7.1 数据预处理
在启动训练任务之前,DGL要求输入数据被分区并分发到目标机器。为了处理不同规模的图,DGL提供了两种分区方法:
适用于可以放入单机内存的图的分区API。
一个分布式分区管道,用于处理超出单机容量的图。
7.1.1 分区API
对于相对较小的图,DGL 提供了一个分区 API
partition_graph(),它可以对内存中的
DGLGraph 对象进行分区。它支持多种分区算法,如随机分区和
Metis。
Metis 分区的优势在于它可以生成具有最小边切割的分区,以减少分布式训练和推理中的网络通信。DGL 使用最新版本的 Metis,并针对具有幂律分布的真实世界图进行了优化。分区后,API 会以易于在训练期间加载的格式构建分区结果。例如,
import dgl
g = ... # create or load a DGLGraph object
dgl.distributed.partition_graph(g, 'mygraph', 2, 'data_root_dir')
将输出以下数据文件。
data_root_dir/
|-- mygraph.json # metadata JSON. File name is the given graph name.
|-- part0/ # data for partition 0
| |-- node_feats.dgl # node features stored in binary format
| |-- edge_feats.dgl # edge features stored in binary format
| |-- graph.dgl # graph structure of this partition stored in binary format
|
|-- part1/ # data for partition 1
|-- node_feats.dgl
|-- edge_feats.dgl
|-- graph.dgl
第7.4 高级图分区章节涵盖了关于分区格式的更多细节。要将分区分发到集群,用户可以将数据保存在所有机器都可以访问的共享文件夹中,或者将元数据JSON以及相应的分区文件夹partX复制到第X台机器上。
使用 partition_graph() 需要一个具有足够大CPU内存的实例来保存整个图结构和特征,这对于具有数千亿条边或大特征的图可能不可行。接下来我们将描述如何在这种情况下使用并行数据准备管道。
负载均衡
在对图进行分区时,默认情况下,METIS 只平衡每个分区中的节点数量。这可能会导致次优的配置,具体取决于手头的任务。例如,在半监督节点分类的情况下,训练器在本地分区中的标记节点子集上执行计算。仅平衡图中节点(包括标记和未标记节点)的分区可能会导致计算负载不平衡。为了在每个分区中获得平衡的工作负载,分区 API 允许通过指定 balance_ntypes 在 partition_graph() 中平衡每个节点类型的节点数量。用户可以利用这一点,并考虑训练集、验证集和测试集中的节点属于不同的节点类型。
以下示例考虑训练集内和训练集外的节点是两种类型的节点:
dgl.distributed.partition_graph(g, 'graph_name', 4, '/tmp/test', balance_ntypes=g.ndata['train_mask'])
除了平衡节点类型,
dgl.distributed.partition_graph() 还允许通过指定 balance_edges 来平衡不同节点类型的节点的入度。
这平衡了不同类型节点的边的数量。
ID映射
分区后,partition_graph() 会重新映射节点和边的ID,使得同一分区的节点排列在一起(在一个连续的ID范围内),从而更容易存储分区的节点/边特征。该API还会根据新的ID自动打乱节点/边特征。然而,一些下游任务可能希望恢复原始的节点/边ID(例如提取计算后的节点嵌入以供后续使用)。对于这种情况,传递return_mapping=True给partition_graph(),这将使API返回重新映射的节点/边ID与其原始ID之间的映射关系。对于同构图,它返回两个向量。第一个向量将每个新节点ID映射到其原始ID;第二个向量将每个新边ID映射到其原始ID。对于异构图,它返回两个字典的向量。第一个字典包含每种节点类型的映射;第二个字典包含每种边类型的映射。
node_map, edge_map = dgl.distributed.partition_graph(g, 'graph_name', 4, '/tmp/test',
balance_ntypes=g.ndata['train_mask'],
return_mapping=True)
# Let's assume that node_emb is saved from the distributed training.
orig_node_emb = th.zeros(node_emb.shape, dtype=node_emb.dtype)
orig_node_emb[node_map] = node_emb
加载分区图
DGL provides a dgl.distributed.load_partition() function to load one partition
for inspection.
>>> import dgl
>>> # load partition 0
>>> part_data = dgl.distributed.load_partition('data_root_dir/graph_name.json', 0)
>>> g, nfeat, efeat, partition_book, graph_name, ntypes, etypes = part_data # unpack
>>> print(g)
Graph(num_nodes=966043, num_edges=34270118,
ndata_schemes={'orig_id': Scheme(shape=(), dtype=torch.int64),
'part_id': Scheme(shape=(), dtype=torch.int64),
'_ID': Scheme(shape=(), dtype=torch.int64),
'inner_node': Scheme(shape=(), dtype=torch.int32)}
edata_schemes={'_ID': Scheme(shape=(), dtype=torch.int64),
'inner_edge': Scheme(shape=(), dtype=torch.int8),
'orig_id': Scheme(shape=(), dtype=torch.int64)})
如ID映射部分所述,每个分区都携带辅助信息,这些信息保存为ndata或edata,例如原始节点/边ID、分区ID等。每个分区不仅保存它拥有的节点/边,还包括与分区相邻的节点/边(称为HALO节点/边)。inner_node和inner_edge指示一个节点/边是否真正属于该分区(值为True)或者是HALO节点/边(值为False)。
The load_partition() function loads all data at once. Users can
load features or the partition book using the dgl.distributed.load_partition_feats()
and dgl.distributed.load_partition_book() APIs respectively.
7.1.2 分布式图分区管道
为了处理无法适应单机CPU RAM的大规模图数据,DGL利用数据分块和并行处理来减少内存占用和运行时间。下图展示了该流程:
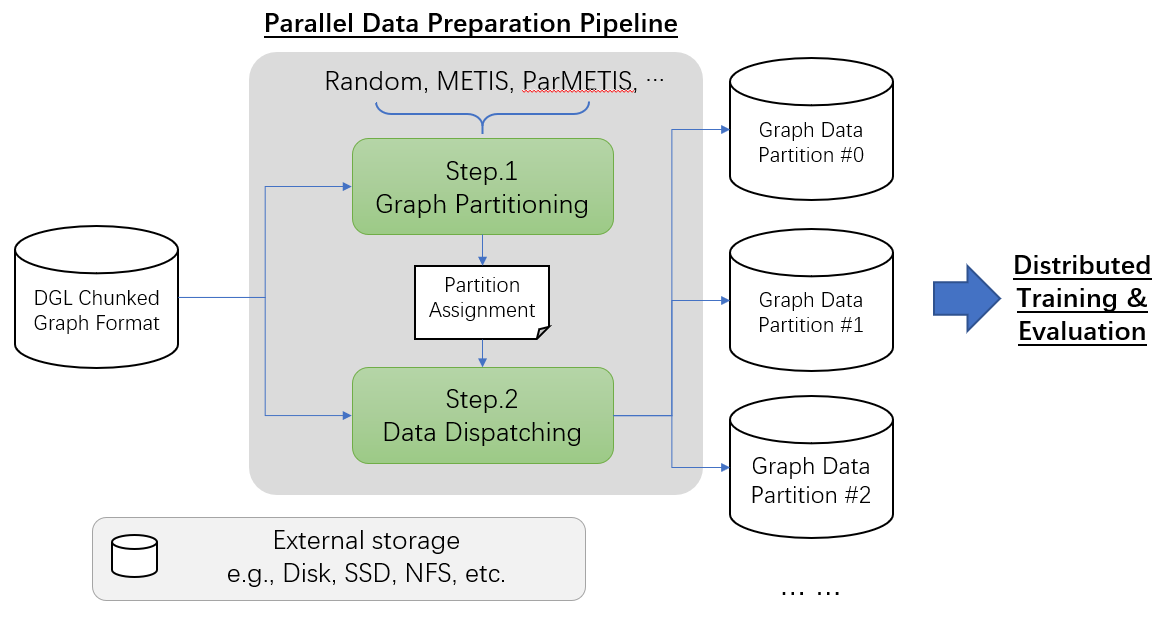
该管道接收存储在Chunked Graph Format中的输入数据,并生成并将数据分区分发到目标机器。
步骤1. 图分区: 它计算每个分区的所有权 并将结果保存为一组称为分区分配的文件。 为了加速此步骤,一些算法(例如,ParMETIS)支持使用多台机器进行并行计算。
步骤2 数据分发: 根据分区分配,此步骤将图数据物理分区并将其分发到用户指定的机器上。它还将图数据转换为适合分布式训练和评估的格式。
整个流程是模块化的,因此每个步骤都可以单独调用。例如,用户可以用一些自定义的图分区算法替换Step.1,只要它能正确生成分区分配文件。
分块图格式
要运行管道,DGL要求输入图存储在多个数据块中。每个数据块是数据预处理的单位,因此应适合放入CPU RAM中。在本节中,我们使用来自Open Graph Benchmark的MAG240M-LSC数据作为示例来描述整体设计,随后是创建此类数据格式的正式规范和提示。
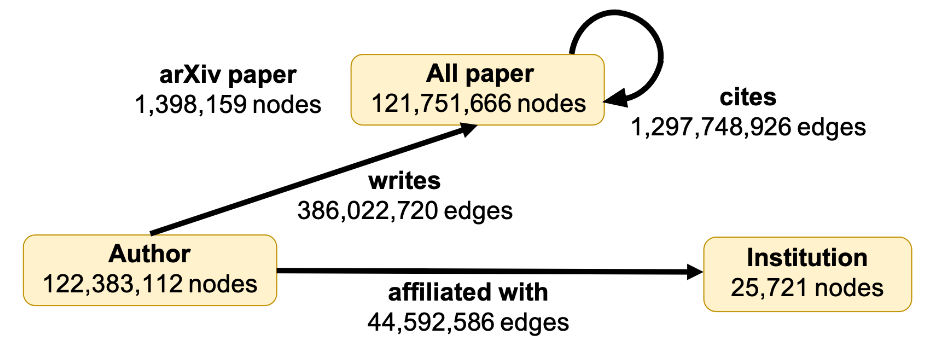
示例:MAG240M-LSC
MAG240M-LSC图是从微软学术图(MAG)中提取的异质学术图,其模式图如下所示:
其原始数据文件的组织方式如下:
/mydata/MAG240M-LSC/
|-- meta.pt # # A dictionary of the number of nodes for each type saved by torch.save,
| # as well as num_classes
|-- processed/
|-- author___affiliated_with___institution/
| |-- edge_index.npy # graph, 713 MB
|
|-- paper/
| |-- node_feat.npy # feature, 187 GB, (numpy memmap format)
| |-- node_label.npy # label, 974 MB
| |-- node_year.npy # year, 974 MB
|
|-- paper___cites___paper/
| |-- edge_index.npy # graph, 21 GB
|
|-- author___writes___paper/
|-- edge_index.npy # graph, 6GB
该图有三种节点类型("paper"、"author" 和 "institution"),
三种边类型/关系("cites"、"writes" 和 "affiliated_with")。
"paper" 节点有三个属性("feat"、"label"、"year"'),而
其他类型的节点和边没有特征。下面展示了以DGL分块图格式存储时的数据文件:
/mydata/MAG240M-LSC_chunked/
|-- metadata.json # metadata json file
|-- edges/ # stores edge ID data
| |-- writes-part1.csv
| |-- writes-part2.csv
| |-- affiliated_with-part1.csv
| |-- affiliated_with-part2.csv
| |-- cites-part1.csv
| |-- cites-part1.csv
|
|-- node_data/ # stores node feature data
|-- paper-feat-part1.npy
|-- paper-feat-part2.npy
|-- paper-label-part1.npy
|-- paper-label-part2.npy
|-- paper-year-part1.npy
|-- paper-year-part2.npy
所有数据文件被分成两部分,包括每个关系的边(例如,writes, affiliates, cites)和节点特征。如果图有边特征,它们也会被分成多个文件。所有ID数据都存储在CSV中(我们很快会说明内容),而节点特征则存储在numpy数组中。
metadata.json 存储了所有的元数据信息,例如文件名和块大小(例如,节点数量,边数量)。
{
"graph_name" : "MAG240M-LSC", # given graph name
"node_type": ["author", "paper", "institution"],
"num_nodes_per_chunk": [
[61191556, 61191556], # number of author nodes per chunk
[61191553, 61191552], # number of paper nodes per chunk
[12861, 12860] # number of institution nodes per chunk
],
# The edge type name is a colon-joined string of source, edge, and destination type.
"edge_type": [
"author:writes:paper",
"author:affiliated_with:institution",
"paper:cites:paper"
],
"num_edges_per_chunk": [
[193011360, 193011360], # number of author:writes:paper edges per chunk
[22296293, 22296293], # number of author:affiliated_with:institution edges per chunk
[648874463, 648874463] # number of paper:cites:paper edges per chunk
],
"edges" : {
"author:writes:paper" : { # edge type
"format" : {"name": "csv", "delimiter": " "},
# The list of paths. Can be relative or absolute.
"data" : ["edges/writes-part1.csv", "edges/writes-part2.csv"]
},
"author:affiliated_with:institution" : {
"format" : {"name": "csv", "delimiter": " "},
"data" : ["edges/affiliated_with-part1.csv", "edges/affiliated_with-part2.csv"]
},
"paper:cites:paper" : {
"format" : {"name": "csv", "delimiter": " "},
"data" : ["edges/cites-part1.csv", "edges/cites-part2.csv"]
}
},
"node_data" : {
"paper": { # node type
"feat": { # feature key
"format": {"name": "numpy"},
"data": ["node_data/paper-feat-part1.npy", "node_data/paper-feat-part2.npy"]
},
"label": { # feature key
"format": {"name": "numpy"},
"data": ["node_data/paper-label-part1.npy", "node_data/paper-label-part2.npy"]
},
"year": { # feature key
"format": {"name": "numpy"},
"data": ["node_data/paper-year-part1.npy", "node_data/paper-year-part2.npy"]
}
}
},
"edge_data" : {} # MAG240M-LSC does not have edge features
}
metadata.json 中有三个部分:
图模式信息和块大小,例如
"node_type","num_nodes_per_chunk", 等。键
"edges"下的边索引数据。键
"node_data"和"edge_data"下的节点/边特征数据。
边缘索引文件包含以节点ID对形式表示的边缘:
# writes-part1.csv
0 0
0 1
0 20
0 29
0 1203
...
规范
通常,一个分块的图数据文件夹只需要一个metadata.json和一些数据文件。MAG240M-LSC示例中的文件夹结构并不是严格要求的,只要metadata.json包含有效的文件路径即可。
metadata.json 顶级键:
graph_name: 字符串。由dgl.distributed.DistGraph用于加载图的唯一名称。node_type: 字符串列表。节点类型名称。num_nodes_per_chunk: 整数列表的列表。对于存储在\(P\)个块中的\(T\)种节点类型的图,该值包含\(T\)个整数列表。每个列表包含\(P\)个整数,这些整数指定每个块中的节点数量。edge_type: 字符串列表。边类型名称的格式为: num_edges_per_chunk: 整数列表的列表。对于存储在\(P\)个块中的\(R\)种边类型的图,该值包含\(R\)个整数列表。每个列表包含\(P\)个整数,这些整数指定每个块中的边数。edges:ChunkFileSpec的字典。边缘索引文件。 字典键是边缘类型名称,格式为: node_data:ChunkFileSpec的字典。存储节点属性的数据文件可以有任意数量的文件,不受num_parts的限制。字典的键是节点类型名称。edge_data:ChunkFileSpec的字典。存储边属性的数据文件可以有任意数量的文件,不受num_parts的限制。字典的键是边类型名称,格式为:
ChunkFileSpec 有两个键:
format: 文件格式。根据格式name,用户可以配置更多关于如何解析每个数据文件的详细信息。"csv": CSV 文件。使用delimiter键来指定使用的分隔符。"numpy": 由numpy.save()创建的NumPy数组二进制文件。"parquet": 由pyarrow.parquet.write_table()创建的parquet表二进制文件。
data: 字符串列表。每个数据块的文件路径。支持绝对路径。
制作分块图形数据的技巧
根据原始数据,实现可能包括:
从非结构化数据(如文本或表格数据)构建图形。
增强或转换输入图结构或特征。例如,添加反向或自环边,归一化特征等。
将输入的图结构和特征分块成多个数据文件,以便每个文件都能适应CPU RAM,用于后续的预处理步骤。
为了避免出现内存不足的错误,建议分别处理图结构和特征数据。一次处理一个数据块也可以减少最大运行时内存占用。例如,DGL提供了一个tools/chunk_graph.py脚本,该脚本将内存中的无特征DGLGraph和存储在numpy.memmap中的特征张量分块处理。
步骤1:图分区
此步骤读取分块的图数据并计算每个节点应属于哪个分区。结果保存在一组分区分配文件中。例如,要将MAG240M-LSC随机分区为两部分,请运行tools文件夹中的partition_algo/random_partition.py脚本:
python /my/repo/dgl/tools/partition_algo/random_partition.py
--in_dir /mydata/MAG240M-LSC_chunked
--out_dir /mydata/MAG240M-LSC_2parts
--num_partitions 2
,输出文件如下:
MAG240M-LSC_2parts/
|-- paper.txt
|-- author.txt
|-- institution.txt
每个文件存储相应节点类型的分区分配。 内容是按行存储的每个节点的分区ID,即第i行是节点i的分区ID。
# paper.txt
0
1
1
0
0
1
0
...
尽管其简单,随机分区可能会导致频繁的跨机器通信。查看章节 7.4 高级图分区 以获取更多高级选项。
步骤2:数据分发
DGL 提供了一个 dispatch_data.py 脚本来物理分区数据并将分区分发到每个训练机器上。它还会再次将数据转换为可以被 DGL 训练进程高效加载的数据对象。整个步骤可以使用多进程进一步加速。
python /myrepo/dgl/tools/dispatch_data.py \
--in-dir /mydata/MAG240M-LSC_chunked/ \
--partitions-dir /mydata/MAG240M-LSC_2parts/ \
--out-dir data/MAG_LSC_partitioned \
--ip-config ip_config.txt
--in-dir指定了输入分块图数据文件夹的路径--partitions-dir指定了由步骤1生成的分区分配文件夹的路径。--out-dir指定了每台机器上存储数据分区的路径。--ip-config指定集群的IP配置文件。
一个示例IP配置文件如下:
172.31.19.1
172.31.23.205
作为partition_graph()中return_mapping=True的对应部分,
分布式分区管道
在dispatch_data.py中提供了两个参数来将原始节点/边ID保存到磁盘。
--save-orig-nids将原始节点ID保存到文件中。--save-orig-eids将原始边ID保存到文件中。
指定这两个选项将在每个分区文件夹下创建两个文件 orig_nids.dgl 和 orig_eids.dgl。
data_root_dir/
|-- graph_name.json # partition configuration file in JSON
|-- part0/ # data for partition 0
| |-- orig_nids.dgl # original node IDs
| |-- orig_eids.dgl # original edge IDs
| |-- ... # other data such as graph and node/edge feats
|
|-- part1/ # data for partition 1
| |-- orig_nids.dgl
| |-- orig_eids.dgl
| |-- ...
|
|-- ... # data for other partitions
这两个文件将原始ID存储为张量字典,其中键是节点/边类型名称,值是ID张量。用户可以使用dgl.data.load_tensors()工具来加载它们:
# Load the original IDs for the nodes in partition 0.
orig_nids_0 = dgl.data.load_tensors('/path/to/data/part0/orig_nids.dgl')
# Get the original node IDs for node type 'user'
user_orig_nids_0 = orig_nids_0['user']
# Load the original IDs for the edges in partition 0.
orig_eids_0 = dgl.data.load_tensors('/path/to/data/part0/orig_eids.dgl')
# Get the original edge IDs for edge type 'like'
like_orig_eids_0 = orig_nids_0['like']
在数据分发过程中,DGL假设集群的CPU内存总和能够容纳整个图数据。节点所有权由分区算法的结果决定,而对于边,目标节点的所有者也拥有该边。