4. 过采样和欠采样的组合#
我们之前介绍了SMOTE,并展示了这种方法通过在边缘异常值和正常值之间插值新点来生成噪声样本。这个问题可以通过清理过采样产生的空间来解决。
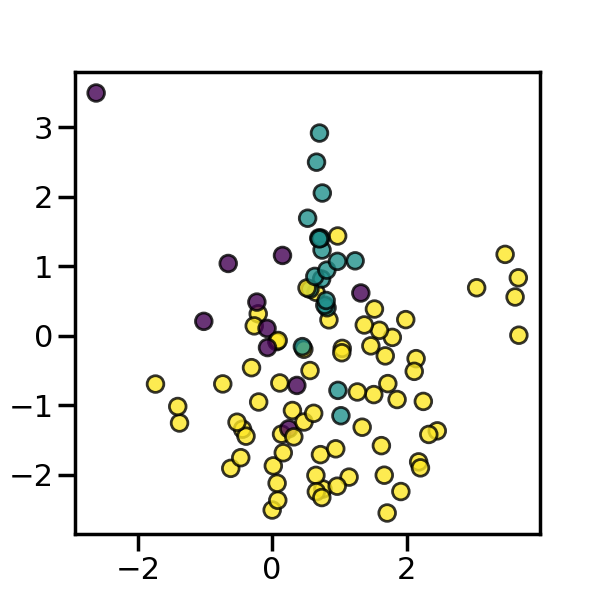
在这方面,Tomek的链接和编辑的最近邻是两种清理方法,它们在应用SMOTE过采样后添加到管道中,以获得更干净的空间。imbalanced-learn实现了两种即用类,用于结合过采样和欠采样方法:(i) SMOTETomek [BPM04] 和 (ii) SMOTEENN [BBM03]。
这两个类可以像任何其他采样器一样使用,参数与它们之前的采样器相同:
>>> from collections import Counter
>>> from sklearn.datasets import make_classification
>>> X, y = make_classification(n_samples=5000, n_features=2, n_informative=2,
... n_redundant=0, n_repeated=0, n_classes=3,
... n_clusters_per_class=1,
... weights=[0.01, 0.05, 0.94],
... class_sep=0.8, random_state=0)
>>> print(sorted(Counter(y).items()))
[(0, 64), (1, 262), (2, 4674)]
>>> from imblearn.combine import SMOTEENN
>>> smote_enn = SMOTEENN(random_state=0)
>>> X_resampled, y_resampled = smote_enn.fit_resample(X, y)
>>> print(sorted(Counter(y_resampled).items()))
[(0, 4060), (1, 4381), (2, 3502)]
>>> from imblearn.combine import SMOTETomek
>>> smote_tomek = SMOTETomek(random_state=0)
>>> X_resampled, y_resampled = smote_tomek.fit_resample(X, y)
>>> print(sorted(Counter(y_resampled).items()))
[(0, 4499), (1, 4566), (2, 4413)]
我们还可以在下面的示例中看到,SMOTEENN 倾向于清理更多的噪声样本,相比于 SMOTETomek。