发布 0.6.1¶
statsmodels 0.6.1 是一个错误修复版本。建议所有用户升级到 0.6.1。
请参阅已修复问题的列表以了解具体的回溯修复。
发布 0.6.0¶
statsmodels 0.6.0 是另一个大型发布版本。这是过去一年中37位作者共同努力的成果,包含了超过1500次提交。它包含了许多新功能、改进和错误修复,详情如下。
查看具体的已关闭问题,请参见已修复问题列表。
以下是此版本中的主要新功能。
广义估计方程¶
广义估计方程(GEE)提供了一种处理回归分析中依赖数据的方法。依赖数据在实践中很常见,例如在纵向研究中,对受试者进行重复观察。GEE可以被视为广义线性模型(GLM)框架在依赖数据环境中的扩展。熟悉的GLM族,如高斯族、泊松族和逻辑族,可以用于适应具有各种分布的依赖变量。
这是一个在每个受试者有四个计数型重复测量的数据集中,使用GEE泊松回归的示例,并且有三个解释性协变量。
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
data = sm.datasets.get_rdataset("epil", "MASS").data
md = smf.gee("y ~ age + trt + base", "subject", data,
cov_struct=sm.cov_struct.Independence(),
family=sm.families.Poisson())
mdf = md.fit()
print(mdf.summary())
GEE中的依赖结构被视为一个干扰参数,并通过“工作依赖结构”进行建模。statsmodels GEE实现目前包括五种工作依赖结构(独立、可交换、自回归、嵌套以及用于处理分类数据的全局优势比)。由于GEE估计不是最大似然估计,因此已经开发了一些替代方法来处理一些常见的推断程序。statsmodels GEE实现目前提供了标准误差、Wald检验、任意参数对比的得分检验以及边际效应的估计和检验。提供了几种形式的标准误差,包括即使在指定的工作依赖结构错误时仍能近似正确的稳健标准误差。
季节性图表¶
添加功能以查看图表中的季节性。两个新函数是 sm.graphics.tsa.month_plot 和 sm.graphics.tsa.quarter_plot。另一个函数 sm.graphics.tsa.seasonal_plot 可供高级用户使用。
import statsmodels.api as sm
import pandas as pd
dta = sm.datasets.elnino.load_pandas().data
dta['YEAR'] = dta.YEAR.astype(int).astype(str)
dta = dta.set_index('YEAR').T.unstack()
date_str = [f"{yr}-{mo}-01" for yr, mo in dta.index.values]
dta.index = pd.DatetimeIndex(pd.to_datetime(date_str,format="%Y-%b-%d"), freq='MS')
fig = sm.tsa.graphics.month_plot(dta)
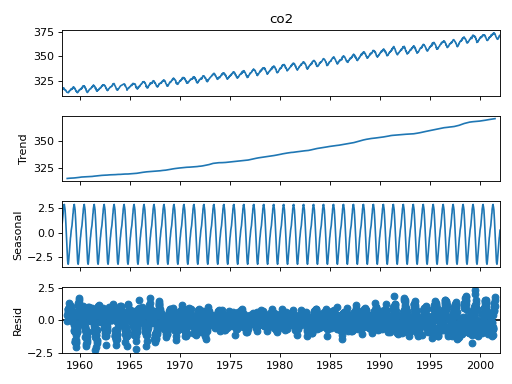
季节性分解¶
我们添加了一个简单的季节性分解工具,类似于R的decompose。这个函数可以在sm.tsa.seasonal_decompose中找到。
import statsmodels.api as sm
dta = sm.datasets.co2.load_pandas().data
# deal with missing values. see issue
co2 = dta.co2.interpolate()
res = sm.tsa.seasonal_decompose(co2)
res.plot()
{kind=link}
{kind=link}
添加线性混合效应模型(MixedLM)
线性混合效应模型¶
线性混合效应模型用于涉及依赖数据的回归分析。这种数据在处理纵向研究设计或其他涉及对每个受试者进行多次观察的研究设计时出现。两种特定的混合效应模型是“随机截距模型”,其中单个组中的所有响应都根据特定于该组的值进行加性偏移,以及“随机斜率模型”,其中值遵循在观测协变量中线性的平均轨迹,斜率和截距都特定于该组。statsmodels的MixedLM实现允许为组指定任意随机效应设计矩阵,因此这些和其他类型的随机效应模型都可以拟合。
这是一个将随机截距模型拟合到纵向研究数据的示例:
import statsmodels.api as sm
import statsmodels.formula.api as smf
data = sm.datasets.get_rdataset('dietox', 'geepack', cache=True).data
md = smf.mixedlm("Weight ~ Time", data, groups=data["Pig"])
mdf = md.fit()
print(mdf.summary())
statsmodels LME 框架目前支持通过 Wald 检验和系数上的置信区间进行事后推断,轮廓似然分析,似然比检验,以及 AIC。当前实现的一些限制是它不支持更复杂的残差结构(它们总是同方差的),并且不支持交叉随机效应。我们希望在下一个版本中实现这些功能。
包装 X-12-ARIMA/X-13-ARIMA¶
现在可以从 statsmodels 调用 X-12-ARIMA 或 X-13ARIMA-SEATS。这些库必须单独安装。
import statsmodels.api as sm
dta = sm.datasets.co2.load_pandas().data
co2 = dta.co2.interpolate()
co2 = co2.resample('M').last()
res = sm.tsa.x13_arima_select_order(dta.co2)
print(res.order, res.sorder)
results = sm.tsa.x13_arima_analysis(co2)
fig = results.plot()
fig.set_size_inches(12, 5)
fig.tight_layout()
其他重要的新功能¶
用于AR(I)MA估计的卡尔曼滤波Cython代码已经得到了显著优化。你可以预期速度提升一到两个数量级。
添加了
sm.tsa.arma_order_select_ic。这是一个便捷函数,用于快速获取信息准则,以便在ARMA过程的初步顺序选择中使用。时间序列的绘图函数现在除了在
sm.graphics.tsa命名空间下导入外,还在sm.tsa.graphics命名空间下导入。新的 distributions.ExpandedNormal 类实现了弱非正态分布的Edgeworth展开。
新数据集:添加了新的数据集用于示例。
sm.datasets.co2是一个单变量时间序列数据集,包含每周的二氧化碳读数。它展示了趋势和季节性,并且包含缺失值。在
sm.stats.stattools.robust_skewness和sm.stats.stattools.robust_kurtosis中分别添加了稳健的偏度和峰度估计器。在sm.stats.stattools.medcouple中添加了另一种稳健的偏度度量。新增到相关性工具的函数:corr_nearest_factor 在Frobenius范数中找到最接近给定方阵的因子结构相关矩阵;corr_thresholded 使用稀疏矩阵操作高效构建硬阈值相关矩阵。
新 dot_plot 在图形中:点图是一种可视化小数据集的方法,能够立即传达图中每个点的身份。点图常见于元分析中,被称为“森林图”,但也可以在许多其他场景中使用。研究论文中出现的大多数表格都可以用点图来图形化表示。
statsmodels 添加了自定义警告到
statsmodels.tools.sm_exceptions。默认情况下,所有这些警告将在适当的时候被引发。如果需要,可以使用warnings.simplefilter来关闭它们。允许通过
eval_env关键字参数控制用于通过 patsy 评估公式的命名空间。有关更多信息,请参阅 命名空间 文档。
主要修复的Bug¶
公式中的NA处理现在已正确处理。Issue #805, Issue #1877.
当使用具有对象数据类型的数组时,提供更好的错误信息。Issue #2013。
ARIMA 预测的差分阶数被硬编码为
d = 1。Issue #1562。
向后不兼容的更改和弃用¶
RegressionResults.norm_resid 现在是一个只读属性,而不是一个函数。
函数
statsmodels.tsa.filters.arfilter已被移除。这并不是计算递归AR滤波器,而是一个卷积滤波器。添加了两个具有更清晰名称的新函数sm.tsa.filters.recursive_filter和sm.tsa.filters.convolution_filter。
开发总结与致谢¶
上一个版本(0.5.0)于2014年8月14日发布。自那时以来,我们总共关闭了528个问题,276个拉取请求和252个常规问题。有关更多信息,请参阅详细列表。
此版本是以下37位作者共同努力的结果,他们总共贡献了1531次提交。如果我们因任何原因未能将您的名字列在下文中,请与我们联系:
关于更改次数和贡献者列表的简介。
亚历克斯·格里芬
亚历克斯·帕里吉
安娜·马丁内斯·帕尔多
安德鲁·克莱格
本·达菲尔德
查德·富尔顿
克里斯·克尔
埃里克·蒋
Evgeni Burovski
gliptak
汉斯-马丁·冯·高德克
扬·舒尔茨
jfoo
乔·汉德
约瑟夫·珀克托德
jsphon
贾斯汀·格拉纳
Kerby Shedden
凯文·谢泼德
Kyle Beauchamp
Lars Buitinck
马克斯·林克
米罗斯拉夫·巴奇卡罗夫
m
Padarn Wilson
保罗·霍布森
皮特罗·巴蒂斯通
Radim Řehůřek
拉尔夫·戈默斯
理查德·T·盖伊
Roy Hyunjin Han
Skipper Seabold
汤姆·奥格斯珀格
特伦特·豪克
Valentin Haenel
文森特·阿雷-邦多克
Yaroslav Halchenko
注意
通过运行 git log v0.5.0..HEAD --format='* %aN <%aE>' | sed 's/@/\-at\-/' | sed 's/<>//' | sort -u 获得。
在0.6.0开发周期中关闭的问题¶
在0.6.0中关闭的问题¶
GitHub 统计数据 2013/08/14 - 2014/10/15 (标签: v0.5.0)
我们总共关闭了528个问题,276个拉取请求和252个常规问题;
这是完整的列表(使用脚本tools/github_stats.py生成):
此列表是自动生成的,可能不完整。
拉取请求 (276):
PR #2044: 增强:允许二元模型的单位区间。关闭 #2040。
PR #1426: 增强:将arima_process内容导入tsa.api
PR #2042: 修复contrast.py中的两个小拼写错误
PR #2034: 增强:处理带有公式的额外数据的缺失值
PR #2035: 维护:删除0.6的已弃用代码
PR #1325: 增强:基于正态分布添加Edgeworth展开
PR #2032: 文档:它是什么就是什么。
PR #2031: 增强:向用户公开patsy eval_env。
PR #2028: 增强:修复链接和族中的数值问题。
PR #2029: 文档:修复版本以匹配其他文档。
PR #1647: 增强:在非收敛时发出警告。
PR #2014: BUG: 修复ARIMA中d == 2的预测问题
PR #2013: 增强:在对象数据类型上提供更好的错误信息
PR #2012: 错误:2维1列 -> 1维。关闭 #322。
PR #2009: 文档:重构后更新。使用代码块。
PR #2008: 增强:为 MixedLM 添加包装器
PR #1954: 增强:PHReg 公式改进
PR #2007: BLD: 修复构建问题
PR #2006: BLD: 在清理时不生成cython。关闭 #1852。
PR #2000: BLD: 让 pip/setuptools 处理根本没有安装的依赖项。
PR #1999: Gee 偏移暴露 1994 重新基准
PR #1998: 错误/增强 Lasso 空模型重新基于
PR #1989: 错误/增强:WLS通用稳健协方差类型未使用白化,
PR #1587: 增强:包装 X12/X13-ARIMA AUTOMDL。关闭 #442。
PR #1563: 增强:为ARIMA模型添加plot_predict方法。
PR #1995: BUG: 修复问题 #1993
PR #1981: 增强:添加 covstruct 的 API。清理 __init__。关闭 #1917。
PR #1996: 开发:忽略 .venv 文件。
PR #1982: 参考:将 jac 重命名为 score_obs。关闭 #1785。
PR #1987: BUG tsa pacf, base bootstrap
PR #1986: Bug multicomp 1927 重新合并
PR #1984: 文档添加 gee.rst
PR #1985: 未居中的latex表格1929重新调整
PR #1983: BUG: 修复 compat asunicode
PR #1574: 文档:修复数学公式。
PR #1980: 文档:文档修复
PR #1974: 参考/文档 beanplot 更改默认颜色,添加笔记本
PR #1978: 增强:检查二元模型的输入
PR #1979: 错误: 拼写错误
PR #1976: 增强:为 SimpleTable 添加 _repr_html_
PR #1977: 错误:修复导入重构的受害者。
PR #1975: BUG: Yule walker 转换为浮点数
PR #1973: 参考:移动并公开webuse
PR #1972: TST: 添加对NumPy 1.9和matplotlib 1.4的测试
PR #1939: 增强:Binstar 构建文件
PR #1952: 参考/文档: 杂项
PR #1940: 参考:重构和加速混合LME
PR #1937: 增强:快速访问在线文档
PR #1942: 文档: 将README类型更改为rst
PR #1938: 增强:启用 Python 3.4 测试
PR #1924: Bug gee cov type 1906 rebased
PR #1870: 稳健协方差,fit中的cov_type
PR #1859: BUG: 不要在 k_ar == 0 时使用负索引。关闭 #1858。
PR #1914: 错误:LikelihoodModelResults.pvalues 使用 df_resid_inference
PR #1899: TST: 修复 pandas 索引的 assert_equal
PR #1895: Bug multicomp pandas
PR #1894: BUG修复更多ix索引情况以兼容pandas
PR #1889: BUG: 修复 ytick 位置 关闭 #1561
PR #1887: Bug pandas 兼容性断言
PR #1888: TST test_corrpsd 测试因子:向数据添加噪声
PR #1886: BUG pandas 0.15 兼容性问题在 grouputils 标签中
PR #1885: TST: corr_nearest_factor, 更多信息化的测试
PR #1884: 修复:为 pandas>=0.15 中的 pd.Categorical 添加兼容代码
PR #1883: BUG: 在 TransfGen 分布中添加 _ctor_param
PR #1872: TST: 修复 _infer_freq 以兼容 pandas .14+
PR #1867: 参考 covtype 拟合
PR #1865: 禁用tst分布1864
PR #1856: _spg_optim 返回目标函数值的历史记录
PR #1854: BLD: 不要在构建笔记本时硬编码路径。关闭 #1249
PR #1851: 维护:Cor 最近因子测试
PR #1847: 牛顿正则化
PR #1623: BUG Negbin 拟合正则化
PR #1797: 错误/增强:修复并改进常数检测
PR #1770: TST: 使用 -1 无常数项的方差分析,添加测试
PR #1837: 允许在使用公式时将组变量作为变量名传递
PR #1839: 错误:GEE 得分
PR #1830: BUG/ENH 使用 t
PR #1832: 使用scipy 0.14位置分布类时的TST错误
PR #1827: 线性模型的fit_regularized 重新基于1674
PR #1825: Phreg 1312 重新基于
PR #1826: Lme API 文档
PR #1824: Lme profile 1695 重新基于
PR #1823: Gee cat 子类 1694 重基
PR #1781: 增强:Glm 添加 score_obs
PR #1821: Glm 维护 #1734 重新基于
PR #1820: BUG: 恢复PR #1819中对conf_int的更改
PR #1819: 文档工作
PR #1772: 参考: cov_params 允许仅定义 cov_params_default 的情况
PR #1771: REF numpy >1.9 兼容性,索引到空切片关闭 #1754
PR #1769: 修复 ttest 1d
PR #1766: TST: TestProbitCG 增加 fcalls 的边界 关闭 #1690
PR #1709: BLD: 使构建扩展更加灵活
PR #1714: 进行中: fit_constrained
PR #1706: 参考:在测试中使用固定参数。关闭 #910。
PR #1701: 错误:修复错误的逻辑。当missing=’raise’且没有缺失数据时不抛出异常。
PR #1699: TST/ENH 标准化变换,重新参数化 TestProbitCG
PR #1697: 修复 statsmodels/statsmodels#1689
PR #1692: OSL 示例:删除了示例中的冗余单元格
PR #1688: Kshedden 混合重写了 #1398
PR #1629: 拉取请求以修复问题597中的带宽错误
PR #1666: 在sdist中包含pyx但不安装
PR #1683: TST: GLM 缩短随机种子关闭 #1682
PR #1681: Dotplot kshedden 对 1294 进行了 rebase
PR #1679: BUG: 修复预测处理偏移量和暴露的问题
PR #1677: 更新 RegressionModel.predict() 的文档字符串
PR #1635: 允许偏移量和暴露量与对数链接一起使用;引发异常…
PR #1676: SVAR 的测试
PR #1671: 增强:避免硬编码的带宽 – 使用现有的字典(+修正拼写错误)
PR #1643: 允许在协方差矩阵中利用矩阵结构
PR #1657: BUG: 修复重构受害者。
PR #1630: 文档: 拼写错误, “intercept”
PR #1619: 维护:数据集文档清理和文档的自动构建
PR #1612: BUG/ENH 修复 negbin 暴露 #1611
PR #1610: BUG/ENH 修复 llnull,额外关键字参数以重新创建模型
PR #1582: 错误:wls_prediction_std 修复权重处理,参见 987
PR #1613: 错误:修复比例 allpairs #1493
PR #1607: 测试:调整精度,CI Debian,Ubuntu 测试
PR #1603: 增强:允许在GLM中使用start_params
PR #1600: 清理:回归图修复
PR #1592: 文档:添加和修复
PR #1520: CLN: 重构后不再需要2to3
PR #1585: 最近邻1384重新基于
PR #1553: Gee maint 1528 重新基于
PR #1583: 错误:对于ARMA(0,0),确保1维bse并修复摘要。
PR #1580: 文档:修复链接。[跳过持续集成]
PR #1572: 文档:修复链接标题 [跳过持续集成]
PR #1566: BLD: 修复 >= 3.3 Windows 构建中的复制粘贴路径错误
PR #1524: 增强:优化Cython代码。使用scipy blas函数指针。
PR #1560: 增强:允许在顺序选择中使用ARMA(0,0)
PR #1559: 维护:恢复从vbench PR丢失的提交
PR #1554: 在medcouple中引入的测试输出已被静音
PR #1234: 增强:稳健的偏度、峰度和中位数耦合度量
PR #1484: 增强:添加朴素季节性分解函数
PR #1551: 兼容性:修复在Python 2.6上失败的测试
PR #1472: 增强:在MultiComparison中使用人类可读的组名代替整数ID
PR #1437: 增强:接受非整数定义的聚类组
PR #1550: 修复测试 gmm poisson
PR #1549: TST: 修复本地失败的测试。
PR #1121: 进行中: 重构优化代码。
PR #1547: 兼容性:修正2.6的bit_length
PR #1545: 维护:修复遗漏的已弃用工具.rank的使用
PR #1196: 参考:确保在使用fft进行acf时为O(N log N)
PR #1154: 文档:为构建机器添加链接。
PR #1546: 文档:修复指向错误笔记本的链接
PR #1383: 维护:弃用rank以支持np.linalg.matrix_rank
PR #1432: 兼容性:从scipy添加NumpyVersion
PR #1438: 增强:避免使用“center”环境的选项。
PR #1544: BUG: Travis miniconda
PR #1510: CLN: 改进警告以避免通用警告消息
PR #1543: TST: 抑制L-BFGS-B的RuntimeWarning
PR #1507: 清理:静默测试输出
PR #1540: 错误:修正指数变换的导数。
PR #1536: 错误:为单个构建恢复coveralls
PR #1535: BUG: 修复2.6测试失败问题,将astype(str)替换为apply(str)
PR #1523: Travis miniconda
PR #1533: 文档:修复指向github上代码的链接
PR #1531: 文档:使用linkcheck修复过时的链接
PR #1530: 文档: 修复链接
PR #1527: 文档:更新文档添加常见问题页面
PR #1525: 文档: 更新包含Python 3.4构建笔记
PR #1518: 文档:请求发布说明和示例。
PR #1516: 文档:更新示例贡献文档以符合当前实践。
PR #1517: 文档:明确数据集的数据属性
PR #1515: 文档:修复损坏的链接
PR #1514: 文档:修复公式导入惯例。
PR #1506: 错误:Python 2.6中的格式和解码错误
PR #1505: TST: 测试 co2 load_data 在 Python 3 上的运行情况。
PR #1504: BLD: 新版R需要NAMESPACE文件。关闭 #1497。
PR #1483: 增强:一些用于处理日期的实用函数
PR #1482: 参考: 优先使用 filters.api 而不是 __init__
PR #1481: 增强:添加每周二氧化碳数据集
PR #1474: 文档:为标准过滤方法添加图表。
PR #1471: 文档:修复导入
PR #1470: 文档/构建: 从nbgenerate记录代码异常
PR #1469: 文档:修复错误链接
PR #1468: 维护:CSS修复
PR #1463: 文档:移除失效参数。更改默认关键字参数。关闭 #1462。
PR #1452: STY: 导入 pandas 为 pd
PR #1458: BUG/BLD: 在相对路径中排除沙箱,而不是绝对路径
PR #1447: 文档:仅在需要时构建和上传文档。
PR #1445: 文档: 示例登录页面
PR #1436: 文档:修复自动文档构建。
PR #1431: 文档:为getenv添加默认值。修复路径。添加print_info
PR #1429: 维护:使用随IPython一起提供的ip_directive
PR #1427: TST: 使测试静默运行
PR #1424: 增强:transform_slices 的一致结果
PR #1421: 增强:添加分组工具代码
PR #1419: Gee 1314 重新基于
PR #1414: TST 暂时重命名测试 probplot other 以跳过它们
PR #1403: Bug norm expan shapes
PR #1417: 参考:让子类保持与数据关联的kwds。
PR #1416: 增强:使handle_data可被子类覆盖。
PR #1410: 增强:处理缺失为无
PR #1402: 参考:将缺失数据处理作为类方法公开
PR #1387: 维护:修复失败的测试
PR #1406: 维护:工具改进
PR #1404: 测试修复广义线性模型的链接测试
PR #1396: 参考:减少多重检验的内存使用
PR #1380: 文档 :更新 vector_ar.rst
PR #1381: BLD: 在 egg_info 中不要检查 pip 的依赖项。关闭 #1267。
PR #1302: 错误:修正拼写错误。
PR #1375: STY: 移除未使用的导入并在setup.py中注释掉未使用的库
PR #1143: 文档:更新新工作流程的后端注释。
PR #1374: 增强:将 tsaplots 导入 tsa 命名空间。关闭 #1359。
PR #1369: 样式:Pep-8 清理
PR #1370: 增强:支持ARMA(0,0)模型。
PR #1368: 样式:Pep 8 清理
PR #1367: 增强:确保mle返回附加到结果。
PR #1365: 样式:导入和pep 8清理
PR #1364: 增强:去除硬编码的lbfgs。关闭 #988。
PR #1363: 错误:修正拼写错误。
PR #1361: 增强:将mlefit附加到结果而不是模型。
PR #1360: 增强:将adfuller导入tsa命名空间
PR #1346: 样式: PEP-8 清理
PR #1344: 错误:使用给定的ARMA缺失关键字。
PR #1340: 增强:防止ARMA收敛失败。
PR #1334: 增强:ARMA 阶数选择便利函数
PR #1339: 修复拼写错误
PR #1336: 参考: 去掉普通的断言。
PR #1333: STY: __all__ 应在导入之后。
PR #1332: 增强:向工具添加Bunch对象。
PR #1331: 增强:始终使用Unicode。
PR #1329: 错误:将元数据解码为utf-8。关闭 #1326。
PR #1330: 文档: 修正拼写错误。关闭 #1327。
PR #1185: 当直接从git主干安装pandas时,增加了对pandas的支持
PR #1315: 维护:更改回构建盒的路径
PR #1305: TST: 更新硬编码路径。
PR #1290: 增强:添加季节性绘图。
PR #1296: BUG/TST: 修复当 start == len(endog) 时的 ARMA 预测问题。关闭 #1295
PR #1292: 文档:清理示例文件夹和网页
PR #1286: 确保PeriodIndex通过tsa。关闭 #1285。
PR #1271: Silverman 增强 - 问题 #1243
PR #1264: GEE、GMM、sphinx警告的文档工作
PR #1179: 参考/测试: ProbPlot 现在使用 resettable_cache 并在绘图函数中添加了一些关键字参数
PR #1225: 三明治 mle
PR #1258: Gmm 新重构
PR #1255: 增强功能:将GEE添加到genmod
PR #1254: 参考:Results.predict 转换为数组并调整形状
PR #1192: TST: 在WLS.loglike更改后启用llf测试,参见 #1170
PR #1253: Wls llf 修复
PR #1233: 沙盒内核错误统一内核和置信区间
PR #1240: Kde 权重 1103 823
PR #1228: 在adfuller()文档中添加默认值标签
PR #1198: 修复拼写错误
PR #1230: BUG: 在完美拟合情况下resid_pearson的数值精度问题 #1229
PR #1214: 比较 lr 测试重新基于
PR #1200: BLD: 不要安装 *.pyx *.c MANIFEST.in
PR #1202: 维护:对backports进行排序以简化应用。
PR #1157: 测试精度
PR #1161: 添加一个用于同时对数似然和分数的拟合接口,适用于lbfgs,使用MNLogit进行测试
PR #1160: 文档: 将scipy版本从0.7更新到0.9.0
PR #1147: 增强:添加lbfgs用于拟合
PR #1156: 增强:在AR(I)MA中对0,0阶模型引发异常。关闭 #1123
PR #1149: BUG: 修复ARIMA的小数据问题。
PR #1092: 修复了RegressionModel中的重复svd
PR #1139: TST: 静默测试
PR #1135: 杂项样式
PR #1088: 增强:为泊松分布添加predict_prob方法
PR #1125: 参考/错误:一些GLM清理。在NegativeBinomial方差中使用了修剪后的结果。
PR #1124: 错误:修复当没有趋势时ARIMA预测的问题。
PR #1118: 文档: 更新 gettingstarted.rst
PR #1117: 更新 ex_arma2.py
PR #1107: 参考: 弃用 stand_mad。添加 center 关键字到 mad。关闭 #658。
PR #1089: 增强:对于泊松分布,exp(poisson.logpmf()) 表现更好。
PR #1077: 错误:允许在ARMAX预测中使用1维外生变量。
PR #1075: BLD: 修复在某些版本的easy_install上的构建问题。
PR #1071: 更新 setup.py 以修复在 OSX 上的安装问题
PR #1052: 文档: 更新贡献文档
PR #1136: RLS: 添加 IPython 工具以简化问题的回溯。
PR #1091: 文档: 小的git拼写错误
PR #1082: coveralls 支持
PR #1072: 笔记本示例标题单元格
PR #1056: 示例: 回归诊断
PR #1057: 兼容性:修复py3中get_rdatasets的缓存问题。
PR #1045: 文档/构建: 从 nbconvert 更新到 IPython 1.0。
PR #1026: 文档/构建: 在文档构建的环境中添加LD_LIBRARY_PATH。
问题 (252):
问题 #2040: 增强: 分数 Logit, Probit
问题 #1220: 额外数据中缺失(例如三明治,稳健协方差)
问题 #1877: 缺失数据上的GEE错误。
问题 #805: 公式中的分类变量导致NaN
问题 #2036: 链接中的测试需要精确的类,因此 Logit 不能替代 logit
问题 #2010: 再次检查0.6版本的弃用项。
问题 #1303: patsy 库未自动安装
问题 #2024: genmod 链接数值改进
问题 #2025: GEE 需要精确导入 cov_struct
问题 #2017: 关于太多图形的 Matplotlib 警告
问题 #724: 检查警告
问题 #1562: ARIMA 预测对 d=1 进行了硬编码
问题 #880: 带有布尔类型的DataFrame未正确转换。
问题 #1992: MixedLM 样式
问题 #322: acf / pacf 在 pandas 对象上不起作用
问题 #1317: AssertionError: attr 不相等 [dtype]: dtype(‘object’) != dtype(‘datetime64[ns]’)
问题 #1875: 对象数组的dtype错误(在聚类标准误差代码中引发)
问题 #1842: dtype 对象, glm.fit() 给出 AttributeError: sqrt
问题 #1300: 文档错误, 缺失
问题 #1164: RLM cov_params, t_test, f_test 不使用 bcov_scaled
Issue #1019: 0.6.0 路线图
问题 #554: 预测标准误差
问题 #333: 增强工具: 在R导出文件中压缩
问题 #1990: MixedLM 没有包装器
问题 #1897: 考虑在 setup.py 中依赖 setuptools
问题 #2003: pip 安装现在会静默失败
问题 #1852: 清理时不进行cythonize
问题 #1991: GEE 公式接口不接受偏移/暴露
问题 #442: 封装 x-12 arima
问题 #1993: MixedLM 错误
问题 #1917: API: GEE 通过 API 访问 genmod.covariance_structure
问题 #1785: 参考: 重命名 jac -> score_obs
问题 #1969: pacf 对滞后 0 的标准误差不正确
问题 #1434: GenericLikelihoodModelResults.bootstrap() 中的一个小错误
问题 #1408: BUG tsa_plots 测试失败
问题 #1337: 文档: HCCM 现在可用于 WLS
问题 #546: 影响和异常值文档
问题 #1532: 文档: 相关页面已过时
问题 #1386: 在文档中添加最低matplotlib版本
问题 #1068: 文档:在sourceforge上保留旧版本的文档
问题 #329: 从模块页面链接到示例和数据集
问题 #1804: statsmodels 的 PDF 文档
问题 #202: 扩展WLS/GLS的稳健标准误差
问题 #1519: 在文档中链接到用户贡献的示例
问题 #1053: 不方便:当 endog 是 (1,2) 而不是 (0,1) 时的 logit
问题 #1555: SimpleTable: 为 ipython notebook 添加 repr html
问题 #1366: 将ARMA中的默认start_params更改为0.1
问题 #1869: yule_walker(来自 statsmodels.regression)在给定整数数组时引发异常
问题 #1651: statsmodels.tsa.ar_model.ARResults.predict
问题 #1738: GLM 稳健三明治协方差矩阵
问题 #1779: statsmodels 下的一些目录没有 __init_.py
问题 #1242: 不支持 (0, 1, 0) ARIMA 模型
问题 #1571: 暴露 webuse,使用缓存
问题 #1860: 增强/错误/文档: Bean 图应允许 Bean 和小提琴的宽度分开。
问题 #1831: TestRegressionNM.test_ci_beta2 i386 AssertionError
问题 #1079: 错误修复版本 0.5.1
问题 #1338: 在使用 WLS/GLS 时对 HCCM 使用发出警告
问题 #1430: scipy 最低版本 / 问题
问题 #276:记忆化,最后一个参数获胜,如何将三明治附加到结果?
问题 #1943: REF/ENH: LikelihoodModel.fit 优化,使 Hessian 可选
问题 #1957: BUG: 使用 _init_keys 重新创建 OLS 模型
问题 #1905: 文档: 在线文档缺少GEE
问题 #1898: 添加 Python 3.4 到持续集成测试中
问题 #1684: BUG: GLM NegativeBinomial: llf 忽略偏移量和暴露
问题 #1256: 参考: GEE 处理默认协方差矩阵
问题 #1760: 更改结果中的协方差类型
问题 #1906: BUG: GEE 默认协方差未被使用
问题 #1931: BUG: GEE 子类 NominalGEE 不适用于 pandas exog
问题 #1904: GEE 结果没有包装器
问题 #1918: GEE: 必需的属性缺失, df_resid
问题 #1919: BUG GEE.predict 使用 link 而不是 link.inverse
问题 #1858: BUG: arimax 预测应特殊处理 k_ar == 0 的情况
问题 #1903: BUG: 对于集群稳健性,使用 use_t 时,p 值不使用 df_resid_inference
问题 #1243: 非高斯核的kde silverman带宽
问题 #1866: Pip 依赖项
问题 #1850: TST test_corr_nearest_factor 在 Ubuntu 上失败
问题 #292: python 3 示例
问题 #1868: ImportError: 没有名为 compat 的模块 [ from statsmodels.compat import lmap ]
问题 #1890: BUG tukeyhsd 组标签中的 nan
问题 #1891: TST test_gmm 过时的 pandas, compat
问题 #1561: BUG 图表用于 tukeyhsd, MultipleComparison
问题 #1864: 使用 scipy 0.14.0 的测试失败沙盒分布转换
问题 #576: 添加贡献指南
问题 #1873: GenericLikelihoodModel 不可序列化
问题 #1822: 在 Ubuntu pandas 0.14.0 上的 TST 失败,频率问题
问题 #1249: 笔记本示例的源目录问题
问题 #1855: anova_lm 在从 api.ols 创建的模型上抛出错误,而不是 formula.api.ols
问题 #1853: 大量硬编码路径
问题 #1792: 包含交互项后调整后的R²异常
问题 #1794: REF: has_constant, k_constant, 在基础中包含隐式常数检测
问题 #1454: NegativeBinomial 缺少 fit_regularized 方法
问题 #1615: 简化拟合方法
问题 #1453: 离散 NegativeBinomialModel regularized_fit 值错误: 矩阵未对齐
问题 #1836: BUG 尝试导入 statsmodels.api 时遇到 TypeError
问题 #1829: BUG: GLM 摘要显示“t” use_t=True 用于摘要
问题 #1828: BUG summary2 不传播/使用 use_t
问题 #1812: BUG/ REF conf_int 和 use_t
问题 #1835: 使用 easy_install 安装时遇到的问题
问题 #1801: BUG ‘f_gen’ 在 scipy 0.14.0 中缺失
问题 #1803: 由 numpy 1.9.0r1 引发的错误
问题 #1834: stackloss
问题 #1728: GLM.fit maxiter=0 不正确
问题 #1795: 带有偏移量的奇异设计?
问题 #1730: 增强/错误 cov_params,通用化,避免 ValueError
问题 #1754: BUG/REF: 在 numpy >= 1.9 中对切片的赋值 (emplike)
问题 #1409: 在 Debian Wheezy 上的 GEE 测试错误
问题 #1521: ubuntu 失败: tsa_plot 和 grouputils
问题 #1415: 测试失败 test_arima.test_small_data
问题 #1213: anova_lm 中的 df_diff
问题 #1323: t_test 摘要后对比结果对1个参数损坏
问题 #109: 在Ubuntu上TestProbitCG失败
问题 #1690: TestProbitCG: 8个失败的测试 (Python 3.4 / Ubuntu 12.04)
问题 #1763: Johansen 方法未给出正确的指数值
问题 #1761: 文档构建失败: ipython 版本 ? ipython 指令
问题 #1762: 无法构建
问题 #1745: get_rdataset(“Guerry”, “HistData”) 引发的 UnicodeDecodeError
问题 #611: 使用 pandas 0.7.3 测试失败 foreign
问题 #1700: 缺失处理中的错误逻辑
问题 #1648: ProbitCG 失败
问题 #1689: test_arima.test_small_data: SVD 无法收敛 (Python 3.4 / Ubuntu 12.04)
问题 #597: BUG: 非参数: 核函数, efficient=True 即使给定也会改变 bw
问题 #1606: 如果 cython 可用,从 sdist 构建失败
问题 #1246: 测试失败 test_anova.TestAnova2.test_results
问题 #50: t_test, f_test, model.py 使用正态分布而不是 t 分布
问题 #1655: newey-west 与 R 不同?
问题 #1682: 在Ubuntu上的TST测试失败,random.seed
问题 #1614: 回归.线性_模型.回归模型.预测() 的文档字符串与实现不匹配
问题 #1318: GEE 和 GLM 尺度参数
问题 #519: L1 fit_regularized 清理, 注释
问题 #651: 添加示例页面的结构
Issue #1067: 卡尔曼滤波器收敛性。多接近才算足够接近?
问题 #1281: 牛顿收敛失败打印警告而不是警告
问题 #1628: 无法在同一个需求文件中安装 statsmodels 以及 numpy、pandas 等。
问题 #617: 在 Fedora 17 64 位系统中安装 statsmodels 的问题
问题 #935: 在 likelihoodmodels 离散模型中的 ll_null
问题 #704: datasets.sunspot: 描述中的链接错误
问题 #1222: NegativeBinomial 忽略曝光
问题 #1611: BUG NegativeBinomial 忽略 exposure 和 offset
问题 #1608: BUG: NegativeBinomial, llnul 总是默认 ‘nb2’
问题 #1221: llnull 是否考虑了暴露?
问题 #1493: statsmodels.stats.proportion.proportions_chisquare_allpairs 有硬编码值
问题 #1260: 在Debian上的GEE测试失败
问题 #1261: 在Debian上的测试失败
问题 #443: GLM.fit 不允许 start_params
问题 #1602: 使用预分配的起始参数拟合GLM
问题 #1601: 使用预分配的起始参数拟合GLM
问题 #890: 回归图问题 (pylint) 和缺少测试覆盖
问题 #1598: “旧”字符串格式化在Python 3中兼容吗?
问题 #1589: AR 与 ARMA 阶数规范
问题 #1134: 标记已知的失败
问题 #1259: 无参数模型
问题 #616: 单一代码库中的 python 2.6, python 3
问题 #1586: 使用新的 pyx 时卡尔曼滤波器错误
问题 #1565: build_win_bdist*_py3*.bat 使用了错误的编译器
问题 #843: 尝试在 OS X 上安装时出现 UnboundLocalError
问题 #713: arima.fit 性能
问题 #367: 无法在 RHEL 5.6 上安装
问题 #1548: testtransf 错误
问题 #1478: sm.tsa.filters.arfilter 是一个 AR 滤波器吗?
问题 #1420: GMM 泊松测试失败
问题 #1145: test_multi 噪音
问题 #1539: NegativeBinomial 使用 bfgs 时出现奇怪的结果
问题 #936: statsmodels 的 vbench
问题 #1153: 我们的所有测试机器在哪里?
问题 #1500: 使用 Miniconda 进行测试构建
问题 #1526: 过时的文档
问题 #1311: BUG/BLD 3.4 cython c 文件的兼容性
问题 #1513: 在 osx 上构建 -python-3.4
问题 #1497: r2nparray 需要 NAMESPACE 文件
问题 #1502: coveralls 文件覆盖率报告损坏
问题 #1501: 预测中的 pandas 输入/输出
问题 #1494: 截断的小提琴图
问题 #1443: 使用 statsmodels 进行线性回归时 python.exe 崩溃
问题 #1462: qqplot 线 kwarg 损坏/文档字符串错误
问题 #1457: BUG/BLD: 如果在 statsmodels 路径中任何地方出现“sandbox”,构建失败
问题 #1441: wls 函数: 当因变量名称以数字开头时,出现语法错误“解析时意外的文件结束”
问题 #1428: ipython_directive 在 ipython 中无法工作
问题 #1385: Summary 中的 SimpleTable (例如 OLS) 在大模型中运行缓慢
问题 #1399: UnboundLocalError: 局部变量‘fittedvalues’在赋值前被引用
问题 #1377: TestAnova2.test_results 在 pandas 0.13.1 下失败
问题 #1394: multipletests: 减少内存消耗
问题 #1267: 包不能同时包含 pandas 和 statsmodels 在 install_requires 中
问题 #1359: 将 graphics.tsa 移动到 tsa.graphics
问题 #356: 文档占用大量空间
问题 #988: AR.fit 没有 fmin_l_bfgs_b 的精度选项
问题 #990: 使用bfgs进行AR拟合: 大的得分
问题 #14: 带有外生变量的arma
问题 #1348: reset_index + set_index with drop=False
问题 #1343: ARMA 未将缺失关键字传递给 TimeSeriesModel
问题 #1326: 公式示例笔记本损坏
问题 #1327: “异常值和影响诊断措施”文档代码中的拼写错误
问题 #1309: Box-Cox 变换 (需要一些代码: lambda 估计器)
问题 #1059: sm.tsa.ARMA 使 ma 可逆
问题 #1295: 当 start 是 int len(endog) 且给出日期时,ARIMA 预测中的错误
问题 #1285: tsa 模型在带有 pandas 的 PeriodIndex 上失败
问题 #1269: 平稳过程的KPSS检验
问题 #1268: 功能请求: 指数平滑
问题 #1250: var_plots 中的文档错误
问题 #1032: Poisson predict 在列表上中断
问题 #347:最小观测数量 - 文档或检查?
问题 #1170: WLS 对数似然,aic 和 bic
问题 #1187: sm.tsa.acovf 在 unbiased 和 fft 都为 True 时失败
问题 #1239: 沙盒内核, inDomain 的问题
问题 #1231: 沙盒内核 confint 缺少 alpha
问题 #1245: 核函数余弦与Stata不同
问题 #823: 带权重的KDEUnivariate
问题 #1229: 退化情况下的精度问题
问题 #1219: select_order
问题 #1206: REF: RegressionResults cov-HCx 到缓存属性
问题 #1152: statsmodels 在 pandas 上测试失败
问题 #1195: 在导入api之前调用pyximport.install()导致崩溃
问题 #1066: gmm.IV2SLS 的预测签名错误
问题 #1186: 当 exog 是 1d 时的 OLS
问题 #1113: TST: 测试_正态性中的精度太高
问题 #1159: scipy 版本仍然是 >= 0.7?
问题 #1108: SyntaxError: 在函数‘test_EvalEnvironment_capture_flag’中不允许使用不合格的exec
问题 #1116: 示例文档中的拼写错误?
问题 #1123: BUG : arima_model._get_predict_out_of_sample, 忽略外生变量如果没有趋势?
问题 #1155: ARIMA - 计算的初始AR系数不是平稳的
问题 #979: Win64 二进制文件无法找到 Python 安装
问题 #1046: TST: 在当前主分支上测试_arima_small_data_bug
问题 #1146: 由于无效的最大滞后,ARIMA 拟合在小数据集上失败
问题 #1081: 简化线性模型的线性代数
问题 #1138: BUG: pacf_yw 不进行去均值处理
问题 #1127: 允许使用二项分布族的线性链接模型
问题 #1122: statsmodels.genmod.families.varfuncs.NegativeBinomial() 没有数据清理
问题 #658: robust.mad 没有被正确计算或使用了非标准定义;它返回中位数
问题 #1076: ARMAX 预测的一些问题
问题 #1073: easy_install 沙盒违规
问题 #1115: EasyInstall 问题
问题 #1106: 稳健.scale.mad 中的错误?
问题 #1102: 安装问题
问题 #1084: DataFrame.sort_index 在值为单个元素的列表时不使用升序
问题 #393: 离散选择中的边际效应没有定义标准误差
问题 #1078: 使用 pandas.version.short_version
问题 #96: 深拷贝在ResettableCache上中断
问题 #1055: datasets.get_rdataset 在 Python 3 上出现字符串解码错误
问题 #46: tsa.stattools.acf confint 需要检查和测试
问题 #957: 使用 numpy main 进行 ARMA 起始估计
问题 #62: GLSAR 在 whiten 中的初始条件不正确
问题 #1021: from_formula() 抛出错误 - 安装问题
问题 #911: stats.power 测试中的噪声
问题 #472: 更新 0.5 路线图
问题 #238: 发布 0.5
问题 #1006: 更新 nbconvert 到 IPython 1.0
问题 #1038: 带有整数名称的 DataFrame 在 ARIMA 中未处理
问题 #1036: Series 不再继承自 ndarray
问题 #1028: 在Windows和Anaconda上测试失败 - 低优先级
问题 #676: acorr_breush_godfrey 未定义 nlags
问题 #922: lowess 返回结果与选项不一致
问题 #425: 在 norm=TrimmedMean 的情况下,没有 bse
问题 #1025: add_constant 错误地检测到常量列