贡献者指南¶
本指南涵盖了作为开发者向Horovod贡献的过程。
环境设置¶
在本地克隆仓库:
$ git clone --recursive https://github.com/horovod/horovod.git
在虚拟环境中开发以避免依赖问题:
$ python3 -m venv env
$ . env/bin/activate
我们建议安装与Buildkite中测试环境相匹配的软件包版本。
推荐使用以下版本(请参阅通过Dockerfile.test.cpu和Dockerfile.test.gpu文件中ARG定义的默认版本)。
您可以在Dockerfile.test.cpu和Dockerfile.test.gpu文件中找到Horovod构建所需安装在系统上的所有其他非Python软件包。
具体来说,请查看所有RUN apt-get install行。
构建与安装¶
从 Horovod 根目录内部,以开发/可编辑模式安装 Horovod:
$ HOROVOD_WITH_PYTORCH=1 HOROVOD_WITH_TENSORFLOW=1 pip install -v -e .
设置 HOROVOD_WITHOUT_[FRAMEWORK]=1 来禁用为特定框架构建 Horovod 插件。
这在您特别测试某个框架的功能并希望节省时间时非常有用。
设置 HOROVOD_WITH_[FRAMEWORK]=1 以便在该框架的 Horovod 插件构建失败时生成错误。
设置 HOROVOD_DEBUG=1 以启用调试构建,包含检查断言、禁用编译器优化等功能。
其他环境变量可以在安装文档中找到。
你可以通过在命令行末尾添加括号来安装setup.py中定义的可选依赖项,例如[test]用于测试依赖项。
如果你尚未安装特定的深度学习框架,请添加[dev]来安装所有支持的深度学习框架的CPU版本。
在开发模式下,你可以直接在代码仓库文件夹中编辑 Horovod 源码。对于 Python 代码,更改会立即生效。对于C++/CUDA 代码,需要再次调用 ... pip install -v -e . 命令以执行增量构建。
测试¶
Horovod 在 test/parallel 目录下为所有框架提供了单元测试。这些测试应通过 horovodrun 或
mpirun 调用,且每个测试脚本可能需要独立于其他测试脚本运行:
$ cd test/parallel
$ horovodrun -np 2 pytest -v test_tensorflow.py
$ horovodrun -np 2 pytest -v test_torch.py
# ...
# Or to run all framework tests:
$ cd test/parallel
$ ls -1 test_*.py | xargs -n 1 horovodrun -np 2 pytest -v
此外,还有需要通过 pytest 直接运行的集成测试和非并行化测试:
$ cd test/integration
$ pytest -v
$ cd test/single
$ pytest -v
注意: 运行Spark测试需要安装PySpark和Java。
重要提示: 部分测试包含仅GPU代码路径,若在没有GPU支持的情况下运行,或在某些情况下若安装的GPU少于四个,这些测试将被跳过。
持续集成¶
Horovod 使用 Buildkite 在 AWS 上运行于 Intel CPU 硬件和 NVIDIA GPU(带 NCCL)进行持续集成。测试每晚在 master 分支上自动运行一次,并在每次提交到远程分支时运行。
Buildkite 测试配置在 docker-compose.test.yml 中定义。每个测试 配置定义了一个 Docker 镜像,该镜像基于 Docker.test.cpu(用于 CPU 测试)或 Docker.test.gpu(用于 GPU 测试)构建。
每个配置上的独立测试按照gen-pipeline.sh中的定义运行。每个测试配置也需要在此处定义,以便在测试时运行。每次调用run_test时,都会在Buildkite中生成一个新的测试工件,根据退出代码决定成功或失败。
在我们的AWS配置中,GPU测试每个容器使用4个GPU运行。大多数测试每个工作进程使用2个GPU运行,然而,模型并行需要每个工作进程2个GPU,总共需要4个GPU。
文档¶
Horovod 文档发布在 https://horovod.readthedocs.io/。
这些HTML页面可以从位于docs目录中的.rst文件渲染生成。
首次编译文档前,您需要先设置Sphinx:
$ cd docs
$ pip install -r requirements.txt
$ make clean
然后你可以构建HTML页面并打开docs/_build/html/index.html:
$ cd docs
$ make html
$ open _build/html/index.html
Sphinx 可以以多种其他格式呈现文档。输入 make 以获取可用格式列表。
添加自定义操作¶
Horovod中的操作用于在不同工作节点间转换张量。Horovod目前支持实现广播、全归约和全收集接口的操作。Horovod中的梯度通过全归约操作进行聚合(稀疏梯度除外,它们使用全收集)。
所有数据传输操作都在horovod/common/ops目录中实现。实现方式根据用于执行操作的集合通信库进行组织(例如,mpi_operations.cc用于MPI)。
要创建新的自定义操作,首先从基础操作继承一个新类,在对应您将用于实现该操作的库的文件中:
class CustomAllreduce : public AllreduceOp {
public:
CustomAllreduce(MPIContext* mpi_context, HorovodGlobalState* global_state);
virtual ~CustomAllreduce() = default;
Status Execute(std::vector<TensorTableEntry>& entries, const Response& response) override;
bool Enabled(const ParameterManager& parameter_manager,
const std::vector<TensorTableEntry>& entries,
const Response& response) const override;
Execute 成员函数负责对张量列表执行操作。entries
参数提供对所有需要处理的张量缓冲区和元数据的访问,
而 response 参数包含额外的元数据,包括不同等级正在使用的设备信息。
Enabled 如果您的操作可以在当前参数设置和响应元数据下对给定的张量条目执行,则应返回 true。
一旦你为你的操作编写了实现,将其添加到operations.cc的CreateOperationManager函数中的OperationManager中。由于可能有多个操作同时启用,但只有一个会在给定的Tensor条目向量上执行,因此在添加之前请考虑你的操作在OperationManager向量中的顺序。
向量中的首个操作将在末尾操作之前被检查,而第一个启用的操作将被执行。总的来说,操作的顺序应为:
基于运行时配置的参数触发的自定义操作(例如,
NCCLHierarchicalAllreduce)。利用可用专用硬件加速操作(例如,
NCCLAllreduce)。可以使用标准CPU和主机内存运行的默认操作(例如,
MPIAllreduce)。
大多数需要前提条件(如运行时标志)的自定义操作将属于第一类。
Adding Compression Algorithms¶
梯度压缩用于减少在Allreduce操作期间通过网络发送的数据量。这类压缩算法在每个框架(TensorFlow、PyTorch、MXNet等)中通过
horovod/[framework]/compression.py
实现(参见:TensorFlow,
PyTorch)。
要实现一个新的压缩算法,首先添加一个继承自 Compressor 的新类:
class CustomCompressor(Compressor):
@staticmethod
def compress(tensor):
# do something here ...
return tensor_compressed, ctx
@staticmethod
def decompress(tensor, ctx):
# do something here ...
return tensor_decompressed
compress 方法接收一个张量梯度,并将其以压缩形式返回,同时附带任何必要的额外上下文信息,以便将张量解压缩回其原始形式。类似地,decompress 接收一个压缩张量及其上下文,并返回一个解压缩后的张量。压缩可以在纯 Python 中完成,也可以使用自定义操作(例如,在 TensorFlow 的 mpi_ops.cc 中)在 C++ 中完成。
实现后,将您的Compressor子类添加到Compressor类中,该类模拟枚举API:
class Compression(object):
# ...
custom = CustomCompressor
最后,你可以通过将新的压缩器传递给 DistributedOptimizer 来开始使用它:
opt = hvd.DistributedOptimizer(opt, compression=hvd.Compression.custom)
Horovod on Spark¶
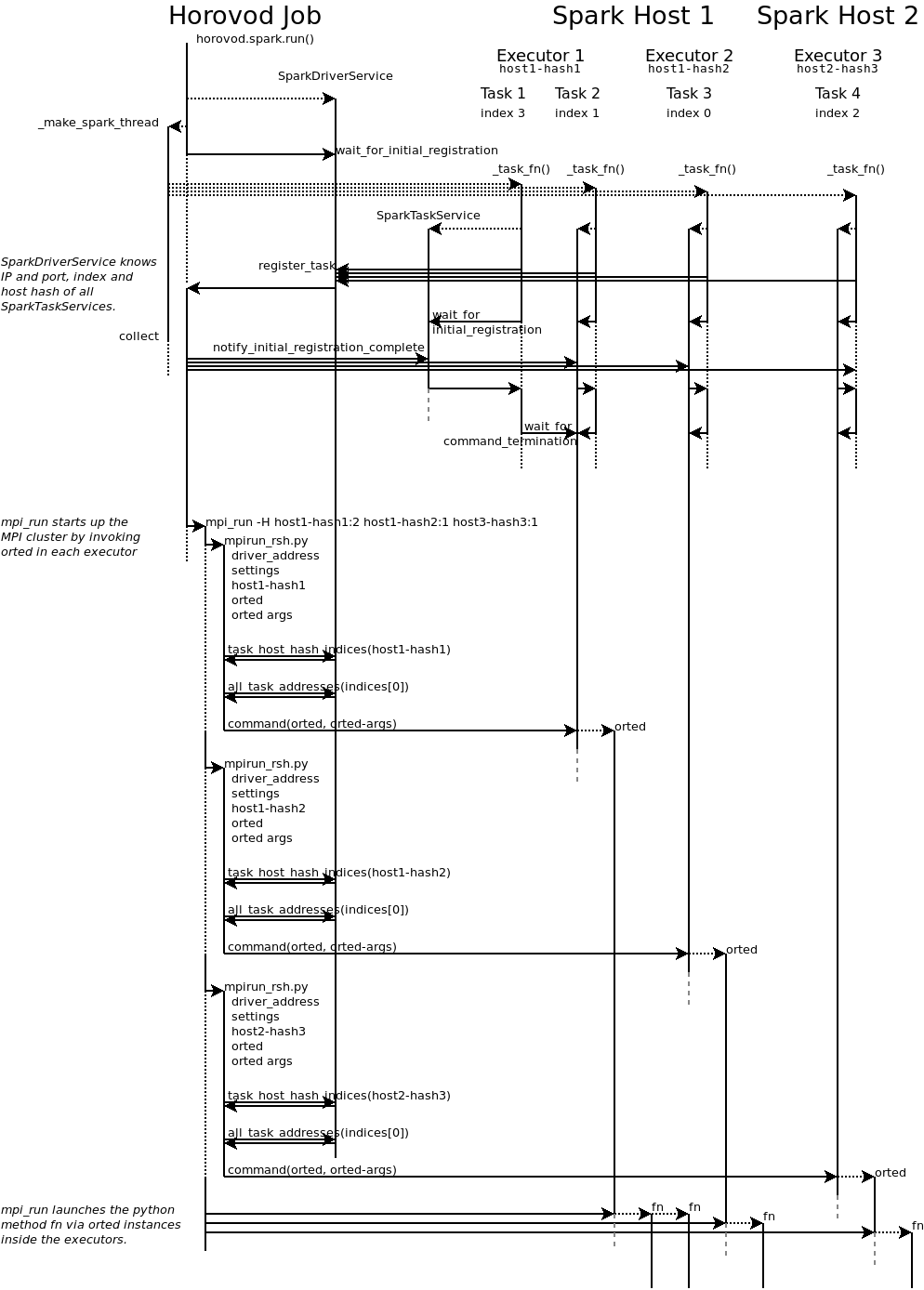
horovod.spark 包使得在 Spark 集群中运行 Horovod 任务变得简单。以下部分概述了 Horovod 如何协调 Spark 和 MPI。
您的 Horovod 任务成为 Spark 驱动程序,并在 Spark 集群上创建 num_proc 个任务(horovod.spark._make_spark_thread)。
每个任务运行 horovod.spark._task_fn,该函数会向驱动程序注册,以便驱动程序知道所有任务何时启动以及它们运行的 IP 和端口。它们还会发送其主机哈希,这是一个被 MPI 视为主机名的字符串。
注意: Horovod 期望所有任务同时运行,因此您的集群必须为 Horovod 作业提供至少 num_proc 个核心。
每个执行器可以有多个核心,因此一个执行器可以处理多个任务。主机也可以有多个执行器。
驱动程序通知所有任务,其他所有任务都已启动运行。每个任务继续初始化,然后等待RPC终止。
在所有任务启动信号发出后,驱动程序运行mpi_run来在这些任务(RPC)中启动Python函数。
通常,MPI通过SSH连接到主机,但这无法在Spark执行器内部启动Python函数。
因此,MPI通过调用horovod.spark.driver.mpirun_rsh方法连接到每个执行器,以"远程shell"方式
进入执行器。该方法与每个主机哈希值中索引最小的任务进行通信。
该任务执行由MPI提供的orted命令。
这样,即使执行器有多个核心/任务,每个执行器也只运行一个orted进程。
然后MPI使用orted为该执行器启动Python函数。
在第一个任务中,每个执行器的每个核心将运行一个Python函数。
具有相同主机哈希值的所有其他任务等待第一个任务终止。
下图展示了这一过程:
Spark上的弹性Horovod¶
Elastic Horovod on Spark 有一些限制条件:
每个主机最多只有一个插槽,这简化了Spark上的自动扩展 - 为此,主机哈希包含任务的索引 - 这不允许在同一主机上运行的任务之间共享内存 - 请参阅下面的“主机哈希”。
主机哈希¶
主机哈希代表共享内存的单个处理单元。通常,这是一个常规主机。 在使用YARN为Spark作业分配核心的场景中,内存分配仅在执行器内部共享。 同一主机上可能有多个执行器为您的Horovod作业运行,但它们各自的内存分配有限。 因此每个执行器都会获得自己的主机哈希。
如果你要求每个Python函数在Spark执行器内运行在自己的任务进程中,那么任务的索引也必须成为主机哈希的一部分。这仅在Elastic Horovod on Spark中显示有用,但也仅是为了简化。