AutoGen Studio: 使用多个代理解决任务,生成带有图像的PDF文档。
TL;DR
为了帮助你快速为任务构建多智能体解决方案的原型,我们引入了由 AutoGen 驱动的 AutoGen Studio 界面。它允许你:
- 通过点击和拖放的界面,声明式地定义和修改代理和多代理工作流程(例如,你可以选择两个将进行通信以解决你任务的代理的参数)。
- 使用我们的UI与指定代理创建聊天会话并查看结果(例如,查看聊天记录、生成的文件和所用时间)。
- 明确地为您的代理添加技能,并完成更多任务。
- 将您的会话发布到本地画廊。
详情请参阅官方AutoGen Studio文档 这里。
AutoGen Studio 是开源的 代码在这里,可以通过 pip 安装。试试看吧!
pip install autogenstudio
技术的加速发展引领我们进入了一个数字助手(或代理)逐渐成为我们生活中不可或缺部分的时代。AutoGen作为一个编排代理能力的领先框架已经崭露头角。本着扩展这一前沿并普及这一能力的精神,我们非常兴奋地推出一个新的用户友好界面:AutoGen Studio。
使用AutoGen Studio,用户可以快速创建、管理和与能够学习、适应和协作的代理进行交互。当我们向开源社区发布此界面时,我们的目标不仅是提高生产力,还要激发人类与代理之间的个性化互动水平。
注意: AutoGen Studio旨在帮助您快速原型化多代理工作流,并展示使用AutoGen构建的终端用户界面示例。它并不打算成为一个生产就绪的应用程序。
开始使用 AutoGen Studio
以下指南将帮助您在您的系统上启动并运行AutoGen Studio。
配置LLM供应商
要开始使用,你需要访问一个语言模型。你可以按照AutoGen文档此处的步骤进行设置。使用OPENAI_API_KEY或AZURE_OPENAI_API_KEY配置你的环境。
例如,在终端中,你可以像这样设置API密钥:
export OPENAI_API_KEY=<your_api_key>
你也可以直接在代理的配置中指定模型,如下所示。
llm_config = LLMConfig(
config_list=[{
"model": "gpt-4",
"api_key": "<azure_api_key>",
"base_url": "<azure api base url>",
"api_type": "azure",
"api_version": "2024-02-01"
}],
temperature=0,
)
有两种安装AutoGen Studio的方式——通过PyPi或从源代码安装。除非你计划修改源代码,否则我们推荐通过PyPi安装。
-
从PyPi安装
我们建议使用虚拟环境(例如conda)以避免与现有的Python包冲突。在您的虚拟环境中激活Python 3.10或更新版本后,使用pip安装AutoGen Studio:
pip install autogenstudio
-
从源代码安装
注意:此方法需要对在React中构建界面有一定的了解。
如果您更喜欢从源代码安装,请确保您已安装Python 3.10+和Node.js(版本高于14.15.0)。以下是您开始的方法:
对于Windows用户,要构建前端,您可能需要autogen studio readme中提供的替代命令。
运行应用程序
安装完成后,通过终端输入以下命令来运行web UI:
autogenstudio ui --port 8081
这将在指定的端口上启动应用程序。打开您的网页浏览器并访问http://localhost:8081/以开始使用AutoGen Studio。
现在你已经安装并运行了AutoGen Studio,你可以开始探索它的功能,包括定义和修改代理工作流、与代理和会话进行交互,以及扩展代理技能。
AutoGen Studio能做什么?
AutoGen Studio 的用户界面分为三个主要部分 - 构建, 游乐场, 和 画廊.
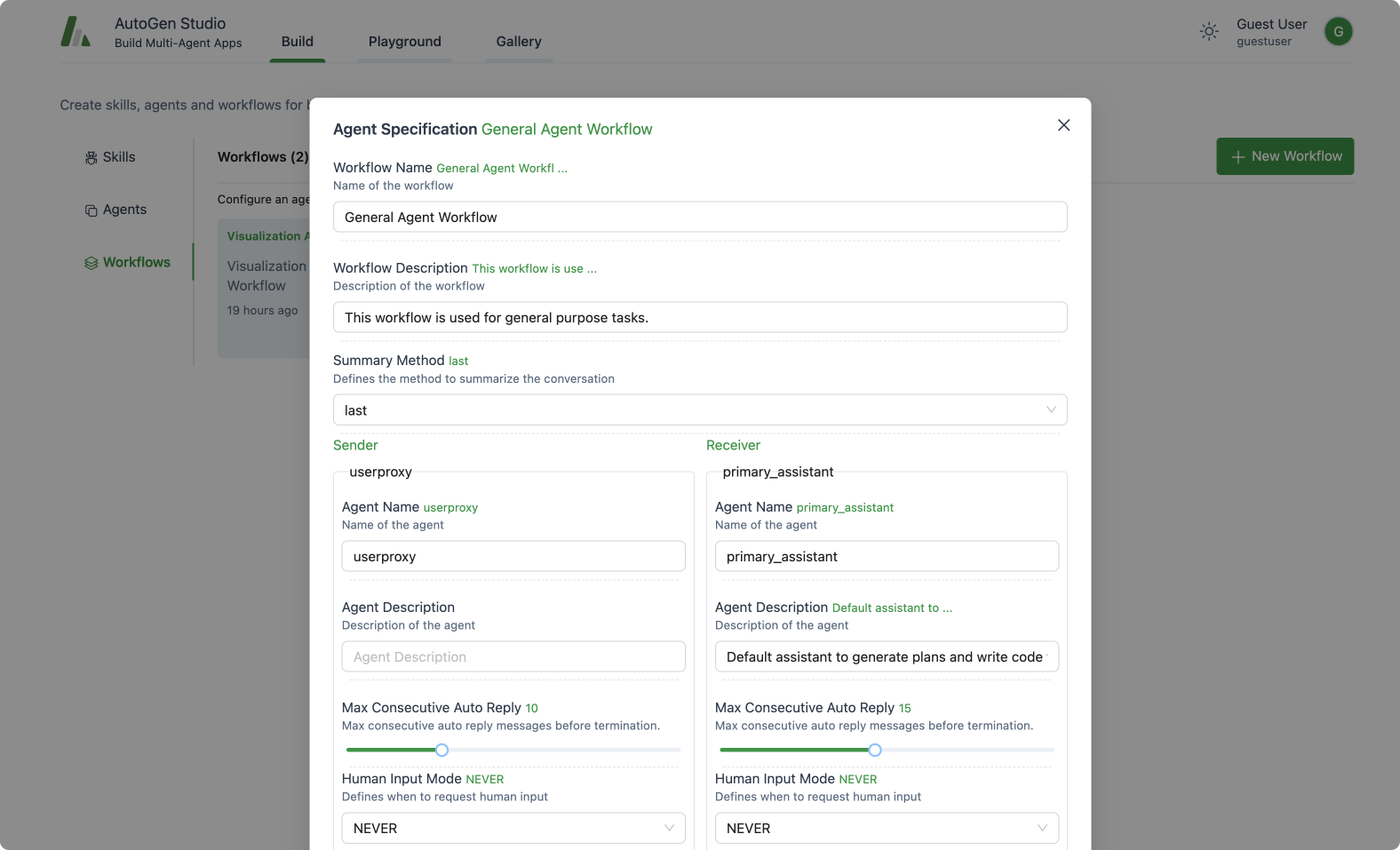
本节重点介绍定义代理和代理工作流的属性。它包括以下概念:
技能: 技能是指用于描述如何解决任务的函数(例如Python函数)。通常,一个好的技能应具有描述性名称(如generate_images)、详细的文档字符串和良好的默认设置(例如将文件写入磁盘以实现持久化和重用)。你可以通过提供的用户界面将新技能添加到AutoGen Studio中。在推理时,这些技能将被提供给助手代理,以帮助你完成任务。
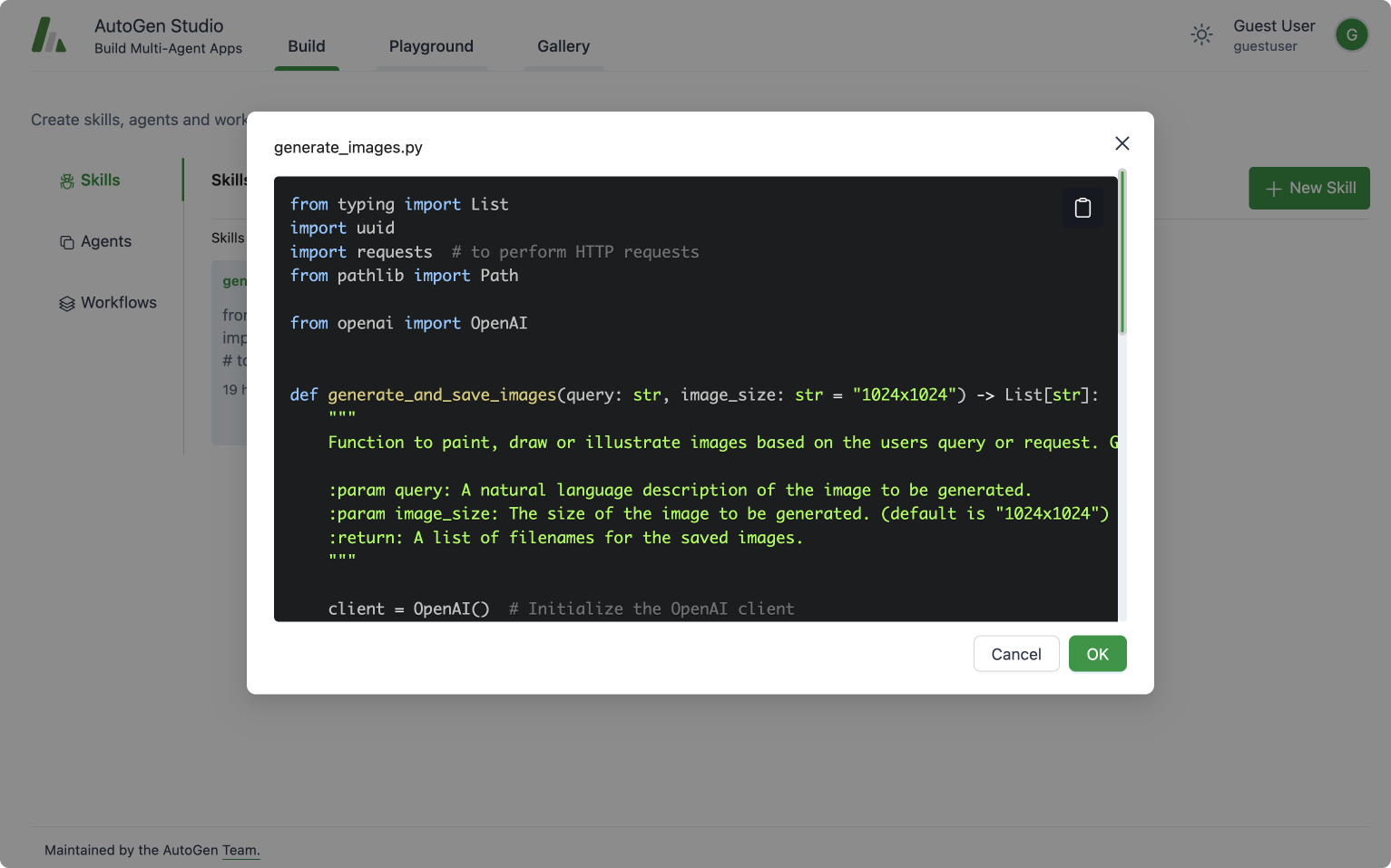
AutoGen Studio 构建视图:查看、添加或编辑代理在解决任务时可以使用的技能。
代理: 这提供了一个接口,用于以声明方式指定一个autogen代理的属性(反映了大多数基础AutoGen conversable agent类的成员)。
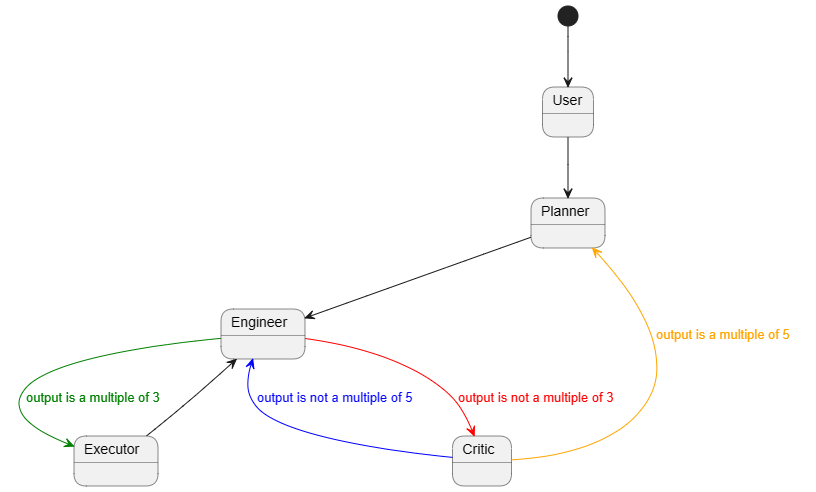
代理工作流: 代理工作流是一组代理协同工作以完成任务的一种规范。最简单的版本是由两个代理组成的设置——一个用户代理(代表用户,即它编译代码并打印结果)和一个可以处理任务请求的助手(例如,生成计划、编写代码、评估响应、提出错误恢复步骤等)。更复杂的流程可能是一个群聊,其中更多的代理共同寻求解决方案。
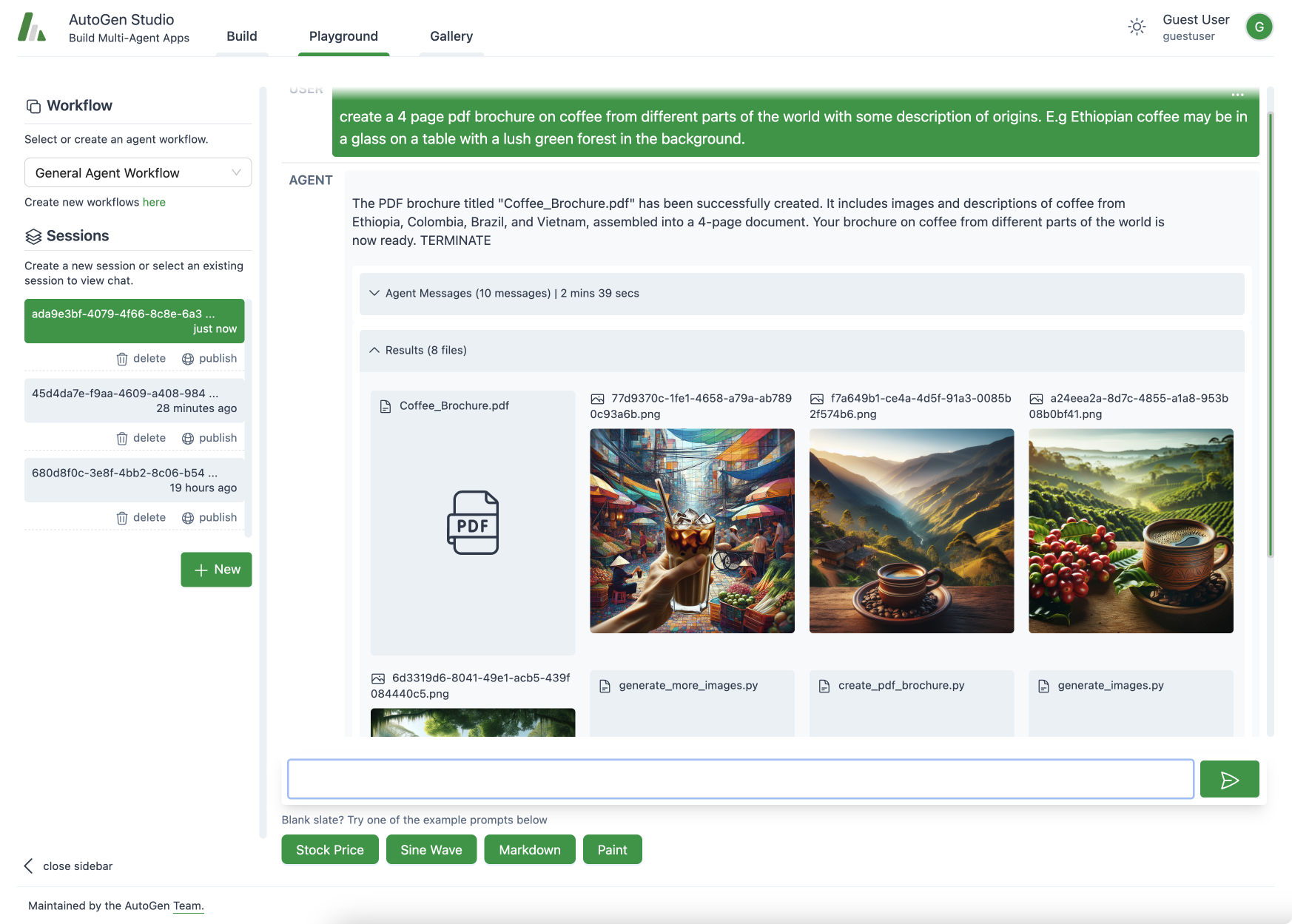
Playground
AutoGen Studio 游乐场视图:代理协作,使用可用技能(生成图像的能力)来处理用户任务(生成PDF文件)。
playground部分专注于交互之前build部分定义的代理工作流。它包含以下概念:
会话: 会话指的是与代理工作流程的持续互动或参与的一段时间,通常以一系列旨在实现特定目标的活动或操作为特征。它包括代理工作流程配置、用户与代理之间的互动。会话可以“发布”到“画廊”。
聊天视图: 聊天是用户和代理之间的一系列交互。它是会话的一部分。
本节重点介绍分享和重用工件(例如,工作流配置、会话等)。
AutoGen Studio 配备了3个示例技能:fetch_profile, find_papers, generate_images。请随意查看仓库以了解更多关于它们如何工作的信息。
AutoGen Studio API
虽然AutoGen Studio是一个Web界面,但它由一个底层Python API驱动,该API是可重用和模块化的。重要的是,我们实现了一个API,其中可以以声明方式(使用JSON)指定、加载和运行代理工作流。下面显示了当前API的一个示例。更多详情请参阅AutoGen Studio仓库。
import json
from autogenstudio import AutoGenWorkFlowManager, AgentWorkFlowConfig
agent_spec = json.load(open('agent_spec.json'))
agent_work_flow_config = FlowConfig(**agent_spec)
agent_work_flow = AutoGenWorkFlowManager(agent_work_flow_config)
task_query = "What is the height of the Eiffel Tower?"
agent_work_flow.run(message=task_query)
路线图和下一步
随着我们继续开发和优化AutoGen Studio,以下路线图概述了未来版本计划的一系列增强功能和新特性。用户可以期待以下内容:
- 复杂代理工作流程:我们正在努力集成对更复杂代理工作流程的支持,例如
GroupChat,允许多个代理之间进行更丰富的交互或动态拓扑结构。
- 改进的用户体验: 这包括流式传输中间模型输出以提供实时反馈、更好地总结代理响应、每次互动的成本信息等功能。我们还将投资于改进代理组合和重用工作流程。我们还将探索支持更多交互式的人在内的循环反馈给代理。
- 扩展代理技能:我们将努力改进编写、组合和重用代理技能的工作流程。
- 社区功能:在AutoGen Studio用户社区内促进分享和协作是一个关键目标。我们正在探索如何更轻松地在用户之间分享会话和结果,并为共享的技能、代理和代理工作流库做出贡献。
贡献指南
我们欢迎对AutoGen Studio的贡献。我们建议按照以下一般步骤来为项目做出贡献:
- 查看AutoGen项目的整体贡献指南。
- 请查阅 AutoGen Studio 的路线图,了解项目的当前优先级。特别是带有
help-wanted标签的 Studio 问题,您的帮助将非常感激。
- 请在路线图问题或新问题上发起讨论,以讨论您提出的贡献。
- 请查看此处的 autogenstudio 开发分支 [dev branch] (https://github.com/microsoft/autogen/tree/autogenstudio),并将其作为您贡献的基础。这样,您的贡献将与 AutoGen Studio 项目的最新更改保持一致。
- 提交一个包含您贡献的拉取请求!
- 如果你在VSCode中修改AutoGen Studio,它有自己的devcontainer来简化开发工作。请参阅
.devcontainer/README.md中的使用说明。
- 请使用标签
studio 来处理与 Studio 相关的任何问题、疑问和 PR。
常见问题解答
问:我可以在哪里调整默认的技能、代理和工作流配置?
答:您可以直接通过UI修改代理配置,或者通过编辑autogentstudio/utils/dbdefaults.json文件来初始化数据库。
问:如果我想重置与代理的整个对话,我该怎么做?
答:要重置您的对话历史记录,您可以删除database.sqlite文件。如果您需要清除用户特定的数据,请删除相关的autogenstudio/web/files/user/<user_id_md5hash>文件夹。
问:是否可以查看代理在交互过程中生成的输出和消息?
答:是的,您可以在Web UI的调试控制台中查看生成的消息,以了解代理之间的交互情况。或者,您可以检查database.sqlite文件以获取消息的完整记录。
问:在哪里可以找到AutoGen Studio的文档和支持?
答:我们不断努力改进AutoGen Studio。有关最新更新,请参阅AutoGen Studio自述文件。如需更多支持,请在GitHub上提交问题或在Discord上提问。
问:我可以在AutoGen Studio中使用其他模型吗?
是的。AutoGen 标准化了 openai 模型 api 格式,你可以使用任何提供 openai 兼容端点的 api 服务器。在 AutoGen Studio 用户界面中,每个代理都有一个 llm_config 字段,你可以在其中输入模型端点的详细信息,包括 模型名称、api 密钥、基础 URL、模型类型 和 api 版本。对于 Azure OpenAI 模型,你可以在 Azure 门户中找到这些详细信息。需要注意的是,对于 Azure OpenAI,模型名称 是部署 ID 或引擎,模型类型 是 "azure"。
对于其他开源模型,我们建议使用像 vllm 这样的服务器来实例化一个 openai 兼容的端点。
问:服务器启动但我无法访问界面
答:如果您在远程机器上运行服务器(或本地机器无法正确解析localhost),则可能需要指定主机地址。默认情况下,主机地址设置为localhost。您可以使用--host <host>参数指定主机地址。例如,要在端口8081和本地地址上启动服务器,以便可以从网络上的其他机器访问,您可以运行以下命令:
autogenstudio ui --port 8081 --host 0.0.0.0