分析性能¶
Horovod 具备记录其活动时间轴的能力,称为 Horovod Timeline。
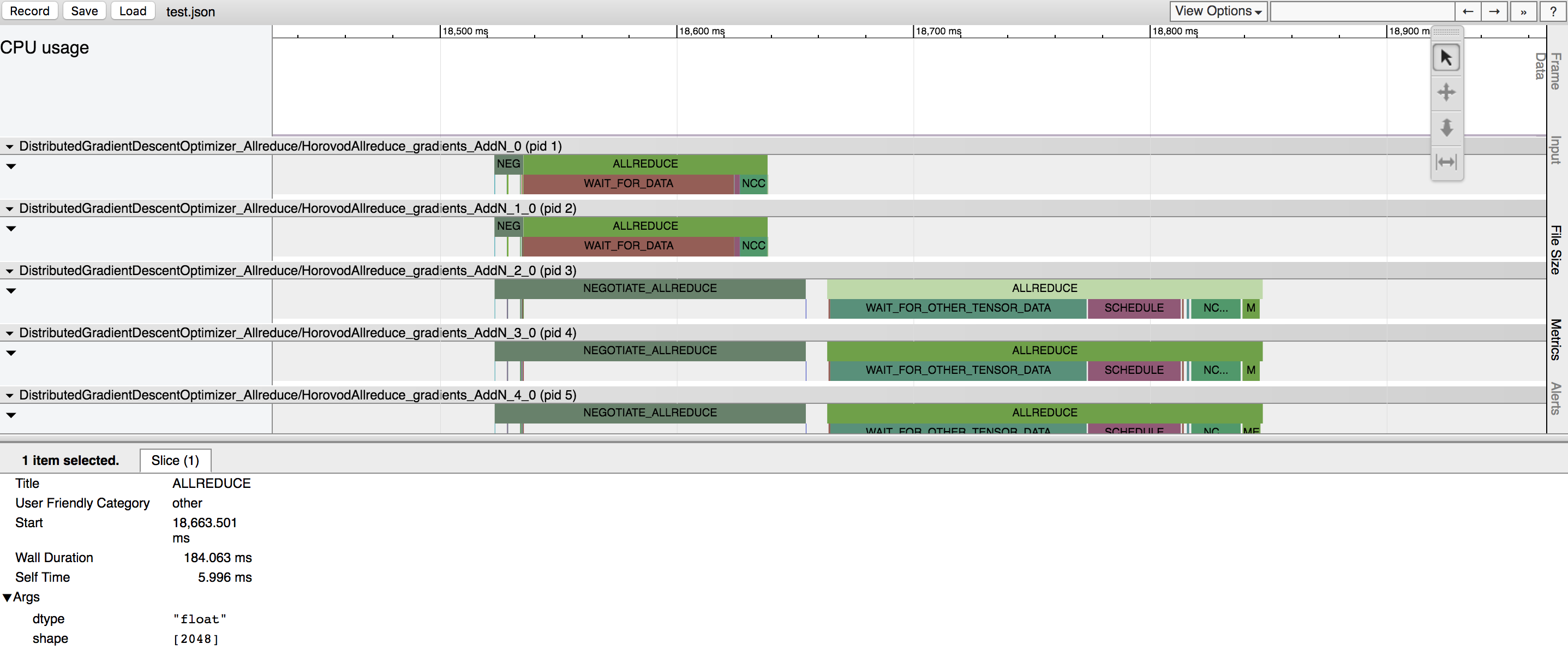
要记录 Horovod 时间线,请将 --timeline-filename 命令行参数设置为要创建的时间线文件的位置。该文件仅在 rank 0 上记录,但包含所有工作节点活动的信息。
$ horovodrun -np 4 --timeline-filename /path/to/timeline.json python train.py
然后你可以使用Chrome浏览器的chrome://tracing功能打开时间线文件。
在上面的示例中,你可以看到几个张量被规约。每个张量规约有两个主要阶段:
协商阶段 - 所有工作节点向0号节点发送信号,表明它们已准备好对给定张量进行规约的阶段。
每个报告就绪的工作器在
NEGOTIATE_ALLREDUCE栏下用一个勾号表示,因此你可以看到哪些工作器较早,哪些较晚。协商完成后,rank 0 立即向所有其他工作节点发送信号,开始减少张量。
处理 - 实际操作发生的阶段。它进一步细分为多个子阶段:
WAIT_FOR_DATA表示等待GPU完成对allreduce、allgather或broadcast操作的输入计算所花费的时间。这种情况发生是因为TensorFlow试图智能地交错调度和GPU计算。这仅适用于Horovod操作被放置在GPU上的情况。WAIT_FOR_OTHER_TENSOR_DATA表示等待GPU完成同一融合批次中其他操作的其他输入计算所花费的时间。QUEUE在使用NCCL进行归约操作时发生,且先前的NCCL操作尚未完成。MEMCPY_IN_FUSION_BUFFER和MEMCPY_OUT_FUSION_BUFFER表示将数据复制到融合缓冲区和从融合缓冲区复制出数据所花费的时间。NCCL_ALLREDUCE,MPI_ALLREDUCE,MPI_ALLGATHER, orMPI_BCAST表示在GPU(或CPU)上执行实际操作所花费的时间,并突出显示该操作是使用NCCL还是纯MPI执行的。当
HOROVOD_HIERARCHICAL_ALLREDUCE=1时,NCCL_ALLREDUCE将变为NCCL_REDUCESCATTER、NCCL_REDUCE、MEMCPY_IN_HOST_BUFFER、MPI_ALLREDUCE、MEMCPY_OUT_HOST_BUFFER、NCCL_ALLGATHER、NCCL_BCAST的一个序列或子序列。
添加循环标记¶
Horovod 以循环方式执行工作。这些循环用于辅助 Tensor Fusion。Horovod 能够记录每个循环开始的时刻,以便调试 Tensor Fusion。

由于这些信息会使时间线视图非常拥挤,默认情况下未启用。要将循环标记添加到时间线中,请设置 --timeline-mark-cycles 标志:
$ horovodrun -np 4 --timeline-filename /path/to/timeline.json --timeline-mark-cycles python train.py