
掩码数组#
你将做什么#
使用 NumPy 的掩码数组模块来分析 COVID-19 数据并处理缺失值。
你将学到什么#
你将了解什么是掩码数组以及如何创建它们
你将看到如何访问和修改掩码数组的数据
你将能够决定在你的某些应用中何时使用掩码数组是合适的
你需要什么#
对 Python 有基本的了解。如果你想复习一下,可以看看 Python 教程。
对NumPy有基本的了解
要在您的计算机上运行绘图,您需要 matplotlib。
什么是掩码数组?#
考虑以下问题。你有一个包含缺失或无效条目的数据集。如果你在对此数据进行任何类型的处理,并且希望在不直接删除这些不需要的条目的情况下 跳过 或标记它们,你可能需要使用条件语句或以某种方式过滤你的数据。numpy.ma 模块提供了与 NumPy ndarrays 相同的一些功能,并增加了结构以确保无效条目不会在计算中使用。
来自 参考指南:
掩码数组是标准 numpy.ndarray 和 掩码 的组合。掩码要么是
nomask,表示关联数组中没有值是无效的,要么是布尔数组,确定关联数组的每个元素是否有效。当掩码的元素为False时,关联数组的相应元素是有效的,并且被称为未掩码。当掩码的元素为True时,关联数组的相应元素被称为掩码(无效)。
我们可以将 MaskedArray 视为以下组合:
数据,作为一个常规的
numpy.ndarray,可以是任何形状或数据类型;与数据具有相同形状的布尔掩码;
fill_value是一个值,该值可用于替换无效条目,以便返回标准的numpy.ndarray。
它们什么时候有用?#
在某些情况下,掩码数组可能比仅仅消除数组中的无效条目更有用:
当你想保留你屏蔽的值以供后续处理,而不复制数组时;
当你需要处理许多数组,每个数组都有自己的掩码时。如果掩码是数组的一部分,你可以避免错误,代码也可能更紧凑;
当你对缺失或无效值有不同的标志,并希望在原始数据集中保留这些标志而不替换它们,但将它们从计算中排除时;
如果你无法避免或消除缺失值,但不想在操作中处理 NaN (Not a Number) 值。
掩码数组也是一个好主意,因为 numpy.ma 模块还带有大多数 NumPy 通用函数 (ufuncs) 的特定实现,这意味着你仍然可以在掩码数据上应用快速矢量化函数和操作。输出结果是一个掩码数组。我们将在下面看到一些实际操作的例子。
使用掩码数组查看 COVID-19 数据#
从 Kaggle 可以下载一个包含2020年初COVID-19疫情初始数据的数据集。我们将查看该数据的一个小子集,包含在文件 who_covid_19_sit_rep_time_series.csv 中。(注意,该文件在2020年末被替换为没有缺失数据的版本。)
import numpy as np
import os
# The os.getcwd() function returns the current folder; you can change
# the filepath variable to point to the folder where you saved the .csv file
filepath = os.getcwd()
filename = os.path.join(filepath, "who_covid_19_sit_rep_time_series.csv")
数据文件包含不同类型的数据,其组织方式如下:
第一行是一个标题行,它(大部分)描述了下面各行中每列的数据,从第四列开始,标题是观测日期。
第二到第七行包含的是与我们即将要检查的数据类型不同的汇总数据,因此我们需要将其从我们将要处理的数据中排除。
我们希望处理的数值数据从第4列、第8行开始,并从那里延伸到最右列和最底行。
让我们探索这个文件中前14天的记录数据。为了从 .csv 文件中收集数据,我们将使用 numpy.genfromtxt 函数,确保我们只选择包含实际数字的列,而不是包含位置数据的前四列。我们还跳过文件的前6行,因为它们包含我们不感兴趣的其他数据。另外,我们将提取关于日期和位置的此数据信息。
# Note we are using skip_header and usecols to read only portions of the
# data file into each variable.
# Read just the dates for columns 4-18 from the first row
dates = np.genfromtxt(
filename,
dtype=np.str_,
delimiter=",",
max_rows=1,
usecols=range(4, 18),
encoding="utf-8-sig",
)
# Read the names of the geographic locations from the first two
# columns, skipping the first six rows
locations = np.genfromtxt(
filename,
dtype=np.str_,
delimiter=",",
skip_header=6,
usecols=(0, 1),
encoding="utf-8-sig",
)
# Read the numeric data from just the first 14 days
nbcases = np.genfromtxt(
filename,
dtype=np.int_,
delimiter=",",
skip_header=6,
usecols=range(4, 18),
encoding="utf-8-sig",
)
在 numpy.genfromtxt 函数调用中,我们为数据的每个子集选择了 numpy.dtype(整数 - numpy.int_ - 或字符串 - numpy.str_)。我们还使用了 encoding 参数来选择 utf-8-sig 作为文件的编码(更多关于编码的信息请参阅 官方 Python 文档。您可以从 参考文档 或 基本 IO 教程 中了解更多关于 numpy.genfromtxt 函数的信息。
探索数据#
首先,我们可以绘制我们拥有的整个数据集,看看它是什么样子。为了得到一个可读的图表,我们只选择几个日期显示在我们的 x轴刻度 中。还要注意,在我们的绘图命令中,我们使用 nbcases.T(nbcases 数组的转置),因为这意味着我们将把文件的每一行绘制为一条单独的线。我们选择绘制虚线(使用 '--' 线型)。有关更多信息,请参阅 matplotlib 文档。
import matplotlib.pyplot as plt
selected_dates = [0, 3, 11, 13]
plt.plot(dates, nbcases.T, "--")
plt.xticks(selected_dates, dates[selected_dates])
plt.title("COVID-19 cumulative cases from Jan 21 to Feb 3 2020")
Text(0.5, 1.0, 'COVID-19 cumulative cases from Jan 21 to Feb 3 2020')
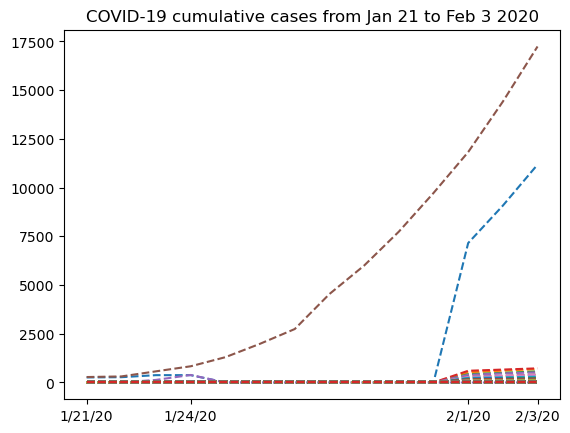
该图从1月24日到2月1日有一个奇怪的形状。知道这些数据的来源会很有趣。如果我们查看从 .csv 文件中提取的 locations 数组,我们可以看到我们有两列,第一列包含地区,第二列包含国家名称。然而,只有前几行包含第一列的数据(中国的省份名称)。之后,我们只有国家名称。因此,将所有来自中国的数据合并到一行是有意义的。为此,我们将从 nbcases 数组中选择 locations 数组的第二个条目对应于中国的行。接下来,我们将使用 numpy.sum 函数来求和所有选定的行(axis=0)。还要注意,第35行对应于每个日期全国的总数。由于我们想从省份数据中自己计算总和,我们必须首先从 locations 和 nbcases 中删除该行:
totals_row = 35
locations = np.delete(locations, (totals_row), axis=0)
nbcases = np.delete(nbcases, (totals_row), axis=0)
china_total = nbcases[locations[:, 1] == "China"].sum(axis=0)
china_total
array([ 247, 288, 556, 817, -22, -22, -15, -10, -9,
-7, -4, 11820, 14410, 17237])
这些数据有问题 - 我们不应该在累积数据集中有负值。发生了什么?
缺失数据#
查看数据,我们发现以下情况:存在一个数据缺失的时期:
nbcases
array([[ 258, 270, 375, ..., 7153, 9074, 11177],
[ 14, 17, 26, ..., 520, 604, 683],
[ -1, 1, 1, ..., 422, 493, 566],
...,
[ -1, -1, -1, ..., -1, -1, -1],
[ -1, -1, -1, ..., -1, -1, -1],
[ -1, -1, -1, ..., -1, -1, -1]])
我们看到的所有 -1 值都来自 numpy.genfromtxt 尝试从原始 .csv 文件中读取缺失数据。显然,我们不希望将缺失数据计算为 -1 - 我们只是想跳过这个值,以免它干扰我们的分析。导入 numpy.ma 模块后,我们将创建一个新数组,这次将屏蔽无效值:
from numpy import ma
nbcases_ma = ma.masked_values(nbcases, -1)
如果我们查看 nbcases_ma 掩码数组,这就是我们所拥有的:
nbcases_ma
masked_array(
data=[[258, 270, 375, ..., 7153, 9074, 11177],
[14, 17, 26, ..., 520, 604, 683],
[--, 1, 1, ..., 422, 493, 566],
...,
[--, --, --, ..., --, --, --],
[--, --, --, ..., --, --, --],
[--, --, --, ..., --, --, --]],
mask=[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[ True, False, False, ..., False, False, False],
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]],
fill_value=-1)
我们可以看到这是一种不同类型的数组。如前言所述,它有三个属性(data、mask 和 fill_value)。请记住,mask 属性对于对应于 无效 数据的元素(在 data 属性中用两个破折号表示)具有 True 值。
让我们尝试并看看排除第一行(来自中国湖北省的数据)的数据是什么样子的,这样我们可以更仔细地查看缺失的数据:
plt.plot(dates, nbcases_ma[1:].T, "--")
plt.xticks(selected_dates, dates[selected_dates])
plt.title("COVID-19 cumulative cases from Jan 21 to Feb 3 2020")
Text(0.5, 1.0, 'COVID-19 cumulative cases from Jan 21 to Feb 3 2020')
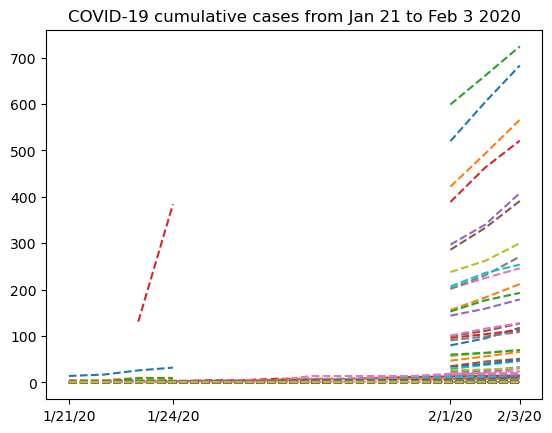
现在我们的数据已经被掩码处理,让我们尝试汇总中国的所有病例:
china_masked = nbcases_ma[locations[:, 1] == "China"].sum(axis=0)
china_masked
masked_array(data=[278, 309, 574, 835, 10, 10, 17, 22, 23, 25, 28, 11821,
14411, 17238],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False],
fill_value=999999)
注意 china_masked 是一个掩码数组,所以它的数据结构与常规的 NumPy 数组不同。现在,我们可以通过使用 .data 属性直接访问它的数据:
china_total = china_masked.data
china_total
array([ 278, 309, 574, 835, 10, 10, 17, 22, 23,
25, 28, 11821, 14411, 17238])
这样更好:不再有负值。然而,我们仍然可以看到,对于某些天,累计病例数似乎在下降(例如从835例降到10例),这与“累计数据”的定义不符。如果我们更仔细地查看数据,我们可以看到在中国大陆数据缺失的时期,香港、台湾、澳门和中国“未指定”地区的数据是有效的。也许我们可以从中国的总病例数中去除这些数据,以便更好地理解数据。
首先,我们将识别中国大陆地区的位置索引:
china_mask = (
(locations[:, 1] == "China")
& (locations[:, 0] != "Hong Kong")
& (locations[:, 0] != "Taiwan")
& (locations[:, 0] != "Macau")
& (locations[:, 0] != "Unspecified*")
)
现在,china_mask 是一个布尔值数组(True 或 False);我们可以使用掩码数组的 ma.nonzero 方法检查索引是否是我们想要的:
china_mask.nonzero()
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 25, 26, 27, 28, 29, 31, 33]),)
现在我们可以正确地汇总中国大陆的条目:
china_total = nbcases_ma[china_mask].sum(axis=0)
china_total
masked_array(data=[278, 308, 440, 446, --, --, --, --, --, --, --, 11791,
14380, 17205],
mask=[False, False, False, False, True, True, True, True,
True, True, True, False, False, False],
fill_value=999999)
我们可以用这些信息替换数据并绘制一个新的图表,重点关注中国大陆:
plt.plot(dates, china_total.T, "--")
plt.xticks(selected_dates, dates[selected_dates])
plt.title("COVID-19 cumulative cases from Jan 21 to Feb 3 2020 - Mainland China")
Text(0.5, 1.0, 'COVID-19 cumulative cases from Jan 21 to Feb 3 2020 - Mainland China')
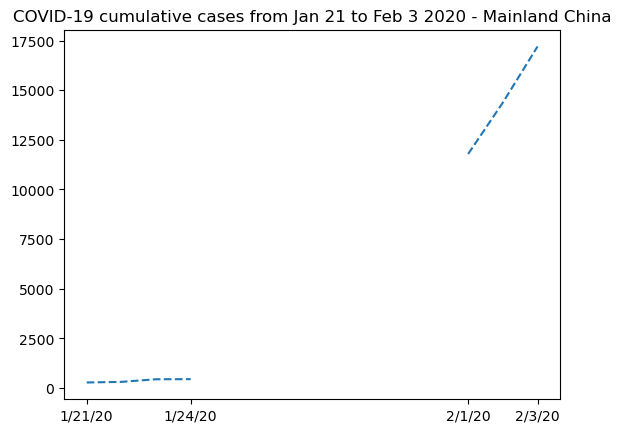
显然,掩码数组是这里的正确解决方案。我们不能在不曲解曲线演变的情况下表示缺失数据。
拟合数据#
我们可以想到的一种可能性是插值缺失的数据,以估计1月底的病例数。注意,我们可以使用 .mask 属性选择掩码元素:
china_total.mask
invalid = china_total[china_total.mask]
invalid
masked_array(data=[--, --, --, --, --, --, --],
mask=[ True, True, True, True, True, True, True],
fill_value=999999,
dtype=int64)
我们也可以通过使用这个掩码的逻辑非来访问有效条目:
valid = china_total[~china_total.mask]
valid
masked_array(data=[278, 308, 440, 446, 11791, 14380, 17205],
mask=[False, False, False, False, False, False, False],
fill_value=999999)
现在,如果我们想为这些数据创建一个非常简单的近似值,我们应该考虑无效条目周围的有效条目。因此,首先让我们选择数据有效的日期。请注意,我们可以使用 china_total 掩码数组中的掩码来索引日期数组:
dates[~china_total.mask]
array(['1/21/20', '1/22/20', '1/23/20', '1/24/20', '2/1/20', '2/2/20',
'2/3/20'], dtype='<U7')
最后,我们可以使用 numpy.polynomial 的拟合功能 包来创建一个尽可能拟合数据的三次多项式模型:
t = np.arange(len(china_total))
model = np.polynomial.Polynomial.fit(t[~china_total.mask], valid, deg=3)
plt.plot(t, china_total)
plt.plot(t, model(t), "--")
[<matplotlib.lines.Line2D at 0x1171b3dd0>]
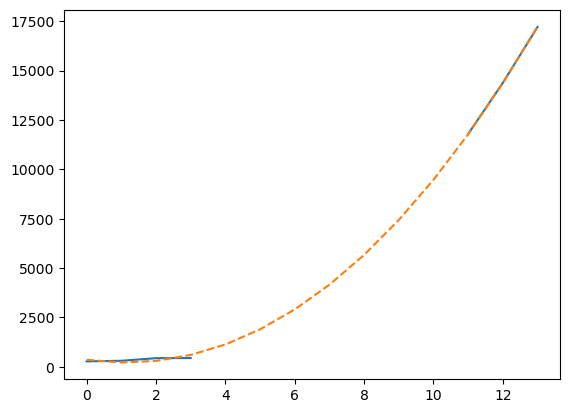
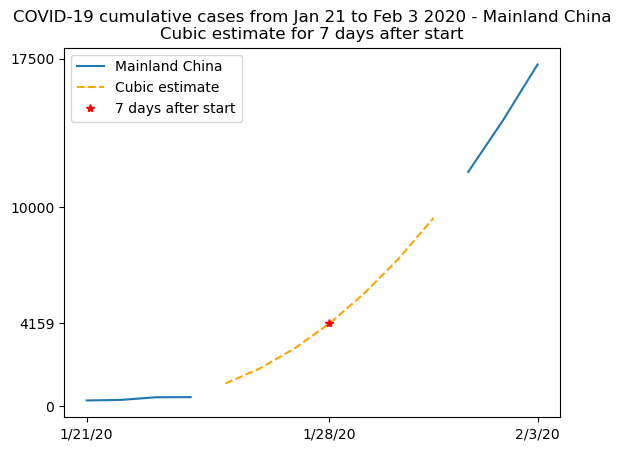
这个图表不太易读,因为线条似乎重叠在一起,所以让我们在一个更详细的图表中总结。当有真实数据时,我们将绘制真实数据,并使用三次拟合来显示不可用数据,利用这个拟合来计算2020年1月28日观察到的病例数的估计值,这是记录开始后7天的数据:
plt.plot(t, china_total)
plt.plot(t[china_total.mask], model(t)[china_total.mask], "--", color="orange")
plt.plot(7, model(7), "r*")
plt.xticks([0, 7, 13], dates[[0, 7, 13]])
plt.yticks([0, model(7), 10000, 17500])
plt.legend(["Mainland China", "Cubic estimate", "7 days after start"])
plt.title(
"COVID-19 cumulative cases from Jan 21 to Feb 3 2020 - Mainland China\n"
"Cubic estimate for 7 days after start"
)
Text(0.5, 1.0, 'COVID-19 cumulative cases from Jan 21 to Feb 3 2020 - Mainland China\nCubic estimate for 7 days after start')
在实践中#
在缺失数据中添加
-1对于numpy.genfromtxt来说不是问题;在这种特定情况下,用0替换缺失值可能也是可以的,但我们稍后会看到,这远不是一个通用解决方案。此外,可以通过使用usemask参数调用numpy.genfromtxt函数。如果usemask=True,numpy.genfromtxt会自动返回一个掩码数组。
进一步阅读#
本教程未涵盖的主题可以在文档中找到:
参考#
董恩盛, 杜鸿儒, Lauren Gardner, 一个交互式的基于网络的仪表板,实时追踪COVID-19, 《柳叶刀传染病》, 第20卷, 第5期, 2020年, 第533-534页, ISSN 1473-3099, https://doi.org/10.1016/S1473-3099(20)30120-1.