贝叶斯分类器
作者: Jacob Schreiber 联系方式: jmschreiber91@gmail.com
尽管pomegranate中实现的大多数模型都是无监督的,但使用概率模型构建分类器的一种简单方法是应用贝叶斯规则。具体来说,给定一组概率模型M,可以通过计算数据D在每个模型下的后验概率来进行分类。
- :nbsphinx-math:`begin{equation}
P(M|D) = frac{P(D|M)P(M)}{P(D)}
end{equation}`
具体来说,这个方程式的含义是:应该计算数据在每个组件下的似然度\(P(D|M)\),乘以无论数据实际是什么情况下来自该组件的先验概率\(P(M)\),然后除以某个因子。
更具体地说:如果你有一组概率分布,并希望将数据点分类为来自其中某一个分布,你只需计算给定分布下数据的似然值,然后乘以每个分布的先验概率(可以简单地采用均匀分布)。
[1]:
%pylab inline
import seaborn; seaborn.set_style('whitegrid')
import torch
from pomegranate.bayes_classifier import BayesClassifier
from pomegranate.distributions import *
numpy.random.seed(0)
numpy.set_printoptions(suppress=True)
%load_ext watermark
%watermark -m -n -p numpy,scipy,torch,pomegranate
Populating the interactive namespace from numpy and matplotlib
numpy : 1.23.4
scipy : 1.9.3
torch : 1.13.0
pomegranate: 1.0.0
Compiler : GCC 11.2.0
OS : Linux
Release : 4.15.0-208-generic
Machine : x86_64
Processor : x86_64
CPU cores : 8
Architecture: 64bit
朴素贝叶斯
贝叶斯分类器最简单的形式是朴素贝叶斯分类器。之所以称为"朴素",是因为该分类器假设所有特征彼此独立。这个假设使得分类器既快速又可解释。
初始化与拟合
贝叶斯分类器可以像混合模型一样进行初始化或拟合。具体来说,您可以传入已学习的分布,或者传入未初始化的分布然后进行拟合。
[2]:
numpy.random.seed(0)
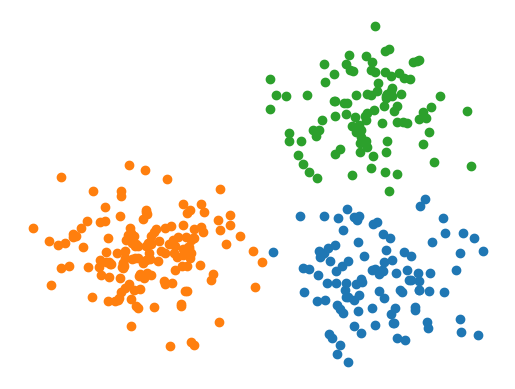
X = numpy.concatenate([numpy.random.normal((7, 2), 1, size=(100, 2)),
numpy.random.normal((2, 3), 1, size=(150, 2)),
numpy.random.normal((7, 7), 1, size=(100, 2))])
y = numpy.concatenate([numpy.zeros(100), numpy.zeros(150)+1, numpy.zeros(100)+2])
plt.figure(figsize=(6, 5))
plt.scatter(X[:,0], X[:,1])
plt.axis(False)
plt.show()
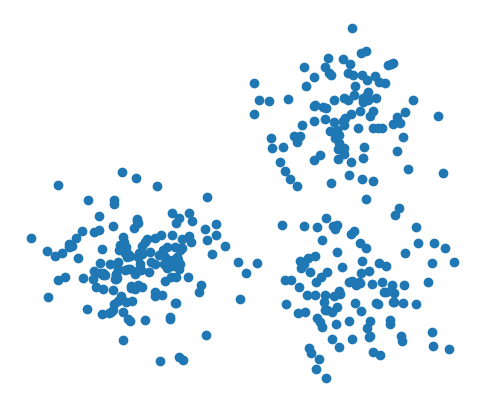
可以像下面这样初始化一个高斯朴素贝叶斯模型:
[3]:
d1 = Normal([1.1, 1.3], [0.3, 0.9], covariance_type='diag')
d2 = Normal([1.3, 1.8], [1.1, 1.5], covariance_type='diag')
d3 = Normal([2.1, 2.3], [0.5, 1.8], covariance_type='diag')
model = BayesClassifier([d1, d2, d3])
我们可以像其他方法一样对上述点进行预测:
[4]:
y_hat = model.predict(X)
for i in range(3):
plt.scatter(*X[y_hat == i].T)
plt.axis(False)
plt.show()
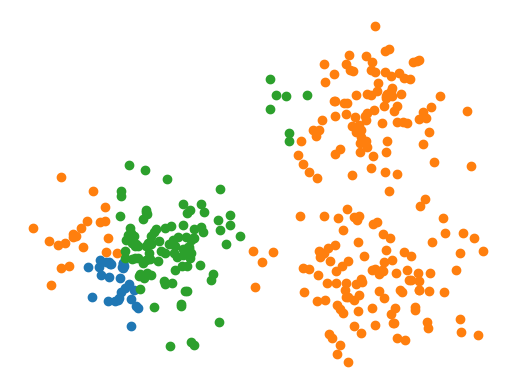
哇,看起来情况不妙。让我们尝试拟合数据。
[5]:
model = BayesClassifier([Normal(covariance_type='diag') for i in range(3)]).fit(X, y)
y_hat = model.predict(X)
for i in range(3):
plt.scatter(*X[y_hat == i].T)
plt.axis(False)
plt.show()