit字符串字面量是由双引号(")分隔的Unicode字符序列。
// Filter by a string value FROM index | WHERE first_name == "Georgi"
如果字符串本身包含引号,这些引号需要进行转义(\\")。
ES|QL 还支持三重引号(""")分隔符,以方便使用:
ROW name = """Indiana "Indy" Jones"""
特殊字符 CR、LF 和 TAB 可以使用通常的转义方式表示:
\r、\n、\t。
数值字面量
edit数值字面量可以接受十进制和科学计数法表示,使用指数标记(e 或 E),可以以数字、小数点 . 或负号 - 开头:
1969 -- integer notation 3.14 -- decimal notation .1234 -- decimal notation starting with decimal point 4E5 -- scientific notation (with exponent marker) 1.2e-3 -- scientific notation with decimal point -.1e2 -- scientific notation starting with the negative sign
整数数值字面量会被隐式转换为 integer、long 或 double 类型,具体取决于哪个类型首先能够容纳字面量的值。
浮点字面量被隐式转换为double类型。
要获取不同类型的常量值,请使用其中一个数值类型的转换函数。
注释
editES|QL 使用 C++ 风格的注释:
-
双斜杠
//用于单行注释 -
/*和*/用于块注释
// Query the employees index FROM employees | WHERE height > 2
FROM /* Query the employees index */ employees | WHERE height > 2
FROM employees /* Query the * employees * index */ | WHERE height > 2
时间跨度字面量
edit日期时间间隔和时间段可以使用时间段字面量来表示。 时间段字面量由一个数字和一个限定符组成。这些限定符支持以下内容:
-
毫秒/毫秒/毫秒 -
秒/秒/秒/秒 -
分钟/分钟/分钟 -
小时/小时/小时 -
天/天/天 -
周/周/周 -
月/月/月 -
季度/季度/季度 -
年/年/年/年
时间跨度字面量对空格不敏感。这些表达式都是有效的:
-
1天 -
1天 -
1天
ES|QL 命令
edit
处理命令
editES|QL 处理命令通过添加、删除或更改行和列来改变输入表。

ES|QL 支持这些处理命令:
-
DISSECT -
DROP -
ENRICH -
EVAL -
GROK -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
INLINESTATS ... BY -
KEEP -
LIMIT -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
LOOKUP -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
MV_EXPAND -
RENAME -
SORT -
STATS ... BY -
WHERE
FROM
editThe FROM 源命令返回一个包含来自数据流、索引或别名的数据的表。
语法
FROM index_pattern [METADATA fields]
参数
-
index_pattern - 索引、数据流或别名的列表。支持通配符和日期数学。
-
fields - 要检索的以逗号分隔的元数据字段列表。
描述
The FROM source command returns a table with data from a data stream, index,
or alias. Each row in the resulting table represents a document. Each column
corresponds to a field, and can be accessed by the name of that field.
默认情况下,没有显式LIMIT的ES|QL查询使用隐式限制1000。这也适用于FROM。没有LIMIT的FROM命令:
FROM employees
执行如下:
FROM employees | LIMIT 1000
示例
FROM employees
您可以使用日期数学来引用索引、别名和数据流。这对于时间序列数据非常有用,例如访问今天的索引:
FROM <logs-{now/d}>
使用逗号分隔的列表或通配符来查询多个数据流、索引或别名:
FROM employees-00001,other-employees-*
使用格式
FROM cluster_one:employees-00001,cluster_two:other-employees-*
使用可选的 METADATA 指令来启用 元数据字段:
FROM employees METADATA _id
使用封闭的双引号(")或三个封闭的双引号(""")来转义包含特殊字符的索引名称:
FROM "this=that", """this[that"""
ROW
editThe ROW 源命令生成一行,其中包含一个或多个您指定的值的列。这对于测试非常有用。
语法
ROW column1 = value1[, ..., columnN = valueN]
参数
-
columnX - 列名。 在列名重复的情况下,只有最右边的重复列会创建一个列。
-
valueX - 列的值。可以是字面量、表达式或一个 函数。
示例
ROW a = 1, b = "two", c = null
| a:integer | b:keyword | c:null |
|---|---|---|
1 |
"二" |
空 |
使用方括号创建多值列:
ROW a = [2, 1]
ROW 支持使用 函数:
ROW a = ROUND(1.23, 0)
SHOW
editThe SHOW source 命令返回有关部署及其功能的信息。
语法
SHOW item
参数
-
item -
只能是
INFO。
示例
使用 SHOW INFO 返回部署的版本、构建日期和哈希值。
SHOW INFO
| version | date | hash |
|---|---|---|
8.13.0 |
2024-02-23T10:04:18.123117961Z |
04ba8c8db2507501c88f215e475de7b0798cb3b3 |
DISSECT
editDISSECT 使您能够 从字符串中提取结构化数据。
语法
DISSECT input "pattern" [APPEND_SEPARATOR="<separator>"]
参数
-
input -
包含您想要结构化的字符串的列。如果该列有多个值,
DISSECT将处理每个值。 -
pattern - 一个解析模式。 如果字段名与现有列冲突,则删除现有列。 如果字段名被多次使用,则只有最右边的重复项会创建列。
-
<separator> - 当使用append modifier时,用作附加值之间的分隔符的字符串。
描述
DISSECT 使您能够 从字符串中提取结构化数据。DISSECT 将字符串与基于分隔符的模式匹配,并提取指定的键作为列。
请参阅使用DISSECT处理数据以了解dissect模式的语法。
示例
以下示例解析包含时间戳、一些文本和IP地址的字符串:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a "%{date} - %{msg} - %{ip}"
| KEEP date, msg, ip
| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
一些文本 |
127.0.0.1 |
默认情况下,DISSECT 输出关键词字符串列。要转换为其他类型,请使用 类型转换函数:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a "%{date} - %{msg} - %{ip}"
| KEEP date, msg, ip
| EVAL date = TO_DATETIME(date)
| msg:keyword | ip:keyword | date:date |
|---|---|---|
一些文本 |
127.0.0.1 |
2023-01-23T12:15:00.000Z |
删除
editThe DROP 处理命令删除一个或多个列。
语法
DROP columns
参数
-
columns - 要移除的列的逗号分隔列表。支持通配符。
示例
FROM employees | DROP height
与其逐个指定列名,您可以使用通配符来删除所有名称与特定模式匹配的列:
FROM employees | DROP height*
ENRICH
editENRICH 使您能够使用扩充策略将现有索引中的数据添加为新列。
语法
ENRICH policy [ON match_field] [WITH [new_name1 = ]field1, [new_name2 = ]field2, ...]
参数
-
policy - 丰富策略的名称。你需要先创建 并执行丰富策略。
-
mode - 跨集群 ES|QL 中 enrich 命令的模式。 参见 跨集群 enrich。
-
match_field -
匹配字段。
ENRICH使用其值在 enrich 索引中查找记录。如果未指定,则将在与 enrich policy 中定义的match_field同名的列上执行匹配。 -
fieldX - 从扩展索引中添加到结果中的丰富字段作为新列。如果结果中已存在与丰富字段同名的列,则现有列将被新列替换。如果未指定,则策略中定义的每个丰富字段都将被添加。 除非丰富字段被重命名,否则与丰富字段同名的列将被删除。
-
new_nameX - 使您能够更改为每个丰富字段添加的列的名称。默认为丰富字段名称。 如果某一列的名称与新名称相同,它将被丢弃。 如果一个名称(新名称或原始名称)出现多次,只有最右边的重复项会创建一个新列。
描述
ENRICH 允许您使用扩充策略将现有索引中的数据添加为新列。有关设置策略的信息,请参阅数据扩充。

在使用 ENRICH 之前,您需要 创建并执行一个丰富策略。
示例
以下示例使用 languages_policy 丰富策略为策略中定义的每个丰富字段添加一个新列。匹配是使用 丰富策略 中定义的 match_field 执行的,并且要求输入表具有同名的列(在本例中为 language_code)。ENRICH 将根据匹配字段值在 丰富索引 中查找记录。
ROW language_code = "1" | ENRICH languages_policy
| language_code:keyword | language_name:keyword |
|---|---|
1 |
英语 |
要使用与策略中定义的 match_field 不同名称的列作为匹配字段,请使用 ON :
ROW a = "1" | ENRICH languages_policy ON a
| a:keyword | language_name:keyword |
|---|---|
1 |
英语 |
默认情况下,策略中定义的每个丰富字段都会被添加为一个列。要显式选择要添加的丰富字段,请使用WITH :
ROW a = "1" | ENRICH languages_policy ON a WITH language_name
| a:keyword | language_name:keyword |
|---|---|
1 |
英语 |
您可以使用 WITH new_name= 重命名添加的列:
ROW a = "1" | ENRICH languages_policy ON a WITH name = language_name
| a:keyword | name:keyword |
|---|---|
1 |
英语 |
如果发生名称冲突,新创建的列将覆盖现有列。
EVAL
editThe EVAL 处理命令使您能够添加具有计算值的新列。
语法
EVAL [column1 =] value1[, ..., [columnN =] valueN]
参数
-
columnX - 列名。 如果已存在同名列,则删除现有列。 如果列名被多次使用,则只有最右边的重复项会创建列。
-
valueX - 列的值。可以是字面量、表达式或函数。可以使用在此列左侧定义的列。
描述
The EVAL 处理命令使您能够添加具有计算值的新列。EVAL 支持各种用于计算值的函数。更多信息请参阅函数。
示例
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height_feet = height * 3.281, height_cm = height * 100
| first_name:keyword | last_name:keyword | height:double | height_feet:double | height_cm:double |
|---|---|---|---|---|
格奥尔基 |
法塞洛 |
2.03 |
6.66043 |
202.99999999999997 |
比撒列 |
齐美尔 |
2.08 |
6.82448 |
208.0 |
帕托 |
班福德 |
1.83 |
6.004230000000001 |
183.0 |
如果指定的列已经存在,现有的列将被删除,新的列将被添加到表中:
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height = height * 3.281
| first_name:keyword | last_name:keyword | height:double |
|---|---|---|
格奥尔基 |
法塞洛 |
6.66043 |
比撒列 |
齐美尔 |
6.82448 |
帕托 |
班福德 |
6.004230000000001 |
指定输出列名是可选的。如果未指定,新列名等于表达式。以下查询添加了一个名为height*3.281的列:
FROM employees | SORT emp_no | KEEP first_name, last_name, height | EVAL height * 3.281
| first_name:keyword | last_name:keyword | height:double | height * 3.281:double |
|---|---|---|---|
格奥尔基 |
法塞洛 |
2.03 |
6.66043 |
比撒列 |
齐美尔 |
2.08 |
6.82448 |
帕托 |
班福德 |
1.83 |
6.004230000000001 |
因为此名称包含特殊字符,在使用后续命令时需要用反引号(`)括起来:
FROM employees | EVAL height * 3.281 | STATS avg_height_feet = AVG(`height * 3.281`)
| avg_height_feet:double |
|---|
5.801464200000001 |
GROK
editGROK 使您能够 从字符串中提取结构化数据。
语法
GROK input "pattern"
参数
-
input -
包含您想要结构化的字符串的列。如果该列有多个值,
GROK将处理每个值。 -
pattern - 一个grok模式。 如果字段名与现有列冲突,则丢弃现有列。 如果字段名被多次使用,将创建一个多值列,每个字段名出现一次对应一个值。
描述
GROK 使您能够 从字符串中提取结构化数据。GROK 根据正则表达式匹配字符串,并将指定的模式提取为列。
请参阅使用GROK处理数据以了解grok模式的语法。
示例
以下示例解析包含时间戳、IP 地址、电子邮件地址和数字的字符串:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}"
| KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
默认情况下,GROK 输出关键词字符串列。int 和 float 类型可以通过在模式中的语义后附加 :type 来转换。例如 {NUMBER:num:int}:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
对于其他类型转换,请使用类型转换函数:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num
| EVAL date = TO_DATETIME(date)
| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
127.0.0.1 |
42 |
2023-01-23T12:15:00.000Z |
如果一个字段名称被多次使用,GROK 会创建一个多值列:
FROM addresses
| KEEP city.name, zip_code
| GROK zip_code "%{WORD:zip_parts} %{WORD:zip_parts}"
| city.name:keyword | zip_code:keyword | zip_parts:keyword |
|---|---|---|
阿姆斯特丹 |
1016 教育 |
["1016", "急诊"] |
旧金山 |
加利福尼亚州 94108 |
["加利福尼亚", "94108"] |
东京 |
100-7014 |
空 |
INLINESTATS ... BY
editINLINESTATS 高度实验性,仅在 SNAPSHOT 版本中可用。
The INLINESTATS 命令计算一个聚合结果,并将结果添加到输入数据流的新列中。
语法
INLINESTATS [column1 =] expression1[, ..., [columnN =] expressionN] [BY grouping_expression1[, ..., grouping_expressionN]]
参数
-
columnX -
返回的聚合值的名称。如果省略,名称等于相应的表达式(
expressionX)。如果多列具有相同的名称,则除具有此名称的最右列之外的所有列都将被忽略。 -
expressionX - 一个计算聚合值的表达式。如果其名称与某个计算列的名称相同,则该列将被忽略。
-
grouping_expressionX - 一个用于输出分组依据值的表达式。
在计算聚合时,会跳过单个的 null 值。
描述
The INLINESTATS 命令计算一个聚合结果并将该结果合并回输入数据的流中。如果没有可选的 BY 子句,这将生成一个结果并将其附加到每一行。使用 BY 子句时,这将按分组生成一个结果,并根据匹配的分组键将结果合并到流中。
所有聚合函数都受支持。
示例
找出会说最多语言的员工(这是一个平局!):
FROM employees | KEEP emp_no, languages | INLINESTATS max_lang = MAX(languages) | WHERE max_lang == languages | SORT emp_no ASC | LIMIT 5
| emp_no:integer | languages:integer | max_lang:integer |
|---|---|---|
10002 |
5 |
5 |
10004 |
5 |
5 |
10011 |
5 |
5 |
10012 |
5 |
5 |
10014 |
5 |
5 |
找出姓氏以字母表中每个字母开头的任职时间最长的员工:
FROM employees | KEEP emp_no, avg_worked_seconds, last_name | INLINESTATS max_avg_worked_seconds = MAX(avg_worked_seconds) BY SUBSTRING(last_name, 0, 1) | WHERE max_avg_worked_seconds == avg_worked_seconds | SORT last_name ASC | LIMIT 5
| emp_no:integer | avg_worked_seconds:long | last_name:keyword | SUBSTRING(last_name, 0, 1):keyword | max_avg_worked_seconds:long |
|---|---|---|---|---|
10065 |
372660279 |
阿德赫 |
一个 |
372660279 |
10074 |
382397583 |
伯纳茨基 |
B |
382397583 |
10044 |
387408356 |
卡斯利 |
摄氏度 |
387408356 |
10030 |
394597613 |
德梅尔 |
D |
394597613 |
10087 |
305782871 |
尤金尼奥 |
E |
305782871 |
查找最北和最南的机场:
FROM airports | MV_EXPAND type | EVAL lat = ST_Y(location) | INLINESTATS most_northern=MAX(lat), most_southern=MIN(lat) BY type | WHERE lat == most_northern OR lat == most_southern | SORT lat DESC | KEEP type, name, location
| type:keyword | name:text | location:geo_point |
|---|---|---|
中 |
斯瓦尔巴群岛朗伊尔城 |
POINT (15.495229 78.246717) |
专业 |
特罗姆瑟朗内斯 |
POINT (18.9072624292132 69.6796790473478) |
军事 |
谢韦罗莫斯克-3(摩尔曼斯克东北部) |
POINT (33.2903527616285 69.0168711826804) |
太空港 |
拜科努尔航天发射场 |
POINT (63.307354423875 45.9635739403124) |
小的 |
达米亚尔 |
POINT (73.0320498392002 33.5614146278861) |
小 |
桑赫纳尔 |
POINT (75.9570722403652 30.8503598561702) |
太空港 |
圭亚那航天中心 |
POINT (-52.7684296893452 5.23941001258035) |
军事 |
桑托斯空军基地 |
POINT (-46.3052704931003 -23.9237590410637) |
专业 |
基督城国际机场 |
POINT (172.538675565223 -43.4885486784104) |
中 |
赫尔墨斯·奎贾达国际 |
POINT (-67.7530268462675 -53.7814746058316) |
我们的测试数据没有很多“小型”机场。
如果一个 BY 字段是多值的,那么 INLINESTATS 会将行放入 每个
桶中,就像 STATS ... BY 一样:
FROM airports | INLINESTATS min_scalerank=MIN(scalerank) BY type | EVAL type=MV_SORT(type), min_scalerank=MV_SORT(min_scalerank) | KEEP abbrev, type, scalerank, min_scalerank | WHERE abbrev == "GWL"
| abbrev:keyword | type:keyword | scalerank:integer | min_scalerank:integer |
|---|---|---|---|
GWL |
[中, 军事] |
9 |
[2, 4] |
要将每个组键视为单独的行,请在INLINESTATS之前使用MV_EXPAND:
FROM airports | KEEP abbrev, type, scalerank | MV_EXPAND type | INLINESTATS min_scalerank=MIN(scalerank) BY type | SORT min_scalerank ASC | WHERE abbrev == "GWL"
| abbrev:keyword | type:keyword | scalerank:integer | min_scalerank:integer |
|---|---|---|---|
GWL |
中 |
9 |
2 |
GWL |
军事 |
9 |
4 |
KEEP
editThe KEEP 处理命令使您能够指定返回哪些列以及它们返回的顺序。
语法
KEEP columns
参数
-
columns - 要保留的列的逗号分隔列表。支持通配符。 有关现有列与多个给定通配符或列名匹配的情况下的行为,请参见下文。
描述
The KEEP 处理命令使您能够指定返回哪些列以及它们返回的顺序。
当字段名称匹配多个表达式时,会应用优先级规则。 字段按它们出现的顺序添加。如果一个字段匹配多个表达式,则应用以下优先级规则(从最高到最低优先级):
- 完整字段名称(无通配符)
-
部分通配符表达式(例如:
fieldNam*) -
仅通配符(
*)
如果一个字段匹配了两个具有相同优先级的表达式,则最右边的表达式胜出。
请参考示例以了解这些优先级规则的说明。
示例
列按指定顺序返回:
FROM employees | KEEP emp_no, first_name, last_name, height
| emp_no:integer | first_name:keyword | last_name:keyword | height:double |
|---|---|---|---|
10001 |
格奥尔基 |
法塞洛 |
2.03 |
10002 |
比撒列 |
齐美尔 |
2.08 |
10003 |
帕托 |
班福德 |
1.83 |
10004 |
基督教 |
科布利克 |
1.78 |
10005 |
京一 |
马利尼亚克 |
2.05 |
与其按名称指定每个列,您可以使用通配符来返回所有名称与模式匹配的列:
FROM employees | KEEP h*
| height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date |
|---|
星号通配符(*)本身表示所有不匹配其他参数的列。
此查询将首先返回所有名称以 h 开头的列,然后返回所有其他列:
FROM employees | KEEP h*, *
| height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date | avg_worked_seconds:long | birth_date:date | emp_no:integer | first_name:keyword | gender:keyword | is_rehired:boolean | job_positions:keyword | languages:integer | languages.byte:integer | languages.long:long | languages.short:integer | last_name:keyword | salary:integer | salary_change:double | salary_change.int:integer | salary_change.keyword:keyword | salary_change.long:long | still_hired:boolean |
|---|
以下示例展示了当字段名称匹配多个表达式时,优先级规则的工作方式。
完整字段名称优先于通配符表达式:
FROM employees | KEEP first_name, last_name, first_name*
| first_name:keyword | last_name:keyword |
|---|
通配符表达式具有相同的优先级,但最后一条优先级最高(尽管它可能不太具体):
FROM employees | KEEP first_name*, last_name, first_na*
| last_name:keyword | first_name:keyword |
|---|
一个简单的通配符表达式 * 具有最低的优先级。
输出顺序由其他参数决定:
FROM employees | KEEP *, first_name
| avg_worked_seconds:long | birth_date:date | emp_no:integer | gender:keyword | height:double | height.float:double | height.half_float:double | height.scaled_float:double | hire_date:date | is_rehired:boolean | job_positions:keyword | languages:integer | languages.byte:integer | languages.long:long | languages.short:integer | last_name:keyword | salary:integer | salary_change:double | salary_change.int:integer | salary_change.keyword:keyword | salary_change.long:long | still_hired:boolean | first_name:keyword |
|---|
LIMIT
editThe LIMIT 处理命令使您能够限制返回的行数。
语法
LIMIT max_number_of_rows
参数
-
max_number_of_rows - 返回的最大行数。
描述
The LIMIT 处理命令使您能够限制返回的行数。
无论 LIMIT 命令的值如何,查询都不会返回超过 10,000 行。
此限制仅适用于查询检索的行数。 查询和聚合在完整数据集上运行。
为了克服这一限制:
-
通过修改查询以仅返回相关数据来减少结果集的大小。使用
WHERE来选择数据的一个较小子集。 -
将任何查询后处理转移到查询本身。您可以使用ES|QL的
STATS ... BY命令在查询中聚合数据。
可以使用这些动态集群设置来更改默认和最大限制:
-
esql.query.result_truncation_default_size -
esql.query.result_truncation_max_size
示例
FROM employees | SORT emp_no ASC | LIMIT 5
查找
editLOOKUP 是高度实验性的,仅在 SNAPSHOT 版本中可用。
LOOKUP 将输入的值与请求中提供的 table 进行匹配,并将 table 中的其他字段添加到输出中。
语法
LOOKUP table ON match_field1[, match_field2, ...]
参数
-
table -
请求中提供的
表的名称以进行匹配。 如果表的列名与现有列冲突,将删除现有列。 -
match_field - 输入中要与表匹配的字段。
示例
POST /_query?format=txt
{
"query": """
FROM library
| SORT page_count DESC
| KEEP name, author
| LOOKUP era ON author
| LIMIT 5
""",
"tables": {
"era": {
"author": {"keyword": ["Frank Herbert", "Peter F. Hamilton", "Vernor Vinge", "Alastair Reynolds", "James S.A. Corey"]},
"era": {"keyword": [ "The New Wave", "Diamond", "Diamond", "Diamond", "Hadron"]}
}
}
}
返回结果:
name | author | era --------------------+-----------------+--------------- Pandora's Star |Peter F. Hamilton|Diamond A Fire Upon the Deep|Vernor Vinge |Diamond Dune |Frank Herbert |The New Wave Revelation Space |Alastair Reynolds|Diamond Leviathan Wakes |James S.A. Corey |Hadron
MV_EXPAND
edit此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
处理命令 MV_EXPAND 将多值列扩展为每行一个值,并复制其他列。
语法
MV_EXPAND column
参数
-
column - 要展开的多值列。
示例
ROW a=[1,2,3], b="b", j=["a","b"] | MV_EXPAND a
| a:integer | b:keyword | j:keyword |
|---|---|---|
1 |
b |
["a", "b"] |
2 |
b |
["a", "b"] |
3 |
b |
["a", "b"] |
重命名
editThe RENAME 处理命令用于重命名一个或多个列。
语法
RENAME old_name1 AS new_name1[, ..., old_nameN AS new_nameN]
参数
-
old_nameX - 您想要重命名的列的名称。
-
new_nameX - 新列的名称。如果与现有列名冲突,则删除现有列。如果多个列被重命名为相同的名称,则除具有相同新名称的最右列之外的所有列都将被删除。
描述
The RENAME 处理命令用于重命名一个或多个列。如果新名称的列已经存在,它将被新列替换。
示例
FROM employees | KEEP first_name, last_name, still_hired | RENAME still_hired AS employed
可以使用单个 RENAME 命令重命名多个列:
FROM employees | KEEP first_name, last_name | RENAME first_name AS fn, last_name AS ln
SORT
editThe SORT 处理命令对一个或多个列上的表进行排序。
语法
SORT column1 [ASC/DESC][NULLS FIRST/NULLS LAST][, ..., columnN [ASC/DESC][NULLS FIRST/NULLS LAST]]
参数
-
columnX - 要排序的列。
描述
The SORT 处理命令对一个或多个列上的表进行排序。
默认排序顺序是升序。使用 ASC 或 DESC 来指定明确的排序顺序。
具有相同排序键的两行被视为相等。您可以提供额外的排序表达式作为决胜依据。
对多值列进行排序时,升序排序使用最低值,降序排序使用最高值。
默认情况下,null 值被视为比任何其他值都大。在升序排序时,null 值排在最后,而在降序排序时,null 值排在最前。你可以通过提供 NULLS FIRST 或 NULLS LAST 来改变这一行为。
示例
FROM employees | KEEP first_name, last_name, height | SORT height
显式地按升序排序,使用 ASC:
FROM employees | KEEP first_name, last_name, height | SORT height DESC
提供额外的排序表达式作为平局决胜依据:
FROM employees | KEEP first_name, last_name, height | SORT height DESC, first_name ASC
使用 NULLS FIRST 将 null 值排在前面:
FROM employees | KEEP first_name, last_name, height | SORT first_name ASC NULLS FIRST
STATS ... BY
editThe STATS ... BY 处理命令根据一个共同值对行进行分组,并在分组后的行上计算一个或多个聚合值。
语法
STATS [column1 =] expression1[, ..., [columnN =] expressionN] [BY grouping_expression1[, ..., grouping_expressionN]]
参数
-
columnX -
返回的聚合值的名称。如果省略,名称等于相应的表达式(
expressionX)。如果多列具有相同的名称,则除具有此名称的最右列之外的所有列都将被忽略。 -
expressionX - 一个计算聚合值的表达式。
-
grouping_expressionX - 一个用于输出分组依据的值的表达式。 如果其名称与某个计算列的名称相同,则该列将被忽略。
在计算聚合时,会跳过单个的 null 值。
描述
The STATS ... BY 处理命令根据一个共同值对行进行分组,并在分组后的行上计算一个或多个聚合值。如果省略 BY,输出表将包含一行,该行应用了整个数据集的聚合。
支持以下聚合函数:
-
AVG -
COUNT -
COUNT_DISTINCT -
MAX -
MEDIAN -
MEDIAN_ABSOLUTE_DEVIATION -
MIN -
PERCENTILE -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能的 SLA 支持。
ST_CENTROID_AGG -
SUM -
TOP -
VALUES -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能的 SLA 支持。
WEIGHTED_AVG
支持以下分组函数:
STATS 没有任何分组时比添加分组要快得多。
目前,对单个表达式进行分组比对多个表达式进行分组要优化得多。在一些测试中,我们发现对单个keyword列进行分组的速度比对两个keyword列进行分组快五倍。不要试图通过使用CONCAT将两列合并在一起然后进行分组来绕过这个问题——那样并不会更快。
示例
计算一个统计量并按另一列的值进行分组:
FROM employees | STATS count = COUNT(emp_no) BY languages | SORT languages
| count:long | languages:integer |
|---|---|
15 |
1 |
19 |
2 |
17 |
3 |
18 |
4 |
21 |
5 |
10 |
空 |
省略 BY 将返回一行,其中聚合应用于整个数据集:
FROM employees | STATS avg_lang = AVG(languages)
| avg_lang:double |
|---|
3.1222222222222222 |
可以计算多个值:
FROM employees | STATS avg_lang = AVG(languages), max_lang = MAX(languages)
| avg_lang:double | max_lang:integer |
|---|---|
3.1222222222222222 |
5 |
ROW i=1, a=["a", "b"] | STATS MIN(i) BY a | SORT a ASC
| MIN(i):integer | a:keyword |
|---|---|
1 |
一个 |
1 |
b |
也可以按多个值进行分组:
FROM employees
| EVAL hired = DATE_FORMAT("yyyy", hire_date)
| STATS avg_salary = AVG(salary) BY hired, languages.long
| EVAL avg_salary = ROUND(avg_salary)
| SORT hired, languages.long
如果所有分组键都是多值的,那么输入行将属于所有组:
ROW i=1, a=["a", "b"], b=[2, 3] | STATS MIN(i) BY a, b | SORT a ASC, b ASC
| MIN(i):integer | a:keyword | b:integer |
|---|---|---|
1 |
一个 |
2 |
1 |
一个 |
3 |
1 |
b |
2 |
1 |
b |
3 |
聚合函数和分组表达式都接受其他函数。这对于在多值列上使用STATS...BY非常有用。例如,要计算平均工资变化,可以使用MV_AVG首先对每个员工的多个值进行平均,然后使用AVG函数的结果:
FROM employees | STATS avg_salary_change = ROUND(AVG(MV_AVG(salary_change)), 10)
| avg_salary_change:double |
|---|
1.3904535865 |
按表达式分组的一个示例是根据员工姓氏的首字母对员工进行分组:
FROM employees | STATS my_count = COUNT() BY LEFT(last_name, 1) | SORT `LEFT(last_name, 1)`
| my_count:long | LEFT(last_name, 1):keyword |
|---|---|
2 |
一个 |
11 |
B |
5 |
摄氏度 |
5 |
D |
2 |
E |
4 |
F |
4 |
克 |
6 |
H |
2 |
J |
3 |
K |
5 |
L |
12 |
米 |
4 |
N |
1 |
哦 |
7 |
P |
5 |
R |
13 |
S |
4 |
T |
2 |
W |
3 |
Z |
指定输出列名是可选的。如果未指定,新列名等于表达式。以下查询返回名为AVG(salary)的列:
FROM employees | STATS AVG(salary)
| AVG(salary):double |
|---|
48248.55 |
因为此名称包含特殊字符,在使用后续命令时需要用反引号(`)括起来:
FROM employees | STATS AVG(salary) | EVAL avg_salary_rounded = ROUND(`AVG(salary)`)
| AVG(salary):double | avg_salary_rounded:double |
|---|---|
48248.55 |
48249.0 |
WHERE
edit处理命令 WHERE 生成一个包含输入表中所有行的表,其中提供的条件评估为 true。
在值排除的情况下,具有null值的字段将被排除在搜索结果之外。
在这种情况下,null意味着文档中存在显式的null值或根本没有值。
例如:WHERE field != "value"将被解释为WHERE field != "value" AND field IS NOT NULL。
语法
WHERE expression
参数
-
expression - 一个布尔表达式。
示例
FROM employees | KEEP first_name, last_name, still_hired | WHERE still_hired == true
哪个,如果 still_hired 是一个布尔字段,可以简化为:
FROM employees | KEEP first_name, last_name, still_hired | WHERE still_hired
使用日期数学从特定时间范围检索数据。例如,要检索最近一小时的日志:
FROM sample_data | WHERE @timestamp > NOW() - 1 hour
FROM employees | KEEP first_name, last_name, height | WHERE LENGTH(first_name) < 4
有关所有函数的完整列表,请参阅函数概述。
对于NULL比较,使用IS NULL和IS NOT NULL谓词:
FROM employees | WHERE birth_date IS NULL | KEEP first_name, last_name | SORT first_name | LIMIT 3
| first_name:keyword | last_name:keyword |
|---|---|
罗勒 |
特拉默 |
弗洛里安 |
西罗季克 |
卢西恩 |
罗森鲍姆 |
FROM employees | WHERE is_rehired IS NOT NULL | STATS COUNT(emp_no)
| COUNT(emp_no):long |
|---|
84 |
使用 LIKE 根据通配符过滤基于字符串模式的数据。LIKE 通常作用于操作符左侧的字段,但它也可以作用于常量(字面量)表达式。操作符的右侧表示模式。
以下通配符受支持:
-
*匹配零个或多个字符。 -
?匹配一个字符。
支持的类型
| str | pattern | result |
|---|---|---|
关键词 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
FROM employees | WHERE first_name LIKE "?b*" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
埃布 |
卡拉威 |
埃伯哈特 |
Terkki |
使用 RLIKE 根据使用 正则表达式 的字符串模式过滤数据。RLIKE 通常作用于操作符左侧的字段,但它也可以作用于常量(字面量)表达式。操作符的右侧表示模式。
支持的类型
| str | pattern | result |
|---|---|---|
关键词 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
FROM employees | WHERE first_name RLIKE ".leja.*" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
亚历杭德罗 |
麦卡尔平 |
运算符 IN 允许测试一个字段或表达式是否等于一个字面量、字段或表达式列表中的元素:
ROW a = 1, b = 4, c = 3 | WHERE c-a IN (3, b / 2, a)
| a:integer | b:integer | c:integer |
|---|---|---|
1 |
4 |
3 |
有关所有运算符的完整列表,请参阅运算符。
ES|QL 函数和操作符
editES|QL 提供了一套全面的功能和操作符,用于处理数据。 参考文档分为以下几类:
函数概览
edit聚合函数
-
AVG -
COUNT -
COUNT_DISTINCT -
MAX -
MEDIAN -
MEDIAN_ABSOLUTE_DEVIATION -
MIN -
PERCENTILE -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中进行更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_CENTROID_AGG -
SUM -
TOP -
VALUES -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中进行更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
WEIGHTED_AVG
分组函数
Date and time functions
IP 函数
数学函数
空间函数
-
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_INTERSECTS -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_DISJOINT -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_CONTAINS -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_WITHIN -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_X -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_Y -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_DISTANCE
字符串函数
类型转换函数
-
TO_BOOLEAN -
TO_CARTESIANPOINT -
TO_CARTESIANSHAPE -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
TO_DATEPERIOD -
TO_DATETIME -
TO_DEGREES -
TO_DOUBLE -
TO_GEOPOINT -
TO_GEOSHAPE -
TO_INTEGER -
TO_IP -
TO_LONG -
TO_RADIANS -
TO_STRING -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
TO_TIMEDURATION -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
TO_UNSIGNED_LONG -
TO_VERSION
ES|QL 聚合函数
editThe STATS ... BY 命令支持这些聚合函数:
-
AVG -
COUNT -
COUNT_DISTINCT -
MAX -
MEDIAN -
MEDIAN_ABSOLUTE_DEVIATION -
MIN -
PERCENTILE -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中进行更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能的 SLA 支持。
ST_CENTROID_AGG -
SUM -
TOP -
VALUES -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中进行更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能的 SLA 支持。
WEIGHTED_AVG
平均值
edit语法
参数
-
number
描述
数值字段的平均值。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
示例
FROM employees | STATS AVG(height)
| AVG(height):double |
|---|
1.7682 |
表达式可以使用内联函数。例如,要计算多值列的平均值,首先使用 MV_AVG 对每行的多个值进行平均,然后使用 AVG 函数处理结果。
FROM employees | STATS avg_salary_change = ROUND(AVG(MV_AVG(salary_change)), 10)
| avg_salary_change:double |
|---|
1.3904535865 |
COUNT
edit语法
参数
-
field -
输出要计数的值的表达式。如果省略,相当于
COUNT(*)(行数)。
描述
返回输入值的总数(计数)。
支持的类型
| field | result |
|---|---|
布尔值 |
长 |
笛卡尔点 |
长 |
日期 |
长 |
双精度 |
长 |
地理点 |
长 |
整数 |
长 |
IP |
长 |
关键词 |
长 |
长 |
长 |
文本 |
长 |
无符号长整型 |
长 |
版本 |
长 |
示例
FROM employees | STATS COUNT(height)
| COUNT(height):long |
|---|
100 |
要计算行数,请使用 COUNT() 或 COUNT(*)
FROM employees | STATS count = COUNT(*) BY languages | SORT languages DESC
| count:long | languages:integer |
|---|---|
10 |
空 |
21 |
5 |
18 |
4 |
17 |
3 |
19 |
2 |
15 |
1 |
该表达式可以使用内联函数。此示例使用SPLIT函数将字符串拆分为多个值,并计算这些值的数量
ROW words="foo;bar;baz;qux;quux;foo" | STATS word_count = COUNT(SPLIT(words, ";"))
| word_count:long |
|---|
6 |
要计算表达式返回TRUE的次数,请使用WHERE命令来移除不应包含的行
ROW n=1 | WHERE n < 0 | STATS COUNT(n)
| COUNT(n):long |
|---|
0 |
要基于两个不同的表达式计算相同的数据流,请使用模式 COUNT(
ROW n=1 | STATS COUNT(n > 0 OR NULL), COUNT(n < 0 OR NULL)
| COUNT(n > 0 OR NULL):long | COUNT(n < 0 OR NULL):long |
|---|---|
1 |
0 |
COUNT_DISTINCT
edit语法
参数
-
field - 要计算不同值数量的列或字面量。
-
precision - 精确度阈值。参考计数是近似的。最大支持值为40000。高于此数值的阈值将具有与40000阈值相同的效果。默认值为3000。
描述
返回近似的不同值的数量。
支持的类型
| field | precision | result |
|---|---|---|
布尔值 |
整数 |
长 |
布尔值 |
长 |
长 |
布尔值 |
无符号长整型 |
长 |
布尔值 |
长 |
|
日期 |
整数 |
长 |
日期 |
长 |
长 |
日期 |
无符号长整型 |
长 |
日期 |
长 |
|
双精度 |
整数 |
长 |
双精度 |
长 |
长 |
双精度 |
无符号长整型 |
长 |
双精度 |
长 |
|
整数 |
整数 |
长 |
整数 |
长 |
长 |
整数 |
无符号长整型 |
长 |
整数 |
长 |
|
IP |
整数 |
长 |
IP |
长 |
长 |
IP |
无符号长整型 |
长 |
IP |
长 |
|
关键词 |
整数 |
长 |
关键词 |
长 |
长 |
关键词 |
无符号长整型 |
长 |
关键词 |
长 |
|
长 |
整数 |
长 |
长 |
长 |
长 |
长 |
无符号长整型 |
长 |
长 |
长 |
|
文本 |
整数 |
长 |
文本 |
长 |
长 |
文本 |
无符号长整型 |
长 |
文本 |
长 |
|
版本 |
整数 |
长 |
版本 |
长 |
长 |
版本 |
无符号长整型 |
长 |
版本 |
长 |
示例
FROM hosts | STATS COUNT_DISTINCT(ip0), COUNT_DISTINCT(ip1)
| COUNT_DISTINCT(ip0):long | COUNT_DISTINCT(ip1):long |
|---|---|
7 |
8 |
使用可选的第二个参数来配置精度阈值
FROM hosts | STATS COUNT_DISTINCT(ip0, 80000), COUNT_DISTINCT(ip1, 5)
| COUNT_DISTINCT(ip0, 80000):long | COUNT_DISTINCT(ip1, 5):long |
|---|---|
7 |
9 |
该表达式可以使用内联函数。此示例使用SPLIT函数将字符串拆分为多个值,并计算唯一值的数量
ROW words="foo;bar;baz;qux;quux;foo" | STATS distinct_word_count = COUNT_DISTINCT(SPLIT(words, ";"))
| distinct_word_count:long |
|---|
5 |
计数是近似的
edit计算精确计数需要将值加载到集合中并返回其大小。这在处理高基数集合和/或大值时无法扩展,因为所需的内存使用量以及在节点之间通信这些每个分片集合的需求会占用集群的太多资源。
这个 COUNT_DISTINCT 函数基于
HyperLogLog++
算法,该算法根据值的哈希进行计数,并具有一些有趣的特性:
- 可配置的精度,决定如何权衡内存与准确性,
- 在低基数集合上具有出色的准确性,
- 固定的内存使用量:无论存在数十个还是数十亿个唯一值,内存使用量仅取决于配置的精度。
对于精度阈值 c,我们使用的实现大约需要 c * 8 字节。
以下图表展示了在阈值前后误差的变化情况:
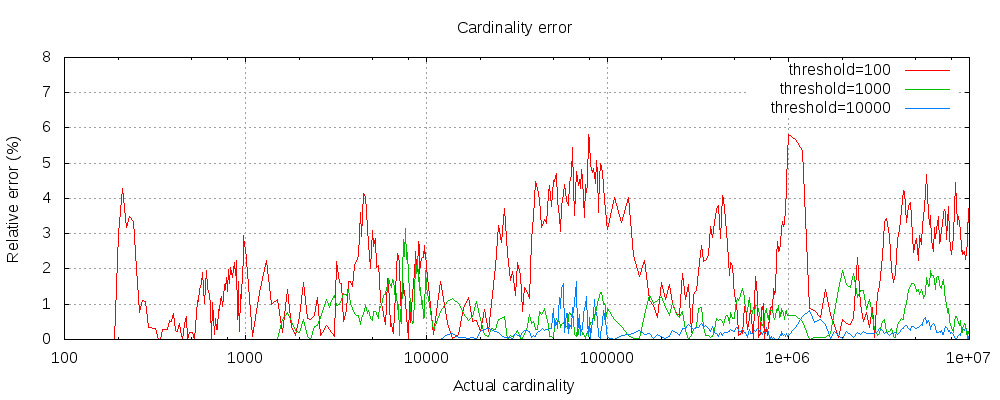
对于所有3个阈值,计数在配置的阈值内都是准确的。 虽然不保证,但这种情况很可能是这样。实际中的准确性取决于所讨论的数据集。一般来说,大多数数据集都显示出一致的良好准确性。还要注意,即使阈值低至100,即使在计数数百万个项目时,误差仍然非常低(如上图所示为1-6%)。
HyperLogLog++ 算法依赖于哈希值的前导零,数据集中哈希的确切分布会影响基数的准确性。
The COUNT_DISTINCT 函数接受一个可选的第二个参数来配置精度阈值。precision_threshold 选项允许在内存和准确性之间进行权衡,并定义一个唯一计数,低于此计数的计数预计接近准确。高于此值时,计数可能会变得稍微模糊。最大支持的值是 40000,高于此数的阈值将具有与阈值 40000 相同的效果。默认值是 3000。
最大值
edit语法
参数
-
field
描述
字段的最大值。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
日期 |
日期 |
双精度 |
双精度 |
整数 |
整数 |
IP |
IP |
关键词 |
关键词 |
长 |
长 |
文本 |
文本 |
版本 |
版本 |
示例
FROM employees | STATS MAX(languages)
| MAX(languages):integer |
|---|
5 |
该表达式可以使用内联函数。例如,要计算多值列的平均值的最大值,请使用 MV_AVG 首先对每行的多个值进行平均,然后使用 MAX 函数处理结果。
FROM employees | STATS max_avg_salary_change = MAX(MV_AVG(salary_change))
| max_avg_salary_change:double |
|---|
13.75 |
中位数
edit语法
参数
-
number
描述
大于所有值的一半且小于所有值的一半的值,也称为50% PERCENTILE。
像PERCENTILE一样,MEDIAN 也是通常是近似的。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
示例
FROM employees | STATS MEDIAN(salary), PERCENTILE(salary, 50)
| MEDIAN(salary):double | PERCENTILE(salary, 50):double |
|---|---|
47003 |
47003 |
该表达式可以使用内联函数。例如,要计算多值列的最大值的中位数,首先使用 MV_MAX 获取每行的最大值,然后使用 MEDIAN 函数处理结果
FROM employees | STATS median_max_salary_change = MEDIAN(MV_MAX(salary_change))
| median_max_salary_change:double |
|---|
7.69 |
MEDIAN 也是 非确定性的。
这意味着使用相同的数据可能会得到稍微不同的结果。
中位数绝对偏差
edit语法
参数
-
number
描述
返回中位数绝对偏差,一种衡量变异性的指标。它是一种稳健统计量,意味着它对于描述可能存在异常值或非正态分布的数据非常有用。对于此类数据,它可能比标准差更具描述性。它是通过计算每个数据点与整个样本中位数的偏差的中位数来计算的。也就是说,对于随机变量 X,中位数绝对偏差为 median(|median(X) - X|)。
像PERCENTILE一样,MEDIAN_ABSOLUTE_DEVIATION 也是通常是近似的。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
示例
FROM employees | STATS MEDIAN(salary), MEDIAN_ABSOLUTE_DEVIATION(salary)
| MEDIAN(salary):double | MEDIAN_ABSOLUTE_DEVIATION(salary):double |
|---|---|
47003 |
10096.5 |
该表达式可以使用内联函数。例如,要计算多值列的最大值的中位数绝对偏差,首先使用 MV_MAX 获取每行的最大值,然后使用 MEDIAN_ABSOLUTE_DEVIATION 函数处理结果。
FROM employees | STATS m_a_d_max_salary_change = MEDIAN_ABSOLUTE_DEVIATION(MV_MAX(salary_change))
| m_a_d_max_salary_change:double |
|---|
5.69 |
MEDIAN_ABSOLUTE_DEVIATION 也是 非确定性的。
这意味着使用相同的数据可能会得到略有不同的结果。
最小值
edit语法
参数
-
field
描述
字段的最小值。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
日期 |
日期 |
双精度 |
双精度 |
整数 |
整数 |
IP |
IP |
关键词 |
关键词 |
长 |
长 |
文本 |
文本 |
版本 |
版本 |
示例
FROM employees | STATS MIN(languages)
| MIN(languages):integer |
|---|
1 |
表达式可以使用内联函数。例如,要计算多值列的平均值的最小值,使用 MV_AVG 首先对每行的多个值进行平均,然后使用 MIN 函数处理结果。
FROM employees | STATS min_avg_salary_change = MIN(MV_AVG(salary_change))
| min_avg_salary_change:double |
|---|
-8.46 |
PERCENTILE
edit语法
参数
-
number -
percentile
描述
返回某个百分比的观测值出现的值。例如,第95百分位数是大于95%观测值的值,而第50百分位数是中位数。
支持的类型
| number | percentile | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
双精度 |
整数 |
长 |
双精度 |
长 |
双精度 |
双精度 |
长 |
整数 |
双精度 |
长 |
长 |
双精度 |
示例
FROM employees
| STATS p0 = PERCENTILE(salary, 0)
, p50 = PERCENTILE(salary, 50)
, p99 = PERCENTILE(salary, 99)
| p0:double | p50:double | p99:double |
|---|---|---|
25324 |
47003 |
74970.29 |
表达式可以使用内联函数。例如,要计算多值列的最大值的百分位数,首先使用 MV_MAX 获取每行的最大值,然后使用 PERCENTILE 函数处理结果
FROM employees | STATS p80_max_salary_change = PERCENTILE(MV_MAX(salary_change), 80)
| p80_max_salary_change:double |
|---|
12.132 |
PERCENTILE 是(通常)近似的
edit有许多不同的算法来计算百分位数。天真的实现只是将所有值存储在一个已排序的数组中。要找到第50个百分位数,你只需找到位于my_array[count(my_array) * 0.5]的值。
显然,朴素的实现方式无法扩展——排序数组随着数据集中值的数量线性增长。为了在Elasticsearch集群中计算可能包含数十亿个值的百分位数,会计算近似百分位数。
用于 percentile 指标的算法称为 TDigest(由 Ted Dunning 在
Computing Accurate Quantiles using T-Digests 中引入)。
使用此指标时,请记住以下几点指导原则:
-
准确性与
q(1-q)成正比。这意味着极端百分位数(例如99%)比不太极端的百分位数(例如中位数)更准确。 - 对于小数据集,百分位数非常准确(如果数据足够小,甚至可以达到100%准确)。
- 随着桶中值的数量增加,算法开始近似计算百分位数。它实际上是在用准确性换取内存节省。确切的不准确程度很难概括,因为它取决于您的数据分布和正在聚合的数据量。
以下图表显示了在均匀分布上,根据收集的值的数量和请求的分位数,相对误差的差异:
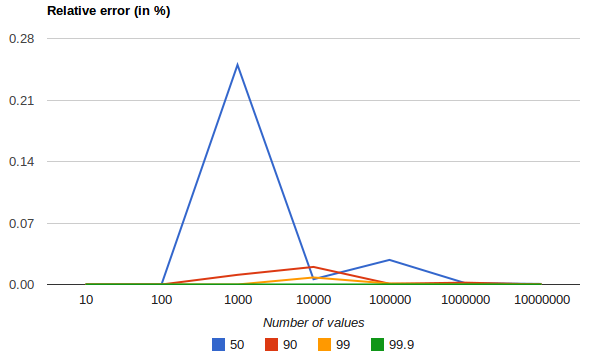
它展示了对于极端百分位数,精度是如何更好的。误差随着数值数量的增加而减小的原因是,大数定律使得数值的分布越来越均匀,而t-digest树能够更好地对其进行总结。在更偏斜的分布上,情况则不会如此。
PERCENTILE 也是 非确定性的。
这意味着使用相同的数据可能会得到稍微不同的结果。
ST_CENTROID_AGG
edit语法
参数
-
field
描述
计算具有空间点几何类型的字段上的空间质心。
支持的类型
| field | result |
|---|---|
笛卡尔点 |
笛卡尔点 |
地理点 |
地理点 |
示例
FROM airports | STATS centroid=ST_CENTROID_AGG(location)
| centroid:geo_point |
|---|
POINT(-0.030548143003023033 24.37553649504829) |
SUM
edit语法
参数
-
number
描述
数值表达式的总和。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
长 |
长 |
长 |
示例
FROM employees | STATS SUM(languages)
| SUM(languages):long |
|---|
281 |
该表达式可以使用内联函数。例如,要计算每位员工的最大薪资变化的总和,对每一行应用MV_MAX函数,然后对结果求和
FROM employees | STATS total_salary_changes = SUM(MV_MAX(salary_change))
| total_salary_changes:double |
|---|
446.75 |
TOP
edit语法
参数
-
field - 用于收集最高值的字段。
-
limit - 收集的最大值数量。
-
order -
计算最高值的顺序。可以是
asc或desc。
描述
收集字段的前几个值。包含重复值。
支持的类型
| field | limit | order | result |
|---|---|---|---|
布尔值 |
整数 |
关键词 |
布尔值 |
日期 |
整数 |
关键词 |
日期 |
双精度 |
整数 |
关键词 |
双精度 |
整数 |
整数 |
关键词 |
整数 |
IP |
整数 |
关键词 |
IP |
关键词 |
整数 |
关键词 |
关键词 |
长 |
整数 |
关键词 |
长 |
文本 |
整数 |
关键词 |
文本 |
示例
FROM employees | STATS top_salaries = TOP(salary, 3, "desc"), top_salary = MAX(salary)
| top_salaries:integer | top_salary:integer |
|---|---|
[74999, 74970, 74572] |
74999 |
VALUES
edit请勿在生产环境中使用。此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
语法
参数
-
field
描述
返回组中的所有值作为一个多值字段。返回值的顺序不保证。如果需要按顺序返回值,请使用MV_SORT。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
日期 |
日期 |
双精度 |
双精度 |
整数 |
整数 |
IP |
IP |
关键词 |
关键词 |
长 |
长 |
文本 |
文本 |
版本 |
版本 |
示例
FROM employees | EVAL first_letter = SUBSTRING(first_name, 0, 1) | STATS first_name=MV_SORT(VALUES(first_name)) BY first_letter | SORT first_letter
| first_name:keyword | first_letter:keyword |
|---|---|
[亚历杭德罗, 阿马比尔, 安妮克, 阿努什, 阿鲁穆加姆] |
一个 |
[罗勒, 伯恩哈德, 伯尼, 贝扎莱尔, 博扬, 布伦南达, 布伦登] |
B |
[夏琳, 克里斯蒂安, 克劳迪, 克里斯蒂内尔] |
摄氏度 |
[丹尼尔, 迪维尔, 多梅尼克, 杜昂卡维] |
D |
[埃贝, 埃伯哈特, 埃雷兹] |
E |
弗洛里安 |
F |
[高, 格奥尔基, 格奥尔格, 吉诺, 国祥] |
克 |
[和平, 秀文, 希拉里, 弘信, 弘信, 久雄] |
H |
[杰森, 郑顺] |
J |
[和泉, 和仁, 肯德拉, 兼六, 克什蒂, 奎, 京一] |
K |
[莉莲, 卢西安] |
L |
[玛吉, 玛格丽塔, 玛丽, 真子, 真由美, 明森, 莫赫塔尔, 莫娜, 莫斯] |
米 |
奥特马尔 |
哦 |
[帕尔托, 帕尔维兹, 帕特里西奥, 普拉萨德拉姆, 普雷马尔] |
P |
[拉姆齐, 雷姆齐, 鲁文] |
R |
[萨拉贾, 萨尼亚, 桑吉夫, 佐藤, 沙哈夫, 希尔, 索姆纳特, 斯里克里希纳, 苏达山, 苏曼特, 苏泽特] |
S |
[Tse, Tuval, Tzvetan] |
T |
[乌迪, 乌里] |
U |
[瓦尔迪奥迪奥, 瓦尔特, 维什夫] |
V |
微一 |
W |
星林 |
X |
[英华, 伊沙伊, 永桥] |
Y |
[钟伟, Zvonko] |
Z |
空 |
空 |
这可能会使用大量的内存,而ES|QL目前还不能将聚合扩展到内存之外。因此,这个聚合将在收集的值超过内存容量之前正常工作。一旦收集的值过多,它将导致查询失败,并出现断路器错误。
加权平均
edit语法
参数
-
number - 一个数值。
-
weight - 一个数值权重。
描述
数值表达式的加权平均值。
支持的类型
| number | weight | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
双精度 |
整数 |
长 |
双精度 |
长 |
双精度 |
双精度 |
长 |
整数 |
双精度 |
长 |
长 |
双精度 |
示例
FROM employees | STATS w_avg = WEIGHTED_AVG(salary, height) by languages | EVAL w_avg = ROUND(w_avg) | KEEP w_avg, languages | SORT languages
| w_avg:double | languages:integer |
|---|---|
51464.0 |
1 |
48477.0 |
2 |
52379.0 |
3 |
47990.0 |
4 |
42119.0 |
5 |
52142.0 |
空 |
ES|QL 分组函数
editThe STATS ... BY 命令支持这些分组函数:
BUCKET
edit语法
参数
-
field - 用于生成桶的数值或日期表达式。
-
buckets -
目标桶的数量,或者如果省略了
from和to参数,则为期望的桶大小。 -
from - 范围的开始。可以是数字、日期或以字符串表示的日期。
-
to - 范围的结束。可以是数字、日期或以字符串表示的日期。
描述
根据日期时间或数值输入创建值的分组 - 桶。桶的大小可以直接提供,或者根据推荐的计数和值范围选择。
支持的类型
| field | buckets | from | to | result |
|---|---|---|---|---|
日期 |
日期区间 |
日期 |
||
日期 |
整数 |
日期 |
日期 |
日期 |
日期 |
整数 |
日期 |
关键词 |
日期 |
日期 |
整数 |
日期 |
文本 |
日期 |
日期 |
整数 |
关键词 |
日期 |
日期 |
日期 |
整数 |
关键词 |
关键词 |
日期 |
日期 |
整数 |
关键词 |
文本 |
日期 |
日期 |
整数 |
文本 |
日期 |
日期 |
日期 |
整数 |
文本 |
关键词 |
日期 |
日期 |
整数 |
文本 |
文本 |
日期 |
日期 |
时间间隔 |
日期 |
||
双精度 |
双精度 |
双精度 |
||
双精度 |
整数 |
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
双精度 |
整数 |
整数 |
双精度 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
长 |
双精度 |
双精度 |
整数 |
长 |
双精度 |
双精度 |
双精度 |
整数 |
长 |
整数 |
双精度 |
双精度 |
整数 |
长 |
长 |
双精度 |
双精度 |
整数 |
双精度 |
||
双精度 |
长 |
双精度 |
||
整数 |
双精度 |
双精度 |
||
整数 |
整数 |
双精度 |
双精度 |
双精度 |
整数 |
整数 |
双精度 |
整数 |
双精度 |
整数 |
整数 |
双精度 |
长 |
双精度 |
整数 |
整数 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
整数 |
双精度 |
整数 |
整数 |
整数 |
长 |
双精度 |
整数 |
整数 |
长 |
双精度 |
双精度 |
整数 |
整数 |
长 |
整数 |
双精度 |
整数 |
整数 |
长 |
长 |
双精度 |
整数 |
整数 |
双精度 |
||
整数 |
长 |
双精度 |
||
长 |
双精度 |
双精度 |
||
长 |
整数 |
双精度 |
双精度 |
双精度 |
长 |
整数 |
双精度 |
整数 |
双精度 |
长 |
整数 |
双精度 |
长 |
双精度 |
长 |
整数 |
整数 |
双精度 |
双精度 |
长 |
整数 |
整数 |
整数 |
双精度 |
长 |
整数 |
整数 |
长 |
双精度 |
长 |
整数 |
长 |
双精度 |
双精度 |
长 |
整数 |
长 |
整数 |
双精度 |
长 |
整数 |
长 |
长 |
双精度 |
长 |
整数 |
双精度 |
||
长 |
长 |
双精度 |
示例
BUCKET 可以以两种模式工作:一种模式是根据桶的数量推荐(四个参数)和一个范围来计算桶的大小,另一种模式是直接提供桶的大小(两个参数)。
使用目标桶数、范围的起始值和范围的结束值,BUCKET 会选择一个合适的桶大小来生成目标数量的桶或更少的桶。例如,要求在一年的范围内最多生成20个桶,结果会是按月划分的桶:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | STATS hire_date = MV_SORT(VALUES(hire_date)) BY month = BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z") | SORT hire_date
| hire_date:date | month:date |
|---|---|
[1985-02-18T00:00:00.000Z, 1985-02-24T00:00:00.000Z] |
1985-02-01T00:00:00.000Z |
1985-05-13T00:00:00.000Z |
1985-05-01T00:00:00.000Z |
1985年7月9日00:00:00.000Z |
1985年7月1日00:00:00.000Z |
1985-09-17T00:00:00.000Z |
1985-09-01T00:00:00.000Z |
[1985-10-14T00:00:00.000Z, 1985-10-20T00:00:00.000Z] |
1985-10-01T00:00:00.000Z |
[1985-11-19T00:00:00.000Z, 1985-11-20T00:00:00.000Z, 1985-11-21T00:00:00.000Z] |
1985年11月1日T00:00:00.000Z |
目标并不是提供完全符合目标数量的桶数,而是选择一个人们感到舒适的范围,最多提供目标数量的桶数。
将 BUCKET 与 聚合 结合使用以创建直方图:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | STATS hires_per_month = COUNT(*) BY month = BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z") | SORT month
| hires_per_month:long | month:date |
|---|---|
2 |
1985-02-01T00:00:00.000Z |
1 |
1985-05-01T00:00:00.000Z |
1 |
1985年7月1日00:00:00.000Z |
1 |
1985年9月1日00:00:00.000Z |
2 |
1985-10-01T00:00:00.000Z |
4 |
1985年11月1日T00:00:00.000Z |
BUCKET 不会创建与任何文档不匹配的存储桶。
这就是为什么这个示例缺少 1985-03-01 和其他日期。
请求更多的桶可以导致更小的范围。 例如,请求一年内最多100个桶会导致每周的桶:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | STATS hires_per_week = COUNT(*) BY week = BUCKET(hire_date, 100, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z") | SORT week
| hires_per_week:long | week:date |
|---|---|
2 |
1985-02-18T00:00:00.000Z |
1 |
1985-05-13T00:00:00.000Z |
1 |
1985年7月8日00:00:00.000Z |
1 |
1985年9月16日00:00:00.000Z |
2 |
1985年10月14日 00:00:00.000Z |
4 |
1985年11月18日00:00:00.000Z |
BUCKET 不会过滤任何行。它仅使用提供的范围来选择一个合适的桶大小。
对于值超出范围的行,它返回一个对应于范围外桶的桶值。
将`BUCKET`与WHERE结合使用以过滤行。
如果已提前知道所需的桶大小,只需将其作为第二个参数提供,省略范围:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | STATS hires_per_week = COUNT(*) BY week = BUCKET(hire_date, 1 week) | SORT week
| hires_per_week:long | week:date |
|---|---|
2 |
1985-02-18T00:00:00.000Z |
1 |
1985-05-13T00:00:00.000Z |
1 |
1985年7月8日00:00:00.000Z |
1 |
1985年9月16日 00:00:00.000Z |
2 |
1985年10月14日 00:00:00.000Z |
4 |
1985年11月18日00:00:00.000Z |
当将桶大小作为第二个参数提供时,它必须是时间持续时间或日期周期。
BUCKET 也可以对数值字段进行操作。例如,要创建一个薪资直方图:
FROM employees | STATS COUNT(*) by bs = BUCKET(salary, 20, 25324, 74999) | SORT bs
| COUNT(*):long | bs:double |
|---|---|
9 |
25000.0 |
9 |
30000.0 |
18 |
35000.0 |
11 |
40000.0 |
11 |
45000.0 |
10 |
50000.0 |
7 |
55000.0 |
9 |
60000.0 |
8 |
65000.0 |
8 |
70000.0 |
与之前有意在日期范围内进行过滤的示例不同,您很少希望在数值范围内进行过滤。
您必须分别找到 min 和 max。ES|QL 目前还没有自动执行此操作的简便方法。
如果预先知道所需的桶大小,可以省略范围。只需将其作为第二个参数提供:
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | STATS c = COUNT(1) BY b = BUCKET(salary, 5000.) | SORT b
| c:long | b:double |
|---|---|
1 |
25000.0 |
1 |
30000.0 |
1 |
40000.0 |
2 |
45000.0 |
2 |
50000.0 |
1 |
55000.0 |
1 |
60000.0 |
1 |
65000.0 |
1 |
70000.0 |
创建过去24小时的每小时时段,并计算每小时的事件数量:
FROM sample_data | WHERE @timestamp >= NOW() - 1 day and @timestamp < NOW() | STATS COUNT(*) BY bucket = BUCKET(@timestamp, 25, NOW() - 1 day, NOW())
| COUNT(*):long | bucket:date |
|---|
为1985年创建每月的桶,并按雇佣月份计算平均工资
FROM employees | WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z" | STATS AVG(salary) BY bucket = BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z") | SORT bucket
| AVG(salary):double | bucket:date |
|---|---|
46305.0 |
1985-02-01T00:00:00.000Z |
44817.0 |
1985-05-01T00:00:00.000Z |
62405.0 |
1985年7月1日00:00:00.000Z |
49095.0 |
1985年9月1日00:00:00.000Z |
51532.0 |
1985-10-01T00:00:00.000Z |
54539.75 |
1985年11月1日T00:00:00.000Z |
BUCKET 可以在聚合和分组部分的
STATS … BY … 命令中使用,前提是在聚合部分中,函数是通过在分组部分中定义的别名引用的,或者它是使用完全相同的表达式调用的:
FROM employees | STATS s1 = b1 + 1, s2 = BUCKET(salary / 1000 + 999, 50.) + 2 BY b1 = BUCKET(salary / 100 + 99, 50.), b2 = BUCKET(salary / 1000 + 999, 50.) | SORT b1, b2 | KEEP s1, b1, s2, b2
| s1:double | b1:double | s2:double | b2:double |
|---|---|---|---|
351.0 |
350.0 |
1002.0 |
1000.0 |
401.0 |
400.0 |
1002.0 |
1000.0 |
451.0 |
450.0 |
1002.0 |
1000.0 |
501.0 |
500.0 |
1002.0 |
1000.0 |
551.0 |
550.0 |
1002.0 |
1000.0 |
601.0 |
600.0 |
1002.0 |
1000.0 |
601.0 |
600.0 |
1052.0 |
1050.0 |
651.0 |
650.0 |
1052.0 |
1050.0 |
701.0 |
700.0 |
1052.0 |
1050.0 |
751.0 |
750.0 |
1052.0 |
1050.0 |
801.0 |
800.0 |
1052.0 |
1050.0 |
ES|QL 条件函数和表达式
edit条件函数通过以if-else方式进行评估,返回其参数之一。ES|QL支持以下条件函数:
CASE
edit语法
参数
-
condition - 一个条件。
-
trueValue -
当对应的条件是第一个评估为
true时返回的值。当没有条件匹配时,返回默认值。 -
elseValue -
当没有条件评估为
true时返回的值。
描述
接受条件和值的对。该函数返回属于第一个评估为true的条件的值。如果参数的数量为奇数,最后一个参数是默认值,当没有条件匹配时返回该值。如果参数的数量为偶数,且没有条件匹配,该函数返回null。
支持的类型
| condition | trueValue | elseValue | result |
|---|---|---|---|
布尔值 |
布尔值 |
布尔值 |
布尔值 |
布尔值 |
布尔值 |
布尔值 |
|
布尔值 |
笛卡尔点 |
笛卡尔点 |
笛卡尔点 |
布尔值 |
笛卡尔点 |
笛卡尔点 |
|
布尔值 |
笛卡尔形状 |
笛卡尔形状 |
笛卡尔形状 |
布尔值 |
笛卡尔形状 |
笛卡尔形状 |
|
布尔值 |
日期 |
日期 |
日期 |
布尔值 |
日期 |
日期 |
|
布尔值 |
双精度 |
双精度 |
双精度 |
布尔值 |
双精度 |
双精度 |
|
布尔值 |
地理点 |
地理点 |
地理点 |
布尔值 |
地理点 |
地理点 |
|
布尔值 |
地理形状 |
地理形状 |
地理形状 |
布尔值 |
地理形状 |
地理形状 |
|
布尔值 |
整数 |
整数 |
整数 |
布尔值 |
整数 |
整数 |
|
布尔值 |
IP |
IP |
IP |
布尔值 |
IP |
IP |
|
布尔值 |
关键词 |
关键词 |
关键词 |
布尔值 |
关键词 |
关键词 |
|
布尔值 |
长 |
长 |
长 |
布尔值 |
长 |
长 |
|
布尔值 |
文本 |
文本 |
文本 |
布尔值 |
文本 |
文本 |
|
布尔值 |
无符号长整型 |
无符号长整型 |
无符号长整型 |
布尔值 |
无符号长整型 |
无符号长整型 |
|
布尔值 |
版本 |
版本 |
版本 |
布尔值 |
版本 |
版本 |
示例
确定员工是单语者、双语者还是多语者:
FROM employees
| EVAL type = CASE(
languages <= 1, "monolingual",
languages <= 2, "bilingual",
"polyglot")
| KEEP emp_no, languages, type
| emp_no:integer | languages:integer | type:keyword |
|---|---|---|
10001 |
2 |
双语 |
10002 |
5 |
多语言 |
10003 |
4 |
多语言 |
10004 |
5 |
多语言 |
10005 |
1 |
单语 |
根据日志消息计算总连接成功率:
FROM sample_data
| EVAL successful = CASE(
STARTS_WITH(message, "Connected to"), 1,
message == "Connection error", 0
)
| STATS success_rate = AVG(successful)
| success_rate:double |
|---|
0.5 |
计算每小时的错误率,作为总日志消息数的百分比:
FROM sample_data | EVAL error = CASE(message LIKE "*error*", 1, 0) | EVAL hour = DATE_TRUNC(1 hour, @timestamp) | STATS error_rate = AVG(error) by hour | SORT hour
| error_rate:double | hour:date |
|---|---|
0.0 |
2023-10-23T12:00:00.000Z |
0.6 |
2023年10月23日 13:00:00.000Z |
COALESCE
edit语法
参数
-
first - 要计算的表达式。
-
rest - 其他要评估的表达式。
描述
返回其参数中第一个不为空的值。如果所有参数都为空,则返回null。
支持的类型
| first | rest | result |
|---|---|---|
布尔值 |
布尔值 |
布尔值 |
布尔值 |
布尔值 |
|
笛卡尔点 |
笛卡尔点 |
笛卡尔点 |
笛卡尔形状 |
笛卡尔形状 |
笛卡尔形状 |
日期 |
日期 |
日期 |
地理点 |
地理点 |
地理点 |
地理形状 |
地理形状 |
地理形状 |
整数 |
整数 |
整数 |
整数 |
整数 |
|
IP |
IP |
IP |
关键词 |
关键词 |
关键词 |
关键词 |
关键词 |
|
长 |
长 |
长 |
长 |
长 |
|
文本 |
文本 |
文本 |
文本 |
文本 |
|
版本 |
版本 |
版本 |
示例
ROW a=null, b="b" | EVAL COALESCE(a, b)
| a:null | b:keyword | COALESCE(a, b):keyword |
|---|---|---|
空 |
b |
b |
GREATEST
edit语法
参数
-
first - 要评估的第一列。
-
rest - 其余要评估的列。
描述
返回多个列中的最大值。这与MV_MAX类似,但它旨在一次运行于多个列上。
当在keyword或text字段上运行时,这将返回按字母顺序排列的最后一个字符串。当在boolean列上运行时,如果任何值为true,则将返回true。
支持的类型
| first | rest | result |
|---|---|---|
布尔值 |
布尔值 |
布尔值 |
布尔值 |
布尔值 |
|
日期 |
日期 |
日期 |
双精度 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
整数 |
整数 |
|
IP |
IP |
IP |
关键词 |
关键词 |
关键词 |
关键词 |
关键词 |
|
长 |
长 |
长 |
长 |
长 |
|
文本 |
文本 |
文本 |
文本 |
文本 |
|
版本 |
版本 |
版本 |
示例
ROW a = 10, b = 20 | EVAL g = GREATEST(a, b)
| a:integer | b:integer | g:integer |
|---|---|---|
10 |
20 |
20 |
最小值
edit语法
参数
-
first - 要评估的第一列。
-
rest - 其余要评估的列。
描述
返回多个列中的最小值。这与MV_MIN类似,但它旨在一次运行于多个列上。
支持的类型
| first | rest | result |
|---|---|---|
布尔值 |
布尔值 |
布尔值 |
布尔值 |
布尔值 |
|
日期 |
日期 |
日期 |
双精度 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
整数 |
整数 |
|
IP |
IP |
IP |
关键词 |
关键词 |
关键词 |
关键词 |
关键词 |
|
长 |
长 |
长 |
长 |
长 |
|
文本 |
文本 |
文本 |
文本 |
文本 |
|
版本 |
版本 |
版本 |
示例
ROW a = 10, b = 20 | EVAL l = LEAST(a, b)
| a:integer | b:integer | l:integer |
|---|---|---|
10 |
20 |
10 |
ES|QL 日期时间函数
editES|QL 支持这些日期时间函数:
DATE_DIFF
edit语法
参数
-
unit - 时间差单位
-
startTimestamp - 表示开始时间戳的字符串
-
endTimestamp - 表示结束时间戳的字符串
描述
从 endTimestamp 中减去 startTimestamp,并以 unit 的倍数返回差值。如果 startTimestamp 晚于 endTimestamp,则返回负值。
| Datetime difference units | |
|---|---|
单位 |
缩写 |
年 |
年份, yy, yyyy |
季度 |
季度, qq, q |
月份 |
月份, mm, m |
一年中的第几天 |
dy, y |
天 |
天数, dd, d |
周 |
周, 周, 周 |
工作日 |
工作日, dw |
小时 |
小时, hh |
分钟 |
分钟, mi, n |
第二 |
秒, ss, s |
毫秒 |
毫秒, ms |
微秒 |
微秒, mcs |
纳秒 |
纳秒, ns |
请注意,尽管该函数支持的单位与ES|QL支持的时间跨度字面量之间存在重叠,但这两个集合是不同的,不能互换。同样,支持的缩写与该函数在其他成熟产品中的实现共享,但不一定与Elasticsearch使用的日期时间命名法通用。
支持的类型
| unit | startTimestamp | endTimestamp | result |
|---|---|---|---|
关键词 |
日期 |
日期 |
整数 |
文本 |
日期 |
日期 |
整数 |
示例
ROW date1 = TO_DATETIME("2023-12-02T11:00:00.000Z"), date2 = TO_DATETIME("2023-12-02T11:00:00.001Z")
| EVAL dd_ms = DATE_DIFF("microseconds", date1, date2)
| date1:date | date2:date | dd_ms:integer |
|---|---|---|
2023年12月2日 11:00:00.000Z |
2023年12月2日 11:00:00.001Z |
1000 |
在按日历单位(如年、月等)进行减法运算时,只会计算完全过去的时间单位。 为了避免这种情况并获得余数,只需切换到下一个较小的单位并相应地进行日期计算。
ROW end_23=TO_DATETIME("2023-12-31T23:59:59.999Z"),
start_24=TO_DATETIME("2024-01-01T00:00:00.000Z"),
end_24=TO_DATETIME("2024-12-31T23:59:59.999")
| EVAL end23_to_start24=DATE_DIFF("year", end_23, start_24)
| EVAL end23_to_end24=DATE_DIFF("year", end_23, end_24)
| EVAL start_to_end_24=DATE_DIFF("year", start_24, end_24)
| end_23:date | start_24:date | end_24:date | end23_to_start24:integer | end23_to_end24:integer | start_to_end_24:integer |
|---|---|---|---|---|---|
2023年12月31日 23:59:59.999Z |
2024-01-01T00:00:00.000Z |
2024年12月31日23:59:59.999Z |
0 |
1 |
0 |
DATE_EXTRACT
edit语法
参数
-
datePart -
要提取的日期部分。可以是:
aligned_day_of_week_in_month、aligned_day_of_week_in_year、aligned_week_of_month、aligned_week_of_year、ampm_of_day、clock_hour_of_ampm、clock_hour_of_day、day_of_month、day_of_week、day_of_year、epoch_day、era、hour_of_ampm、hour_of_day、instant_seconds、micro_of_day、micro_of_second、milli_of_day、milli_of_second、minute_of_day、minute_of_hour、month_of_year、nano_of_day、nano_of_second、offset_seconds、proleptic_month、second_of_day、second_of_minute、year或year_of_era。有关这些值的描述,请参阅 java.time.temporal.ChronoField。如果为null,则函数返回null。 -
date -
日期表达式。如果为
null,函数返回null。
描述
提取日期的一部分,如年、月、日、小时。
支持的类型
| datePart | date | result |
|---|---|---|
关键词 |
日期 |
长 |
文本 |
日期 |
长 |
示例
ROW date = DATE_PARSE("yyyy-MM-dd", "2022-05-06")
| EVAL year = DATE_EXTRACT("year", date)
| date:date | year:long |
|---|---|
2022-05-06T00:00:00.000Z |
2022 |
查找所有在营业时间外(上午9点前或下午5点后)发生的任何日期的事件:
FROM sample_data
| WHERE DATE_EXTRACT("hour_of_day", @timestamp) < 9 AND DATE_EXTRACT("hour_of_day", @timestamp) >= 17
| @timestamp:date | client_ip:ip | event_duration:long | message:keyword |
|---|
DATE_FORMAT
edit语法
参数
-
dateFormat -
日期格式(可选)。如果没有指定格式,则使用
yyyy-MM-dd'T'HH:mm:ss.SSSZ格式。如果为null,函数返回null。 -
date -
日期表达式。如果为
null,函数返回null。
描述
返回一个日期在指定格式下的字符串表示。
支持的类型
| dateFormat | date | result |
|---|---|---|
关键词 |
日期 |
关键词 |
文本 |
日期 |
关键词 |
示例
FROM employees
| KEEP first_name, last_name, hire_date
| EVAL hired = DATE_FORMAT("yyyy-MM-dd", hire_date)
| first_name:keyword | last_name:keyword | hire_date:date | hired:keyword |
|---|---|---|---|
亚历杭德罗 |
麦卡尔平 |
1991年6月26日00:00:00.000Z |
1991年6月26日 |
阿马比尔 |
Gomatam |
1992-11-18T00:00:00.000Z |
1992年11月18日 |
安妮克 |
普罗伊斯格 |
1989-06-02T00:00:00.000Z |
1989年6月2日 |
DATE_PARSE
edit语法
参数
-
datePattern -
日期格式。请参考
DateTimeFormatter文档以了解语法。如果为null,函数将返回null。 -
dateString -
日期表达式作为字符串。如果为
null或空字符串,函数返回null。
描述
通过解析第一个参数中指定的格式,返回由第二个参数解析得到的日期。
支持的类型
| datePattern | dateString | result |
|---|---|---|
关键词 |
关键词 |
日期 |
关键词 |
文本 |
日期 |
文本 |
关键词 |
日期 |
文本 |
文本 |
日期 |
示例
ROW date_string = "2022-05-06"
| EVAL date = DATE_PARSE("yyyy-MM-dd", date_string)
| date_string:keyword | date:date |
|---|---|
2022年5月6日 |
2022-05-06T00:00:00.000Z |
DATE_TRUNC
edit语法
参数
-
interval - 时间间隔;使用时间跨度字面量语法表示。
-
date - 日期表达式
描述
将日期向下舍入到最接近的间隔。
支持的类型
| interval | date | result |
|---|---|---|
日期区间 |
日期 |
日期 |
时间间隔 |
日期 |
日期 |
示例
FROM employees | KEEP first_name, last_name, hire_date | EVAL year_hired = DATE_TRUNC(1 year, hire_date)
| first_name:keyword | last_name:keyword | hire_date:date | year_hired:date |
|---|---|---|---|
亚历杭德罗 |
麦卡尔平 |
1991年6月26日00:00:00.000Z |
1991-01-01T00:00:00.000Z |
阿马比尔 |
Gomatam |
1992年11月18日00:00:00.000Z |
1992-01-01T00:00:00.000Z |
安妮克 |
普罗伊斯格 |
1989-06-02T00:00:00.000Z |
1989-01-01T00:00:00.000Z |
结合 DATE_TRUNC 与 STATS ... BY 来创建日期直方图。例如,每年的招聘人数:
FROM employees | EVAL year = DATE_TRUNC(1 year, hire_date) | STATS hires = COUNT(emp_no) BY year | SORT year
| hires:long | year:date |
|---|---|
11 |
1985-01-01T00:00:00.000Z |
11 |
1986-01-01T00:00:00.000Z |
15 |
1987-01-01T00:00:00.000Z |
9 |
1988-01-01T00:00:00.000Z |
13 |
1989-01-01T00:00:00.000Z |
12 |
1990-01-01T00:00:00.000Z |
6 |
1991-01-01T00:00:00.000Z |
8 |
1992-01-01T00:00:00.000Z |
3 |
1993-01-01T00:00:00.000Z |
4 |
1994-01-01T00:00:00.000Z |
5 |
1995-01-01T00:00:00.000Z |
1 |
1996-01-01T00:00:00.000Z |
1 |
1997-01-01T00:00:00.000Z |
1 |
1999-01-01T00:00:00.000Z |
或每小时的错误率:
FROM sample_data | EVAL error = CASE(message LIKE "*error*", 1, 0) | EVAL hour = DATE_TRUNC(1 hour, @timestamp) | STATS error_rate = AVG(error) by hour | SORT hour
| error_rate:double | hour:date |
|---|---|
0.0 |
2023-10-23T12:00:00.000Z |
0.6 |
2023年10月23日 13:00:00.000Z |
当前时间
edit语法
参数
描述
返回当前日期和时间。
支持的类型
| result |
|---|
日期 |
示例
ROW current_date = NOW()
| y:keyword |
|---|
20 |
获取过去一小时的日志:
FROM sample_data | WHERE @timestamp > NOW() - 1 hour
| @timestamp:date | client_ip:ip | event_duration:long | message:keyword |
|---|
ES|QL IP 函数
editES|QL 支持这些 IP 函数:
CIDR_MATCH
edit语法
参数
-
ip -
类型为
ip的 IP 地址(支持 IPv4 和 IPv6)。 -
blockX - 要测试IP的CIDR块。
描述
如果提供的IP地址包含在提供的CIDR块之一中,则返回true。
支持的类型
| ip | blockX | result |
|---|---|---|
IP |
关键词 |
布尔值 |
IP |
文本 |
布尔值 |
示例
FROM hosts | WHERE CIDR_MATCH(ip1, "127.0.0.2/32", "127.0.0.3/32") | KEEP card, host, ip0, ip1
| card:keyword | host:keyword | ip0:ip | ip1:ip |
|---|---|---|---|
eth1 |
贝塔 |
127.0.0.1 |
127.0.0.2 |
eth0 |
伽马 |
fe80::cae2:65ff:fece:feb9 |
127.0.0.3 |
IP_PREFIX
edit语法
参数
-
ip -
类型为
ip的 IP 地址(支持 IPv4 和 IPv6)。 -
prefixLengthV4 - IPv4地址的前缀长度。
-
prefixLengthV6 - IPv6地址的前缀长度。
描述
将IP地址截断到给定的前缀长度。
支持的类型
| ip | prefixLengthV4 | prefixLengthV6 | result |
|---|---|---|---|
IP |
整数 |
整数 |
IP |
示例
row ip4 = to_ip("1.2.3.4"), ip6 = to_ip("fe80::cae2:65ff:fece:feb9")
| eval ip4_prefix = ip_prefix(ip4, 24, 0), ip6_prefix = ip_prefix(ip6, 0, 112);
| ip4:ip | ip6:ip | ip4_prefix:ip | ip6_prefix:ip |
|---|---|---|---|
1.2.3.4 |
fe80::cae2:65ff:fece:feb9 |
1.2.3.0 |
fe80::cae2:65ff:fece:0000 |
ES|QL 数学函数
editES|QL 支持这些数学函数:
ABS
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回绝对值。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
整数 |
长 |
长 |
无符号长整型 |
无符号长整型 |
示例
ROW number = -1.0 | EVAL abs_number = ABS(number)
| number:double | abs_number:double |
|---|---|
-1.0 |
1.0 |
FROM employees | KEEP first_name, last_name, height | EVAL abs_height = ABS(0.0 - height)
| first_name:keyword | last_name:keyword | height:double | abs_height:double |
|---|---|---|---|
亚历杭德罗 |
麦卡尔平 |
1.48 |
1.48 |
阿马比尔 |
Gomatam |
2.09 |
2.09 |
安妮克 |
普罗伊斯格 |
1.56 |
1.56 |
ACOS
edit语法
参数
-
number -
Number between -1 and 1. If
null, the function returnsnull.
描述
返回 n 的 反余弦 作为角度,以弧度表示。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=.9 | EVAL acos=ACOS(a)
| a:double | acos:double |
|---|---|
0.9 |
0.45102681179626236 |
ASIN
edit语法
参数
-
number -
数值介于 -1 和 1 之间。如果为
null,函数返回null。
描述
返回输入数值表达式的反正弦,以弧度表示的角度。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=.9 | EVAL asin=ASIN(a)
| a:double | asin:double |
|---|---|
0.9 |
1.1197695149986342 |
ATAN
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回输入数值表达式的反正切值,以弧度表示的角度。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=12.9 | EVAL atan=ATAN(a)
| a:double | atan:double |
|---|---|
12.9 |
1.4934316673669235 |
ATAN2
edit语法
参数
-
y_coordinate -
y coordinate. If
null, the function returnsnull. -
x_coordinate -
x 坐标。如果
null,函数返回null。
描述
在笛卡尔平面中,从原点到点 (x, y) 的射线与正 x 轴之间的角度,以弧度表示。
支持的类型
| y_coordinate | x_coordinate | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
双精度 |
无符号长整型 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
双精度 |
整数 |
长 |
双精度 |
整数 |
无符号长整型 |
双精度 |
长 |
双精度 |
双精度 |
长 |
整数 |
双精度 |
长 |
长 |
双精度 |
长 |
无符号长整型 |
双精度 |
无符号长整型 |
双精度 |
双精度 |
无符号长整型 |
整数 |
双精度 |
无符号长整型 |
长 |
双精度 |
无符号长整型 |
无符号长整型 |
双精度 |
示例
ROW y=12.9, x=.6 | EVAL atan2=ATAN2(y, x)
| y:double | x:double | atan2:double |
|---|---|---|
12.9 |
0.6 |
1.5243181954438936 |
立方根
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回一个数字的立方根。输入可以是任何数值,返回值始终是双精度浮点数。无穷大的立方根为空。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW d = 1000.0 | EVAL c = cbrt(d)
| d: double | c:double |
|---|---|
1000.0 |
10.0 |
CEIL
edit语法
参数
-
number -
Numeric expression. If
null, the function returnsnull.
描述
将数字向上舍入到最近的整数。
对于 long(包括无符号)和 integer,这是一个空操作。对于 double,这会选择最接近的 double 值到整数,类似于 Math.ceil。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
整数 |
长 |
长 |
无符号长整型 |
无符号长整型 |
示例
ROW a=1.8 | EVAL a=CEIL(a)
| a:double |
|---|
2 |
余弦
edit语法
参数
-
angle -
An angle, in radians. If
null, the function returnsnull.
描述
返回一个角度的余弦值。
支持的类型
| angle | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=1.8 | EVAL cos=COS(a)
| a:double | cos:double |
|---|---|
1.8 |
-0.2272020946930871 |
双曲余弦
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回一个数的双曲余弦值。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=1.8 | EVAL cosh=COSH(a)
| a:double | cosh:double |
|---|---|
1.8 |
3.1074731763172667 |
E
edit语法
参数
描述
返回欧拉数。
支持的类型
| result |
|---|
双精度 |
示例
ROW E()
| E():double |
|---|
2.718281828459045 |
EXP
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回 e 的给定数字次幂的值。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW d = 5.0 | EVAL s = EXP(d)
| d: double | s:double |
|---|---|
5.0 |
148.413159102576603 |
FLOOR
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
将数字向下舍入到最接近的整数。
对于 long(包括无符号)和 integer,这是一个空操作。
对于 double,这会选择最接近的 double 值到整数,
类似于 Math.floor。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
整数 |
长 |
长 |
无符号长整型 |
无符号长整型 |
示例
ROW a=1.8 | EVAL a=FLOOR(a)
| a:double |
|---|
1 |
HYPOT
edit语法
参数
-
number1 -
数值表达式。如果为
null,函数返回null。 -
number2 -
数值表达式。如果为
null,函数返回null。
描述
返回两个数字的斜边。输入可以是任何数值,返回值始终为双精度数。无穷大的斜边为空。
支持的类型
| number1 | number2 | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
双精度 |
无符号长整型 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
双精度 |
整数 |
长 |
双精度 |
整数 |
无符号长整型 |
双精度 |
长 |
双精度 |
双精度 |
长 |
整数 |
双精度 |
长 |
长 |
双精度 |
长 |
无符号长整型 |
双精度 |
无符号长整型 |
双精度 |
双精度 |
无符号长整型 |
整数 |
双精度 |
无符号长整型 |
长 |
双精度 |
无符号长整型 |
无符号长整型 |
双精度 |
示例
ROW a = 3.0, b = 4.0 | EVAL c = HYPOT(a, b)
| a:double | b:double | c:double |
|---|---|---|
3.0 |
4.0 |
5.0 |
LOG
edit语法
参数
-
base -
Base of logarithm. If
null, the function returnsnull. If not provided, this function returns the natural logarithm (base e) of a value. -
number -
Numeric expression. If
null, the function returnsnull.
描述
返回一个值对某个基数的对数。输入可以是任何数值,返回值始终是双精度数。零、负数和基数为一的对数返回null以及一个警告。
支持的类型
| base | number | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
双精度 |
无符号长整型 |
双精度 |
双精度 |
双精度 |
|
整数 |
双精度 |
双精度 |
整数 |
整数 |
双精度 |
整数 |
长 |
双精度 |
整数 |
无符号长整型 |
双精度 |
整数 |
双精度 |
|
长 |
双精度 |
双精度 |
长 |
整数 |
双精度 |
长 |
长 |
双精度 |
长 |
无符号长整型 |
双精度 |
长 |
双精度 |
|
无符号长整型 |
双精度 |
双精度 |
无符号长整型 |
整数 |
双精度 |
无符号长整型 |
长 |
双精度 |
无符号长整型 |
无符号长整型 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW base = 2.0, value = 8.0 | EVAL s = LOG(base, value)
| base: double | value: double | s:double |
|---|---|---|
2.0 |
8.0 |
3.0 |
row value = 100 | EVAL s = LOG(value);
| value: integer | s:double |
|---|---|
100 |
4.605170185988092 |
LOG10
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回以10为底的对数值。输入可以是任何数值,返回值始终为双精度浮点数。0和负数的对数返回null以及警告。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW d = 1000.0 | EVAL s = LOG10(d)
| d: double | s:double |
|---|---|
1000.0 |
3.0 |
PI
edit语法
参数
描述
返回Pi,即圆的周长与其直径的比值。
支持的类型
| result |
|---|
双精度 |
示例
ROW PI()
| PI():double |
|---|
3.141592653589793 |
POW
edit语法
参数
-
base -
Numeric expression for the base. If
null, the function returnsnull. -
exponent -
Numeric expression for the exponent. If
null, the function returnsnull.
描述
返回 base 的 exponent 次幂的值。
这里仍然有可能导致双精度结果溢出;在这种情况下,将返回null。
支持的类型
| base | exponent | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
双精度 |
无符号长整型 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
双精度 |
整数 |
长 |
双精度 |
整数 |
无符号长整型 |
双精度 |
长 |
双精度 |
双精度 |
长 |
整数 |
双精度 |
长 |
长 |
双精度 |
长 |
无符号长整型 |
双精度 |
无符号长整型 |
双精度 |
双精度 |
无符号长整型 |
整数 |
双精度 |
无符号长整型 |
长 |
双精度 |
无符号长整型 |
无符号长整型 |
双精度 |
示例
ROW base = 2.0, exponent = 2 | EVAL result = POW(base, exponent)
| base:double | exponent:integer | result:double |
|---|---|---|
2.0 |
2 |
4.0 |
指数可以是一个分数,这类似于执行一个根运算。
例如,指数为 0.5 将给出基数的平方根:
ROW base = 4, exponent = 0.5 | EVAL s = POW(base, exponent)
| base:integer | exponent:double | s:double |
|---|---|---|
4 |
0.5 |
2.0 |
ROUND
edit语法
参数
-
number -
The numeric value to round. If
null, the function returnsnull. -
decimals -
要舍入的小数位数。默认为 0。如果
null,函数返回null。
描述
将数字四舍五入到指定的小数位数。默认为0,返回最接近的整数。如果精度为负数,则四舍五入到小数点左侧的位数。
支持的类型
| number | decimals | result |
|---|---|---|
双精度 |
整数 |
双精度 |
双精度 |
双精度 |
|
整数 |
整数 |
整数 |
整数 |
整数 |
|
长 |
整数 |
长 |
长 |
长 |
|
无符号长整型 |
无符号长整型 |
示例
FROM employees | KEEP first_name, last_name, height | EVAL height_ft = ROUND(height * 3.281, 1)
| first_name:keyword | last_name:keyword | height:double | height_ft:double |
|---|---|---|---|
阿鲁穆加姆 |
奥森布鲁根 |
2.1 |
6.9 |
奎 |
舒斯勒 |
2.1 |
6.9 |
萨尼亚 |
卡卢菲 |
2.1 |
6.9 |
SIGNUM
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回给定数字的符号。对于负数返回 -1,对于 0 返回 0,对于正数返回 1。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW d = 100.0 | EVAL s = SIGNUM(d)
| d: double | s:double |
|---|---|
100 |
1.0 |
SIN
edit语法
参数
-
angle -
一个角度,以弧度为单位。如果
null,函数返回null。
描述
返回一个角度的正弦值。
支持的类型
| angle | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=1.8 | EVAL sin=SIN(a)
| a:double | sin:double |
|---|---|
1.8 |
0.9738476308781951 |
双曲正弦函数
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回一个数的双曲正弦。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=1.8 | EVAL sinh=SINH(a)
| a:double | sinh:double |
|---|---|
1.8 |
2.94217428809568 |
SQRT
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回一个数字的平方根。输入可以是任何数值,返回值始终是双精度数。负数和无穷大的平方根为空。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW d = 100.0 | EVAL s = SQRT(d)
| d: double | s:double |
|---|---|
100.0 |
10.0 |
TAN
edit语法
参数
-
angle -
一个角度,以弧度为单位。如果
null,函数返回null。
描述
返回一个角度的正切值。
支持的类型
| angle | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=1.8 | EVAL tan=TAN(a)
| a:double | tan:double |
|---|---|
1.8 |
-4.286261674628062 |
双曲正切函数
edit语法
参数
-
number -
数值表达式。如果为
null,函数返回null。
描述
返回一个数的双曲正切。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=1.8 | EVAL tanh=TANH(a)
| a:double | tanh:double |
|---|---|
1.8 |
0.9468060128462683 |
TAU
edit语法
参数
描述
返回一个圆的周长与其半径的比率。
支持的类型
| result |
|---|
双精度 |
示例
ROW TAU()
| TAU():double |
|---|
6.283185307179586 |
ES|QL 空间函数
editES|QL 支持这些空间函数:
-
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_INTERSECTS -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_DISJOINT -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_CONTAINS -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_WITHIN -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_X -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_Y -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或移除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
ST_DISTANCE
ST_INTERSECTS
edit语法
参数
-
geomA -
类型表达式
geo_point、cartesian_point、geo_shape或cartesian_shape。如果为null,函数返回null。 -
geomB -
类型为
geo_point、cartesian_point、geo_shape或cartesian_shape的表达式。如果为null,函数返回null。第二个参数也必须与第一个参数具有相同的坐标系。这意味着不能将geo_*和cartesian_*参数组合在一起。
描述
如果两个几何体相交,则返回 true。如果它们有任何共同点,包括它们的内部点(沿线的点或多边形内的点),则它们相交。这是 ST_DISJOINT 函数的逆函数。在数学术语中:ST_Intersects(A, B) ⇔ A ⋂ B ≠ ∅
支持的类型
| geomA | geomB | result |
|---|---|---|
笛卡尔点 |
笛卡尔点 |
布尔值 |
笛卡尔点 |
笛卡尔形状 |
布尔值 |
笛卡尔形状 |
笛卡尔点 |
布尔值 |
笛卡尔形状 |
笛卡尔形状 |
布尔值 |
地理点 |
地理点 |
布尔值 |
地理点 |
地理形状 |
布尔值 |
地理形状 |
地理点 |
布尔值 |
地理形状 |
地理形状 |
布尔值 |
示例
FROM airports
| WHERE ST_INTERSECTS(location, TO_GEOSHAPE("POLYGON((42 14, 43 14, 43 15, 42 15, 42 14))"))
| abbrev:keyword | city:keyword | city_location:geo_point | country:keyword | location:geo_point | name:text | scalerank:i | type:k |
|---|---|---|---|---|---|---|---|
HOD |
荷台达 |
POINT(42.9511 14.8022) |
也门 |
POINT(42.97109630194 14.7552534413725) |
荷台达国际机场 |
9 |
中 |
ST_DISJOINT
edit语法
参数
-
geomA -
类型表达式
geo_point、cartesian_point、geo_shape或cartesian_shape。如果为null,函数返回null。 -
geomB -
类型为
geo_point、cartesian_point、geo_shape或cartesian_shape的表达式。如果为null,函数返回null。第二个参数也必须与第一个参数具有相同的坐标系。这意味着不能将geo_*和cartesian_*参数组合在一起。
描述
返回两个几何或几何列是否不相交。这是ST_INTERSECTS函数的逆函数。在数学术语中:ST_Disjoint(A, B) ⇔ A ⋂ B = ∅
支持的类型
| geomA | geomB | result |
|---|---|---|
笛卡尔点 |
笛卡尔点 |
布尔值 |
笛卡尔点 |
笛卡尔形状 |
布尔值 |
笛卡尔形状 |
笛卡尔点 |
布尔值 |
笛卡尔形状 |
笛卡尔形状 |
布尔值 |
地理点 |
地理点 |
布尔值 |
地理点 |
地理形状 |
布尔值 |
地理形状 |
地理点 |
布尔值 |
地理形状 |
地理形状 |
布尔值 |
示例
FROM airport_city_boundaries
| WHERE ST_DISJOINT(city_boundary, TO_GEOSHAPE("POLYGON((-10 -60, 120 -60, 120 60, -10 60, -10 -60))"))
| KEEP abbrev, airport, region, city, city_location
| abbrev:keyword | airport:text | region:text | city:keyword | city_location:geo_point |
|---|---|---|---|---|
平价医疗保险计划 |
一般胡安·N·阿尔瓦雷斯国际机场 |
阿卡普尔科德胡亚雷斯 |
阿卡普尔科德胡亚雷斯 |
POINT (-99.8825 16.8636) |
ST_CONTAINS
edit语法
参数
-
geomA -
类型表达式
geo_point、cartesian_point、geo_shape或cartesian_shape。如果为null,函数返回null。 -
geomB -
类型为
geo_point、cartesian_point、geo_shape或cartesian_shape的表达式。如果为null,函数返回null。第二个参数也必须与第一个参数具有相同的坐标系。这意味着不能将geo_*和cartesian_*参数组合在一起。
描述
返回第一个几何是否包含第二个几何。这是ST_WITHIN函数的逆函数。
支持的类型
| geomA | geomB | result |
|---|---|---|
笛卡尔点 |
笛卡尔点 |
布尔值 |
笛卡尔点 |
笛卡尔形状 |
布尔值 |
笛卡尔形状 |
笛卡尔点 |
布尔值 |
笛卡尔形状 |
笛卡尔形状 |
布尔值 |
地理点 |
地理点 |
布尔值 |
地理点 |
地理形状 |
布尔值 |
地理形状 |
地理点 |
布尔值 |
地理形状 |
地理形状 |
布尔值 |
示例
FROM airport_city_boundaries
| WHERE ST_CONTAINS(city_boundary, TO_GEOSHAPE("POLYGON((109.35 18.3, 109.45 18.3, 109.45 18.4, 109.35 18.4, 109.35 18.3))"))
| KEEP abbrev, airport, region, city, city_location
| abbrev:keyword | airport:text | region:text | city:keyword | city_location:geo_point |
|---|---|---|---|---|
SYX |
三亚凤凰国际机场 |
天涯区 |
三亚 |
POINT(109.5036 18.2533) |
ST_WITHIN
edit语法
参数
-
geomA -
类型表达式
geo_point、cartesian_point、geo_shape或cartesian_shape。如果为null,函数返回null。 -
geomB -
类型为
geo_point、cartesian_point、geo_shape或cartesian_shape的表达式。如果为null,函数返回null。第二个参数也必须与第一个参数具有相同的坐标系。这意味着不能将geo_*和cartesian_*参数组合在一起。
描述
返回第一个几何是否在第二个几何内。这是ST_CONTAINS函数的逆函数。
支持的类型
| geomA | geomB | result |
|---|---|---|
笛卡尔点 |
笛卡尔点 |
布尔值 |
笛卡尔点 |
笛卡尔形状 |
布尔值 |
笛卡尔形状 |
笛卡尔点 |
布尔值 |
笛卡尔形状 |
笛卡尔形状 |
布尔值 |
地理点 |
地理点 |
布尔值 |
地理点 |
地理形状 |
布尔值 |
地理形状 |
地理点 |
布尔值 |
地理形状 |
地理形状 |
布尔值 |
示例
FROM airport_city_boundaries
| WHERE ST_WITHIN(city_boundary, TO_GEOSHAPE("POLYGON((109.1 18.15, 109.6 18.15, 109.6 18.65, 109.1 18.65, 109.1 18.15))"))
| KEEP abbrev, airport, region, city, city_location
| abbrev:keyword | airport:text | region:text | city:keyword | city_location:geo_point |
|---|---|---|---|---|
SYX |
三亚凤凰国际机场 |
天涯区 |
三亚 |
POINT(109.5036 18.2533) |
ST_X
edit语法
参数
-
point -
表达式类型为
geo_point或cartesian_point。如果为null,函数返回null。
描述
从提供的点中提取x坐标。如果点的类型是geo_point,这相当于提取longitude值。
支持的类型
| point | result |
|---|---|
笛卡尔点 |
双精度 |
地理点 |
双精度 |
示例
ROW point = TO_GEOPOINT("POINT(42.97109629958868 14.7552534006536)")
| EVAL x = ST_X(point), y = ST_Y(point)
| point:geo_point | x:double | y:double |
|---|---|---|
POINT(42.97109629958868 14.7552534006536) |
42.97109629958868 |
14.7552534006536 |
ST_Y
edit语法
参数
-
point -
类型为
geo_point或cartesian_point的表达式。如果为null,函数返回null。
描述
从提供的点中提取y坐标。如果点是geo_point类型,这相当于提取latitude值。
支持的类型
| point | result |
|---|---|
笛卡尔点 |
双精度 |
地理点 |
双精度 |
示例
ROW point = TO_GEOPOINT("POINT(42.97109629958868 14.7552534006536)")
| EVAL x = ST_X(point), y = ST_Y(point)
| point:geo_point | x:double | y:double |
|---|---|---|
POINT(42.97109629958868 14.7552534006536) |
42.97109629958868 |
14.7552534006536 |
ST_DISTANCE
edit语法
参数
-
geomA -
类型为
geo_point或cartesian_point的表达式。如果为null,函数返回null。 -
geomB -
类型为
geo_point或cartesian_point的表达式。如果为null,函数返回null。第二个参数也必须与第一个参数具有相同的坐标系。这意味着不能将geo_point和cartesian_point参数组合在一起。
描述
计算两个点之间的距离。对于笛卡尔几何,这是与原始坐标相同单位的勾股距离。对于地理几何,这是沿大圆的圆形距离,单位为米。
支持的类型
| geomA | geomB | result |
|---|---|---|
笛卡尔点 |
笛卡尔点 |
双精度 |
地理点 |
地理点 |
双精度 |
示例
FROM airports | WHERE abbrev == "CPH" | EVAL distance = ST_DISTANCE(location, city_location) | KEEP abbrev, name, location, city_location, distance
| abbrev:k | name:text | location:geo_point | city_location:geo_point | distance:d |
|---|---|---|---|---|
哥本哈根 |
哥本哈根 |
POINT(12.6493508684508 55.6285017221528) |
POINT(12.5683 55.6761) |
7339.573896618216 |
ES|QL 字符串函数
editES|QL 支持这些字符串函数:
CONCAT
edit语法
参数
-
string1 - 要连接的字符串。
-
string2 - 要连接的字符串。
描述
连接两个或多个字符串。
支持的类型
| string1 | string2 | result |
|---|---|---|
关键词 |
关键词 |
关键词 |
关键词 |
文本 |
关键词 |
文本 |
关键词 |
关键词 |
文本 |
文本 |
关键词 |
示例
FROM employees | KEEP first_name, last_name | EVAL fullname = CONCAT(first_name, " ", last_name)
| first_name:keyword | last_name:keyword | fullname:keyword |
|---|---|---|
亚历杭德罗 |
麦卡尔平 |
亚历杭德罗·麦卡尔平 |
阿马比尔 |
Gomatam |
阿马比勒·戈马塔姆 |
安妮克 |
普罗伊斯格 |
安妮克·普鲁西格 |
ENDS_WITH
edit语法
参数
-
str -
字符串表达式。如果为
null,函数返回null。 -
suffix -
字符串表达式。如果为
null,函数返回null。
描述
返回一个布尔值,指示关键字字符串是否以另一个字符串结尾。
支持的类型
| str | suffix | result |
|---|---|---|
关键词 |
关键词 |
布尔值 |
关键词 |
文本 |
布尔值 |
文本 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
示例
FROM employees | KEEP last_name | EVAL ln_E = ENDS_WITH(last_name, "d")
| last_name:keyword | ln_E:boolean |
|---|---|
阿德赫 |
假 |
东 |
假 |
白 |
假 |
班福德 |
真 |
伯纳茨基 |
假 |
FROM_BASE64
edit语法
参数
-
string - 一个Base64字符串。
描述
解码一个base64字符串。
支持的类型
| string | result |
|---|---|
关键词 |
关键词 |
文本 |
关键词 |
示例
row a = "ZWxhc3RpYw==" | eval d = from_base64(a)
| a:keyword | d:keyword |
|---|---|
大数据 |
弹性 |
LEFT
edit语法
参数
-
string - 要从中返回子字符串的字符串。
-
length - 返回的字符数。
描述
返回从字符串的左侧开始提取的指定长度的子字符串。
支持的类型
| string | length | result |
|---|---|---|
关键词 |
整数 |
关键词 |
文本 |
整数 |
关键词 |
示例
FROM employees | KEEP last_name | EVAL left = LEFT(last_name, 3) | SORT last_name ASC | LIMIT 5
| last_name:keyword | left:keyword |
|---|---|
阿德赫 |
Awd |
东 |
Azu |
白 |
贝 |
班福德 |
砰 |
伯纳茨基 |
伯 |
LENGTH
edit语法
参数
-
string -
字符串表达式。如果为
null,函数返回null。
描述
返回字符串的字符长度。
支持的类型
| string | result |
|---|---|
关键词 |
整数 |
文本 |
整数 |
示例
FROM employees | KEEP first_name, last_name | EVAL fn_length = LENGTH(first_name)
| first_name:keyword | last_name:keyword | fn_length:integer |
|---|---|---|
亚历杭德罗 |
麦卡尔平 |
9 |
阿马比尔 |
Gomatam |
7 |
安妮克 |
普罗伊斯格 |
6 |
LOCATE
edit语法
参数
-
string - 一个输入字符串
-
substring - 要在输入字符串中定位的子字符串
-
start - 起始索引
描述
返回一个整数,表示关键字子字符串在另一个字符串中的位置。如果找不到子字符串,则返回0。请注意,字符串位置从1开始。
支持的类型
| string | substring | start | result |
|---|---|---|---|
关键词 |
关键词 |
整数 |
整数 |
关键词 |
关键词 |
整数 |
|
关键词 |
文本 |
整数 |
整数 |
关键词 |
文本 |
整数 |
|
文本 |
关键词 |
整数 |
整数 |
文本 |
关键词 |
整数 |
|
文本 |
文本 |
整数 |
整数 |
文本 |
文本 |
整数 |
示例
row a = "hello" | eval a_ll = locate(a, "ll")
| a:keyword | a_ll:integer |
|---|---|
你好 |
3 |
LTRIM
edit语法
参数
-
string -
字符串表达式。如果为
null,函数返回null。
描述
从字符串中移除前导空白字符。
支持的类型
| string | result |
|---|---|
关键词 |
关键词 |
文本 |
文本 |
示例
ROW message = " some text ", color = " red "
| EVAL message = LTRIM(message)
| EVAL color = LTRIM(color)
| EVAL message = CONCAT("'", message, "'")
| EVAL color = CONCAT("'", color, "'")
| message:keyword | color:keyword |
|---|---|
'一些文本 ' |
'红色 ' |
REPEAT
edit语法
参数
-
string - 字符串表达式。
-
number - 重复的次数。
描述
返回一个由 string 自身连接指定 number 次数构成的字符串。
支持的类型
| string | number | result |
|---|---|---|
关键词 |
整数 |
关键词 |
文本 |
整数 |
关键词 |
示例
ROW a = "Hello!" | EVAL triple_a = REPEAT(a, 3);
| a:keyword | triple_a:keyword |
|---|---|
你好! |
你好!你好!你好! |
REPLACE
edit语法
参数
-
string - 字符串表达式。
-
regex - 正则表达式。
-
newString - 替换字符串。
描述
该函数在字符串 str 中,将正则表达式 regex 的任何匹配项替换为替换字符串 newStr。
支持的类型
| string | regex | newString | result |
|---|---|---|---|
关键词 |
关键词 |
关键词 |
关键词 |
关键词 |
关键词 |
文本 |
关键词 |
关键词 |
文本 |
关键词 |
关键词 |
关键词 |
文本 |
文本 |
关键词 |
文本 |
关键词 |
关键词 |
关键词 |
文本 |
关键词 |
文本 |
关键词 |
文本 |
文本 |
关键词 |
关键词 |
文本 |
文本 |
文本 |
关键词 |
示例
这个示例将任何出现的单词“World”替换为单词“Universe”:
ROW str = "Hello World" | EVAL str = REPLACE(str, "World", "Universe") | KEEP str
| str:keyword |
|---|
你好,宇宙 |
反转
edit语法
参数
-
str -
字符串表达式。如果为
null,函数返回null。
描述
返回一个新字符串,表示输入字符串的逆序。
支持的类型
| str | result |
|---|---|
关键词 |
关键词 |
文本 |
文本 |
示例
ROW message = "Some Text" | EVAL message_reversed = REVERSE(message);
| message:keyword | message_reversed:keyword |
|---|---|
一些文本 |
示例文本 |
REVERSE 也适用于Unicode!它在反转过程中保持Unicode字素簇在一起。
ROW bending_arts = "💧🪨🔥💨" | EVAL bending_arts_reversed = REVERSE(bending_arts);
| bending_arts:keyword | bending_arts_reversed:keyword |
|---|---|
💧🪨🔥💨 |
💨🔥🪨💧 |
RIGHT
edit语法
参数
-
string - 从中返回子字符串的字符串。
-
length - 返回的字符数。
描述
返回从右侧开始从str中提取的length个字符的子字符串。
支持的类型
| string | length | result |
|---|---|---|
关键词 |
整数 |
关键词 |
文本 |
整数 |
关键词 |
示例
FROM employees | KEEP last_name | EVAL right = RIGHT(last_name, 3) | SORT last_name ASC | LIMIT 5
| last_name:keyword | right:keyword |
|---|---|
阿德赫 |
德 |
东 |
乌玛 |
白 |
aek |
班福德 |
ord |
伯纳茨基 |
天空 |
RTRIM
edit语法
参数
-
string -
字符串表达式。如果为
null,函数返回null。
描述
移除字符串末尾的空白字符。
支持的类型
| string | result |
|---|---|
关键词 |
关键词 |
文本 |
文本 |
示例
ROW message = " some text ", color = " red "
| EVAL message = RTRIM(message)
| EVAL color = RTRIM(color)
| EVAL message = CONCAT("'", message, "'")
| EVAL color = CONCAT("'", color, "'")
| message:keyword | color:keyword |
|---|---|
' 一些文本' |
'红色' |
SPACE
edit语法
参数
-
number - 结果中的空格数。
描述
返回由number个空格组成的字符串。
支持的类型
| number | result |
|---|---|
整数 |
关键词 |
示例
ROW message = CONCAT("Hello", SPACE(1), "World!");
| message:keyword |
|---|
你好,世界! |
SPLIT
edit语法
参数
-
string -
字符串表达式。如果为
null,函数返回null。 -
delim - 分隔符。目前仅支持单字节分隔符。
描述
将单值字符串拆分为多个字符串。
支持的类型
| string | delim | result |
|---|---|---|
关键词 |
关键词 |
关键词 |
关键词 |
文本 |
关键词 |
文本 |
关键词 |
关键词 |
文本 |
文本 |
关键词 |
示例
ROW words="foo;bar;baz;qux;quux;corge" | EVAL word = SPLIT(words, ";")
| words:keyword | word:keyword |
|---|---|
foo;bar;baz;qux;quux;corge |
[foo, bar, baz, qux, quux, corge] |
STARTS_WITH
edit语法
参数
-
str -
字符串表达式。如果为
null,函数返回null。 -
prefix -
字符串表达式。如果为
null,函数返回null。
描述
返回一个布尔值,指示关键字字符串是否以另一个字符串开头。
支持的类型
| str | prefix | result |
|---|---|---|
关键词 |
关键词 |
布尔值 |
关键词 |
文本 |
布尔值 |
文本 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
示例
FROM employees | KEEP last_name | EVAL ln_S = STARTS_WITH(last_name, "B")
| last_name:keyword | ln_S:boolean |
|---|---|
阿德赫 |
假 |
东 |
假 |
白 |
真 |
班福德 |
真 |
伯纳茨基 |
真 |
SUBSTRING
edit语法
参数
-
string -
字符串表达式。如果为
null,函数返回null。 -
start - 起始位置。
-
length -
从起始位置开始的子字符串长度。可选;如果省略,则返回
start之后的所有位置。
描述
返回字符串的子字符串,由起始位置和可选的长度指定。
支持的类型
| string | start | length | result |
|---|---|---|---|
关键词 |
整数 |
整数 |
关键词 |
文本 |
整数 |
整数 |
关键词 |
示例
此示例返回每个姓氏的前三个字符:
FROM employees | KEEP last_name | EVAL ln_sub = SUBSTRING(last_name, 1, 3)
| last_name:keyword | ln_sub:keyword |
|---|---|
阿德赫 |
Awd |
东 |
Azu |
白 |
贝 |
班福德 |
砰 |
伯纳茨基 |
伯 |
负的开始位置被解释为相对于字符串末尾的位置。 这个例子返回每个姓氏的最后三个字符:
FROM employees | KEEP last_name | EVAL ln_sub = SUBSTRING(last_name, -3, 3)
| last_name:keyword | ln_sub:keyword |
|---|---|
阿德赫 |
德 |
东 |
乌玛 |
白 |
aek |
班福德 |
ord |
伯纳茨基 |
天空 |
如果省略长度,substring 将返回字符串的剩余部分。 这个例子返回除第一个字符外的所有字符:
FROM employees | KEEP last_name | EVAL ln_sub = SUBSTRING(last_name, 2)
| last_name:keyword | ln_sub:keyword |
|---|---|
阿德赫 |
wdeh |
东 |
祖玛 |
白 |
aek |
班福德 |
阿姆福德 |
伯纳茨基 |
埃尔纳茨基 |
TO_BASE64
edit语法
参数
-
string - 一个字符串。
描述
将字符串编码为base64字符串。
支持的类型
| string | result |
|---|---|
关键词 |
关键词 |
文本 |
关键词 |
示例
row a = "elastic" | eval e = to_base64(a)
| a:keyword | e:keyword |
|---|---|
弹性 |
大数据 |
TO_LOWER
edit语法
参数
-
str -
字符串表达式。如果为
null,函数返回null。
描述
返回一个新字符串,表示将输入字符串转换为小写。
支持的类型
| str | result |
|---|---|
关键词 |
关键词 |
文本 |
文本 |
示例
ROW message = "Some Text" | EVAL message_lower = TO_LOWER(message)
| message:keyword | message_lower:keyword |
|---|---|
一些文本 |
一些文本 |
TO_UPPER
edit语法
参数
-
str -
字符串表达式。如果为
null,函数返回null。
描述
返回一个新字符串,表示将输入字符串转换为大写。
支持的类型
| str | result |
|---|---|
关键词 |
关键词 |
文本 |
文本 |
示例
ROW message = "Some Text" | EVAL message_upper = TO_UPPER(message)
| message:keyword | message_upper:keyword |
|---|---|
一些文本 |
一些文本 |
TRIM
edit语法
参数
-
string -
字符串表达式。如果为
null,函数返回null。
描述
移除字符串前后的空白字符。
支持的类型
| string | result |
|---|---|
关键词 |
关键词 |
文本 |
文本 |
示例
ROW message = " some text ", color = " red " | EVAL message = TRIM(message) | EVAL color = TRIM(color)
| message:s | color:s |
|---|---|
一些文本 |
红色 |
ES|QL 类型转换函数
editES|QL 支持从字符串字面量到某些数据类型的隐式转换。详情请参阅 隐式转换。
ES|QL 支持这些类型转换函数:
-
TO_BOOLEAN -
TO_CARTESIANPOINT -
TO_CARTESIANSHAPE -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
TO_DATEPERIOD -
TO_DATETIME -
TO_DEGREES -
TO_DOUBLE -
TO_GEOPOINT -
TO_GEOSHAPE -
TO_INTEGER -
TO_IP -
TO_LONG -
TO_RADIANS -
TO_STRING -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
TO_TIMEDURATION -
[预览]
此功能处于技术预览阶段,可能会在未来的版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能支持 SLA 的约束。
TO_UNSIGNED_LONG -
TO_VERSION
TO_BOOLEAN
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入值转换为布尔值。字符串值 true 将不区分大小写地转换为布尔值 true。对于其他任何值,包括空字符串,函数将返回 false。数值 0 将转换为 false,其他任何值将转换为 true。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
双精度 |
布尔值 |
整数 |
布尔值 |
关键词 |
布尔值 |
长 |
布尔值 |
文本 |
布尔值 |
无符号长整型 |
布尔值 |
示例
ROW str = ["true", "TRuE", "false", "", "yes", "1"] | EVAL bool = TO_BOOLEAN(str)
| str:keyword | bool:boolean |
|---|---|
["真", "真", "假", "", "是", "1"] |
[真, 真, 假, 假, 假, 假] |
TO_CARTESIANPOINT
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入值转换为cartesian_point值。只有当字符串符合WKT Point格式时,才能成功转换。
支持的类型
| field | result |
|---|---|
笛卡尔点 |
笛卡尔点 |
关键词 |
笛卡尔点 |
文本 |
笛卡尔点 |
示例
ROW wkt = ["POINT(4297.11 -1475.53)", "POINT(7580.93 2272.77)"] | MV_EXPAND wkt | EVAL pt = TO_CARTESIANPOINT(wkt)
| wkt:keyword | pt:cartesian_point |
|---|---|
"POINT(4297.11 -1475.53)" |
POINT(4297.11 -1475.53) |
"POINT(7580.93 2272.77)" |
POINT(7580.93 2272.77) |
TO_CARTESIANSHAPE
edit语法
参数
-
field - 输入值。输入可以是单值或多值列,也可以是一个表达式。
描述
将输入值转换为cartesian_shape值。只有当字符串符合WKT格式时,才能成功转换。
支持的类型
| field | result |
|---|---|
笛卡尔点 |
笛卡尔形状 |
笛卡尔形状 |
笛卡尔形状 |
关键词 |
笛卡尔形状 |
文本 |
笛卡尔形状 |
示例
ROW wkt = ["POINT(4297.11 -1475.53)", "POLYGON ((3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97))"] | MV_EXPAND wkt | EVAL geom = TO_CARTESIANSHAPE(wkt)
| wkt:keyword | geom:cartesian_shape |
|---|---|
"POINT(4297.11 -1475.53)" |
POINT(4297.11 -1475.53) |
"POLYGON 3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97" |
POLYGON 3339584.72 1118889.97, 4452779.63 4865942.27, 2226389.81 4865942.27, 1113194.90 2273030.92, 3339584.72 1118889.97 |
TO_DATEPERIOD
edit语法
参数
-
field - 输入值。输入是一个有效的常量日期周期表达式。
描述
将输入值转换为date_period值。
支持的类型
| field | result |
|---|---|
日期区间 |
日期区间 |
关键词 |
日期区间 |
文本 |
日期区间 |
示例
row x = "2024-01-01"::datetime | eval y = x + "3 DAYS"::date_period, z = x - to_dateperiod("3 days");
| x:datetime | y:datetime | z:datetime |
|---|---|---|
2024年1月1日 |
2024年1月4日 |
2023年12月29日 |
TO_DATETIME
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入值转换为日期值。只有当字符串符合格式 yyyy-MM-dd'T'HH:mm:ss.SSS'Z' 时,才能成功转换。要转换其他格式的日期,请使用 DATE_PARSE。
请注意,当使用此函数将纳秒分辨率转换为毫秒分辨率时,纳秒日期会被截断,而不是四舍五入。
支持的类型
| field | result |
|---|---|
日期 |
日期 |
双精度 |
日期 |
整数 |
日期 |
关键词 |
日期 |
长 |
日期 |
文本 |
日期 |
无符号长整型 |
日期 |
示例
ROW string = ["1953-09-02T00:00:00.000Z", "1964-06-02T00:00:00.000Z", "1964-06-02 00:00:00"] | EVAL datetime = TO_DATETIME(string)
| string:keyword | datetime:date |
|---|---|
["1953-09-02T00:00:00.000Z", "1964-06-02T00:00:00.000Z", "1964-06-02 00:00:00"] |
[1953-09-02T00:00:00.000Z, 1964-06-02T00:00:00.000Z] |
请注意,在此示例中,源多值字段中的最后一个值尚未转换。 原因是如果日期格式未被遵守,转换将导致一个空值。 当这种情况发生时,响应中会添加一个警告头。 该头将提供关于失败来源的信息:
"第1行:112: 对[TO_DATETIME(string)]的评估失败,将结果视为null。 "仅记录前20次失败。"
以下标题将包含失败原因和违规值:
"java.lang.IllegalArgumentException: 无法解析日期字段 [1964-06-02 00:00:00]
格式为 [yyyy-MM-dd'T'HH:mm:ss.SSS'Z']"
如果输入参数是数值类型,其值将被解释为自Unix纪元以来的毫秒数。例如:
ROW int = [0, 1] | EVAL dt = TO_DATETIME(int)
| int:integer | dt:date |
|---|---|
[0, 1] |
[1970-01-01T00:00:00.000Z, 1970-01-01T00:00:00.001Z] |
TO_DEGREES
edit语法
参数
-
number - 输入值。输入可以是单值或多值列,也可以是一个表达式。
描述
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW rad = [1.57, 3.14, 4.71] | EVAL deg = TO_DEGREES(rad)
| rad:double | deg:double |
|---|---|
[1.57, 3.14, 4.71] |
[89.95437383553924, 179.9087476710785, 269.86312150661774] |
TO_DOUBLE
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入值转换为双精度值。如果输入参数是日期类型,其值将被解释为自Unix纪元以来的毫秒数,并转换为双精度值。布尔值true将转换为双精度值1.0,false将转换为双精度值0.0。
支持的类型
| field | result |
|---|---|
布尔值 |
双精度 |
计数器_双倍 |
双精度 |
计数器整数 |
双精度 |
长计数器 |
双精度 |
日期 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
关键词 |
双精度 |
长 |
双精度 |
文本 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW str1 = "5.20128E11", str2 = "foo"
| EVAL dbl = TO_DOUBLE("520128000000"), dbl1 = TO_DOUBLE(str1), dbl2 = TO_DOUBLE(str2)
| str1:keyword | str2:keyword | dbl:double | dbl1:double | dbl2:double |
|---|---|---|---|---|
5.20128E11 |
foo |
5.20128E11 |
5.20128E11 |
空 |
请注意,在这个例子中,字符串的最后一次转换是不可能的。 当这种情况发生时,结果是一个空值。在这种情况下,会在响应中添加一个警告头。 该头将提供关于失败来源的信息:
"第1行:115: 评估[TO_DOUBLE(str2)]失败,将结果视为null。仅记录前20次失败。"
以下标题将包含失败原因和违规值:
"java.lang.NumberFormatException: 对于输入字符串: "foo""
TO_GEOPOINT
edit语法
参数
-
field - 输入值。输入可以是单值或多值列,也可以是一个表达式。
描述
将输入值转换为geo_point值。只有当字符串符合WKT Point格式时,才能成功转换。
支持的类型
| field | result |
|---|---|
地理点 |
地理点 |
关键词 |
地理点 |
文本 |
地理点 |
示例
ROW wkt = "POINT(42.97109630194 14.7552534413725)" | EVAL pt = TO_GEOPOINT(wkt)
| wkt:keyword | pt:geo_point |
|---|---|
"POINT(42.97109630194 14.7552534413725)" |
POINT(42.97109630194 14.7552534413725) |
TO_GEOSHAPE
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入值转换为geo_shape值。只有当字符串符合WKT格式时,才能成功转换。
支持的类型
| field | result |
|---|---|
地理点 |
地理形状 |
地理形状 |
地理形状 |
关键词 |
地理形状 |
文本 |
地理形状 |
示例
ROW wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))" | EVAL geom = TO_GEOSHAPE(wkt)
| wkt:keyword | geom:geo_shape |
|---|---|
"多边形 30 10, 40 40, 20 40, 10 20, 30 10" |
多边形 30 10, 40 40, 20 40, 10 20, 30 10 |
TO_INTEGER
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入值转换为整数值。如果输入参数是日期类型,其值将被解释为自Unix纪元以来的毫秒数,并转换为整数。布尔值true将转换为整数1,false将转换为整数0。
支持的类型
| field | result |
|---|---|
布尔值 |
整数 |
计数器整数 |
整数 |
日期 |
整数 |
双精度 |
整数 |
整数 |
整数 |
关键词 |
整数 |
长 |
整数 |
文本 |
整数 |
无符号长整型 |
整数 |
示例
ROW long = [5013792, 2147483647, 501379200000] | EVAL int = TO_INTEGER(long)
| long:long | int:integer |
|---|---|
[5013792, 2147483647, 501379200000] |
[5013792, 2147483647] |
请注意,在这个示例中,多值字段的最后一个值无法转换为整数。 当这种情况发生时,结果是一个空值。在这种情况下,会在响应中添加一个警告头。 该头将提供有关失败来源的信息:
"第1行:61: 对[TO_INTEGER(long)]的求值失败,将结果视为null。仅记录前20次失败。"
以下标题将包含失败原因和违规值:
"org.elasticsearch.xpack.esql.core.InvalidArgumentException: [501379200000] 超出 [integer] 范围"
TO_IP
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入字符串转换为IP值。
支持的类型
| field | result |
|---|---|
IP |
IP |
关键词 |
IP |
文本 |
IP |
示例
ROW str1 = "1.1.1.1", str2 = "foo" | EVAL ip1 = TO_IP(str1), ip2 = TO_IP(str2) | WHERE CIDR_MATCH(ip1, "1.0.0.0/8")
| str1:keyword | str2:keyword | ip1:ip | ip2:ip |
|---|---|---|---|
1.1.1.1 |
foo |
1.1.1.1 |
空 |
请注意,在这个例子中,字符串的最后一次转换是不可能的。 当这种情况发生时,结果是一个空值。在这种情况下,会在响应中添加一个警告头。 该头将提供关于失败来源的信息:
"第1行:68: 对[TO_IP(str2)]的评估失败,将结果视为null。仅记录前20次失败。"
以下标题将包含失败原因和违规值:
"java.lang.IllegalArgumentException: 'foo' 不是一个IP字符串字面量。"
TO_LONG
edit语法
参数
-
field - 输入值。输入可以是单值或多值列,也可以是一个表达式。
描述
将输入值转换为长整型值。如果输入参数是日期类型,其值将被解释为自Unix纪元以来的毫秒数,转换为长整型。布尔值真将转换为长整型1,假转换为长整型0。
支持的类型
| field | result |
|---|---|
布尔值 |
长 |
计数器整数 |
长 |
长计数器 |
长 |
日期 |
长 |
双精度 |
长 |
整数 |
长 |
关键词 |
长 |
长 |
长 |
文本 |
长 |
无符号长整型 |
长 |
示例
ROW str1 = "2147483648", str2 = "2147483648.2", str3 = "foo" | EVAL long1 = TO_LONG(str1), long2 = TO_LONG(str2), long3 = TO_LONG(str3)
| str1:keyword | str2:keyword | str3:keyword | long1:long | long2:long | long3:long |
|---|---|---|---|---|---|
2147483648 |
2147483648.2 |
foo |
2147483648 |
2147483648 |
空 |
请注意,在这个例子中,字符串的最后一次转换是不可能的。 当这种情况发生时,结果是一个空值。在这种情况下,会在响应中添加一个警告头。 该头将提供关于失败来源的信息:
"第1行:113: 对[TO_LONG(str3)]的求值失败,将结果视为null。仅记录前20次失败。"
以下标题将包含失败原因和违规值:
"java.lang.NumberFormatException: 对于输入字符串: "foo""
TO_RADIANS
edit语法
参数
-
number - 输入值。输入可以是单值或多值列或表达式。
描述
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW deg = [90.0, 180.0, 270.0] | EVAL rad = TO_RADIANS(deg)
| deg:double | rad:double |
|---|---|
[90.0, 180.0, 270.0] |
[1.5707963267948966, 3.141592653589793, 4.71238898038469] |
TO_STRING
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入值转换为字符串。
支持的类型
| field | result |
|---|---|
布尔值 |
关键词 |
笛卡尔点 |
关键词 |
笛卡尔形状 |
关键词 |
日期 |
关键词 |
双精度 |
关键词 |
地理点 |
关键词 |
地理形状 |
关键词 |
整数 |
关键词 |
IP |
关键词 |
关键词 |
关键词 |
长 |
关键词 |
文本 |
关键词 |
无符号长整型 |
关键词 |
版本 |
关键词 |
示例
ROW a=10 | EVAL j = TO_STRING(a)
| a:integer | j:keyword |
|---|---|
10 |
"10" |
它也可以很好地处理多值字段:
ROW a=[10, 9, 8] | EVAL j = TO_STRING(a)
| a:integer | j:keyword |
|---|---|
[10, 9, 8] |
["10", "9", "8"] |
TO_TIMEDURATION
edit语法
参数
-
field - 输入值。输入是一个有效的常量时间持续时间表达式。
描述
将输入值转换为time_duration值。
支持的类型
| field | result |
|---|---|
关键词 |
时间间隔 |
文本 |
时间间隔 |
时间间隔 |
时间间隔 |
示例
row x = "2024-01-01"::datetime | eval y = x + "3 hours"::time_duration, z = x - to_timeduration("3 hours");
| x:datetime | y:datetime | z:datetime |
|---|---|---|
2024年1月1日 |
2024-01-01T03:00:00.000Z |
2023年12月31日 21:00:00.000Z |
TO_UNSIGNED_LONG
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入值转换为无符号长整型值。如果输入参数是日期类型,其值将被解释为自Unix纪元以来的毫秒数,转换为无符号长整型。布尔值真将转换为无符号长整型1,假转换为0。
支持的类型
| field | result |
|---|---|
布尔值 |
无符号长整型 |
日期 |
无符号长整型 |
双精度 |
无符号长整型 |
整数 |
无符号长整型 |
关键词 |
无符号长整型 |
长 |
无符号长整型 |
文本 |
无符号长整型 |
无符号长整型 |
无符号长整型 |
示例
ROW str1 = "2147483648", str2 = "2147483648.2", str3 = "foo" | EVAL long1 = TO_UNSIGNED_LONG(str1), long2 = TO_ULONG(str2), long3 = TO_UL(str3)
| str1:keyword | str2:keyword | str3:keyword | long1:unsigned_long | long2:unsigned_long | long3:unsigned_long |
|---|---|---|---|---|---|
2147483648 |
2147483648.2 |
foo |
2147483648 |
2147483648 |
空 |
请注意,在这个例子中,字符串的最后一次转换是不可能的。 当这种情况发生时,结果是一个空值。在这种情况下,会在响应中添加一个警告头。 该头将提供关于失败来源的信息:
"第1行:133: 评估[TO_UL(str3)]失败,将结果视为null。仅记录前20次失败。"
以下标题将包含失败原因和违规值:
"java.lang.NumberFormatException: 字符 f 既不是十进制数字,也不是小数点,也不是 "e" 表示法的指数标记。"
TO_VERSION
edit语法
参数
-
field - 输入值。输入可以是单值或多值列或表达式。
描述
将输入字符串转换为版本值。
支持的类型
| field | result |
|---|---|
关键词 |
版本 |
文本 |
版本 |
版本 |
版本 |
示例
ROW v = TO_VERSION("1.2.3")
| v:version |
|---|
1.2.3 |
ES|QL 多值函数
editES|QL 支持这些多值函数:
MV_APPEND
edit语法
参数
-
field1 -
field2
描述
连接两个多值字段的值。
支持的类型
| field1 | field2 | result |
|---|---|---|
布尔值 |
布尔值 |
布尔值 |
笛卡尔点 |
笛卡尔点 |
笛卡尔点 |
笛卡尔形状 |
笛卡尔形状 |
笛卡尔形状 |
日期 |
日期 |
日期 |
双精度 |
双精度 |
双精度 |
地理点 |
地理点 |
地理点 |
地理形状 |
地理形状 |
地理形状 |
整数 |
整数 |
整数 |
IP |
IP |
IP |
关键词 |
关键词 |
关键词 |
长 |
长 |
长 |
文本 |
文本 |
文本 |
版本 |
版本 |
版本 |
MV_AVG
edit语法
参数
-
number - 多值表达式。
描述
将多值字段转换为包含所有值平均值的单值字段。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
双精度 |
长 |
双精度 |
无符号长整型 |
双精度 |
示例
ROW a=[3, 5, 1, 6] | EVAL avg_a = MV_AVG(a)
| a:integer | avg_a:double |
|---|---|
[3, 5, 1, 6] |
3.75 |
MV_CONCAT
edit语法
参数
-
string - 多值表达式。
-
delim - 分隔符。
描述
将多值字符串表达式转换为包含所有值用分隔符连接的单值列。
支持的类型
| string | delim | result |
|---|---|---|
关键词 |
关键词 |
关键词 |
关键词 |
文本 |
关键词 |
文本 |
关键词 |
关键词 |
文本 |
文本 |
关键词 |
示例
ROW a=["foo", "zoo", "bar"] | EVAL j = MV_CONCAT(a, ", ")
| a:keyword | j:keyword |
|---|---|
["foo", "zoo", "bar"] |
"foo, zoo, bar" |
要连接非字符串列,请先调用 TO_STRING:
ROW a=[10, 9, 8] | EVAL j = MV_CONCAT(TO_STRING(a), ", ")
| a:integer | j:keyword |
|---|---|
[10, 9, 8] |
"10, 9, 8" |
MV_COUNT
edit语法
参数
-
field - 多值表达式。
描述
将多值表达式转换为包含值数量计数的单值列。
支持的类型
| field | result |
|---|---|
布尔值 |
整数 |
笛卡尔点 |
整数 |
笛卡尔形状 |
整数 |
日期 |
整数 |
双精度 |
整数 |
地理点 |
整数 |
地理形状 |
整数 |
整数 |
整数 |
IP |
整数 |
关键词 |
整数 |
长 |
整数 |
文本 |
整数 |
无符号长整型 |
整数 |
版本 |
整数 |
示例
ROW a=["foo", "zoo", "bar"] | EVAL count_a = MV_COUNT(a)
| a:keyword | count_a:integer |
|---|---|
["foo", "zoo", "bar"] |
3 |
MV_DEDUPE
edit语法
参数
-
field - 多值表达式。
描述
从多值字段中移除重复值。
MV_DEDUPE 可能会,但并不总是,对列中的值进行排序。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
笛卡尔点 |
笛卡尔点 |
笛卡尔形状 |
笛卡尔形状 |
日期 |
日期 |
双精度 |
双精度 |
地理点 |
地理点 |
地理形状 |
地理形状 |
整数 |
整数 |
IP |
IP |
关键词 |
关键词 |
长 |
长 |
文本 |
文本 |
版本 |
版本 |
示例
ROW a=["foo", "foo", "bar", "foo"] | EVAL dedupe_a = MV_DEDUPE(a)
| a:keyword | dedupe_a:keyword |
|---|---|
["foo", "foo", "bar", "foo"] |
["foo", "bar"] |
MV_FIRST
edit语法
参数
-
field - 多值表达式。
描述
将多值表达式转换为包含第一个值的单值列。这在从以已知顺序发出多值列的函数(如SPLIT)读取时非常有用。
从底层存储读取多值字段的顺序是不保证的。它通常是升序的,但不要依赖于此。如果你需要最小值,请使用MV_MIN而不是MV_FIRST。MV_MIN对已排序的值有优化,因此MV_FIRST并没有性能优势。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
笛卡尔点 |
笛卡尔点 |
笛卡尔形状 |
笛卡尔形状 |
日期 |
日期 |
双精度 |
双精度 |
地理点 |
地理点 |
地理形状 |
地理形状 |
整数 |
整数 |
IP |
IP |
关键词 |
关键词 |
长 |
长 |
文本 |
文本 |
无符号长整型 |
无符号长整型 |
版本 |
版本 |
示例
ROW a="foo;bar;baz" | EVAL first_a = MV_FIRST(SPLIT(a, ";"))
| a:keyword | first_a:keyword |
|---|---|
foo;bar;baz |
"foo" |
MV_LAST
edit语法
参数
-
field - 多值表达式。
描述
将多值表达式转换为包含最后一个值的单值列。这在从以已知顺序发出多值列的函数(如SPLIT)读取时非常有用。
从底层存储读取多值字段的顺序是不保证的。它通常是升序的,但不要依赖于此。如果你需要最大值,请使用MV_MAX而不是MV_LAST。MV_MAX对已排序的值有优化,因此MV_LAST并没有性能优势。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
笛卡尔点 |
笛卡尔点 |
笛卡尔形状 |
笛卡尔形状 |
日期 |
日期 |
双精度 |
双精度 |
地理点 |
地理点 |
地理形状 |
地理形状 |
整数 |
整数 |
IP |
IP |
关键词 |
关键词 |
长 |
长 |
文本 |
文本 |
无符号长整型 |
无符号长整型 |
版本 |
版本 |
示例
ROW a="foo;bar;baz" | EVAL last_a = MV_LAST(SPLIT(a, ";"))
| a:keyword | last_a:keyword |
|---|---|
foo;bar;baz |
"baz" |
MV_MAX
edit语法
参数
-
field - 多值表达式。
描述
将多值表达式转换为包含最大值的单值列。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
日期 |
日期 |
双精度 |
双精度 |
整数 |
整数 |
IP |
IP |
关键词 |
关键词 |
长 |
长 |
文本 |
文本 |
无符号长整型 |
无符号长整型 |
版本 |
版本 |
示例
ROW a=[3, 5, 1] | EVAL max_a = MV_MAX(a)
| a:integer | max_a:integer |
|---|---|
[3, 5, 1] |
5 |
它可以用于任何列类型,包括 keyword 列。在这种情况下,它会选取最后一个字符串,逐字节比较它们的utf-8表示:
ROW a=["foo", "zoo", "bar"] | EVAL max_a = MV_MAX(a)
| a:keyword | max_a:keyword |
|---|---|
["foo", "zoo", "bar"] |
"动物园" |
MV_MEDIAN
edit语法
参数
-
number - 多值表达式。
描述
将多值字段转换为包含中值的单值字段。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
整数 |
长 |
长 |
无符号长整型 |
无符号长整型 |
示例
ROW a=[3, 5, 1] | EVAL median_a = MV_MEDIAN(a)
| a:integer | median_a:integer |
|---|---|
[3, 5, 1] |
3 |
如果某列的值数量为偶数,结果将是中间两个值的平均值。如果该列不是浮点数,平均值将向下取整:
ROW a=[3, 7, 1, 6] | EVAL median_a = MV_MEDIAN(a)
| a:integer | median_a:integer |
|---|---|
[3, 7, 1, 6] |
4 |
MV_MEDIAN_ABSOLUTE_DEVIATION
edit语法
参数
-
number - 多值表达式。
描述
将多值字段转换为包含中位数绝对偏差的单值字段。它是通过计算每个数据点与整个样本中位数的偏差的中位数来计算的。也就是说,对于随机变量 X,中位数绝对偏差为 median(|median(X) - X|)。
如果字段有偶数个值,中位数将计算为中间两个值的平均值。如果该值不是浮点数,则平均值向0方向取整。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
整数 |
长 |
长 |
无符号长整型 |
无符号长整型 |
示例
ROW values = [0, 2, 5, 6] | EVAL median_absolute_deviation = MV_MEDIAN_ABSOLUTE_DEVIATION(values), median = MV_MEDIAN(values)
| values:integer | median_absolute_deviation:integer | median:integer |
|---|---|---|
[0, 2, 5, 6] |
2 |
3 |
MV_MIN
edit语法
参数
-
field - 多值表达式。
描述
将多值表达式转换为包含最小值的单值列。
支持的类型
| field | result |
|---|---|
布尔值 |
布尔值 |
日期 |
日期 |
双精度 |
双精度 |
整数 |
整数 |
IP |
IP |
关键词 |
关键词 |
长 |
长 |
文本 |
文本 |
无符号长整型 |
无符号长整型 |
版本 |
版本 |
示例
ROW a=[2, 1] | EVAL min_a = MV_MIN(a)
| a:integer | min_a:integer |
|---|---|
[2, 1] |
1 |
它可以用于任何列类型,包括 keyword 列。在这种情况下,它会选取第一个字符串,逐字节比较它们的 utf-8 表示:
ROW a=["foo", "bar"] | EVAL min_a = MV_MIN(a)
| a:keyword | min_a:keyword |
|---|---|
["foo", "bar"] |
"条形图" |
MV_PSERIES_WEIGHTED_SUM
edit语法
参数
-
number - 多值表达式。
-
p - 这是一个常数,表示P-Series中的p参数。它影响每个元素对加权和的贡献。
描述
通过将输入列表中的每个元素乘以其对应的P-Series项并计算总和,将多值表达式转换为单值列。
支持的类型
| number | p | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
示例
ROW a = [70.0, 45.0, 21.0, 21.0, 21.0] | EVAL sum = MV_PSERIES_WEIGHTED_SUM(a, 1.5) | KEEP sum
| sum:double |
|---|
94.45465156212452 |
MV_SLICE
edit语法
参数
-
field -
多值表达式。如果
null,函数返回null。 -
start -
起始位置。如果为
null,函数返回null。起始参数可以为负数。索引为-1表示指定列表中的最后一个值。 -
end -
结束位置(包含)。可选;如果省略,则返回位于
start位置的值。end参数可以为负数。索引为-1表示指定列表中的最后一个值。
描述
返回使用起始和结束索引值的多值字段子集。这在从以已知顺序发出多值列的函数中读取时非常有用,例如 SPLIT 或 MV_SORT。
从底层存储中读取多值字段的顺序是不保证的。它通常是升序的,但不要依赖于此。
支持的类型
| field | start | end | result |
|---|---|---|---|
布尔值 |
整数 |
整数 |
布尔值 |
笛卡尔点 |
整数 |
整数 |
笛卡尔点 |
笛卡尔形状 |
整数 |
整数 |
笛卡尔形状 |
日期 |
整数 |
整数 |
日期 |
双精度 |
整数 |
整数 |
双精度 |
地理点 |
整数 |
整数 |
地理点 |
地理形状 |
整数 |
整数 |
地理形状 |
整数 |
整数 |
整数 |
整数 |
IP |
整数 |
整数 |
IP |
关键词 |
整数 |
整数 |
关键词 |
长 |
整数 |
整数 |
长 |
文本 |
整数 |
整数 |
文本 |
版本 |
整数 |
整数 |
版本 |
示例
row a = [1, 2, 2, 3] | eval a1 = mv_slice(a, 1), a2 = mv_slice(a, 2, 3)
| a:integer | a1:integer | a2:integer |
|---|---|---|
[1, 2, 2, 3] |
2 |
[2, 3] |
row a = [1, 2, 2, 3] | eval a1 = mv_slice(a, -2), a2 = mv_slice(a, -3, -1)
| a:integer | a1:integer | a2:integer |
|---|---|---|
[1, 2, 2, 3] |
2 |
[2, 2, 3] |
MV_SORT
edit语法
参数
-
field -
多值表达式。如果
null,函数返回null。 -
order - 排序顺序。有效选项为 ASC 和 DESC,默认值为 ASC。
描述
对多值字段按字典顺序进行排序。
支持的类型
| field | order | result |
|---|---|---|
布尔值 |
关键词 |
布尔值 |
日期 |
关键词 |
日期 |
双精度 |
关键词 |
双精度 |
整数 |
关键词 |
整数 |
IP |
关键词 |
IP |
关键词 |
关键词 |
关键词 |
长 |
关键词 |
长 |
文本 |
关键词 |
文本 |
版本 |
关键词 |
版本 |
示例
ROW a = [4, 2, -3, 2] | EVAL sa = mv_sort(a), sd = mv_sort(a, "DESC")
| a:integer | sa:integer | sd:integer |
|---|---|---|
[4, 2, -3, 2] |
[-3, 2, 2, 4] |
[4, 2, 2, -3] |
MV_SUM
edit语法
参数
-
number - 多值表达式。
描述
将多值字段转换为包含所有值之和的单值字段。
支持的类型
| number | result |
|---|---|
双精度 |
双精度 |
整数 |
整数 |
长 |
长 |
无符号长整型 |
无符号长整型 |
示例
ROW a=[3, 5, 6] | EVAL sum_a = MV_SUM(a)
| a:integer | sum_a:integer |
|---|---|
[3, 5, 6] |
14 |
MV_ZIP
edit语法
参数
-
string1 - 多值表达式。
-
string2 - 多值表达式。
-
delim -
分隔符。可选;如果省略,
,将作为默认分隔符使用。
描述
将两个多值字段中的值与一个分隔符组合在一起,将它们连接起来。
支持的类型
| string1 | string2 | delim | result |
|---|---|---|---|
关键词 |
关键词 |
关键词 |
关键词 |
关键词 |
关键词 |
文本 |
关键词 |
关键词 |
关键词 |
关键词 |
|
关键词 |
文本 |
关键词 |
关键词 |
关键词 |
文本 |
文本 |
关键词 |
关键词 |
文本 |
关键词 |
|
文本 |
关键词 |
关键词 |
关键词 |
文本 |
关键词 |
文本 |
关键词 |
文本 |
关键词 |
关键词 |
|
文本 |
文本 |
关键词 |
关键词 |
文本 |
文本 |
文本 |
关键词 |
文本 |
文本 |
关键词 |
示例
ROW a = ["x", "y", "z"], b = ["1", "2"] | EVAL c = mv_zip(a, b, "-") | KEEP a, b, c
| a:keyword | b:keyword | c:keyword |
|---|---|---|
[x, y, z] |
[1 ,2] |
[x-1, y-2, z] |
相等
edit检查两个字段是否相等。如果任一字段是多值字段,则结果为null。
如果比较的一侧是常量,而另一侧是索引中同时具有index和doc_values的字段,则此内容会被推送到底层搜索索引。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
布尔值 |
布尔值 |
布尔值 |
笛卡尔点 |
笛卡尔点 |
布尔值 |
笛卡尔形状 |
笛卡尔形状 |
布尔值 |
日期 |
日期 |
布尔值 |
双精度 |
双精度 |
布尔值 |
双精度 |
整数 |
布尔值 |
双精度 |
长 |
布尔值 |
地理点 |
地理点 |
布尔值 |
地理形状 |
地理形状 |
布尔值 |
整数 |
双精度 |
布尔值 |
整数 |
整数 |
布尔值 |
整数 |
长 |
布尔值 |
IP |
IP |
布尔值 |
关键词 |
关键词 |
布尔值 |
关键词 |
文本 |
布尔值 |
长 |
双精度 |
布尔值 |
长 |
整数 |
布尔值 |
长 |
长 |
布尔值 |
文本 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
无符号长整型 |
无符号长整型 |
布尔值 |
版本 |
版本 |
布尔值 |
不等式 !=
edit检查两个字段是否不相等。如果任一字段是多值字段,则结果为null。
如果比较的一侧是常量,而另一侧是索引中同时具有index和doc_values的字段,则此内容会被推送到底层搜索索引。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
布尔值 |
布尔值 |
布尔值 |
笛卡尔点 |
笛卡尔点 |
布尔值 |
笛卡尔形状 |
笛卡尔形状 |
布尔值 |
日期 |
日期 |
布尔值 |
双精度 |
双精度 |
布尔值 |
双精度 |
整数 |
布尔值 |
双精度 |
长 |
布尔值 |
地理点 |
地理点 |
布尔值 |
地理形状 |
地理形状 |
布尔值 |
整数 |
双精度 |
布尔值 |
整数 |
整数 |
布尔值 |
整数 |
长 |
布尔值 |
IP |
IP |
布尔值 |
关键词 |
关键词 |
布尔值 |
关键词 |
文本 |
布尔值 |
长 |
双精度 |
布尔值 |
长 |
整数 |
布尔值 |
长 |
长 |
布尔值 |
文本 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
无符号长整型 |
无符号长整型 |
布尔值 |
版本 |
版本 |
布尔值 |
小于 <
edit检查一个字段是否小于另一个字段。如果任一字段是多值字段,则结果为null。
如果比较的一侧是常量,而另一侧是索引中同时具有index和doc_values的字段,则此内容会被推送到底层搜索索引。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
日期 |
日期 |
布尔值 |
双精度 |
双精度 |
布尔值 |
双精度 |
整数 |
布尔值 |
双精度 |
长 |
布尔值 |
整数 |
双精度 |
布尔值 |
整数 |
整数 |
布尔值 |
整数 |
长 |
布尔值 |
IP |
IP |
布尔值 |
关键词 |
关键词 |
布尔值 |
关键词 |
文本 |
布尔值 |
长 |
双精度 |
布尔值 |
长 |
整数 |
布尔值 |
长 |
长 |
布尔值 |
文本 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
无符号长整型 |
无符号长整型 |
布尔值 |
版本 |
版本 |
布尔值 |
小于或等于 <=
edit检查一个字段是否小于或等于另一个字段。如果任一字段是多值字段,则结果为null。
如果比较的一侧是常量,而另一侧是索引中同时具有index和doc_values的字段,则此内容会被推送到底层搜索索引。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
日期 |
日期 |
布尔值 |
双精度 |
双精度 |
布尔值 |
双精度 |
整数 |
布尔值 |
双精度 |
长 |
布尔值 |
整数 |
双精度 |
布尔值 |
整数 |
整数 |
布尔值 |
整数 |
长 |
布尔值 |
IP |
IP |
布尔值 |
关键词 |
关键词 |
布尔值 |
关键词 |
文本 |
布尔值 |
长 |
双精度 |
布尔值 |
长 |
整数 |
布尔值 |
长 |
长 |
布尔值 |
文本 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
无符号长整型 |
无符号长整型 |
布尔值 |
版本 |
版本 |
布尔值 |
大于 >
edit检查一个字段是否大于另一个字段。如果任一字段是多值字段,则结果为null。
如果比较的一侧是常量,而另一侧是索引中同时具有index和doc_values的字段,则此内容会被推送到底层搜索索引。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
日期 |
日期 |
布尔值 |
双精度 |
双精度 |
布尔值 |
双精度 |
整数 |
布尔值 |
双精度 |
长 |
布尔值 |
整数 |
双精度 |
布尔值 |
整数 |
整数 |
布尔值 |
整数 |
长 |
布尔值 |
IP |
IP |
布尔值 |
关键词 |
关键词 |
布尔值 |
关键词 |
文本 |
布尔值 |
长 |
双精度 |
布尔值 |
长 |
整数 |
布尔值 |
长 |
长 |
布尔值 |
文本 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
无符号长整型 |
无符号长整型 |
布尔值 |
版本 |
版本 |
布尔值 |
大于或等于 >=
edit检查一个字段是否大于或等于另一个字段。如果任一字段是多值字段,则结果为null。
如果比较的一侧是常量,而另一侧是索引中同时具有index和doc_values的字段,则此内容会被推送到底层搜索索引。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
日期 |
日期 |
布尔值 |
双精度 |
双精度 |
布尔值 |
双精度 |
整数 |
布尔值 |
双精度 |
长 |
布尔值 |
整数 |
双精度 |
布尔值 |
整数 |
整数 |
布尔值 |
整数 |
长 |
布尔值 |
IP |
IP |
布尔值 |
关键词 |
关键词 |
布尔值 |
关键词 |
文本 |
布尔值 |
长 |
双精度 |
布尔值 |
长 |
整数 |
布尔值 |
长 |
长 |
布尔值 |
文本 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
无符号长整型 |
无符号长整型 |
布尔值 |
版本 |
版本 |
布尔值 |
添加 +
edit将两个数字相加。如果任一字段是多值字段,则结果为null。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
日期 |
日期区间 |
日期 |
日期 |
时间间隔 |
日期 |
日期区间 |
日期 |
日期 |
日期区间 |
日期区间 |
日期区间 |
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
整数 |
长 |
长 |
长 |
双精度 |
双精度 |
长 |
整数 |
长 |
长 |
长 |
长 |
时间间隔 |
日期 |
日期 |
时间间隔 |
时间间隔 |
时间间隔 |
无符号长整型 |
无符号长整型 |
无符号长整型 |
减法 -
edit从一个数中减去另一个数。如果任一字段是多值字段,则结果为null。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
日期 |
日期区间 |
日期 |
日期 |
时间间隔 |
日期 |
日期区间 |
日期区间 |
日期区间 |
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
整数 |
长 |
长 |
长 |
双精度 |
双精度 |
长 |
整数 |
长 |
长 |
长 |
长 |
时间间隔 |
时间间隔 |
时间间隔 |
无符号长整型 |
无符号长整型 |
无符号长整型 |
乘法 *
edit将两个数字相乘。如果任一字段是多值字段,则结果为null。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
整数 |
长 |
长 |
长 |
双精度 |
双精度 |
长 |
整数 |
长 |
长 |
长 |
长 |
无符号长整型 |
无符号长整型 |
无符号长整型 |
除法 /
edit将一个数除以另一个数。如果任一字段是多值字段,则结果为null。
两个整数类型的除法将产生一个整数结果,向0方向取整。
如果你需要浮点数除法,Cast (::) 将其中一个参数转换为 DOUBLE。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
整数 |
长 |
长 |
长 |
双精度 |
双精度 |
长 |
整数 |
长 |
长 |
长 |
长 |
无符号长整型 |
无符号长整型 |
无符号长整型 |
取模 %
edit将一个数除以另一个数并返回余数。如果任一字段是多值字段,则结果为null。
支持的类型:
支持的类型
| lhs | rhs | result |
|---|---|---|
双精度 |
双精度 |
双精度 |
双精度 |
整数 |
双精度 |
双精度 |
长 |
双精度 |
整数 |
双精度 |
双精度 |
整数 |
整数 |
整数 |
整数 |
长 |
长 |
长 |
双精度 |
双精度 |
长 |
整数 |
长 |
长 |
长 |
长 |
无符号长整型 |
无符号长整型 |
无符号长整型 |
一元运算符
edit唯一的单目运算符是取反(-):
支持的类型:
支持的类型
| field | result |
|---|---|
日期区间 |
日期区间 |
双精度 |
双精度 |
整数 |
整数 |
长 |
长 |
时间间隔 |
时间间隔 |
逻辑运算符
edit支持以下逻辑运算符:
-
AND -
OR -
NOT
IS NULL 和 IS NOT NULL 谓词
edit对于NULL比较,使用IS NULL和IS NOT NULL谓词:
FROM employees | WHERE birth_date IS NULL | KEEP first_name, last_name | SORT first_name | LIMIT 3
| first_name:keyword | last_name:keyword |
|---|---|
罗勒 |
特拉默 |
弗洛里安 |
西罗季克 |
卢西恩 |
罗森鲍姆 |
FROM employees | WHERE is_rehired IS NOT NULL | STATS COUNT(emp_no)
| COUNT(emp_no):long |
|---|
84 |
类型转换 (::)
edit运算符 :: 提供了一种方便的替代语法,用于 转换函数 TO_
ROW ver = CONCAT(("0"::INT + 1)::STRING, ".2.3")::VERSION
| ver:version |
|---|
1.2.3 |
IN
edit运算符 IN 允许测试一个字段或表达式是否等于一个字面量、字段或表达式列表中的元素:
ROW a = 1, b = 4, c = 3 | WHERE c-a IN (3, b / 2, a)
| a:integer | b:integer | c:integer |
|---|---|---|
1 |
4 |
3 |
LIKE
edit使用 LIKE 根据通配符过滤基于字符串模式的数据。LIKE 通常作用于操作符左侧的字段,但它也可以作用于常量(字面量)表达式。操作符的右侧表示模式。
以下通配符受支持:
-
*匹配零个或多个字符。 -
?匹配一个字符。
支持的类型
| str | pattern | result |
|---|---|---|
关键词 |
关键词 |
布尔值 |
文本 |
文本 |
布尔值 |
FROM employees | WHERE first_name LIKE "?b*" | KEEP first_name, last_name
| first_name:keyword | last_name:keyword |
|---|---|
埃布 |
卡拉威 |
埃伯哈特 |
Terkki |
ES|QL 元数据字段
editES|QL 可以访问 元数据字段。目前支持的有:
要启用对这些字段的访问,需要为FROM源命令提供一个专用指令:
FROM index METADATA _index, _id
元数据字段仅在数据源为索引时可用。
因此,FROM 是唯一支持 METADATA 指令的源命令。
一旦启用,这些字段将可用于后续的处理命令,就像其他索引字段一样:
FROM ul_logs, apps METADATA _index, _version | WHERE id IN (13, 14) AND _version == 1 | EVAL key = CONCAT(_index, "_", TO_STR(id)) | SORT id, _index | KEEP id, _index, _version, key
| id:long | _index:keyword | _version:long | key:keyword |
|---|---|---|---|
13 |
应用程序 |
1 |
应用_13 |
13 |
ul_logs |
1 |
ul_logs_13 |
14 |
应用程序 |
1 |
应用_14 |
14 |
ul_logs |
1 |
ul_logs_14 |
与索引字段类似,一旦执行了聚合操作,元数据字段将不再可用于后续命令,除非将其用作分组字段:
FROM employees METADATA _index, _id | STATS max = MAX(emp_no) BY _index
| max:integer | _index:keyword |
|---|---|
10100 |
员工 |
ES|QL 多值字段
editES|QL 可以很好地从多值字段中读取数据:
POST /mv/_bulk?refresh
{ "index" : {} }
{ "a": 1, "b": [2, 1] }
{ "index" : {} }
{ "a": 2, "b": 3 }
POST /_query
{
"query": "FROM mv | LIMIT 2"
}
多值字段返回为JSON数组:
{
"took": 28,
"columns": [
{ "name": "a", "type": "long"},
{ "name": "b", "type": "long"}
],
"values": [
[1, [1, 2]],
[2, 3]
]
}
多值字段中值的相对顺序是未定义的。它们通常会按升序排列,但不要依赖于此。
重复值
edit某些字段类型,如keyword,在写入时会去除重复值:
PUT /mv
{
"mappings": {
"properties": {
"b": {"type": "keyword"}
}
}
}
POST /mv/_bulk?refresh
{ "index" : {} }
{ "a": 1, "b": ["foo", "foo", "bar"] }
{ "index" : {} }
{ "a": 2, "b": ["bar", "bar"] }
POST /_query
{
"query": "FROM mv | LIMIT 2"
}
并且 ES|QL 看到了这种移除:
{
"took": 28,
"columns": [
{ "name": "a", "type": "long"},
{ "name": "b", "type": "keyword"}
],
"values": [
[1, ["bar", "foo"]],
[2, "bar"]
]
}
但其他类型,如 long 不会去除重复项。
PUT /mv
{
"mappings": {
"properties": {
"b": {"type": "long"}
}
}
}
POST /mv/_bulk?refresh
{ "index" : {} }
{ "a": 1, "b": [2, 2, 1] }
{ "index" : {} }
{ "a": 2, "b": [1, 1] }
POST /_query
{
"query": "FROM mv | LIMIT 2"
}
并且 ES|QL 也看到了:
{
"took": 28,
"columns": [
{ "name": "a", "type": "long"},
{ "name": "b", "type": "long"}
],
"values": [
[1, [1, 2, 2]],
[2, [1, 1]]
]
}
这一切都发生在存储层。如果你存储重复的 `long` 类型数据,然后将它们转换为字符串,重复的数据仍然会保留:
PUT /mv
{
"mappings": {
"properties": {
"b": {"type": "long"}
}
}
}
POST /mv/_bulk?refresh
{ "index" : {} }
{ "a": 1, "b": [2, 2, 1] }
{ "index" : {} }
{ "a": 2, "b": [1, 1] }
POST /_query
{
"query": "FROM mv | EVAL b=TO_STRING(b) | LIMIT 2"
}
{
"took": 28,
"columns": [
{ "name": "a", "type": "long"},
{ "name": "b", "type": "keyword"}
],
"values": [
[1, ["1", "2", "2"]],
[2, ["1", "1"]]
]
}
null 在列表中
editnull 值在列表中不会在存储层保留:
POST /mv/_doc?refresh
{ "a": [2, null, 1] }
POST /_query
{
"query": "FROM mv | LIMIT 1"
}
{
"took": 28,
"columns": [
{ "name": "a", "type": "long"},
],
"values": [
[[1, 2]],
]
}
函数
edit除非另有说明,函数在应用于多值字段时将返回null。
POST /mv/_bulk?refresh
{ "index" : {} }
{ "a": 1, "b": [2, 1] }
{ "index" : {} }
{ "a": 2, "b": 3 }
POST /_query
{
"query": "FROM mv | EVAL b + 2, a + b | LIMIT 4"
}
{
"took": 28,
"columns": [
{ "name": "a", "type": "long"},
{ "name": "b", "type": "long"},
{ "name": "b + 2", "type": "long"},
{ "name": "a + b", "type": "long"}
],
"values": [
[1, [1, 2], null, null],
[2, 3, 5, 5]
]
}
通过将字段转换为单值来绕过此限制,可以使用以下方法之一:
POST /_query
{
"query": "FROM mv | EVAL b=MV_MIN(b) | EVAL b + 2, a + b | LIMIT 4"
}
{
"took": 28,
"columns": [
{ "name": "a", "type": "long"},
{ "name": "b", "type": "long"},
{ "name": "b + 2", "type": "long"},
{ "name": "a + b", "type": "long"}
],
"values": [
[1, 1, 3, 2],
[2, 3, 5, 5]
]
}
使用DISSECT和GROK处理数据
edit您的数据可能包含您想要结构化的非结构化字符串。这使得分析数据更加容易。例如,日志消息可能包含您想要提取的IP地址,以便您可以找到最活跃的IP地址。

Elasticsearch 可以在索引时或查询时结构化您的数据。在索引时,您可以使用 Dissect 和 Grok 摄取处理器,或者使用 Logstash 的 Dissect 和 Grok 过滤器。在查询时,您可以使用 ES|QL 的 DISSECT 和 GROK 命令。
DISSECT 或 GROK?还是两者都用?
editDISSECT 通过使用基于分隔符的模式来分解字符串。GROK
的工作方式类似,但使用正则表达式。这使得 GROK 更强大,
但通常也更慢。DISSECT 在数据可靠重复时表现良好。
GROK 是当你真正需要正则表达式的强大功能时的更好选择,
例如当你的文本结构在每一行之间变化时。
您可以同时使用 DISSECT 和 GROK 来处理混合用例。例如,当行的一部分是可靠重复的,但整个行不是时。DISSECT 可以解构行中重复的部分。GROK 可以使用正则表达式处理剩余的字段值。
使用 DISSECT 处理数据
edit处理命令 DISSECT 根据基于分隔符的模式匹配字符串,并将指定的键提取为列。
例如,以下模式:
%{clientip} [%{@timestamp}] %{status}
匹配这种格式的日志行:
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected
并将以下列添加到输入表中:
| clientip:keyword | @timestamp:keyword | status:keyword |
|---|---|---|
1.2.3.4 |
2023-01-23T12:15:00.000Z |
已连接 |
剖析模式
edit解剖模式由将被丢弃的字符串部分定义。在前面的示例中,第一个要丢弃的部分是单个空格。解剖找到这个空格,然后将clientip的值分配给直到该空格之前的所有内容。
接下来,解剖匹配[,然后是],然后将@timestamp分配给[和]之间的所有内容。
特别注意要丢弃的字符串部分将有助于构建成功的解剖模式。
一个空键(%{})或命名跳过键可以用于匹配值,但将该值从输出中排除。
所有匹配的值都输出为关键词字符串数据类型。使用类型转换函数将其转换为另一种数据类型。
Dissect 还支持 键修饰符,这些修饰符可以改变 dissect 的默认行为。例如,您可以指示 dissect 忽略某些字段、附加字段、跳过填充等。
术语
edit- dissect pattern
-
描述文本格式的字段和分隔符的集合。也称为解剖。
解剖使用一组
%{}部分来描述:%{a} - %{b} - %{c} - field
-
从
%{到}的文本。 - delimiter
-
}和下一个%{字符之间的文本。 除了%{、'not }'或}之外的任何字符集都是分隔符。 - key
-
在
%{和}之间的文本,不包括?、+、&前缀和序号后缀。示例:
-
%{?aaa}- 键是aaa -
%{+bbb/3}- 键是bbb -
%{&ccc}- 键是ccc
-
示例
edit以下示例解析包含时间戳、一些文本和IP地址的字符串:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a "%{date} - %{msg} - %{ip}"
| KEEP date, msg, ip
| date:keyword | msg:keyword | ip:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
一些文本 |
127.0.0.1 |
默认情况下,DISSECT 输出关键词字符串列。要转换为其他类型,请使用 类型转换函数:
ROW a = "2023-01-23T12:15:00.000Z - some text - 127.0.0.1"
| DISSECT a "%{date} - %{msg} - %{ip}"
| KEEP date, msg, ip
| EVAL date = TO_DATETIME(date)
| msg:keyword | ip:keyword | date:date |
|---|---|---|
一些文本 |
127.0.0.1 |
2023-01-23T12:15:00.000Z |
解剖键修饰符
edit键修饰符可以改变解剖的默认行为。键修饰符可能位于%{keyname}的左侧或右侧,始终位于%{和}内。例如,%{+keyname ->}具有追加和右填充修饰符。
右填充修饰符 (->)
edit执行分解的算法非常严格,因为它要求模式中的所有字符都与源字符串匹配。例如,模式 %{fookey} %{barkey}(1 个空格),将匹配字符串 "foo bar"(1 个空格),但不会匹配字符串 "foo bar"(2 个空格),因为模式只有 1 个空格,而源字符串有 2 个空格。
右填充修饰符有助于解决这种情况。将右填充修饰符添加到模式 %{fookey->} %{barkey} 中,
它现在将匹配 "foo bar"(1个空格)和 "foo bar"(2个空格)
甚至 "foo bar"(10个空格)。
使用正确的填充修饰符,以允许在%{keyname->}之后重复字符。
右填充修饰符可以放置在任何带有其他修饰符的键上。它应该始终是最右边的修饰符。例如:%{+keyname/1->} 和 %{->}
例如:
ROW message="1998-08-10T17:15:42 WARN"
| DISSECT message "%{ts->} %{level}"
| message:keyword | ts:keyword | level:keyword |
|---|---|---|
1998-08-10T17:15:42 警告 |
1998-08-10T17:15:42 |
警告 |
可以使用空的右填充修饰符来帮助跳过不需要的数据。例如,相同的输入字符串,但用括号包裹时,需要使用空的右填充键来实现相同的结果。
例如:
ROW message="[1998-08-10T17:15:42] [WARN]"
| DISSECT message "[%{ts}]%{->}[%{level}]"
| message:keyword | ts:keyword | level:keyword |
|---|---|---|
["[1998-08-10T17:15:42] [警告]"] |
1998-08-10T17:15:42 |
警告 |
追加修饰符 (+)
editDissect 支持将两个或多个结果一起附加到输出中。 值从左到右附加。可以指定附加分隔符。 在此示例中,附加分隔符定义为一个空格。
ROW message="john jacob jingleheimer schmidt"
| DISSECT message "%{+name} %{+name} %{+name} %{+name}" APPEND_SEPARATOR=" "
| message:keyword | name:keyword |
|---|---|
约翰·雅各布·金格海默·施密特 |
约翰·雅各布·金格海默·施密特 |
附加顺序修饰符(+ 和 /n)
editDissect 支持将两个或多个结果一起附加到输出中。
值根据定义的顺序(/n)进行附加。可以指定附加分隔符。
在这个例子中,附加分隔符被定义为逗号。
ROW message="john jacob jingleheimer schmidt"
| DISSECT message "%{+name/2} %{+name/4} %{+name/3} %{+name/1}" APPEND_SEPARATOR=","
| message:keyword | name:keyword |
|---|---|
约翰·雅各布·金格海默·施密特 |
施密特,约翰,金格尔海默,雅各布 |
命名跳过键 (?)
editDissect 支持在最终结果中忽略匹配项。这可以通过使用空键 %{} 来实现,但为了提高可读性,可能希望为该空键指定一个名称。
这可以通过使用带有命名跳过键的 {?name} 语法来实现。在以下查询中,ident 和 auth 不会被添加到输出表中:
ROW message="1.2.3.4 - - 30/Apr/1998:22:00:52 +0000"
| DISSECT message "%{clientip} %{?ident} %{?auth} %{@timestamp}"
| message:keyword | clientip:keyword | @timestamp:keyword |
|---|---|---|
1.2.3.4 - - 30/4/1998:22:00:52 +0000 |
1.2.3.4 |
1998年4月30日 22:00:52 +0000 |
限制
editThe DISSECT 命令不支持引用键。
使用GROK处理数据
editThe GROK 处理命令根据正则表达式匹配字符串,并提取指定的键作为列。
例如,以下模式:
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}
匹配这种格式的日志行:
1.2.3.4 [2023-01-23T12:15:00.000Z] Connected
将其组合为 ES|QL 查询:
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected"
| GROK a "%{IP:ip} \\[%{TIMESTAMP_ISO8601:@timestamp}\\] %{GREEDYDATA:status}"
GROK 向输入表添加了以下列:
| @timestamp:keyword | ip:keyword | status:keyword |
|---|---|---|
2023-01-23T12:15:00.000Z |
1.2.3.4 |
已连接 |
grok模式中的特殊正则表达式字符,如[和],需要使用\进行转义。例如,在之前的模式中:
%{IP:ip} \[%{TIMESTAMP_ISO8601:@timestamp}\] %{GREEDYDATA:status}
在ES|QL查询中,反斜杠字符本身是一个特殊字符,需要用另一个\进行转义。对于这个例子,相应的ES|QL查询变为:
ROW a = "1.2.3.4 [2023-01-23T12:15:00.000Z] Connected"
| GROK a "%{IP:ip} \\[%{TIMESTAMP_ISO8601:@timestamp}\\] %{GREEDYDATA:status}"
Grok 模式
editgrok 模式的语法是 %{SYNTAX:SEMANTIC}
The SYNTAX 是匹配您文本的模式的名称。例如,3.44 由 NUMBER 模式匹配,而 55.3.244.1 由 IP 模式匹配。语法是您匹配的方式。
The SEMANTIC 是你为正在匹配的文本片段提供的标识符。
例如,3.44 可能是某个事件的持续时间,因此你可以简单地称它为 duration。此外,字符串 55.3.244.1 可能标识发出请求的 client。
默认情况下,匹配的值会以关键字字符串数据类型输出。要转换语义的数据类型,请在其后加上目标数据类型。例如,%{NUMBER:num:int},它将num语义从字符串转换为整数。目前唯一支持的转换是int和float。对于其他类型,请使用类型转换函数。
正则表达式
editGrok 基于正则表达式。任何正则表达式在 grok 中也是有效的。Grok 使用 Oniguruma 正则表达式库。请参考 Oniguruma GitHub 仓库 以获取完整的支持的正则表达式语法。
自定义模式
edit如果 grok 没有您需要的模式,您可以使用 Oniguruma 语法进行命名捕获,这允许您匹配一段文本并将其保存为列:
(?<field_name>the pattern here)
例如,postfix 日志有一个 queue id,它是一个 10 或 11 个字符的十六进制值。这可以通过以下方式捕获到一个名为 queue_id 的列中:
(?<queue_id>[0-9A-F]{10,11})
示例
edit以下示例解析包含时间戳、IP 地址、电子邮件地址和数字的字符串:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num}"
| KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:keyword |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
默认情况下,GROK 输出关键词字符串列。int 和 float 类型可以通过在模式中的语义后附加 :type 来转换。例如 {NUMBER:num:int}:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num
| date:keyword | ip:keyword | email:keyword | num:integer |
|---|---|---|---|
2023-01-23T12:15:00.000Z |
127.0.0.1 |
42 |
对于其他类型转换,请使用类型转换函数:
ROW a = "2023-01-23T12:15:00.000Z 127.0.0.1 some.email@foo.com 42"
| GROK a "%{TIMESTAMP_ISO8601:date} %{IP:ip} %{EMAILADDRESS:email} %{NUMBER:num:int}"
| KEEP date, ip, email, num
| EVAL date = TO_DATETIME(date)
| ip:keyword | email:keyword | num:integer | date:date |
|---|---|---|---|
127.0.0.1 |
42 |
2023-01-23T12:15:00.000Z |
如果一个字段名称被多次使用,GROK 会创建一个多值列:
FROM addresses
| KEEP city.name, zip_code
| GROK zip_code "%{WORD:zip_parts} %{WORD:zip_parts}"
| city.name:keyword | zip_code:keyword | zip_parts:keyword |
|---|---|---|
阿姆斯特丹 |
1016 教育 |
["1016", "急诊"] |
旧金山 |
加利福尼亚州 94108 |
["加利福尼亚", "94108"] |
东京 |
100-7014 |
空 |
Grok 调试器
edit要编写和调试 grok 模式,您可以使用
Grok Debugger。它提供了一个 UI 来
针对示例数据测试模式。在底层,它使用了与 GROK 命令相同的引擎。
限制
editThe GROK 命令不支持配置 自定义模式,或 多个模式。The GROK 命令不受 Grok watchdog 设置的限制。
数据丰富
editES|QL 的 ENRICH 处理命令在查询时将一个或多个源索引中的数据与 Elasticsearch 丰富索引中找到的字段值组合结合起来。
例如,您可以使用 ENRICH 来:
- 根据已知的IP地址识别网络服务或供应商
- 根据产品ID将产品信息添加到零售订单中
- 根据电子邮件地址补充联系信息
ENRICH 命令的工作原理
editThe ENRICH 命令向表中添加新列,数据来自 Elasticsearch 索引。
它需要一些特殊的组件:
- Source index
-
一个存储丰富数据的索引,
ENRICH命令可以将这些数据添加到输入表中。您可以像管理常规 Elasticsearch 索引一样创建和管理这些索引。 您可以在一个丰富策略中使用多个源索引。您也可以在多个丰富策略中使用相同的源索引。
- Enrich index
-
一个与特定富化策略绑定的特殊系统索引。
直接将输入表中的行与源索引中的文档进行匹配可能会很慢且资源消耗大。为了加快速度,
ENRICH命令使用了一个增强索引。Enrich 索引包含从源索引中提取的 enrich 数据,但具有一些特殊的属性,以帮助简化它们:
-
它们是系统索引,意味着它们由 Elasticsearch 内部管理,并且仅用于 enrich 处理器和 ES|QL
ENRICH命令。 -
它们总是以
.enrich-*开头。 - 它们是只读的,意味着你不能直接更改它们。
- 它们是为了快速检索而 强制合并 的。
-
它们是系统索引,意味着它们由 Elasticsearch 内部管理,并且仅用于 enrich 处理器和 ES|QL
设置一个丰富策略
edit要开始使用ENRICH,请按照以下步骤操作:
一旦设置了丰富策略,您可以更新您的丰富数据和更新您的丰富策略。
命令ENRICH执行多项操作,可能会影响查询的速度。
先决条件
edit要使用丰富策略,您必须具备:
-
read对任何使用的索引的读取权限 -
enrich_user内置角色
添加丰富数据
edit首先,将文档添加到一个或多个源索引中。这些文档应包含您最终希望添加到传入数据中的丰富数据。
您可以使用文档和索引 API 来管理源索引,就像管理常规的 Elasticsearch 索引一样。
您还可以设置Beats,例如Filebeat,以自动发送和索引文档到您的源索引。请参阅Beats入门。
创建一个丰富策略
edit在将丰富数据添加到源索引后,使用创建丰富策略 API或Kibana 中的索引管理来创建一个丰富策略。
一旦创建,您无法更新或更改一个富化策略。 请参阅更新一个富化策略。
执行丰富策略
edit一旦创建了丰富策略,您需要使用 执行丰富策略 API 或 Kibana 中的索引管理 来创建一个 丰富索引。

该丰富索引包含来自策略源索引的文档。
丰富索引始终以.enrich-*开头,
是只读的,
并且会进行强制合并。
Enrich 索引应仅由 enrich 处理器
或 ES|QL ENRICH 命令使用。避免将 enrich 索引用于其他目的。
使用丰富策略
edit策略执行后,您可以使用ENRICH
命令来丰富您的数据。

以下示例使用 languages_policy 丰富策略为策略中定义的每个丰富字段添加一个新列。匹配是使用 丰富策略 中定义的 match_field 执行的,并且要求输入表具有同名的列(在本例中为 language_code)。ENRICH 将根据匹配字段值在 丰富索引 中查找记录。
ROW language_code = "1" | ENRICH languages_policy
| language_code:keyword | language_name:keyword |
|---|---|
1 |
英语 |
要使用与策略中定义的 match_field 不同名称的列作为匹配字段,请使用 ON :
ROW a = "1" | ENRICH languages_policy ON a
| a:keyword | language_name:keyword |
|---|---|
1 |
英语 |
默认情况下,策略中定义的每个丰富字段都会被添加为一个列。要显式选择要添加的丰富字段,请使用WITH :
ROW a = "1" | ENRICH languages_policy ON a WITH language_name
| a:keyword | language_name:keyword |
|---|---|
1 |
英语 |
您可以使用 WITH new_name= 重命名添加的列:
ROW a = "1" | ENRICH languages_policy ON a WITH name = language_name
| a:keyword | name:keyword |
|---|---|
1 |
英语 |
如果发生名称冲突,新创建的列将覆盖现有列。
更新一个富化索引
edit一旦创建,您无法更新或将文档索引到扩展索引中。 相反,请更新您的源索引并执行扩展策略。 这将使用您更新的源索引创建一个新的扩展索引。 之前的扩展索引将通过延迟维护作业删除。 默认情况下,这是每15分钟执行一次。
更新一个丰富策略
edit一旦创建,您无法更新或更改一个富化策略。 相反,您可以:
- 创建并执行一个新的丰富策略。
- 用新的丰富策略替换之前使用的丰富策略, 在任何正在使用的丰富处理器或ES|QL查询中。
- 使用删除丰富策略 API 或 Kibana中的索引管理 删除之前的丰富策略。
限制
editES|QL 的 ENRICH 命令仅支持类型为 match 的丰富策略。
此外,ENRICH 仅支持在类型为 keyword 的列上进行丰富。
ES|QL 隐式类型转换
edit通常,用户会在其查询中将datetime、ip、version或地理空间对象作为简单字符串输入,用于谓词、函数或表达式中。ES|QL 提供了类型转换函数,以显式地将这些字符串转换为所需的数据类型。
在没有隐式转换的情况下,用户必须在查询中显式编写这些to_X函数,当字符串字面量与它们被分配或比较的目标数据类型不匹配时。以下是使用to_datetime显式执行数据类型转换的示例。
FROM employees
| EVAL dd_ns1=date_diff("day", to_datetime("2023-12-02T11:00:00.00Z"), birth_date)
| SORT emp_no
| KEEP dd_ns1
| LIMIT 1
隐式转换通过自动将字符串字面量转换为目标数据类型来提高可用性。当目标数据类型为datetime、ip、version或地理空间类型时,这一点最为有用。在查询中以字符串形式指定这些内容是很自然的。
第一个查询可以在不调用to_datetime函数的情况下编写,如下所示:
FROM employees
| EVAL dd_ns1=date_diff("day", "2023-12-02T11:00:00.00Z", birth_date)
| SORT emp_no
| KEEP dd_ns1
| LIMIT 1
隐式类型转换支持
edit下表详细列出了哪些 ES|QL 操作支持不同数据类型的隐式转换。
| ScalarFunction | BinaryComparison | ArithmeticOperation | InListPredicate | AggregateFunction | ||
|---|---|---|---|---|---|---|
日期时间 |
Y |
Y |
Y |
Y |
N |
|
双精度 |
Y |
N |
N |
N |
N |
|
长 |
Y |
N |
N |
N |
N |
|
整数 |
Y |
N |
N |
N |
N |
|
IP |
Y |
Y |
Y |
Y |
N |
|
版本 |
Y |
Y |
Y |
Y |
N |
|
GEO_POINT |
Y |
N |
N |
N |
N |
|
GEO_SHAPE |
Y |
N |
N |
N |
N |
|
笛卡尔点 |
Y |
N |
N |
N |
N |
|
笛卡尔形状 |
Y |
N |
N |
N |
N |
|
布尔值 |
Y |
Y |
Y |
Y |
N |