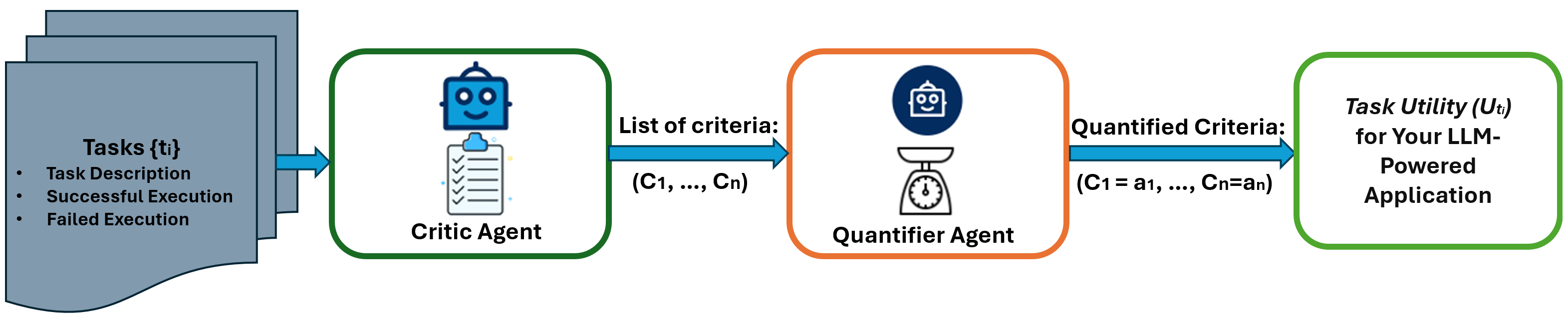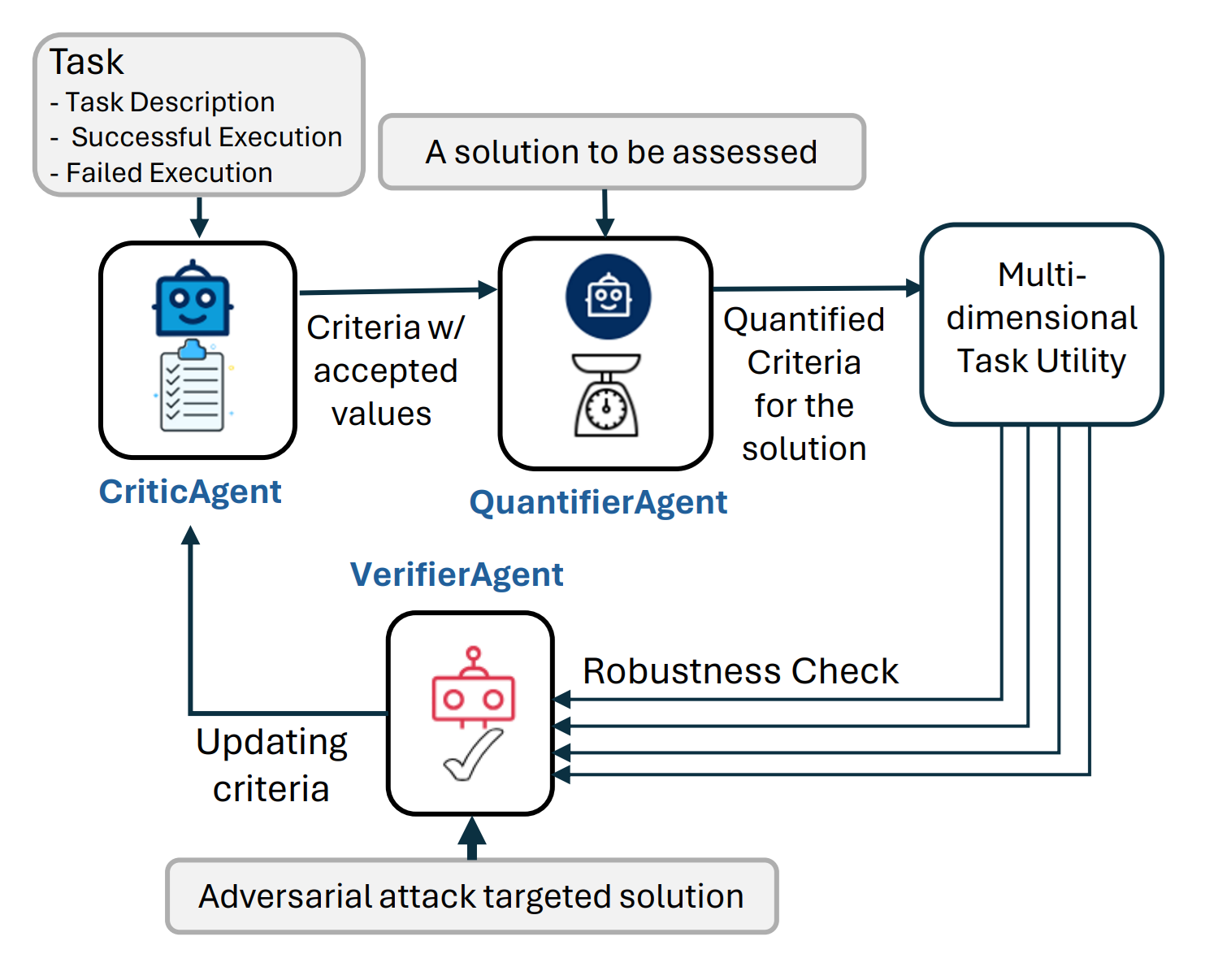
图1展示了AgentEval的一般流程,包括验证步骤
TL;DR:
- 作为一名开发者,如何评估一个基于LLM的应用程序在帮助终端用户完成任务方面的实用性和有效性?
- 为了阐明上述问题,我们之前引入了
AgentEval——一个评估任何LLM驱动的应用程序的多维度实用性的框架,旨在帮助用户完成特定任务。我们现在已将其嵌入到AutoGen库中,以便开发人员更容易采用。 - 在这里,我们介绍了一个更新版本的AgentEval,其中包括了一个验证过程,用于评估QuantifierAgent的鲁棒性。更多详细信息可以在这篇论文中找到。
介绍
之前介绍的 AgentEval 是一个全面的框架,旨在弥合评估由LLM驱动的应用程序效用的差距。它利用了LLM的最新进展,提供了一种可扩展且经济高效的替代方案,代替了传统的人工评估。该框架包括三个主要代理:CriticAgent、QuantifierAgent 和 VerifierAgent,每个代理在评估应用程序的任务效用中都扮演着关键角色。
CriticAgent: 定义标准
CriticAgent的主要功能是根据任务描述以及成功和失败执行的示例,为评估应用程序提出一套标准。例如,在一个数学辅导应用程序的背景下,CriticAgent可能会提出诸如效率、清晰度和正确性等标准。这些标准对于理解应用程序性能的各个方面至关重要。强烈建议应用程序开发者利用他们的领域专业知识来验证提出的标准。
QuantifierAgent:量化性能
一旦标准确定,QuantifierAgent将接管以量化应用程序在每个标准下的表现。此量化过程产生对应用程序效用的多维评估,提供其优缺点的详细视图。
验证器代理:确保鲁棒性和相关性
VerifierAgent确保用于评估效用的标准对最终用户有效,保持鲁棒性和高判别力。它通过两个主要操作来实现这一点:
-
标准稳定性:
- 确保标准是关键的、非冗余的,并且可以一致地衡量。
- 迭代生成和量化标准,消除冗余,并评估其稳定性。
- 仅保留最稳健的标准。
-
区分能力:
- 通过引入对抗性示例(噪声或受损数据)来测试系统的可靠性。
- 评估系统区分这些与标准案例的能力。
- 如果系统失败,这表明需要更好的标准来有效处理各种情况。
一个灵活且可扩展的框架
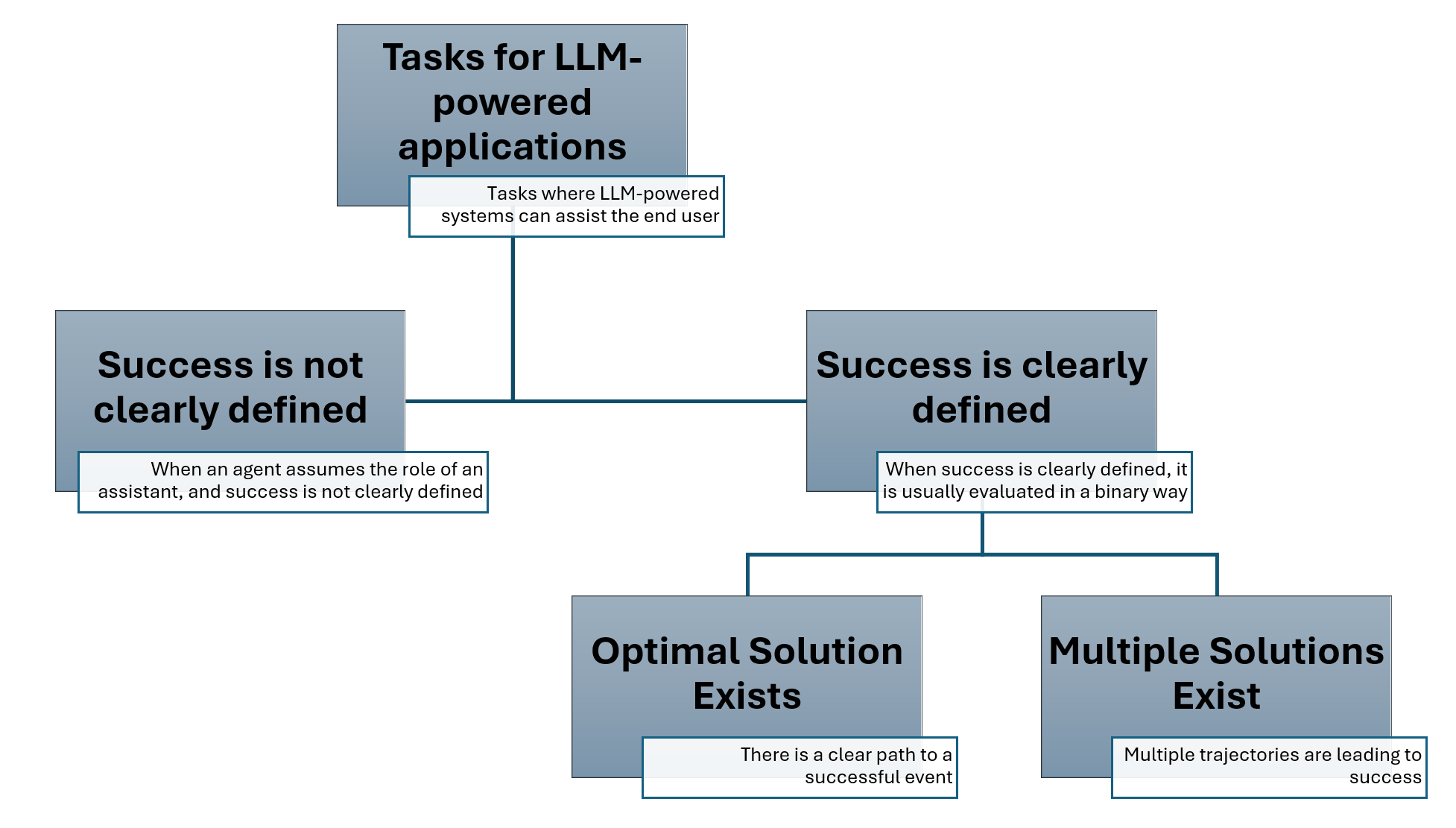
AgentEval 的一个关键优势是其灵活性。它可以应用于多种任务,无论这些任务的成功标准是否明确。对于具有明确定义的成功标准的任务,如家务,该框架可以评估是否存在多个成功的解决方案以及它们的比较情况。对于更开放的任务,如生成电子邮件模板,AgentEval 可以评估系统建议的实用性。
此外,AgentEval允许融入人类专业知识。领域专家可以通过建议相关标准或验证由代理识别的标准的有用性来参与评估过程。这种人在回路的方法确保评估基于实际的现实世界考虑。
实证验证
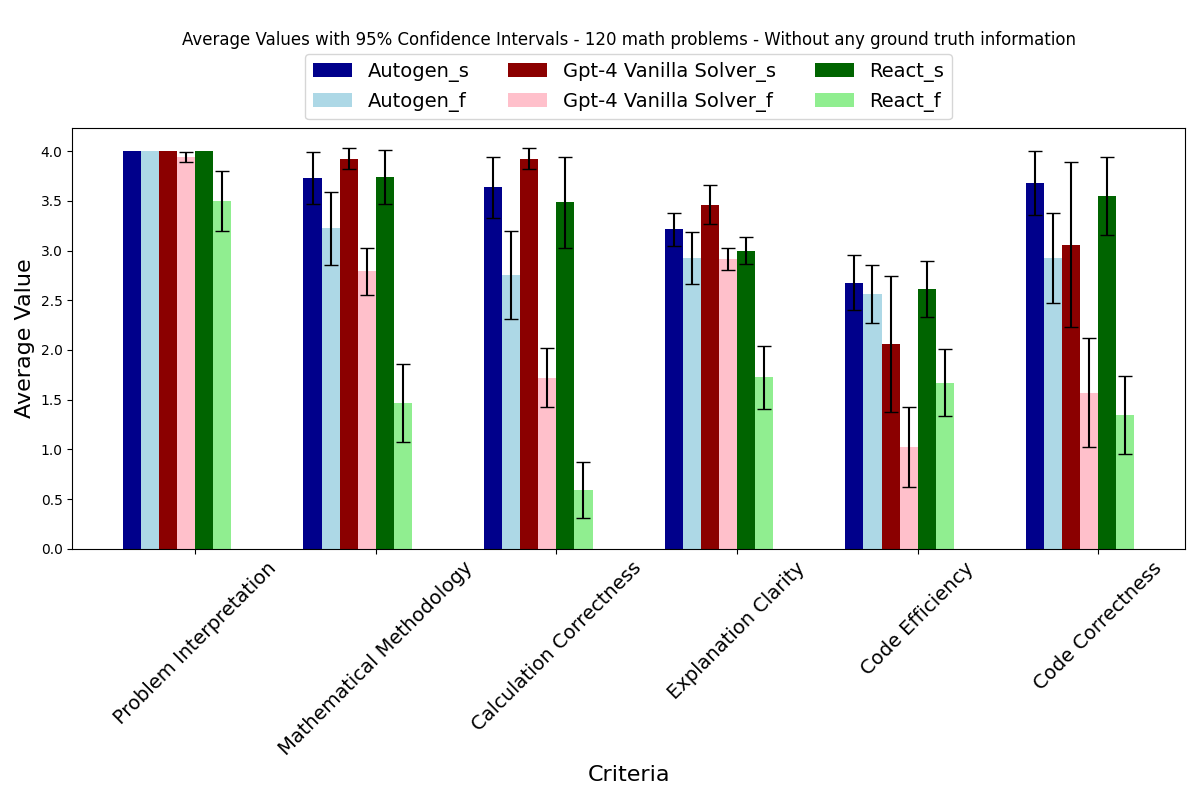
为了验证AgentEval,该框架在两个应用上进行了测试:数学问题解决和ALFWorld,一个家庭任务模拟。数学数据集包含12,500个具有挑战性的问题,每个问题都有逐步的解决方案,而ALFWorld数据集则涉及在模拟环境中的多轮交互。在这两种情况下,AgentEval成功识别了相关标准,量化了性能,并验证了评估的鲁棒性,展示了其有效性和多功能性。
如何使用 AgentEval
AgentEval 目前有两个主要阶段;标准生成和标准量化(标准验证仍在开发中)。这两个阶段都利用顺序的LLM驱动的代理来做出决定。
标准生成:
在评估标准生成过程中,AgentEval使用示例执行消息链来创建一组标准,用于量化应用程序在给定任务中的表现。
def generate_criteria(
llm_config: Optional[Union[Dict, Literal[False]]] = None,
task: Task = None,
additional_instructions: str = "",
max_round=2,
use_subcritic: bool = False,
)
参数:
- llm_config (dict or bool): llm推理配置。
- 任务 (Task): 要评估的任务。
- additional_instructions (str, 可选): 为criteria代理提供的额外指令。
- max_round (int, 可选): 运行对话的最大轮数。
- use_subcritic (bool, 可选): 是否使用Subcritic代理生成子标准。Subcritic代理会将生成的标准分解为更小的标准进行评估。
示例代码:
config_list = autogen.config_list_from_json("OAI_CONFIG_LIST")
task = Task(
**{
"name": "Math problem solving",
"description": "Given any question, the system needs to solve the problem as consisely and accurately as possible",
"successful_response": response_successful,
"failed_response": response_failed,
}
)
criteria = generate_criteria(task=task, llm_config={"config_list": config_list})
注意:任务对象只需要一个样本执行链(成功/失败),但AgentEval在每种情况都有示例时会表现得更好。
示例输出:
[
{
"name": "Accuracy",
"description": "The solution must be correct and adhere strictly to mathematical principles and techniques appropriate for the problem.",
"accepted_values": ["Correct", "Minor errors", "Major errors", "Incorrect"]
},
{
"name": "Conciseness",
"description": "The explanation and method provided should be direct and to the point, avoiding unnecessary steps or complexity.",
"accepted_values": ["Very concise", "Concise", "Somewhat verbose", "Verbose"]
},
{
"name": "Relevance",
"description": "The content of the response must be relevant to the question posed and should address the specific problem requirements.",
"accepted_values": ["Highly relevant", "Relevant", "Somewhat relevant", "Not relevant"]
}
]
标准量化:
在量化阶段,AgentEval 将使用生成的标准(或用户定义的标准)来评估给定的执行链,以确定应用程序的表现如何。
def quantify_criteria(
llm_config: Optional[Union[Dict, Literal[False]]],
criteria: List[Criterion],
task: Task,
test_case: str,
ground_truth: str,
)
参数:
- llm_config (dict or bool): llm推理配置。
- criteria (Criterion): 用于评估给定任务效用的一系列标准。这可以通过
generate_criteria函数生成或手动创建。 - 任务 (Task): 要评估的任务。它应该与在
generate_criteria步骤中使用的任务匹配。 - test_case (str): 用于评估的执行链。这通常是一个消息的json列表,但也可以是对话链的任何字符串表示。
- ground_truth (str): 测试用例的真实值。
示例代码:
test_case="""[
{
"content": "Find $24^{-1} \\pmod{11^2}$. That is, find the residue $b$ for which $24b \\equiv 1\\pmod{11^2}$.\n\nExpress your answer as an integer from $0$ to $11^2-1$, inclusive.",
"role": "user"
},
{
"content": "To find the modular inverse of 24 modulo 11^2, we can use the Extended Euclidean Algorithm. Here is a Python function to compute the modular inverse using this algorithm:\n\n```python\ndef mod_inverse(a, m):\n..."
"role": "assistant"
}
]"""
quantifier_output = quantify_criteria(
llm_config={"config_list": config_list},
criteria=criteria,
task=task,
test_case=test_case,
ground_truth="true",
)
输出将是一个包含真实值和每个标准到其得分映射的字典的json对象。
{
"actual_success": true,
"estimated_performance": {
"Accuracy": "Correct",
"Conciseness": "Concise",
"Relevance": "Highly relevant"
}
}
接下来是什么?
- 在AutoGen Studio中启用AgentEval以实现无代码解决方案。
- 在AgentEval框架中完全实现VerifierAgent。
结论
AgentEval代表了在评估LLM驱动应用程序方面的重大进步。通过结合CriticAgent、QuantifierAgent和VerifierAgent的优势,该框架提供了一个强大、可扩展且灵活的解决方案,用于评估任务效用。这种创新方法不仅帮助开发者了解其应用程序的当前表现,还提供了有价值的见解,可以推动未来的改进。随着智能代理领域的不断发展,像AgentEval这样的框架将在确保这些应用程序满足用户多样化和动态需求方面发挥关键作用。
进一步阅读
请参考我们的论文和代码库了解有关AgentEval的更多详细信息。
如果你发现这个博客有用,请考虑引用:
@article{arabzadeh2024assessing,
title={Assessing and Verifying Task Utility in LLM-Powered Applications},
author={Arabzadeh, Negar and Huo, Siging and Mehta, Nikhil and Wu, Qinqyun and Wang, Chi and Awadallah, Ahmed and Clarke, Charles LA and Kiseleva, Julia},
journal={arXiv preprint arXiv:2405.02178},
year={2024}
}