分布式超参数搜索¶
Horovod的数据并行训练能力使您能够扩展并加速深度学习模型的训练工作负载。然而,仅仅使用2倍的工作节点并不一定意味着模型能在2倍的时间内达到相同的准确度。
为了解决这个问题,在规模化训练时通常需要重新调整超参数,因为许多超参数在更大规模下会表现出不同的行为。
Horovod 提供了一个 Ray Tune 集成,以支持使用分布式训练进行并行超参数调优。

Ray Tune 是一个用于分布式超参数调优的行业标准工具。Ray Tune 包含最新的超参数搜索算法,与 TensorBoard 和其他分析库集成,并原生支持分布式训练。Ray Tune + Horovod 集成利用底层的 Ray 框架,提供了一个可扩展且全面的超参数调优设置。
在本指南结束时,您将学习到:
如何设置Ray Tune和Horovod来调整您的超参数
分布式训练中需要配置的典型超参数
Horovod + Ray Tune¶
利用Ray Tune与Horovod结合,将分布式超参数调优与分布式训练相结合。以下是一个展示基本用法的示例:
import horovod.torch as hvd
from ray import tune
import time
def training_function(config: Dict):
hvd.init()
for i in range(config["epochs"]):
time.sleep(1)
model = Model(learning_rate=config["lr"])
tune.report(test=1, rank=hvd.rank())
trainable = DistributedTrainableCreator(
training_function, num_slots=2, use_gpu=use_gpu)
analysis = tune.run(
trainable,
num_samples=2,
config={
"epochs": tune.grid_search([1, 2, 3]),
"lr": tune.grid_search([0.1, 0.2, 0.3]),
}
)
print(analysis.best_config)
基础设置¶
使用 Ray Tune 的 DistributedTrainableCreator 函数来调整您的 Horovod 训练函数,使其与 Ray Tune 兼容。
DistributedTrainableCreator 暴露了 num_hosts, num_slots, use_gpu, 和 num_cpus_per_slot。使用这些参数来指定单个“试验”(或“可训练体”)的资源分配,其本身可以是一个分布式训练作业。
# Each training job will use 2 GPUs.
trainable = DistributedTrainableCreator(
training_function, num_slots=2, use_gpu=True)
训练函数本身必须完成三件事:
它必须遵循Tune函数API签名。
其主体必须包含一个
horovod.init()调用。它必须在训练期间调用
tune.report(docs),通常在每个训练周期结束时迭代调用。
Optimization of hyperparameters¶
Ray Tune 能够通过 Ray Actor API 编排复杂的计算模式。对于超参数调优,Ray Tune 能够在一组分布式模型上执行 并行贝叶斯优化 和 基于群体的训练。
您可能需要实现模型检查点功能。其余的优化过程可以通过几行代码进行配置。
from ray import tune
from ray.tune.suggest.bayesopt import BayesOptSearch
from ray.tune.suggest import ConcurrencyLimiter
def training_function(config):
...
algo = BayesOptSearch()
algo = ConcurrencyLimiter(algo, max_concurrent=4)
results = tune.run(
training_function,
config={"lr": tune.uniform(0.001, 0.1)},
name="horovod",
metric="mean_loss",
mode="min",
search_alg=algo)
print(results.best_config)
搜索空间
Tune有一个原生接口用于指定搜索空间。您可以通过tune.run(config=...)来指定搜索空间。
因此,要么使用 tune.grid_search 原语来指定网格搜索的一个轴…
tune.run(
trainable,
config={"bar": tune.grid_search([True, False])})
… 或使用随机抽样原语之一来指定分布:
tune.run(
trainable,
config={
"param1": tune.choice([True, False]),
"bar": tune.uniform(0, 10),
"alpha": tune.sample_from(lambda _: np.random.uniform(100) ** 2),
"const": "hello" # It is also ok to specify constant values.
})
了解更多关于Tune的搜索空间API。
分析结果
tune.run 返回一个 Analysis 对象,该对象包含用于分析训练的方法。
analysis = tune.run(trainable, search_alg=algo, stop={"training_iteration": 20})
best_trial = analysis.best_trial # Get best trial
best_config = analysis.best_config # Get best trial's hyperparameters
best_logdir = analysis.best_logdir # Get best trial's logdir
best_checkpoint = analysis.best_checkpoint # Get best trial's best checkpoint
best_result = analysis.best_result # Get best trial's last results
best_result_df = analysis.best_result_df # Get best result as pandas dataframe
设置调优集群¶
利用Ray Tune与Horovod在笔记本电脑、带多个GPU的单台机器或多台机器上运行。要在单台机器上运行,直接执行您的Python脚本(例如,horovod_simple.py,假设Ray和Horovod已正确安装):
python horovod_simple.py
要利用Ray Tune + Horovod的分布式超参数调优设置,请安装Ray并设置一个Ray集群。使用Ray集群启动器或手动启动Ray集群。
下面,我们将使用 Ray Cluster Launcher,但你可以在任何节点列表、任何集群管理器或云提供商上启动 Ray。
首先,指定一个配置文件。下面我们有一个使用AWS EC2的示例,但您可以在任何云提供商上启动集群:
# ray_cluster.yaml
cluster_name: horovod-cluster
provider: {type: aws, region: us-west-2}
auth: {ssh_user: ubuntu}
min_workers: 3
max_workers: 3
# Deep Learning AMI (Ubuntu) Version 21.0
head_node: {InstanceType: p3.2xlarge, ImageId: ami-0b294f219d14e6a82}
worker_nodes: {
InstanceType: p3.2xlarge, ImageId: ami-0b294f219d14e6a82}
setup_commands: # Set up each node.
- HOROVOD_WITH_GLOO=1 HOROVOD_GPU_OPERATIONS=NCCL pip install horovod[ray]
运行 ray up ray_cluster.yaml,一个包含4个节点(1个头节点 + 3个工作节点)的集群将自动启动并运行Ray。
[6/6] Starting the Ray runtime
Did not find any active Ray processes.
Shared connection to 34.217.192.11 closed.
Local node IP: 172.31.43.22
2020-11-04 04:24:33,882 INFO services.py:1106 -- View the Ray dashboard at http://localhost:8265
--------------------
Ray runtime started.
--------------------
Next steps
To connect to this Ray runtime from another node, run
ray start --address='172.31.43.22:6379' --redis-password='5241590000000000'
Alternatively, use the following Python code:
import ray
ray.init(address='auto', _redis_password='5241590000000000')
If connection fails, check your firewall settings and network configuration.
To terminate the Ray runtime, run
ray stop
Shared connection to 34.217.192.11 closed.
New status: up-to-date
Useful commands
Monitor autoscaling with
ray exec ~/dev/cfgs/check-autoscaler.yaml 'tail -n 100 -f /tmp/ray/session_latest/logs/monitor*'
Connect to a terminal on the cluster head:
ray attach ~/dev/cfgs/check-autoscaler.yaml
Get a remote shell to the cluster manually:
ssh -o IdentitiesOnly=yes -i ~/.ssh/ray-autoscaler_2_us-west-2.pem ubuntu@34.217.192.11
集群启动后,你可以通过ssh连接到主节点并在那里运行你的Tune脚本。
Implementation (underneath the hood)¶
在底层,Ray Tune 会并行启动多个“试验”。每个试验都引用一个Ray 智能体集合。对于每个试验,会有1个“协调器智能体”,这个协调器智能体会管理 N 个训练智能体。此实现的一个基本假设是,试验的所有子工作器将均匀分布在不同机器上。
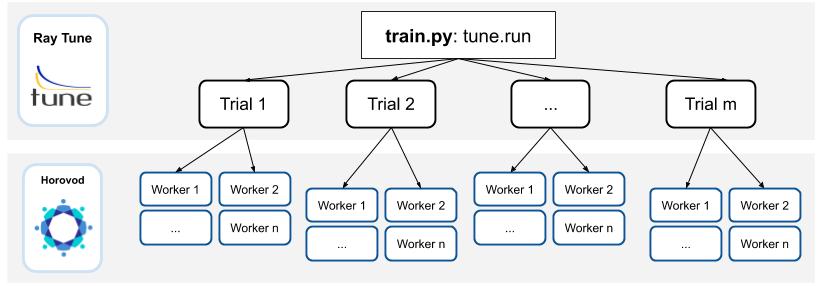
训练智能体将各自持有模型的副本,并为Horovod allreduce创建一个通信组。训练将在每个智能体上执行,将中间指标报告回Tune。
此API需要Gloo作为底层通信原语。请确保安装Horovod时启用HOROVOD_WITH_GLOO enabled。
通用超参数¶
我们将介绍几个常见的超参数,你可能需要在大规模环境下重新调整:
批处理大小
学习率调度
优化器
参数: 批处理大小¶
通过使用数据并行,必须随着工作节点数量扩展批次大小,以避免减少每个工作节点的工作负载并最大化工作节点效率。然而,增加批次大小很容易导致泛化问题(更多细节请参阅此Facebook Imagenet训练论文)。
常见的解决方案有哪些?
学习率的线性缩放:当小批量大小乘以k时,将学习率乘以k。
在训练过程中动态调整批次大小:
其中一篇原始论文提出了一个随时间增加批次大小的简单基线
ABSA提供了一种方法,利用二阶信息随时间指导批次大小
Gradient noise scale 可被计算用于指导随时间增加批量大小
为了在训练中利用动态变化的批次大小,您应该:
利用梯度累积
实现你自己的TrialScheduler以动态更改工作器数量(即将推出)
参数:学习率调度(预热)¶
正如这篇Facebook Imagenet训练论文所述,当网络快速变化时(这在训练早期阶段经常发生),线性缩放规则会失效。这个问题可以通过"预热"来解决,这是一种在训练开始时使用较低学习率的策略。
常见的解决方案有哪些?
Goyal等人(2017年)提出了一种预热调度方案,其中训练通常以较小的学习率开始,并逐渐增加以匹配较大的目标学习率。在预热期(通常为几个周期)之后,使用常规的学习率调度方案("多步"、多项式衰减等)。因此,预热调度通常有三个参数:
预热时长(轮次数)
初始学习率
峰值学习率
参数: 优化器¶
优化器是用于迭代更新网络权重的算法/方法。深度学习中的常见优化器包括Adam、RMSProp和带动量的SGD。
在大规模学习中,采用朴素的方法来优化和更新神经网络权重可能导致泛化能力差或性能下降。例如,在Imagenet上使用带动量(及预热方案)的标准SGD训练Alexnet,在B=2K之后将停止扩展。
常见的解决方案有哪些?