
Google BigQuery 是一个用于处理非常大数据集的基于云的服务。它是一个无服务器且高度可扩展的数据仓库解决方案,使用户能够使用类似SQL的查询来分析数据。
在本教程中,我们将向您展示如何在Python中查询BigQuery数据集,并使用gradio在实时更新的仪表板中显示数据。仪表板将如下所示:
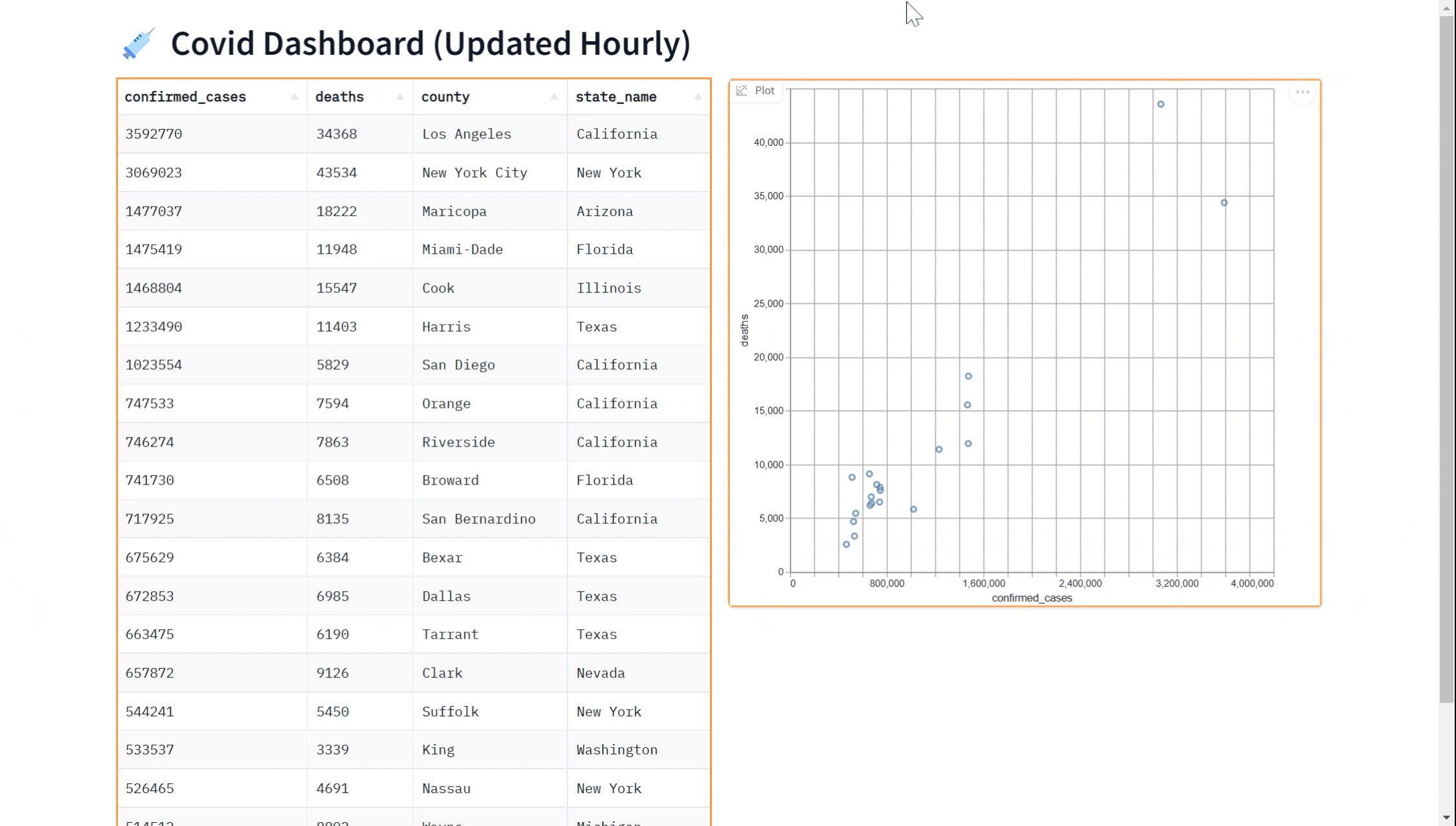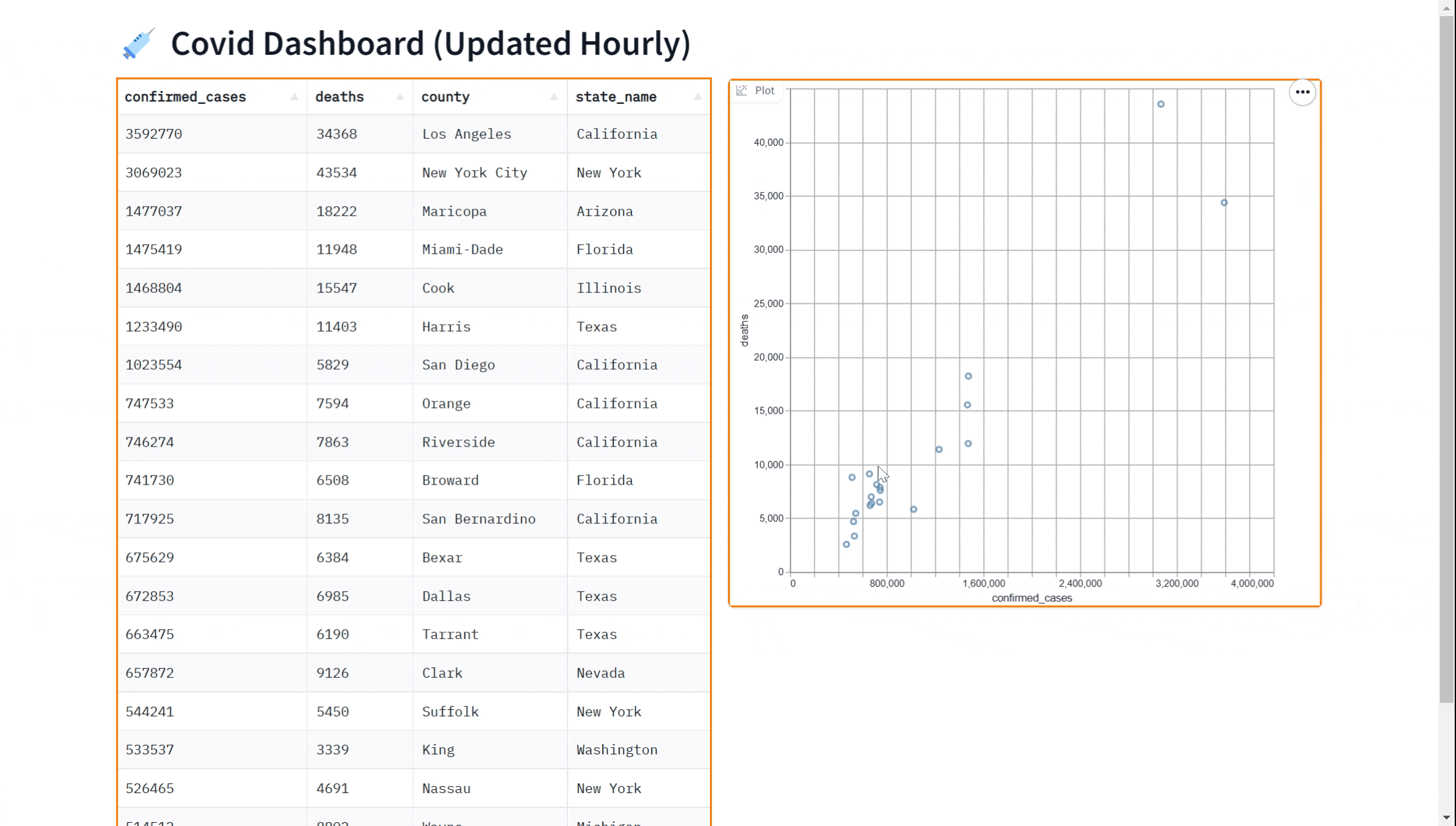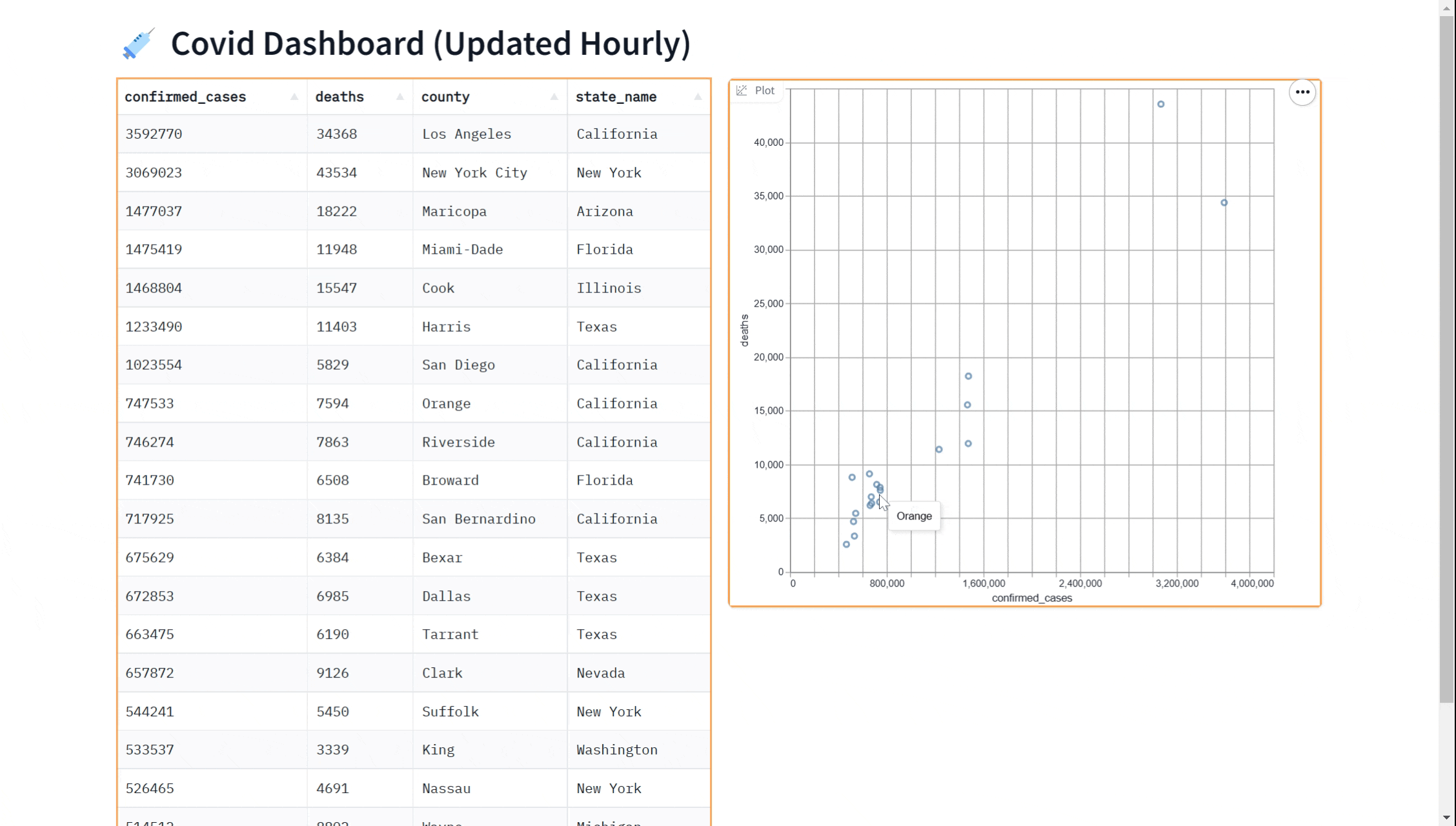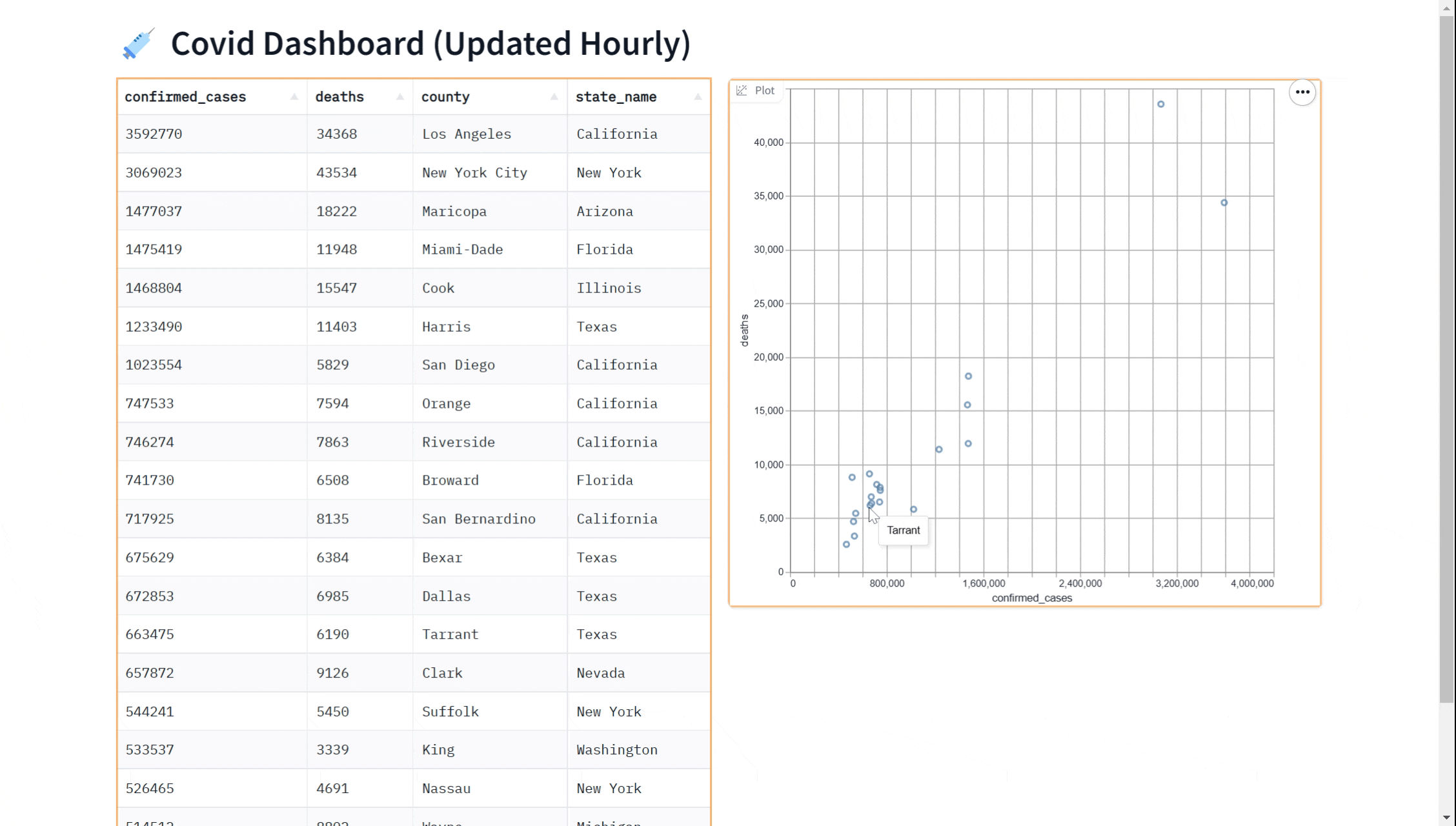
在本指南中,我们将涵盖以下步骤:
我们将使用纽约时报的COVID数据集,该数据集在BigQuery上作为公共数据集提供。该数据集名为covid19_nyt.us_counties,包含美国各县最新的COVID确诊病例和死亡人数的信息。
先决条件: 本指南使用 Gradio Blocks,因此请确保您熟悉 Blocks 类。
%20Copyright%202022%20Fonticons,%20Inc.%20--%3e%3cpath%20d='M172.5%20131.1C228.1%2075.51%20320.5%2075.51%20376.1%20131.1C426.1%20181.1%20433.5%20260.8%20392.4%20318.3L391.3%20319.9C381%20334.2%20361%20337.6%20346.7%20327.3C332.3%20317%20328.9%20297%20339.2%20282.7L340.3%20281.1C363.2%20249%20359.6%20205.1%20331.7%20177.2C300.3%20145.8%20249.2%20145.8%20217.7%20177.2L105.5%20289.5C73.99%20320.1%2073.99%20372%20105.5%20403.5C133.3%20431.4%20177.3%20435%20209.3%20412.1L210.9%20410.1C225.3%20400.7%20245.3%20404%20255.5%20418.4C265.8%20432.8%20262.5%20452.8%20248.1%20463.1L246.5%20464.2C188.1%20505.3%20110.2%20498.7%2060.21%20448.8C3.741%20392.3%203.741%20300.7%2060.21%20244.3L172.5%20131.1zM467.5%20380C411%20436.5%20319.5%20436.5%20263%20380C213%20330%20206.5%20251.2%20247.6%20193.7L248.7%20192.1C258.1%20177.8%20278.1%20174.4%20293.3%20184.7C307.7%20194.1%20311.1%20214.1%20300.8%20229.3L299.7%20230.9C276.8%20262.1%20280.4%20306.9%20308.3%20334.8C339.7%20366.2%20390.8%20366.2%20422.3%20334.8L534.5%20222.5C566%20191%20566%20139.1%20534.5%20108.5C506.7%2080.63%20462.7%2076.99%20430.7%2099.9L429.1%20101C414.7%20111.3%20394.7%20107.1%20384.5%2093.58C374.2%2079.2%20377.5%2059.21%20391.9%2048.94L393.5%2047.82C451%206.731%20529.8%2013.25%20579.8%2063.24C636.3%20119.7%20636.3%20211.3%20579.8%20267.7L467.5%20380z'/%3e%3c/svg%3e)
要使用Gradio与BigQuery,您需要获取您的BigQuery凭证,并将其与BigQuery Python客户端一起使用。如果您已经有BigQuery凭证(作为.json文件),您可以跳过此部分。如果没有,您可以在几分钟内免费完成此操作。
首先,登录您的Google Cloud账户并进入Google Cloud控制台 (https://console.cloud.google.com/)
在云控制台中,点击左上角的三明治菜单,并从菜单中选择“APIs & Services”。如果您没有现有项目,则需要创建一个。
然后,点击“+ 启用的API和服务”按钮,这将允许您为项目启用特定服务。搜索“BigQuery API”,点击它,然后点击“启用”按钮。如果您看到“管理”按钮,那么BigQuery已经启用,您已经准备就绪。
在API和服务菜单中,点击“凭据”标签,然后点击“创建凭据”按钮。
在“创建凭据”对话框中,选择“服务帐户密钥”作为要创建的凭据类型,并为其命名。同时,通过为其分配角色(如“BigQuery 用户”)来授予服务帐户权限,这将允许您运行查询。
选择服务账户后,选择“JSON”密钥类型,然后点击“创建”按钮。这将下载包含您凭据的JSON密钥文件到您的计算机。它看起来会像这样:
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}一旦你获得了凭证,你将需要使用BigQuery Python客户端来使用你的凭证进行认证。为此,你需要在终端中运行以下命令来安装BigQuery Python客户端:
pip install google-cloud-bigquery[pandas]你会注意到我们已经安装了pandas插件,这将有助于将BigQuery数据集处理为pandas数据框。安装客户端后,你可以通过运行以下代码使用你的凭证进行身份验证:
from google.cloud import bigquery
client = bigquery.Client.from_service_account_json("path/to/key.json")在您的凭据通过验证后,您现在可以使用 BigQuery Python 客户端与您的 BigQuery 数据集进行交互。
以下是一个函数的示例,该函数查询BigQuery中的covid19_nyt.us_counties数据集,以显示截至当天确诊病例最多的前20个县:
import numpy as np
QUERY = (
'SELECT * FROM `bigquery-public-data.covid19_nyt.us_counties` '
'ORDER BY date DESC,confirmed_cases DESC '
'LIMIT 20')
def run_query():
query_job = client.query(QUERY)
query_result = query_job.result()
df = query_result.to_dataframe()
# Select a subset of columns
df = df[["confirmed_cases", "deaths", "county", "state_name"]]
# Convert numeric columns to standard numpy types
df = df.astype({"deaths": np.int64, "confirmed_cases": np.int64})
return df一旦你有了查询数据的函数,你可以使用Gradio库中的gr.DataFrame组件以表格形式显示结果。这是检查数据并确保其被正确查询的有用方法。
这里是一个如何使用gr.DataFrame组件来显示结果的示例。通过将run_query函数传递给gr.DataFrame,我们指示Gradio在页面加载时立即运行该函数并显示结果。此外,您还可以传入关键字every来告诉仪表板每小时(60*60秒)刷新一次。
import gradio as gr
with gr.Blocks() as demo:
gr.DataFrame(run_query, every=gr.Timer(60*60))
demo.launch()也许您想在我们的仪表板上添加一个可视化图表。您可以使用gr.ScatterPlot()组件将数据可视化为散点图。这使您能够看到数据集中不同变量之间的关系,例如病例数和病例死亡数,这对于探索数据和获得洞察非常有用。同样,我们可以通过传入every参数实时完成此操作。
这里是一个完整的示例,展示了如何使用gr.ScatterPlot来可视化数据,同时使用gr.DataFrame显示数据。
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 💉 Covid Dashboard (Updated Hourly)")
with gr.Row():
gr.DataFrame(run_query, every=gr.Timer(60*60))
gr.ScatterPlot(run_query, every=gr.Timer(60*60), x="confirmed_cases",
y="deaths", tooltip="county", width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled