使用spaCy和Label Studio评估命名实体识别解析器

本教程将指导您使用Label Studio评估命名实体识别(NER)标注器的准确性。收集基于《This American Life》播客转录数据集的spaCY标准语言模型预测结果,然后使用Label Studio修正转录文本并确定哪个模型表现更优,以便集中未来的再训练工作。
命名实体识别(NER)解析器通过分类文本中的组织、日期、国家、职业等信息,将非结构化文本转化为结构化内容。当模型检测到这些实体后,可以对它们进行标记和分类以便进一步分析。为了选择最适合您数据分析需求的NER解析器,您需要根据相关数据集评估模型性能。
您可以使用现成的解析器和NER标注器来处理命名实体解析和标注,但对于专业或小型文本语料库,这些工具的标注准确率通常较低。因此,在许多实际应用场景中,您需要评估不同NER标注器的准确性,并对最有潜力的模型进行微调,以提高其在您数据上的准确率。
开始之前
本教程假设您已熟悉基本的自然语言处理(NLP)和机器学习(ML)术语,例如评估的技术含义以及命名实体识别(NER)标注器提供的基本功能和结果。
要跟随本教程进行操作,您需要完成以下步骤:
- 设置本地Python环境
- 使用pip安装软件包
- 运行Python代码来评估结果
本教程步骤
- 从data.world下载播客转录数据集。
- 安装spaCy、pandas以及相关的spaCy模型。
- 使用spaCy解析下载的数据集。
- 将数据集预测导入Label Studio。
- 使用Label Studio修正预测的NER标签,创建黄金标准数据样本。
- 评估模型结果并将预测与黄金标准进行比较。
下载数据集并安装spaCy和pandas
下载data.world上的This American Life数据集。它包含自1995年11月以来每期节目的文字记录。您需要一个data.world账户才能下载该数据集。
文本语料库以CSV格式的两个文件提供。下载按文本行排序的lines_clean.csv版本文件。该文件的格式化方式更便于分析播客转录文本的原始内容。
文件片段如下所示:

安装spaCy和pandas
在安装spaCy之前,请确保pip已安装且最近已更新。在命令行中输入以下内容:
python -m pip install -U pip 安装或更新pip后,使用pip安装最新版本的spaCy:
pip install -U spacy 您还需要安装pandas,它提供了用于数据集预处理的方法和数据结构,以便实现spaCy处理。使用以下pip命令:
pip install pandas 导入预标注数据
为了评估和修正spaCy模型针对关键词"Easter"的性能表现,请生成并将spaCy模型预测结果导入Label Studio。
本教程比较了小型和大型英语命名实体识别(NER) spaCy模型在播客转录数据集上的预测质量,这些模型是基于网络书面文本训练的。
运行以下脚本来解析数据集,并将spaCy模型的预测结果以JSON格式输出为Label Studio任务:
import spacy
import pandas as pd
import json
from itertools import groupby
# Download spaCy models:
models = {
'en_core_web_sm': spacy.load("en_core_web_sm"),
'en_core_web_lg': spacy.load("en_core_web_lg")
}
# This function converts spaCy docs to the list of named entity spans in Label Studio compatible JSON format:
def doc_to_spans(doc):
tokens = [(tok.text, tok.idx, tok.ent_type_) for tok in doc]
results = []
entities = set()
for entity, group in groupby(tokens, key=lambda t: t[-1]):
if not entity:
continue
group = list(group)
_, start, _ = group[0]
word, last, _ = group[-1]
text = ' '.join(item[0] for item in group)
end = last + len(word)
results.append({
'from_name': 'label',
'to_name': 'text',
'type': 'labels',
'value': {
'start': start,
'end': end,
'text': text,
'labels': [entity]
}
})
entities.add(entity)
return results, entities
# Now load the dataset and include only lines containing "Easter ":
df = pd.read_csv('lines_clean.csv')
df = df[df['line_text'].str.contains("Easter ", na=False)]
print(df.head())
texts = df['line_text']
# Prepare Label Studio tasks in import JSON format with the model predictions:
entities = set()
tasks = []
for text in texts:
predictions = []
for model_name, nlp in models.items():
doc = nlp(text)
spans, ents = doc_to_spans(doc)
entities |= ents
predictions.append({'model_version': model_name, 'result': spans})
tasks.append({
'data': {'text': text},
'predictions': predictions
})
# Save Label Studio tasks.json
print(f'Save {len(tasks)} tasks to "tasks.json"')
with open('tasks.json', mode='w') as f:
json.dump(tasks, f, indent=2)
# Save class labels as a txt file
print('Named entities are saved to "named_entities.txt"')
with open('named_entities.txt', mode='w') as f:
f.write('\n'.join(sorted(entities)))运行脚本后,您将获得两个文件:
- 一个包含来自大小spaCy模型预测结果的
tasks.json文件,用于导入到Label Studio中。 - 一个名为
named_entities.txt的文件,其中包含用作标签的实体列表。
在Label Studio中修正预测的命名实体
要对命名实体进行分类,您需要创建一个包含适用于您用例的黄金标准标签的数据集。为此,请使用开源数据标注工具Label Studio。
安装并启动Label Studio
使用以下命令在虚拟环境中通过pip安装Label Studio:
python3 -m venv env
source env/bin/activate
python -m pip install label-studio安装Label Studio后,启动服务器并指定项目名称:
label-studio start ner-tagging 在您的网页浏览器中打开Label Studio,访问http://localhost:8080/并创建账户。
设置您的Label Studio项目
打开ner-tagging项目并执行以下操作:
- 点击导入添加数据。
- 上传
tasks.json文件。

接下来,使用spaCy NER标签设置标注界面,以创建黄金标准数据集。
- 在Label Studio项目中,点击设置,然后点击标注界面。
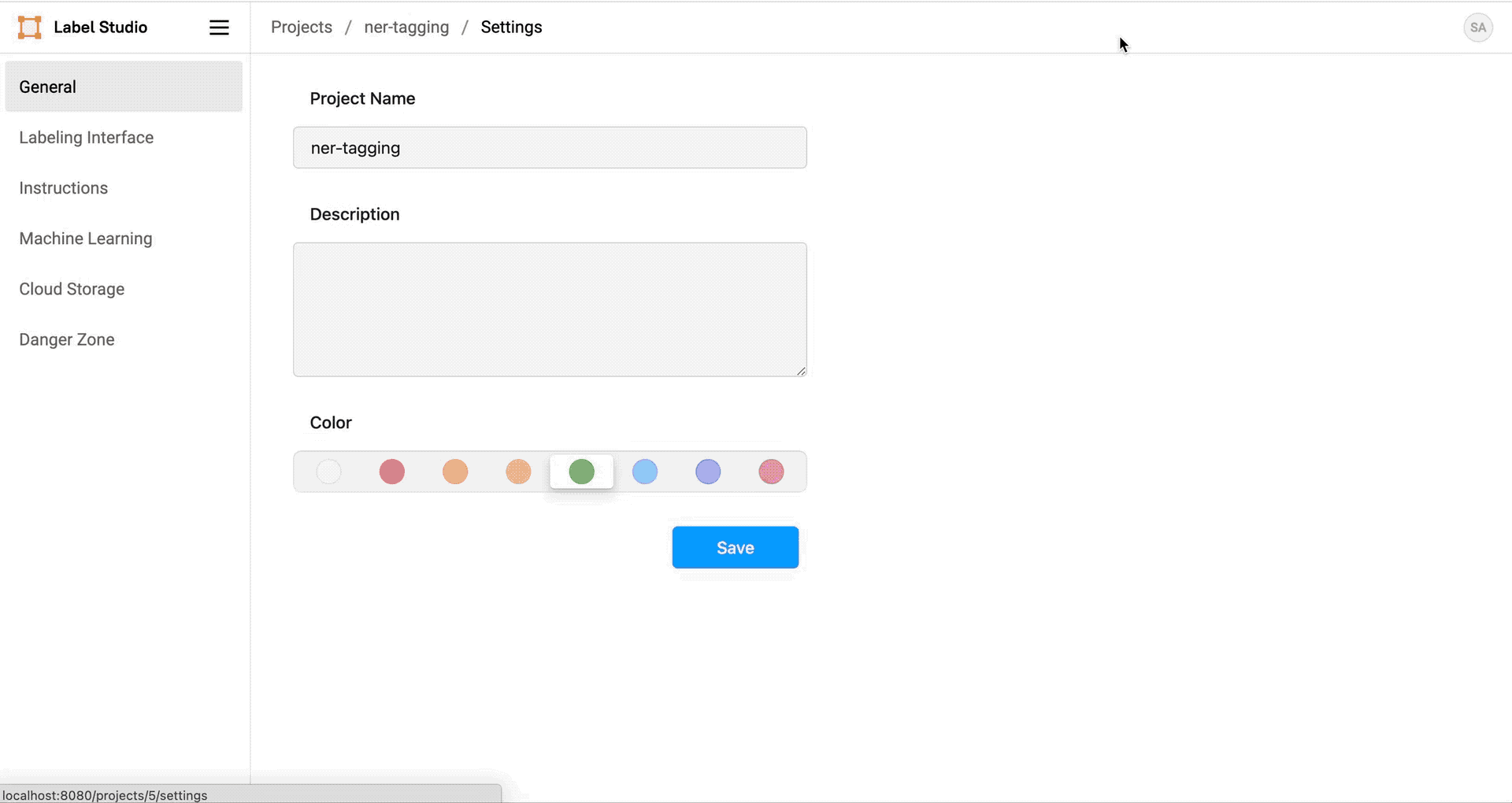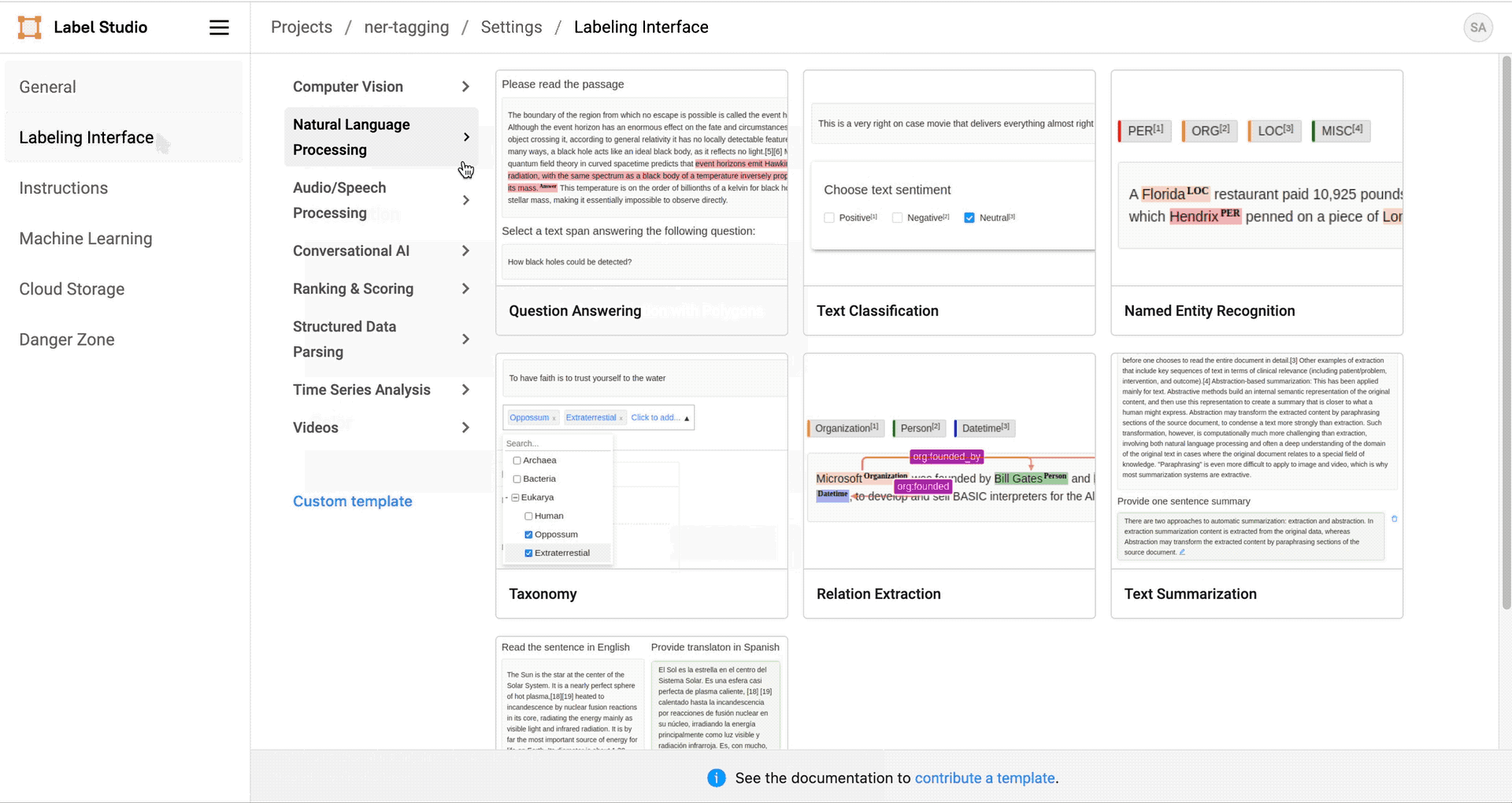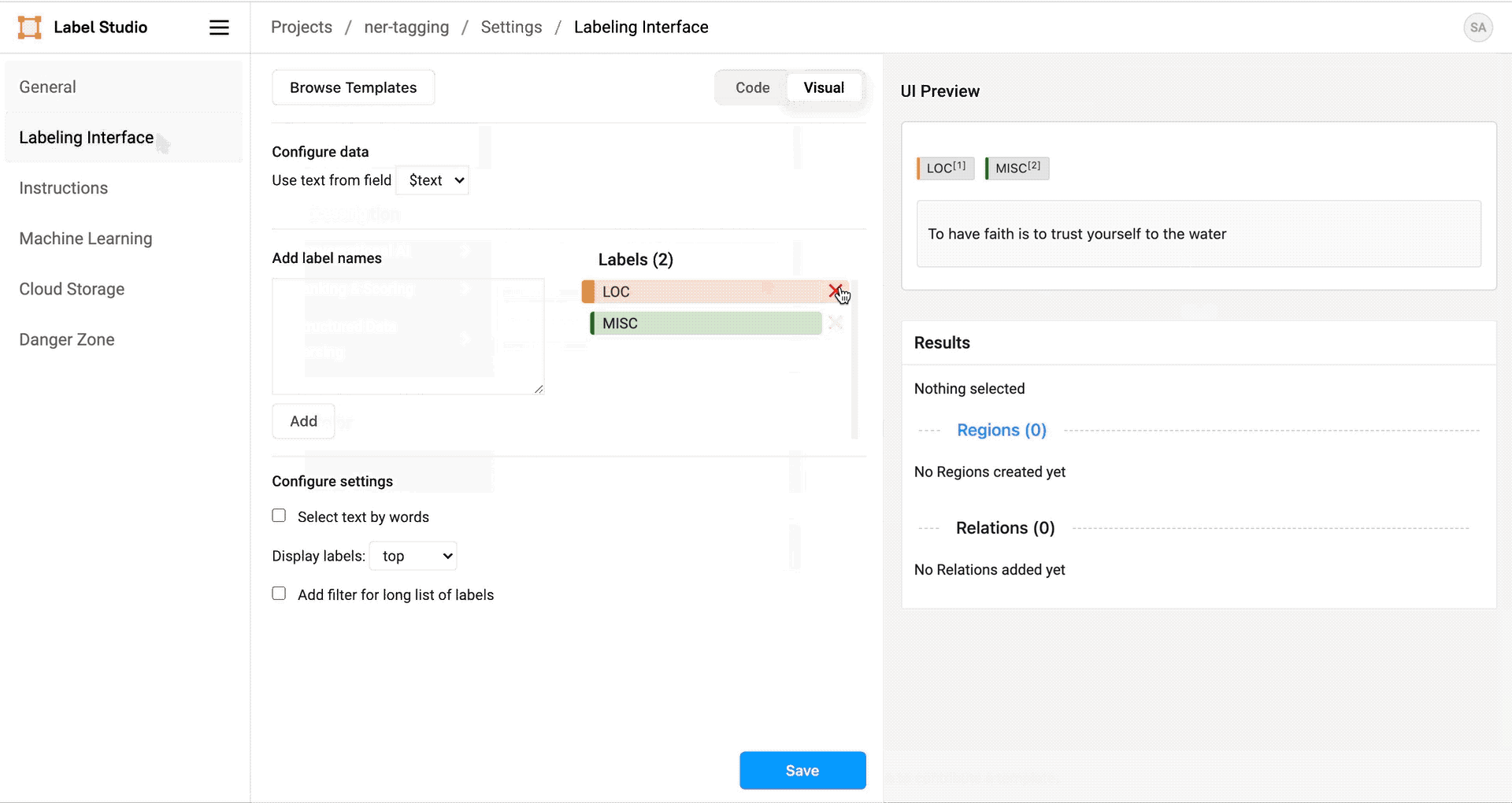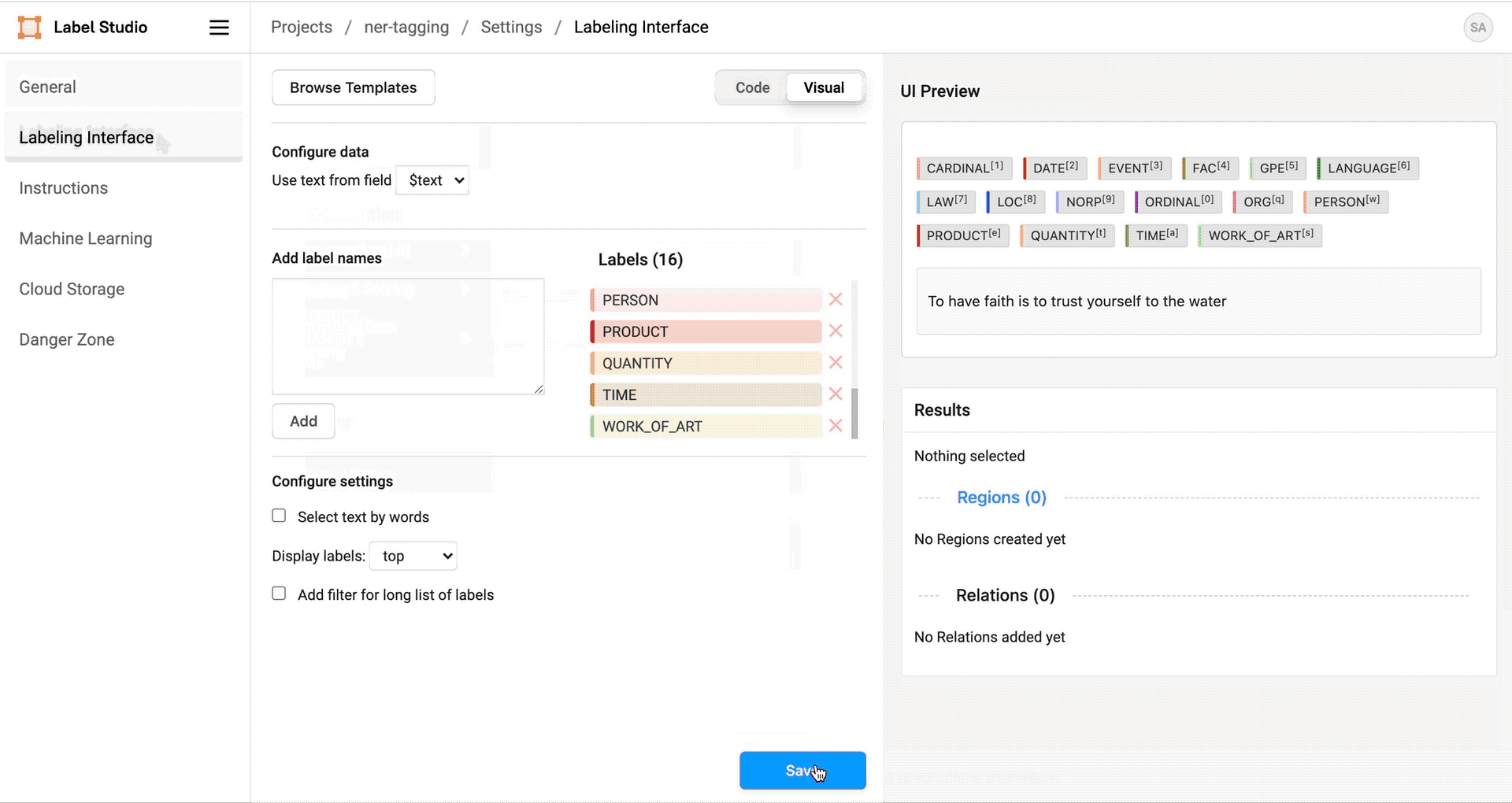
- 选择命名实体识别模板,并将
named_entities.txt文件内容粘贴作为该模板的标签。 - 点击保存以保存配置并返回项目数据。
在Label Studio中标注您的黄金标准数据集
点击标注开始校正数据中"Easter"的标注实例。与所有人机协同数据标注项目一样,"Easter"的正确标签可能具有主观性和上下文相关性。某些"Easter"实例可能被标记为EVT表示事件,而如果讨论的是复活节兔子,则可能标记为PER。请根据您的具体使用场景选择最合适的标签。
- 对于每个任务,检查模型预测结果,如有需要,请更正单词"Easter"的标签。您可以使用键盘快捷键选择正确的标签,然后在文本中高亮显示单词Easter进行标注。
- 点击提交保存新标注并标记下一个任务。
- 继续操作,直到标记完所有任务。

导出数据以准备评估模型准确度
在手动完成数据集中复活节实例的标注后,导出已标注数据以便评估模型准确性,并确定可能需要重新训练哪个spaCy模型。
- 从您的Label Studio项目中,点击导出。
- 选择JSON文件格式并下载数据和标注。
- 将下载的文件重命名为
annotations.json。

比较spaCy模型与黄金标准数据集
在您修正spaCy模型的预测结果并创建新的黄金标准数据集后,您可以编程方式将每个模型的准确率与您创建的黄金标准进行对比。
运行此脚本以根据spaCy模型评估导出的标注:
import json
from collections import defaultdict
tasks = json.load(open('annotations.json'))
model_hits = defaultdict(int)
for task in tasks:
annotation_result = task['annotations'][0]['result']
for r in annotation_result:
r.pop('id')
for prediction in task['predictions']:
model_hits[prediction['model_version']] += int(prediction['result'] == annotation_result)
num_task = len(tasks)
for model_name, num_hits in model_hits.items():
acc = num_hits / num_task
print(f'Accuracy for {model_name}: {acc:.2f}%')该脚本会产生类似以下的输出:
Accuracy for en_core_web_sm: 0.03%
Accuracy for en_core_web_lg: 0.41%两个模型很少能正确预测Easter关键词,因此准确率相当低。不过很明显,在这种情况下,较大的spaCy卷积神经网络(CNN)模型表现明显优于较小的spaCy模型。
通过这些步骤,可以清楚地看到,您只需几分钟的标注就能评估两种不同模型的性能结果,而无需花费大量时间构建基于静态数据集的复杂评估流程。
接下来是什么?
这是一个仅基于Easter关键词的特定边界案例的简单示例。您可以扩展此示例来监控更复杂的语义,并一次性评估超过2个模型。在实际应用场景中,当您完成与项目相关的大量数据标签修正后,就可以基于这个新数据集重新训练spaCy的模型。
您还可以使用黄金标准数据集来评估模型变更,并确定特定模型的最佳参数,以针对特定数据类型微调准确性。例如,根据黄金标准数据集评估并修正一个模型的预测结果,然后使用另一组参数创建第二个模型,再根据黄金标准数据集进行评估。表现更优的模型通常更适合您的数据和使用场景。
查阅使用Label Studio创建机器学习后端的示例教程,了解如何进一步实现模型自动重训练,并在模型开发流程中运用Label Studio。
相关内容
-

学习如何使用Label Studio的提示功能生成问答对合成数据。本逐步指南将带您完成创建项目、编写提示词以及审阅模型生成数据的全过程——非常适合在标注数据有限时启动RAG系统或训练大语言模型。

Micaela Kaplan
2025年4月23日
-
如何在Label Studio中使用提示词评估和比较大语言模型
使用大语言模型标注数据很快——但它准确吗?本文展示了在Label Studio中评估模型性能的两种方法,无论是否有真实标签数据。学习如何比较输出结果、跟踪准确率和成本,并为你的工作流程选择合适的模型。
米凯拉·卡普兰
2025年4月2日
-

在这篇文章中,我们将介绍Label Studio AI助手和提示词的一个创意用例:生成丰富的图像叙事。跟随我们的步骤,了解如何构建一个将结构化标注与故事讲述相结合的项目。

Sheree Zhang
2025年4月1日