
MNIST上的深度学习#
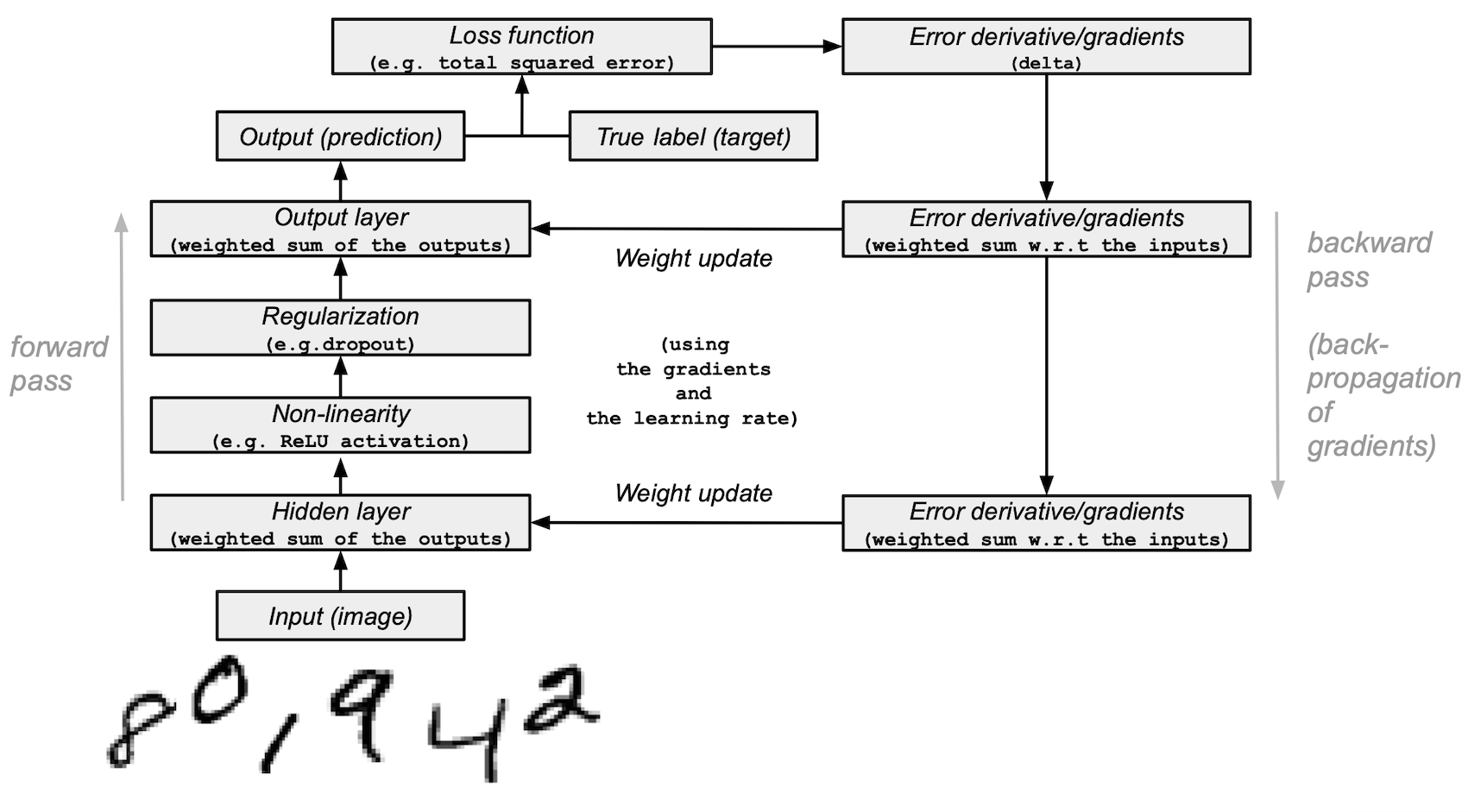
本教程演示了如何构建一个简单的 前馈神经网络 (带有一个隐藏层)并使用 NumPy 从头开始训练它以识别手写数字图像。
你的深度学习模型——一个最基本的人工神经网络,类似于最初的 多层感知器——将学习从 MNIST 数据集中分类数字 0 到 9。该数据集包含 60,000 个训练图像和 10,000 个测试图像及其对应的标签。每个训练和测试图像的大小为 784(或 28x28 像素)——这将是神经网络的输入。
基于图像输入及其标签(监督学习),你的神经网络将使用前向传播和反向传播(反向模式微分)来学习它们的特征。网络的最终输出是一个包含10个分数的向量——每个手写数字图像一个。你还将评估你的模型在测试集上对图像分类的效果。
本教程改编自 Andrew Trask 的作品(经作者许可)。
前提条件#
读者应该具备一些 Python、NumPy 数组操作和线性代数的知识。此外,你应该熟悉 深度学习 的主要概念。
为了复习记忆,你可以参加 Python 和 线性代数在 n 维数组上的应用 教程。
建议阅读 Yann LeCun、Yoshua Bengio 和 Geoffrey Hinton 在 2015 年发表的 深度学习 论文,他们被认为是该领域的先驱之一。还应考虑阅读 Andrew Trask 的 Grokking 深度学习,该书使用 NumPy 教授深度学习。
除了 NumPy 之外,您还将使用以下 Python 标准模块进行数据加载和处理:
urllib用于 URL 处理request用于 URL 打开gzip用于 gzip 文件解压缩pickle用于处理 pickle 文件格式以及:
Matplotlib 用于数据可视化
本教程可以在一个隔离的环境中本地运行,例如 Virtualenv 或 conda。你可以使用 Jupyter Notebook 或 JupyterLab 来运行每个笔记本单元。不要忘记 设置 NumPy 和 Matplotlib。
目录#
加载 MNIST 数据集
预处理数据集
从头开始构建和训练一个小型神经网络
下一步
1. Load the MNIST dataset#
在本节中,您将下载最初存储在 Yann LeCun 的网站 上的压缩 MNIST 数据集文件。然后,您将使用内置的 Python 模块将它们转换为 4 个 NumPy 数组类型的文件。最后,您将把这些数组拆分为训练集和测试集。
1. 定义一个变量来存储 MNIST 数据集的训练/测试图像/标签名称到一个列表中:
data_sources = {
"training_images": "train-images-idx3-ubyte.gz", # 60,000 training images.
"test_images": "t10k-images-idx3-ubyte.gz", # 10,000 test images.
"training_labels": "train-labels-idx1-ubyte.gz", # 60,000 training labels.
"test_labels": "t10k-labels-idx1-ubyte.gz", # 10,000 test labels.
}
2. 加载数据。首先检查数据是否存储在本地;如果没有,则下载它。
import requests
import os
data_dir = "../_data"
os.makedirs(data_dir, exist_ok=True)
base_url = "https://github.com/rossbar/numpy-tutorial-data-mirror/blob/main/"
for fname in data_sources.values():
fpath = os.path.join(data_dir, fname)
if not os.path.exists(fpath):
print("Downloading file: " + fname)
resp = requests.get(base_url + fname, stream=True, **request_opts)
resp.raise_for_status() # Ensure download was succesful
with open(fpath, "wb") as fh:
for chunk in resp.iter_content(chunk_size=128):
fh.write(chunk)
3. 解压4个文件并创建4个ndarrays,将它们保存到一个字典中。每个原始图像的大小为28x28,神经网络通常期望一个1D向量输入;因此,您还需要通过将28乘以28(784)来重塑图像。
import gzip
import numpy as np
mnist_dataset = {}
# Images
for key in ("training_images", "test_images"):
with gzip.open(os.path.join(data_dir, data_sources[key]), "rb") as mnist_file:
mnist_dataset[key] = np.frombuffer(
mnist_file.read(), np.uint8, offset=16
).reshape(-1, 28 * 28)
# Labels
for key in ("training_labels", "test_labels"):
with gzip.open(os.path.join(data_dir, data_sources[key]), "rb") as mnist_file:
mnist_dataset[key] = np.frombuffer(mnist_file.read(), np.uint8, offset=8)
4. 使用标准的 x 表示数据,y 表示标签,将数据分为训练集和测试集,调用训练集和测试集图像为 x_train 和 x_test,标签为 y_train 和 y_test:
x_train, y_train, x_test, y_test = (
mnist_dataset["training_images"],
mnist_dataset["training_labels"],
mnist_dataset["test_images"],
mnist_dataset["test_labels"],
)
5. 你可以确认图像数组的形状分别为训练集的 (60000, 784) 和测试集的 (10000, 784),标签分别为 (60000,) 和 (10000,):
print(
"The shape of training images: {} and training labels: {}".format(
x_train.shape, y_train.shape
)
)
print(
"The shape of test images: {} and test labels: {}".format(
x_test.shape, y_test.shape
)
)
The shape of training images: (60000, 784) and training labels: (60000,)
The shape of test images: (10000, 784) and test labels: (10000,)
6. 你可以使用 Matplotlib 检查一些图像:
import matplotlib.pyplot as plt
# Take the 60,000th image (indexed at 59,999) from the training set,
# reshape from (784, ) to (28, 28) to have a valid shape for displaying purposes.
mnist_image = x_train[59999, :].reshape(28, 28)
# Set the color mapping to grayscale to have a black background.
plt.imshow(mnist_image, cmap="gray")
# Display the image.
plt.show()
# Display 5 random images from the training set.
num_examples = 5
seed = 147197952744
rng = np.random.default_rng(seed)
fig, axes = plt.subplots(1, num_examples)
for sample, ax in zip(rng.choice(x_train, size=num_examples, replace=False), axes):
ax.imshow(sample.reshape(28, 28), cmap="gray")
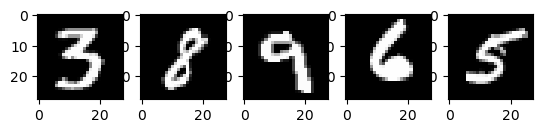
上面是从MNIST训练集中提取的五张图片。展示了各种手绘的阿拉伯数字,每次运行代码时,具体数值都是随机选择的。
注意: 你也可以通过打印
x_train[59999]来可视化一个样本图像作为数组。这里,59999是你的第 60,000 个训练图像样本(0是你的第一个)。你的输出将会非常长,并且应该包含一个由 8 位整数组成的数组:... 0, 0, 38, 48, 48, 22, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 62, 97, 198, 243, 254, 254, 212, 27, 0, 0, 0, 0, ...
# Display the label of the 60,000th image (indexed at 59,999) from the training set.
y_train[59999]
np.uint8(8)
2. Preprocess the data#
神经网络可以处理以浮点类型张量(多维数组)形式的输入。在预处理数据时,你应该考虑以下过程:向量化 和 转换为浮点格式。
由于 MNIST 数据已经向量化,并且数组是 dtype uint8 类型,你的下一个挑战是将它们转换为浮点格式,例如 float64(双精度):
One-hot/类别编码 的图像标签。
在实践中,您可以根据您的目标使用不同类型的浮点精度,您可以在 Nvidia 和 Google Cloud 博客文章中找到更多信息。
将图像数据转换为浮点格式#
图像数据包含在 [0, 255] 区间内编码的 8 位整数,颜色值在 0 到 255 之间。
你将通过将它们除以255,将它们归一化为[0, 1]区间内的浮点数数组。
1. 检查矢量化图像数据是否为 uint8 类型:
print("The data type of training images: {}".format(x_train.dtype))
print("The data type of test images: {}".format(x_test.dtype))
The data type of training images: uint8
The data type of test images: uint8
2. 通过将数组除以255(从而将数据类型从uint8提升到float64)来归一化数组,然后将训练和测试图像数据变量——x_train和x_test——分别赋值给training_images和train_labels。为了在这个例子中减少模型训练和评估时间,只使用训练和测试图像的一个子集。training_images和test_images各自只包含1,000个样本,分别来自完整的60,000和10,000个图像数据集。这些值可以通过更改下面的training_sample和test_sample来控制,最大值分别为60,000和10,000。
training_sample, test_sample = 1000, 1000
training_images = x_train[0:training_sample] / 255
test_images = x_test[0:test_sample] / 255
3. 确认图像数据已更改为浮点格式:
print("The data type of training images: {}".format(training_images.dtype))
print("The data type of test images: {}".format(test_images.dtype))
The data type of training images: float64
The data type of test images: float64
注意: 你也可以通过在一个笔记本单元中打印
training_images[0]来检查归一化是否成功。你的长输出应包含一个浮点数数组:... 0. , 0. , 0.01176471, 0.07058824, 0.07058824, 0.07058824, 0.49411765, 0.53333333, 0.68627451, 0.10196078, 0.65098039, 1. , 0.96862745, 0.49803922, 0. , ...
通过分类/独热编码将标签转换为浮点数#
你将使用独热编码将每个数字标签嵌入为一个全零向量,并使用 np.zeros() 在标签索引位置放置 1。结果,你的标签数据将是数组,每个图像标签位置为 1.0(或 1.)。
由于总共有10个标签(从0到9),您的数组将看起来类似于这样:
array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.])
1. 确认图像标签数据是带有 dtype uint8 的整数:
print("The data type of training labels: {}".format(y_train.dtype))
print("The data type of test labels: {}".format(y_test.dtype))
The data type of training labels: uint8
The data type of test labels: uint8
2. 定义一个对数组执行独热编码的函数:
def one_hot_encoding(labels, dimension=10):
# Define a one-hot variable for an all-zero vector
# with 10 dimensions (number labels from 0 to 9).
one_hot_labels = labels[..., None] == np.arange(dimension)[None]
# Return one-hot encoded labels.
return one_hot_labels.astype(np.float64)
3. 编码标签并将值分配给新变量:
training_labels = one_hot_encoding(y_train[:training_sample])
test_labels = one_hot_encoding(y_test[:test_sample])
4. 检查数据类型是否已更改为浮点型:
print("The data type of training labels: {}".format(training_labels.dtype))
print("The data type of test labels: {}".format(test_labels.dtype))
The data type of training labels: float64
The data type of test labels: float64
5. 检查一些编码标签:
print(training_labels[0])
print(training_labels[1])
print(training_labels[2])
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
…并与原文进行比较:
print(y_train[0])
print(y_train[1])
print(y_train[2])
5
0
4
您已完成数据集的准备。
3. Build and train a small neural network from scratch#
在本节中,您将熟悉深度学习模型的一些高级概念的基本构建块。您可以参考原始的深度学习研究出版物以获取更多信息。
之后,你将使用 Python 和 NumPy 构建一个简单深度学习模型的基本组件,并训练它以一定的准确率从 MNIST 数据集中识别手写数字。
使用 NumPy 的神经网络构建模块#
层: 这些构建块作为数据过滤器——它们处理数据并从输入中学习表示,以更好地预测目标输出。
你将在模型中使用1个隐藏层来向前传递输入(前向传播)和向后传播损失函数的梯度/误差导数(反向传播)。这些是输入层、隐藏层和输出层。
在隐藏(中间)和输出(最后)层中,神经网络模型将计算输入的加权和。为了计算这个过程,你将使用 NumPy 的矩阵乘法函数(即“点乘”或
np.dot(layer, weights))。注意: 为了简单起见,在此示例中省略了偏置项(没有
np.dot(layer, weights) + bias)。权重: 这些是神经网络通过前向和后向传播数据进行微调的重要可调参数。它们通过一个称为梯度下降的过程进行优化。在模型训练开始之前,权重使用NumPy的
Generator.random()随机初始化。最优权重应在训练和测试集上产生最高的预测准确率和最低的误差。
激活函数: 深度学习模型能够确定输入和输出之间的非线性关系,这些非线性函数通常应用于每一层的输出。
你将使用一个 修正线性单元 (ReLU) 到隐藏层的输出(例如,
relu(np.dot(layer, weights)))。-
在这个例子中,你将使用一种称为 dropout 的方法——稀释——它随机将层中的一些特征设置为 0。你将使用 NumPy 的
Generator.integers()方法来定义它,并将其应用于网络的隐藏层。 损失函数: 通过将图像标签(真实值)与最终层输出的预测值进行比较,计算决定了预测的质量。
为了简单起见,您将使用一个基本的总平方误差,使用 NumPy 的
np.sum()函数(例如,np.sum((final_layer_output - image_labels) ** 2))。准确性:此指标衡量网络对其未见数据的预测能力的准确性。
模型架构和训练总结#
以下是神经网络模型架构和训练过程的总结:
输入层:
这是网络的输入——从
training_images加载到layer_0的预处理数据。隐藏(中间)层
layer_1接收前一层的输出,并通过 NumPy 的np.dot()对输入进行权重 (weights_1) 的矩阵乘法。然后,这个输出通过 ReLU 激活函数进行非线性处理,然后应用 dropout 以帮助减少过拟合。
输出(最后)层:
layer_2摄取layer_1的输出,并与weights_2重复相同的“点乘”过程。最终输出返回每个0-9数字标签的10个分数。网络模型以一个大小为10的层结束——一个10维向量。
前向传播, 反向传播, 训练循环:
在模型训练的开始阶段,你的网络会随机初始化权重,并通过隐藏层和输出层将输入数据前馈。这个过程称为前向传递或前向传播。
然后,网络从损失函数传播“信号”回隐藏层,并在学习率参数的帮助下调整权重值(稍后会详细介绍)。
组合模型并开始训练和测试它#
在涵盖了主要的深度学习概念和神经网络架构之后,让我们来写代码。
1. 我们将首先创建一个新的随机数生成器,提供一个种子以确保可重复性:
seed = 884736743
rng = np.random.default_rng(seed)
2. 对于隐藏层,定义用于前向传播的 ReLU 激活函数和在反向传播期间将使用的 ReLU 的导数:
# Define ReLU that returns the input if it's positive and 0 otherwise.
def relu(x):
return (x >= 0) * x
# Set up a derivative of the ReLU function that returns 1 for a positive input
# and 0 otherwise.
def relu2deriv(output):
return output >= 0
3. 设置 超参数 的某些默认值,例如:
学习率:
learning_rate— 有助于限制权重更新的幅度,以防止它们过度校正。Epochs (迭代):
epochs— 数据通过网络的完整传递次数 — 前向和后向传播 — 。这个参数可以正面或负面影响结果。迭代次数越高,学习过程可能越长。因为这是一个计算密集型任务,我们选择了一个非常低的epochs数量(20)。为了获得有意义的结果,你应该选择一个更大的数字。网络中隐藏(中间)层的大小:
hidden_size— 隐藏层的大小在训练和测试期间可以影响结果。输入的大小:
pixels_per_image— 你已经确定图像输入是 784 (28x28) 像素。标签数量:
num_labels— 表示输出层的输出数量,在该层进行10(0到9)个手写数字标签的预测。
learning_rate = 0.005
epochs = 20
hidden_size = 100
pixels_per_image = 784
num_labels = 10
4. 使用随机值初始化将在隐藏层和输出层中使用的权重向量:
weights_1 = 0.2 * rng.random((pixels_per_image, hidden_size)) - 0.1
weights_2 = 0.2 * rng.random((hidden_size, num_labels)) - 0.1
5. 使用训练循环设置神经网络的学习实验并开始训练过程。注意,模型在每个时期都会针对测试集进行评估,以跟踪其在训练时期的表现。
开始训练过程:
# To store training and test set losses and accurate predictions
# for visualization.
store_training_loss = []
store_training_accurate_pred = []
store_test_loss = []
store_test_accurate_pred = []
# This is a training loop.
# Run the learning experiment for a defined number of epochs (iterations).
for j in range(epochs):
#################
# Training step #
#################
# Set the initial loss/error and the number of accurate predictions to zero.
training_loss = 0.0
training_accurate_predictions = 0
# For all images in the training set, perform a forward pass
# and backpropagation and adjust the weights accordingly.
for i in range(len(training_images)):
# Forward propagation/forward pass:
# 1. The input layer:
# Initialize the training image data as inputs.
layer_0 = training_images[i]
# 2. The hidden layer:
# Take in the training image data into the middle layer by
# matrix-multiplying it by randomly initialized weights.
layer_1 = np.dot(layer_0, weights_1)
# 3. Pass the hidden layer's output through the ReLU activation function.
layer_1 = relu(layer_1)
# 4. Define the dropout function for regularization.
dropout_mask = rng.integers(low=0, high=2, size=layer_1.shape)
# 5. Apply dropout to the hidden layer's output.
layer_1 *= dropout_mask * 2
# 6. The output layer:
# Ingest the output of the middle layer into the the final layer
# by matrix-multiplying it by randomly initialized weights.
# Produce a 10-dimension vector with 10 scores.
layer_2 = np.dot(layer_1, weights_2)
# Backpropagation/backward pass:
# 1. Measure the training error (loss function) between the actual
# image labels (the truth) and the prediction by the model.
training_loss += np.sum((training_labels[i] - layer_2) ** 2)
# 2. Increment the accurate prediction count.
training_accurate_predictions += int(
np.argmax(layer_2) == np.argmax(training_labels[i])
)
# 3. Differentiate the loss function/error.
layer_2_delta = training_labels[i] - layer_2
# 4. Propagate the gradients of the loss function back through the hidden layer.
layer_1_delta = np.dot(weights_2, layer_2_delta) * relu2deriv(layer_1)
# 5. Apply the dropout to the gradients.
layer_1_delta *= dropout_mask
# 6. Update the weights for the middle and input layers
# by multiplying them by the learning rate and the gradients.
weights_1 += learning_rate * np.outer(layer_0, layer_1_delta)
weights_2 += learning_rate * np.outer(layer_1, layer_2_delta)
# Store training set losses and accurate predictions.
store_training_loss.append(training_loss)
store_training_accurate_pred.append(training_accurate_predictions)
###################
# Evaluation step #
###################
# Evaluate model performance on the test set at each epoch.
# Unlike the training step, the weights are not modified for each image
# (or batch). Therefore the model can be applied to the test images in a
# vectorized manner, eliminating the need to loop over each image
# individually:
results = relu(test_images @ weights_1) @ weights_2
# Measure the error between the actual label (truth) and prediction values.
test_loss = np.sum((test_labels - results) ** 2)
# Measure prediction accuracy on test set
test_accurate_predictions = np.sum(
np.argmax(results, axis=1) == np.argmax(test_labels, axis=1)
)
# Store test set losses and accurate predictions.
store_test_loss.append(test_loss)
store_test_accurate_pred.append(test_accurate_predictions)
# Summarize error and accuracy metrics at each epoch
print(
(
f"Epoch: {j}\n"
f" Training set error: {training_loss / len(training_images):.3f}\n"
f" Training set accuracy: {training_accurate_predictions / len(training_images)}\n"
f" Test set error: {test_loss / len(test_images):.3f}\n"
f" Test set accuracy: {test_accurate_predictions / len(test_images)}"
)
)
Epoch: 0
Training set error: 0.898
Training set accuracy: 0.397
Test set error: 0.680
Test set accuracy: 0.582
Epoch: 1
Training set error: 0.656
Training set accuracy: 0.633
Test set error: 0.607
Test set accuracy: 0.641
Epoch: 2
Training set error: 0.592
Training set accuracy: 0.68
Test set error: 0.569
Test set accuracy: 0.679
Epoch: 3
Training set error: 0.556
Training set accuracy: 0.7
Test set error: 0.541
Test set accuracy: 0.708
Epoch: 4
Training set error: 0.534
Training set accuracy: 0.732
Test set error: 0.526
Test set accuracy: 0.729
Epoch: 5
Training set error: 0.515
Training set accuracy: 0.715
Test set error: 0.500
Test set accuracy: 0.739
Epoch: 6
Training set error: 0.495
Training set accuracy: 0.748
Test set error: 0.487
Test set accuracy: 0.753
Epoch: 7
Training set error: 0.483
Training set accuracy: 0.769
Test set error: 0.486
Test set accuracy: 0.747
Epoch: 8
Training set error: 0.473
Training set accuracy: 0.776
Test set error: 0.473
Test set accuracy: 0.752
Epoch: 9
Training set error: 0.460
Training set accuracy: 0.788
Test set error: 0.462
Test set accuracy: 0.762
Epoch: 10
Training set error: 0.465
Training set accuracy: 0.769
Test set error: 0.462
Test set accuracy: 0.767
Epoch: 11
Training set error: 0.443
Training set accuracy: 0.801
Test set error: 0.456
Test set accuracy: 0.775
Epoch: 12
Training set error: 0.448
Training set accuracy: 0.795
Test set error: 0.455
Test set accuracy: 0.772
Epoch: 13
Training set error: 0.438
Training set accuracy: 0.787
Test set error: 0.453
Test set accuracy: 0.778
Epoch: 14
Training set error: 0.446
Training set accuracy: 0.791
Test set error: 0.450
Test set accuracy: 0.779
Epoch: 15
Training set error: 0.441
Training set accuracy: 0.788
Test set error: 0.452
Test set accuracy: 0.772
Epoch: 16
Training set error: 0.437
Training set accuracy: 0.786
Test set error: 0.453
Test set accuracy: 0.772
Epoch: 17
Training set error: 0.436
Training set accuracy: 0.794
Test set error: 0.449
Test set accuracy: 0.778
Epoch: 18
Training set error: 0.433
Training set accuracy: 0.801
Test set error: 0.450
Test set accuracy: 0.774
Epoch: 19
Training set error: 0.429
Training set accuracy: 0.785
Test set error: 0.436
Test set accuracy: 0.784
训练过程可能需要很多分钟,这取决于许多因素,例如您运行实验的机器的处理能力以及训练的轮数。为了减少等待时间,您可以将轮数(迭代)变量从100改为较低的数字,重置运行时(这将重置权重),然后再次运行笔记本单元。
在执行上述单元格之后,您可以可视化此训练过程的一个实例的训练集和测试集的误差和准确性。
epoch_range = np.arange(epochs) + 1 # Starting from 1
# The training set metrics.
training_metrics = {
"accuracy": np.asarray(store_training_accurate_pred) / len(training_images),
"error": np.asarray(store_training_loss) / len(training_images),
}
# The test set metrics.
test_metrics = {
"accuracy": np.asarray(store_test_accurate_pred) / len(test_images),
"error": np.asarray(store_test_loss) / len(test_images),
}
# Display the plots.
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 5))
for ax, metrics, title in zip(
axes, (training_metrics, test_metrics), ("Training set", "Test set")
):
# Plot the metrics
for metric, values in metrics.items():
ax.plot(epoch_range, values, label=metric.capitalize())
ax.set_title(title)
ax.set_xlabel("Epochs")
ax.legend()
plt.show()
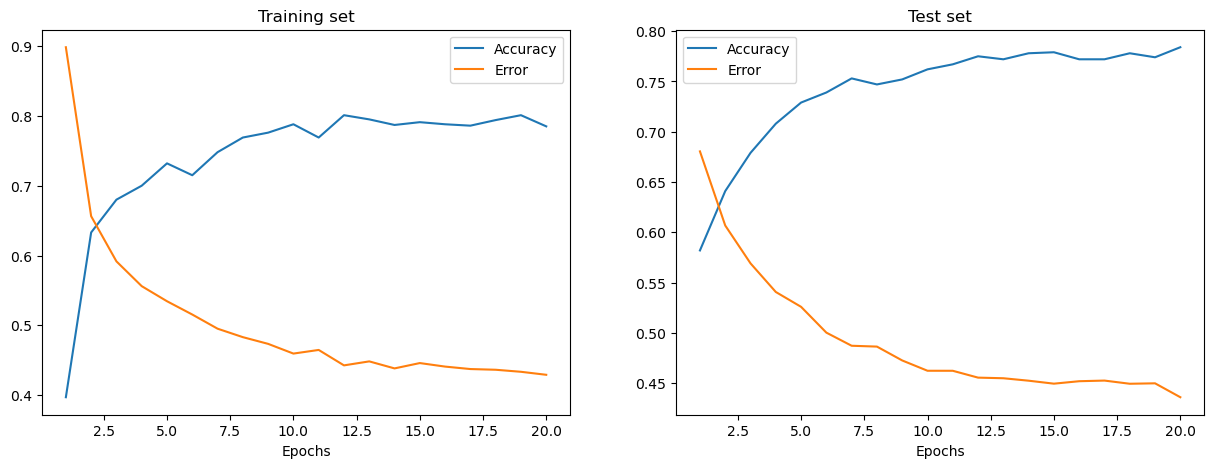
训练和测试误差分别显示在上述左图和右图中。随着Epochs数量的增加,总误差减少,准确性增加。
在训练和测试期间,您的模型达到的准确率可能看起来有些合理,但您也可能发现错误率相当高。
为了减少训练和测试过程中的误差,你可以考虑将简单的损失函数改为,例如,分类 交叉熵。其他可能的解决方案在下面讨论。
下一步#
你已经学会了如何使用仅 NumPy 从头构建和训练一个简单的全连接神经网络,以分类手写 MNIST 数字。
为了进一步增强和优化你的神经网络模型,你可以考虑以下混合方法之一:
将训练样本大小从1,000增加到一个更高的数字(最高可达60,000)。
使用 小批量和降低学习率。
通过引入更多的隐藏层来改变架构,使网络 更深。
介绍卷积层:用 卷积神经网络 架构替换前馈网络。
使用更高的 epoch 大小进行更长时间的训练,并添加更多的正则化技术,例如 early stopping,以防止 overfitting。
引入一个 验证集 以进行模型拟合的无偏评估。
应用 批量归一化 以实现更快和更稳定的训练。
调整其他参数,例如学习率和隐藏层大小。
使用 NumPy 从头构建一个神经网络是学习更多关于 NumPy 和深度学习的一个好方法。然而,对于实际应用,你应该使用专门的框架——例如 PyTorch、JAX、TensorFlow 或 MXNet——它们提供了类似 NumPy 的 API,内置了 自动微分 和 GPU 支持,并且设计用于高性能数值计算和机器学习。
最后,在开发机器学习模型时,你应该考虑潜在的伦理问题并应用实践来避免或减轻这些问题:
使用模型卡记录训练好的模型 - 参见 Margaret Mitchell 等人的 模型报告的模型卡论文。
用Datasheet记录一个数据集 - 参见Timnit Gebru等人的Datasheets for Datasets论文。
更多资源,请参见 Rachel Thomas 的这篇博客文章 和 Radical AI 播客。
(感谢 hsjeong5 演示了如何在不使用外部库的情况下下载 MNIST。)