6.7 大型图上的精确离线推理
子图采样和邻域采样都是为了减少使用GPU训练GNN时的内存和时间消耗。在进行推理时,通常最好真正聚合所有邻居,以消除采样引入的随机性。然而,由于内存有限,全图前向传播通常在GPU上不可行,而在CPU上由于计算速度慢也很慢。本节介绍了通过小批量和邻域采样在有限GPU内存下进行全图前向传播的方法。
推理算法与训练算法不同,因为所有节点的表示应该从第一层开始逐层计算。具体来说,对于特定层,我们需要以小批次计算该GNN层中所有节点的输出表示。结果是推理算法将有一个外层循环遍历层,以及一个内层循环遍历节点的小批次。相比之下,训练算法有一个外层循环遍历节点的小批次,以及一个内层循环遍历层以进行邻居采样和消息传递。
以下动画展示了计算过程的样子(注意,对于每一层,只绘制了前三个小批量数据)。
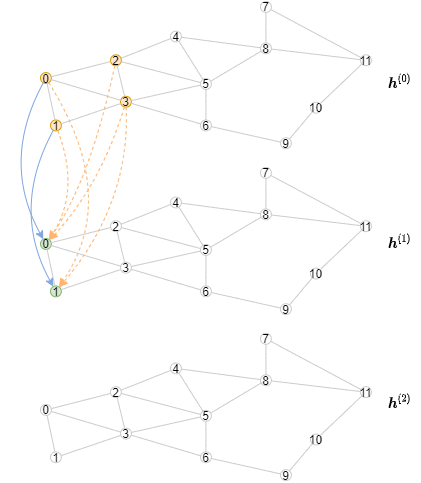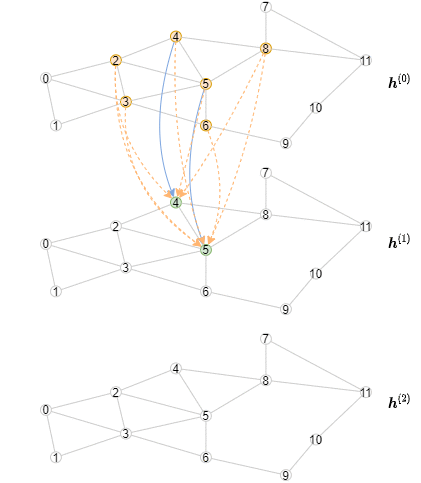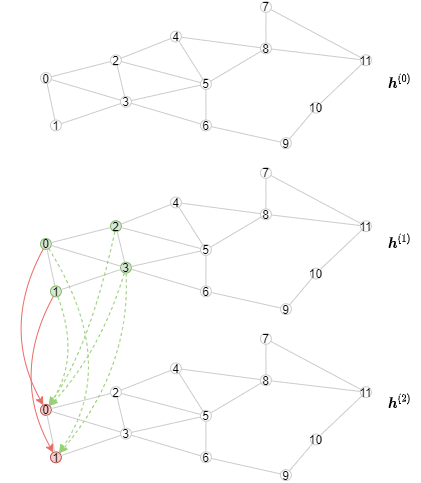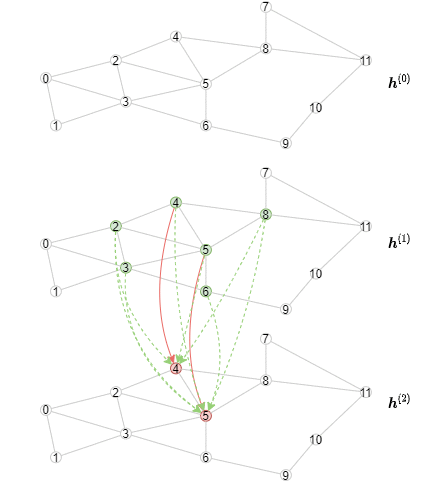
实现离线推理
考虑我们在第6.1节中提到的两层GCN
Adapt your model for minibatch training。实现离线推理的方法仍然涉及使用
NeighborSampler,但每次只对一层进行采样。
datapipe = gb.ItemSampler(all_nodes_set, batch_size=1024, shuffle=True)
datapipe = datapipe.sample_neighbor(g, [-1]) # 1 layers.
datapipe = datapipe.fetch_feature(feature, node_feature_keys=["feat"])
datapipe = datapipe.copy_to(device)
dataloader = gb.DataLoader(datapipe)
请注意,离线推理是作为GNN模块的一个方法实现的,因为在一层上的计算取决于消息是如何聚合和组合的。
class SAGE(nn.Module):
def __init__(self, in_size, hidden_size, out_size):
super().__init__()
self.layers = nn.ModuleList()
# Three-layer GraphSAGE-mean.
self.layers.append(dglnn.SAGEConv(in_size, hidden_size, "mean"))
self.layers.append(dglnn.SAGEConv(hidden_size, hidden_size, "mean"))
self.layers.append(dglnn.SAGEConv(hidden_size, out_size, "mean"))
self.dropout = nn.Dropout(0.5)
self.hidden_size = hidden_size
self.out_size = out_size
def forward(self, blocks, x):
hidden_x = x
for layer_idx, (layer, block) in enumerate(zip(self.layers, blocks)):
hidden_x = layer(block, hidden_x)
is_last_layer = layer_idx == len(self.layers) - 1
if not is_last_layer:
hidden_x = F.relu(hidden_x)
hidden_x = self.dropout(hidden_x)
return hidden_x
def inference(self, graph, features, dataloader, device):
"""
Offline inference with this module
"""
feature = features.read("node", None, "feat")
# Compute representations layer by layer
for layer_idx, layer in enumerate(self.layers):
is_last_layer = layer_idx == len(self.layers) - 1
y = torch.empty(
graph.total_num_nodes,
self.out_size if is_last_layer else self.hidden_size,
dtype=torch.float32,
device=buffer_device,
pin_memory=pin_memory,
)
feature = feature.to(device)
for step, data in tqdm(enumerate(dataloader)):
x = feature[data.input_nodes]
hidden_x = layer(data.blocks[0], x) # len(blocks) = 1
if not is_last_layer:
hidden_x = F.relu(hidden_x)
hidden_x = self.dropout(hidden_x)
# By design, our output nodes are contiguous.
y[
data.seeds[0] : data.seeds[-1] + 1
] = hidden_x.to(device)
feature = y
return y
请注意,为了在验证集上计算评估指标以进行模型选择,我们通常不需要计算精确的离线推理。原因是我们需要为每一层的每个节点计算表示,这通常非常昂贵,尤其是在有大量未标记数据的半监督情况下。邻域采样对于模型选择和验证来说效果很好。