
这是两篇系列文章中的第一篇,我们将构建一个自定义的多模态聊天机器人组件。 在第一部分中,我们将修改Gradio聊天机器人组件,以在同一消息中显示文本和媒体文件(视频、音频、图像)。 在第二部分中,我们将构建一个自定义的文本框组件,该组件将能够向聊天机器人发送多模态消息(文本和媒体文件)。
您可以跟随本文的作者在以下YouTube视频中实现聊天机器人组件!
这是我们多模态聊天机器人组件的预览:
%20Copyright%202022%20Fonticons,%20Inc.%20--%3e%3cpath%20d='M172.5%20131.1C228.1%2075.51%20320.5%2075.51%20376.1%20131.1C426.1%20181.1%20433.5%20260.8%20392.4%20318.3L391.3%20319.9C381%20334.2%20361%20337.6%20346.7%20327.3C332.3%20317%20328.9%20297%20339.2%20282.7L340.3%20281.1C363.2%20249%20359.6%20205.1%20331.7%20177.2C300.3%20145.8%20249.2%20145.8%20217.7%20177.2L105.5%20289.5C73.99%20320.1%2073.99%20372%20105.5%20403.5C133.3%20431.4%20177.3%20435%20209.3%20412.1L210.9%20410.1C225.3%20400.7%20245.3%20404%20255.5%20418.4C265.8%20432.8%20262.5%20452.8%20248.1%20463.1L246.5%20464.2C188.1%20505.3%20110.2%20498.7%2060.21%20448.8C3.741%20392.3%203.741%20300.7%2060.21%20244.3L172.5%20131.1zM467.5%20380C411%20436.5%20319.5%20436.5%20263%20380C213%20330%20206.5%20251.2%20247.6%20193.7L248.7%20192.1C258.1%20177.8%20278.1%20174.4%20293.3%20184.7C307.7%20194.1%20311.1%20214.1%20300.8%20229.3L299.7%20230.9C276.8%20262.1%20280.4%20306.9%20308.3%20334.8C339.7%20366.2%20390.8%20366.2%20422.3%20334.8L534.5%20222.5C566%20191%20566%20139.1%20534.5%20108.5C506.7%2080.63%20462.7%2076.99%20430.7%2099.9L429.1%20101C414.7%20111.3%20394.7%20107.1%20384.5%2093.58C374.2%2079.2%20377.5%2059.21%20391.9%2048.94L393.5%2047.82C451%206.731%20529.8%2013.25%20579.8%2063.24C636.3%20119.7%20636.3%20211.3%20579.8%20267.7L467.5%20380z'/%3e%3c/svg%3e)
在这个演示中,我们将调整现有的Gradio Chatbot组件,以在同一消息中显示文本和媒体文件。
让我们通过模板化Chatbot组件的源代码来创建一个新的自定义组件目录。
gradio cc create MultimodalChatbot --template Chatbot我们准备好了!
提示: 确保修改 `pyproject.toml` 文件中的 `Author` 键。
打开你最喜欢的代码编辑器中的multimodalchatbot.py文件,让我们开始修改我们组件的后端。
我们要做的第一件事是创建我们组件的data_model。
data_model是您的python组件将接收并发送给运行UI的javascript客户端的数据格式。
您可以在后端指南中阅读更多关于data_model的信息。
对于我们的组件,每个聊天机器人消息将包含两个键:一个text键,用于显示文本消息,以及一个可选的媒体文件列表,可以显示在文本下方。
从gradio.data_classes导入FileData和GradioModel类,并将现有的ChatbotData类修改为如下所示:
class FileMessage(GradioModel):
file: FileData
alt_text: Optional[str] = None
class MultimodalMessage(GradioModel):
text: Optional[str] = None
files: Optional[List[FileMessage]] = None
class ChatbotData(GradioRootModel):
root: List[Tuple[Optional[MultimodalMessage], Optional[MultimodalMessage]]]
class MultimodalChatbot(Component):
...
data_model = ChatbotData提示: `data_model`s 是使用 `Pydantic V2` 实现的。阅读文档 [here](https://docs.pydantic.dev/latest/)。
我们已经完成了最困难的部分!
对于preprocess方法,我们将保持简单,并将MultimodalMessage列表传递给使用此组件作为输入的python函数。
这将让我们的组件用户通过.text和.files属性访问聊天机器人数据。
这是一个设计选择,您可以在您的实现中进行修改!
我们可以像这样使用ChatbotData的root属性返回消息列表:
def preprocess(
self,
payload: ChatbotData | None,
) -> List[MultimodalMessage] | None:
if payload is None:
return payload
return payload.root提示: 了解有关`preprocess`和`postprocess`方法背后的推理,请参阅[关键概念指南](./key-component-concepts)
在postprocess方法中,我们将强制将python函数返回的每条消息转换为MultimodalMessage类。
我们还将清理text字段中的任何缩进,以便它可以在前端正确显示为markdown。
我们可以保持postprocess方法不变,并修改_postprocess_chat_messages
def _postprocess_chat_messages(
self, chat_message: MultimodalMessage | dict | None
) -> MultimodalMessage | None:
if chat_message is None:
return None
if isinstance(chat_message, dict):
chat_message = MultimodalMessage(**chat_message)
chat_message.text = inspect.cleandoc(chat_message.text or "")
for file_ in chat_message.files:
file_.file.mime_type = client_utils.get_mimetype(file_.file.path)
return chat_message在我们结束后端代码之前,让我们修改example_value和example_payload方法,以返回ChatbotData的有效字典表示:
def example_value(self) -> Any:
return [[{"text": "Hello!", "files": []}, None]]
def example_payload(self) -> Any:
return [[{"text": "Hello!", "files": []}, None]]恭喜 - 后端已完成!
Chatbot组件的前端分为两部分 - Index.svelte文件和shared/Chatbot.svelte文件。
Index.svelte文件对从服务器接收到的数据进行一些处理,然后将对话的渲染委托给shared/Chatbot.svelte文件。
首先,我们将修改Index.svelte文件以对后端将返回的新数据类型进行处理。
让我们开始将我们的自定义类型从我们的python data_model移植到typescript。
打开frontend/shared/utils.ts并在文件顶部添加以下类型定义:
export type FileMessage = {
file: FileData;
alt_text?: string;
};
export type MultimodalMessage = {
text: string;
files?: FileMessage[];
}现在让我们在Index.svelte中导入它们,并修改value和_value的类型注释。
import type { FileMessage, MultimodalMessage } from "./shared/utils";
export let value: [
MultimodalMessage | null,
MultimodalMessage | null
][] = [];
let _value: [
MultimodalMessage | null,
MultimodalMessage | null
][];我们需要对每条消息进行规范化,以确保每个文件都有一个正确的URL来获取其内容。
我们还需要格式化text键中的任何嵌入文件链接。
让我们添加一个process_message实用函数,并在value发生变化时应用它。
function process_message(msg: MultimodalMessage | null): MultimodalMessage | null {
if (msg === null) {
return msg;
}
msg.text = redirect_src_url(msg.text);
msg.files = msg.files.map(normalize_messages);
return msg;
}
$: _value = value
? value.map(([user_msg, bot_msg]) => [
process_message(user_msg),
process_message(bot_msg)
])
: [];让我们从类似于Index.svelte文件的方式开始,首先修改类型注释。
在
import type { MultimodalMessage } from "./utils";
export let value:
| [
MultimodalMessage | null,
MultimodalMessage | null
][]
| null;
let old_value:
| [
MultimodalMessage | null,
MultimodalMessage | null
][]
| null = null;我们还需要修改 handle_select 和 handle_like 函数:
function handle_select(
i: number,
j: number,
message: MultimodalMessage | null
): void {
dispatch("select", {
index: [i, j],
value: message
});
}
function handle_like(
i: number,
j: number,
message: MultimodalMessage | null,
liked: boolean
): void {
dispatch("like", {
index: [i, j],
value: message,
liked: liked
});
}现在是更有趣的部分,实际上在同一消息中渲染文本和文件!
你应该会看到一些类似以下的代码,它根据消息的类型决定是显示文件还是markdown消息:
{#if typeof message === "string"}
<Markdown
{message}
{latex_delimiters}
{sanitize_html}
{render_markdown}
{line_breaks}
on:load={scroll}
/>
{:else if message !== null && message.file?.mime_type?.includes("audio")}
<audio
data-testid="chatbot-audio"
controls
preload="metadata"
...我们将修改此代码以始终显示文本消息,然后遍历文件并显示所有存在的文件:
<Markdown
message={message.text}
{latex_delimiters}
{sanitize_html}
{render_markdown}
{line_breaks}
on:load={scroll}
/>
{#each message.files as file, k}
{#if file !== null && file.file.mime_type?.includes("audio")}
<audio
data-testid="chatbot-audio"
controls
preload="metadata"
src={file.file?.url}
title={file.alt_text}
on:play
on:pause
on:ended
/>
{:else if message !== null && file.file?.mime_type?.includes("video")}
<video
data-testid="chatbot-video"
controls
src={file.file?.url}
title={file.alt_text}
preload="auto"
on:play
on:pause
on:ended
>
<track kind="captions" />
</video>
{:else if message !== null && file.file?.mime_type?.includes("image")}
<img
data-testid="chatbot-image"
src={file.file?.url}
alt={file.alt_text}
/>
{:else if message !== null && file.file?.url !== null}
<a
data-testid="chatbot-file"
href={file.file?.url}
target="_blank"
download={window.__is_colab__
? null
: file.file?.orig_name || file.file?.path}
>
{file.file?.orig_name || file.file?.path}
</a>
{:else if pending_message && j === 1}
<Pending {layout} />
{/if}
{/each}我们做到了!🎉
在本教程中,让我们保持演示简单,仅显示假设用户和机器人之间的静态对话。 此演示将展示用户和机器人如何发送文件。 在本教程系列的第2部分中,我们将构建一个功能齐全的聊天机器人演示!
演示代码将如下所示:
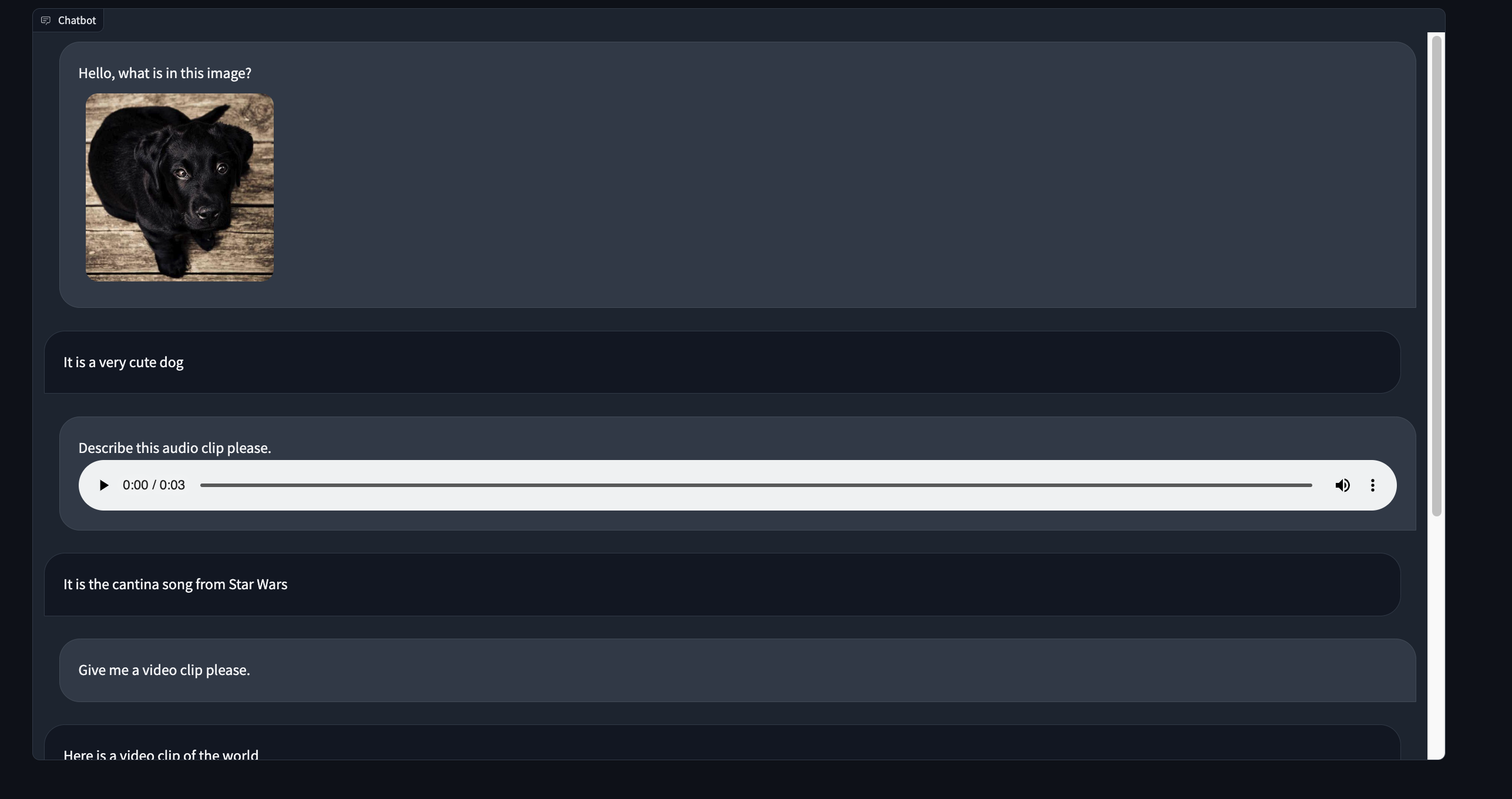
import gradio as gr
from gradio_multimodalchatbot import MultimodalChatbot
from gradio.data_classes import FileData
user_msg1 = {"text": "Hello, what is in this image?",
"files": [{"file": FileData(path="https://gradio-builds.s3.amazonaws.com/diffusion_image/cute_dog.jpg")}]
}
bot_msg1 = {"text": "It is a very cute dog",
"files": []}
user_msg2 = {"text": "Describe this audio clip please.",
"files": [{"file": FileData(path="cantina.wav")}]}
bot_msg2 = {"text": "It is the cantina song from Star Wars",
"files": []}
user_msg3 = {"text": "Give me a video clip please.",
"files": []}
bot_msg3 = {"text": "Here is a video clip of the world",
"files": [{"file": FileData(path="world.mp4")},
{"file": FileData(path="cantina.wav")}]}
conversation = [[user_msg1, bot_msg1], [user_msg2, bot_msg2], [user_msg3, bot_msg3]]
with gr.Blocks() as demo:
MultimodalChatbot(value=conversation, height=800)
demo.launch()提示: 更改文件路径,使其与您机器上的文件相对应。此外,如果您在开发模式下运行,请确保文件位于自定义组件目录的顶层。
让我们使用gradio cc build和gradio cc deploy来构建和部署我们的演示!
你可以查看我们部署到HuggingFace Spaces的组件,所有源代码都可以在这里找到。
在本系列的下一部分再见!