第7章:分布式训练
注意
分布式训练仅适用于PyTorch后端。
DGL采用完全分布式的方法,将数据和计算分布在一组计算资源上。在本节的上下文中,我们将假设一个集群设置(即一组机器)。DGL将图划分为子图,集群中的每台机器负责一个子图(分区)。DGL在集群中的所有机器上运行相同的训练脚本以并行化计算,并在同一台机器上运行服务器,为训练器提供分区数据。
对于训练脚本,DGL提供了与迷你批次训练相似的分布式API。这使得分布式训练只需要对单机上的迷你批次训练进行少量代码修改。下面展示了以分布式方式训练GraphSage的示例。显著的代码修改包括: 1) 初始化DGL的分布式模块,2) 创建一个分布式图对象,以及 3) 分割训练集并计算本地进程的节点。 其余的代码,包括采样器创建、模型定义、训练循环 与迷你批次训练相同。
import dgl
from dgl.dataloading import NeighborSampler
from dgl.distributed import DistGraph, DistDataLoader, node_split
import torch as th
# initialize distributed contexts
dgl.distributed.initialize('ip_config.txt')
th.distributed.init_process_group(backend='gloo')
# load distributed graph
g = DistGraph('graph_name', 'part_config.json')
pb = g.get_partition_book()
# get training workload, i.e., training node IDs
train_nid = node_split(g.ndata['train_mask'], pb, force_even=True)
# Create sampler
sampler = NeighborSampler(g, [10,25],
dgl.distributed.sample_neighbors,
device)
dataloader = DistDataLoader(
dataset=train_nid.numpy(),
batch_size=batch_size,
collate_fn=sampler.sample_blocks,
shuffle=True,
drop_last=False)
# Define model and optimizer
model = SAGE(in_feats, num_hidden, n_classes, num_layers, F.relu, dropout)
model = th.nn.parallel.DistributedDataParallel(model)
loss_fcn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
# training loop
for epoch in range(args.num_epochs):
with model.join():
for step, blocks in enumerate(dataloader):
batch_inputs, batch_labels = load_subtensor(g, blocks[0].srcdata[dgl.NID],
blocks[-1].dstdata[dgl.NID])
batch_pred = model(blocks, batch_inputs)
loss = loss_fcn(batch_pred, batch_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
DGL 实现了一些分布式组件来支持分布式训练。下图展示了这些组件及其交互。
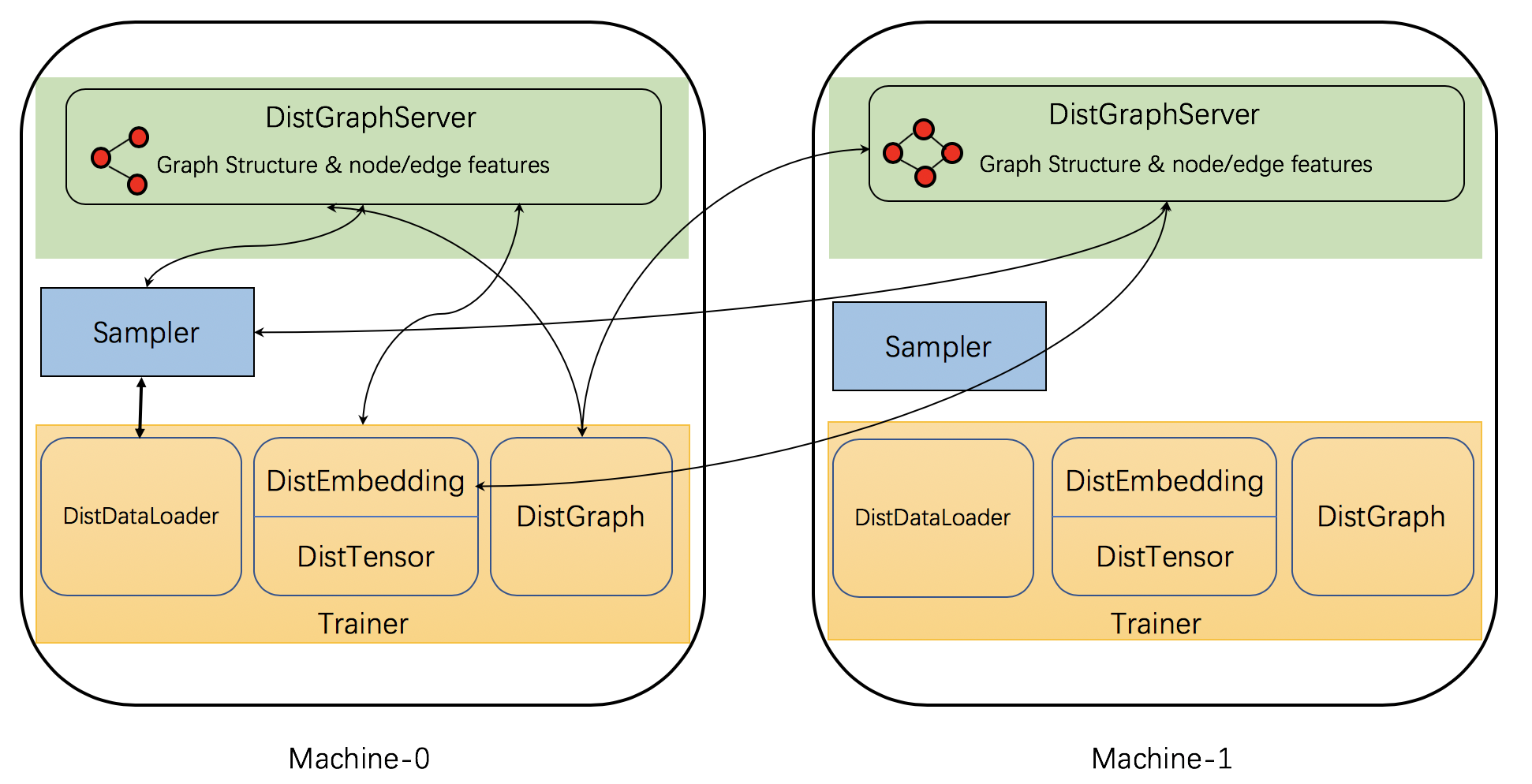
具体来说,DGL的分布式训练有三种交互过程: server,sampler 和 trainer。
服务器存储图分区,包括结构数据和节点/边特征。它们提供服务,如采样、获取或更新节点/边特征。请注意,每台机器可能同时运行多个服务器进程,以增加服务吞吐量。其中一个是主服务器,负责数据加载并通过共享内存与提供服务的备份服务器共享数据。
采样器进程与服务器和采样节点及边进行交互,以生成用于训练的小批量数据。
训练器负责在小批量数据上训练网络。它们利用诸如
DistGraph的API来访问分区图数据,DistEmbedding和DistTensor来访问节点/边的特征/嵌入,以及DistDataLoader与采样器交互以获取小批量数据。训练器使用PyTorch的原生DistributedDataParallel范式在彼此之间通信梯度。
除了Python API,DGL还提供了工具,用于为整个集群提供图数据和进程。
考虑到分布式组件,本节其余部分将涵盖以下分布式组件:
对于对更多细节感兴趣的高级用户: