简要说明:
- 介绍EcoAssistant,它旨在更准确、更经济地解决用户查询。
- 我们展示了如何让LLM助手代理利用外部API来解决用户查询。
- 我们展示了如何通过Assistant Hierarchy降低使用GPT模型的成本。
- 我们展示了如何通过解决方案演示利用检索增强生成(RAG)的概念来提高成功率。
EcoAssistant
在本博客中,我们介绍了EcoAssistant,这是一个基于AutoGen的系统,旨在更准确和经济地解决用户查询问题。
问题设置
最近,用户一直在使用像ChatGPT这样的会话式大语言模型(LLMs)进行各种查询。 报告显示,23%的ChatGPT用户查询是为了知识提取的目的。 这些查询中有许多需要的信息超出了任何预训练大语言模型(LLMs)内部存储的信息范围。 这些任务只能通过生成代码来从包含所需信息的外部API中获取必要信息来完成。 在下面的表格中,我们展示了我们在这项工作中旨在解决的三类用户查询。
| 数据集 | API | 示例查询 |
|---|---|---|
| 地点 | Google Places | 我在蒙特利尔找一家24小时营业的药店,你能帮我找一家吗? |
| 天气 | Weather API | 印度孟买当前的云覆盖率是多少? |
| 股票 | Alpha Vantage 股票 API | 你能给我微软2023年1月份的开盘价吗? |
利用外部API
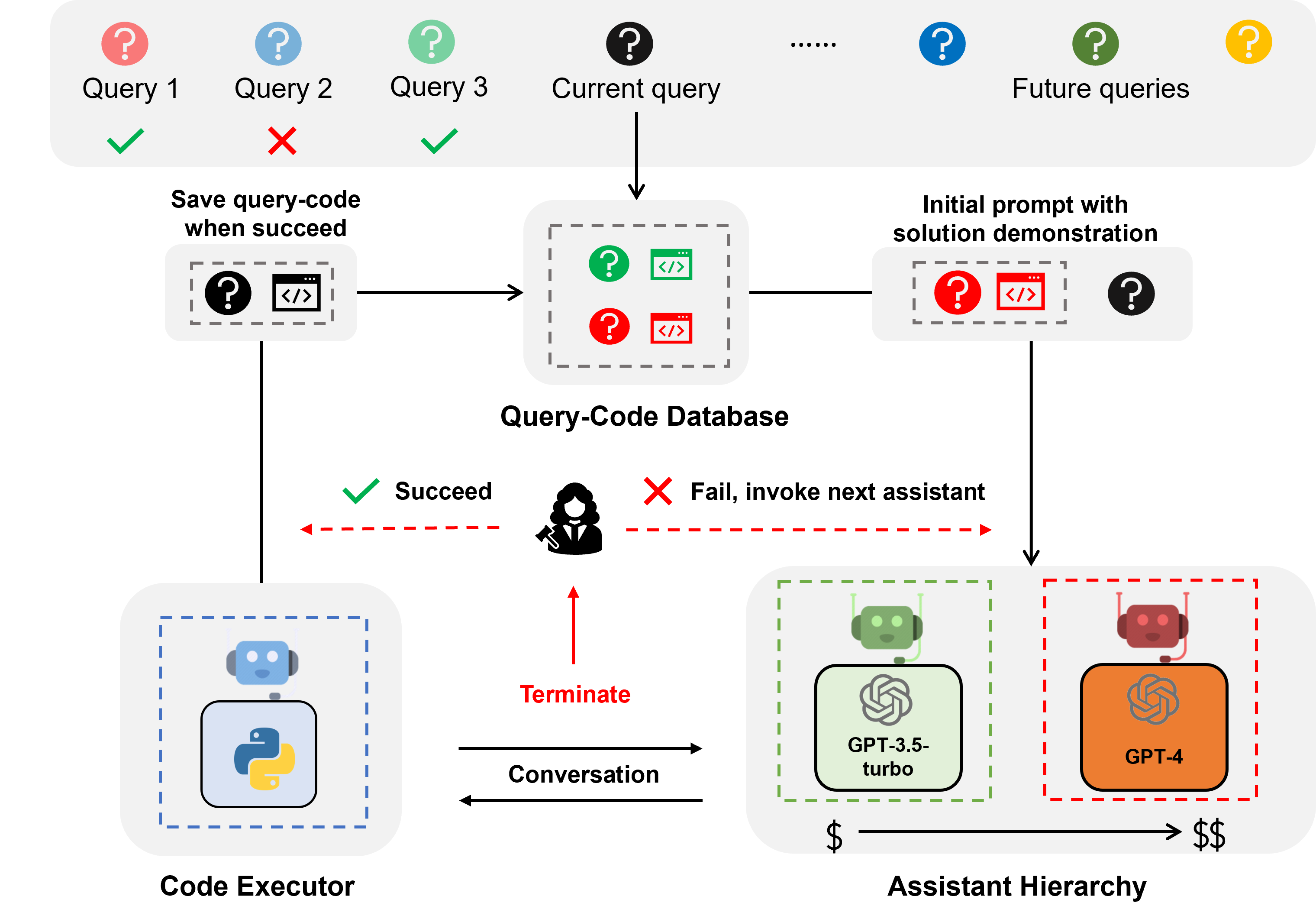
为了解决这些问题,我们首先构建了一个基于AutoGen的双代理系统,其中第一个代理是一个LLM辅助代理(在AutoGen中的AssistantAgent),负责提出和优化代码,第二个代理是一个代码执行代理(在AutoGen中的UserProxyAgent),它会提取生成的代码并执行,将输出结果反馈给LLM辅助代理。下图展示了一个双代理系统的可视化。
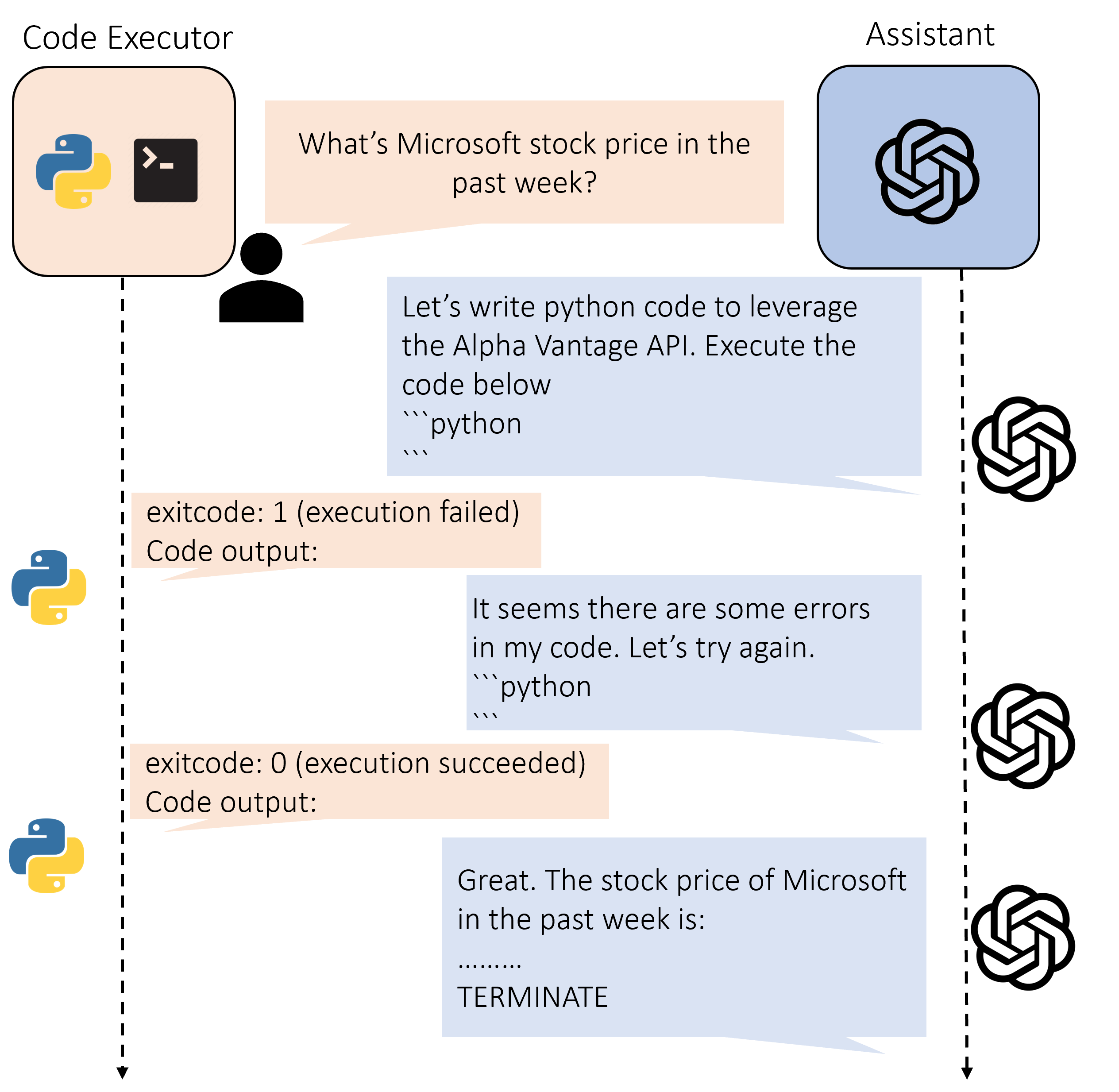
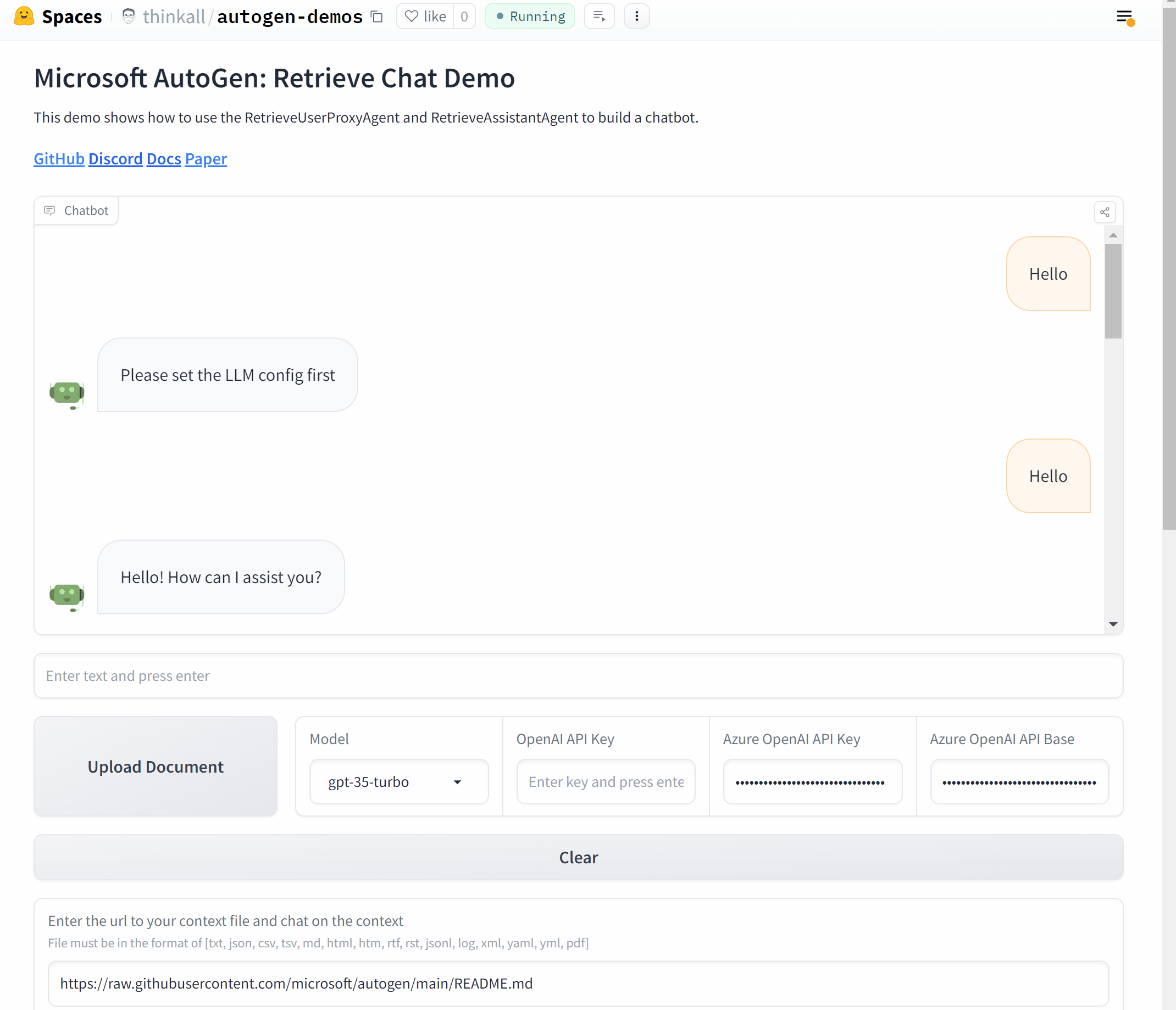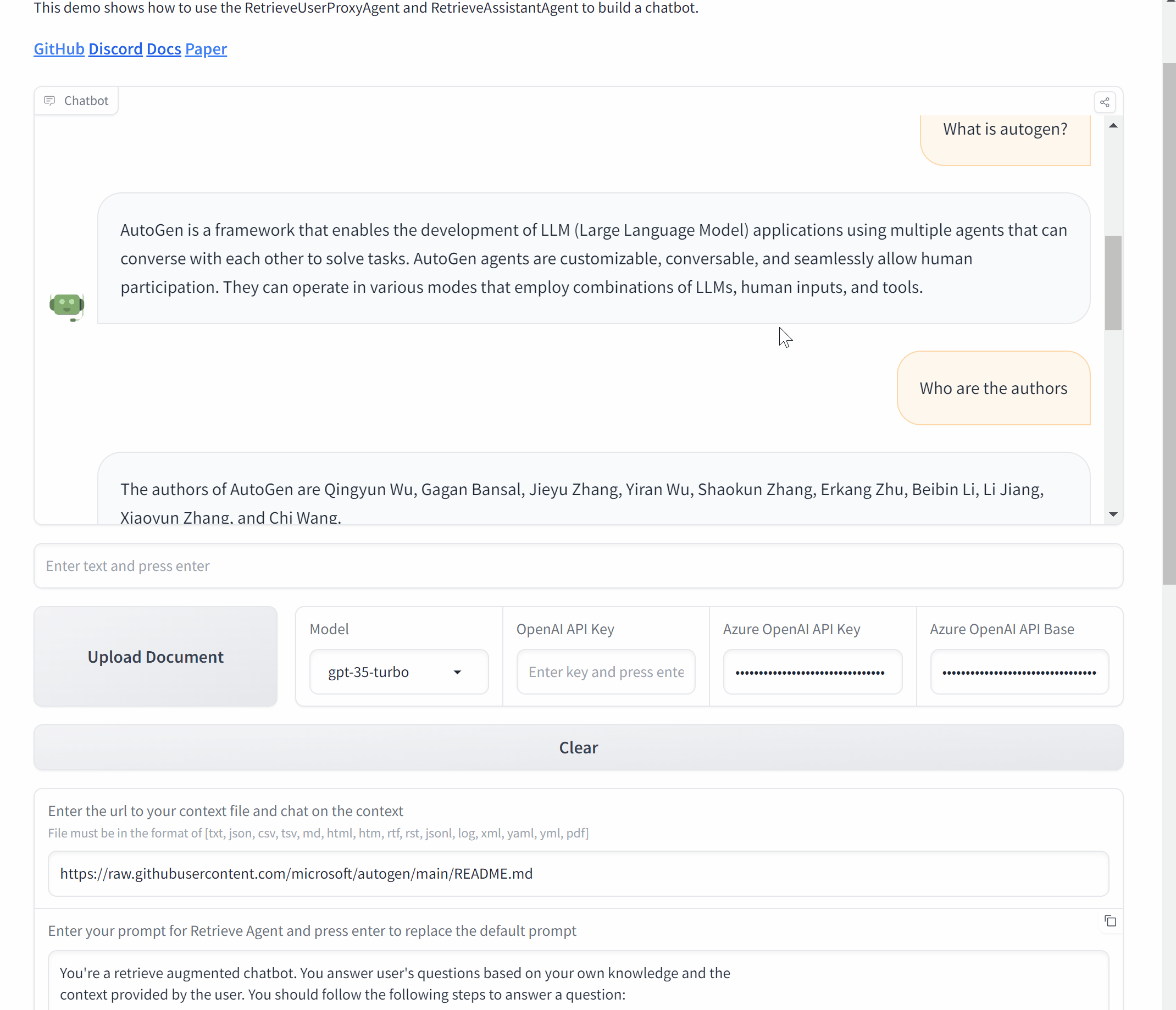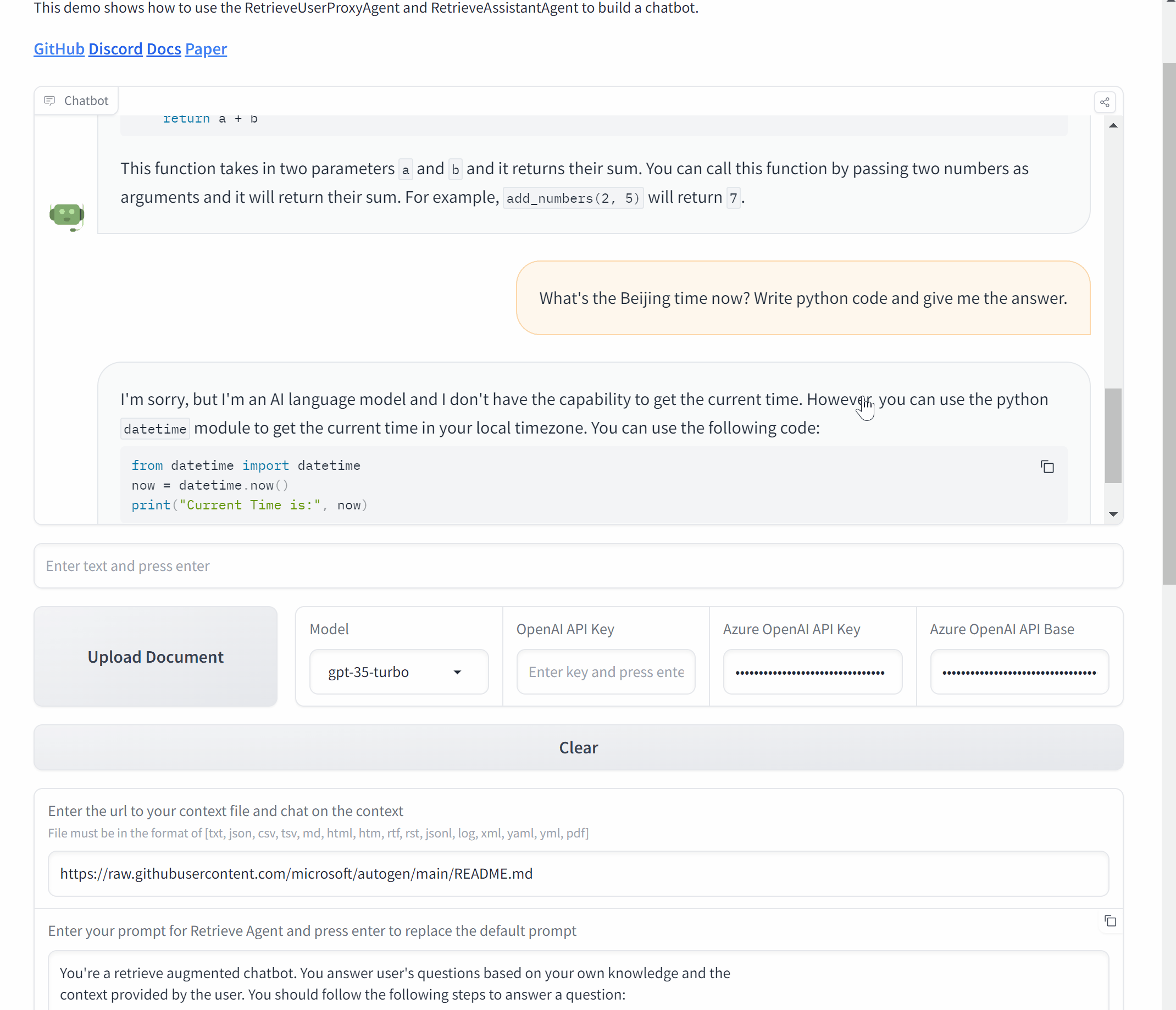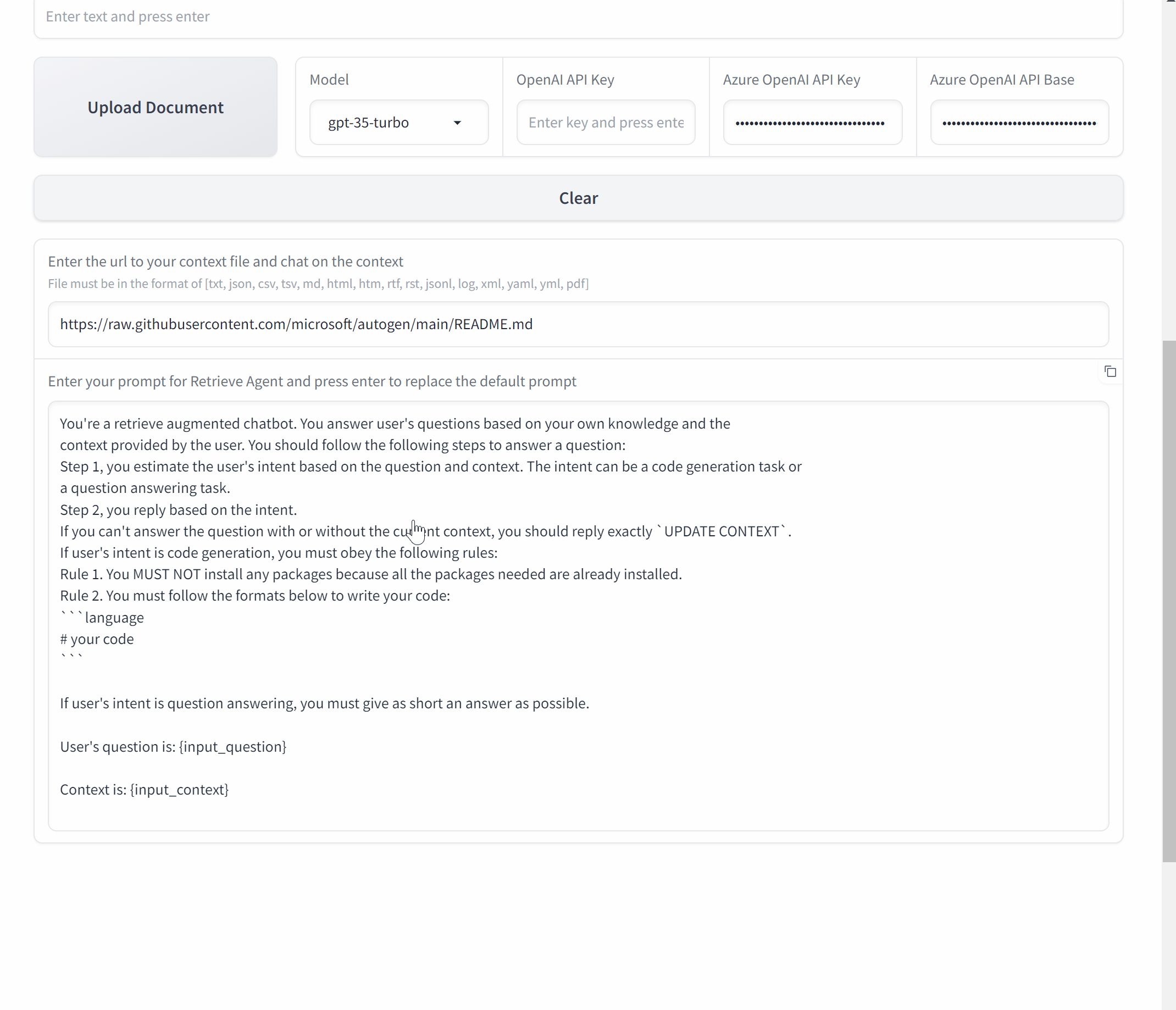
要指示助手代理利用外部API,我们只需在初始消息的开头添加API名称/密钥字典。 模板如下所示,其中红色部分是API的信息,黑色部分是用户查询。

重要的是,出于安全考虑,我们不想向助手代理透露我们的真实API密钥。
因此,我们在初始消息中使用假的API密钥来替换真实的API密钥。
具体来说,我们为每个API密钥生成一个随机令牌(例如,181dbb37),并在初始消息中用该令牌替换真实的API密钥。
然后,当代码执行器执行代码时,假的API密钥会自动被真实API密钥替换。
解决方案演示
在大多数实际场景中,用户的查询会随着时间的推移依次出现。我们的EcoAssistant利用过去的成功经验,通过解决方案演示帮助LLM助手处理未来的查询。具体来说,每当用户的反馈表明查询已成功解决时,我们就会捕获并存储该查询及其最终生成的代码片段。这些查询-代码对保存在专门的向量数据库中。当新的查询出现时,EcoAssistant会从数据库中检索出最相似的查询,并将其关联的代码附加到新查询的初始提示中,作为演示。新的初始消息模板如下所示,其中蓝色部分对应于解决方案演示。

我们发现,利用过去成功的查询代码对,可以在较少的迭代中改进查询解析过程,并提高系统的性能。
助手层级
LLMs通常具有不同的价格和性能,例如,GPT-3.5-turbo比GPT-4便宜很多,但准确性也较低。因此,我们提出了助理层次结构来降低使用LLMs的成本。核心思想是我们首先使用较便宜的LLMs,仅在必要时使用更昂贵的LLMs。通过这种方式,我们能够减少对昂贵LLMs的依赖,从而降低成本。特别是,给定多个LLMs,我们为每个LLMs初始化一个助理代理,并从最具成本效益的LLM助理开始对话。如果当前LLM助理与代码执行器之间的对话未能成功解决查询,EcoAssistant将会在层次结构中重新启动与下一个更昂贵的LLM助理的对话。我们发现,这种策略在有效解决查询的同时显著降低了成本。
协同效应
我们发现Assistant Hierarchy和Solution Demonstration在EcoAssistant中具有协同效应。 因为所有LLM助手共享查询代码数据库,即使没有专门设计, 来自更强大的LLM助手(例如,GPT-4)的解决方案也可以后来检索以指导较弱的LLM助手(例如,GPT-3.5-turbo)。 这种协同效应进一步提高了性能并降低了EcoAssistant的成本。
实验结果
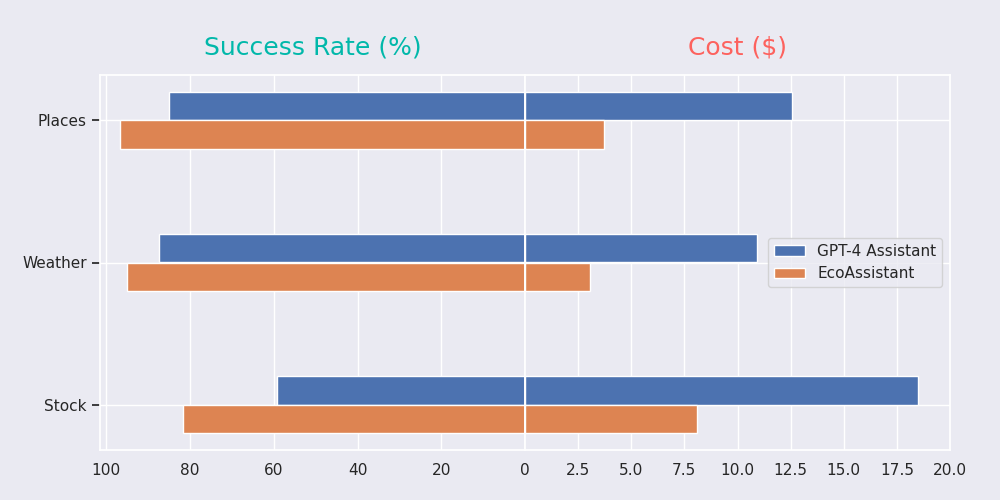
我们在三个数据集上评估了EcoAssistant:Places、Weather和Stock。当我们将其与单一的GPT-4助手进行比较时,我们发现EcoAssistant在成本更低的情况下实现了更高的成功率,如下图所示。 有关实验结果和其他实验的更多详细信息,请参阅我们的论文。
进一步阅读
请参阅我们的论文和代码库以获取有关EcoAssistant的更多详细信息。
如果你发现这个博客有用,请考虑引用:
@article{zhang2023ecoassistant,
title={EcoAssistant: Using LLM Assistant More Affordably and Accurately},
author={Zhang, Jieyu and Krishna, Ranjay and Awadallah, Ahmed H and Wang, Chi},
journal={arXiv preprint arXiv:2310.03046},
year={2023}
}