指标聚合
edit指标聚合
edit这个系列的聚合基于从正在聚合的文档中以某种方式提取的值来计算指标。这些值通常从文档的字段中提取(使用字段数据),但也可以使用脚本生成。
数值度量聚合是一种特殊的度量聚合,它输出数值。一些聚合输出单个数值度量(例如 avg),被称为 单值数值度量聚合,而其他聚合生成多个度量(例如 stats),被称为 多值数值度量聚合。单值和多值数值度量聚合之间的区别在某些情况下起作用,例如当这些聚合作为某些桶聚合的直接子聚合时(某些桶聚合允许您根据每个桶中的数值度量对返回的桶进行排序)。
平均值聚合
edit一个单值指标聚合,用于计算从聚合文档中提取的数值的平均值。这些值可以从文档中的特定数值字段或直方图字段中提取。
假设数据由表示学生考试成绩(介于0到100之间)的文档组成,我们可以用以下方法计算他们的平均分:
POST /exams/_search?size=0
{
"aggs": {
"avg_grade": { "avg": { "field": "grade" } }
}
}
上述聚合计算了所有文档的平均成绩。聚合类型是avg,而field设置定义了将计算平均值的文档的数值字段。上述操作将返回以下结果:
{
...
"aggregations": {
"avg_grade": {
"value": 75.0
}
}
}
聚合的名称(如上例中的avg_grade)也作为从返回的响应中检索聚合结果的键。
脚本
edit假设考试极其困难,你需要进行成绩修正。计算一个运行时字段的平均值以获得修正后的平均值:
POST /exams/_search?size=0
{
"runtime_mappings": {
"grade.corrected": {
"type": "double",
"script": {
"source": "emit(Math.min(100, doc['grade'].value * params.correction))",
"params": {
"correction": 1.2
}
}
}
},
"aggs": {
"avg_corrected_grade": {
"avg": {
"field": "grade.corrected"
}
}
}
}
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
直方图字段
edit当在直方图字段上计算平均值时,聚合的结果是所有元素的加权平均值,这些元素在values数组中,考虑到counts数组中相同位置的数值。
例如,对于以下存储不同网络的延迟指标的预聚合直方图的索引:
PUT metrics_index/_doc/1
{
"network.name" : "net-1",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [3, 7, 23, 12, 6]
}
}
PUT metrics_index/_doc/2
{
"network.name" : "net-2",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [8, 17, 8, 7, 6]
}
}
POST /metrics_index/_search?size=0
{
"aggs": {
"avg_latency":
{ "avg": { "field": "latency_histo" }
}
}
}
对于每个直方图字段,avg 聚合将 values 数组 <1> 中的每个数字乘以其关联的计数,并将其添加到 counts 数组 <2> 中。最终,它将计算所有直方图的这些值的平均值,并返回以下结果:
{
...
"aggregations": {
"avg_latency": {
"value": 0.29690721649
}
}
}
箱线图聚合
edit一个 boxplot 指标聚合,用于计算从聚合文档中提取的数值的箱线图。
这些值可以从文档中的特定数值或 直方图字段 生成。
The boxplot aggregation returns essential information for making a box plot: 最小值、最大值、中位数、第一四分位数(25百分位数)和第三四分位数(75百分位数)。
语法
edit一个 boxplot 聚合单独看起来是这样的:
{
"boxplot": {
"field": "load_time"
}
}
让我们来看一个表示加载时间的箱线图:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_boxplot": {
"boxplot": {
"field": "load_time"
}
}
}
}
响应将会是这样的:
{
...
"aggregations": {
"load_time_boxplot": {
"min": 0.0,
"max": 990.0,
"q1": 167.5,
"q2": 445.0,
"q3": 722.5,
"lower": 0.0,
"upper": 990.0
}
}
}
在这种情况下,下限和上限须值等于最小值和最大值。一般来说,这些值是1.5 * IQR范围,也就是说,最接近q1 - (1.5 * IQR)和q3 + (1.5 * IQR)的值。由于这是一个近似值,给出的值可能实际上并不是数据中的观测值,但应该在合理的误差范围内。虽然箱线图聚合不直接返回异常点,但您可以检查lower > min或upper < max来查看是否存在异常值,然后直接查询它们。
脚本
edit如果你需要为不是完全索引的值创建箱线图,你应该创建一个运行时字段并获取该字段的箱线图。例如,如果你的加载时间是以毫秒为单位,但你想以秒为单位计算值,使用运行时字段进行转换:
GET latency/_search
{
"size": 0,
"runtime_mappings": {
"load_time.seconds": {
"type": "long",
"script": {
"source": "emit(doc['load_time'].value / params.timeUnit)",
"params": {
"timeUnit": 1000
}
}
}
},
"aggs": {
"load_time_boxplot": {
"boxplot": { "field": "load_time.seconds" }
}
}
}
箱线图值通常是近似的
edit由 boxplot 指标使用的算法称为 TDigest(由 Ted Dunning 在
使用 T-Digests 计算精确分位数中引入)。
箱线图以及其他百分位数聚合也是 非确定性的。 这意味着使用相同的数据可能会得到略有不同的结果。
压缩
edit近似算法必须在内存利用率和估计精度之间取得平衡。
这种平衡可以通过使用压缩参数来控制:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_boxplot": {
"boxplot": {
"field": "load_time",
"compression": 200
}
}
}
}
TDigest算法使用多个“节点”来近似百分位数——可用节点越多,精度越高(以及与数据量成比例的大内存占用)。compression参数限制最大节点数为20 * compression。
因此,通过增加压缩值,您可以在消耗更多内存的情况下提高百分位数的准确性。较大的压缩值也会使算法变慢,因为底层树数据结构的大小增加,导致操作成本更高。默认的压缩值是100。
一个“节点”大约使用32字节的内存,因此在最坏情况下(大量数据按顺序到达),默认设置将生成一个大约64KB大小的TDigest。实际上,数据往往更加随机,TDigest将使用更少的内存。
执行提示
editTDigest 的默认实现针对性能进行了优化,能够在保持可接受精度水平(在某些情况下,对于数百万个样本,相对误差接近 1%)的同时,扩展到数百万甚至数十亿个样本值。可以通过将参数 execution_hint 设置为值 high_accuracy 来选择使用针对精度优化的实现:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_boxplot": {
"boxplot": {
"field": "load_time",
"execution_hint": "high_accuracy"
}
}
}
}
此选项可以提高准确性(在某些情况下,对于数百万个样本,相对误差接近0.01%),但百分位查询的完成时间会增加2倍到10倍。
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
基数聚合
edit一个单值指标聚合,用于计算不同值的近似计数。
假设你正在索引商店销售数据,并希望统计与查询匹配的已售产品的唯一数量:
POST /sales/_search?size=0
{
"aggs": {
"type_count": {
"cardinality": {
"field": "type"
}
}
}
}
响应:
{
...
"aggregations": {
"type_count": {
"value": 3
}
}
}
精度控制
edit此聚合还支持 precision_threshold 选项:
计数是近似的
edit计算精确计数需要将值加载到哈希集中并返回其大小。这在处理高基数集合和/或大值时无法扩展,因为所需的内存使用量和在节点之间通信这些每个分片集的需求会占用集群的太多资源。
此 cardinality 聚合基于
HyperLogLog++
算法,该算法根据值的哈希进行计数,并具有一些有趣的特性:
- 可配置的精度,决定如何权衡内存与准确性,
- 在低基数集合上具有出色的准确性,
- 固定的内存使用量:无论存在数十个还是数十亿个唯一值,内存使用量仅取决于配置的精度。
对于精度阈值 c,我们使用的实现大约需要 c * 8 字节。
以下图表展示了在阈值前后误差的变化情况:
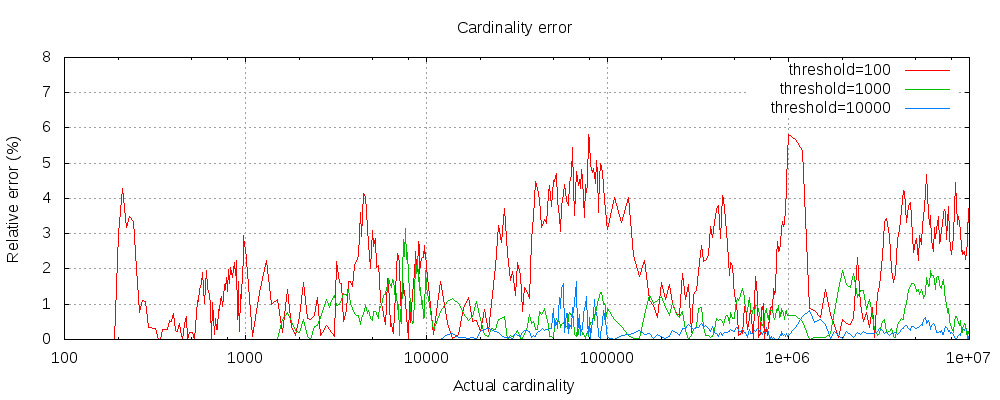
对于所有3个阈值,计数在配置的阈值内都是准确的。 虽然不保证,但这种情况很可能是这样。实际中的准确性取决于所讨论的数据集。一般来说,大多数数据集都显示出一致的良好准确性。还要注意,即使阈值低至100,即使在计数数百万个项目时,误差仍然非常低(如上图所示为1-6%)。
HyperLogLog++ 算法依赖于哈希值的前导零,数据集中哈希的确切分布会影响基数的准确性。
预计算哈希
edit在高基数字符串字段上,将字段值的哈希存储在索引中,然后在此字段上运行基数聚合可能会更快。这可以通过从客户端提供哈希值或通过使用mapper-murmur3插件让Elasticsearch为您计算哈希值来完成。
预计算哈希值通常只在非常大的和/或高基数的字段上有用,因为它节省了CPU和内存。然而,在数值字段上,哈希计算非常快,并且存储原始值所需的内存与存储哈希值所需的内存相当或更少。对于低基数的字符串字段也是如此,特别是考虑到这些字段有一个优化,以确保每个段中的每个唯一值最多计算一次哈希值。
脚本
edit如果你需要两个字段的组合的基数,创建一个运行时字段来组合它们并进行聚合。
POST /sales/_search?size=0
{
"runtime_mappings": {
"type_and_promoted": {
"type": "keyword",
"script": "emit(doc['type'].value + ' ' + doc['promoted'].value)"
}
},
"aggs": {
"type_promoted_count": {
"cardinality": {
"field": "type_and_promoted"
}
}
}
}
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
执行提示
edit您可以使用不同的机制运行基数聚合:
-
通过直接使用字段值(
direct) -
通过使用字段的全局序数并在完成分片后解析这些值(
global_ordinals) -
通过使用段序数值并在每个段后解析这些值(
segment_ordinals)
此外,还有两种“基于启发式”的模式。这些模式将导致Elasticsearch使用有关索引状态的一些数据来选择适当的执行方法。这两种启发式方法是:
-
save_time_heuristic- 这是Elasticsearch 8.4及更高版本的默认设置。 -
save_memory_heuristic- 这是Elasticsearch 8.3及更早版本的默认设置。
当未指定时,Elasticsearch 将应用启发式方法来选择适当的模式。另请注意,对于某些数据(非序数字段),direct 是唯一的选择,并且提示在这些情况下将被忽略。通常情况下,不需要设置此值。
扩展统计聚合
edit一个多值指标聚合,用于计算从聚合文档中提取的数值的统计信息。
extended_stats 聚合是 stats 聚合的扩展版本,其中添加了额外的指标,如 sum_of_squares、variance、std_deviation 和 std_deviation_bounds。
假设数据由代表学生考试成绩(介于0到100之间)的文档组成
GET /exams/_search
{
"size": 0,
"aggs": {
"grades_stats": { "extended_stats": { "field": "grade" } }
}
}
上述聚合计算了所有文档的成绩统计信息。聚合类型是extended_stats,而field设置定义了将计算统计信息的文档的数值字段。上述操作将返回以下内容:
标准差 std_deviation 和方差 variance 是作为总体指标计算的,因此它们始终与 std_deviation_population 和 variance_population 分别相同。
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0,
"sum_of_squares": 12500.0,
"variance": 625.0,
"variance_population": 625.0,
"variance_sampling": 1250.0,
"std_deviation": 25.0,
"std_deviation_population": 25.0,
"std_deviation_sampling": 35.35533905932738,
"std_deviation_bounds": {
"upper": 125.0,
"lower": 25.0,
"upper_population": 125.0,
"lower_population": 25.0,
"upper_sampling": 145.71067811865476,
"lower_sampling": 4.289321881345245
}
}
}
}
聚合的名称(如上例中的grades_stats)也作为从返回响应中检索聚合结果的键。
标准差边界
edit默认情况下,extended_stats 指标将返回一个名为 std_deviation_bounds 的对象,该对象提供了从均值加减两个标准差的区间。这是一种可视化数据方差的有用方法。如果您想要不同的边界,例如三个标准差,您可以在请求中设置 sigma:
GET /exams/_search
{
"size": 0,
"aggs": {
"grades_stats": {
"extended_stats": {
"field": "grade",
"sigma": 3
}
}
}
}
sigma 可以是任何非负的双精度数,这意味着你可以请求非整数值,例如 1.5。值为 0 是有效的,但只会返回 upper 和 lower 边界的平均值。
上界和下界是作为总体指标计算的,因此它们始终与upper_population和lower_population分别相同。
标准差和边界需要正态性
默认情况下会显示标准差及其界限,但这些并不总是适用于所有数据集。您的数据必须呈正态分布,这些指标才有意义。标准差的统计学基础假设数据是正态分布的,因此如果您的数据严重偏向左侧或右侧,返回的值将会产生误导。
脚本
edit如果你需要对一个未索引的值进行聚合,请使用运行时字段。 假设我们发现我们一直在处理的分数是针对一个超出学生水平的考试,我们想要“修正”它:
GET /exams/_search
{
"size": 0,
"runtime_mappings": {
"grade.corrected": {
"type": "double",
"script": {
"source": "emit(Math.min(100, doc['grade'].value * params.correction))",
"params": {
"correction": 1.2
}
}
}
},
"aggs": {
"grades_stats": {
"extended_stats": { "field": "grade.corrected" }
}
}
}
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
地理边界聚合
edit一种度量聚合,用于计算包含 Geopoint 或 Geoshape 字段所有值的地理边界框。
示例:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "POINT (4.912350 52.374081)", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "POINT (4.901618 52.369219)", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "POINT (4.914722 52.371667)", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "POINT (4.405200 51.222900)", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "POINT (2.336389 48.861111)", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "POINT (2.327000 48.860000)", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"query": {
"match": { "name": "musée" }
},
"aggs": {
"viewport": {
"geo_bounds": {
"field": "location",
"wrap_longitude": true
}
}
}
}
|
The |
|
上述聚合展示了如何计算名称匹配“musée”的所有文档的位置字段的边界框。
上述聚合的响应:
{
...
"aggregations": {
"viewport": {
"bounds": {
"top_left": {
"lat": 48.86111099738628,
"lon": 2.3269999679178
},
"bottom_right": {
"lat": 48.85999997612089,
"lon": 2.3363889567553997
}
}
}
}
}
在 geo_shape 字段上的地理边界聚合
edit地理边界聚合也支持在geo_shape字段上进行。
如果wrap_longitude设置为true(默认值),边界框可以跨越国际日期线,并返回一个边界,其中top_left的经度大于top_right的经度。
例如,地理边界框的右上经度通常会大于左下经度。然而,当区域跨越180°经线时,左下经度的值将大于右上经度的值。有关更多信息,请参阅Open Geospatial Consortium网站上的地理边界框。
示例:
PUT /places
{
"mappings": {
"properties": {
"geometry": {
"type": "geo_shape"
}
}
}
}
POST /places/_bulk?refresh
{"index":{"_id":1}}
{"name": "NEMO Science Museum", "geometry": "POINT(4.912350 52.374081)" }
{"index":{"_id":2}}
{"name": "Sportpark De Weeren", "geometry": { "type": "Polygon", "coordinates": [ [ [ 4.965305328369141, 52.39347642069457 ], [ 4.966979026794433, 52.391721758934835 ], [ 4.969425201416015, 52.39238958618537 ], [ 4.967944622039794, 52.39420969150824 ], [ 4.965305328369141, 52.39347642069457 ] ] ] } }
POST /places/_search?size=0
{
"aggs": {
"viewport": {
"geo_bounds": {
"field": "geometry"
}
}
}
}
{
...
"aggregations": {
"viewport": {
"bounds": {
"top_left": {
"lat": 52.39420966710895,
"lon": 4.912349972873926
},
"bottom_right": {
"lat": 52.374080987647176,
"lon": 4.969425117596984
}
}
}
}
}
地理质心聚合
edit一种度量聚合,用于从地理字段的所
示例:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "POINT (4.912350 52.374081)", "city": "Amsterdam", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "POINT (4.901618 52.369219)", "city": "Amsterdam", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "POINT (4.914722 52.371667)", "city": "Amsterdam", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "POINT (4.405200 51.222900)", "city": "Antwerp", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "POINT (2.336389 48.861111)", "city": "Paris", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "POINT (2.327000 48.860000)", "city": "Paris", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"aggs": {
"centroid": {
"geo_centroid": {
"field": "location"
}
}
}
}
|
The |
上述聚合展示了如何计算所有博物馆文档中位置字段的质心。
上述聚合的响应:
{
...
"aggregations": {
"centroid": {
"location": {
"lat": 51.00982965203002,
"lon": 3.9662131341174245
},
"count": 6
}
}
}
当 geo_centroid 聚合与其他桶聚合结合作为子聚合时,它会更加有趣。
示例:
POST /museums/_search?size=0
{
"aggs": {
"cities": {
"terms": { "field": "city.keyword" },
"aggs": {
"centroid": {
"geo_centroid": { "field": "location" }
}
}
}
}
}
上述示例使用 geo_centroid 作为子聚合到
terms 桶聚合中,
用于查找每个城市中博物馆的中心位置。
上述聚合的响应:
{
...
"aggregations": {
"cities": {
"sum_other_doc_count": 0,
"doc_count_error_upper_bound": 0,
"buckets": [
{
"key": "Amsterdam",
"doc_count": 3,
"centroid": {
"location": {
"lat": 52.371655656024814,
"lon": 4.909563297405839
},
"count": 3
}
},
{
"key": "Paris",
"doc_count": 2,
"centroid": {
"location": {
"lat": 48.86055548675358,
"lon": 2.3316944623366
},
"count": 2
}
},
{
"key": "Antwerp",
"doc_count": 1,
"centroid": {
"location": {
"lat": 51.22289997059852,
"lon": 4.40519998781383
},
"count": 1
}
}
]
}
}
}
在geo_shape字段上的地理中心聚合
edit地理形状的质心指标比点的质心指标更为复杂。特定聚合桶中包含形状的质心是桶中最高维度形状类型的质心。例如,如果一个桶包含由多边形和线组成的形状,那么线不会对质心指标产生贡献。每种形状的质心计算方式不同。通过Circle摄取的包络和圆被视为多边形。
| Geometry Type | Centroid Calculation |
|---|---|
[多]点 |
所有坐标的等权重平均值 |
[多]线串 |
每个段的所有质心的加权平均值,其中每个段的权重是其以度为单位的长度 |
[多]多边形 |
一个多边形所有三角形质心的加权平均值,其中三角形由每两个连续的顶点和起始点形成。 孔具有负权重。权重表示以度^2计算的三角形面积 |
几何集合 |
所有基础几何图形中具有最高维度的几何图形的质心。如果存在多边形和线和/或点,则线和/或点将被忽略。如果存在线和点,则点将被忽略 |
示例:
PUT /places
{
"mappings": {
"properties": {
"geometry": {
"type": "geo_shape"
}
}
}
}
POST /places/_bulk?refresh
{"index":{"_id":1}}
{"name": "NEMO Science Museum", "geometry": "POINT(4.912350 52.374081)" }
{"index":{"_id":2}}
{"name": "Sportpark De Weeren", "geometry": { "type": "Polygon", "coordinates": [ [ [ 4.965305328369141, 52.39347642069457 ], [ 4.966979026794433, 52.391721758934835 ], [ 4.969425201416015, 52.39238958618537 ], [ 4.967944622039794, 52.39420969150824 ], [ 4.965305328369141, 52.39347642069457 ] ] ] } }
POST /places/_search?size=0
{
"aggs": {
"centroid": {
"geo_centroid": {
"field": "geometry"
}
}
}
}
{
...
"aggregations": {
"centroid": {
"location": {
"lat": 52.39296147599816,
"lon": 4.967404240742326
},
"count": 2
}
}
}
使用 geo_centroid 作为 geohash_grid 的子聚合
聚合将文档(而不是单个地理点)放入桶中。如果文档的geo_point字段包含多个值,则该文档可能会被分配到多个桶中,即使其一个或多个地理点位于桶边界之外。
如果还使用了 geocentroid 子聚合,则每个质心是使用桶中的所有地理点计算的,包括那些位于桶边界之外的点。
这可能导致质心位于桶边界之外。
地理线聚合
editThe geo_line aggregation aggregates all geo_point values within a bucket into a LineString ordered
by the chosen sort field. This sort can be a date field, for example. The bucket returned is a valid
GeoJSON Feature representing the line geometry.
PUT test
{
"mappings": {
"properties": {
"my_location": { "type": "geo_point" },
"group": { "type": "keyword" },
"@timestamp": { "type": "date" }
}
}
}
POST /test/_bulk?refresh
{"index":{}}
{"my_location": {"lat":52.373184, "lon":4.889187}, "@timestamp": "2023-01-02T09:00:00Z"}
{"index":{}}
{"my_location": {"lat":52.370159, "lon":4.885057}, "@timestamp": "2023-01-02T10:00:00Z"}
{"index":{}}
{"my_location": {"lat":52.369219, "lon":4.901618}, "@timestamp": "2023-01-02T13:00:00Z"}
{"index":{}}
{"my_location": {"lat":52.374081, "lon":4.912350}, "@timestamp": "2023-01-02T16:00:00Z"}
{"index":{}}
{"my_location": {"lat":52.371667, "lon":4.914722}, "@timestamp": "2023-01-03T12:00:00Z"}
POST /test/_search?filter_path=aggregations
{
"aggs": {
"line": {
"geo_line": {
"point": {"field": "my_location"},
"sort": {"field": "@timestamp"}
}
}
}
}
返回结果:
{
"aggregations": {
"line": {
"type": "Feature",
"geometry": {
"type": "LineString",
"coordinates": [
[ 4.889187, 52.373184 ],
[ 4.885057, 52.370159 ],
[ 4.901618, 52.369219 ],
[ 4.912350, 52.374081 ],
[ 4.914722, 52.371667 ]
]
},
"properties": {
"complete": true
}
}
}
}
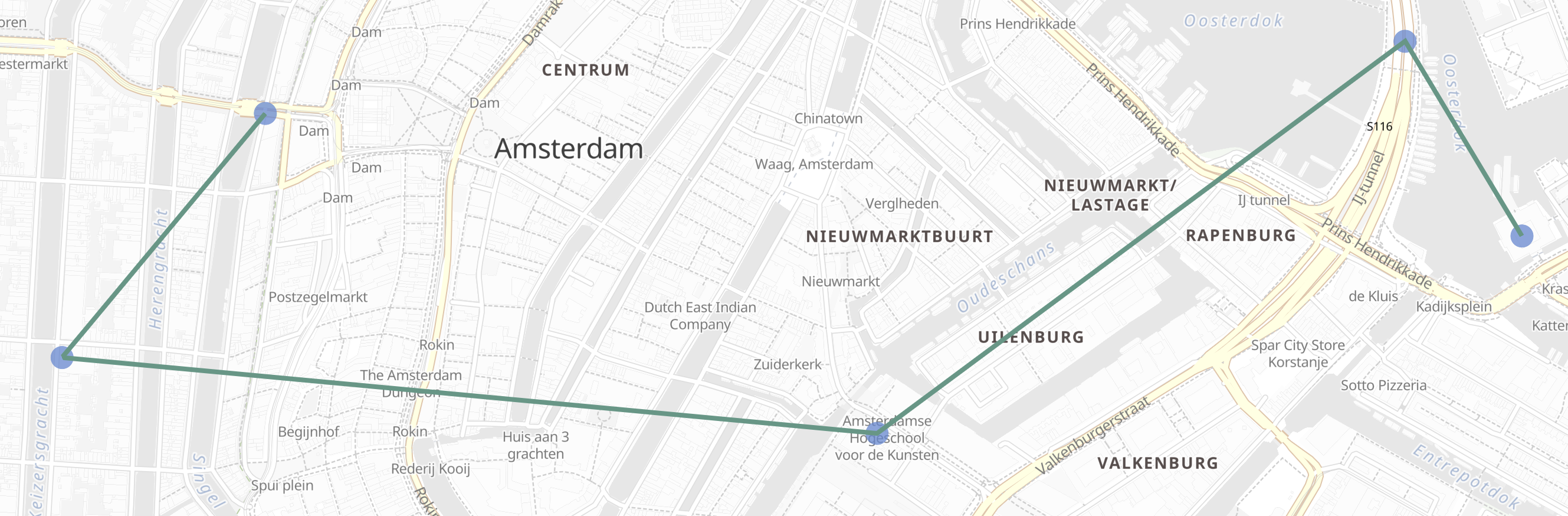
生成的 GeoJSON Feature 包含一个 LineString 几何图形,用于表示由聚合生成的路径,以及一个 properties 映射。属性 complete 指示是否所有匹配的文档都被用于生成几何图形。size 选项 可以用于限制聚合中包含的文档数量,从而导致结果中出现 complete: false。具体哪些文档从结果中被丢弃取决于聚合是否基于 time_series。
此结果可以在地图用户界面中显示:
选项
edit-
point - (必需)
此选项指定geo_point字段的名称
示例用法将 my_location 配置为点字段:
"point": {
"field": "my_location"
}
-
sort -
(在
time_series聚合之外是必需的)
此选项指定用作排序键的数值字段的名称,以对点进行排序。
当 geo_line 聚合嵌套在
time_series
聚合中时,此字段默认为 @timestamp,任何其他值都将导致错误。
示例用法配置@timestamp作为排序键:
"sort": {
"field": "@timestamp"
}
-
include_sort -
(可选,布尔值,默认值:
false) 当设置为true时,此选项会在要素属性中包含一个额外的排序值数组。 -
sort_order -
(可选, 字符串, 默认:
"ASC") 此选项接受两个值之一: "ASC", "DESC". 当设置为 "ASC" 时, 行按排序键的升序排序, 当设置为 "DESC" 时, 行按降序排序.
-
size -
(可选,整数,默认值:
10000) 聚合中表示的线的最大长度。 有效大小在1到10000之间。 在time_series中 聚合使用线简化来约束大小,否则使用截断。 有关涉及的细微差别的讨论,请参阅 为什么要使用时间序列分组?。
分组
edit这个简单的例子为查询选择的所有数据生成一条轨迹。然而,更常见的情况是需要将数据分组到多条轨迹中。例如,在按时间戳对每个航班进行排序并生成每条单独的轨迹之前,先按航班呼号对航班应答器测量值进行分组。
在以下示例中,我们将对阿姆斯特丹、安特卫普和巴黎的兴趣点位置进行分组。 轨迹将按照计划参观顺序排列,用于博物馆和其他景点的步行游览。
为了演示时间序列分组与非时间序列分组之间的区别,我们首先创建一个启用了时间序列的索引,然后给出对相同数据进行非时间序列分组和时间序列分组的示例。
PUT tour
{
"mappings": {
"properties": {
"city": {
"type": "keyword",
"time_series_dimension": true
},
"category": { "type": "keyword" },
"route": { "type": "long" },
"name": { "type": "keyword" },
"location": { "type": "geo_point" },
"@timestamp": { "type": "date" }
}
},
"settings": {
"index": {
"mode": "time_series",
"routing_path": [ "city" ],
"time_series": {
"start_time": "2023-01-01T00:00:00Z",
"end_time": "2024-01-01T00:00:00Z"
}
}
}
}
POST /tour/_bulk?refresh
{"index":{}}
{"@timestamp": "2023-01-02T09:00:00Z", "route": 0, "location": "POINT(4.889187 52.373184)", "city": "Amsterdam", "category": "Attraction", "name": "Royal Palace Amsterdam"}
{"index":{}}
{"@timestamp": "2023-01-02T10:00:00Z", "route": 1, "location": "POINT(4.885057 52.370159)", "city": "Amsterdam", "category": "Attraction", "name": "The Amsterdam Dungeon"}
{"index":{}}
{"@timestamp": "2023-01-02T13:00:00Z", "route": 2, "location": "POINT(4.901618 52.369219)", "city": "Amsterdam", "category": "Museum", "name": "Museum Het Rembrandthuis"}
{"index":{}}
{"@timestamp": "2023-01-02T16:00:00Z", "route": 3, "location": "POINT(4.912350 52.374081)", "city": "Amsterdam", "category": "Museum", "name": "NEMO Science Museum"}
{"index":{}}
{"@timestamp": "2023-01-03T12:00:00Z", "route": 4, "location": "POINT(4.914722 52.371667)", "city": "Amsterdam", "category": "Museum", "name": "Nederlands Scheepvaartmuseum"}
{"index":{}}
{"@timestamp": "2023-01-04T09:00:00Z", "route": 5, "location": "POINT(4.401384 51.220292)", "city": "Antwerp", "category": "Attraction", "name": "Cathedral of Our Lady"}
{"index":{}}
{"@timestamp": "2023-01-04T12:00:00Z", "route": 6, "location": "POINT(4.405819 51.221758)", "city": "Antwerp", "category": "Museum", "name": "Snijders&Rockoxhuis"}
{"index":{}}
{"@timestamp": "2023-01-04T15:00:00Z", "route": 7, "location": "POINT(4.405200 51.222900)", "city": "Antwerp", "category": "Museum", "name": "Letterenhuis"}
{"index":{}}
{"@timestamp": "2023-01-05T10:00:00Z", "route": 8, "location": "POINT(2.336389 48.861111)", "city": "Paris", "category": "Museum", "name": "Musée du Louvre"}
{"index":{}}
{"@timestamp": "2023-01-05T14:00:00Z", "route": 9, "location": "POINT(2.327000 48.860000)", "city": "Paris", "category": "Museum", "name": "Musée dOrsay"}
使用术语进行分组
edit使用这些数据,对于非时间序列用例,可以通过基于城市名称的terms aggregation进行分组。
无论我们是否将tour索引定义为时间序列索引,这种方法都适用。
POST /tour/_search?filter_path=aggregations
{
"aggregations": {
"path": {
"terms": {"field": "city"},
"aggregations": {
"museum_tour": {
"geo_line": {
"point": {"field": "location"},
"sort": {"field": "@timestamp"}
}
}
}
}
}
}
返回结果:
{
"aggregations": {
"path": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Amsterdam",
"doc_count": 5,
"museum_tour": {
"type": "Feature",
"geometry": {
"coordinates": [ [ 4.889187, 52.373184 ], [ 4.885057, 52.370159 ], [ 4.901618, 52.369219 ], [ 4.91235, 52.374081 ], [ 4.914722, 52.371667 ] ],
"type": "LineString"
},
"properties": {
"complete": true
}
}
},
{
"key": "Antwerp",
"doc_count": 3,
"museum_tour": {
"type": "Feature",
"geometry": {
"coordinates": [ [ 4.401384, 51.220292 ], [ 4.405819, 51.221758 ], [ 4.4052, 51.2229 ] ],
"type": "LineString"
},
"properties": {
"complete": true
}
}
},
{
"key": "Paris",
"doc_count": 2,
"museum_tour": {
"type": "Feature",
"geometry": {
"coordinates": [ [ 2.336389, 48.861111 ], [ 2.327, 48.86 ] ],
"type": "LineString"
},
"properties": {
"complete": true
}
}
}
]
}
}
}
这些结果包含一个桶数组,其中每个桶是一个JSON对象,带有显示city字段名称的key,以及一个名为museum_tour的内部聚合结果,其中包含一个描述该城市内各个景点之间实际路线的GeoJSON Feature。
每个结果还包括一个properties对象,其中包含一个complete值,如果几何图形被截断为size参数中指定的限制,则该值将为false。
请注意,当我们在下一个示例中使用time_series时,我们将得到相同的结果,但结构略有不同。
使用时间序列进行分组
edit此功能处于技术预览阶段,可能会在未来的版本中进行更改或移除。Elastic 将努力修复任何问题,但技术预览版中的功能不受官方 GA 功能支持 SLA 的约束。
使用与之前相同的数据,我们还可以使用
time_series 聚合
进行分组。这将按 TSID 分组,TSID 定义为所有具有 time_series_dimension: true 的字段的组合,
在这种情况下,与之前在
词项聚合
中使用的相同 city 字段。
此示例仅在我们将 tour 索引定义为使用 index.mode="time_series" 的时间序列索引时才有效。
POST /tour/_search?filter_path=aggregations
{
"aggregations": {
"path": {
"time_series": {},
"aggregations": {
"museum_tour": {
"geo_line": {
"point": {"field": "location"}
}
}
}
}
}
}
当嵌套在time_series聚合中时,geo_line聚合不再需要sort字段。这是因为排序字段被设置为@timestamp,所有时间序列索引都是按此预先排序的。如果你确实设置了此参数,并将其设置为@timestamp以外的值,你将会收到一个错误。
此查询将产生以下结果:
{
"aggregations": {
"path": {
"buckets": {
"{city=Paris}": {
"key": {
"city": "Paris"
},
"doc_count": 2,
"museum_tour": {
"type": "Feature",
"geometry": {
"coordinates": [ [ 2.336389, 48.861111 ], [ 2.327, 48.86 ] ],
"type": "LineString"
},
"properties": {
"complete": true
}
}
},
"{city=Antwerp}": {
"key": {
"city": "Antwerp"
},
"doc_count": 3,
"museum_tour": {
"type": "Feature",
"geometry": {
"coordinates": [ [ 4.401384, 51.220292 ], [ 4.405819, 51.221758 ], [ 4.4052, 51.2229 ] ],
"type": "LineString"
},
"properties": {
"complete": true
}
}
},
"{city=Amsterdam}": {
"key": {
"city": "Amsterdam"
},
"doc_count": 5,
"museum_tour": {
"type": "Feature",
"geometry": {
"coordinates": [ [ 4.889187, 52.373184 ], [ 4.885057, 52.370159 ], [ 4.901618, 52.369219 ], [ 4.91235, 52.374081 ], [ 4.914722, 52.371667 ] ],
"type": "LineString"
},
"properties": {
"complete": true
}
}
}
}
}
}
}
这些结果本质上与之前的 terms 聚合示例相同,但结构不同。
这里我们看到桶以映射的形式返回,其中键是 TSID 的内部描述。
此 TSID 对于每个具有 time_series_dimension: true 的字段的唯一组合都是唯一的。
每个桶包含一个 key 字段,该字段也是一个映射,包含 TSID 的所有维度值,在这种情况下,仅使用城市名称进行分组。
此外,还有一个名为 museum_tour 的内部聚合结果,其中包含一个
GeoJSON Feature,描述了该城市中各个景点之间的实际路线。
每个结果还包括一个 properties 对象,其中包含一个 complete 值,如果几何图形简化为 size 参数中指定的限制,则该值将为 false。
为什么要使用时间序列进行分组?
edit在查看这些示例时,您可能会认为使用
terms 或
time_series
来分组地理线几乎没有区别。然而,这两种情况在行为上有一些重要的差异。
时间序列索引在磁盘上以非常特定的顺序存储。
它们按时间序列维度字段预先分组,并按 @timestamp 字段预先排序。
这使得 geo_line 聚合可以得到显著优化:
- 为第一个桶分配的相同内存可以重复用于所有后续的桶。 这比非时间序列情况下所需内存要少得多,因为在非时间序列情况下,所有桶都是同时收集的。
-
不需要进行排序,因为数据是按
@timestamp预先排序的。 时间序列数据自然会以DESC顺序到达聚合收集器。 这意味着如果我们指定sort_order:ASC(默认值),我们仍然以DESC顺序收集, 但在生成最终的LineString几何图形之前,执行一个高效的内存反向排序。 -
可以使用
size参数进行流式线简化算法。 在没有时间序列的情况下,我们被迫默认在每个桶10000个文档后截断数据,以防止内存使用不受限制。 这可能导致地理线被截断,从而丢失重要数据。 使用时间序列,我们可以运行流式线简化算法,保持对内存使用的控制,同时保持整体几何形状。 事实上,对于大多数用例,将此size参数设置为更低的界限可能会更有效,并节省更多内存。 例如,如果geo_line要在具有特定分辨率的显示地图上绘制,简化到100或200个点可能会看起来一样好。 这将在服务器、网络和客户端上节省内存。
注意:使用时间序列数据并采用time_series索引模式还有其他显著优势。这些内容在关于时间序列数据流的文档中进行了讨论。
流式线简化
edit线简化是减少最终结果大小并显示在地图用户界面中的一个好方法。然而,通常这些算法会使用大量内存来执行简化,需要将整个几何图形与简化本身所需的支持数据一起保存在内存中。
使用流式线简化算法可以在简化过程中将内存使用量降至最低,方法是将内存限制在为简化几何图形定义的边界内。只有在不需要排序的情况下,这才可能实现,而当通过time_series聚合进行分组时,运行在具有time_series索引模式的索引上,就是这种情况。
在这些条件下,geo_line 聚合会为指定的 size 分配内存,然后使用传入的文档填充该内存。
一旦内存完全填满,随着新文档的添加,线内的文档将被移除。
移除文档的选择是为了最小化对几何形状的视觉影响。
此过程利用了
Visvalingam–Whyatt 算法。
本质上,这意味着如果点的三角形面积最小,则移除该点,三角形由正在考虑的点和线中该点之前和之后的两个点定义。
此外,我们使用球面坐标计算面积,以确保选择不受平面失真的影响。
为了演示线简化比线截断好多少,请考虑这个关于科迪亚克岛北岸的例子。
这个数据只有209个点,但如果我们想将size设置为100,我们会得到显著的截断。

灰色线条是包含209个点的整个几何图形,而蓝色线条是前100个点,与原始几何图形有很大不同。
现在考虑将相同的几何图形简化为100个点。

为了比较,我们用灰色显示了原始图形,用蓝色显示了截断后的图形,用洋红色显示了新的简化几何图形。可以看出新的简化线与原始图形有所偏离,但整体几何形状几乎相同,仍然可以清晰地识别为科迪亚克岛的北岸。
笛卡尔边界聚合
edit一种度量聚合,用于计算包含 点 或 形状 字段所有值的空间边界框。
示例:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "POINT (491.2350 5237.4081)", "city": "Amsterdam", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "POINT (490.1618 5236.9219)", "city": "Amsterdam", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "POINT (491.4722 5237.1667)", "city": "Amsterdam", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "POINT (440.5200 5122.2900)", "city": "Antwerp", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "POINT (233.6389 4886.1111)", "city": "Paris", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "POINT (232.7000 4886.0000)", "city": "Paris", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"query": {
"match": { "name": "musée" }
},
"aggs": {
"viewport": {
"cartesian_bounds": {
"field": "location"
}
}
}
}
与geo_bounds聚合的情况不同,
没有设置wrap_longitude的选项。
这是因为笛卡尔空间是欧几里得空间,不会自我环绕。
因此,边界将始终具有小于或等于最大x值的最小x值。
上述聚合展示了如何计算名称匹配“musée”的所有文档的位置字段的边界框。
上述聚合的响应:
{
...
"aggregations": {
"viewport": {
"bounds": {
"top_left": {
"x": 232.6999969482422,
"y": 4886.111328125
},
"bottom_right": {
"x": 233.63890075683594,
"y": 4886.0
}
}
}
}
}
在 shape 字段上的笛卡尔边界聚合
edit笛卡尔边界聚合也支持在cartesian_shape字段上进行。
示例:
PUT /places
{
"mappings": {
"properties": {
"geometry": {
"type": "shape"
}
}
}
}
POST /places/_bulk?refresh
{"index":{"_id":1}}
{"name": "NEMO Science Museum", "geometry": "POINT(491.2350 5237.4081)" }
{"index":{"_id":2}}
{"name": "Sportpark De Weeren", "geometry": { "type": "Polygon", "coordinates": [ [ [ 496.5305328369141, 5239.347642069457 ], [ 496.6979026794433, 5239.1721758934835 ], [ 496.9425201416015, 5239.238958618537 ], [ 496.7944622039794, 5239.420969150824 ], [ 496.5305328369141, 5239.347642069457 ] ] ] } }
POST /places/_search?size=0
{
"aggs": {
"viewport": {
"cartesian_bounds": {
"field": "geometry"
}
}
}
}
{
...
"aggregations": {
"viewport": {
"bounds": {
"top_left": {
"x": 491.2349853515625,
"y": 5239.4208984375
},
"bottom_right": {
"x": 496.9425048828125,
"y": 5237.408203125
}
}
}
}
}
笛卡尔质心聚合
edit一种度量聚合,用于从点和形状字段的坐标值计算加权质心。
示例:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "POINT (491.2350 5237.4081)", "city": "Amsterdam", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "POINT (490.1618 5236.9219)", "city": "Amsterdam", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "POINT (491.4722 5237.1667)", "city": "Amsterdam", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "POINT (440.5200 5122.2900)", "city": "Antwerp", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "POINT (233.6389 4886.1111)", "city": "Paris", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "POINT (232.7000 4886.0000)", "city": "Paris", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"aggs": {
"centroid": {
"cartesian_centroid": {
"field": "location"
}
}
}
}
上述聚合展示了如何计算所有博物馆文档中位置字段的质心。
上述聚合的响应:
{
...
"aggregations": {
"centroid": {
"location": {
"x": 396.6213124593099,
"y": 5100.982991536458
},
"count": 6
}
}
}
当 cartesian_centroid 聚合作为其他桶聚合的子聚合时,它会更加有趣。
示例:
POST /museums/_search?size=0
{
"aggs": {
"cities": {
"terms": { "field": "city.keyword" },
"aggs": {
"centroid": {
"cartesian_centroid": { "field": "location" }
}
}
}
}
}
上述示例使用 cartesian_centroid 作为子聚合到一个 terms 桶聚合中,用于查找每个城市博物馆的中心位置。
上述聚合的响应:
{
...
"aggregations": {
"cities": {
"sum_other_doc_count": 0,
"doc_count_error_upper_bound": 0,
"buckets": [
{
"key": "Amsterdam",
"doc_count": 3,
"centroid": {
"location": {
"x": 490.9563293457031,
"y": 5237.16552734375
},
"count": 3
}
},
{
"key": "Paris",
"doc_count": 2,
"centroid": {
"location": {
"x": 233.16944885253906,
"y": 4886.0556640625
},
"count": 2
}
},
{
"key": "Antwerp",
"doc_count": 1,
"centroid": {
"location": {
"x": 440.5199890136719,
"y": 5122.2900390625
},
"count": 1
}
}
]
}
}
}
在 shape 字段上的笛卡尔质心聚合
edit形状的质心指标比点的质心指标更为复杂。 特定聚合桶中包含形状的质心是桶中最高维度形状类型的质心。 例如,如果一个桶包含由多边形和线组成的形状,那么线不会对质心指标产生贡献。 每种形状的质心计算方式不同。 通过Circle摄取的包络和圆被视为多边形。
| Geometry Type | Centroid Calculation |
|---|---|
[多]点 |
所有坐标的等权重平均值 |
[多]线串 |
每个段的所有质心的加权平均值,其中每个段的权重是其长度,单位与坐标相同 |
[多]多边形 |
多边形中所有三角形的所有质心的加权平均值,其中三角形由每两个连续的顶点和起点形成。 孔具有负权重。权重表示三角形的面积,以坐标单位的平方计算 |
几何集合 |
所有基础几何图形中具有最高维度的几何图形的质心。如果存在多边形和线和/或点,则线和/或点将被忽略。如果存在线和点,则点将被忽略。 |
示例:
PUT /places
{
"mappings": {
"properties": {
"geometry": {
"type": "shape"
}
}
}
}
POST /places/_bulk?refresh
{"index":{"_id":1}}
{"name": "NEMO Science Museum", "geometry": "POINT(491.2350 5237.4081)" }
{"index":{"_id":2}}
{"name": "Sportpark De Weeren", "geometry": { "type": "Polygon", "coordinates": [ [ [ 496.5305328369141, 5239.347642069457 ], [ 496.6979026794433, 5239.1721758934835 ], [ 496.9425201416015, 5239.238958618537 ], [ 496.7944622039794, 5239.420969150824 ], [ 496.5305328369141, 5239.347642069457 ] ] ] } }
POST /places/_search?size=0
{
"aggs": {
"centroid": {
"cartesian_centroid": {
"field": "geometry"
}
}
}
}
{
...
"aggregations": {
"centroid": {
"location": {
"x": 496.74041748046875,
"y": 5239.29638671875
},
"count": 2
}
}
}
矩阵统计聚合
editThe matrix_stats aggregation 是一种数值聚合,用于计算一组文档字段的以下统计数据:
|
|
计算中包含的每个字段的样本数量。 |
|
|
每个字段的平均值。 |
|
|
每个字段的测量值,用于衡量样本与均值的分散程度。 |
|
|
每个字段的测量值量化了围绕均值的不对称分布。 |
|
|
每个字段的测量值,量化分布的形状。 |
|
|
一个定量描述一个领域变化如何与另一个领域相关联的矩阵。 |
|
|
协方差矩阵缩放到-1到1的范围,包括-1和1。描述字段分布之间的关系。 |
与其他指标聚合不同,matrix_stats 聚合不支持脚本。
以下示例演示了使用矩阵统计来描述收入与贫困之间的关系。
GET /_search
{
"aggs": {
"statistics": {
"matrix_stats": {
"fields": [ "poverty", "income" ]
}
}
}
}
聚合类型是 matrix_stats,而 fields 设置定义了用于计算统计信息的一组字段(作为数组)。上述请求返回以下响应:
{
...
"aggregations": {
"statistics": {
"doc_count": 50,
"fields": [ {
"name": "income",
"count": 50,
"mean": 51985.1,
"variance": 7.383377037755103E7,
"skewness": 0.5595114003506483,
"kurtosis": 2.5692365287787124,
"covariance": {
"income": 7.383377037755103E7,
"poverty": -21093.65836734694
},
"correlation": {
"income": 1.0,
"poverty": -0.8352655256272504
}
}, {
"name": "poverty",
"count": 50,
"mean": 12.732000000000001,
"variance": 8.637730612244896,
"skewness": 0.4516049811903419,
"kurtosis": 2.8615929677997767,
"covariance": {
"income": -21093.65836734694,
"poverty": 8.637730612244896
},
"correlation": {
"income": -0.8352655256272504,
"poverty": 1.0
}
} ]
}
}
}
The doc_count 字段表示参与统计计算的文档数量。
多值字段
editThe matrix_stats aggregation treats each document field as an independent sample. The mode parameter controls what
array value the aggregation will use for array or multi-valued fields. This parameter can take one of the following:
|
|
(默认) 使用所有值的平均值。 |
|
|
选择最低值。 |
|
|
选择最高值。 |
|
|
使用所有值的总和。 |
|
|
使用所有值的中位数。 |
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有某个值。这是通过添加一组字段名 : 值映射来为每个字段指定默认值来实现的。
最大值聚合
edit一个单值指标聚合,用于跟踪并返回从聚合文档中提取的数值中的最大值。
聚合操作在数据的 double 表示上进行。因此,当处理绝对值大于 2^53 的长整型时,结果可能是近似的。
计算所有文档中的最大价格值
POST /sales/_search?size=0
{
"aggs": {
"max_price": { "max": { "field": "price" } }
}
}
响应:
{
...
"aggregations": {
"max_price": {
"value": 200.0
}
}
}
如上所示,聚合的名称(max_price)也作为从返回的响应中检索聚合结果的键。
脚本
edit如果你需要获取比单个字段更复杂的某个值的最大值,请在运行时字段上运行聚合。
POST /sales/_search
{
"size": 0,
"runtime_mappings": {
"price.adjusted": {
"type": "double",
"script": """
double price = doc['price'].value;
if (doc['promoted'].value) {
price *= 0.8;
}
emit(price);
"""
}
},
"aggs": {
"max_price": {
"max": { "field": "price.adjusted" }
}
}
}
缺失值
edit参数missing定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有某个值。
直方图字段
edit当在直方图字段上计算max时,聚合的结果是values数组中所有元素的最大值。请注意,直方图的counts数组被忽略了。
例如,对于以下存储不同网络的延迟指标的预聚合直方图的索引:
PUT metrics_index
{
"mappings": {
"properties": {
"latency_histo": { "type": "histogram" }
}
}
}
PUT metrics_index/_doc/1?refresh
{
"network.name" : "net-1",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [3, 7, 23, 12, 6]
}
}
PUT metrics_index/_doc/2?refresh
{
"network.name" : "net-2",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [8, 17, 8, 7, 6]
}
}
POST /metrics_index/_search?size=0&filter_path=aggregations
{
"aggs" : {
"max_latency" : { "max" : { "field" : "latency_histo" } }
}
}
聚合将返回所有直方图字段的最大值:
{
"aggregations": {
"max_latency": {
"value": 0.5
}
}
}
中位数绝对偏差聚合
edit这个 单值 聚合近似于其搜索结果的 中位数绝对偏差。
中位数绝对偏差是一种变异性度量。它是一种稳健统计量,意味着它对于描述可能存在异常值或非正态分布的数据非常有用。对于此类数据,它可能比标准差更具描述性。
它是通过计算每个数据点与整个样本中位数的偏差的中位数来计算的。也就是说,对于一个随机变量 X,中位数绝对偏差是中位数(|中位数(X) - Xi|)。
示例
edit假设我们的数据代表产品在一到五星评分范围内的评论。 这类评论通常被总结为一个平均值,这很容易理解 但并不能描述评论的变异性。估计中位数绝对偏差可以提供关于评论之间差异的洞察。
在这个例子中,我们有一个产品,它的平均评分为3星。让我们看看它的评分的绝对中位差,以确定它们的差异程度。
GET reviews/_search
{
"size": 0,
"aggs": {
"review_average": {
"avg": {
"field": "rating"
}
},
"review_variability": {
"median_absolute_deviation": {
"field": "rating"
}
}
}
}
结果的中位数绝对偏差为 2,这表明评分的变异性相当大。评论者对该产品的意见一定非常多样化。
{
...
"aggregations": {
"review_average": {
"value": 3.0
},
"review_variability": {
"value": 2.0
}
}
}
近似
edit计算中位数绝对偏差的朴素实现会将整个样本存储在内存中,因此此聚合改为计算一个近似值。它使用TDigest数据结构来近似样本中位数和样本中位数偏差的中位数。有关TDigest近似特性的更多信息,请参阅百分位数通常是近似的。
TDigest的分位数近似值的资源使用与准确性之间的权衡,以及因此这个聚合的中位数绝对偏差近似值的准确性,是由compression参数控制的。较高的compression设置提供了更准确的近似值,但代价是更高的内存使用。有关TDigestcompression参数的特性的更多信息,请参见Compression。
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"field": "rating",
"compression": 100
}
}
}
}
此聚合的默认 compression 值为 1000。在此压缩级别下,此聚合通常在精确结果的 5% 以内,但观察到的性能将取决于样本数据。
脚本
edit在上面的示例中,产品评论的评分范围是从一到五。如果您想将其修改为一到十的评分范围,请使用运行时字段。
GET reviews/_search?filter_path=aggregations
{
"size": 0,
"runtime_mappings": {
"rating.out_of_ten": {
"type": "long",
"script": {
"source": "emit(doc['rating'].value * params.scaleFactor)",
"params": {
"scaleFactor": 2
}
}
}
},
"aggs": {
"review_average": {
"avg": {
"field": "rating.out_of_ten"
}
},
"review_variability": {
"median_absolute_deviation": {
"field": "rating.out_of_ten"
}
}
}
}
这将导致:
{
"aggregations": {
"review_average": {
"value": 6.0
},
"review_variability": {
"value": 4.0
}
}
}
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有某个值。
让我们乐观一点,假设一些评论者非常喜欢这个产品,以至于他们忘记了给它评分。我们将给他们五星
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"field": "rating",
"missing": 5
}
}
}
}
最小值聚合
edit一个单值指标聚合,用于跟踪并返回从聚合文档中提取的数值中的最小值。
聚合操作在数据的 double 表示上进行。因此,当处理绝对值大于 2^53 的长整型时,结果可能是近似的。
计算所有文档中的最小价格值:
POST /sales/_search?size=0
{
"aggs": {
"min_price": { "min": { "field": "price" } }
}
}
响应:
{
...
"aggregations": {
"min_price": {
"value": 10.0
}
}
}
如上所示,聚合的名称(min_price)也作为从返回的响应中检索聚合结果的键。
脚本
edit如果你需要获取比单个字段更复杂的事物的最小值,请在运行时字段上运行聚合。
POST /sales/_search
{
"size": 0,
"runtime_mappings": {
"price.adjusted": {
"type": "double",
"script": """
double price = doc['price'].value;
if (doc['promoted'].value) {
price *= 0.8;
}
emit(price);
"""
}
},
"aggs": {
"min_price": {
"min": { "field": "price.adjusted" }
}
}
}
缺失值
edit参数missing定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有某个值。
直方图字段
edit当在直方图字段上计算min时,聚合的结果是values数组中所有元素的最小值。请注意,直方图的counts数组被忽略了。
例如,对于以下存储不同网络的延迟指标的预聚合直方图的索引:
PUT metrics_index
{
"mappings": {
"properties": {
"latency_histo": { "type": "histogram" }
}
}
}
PUT metrics_index/_doc/1?refresh
{
"network.name" : "net-1",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [3, 7, 23, 12, 6]
}
}
PUT metrics_index/_doc/2?refresh
{
"network.name" : "net-2",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [8, 17, 8, 7, 6]
}
}
POST /metrics_index/_search?size=0&filter_path=aggregations
{
"aggs" : {
"min_latency" : { "min" : { "field" : "latency_histo" } }
}
}
The min aggregation 将返回所有直方图字段的最小值:
{
"aggregations": {
"min_latency": {
"value": 0.1
}
}
}
百分位排名聚合
edit一个多值指标聚合,用于计算一个或多个百分位秩,这些百分位秩基于从聚合文档中提取的数值。这些值可以从文档中的特定数值或直方图字段中提取。
请参阅百分位数通常是近似的, 压缩和 执行提示以获取有关百分位数排名聚合的近似值、性能和内存使用的建议
百分位排名显示低于某个特定值的观测值的百分比。例如,如果一个值大于或等于95%的观测值,则称其为第95百分位排名。
假设您的数据由网站加载时间组成。您可能有一个服务协议,其中95%的页面加载在500毫秒内完成,99%的页面加载在600毫秒内完成。
让我们来看一下表示加载时间的百分位范围:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"field": "load_time",
"values": [ 500, 600 ]
}
}
}
}
响应将会是这样的:
{
...
"aggregations": {
"load_time_ranks": {
"values": {
"500.0": 55.0,
"600.0": 64.0
}
}
}
}
根据这些信息,您可以确定您达到了99%的加载时间目标,但尚未完全达到95%的加载时间目标
键控响应
edit默认情况下,keyed 标志设置为 true,它将唯一的字符串键与每个桶关联,并将范围作为哈希而不是数组返回。将 keyed 标志设置为 false 将禁用此行为:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"field": "load_time",
"values": [ 500, 600 ],
"keyed": false
}
}
}
}
响应:
{
...
"aggregations": {
"load_time_ranks": {
"values": [
{
"key": 500.0,
"value": 55.0
},
{
"key": 600.0,
"value": 64.0
}
]
}
}
}
脚本
edit如果你需要对未索引的值进行聚合操作,请使用运行时字段。例如,如果我们的加载时间是以毫秒为单位,但我们希望以秒为单位计算百分位数:
GET latency/_search
{
"size": 0,
"runtime_mappings": {
"load_time.seconds": {
"type": "long",
"script": {
"source": "emit(doc['load_time'].value / params.timeUnit)",
"params": {
"timeUnit": 1000
}
}
}
},
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"values": [ 500, 600 ],
"field": "load_time.seconds"
}
}
}
}
HDR 直方图
editHDR Histogram(高动态范围直方图)是一个替代实现,在计算延迟测量的百分位排名时非常有用,因为它可以比t-digest实现更快,但代价是内存占用更大。此实现保持固定的最坏情况百分比误差(以有效位数指定)。这意味着,如果在直方图中记录了从1微秒到1小时(3,600,000,000微秒)的值,并设置为3位有效数字,它将保持1微秒的值分辨率,直到1毫秒,并且在最大跟踪值(1小时)时保持3.6秒(或更好)的分辨率。
可以通过在请求中指定hdr对象来使用HDR直方图:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"field": "load_time",
"values": [ 500, 600 ],
"hdr": {
"number_of_significant_value_digits": 3
}
}
}
}
}
|
|
|
|
|
HDRHistogram 仅支持正数值,如果传递负值将会报错。如果值的范围未知,也不建议使用 HDRHistogram,因为这可能会导致内存使用量过高。
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
百分位数聚合
edit一个多值指标聚合,用于计算从聚合文档中提取的数值的一个或多个百分位数。这些值可以从文档中的特定数值或直方图字段中提取。
百分位数显示在某个百分比处观察到的值。例如,第95百分位数是大于95%观察值的值。
百分位数常用于查找异常值。在正态分布中,0.13和99.87百分位数表示距离均值三个标准差。任何落在三个标准差之外的数据通常被认为是异常值。
当检索到一系列百分位数时,它们可以用来估计数据分布并确定数据是否偏斜、双峰等。
假设您的数据由网站加载时间组成。平均值和中位数加载时间对管理员来说并不是特别有用。最大值可能是有趣的,但它可能会被单个缓慢的响应轻易地扭曲。
让我们来看一下表示加载时间的百分位范围:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time"
}
}
}
}
默认情况下,percentile 指标将生成一系列百分位数:[ 1, 5, 25, 50, 75, 95, 99 ]。响应将如下所示:
{
...
"aggregations": {
"load_time_outlier": {
"values": {
"1.0": 10.0,
"5.0": 30.0,
"25.0": 170.0,
"50.0": 445.0,
"75.0": 720.0,
"95.0": 940.0,
"99.0": 980.0
}
}
}
}
如您所见,聚合将返回默认范围内每个百分位的计算值。如果我们假设响应时间是以毫秒为单位,那么很明显网页通常在10-725毫秒内加载,但偶尔会飙升至945-985毫秒。
通常,管理员只对异常值感兴趣——极端百分位数。 我们可以指定我们感兴趣的百分位数(请求的百分位数 必须是一个介于0-100之间的值,包括0和100):
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"percents": [ 95, 99, 99.9 ]
}
}
}
}
键控响应
edit默认情况下,keyed 标志设置为 true,这将为每个桶关联一个唯一的字符串键,并将范围作为哈希而不是数组返回。将 keyed 标志设置为 false 将禁用此行为:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"keyed": false
}
}
}
}
响应:
{
...
"aggregations": {
"load_time_outlier": {
"values": [
{
"key": 1.0,
"value": 10.0
},
{
"key": 5.0,
"value": 30.0
},
{
"key": 25.0,
"value": 170.0
},
{
"key": 50.0,
"value": 445.0
},
{
"key": 75.0,
"value": 720.0
},
{
"key": 95.0,
"value": 940.0
},
{
"key": 99.0,
"value": 980.0
}
]
}
}
}
脚本
edit如果你需要对未索引的值进行聚合操作,请使用运行时字段。例如,如果我们的加载时间是以毫秒为单位,但你想以秒为单位计算百分位数:
GET latency/_search
{
"size": 0,
"runtime_mappings": {
"load_time.seconds": {
"type": "long",
"script": {
"source": "emit(doc['load_time'].value / params.timeUnit)",
"params": {
"timeUnit": 1000
}
}
}
},
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time.seconds"
}
}
}
}
百分位数通常是近似的
edit有许多不同的算法来计算百分位数。天真的实现只是将所有值存储在一个已排序的数组中。要找到第50个百分位数,你只需找到位于my_array[count(my_array) * 0.5]的值。
显然,朴素的实现方式无法扩展——排序数组随着数据集中值的数量线性增长。为了在Elasticsearch集群中计算可能包含数十亿个值的百分位数,会计算近似百分位数。
用于 percentile 指标的算法称为 TDigest(由 Ted Dunning 在
Computing Accurate Quantiles using T-Digests 中引入)。
使用此指标时,请记住以下几点指导原则:
-
准确性与
q(1-q)成正比。这意味着极端百分位数(例如99%)比不太极端的百分位数(例如中位数)更准确。 - 对于小数据集,百分位数非常准确(如果数据足够小,甚至可以达到100%准确)。
- 随着桶中值的数量增加,算法开始近似计算百分位数。它实际上是在用准确性换取内存节省。确切的不准确程度很难概括,因为它取决于您的数据分布和正在聚合的数据量。
以下图表显示了在均匀分布上,根据收集的值的数量和请求的分位数,相对误差的差异:
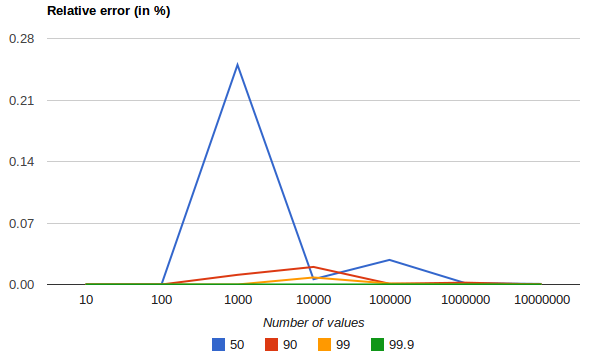
它展示了对于极端百分位数,精度是如何更好的。误差随着数值数量的增加而减小的原因是,大数定律使得数值的分布越来越均匀,而t-digest树能够更好地对其进行总结。在更偏斜的分布上,情况则不会如此。
百分位数聚合也是 非确定性的。 这意味着使用相同的数据可能会得到稍微不同的结果。
压缩
edit近似算法必须在内存利用率和估计精度之间取得平衡。
这种平衡可以通过使用压缩参数来控制:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"tdigest": {
"compression": 200
}
}
}
}
}
TDigest算法使用多个“节点”来近似百分位数——可用节点越多,精度越高(以及与数据量成比例的大内存占用)。compression参数限制最大节点数为20 * compression。
因此,通过增加压缩值,您可以在消耗更多内存的情况下提高百分位数的准确性。较大的压缩值也会使算法变慢,因为底层树数据结构的大小增加,导致操作成本更高。默认的压缩值是100。
一个“节点”大约使用32字节的内存,因此在最坏情况下(大量数据按顺序到达),默认设置将生成一个大约64KB大小的TDigest。实际上,数据往往更加随机,TDigest将使用更少的内存。
执行提示
editTDigest 的默认实现针对性能进行了优化,能够在保持可接受精度水平(在某些情况下,对于数百万个样本,相对误差接近 1%)的同时,扩展到数百万甚至数十亿个样本值。可以通过将参数 execution_hint 设置为值 high_accuracy 来选择使用针对精度优化的实现:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"tdigest": {
"execution_hint": "high_accuracy"
}
}
}
}
}
此选项可以提高准确性(在某些情况下,对于数百万个样本,相对误差接近0.01%),但百分位查询的完成时间会增加2倍到10倍。
HDR 直方图
editHDR Histogram(高动态范围直方图)是一种替代实现,在计算延迟测量的百分位数时非常有用,因为它可以比t-digest实现更快,但代价是内存占用更大。此实现保持固定的最坏情况百分比误差(以有效位数指定)。这意味着,如果在直方图中记录了从1微秒到1小时(3,600,000,000微秒)的值,并设置为3位有效数字,它将在1毫秒以内保持1微秒的值分辨率,并在最大跟踪值(1小时)时保持3.6秒(或更好)的分辨率。
可以通过在请求中指定hdr参数来使用HDR直方图:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"percents": [ 95, 99, 99.9 ],
"hdr": {
"number_of_significant_value_digits": 3
}
}
}
}
}
|
|
|
|
|
HDRHistogram 仅支持正数值,如果传递负值将会报错。如果值的范围未知,也不建议使用 HDRHistogram,因为这可能会导致内存使用量过高。
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
速率聚合
edit一个 rate 指标聚合只能在 date_histogram 或 composite 聚合内部使用。它计算每个桶中的文档速率或字段速率。字段值可以从文档中的特定数值或 直方图字段 中提取。
对于复合聚合,必须有且仅有一个日期直方图源,以便支持速率聚合。
语法
edit一个 rate 聚合单独看起来像这样:
{
"rate": {
"unit": "month",
"field": "requests"
}
}
以下请求将所有销售记录按月分组,然后将每个分组中的销售交易数量转换为每年的销售率。
GET sales/_search
{
"size": 0,
"aggs": {
"by_date": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"my_rate": {
"rate": {
"unit": "year"
}
}
}
}
}
}
响应将返回每个桶中的年度交易率。由于每年有12个月,年度率将通过将月度率乘以12自动计算。
{
...
"aggregations" : {
"by_date" : {
"buckets" : [
{
"key_as_string" : "2015/01/01 00:00:00",
"key" : 1420070400000,
"doc_count" : 3,
"my_rate" : {
"value" : 36.0
}
},
{
"key_as_string" : "2015/02/01 00:00:00",
"key" : 1422748800000,
"doc_count" : 2,
"my_rate" : {
"value" : 24.0
}
},
{
"key_as_string" : "2015/03/01 00:00:00",
"key" : 1425168000000,
"doc_count" : 2,
"my_rate" : {
"value" : 24.0
}
}
]
}
}
}
除了统计文档数量外,还可以计算每个桶中文档字段值的总和,或者每个桶中值的数量。以下请求将所有销售记录按月分组,然后计算每月的总销售额,并将其转换为每日平均销售额。
GET sales/_search
{
"size": 0,
"aggs": {
"by_date": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"avg_price": {
"rate": {
"field": "price",
"unit": "day"
}
}
}
}
}
}
响应将包含每个月的平均日销售价格。
{
...
"aggregations" : {
"by_date" : {
"buckets" : [
{
"key_as_string" : "2015/01/01 00:00:00",
"key" : 1420070400000,
"doc_count" : 3,
"avg_price" : {
"value" : 17.741935483870968
}
},
{
"key_as_string" : "2015/02/01 00:00:00",
"key" : 1422748800000,
"doc_count" : 2,
"avg_price" : {
"value" : 2.142857142857143
}
},
{
"key_as_string" : "2015/03/01 00:00:00",
"key" : 1425168000000,
"doc_count" : 2,
"avg_price" : {
"value" : 12.096774193548388
}
}
]
}
}
}
您还可以利用复合聚合来计算库存中每个商品的平均每日销售价格
GET sales/_search?filter_path=aggregations&size=0
{
"aggs": {
"buckets": {
"composite": {
"sources": [
{
"month": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
}
}
},
{
"type": {
"terms": {
"field": "type"
}
}
}
]
},
"aggs": {
"avg_price": {
"rate": {
"field": "price",
"unit": "day"
}
}
}
}
}
}
响应将包含每个商品每月每日平均销售价格。
{
"aggregations" : {
"buckets" : {
"after_key" : {
"month" : 1425168000000,
"type" : "t-shirt"
},
"buckets" : [
{
"key" : {
"month" : 1420070400000,
"type" : "bag"
},
"doc_count" : 1,
"avg_price" : {
"value" : 4.838709677419355
}
},
{
"key" : {
"month" : 1420070400000,
"type" : "hat"
},
"doc_count" : 1,
"avg_price" : {
"value" : 6.451612903225806
}
},
{
"key" : {
"month" : 1420070400000,
"type" : "t-shirt"
},
"doc_count" : 1,
"avg_price" : {
"value" : 6.451612903225806
}
},
{
"key" : {
"month" : 1422748800000,
"type" : "hat"
},
"doc_count" : 1,
"avg_price" : {
"value" : 1.7857142857142858
}
},
{
"key" : {
"month" : 1422748800000,
"type" : "t-shirt"
},
"doc_count" : 1,
"avg_price" : {
"value" : 0.35714285714285715
}
},
{
"key" : {
"month" : 1425168000000,
"type" : "hat"
},
"doc_count" : 1,
"avg_price" : {
"value" : 6.451612903225806
}
},
{
"key" : {
"month" : 1425168000000,
"type" : "t-shirt"
},
"doc_count" : 1,
"avg_price" : {
"value" : 5.645161290322581
}
}
]
}
}
}
通过添加mode参数并将其值设置为value_count,我们可以将计算从sum更改为字段值的数量:
GET sales/_search
{
"size": 0,
"aggs": {
"by_date": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"avg_number_of_sales_per_year": {
"rate": {
"field": "price",
"unit": "year",
"mode": "value_count"
}
}
}
}
}
}
响应将包含每个月的平均日销售价格。
{
...
"aggregations" : {
"by_date" : {
"buckets" : [
{
"key_as_string" : "2015/01/01 00:00:00",
"key" : 1420070400000,
"doc_count" : 3,
"avg_number_of_sales_per_year" : {
"value" : 36.0
}
},
{
"key_as_string" : "2015/02/01 00:00:00",
"key" : 1422748800000,
"doc_count" : 2,
"avg_number_of_sales_per_year" : {
"value" : 24.0
}
},
{
"key_as_string" : "2015/03/01 00:00:00",
"key" : 1425168000000,
"doc_count" : 2,
"avg_number_of_sales_per_year" : {
"value" : 24.0
}
}
]
}
}
}
默认情况下使用 sum 模式。
-
"mode": "sum" - 计算所有值字段的总和
-
"mode": "value_count" - 使用字段中的值的数量
桶大小与速率之间的关系
editThe rate aggregation supports all rate that can be used calendar_intervals parameter of date_histogram
aggregation. The specified rate should compatible with the date_histogram aggregation interval, i.e. it should be possible to
convert the bucket size into the rate. By default the interval of the date_histogram is used.
-
"rate": "second" - 兼容所有区间
-
"rate": "minute" - 兼容所有区间
-
"rate": "hour" - 兼容所有区间
-
"rate": "day" - 兼容所有区间
-
"rate": "week" - 兼容所有区间
-
"rate": "month" -
仅兼容
month、quarter和year日历间隔 -
"rate": "quarter" -
仅兼容
month、quarter和year日历间隔 -
"rate": "year" -
仅兼容
month、quarter和year日历间隔
如果日期直方图不是速率直方图的直接父级,也存在额外的限制。在这种情况下,速率间隔和直方图间隔必须在同一组中:[秒, `分钟`, 小时, 天, 周] 或 [月, 季度, 年]。例如,如果日期直方图是基于月的,则仅支持月、季度或年的速率间隔。如果日期直方图是基于天的,则仅支持秒、`分钟`、小时、天和周的速率间隔。
脚本
edit如果您需要对未索引的值进行聚合操作,请在运行时字段上运行聚合。例如,如果我们需要在计算费率之前调整价格:
GET sales/_search
{
"size": 0,
"runtime_mappings": {
"price.adjusted": {
"type": "double",
"script": {
"source": "emit(doc['price'].value * params.adjustment)",
"params": {
"adjustment": 0.9
}
}
}
},
"aggs": {
"by_date": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"avg_price": {
"rate": {
"field": "price.adjusted"
}
}
}
}
}
}
{
...
"aggregations" : {
"by_date" : {
"buckets" : [
{
"key_as_string" : "2015/01/01 00:00:00",
"key" : 1420070400000,
"doc_count" : 3,
"avg_price" : {
"value" : 495.0
}
},
{
"key_as_string" : "2015/02/01 00:00:00",
"key" : 1422748800000,
"doc_count" : 2,
"avg_price" : {
"value" : 54.0
}
},
{
"key_as_string" : "2015/03/01 00:00:00",
"key" : 1425168000000,
"doc_count" : 2,
"avg_price" : {
"value" : 337.5
}
}
]
}
}
}
脚本化度量聚合
edit一种使用脚本执行并提供度量输出的度量聚合。
scripted_metric 在 Elastic Cloud 无服务器环境中不可用。
使用脚本可能导致搜索速度变慢。请参阅 脚本、缓存和搜索速度。
示例:
POST ledger/_search?size=0
{
"query": {
"match_all": {}
},
"aggs": {
"profit": {
"scripted_metric": {
"init_script": "state.transactions = []",
"map_script": "state.transactions.add(doc.type.value == 'sale' ? doc.amount.value : -1 * doc.amount.value)",
"combine_script": "double profit = 0; for (t in state.transactions) { profit += t } return profit",
"reduce_script": "double profit = 0; for (a in states) { profit += a } return profit"
}
}
}
}
上述聚合展示了如何使用脚本聚合计算销售和成本交易的总利润。
上述聚合的响应:
{
"took": 218,
...
"aggregations": {
"profit": {
"value": 240.0
}
}
}
上述示例也可以使用存储脚本来指定,如下所示:
POST ledger/_search?size=0
{
"aggs": {
"profit": {
"scripted_metric": {
"init_script": {
"id": "my_init_script"
},
"map_script": {
"id": "my_map_script"
},
"combine_script": {
"id": "my_combine_script"
},
"params": {
"field": "amount"
},
"reduce_script": {
"id": "my_reduce_script"
}
}
}
}
}
有关指定脚本的更多详细信息,请参阅脚本文档。
允许的返回类型
edit虽然任何有效的脚本对象都可以在单个脚本中使用,但脚本必须返回或存储在 state 对象中仅限于以下类型:
- 基本类型
- 字符串
- 映射(仅包含此处列出的类型的键和值)
- 数组(仅包含此处列出的类型的元素)
脚本的范围
edit脚本化指标聚合在执行的4个阶段使用脚本:
- init_script
-
在收集任何文档之前执行。允许聚合设置任何初始状态。
在上面的示例中,
init_script在state对象中创建了一个数组transactions。 - map_script
-
每收集一个文档执行一次。这是一个必需的脚本。
在上面的示例中,
map_script检查 type 字段的值。如果值是 sale,则将 amount 字段的值添加到 transactions 数组中。如果 type 字段的值不是 sale,则将 amount 字段的负值添加到 transactions 中。 - combine_script
-
在文档收集完成后,每个分片执行一次。这是一个必需的脚本。允许聚合从每个分片返回的状态进行合并。
在上面的示例中,
combine_script遍历所有存储的事务,将profit变量中的值相加,最后返回profit。 - reduce_script
-
在所有分片返回结果后,在协调节点上执行一次。这是一个必需的脚本。脚本可以访问一个名为
states的变量,该变量是每个分片上 combine_script 结果的数组。在上面的示例中,
reduce_script遍历每个分片返回的profit,在返回最终合并的利润之前对这些值进行求和,该利润将作为聚合响应的一部分返回。
工作示例
edit想象一下,您将以下文档索引到一个包含2个分片的索引中的情况:
PUT /transactions/_bulk?refresh
{"index":{"_id":1}}
{"type": "sale","amount": 80}
{"index":{"_id":2}}
{"type": "cost","amount": 10}
{"index":{"_id":3}}
{"type": "cost","amount": 30}
{"index":{"_id":4}}
{"type": "sale","amount": 130}
假设文档1和3最终落在分片A上,文档2和4最终落在分片B上。以下是上述示例中每个阶段的聚合结果的详细说明。
初始化脚本之后
edit这是在每个分片上执行文档收集之前运行一次的操作,因此我们将在每个分片上都有一个副本:
- Shard A
-
"state" : { "transactions" : [] } - Shard B
-
"state" : { "transactions" : [] }
地图脚本之后
edit每个分片收集其文档并在收集的每个文档上运行map_script:
- Shard A
-
"state" : { "transactions" : [ 80, -30 ] } - Shard B
-
"state" : { "transactions" : [ -10, 130 ] }
合并脚本后
editcombine_script 在文档收集完成后在每个分片上执行,并将所有交易减少为每个分片的单一利润值(通过将交易数组中的值相加),该值将传递回协调节点:
- Shard A
- 50
- Shard B
- 120
reduce_script 之后
editreduce_script 接收一个包含每个分片 combine script 结果的 states 数组:
"states" : [
50,
120
]
它将分片的响应减少到一个最终的整体利润数字(通过求和值),并将此作为聚合的结果返回以生成响应:
{
...
"aggregations": {
"profit": {
"value": 170
}
}
}
其他参数
edit|
参数 |
可选。一个对象,其内容将作为变量传递给 "params" : {}
|
空桶
edit如果脚本化度量聚合的父桶没有收集任何文档,将从分片返回一个空的聚合响应,其值为null。在这种情况下,reduce_script的states变量将包含来自该分片的null响应。因此,reduce_script应该预期并处理来自分片的null响应。
统计聚合
edit一个多值指标聚合,用于计算从聚合文档中提取的数值的统计信息。
返回的统计数据包括:min、max、sum、count 和 avg。
假设数据由代表学生考试成绩(介于0到100之间)的文档组成
POST /exams/_search?size=0
{
"aggs": {
"grades_stats": { "stats": { "field": "grade" } }
}
}
上述聚合计算了所有文档的成绩统计数据。聚合类型是stats,而field设置定义了将计算统计数据的文档的数值字段。上述操作将返回以下内容:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0
}
}
}
聚合的名称(如上例中的grades_stats)也作为从返回响应中检索聚合结果的键。
脚本
edit如果你需要获取比单个字段更复杂的统计信息,请在运行时字段上运行聚合。
POST /exams/_search
{
"size": 0,
"runtime_mappings": {
"grade.weighted": {
"type": "double",
"script": """
emit(doc['grade'].value * doc['weight'].value)
"""
}
},
"aggs": {
"grades_stats": {
"stats": {
"field": "grade.weighted"
}
}
}
}
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
字符串统计聚合
edit一个多值指标聚合,用于计算从聚合文档中提取的字符串值的统计信息。
这些值可以从特定的关键词字段中检索。
字符串统计聚合返回以下结果:
-
count- 计算的非空字段数量。 -
min_length- 最短词项的长度。 -
max_length- 最长词项的长度。 -
avg_length- 所有词项的平均长度。 -
entropy- 通过聚合收集的所有词项计算的香农熵值。香农熵量化了字段中包含的信息量。它是衡量数据集多样性、相似性、随机性等广泛属性的非常有用的指标。
例如:
POST /my-index-000001/_search?size=0
{
"aggs": {
"message_stats": { "string_stats": { "field": "message.keyword" } }
}
}
上述聚合计算了所有文档中message字段的字符串统计信息。聚合类型是string_stats,而field参数定义了将对其进行统计计算的文档字段。上述操作将返回以下内容:
{
...
"aggregations": {
"message_stats": {
"count": 5,
"min_length": 24,
"max_length": 30,
"avg_length": 28.8,
"entropy": 3.94617750050791
}
}
}
聚合的名称(如上所示的message_stats)也作为从返回的响应中检索聚合结果的键。
字符分布
edit香农熵值的计算基于聚合收集的所有词项中每个字符出现的概率。要查看所有字符的概率分布,我们可以添加 show_distribution(默认值:false)参数。
POST /my-index-000001/_search?size=0
{
"aggs": {
"message_stats": {
"string_stats": {
"field": "message.keyword",
"show_distribution": true
}
}
}
}
{
...
"aggregations": {
"message_stats": {
"count": 5,
"min_length": 24,
"max_length": 30,
"avg_length": 28.8,
"entropy": 3.94617750050791,
"distribution": {
" ": 0.1527777777777778,
"e": 0.14583333333333334,
"s": 0.09722222222222222,
"m": 0.08333333333333333,
"t": 0.0763888888888889,
"h": 0.0625,
"a": 0.041666666666666664,
"i": 0.041666666666666664,
"r": 0.041666666666666664,
"g": 0.034722222222222224,
"n": 0.034722222222222224,
"o": 0.034722222222222224,
"u": 0.034722222222222224,
"b": 0.027777777777777776,
"w": 0.027777777777777776,
"c": 0.013888888888888888,
"E": 0.006944444444444444,
"l": 0.006944444444444444,
"1": 0.006944444444444444,
"2": 0.006944444444444444,
"3": 0.006944444444444444,
"4": 0.006944444444444444,
"y": 0.006944444444444444
}
}
}
}
The distribution 对象显示了每个字符在所有术语中出现的概率。字符按概率降序排列。
脚本
edit如果你需要获取比单个字段更复杂的string_stats,请在运行时字段上运行聚合。
POST /my-index-000001/_search
{
"size": 0,
"runtime_mappings": {
"message_and_context": {
"type": "keyword",
"script": """
emit(doc['message.keyword'].value + ' ' + doc['context.keyword'].value)
"""
}
},
"aggs": {
"message_stats": {
"string_stats": { "field": "message_and_context" }
}
}
}
缺失值
edit参数missing定义了如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
求和聚合
edit一个单值指标聚合,它对从聚合文档中提取的数值进行求和。
这些值可以从特定的数值或直方图字段中提取。
假设数据由表示销售记录的文档组成,我们可以对所有帽子的销售价格进行求和:
POST /sales/_search?size=0
{
"query": {
"constant_score": {
"filter": {
"match": { "type": "hat" }
}
}
},
"aggs": {
"hat_prices": { "sum": { "field": "price" } }
}
}
结果为:
{
...
"aggregations": {
"hat_prices": {
"value": 450.0
}
}
}
聚合的名称(如上例中的hat_prices)也作为从返回的响应中检索聚合结果的键。
脚本
edit如果你需要对一个比单个字段更复杂的对象求和,可以在一个运行时字段上运行聚合。
POST /sales/_search?size=0
{
"runtime_mappings": {
"price.weighted": {
"type": "double",
"script": """
double price = doc['price'].value;
if (doc['promoted'].value) {
price *= 0.8;
}
emit(price);
"""
}
},
"query": {
"constant_score": {
"filter": {
"match": { "type": "hat" }
}
}
},
"aggs": {
"hat_prices": {
"sum": {
"field": "price.weighted"
}
}
}
}
缺失值
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,缺少值的文档将被忽略,但也可以将它们视为具有某个值。例如,这将所有没有价格的帽子销售视为 100。
直方图字段
edit当对直方图字段进行求和计算时,聚合的结果是values数组中所有元素的总和乘以counts数组中相同位置的数字。
例如,对于以下存储不同网络的延迟指标的预聚合直方图的索引:
PUT metrics_index
{
"mappings": {
"properties": {
"latency_histo": { "type": "histogram" }
}
}
}
PUT metrics_index/_doc/1?refresh
{
"network.name" : "net-1",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [3, 7, 23, 12, 6]
}
}
PUT metrics_index/_doc/2?refresh
{
"network.name" : "net-2",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [8, 17, 8, 7, 6]
}
}
POST /metrics_index/_search?size=0&filter_path=aggregations
{
"aggs" : {
"total_latency" : { "sum" : { "field" : "latency_histo" } }
}
}
对于每个直方图字段,sum 聚合将把 values 数组中的每个数字乘以其对应的 counts 数组中的计数,然后相加。
最终,它将所有直方图的所有值相加并返回以下结果:
{
"aggregations": {
"total_latency": {
"value": 28.8
}
}
}
T检验聚合
edit一个 t_test 指标聚合,它在从聚合文档中提取的数值上执行统计假设检验,其中检验统计量在零假设下遵循学生 t 分布。实际上,这将告诉你两个总体均值之间的差异是否具有统计显著性,并且不是仅由偶然性引起的。
语法
edit一个 t_test 聚合在独立情况下看起来像这样:
{
"t_test": {
"a": "value_before",
"b": "value_after",
"type": "paired"
}
}
假设我们在升级前后记录了节点启动时间,让我们来看一下t检验,看看升级是否对节点启动时间产生了有意义的影响。
GET node_upgrade/_search
{
"size": 0,
"aggs": {
"startup_time_ttest": {
"t_test": {
"a": { "field": "startup_time_before" },
"b": { "field": "startup_time_after" },
"type": "paired"
}
}
}
}
响应将返回测试的p值或概率值。这是在假设零假设正确(即总体均值之间没有差异)的情况下,获得至少与聚合处理结果一样极端的结果的概率。较小的p值意味着零假设更可能是错误的,且总体均值确实不同。
T检验类型
edit聚合支持未配对和配对的双样本t检验。可以使用参数指定测试的类型:
-
"type": "paired" - 执行配对t检验
-
"type": "homoscedastic" - 执行双样本等方差检验
-
"type": "heteroscedastic" - 执行双样本不等方差检验(这是默认设置)
过滤器
edit也可以使用过滤器在不同的记录集上运行未配对的t检验。例如,如果我们想要测试两个不同节点组在升级前的启动时间差异,我们可以使用相同的字段startup_time_before,并通过在组名字段上使用术语过滤器来分隔节点组:
GET node_upgrade/_search
{
"size": 0,
"aggs": {
"startup_time_ttest": {
"t_test": {
"a": {
"field": "startup_time_before",
"filter": {
"term": {
"group": "A"
}
}
},
"b": {
"field": "startup_time_before",
"filter": {
"term": {
"group": "B"
}
}
},
"type": "heteroscedastic"
}
}
}
}
|
字段 |
|
|
任何区分两个组的查询都可以在这里使用。 |
|
|
我们正在使用相同的字段 |
|
|
但我们使用的是不同的过滤器。 |
|
|
由于我们拥有来自不同节点的数据,因此无法使用配对t检验。 |
群体不必在同一个索引中。如果数据集位于不同的索引中,可以使用 _index 字段上的术语过滤器来选择群体。
脚本
edit如果你需要在不是由字段清晰表示的值上运行 t_test,你应该在一个 运行时字段 上运行聚合。例如,如果你想调整负载时间以适应之前的值:
GET node_upgrade/_search
{
"size": 0,
"runtime_mappings": {
"startup_time_before.adjusted": {
"type": "long",
"script": {
"source": "emit(doc['startup_time_before'].value - params.adjustment)",
"params": {
"adjustment": 10
}
}
}
},
"aggs": {
"startup_time_ttest": {
"t_test": {
"a": {
"field": "startup_time_before.adjusted"
},
"b": {
"field": "startup_time_after"
},
"type": "paired"
}
}
}
}
最高命中聚合
edit一个 top_hits 指标聚合器会跟踪正在聚合的最相关文档。此聚合器旨在用作子聚合器,以便可以按每个桶聚合最匹配的文档。
我们不建议使用 top_hits 作为顶级聚合。如果你想对搜索结果进行分组,请使用 collapse 参数。
The top_hits 聚合器可以有效地用于通过桶聚合器按某些字段对结果集进行分组。
一个或多个桶聚合器决定了结果集按哪些属性进行切片。
选项
edit-
from- 您希望获取的结果相对于第一个结果的偏移量。 -
size- 每个桶返回的最大匹配命中数。默认情况下,返回前三个匹配的命中。 -
sort- 顶部匹配的命中应如何排序。默认情况下,命中按主查询的分数排序。
每次点击支持的功能
edittop_hits 聚合返回常规搜索命中结果,因此可以支持许多每命中特征:
如果你只需要docvalue_fields、size和sort,那么Top metrics可能比Top Hits Aggregation更高效。
top_hits 不支持 rescore 参数。查询重新评分仅适用于搜索命中结果,不适用于聚合结果。要更改聚合使用的分数,请使用 function_score 或 script_score 查询。
示例
edit在下面的示例中,我们按类型对销售进行分组,并且对于每种类型,我们显示最后一次销售。 对于每次销售,源数据中仅包含日期和价格字段。
POST /sales/_search?size=0
{
"aggs": {
"top_tags": {
"terms": {
"field": "type",
"size": 3
},
"aggs": {
"top_sales_hits": {
"top_hits": {
"sort": [
{
"date": {
"order": "desc"
}
}
],
"_source": {
"includes": [ "date", "price" ]
},
"size": 1
}
}
}
}
}
}
可能的响应:
{
...
"aggregations": {
"top_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "hat",
"doc_count": 3,
"top_sales_hits": {
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_id": "AVnNBmauCQpcRyxw6ChK",
"_source": {
"date": "2015/03/01 00:00:00",
"price": 200
},
"sort": [
1425168000000
],
"_score": null
}
]
}
}
},
{
"key": "t-shirt",
"doc_count": 3,
"top_sales_hits": {
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_id": "AVnNBmauCQpcRyxw6ChL",
"_source": {
"date": "2015/03/01 00:00:00",
"price": 175
},
"sort": [
1425168000000
],
"_score": null
}
]
}
}
},
{
"key": "bag",
"doc_count": 1,
"top_sales_hits": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_id": "AVnNBmatCQpcRyxw6ChH",
"_source": {
"date": "2015/01/01 00:00:00",
"price": 150
},
"sort": [
1420070400000
],
"_score": null
}
]
}
}
}
]
}
}
}
字段折叠示例
edit字段折叠或结果分组是一种功能,它将结果集逻辑分组为多个组,并为每个组返回顶部文档。组的排序由组中第一个文档的相关性决定。在Elasticsearch中,这可以通过一个包含top_hits聚合器的桶聚合器来实现,作为子聚合器。
在下面的示例中,我们在抓取的网页中进行搜索。对于每个网页,我们存储其正文和网页所属的域名。通过在domain字段上定义一个terms聚合器,我们将结果集按域名分组。然后,top_hits聚合器被定义为子聚合器,以便为每个桶收集最匹配的点击。
还定义了一个max聚合器,该聚合器由terms聚合器的排序功能使用,以按相关性顺序返回桶中与最相关文档的相关性顺序。
POST /sales/_search
{
"query": {
"match": {
"body": "elections"
}
},
"aggs": {
"top_sites": {
"terms": {
"field": "domain",
"order": {
"top_hit": "desc"
}
},
"aggs": {
"top_tags_hits": {
"top_hits": {}
},
"top_hit" : {
"max": {
"script": {
"source": "_score"
}
}
}
}
}
}
}
目前,需要使用max(或min)聚合器来确保来自terms聚合器的数据桶根据每个域名中最相关网页的得分进行排序。不幸的是,top_hits聚合器还不能在terms聚合器的order选项中使用。
嵌套或反向嵌套聚合器中的top_hits支持
edit如果 top_hits 聚合器被包裹在 nested 或 reverse_nested 聚合器中,那么将返回嵌套的命中结果。
嵌套的命中结果在某种意义上是隐藏的迷你文档,它们是常规文档的一部分,在映射中配置了嵌套字段类型。top_hits 聚合器具有在包裹在 nested 或 reverse_nested 聚合器中时,能够揭示这些文档的能力。更多关于嵌套的信息,请阅读 嵌套类型映射。
如果已配置嵌套类型,实际上一个文档会被索引为多个Lucene文档,并且它们共享相同的ID。为了确定嵌套命中的身份,仅凭ID是不够的,这就是为什么嵌套命中也包含它们的嵌套身份。嵌套身份保存在搜索命中的_nested字段中,并包括数组字段以及嵌套命中所属的数组字段中的偏移量。偏移量是从零开始的。
让我们看看它如何在一个真实样本中工作。考虑以下映射:
PUT /sales
{
"mappings": {
"properties": {
"tags": { "type": "keyword" },
"comments": {
"type": "nested",
"properties": {
"username": { "type": "keyword" },
"comment": { "type": "text" }
}
}
}
}
}
以及一些文档:
PUT /sales/_doc/1?refresh
{
"tags": [ "car", "auto" ],
"comments": [
{ "username": "baddriver007", "comment": "This car could have better brakes" },
{ "username": "dr_who", "comment": "Where's the autopilot? Can't find it" },
{ "username": "ilovemotorbikes", "comment": "This car has two extra wheels" }
]
}
现在可以执行以下 top_hits 聚合(包裹在一个 nested 聚合中):
POST /sales/_search
{
"query": {
"term": { "tags": "car" }
},
"aggs": {
"by_sale": {
"nested": {
"path": "comments"
},
"aggs": {
"by_user": {
"terms": {
"field": "comments.username",
"size": 1
},
"aggs": {
"by_nested": {
"top_hits": {}
}
}
}
}
}
}
}
顶部命中响应片段,包含一个嵌套命中,位于数组字段 comments 的第一个位置:
{
...
"aggregations": {
"by_sale": {
"by_user": {
"buckets": [
{
"key": "baddriver007",
"doc_count": 1,
"by_nested": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": 0.3616575,
"hits": [
{
"_index": "sales",
"_id": "1",
"_nested": {
"field": "comments",
"offset": 0
},
"_score": 0.3616575,
"_source": {
"comment": "This car could have better brakes",
"username": "baddriver007"
}
}
]
}
}
}
...
]
}
}
}
}
如果请求了 _source,则仅返回嵌套对象的源部分,而不是整个文档的源。
此外,存储在 嵌套 内部对象级别的字段可以通过位于 nested 或 reverse_nested 聚合器中的 top_hits 聚合器访问。
只有嵌套的命中结果会在命中结果中包含_nested字段,非嵌套(常规)的命中结果则不会包含_nested字段。
如果未启用 _source,_nested 中的信息也可以用于在其他地方解析原始源。
如果在映射中定义了多层嵌套的对象类型,那么_nested信息也可以是分层的,以便表达两层或更多层深的嵌套命中的身份。
在下面的示例中,嵌套的命中位于字段 nested_grand_child_field 的第一个槽中,然后该槽位于字段 nested_child_field 的第二个槽中:
...
"hits": {
"total" : {
"value": 2565,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "a",
"_id": "1",
"_score": 1,
"_nested" : {
"field" : "nested_child_field",
"offset" : 1,
"_nested" : {
"field" : "nested_grand_child_field",
"offset" : 0
}
}
"_source": ...
},
...
]
}
...
在管道聚合中的使用
edittop_hits 可以在管道聚合中使用,这些聚合每个桶只消费一个值,例如 bucket_selector,它按桶应用过滤,类似于在 SQL 中使用 HAVING 子句。这需要将 size 设置为 1,并指定要传递给包装聚合器的值的正确路径。后者可以是 _source、_sort 或 _score 值。例如:
POST /sales/_search?size=0
{
"aggs": {
"top_tags": {
"terms": {
"field": "type",
"size": 3
},
"aggs": {
"top_sales_hits": {
"top_hits": {
"sort": [
{
"date": {
"order": "desc"
}
}
],
"_source": {
"includes": [ "date", "price" ]
},
"size": 1
}
},
"having.top_salary": {
"bucket_selector": {
"buckets_path": {
"tp": "top_sales_hits[_source.price]"
},
"script": "params.tp < 180"
}
}
}
}
}
}
The bucket_path 使用 top_hits 名称 top_sales_hits 和提供聚合值的字段的关键字,即上例中的 _source 字段 price。其他选项包括 top_sales_hits[_sort],用于根据上面的排序值 date 进行过滤,以及 top_sales_hits[_score],用于根据最高分的分数进行过滤。
顶部指标聚合
editThe top_metrics aggregation selects metrics from the document with the largest or smallest "sort"
value. For example, this gets the value of the m field on the document with the largest value of s:
POST /test/_bulk?refresh
{"index": {}}
{"s": 1, "m": 3.1415}
{"index": {}}
{"s": 2, "m": 1.0}
{"index": {}}
{"s": 3, "m": 2.71828}
POST /test/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "desc"}
}
}
}
}
返回结果:
{
"aggregations": {
"tm": {
"top": [ {"sort": [3], "metrics": {"m": 2.718280076980591 } } ]
}
}
}
top_metrics 在精神上与 top_hits 非常相似,但由于它的限制更多,因此它能够使用更少的内存来完成其工作,并且通常更快。
sort
edit在metric请求中的sort字段与搜索请求中的sort字段完全相同,除了:
聚合返回的指标是搜索请求将返回的第一个命中结果。所以,
-
"sort": {"s": "desc"} -
从具有最高
s的文档中获取指标 -
"sort": {"s": "asc"} -
获取具有最低
s的文档的指标 -
"sort": {"_geo_distance": {"location": "POINT (-78.6382 35.7796)"}} -
从文档中获取与
location最近 的35.7796, -78.6382的指标 -
"sort": "_score" - 从得分最高的文档中获取指标
metrics
editmetrics 选择要返回的“top”文档的字段。你可以通过类似 "metrics": {"field": "m"} 的方式请求单个指标,或者通过请求指标列表的方式请求多个指标,例如 "metrics": [{"field": "m"}, {"field": "i"}。
metrics.field 支持以下字段类型:
除了关键词外,还支持相应类型的运行时字段。metrics.field 不支持具有数组值的字段。对数组值进行 top_metric 聚合可能会返回不一致的结果。
以下示例在几种字段类型上运行 top_metrics 聚合。
PUT /test
{
"mappings": {
"properties": {
"d": {"type": "date"}
}
}
}
POST /test/_bulk?refresh
{"index": {}}
{"s": 1, "m": 3.1415, "i": 1, "d": "2020-01-01T00:12:12Z", "t": "cat"}
{"index": {}}
{"s": 2, "m": 1.0, "i": 6, "d": "2020-01-02T00:12:12Z", "t": "dog"}
{"index": {}}
{"s": 3, "m": 2.71828, "i": -12, "d": "2019-12-31T00:12:12Z", "t": "chicken"}
POST /test/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": [
{"field": "m"},
{"field": "i"},
{"field": "d"},
{"field": "t.keyword"}
],
"sort": {"s": "desc"}
}
}
}
}
返回结果:
{
"aggregations": {
"tm": {
"top": [ {
"sort": [3],
"metrics": {
"m": 2.718280076980591,
"i": -12,
"d": "2019-12-31T00:12:12.000Z",
"t.keyword": "chicken"
}
} ]
}
}
}
missing
edit参数 missing 定义了如何处理缺少值的文档。默认情况下,如果任何关键组件缺失,整个文档都会被忽略。通过使用 missing 参数,可以将缺失的组件视为它们具有值。
PUT /my-index
{
"mappings": {
"properties": {
"nr": { "type": "integer" },
"state": { "type": "keyword" }
}
}
}
POST /my-index/_bulk?refresh
{"index": {}}
{"nr": 1, "state": "started"}
{"index": {}}
{"nr": 2, "state": "stopped"}
{"index": {}}
{"nr": 3, "state": "N/A"}
{"index": {}}
{"nr": 4}
POST /my-index/_search?filter_path=aggregations
{
"aggs": {
"my_top_metrics": {
"top_metrics": {
"metrics": {
"field": "state",
"missing": "N/A"},
"sort": {"nr": "desc"}
}
}
}
}
|
如果你想对文本内容进行聚合,它必须是一个 |
|
|
此文档缺少 |
|
|
参数 |
请求结果如下:
{
"aggregations": {
"my_top_metrics": {
"top": [
{
"sort": [
4
],
"metrics": {
"state": "N/A"
}
}
]
}
}
}
size
edittop_metrics 可以使用 size 参数返回前几个文档的指标:
POST /test/_bulk?refresh
{"index": {}}
{"s": 1, "m": 3.1415}
{"index": {}}
{"s": 2, "m": 1.0}
{"index": {}}
{"s": 3, "m": 2.71828}
POST /test/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "desc"},
"size": 3
}
}
}
}
返回结果:
{
"aggregations": {
"tm": {
"top": [
{"sort": [3], "metrics": {"m": 2.718280076980591 } },
{"sort": [2], "metrics": {"m": 1.0 } },
{"sort": [1], "metrics": {"m": 3.1414999961853027 } }
]
}
}
}
默认的 size 是 1。默认的最大大小是 10,因为聚合的工作存储是“密集”的,这意味着我们为每个桶分配 size 个槽。10 是一个非常保守的默认最大值,如果你需要的话,可以通过更改 top_metrics_max_size 索引设置来提高它。但要知道,较大的大小可能会占用相当多的内存,特别是在包含在一个生成许多桶的聚合中,比如一个大的 terms aggregation。如果你仍然想提高它,可以使用类似以下的设置:
PUT /test/_settings
{
"top_metrics_max_size": 100
}
如果 size 大于 1,则 top_metrics 聚合不能作为排序的 目标。
示例
edit与术语一起使用
edit这种聚合在terms聚合中应该非常有用,比如说,找到每个服务器报告的最后一个值。
PUT /node
{
"mappings": {
"properties": {
"ip": {"type": "ip"},
"date": {"type": "date"}
}
}
}
POST /node/_bulk?refresh
{"index": {}}
{"ip": "192.168.0.1", "date": "2020-01-01T01:01:01", "m": 1}
{"index": {}}
{"ip": "192.168.0.1", "date": "2020-01-01T02:01:01", "m": 2}
{"index": {}}
{"ip": "192.168.0.2", "date": "2020-01-01T02:01:01", "m": 3}
POST /node/_search?filter_path=aggregations
{
"aggs": {
"ip": {
"terms": {
"field": "ip"
},
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"date": "desc"}
}
}
}
}
}
}
返回结果:
{
"aggregations": {
"ip": {
"buckets": [
{
"key": "192.168.0.1",
"doc_count": 2,
"tm": {
"top": [ {"sort": ["2020-01-01T02:01:01.000Z"], "metrics": {"m": 2 } } ]
}
},
{
"key": "192.168.0.2",
"doc_count": 1,
"tm": {
"top": [ {"sort": ["2020-01-01T02:01:01.000Z"], "metrics": {"m": 3 } } ]
}
}
],
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0
}
}
}
与top_hits不同,您可以按此指标的结果对存储桶进行排序:
POST /node/_search?filter_path=aggregations
{
"aggs": {
"ip": {
"terms": {
"field": "ip",
"order": {"tm.m": "desc"}
},
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"date": "desc"}
}
}
}
}
}
}
返回结果:
{
"aggregations": {
"ip": {
"buckets": [
{
"key": "192.168.0.2",
"doc_count": 1,
"tm": {
"top": [ {"sort": ["2020-01-01T02:01:01.000Z"], "metrics": {"m": 3 } } ]
}
},
{
"key": "192.168.0.1",
"doc_count": 2,
"tm": {
"top": [ {"sort": ["2020-01-01T02:01:01.000Z"], "metrics": {"m": 2 } } ]
}
}
],
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0
}
}
}
混合排序类型
edit对 top_metrics 按一个在不同索引中具有不同类型的字段进行排序会产生一些令人惊讶的结果:浮点数字段总是独立于整数字段进行排序。
POST /test/_bulk?refresh
{"index": {"_index": "test1"}}
{"s": 1, "m": 3.1415}
{"index": {"_index": "test1"}}
{"s": 2, "m": 1}
{"index": {"_index": "test2"}}
{"s": 3.1, "m": 2.71828}
POST /test*/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "asc"}
}
}
}
}
返回结果:
{
"aggregations": {
"tm": {
"top": [ {"sort": [3.0999999046325684], "metrics": {"m": 2.718280076980591 } } ]
}
}
}
虽然这比错误要好,但它可能不是你想要的。 虽然它会失去一些精度,但你可以通过类似的方式将整数字段显式转换为浮点数:
POST /test*/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": {"order": "asc", "numeric_type": "double"}}
}
}
}
}
返回的结果更加符合预期:
{
"aggregations": {
"tm": {
"top": [ {"sort": [1.0], "metrics": {"m": 3.1414999961853027 } } ]
}
}
}
在管道聚合中的使用
edittop_metrics 可以用于消费每个桶中单个值的管道聚合,例如 bucket_selector,它按桶应用过滤,类似于在 SQL 中使用 HAVING 子句。这需要将 size 设置为 1,并指定传递给包装聚合器的(单个)指标的正确路径。例如:
POST /test*/_search?filter_path=aggregations
{
"aggs": {
"ip": {
"terms": {
"field": "ip"
},
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "desc"},
"size": 1
}
},
"having_tm": {
"bucket_selector": {
"buckets_path": {
"top_m": "tm[m]"
},
"script": "params.top_m < 1000"
}
}
}
}
}
}
The bucket_path 使用 top_metrics 名称 tm 和提供聚合值的指标的关键字,即 m。
值计数聚合
edit一个单值指标聚合,用于计算从聚合文档中提取的值的数量。这些值可以从文档中的特定字段提取,或者由提供的脚本生成。通常,此聚合器将与其他单值聚合一起使用。例如,在计算平均值时,可能对计算平均值所基于的值的数量感兴趣。
value_count 不会去重值,因此即使字段中有重复值,每个值也会单独计数。
POST /sales/_search?size=0
{
"aggs" : {
"types_count" : { "value_count" : { "field" : "type" } }
}
}
响应:
{
...
"aggregations": {
"types_count": {
"value": 7
}
}
}
聚合的名称(如上所示的types_count)也作为从返回的响应中检索聚合结果的键。
脚本
edit如果你需要计算比单个字段中的值更复杂的内容,你应该在运行时字段上运行聚合。
POST /sales/_search
{
"size": 0,
"runtime_mappings": {
"tags": {
"type": "keyword",
"script": """
emit(doc['type'].value);
if (doc['promoted'].value) {
emit('hot');
}
"""
}
},
"aggs": {
"tags_count": {
"value_count": {
"field": "tags"
}
}
}
}
直方图字段
edit当在直方图字段上计算value_count聚合时,聚合的结果是直方图中counts数组中所有数字的总和。
例如,对于以下存储不同网络的延迟指标的预聚合直方图的索引:
PUT metrics_index/_doc/1
{
"network.name" : "net-1",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [3, 7, 23, 12, 6]
}
}
PUT metrics_index/_doc/2
{
"network.name" : "net-2",
"latency_histo" : {
"values" : [0.1, 0.2, 0.3, 0.4, 0.5],
"counts" : [8, 17, 8, 7, 6]
}
}
POST /metrics_index/_search?size=0
{
"aggs": {
"total_requests": {
"value_count": { "field": "latency_histo" }
}
}
}
对于每个直方图字段,value_count 聚合将汇总 counts 数组中的所有数字 <1>。
最终,它将汇总所有直方图的所有值并返回以下结果:
{
...
"aggregations": {
"total_requests": {
"value": 97
}
}
}
加权平均聚合
edit一种单值指标聚合,用于计算从聚合文档中提取的数值的加权平均值。
这些值可以从文档中的特定数值字段中提取。
在计算常规平均值时,每个数据点具有相同的“权重”……它对最终值的贡献是相等的。而加权平均值则不同,每个数据点的权重不同。每个数据点对最终值的贡献量是从文档中提取的。
作为一个公式,加权平均数是 ∑(value * weight) / ∑(weight)
常规平均数可以被视为加权平均数,其中每个值都有一个隐含的权重为1。
表52. weighted_avg 参数
| Parameter Name | Description | Required | Default Value |
|---|---|---|---|
|
提供值的字段或脚本的配置 |
必需 |
|
|
为提供权重的字段或脚本配置 |
必需 |
|
|
数值响应格式化器 |
可选 |
The value 和 weight 对象具有每个字段特定的配置:
表53. value 参数
| Parameter Name | Description | Required | Default Value |
|---|---|---|---|
|
应从中提取值的字段 |
必需 |
|
|
如果字段完全缺失,则使用的值 |
可选 |
表54. weight 参数
| Parameter Name | Description | Required | Default Value |
|---|---|---|---|
|
应从中提取权重的字段 |
必需 |
|
|
如果字段完全缺失,则使用的权重 |
可选 |
示例
edit如果我们的文档有一个包含0-100数值分数的"grade"字段,以及一个包含任意数值权重的"weight"字段,我们可以使用以下方法计算加权平均值:
POST /exams/_search
{
"size": 0,
"aggs": {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
这将产生类似以下的响应:
{
...
"aggregations": {
"weighted_grade": {
"value": 70.0
}
}
}
虽然允许每个字段有多个值,但只允许一个权重。如果聚合遇到一个文档有多个权重(例如,权重字段是一个多值字段),它将中止搜索。如果你遇到这种情况,你应该构建一个运行时字段来将这些值合并为一个权重。
这个单一权重将独立应用于从value字段中提取的每个值。
此示例展示了如何使用单个权重对包含多个值的单个文档进行平均:
POST /exams/_doc?refresh
{
"grade": [1, 2, 3],
"weight": 2
}
POST /exams/_search
{
"size": 0,
"aggs": {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
这三个值(1、2 和 3)将被包含为独立值,所有值的权重均为 2:
{
...
"aggregations": {
"weighted_grade": {
"value": 2.0
}
}
}
聚合返回 2.0 作为结果,这与我们手动计算时所期望的结果一致:
((1*2) + (2*2) + (3*2)) / (2+2+2) == 2
运行时字段
edit如果你需要对不完全与索引值对齐的值进行求和或加权,请在运行时字段上运行聚合。
POST /exams/_doc?refresh
{
"grade": 100,
"weight": [2, 3]
}
POST /exams/_doc?refresh
{
"grade": 80,
"weight": 3
}
POST /exams/_search?filter_path=aggregations
{
"size": 0,
"runtime_mappings": {
"weight.combined": {
"type": "double",
"script": """
double s = 0;
for (double w : doc['weight']) {
s += w;
}
emit(s);
"""
}
},
"aggs": {
"weighted_grade": {
"weighted_avg": {
"value": {
"script": "doc.grade.value + 1"
},
"weight": {
"field": "weight.combined"
}
}
}
}
}
看起来应该是:
{
"aggregations": {
"weighted_grade": {
"value": 93.5
}
}
}
缺失值
edit默认情况下,聚合会排除缺少或null值的文档,这些文档的value或weight字段。可以使用missing参数为这些文档指定一个默认值。
POST /exams/_search
{
"size": 0,
"aggs": {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade",
"missing": 2
},
"weight": {
"field": "weight",
"missing": 3
}
}
}
}
}