![]()
时间序列分类¶
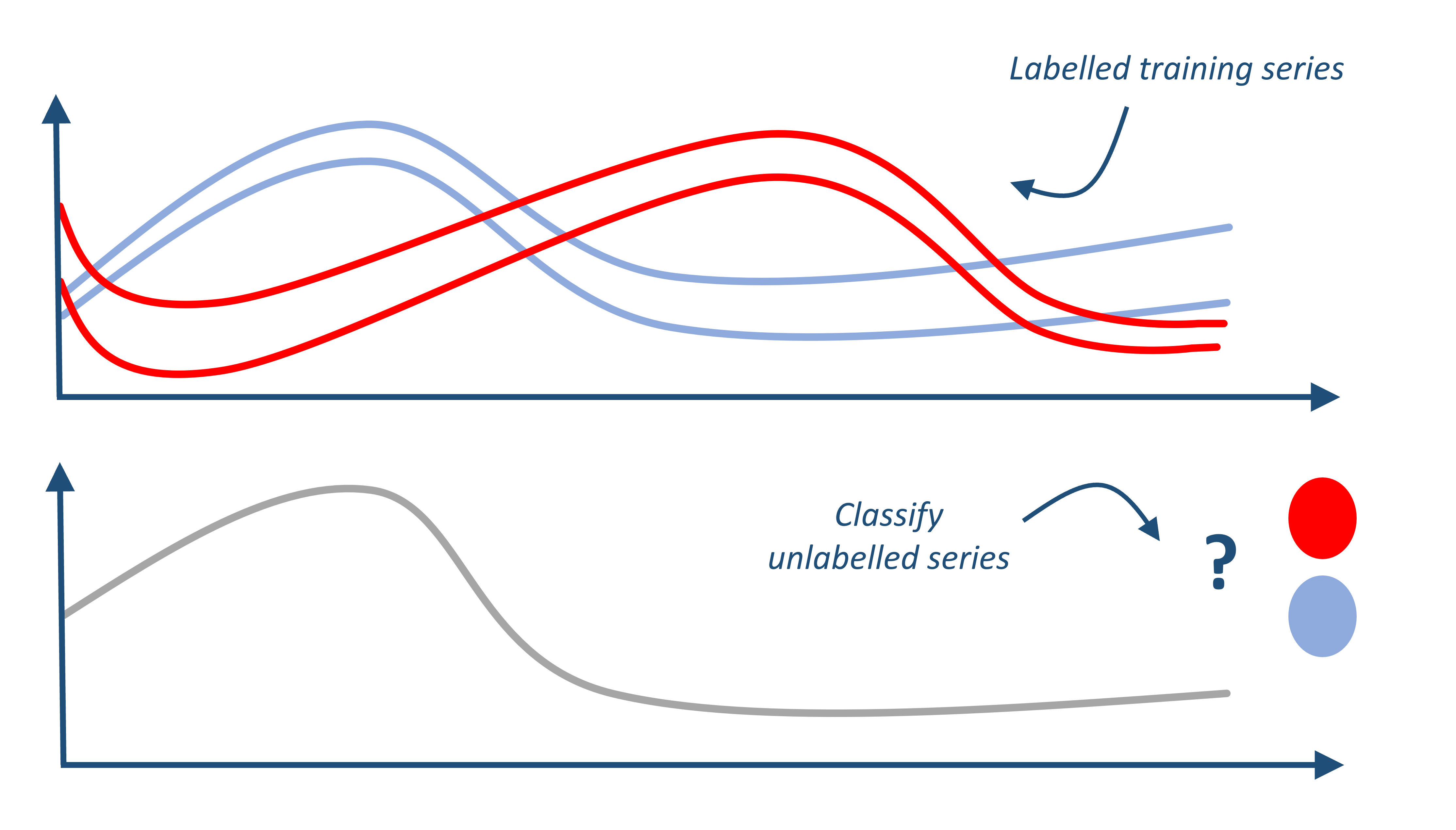
时间序列分类(TSC)涉及从一组时间序列(实值、有序数据)中训练模型,以预测一个离散的目标变量。例如,我们可能希望构建一个模型,可以根据患者的心电图读数预测他们是否生病,或者根据他们手部位置的轨迹预测一个人的运动类型。本笔记本提供了一个快速指南,帮助您开始使用aeon时间序列分类器。如果您可以使用scikit-learn,那么这应该很容易,因为基本用法是相同的。
分类笔记本¶
本笔记本概述了TSC。关于TSC的更具体的笔记本基于它们使用的表示或转换类型:
数据存储和问题类型¶
时间序列可以是单变量的(每个观测值是一个单一的值)或多变量的(每个观测值是一个向量)。例如,来自单个传感器的ECG读数是一个单变量序列,但来自智能手表的运动轨迹将是多变量的,至少有三个维度(x、y、z坐标)。上图是一个单变量问题:每个序列都有自己的标签。时间序列实例的维度也常被称为通道。我们建议将时间序列存储在形状为(n_cases, n_channels, n_timepoints)的3D numpy数组中,并且在可能的情况下,我们的单一问题加载器将返回一个3D numpy。不等长分类问题存储在2D numpy数组的列表中。有关数据存储的更多详细信息可以在data storage笔记本中找到。
[1]:
# Plotting and data loading imports used in this notebook
import matplotlib.pyplot as plt
from aeon.datasets import load_arrow_head, load_basic_motions
arrow, arrow_labels = load_arrow_head(split="train")
motions, motions_labels = load_basic_motions(split="train")
print(f"ArrowHead series of type {type(arrow)} and shape {arrow.shape}")
print(f"Motions type {type(motions)} of shape {motions_labels.shape}")
ArrowHead series of type <class 'numpy.ndarray'> and shape (36, 1, 251)
Motions type <class 'numpy.ndarray'> of shape (40,)
即使数据是单变量的,我们也使用3D numpy:尽管分类器可以使用形状为(n_cases, n_timepoints)的2D数组工作,但这种2D形状可能会与形状为(n_channels, n_timepoints)的单个多变量时间序列混淆。因此,为了区分这两种情况,我们强制使用3D格式(n_cases, n_channels, n_timepoints)以避免任何混淆。
如果你的序列长度不等,有缺失值或在不规则的时间间隔采样,你应该阅读关于数据预处理的笔记。
TSC数据集存档包含了大量用于评估TSC算法的示例TSC问题,这些问题在文献中已被使用了数千次。这些数据集具有某些特性,这些特性影响了我们在内存中存储它们时所使用的数据结构。
存档中的大多数数据集包含长度相同的时间序列。例如,我们刚刚加载的ArrowHead数据集由箭头图像的轮廓组成。投射点的分类是人类学中的一个重要主题。
![]()
弹丸点的形状使用基于角度的方法转换为序列,如这篇关于将图像转换为时间序列以进行数据挖掘的博客文章所述。

每个实例由一个单一的时间序列(即问题是单变量的)组成,长度相等,并且基于形状差异(如箭头中凹口的存在和位置)有一个类别标签。数据集由210个实例组成,默认情况下分为36个训练实例和175个测试实例。
BasicMotions 数据集 是一个多元时间序列分类(TSC)问题的示例。它是在一个项目中生成的,该项目中四名学生佩戴智能手表进行了四项活动。手表收集了3D加速度计和3D陀螺仪数据。每个实例涉及一个受试者在十秒钟内执行四项任务之一(步行、休息、跑步和羽毛球)。此数据集中的时间序列有六个维度或通道。
[2]:
plt.title(
f"First and second dimensions of the first instance in BasicMotions data, "
f"(student {motions_labels[0]})"
)
plt.plot(motions[0][0])
plt.plot(motions[0][1])
[2]:
[<matplotlib.lines.Line2D at 0x290fb1823a0>]

[3]:
plt.title(f"First instance in ArrowHead data (class {arrow_labels[0]})")
plt.plot(arrow[0, 0])
[3]:
[<matplotlib.lines.Line2D at 0x290fc1bfbe0>]

可以使用标准的sklearn分类器来处理单变量、等长的分类问题,但由于sklearn分类器忽略了变量中的序列信息,因此其性能可能不如专门的时间序列分类器。
要直接应用sklearn分类器,数据需要重塑为2D numpy数组。尽管我们建议使用形状为(n_channels, 1, n_timepoints)的3D numpy数组来处理单变量集合,但我们还提供了直接加载2D数组中的单变量TSC问题的功能。
[4]:
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
rand_forest = RandomForestClassifier(n_estimators=100)
arrow2d = arrow.squeeze()
arrow_test, arrow_test_labels = load_arrow_head(split="test", return_type="numpy2d")
rand_forest.fit(arrow2d, arrow_labels)
y_pred = rand_forest.predict(arrow_test)
accuracy_score(arrow_test_labels, y_pred)
[4]:
0.7028571428571428
aeon中的时间序列分类器¶
aeon 包含了在 classification 包中最先进的时间序列分类器。这些分类器根据用于发现区分特征的数据表示进行分组。我们为每种类型提供了一个单独的笔记本:基于卷积的、深度学习的、基于距离的、基于字典的、基于特征的、混合的、基于区间的 和 基于形状的。我们还在 sklearn 包中提供了一些 scikit learn 中没有的标准分类器。我们展示了分类器的最简单用例,并演示了如何为时间序列分类构建定制的管道。一个准确且相对快速的分类器是 ROCKET 分类器。ROCKET 是一种基于卷积的算法,在 基于卷积的 笔记本中有详细描述。
[1]:
from aeon.classification.convolution_based import RocketClassifier
rocket = RocketClassifier(n_kernels=2000)
rocket.fit(arrow, arrow_labels)
y_pred = rocket.predict(arrow_test)
accuracy_score(arrow_test_labels, y_pred)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[1], line 4
1 from aeon.classification.convolution_based import RocketClassifier
3 rocket = RocketClassifier(n_kernels=2000)
----> 4 rocket.fit(arrow, arrow_labels)
5 y_pred = rocket.predict(arrow_test)
7 accuracy_score(arrow_test_labels, y_pred)
NameError: name 'arrow' is not defined
一个较慢但通常更准确的时间序列分类器是HIVE-COTE算法的第2版。(HC2)在混合笔记本笔记本中有描述。HC2在这些小问题上特别慢。然而,它可以配置一个近似的最长运行时间,如下所示(运行这个单元格可能需要比12秒稍长的时间,非常短的时间是近似的,因为分类器需要完成一定量的工作):
[6]:
from aeon.classification.hybrid import HIVECOTEV2
hc2 = HIVECOTEV2(time_limit_in_minutes=0.2)
hc2.fit(arrow, arrow_labels)
y_pred = hc2.predict(arrow_test)
accuracy_score(arrow_test_labels, y_pred)
[6]:
0.8685714285714285
多变量分类¶
要在多元数据上直接使用sklearn分类器,一种选择是将数据展平,使得3D数组(n_cases, n_channels, n_timepoints)变为形状为(n_cases, n_channels*n_timepoints)的2D数组。
[7]:
motions_test, motions_test_labels = load_basic_motions(split="test")
motions2d = motions.reshape(motions.shape[0], motions.shape[1] * motions.shape[2])
motions2d_test = motions_test.reshape(
motions_test.shape[0], motions_test.shape[1] * motions_test.shape[2]
)
rand_forest.fit(motions2d, motions_labels)
y_pred = rand_forest.predict(motions2d_test)
accuracy_score(motions_test_labels, y_pred)
[7]:
0.925
然而,许多aeon分类器,包括ROCKET和HC2,都被配置为处理多变量输入。这与单变量分类的工作方式完全相同。例如:
[8]:
rocket.fit(motions, motions_labels)
y_pred = rocket.predict(motions_test)
accuracy_score(motions_test_labels, y_pred)
[8]:
1.0
可以使用此代码获取能够处理多元分类的分类器列表
[9]:
from aeon.utils.discovery import all_estimators
all_estimators(
tag_filter={"capability:multivariate": True},
type_filter="classifier",
)
[9]:
[('Arsenal', aeon.classification.convolution_based._arsenal.Arsenal),
('CNNClassifier', aeon.classification.deep_learning.cnn.CNNClassifier),
('CanonicalIntervalForestClassifier',
aeon.classification.interval_based._cif.CanonicalIntervalForestClassifier),
('Catch22Classifier',
aeon.classification.feature_based._catch22.Catch22Classifier),
('ChannelEnsembleClassifier',
aeon.classification.compose._channel_ensemble.ChannelEnsembleClassifier),
('DrCIFClassifier',
aeon.classification.interval_based._drcif.DrCIFClassifier),
('DummyClassifier', aeon.classification._dummy.DummyClassifier),
('ElasticEnsemble',
aeon.classification.distance_based._elastic_ensemble.ElasticEnsemble),
('EncoderClassifier',
aeon.classification.deep_learning.encoder.EncoderClassifier),
('FCNClassifier', aeon.classification.deep_learning.fcn.FCNClassifier),
('FreshPRINCEClassifier',
aeon.classification.feature_based._fresh_prince.FreshPRINCEClassifier),
('HIVECOTEV2', aeon.classification.hybrid._hivecote_v2.HIVECOTEV2),
('InceptionTimeClassifier',
aeon.classification.deep_learning.inception_time.InceptionTimeClassifier),
('IndividualInceptionClassifier',
aeon.classification.deep_learning.inception_time.IndividualInceptionClassifier),
('IndividualOrdinalTDE',
aeon.classification.ordinal_classification._ordinal_tde.IndividualOrdinalTDE),
('IndividualTDE', aeon.classification.dictionary_based._tde.IndividualTDE),
('IntervalForestClassifier',
aeon.classification.interval_based._interval_forest.IntervalForestClassifier),
('KNeighborsTimeSeriesClassifier',
aeon.classification.distance_based._time_series_neighbors.KNeighborsTimeSeriesClassifier),
('MLPClassifier', aeon.classification.deep_learning.mlp.MLPClassifier),
('MUSE', aeon.classification.dictionary_based._muse.MUSE),
('OrdinalTDE',
aeon.classification.ordinal_classification._ordinal_tde.OrdinalTDE),
('RDSTClassifier', aeon.classification.shapelet_based._rdst.RDSTClassifier),
('RSTSF', aeon.classification.interval_based._rstsf.RSTSF),
('RandomIntervalClassifier',
aeon.classification.interval_based._interval_pipelines.RandomIntervalClassifier),
('RandomIntervalSpectralEnsembleClassifier',
aeon.classification.interval_based._rise.RandomIntervalSpectralEnsembleClassifier),
('ResNetClassifier',
aeon.classification.deep_learning.resnet.ResNetClassifier),
('RocketClassifier',
aeon.classification.convolution_based._rocket_classifier.RocketClassifier),
('ShapeletTransformClassifier',
aeon.classification.shapelet_based._stc.ShapeletTransformClassifier),
('SignatureClassifier',
aeon.classification.feature_based._signature_classifier.SignatureClassifier),
('SummaryClassifier',
aeon.classification.feature_based._summary_classifier.SummaryClassifier),
('SupervisedIntervalClassifier',
aeon.classification.interval_based._interval_pipelines.SupervisedIntervalClassifier),
('SupervisedTimeSeriesForest',
aeon.classification.interval_based._stsf.SupervisedTimeSeriesForest),
('TSFreshClassifier',
aeon.classification.feature_based._tsfresh_classifier.TSFreshClassifier),
('TapNetClassifier',
aeon.classification.deep_learning.tapnet.TapNetClassifier),
('TemporalDictionaryEnsemble',
aeon.classification.dictionary_based._tde.TemporalDictionaryEnsemble),
('TimeSeriesForestClassifier',
aeon.classification.interval_based._tsf.TimeSeriesForestClassifier)]
MTSC 的另一种方法是在每个通道上构建一个单变量分类器,然后进行集成。通道集成可以通过 ClassifierChannelEnsemble 轻松完成,它独立地将分类器拟合到指定的通道,然后通过投票方案组合预测。下面的示例在第一个通道上构建了一个 DrCIF 分类器,并在第四和第五维度上构建了一个 RocketClassifier,忽略了第二、第三和第六维度。
[10]:
from aeon.classification.compose import ClassifierChannelEnsemble
from aeon.classification.interval_based import DrCIFClassifier
cls = ClassifierChannelEnsemble(
classifiers=[
("DrCIF0", DrCIFClassifier(n_estimators=5, n_intervals=2)),
("ROCKET3", RocketClassifier(n_kernels=1000)),
],
channels=[[0], [3, 4]],
)
cls.fit(motions, motions_labels)
y_pred = cls.predict(motions_test)
accuracy_score(motions_test_labels, y_pred)
[10]:
0.925
sklearn 兼容性¶
aeon 分类器与使用 aeon 数据格式的 sklearn 模型选择和组合工具兼容。例如,可以使用 sklearn 的 cross_val_score 和 KFold 功能进行交叉验证:
[11]:
from sklearn.model_selection import KFold, cross_val_score
cross_val_score(rocket, arrow, y=arrow_labels, cv=KFold(n_splits=4))
[11]:
array([0.88888889, 0.66666667, 0.88888889, 0.77777778])
参数调优可以使用sklearn GridSearchCV来完成。例如,我们可以为K-NN分类器调整k和距离度量:
[12]:
from sklearn.model_selection import GridSearchCV
from aeon.classification.distance_based import KNeighborsTimeSeriesClassifier
knn = KNeighborsTimeSeriesClassifier()
param_grid = {"n_neighbors": [1, 5], "distance": ["euclidean", "dtw"]}
parameter_tuning_method = GridSearchCV(knn, param_grid, cv=KFold(n_splits=4))
parameter_tuning_method.fit(arrow, arrow_labels)
y_pred = parameter_tuning_method.predict(arrow_test)
accuracy_score(arrow_test_labels, y_pred)
[12]:
0.8
概率校准可以通过sklearn的CalibratedClassifierCV实现:
[13]:
from sklearn.calibration import CalibratedClassifierCV
from aeon.classification.interval_based import DrCIFClassifier
calibrated_drcif = CalibratedClassifierCV(
estimator=DrCIFClassifier(n_estimators=10, n_intervals=5), cv=4
)
calibrated_drcif.fit(arrow, arrow_labels)
y_pred = calibrated_drcif.predict(arrow_test)
accuracy_score(arrow_test_labels, y_pred)
[13]:
0.7714285714285715
此处使用的分类器的背景信息和参考文献¶
KNeighborsTimeSeries分类器¶
使用动态时间规整(DTW)的最近邻(1-NN)分类是一种基于距离的分类器,也是最常用的方法之一,尽管其平均准确率低于最先进的技术。
RocketClassifier¶
RocketClassifier 是一个基于卷积的分类器,由ROCKET变换(transformations.panel.rocket)和sklearn的RidgeClassifierCV分类器组成的管道组合而成。RocketClassifier可配置为使用MiniRocket和MultiRocket变体。ROCKET基于生成随机卷积核。生成大量卷积核后,在其输出上构建线性分类器。
[1] Dempster, Angus, François Petitjean, 和 Geoffrey I. Webb. “Rocket: 使用随机卷积核进行异常快速和准确的时间序列分类。” 数据挖掘与知识发现 (2020) arXiv 版本 DAMI 2020
DrCIF¶
多样化表示规范区间森林分类器(DrCIF)是一种基于区间的分类器。该算法从每个系列中提取多个随机区间,并提取一系列特征。这些特征用于构建决策树,进而以随机森林的方式集成到决策树森林中。
原始CIF分类器:[2] Matthew Middlehurst、James Large和Anthony Bagnall。“用于时间序列分类的规范区间森林(CIF)分类器。”IEEE国际大数据会议(2020)arXiv版本 IEEE BigData (2020)
DrCIF调整在[3]中被提出。
HIVE-COTE 2.0 (HC2)¶
基于转换的层次投票集体集成是一种元集成混合,它结合了基于不同表示构建的分类器。版本2结合了DrCIF、TDE、称为Arsenal的RocketClassifiers集成以及ShapeletTransformClassifier。它是UCR和UEA时间序列档案中最准确的分类器之一。
[3] Middlehurst, Matthew, James Large, Michael Flynn, Jason Lines, Aaron Bostrom, 和 Anthony Bagnall. “HIVE-COTE 2.0: 时间序列分类的新元集成。” 机器学习 (2021) ML 2021