1. 介绍#
1.1. 不平衡学习采样器的API#
可用的采样器遵循
scikit-learn API
使用基础估计器
并通过sample方法集成采样功能:
- Estimator:
基础对象,实现了一个
fit方法以从数据中学习:estimator = obj.fit(data, targets)
- Resampler:
要对数据集进行重采样,每个采样器都实现了一个
fit_resample方法:data_resampled, targets_resampled = obj.fit_resample(data, targets)
Imbalanced-learn 采样器接受与 scikit-learn 估计器相同的输入:
data, 2-dimensional array-like structures, such as:Python的列表列表
list,Numpy数组
numpy.ndarray,Panda数据框架
pandas.DataFrame,Scipy稀疏矩阵
scipy.sparse.csr_matrix或scipy.sparse.csc_matrix;
targets, 1-dimensional array-like structures, such as:Numpy数组
numpy.ndarray,Pandas 系列
pandas.Series.
输出将是以下类型:
data_resampled, 2-dimensional aray-like structures, such as:Numpy数组
numpy.ndarray,Pandas 数据框架
pandas.DataFrame,Scipy 稀疏矩阵
scipy.sparse.csr_matrix或scipy.sparse.csc_matrix;
targets_resampled, 1-dimensional array-like structures, such as:Numpy数组
numpy.ndarray,Pandas系列
pandas.Series.
1.2. 关于不平衡数据集的问题陈述#
机器学习算法的学习和预测阶段可能会受到不平衡数据集问题的影响。这种不平衡指的是不同类别样本数量的差异。我们通过调整权重来展示训练Logistic Regression classifier时不同类别平衡水平的效果。
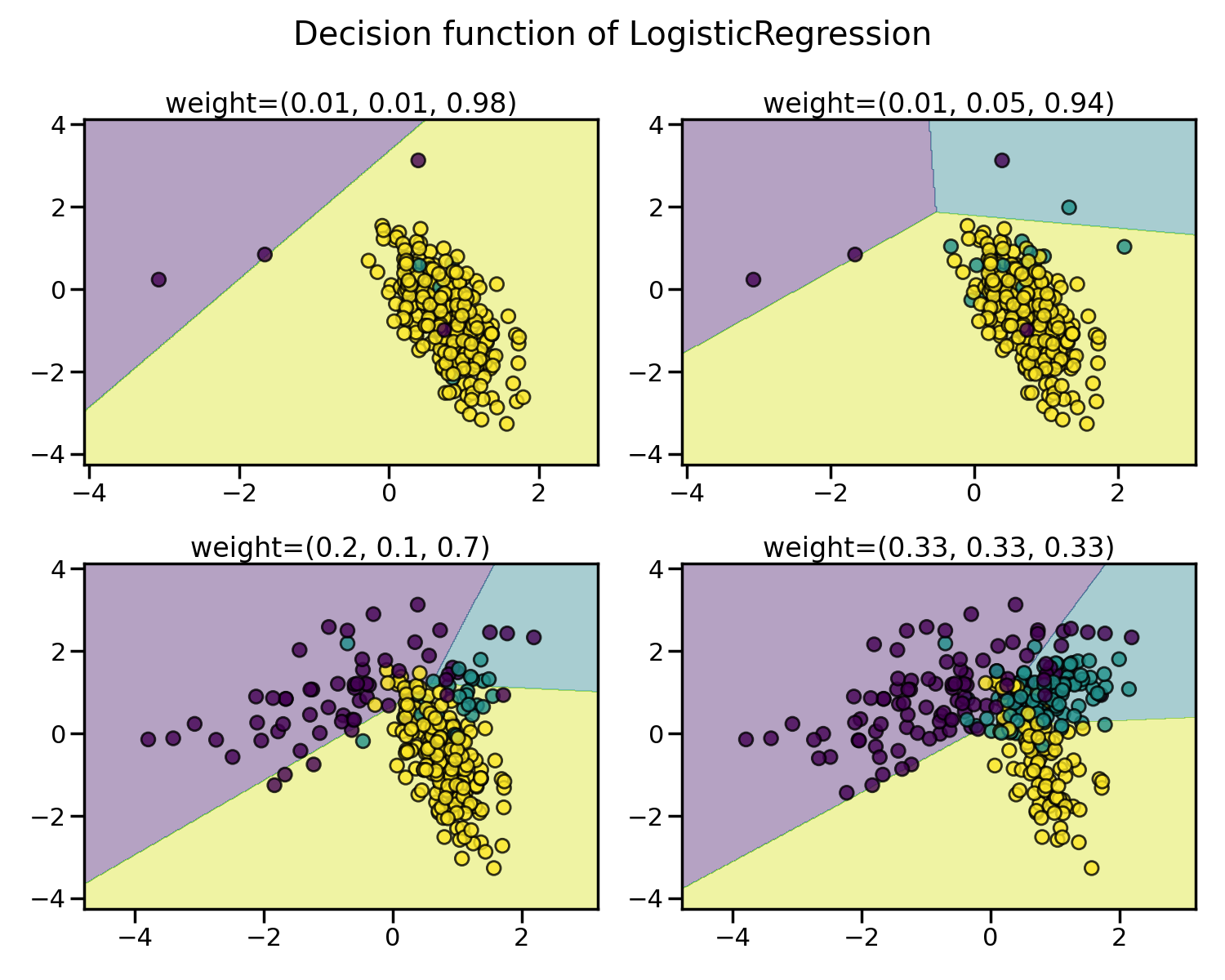
正如预期的那样,逻辑回归分类器的决策函数显著变化取决于数据的不平衡程度。随着不平衡比率的增加,决策函数倾向于支持样本数量较多的类别,通常称为多数类。