发布说明¶
此页面包含PennyLane的发行说明。
- orphan
版本 0.40.0 (当前版本)¶
自上次发布以来的新特性
高效的状态准备方法 🦾
State preparation tailored for matrix product states (MPS) is now supported with
qml.MPSPrepon thelightning.tensordevice. (#6431)Given a list of \(n\) tensors that represents an MPS, \([A^{(0)}, ..., A^{(n-1)}]\),
qml.MPSPreplets you directly inject the MPS into a QNode as the initial state of the circuit without any need for pre-processing. The first and last tensors in the list must be rank-2, while all intermediate tensors should be rank-3.import pennylane as qml import numpy as np mps = [ np.array([[0.0, 0.107], [0.994, 0.0]]), np.array( [ [[0.0, 0.0, 0.0, -0.0], [1.0, 0.0, 0.0, -0.0]], [[0.0, 1.0, 0.0, -0.0], [0.0, 0.0, 0.0, -0.0]], ] ), np.array( [ [[-1.0, 0.0], [0.0, 0.0]], [[0.0, 0.0], [0.0, 1.0]], [[0.0, -1.0], [0.0, 0.0]], [[0.0, 0.0], [1.0, 0.0]], ] ), np.array([[-1.0, -0.0], [-0.0, -1.0]]), ] dev = qml.device("lightning.tensor", wires = [0, 1, 2, 3]) @qml.qnode(dev) def circuit(): qml.MPSPrep(mps, wires = [0,1,2]) return qml.state()
>>> print(circuit()) [ 0. +0.j 0. +0.j 0. +0.j -0.1066+0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0.9943+0.j 0. +0.j 0. +0.j 0. +0.j]
At this time,
qml.MPSPrepis only supported on thelightning.tensordevice.现在可以使用
qml.Superposition进行自定义状态准备以实现量子态的线性组合。 (#6670)给定一组 \(m\) 系数 \(c_i\) 和基本状态 \(|b_i\rangle\),
qml.Superposition准备 \(|\phi\rangle = \sum_i^m c_i |b_i\rangle\)。以下是一个简单示例,展示如何使用qml.Superposition准备 \(\tfrac{1}{\sqrt{2}} |00\rangle + \tfrac{1}{\sqrt{2}} |10\rangle\)。coeffs = np.array([0.70710678, 0.70710678]) basis = np.array([[0, 0], [1, 0]]) @qml.qnode(qml.device('default.qubit')) def circuit(): qml.Superposition(coeffs, basis, wires=[0, 1], work_wire=[2]) return qml.state()
>>> circuit() Array([0.7071068 +0.j, 0. +0.j, 0. +0.j, 0. +0.j, 0.70710677+0.j, 0. +0.j, 0. +0.j, 0. +0.j], dtype=complex64)
请注意,必须指定一个
work_wire。
增强的 QSVT 功能 🤩
已添加新的功能,以计算和转换 QSP 和 QSVT 的相位角,使用
qml.poly_to_angles和qml.transform_angles。qml.poly_to_angles函数根据多项式系数直接计算相位角,并指定将要使用这些角的程序 ("QSVT","QSP", 或"GQSP"):>>> poly = [0, 1.0, 0, -1/2, 0, 1/3] >>> qsvt_angles = qml.poly_to_angles(poly, "QSVT") >>> print(qsvt_angles) [-5.49778714 1.57079633 1.57079633 0.5833829 1.61095884 0.74753829]
qml.transform_angles函数可用于将一种程序的角转换为另一种程序的角:>>> qsp_angles = np.array([0.2, 0.3, 0.5]) >>> qsvt_angles = qml.transform_angles(qsp_angles, "QSP", "QSVT") >>> print(qsvt_angles) [-6.86858347 1.87079633 -0.28539816]
The
qml.qsvtfunction has been improved to be more user-friendly, with enhanced capabilities. (#6520) (#6693)Block encoding and phase angle computation are now handled automatically, given a matrix to encode, polynomial coefficients, and a block encoding method (
"prepselprep","qubitization","embedding", or"fable", all implemented with their corresponding operators in PennyLane).# P(x) = -x + 0.5 x^3 + 0.5 x^5 poly = np.array([0, -1, 0, 0.5, 0, 0.5]) hamiltonian = qml.dot([0.3, 0.7], [qml.Z(1), qml.X(1) @ qml.Z(2)]) dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.qsvt(hamiltonian, poly, encoding_wires=[0], block_encoding="prepselprep") return qml.state() matrix = qml.matrix(circuit, wire_order=[0, 1, 2])()
>>> print(matrix[:4, :4].real) [[-0.1625 0. -0.3793 0. ] [ 0. -0.1625 0. 0.3793] [-0.3793 0. 0.1625 0. ] [ 0. 0.3793 0. 0.1625]]
The old functionality can still be accessed with
qml.qsvt_legacy.一个新的
qml.GQSP模板已被添加,以执行广义量子信号处理 (GQSP)。 (#6565) 与 QSVT 类似,GQSP 是一种多项式变换输入单位算子的算法,但对所选多项式的限制较少。您还可以使用
qml.poly_to_angles来获得 GQSP 的角度!# P(x) = 0.1 + 0.2j x + 0.3 x^2 poly = [0.1, 0.2j, 0.3] angles = qml.poly_to_angles(poly, "GQSP") @qml.prod # 将 qfunc 转换为操作符 def unitary(wires): qml.RX(0.3, wires) dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(angles): qml.GQSP(unitary(wires = 1), angles, control = 0) return qml.state() matrix = qml.matrix(circuit, wire_order=[0, 1])(angles)
>>> print(np.round(matrix,3)[:2, :2]) [[0.387+0.198j 0.03 -0.089j] [0.03 -0.089j 0.387+0.198j]]
广义Trotter积 🐖
Trotter products that work on exponentiated operators directly instead of full system hamiltonians can now be encoded into circuits with the addition of
qml.TrotterizedQfuncandqml.trotterize. This allows for custom specification of the first-order expansion of the Suzuki-Trotter product formula and extrapolating it to the \(n^{\text{th}}\) order. (#6627)If the first-order of the Suzuki-Trotter product formula for a given problem is known,
qml.TrotterizedQfuncandqml.trotterizelet you implement the \(n^{\text{th}}\)-order product formula while only specifying the first-order term as a quantum function.def my_custom_first_order_expansion(time, theta, phi, wires, flip): qml.RX(time * theta, wires[0]) qml.RY(time * phi, wires[1]) if flip: qml.CNOT(wires=wires[:2])
qml.trotterizerequires the quantum function representing the first-order product formula, the number of Trotter steps, and the desired order. It returns a function with the same call signature as the first-order product formula quantum function:@qml.qnode(qml.device("default.qubit")) def my_circuit(time, theta, phi, num_trotter_steps): qml.trotterize( first_order_expansion, n=num_trotter_steps, order=2, )(time, theta, phi, wires=['a', 'b'], flip=True) return qml.state()
Alternatively,
qml.TrotterizedQfunccan be used as follows:@qml.qnode(qml.device("default.qubit")) def my_circuit(time, theta, phi, num_trotter_steps): qml.TrotterizedQfunc( time, theta, phi, qfunc=my_custom_first_order_expansion, n=num_trotter_steps, order=2, wires=['a', 'b'], flip=True, ) return qml.state()
>>> time = 0.1 >>> theta, phi = (0.12, -3.45) >>> print(qml.draw(my_circuit, level="device")(time, theta, phi, num_trotter_steps=1)) a: ──RX(0.01)──╭●─╭●──RX(0.01)──┤ State b: ──RY(-0.17)─╰X─╰X──RY(-0.17)─┤ State
Both methods produce the same results, but offer different interfaces based on the application or overall preference.
玻色算子 🎈
一个新模块,qml.bose,已添加到PennyLane中,支持构建和操作玻色算子,并在玻色算子和量子比特算子之间转换。
与
qml.FermiWord和qml.FermiSentence类似的玻色子算子现在可以通过qml.BoseWord和qml.BoseSentence获得。 (#6518)qml.BoseWord和qml.BoseSentence的操作方式与它们的费米子对应物相似。要创建一个玻色词,需要一个字典作为输入,其中键是玻色子索引的元组,值是'+/-'(表示玻色子创建/湮灭算子)。例如,可以如下构造 \(b^{\dagger}_0 b_1\)。>>> w = qml.BoseWord({(0, 0) : '+', (1, 1) : '-'}) >>> print(w) b⁺(0) b(1)
然后可以将多个玻色词组合成一个玻色句子:
>>> w1 = qml.BoseWord({(0, 0) : '+', (1, 1) : '-'}) >>> w2 = qml.BoseWord({(0, 1) : '+', (1, 2) : '-'}) >>> s = qml.BoseSentence({w1 : 1.2, w2: 3.1}) >>> print(s) 1.2 * b⁺(0) b(1) + 3.1 * b⁺(1) b(2)
将玻色算符转换为量子比特算符的功能可通过
qml.unary_mapping,qml.binary_mapping, 和qml.christiansen_mapping获得。 (#6623) (#6576) (#6564)这三种映射遵循相同的语法,其中需要输入一个
qml.BoseWord或qml.BoseSentence。>>> w = qml.BoseWord({(0, 0): "+"}) >>> qml.binary_mapping(w, n_states=4) 0.6830127018922193 * X(0) + -0.1830127018922193 * X(0) @ Z(1) + -0.6830127018922193j * Y(0) + 0.1830127018922193j * Y(0) @ Z(1) + 0.3535533905932738 * X(0) @ X(1) + -0.3535533905932738j * X(0) @ Y(1) + 0.3535533905932738j * Y(0) @ X(1) + (0.3535533905932738+0j) * Y(0) @ Y(1)
每个函数内部还提供了额外的微调功能,例如允许的最大玻色态数和丢弃系数的虚部的容差。
构建振动哈密顿量 🔨
在
qml.qchem模块中提供了几个新功能,以帮助构建振动哈密顿量。这包括:用于存储势能面信息的
VibrationalPES类。(#6652)
pes_onemode = np.array([[0.309, 0.115, 0.038, 0.008, 0.000, 0.006, 0.020, 0.041, 0.070]]) pes_twomode = np.zeros((1, 1, 9, 9)) dipole_onemode = np.zeros((1, 9, 3)) gauss_weights = np.array([3.96e-05, 4.94e-03, 8.85e-02, 4.33e-01, 7.20e-01, 4.33e-01, 8.85e-02, 4.94e-03, 3.96e-05]) grid = np.array([-3.19, -2.27, -1.47, -0.72, 0.0, 0.72, 1.47, 2.27, 3.19]) pes_object = qml.qchem.VibrationalPES( freqs=np.array([0.025]), grid=grid, uloc=np.array([[1.0]]), gauss_weights=gauss_weights, pes_data=[pes_onemode, pes_twomode], dipole_data=[dipole_onemode], localized=False, dipole_level=1, )
构建泰勒哈密顿量的
taylor_hamiltonian()函数,来自一个VibrationalPES对象。 (#6523)
>>> qml.qchem.taylor_hamiltonian(pes_object, 4, 2) ( 0.016867926879358452 * I(0) + -0.007078617919572303 * Z(0) + 0.0008679410939323631 * X(0) )
构建泰勒哈密顿量的
taylor_bosonic()函数,使用博松算子。 (#6523)
>>> coeffs_arr = qml.qchem.taylor_coeffs(pes_object) >>> bose_op = qml.qchem.taylor_bosonic(coeffs_arr, pes_object.freqs, is_local=pes_object.localized, uloc=pes_object.uloc) >>> type(bose_op) pennylane.bose.bosonic.BoseSentence
还有附加功能可用于优化分子几何结构和在不同表示法之间转换:
将基于谐振子基的Christiansen哈密顿积分转换为基于振动自洽场(VSCF)的积分,使用
vscf_integrals()函数。 (#6688)查找分子的最低能量构型,使用
optimize_geometry()。 (#6453) (#6666)将正常模式频率分离并使用
localize_normal_modes()对它们进行定位。(#6453)
实验室:一个统一和快速原型设计研究软件的地方 🧑🔬
新的 qml.labs 模块将容纳实验研究软件 🔬。这里的功能可能对最先进的研究、测试版测试或在将新的潜在功能添加到 PennyLane 之前,提前了解它们有所帮助。
该模块的实验性质意味着其功能可能无法与其他PennyLane的重要特性(如可微性、JAX或JIT兼容性)很好地集成。也可能会出现意想不到的尖锐部分🔪和错误❌。
警告
该模块是实验性的!将会在没有警告的情况下发生重大变化和移除。 请谨慎使用这些功能,并让我们知道您的想法。您的反馈将影响这些功能如何成为主线PennyLane的一部分。
资源估计
实验室中的资源估计功能专注于轻量和灵活。实验室
qml.labs.resource_estimation模块涉及对核心 Pennylane 的修改,以减少资源估计的内存需求和计算时间。这些包括新的或修改的基类和一个新函数:Resources- 这个类在labs中被简化,去掉了参数:gate_sizes、depth和shots。 (#6428)ResourceOperator- 替代ResourceOperation,扩展以包括分解。 (#6428)CompressedResourceOp- 一个新类,包含估算资源所需的最少信息:操作符类型和分解所需的参数。(#6428)ResourceOperator- 许多现有PennyLane操作的版本,如保利算子,ResourceHadamard,和ResourceCNOT。 (#6447) (#6579) (#6538) (#6592)get_resources()- 获取量子电路资源的新入口。(#6500)
使用现有操作的新资源版本和
get_resources(),我们可以快速估算资源:import pennylane.labs.resource_estimation as re def my_circuit(): for w in range(2): re.ResourceHadamard(w) re.ResourceCNOT([0, 1]) re.ResourceRX(1.23, 0) re.ResourceRY(-4.56, 1) re.ResourceQFT(wires=[0, 1, 2]) return qml.expval(re.ResourceHadamard(2))
>>> res = re.get_resources(my_circuit)() >>> print(res) wires: 3 gates: 202 gate_types: {'Hadamard': 5, 'CNOT': 10, 'T': 187}
我们还可以为分解设置自定义门集:
>>> gate_set={"Hadamard","CNOT","RZ", "RX", "RY", "SWAP"} >>> res = re.get_resources(my_circuit, gate_set=gate_set)() >>> print(res) wires: 3 gates: 24 gate_types: {'Hadamard': 5, 'CNOT': 7, 'RX': 1, 'RY': 1, 'SWAP': 1, 'RZ': 9}
另外,可以手动替换相关资源:
>>> new_resources = re.substitute(res, "SWAP", re.Resources(2, 3, {"CNOT":3})) >>> print(new_resources) {'Hadamard': 5, 'CNOT': 10, 'RX': 1, 'RY': 1, 'RZ': 9}
处理动态李代数 (DLAs) 的实验功能
使用
qml.labs.dla模块来执行KAK分解:cartan_decomp(): 获得输入李代数的卡尔坦分解通过一个自反运算。(#6392)我们提供多种卷积,例如
concurrence_involution()、even_odd_involution()和典型的Cartan卷积。 (#6392) (#6396)cartan_subalgebra(): 计算一个水平卡尔坦副代数。 (#6403)variational_kak_adj(): 计算一个变分KAK分解的厄米算符,使用卡尔坦分解和水平卡尔坦子代数的伴随表示。 (#6446)
要使用此功能,我们首先需要一组厄米算子。
>>> n = 3 >>> gens = [qml.X(i) @ qml.X(i + 1) for i in range(n - 1)] >>> gens += [qml.Z(i) for i in range(n)] >>> H = qml.sum(*gens)
然后我们通过计算李闭包生成它的李代数。
>>> g = qml.lie_closure(gens) >>> g = [op.pauli_rep for op in g] >>> print(g) [1 * X(0) @ X(1), 1 * X(1) @ X(2), 1.0 * Z(0), ...]
然后我们选择一个对易变换(例如
concurrence_involution()),它定义了一个卡尔坦分解g = k + m。k是垂直子代数,m是它的水平补空间(不是一个子代数)。>>> from pennylane.labs.dla import concurrence_involution, cartan_decomp >>> involution = concurrence_involution >>> k, m = cartan_decomp(g, involution=involution)
下一步就是重新排列
g中的基元素并计算其structure_constants。>>> g = k + m >>> adj = qml.structure_constants(g)
我们可以计算一个(水平)卡尔坦子代数
a,也就是说,它是m的一个最大的阿贝尔子代数。>>> from pennylane.labs.dla import cartan_subalgebra >>> g, k, mtilde, a, adj = cartan_subalgebra(g, k, m, adj)
在确定了两个子代数
k和a后,我们可以像在 2104.00728 中那样以变分法计算 KAK 分解,参见我们的 演示 KAK 分解的实践。>>> from pennylane.labs.dla import variational_kak_adj >>> dims = (len(k), len(mtilde), len(a)) >>> adjvec_a, theta_opt = variational_kak_adj(H, g, dims, adj, opt_kwargs={"n_epochs": 3000})
我们还提供了一些附加功能,这些功能对于处理动态李代数非常有用。
recursive_cartan_decomp(): 执行连续的递归卡尔坦分解。 (#6396)lie_closure_dense(): 使用密集矩阵扩展的qml.lie_closure。 (#6371) (#6695)structure_constants_dense(): 使用密集矩阵的qml.structure_constants的扩展。 (#6396) (#6376)
振动哈密顿量
实验室中的新功能可以帮助构建振动哈密顿量。
>>> symbols = ['H', 'F'] >>> geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) >>> mol = qml.qchem.Molecule(symbols, geometry) >>> pes = vibrational_pes(mol)
使用
qml.labs.vibrational.christiansen_hamiltonian函数和势能面生成基于Christiansen形式的哈密顿量。 (#6560)
改进 🛠
QChem 改进
现在,
qml.qchem.factorize函数支持双重因式分解的新方法: Cholesky 分解 (cholesky=True) 和压缩双重因式分解 (compressed=True)。 (#6573) (#6611)新增了一个用于对电子积分执行块不变对称移位的函数,使用
qml.qchem.symmetry_shift。
用于组合GlobalPhase实例的变换
新增了一个名为
qml.transforms.combine_global_phases的变换。它将电路中的所有qml.GlobalPhase门合并为一个在最后应用的单门。这对于包含大量直接在电路创建期间引入的qml.GlobalPhase门、电路分解中包含qml.GlobalPhase门等的电路非常有用。(#6686)
更好的绘图功能
qml.draw_mpl现在拥有一个wire_options关键字参数,允许使用color、linestyle和linewidth等选项进行全局和每个线路的自定义。(#6486)以下是一个示例,它将所有线路设置为青色和加粗,除了线路 2 和 6,它们是虚线和不同的颜色。
@qml.qnode(qml.device("default.qubit")) def circuit(x): for w in range(5): qml.Hadamard(w) return qml.expval(qml.PauliZ(0) @ qml.PauliY(1)) wire_options = {"color": "cyan", "linewidth": 5, 2: {"linestyle": "--", "color": "red"}, 6: {"linestyle": "--", "color": "orange"} } print(qml.draw_mpl(circuit, wire_options=wire_options)(0.52))
新设备功能 💾
新增了两个方法,
setup_execution_config和preprocess_transforms,到Device类中。设备开发者被鼓励分别覆盖这两个方法,而不是preprocess方法。为了避免歧义,设备目前允许只覆盖这两个方法中的任一,或preprocess,但不能同时覆盖。从长远来看,我们会逐步淘汰preprocess的使用,转而采用这两个方法,以便更好地分离关注点。 (#6617)插件设备的开发者现在可以选择提供一个TOML格式的配置文件来声明设备的功能。有关详细信息,请参见设备功能。
添加了一个名为
qml.devices.capabilities的内部模块,该模块定义了一个新的DeviceCapabilites数据类,以及加载和解析 TOML 格式的配置文件的函数。 (#6407)>>> from pennylane.devices.capabilities import DeviceCapabilities >>> capabilities = DeviceCapabilities.from_toml_file("my_device.toml") >>> isinstance(capabilities, DeviceCapabilities) True
扩展了
qml.devices.Device的设备现在有一个可选的类属性叫做capabilities,它是从配置文件构建的DeviceCapabilities数据类的一个实例(如果存在的话)。否则,它被设置为None。(#6433)from pennylane.devices import Device class MyDevice(Device): config_filepath = "path/to/config.toml" ...
>>> isinstance(MyDevice.capabilities, DeviceCapabilities) True
为提供TOML配置文件的设备添加了
(#6632)(#6653)Device.setup_execution_config和Device.preprocess_transforms的默认实现,因此,具有capabilities属性。
捕获和表示混合程序
已支持在使用
qml.capture.enabled执行的电路中使用if/else语句,以及for和while循环。默认情况下,make_plxpr现在使用 Autograph 转换,但可以通过autograph=False来跳过。 (#6406) (#6413) (#6426) (#6645) (#6685)qml.transform现在接受一个plxpr_transform参数。这个参数必须是一个可以转换 plxpr 的函数。注意,执行一个转换后的函数目前将引发一个NotImplementedError。要查看更多详细信息,请查看documentation of qml.transform。Users can now apply transforms with program capture enabled. Transformed functions cannot be executed by default. To apply the transforms (and to be able to execute the function), it must be decorated with the new
qml.capture.expand_plxpr_transformsfunction, which accepts a callable as input and returns a new function for which all present transforms have been applied. (#6722)from functools import partial qml.capture.enable() wire_map = {0: 3, 1: 6, 2: 9} @partial(qml.map_wires, wire_map=wire_map) def circuit(x, y): qml.RX(x, 0) qml.CNOT([0, 1]) qml.CRY(y, [1, 2]) return qml.expval(qml.Z(2))
>>> qml.capture.make_plxpr(circuit)(1.2, 3.4) { lambda ; a:f32[] b:f32[]. let c:AbstractMeasurement(n_wires=None) = _map_wires_transform_transform[ args_slice=slice(0, 2, None) consts_slice=slice(2, 2, None) inner_jaxpr={ lambda ; d:f32[] e:f32[]. let _:AbstractOperator() = RX[n_wires=1] d 0 _:AbstractOperator() = CNOT[n_wires=2] 0 1 _:AbstractOperator() = CRY[n_wires=2] e 1 2 f:AbstractOperator() = PauliZ[n_wires=1] 2 g:AbstractMeasurement(n_wires=None) = expval_obs f in (g,) } targs_slice=slice(2, None, None) tkwargs={'wire_map': {0: 3, 1: 6, 2: 9}, 'queue': False} ] a b in (c,) } >>> transformed_circuit = qml.capture.expand_plxpr_transforms(circuit) >>> jax.make_jaxpr(transformed_circuit)(1.2, 3.4) { lambda ; a:f32[] b:f32[]. let _:AbstractOperator() = RX[n_wires=1] a 3 _:AbstractOperator() = CNOT[n_wires=2] 3 6 _:AbstractOperator() = CRY[n_wires=2] b 6 9 c:AbstractOperator() = PauliZ[n_wires=1] 9 d:AbstractMeasurement(n_wires=None) = expval_obs c in (d,) }
现在可以将
qml.iterative_qpe函数紧凑地捕获到 plxpr 中。 (#6680)添加了三个新的 plxpr 解释器,它们允许在启用程序捕获时,使用与 PennyLane 中相应现有变换相同的 API 原生转换函数和 plxpr:
qml.capture.transforms.CancelInterpreter: 这个类取消连续出现的算子,这些算子是彼此的伴随算子,遵循与qml.transforms.cancel_inverses相同的 API。(#6692)qml.capture.transforms.DecomposeInterpreter: 这个类分解pennylane运算符,遵循与qml.transforms.decompose相同的API。 (#6691)qml.capture.transforms.MapWiresInterpreter:这个类将电线映射到新的值,遵循与qml.map_wires相同的API。 (#6697)
现在可用一个
qml.tape.plxpr_to_tape函数,将 plxpr 转换为 tape。(#6343)启用捕获的执行现在遵循新的执行管道,并将捕获的plxpr原生传递给设备。由于不再回退到旧管道,执行仅在减少的功能集下工作。 (#6655) (#6596)
PennyLane 变换现在可以在启用实验性程序捕获的情况下作为原语进行捕获。 (#6633)
jax.vmap可以通过qml.capture.make_plxpr捕获,并且与量子电路兼容。 (#6349) (#6422) (#6668)增加了一个
qml.capture.PlxprInterpreter基类,以便于对 plxpr 的转换和执行。 (#6141)添加了一个
DefaultQubitInterpreter类,以便使用基于 python 的工具提供 plxpr 执行,并且实现了DefaultQubit.eval_jaxpr方法。(#6594) (#6328)设备 API 中添加了一个可选方法,
eval_jaxpr,用于原生执行 plxpr 程序。(#6580)qml.capture.qnode_call已被设置为私有并移动到workflow模块。 (#6620)
其他改进
qml.math.grad和qml.math.jacobian已被添加以以JAX类似的方式对具有任何接口输入的函数进行微分。 (#6741)qml.GroverOperator现在拥有一个work_wires属性。 (#6738)在 Pennylane 源代码中,
Wires对象的使用已被整理,确保内部一致性。 (#6689)qml.equal现在支持qml.PauliWord和qml.PauliSentence实例。 (#6703)已删除来自
qml.lie_closure的冗余对易子计算。 (#6724)现在在使用
qml.fourier.qnode_spectrum与标准 Numpy 参数和interface="auto"时,会引发全面的错误。 (#6622)已添加门的泡利字符串表示
{X, Y, Z, S, T, SX, SWAP, ISWAP, ECR, SISWAP},并修复了qml.PauliSentence在使用list或array输入时的矩阵转换中的形状错误。 (#6562) (#6587)qml.QNode和qml.execute现在禁止某些关键字参数以位置形式传递。 (#6610)对于
qml.S、qml.T和qml.SX的字符串表示已被缩短。 (#6542)内部类函数和双下划线方法已经添加,以允许以系列和并行方式相乘资源对象。 (#6567)
该
diagonalize_measurements转换不再对未知的可观测量引发错误。相反,它们保持未对角化,期望可观测量验证会捕捉到任何未对角化且设备不支持的可观测量。(#6653)现在可以将一个
(#6699)qml.wires.Wires对象转换为 JAX 数组,如果所有的线标签都被支持作为 JAX 数组元素。一个专注于
run函数的开发者已被添加到qml.workflow模块,以便以更清晰和标准化的方式在 ML 接口上执行胶带。 (#6657)内部已进行更改,以标准化执行接口,这解决了在执行过程中如何处理
interface值的模糊性。 (#6643)所有接口处理逻辑已移至
interface_utils.py在qml.math模块中。 (#6649)qml.execute现在可以与diff_method="best"一起使用。经典的共同变换信息现在由工作流懒加载处理。梯度方法验证和程序设置现在在qml.execute内部处理,而不是在QNode中处理。(#6716)已添加对电路中测量的PyTree支持。 (#6378)
@qml.qnode(qml.device("default.qubit")) def circuit(): qml.Hadamard(0) qml.CNOT([0,1]) return {"Probabilities": qml.probs(), "State": qml.state()}
>>> circuit() {'Probabilities': array([0.5, 0. , 0. , 0.5]), 'State': array([0.70710678+0.j, 0. +0.j, 0. +0.j, 0.70710678+0.j])}
(#6624)_cache_transform变换已被移动到它自己的文件,位于pennylane/workflow/_cache_transform.py。现在,
for_loop、while_loop和cond的Jaxpr原语存储切片而不是参数的数量。这有助于跟踪参数的顺序。 (#6521)ExecutionConfig.gradient_method函数已经扩展为存储TransformDispatcher类型。 (#6455)Resources实例的字符串表示已经改进,以匹配属性名称。(#6581)dynamic_one_shot转换的文档已得到改进,并且当用户应用的dynamic_one_shot转换被忽略而选择设备的预处理转换程序中的现有转换时,会产生警告。 (#6701)新增了一个
qml.devices.qubit_mixed模块,以支持混合态量子比特设备。该模块引入了一个apply_operation辅助函数,具有:两种密度矩阵收缩方法,使用
einsum和tensordot优化处理特殊案例,包括:对角算符、恒等算符、CX(控制-X)、多重控制X门、Grover算符 (#6379)
新增了一个名为
create_initial_state的函数,以允许使用qml.StatePrep或qml.QubitDensityMatrix用密度矩阵初始化电路。 (#6503)已经进行了几项添加,以最终将
"default.mixed"设备迁移到新的设备 API:已经向
(#6601)QubitMixed设备类添加了一个preprocess方法,以在执行之前对量子电路进行预处理。在
qml.devices.qubit_mixed模块中增加了一个名为DefaultMixedNewAPI的新类,将替代旧版DefaultMixed。 (#6607)新增了一个子模块,名为
devices.qubit_mixed.measure,该模块具有一个measure函数,用于测量混态设备中的量子比特。 (#6637)新增了一个名为
devices.qubit_mixed.simulate的子模块,具有simulate函数,用于在解析模式下模拟混合态。 (#6618)新增了一个名为
devices.qubit_mixed.sampling的子模块,包含用于在混合态设备中对量子比特进行采样的函数sample_state、measure_with_samples和sample_probs。 (#6639)添加了
devices.qubit_mixed.simulate的有限射分支,它允许接受随机参数,如shots、rng和prng_key。(#6665)已添加对
qml.Snapshot的支持。 (#6659)
测试警告作为失败的报告功能已添加。 (#6217)
在梯度和训练文档中添加了与
ComplexWarning相关的警告信息。 (#6543)在PennyLane网站的登录页面上添加了一个新图形。 (#6696)
重大变更 💔
qml.dot、qml.sum和qml.pauli.optimize_measurements的默认图着色方法用于分组可观测量已从"rlf"更改为"lf"。内部,qml.pauli.group_observables已在几个地方被qml.pauli.compute_partition_indices替换,以提高效率。 (#6706)
(#6622)qml.fourier.qnode_spectrum不再自动将纯Numpy参数转换为Autograd框架。由于该函数使用自动微分进行验证,因此必须使用来自该框架的参数。qml.math.jax_argnums_to_tape_trainable已被移到私有以避免在qml.math模块中出现不必要的 QNode 依赖。 (#6609)梯度变换现在在用户的变换程序之后应用。这确保用户 变换在初始结构上按预期工作(例如,嵌入或纠缠层), 保证梯度变换只处理兼容的操作,调整变换顺序 以符合用户的期望,并避免混淆。 (#6590)
遗留运算符算术已被移除。这包括
qml.ops.Hamiltonian,qml.operation.Tensor,qml.operation.enable_new_opmath,qml.operation.disable_new_opmath, 和qml.operation.convert_to_legacy_H。请注意qml.Hamiltonian将继续调度到qml.ops.LinearCombination。有关更多信息,请查看更新的运算符故障排除页面。 (#6548) (#6602) (#6589)面向开发者的
qml.utils模块已被移除。 (#6588):具体来说,以下4组函数已经被移动或删除:
qml.utils._flatten,qml.utils.unflatten已被移动并重命名为qml.optimize.qng._flatten_np和qml.optimize.qng._unflatten_np。qml.utils._inv_dict和qml._get_default_args已被移除。qml.utils.pauli_eigs已经移动到qml.pauli.utils。qml.utils.expand_vector已被移动到qml.math.expand_vector。
模块
qml.qinfo已被移除。请使用相应的函数在qml.math和qml.measurements模块中。 (#6584)对
Device、QubitDevice和QutritDevice的顶级访问已被移除。相应地,它们现在作为qml.devices.LegacyDevice、qml.devices.QubitDevice和qml.devices.QutritDevice提供。(#6537)对于
qml.iterative_qpe的'ancilla'参数已被移除。请改为使用'aux_wire'参数。 (#6532)已移除
qml.BasisStatePreparation模板。请改用qml.BasisState。 (#6528)已删除
qml.workflow.set_shots助手函数。我们不再在代码中与遗留设备接口交互。相反,shots 应该在 tape 上指定,设备应使用这些 shots。QNode.gradient_fn已被移除。请改用QNode.diff_method。QNode.get_gradient_fn也可以用于处理微分方法。 (#6535)已删除
qml.QubitStateVector模板。请改用qml.StatePrep。 (#6525)qml.broadcast已被移除。用户应该改用for循环。 (#6527)参数
max_expansion在qml.transforms.clifford_t_decomposition中已被移除。 (#6571)qml.compile的expand_depth参数已被移除。 (#6531)已删除
qml.shadows.shadow_expval变换。请改为使用qml.shadow_expval测量过程。 (#6530) (#6561)面向开发者的
qml.drawer.MPLDrawer参数n_wires已被替换为wire_map,它包含关于电线标签和顺序的更完整信息。这允许新功能在使用字符串电线标签或非连续电线排序时,为特定电线指定wire_options。
弃用功能 👋
QNode的tape和qtape属性已被弃用。请改用qml.workflow.construct_tape函数。 (#6583) (#6650)qml.devices.preprocess.decompose中的max_expansion参数已经弃用,并将在v0.41中移除。 (#6400)qml.transforms.set_decomposition中的decomp_depth参数已被弃用,将在 v0.41 中移除。(#6400)qml.tape.QuantumScript的output_dim属性已被弃用。请改用QuantumScript或MeasurementProcess的shape方法以获取相同的信息。 (#6577)方法
QNode.get_best_method和QNode.best_method_str已被弃用。请改用qml.workflow.get_best_diff_method函数。qml.executegradient_fn关键字参数已更名为diff_method以更好地与 QNode 使用的术语对齐。gradient_fn将在 v0.41 中被移除。 (#6549)旧的
qml.qsvt功能已移至qml.qsvt_legacy并且现在已被弃用。将于 v0.41 中删除。 (#6520)
文档 📝
qml.qchem.Molecule和qml.qchem.molecular_hamiltonian的文档字符串已更新,包含一条说明,指出它们与qjit或jit不兼容。
(#6702)文档已更新,以包括哈密顿量中操作数对创建电路结构的影响。 (#6629)
QSVT的文档已经更新,包含不同块编码的示例。 (#6673)在
QubitUnitary文档字符串中修复了对qml.ops.one_qubit_transform的链接。 (#6745)
修复错误 🐛
已增加验证,以确保设备 vjp 仅在设备实际支持时使用。 (#6755)
qml.counts现在在all_outcomes参数为True并且存在中途测量时返回所有结果。 (#6732)qml.ControlledQubitUnitary现在在启用程序捕获时具有一致的行为。 (#6719)qml.Hermitian类不再检查提供的矩阵是否为厄米矩阵。移除此检查的原因是为了实现更快的执行并避免与jax.jit的不兼容。(#6642)当启用程序捕获时,
qml.ops.Controlled的子类不再绑定其基础操作符的原语。 (#6672)现在,
qml.HilbertSchmidt和qml.LocalHilbertSchmidt模板应用单位算符的复共轭而不是伴随,提供正确的结果。 (#6604)QNode 的返回行为现在对列表和元组是一致的。 (#6568)
QNodes 现在接受在不一定在支持接口列表中的库中定义的类型的参数,例如在
networkx中定义的Graph类。(#6600)qml.math.get_deep_interface现在可以正常处理 Autograd 数组。 (#6557)打印
qml.Identity实例现在返回正确的导线列表。 (#6506)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
吉列尔莫·阿隆索, 施文·安, 乌特卡什·阿扎德, 阿斯特拉尔·蔡, 余绍·陈, 艾萨克·德·弗卢赫, 迪克沙·达万, 拉塞·迪里赫, 莉莉安·弗雷德里克森, 皮埃尔托帕洛·弗里索尼, 西蒙·加斯佩里尼, 迭戈·瓜拉, 奥斯汀·黄, 科尔比安·科特曼, 克里斯蒂娜·李, 阿兰·马丁, 威廉·麦克斯韦, 安东·奈姆·易卜拉欣, 安德里亚·帕乌雷维奇, 贾斯廷·皮克林, 杰伊·索尼, 大卫·维里希斯。
- orphan
版本 0.39.0¶
自上次发布以来的新特性
在晶格上创建自旋哈密顿量 💞
已经添加了在任意晶格上创建自定义哈密顿量的功能。 (#6226) (#6237)
在
qml.spin模块中,除了可用的模板哈密顿量外,还可以通过添加三个新函数来创建:qml.spin.Lattice: 一个用于通过原始平移向量和单位元参数实例化自定义晶格的新对象,qml.spin.generate_lattice: 用于创建标准Lattice对象的工具函数,包括'chain','square','rectangle','triangle','honeycomb','kagome','lieb','cubic','bcc','fcc', 和'diamond',qml.spin.spin_hamiltonian: 生成一个自定义边/节点的Lattice对象所需的自旋Hamiltonian对象。
下面展示了一个具有开边界条件的\(3 \times 3\)三角晶格的示例。
lattice = qml.spin.Lattice( n_cells=[3, 3], vectors=[[1, 0], [np.cos(np.pi/3), np.sin(np.pi/3)]], positions=[[0, 0]], boundary_condition=False )
我们可以通过检查
lattice_points(晶格中所有位置的\((x, y)\)坐标)来验证这个lattice与qml.spin.generate_lattice('triangle', ...)的匹配:>>> lp = lattice.lattice_points >>> triangular_lattice = qml.spin.generate_lattice('triangle', n_cells=[3, 3]) >>> np.allclose(lp, triangular_lattice.lattice_points) True
默认情况下,
Lattice对象的edges是最近邻的,我们可以通过使用其add_edge方法来添加边。可选地,
Lattice对象可以通过指定其custom_edges和custom_nodes关键字参数的值来赋予互动和场。然后可以通过qml.spin.spin_hamiltonian函数提取哈密顿量。下面展示了一个在 \(3 \times 3\) 三角晶格上横场伊辛模型哈密顿量的示例。请注意,custom_edges和custom_nodes关键字参数只需要为一个单位胞重复定义一次。edges = [ (0, 1), (0, 3), (1, 3) ] lattice = qml.spin.Lattice( n_cells=[3, 3], vectors=[[1, 0], [np.cos(np.pi/3), np.sin(np.pi/3)]], positions=[[0, 0]], boundary_condition=False, custom_edges=[[edge, ("ZZ", -1.0)] for edge in edges], custom_nodes=[[i, ("X", -0.5)] for i in range(3*3)], )
>>> tfim_ham = qml.spin.transverse_ising('triangle', [3, 3], coupling=1.0, h=0.5) >>> tfim_ham == qml.spin.spin_hamiltonian(lattice=lattice) True
在
qml.spin模块中添加了更多行业标准的自旋哈密顿量。 (#6174) (#6201)现在可以使用PennyLane v0.39获得三个新的行业标准自旋哈密顿量:
这些添加伴随着
qml.spin.heisenberg,qml.spin.transverse_ising, 和qml.spin.fermi_hubbard, 它们是在 v0.38 中引入的。
计算多项式 🔢
多项式函数现在可以轻松编码成量子电路,使用
qml.OutPoly。 (#6320)一个新的模板叫做
qml.OutPoly可用,它提供了在量子电路中编码多项式函数的能力。给定一个多项式函数 \(f(x_1, x_2, \cdots, x_N)\),qml.OutPoly需要:f: 一个标准的Python函数,表示 \(f(x_1, x_2, \cdots, x_N)\),input_registers(\(\vert x_1 \rangle\), \(\vert x_2 \rangle\), …, \(\vert x_N \rangle\)) : 包含与嵌入的数值 \(x_1, x_2, \cdots, x_N\) 对应的Wires对象的列表/元组,output_wires: 存储\(f(x_1, x_2, \cdots, x_N)\)的数值的Wires。
以下是使用
qml.OutPoly计算 \(f(x_1, x_2) = 3x_1^2 - x_1x_2\) 的一个示例,结果为 \(f(1, 2) = 1\)。wires = qml.registers({"x1": 1, "x2": 2, "output": 2}) def f(x1, x2): return 3 * x1 ** 2 - x1 * x2 @qml.qnode(qml.device("default.qubit", shots = 1)) def circuit(): # load values of x1 and x2 qml.BasisEmbedding(1, wires=wires["x1"]) qml.BasisEmbedding(2, wires=wires["x2"]) # apply the polynomial qml.OutPoly( f, input_registers = [wires["x1"], wires["x2"]], output_wires = wires["output"]) return qml.sample(wires=wires["output"])
>>> circuit() array([0, 1])
结果,
[0, 1],是\(1\)的二进制表示。默认情况下,结果是通过模运算计算的,模为\(2^\text{len(output_wires)}\),但可以通过mod关键字参数覆盖。
读出噪声 📠
Readout errors can now be included in
qml.NoiseModelandqml.add_noisewith the newqml.noise.meas_eqfunction. (#6321)Measurement/readout errors can be specified in a similar fashion to regular gate noise in PennyLane: a newly added Boolean function called
qml.noise.meas_eqthat accepts a measurement function (e.g.,qml.expval,qml.sample, or any other function that can be returned from a QNode) that, when present in the QNode, inserts a noisy operation viaqml.noise.partial_wiresor a custom noise function. Readout noise in PennyLane also follows the insertion convention, where the specified noise is inserted before the measurement.Here is an example of adding
qml.PhaseFlipnoise to anyqml.expvalmeasurement:c0 = qml.noise.meas_eq(qml.expval) n0 = qml.noise.partial_wires(qml.PhaseFlip, 0.2)
To include this in a
qml.NoiseModel, use itsmeas_mapkeyword argument:# gate-based noise c1 = qml.noise.wires_in([0, 2]) n1 = qml.noise.partial_wires(qml.RY, -0.42) noise_model = qml.NoiseModel({c1: n1}, meas_map={c0: n0})
>>> noise_model NoiseModel({ WiresIn([0, 2]): RY(phi=-0.42) }, meas_map = { MeasEq(expval): PhaseFlip(p=0.2) })
qml.noise.meas_eqcan also be combined with other Boolean functions inqml.noisevia bitwise operators for more versatility.To add this
noise_modelto a circuit, use theqml.add_noisetransform as per usual. For example,@qml.qnode(qml.device("default.mixed", wires=3)) def circuit(): qml.RX(0.1967, wires=0) for i in range(3): qml.Hadamard(i) return qml.expval(qml.X(0) @ qml.X(1))
>>> noisy_circuit = qml.add_noise(circuit, noise_model) >>> print(qml.draw(noisy_circuit)()) 0: ──RX(0.20)──RY(-0.42)────────H──RY(-0.42)──PhaseFlip(0.20)─┤ ╭<X@X> 1: ──H─────────PhaseFlip(0.20)────────────────────────────────┤ ╰<X@X> 2: ──H─────────RY(-0.42)──────────────────────────────────────┤ >>> print(circuit(), noisy_circuit()) 0.9807168489852615 0.35305806563469433
用户友好的分解 📠
新增了一种变换,叫做
qml.transforms.decompose,以更好地便利在PennyLane电路中对算子的自定义分解。 (#6334)在添加
qml.transforms.decompose之前,在 PennyLane 中分解算子必须通过在qml.device.preprocess.decompose中指定stopping_condition来完成。使用qml.transforms.decompose后,指定分解的用户界面变得更加简单和灵活。电路中门的分解可以通过几种方式完成:
指定一个
gate_set,包含 PennyLaneOperator,用于分解为:from functools import partial dev = qml.device('default.qubit') allowed_gates = {qml.Toffoli, qml.RX, qml.RZ} @partial(qml.transforms.decompose, gate_set=allowed_gates) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=[0]) qml.Toffoli(wires=[0, 1, 2]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ──RZ(1.57)──RX(1.57)──RZ(1.57)─╭●─┤
1: ───────────────────────────────├●─┤ 2: ───────────────────────────────╰X─┤ 指定一个由规则(布尔函数)定义的
gate_set。例如,可以指定一个任意的门集进行分解,只要结果门仅作用于一个或两个量子比特:@partial(qml.transforms.decompose, gate_set = lambda op: len(op.wires) <= 2) @qml.qnode(dev) def circuit(): qml.Toffoli(wires=[0, 1, 2]) return qml.expval(qml.Z(0))
>>> print(qml.draw(circuit)()) 0: ───────────╭●───────────╭●────╭●──T──╭●─┤
1: ────╭●─────│─────╭●─────│───T─╰X──T†─╰X─┤ 2: ──H─╰X──T†─╰X──T─╰X──T†─╰X──T──H────────┤ 为
max_expansion指定一个值。默认情况下,分解会递归发生,直到达到所需的门集,但这可以被覆盖以控制通过的次数。phase = 1.0 target_wires = [0] unitary = qml.RX(phase, wires=0).matrix() n_estimation_wires = 1 estimation_wires = range(1, n_estimation_wires + 1) def qfunc(): qml.QuantumPhaseEstimation( unitary, target_wires=target_wires, estimation_wires=estimation_wires, ) decompose_once = qml.transforms.decompose(qfunc, max_expansion=1) decompose_twice = qml.transforms.decompose(qfunc, max_expansion=2)
>>> print(qml.draw(decompose_once)()) 0: ────╭U(M0)¹───────┤ 1: ──H─╰●───────QFT†─┤ M0 = [[0.87758256+0.j 0. -0.47942554j] [0. -0.47942554j 0.87758256+0.j ]] >>> print(qml.draw(decompose_twice)()) 0: ──RZ(1.57)──RY(0.50)─╭X──RY(-0.50)──RZ(-6.28)─╭X──RZ(4.71)─┤ 1: ──H──────────────────╰●───────────────────────╰●──H†───────┤
改进 🛠
qjit/jit 兼容性和改进
量子即时编译 (qjit)是在程序执行期间编译混合量子-经典程序,而不是在执行之前。PennyLane使用其@qml.qjit装饰器提供即时编译,支持Catalyst编译器。
现在有几个模板与qjit兼容:
基于样本的测量现在支持作为 JAX 跟踪器的样本,允许与 qjit 工作流兼容。 (#6211)
当启用jit时,
qml.FABLE模板现在返回正确的值。 (#6263)qml.metric_tensor现在与 jit 兼容。qml.QutritBasisStatePreparation现在与 jit 兼容。 (#6308)所有PennyLane模板现在都进行了单元测试,以确保与jit兼容。 (#6309)
对费米子算子的各种改进
qml.fermi.FermiWord和qml.fermi.FermiSentence现在与 JAX 数组兼容。 (#6324)以某种方式与 JAX 数组交互的费米子算子将不再引发错误。比如:
>>> import jax.numpy as jnp >>> w = qml.fermi.FermiWord({(0, 0) : '+', (1, 1) : '-'}) >>> jnp.array([3]) * w FermiSentence({FermiWord({(0, 0): '+', (1, 1): '-'}): Array([3], dtype=int32)})
qml.fermi.FermiWord类现在有一个shift_operator方法来应用反对易关系。 (#6196)>>> w = qml.fermi.FermiWord({(0, 0): '+', (1, 1): '-'}) >>> w FermiWord({(0, 0): '+', (1, 1): '-'}) >>> w.shift_operator(0, 1) FermiSentence({FermiWord({(0, 1): '-', (1, 0): '+'}): -1})
现在
qml.fermi.FermiWord和qml.fermi.FermiSentence类有一个adjoint方法。 (#6166)>>> w = qml.fermi.FermiWord({(0, 0): '+', (1, 1): '-'}) >>> w.adjoint() FermiWord({(0, 1): '+', (1, 0): '-'})
to_mat方法对于qml.fermi.FermiWord和qml.fermi.FermiSentence现在可以选择性地返回一个稀疏矩阵,带有format关键字参数。(#6173)>>> w = qml.fermi.FermiWord({(0, 0) : '+', (1, 1) : '-'}) >>> w.to_mat(format="dense") array([[0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], [0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], [0.+0.j, 1.+0.j, 0.+0.j, 0.+0.j], [0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j]]) >>> w.to_mat(format="csr") <4x4 稀疏矩阵,类型为 '
' 在压缩稀疏行格式中存储了 1 个元素>打印时,
qml.fermi.FermiWord和qml.fermi.FermiSentence现在返回对象的唯一表示。 (#6167)>>> w = qml.fermi.FermiWord({(0, 0) : '+', (1, 1) : '-'}) >>> print(w) a⁺(0) a(1)
qml.qchem.excitations现在可选地返回具有新fermionic关键字参数的费米子算符(默认值为False)。(#6171)>>> singles, doubles = excitations(electrons, orbitals, fermionic=True) >>> print(singles) [FermiWord({(0, 0): '+', (1, 2): '-'}), FermiWord({(0, 1): '+', (1, 3): '-'})]
一个新的优化器
新增了一个名为
qml.MomentumQNGOptimizer的优化器。它继承自基本的qml.QNGOptimizer优化器,并需要一个额外的超参数:动量系数 \(0 \leq \rho < 1\),默认值为 \(\rho=0.9\)。对于 \(\rho=0\),qml.MomentumQNGOptimizer降级为qml.QNGOptimizer。 (#6240)
其他改进
default.tensor现在可以通过延迟测量原理处理中途电路测量。 (#6408)process_density_matrix在 5 个StateMeasurement子类中实现:ExpVal,Var,Purity,MutualInformation, 和VnEntropy。这将便于将来对混合态设备和扩展密度矩阵操作的支持。同时,在ProbabilityMP类中进行了修复,以使用qml.math.sqrt而不是np.sqrt。 (#6330)对
qml.Qubitization的分解已被改进为使用qml.PrepSelPrep。 (#6182)一个
ReferenceQubit设备(简称:"reference.qubit")已被引入用于测试目的和未来插件开发的参考。 (#6181)qml.transforms.mitigate_with_zne现在在应用于包含通道噪声的电路而不是设备时,提供了更清晰的错误信息。 (#6346)新增了一个名为
get_best_diff_method的函数到qml.workflow中。 (#6399)一个名为
(#6419)construct_tape的新方法已添加到qml.workflow,供用户从QNode构建单个录音带。对PennyLane数据集进行了基础设施改进,使我们能够更轻松地上传数据集。 (#6126)
qml.Hadamard现在有一个更友好的别名:qml.H. (#6450)一个名为
show_wire_labels的布尔关键字参数已经被添加到draw和draw_mpl,当设置为False时会隐藏电线标签(默认值为True)。(#6410)一个新的函数叫做
sample_probs已经添加到qml.devices.qubit和qml.devices.qutrit_mixed模块。这个函数接受概率分布作为输入,并返回抽样结果,通过将抽样过程与测量链中的其他操作分离,简化了抽样过程并提高了模块化程度。 (#6354)一个
has_sparse_matrix属性已被添加到Operator中,以指示是否定义了稀疏矩阵。 (#6278) (#6310)qml.matrix现在支持空对象(例如,空电路、QNodes 和不调用操作的量子函数,以及具有空分解的单个算子)。 (#6347)dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def node(): return qml.expval(qml.Z(0))
>>> qml.matrix(node)() array([[1., 0.], [0., 1.]])
PennyLane 现在与 Jax 0.4.28 兼容。 (#6255)
现在,
diagonalize_measurements转换在可能的情况下使用更高效的对角化方法,基于相关可观测量的pauli_rep。(#6113)现在,
QuantumScript.copy方法接收operations、measurements、shots和trainable_params作为关键字参数。如果在复制胶带时传递了这些参数,则指定的属性将替换新胶带上的复制属性。 (#6285) (#6363)现在
Hermitian算子有了compute_sparse_matrix的实现。 (#6225)当一个可观察量在一个磁带上被重复时,
tape.diagonalizing_gates不再返回每个可观察量实例的对角化门。相反,磁带上每个可观察量的对角化门仅包含一次。 (#6288)在
qml.specs中返回的对角化门的数量现在遵循level关键字参数,关于对角化门是否被设备修改,而不是总是计算未处理的对角化门。(#6290)当访问嵌套的
CompositeOp或SProd的属性和方法时,会引发更合理的错误信息,遇到RecursionError。默认情况下,
qml.sum和qml.prod设置lazy=True,这会保持其操作数嵌套。鉴于此类结构的递归性质,如果嵌套层级过多,在访问许多属性和方法时,会发生RecursionError。qml.QFT的分解性能已得到改善。 (#6434)
捕获和表示混合程序
qml.wires.Wires现在接受 JAX 数组作为输入。在许多使用 JAX 的工作流中,PennyLane 可能会尝试将 JAX 数组分配给一个Wires对象,这将导致错误,因为 JAX 数组不可哈希。现在,JAX 数组是有效的Wires类型。此外,在将 JAX 路径提供作为输入给qml.wires.Wires时,JAX 0.4.30+不再会引发FutureWarning。 (#6312)添加了一个新函数
qml.capture.make_plxpr,用于接收一个函数并创建一个Callable,当被调用时,将返回输入函数的 PLxPR 表示。(#6326)`现在可以使用 PLxPR 捕获通过
qml.grad和qml.jacobian的混合程序的微分。 在评估捕获的qml.grad(qml.jacobian) 指令时,它将调度到jax.grad(jax.jacobian),这与没有捕获的 Autograd 实现不同。支持 Pytree 输入和 输出。 (#6120) (#6127) (#6134)对捕获嵌套控制流的单元测试进行了改进。 (#6111)
现在可以通过
from pennylane.capture.primitives import *导入一些用于捕获项目的自定义原语。 (#6129)所有高阶原语现在使用
jax.core.Jaxpr作为元数据,而不是有时使用jax.core.ClosedJaxpr或jax.core.Jaxpr。(#6319)
重大变更 💔
在
QNode.construct中移除了虚假的验证,这修复了一个与qml.GlobalPhase相关的错误。 (#6373)在
QNode.construct中移除AllWires验证是解决以下示例无法运行的方案:@qml.qnode(qml.device('default.qubit', wires=2)) def circuit(x): qml.GlobalPhase(x, wires=0) return qml.state()
>>> circuit(0.5) array([0.87758256-0.47942554j, 0. +0.j , 1. +0.j , 0. +0.j ])
在
qml.Hamiltonian和qml.ops.LinearCombination中,simplify参数已被移除。相反,可以在构造的算子上调用qml.simplify()。(#6279)函数
qml.qinfo.classical_fisher和qml.qinfo.quantum_fisher已被移除并迁移到qml.gradients模块。应使用qml.gradients.classical_fisher和qml.gradients.quantum_fisher。(#5911)Python 3.9 不再支持。请更新到 3.10 或更新版本。 (#6223)
default.qubit.legacy、default.qubit.tf、default.qubit.torch、default.qubit.jax和default.qubit.autograd已被移除。请使用default.qubit进行所有接口。 (#6207) (#6208) (#6209) (#6210) (#6266)expand_fn、max_expansion、override_shots和device_batch_transform已从qml.execute的签名中移除。 (#6203)max_expansion和expansion_strategy已从QNode中移除。 (#6203)expansion_strategy已从qml.draw、qml.draw_mpl和qml.specs中移除。max_expansion已从qml.specs中移除,因为它对输出没有影响。 (#6203)qml.transforms.hamiltonian_expand和qml.transforms.sum_expand已被移除。请使用qml.transforms.split_non_commuting代替。 (#6204)对
qml.device的decomp_depth关键字参数已被移除。 (#6234)Operator.expand已被删除。请改用qml.tape.QuantumScript(op.decomposition())。 (#6227)原生折叠方法
qml.transforms.fold_global对于qml.transforms.mitigate_with_zne变换不再自动扩展电路。相反,用户应先应用qml.transforms.decompose将电路分解为目标门集,然后再应用fold_global或mitigate_with_zne。(#6382)已经移除
LightningVJPs类,因为所有闪电设备现在都遵循新的设备接口。 (#6420)
弃用功能 👋
参数
expand_depth和max_expansion对于qml.transforms.compile和qml.transforms.decompositions.clifford_t_decomposition分别已被弃用。 (#6404)传统的运算符算术已被弃用。这包括
qml.ops.Hamiltonian、qml.operation.Tensor、qml.operation.enable_new_opmath、qml.operation.disable_new_opmath和qml.operation.convert_to_legacy_H。请注意,当启用新的运算符算术时,qml.Hamiltonian将继续分派到qml.ops.LinearCombination;这种行为并未被弃用。有关更多信息,请查看更新的运算符故障排除页面。(#6287)(#6365)qml.pauli.PauliSentence.hamiltonian和qml.pauli.PauliWord.hamiltonian已被弃用。 请改用qml.pauli.PauliSentence.operation和qml.pauli.PauliWord.operation,分别。 (#6287)qml.pauli.simplify()已被弃用。请使用qml.simplify(op)或op.simplify()。 (#6287)模板
qml.BasisStatePreparation已被弃用。请使用qml.BasisState代替。 (#6021)对于
qml.iterative_qpe的'ancilla'参数已经被弃用。请改用'aux_wire'参数。 (#6277)qml.shadows.shadow_expval已不推荐使用。请改用qml.shadow_expval测量过程。 (#6277)qml.broadcast已被弃用。请改用 Pythonfor循环。 (#6277)模板
qml.QubitStateVector已被弃用。请改用qml.StatePrep。 (#6172)模块
qml.qinfo已被弃用。请查看qml.math和qml.measurements模块中的相关函数。 (#5911)Device、QubitDevice和QutritDevice将不再在 v0.40 中通过顶级导入访问。它们仍然可以分别通过qml.devices.LegacyDevice、qml.devices.QubitDevice和qml.devices.QutritDevice访问。(#6238)QNode.gradient_fn已被弃用。请改用QNode.diff_method和QNode.get_gradient_fn。 (#6244)
文档 📝
更新了
qml.spin文档。 (#6387)已更新文档中指向PennyLane.ai的链接,以使用最新的URL格式,省略了
.html前缀。 (#6412)更新
qml.Qubitization文档以基于新的分解。 (#6276)修正了文档中多个地方的拼写错误。 (#6280)
在
qml.MultiControlledX文档字符串签名中添加work_wires参数。 (#6271)消除了
PauliRot类引发的错误中的歧义。 (#6298)在
test_pow_ops.py中重命名了一个命名错误的测试。 (#6388)从安装页面移除了过时的Docker描述。 (#6487)
修复错误 🐛
快照的线序现在与设备的线序相匹配,而不是与仿真相匹配。 (#6461)修复了一个错误,即当度量张量变为奇异时,
QNSPSAOptimizer、QNGOptimizer和MomentumQNGOptimizer计算无效的参数更新。 (#6471)现在,
default.qubit设备支持与qml.classical_shadow和qml.shadow_expval的参数广播。 (#6301)修复了在
qml.ops.op_math.decompositions.two_qubit_unitary.py中不必要的eigvals调用,这导致 VJP 中出现错误。如果使用此本质上不可微分的模块,将向用户发出警告。 (#6437)修补
math模块以与 autoray 0.7.0 一起使用。 (#6429)修正了使用
(#6423)diff_method="parameter-shift"时PrepSelPrep的不正确微分。现在,如果提供了抽象线,
validate_device_wires转换将引发错误。 (#6405)修复了
qml.math.expand_matrix用于三能级和任意多能级算符的问题。 (#6398)MeasurementValue现在在作为布尔值使用时会引发错误。 (#6386)default.qutrit现在返回整数样本。 (#6385)adjoint_metric_tensor现在可以与包含状态准备操作的电路一起使用。 (#6358)quantum_fisher现在遵循 QNodes 的经典雅可比矩阵。 (#6350)qml.map_wires现在可以应用于一组带子。 (#6295)修复了在存在射击向量时错误计算零值JVP的漏洞。 (#6219)
修复了
(#6191)qml.PrepSelPrep模板以适应torch。修复了一个错误,现在
qml.equal正确比较qml.PrepSelPrep运算符。 (#6182)现在,
qml.QSVT模板首先排列projector线,然后是UA线,这是分解的预期顺序。 (#6212)现在,
qml.Qubitization模板首先排列control量子线,然后是hamiltonian量子线, 这与其他模板的预期一致。 (#6229)修复了一个错误,使用
autograd接口的电路有时会返回不是autograd接口的嵌套值。 (#6225)修复了一个错误,在没有参数或仅使用内置/NumPy数组作为参数的简单电路中返回autograd张量。(#6225)
qml.pauli.PauliVSpace现在使用更稳定的基于SVD的线性独立性检查,以避免遇到LinAlgError: Singular matrix。这稳定了qml.lie_closure的使用。它还引入了基向量内部表示_M的归一化,以避免系数爆炸。 (#6232)修复了一个错误,之前在测量时使用了
csc_dot_product,用于Sum/Hamiltonian,这包含了未定义稀疏矩阵的可观测量。 (#6278) (#6310)修复了一个错误,该错误使得
None被添加到qml.PhaseAdder,qml.Adder和qml.OutAdder的连接中。(#6360)在更新到Catalyst的夜间版本后修复了一个测试。 (#6362)
修复了一个错误,使用可训练的
Hamiltonian的CommutingEvolution无法通过参数位移进行微分。 (#6372)修复了一个bug,使用
mitigate_with_zne时丢失了原始电路的shots信息。 (#6444)修复了一个错误,即在没有线时应用
Identity/GlobalPhase时default.tensor会引发错误,且在单根线上应用PauliRot/MultiRZ时也会引发错误。(#6448)修复了一个错误,问题是对操作符类型而不是操作符实例应用
qml.ctrl和qml.adjoint会导致队列中出现额外的操作符。 (#6284)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
吉列尔莫·阿隆索,
乌特卡什·阿扎德,
奥列克桑德·博里森科,
阿斯特拉尔·蔡,
尤肖·陈,
艾萨克·德·弗吕特,
迪克莎·达万,
莉莲·M·A·弗雷德里克森,
皮埃特拉波罗·弗里索尼,
埃米利亚诺·戈迪内斯,
安东尼·海斯,
奥斯丁·霍华德,
索兰·贾汉吉里,
雅各布·基钦,
科尔比安·科特曼,
克里斯蒂娜·李,
威廉·麦克斯韦,
埃里克·奥乔·洛佩斯,
李·J·奥里尔登,
穆迪特·潘迪,
安德利亚·帕乌雷维奇,
亚历克斯·普雷西亚多,
阿西什·坎瓦尔·辛格,
大卫·维里克斯,
- orphan
发布 0.38.0¶
自上次发布以来的新特性
电线的注册 🧸
新增了一个名为
qml.registers的函数,可以让您无缝创建线圈的注册。使用寄存器,通过对预定义的电线集合应用门和操作,更容易构建大型算法和电路。通过
qml.registers,您可以通过提供一个字典来创建电线寄存器,该字典的键是寄存器名称,值是每个寄存器中的电线数量。>>> wire_reg = qml.registers({"alice": 4, "bob": 3}) >>> wire_reg {'alice': Wires([0, 1, 2, 3]), 'bob': Wires([4, 5, 6])}
qml.registers产生的数据结构是一个字典,其注册名称作为键,但值是qml.wires.Wires实例。在其他寄存器中嵌套寄存器可以通过提供嵌套字典来完成,其中线标签的顺序基于出现顺序和嵌套程度。
>>> wire_reg = qml.registers({"alice": {"alice1": 1, "alice2": 2}, "bob": {"bob1": 2, "bob2": 1}}) >>> wire_reg {'alice1': Wires([0]), 'alice2': Wires([1, 2]), 'alice': Wires([0, 1, 2]), 'bob1': Wires([3, 4]), 'bob2': Wires([5]), 'bob': Wires([3, 4, 5])}
由于字典的值是
Wires实例,它们在量子电路中的使用与list整数的使用非常相似。dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): for w in wire_reg["alice"]: qml.Hadamard(w) for w in wire_reg["bob1"]: qml.RX(0.1967, wires=w) qml.CNOT(wires=[wire_reg["alice1"][0], wire_reg["bob2"][0]]) return [qml.expval(qml.Y(w)) for w in wire_reg["bob1"]] print(qml.draw(circuit)())
0: ──H────────╭●─┤ 1: ──H────────│──┤ 2: ──H────────│──┤ 3: ──RX(0.20)─│──┤ <Y> 4: ──RX(0.20)─│──┤ <Y> 5: ───────────╰X─┤
与
qml.registers一起,我们还对qml.wires.Wires做了以下改进:Wires实例在打印时现在有了更方便复制粘贴的表示形式。 (#5958)>>> 从 pennylane.wires 导入 Wires >>> w = Wires([1, 2, 3]) >>> w Wires([1, 2, 3])
现在支持基于集合的 Python 组合通过
(#5983)Wires。此新功能解锁了以下方式组合
Wires实例的能力:与
&或intersection()的交集:>>> wires1 = Wires([1, 2, 3]) >>> wires2 = Wires([2, 3, 4]) >>> wires1.intersection(wires2) # 或 wires1 & wires2 Wires([2, 3])
对称差异,使用
^或symmetric_difference():>>> wires1.symmetric_difference(wires2) # 或 wires1 ^ wires2 Wires([1, 4])
与
|或union()合并:>>> wires1.union(wires2) # 或 wires1 | wires2 Wires([1, 2, 3, 4])
与
-或difference()的区别:>>> wires1.difference(wires2) # 或 wires1 - wires2 Wires([1])
量子算术操作 🧮
在PennyLane中添加了几个新的操作符模板,使您可以执行量子算术运算。 (#6109) (#6112) (#6121)
qml.Adder进行就地模加: \(\text{Adder}(k, m)\vert x \rangle = \vert x + k \; \text{mod} \; m\rangle\).qml.PhaseAdder类似于qml.Adder,但它在傅里叶基下执行就地模加法。qml.Multiplier进行原位乘法: \(\text{Multiplier}(k, m)\vert x \rangle = \vert x \times k \; \text{mod} \; m \rangle\).qml.OutAdder进行外部模加运算: \(\text{OutAdder}(m)\vert x \rangle \vert y \rangle \vert b \rangle = \vert x \rangle \vert y \rangle \vert b + x + y \; \text{mod} \; m \rangle\).qml.OutMultiplier执行外部模乘法运算: \(\text{OutMultiplier}(m)\vert x \rangle \vert y \rangle \vert b \rangle = \vert x \rangle \vert y \rangle \vert b + x \times y \; \text{mod} \; m \rangle\).qml.ModExp执行模幂运算: \(\text{ModExp}(base, m) \vert x \rangle \vert k \rangle = \vert x \rangle \vert k \times base^x \; \text{mod} \; m \rangle\).
这是一个综合示例,执行以下计算:
(2 + 1) * 3 mod 7 = 2(或者010在二进制中)。dev = qml.device("default.qubit", shots=1) wire_reg = qml.registers({ "x_wires": 2, # |x>: stores the result of 2 + 1 = 3 "y_wires": 2, # |y>: multiples x by 3 "output_wires": 3, # stores the result of (2 + 1) * 3 m 7 = 2 "work_wires": 2 # for qml.OutMultiplier }) @qml.qnode(dev) def circuit(): # In-place addition qml.BasisEmbedding(2, wires=wire_reg["x_wires"]) qml.Adder(1, x_wires=wire_reg["x_wires"]) # add 1 to wires [0, 1] # Out-place multiplication qml.BasisEmbedding(3, wires=wire_reg["y_wires"]) qml.OutMultiplier( wire_reg["x_wires"], wire_reg["y_wires"], wire_reg["output_wires"], work_wires=wire_reg["work_wires"], mod=7 ) return qml.sample(wires=wire_reg["output_wires"])
>>> circuit() array([0, 1, 0])
从Qiskit转换噪声模型 ♻️
将 Qiskit 噪声模型转换为 PennyLane
NoiseModel,使用qml.from_qiskit_noise。 (#5996)在最近的几次版本中,我们对 Pennylane-Qiskit 插件进行了重要改进和新增特性。 通过此版本,新的
qml.from_qiskit_noise函数允许您将 Qiskit 噪声模型 转换为 PennyLaneNoiseModel。以下是一个包含两个量子错误的简单示例,这两个不同的去极化错误是基于电路中不同门的存在添加的:import pennylane as qml import qiskit_aer.noise as noise error_1 = noise.depolarizing_error(0.001, 1) # 1量子位噪声 error_2 = noise.depolarizing_error(0.01, 2) # 2量子位噪声 noise_model = noise.NoiseModel() noise_model.add_all_qubit_quantum_error(error_1, ['rz', 'ry']) noise_model.add_all_qubit_quantum_error(error_2, ['cx'])
>>> qml.from_qiskit_noise(noise_model) NoiseModel({ OpIn(['RZ', 'RY']): QubitChannel(num_kraus=4, num_wires=1) OpIn(['CNOT']): QubitChannel(num_kraus=16, num_wires=2) })
在底层,PennyLane 将 Qiskit 噪声模型中的每个量子错误转换为具有相同典型
qml.QubitChannel操作符的等效 Kraus 表示。目前, PennyLane 中的噪声模型不支持读取错误。因此,如果在 Qiskit 噪声模型中存在这些错误,则在转换时将跳过它们。确保
pip install pennylane-qiskit以访问此新功能!
通过树遍历对中途测量进行实质性升级 🌳
用于中间电路测量(MCMs)的
"tree-traversal"算法在default.qubit上进行了内部重设计,以提高性能。 (#5868)在上一个版本(v0.37)中,我们引入了树遍历 MCM 方法,该方法以递归方式实现,以简化使用。然而,这导致了在有很多 MCM 的电路中出现非常深的 栈调用,在某些情况下导致 栈溢出。在本次发布中,我们将树遍历方法的实现重构为迭代方法,这解决了在电路中存在多个 MCM 时的效率问题。
现在
tree-traversal算法与分析模式执行(shots=None)兼容。 (#5868)dev = qml.device("default.qubit") n_qubits = 5 @qml.qnode(dev, mcm_method="tree-traversal") def circuit(): for w in range(n_qubits): qml.Hadamard(w) for w in range(n_qubits - 1): qml.CNOT(wires=[w, w+1]) for w in range(n_qubits): m = qml.measure(w) qml.cond(m == 1, qml.RX)(0.1967 * (w + 1), w) return [qml.expval(qml.Z(w)) for w in range(n_qubits)]
>>> circuit() [tensor(0.00964158, requires_grad=True), tensor(0.03819446, requires_grad=True), tensor(0.08455748, requires_grad=True), tensor(0.14694258, requires_grad=True), tensor(0.2229438, requires_grad=True)]
改进 🛠
创建自旋哈密顿量
现在可以使用三个新函数来创建在PennyLane中常用的自旋哈密顿量: (#6106) (#6128)
qml.spin.transverse_ising创建 横场伊辛模型 哈密顿量。qml.spin.heisenberg创建海森堡模型哈密顿量。qml.spin.fermi_hubbard创建 费米-哈伯德模型 哈密顿量。
每个哈密顿量可以通过指定一个
lattice、单元格的数量 unit cells,n_cells,及作为关键字参数的哈密顿量参数来实例化。以下是一个横场伊辛模型的示例:>>> tfim_ham = qml.spin.transverse_ising(lattice="square", n_cells=[2, 2], coupling=0.5, h=0.2) >>> tfim_ham ( -0.5 * (Z(0) @ Z(1)) + -0.5 * (Z(0) @ Z(2)) + -0.5 * (Z(1) @ Z(3)) + -0.5 * (Z(2) @ Z(3)) + -0.2 * X(0) + -0.2 * X(1) + -0.2 * X(2) + -0.2 * X(3) )
生成的对象是一个
qml.Hamiltonian实例,使其可以方便地用于如下电路。dev = qml.device("default.qubit", shots=1) @qml.qnode(dev) def circuit(): return qml.expval(tfim_ham)
>>> circuit() -2.0
将会在即将发布的版本中向
qml.spin模块添加更多功能,请保持关注!
一个 Prep-Select-Prep 模板
A new template called
qml.PrepSelPrephas been added that implements a block-encoding of a linear combination of unitaries. (#5756) (#5987)This operator acts as a nice wrapper for having to perform
qml.StatePrep,qml.Select, andqml.adjoint(qml.StatePrep)in succession, which is quite common in many quantum algorithms (e.g., LCU and block encoding). Here is an example showing the equivalence between usingqml.PrepSelPrepandqml.StatePrep,qml.Select, andqml.adjoint(qml.StatePrep).coeffs = [0.3, 0.1] alphas = (np.sqrt(coeffs) / np.linalg.norm(np.sqrt(coeffs))) unitaries = [qml.X(2), qml.Z(2)] lcu = qml.dot(coeffs, unitaries) control = [0, 1] def prep_sel_prep(alphas, unitaries): qml.StatePrep(alphas, wires=control, pad_with=0) qml.Select(unitaries, control=control) qml.adjoint(qml.StatePrep)(alphas, wires=control, pad_with=0) @qml.qnode(qml.device("default.qubit")) def circuit(lcu, control, alphas, unitaries): qml.PrepSelPrep(lcu, control) qml.adjoint(prep_sel_prep)(alphas, unitaries) return qml.state()
>>> import numpy as np >>> np.round(circuit(lcu, control, alphas, unitaries), decimals=2) tensor([1.+0.j -0.+0.j -0.+0.j -0.+0.j 0.+0.j 0.+0.j 0.+0.j 0.+0.j], requires_grad=True)
QChem 改进
现在可以为周期表中所有元素构建分子和哈密顿量。 (#5821)
这个新功能是通过与basis-set-exchange package的集成实现的。 如果您的分子需要从
basis-set-exchange加载基组,确保您pip install basis-set-exchange并设置load_data=True。symbols = ['Ti', 'Ti'] geometry = np.array([[0.0, 0.0, -1.1967], [0.0, 0.0, 1.1967]], requires_grad=True) mol = qml.qchem.Molecule(symbols, geometry, load_data=True)
>>> mol.n_electrons 44
qml.UCCSD现在接受一个额外的可选参数n_repeats,该参数定义了 UCCSD 模板的重复次数。这可以通过减少 Trotter 错误来提高模板的准确性,但会导致电路更深。 (#5801)该
qml.qchem.qubit_observable函数已被修改为返回分子哈密顿量的升序线路顺序。(#5950)一个名为
to_mat的新方法已被添加到qml.FermiWord和qml.FermiSentence类中, 它允许计算这些费米算子的矩阵表示。 (#5920)
运算符的改进
qml.GlobalPhase现在支持参数广播。 (#5923)qml.Hermitian现在有一个compute_decomposition方法。(#6062)对
qml.PhaseShift,qml.S和qml.T的实现进行了改进,从而实现了更快的电路执行时间。 (#5876)该
qml.CNOT运算符不再分解为自身。相反,它会引发一个qml.DecompositionUndefinedError。 (#6039)
中途测量
现在
qml.dynamic_one_shot变换支持使用"tensorflow"接口的电路。 (#5973)如果条件中不包括中途测量,那么
qml.cond将自动使用标准 Python 控制流评估条件。这使得
qml.cond可以用来表示更广泛的条件:dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): c = qml.cond(x > 2.7, qml.RX, qml.RZ) c(x, wires=0) return qml.probs(wires=0)
>>> print(qml.draw(circuit)(3.8)) 0: ──RX(3.80)─┤ Probs >>> print(qml.draw(circuit)(0.54)) 0: ──RZ(0.54)─┤ Probs
变换
qml.transforms.single_qubit_fusion和qml.transforms.merge_rotations现在尊重全局相位。 (#6031)新增了一种变换,叫做
qml.transforms.diagonalize_measurements。该变换通过应用相关的对角化门将测量转换为计算基。它可以设置为仅对基础可观测量的子集{qml.X, qml.Y, qml.Z, qml.Hadamard}进行对角化。 (#5829)新增了一种变换叫做
split_to_single_terms。这个变换将和的期望值拆分为多个单项测量,放在单个记录中,为能够处理不对易观测量但不原生支持多项观测量的模拟器提供了更好的支持。 (#5884)新增功能,原生支持在使用
qml.transforms.mitigate_with_zne时进行指数外推。这使用户能够更好地控制错误缓解协议,而无需添加更多依赖项。 (#5972)
捕获和表示混合程序
qml.for_loop现在支持range类似的语法,默认step=1。 (#6068)应用
adjoint和ctrl到量子函数现在可以被捕获到 plxpr 中。此外,qml.cond函数也可以被捕获到 plxpr 中。 (#5966) (#5967) (#5999) (#6058)在实验程序捕获期间,接受和/或返回
pytree结构的函数现在可以在qml.QNode调用、qml.cond、qml.for_loop和qml.while_loop中处理。 (#6081)在实验程序捕获期间,QNodes 现在可以使用闭包变量。
现在可以使用
qml.capture启用中间电路测量的捕获。 (#6015)qml.for_loopandqml.while_loopnow fall back to standard Python control flow if@qjitis not present, allowing the same code to work with and without@qjitwithout any rewrites. (#6014)dev = qml.device("lightning.qubit", wires=3) @qml.qnode(dev) def circuit(x, n): @qml.for_loop(0, n, 1) def init_state(i): qml.Hadamard(wires=i) init_state() @qml.for_loop(0, n, 1) def apply_operations(i, x): qml.RX(x, wires=i) @qml.for_loop(i + 1, n, 1) def inner(j): qml.CRY(x**2, [i, j]) inner() return jnp.sin(x) apply_operations(x) return qml.probs()
>>> print(qml.draw(circuit)(0.5, 3)) 0: ──H──RX(0.50)─╭●────────╭●──────────────────────────────────────┤ Probs 1: ──H───────────╰RY(0.25)─│──────────RX(0.48)─╭●──────────────────┤ Probs 2: ──H─────────────────────╰RY(0.25)───────────╰RY(0.23)──RX(0.46)─┤ Probs >>> circuit(0.5, 3) array([0.125 , 0.125 , 0.09949758, 0.15050242, 0.07594666, 0.11917543, 0.08942104, 0.21545687]) >>> qml.qjit(circuit)(0.5, 3) Array([0.125 , 0.125 , 0.09949758, 0.15050242, 0.07594666, 0.11917543, 0.08942104, 0.21545687], dtype=float64)
社区贡献 🥳
修复了
qml.ThermalRelaxationError中的一个错误,该错误将tq错拼为tg。 (#5988)读出误差已通过参数
readout_relaxation_probs和readout_misclassification_probs添加到default.qutrit.mixed设备上。这些参数分别在测量对角化后添加了一个qml.QutritAmplitudeDamping和一个qml.TritFlip通道。幅度衰减误差表示在更长测量过程中放松发生的潜力。三元翻转误差表示在读出过程中发生的误分类。(#5842)qml.ops.qubit.BasisStateProjector现在有一个compute_sparse_matrix方法,该方法计算给定基态下投影算子的稀疏 CSR 矩阵表示。 (#5790)
其他改进
qml.pauli.group_observables现在使用rustworkx着色算法来解决 最小团覆盖问题,从而在性能上实现数量级的提升。 (#6043)这为
method参数增加了两个新选项:dsatur(饱和度)和gis(独立集)。此外,邻接矩阵的创建现在利用了Pauli可观察量的辛表示。此外,新增了一个名为
qml.pauli.compute_partition_indices的函数,用于更高效地计算 来自分区观察量的索引。这些更改在数量级上提高了qml.LinearCombination.compute_grouping和grouping_type='qwc'的运行时间。qml.counts测量与all_outcomes=True现在可以与 JAX jitting 一起使用。此外,跨所有可用导线广播的测量(例如,qml.probs())现在可以与 JAX jit 和允许动态数量导线的设备一起使用(目前仅'default.qubit')。(#6108)qml.ops.op_math.ctrl_decomp_zyz现在可以分解具有多个控制线的特殊酉矩阵。 (#6042)新增了一种名为
process_density_matrix的方法,已添加到ProbabilityMP和DensityMatrixMP测量过程中,允许更有效地处理量子密度矩阵,特别是支持批处理。此方法简化了从以密度矩阵表示的量子状态计算概率的过程。 (#5830)SProd.terms现在会将项展平,如果基础是多项可观测量。 (#5885)qml.QNGOptimizer现在支持多个参数的代价函数,独立更新每个参数。 (#5926)semantic_version已从 PennyLane 所需包列表中移除。 (#5836)qml.devices.LegacyDeviceFacade已被添加,以将旧设备映射到新设备接口,从而使开发人员更容易开发旧设备。(#5927)StateMP.process_state现在在cast_to_complex中定义了复杂转换的规则,避免了在 PennyLane-Lightning 模拟中不必要的状态向量复制。 (#5995)QuantumScript.hash现已被缓存,从而提高了性能。 (#5919)对于
default.qubit的可观察验证现在基于执行模式(解析模式与有限拍摄) 和测量类型(样本测量与状态测量)。这改善了我们的错误处理,比如当给定非厄米算符到qml.expval时。 (#5890)在
qml.pytrees模块的函数flatten中添加了一个新的is_leaf参数。这是为了允许在is_leaf可选参数的值为True的任何节点上停止节点的扁平化。(#6107)在下载数据集时,
qml.data.load()已添加进度条。 (#5560)升级并简化了
BasisState和BasisEmbedding模板。 (#6021)
重大变更 💔
MeasurementProcess.shape(shots: Shots, device:Device)现在是MeasurementProcess.shape(shots: Optional[int], num_device_wires:int = 0)。这样做是为了 在测量广播到所有可用电线时允许进行即时编译,但设备没有 指定电线。 (#6108)如果概率测量的形状受到
Device.cutoff属性的影响,它将不再与 jitting 一起工作。 (#6108)qml.GlobalPhase被认为是不可微分的,与 tape 变换相关。因此,qml.gradients.finite_diff和qml.gradients.spsa_grad不再支持使用基于状态的输出对qml.GlobalPhase进行微分。 (#5620)现在,
CircuitGraph.graphrustworkx图将电路的索引存储为节点标签,而不是操作符/测量本身。这允许相同的操作符在电路中出现多次。 (#5907)已从
Operator、CompositeOp和SymbolicOp类中移除queue_idx属性。 (#6005)qml.from_qasm不再从QASM代码中移除测量。使用measurements=[]从原始电路中移除测量。 (#5982)qml.transforms.map_batch_transform已被移除,因为变换可以直接应用于一批胶带。有关更多信息,请参阅qml.transform。 (#5981)QuantumScript.interface已被移除。 (#5980)
弃用功能 👋
在
qml.device中的decomp_depth参数已被弃用。 (#6026)在
qml.QNode中,max_expansion参数已被弃用。 (#6026)属性
expansion_strategyqml.QNode已被弃用。 (#5989)在所有的
qml.draw,qml.draw_mpl, 和qml.specs中,expansion_strategy参数已被弃用。应使用level参数。(#5989)Operator.expand已被弃用。用户应简单地使用qml.tape.QuantumScript(op.decomposition())以获得等效的行为。 (#5994)qml.transforms.sum_expand和qml.transforms.hamiltonian_expand已被弃用。用户应改为使用qml.transforms.split_non_commuting以获得等效的行为。 (#6003)在
(#5984)qml.execute中,expand_fn参数已被弃用。请创建一个qml.transforms.core.TransformProgram,并将所需的预处理传递给qml.execute的transform_program参数。在
qml.execute中的max_expansion参数已被弃用。 请改为使用qml.devices.preprocess.decompose并指定所需的扩展级别,将其添加到qml.transforms.core.TransformProgram中,并将其传递给qml.execute的transform_program参数。 (#5984)qml.execute中的override_shots参数已弃用。请将镜头添加到待执行的QuantumTape中。(#5984)qml.execute中的device_batch_transform参数已被弃用。
请创建一个带有所需预处理的qml.transforms.core.TransformProgram,并将其传递给qml.execute的transform_program参数。(#5984)qml.qinfo.classical_fisher和qml.qinfo.quantum_fisher已被弃用。 请使用qml.gradients.classical_fisher和qml.gradients.quantum_fisher。 (#5985)遗留设备
default.qubit.{autograd,torch,tf,jax,legacy}已被弃用。现在,请使用default.qubit,因为它现在支持通过多个后端的反向传播。(#5997)用于内部切换设备以适应不同反向传播兼容设备的逻辑现在已被弃用,因为它是为已弃用的
default.qubit.legacy设置的。 (#6032)
文档 📝
关于内部使用的函数和可能需要的辅助线的
qml.qinfo.quantum_fisher的文档字符串已进行了改进。 (#6074)对于
QuantumScript.expand和qml.tape.tape.expand_tape的文档字符串进行了改进。 (#5974)
修复错误 🐛
现在可以计算出稀疏矩阵,当一个操作数是一个
(#6197)GlobalPhase且没有线路时的乘积算子。对于
default.qubit,当状态是 JAX 数组时,现在使用 JAX 进行采样。这解决了当状态使用 32 位精度时可能出现的归一化问题。 (#6190)修复具有空镜头向量的算子的Pytree序列化 (#6155)
修复了在与单次采样一起使用时,
dynamic_one_shot变换中的一个错误。 (#6149)qml.transforms.pattern_matching_optimization现在保留了磁带测量。 (#6153)
(#6147)qml.transforms.broadcast_expand不再压缩大小为1的批次,因为大小为1的批次仍然是一个批次。Catalyst 在与梯度相关的函数中用
argnums替换了argnum,因此我们更新了在 PennyLane 中对这些函数的 Catalyst 调用。 (#6117)fuse_rot_angles现在在奇异点返回 NaN 而不是不正确的导数。 (#6031)qml.GlobalPhase和qml.Identity现在可以在不作用于任何线时通过 plxpr 捕获。(#6060)修复了
jax.grad和jax.jit以支持qml.AmplitudeEmbedding、qml.StatePrep和qml.MottonenStatePreparation。 (#5620)修复了在
qml.center中的一个错误,该错误遗漏了线性组合的中心元素 如果它们是输入元素的线性组合。 (#6049)修复了一个错误,即
one_qubit_decomposition返回的全球相位增加了一个广播维度。 (#5923)修复了
qml.SPSAOptimizer中一个忽略目标函数中关键字参数的错误。 (#6027)修复了
dynamic_one_shot以便与使用旧设备API的设备兼容,因为override_shots已被弃用。 (#6024)CircuitGraph现在可以处理同一操作实例多次出现的电路。 (#5907)qml.QSVT已被更新以正确存储线的顺序。 (#5959)qml.devices.qubit.measure_with_samples现在如果提供的测量包含作用在同一线路上的算子的和,将返回正确的结果。 (#5978)qml.AmplitudeEmbedding更好地支持使用低精度整数数据类型的特性。 (#5969)qml.BasisState和qml.BasisEmbedding现在可以与 jax.jit、lightning.qubit一起使用,并给出正确的分解。(#6021)雅可比形状已针对维度为
qml.gradients.vjp.compute_vjp_single的测量进行修复。 (5986)qml.lie_closure现在可以与保罗和的求和一起使用。 (#6023)现在参数化
qml.exp系数的工作流与jit兼容。 (#6082)修复了一个错误,即
(#6091)CompositeOp.overlapping_ops更改了操作符的原始顺序,导致为Prod生成了不正确的矩阵,操作数为Sum。qml.qsvt现在支持“Wx”约定和任意数量的角度。 (#6105)现在可以加载具有
SPD类型轨道的元素的基组数据,来自基组交换库。 (#6159)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
塔伦·库马尔·阿拉姆塞提, 吉列尔莫·阿朗索, 阿里·阿萨迪, 乌特卡什·阿扎德, 托姆伊·T·巴塔查里亚, 加布里埃尔·博特里尔, 杰克·布朗, 艾哈迈德·达尔维什, 阿斯特拉尔·蔡, 余少辰, 艾哈迈德·达尔维什, 迪克沙·达万 玛雅·弗朗兹, 莉莉安·M·A·弗雷德里克森, 皮耶特罗波洛·弗里索尼, 埃米利亚诺·戈丁斯, 奥斯汀·黄, 任克·黄, 乔什·艾扎克, 索兰·贾汉吉里, 科尔比安·科特曼, 克里斯蒂娜·李, 豪尔赫·马丁内斯·德·莱哈尔萨, 威廉·麦克斯韦尔, 文森特·米肖-里约, 阿努拉夫·莫达克, 穆迪特·潘迪, 安德里亚·保雷维奇, 埃里克·舒尔特海斯, 内特·斯特门, 大卫·维里希斯,
- orphan
发布 0.37.0¶
自上次发布以来的新特性
使用默认张量执行广泛电路 🔗
A new
default.tensordevice is now available for performing tensor network and matrix product state simulations of quantum circuits using the quimb backend. (#5699) (#5744) (#5786) (#5795)Either method can be selected when instantiating the
default.tensordevice by setting themethodkeyword argument to"tn"(tensor network) or"mps"(matrix product state).There are several templates in PennyLane that are tensor-network focused, which are excellent candidates for the
"tn"method fordefault.tensor. The following example shows how a circuit comprising gates in a tree tensor network architecture can be efficiently simulated usingmethod="tn".import pennylane as qml n_wires = 16 dev = qml.device("default.tensor", method="tn") def block(weights, wires): qml.CNOT(wires=[wires[0], wires[1]]) qml.RY(weights[0], wires=wires[0]) qml.RY(weights[1], wires=wires[1]) n_block_wires = 2 n_params_block = 2 n_blocks = qml.TTN.get_n_blocks(range(n_wires), n_block_wires) template_weights = [[0.1, -0.3]] * n_blocks @qml.qnode(dev) def circuit(template_weights): for i in range(n_wires): qml.Hadamard(i) qml.TTN(range(n_wires), n_block_wires, block, n_params_block, template_weights) return qml.expval(qml.Z(n_wires - 1))
>>> circuit(template_weights) 0.3839174759751649
For matrix product state simulations (
method="mps"), we can make the execution be approximate by settingmax_bond_dim(see the device’s documentation for more details). The maximum bond dimension has implications for the speed of the simulation and lets us control the degree of the approximation, as shown in the following example. First, set up the circuit:import numpy as np n_layers = 10 n_wires = 10 initial_shape, weights_shape = qml.SimplifiedTwoDesign.shape(n_layers, n_wires) np.random.seed(1967) initial_layer_weights = np.random.random(initial_shape) weights = np.random.random(weights_shape) def f(): qml.SimplifiedTwoDesign(initial_layer_weights, weights, range(n_wires)) return qml.expval(qml.Z(0))
The
default.tensordevice is instantiated with amax_bond_dimvalue:dev_dq = qml.device("default.qubit") value_dq = qml.QNode(f, dev_dq)() dev_mps = qml.device("default.tensor", max_bond_dim=5) value_mps = qml.QNode(f, dev_mps)()
With this bond dimension, the expectation values calculated for
default.qubitanddefault.tensorare different:>>> np.abs(value_dq - value_mps) tensor(0.0253213, requires_grad=True)
Learn more about
default.tensorand how to configure it by visiting the how-to guide.
向您的量子电路添加噪声模型 📺
已添加对构建噪声模型并将其应用于量子电路的支持,通过
NoiseModel类和add_noise变换。(#5674) (#5684) (#5718)在幕后,PennyLane 对噪声模型的处理是基于插入的,这意味着噪声是通过 插入 描述噪声的额外算符(门或通道)到量子电路中来实现的。创建一个
NoiseModel的核心是定义布尔条件,在这些条件下插入特定的噪声操作。有几种方法可以指定添加噪声操作的条件:qml.noise.op_eq(op): 如果在电路中遇到运算符op,则添加噪声。qml.noise.op_in(ops): 如果在电路中遇到ops中的任何算子,则添加噪声。qml.noise.wires_eq(wires): 如果对wires应用了一个算子,则添加噪声。qml.noise.wires_in(wires): 如果对wires中的任何一条线施加操作,则添加噪音。自定义噪声条件:自定义条件可以被定义为用
qml.BooleanFn装饰的返回布尔值的函数。例如,以下函数将在遇到旋转角度小于0.5的qml.RY操作符时插入噪声:@qml.BooleanFn def c0(op): return isinstance(op, qml.RY) and op.parameters[0] < 0.5
条件还可以通过
&,and,|等组合在一起。一旦确定了要插入噪声的条件,我们可以通过以下方式准确指定插入的噪声:qml.noise.partial_wires(op): 在由触发添加此噪声的条件指定的线路上插入op自定义噪声操作:可以通过定义以下标准量子函数来指定自定义噪声。
def n0(op, **kwargs): qml.RY(op.parameters[0] * 0.05, wires=op.wires)
这样,我们可以创建一个
qml.NoiseModel对象,其参数必须是一个将条件映射到噪声的字典:c1 = qml.noise.op_eq(qml.X) & qml.noise.wires_in([0, 1]) n1 = qml.noise.partial_wires(qml.AmplitudeDamping, 0.4) noise_model = qml.NoiseModel({c0: n0, c1: n1})
>>> noise_model NoiseModel({ BooleanFn(c0): n0 OpEq(PauliX) | WiresIn([0, 1]): AmplitudeDamping(gamma=0.4) })
创建的噪声模型可以通过
qml.add_noise添加到 QNode 中:dev = qml.device("lightning.qubit", wires=3) @qml.qnode(dev) def circuit(): qml.Y(0) qml.CNOT([0, 1]) qml.RY(0.3, wires=2) # triggers c0 qml.X(1) # triggers c1 return qml.state()
>>> print(qml.draw(circuit)()) 0: ──Y────────╭●────┤ State 1: ───────────╰X──X─┤ State 2: ──RY(0.30)───────┤ State >>> circuit = qml.add_noise(circuit, noise_model) >>> print(qml.draw(circuit)()) 0: ──Y────────╭●───────────────────────────────────┤ State 1: ───────────╰X─────────X──AmplitudeDamping(0.40)─┤ State 2: ──RY(0.30)──RY(0.01)────────────────────────────┤ State
如果对一个QNode应用了多个变换,可以通过
level关键字参数控制add_noise变换与其他变换之间的应用顺序/位置。默认情况下,add_noise在此之前手动应用于QNode的所有变换之后被应用。要了解更多关于此新功能的信息,请查看我们的噪声模块文档,并密切关注详细演示!
使用PennyLane调试器捕捉错误 🚫🐞
The new PennyLane quantum debugger allows pausing simulation via the
qml.breakpoint()command and provides tools for analyzing quantum circuits during execution. (#5680) (#5749) (#5789)This includes monitoring the circuit via measurements using
qml.debug_state(),qml.debug_probs(),qml.debug_expval(), andqml.debug_tape(), stepping through the operations in a quantum circuit, and interactively adding operations during execution.Including
qml.breakpoint()in a circuit will cause the simulation to pause during execution and bring up the interactive console. For example, consider the following code in a Python file calledscript.py:@qml.qnode(qml.device('default.qubit', wires=(0,1,2))) def circuit(x): qml.Hadamard(wires=0) qml.CNOT(wires=(0,2)) qml.breakpoint() qml.RX(x, wires=1) qml.RY(x, wires=2) qml.breakpoint() return qml.sample() circuit(1.2345)
Upon executing
script.py, the simulation pauses at the first breakpoint:> /Users/your/path/to/script.py(8)circuit() -> qml.RX(x, wires=1) (pldb):
While debugging, we can access circuit information. For example,
qml.debug_tape()returns the tape of the circuit, giving access to its operations and drawing:[pldb] tape = qml.debug_tape() [pldb] print(tape.draw(wire_order=[0,1,2])) 0: ──H─╭●─┤ 2: ────╰X─┤ [pldb] tape.operations [Hadamard(wires=[0]), CNOT(wires=[0, 2])]
While
qml.debug_state()is equivalent toqml.state()and gives the current state:[pldb] print(qml.debug_state()) [0.70710678+0.j 0. +0.j 0. +0.j 0. +0.j 1. +0.j 0.70710678+0.j 0. +0.j 0. +0.j]
Other debugger functions like
qml.debug_probs()andqml.debug_expval()also function like their simulation counterparts (qml.probsandqml.expval, respectively) and are described in more detail in the debugger documentationAdditionally, standard debugging commands are available to navigate through code, including
list,longlist,next,continue, andquit, as described in the debugging documentation.Finally, to modify a circuit mid-run, simply call the desired PennyLane operations:
[pldb] qml.CNOT(wires=(0,2)) CNOT(wires=[0, 2]) [pldb] print(qml.debug_tape().draw(wire_order=[0,1,2])) 0: ──H─╭●─╭●─┤ 2: ────╰X─╰X─┤
敬请期待有关如何在实际示例中使用此功能的深入演示!
在OpenFermion和PennyLane之间转换 🤝
现在有两个新函数叫做
qml.from_openfermion和qml.to_openfermion可用于在 OpenFermion 和 PennyLane 对象之间进行转换。这包括费米子和量子比特运算符。 (#5773) (#5808) (#5881)对于费米子运算符:
>>> import openfermion >>> of_fermionic = openfermion.FermionOperator('0^ 2') >>> type(of_fermionic)
>>> pl_fermionic = qml.from_openfermion(of_fermionic) >>> type(pl_fermionic) >>> print(pl_fermionic) a⁺(0) a(2) 而对于量子比特运算符:
>>> of_qubit = 0.5 * openfermion.QubitOperator('X0 X5') >>> pl_qubit = qml.from_openfermion(of_qubit) >>> print(pl_qubit) 0.5 * (X(0) @ X(5))
更好地控制绘制和规格发生的时间 🎚️
It is now possible to control the stage at which
qml.draw,qml.draw_mpl, andqml.specsoccur within a QNode’s transform program. (#5855) (#5781)Consider the following circuit which has multiple transforms applied:
@qml.transforms.split_non_commuting @qml.transforms.cancel_inverses @qml.transforms.merge_rotations @qml.qnode(qml.device("default.qubit")) def f(): qml.Hadamard(0) qml.Y(0) qml.RX(0.4, 0) qml.RX(-0.4, 0) qml.Y(0) return qml.expval(qml.X(0) + 2 * qml.Y(0))
We can specify a
levelvalue when usingqml.draw():>>> print(qml.draw(f, level=0)()) # input program 0: ──H──Y──RX(0.40)──RX(-0.40)──Y─┤ <X+(2.00*Y)> >>> print(qml.draw(f, level=1)()) # rotations merged 0: ──H──Y──Y─┤ <X+(2.00*Y)> >>> print(qml.draw(f, level=2)()) # inverses cancelled 0: ──H─┤ <X+(2.00*Y)> >>> print(qml.draw(f, level=3)()) # Hamiltonian expanded 0: ──H─┤ <X> 0: ──H─┤ <Y>
The qml.workflow.get_transform_program function can be used to see the full transform program.
>>> qml.workflow.get_transform_program(f) TransformProgram(merge_rotations, cancel_inverses, split_non_commuting, validate_device_wires, mid_circuit_measurements, decompose, validate_measurements, validate_observables, no_sampling)
Note that additional transforms can be added automatically from device preprocessing or gradient calculations. Rather than providing an integer value to
level, it is possible to target the"user","gradient"or"device"stages:n_wires = 3 x = np.random.random((2, n_wires)) @qml.qnode(qml.device("default.qubit")) def f(): qml.BasicEntanglerLayers(x, range(n_wires)) return qml.expval(qml.X(0))
>>> print(qml.draw(f, level="device")()) 0: ──RX(0.28)─╭●────╭X──RX(0.70)─╭●────╭X─┤ <X> 1: ──RX(0.52)─╰X─╭●─│───RX(0.65)─╰X─╭●─│──┤ 2: ──RX(0.00)────╰X─╰●──RX(0.03)────╰X─╰●─┤
改进 🛠
社区贡献,包括 UnitaryHACK 💛
default.clifford现在支持基于任意状态的测量,使用qml.Snapshot。 (#5794)qml.equal现在可以正确处理Pow、Adjoint、Exp和SProd运算符作为不同接口和容差的参数,并增加了四个新的关键字参数:check_interface、check_trainability、atol和rtol。(#5668)qml.assert_equal的实现已更新为Operator、Controlled、Adjoint、Pow、Exp、SProd、ControlledSequence、Prod、Sum、Tensor和Hamiltonian实例。(#5780) (#5877)qml.from_qasm现在支持将中间电路测量转换为OpenQASM 2代码的能力,并且现在还可以接受一个可选参数来指定在电路末尾要执行的测量列表,正如qml.from_qiskit一样。(#5818)为在
default.qutrit.mixed设备上模拟噪声添加了四个新运算符: (#5502) (#5793) (#5503) (#5757) (#5799) (#5784)qml.QutritDepolarizingChannel: 一个添加去极化噪声的通道。qml.QutritChannel: 允许使用一组(3x3)Kraus 矩阵来指定噪声。qml.QutritAmplitudeDamping: 一个添加由幅度耗散模型的噪声过程的通道。qml.TritFlip: 一个添加三值翻转错误的通道,例如误分类。
更快更灵活的中间电路测量
该
default.qubit设备支持深度优先树遍历算法,以加速本地中途测量执行。通过QNode参数mcm_method="tree-traversal"进行访问,这一新实现支持经典控制、收集统计数据以及后选,此外还支持所有启用的测量qml.dynamic_one_shot。有关这种新中途测量方法的更多信息可以在我们的测量文档页面中找到。(#5180)qml.QNode和@qml.qnode装饰器现在接受两个新的关键字参数:postselect_mode和mcm_method。这些关键字参数可以用来配置设备在运行带有中间测量的电路时的行为。 (#5679) (#5833) (#5850)postselect_mode="hw-like"表示在后选择中断电路测量时设备丢弃无效的抽样。使用postselect_mode="fill-shots"可以无条件地抽样后选择的值,从而使所有样本有效。这相当于抽样直到有效样本的数量与总抽样数量匹配。mcm_method将指示在具有中间测量的电路中使用哪种策略。使用mcm_method="deferred"来应用延迟测量原则,或mcm_method="one-shot"每次执行一次。如果正在使用qml.qjit(Catalyst 编译器),mcm_method="single-branch-statistics"也可以使用。使用此方法,将随机探索执行树的单个分支。
函数
dynamic_one_shot进行了几项改进:When using
defer_measurementswith postselection, operations that will never be active due to the postselected state are skipped in the transformed quantum circuit. In addition, postselected controls are skipped, as they are evaluated when the transform is applied. This optimization feature can be turned off by settingreduce_postselected=False. (#5558)Consider a simple circuit with three mid-circuit measurements, two of which are postselecting, and a single gate conditioned on those measurements:
@qml.qnode(qml.device("default.qubit")) def node(x): qml.RX(x, 0) qml.RX(x, 1) qml.RX(x, 2) mcm0 = qml.measure(0, postselect=0, reset=False) mcm1 = qml.measure(1, postselect=None, reset=True) mcm2 = qml.measure(2, postselect=1, reset=False) qml.cond(mcm0 + mcm1 + mcm2 == 1, qml.RX)(0.5, 3) return qml.expval(qml.Z(0) @ qml.Z(3))
Without the new optimization, we obtain three gates, each controlled on the three measured qubits. They correspond to the combinations of controls that satisfy the condition
mcm0 + mcm1 + mcm2 == 1:>>> print(qml.draw(qml.defer_measurements(node, reduce_postselected=False))(0.6)) 0: ──RX(0.60)──|0⟩⟨0|─╭●─────────────────────────────────────────────┤ ╭<Z@Z> 1: ──RX(0.60)─────────│──╭●─╭X───────────────────────────────────────┤ │ 2: ──RX(0.60)─────────│──│──│───|1⟩⟨1|─╭○────────╭○────────╭●────────┤ │ 3: ───────────────────│──│──│──────────├RX(0.50)─├RX(0.50)─├RX(0.50)─┤ ╰<Z@Z> 4: ───────────────────╰X─│──│──────────├○────────├●────────├○────────┤ 5: ──────────────────────╰X─╰●─────────╰●────────╰○────────╰○────────┤
If we do not explicitly deactivate the optimization, we obtain a much simpler circuit:
>>> print(qml.draw(qml.defer_measurements(node))(0.6)) 0: ──RX(0.60)──|0⟩⟨0|─╭●─────────────────┤ ╭<Z@Z> 1: ──RX(0.60)─────────│──╭●─╭X───────────┤ │ 2: ──RX(0.60)─────────│──│──│───|1⟩⟨1|───┤ │ 3: ───────────────────│──│──│──╭RX(0.50)─┤ ╰<Z@Z> 4: ───────────────────╰X─│──│──│─────────┤ 5: ──────────────────────╰X─╰●─╰○────────┤
There is only one controlled gate with only one control wire.
中途测量测试已被简化和重构,从原生MCM测试文件中移除大部分端到端测试,但保留了一个验证多个中途测量的测试,该测试允许任何返回和接口端到端测试。
(#5787)
访问QROM
QROM算法 现在可以在 PennyLane 中使用
qml.QROM。 该模板允许您以比特串的形式输入经典数据。 (#5688)比特串 = ["010", "111", "110", "000"] 设备 = qml.device("default.qubit", shots = 1) @qml.qnode(设备) def 电路(): qml.BasisEmbedding(2, wires = [0,1]) qml.QROM(比特串 = 比特串, control_wires = [0,1], target_wires = [2,3,4], work_wires = [5,6,7]) return qml.sample(wires = [2,3,4])
>>> print(电路()) [1 1 0]
捕获和表示混合程序
许多模板已更新为有效的 PyTrees 和 PennyLane 操作。 (#5698)
PennyLane 运算符、测量和 QNodes 现在可以自动作为指令捕获在 JAXPR 中。 (#5564) (#5511) (#5708) (#5523) (#5686) (#5889)
qml.PyTrees模块现在具有flatten和unflatten方法,用于序列化 PyTrees。 (#5701)qml.sample现在可以用于表示中间电路测量结果的布尔值,在被追踪的量子函数中使用。此功能与Catalyst一起使用,以启用模式m = measure(0); qml.sample(m)。(#5673)
量子化学
qml.qchem.Molecule对象获得了一些改进:现在,
qml.qchem.molecular_hamiltonian函数支持奇偶性和 Bravyi-Kitaev 映射。 (#5657)qml.qchem.molecular_dipole函数已添加,用于使用"dhf"和"openfermion"后端计算偶极子算符。 (#5764)qchem模块现在有专门的函数用于调用
pyscf和openfermion后端,并且molecular_hamiltonian和molecular_dipole函数已移到hamiltonian和dipole模块。 (#5553) (#5863)已添加更多费米子到量子位的测试,以覆盖当映射算子在不同映射方案中有所不同的情况。 (#5873)
更简单的开发
日志记录现在允许在整个堆栈中更容易地选择加入,并且对Catalyst的支持已得到扩展。 (#5528)
新增了三个 Pytest 标记,以更轻松地管理我们的测试套件:
unit,integration和system。(#5517)
其他改进
qml.MultiControlledX现在可以在没有work_wires提供的情况下进行分解。该实现返回 \(\mathcal{O}(\mbox{len(control wires)}^2)\) 次操作,并适用于任何多重控制的单位门。该分解已在 arXiv:quant-ph/9503016 中提供。 (#5735)一个名为
expectation_value的新函数已经被添加到qml.math以计算纯态矩阵的期望值。(#4484)>>> state_vector = [1/np.sqrt(2), 0, 1/np.sqrt(2), 0] >>> operator_matrix = qml.matrix(qml.PauliZ(0), wire_order=[0,1]) >>> qml.math.expectation_value(operator_matrix, state_vector) tensor(-2.23711432e-17+0.j, requires_grad=True)
param_shift现在可以支持参数broadcast=True选项的射击向量和多次测量。 (#5667)qml.TrotterProduct现在通过继承ResourcesOperation兼容资源跟踪。 (#5680)packaging现在是PennyLane中必需的包。 (#5769)qml.ctrl现在可以在应用于任何已经控制的操作时,处理元组值的control_values。 (#5725)参数移动项的排序顺序现在确保能够根据移动的符号解决绝对值的平局。(#5582)
qml.transforms.split_non_commuting现在可以处理包含多项可观测量测量的电路。 (#5729) (#5838) (#5828) (#5869) (#5939) (#5945)qml.devices.LegacyDevice现在是qml.Device的别名,因此更容易与qml.devices.Device区分开来,后者遵循新的设备API。 (#5581)对于
X、Y、Z和Hadamard的eigvals,dtype从int更改为float,使它们与其他观测量一致。在对这些观测量进行采样时(例如qml.sample(X(0))),返回值的dtype也更改为float。 (#5607)该
decompose变换有一个error关键字参数,用于指定应该引发的错误类型,从而使错误类型与decompose函数使用的上下文更加一致。(#5669)允许
PauliVSpace的空初始化。 (#5675)qml.tape.QuantumScript属性仅在需要时计算,而不是在初始化时。 这减少了超过 20% 的经典开销。此外,par_info,obs_sharing_wires和obs_sharing_wires_id现在是公共属性。 (#5696)现在,
qml.data模块支持将PyTree数据类型作为数据集属性(#5732)qml.ops.Conditional现在继承自qml.ops.SymbolicOp,因此它继承了一些有用的通用功能。其他属性,如伴随和对角化门,已经通过base属性添加。已添加新的调度到
qml.ops.Conditional和qml.MeasurementValue的qml.equal中。 (##5772)
(#5805)qml.snapshots变换现在通过为不支持的设备运行单独的录音来支持任意设备。现在,
qml.Snapshot算子可以接受基于样本的测量用于有限拍摄设备。 (#5805)设备预处理转换现在发生在机器学习边界内。(#5791)
应用于可调用对象的变换现在使用
functools.wraps来保留原始函数的文档字符串和调用签名。 (#5857)qml.qsvt()现在支持带角度转换的 JAX 数组。 (#5853)参数偏移项的排序顺序现在保证在绝对值上解决平局时考虑偏移的符号。 (#5583)
重大变更 💔
将
shots作为关键字参数传递给QNode初始化现在会引发错误,而不是忽略输入。 (#5748)无法再向
qml.QDrift提供自定义分解。相反,请直接使用qml.apply应用您的自定义操作中的操作。 (#5698)由
X,Y,Z和Hadamard组成的可观察量采样现在返回float类型的值,而不是int类型的值。 (#5607)qml.is_commuting不再接受wire_map参数,因为这个参数没有带来任何功能。 (#5660)qml.from_qasm_file已被移除。用户可以使用qml.from_qasm打开文件并加载其内容。 (#5659)qml.load已被移除,取而代之的是更具体的函数,如qml.from_qiskit等。 (#5654)qml.transforms.convert_to_numpy_parameters现在是一个正式的变换,其输出签名已经更改,返回一个QuantumScript列表和一个后处理函数,而不是简单地返回变换后的电路。 (#5693)Controlled.wires不再包含self.work_wires。可以通过Controlled.work_wires单独访问。因此,Controlled.active_wires已被移除,取而代之的是更常用的Controlled.wires。(#5728)
弃用功能 👋
在
qml.Hamiltonian和qml.ops.LinearCombination中的simplify参数已被弃用。相反,可以在构造的算子上调用qml.simplify()。(#5677)qml.transforms.map_batch_transform已弃用,因为转换可以直接应用于一批录音带。 (#5676)默认行为
qml.from_qasm()删除 QASM 代码中的测量功能已经被弃用。使用measurements=[]来保持这种行为,或使用measurements=None来保留 QASM 代码中的测量。(#5882)(#5904)
文档 📝
已修复了测量过程文档字符串中几个链接到其他函数的问题。 (#5913)
关于中途测量的信息已从测量快速入门页面移至其专属 中途测量快速入门页面 (#5870)
已添加对
default.tensor设备的文档。 (#5719)文档字符串中的一个小错误已修正,针对
qml.sample。 (#5685)修正了一些文档的排版(使用左/右分隔符、分数,修正错误设置的命令)(#5804)
qml.Tracker示例已更新。 (#5803)在
qml.transpile中coupling_map的输入类型已更新,以反映所有由nx.to_networkx_graph允许的输入类型。 (#5864)qml.data模块和数据集快速入门中的文本已稍作修改,以引导用户 快速入门并突出显示list_datasets。 (5484)
修复错误 🐛
qml.compiler.active首先检查是否导入了 Catalyst,以避免在模块初始化时更改jax_enable_x64。 (#5960)__invert__方法的MeasurementValue类使用一个数组值函数。 (#5955)跳过
Projector- 测量测试在不支持的设备上。 (#5951)现在,如果初始 MPS 是由密集状态向量创建的,
default.tensor设备将保留线路的顺序。(#5892)修复了一个错误,
hadamard_grad在没有 wires 的情况下返回了错误的形状,针对qml.probs()。 (#5860)如果队列包含除
Operator、MeasurementProcess或QuantumScript之外的其他内容,则在将AnnotatedQueue处理为QuantumScript时会引发错误。(#5866)修复了在特殊控制操作中处理线缆的错误。 (#5856)
修复了一个错误,其中
Sum的重复相同操作最终与不同重复次数的Sum具有相同的哈希值。 (#5851)qml.qaoa.cost_layer和qml.qaoa.mixer_layer现在可以与Sum操作符一起使用。 (#5846)修复了一个错误,即
qml.MottonenStatePreparation在特定参数值下产生错误的导数。 (#5774)修复了一个错误,即分数次幂和算子的伴随运算被交换,这在一般情况下并不明确定义/正确。分数次幂的伴随运算不再可被求值。
(#5835)qml.qnn.TorchLayer现在可以处理元组返回值。 (#5816)如果对催化剂 qjit 对象应用转换,则会引发错误。(#5826)
qml.qnn.KerasLayer和qml.qnn.TorchLayer不再改变输入qml.QNode的接口。 (#5800)已禁用PR合并时的Docker构建。 (#5777)
现在,
DefaultQubit中伴随方法的验证正确处理设备线路。 (#5761)QuantumPhaseEstimation.map_wires不再修改原始操作实例。 (#5698)qml.AmplitudeAmplification的分解现在正确地排队所有操作。 (#5698)用
(#5754)packaging.version.Version替换了semantic_version,因为前者无法处理版本字符串中的元数据.post。现在,
dynamic_one_shot变换已扩展对jax和torch接口的支持。 (#5672)StronglyEntanglingLayers的分解现在与广播兼容。 (#5716)
(#5725)qml.cond现在可以应用于ControlledOp操作,以延迟测量。遗留的
Tensor类现在可以处理具有抽象追踪输入的Projector。 (#5720)修复了一个关于预期和实际
dtype的错误,该错误在使用JAX-JIT在返回包含qml.Identity操作符的观察样本的电路时出现。 (#5607)CaptureMeta对象(如Operator)的签名现在与__init__调用的签名匹配。 (#5727)现在在
test_projector_expectation中使用了普通的 NumPy 数组,以避免对状态属性的qml.Projector进行微分。 (#5683)qml.Projector现在兼容jax.jit。(#5595)具有
qml.probs测量的有限拍电路,无论是使用wires还是op参数,现在都可以使用jax.jit进行编译。 (#5619)param_shift,finite_diff,compile,insert,merge_rotations, 和transpile现在 都可以与具有非交换测量的电路一起使用。 (#5424) (#5681)已对
qml.bravyi_kitaev添加了修正,以便为qml.FermiSentence输入调用正确的函数。 (#5671)修复了一个错误,此错误导致
sum_expand在与射击向量、多次测量和参数广播结合时产生不正确的结果维度。 (#5702)修复了一个在
qml.math.dot中出现的错误,当操作数中只有一个是标量时会引发该错误。(#5702)
(#5753)qml.matrix现在与由qml.qjit编译的 QNodes 兼容。qml.snapshots在请求其他测量(而不是qml.state)时会引发错误,而不是静默返回状态向量。(#5805)修复了一个错误,即
default.qutrit被错误地判断为与qml.snapshots原生兼容。 (#5805)修复了一个错误,在
qml.adjoint和qml.ctrl操作期间,qml.Snapshot实例的测量未被传递。 (#5805)qml.CNOT和qml.Toffoli现在具有一个arithmetic_depth等于1,因为它们是受控操作。 (#5797)修复了一个错误,
default.qubit.legacy上ControlledSequence、Reflection、AmplitudeAmplification和Qubitization的梯度不正确的问题,使用了parameter_shift。 (#5806)修复了一个错误,即当电路包含非保利字的可观测量测量时,
split_non_commuting会引发错误。(#5827)qml.Exp的simplify方法现在返回一个具有正确Trotter步骤数量的运算符, 即等于预简化运算符的数量。 (#5831)修复了一个错误,
CompositeOp.overlapping_ops会将重叠的运算符放入不同的组,导致LinearCombination.eigvals()返回不正确的结果。 (#5847)实现了正确的分解,适用于
qml.PauliRot,当pauli_word为单位时,即返回一个角度为一半的qml.GlobalPhase。qml.pauli_decompose现在可以在jit-ted上下文中使用,例如jax.jit和qml.qjit。 (#5878)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
Tarun Kumar Allamsetty, Guillermo Alonso-Linaje, Utkarsh Azad, Lillian M. A. Frederiksen, Ludmila Botelho, Gabriel Bottrill, Thomas Bromley, Jack Brown, Astral Cai, Ahmed Darwish, Isaac De Vlugt, Diksha Dhawan, Pietropaolo Frisoni, Emiliano Godinez, Diego Guala, Daria Van Hende, Austin Huang, David Ittah, Soran Jahangiri, Rohan Jain, Mashhood Khan, Korbinian Kottmann, Christina Lee, Vincent Michaud-Rioux, Lee James O’Riordan, Mudit Pandey, Kenya Sakka, Jay Soni, Kazuki Tsuoka, Haochen Paul Wang, David Wierichs.
- orphan
版本 0.36.0¶
自上次发布以来的新特性
估计量子电路中的错误 🧮
此版本的 PennyLane 为从单个门错误的组合中估计量子电路的总错误奠定了基础。 (#5154) (#5464) (#5465) (#5278) (#5384)
两个面向用户的新类使得在PennyLane中计算和传播门错误成为可能:
qml.resource.SpectralNormError: 谱范数误差定义为我们打算应用的真实单位和实际应用的近似单位之间的距离,以谱范数表示。qml.resource.ErrorOperation: 一个继承自qml.operation.Operation的基类,表示携带某种形式算法错误的量子操作。
SpectralNormError可用于进行大概估算,比如通过get_error获取两个单元之间的谱范数误差:import pennylane as qml from pennylane.resource import ErrorOperation, SpectralNormError intended_op = qml.RY(0.40, 0) actual_op = qml.RY(0.41, 0) # angle of rotation is slightly off
>>> SpectralNormError.get_error(intended_op, actual_op) 0.004999994791668309
SpectralNormError也是一个关键工具,用于指定更大量子电路中的错误:对于代表算法主要构建模块的操作,我们可以创建一个自定义操作,该操作继承自
ErrorOperation。这个子类必须重写error方法,并应返回一个SpectralNormError实例:class MyErrorOperation(ErrorOperation): def __init__(self, error_val, wires): self.error_val = error_val super().__init__(wires=wires) def error(self): return SpectralNormError(self.error_val)
在这个玩具示例中,
MyErrorOperation在 QNode 中被调用时引入一个任意的SpectralNormError。它在与null.qubit一起使用时不需要分解或矩阵表示(建议在资源和误差估计时使用,因为计算资源或误差不需要电路执行)。dev = qml.device("null.qubit") @qml.qnode(dev) def circuit(): MyErrorOperation(0.1, wires=0) MyErrorOperation(0.2, wires=1) return qml.state()
电路的总光谱范数误差可以使用
qml.specs计算:>>> qml.specs(circuit)()['errors'] {'SpectralNormError': SpectralNormError(0.30000000000000004)}
PennyLane 已经包含了一些内置的构建块,用于诸如
QuantumPhaseEstimation和TrotterProduct这样的算法。TrotterProduct现在根据在 Trotter 乘法中执行的步骤数量传播错误。QuantumPhaseEstimation现在根据其输入单元的错误传播错误。dev = qml.device('null.qubit') hamiltonian = qml.dot([1.0, 0.5, -0.25], [qml.X(0), qml.Y(0), qml.Z(0)]) @qml.qnode(dev) def circuit(): qml.TrotterProduct(hamiltonian, time=0.1, order=2) qml.QuantumPhaseEstimation(MyErrorOperation(0.01, wires=0), estimation_wires=[1, 2, 3]) return qml.state()
再次,电路的总谱范数误差可以使用
qml.specs计算:>>> qml.specs(circuit)()["errors"] {'SpectralNormError': SpectralNormError(0.07616666666666666)}
查看我们的 误差传播演示,了解如何在实际示例中使用这些新功能!
访问扩展的量子算法武器库 🏹
快速近似块编码(FABLE)算法用于将矩阵嵌入量子电路,如arXiv:2205.00081中所述,现在可以通过
qml.FABLE模板访问。使用
qml.FABLE与qml.BlockEncode相似,但提供了更高效的电路构建,代价是用户定义的近似级别tol。qml.FABLE操作的线路数量为2*n + 1,其中n定义我们想要块编码的\(2^n \times 2^n\)矩阵的维度。import numpy as np A = np.array([[0.1, 0.2], [0.3, 0.4]]) dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) def circuit(): qml.FABLE(A, tol = 0.001, wires=range(3)) return qml.state()
>>> mat = qml.matrix(circuit)() >>> 2 * mat[0:2, 0:2] array([[0.1+0.j, 0.2+0.j], [0.3+0.j, 0.4+0.j]])
A high-level interface for amplitude amplification and its variants is now available via the new
qml.AmplitudeAmplificationtemplate. (#5160)Based on arXiv:quant-ph/0005055, given a state \(\vert \Psi \rangle = \alpha \vert \phi \rangle + \beta \vert \phi^{\perp} \rangle\),
qml.AmplitudeAmplificationamplifies the amplitude of \(\vert \phi \rangle\).Here’s an example with a target state \(\vert \phi \rangle = \vert 2 \rangle = \vert 010 \rangle\), an input state \(\vert \Psi \rangle = H^{\otimes 3} \vert 000 \rangle\), as well as an oracle that flips the sign of \(\vert \phi \rangle\) and does nothing to \(\vert \phi^{\perp} \rangle\), which can be achieved in this case through
qml.FlipSign.@qml.prod def generator(wires): for wire in wires: qml.Hadamard(wires=wire) U = generator(wires=range(3)) O = qml.FlipSign(2, wires=range(3))
Here,
Uis a quantum operation that is created by decorating a quantum function with@qml.prod. This could alternatively be done by creating a user-defined custom operation with a decomposition. Amplitude amplification can then be set up within a circuit:dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): generator(wires=range(3)) # prepares |Psi> = U|0> qml.AmplitudeAmplification(U, O, iters=10) return qml.probs(wires=range(3))
>>> print(np.round(circuit(), 3)) [0.01 0.01 0.931 0.01 0.01 0.01 0.01 0.01 ]
As expected, we amplify the \(\vert 2 \rangle\) state.
关于给定量子态的反射现在可以通过
qml.Reflection实现。 这个操作在幅度放大算法中非常有用,并提供了对qml.FlipSign的一种推广, 后者作用于基态。(#5159)qml.Reflection通过提供一个操作 \(U\) 来工作,该操作 准备 我们想要反射的目标态 \(\vert \psi \rangle\)。换句话说,\(U\) 是这样的:\(U \vert 0 \rangle = \vert \psi \rangle\)。在 PennyLane 中,\(U\) 必须是一个Operator。例如,如果我们想要反射关于 \(\vert \psi \rangle = \vert + \rangle\),那么 \(U = H\):
U = qml.Hadamard(wires=0) dev = qml.device('default.qubit') @qml.qnode(dev) def circuit(): qml.Reflection(U) return qml.state()
>>> circuit() tensor([0.-6.123234e-17j, 1.+6.123234e-17j], requires_grad=True)
进行量子比特化现在通过新的
qml.Qubitization操作符变得容易获取。 (#5500)qml.Qubitization将哈密顿量编码为合适的单位操作符。 当与量子相位估计 (QPE) 结合使用时,它可以 计算给定哈密顿量的特征向量的特征值。H = qml.dot([0.1, 0.3, -0.3], [qml.Z(0), qml.Z(1), qml.Z(0) @ qml.Z(2)]) @qml.qnode(qml.device("default.qubit")) def circuit(): # 初始化特征向量 qml.PauliX(2) # 应用 QPE measurements = qml.iterative_qpe( qml.Qubitization(H, control = [3,4]), ancilla = 5, iters = 3 ) return qml.probs(op = measurements)
利用更多方法将分子映射到 🗺️
一个名为
qml.bravyi_kitaev的新函数被添加用于执行费米哈密顿量到量子比特哈密顿量的 Bravyi-Kitaev 映射。 (#5390)该函数提供了一种替代的映射方式,与
qml.jordan_wigner或qml.parity_transform可以帮助我们更高效地在硬件上测量期望值。只需提供一个费米哈密顿量(通过from_string、FermiA、FermiC、FermiSentence或FermiWord创建)以及系统中的量子比特数 / 自旋轨道数n:>>> fermi_ham = qml.fermi.from_string('0+ 1+ 1- 0-') >>> qubit_ham = qml.bravyi_kitaev(fermi_ham, n=6, tol=0.0) >>> print(qubit_ham) 0.25 * I(0) + -0.25 * Z(0) + -0.25 * (Z(0) @ Z(1)) + 0.25 * Z(1)
该
qml.qchem.hf_state函数已升级为与qml.parity_transform以及新的 Bravyi-Kitaev 映射qml.bravyi_kitaev兼容。 (#5472) (#5472)>>> state_bk = qml.qchem.hf_state(2, 6, basis="bravyi_kitaev") >>> print(state_bk) [1 0 0 0 0 0] >>> state_parity = qml.qchem.hf_state(2, 6, basis="parity") >>> print(state_parity) [1 0 0 0 0 0]
计算动力李代数 👾
一组算子的动态李代数(DLA)捕获了这些算子可以生成的单位演化范围。在PennyLane的v0.36版本中,我们增加了对计算重要DLA概念的支持,包括:
A new
qml.lie_closurefunction to compute the Lie closure of a list of operators, providing one way to obtain the DLA. (#5161) (#5169) (#5627)For a list of operators
ops = [op1, op2, op3, ..], one computes all nested commutators betweenopsuntil no new operators are generated from commutation. All these operators together form the DLA, see e.g. section IIB of arXiv:2308.01432.Take for example the following operators:
from pennylane import X, Y, Z ops = [X(0) @ X(1), Z(0), Z(1)]
A first round of commutators between all elements yields the new operators
Y(0) @ X(1)andX(0) @ Y(1)(omitting scalar prefactors).>>> qml.commutator(X(0) @ X(1), Z(0)) -2j * (Y(0) @ X(1)) >>> qml.commutator(X(0) @ X(1), Z(1)) -2j * (X(0) @ Y(1))
A next round of commutators between all elements further yields the new operator
Y(0) @ Y(1).>>> qml.commutator(X(0) @ Y(1), Z(0)) -2j * (Y(0) @ Y(1))
After that, no new operators emerge from taking nested commutators and we have the resulting DLA. This can now be done in short via
qml.lie_closureas follows.>>> ops = [X(0) @ X(1), Z(0), Z(1)] >>> dla = qml.lie_closure(ops) >>> dla [X(0) @ X(1), Z(0), Z(1), -1.0 * (Y(0) @ X(1)), -1.0 * (X(0) @ Y(1)), -1.0 * (Y(0) @ Y(1))]
计算动态李代数的结构常数(伴随表示)。(5406)
例如,我们可以计算横场伊辛模型 DLA 的伴随表示。
>>> dla = [X(0) @ X(1), Z(0), Z(1), Y(0) @ X(1), X(0) @ Y(1), Y(0) @ Y(1)] >>> structure_const = qml.structure_constants(dla) >>> structure_const.shape (6, 6, 6)
访问 qml.structure_constants 的文档 以了解结构常数如何作为表示 DLA 的有用方式。
计算动态李代数的中心。 (#5477)
给定一个 DLA
g,我们现在可以计算它的中心。center是与 DLA 中所有其他算符对易的算符集合。>>> g = [X(0), X(1) @ X(0), Y(1), Z(1) @ X(0)] >>> qml.center(g) [X(0)]
为了帮助解释这些概念,请查看 dynamical Lie algebras demo。
改进 🛠
模拟混合态三元系统
混合三态可以通过
default.qutrit.mixed设备进行模拟。 (#5495) (#5451) (#5186) (#5082) (#5213)感谢来自不列颠哥伦比亚大学的贡献者,目前可以用于模拟的混合态三态设备已可用,提供了一个能够处理噪声的等价于
default.qutrit的设备。dev = qml.device("default.qutrit.mixed") def circuit(): qml.TRY(0.1, wires=0) @qml.qnode(dev) def shots_circuit(): circuit() return qml.sample(), qml.expval(qml.GellMann(wires=0, index=1)) @qml.qnode(dev) def density_matrix_circuit(): circuit() return qml.state()
>>> shots_circuit(shots=5) (array([0, 0, 0, 0, 0]), 0.19999999999999996) >>> density_matrix_circuit() tensor([[0.99750208+0.j, 0.04991671+0.j, 0. +0.j], [0.04991671+0.j, 0.00249792+0.j, 0. +0.j], [0. +0.j, 0. +0.j, 0. +0.j]], requires_grad=True)
不过,我们仍需添加一个关键要素:对三态噪声操作的支持。请关注即将发布的版本!
与操作员轻松高效地合作
此版本完成了PennyLane切换到更新方法处理算术操作的主要阶段。新的方法现在默认为启用,旨在实现几个目标:
让使用PennyLane运算符和使用笔和纸一样简单。
提高运算符算术的效率。
在许多情况下,此更新不应破坏代码。如果出现问题,请查看更新的运算符故障排除页面,并随时在PennyLane 讨论论坛上与我们联系。作为最后的手段,可以通过调用
qml.operation.disable_new_opmath()来启用旧行为,但不推荐这样做,因为将来PennyLane版本(v0.36及更高版本)将不再提供支持。(#5269)引入了一个新的类
qml.ops.LinearCombination。本质上,这个类是现已弃用的qml.ops.Hamiltonian的更新等价物,但用于新的算子运算。(#5216)qml.ops.Sumnow supports storing grouping information. Grouping type and method can be specified during construction using thegrouping_typeandmethodkeyword arguments ofqml.dot,qml.sum, orqml.ops.Sum. The grouping indices are stored inSum.grouping_indices. (#5179)a = qml.X(0) b = qml.prod(qml.X(0), qml.X(1)) c = qml.Z(0) obs = [a, b, c] coeffs = [1.0, 2.0, 3.0] op = qml.dot(coeffs, obs, grouping_type="qwc")
>>> op.grouping_indices ((2,), (0, 1))
Additionally,
grouping_typeandmethodcan be set or changed after construction usingSum.compute_grouping():a = qml.X(0) b = qml.prod(qml.X(0), qml.X(1)) c = qml.Z(0) obs = [a, b, c] coeffs = [1.0, 2.0, 3.0] op = qml.dot(coeffs, obs)
>>> op.grouping_indices is None True >>> op.compute_grouping(grouping_type="qwc") >>> op.grouping_indices ((2,), (0, 1))
Note that the grouping indices refer to the lists returned by
Sum.terms(), notSum.operands.新增了一个名为
qml.operation.convert_to_legacy_H的函数,能够将Sum、SProd和Prod转换为Hamiltonian实例。此函数面向开发者,未来版本中将会移除,且没有弃用周期。 (#5309)现在,
qml.is_commuting函数接受Sum、SProd和Prod实例。 (#5351)运算符现在可以被NumPy数组左侧乘起 (即,
arr * op)。(#5361)op.generator(),其中op是一个Operator实例,现在返回与qml.operator.active_new_opmath()的全局设置一致的操作符,在可能的情况下。即使在禁用新操作符计算的情况下,Sum、SProd和Prod实例仍将被返回,因为它们提供了使用传统操作符无法获得的额外功能。 (#5253) (#5410) (#5411) (#5421)Prod实例暂时具有一个新的obs属性,这有助于平滑过渡到新的运算符算术系统。特别是,旨在防止破坏使用Tensor.obs的代码。该属性已被立即弃用。今后,我们建议使用op.operands。 (#5539)qml.ApproxTimeEvolution现在与任何具有定义pauli_rep的算子兼容。Hamiltonian.pauli_rep现在被定义为当哈密顿量是泡利算符的线性组合时。(#5377)Prod实例使用三能级算子创建,现在具有定义好的eigvals()方法。(#5400)qml.transforms.hamiltonian_expand和qml.transforms.sum_expand现在可以处理带有常量偏移的多项观测量(即,像qml.I()这样的项)。(#5414)(#5543)qml.qchem.taper_operation现在与新的算符算术兼容。 (#5326)在QNode执行中,可能不是厄米的可观察量的警告已经被移除。这使得即时编译成为可能。 (#5506)
qml.transforms.split_non_commuting现在将与单项算符运算兼容。 (#5314)LinearCombination和Sum现在在初始化时接受_grouping_indices。这个新增功能仅与开发者相关。 (#5524)计算
PauliSentence的密集可微分矩阵以及带有泡利算符的泡利句子现在更快了。 (#5578)
社区贡献 🥳
ExpectationMP,VarianceMP,CountsMP, 和SampleMP现在有一个process_counts方法(类似于process_samples)。这允许根据一个counts字典计算测量值。 (#5256) (#5395)在
Operator类中添加了类型提示,以提高可解释性。 (#5490)通过
shots.bins()方法实现了一种具有多个不同shots值的采样替代策略,该方法一次性采样所有shots,然后分别处理每一个。(#5476)
中间电路测量和动态电路
新增了一个名为
qml.capture的模块,该模块将包含 PennyLane 自有的用于混合量子-经典程序的捕获机制。 (#5509)引入了
dynamic_one_shot变换,使得在具有有限shots的电路上以及原生支持中途测量的设备上,能够进行动态电路执行。该
QubitDevice类及其子类支持dynamic_one_shot变换,前提是它们本地支持中途测量操作。 (#5317)default.qubit现在可以提供一个随机种子,用于在有限次数抽样中进行中途测量。这 (1) 确保随机行为与dynamic_one_shot和defer_measurements更加一致,(2) 使我们的持续集成 (CI) 由于随机性而导致的失败减少。(#5337)
性能和广播
梯度变换现在可以应用于批处理/广播的QNodes,只要广播发生在非可训练参数中。 (#5452)
计算
qml.QFT矩阵的性能得到了提升。 (#5351)qml.transforms.broadcast_expand现在在返回qml.sample()时支持射击向量。 (#5473)LightningVJPs现在与使用新设备API的Lightning设备兼容。 (#5469)
设备能力
其他改进
纠缠熵现在可以通过
qml.math.vn_entanglement_entropy计算,该函数从密度矩阵中计算冯·诺依曼纠缠熵。相应的 QNode 变换,qml.qinfo.vn_entanglement_entropy也已添加。 (#5306)qml.draw和qml.draw_mpl现在将在用户或设备未提供线顺序时,尝试对线进行排序。 (#5576)当使用最新版本的 TensorFlow 与 Keras 3 时,会在
KerasLayer中添加清晰的错误信息(目前与KerasLayer不兼容),并链接到启用 Keras 2 的说明。(#5488)qml.ops.Conditional现在存储它包装的算子的data、num_params和ndim_param属性。 (#5473)当选择
method='pyscf'时,molecular_hamiltonian函数直接调用PySCF。 (#5118)cache_execute已被基于@transform的替代实现所取代。 (#5318)QNodes 现在将
diff_method验证延迟到新设备 API 下的设备。 (#5176)在输入不是有效的
pauli_rep时,错误信息中的拼写和字符串格式错误已被修正ClassicalShadow._convert_to_pauli_words。 (#5572)在
lightning.qubit上运行的电路,返回qml.state()时,现在会保留 指定的dtype。 (#5547)
重大变更 💔
qml.matrix()在以下情况下调用将会抛出错误,如果wire_order未被指定:具有多条导线的磁带
量子函数
Operator类,其中num_wires不等于 1如果设备没有指定线路,则为QNodes。
PauliWord和PauliSentence具有多个线圈。
single_tape_transform,batch_transform,qfunc_transform,op_transform,gradient_transform和hessian_transform已被移除。请改用新的qml.transform函数。有关如何实现此操作,请参见 变换文档。 (#5339)尝试使用
PauliWord和PauliSentence进行乘法运算*会引发错误。相反,请使用@以符合 PennyLane 的惯例。 (#5341)DefaultQubit现在使用预先分割密钥的策略,以避免在单个execute调用中重复使用 JAX PRNG 密钥。 (#5515)qml.pauli.pauli_mult和qml.pauli.pauli_mult_with_phase已被移除。请改用qml.simplify(qml.prod(pauli_1, pauli_2))来获取简化后的算子。 (#5324)>>> op = qml.simplify(qml.prod(qml.PauliX(0), qml.PauliZ(0))) >>> op -1j*(PauliY(wires=[0])) >>> [phase], [base] = op.terms() >>> phase, base (-1j, PauliY(wires=[0]))
现在,
dynamic_one_shot变换使用采样 (SampleMP) 来获取中间电路测量的值。 (#5486)Operator下面的方法现在通过lazy=False组合类似运算符的算术类。这减少了出现RecursionError的机会,并且使嵌套运算符更易于处理。 (#5478)来自
pauli模块的私有函数_pauli_mult、_binary_matrix和_get_pauli_map已被移除。相同的功能可以通过pauli模块中的新特性实现。 (#5323)MeasurementProcess.name和MeasurementProcess.data已被移除。请改用MeasurementProcess.obs.name和MeasurementProcess.obs.data。 (#5321)Operator.validate_subspace(subspace)已被移除。请改用qml.ops.qutrit.validate_subspace(subspace)。 (#5311)qml.interfaces的内容已移动到qml.workflow内部。旧的导入路径不再存在。 (#5329)由于
default.mixed不支持带测量的快照,因此尝试这样做将导致出现DeviceError,而不是获取密度矩阵。 (#5416)LinearCombination._obs_data已被移除。您仍然可以使用LinearCombination.compare来检查一个LinearCombination和另一个运算符之间的数学等价性。 (#5504)
弃用功能 👋
访问
qml.ops.Hamiltonian已被弃用,因为它指向旧版本的类,可能与新方法的算子算术不兼容。相反,建议使用qml.Hamiltonian,因为在启用新的算子算术方法时,它会调度到LinearCombination类。这将允许您继续使用qml.Hamiltonian处理现有代码,而无需进行任何更改。(#5393)qml.load已被弃用。请改用导入工作流快速入门指南中概述的函数。(#5312)在
qml.MultiControlledX中使用位字符串指定control_values已被弃用。请改用布尔值或1和0的列表。(#5352)qml.from_qasm_file已被弃用。请打开文件,然后使用qml.from_qasm加载其内容。 (#5331)>>> with open("test.qasm", "r") as f: ... circuit = qml.from_qasm(f.read())
文档 📝
A new page 增加了一页,解释返回类型的形状和嵌套。 (#5418)
多余的文档已从
evolve函数中移除。 (#5347)在
compile文档字符串中的最后一个示例已更新为正确使用变换。 (#5348)已经添加了使用
qml.SpecialUnitary和qml.QNGOptimizer的演示链接到它们各自的文档字符串中。 (#5376)在
qml.measure的文档字符串中添加了一个代码示例,展示了从 QNodes 返回中途测量统计信息的功能。 (#5441)用于
qml.measure的计算基准约定 — 0 和 1 而不是 ±1 — 在其文档字符串中已被澄清。 (#5474)在目录中新增了一个发布新闻部分,包含发布说明、弃用内容以及其他关注近期变化的页面。 (#5548)
修复错误 🐛
修补 QNode,使得如果
qml.metric_tensor在变换程序中,参数偏移将被认为是最佳的。 (#5624)停止在录音带绘制中打印
qcut.MeasureNode和qcut.PrepareNode的 ID。 (#5613)改善了在新设备接口上设置shots时的错误消息,或者尝试访问不再存在的属性时的错误消息。 (#5616)
修复了一个错误,即在使用
qml.defer_measurements时,qml.draw和qml.draw_mpl错误地对收集中间电路测量统计的电路引发错误。 (#5610)使用带有
param_shift(... broadcast=True)的射击向量导致了一个错误。这个组合不再被支持,将在下一个版本中重新添加。修复了一个仅由未偏移项组成的自定义梯度配方的错误。 (#5612) (#5623)qml.counts现在返回相同的键与dynamic_one_shot和defer_measurements。 (#5587)null.qubit现在自动支持任何操作,而无需分解。 (#5582)修复了一个错误,即在对QNode应用梯度变换时,获得的导数的形状和类型因QNode是否使用经典协同处理而异。(#4945)
ApproxTimeEvolution,CommutingEvolution,QDrift, 和TrotterProduct现在从队列中取出它们的输入可观察量。 (#5524)现在
qml.HilbertSchmidt实例的(不)等式由qml.equal正确报告。(#5538)qml.ParticleConservingU1和qml.ParticleConservingU2当初始状态未指定时不再报错,而是默认为全零状态。 (#5535)现在,
dynamic_one_shot变换可以使用广播功能。 (#5473)在Lightning设备上测量
qml.probs时,现在会对非计算基态应用对角化门。 (#5529)two_qubit_decomposition在幺正矩阵的特殊情况下不再发散。 (#5448)现在
qml.QNSPSAOptimizer正确处理不遵循新设备API的遗留设备的优化。 (#5497)应用于所有电线的运算符现在在具有中间电路测量的电路中正确绘制。(#5501)
修复了某些一元中途测量表达式会引发未捕获错误的bug。 (#5480)
现在在使用
torch接口且default_dtype设置为torch.float32时,概率总和为 1。(#5462)Tensorflow 现在可以处理结果为
float32但输入参数为float64的设备。 (#5446)修复了一个错误,
argnum关键字参数的qml.gradients.stoch_pulse_grad引用了带子计算中的错误参数,导致与其他微分方法不一致,并阻止了某些使用案例。 (#5458)由于数字噪声导致的有界值失败现在已通过调用
np.random.binomial得到避免。 (#5447)使用
@与遗留哈密顿算子实例现在正确地解除排队先前存在的操作。 (#5455)现在
QNSPSAOptimizer可以正确处理可微参数,从而能够用于多个优化步骤。 (#5439)如果在执行期间发生错误,QNode接口现在会重置。 (#5449)
由于Lightning的伴随微分管道的更改引起的测试失败已被修复。 (#5450)
修复了在使用配对 CPU 数据进行 autoray 调度的 Torch 调用时发生的失败。 (#5438)
jax.jit现在可以与qml.sample一起使用多线可观测量。 (#5422)qml.qinfo.quantum_fisher现在可以与非default.qubit设备一起使用。 (#5423)我们不再在使用 Tensorflow 时,在
SProd实例的pauli_rep中进行不必要的dtype升级。 (#5246)修复了
TestQubitIntegration.test_counts在tests/interfaces/test_jax_qnode.py中的行为,确保始终为所有结果产生计数。 (#5336)修复了
PauliSentence.to_mat(wire_order)以支持带有导线的单位元。 (#5407)CompositeOp.map_wires现在正确映射overlapping_ops属性。 (#5430)DefaultQubit.supports_derivatives已更新以正确处理包含中间电路测量和伴随微分的电路。 (#5434)SampleMP,ExpectationMP,CountsMP, 和VarianceMP使用eigvals构建,现在可以正确处理样本。 (#5463)修复了一个在
hamiltonian_expand中的错误,该错误在将射击向量与参数广播结合时会产生不正确的输出维度。(#5494)
(#5570)default.qubit现在允许在没有线路上测量Identity,以及包含Identity的可观察量在没有线路上。修复了一个错误,
TorchLayer无法与镜头向量一起工作。 (#5492)修复了一个错误,即当与射击向量结合时,返回包含单个测量的列表的QNode的输出形状不正确。(#5492)
修复了
qml.math.kron中的一个错误,使 Torch 与 NumPy 不兼容。 (#5540)修复了在
_group_measurements中的一个错误,该错误导致当可交换观察量作为Prod的操作数时无法进行分组测量。 (#5525)qml.equal现在可以与不包含任何线的运算符的和与乘积一起使用,例如I和GlobalPhase。 (#5562)CompositeOp.has_diagonalizing_gates现在对基本运算符进行了更全面的检查,以确保op.has_diagonalzing_gates和op.diagonalizing_gates()之间的一致性 (#5603)更新了
method的参数qml.TrotterProduct().error(),以更清楚地表明我们正在计算上界。 (#5637)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
塔伦·库马尔·阿拉姆赛提, 吉列尔莫·阿隆索, 米哈伊尔·安德伦科夫, 乌特卡什·阿扎德, 加布里埃尔·博特里尔, 托马斯·布罗姆利, 阿斯特拉尔·蔡, 迪克夏·达哈万, 艾萨克·德·弗卢赫特, 阿敏托尔·杜斯科, 皮耶特罗帕洛·弗里索尼, 莉莉安·M·A·弗雷德里克森, 迭戈·瓜拉, 奥斯丁·黄, 索兰·贾汉吉里, 科尔比安·科特曼, 克里斯蒂娜·李, 文森特·米肖-里约, 穆迪特·潘迪, 肯尼亚·萨卡, 杰伊·索尼, 马修·西尔弗曼, 大卫·维里希斯。
- orphan
版本 0.35.0¶
自上次发布以来的新特性
Qiskit 1.0 集成 🔌
这个版本的 PennyLane 使从 Qiskit 导入电路变得更容易。 (#5218) (#5168)
qml.from_qiskit函数将 Qiskit QuantumCircuit 转换为 一个 PennyLane quantum function。 尽管qml.from_qiskit在 PennyLane 中已经存在,但我们进行了一些改进,使从 Qiskit 导入变得更加容易。没错 —qml.from_qiskit的功能 与 Qiskit 1.0 及更早版本兼容!以下是改进的全面列表:你现在可以将 PennyLane 测量附加到由
qml.from_qiskit返回的量子函数上。考虑这个简单的 Qiskit 电路:import pennylane as qml from qiskit import QuantumCircuit qc = QuantumCircuit(2) qc.rx(0.785, 0) qc.ry(1.57, 1)
我们可以用几行代码将其转换为 PennyLane QNode,并且可以轻松包含 PennyLane
measurements:>>> dev = qml.device("default.qubit") >>> measurements = qml.expval(qml.Z(0) @ qml.Z(1)) >>> qfunc = qml.from_qiskit(qc, measurements=measurements) >>> qnode = qml.QNode(qfunc, dev) >>> qnode() tensor(0.00056331, requires_grad=True)
已经包含Qiskit侧测量的量子电路可以通过
qml.from_qiskit忠实地转换。考虑这个示例Qiskit电路:qc = QuantumCircuit(3, 2) # 传送 qc.rx(0.9, 0) # 在量子比特0上准备输入状态 qc.h(1) # 在量子比特1和2上准备贝尔态 qc.cx(1, 2) qc.cx(0, 1) # 执行传送 qc.h(0) qc.measure(0, 0) qc.measure(1, 1) with qc.if_test((1, 1)): # 执行第一次条件操作 qc.x(2)
这个电路可以转换为PennyLane,同时保留Qiskit测量仍然可访问。例如,我们可以将这些结果用作PennyLane中中间电路测量的输入:
@qml.qnode(dev) def teleport(): m0, m1 = qml.from_qiskit(qc)() qml.cond(m0, qml.Z)(2) return qml.density_matrix(2)
>>> teleport() tensor([[0.81080498+0.j , 0. +0.39166345j], [0. -0.39166345j, 0.18919502+0.j ]], requires_grad=True)
现在处理和区分参数化的 Qiskit 电路变得更加直观。考虑以下电路:
from qiskit.circuit import Parameter from pennylane import numpy as np angle0 = Parameter("x") angle1 = Parameter("y") qc = QuantumCircuit(2, 2) qc.rx(angle0, 0) qc.ry(angle1, 1) qc.cx(1, 0)
我们可以将这个电路转换为一个具有两个参数的 QNode,分别对应于
x和y:measurements = qml.expval(qml.PauliZ(0)) qfunc = qml.from_qiskit(qc, measurements) qnode = qml.QNode(qfunc, dev)
QNode 可以被评估和求导:
>>> x, y = np.array([0.4, 0.5], requires_grad=True) >>> qnode(x, y) tensor(0.80830707, requires_grad=True) >>> qml.grad(qnode)(x, y) (tensor(-0.34174675, requires_grad=True), tensor(-0.44158016, requires_grad=True))
这表明使用 PennyLane 使 Qiskit 电路可微分是多么容易。
除了电路,还可以使用一个叫做
qml.from_qiskit_op的新函数将Qiskit中的操作符转换为PennyLane。A Qiskit SparsePauliOp 可以使用
qml.from_qiskit_op转换为PennyLane操作符:>>> from qiskit.quantum_info import SparsePauliOp >>> qiskit_op = SparsePauliOp(["II", "XY"]) >>> qiskit_op SparsePauliOp(['II', 'XY'], coeffs=[1.+0.j, 1.+0.j]) >>> pl_op = qml.from_qiskit_op(qiskit_op) >>> pl_op I(0) + X(1) @ Y(0)
结合
qml.from_qiskit,通过将整个工作流程转换为PennyLane,可以轻松快速地计算期望值等量:qc = QuantumCircuit(2) # 创建电路 qc.rx(0.785, 0) qc.ry(1.57, 1) measurements = qml.expval(pl_op) # 创建QNode qfunc = qml.from_qiskit(qc, measurements) qnode = qml.QNode(qfunc, dev)
>>> qnode() # 评估! tensor(0.29317504, requires_grad=True)
默认量子位的本地中途测量 💡
现在,中路测量可以在有限拍摄模式下通过
default.qubit变得更加可扩展和高效,模拟方式与量子硬件上的情况类似。(#5088)(#5120)以前,中路测量(MCMs)会被自动替换为一个额外的量子比特,使用
@qml.defer_measurements转换。下面的电路需要成千上万个量子比特来进行模拟。现在,MCMs的执行方式与量子硬件类似,采用
default.qubit进行有限的采样。在每一轮和每次遇到MCM时,设备评估投影到|0>或|1>的概率,并随机选择以坍缩电路状态。当MCM的数量很多且采样次数不太高时,这种方法效果良好。import pennylane as qml dev = qml.device("default.qubit", shots=10) @qml.qnode(dev) def f(): for i in range(1967): qml.Hadamard(0) qml.measure(0) return qml.sample(qml.PauliX(0))
>>> f() tensor([-1, -1, -1, 1, 1, -1, 1, -1, 1, -1], requires_grad=True)
与操作员轻松高效地合作 🔧
在过去的几个版本中,PennyLane 对算子运算的方法正在进行 overhaul。我们有几个目标:
让使用PennyLane运算符和使用笔和纸一样简单。
提高运算符算术的效率。
更新的操作符算术功能仍在最后确认中,但可以通过
qml.operation.enable_new_opmath()激活。在下一个版本中,新行为将成为默认值,因此我们建议现在启用以熟悉新系统!在这个版本的PennyLane中,已进行以下更新:
您现在可以通过
I、X、Y和Z轻松访问 Pauli 运算符: (#5116)>>> from pennylane import I, X, Y, Z >>> X(0) X(0)
原始的长格式名称
Identity、PauliX、PauliY和PauliZ仍然可用,但现在推荐使用短格式名称。原始的长格式名称
Identity、PauliX、PauliY和PauliZ仍然可用,但现在推荐使用短格式名称。现在提供一个新的
qml.commutator函数,允许您计算PennyLane算符之间的对易子。 (#5051) (#5052) (#5098)>>> qml.commutator(X(0), Y(0)) 2j * Z(0)
PennyLane中的算子可以具有后端的Pauli表示,这可以用于执行更快的算子运算。现在,当可用时,Pauli表示将自动用于计算。 (#4989) (#5001) (#5003) (#5017) (#5027)
可以通过
op.pauli_rep可选地访问Pauli表示:>>> qml.operation.enable_new_opmath() >>> op = X(0) + Y(0) >>> op.pauli_rep 1.0 * X(0) + 1.0 * Y(0)
对PennyLane运算符的字符串表示进行了广泛改进,使其更短并可以作为有效的PennyLane代码进行复制粘贴。 (#5116) (#5138)
>>> 0.5 * X(0) 0.5 * X(0) >>> 0.5 * (X(0) + Y(1)) 0.5 * (X(0) + Y(1))
具有多个项的和被拆分成多行,但仍然可以作为有效代码复制回去:
>>> 0.5 * (X(0) @ X(1)) + 0.7 * (X(1) @ X(2)) + 0.8 * (X(2) @ X(3)) ( 0.5 * (X(0) @ X(1)) + 0.7 * (X(1) @ X(2)) + 0.8 * (X(2) @ X(3)) )
算子的线性组合和算子乘法通过
Sum和Prod分别进行了更新,以实现与Hamiltonian和Tensor的功能一致。这应该最小化迁移现有代码的工作量。(#5070) (#5132) (#5133)更新包括通过
pauli模块支持分组:>>> obs = [X(0) @ Y(1), Z(0), Y(0) @ Z(1), Y(1)] >>> qml.pauli.group_observables(obs) [[Y(0) @ Z(1)], [X(0) @ Y(1), Y(1)], [Z(0)]]
新Clifford设备 🦾
一个新的
default.clifford设备能够通过使用 stim 作为后端,有效地模拟大型Clifford电路,这些电路在PennyLane中定义。 (#4936) (#4954) (#5144)对于仅包含Clifford门的电路,可以使用该设备获得通常的PennyLane 测量 以及以表格形式表示的状态 Aaronson & Gottesman (2004):
import pennylane as qml dev = qml.device("default.clifford", tableau=True) @qml.qnode(dev) def circuit(): qml.CNOT(wires=[0, 1]) qml.PauliX(wires=[1]) qml.ISWAP(wires=[0, 1]) qml.Hadamard(wires=[0]) return qml.state()
>>> circuit() array([[0, 1, 1, 0, 0], [1, 0, 1, 1, 1], [0, 0, 0, 1, 0], [1, 0, 0, 1, 1]])
default.clifford设备还支持PauliError,DepolarizingChannel,BitFlip和PhaseFlip噪声通道 在有限次拍摄模式下运行时。
改进 🛠
通过VJPs和其他性能改进加速梯度计算
向量-雅可比乘积(VJPs)可以在量子节点的输出维度较低时实现更快的计算。通过在加载 QNode 时设置
device_vjp=True可以启用它们。在 PennyLane 的下一个版本中,计划在可用时默认使用 VJPs。在此版本中,我们解锁了:
由于在将样本转换为计数时进行了优化,测量
qml.probs现在更快了。 (#5145)具有大量生成磁带的电路切割工作负载的性能得到了提升。 (#5005)
队列(
AnnotatedQueue)已从qml.cut_circuit和qml.cut_circuit_mc中移除,以提高大规模工作流的性能。 (#5108)
社区贡献 🥳
添加了一个名为
qml.fermi.parity_transform的新函数,用于费米哈密顿量的奇偶映射。 (#4928)现在可以通过奇偶映射将费米哈密顿量转换为量子比特哈密顿量。
import pennylane as qml fermi_ham = qml.fermi.FermiWord({(0, 0) : '+', (1, 1) : '-'}) qubit_ham = qml.fermi.parity_transform(fermi_ham, n=6)
>>> print(qubit_ham) -0.25j * Y(0) + (-0.25+0j) * (X(0) @ Z(1)) + (0.25+0j) * X(0) + 0.25j * (Y(0) @ Z(1))
变换
split_non_commuting现在接受类型为probs、sample和counts的测量,这些测量接受电线和观察值。 (#4972)当一个算子在给定的一组线路上是对称时,矩阵计算的效率得到了提升。 (#3601)
现在,
pennylane/math/quantum.py模块支持计算密度矩阵的最小熵。 (#3959)>>> x = [1, 0, 0, 1] / np.sqrt(2) >>> x = qml.math.dm_from_state_vector(x) >>> qml.math.min_entropy(x, indices=[0]) 0.6931471805599455
一个名为
apply_operation的函数已被添加到新的qutrit_mixed模块,该模块位于qml.devices中。 (#5032)一个名为
measure的函数已被添加到新的qutrit_mixed模块中,该模块位于qml.devices中,测量一系列测量过程的设备兼容状态。 (#5049)一个
partial_trace函数已被添加到qml.math中,用于计算矩阵的部分迹。 (#5152)
其他运算符算术改进
以下功能已添加到Pauli算术中: (#4989) (#5001) (#5003) (#5017) (#5027) (#5018)
您现在可以通过标量(例如,
0.5 * PauliWord({0: "X"})或0.5 * PauliSentence({PauliWord({0: "X"}): 1.}))来相乘PauliWord和PauliSentence实例。您现在可以直观地将
PauliWord和PauliSentence实例以及标量相加和相减(标量被隐式处理为单位的倍数,I)。例如,ps1 + pw1 + 1.对于某个 Pauli 字pw1 = PauliWord({0: "X", 1: "Y"})和 Pauli 句子ps1 = PauliSentence({pw1: 3.})。您现在可以逐元素相乘
PauliWord、PauliSentence和运算符,使用qml.dot(例如,qml.dot([0.5, -1.5, 2], [pw1, ps1, id_word])其中id_word = PauliWord({}))。qml.matrix现在接受PauliWord和PauliSentence实例(例如,qml.matrix(PauliWord({0: "X"}))).现在可以使用新的
commutator方法原生计算泡利算符的对易子。>>> op1 = PauliWord({0: "X", 1: "X"}) >>> op2 = PauliWord({0: "Y"}) + PauliWord({1: "Y"}) >>> op1.commutator(op2) 2j * Z(0) @ X(1) + 2j * X(0) @ Z(1)
复合操作(例如,使用
qml.prod和qml.sum进行的操作)和标量积操作将Hamiltonian和Tensor操作数分别转换为Sum和Prod类型。这有助于避免不兼容的算子类型混合。 (#5031) (#5063)qml.Identity()可以在没有电线的情况下初始化。然而,目前无法对其进行测量。 (#5106)qml.dot现在即使所有系数匹配,也会返回一个Sum类。 (#5143)qml.pauli.group_observables现在支持对Prod和SProd运算符进行分组。 (#5070)与
qml.Hamiltonian特性类似,通过Sum或Prod形成的复合算子的系数和算子现在可以通过terms()方法访问。 (#5132) (#5133) (#5164)>>> qml.operation.enable_new_opmath() >>> op = X(0) @ (0.5 * X(1) + X(2)) >>> op.terms() ([0.5, 1.0], [X(1) @ X(0), X(2) @ X(0)])
ParametrizedHamiltonian的字符串表示已更新,以匹配其他 PL 运算符的样式。(#5215)
其他改进
现在
pl-device-test套件与qml.devices.Device接口兼容。 (#5229)现在
BlockEncode操作符与 JAX 兼容 JIT。 (#5110)该
qml.qsvt函数使用qml.GlobalPhase代替qml.exp来定义全局相位。 (#5105)tests/ops/functions/conftest.py测试已更新,以确保所有操作符类型都经过有效性测试。 (#4978)新增了一个
(#5023)pennylane.workflow模块。该模块现在包含qnode.py、execution.py、set_shots.py、jacobian_products.py和子模块interfaces。调用
adjoint_jacobian进行可训练的状态准备操作时,现在会引发更有信息量的错误。 (#5026)qml.workflow.get_transform_program和qml.workflow.construct_batch已被添加以检查在不同阶段的变换程序和胶卷批次。 (#5084)所有自定义控制操作,如
CRX,CZ,CNOT,ControlledPhaseShift现在都继承自ControlledOp,赋予它们额外的属性,如control_wire和control_values。在RX,RY,RZ,Rot, 和PhaseShift上调用qml.ctrl并使用一个控制线将返回类型为CRX,CRY等的门,而不是一般的Controlled操作符。 (#5069) (#5199)如果覆盖率数据未能上传到codecov,则CI现在会失败。之前,它会默默通过,而codecov检查本身将永远不会执行。 (#5101)
qml.ctrl在具有自定义控制版本的算子上被调用时将返回自定义类的实例,并且会将嵌套的控制算子扁平化为一个单一的多控制操作。对于PauliX、CNOT、Toffoli和MultiControlledX,调用qml.ctrl将始终根据控制线和控制值的数量解析为CNOT、Toffoli或MultiControlledX中的最佳选项。(#5125)不必要的警告过滤器已从测试中移除,并且没有意外出现的
PennyLaneDeprecationWarning。 (#5122)方法
map_batch_transform已被实现于TransformDispatcher的方法_batch_transform替换。 (#5212)TransformDispatcher现在可以在一批磁带上进行调度,使得在磁带范例中工作时更容易组合变换。 (#5163)qml.ctrl现在是一个简单的封装,可以调用 PennyLane 内置的create_controlled_op或使用 Catalyst 实现。现在可以使用 ZYZ 旋转对受控复合操作进行分解。 (#5242)
新增的函数
qml.devices.modifiers.simulator_tracking和qml.devices.modifiers.single_tape_support已添加到设备类上,以提供基本的默认行为。 (#5200)
重大变更 💔
传递额外参数给装饰QNode的变换现在必须通过使用
functools.partial来实现。 (#5046)qml.ExpvalCost已被移除。用户应该继续使用qml.expval()。 (#5097)当
max_diff == 1时,执行的缓存现在默认关闭,因为经典的开销成本超过了存在重复电路的可能性。 (#5243)与Pennylane注册编译器的入口点约定已更改。 (#5140)
为了允许软件包注册多个编译器与Pennylane,
entry_points约定在指定的组名称pennylane.compilers下已被修改。之前,编译器会注册
qjit(JIT装饰器),ops(特定于编译器的操作),以及context(用于追踪和 程序捕获)。现在,编译器必须注册
compiler_name.qjit,compiler_name.ops, 和compiler_name.context,其中compiler_name被提供的编译器名称替代。欲了解更多信息,请参见 添加编译器的文档。
(#5035)gradient_analysis_and_validation已更名为find_and_validate_gradient_methods。现在返回每个参数索引的梯度方法字典,而不是列表,并且不再修改录音带。两个
PauliWord实例相乘不再返回一个元组(new_word, coeff),而是返回PauliSentence({new_word: coeff})。旧的行为仍然可以通过私有方法PauliWord._matmul(other)获得,以便更快的处理。 (#5045)Observable.return_type已被移除。相反,您应该检查周围测量过程的类型。 (#5044)ClassicalShadow.entropy()不再需要atol关键字,因为有一种更好的方法来从近似密度矩阵重建中估计熵(可能具有负特征值)。(#5048)带有自定义控制版本的控制算子分解方式与它们的控制对应物的分解方式相同,而不是分解为它们的控制版本。 (#5069) (#5125)
例如:
>>> qml.ctrl(qml.RX(0.123, wires=1), control=0).decomposition() [ RZ(1.5707963267948966, wires=[1]), RY(0.0615, wires=[1]), CNOT(wires=[0, 1]), RY(-0.0615, wires=[1]), CNOT(wires=[0, 1]), RZ(-1.5707963267948966, wires=[1]) ]
QuantumScript.is_sampled和QuantumScript.all_sampled已被移除。用户现在应该手动验证这些属性。 (#5072)qml.transforms.one_qubit_decomposition和qml.transforms.two_qubit_decomposition已被移除。相反,您应该使用qml.ops.one_qubit_decomposition和qml.ops.two_qubit_decomposition。 (#5091)
弃用功能 👋
调用
qml.matrix而不提供wire_order的情况下,在电路顺序可能模糊的对象上现在会引发警告。在未来,这些情况下将需要wire_order参数。 (#5039)Operator.validate_subspace(subspace)已被迁移至qml.ops.qutrit.parametric_ops模块,并将在即将发布的版本中从 Operator 类中移除。 (#5067)
(#4989)(#5054)PauliWord和PauliSentence实例之间的矩阵和张量乘积是通过使用@运算符进行的,*将仅用于标量乘法。还要注意一个重大变更:两个PauliWord实例的乘积现在返回一个PauliSentence,而不是一个元组(new_word, coeff)。MeasurementProcess.name和MeasurementProcess.data现在已被弃用,因为它们包含不再需要的虚拟值。 (#5047) (#5071) (#5076) (#5122)qml.pauli.pauli_mult和qml.pauli.pauli_mult_with_phase现在已不推荐使用。相反,您应该使用qml.simplify(qml.prod(pauli_1, pauli_2))来获取简化后的算符。 (#5057)来自
pauli模块的私有函数_pauli_mult,_binary_matrix和_get_pauli_map已被弃用,因为它们不再被使用,并且可以使用pauli模块中的新特性实现相同的功能。(#5057)Sum.ops,Sum.coeffs,Prod.ops和Prod.coeffs在未来将被弃用。 (#5164)
文档 📝
pennylane.tape模块的文档现在解释了QuantumTape和QuantumScript之间的区别。(#5065)已修复
qml.transformsAPI中代码示例的拼写错误。 (#5014)qml.data的文档已更新,现在提到了一个可以从多个环境同时访问相同数据集的方法。 (#5029)对添加到梯度方法中的
argnum定义进行了澄清。 (#5035)已修复
qml.qchem.dipole_of代码示例中的一个拼写错误。 (#5036)添加了关于弃用和移除的开发指南。 (#5083)
关于二次量化哈密顿量的特征谱已添加至
qml.eigvals。 (#5095)关于两个数学上等价的哈密顿量经历不同时间演化的警告已添加到
qml.TrotterProduct和qml.ApproxTimeEvolution。 (#5137)已添加对提供
qml.QAOAEmbedding模板图像的论文的引用。 (#5130)qml.sample的文档字符串已更新,建议在区分电路时使用单次测量期望值。 (#5237)新增了一个快速入门页面,称为“导入电路”。该页面解释了如何导入在PennyLane外部定义的量子电路和操作。(#5281)
修复错误 🐛
QubitChannel现在可以与 jitting 一起使用。(#5288)修复了matplotlib绘图工具中的一个错误,其中
Barrier的颜色与请求的样式不匹配。 (#5276)qml.draw和qml.draw_mpl现在在绘制之前应用所有已应用的变换。 (#5277)ctrl_decomp_zyz现在是可微分的。 (#5198)
(#5178)qml.ops.Pow.matrix()现在可以使用 TensorFlow 进行带有整数指数的求导。qml.MottonenStatePreparation模板已更新,以包含全局相位操作。 (#5166)修复了在使用
qml.prod结合排队单个算子的量子函数时的排队错误。(#5170)该
qml.TrotterProduct模板已更新为接受算子的标量乘积作为输入哈密顿量。(#5073)修复了一个错误,即缓存与JIT编译和广播带一起使用时产生了错误的结果
Operator.hash现在依赖于JAX跟踪器的内存位置id,而不是其字符串表示形式。 (#3917)qml.transforms.undo_swaps现在可以与具有超参数或嵌套的算子一起使用。 (#5081)qml.transforms.split_non_commuting现在将传递原始的shots。 (#5081)如果
argnum被提供给一个梯度变换,那么只有在argnum中指定的参数会被验证其梯度方法。 (#5035)StatePrep操作扩展到更多线时现在与反向传播兼容。(#5028)qml.equal在电线标签混合整数和字符串时,与qml.Sum运算符配合良好。 (#5037)Controlled.generator的返回值现在包含一个投影器,该投影器根据指定的控制值投影到正确的子空间。CosineWindow在电路开始时对部分线路使用时不再引发意外错误。 (#5080)tf.function现在通过跳过批量大小计算,与TensorSpec(shape=None)一起工作。 (#5089)PauliSentence.wires不再施加错误的顺序。 (#5041)qml.qchem.import_state现在在从经典预计算的波函数初始化 PennyLane 状态向量时应用了化学家与物理学家的符号约定。也就是说,它对相同空间轨道索引的自旋向上/自旋向下算符进行交错处理,这在 PennyLane 中是标准做法(而不是像量子化学中那样将所有自旋向上算符移到左边)。(#5114)draw_mpl在绘制包含受控操作的伴随操作的电路时不再引发错误。default.mixed在与tensorflow一起使用时,当应用的状态向量不是类型complex128时,不再引发ValueError。 (#5155)ctrl_decomp_zyz不再引发TypeError如果旋转参数的类型是torch.Tensor(#5183)现在,无论嵌套结构如何,使用
qml.equal比较Prod和Sum对象都能正常工作,前提是操作符具有有效的pauli_rep属性。 (#5177)带有非零控制线的
GlobalPhase不再抛出错误。 (#5194)一个
QNode经过mitigate_with_zne转换后现在接受批量参数。 (#5195)一个空的
PauliSentence实例的矩阵现在是正确的(全零)。此外,空的PauliWord和PauliSentence实例的矩阵现在也可以被转换为矩阵。(#5188)PauliSentence实例可以处理与PauliWord实例的矩阵乘法。 (#5208)CompositeOp.eigendecomposition现在与JIT兼容。 (#5207)QubitDensityMatrix现在可以在default.mixed设备上与 JAX-JIT 一起使用。 (#5203) (#5236)当一个 QNode 指定
diff_method="adjoint"时,default.qubit不再尝试分解具有非标量参数的不可训练操作,例如QubitUnitary。(#5233)在初始化时,不再覆盖
I、X、Y和Z的类名,因为这会导致数据集出现问题。现在这会在全局范围内发生。 (#5252)现在
adjoint_metric_tensor变换可以与jax一起使用。 (#5271)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
阿比舍克·阿比舍克, 米哈伊尔·安德连科, 乌特卡什·阿扎德, 特伦登·巴布科克, 加布里埃尔·博特里尔, 托马斯·布朗利, 阿斯特拉尔·蔡, 斯凯拉·陈, 艾萨克·德·弗卢赫特, 迪克沙·达旺, 莉莉安·弗雷德里克森, 皮耶特罗保罗·弗里索尼, 尤金尼奥·吉甘特, 迭戈·瓜拉, 大卫·伊塔, 索兰·贾汉吉里, 杰基·姜, 科尔比尼安·科特曼, 克里斯蒂娜·李, 肖然·李, 文森特·米肖-里奥, 罗曼·莫亚尔, 巴布洛·安东尼奥·莫雷诺·卡萨雷斯, 埃里克·奥乔亚·洛佩斯, 李·J·奥'里尔丹, 穆迪特·潘德, 亚历克斯·普雷西亚多, 马修·西尔弗曼, 杰伊·索尼。
- orphan
发布 0.34.0¶
自上次发布以来的新特性
中途测量的统计和绘图 🎨
It is now possible to return statistics of composite mid-circuit measurements. (#4888)
Mid-circuit measurement results can be composed using basic arithmetic operations and then statistics can be calculated by putting the result within a PennyLane measurement like
qml.expval(). For example:import pennylane as qml dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(phi, theta): qml.RX(phi, wires=0) m0 = qml.measure(wires=0) qml.RY(theta, wires=1) m1 = qml.measure(wires=1) return qml.expval(~m0 + m1) print(circuit(1.23, 4.56))
1.2430187928114291Another option, for ease-of-use when using
qml.sample(),qml.probs(), orqml.counts(), is to provide a simple list of mid-circuit measurement results:dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(phi, theta): qml.RX(phi, wires=0) m0 = qml.measure(wires=0) qml.RY(theta, wires=1) m1 = qml.measure(wires=1) return qml.sample(op=[m0, m1]) print(circuit(1.23, 4.56, shots=5))
[[0 1] [0 1] [0 0] [1 0] [0 1]]
Composite mid-circuit measurement statistics are supported on
default.qubitanddefault.mixed. To learn more about which measurements and arithmetic operators are supported, refer to the measurements page and the documentation for qml.measure.中途测量现在可以通过基于文本的
qml.draw()和图形化的qml.draw_mpl()方法进行可视化。 (#4775) (#4803) (#4832) (#4901) (#4850) (#4917) (#4930) (#4957)现在支持中途测量功能的绘制,包括量子位重用和重置, 后选择、条件化以及收集统计数据。这里 是一个包含所有内容的示例:
def circuit(): m0 = qml.measure(0, reset=True) m1 = qml.measure(1, postselect=1) qml.cond(m0 - m1 == 0, qml.S)(0) m2 = qml.measure(1) qml.cond(m0 + m1 == 2, qml.T)(0) qml.cond(m2, qml.PauliX)(1)
基于文本的绘制器输出:
>>> print(qml.draw(circuit)()) 0: ──┤↗│ │0⟩────────S───────T────┤ 1: ───║────────┤↗₁├──║──┤↗├──║──X─┤ ╚═════════║════╬═══║═══╣ ║ ╚════╩═══║═══╝ ║ ╚══════╝
图形化绘制器输出:
>>> print(qml.draw_mpl(circuit)())
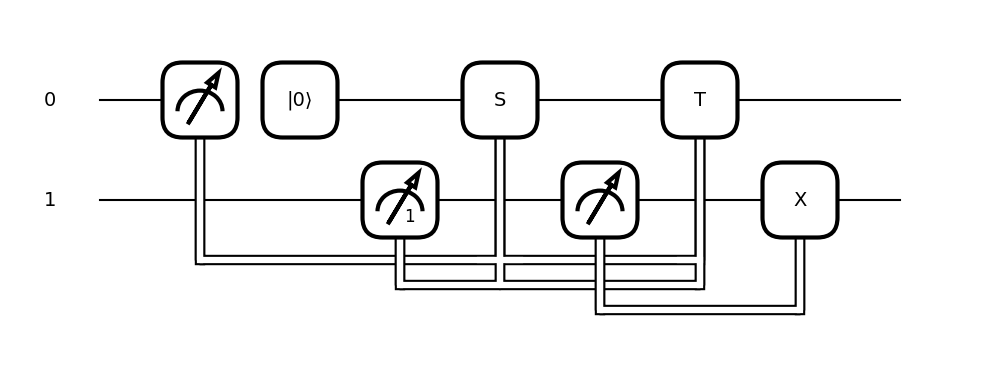
Catalyst与PennyLane无缝集成 ⚗️
Catalyst,我们的下一代编译框架,现在在PennyLane中可用,使您能够更轻松地受益于混合即时编译(JIT)。
要访问这些功能,只需安装
pennylane-catalyst:pip install pennylane-catalyst
qml.compiler 模块为混合量子-经典编译提供支持。 (#4692) (#4979)
通过使用
qml.qjit装饰器,可以即时编译整个工作流——包括量子和经典处理——在首次函数执行时生成机器二进制文件。对已编译函数的后续调用将执行先前编译的二进制文件,从而显著提高性能。import pennylane as qml dev = qml.device("lightning.qubit", wires=2) @qml.qjit @qml.qnode(dev) def circuit(theta): qml.Hadamard(wires=0) qml.RX(theta, wires=1) qml.CNOT(wires=[0,1]) return qml.expval(qml.PauliZ(wires=1))
>>> circuit(0.5) # 第一次调用,这里发生编译 array(0.) >>> circuit(0.5) # 调用预编译的量子函数 array(0.)
目前,PennyLane支持 Catalyst hybrid compiler 与
qml.qjit装饰器。Catalyst的一个显著优点是能够在编译期间保留复杂的控制流,例如涉及量子操作的if语句和for循环,以及包括测量反馈,同时继续支持端到端的自动微分。以下函数现在可以与
qml.qjit装饰器一起使用:qml.grad,qml.jacobian,qml.vjp,qml.jvp, 和qml.adjoint。 (#4709) (#4724) (#4725) (#4726)当
qml.grad或qml.jacobian与@qml.qjit一起使用时,它们分别被修补为 catalyst.grad 和 catalyst.jacobian。dev = qml.device("lightning.qubit", wires=1) @qml.qjit def workflow(x): @qml.qnode(dev) def circuit(x): qml.RX(np.pi * x[0], wires=0) qml.RY(x[1], wires=0) return qml.probs() g = qml.jacobian(circuit) return g(x)
>>> workflow(np.array([2.0, 1.0])) array([[ 3.48786850e-16, -4.20735492e-01], [-8.71967125e-17, 4.20735492e-01]])
JIT-compatible functionality for control flow has been added via
qml.for_loop,qml.while_loop, andqml.cond. (#4698) (#5006)qml.for_loopandqml.while_loopcan be deployed as decorators on functions that are the body of the loop. The arguments to both follow typical conventions:@qml.for_loop(lower_bound, upper_bound, step)
@qml.while_loop(cond_function)
Here is a concrete example with
qml.for_loop:qml.for_loopandqml.while_loopcan be deployed as decorators on functions that are the body of the loop. The arguments to both follow typical conventions:@qml.for_loop(lower_bound, upper_bound, step)
@qml.while_loop(cond_function)
Here is a concrete example with
qml.for_loop:dev = qml.device("lightning.qubit", wires=1) @qml.qjit @qml.qnode(dev) def circuit(n: int, x: float): @qml.for_loop(0, n, 1) def loop_rx(i, x): # perform some work and update (some of) the arguments qml.RX(x, wires=0) # update the value of x for the next iteration return jnp.sin(x) # apply the for loop final_x = loop_rx(x) return qml.expval(qml.PauliZ(0)), final_x
>>> circuit(7, 1.6) (array(0.97926626), array(0.55395718))
将电路分解为Clifford+T门集合 🧩
新的
qml.clifford_t_decomposition()转换提供了输入电路的大致分解 为 Clifford+T 门集合。 在后台,该分解通过sk_decomposition()函数使用 Solovay-Kitaev 算法实现。 (#4801) (#4802)Solovay-Kitaev 算法 大致 将量子电路分解为 Clifford+T 门集合。为此,在使用
qml.clifford_t_decomposition时,必须指定所需的总电路分解误差epsilon:dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.RX(1.1, 0) return qml.state() circuit = qml.clifford_t_decomposition(circuit, epsilon=0.1)
>>> print(qml.draw(circuit)()) 0: ──T†──H──T†──H──T──H──T──H──T──H──T──H──T†──H──T†──T†──H──T†──H──T──H──T──H──T──H──T──H──T†──H ───T†──H──T──H──GlobalPhase(0.39)─┤
此电路的资源需求也可以评估:
>>> with qml.Tracker(dev) as tracker: ... circuit() >>> resources_lst = tracker.history["resources"] >>> resources_lst[0] 电线: 1 门: 34 深度: 34 实验次数: Shots(total=None) 门类型: {'Adjoint(T)': 8, 'Hadamard': 16, 'T': 9, 'GlobalPhase': 1} 门大小: {1: 33, 0: 1}
使用迭代方法进行量子相位估计 🔄
迭代量子相位估计 现在可以通过
qml.iterative_qpe使用。 (#4804)该子例程可以类似于中途电路测量使用:
import pennylane as qml dev = qml.device("default.qubit", shots=5) @qml.qnode(dev) def circuit(): # 初始状态 qml.PauliX(wires=[0]) # 迭代 QPE measurements = qml.iterative_qpe(qml.RZ(2., wires=[0]), ancilla=[1], iters=3) return [qml.sample(op=meas) for meas in measurements]
>>> print(circuit()) [array([0, 0, 0, 0, 0]), array([1, 0, 0, 0, 0]), array([0, 1, 1, 1, 1])]
列表中的 \(i\)-th 元素指的是算法的 \(i\)-th 测量生成的 5 个样本。
改进 🛠
社区贡献 🥳
现在可以将
+=操作符与PauliSentence一起使用,这也提供了性能提升。 (#4662)近似量子傅立叶变换(AQFT)现在可以使用
(#4715)qml.AQFT进行。qml.draw和qml.draw_mpl现在渲染操作符 ID。 (#4749)在实例化操作符时,ID 可以作为关键字参数指定:
>>> def circuit(): ... qml.RX(0.123, id="data", wires=0) >>> print(qml.draw(circuit)()) 0: ──RX(0.12,"data")─┤
非参数操作符,例如
Barrier,Snapshot和Wirecut已被归类并移动到pennylane/ops/meta.py。 此外,相关的测试已被整理并放置在一个新文件中,tests/ops/test_meta.py。 (#4789)现在可以通过反向传播对
TRX,TRY, 和TRZ操作符进行微分,使用的是default.qutrit。 (#4790)函数
qml.equal现在支持ControlledSequence运算符。 (#4829)XZX 分解已被添加到支持的单量子比特单元分解列表中。 (#4862)
==和!=操作符现在可以与TransformProgram和TransformContainers实例一起使用。 (#4858)一个
qutrit_mixed模块已经添加到qml.devices中,用于存储未来 qutrit 混合态设备的辅助函数。这个模块中添加了一个名为create_initial_state的函数,它创建与设备兼容的初始状态。 (#4861)函数
qml.Snapshot现在支持任意基于状态的测量(即,StateMeasurement类型的测量)。(#4876)qml.equal现在支持比较QuantumScript和BasisRotation对象。 (#4902) (#4919)函数
qml.draw_mpl现在接受一个关键字参数fig来指定输出图形窗口。 (#4956)
更好的批处理支持
qml.AmplitudeEmbedding现在在与 Tensorflow 一起使用时支持批处理。 (#4818)
(#4863)default.qubit现在可以使用qml.pulse.ParametrizedEvolution进化已经批处理的状态。qml.ArbitraryUnitary现在支持批处理。操作符和录音带批处理大小是惰性评估的,有助于减少昂贵计算的运行频率,以及Tensorflow预计算批处理大小的问题。 (#4911)
性能提升和基准测试
自动梯度、PyTorch 和 JAX 现在可以使用新设备 API 提供的向量-雅可比乘积 (VJP)。如果设备提供 VJP,可以通过对 QNode 或
qml.execute提供device_vjp=True来选择。>>> dev = qml.device('default.qubit') >>> @qml.qnode(dev, diff_method="adjoint", device_vjp=True) >>> def circuit(x): ... qml.RX(x, wires=0) ... return qml.expval(qml.PauliZ(0)) >>> with dev.tracker: ... g = qml.grad(circuit)(qml.numpy.array(0.1)) >>> dev.tracker.totals {'batches': 1, 'simulations': 1, 'executions': 1, 'vjp_batches': 1, 'vjps': 1} >>> g -0.09983341664682815
qml.expval使用大型Hamiltonian对象现在更快,并且在内存占用上显著降低(与Hamiltonian项数无关),当Hamiltonian是PauliSentence时。这是由于在PauliSentence类中引入了一种专门的dot方法,该方法执行PauliSentence-state乘积。 (#4839)default.qubit对于超过 8 条操作线的MultiControlledX不再使用密集矩阵。 (#4673)一些相关的Pytests已更新,以便可以作为基准测试的一套进行使用。 (#4703)
default.qubit现在通过不使用其矩阵表示而是使用自定义规则来更快地应用GroverOperator,对于apply_operation来说。此外,GroverOperator的矩阵表示现在运行得更快。(#4666)添加了一个新的管道来运行基准测试并绘制与固定参考进行比较的图表。该管道将按计划运行,并可以通过带有标签
ci:run_benchmarks的 PR 启动。(#4741)default.qubit现在支持任意对角状态基础测量的伴随微分。 (#4865)基准测试管道已扩展为将所有基准数据导出到单个JSON文件和一个包含运行时间的CSV文件。这包括所有参考和本地基准测试。 (#4873)
变换更新的最终阶段
qml.quantum_monte_carlo和qml.simplify现在使用新的转换系统。 (#4708) (#4949)在使用
qml.transform装饰器时,必须提供类型提示的正式要求已经被移除。类型提示仍然可以使用,但现在是可选的。如果您希望确保类型正确传递,请使用类型检查器,例如mypy。
其他改进
为
Wires类添加PyTree序列化接口。 (#4998)PennyLane 现在支持 Python 3.12。 (#4985)
SampleMeasurement现在有一个可选的方法process_counts用于从计数字典计算测量结果。 (#4941)新增了一个名为
ops.functions.assert_valid的函数,用于检查Operator类是否正确定义。(#4764)Shots对象现在可以与标量值相乘。 (#4913)GlobalPhase现在会在设备不支持全局相位的情况下分解为空。 (#4855)自定义操作现在可以通过
Operator.matrix()方法直接提供它们的矩阵,而无需更新has_matrix属性。 如果重写了Operator.matrix,那么has_matrix将自动为True,即使没有重写Operator.compute_matrix。 (#4844)在返回状态之前重新排列状态的逻辑得到了改善。 (#4817)
当将
(#4828)SparseHamiltonian乘以一个标量值时,结果现在保持为一个SparseHamiltonian。trainable_params现在可以在初始化QuantumScript时设置,而不必在初始化后再设置该参数。(#4877)default.qubit现在以可微分的方式计算Hermitian运算符的期望值。 (#4866)现在
rot分解支持返回一个全球相位。(#4869)已添加
(#4880)"pennylane_sketch"MPL-drawer 风格。这个风格与"pennylane"风格相同,但使用草图风格的线条。运算符现在定义了一个
(#4915)pauli_rep属性,一个PauliSentence的实例,如果运算符没有定义它(或者在 Pauli 基础中没有定义),默认值为None。qml.ShotAdaptiveOptimizer现在可以使用多项分布来分配在 QNode 中测量的哈密顿量的项上的 shot。请注意,这与可以使用的qml.ExpvalCost是等效的,但这是首选方法,因为ExpvalCost已被弃用。(#4896)现在
qml.PhaseShift的分解使用qml.GlobalPhase来保留全局相位信息。 (#4657) (#4947)qml.equal对于Controlled运算符在比较等效但顺序不同的控制线和控制值时不再返回False。 (#4944)所有PennyLane
Operator子类都通过ops.functions.assert_valid自动测试,以确保它们遵循PennyLaneOperator标准。 (#4922)现在可以从一个
counts字典中计算概率测量,方法是在ProbabilityMP类中添加一个process_counts方法。(#4952)ClassicalShadow.entropy现在使用在 1106.5458 中概述的算法,将近似的密度矩阵(可能具有负特征值)投影到最近的有效密度矩阵上。(#4959)现在,
ControlledSequence.compute_decomposition的默认设置会分解Pow操作符,提升与机器学习接口的兼容性。(#4995)
重大变更 💔
函数
(#4900)qml.transforms.classical_jacobian已经被移动到梯度模块,现在可以作为qml.gradients.classical_jacobian访问。转换子模块
qml.transforms.qcut现在是它自己的模块:qml.qcut。 (#4819)现在
GroverOperator的分解增加了一个额外的全局相位操作。 (#4666)qml.cond和Conditional操作已从transforms文件夹移动到ops/op_math文件夹。qml.transforms.Conditional现在将作为qml.ops.Conditional可用。 (#4860)从
(#4756)QuantumScript和QuantumTape中删除了prep关键字参数。StatePrepBase操作应放置在ops列表的开头。qml.gradients.pulse_generator现在被命名为qml.gradients.pulse_odegen以遵循论文命名规范。 (#4769)不再支持将作为字符串传递给
qml.ctrl的control_values指定方式。 (#4816)现在
rot分解将其旋转角度规范化到范围[0, 4pi]以保持一致性 (#4869)QuantumScript.graph现在使用tape.measurements构建,而不是tape.observables,因为它依赖于现在已弃用的Observable.return_type属性。 (#4762)现在,
"pennylane"MPL-drawer 风格绘制直线,而不是草图风格的线条。 (#4880)ShotAdaptiveOptimizer的term_sampling参数的默认值现在是None,而不是"weighted_random_sampling"。 (#4896)
弃用功能 👋
single_tape_transform,batch_transform,qfunc_transform, 和op_transform已被弃用。 请使用新的qml.transform函数代替。 (#4774)Observable.return_type已弃用。相反,您应该检查周围测量过程的类型。 (#4762) (#4798)现在所有的弃用都会引发一个
qml.PennyLaneDeprecationWarning而不是UserWarning。 (#4814)QuantumScript.is_sampled和QuantumScript.all_sampled已被弃用。 用户现在应该手动验证这些属性。 (#4773)通过对
ClassicalShadow.entropy的算法改进,关键字atol将变得过时,并将在v0.35中被移除。 (#4959)
文档 📝
关于单位和操作的分解的文档已从
qml.transforms移动到qml.ops.ops_math。 (#4906)qml.metric_tensor和qml.adjoint_metric_tensor以及qml.transforms.classical_jacobian的文档现在可以通过文档中的梯度 API 页面qml.gradients访问。 (#4900)qml.specs的文档已移至resource模块。 (#4904)QCut的文档已移至其自己的API页面:
qml.qcut. (#4819)现在,
qml.measurements的文档页面将顶级可访问的函数(例如,qml.expval)链接到它们的顶级页面,而不是它们的模块级页面(例如,qml.measurements.expval)。(#4750)关于在使用
qml.matrix的QNode上的线顺序的信息已添加,该QNode使用的设备为device.wires=None。 (#4874)
修复错误 🐛
TransformDispatcher现在在将变换应用于 qfunc 时停止排队。仅变换的输出将被排队。(#4983)qml.map_wires现在可以正确与qml.cond和qml.measure一起工作。(#4884)
(#4966)Pow操作符现在可以被序列化。有限差分和SPSA现在可以在遇到总线错误的设置中与tensorflow-autograph一起使用。 (#4961)
qml.cond不再错误地排队使用参数的操作符。 (#4948)
(#4933)Attribute对象现在返回False,而不是在检查一个对象是否在集合中时引发TypeError。修复了一个错误,即如果
op具有两个或更多特征值并存储为SparseHamiltonian,则qml.ctrl(op)的参数偏移规则是错误的。(#4899)修复了一个错误,该错误导致在直接对QNode应用变换时,JAX的有限差分后处理中的可训练参数不正确。(#4879)
qml.grad和qml.jacobian现在如果可训练参数是整数会明确引发错误。 (#4836)JAX-JIT 现在支持镜头(shot)向量。 (#4772)
JAX 现在可以区分一批电路,其中一个 tape 没有可训练参数。(#4837)
现在
GroverOperator的分解与其矩阵具有相同的全局相位。 (#4666)通过
tape.to_openqasm方法转换使用非NumPy接口的胶带时,不再错误地在参数字符串中包含接口信息。(#4849)qml.defer_measurements现在在终端测量包含在中途电路测量中使用的导线时正确转换电路。(#4787)修复了一个错误,当存在具有
grad_method=None参数的操作时,伴随微分方法会失败。 (#4820)MottonenStatePreparation和BasisStatePreparation现在在分解广播状态向量时会引发错误。 (#4767)梯度变换现在可以与重载的射击向量和
default.qubit一起使用。 (#4795)任何
ScalarSymbolicOp,例如Evolution,现在表示如果目标是Hamiltonian,它具有一个矩阵。(#4768)在
default.qubit中,初始状态现在使用模拟器的线顺序进行初始化,而不是电路的线顺序。 (#4781)qml.compile现在将始终分解为expand_depth,即使未指定目标基集。(#4800)qml.transforms.transpile现在可以处理广播到所有导线上的测量。 (#4793)参数化电路的操作符不作用于所有线路时,将返回PennyLane张量而不是NumPy数组,如预期的那样。 (#4811) (#4817)
qml.transforms.merge_amplitude_embedding不再依赖于排队,使其能够如预期般与 QNodes 一起工作。 (#4831)qml.pow(op)和qml.QubitUnitary.pow()现在也可以与提升到整数次方的Tensorflow数据一起使用。 (#4827)文本绘制器已修复,以正确标记
qml.qinfo测量,以及qml.classical_shadowqml.shadow_expval. (#4803)移除了一个隐含假设,空的
(#4887)PauliSentence在乘法下被视为恒等。使用
CNOT或PauliZ操作与大批量状态和 Tensorflow 接口不再引发意外错误。 (#4889)qml.map_wires在映射嵌套量子序列时不再失败。 (#4901)电路转换为openqasm现在分解到深度10,支持需要超过2次分解的算子,如
ApproxTimeEvolution门。 (#4951)MPLDrawer在没有经典线路时,不会为经典线路添加额外空间。 (#4987)Projector现在支持参数广播。 (#4993)jax-jit 接口现在可以在 float32 模式下使用。 (#4990)
使用
qnn.KerasLayer的 Keras 模型不再在“weights”命名时失败保存和加载权重。 (#5008)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
吉列尔莫·阿隆索, 阿里·阿萨迪, 乌特卡什·阿扎德, 加布里埃尔·博特里尔, 托马斯·布朗利, 阿斯特拉尔·蔡, 敏·赵, 艾萨克·德·弗吕赫特, 阿敏托尔·杜斯科, 皮特·恩德巴克, 莉莉安·弗雷德里克森, 皮耶特罗保罗·弗里索尼, 乔什·伊扎克, 胡安·基拉尔多, 埃米利亚诺·戈丁斯·拉米雷斯, 安基特·坎德尔瓦尔, 科尔比安·科特曼, 克里斯蒂娜·李, 文森特·米肖-里奥, 阿努拉夫·莫达克, 罗曼·莫亚尔, 穆迪特·潘迪, 马修·西尔弗曼, 杰伊·索尼, 大卫·维里克斯, 贾斯廷·伍德林, 谢尔盖·米罗诺夫。
- orphan
版本 0.33.1¶
修复错误 🐛
修复由于VJP产品扩展导致的梯度性能回归。 (#4806)
qml.defer_measurements现在在终端测量包含在中途电路测量中使用的导线时正确转换电路。(#4787)任何
ScalarSymbolicOp,例如Evolution,现在表示如果目标是Hamiltonian,它具有一个矩阵。(#4768)在
default.qubit中,初始状态现在是根据模拟器的线缆顺序初始化,而不是电路的线缆顺序。(#4781)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
克里斯蒂娜·李,
李·詹姆斯·奥'里奥丹,
穆迪特·潘迪
- orphan
发行版 0.33.0¶
自上次发布以来的新特性
中途测量中的后选择和统计 📌
现在可以请求对中间电路测量进行后选择。 (#4604)
这可以通过在
qml.measure中指定postselect关键字参数为0或1来实现,分别对应基态。import pennylane as qml dev = qml.device("default.qubit") @qml.qnode(dev, interface=None) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) qml.measure(0, postselect=1) return qml.expval(qml.PauliZ(1)), qml.sample(wires=1)
该电路准备了 \(| \Phi^{+} \rangle\) 贝尔态,并对在电线
0中测量 \(|1\rangle\) 进行了后选择。电线1的输出在所有时候也是 \(|1\rangle\):>>> circuit(shots=10) (-1.0, array([1, 1, 1, 1, 1, 1]))
注意,镜头的数量少于请求的数量,因为我们已经丢弃了电线
0中测量到 \(|0\rangle\) 的样本。现在可以收集中途测量的测量统计。 (#4544)
dev = qml.device("default.qubit") @qml.qnode(dev) def circ(x, y): qml.RX(x, wires=0) qml.RY(y, wires=1) m0 = qml.measure(1) return qml.expval(qml.PauliZ(0)), qml.expval(m0), qml.sample(m0)
>>> circ(1.0, 2.0, shots=10000) (0.5606, 0.7089, array([0, 1, 1, ..., 1, 1, 1]))
支持 有限次测量和解析模式 ,并且设备默认使用 延迟测量 原理来执行中途测量。
使用灵活的Trotter积对哈密顿量进行指数化 🐖
高阶Trotter-Suzuki方法现在可以通过一个新操作轻松访问,称为
TrotterProduct。 (#4661)Trotter化技术是实现准确和高效哈密顿模拟的有效途径。Suzuki-Trotter乘积公式允许表达哈密顿的矩阵指数的高阶近似,现在可以通过
TrotterProduct操作在PennyLane中使用。只需指定近似的order和演化time。coeffs = [0.25, 0.75] ops = [qml.PauliX(0), qml.PauliZ(0)] H = qml.dot(coeffs, ops) dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(): qml.Hadamard(0) qml.TrotterProduct(H, time=2.4, order=2) return qml.state()
>>> circuit() [-0.13259524+0.59790098j 0. +0.j -0.13259524-0.77932754j 0. +0.j ]
使用随机乘积公式近似矩阵指数化,qDrift,现已通过新的
QDrift操作可用。 (#4671)如 1811.08017 所示,qDrift 是一个马尔可夫过程,可以加速哈密顿模拟。在高层次上,qDrift 通过依赖于哈密顿系数的概率随机抽样哈密顿项。现在,这种哈密顿模拟方法可以在 PennyLane 中使用
QDrift操作符。只需指定演化time和从哈密顿中抽样的数量n:coeffs = [0.25, 0.75] ops = [qml.PauliX(0), qml.PauliZ(0)] H = qml.dot(coeffs, ops) dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(): qml.Hadamard(0) qml.QDrift(H, time=1.2, n = 10) return qml.probs()
>>> circuit() array([0.61814334, 0. , 0.38185666, 0. ])
量子相位估计的构建模块 🧱
新增了一个叫
CosineWindow的操作符,用于基于余弦波函数准备初始状态。 (#4683)正如在 2110.09590 中概述的那样,余弦渐变窗口是量子相位估计的一个修改部分,可以为算法的错误率提供立方改进。使用
CosineWindow将 准备一个幅度在计算基上遵循余弦分布的状态。import matplotlib.pyplot as plt dev = qml.device('default.qubit', wires=4) @qml.qnode(dev) def example_circuit(): qml.CosineWindow(wires=range(4)) return qml.state() output = example_circuit() plt.style.use("pennylane.drawer.plot") plt.bar(range(len(output)), output) plt.show()
可以使用新的
ControlledSequence操作符创建降幂的受控门序列,这是量子相位估计中的一个子模块。 (#4707)要使用
ControlledSequence,需要指定受控单位算子和控制线control:dev = qml.device("default.qubit", wires = 4) @qml.qnode(dev) def circuit(): for i in range(3): qml.Hadamard(wires = i) qml.ControlledSequence(qml.RX(0.25, wires = 3), control = [0, 1, 2]) qml.adjoint(qml.QFT)(wires = range(3)) return qml.probs(wires = range(3))
>>> print(circuit()) [0.92059345 0.02637178 0.00729619 0.00423258 0.00360545 0.00423258 0.00729619 0.02637178]
新的设备功能,与Catalyst的集成,以及更多!⚗️
default.qubit现在使用新的qml.devices.DeviceAPI 和功能在qml.devices.qubit中。如果您在使用更新的default.qubit时遇到任何问题,请通过 发布问题 告诉我们。 设备的旧版本仍然可以通过短名称default.qubit.legacy访问,或通过qml.devices.DefaultQubitLegacy直接访问。 (#4594) (#4436) (#4620) (#4632)此变更为
default.qubit带来了许多好处,包括:现在电线的数量是可选的——仅仅拥有
qml.device("default.qubit")是有效的!如果在实例化时未提供电线,设备会自动推断为每个执行电路所需的电线数量。dev = qml.device("default.qubit") @qml.qnode(dev) def circuit(): qml.PauliZ(0) qml.RZ(0.1, wires=1) qml.Hadamard(2) return qml.state()
>>> print(qml.draw(circuit)()) 0: ──Z────────┤ 状态 1: ──RZ(0.10)─┤ 状态 2: ──H────────┤ 状态
default.qubit在使用反向传播微分方法时不再被静默替换为接口适配设备。例如,考虑:import jax dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, diff_method="backprop") def f(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0)) f(jax.numpy.array(0.2))
在之前的PennyLane版本中,设备将被替换为JAX等价物:
>>> f.device
>>> f.device == dev False 现在,
default.qubit可以以反向传播兼容的方式调度所有接口,因此不需要被替换:>>> f.device
>>> f.device == dev True
一个使用来自PennyLane的Catalyst库的
qjit进行即时混合编译的QNode现在兼容qml.draw。import catalyst @catalyst.qjit @qml.qnode(qml.device("lightning.qubit", wires=3)) def circuit(x, y, z, c): """一个三线的量子电路.""" @catalyst.for_loop(0, c, 1) def loop(i): qml.Hadamard(wires=i) qml.RX(x, wires=0) loop() qml.RY(y, wires=1) qml.RZ(z, wires=2) return qml.expval(qml.PauliZ(0)) draw = qml.draw(circuit, decimals=None)(1.234, 2.345, 3.456, 1)
>>> print(draw) 0: ──RX──H──┤
1: ──H───RY─┤ 2: ──RZ─────┤
改进 🛠
更多 PyTrees!
MeasurementProcess和QuantumScript对象现在已注册为 JAX PyTrees。 (#4607) (#4608)现在可以对参数为
MeasurementProcess或QuantumScript的函数进行 JIT 编译:import jax tape0 = qml.tape.QuantumTape([qml.RX(1.0, 0), qml.RY(0.5, 0)], [qml.expval(qml.PauliZ(0))]) dev = qml.device('lightning.qubit', wires=5) execute_kwargs = {"device": dev, "gradient_fn": qml.gradients.param_shift, "interface":"jax"} jitted_execute = jax.jit(qml.execute, static_argnames=execute_kwargs.keys()) jitted_execute((tape0, ), **execute_kwargs)
改进 QChem 和现有算法
在
integrals.py中计算开销较大的函数electron_repulsion和_hermite_coulomb已被修改,以用切片替代索引,以提高与 JAX 的兼容性。 (#4685)qml.qchem.import_state已扩展以导入更多的量子化学波函数, 来自使用 Block2 和 Dice 库进行的 MPS、DMRG 和 SHCI 经典计算。 #4523 #4524 #4626 #4634查看我们的 操作指南 以了解更多关于 PennyLane 如何与您喜欢的量子化学库集成的信息。
qchem
fermionic_dipole和particle_number函数已更新为使用FermiSentence。弃用的使用元组表示费米子操作的特性已被移除。 (#4546) (#4556)张量网络模板
qml.MPS现在支持改变后续块之间的offset,以提供更多灵活性。 (#4531)内置类型支持的
qml.pauli_decompose已得到改善。 (#4577)AmplitudeEmbedding现在继承自StatePrep,这使得它在电路的起始处不被分解,从而表现得像StatePrep。(#4583)qml.cut_circuit现在与计算包含两个或多个项的哈密顿量期望值的电路兼容。 (#4642)
下一代设备 API
default.qubit现在跟踪设备在采样时的等效 qpu 执行次数和总拍摄次数。注意,"simulations"表示模拟轮数,而"executions"表示需要采样的不同计算基数。此外,新的default.qubit跟踪device.execute的结果。 (#4628) (#4649)DefaultQubit现在可以接受一个jax.random.PRNGKey作为seed,以设置 JAX 伪随机数生成器的密钥,使用 JAX 接口时。 这对应于旧 API 中的prng_key在default.qubit.jax上。(#4596)抽象基类
JacobianProductCalculator和实现TransformJacobianProductsDeviceDerivatives,以及DeviceJacobianProducts已经被添加到pennylane.interfaces.jacobian_products中。 (#4435) (#4527) (#4637)DefaultQubit在应用ParametrizedEvolution到一个状态时,会调度到一个更快的实现,当演化状态比操作矩阵更高效时。 (#4598) (#4620)
(#4539)qml.sample()在新的设备 API 中现在返回一个np.int64数组,而不是np.bool8。新的设备 API 现在有一个
repr()方法。 (#4562)DefaultQubit现在可以正常工作,适用于不指定导线的测量过程。(#4580)为了在
default.qubit.legacy和新的DefaultQubit之间实现特性一致性,对测量进行了各种改进。这包括不尝试压缩批量CountsMP结果以及实现MutualInfoMP.map_wires。 (#4574)devices.qubit.simulate现在接受一个接口关键字参数。如果一个使用DefaultQubit的 QNode 指定了一个接口,结果将使用该接口进行计算。(#4582)ShotAdaptiveOptimizer已更新为在执行QNode之前传递shots,而不是覆盖设备shots。这使其与新的设备API兼容。 (#4599)pennylane.devices.preprocess现在提供转换decompose,validate_observables,validate_measurements,validate_device_wires,validate_multiprocessing_workers,warn_about_trainable_observables, 和no_sampling,以帮助在新的设备 API 下构建设备。 (#4659)更新了
qml.device、devices.preprocessing和tape_expand.set_decomposition上下文管理器,以使DefaultQubit在使用自定义分解方面与default.qubit.legacy达到功能平衡。现在可以在set_decomposition上下文中包含DefaultQubit设备,也可以使用custom_decomps字典进行初始化,以及自定义max_depth进行分解。 (#4675)
其他改进
现在
StateMP测量接受线顺序(例如,设备线顺序)。process_state方法将重新排列给定状态,从输入的线顺序转换为过程的线顺序。 如果过程的线顺序包含额外的线,它将假设这些线处于零状态。 (#4570) (#4602)方法
add_transform和insert_front_transform已被添加到TransformProgram中。 (#4559)现在可以将
TransformProgram类的实例相加。 (#4549)现在可以将变换应用于遵循新设备API的设备。
所有梯度变换已更新为新的变换程序系统。 (#4595)
现在可以自动分解具有单量子比特特殊幺正目标的多控制操作。
pennylane.defer_measurements现在如果输入不包含中间电路测量,将会提前退出。 (#4659)
(#4558)StateMP的密度矩阵方面已被分割到其自己的测量过程,称为DensityMatrixMP。StateMeasurement.process_state现在假设输入是扁平的。ProbabilityMP.process_state已被更新以反映这一假设并避免冗余的重塑。 (#4602)qml.exp在无法对非单位算子进行分解时返回更具信息量的错误信息。 (#4571)添加了
qml.math.get_deep_interface以获取隐藏在列表或元组中的标量接口。 (#4603)更新了
qml.math.ndim和qml.math.shape以支持包含特定接口的标量数据的内置列表或元组(例如,[(tf.Variable(1.1), tf.Variable(2.2))])。(#4603)当使用
one_qubit_decomposition分解一个单位矩阵并选择在分解中包含GlobalPhase时, 相位不再转换为dtype=complex。 (#4653)_qfunc_output已从QuantumScript中移除,因为它不再必要。QNode实例上仍然有一个_qfunc_output属性。 (#4651)qml.data.load正确处理出现在'full'之后的参数 (#4663)qml.jordan_wigner函数已被修改,以可选地移除计算得到的量子比特算子的虚部,如果虚部小于某个阈值。 (#4639)qml.data.load正确地在已经执行过数据集的部分下载后,执行数据集的完整下载。 (#4681)当部分加载数据集时,
qml.data.load()的性能得到了改善(#4674)使用
pennylane.drawer.plot样式生成的图形现在具有黑色轴标签,并以默认DPI 300生成。 (#4690)现在,
QNode的浅拷贝也会复制execute_kwargs和变换程序。当对QNode应用变换时,新的qnode只是原始的浅拷贝,因此保持相同的设备。 (#4736)QubitDevice和CountsMP已更新以忽略包含失败硬件测量的样本(记录为np.NaN),在计算样本时不再将失败的测量计为基态测量,并正确显示来自这些硬件设备的qml.counts。 (#4739)
重大变更 💔
qml.defer_measurements现在会在转换电路测量qml.probs,qml.sample或qml.counts时,如果没有任何线或可观察量,或者如果它测量qml.state时引发错误。 (#4701)设备测试套件现在会将设备关键字参数转换为整数或浮点数(如果可能的话)。 (#4640)
MeasurementProcess.eigvals()现在会引发一个EigvalsUndefinedError如果测量观测量 没有特征值。 (#4544)__eq__和__hash__方法在Operator和MeasurementProcess中不再依赖于对象在内存中的地址。使用==进行操作符和测量过程的比较将与qml.equal的行为相同,具有相同数据和超参数的相同类型对象将具有相同的哈希值。 (#4536)在以下场景中,第二和第三个代码块展示了操作符和测量过程相等性的之前和当前行为,这由
==决定:op1 = qml.PauliX(0) op2 = qml.PauliX(0) op3 = op1
旧的行为:
>>> op1 == op2 False >>> op1 == op3 True
新的行为:
>>> op1 == op2 True >>> op1 == op3 True
__hash__魔法方法定义了对象的哈希值。对象的默认哈希值由对象的内存地址决定。然而,新的哈希值由操作符和测量过程的属性和特征决定。考虑以下场景。第二和第三个代码块展示了之前和当前的行为。op1 = qml.PauliX(0) op2 = qml.PauliX(0)
旧的行为:
>>> print({op1, op2}) {PauliX(wires=[0]), PauliX(wires=[0])}
新的行为:
>>> print({op1, op2}) {PauliX(wires=[0])}
旧的返回类型和相关函数
qml.enable_return和qml.disable_return已被移除。 (#4503)QNode中的mode关键字参数已被移除。请改用grad_on_execution。 (#4503)CV 可观测量
qml.X和qml.P已被移除。请改用qml.QuadX和qml.QuadP。 (#4533)已移除
qml.gradients.spsa_grad的sampler_seed参数。 相反,应该设置sampler_rng参数,可以是一个整数值,该值将在内部用于创建伪随机数生成器,或者是通过np.random.default_rng(seed)创建的NumPy伪随机数生成器(PRNG)。 (#4550)已移除
(#4548)QuantumScript.set_parameters方法和QuantumScript.data设置器。请改用QuantumScript.bind_new_parameters。方法
tape.unwrap()及相应的UnwrapTape和Unwrap类已被移除。 请使用qml.transforms.convert_to_numpy_parameters替代tape.unwrap()。 (#4535)关键词参数
RandomLayers.compute_decompositionratio_imprivitive已更改为ratio_imprim以匹配操作的调用签名。 (#4552)当θ值可训练时,私有
TmpPauliRot算子用于SpecialUnitary不再分解为无。 (#4585)ProbabilityMP.marginal_prob已被移除。其内容已迁移至process_state, 这实际上只是用np.abs(state) ** 2调用了marginal_prob。 (#4602)
弃用功能 👋
以下的变换装饰器语法已经被废弃,会引发警告: (#4457)
@transform_fn(**transform_kwargs) @qml.qnode(dev) def circuit(): ...
如果您使用的变换支持
transform_kwargs,请直接调用变换,使用circuit = transform_fn(circuit, **transform_kwargs),或使用functools.partial:@functools.partial(transform_fn, **transform_kwargs) @qml.qnode(dev) def circuit(): ...
在
QuantumScript中,prep关键字参数已被弃用,并将在QuantumScript中移除。StatePrepBase操作应放在ops列表的开头。 (#4554)qml.gradients.pulse_generator已更名为qml.gradients.pulse_odegen以遵循论文命名规范。在 v0.33 期间,pulse_generator仍然可用,但会生成警告。 (#4633)
文档 📝
在
DefaultQubit的文档字符串中添加了关于在多处理时使用的启动方法的警告部分。这可能会帮助用户规避在macOS上的Jupyter笔记本中出现的问题。例如。(#4622)对新的设备API进行了文档改进。文档现在正确地说明了接口特定参数仅在反向传播导数时传递给设备。 (#4542)
用于量子比特仿真的函数已添加到“内部”部分的
qml.devices子页面。请注意,在设备升级期间,这些函数不稳定。(#4555)对
(#4593)qml.QuantumMonteCarlo页面中的用例示例进行了文档改进。一个积分缺少了微分 \(dx\)。对使用
pennylane样式的qml.drawer和matplotlib.pyplot样式的pennylane.drawer.plot的文档进行了改进,通过明确默认字体的使用。(#4690)
修复错误 🐛
当概率测量广播到所有导线时,Jax jit 现在可以正常工作。(#4742)
修复了
LocalHilbertSchmidt.compute_decomposition,以便在 QNode 中使用模板。 (#4719)修复了
transforms.transpile与任意测量过程的兼容性。 (#4732)提供
work_wires=None给qml.GroverOperator不再将None解释为一个线。 (#4668)修复了
qml.Select()操作符的__copy__方法尝试访问未初始化数据的问题。 (#4551)修复了
skip_first选项在expand_tape_state_prep中的问题。 (#4564)convert_to_numpy_parameters现在使用qml.ops.functions.bind_new_parameters。这会重新初始化操作,并确保所有内容引用新的NumPy参数。(#4540)tf.function不再打断ProbabilityMP.process_state,这是新设备所需的。 (#4470)修复了
qml.qchem.mol_data的单元测试。 (#4591)修复了
ProbabilityMP.process_state以允许正确的 Autograph 编译。没有这个,当用tf.function装饰返回expval的 QNode 时,在计算期望值时会失败。(#4590)现在可以在
pennylane.qnn.TorchLayer上访问torch.nn.Module属性。 (#4611)qml.math.take现在在 Pytorch 中返回tensor[..., indices]当用户请求最后一个轴 (axis=-1) 时。没有这个修复,它会错误地返回tensor[indices]。 (#4605)确保日志记录
TRACE级别在无梯度执行时正常工作。 (#4669)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
Guillermo Alonso, Utkarsh Azad, Thomas Bromley, Isaac De Vlugt, Jack Brown, Stepan Fomichev, Joana Fraxanet, Diego Guala, Soran Jahangiri, Edward Jiang, Korbinian Kottmann, Ivana Kurečić Christina Lee, Lillian M. A. Frederiksen, Vincent Michaud-Rioux, Romain Moyard, Daniel F. Nino, Lee James O’Riordan, Mudit Pandey, Matthew Silverman, Jay Soni。
- orphan
发布 0.32.0¶
自上次发布以来的新特性
使用幺正算子的线性组合对矩阵进行编码 ⛓️️
It is now possible to encode an operator
Ainto a quantum circuit by decomposing it into a linear combination of unitaries using PREP (qml.StatePrep) and SELECT (qml.Select) routines. (#4431) (#4437) (#4444) (#4450) (#4506) (#4526)Consider an operator
Acomposed of a linear combination of Pauli terms:>>> A = qml.PauliX(2) + 2 * qml.PauliY(2) + 3 * qml.PauliZ(2)
A decomposable block-encoding circuit can be created:
def block_encode(A, control_wires): probs = A.coeffs / np.sum(A.coeffs) state = np.pad(np.sqrt(probs, dtype=complex), (0, 1)) unitaries = A.ops qml.StatePrep(state, wires=control_wires) qml.Select(unitaries, control=control_wires) qml.adjoint(qml.StatePrep)(state, wires=control_wires)
>>> print(qml.draw(block_encode, show_matrices=False)(A, control_wires=[0, 1])) 0: ─╭|Ψ⟩─╭Select─╭|Ψ⟩†─┤ 1: ─╰|Ψ⟩─├Select─╰|Ψ⟩†─┤ 2: ──────╰Select───────┤
This circuit can be used as a building block within a larger QNode to perform algorithms such as QSVT and Hamiltonian simulation.
通过
qml.pauli_decompose将厄米矩阵分解为保利字的线性组合现在更快且可微分。 (#4395) (#4479) (#4493)def find_coeffs(p): mat = np.array([[3, p], [p, 3]]) A = qml.pauli_decompose(mat) return A.coeffs
>>> import jax >>> from jax import numpy as np >>> jax.jacobian(find_coeffs)(np.array(2.)) Array([0., 1.], dtype=float32, weak_type=True)
通过日志监控PennyLane的内部工作 📃
可以通过
qml.logging.enable_logging()启用 Python 原生日志记录。 (#4377) (#4383)考虑以下包含在
my_code.py中的代码:import pennylane as qml qml.logging.enable_logging() # 启用日志记录 dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def f(x): qml.RX(x, wires=0) return qml.state() f(0.5)
以启用日志记录的方式执行
my_code.py将详细记录每一步在 PennyLane 管道中执行你的代码所使用的过程。$ python my_code.py [1967-02-13 15:18:38,591][DEBUG][
] - pennylane.qnode.__init__()::"Creating QNode(func= , device= , interface=auto, diff_method=best, expansion_strategy=gradient, max_expansion=10, grad_on_execution=best, mode=None, cache=True, cachesize=10000, max_diff=1, gradient_kwargs={}" ... 通过修改日志配置文件的内容,可以指定其他日志记录配置设置,可以通过运行
qml.logging.config_path()来找到该文件。请参考我们的 logging docs page 以获得更多详细信息!
更多输入状态用于量子化学计算 ⚛️
从高级量子化学计算获得的输入态可以用于电路。 (#4427) (#4433) (#4461) (#4476) (#4505)
量子化学计算依赖于通常选择的初始态,即平凡的哈特里-福克态。对于具有复杂电子结构的分子,使用从可负担的后哈特里-福克计算获得的初始态有助于提高量子模拟的效率。这些计算可以使用外部量子化学库进行,例如PySCF。
现在可以在PennyLane中导入PySCF求解器对象,并提取相应的波函数,以状态向量的形式直接用于电路。首先,进行你的经典量子化学计算,然后使用 qml.qchem.import_state 函数导入求解器对象并返回状态向量。
>>> from pyscf import gto, scf, ci
>>> mol = gto.M(atom=[['H', (0, 0, 0)], ['H', (0,0,0.71)]], basis='sto6g')
>>> myhf = scf.UHF(mol).run()
>>> myci = ci.UCISD(myhf).run()
>>> wf_cisd = qml.qchem.import_state(myci, tol=1e-1)
>>> print(wf_cisd)
[ 0. +0.j 0. +0.j 0. +0.j 0.1066467 +0.j
1. +0.j 0. +0.j 0. +0.j 0. +0.j
2. +0.j 0. +0.j 0. +0.j 0. +0.j
-0.99429698+0.j 0. +0.j 0. +0.j 0. +0.j]
The state vector can be implemented in a circuit using ``qml.StatePrep``.
>>> dev = qml.device('default.qubit', wires=4)
>>> @qml.qnode(dev)
... def circuit():
... qml.StatePrep(wf_cisd, wires=range(4))
... return qml.state()
>>> print(circuit())
[ 0. +0.j 0. +0.j 0. +0.j 0.1066467 +0.j
1. +0.j 0. +0.j 0. +0.j 0. +0.j
2. +0.j 0. +0.j 0. +0.j 0. +0.j
-0.99429698+0.j 0. +0.j 0. +0.j 0. +0.j]
The currently supported post-Hartree-Fock methods are RCISD, UCISD, RCCSD, and UCCSD which
denote restricted (R) and unrestricted (U) configuration interaction (CI) and coupled cluster (CC)
calculations with single and double (SD) excitations.
在中间电路测量后重用和重置量子比特 ♻️
PennyLane 现在允许您定义在中间电路测量发生后重新使用量子比特的电路。可选地,导线也可以重置为 \(|0\rangle\) 状态。 (#4402) (#4432)
通过在调用 qml.measure 时设置
reset=True可以激活测量后的重置。 在这个版本的 PennyLane 中,执行具有量子比特重用的电路将导致 defer_measurements 变换被应用。此变换将每个重用的导线替换为一个 额外的 量子比特。 然而,PennyLane 的未来版本将探索支持量子比特重用的设备级支持,而无需消耗额外的量子比特。量子比特的重用和重置也是完全可微分的:
dev = qml.device("default.qubit", wires=4) @qml.qnode(dev) def circuit(p): qml.RX(p, wires=0) m = qml.measure(0, reset=True) qml.cond(m, qml.Hadamard)(1) qml.RX(p, wires=0) m = qml.measure(0) qml.cond(m, qml.Hadamard)(1) return qml.expval(qml.PauliZ(1))
>>> jax.grad(circuit)(0.4) Array(-0.35867804, dtype=float32, weak_type=True)
您可以在文档中了解有关中间电路测量的更多信息,并请继续关注下几个版本中更多的中间电路测量功能!
改进 🛠
一种新的PennyLane绘图风格
现在可以按照PennyLane的风格创建电路图和图表。 (#3950)
qml.draw_mpl函数接受一个style='pennylane'参数来创建PennyLane主题的 电路图:def circuit(x, z): qml.QFT(wires=(0,1,2,3)) qml.Toffoli(wires=(0,1,2)) qml.CSWAP(wires=(0,2,3)) qml.RX(x, wires=0) qml.CRZ(z, wires=(3,0)) return qml.expval(qml.PauliZ(0)) qml.draw_mpl(circuit, style="pennylane")(1, 1)

也可以通过将
"pennylane.drawer.plot"传递给Matplotlib的plt.style.use函数来绘制PennyLane风格的图表:import matplotlib.pyplot as plt plt.style.use("pennylane.drawer.plot") for i in range(3): plt.plot(np.random.rand(10))
如果字体 Quicksand Bold 不可用, 则会使用可用的默认字体。
使操作符不可变和PyTrees
现在,任何继承自
Operator的类都会自动作为 pytree 在 JAX 中注册。这解锁了对Operator的函数进行即时编译的能力。 (#4458)>>> op = qml.adjoint(qml.RX(1.0, wires=0)) >>> jax.jit(qml.matrix)(op) Array([[0.87758255-0.j , 0. +0.47942555j], [0. +0.47942555j, 0.87758255-0.j ]], dtype=complex64, weak_type=True) >>> jax.tree_util.tree_map(lambda x: x+1, op) 伴随(RX(2.0, wires=[0]))
所有
Operator对象现在定义了Operator._flatten和Operator._unflatten方法,这些方法用于将可训练和不可训练的组件分离。这些方法将在序列化和 pytree 注册中使用。自定义操作可能需要更新以确保与新的 PennyLane 特性兼容。 (#4483) (#4314)现在,
QuantumScript类具有一个bind_new_parameters方法,允许使用提供的参数创建新的QuantumScript对象。 (#4345)
(#4220)qml.gradients模块不再对任何梯度变换就地修改算子。相反,需要修改的算子会被复制并使用新参数。PennyLane 不再直接依赖于
Operator.__eq__。 (#4398)qml.equal不再在比较不同类型的运算符或测量时引发错误。 取而代之的是,它返回False。 (#4315)
变换
变换程序现已与 QNode 集成。 (#4404)
def null_postprocessing(results: qml.typing.ResultBatch) -> qml.typing.Result: return results[0] @qml.transforms.core.transform def scale_shots(tape: qml.tape.QuantumTape, shot_scaling) -> (Tuple[qml.tape.QuantumTape], Callable): new_shots = tape.shots.total_shots * shot_scaling new_tape = qml.tape.QuantumScript(tape.operations, tape.measurements, shots=new_shots) return (new_tape, ), null_postprocessing dev = qml.devices.experimental.DefaultQubit2() @partial(scale_shots, shot_scaling=2) @qml.qnode(dev, interface=None) def circuit(): return qml.sample(wires=0)
>>> circuit(shots=1) array([False, False])
变换程序,
qml.transforms.core.TransformProgram,现在可以批量调用电路并返回一批新的电路和一个单一的后处理函数。(#4364)TransformDispatcher现在允许注册自定义 QNode 转换。(#4466)QNode 在
qml.qinfo中的变换现在支持自定义线条标签。 #4331qml.transforms.adjoint_metric_tensor现在使用qml.devices.qubit中的仿真工具,而不是使用qml.devices.DefaultQubit的私有方法。 (#4456)辅助线和设备线现在在
qml.transforms.metric_tensor中与qml.gradients.hadamard_grad一样处理。所有有效的线输入格式都支持aux_wire。 (#4328)
下一代设备 API
实验设备接口已与 JAX、JAX-JIT、TensorFlow 和 PyTorch 的 QNode 集成。 (#4323) (#4352) (#4392) (#4393)
实验性的
DefaultQubit2设备现在支持使用伴随方法计算 VJPs 和 JVPs。 (#4374)新增的函数
adjoint_jvp和adjoint_vjp使用伴随方法计算带的 JVP 和 VJP,已添加到qml.devices.qubit.adjoint_jacobian(#4358)DefaultQubit2现在接受一个max_workers参数,该参数控制多进程。ProcessPoolExecutor使用最多max_workers个进程异步执行带子。 如果max_workers为None或未提供,则只有当前进程执行带子。如果您遇到任何问题,比如使用 JAX、TensorFlow、Torch,请尝试将max_workers设置为None。(#4319)(#4425)qml.devices.experimental.Device现在接受一个 shots 关键字参数,并且具有一个shots属性。该属性仅用于为工作流设置默认值,并不会直接影响执行或导数中使用的 shots 数量。 (#4388)expand_fn()对DefaultQubit2已更新,以分解电路中间存在的StatePrep操作。 (#4444)如果在使用
DefaultQubit2初始化时未指定种子,本地随机数生成器将从 NumPy 的全局随机数生成器中获取种子。 (#4394)
对机器学习库接口的改进
pennylane/interfaces已经被重构。传递给机器学习框架边界的execute_fn现在负责将参数转换为 NumPy。渐变模块现在可以处理 TensorFlow 参数,但渐变记录现在保留原始dtype,而不是转化为float64。这可能导致有限差分微分和float32参数的不稳定性。机器学习边界函数现在与它们的遗留对应物解耦。 (#4415)qml.interfaces.set_shots现在接受Shots对象以及int和int的元组。 (#4388)对
pennylane/interfaces/jax_jit_tuple.py进行了可读性改进和风格变更(#4379)
脉冲
现在可以将
HardwareHamiltonian与int或float对象相加。 现在可以通过内置的sum对一系列HardwareHamiltonian进行相加。 (#4343)qml.pulse.transmon_drive已根据 1904.06560 进行了更新。 特别是,功能形式已从 \(\Omega(t)(\cos(\omega_d t + \phi) X - \sin(\omega_d t + \phi) Y)$ 更改为 $\Omega(t) \sin(\omega_d t + \phi) Y\)。 (#4418) (#4465) (#4478) (#4418)
其他改进
稀疏矩阵的
Sum、Prod、SProd、PauliWord和PauliSentence的计算速度快了几个数量级。 (#4475) (#4272) (#4411)一个名为
qml.math.fidelity_statevector的函数被添加,用于计算两个状态矢量之间的保真度。 (#4322)qml.ctrl(qml.PauliX)返回一个CNOT、Toffoli或MultiControlledX操作,而不是Controlled(PauliX)。 (#4339)当给定一个可调用对象时,
qml.ctrl现在会对可调用对象中的所有排队操作进行自定义预处理。 (#4370)该
qchem函数primitive_norm和contracted_norm已被修改以兼容更高版本的 SciPy。私有函数_fac2用于计算双阶乘也已添加。#4321tape_expand现在使用Operator.decomposition代替Operator.expand以便做出更高效的选择。CI 现在使用 TensorFlow 2.13.0 运行测试 (#4472)
现在CI和预提交钩子中的所有测试都启用了代码风格检查。 (#4335)
现在,
StatePrepBase操作符的默认标签是|Ψ⟩。 (#4340)Device.default_expand_fn()已更新,以分解提供电路中间的qml.StatePrep操作。 (#4437)QNode.construct已更新,仅在设备不原生支持中间电路测量时应用qml.defer_measurements转换。 (#4516)将
qml.defer_measurements转换的应用从QNode.construct移动到qml.Device.batch_transform,以便更精细地控制何时使用defer_measurements。 (#4432)ParametrizedEvolution的标签可以显示按照kwargdecimals设置的请求格式的参数。数组类型的参数以与矩阵相同的格式显示,并存储在缓存中。 (#4151)
重大变更 💔
应用梯度变换到广播/批处理的录音带已经被停用,直到它同样被稳定支持QNodes。 (#4480)
梯度变换不再隐式地将
float32参数转换为float64。使用float32参数的有限差分微分可能不再给出准确的结果。 (#4415)在
qml.operation.Operator中,do_queue关键字参数已被移除。请使用qml.QueuingManager.stop_recording()上下文代替设置do_queue=False。Operator.expand现在使用Operator.decomposition的输出,而不是它排队的内容。 (#4355)梯度模块不再需要显式传递射击信息,因为射击信息在磁带上。
(#4448)qml.StatePrep已重命名为qml.StatePrepBase,qml.QubitStateVector已重命名为qml.StatePrep。qml.operation.StatePrep和qml.QubitStateVector仍然可以访问。 (#4450)不再支持 Python 3.8。 (#4453)
MeasurementValue的签名已更新为接受一个MidMeasureMP的列表,而不是它们的ID列表。 (#4446)从
qchem.molecular_hamiltonian中移除了grouping_type和grouping_method关键字参数。 (#4301)zyz_decomposition和xyx_decomposition已被移除。请改用one_qubit_decomposition。 (#4301)LieAlgebraOptimizer已被移除。请改用RiemannianGradientOptimizer。 (#4301)Operation.base_name已被移除。 (#4301)QuantumScript.name已被移除。 (#4301)qml.math.reduced_dm已被移除。请改用qml.math.reduce_dm或qml.math.reduce_statevector。 (#4301)字典
qml.specs不再支持对某些键的直接访问。(#4301)相反,这些量可以作为新的
Resources对象的字段访问,该对象保存在specs_dict["resources"]中:num_operations不再支持,使用specs_dict["resources"].num_gatesnum_used_wires不再受支持,请使用specs_dict["resources"].num_wiresgate_types不再被支持,请使用specs_dict["resources"].gate_typesgate_sizes现已不再支持,请使用specs_dict["resources"].gate_sizesdepth不再被支持,请使用specs_dict["resources"].depth
qml.math.purity,qml.math.vn_entropy,qml.math.mutual_info,qml.math.fidelity,qml.math.relative_entropy, 和qml.math.max_entropy不再支持将状态向量作为输入。 (#4322)私有
QuantumScript._prep列表已被移除,准备操作现在进入_ops列表。 (#4485)
弃用功能 👋
qml.enable_return和qml.disable_return已被弃用。请避免调用disable_return,因为旧的返回系统已经与这些切换函数一起被弃用。 (#4316)qml.qchem.jordan_wigner已被弃用。请改用qml.jordan_wigner。 用于定义费米子算符的列表输入也已被弃用;应改为使用qml.fermi模块中的费米子算符。 (#4332)关键词参数
qml.RandomLayers.compute_decompositionratio_imprimitive将更改为ratio_imprim以匹配操作的调用签名。 (#4314)CV 可观测量
qml.X和qml.P已被弃用。请使用qml.QuadX和qml.QuadP替代。 (#4330)方法
tape.unwrap()和对应的UnwrapTape以及Unwrap类已被弃用。请使用convert_to_numpy_parameters替代。 (#4344)QNode中的
(#4316)mode关键字参数已被弃用,因为它仅在旧的返回系统中使用(该系统也已被弃用)。请改用grad_on_execution。QuantumScript.set_parameters方法和QuantumScript.data设置器已被弃用。请改用QuantumScript.bind_new_parameters。 (#4346)现在,
Operator和MeasurementProcess的__eq__和__hash__魔法方法将引发警告,以反映即将对操作符和测量过程的相等性和哈希处理进行的更改。 (#4144) (#4454) (#4489) (#4498)参数
sampler_seed的qml.gradients.spsa_grad已被弃用,并修复了种子设置行为的错误。 取而代之的是,应该设置sampler_rng参数,可以设置为一个整数值,该值将被用于在内部创建一个伪随机数生成器,或者设为通过np.random.default_rng(seed)创建的 NumPy 伪随机数生成器。 (4165)
文档 📝
与
qml.pulse.transmon_interaction和qml.pulse.transmon_drive相关的文档已更新。 #4327qml.ApproxTimeEvolution.compute_decomposition()现在有了一个代码示例。 (#4354)对于
qml.devices.experimental.Device的文档已经进行了改进,以澄清其使用的一些方面。 (#4391)在
qml.import_operator中指定操作符的输入类型和来源。 (#4476)
修复错误 🐛
qml.Projector可以再被序列化。 (#4452)_copy_and_shift_params不会强制转换或转换整型,只依赖于+和*在这种情况下的类型转换规则。 (#4477)现在允许对包含
Tensor的SProd进行稀疏矩阵计算。当使用Tensor.sparse_matrix()时,建议使用wire_order关键字参数,而不是wires。(#4424)op.adjoint已被qml.adjoint替换在QNSPSAOptimizer中。 (#4421)jax.ad(已弃用)已被jax.interpreters.ad替代。 (#4403)metric_tensor防止意外捕捉源于原始电路中有缺陷的导线分配的错误,从而导致递归错误。(#4328)现在如果在调用
qml.draw_mpl时隐藏控制指示器,将会引发警告 (#4295)qml.qinfo.purity现在在使用自定义线路标签时输出正确的结果。 (#4331)default.qutrit现在支持与qml.adjoint一起使用的所有 qutrit 操作。 (#4348)现在可观察的数据
qml.GellMann包括其索引,使得能够正确比较qml.GellMann的实例,以及包含qml.GellMann的哈密顿量和张量。 (#4366)qml.transforms.merge_amplitude_embedding现在在AmplitudeEmbedding有批次维度时可以正常工作。 (#4353)已修改
jordan_wigner函数以适用于使用激活空间构建的哈密顿量。 (#4372)当未提供
style选项时,qml.draw_mpl会使用当前从qml.drawer.use_style设置的样式,而不是black_white。 (#4357)qml.devices.qubit.preprocess.validate_and_expand_adjoint不再设置扩展胶带的可训练参数。 (#4365)qml.default_expand_fn现在选择性地展开操作或测量,允许在测量非 qwc 哈密顿量时在电路中执行更多操作。(#4401)
(#4407)qml.ControlledQubitUnitary不再在没有真正的分解时报告has_decomposition为True。qml.transforms.split_non_commuting现在正确地在包含expval和var测量的电路上工作。(#4426)从一个算子中减去一个
Prod现在按预期工作。 (#4441)qml.gradients.spsa_grad的sampler_seed参数已更改为sampler_rng。可以提供一个整数,这将用于内部创建一个伪随机数生成器(PRNG)。之前,当num_directions大于 1 时,这会导致采样相同的方向。或者,可以提供一个 NumPy 的 PRNG,这样可以在调用spsa_grad时得到可重复的结果,而不是每次都获得相同的结果。(4165) (4482)qml.math.get_dtype_name现在可以与自动微分数组盒一起使用。 (#4494)qml.math.fidelity的反向传播梯度现在是正确的。 (#4380)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
乌特卡什·阿扎德, 托马斯·布朗普利, 艾萨克·德·弗吕赫特, 阿敏托尔·杜斯科, 斯捷潘·福明切夫, 莉莉安·M·A·弗雷德里克森, 索然·贾汉吉里, 爱德华·姜, 科尔比尼安·科特曼, 伊万娜·库雷西奇, 克里斯蒂娜·李, 文森特·米绍-里乌, 罗曼·莫亚尔, 李·詹姆斯·奥'里奥丹, 穆迪特·潘德, 博尔哈·雷奎纳, 马修·西尔弗曼, 杰伊·索尼, 大卫·维里希斯, 弗雷德里克·维尔德。
- orphan
发布 0.31.0¶
自上次发布以来的新特性
无缝创建和组合费米子算符 🔬
费米子算子和算术现在可用。 (#4191) (#4195) (#4200) (#4201) (#4209) (#4229) (#4253) (#4255) (#4262) (#4278)
有几种方法可以使用这个新功能创建费米子算符:
qml.FermiC和qml.FermiA: 费米创生 和 湮灭算符,分别。这些算符通过传递费米算符作用的轨道索引来定义。例如,算符a⁺(0)和a(3)分别构建如下:>>> qml.FermiC(0) a⁺(0) >>> qml.FermiA(3) a(3)
这些算符可以与 (
*) 组合,并与 (+和-) 其他费米算符线性组合,以创建任意的费米汉密尔顿量。将多个费米算符相乘会创建一个我们称之为费米词的算符:>>> word = qml.FermiC(0) * qml.FermiA(0) * qml.FermiC(3) * qml.FermiA(3) >>> word a⁺(0) a(0) a⁺(3) a(3)
费米词可以线性组合以创建一个我们称之为费米句子的费米算符:
>>> sentence = 1.2 * word - 0.345 * qml.FermiC(3) * qml.FermiA(3) >>> sentence 1.2 * a⁺(0) a(0) a⁺(3) a(3) - 0.345 * a⁺(3) a(3)
通过 qml.fermi.from_string:创建一个费米算符,表示多个产生和湮灭算符相互乘积(一个费米词)。
>>> qml.fermi.from_string('0+ 1- 0+ 1-') a⁺(0) a(1) a⁺(0) a(1) >>> qml.fermi.from_string('0^ 1 0^ 1') a⁺(0) a(1) a⁺(0) a(1)
使用
from_string创建的费米词也可以线性组合以创建一个费米句子:>>> word1 = qml.fermi.from_string('0+ 0- 3+ 3-') >>> word2 = qml.fermi.from_string('3+ 3-') >>> sentence = 1.2 * word1 + 0.345 * word2 >>> sentence 1.2 * a⁺(0) a(0) a⁺(3) a(3) + 0.345 * a⁺(3) a(3)
此外,任何费米子算符,无论是单个费米子产生/湮灭算符、费米词,还是费米句,都可以通过使用 qml.jordan_wigner 映射到量子比特基底:
>>> qml.jordan_wigner(sentence) ((0.4725+0j)*(Identity(wires=[0]))) + ((-0.4725+0j)*(PauliZ(wires=[3]))) + ((-0.3+0j)*(PauliZ(wires=[0]))) + ((0.3+0j)*(PauliZ(wires=[0]) @ PauliZ(wires=[3])))
了解如何创建描述一些简单化学系统的费米哈密顿量,请查看我们的 费米算符演示!
工作流级别资源估算 🧮
PennyLane’s Tracker now monitors the resource requirements of circuits being executed by the device. (#4045) (#4110)
Suppose we have a workflow that involves executing circuits with different qubit numbers. We can obtain the resource requirements as a function of the number of qubits by executing the workflow with the
Trackercontext:dev = qml.device("default.qubit", wires=4) @qml.qnode(dev) def circuit(n_wires): for i in range(n_wires): qml.Hadamard(i) return qml.probs(range(n_wires)) with qml.Tracker(dev) as tracker: for i in range(1, 5): circuit(i)
The resource requirements of individual circuits can then be inspected as follows:
>>> resources = tracker.history["resources"] >>> resources[0] wires: 1 gates: 1 depth: 1 shots: Shots(total=None) gate_types: {'Hadamard': 1} gate_sizes: {1: 1} >>> [r.num_wires for r in resources] [1, 2, 3, 4]
Moreover, it is possible to predict the resource requirements without evaluating circuits using the
null.qubitdevice, which follows the standard execution pipeline but returns numeric zeros. Consider the following workflow that takes the gradient of a50-qubit circuit:n_wires = 50 dev = qml.device("null.qubit", wires=n_wires) weight_shape = qml.StronglyEntanglingLayers.shape(2, n_wires) weights = np.random.random(weight_shape, requires_grad=True) @qml.qnode(dev, diff_method="parameter-shift") def circuit(weights): qml.StronglyEntanglingLayers(weights, wires=range(n_wires)) return qml.expval(qml.PauliZ(0)) with qml.Tracker(dev) as tracker: qml.grad(circuit)(weights)
The tracker can be inspected to extract resource requirements without requiring a 50-qubit circuit run:
>>> tracker.totals {'executions': 451, 'batches': 2, 'batch_len': 451} >>> tracker.history["resources"][0] wires: 50 gates: 200 depth: 77 shots: Shots(total=None) gate_types: {'Rot': 100, 'CNOT': 100} gate_sizes: {1: 100, 2: 100}
Custom operations can now be constructed that solely define resource requirements — an explicit decomposition or matrix representation is not needed. (#4033)
PennyLane is now able to estimate the total resource requirements of circuits that include one or more of these operations, allowing you to estimate requirements for high-level algorithms composed of abstract subroutines.
These operations can be defined by inheriting from ResourcesOperation and overriding the
resources()method to return an appropriate Resources object:class CustomOp(qml.resource.ResourcesOperation): def resources(self): n = len(self.wires) r = qml.resource.Resources( num_wires=n, num_gates=n ** 2, depth=5, ) return r
>>> wires = [0, 1, 2] >>> c = CustomOp(wires) >>> c.resources() wires: 3 gates: 9 depth: 5 shots: Shots(total=None) gate_types: {} gate_sizes: {}
A quantum circuit that contains
CustomOpcan be created and inspected using qml.specs:dev = qml.device("default.qubit", wires=wires) @qml.qnode(dev) def circ(): qml.PauliZ(wires=0) CustomOp(wires) return qml.state()
>>> specs = qml.specs(circ)() >>> specs["resources"].depth 6
来自UnitaryHack的社区贡献 🤝
ParametrizedHamiltonian 现在有了改进的字符串表示。(#4176)
>>> def f1(p, t): return p[0] * jnp.sin(p[1] * t) >>> def f2(p, t): return p * t >>> coeffs = [2., f1, f2] >>> observables = [qml.PauliX(0), qml.PauliY(0), qml.PauliZ(0)] >>> qml.dot(coeffs, observables) (2.0*(PauliX(wires=[0]))) + (f1(params_0, t)*(PauliY(wires=[0]))) + (f2(params_1, t)*(PauliZ(wires=[0])))
量子信息模块现在支持 trace distance。 (#4181)
计算迹距离的两种情况已启用:
通过 qml.qinfo.trace_distance 的 QNode 转换:
dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(param): qml.RY(param, wires=0) qml.CNOT(wires=[0, 1]) return qml.state()
>>> trace_distance_circuit = qml.qinfo.trace_distance(circuit, circuit, wires0=[0], wires1=[0]) >>> x, y = np.array(0.4), np.array(0.6) >>> trace_distance_circuit((x,), (y,)) 0.047862689546603415
通过 qml.math.trace_distance 进行灵活的后处理:
>>> rho = np.array([[0.3, 0], [0, 0.7]]) >>> sigma = np.array([[0.5, 0], [0, 0.5]]) >>> qml.math.trace_distance(rho, sigma) 0.19999999999999998
现在可以使用 qml.QutritBasisState 准备三元比特基态。 (#4185)
wires = range(2) dev = qml.device("default.qutrit", wires=wires) @qml.qnode(dev) def qutrit_circuit(): qml.QutritBasisState([1, 1], wires=wires) qml.TAdd(wires=wires) return qml.probs(wires=1)
>>> qutrit_circuit() array([0., 0., 1.])
新增了一种变换 one_qubit_decomposition,用于提供将单量子比特单位矩阵分解为 X、Y 和 Z 旋转序列的统一接口。所有分解都将旋转角度简化为介于
0和4pi 之间。 (#4210) (#4246)>>> from pennylane.transforms import one_qubit_decomposition >>> U = np.array([[-0.28829348-0.78829734j, 0.30364367+0.45085995j], ... [ 0.53396245-0.10177564j, 0.76279558-0.35024096j]]) >>> one_qubit_decomposition(U, 0, "ZYZ") [RZ(tensor(12.32427531, requires_grad=True), wires=[0]), RY(tensor(1.14938178, requires_grad=True), wires=[0]), RZ(tensor(1.73305815, requires_grad=True), wires=[0])] >>> one_qubit_decomposition(U, 0, "XYX", return_global_phase=True) [RX(tensor(10.84535137, requires_grad=True), wires=[0]), RY(tensor(1.39749741, requires_grad=True), wires=[0]), RX(tensor(0.45246584, requires_grad=True), wires=[0]), (0.38469215914523336-0.9230449299422961j)*(Identity(wires=[0]))]
qml.ops.qubit.attributes中的has_unitary_generator属性不再包含具有非单位生成器的算子。 (#4183)PennyLane Docker 构建已更新,以包含最新的插件和接口版本。 (#4178)
对脉冲进行微分的扩展支持 ⚛️
随机参数移位梯度方法现在可以与硬件兼容的哈密顿量一起使用。 (#4132) (#4215)
这个新特性将随机参数移位梯度变换推广到脉冲 (
stoch_pulse_grad),支持除保利词之外的厄米生成项在脉冲哈密顿量中, 使其变得与硬件兼容。一种新的微分方法叫做 qml.gradients.pulse_generator 可用,它将经典处理与多变量门的参数移位规则相结合,以区分脉冲程序。在您的脉冲程序中通过设置
diff_method=qml.gradients.pulse_generator访问它。 (#4160)qml.pulse.ParametrizedEvolution现在使用 批处理 压缩稀疏行 (BCSR) 格式。 这允许在dense=False时直接计算单位的雅可比。 (#4126)def U(params): H = jnp.polyval * qml.PauliZ(0) # 与时间有关的哈密顿量 Um = qml.evolve(H, dense=False)(params, t=10.) return qml.matrix(Um) params = jnp.array([[0.5]], dtype=complex) jac = jax.jacobian(U, holomorphic=True)(params)
广播和对Torch和Keras层的其他调整 🦾
与
torch.nn和Keras集成的TorchLayer和KerasLayer已经升级。请考虑以下TorchLayer:n_qubits = 2 dev = qml.device("default.qubit", wires=n_qubits) @qml.qnode(dev) def qnode(inputs, weights): qml.AngleEmbedding(inputs, wires=range(n_qubits)) qml.BasicEntanglerLayers(weights, wires=range(n_qubits)) return [qml.expval(qml.PauliZ(wires=i)) for i in range(n_qubits)] n_layers = 6 weight_shapes = {"weights": (n_layers, n_qubits)} qlayer = qml.qnn.TorchLayer(qnode, weight_shapes)
以下功能现在可用:
对参数广播的原生支持。 (#4131)
>>> batch_size = 10 >>> inputs = torch.rand((batch_size, n_qubits)) >>> qlayer(inputs) >>> dev.num_executions == 1 True
使用
qml.draw()和qml.draw_mpl()绘制TorchLayer和KerasLayer的能力。 (#4197)>>> print(qml.draw(qlayer, show_matrices=False)(inputs)) 0: ─╭AngleEmbedding(M0)─╭BasicEntanglerLayers(M1)─┤
1: ─╰AngleEmbedding(M0)─╰BasicEntanglerLayers(M1)─┤ 支持
KerasLayer模型保存,并提供更清晰的TorchLayer模型保存说明。 (#4149) (#4158)>>> torch.save(qlayer.state_dict(), "weights.pt") # 保存 >>> qlayer.load_state_dict(torch.load("weights.pt")) # 加载 >>> qlayer.eval()
包含
KerasLayer或TorchLayer对象的混合模型也可以被保存和加载。
改进 🛠
一个更灵活的投影仪
qml.Projector现在接受状态向量表示,这使得在任何基底中创建投影算子成为可能。 (#4192)dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(state): return qml.expval(qml.Projector(state, wires=[0, 1])) zero_state = [0, 0] plusplus_state = np.array([1, 1, 1, 1]) / 2
>>> circuit(zero_state) tensor(1., requires_grad=True) >>> circuit(plusplus_state) tensor(0.25, requires_grad=True)
使用三态量子比特做更多事情
已经添加了三个类比于
RX、RY和RZ的三维旋转算子:qml.TRX: X旋转qml.TRY: 一个 Y 旋转qml.TRZ: 一个 Z 旋转
三元比特设备现在支持参数移位微分。
qchem模块
qchem.molecular_hamiltonian(),qchem.qubit_observable(),qchem.import_operator(), 和qchem.dipole_moment()现在在enable_new_opmath()激活时返回一个算术运算符。 (#4138) (#4159) (#4189) (#4204)已添加对所有电子资源估算的非立方晶格支持。 (3956)
函数
qchem.molecular_hamiltonian()已升级以支持用于构建可微分哈密顿量的自定义线路。哈密顿量系数的零虚部已被移除。 (#4050) (#4094)缓存保利门对象的乔丹-维根变换已经加速。 (#4046)
当使用
dhf方法对开放壳层系统进行计算时,qchem.molecular_hamiltonian现在会引发错误。这重复了在qchem.Molecule中的类似错误,但明确指出可以使用pyscf后端进行开放壳层计算。 (#4058)更新了各种量子比特削减方法以支持算符算术运算。 (#4252)
下一代设备 API
新的设备接口已经与
qml.execute集成,支持自动求导、反向传播和无导数计算。 (#3903)已向
DefaultQubit2设备添加了对伴随微分的支持。 (#4037)新增了一个名为
measure_with_samples的函数,该函数返回给定状态的基于样本的测量结果。 (#4083) (#4093) (#4162) (#4254)DefaultQubit2.preprocess现在返回一个新的ExecutionConfig对象,该对象包含gradient_method、use_device_gradient和grad_on_execution的决策。 (#4102)支持基于样本的测量已经添加到
DefaultQubit2设备中。 (#4105) (#4114) (#4133) (#4172)现在,
DefaultQubit2设备有一个seed关键字参数。(#4120)为
ParametrizedEvolution添加了一个dense关键字,允许强制使用密集或稀疏矩阵。 (#4079) (#4095) (#4285)添加类型变量
pennylane.typing.Result和pennylane.typing.ResultBatch用于类型提示执行的结果。 (#4018)qml.devices.ExecutionConfig不再有shots属性,因为它现在在QuantumScript上。
现在有一个use_device_gradient属性。ExecutionConfig.grad_on_execution = None表示请求"best",而不是字符串。 (#4102)Jax的新设备接口已与
qml.execute集成。 (#4137)新的设备接口现在与
qml.execute集成了,用于 Tensorflow。 (#4169)实验设备
DefaultQubit2现在支持qml.Snapshot。 (#4193)实验设备接口与
(#4196)QNode集成。新的设备接口与
qml.execute在Torch中集成。 (#4257)
处理镜头
QuantumScript现在有一个shots属性,允许将 shots 绑定到执行而不是设备上。 (#4067) (#4103) (#4106) (#4112)现在为
Shots 类的实例正确地定义了几个Python内置函数。print: 打印Shots实例现在是可读的str: 将Shots实例转换为人类可读的字符串==: 将两个不同的Shots实例进行比较hash: 获取Shots实例的哈希值
qml.devices.ExecutionConfig不再有shots属性,因为它现在在QuantumScript上。它现在有一个use_device_gradient属性。ExecutionConfig.grad_on_execution = None表示请求"best"而不是一个字符串。 (#4102)QuantumScript.shots已与 QNodes 集成,以便在QNode构建期间将 shots 放置在QuantumScript上。 (#4110)该
gradients模块已更新为内部使用新的Shots对象 (#4152)
操作符
qml.prod现在接受单个量子函数输入来创建新的Prod运算符。 (#4011)DiagonalQubitUnitary现在分解为RZ、IsingZZ和MultiRZ门,而不是使用稠密矩阵的QubitUnitary操作。 (#4035)现在,所有被排队的对象在一个
AnnotatedQueue中都被包装,以便AnnotatedQueue不依赖于任何运算符或测量过程的哈希值。(#4087)一个
ParametrizedEvolution的dense关键字已被添加,可以强制使用密集或稀疏矩阵。 (#4079) (#4095)添加了一个新函数
qml.ops.functions.bind_new_parameters,该函数在不改变原始操作符的情况下创建一个带有新参数的操作符副本。 (#4113) (#4256)qml.CY已从qml.ops.qubit.non_parametric_ops移动到qml.ops.op_math.controlled_ops并现在继承自qml.ops.op_math.ControlledOp。 (#4116)qml.CZ现在继承自ControlledOp类,并支持对任意幂的指数运算,使用pow,不再仅限于整数。它还支持sparse_matrix和decomposition表示法。 (#4117)现在为
(#4142)Sum类构建泡利表示的速度更快。qml.drawer.drawable_layers.drawable_layers和qml.CircuitGraph已更新,以不再依赖于Operator的相等性或哈希值来正确工作。 (#4143)
其他改进
已通过
qml.math.reduce_dm和qml.math.reduce_statevector增加了降密度矩阵功能。 两个函数都支持广播。 (#4173)以下在
qml.qinfo中的函数现在支持参数广播:reduced_dmpurityvn_entropymutual_infofidelityrelative_entropytrace_distance
以下函数在
qml.math中现在支持参数广播:purityvn_entropymutual_infofidelityrelative_entropymax_entropysqrt_matrix
pulse.ParametrizedEvolution现在会在输入参数的数量与生成它的ParametrizedHamiltonian中的参数化系数数量不匹配时引发错误。HardwareHamiltonian被排除在外,不会进行检查。 (#4216)所有绘图方法中
show_matrices关键字参数的默认值现在是True。 这允许快速洞察广播的带子,例如。 (#3920)已添加
qml.typing.Result和qml.typing.ResultBatch的类型变量,以对执行结果进行类型提示。 (#4108)Jax-JIT 接口现在使用符号零来确定可训练参数。 (4075)
新增了一个名为
pauli.pauli_word_prefactor()的函数,用于提取给定 Pauli 单词的前因子。(#4164)函数和方法的可变长度参数列表在某些文档字符串中现在更加清晰了。 (#4242)
qml.drawer.drawable_layers.drawable_layers和qml.CircuitGraph已更新,以不再依赖于Operator的相等性或哈希值来正确工作。 (#4143)现在可以通过经典控制信号将中间电路测量连接到条件操作。(#4228)
自动微分接口现在在反向传播中以单个批次提交所有所需的记录。
(#4245)
重大变更 💔
在所有绘图方法中,
show_matrices关键字参数的默认值现在是True。这允许快速洞察广播的录音带,例如。(#3920)DiagonalQubitUnitary现在分解为RZ、IsingZZ和MultiRZ门,而不是QubitUnitary。 (#4035)Jax 可训练参数现在是
Tracer而不是JVPTracer。这并不总是 JIT 接口的正确定义,但我们在自定义 JVP 中使用符号零进行更新。 (4075)实验设备接口
qml.devices.experimental.Device现在要求preprocess方法 也要返回一个ExecutionConfig对象。这允许设备选择对于各种超参数如gradient_method和grad_on_execution来说,"best"的含义是什么。 (#4007) (#4102)使用Jax的梯度变换不再支持
argnum。请改用argnums。 (#4076)qml.collections,qml.op_sum,和qml.utils.sparse_hamiltonian已被移除。 (#4071)现在,
pennylane.transforms.qcut模块在电路切割工作流中使用(op, id(op))作为有向多重图中的节点,而不是op。此更改消除了模块对算子哈希的依赖。 (#4227)Operator.data现在返回一个tuple而不是一个list。 (#4222)脉冲微分方法,
pulse_generator和stoch_pulse_grad,现在在直接应用于 QNode 时会引发错误。相反,使用通过 JAX 入口点进行微分 (jax.grad,jax.jacobian, …)。(#4241)
弃用功能 👋
LieAlgebraOptimizer已更名为RiemannianGradientOptimizer。 [(#4153)(https://github.com/PennyLaneAI/pennylane/pull/4153)]Operation.base_name已被弃用。请改用Operation.name或type(op).__name__。QuantumScript的name关键字参数和属性已被弃用。 这也影响到QuantumTape和OperationRecorder。 (#4141)已移除
qml.grouping模块。它的功能已在qml.pauli模块中重新组织。DefaultQubit的公共方法正在进行更改,以遵循新设备 API,正如在DefaultQubit2中使用的那样。文档字符串中已经添加了警告以反映这一点。 (#4145)qml.math.reduced_dm已被弃用。请使用qml.math.reduce_dm或qml.math.reduce_statevector代替。 (#4173)qml.math.purity、qml.math.vn_entropy、qml.math.mutual_info、qml.math.fidelity、qml.math.relative_entropy和qml.math.max_entropy不再支持向量状态作为输入。请在传递给任何这些函数之前,对输入调用qml.math.dm_from_state_vector。 (#4186)qml.operation.Operator中的do_queue关键字参数已被弃用。请使用qml.QueuingManager.stop_recording()上下文,代替设置do_queue=False。 (#4148)zyz_decomposition和xyx_decomposition现在已不推荐使用,建议使用one_qubit_decomposition。 (#4230)
文档 📝
文档已更新,以在初始化时构造
QuantumTape,而不是使用排队方式。 (#4243)qml.ops.op_math.Pow.__new__的文档字符串现在已完成,并且与qml.ops.op_math.Adjoint.__new__一起进行了更新。 (#4231)现在
qml.grad的文档字符串说明它只应与Autograd接口一起使用。 (#4202)在
qchem.Molecule的文档字符串中,mult的描述现在正确说明了支持的mult值。 (#4058)
错误修复 🐛
修复了在 JAX-JIT 接口中使用
grad_on_execution=False的伴随雅可比结果。 (4217)修复了当系数为tensorflow且目标矩阵不是
(#4249)complex128时的SProd矩阵。修复了一个错误,即
stoch_pulse_grad会忽略脉冲哈密顿量生成项中重新缩放的保利字的前因子。 (4156)修复了一个错误,
wires参数传递给qml.density_matrix时未考虑电线的顺序。 (#4072)在
interfaces/autograd.py中的一个补丁检查了strawberryfields.gbs设备已被移除。 该设备固定在 PennyLane <= v0.29.0,因此该补丁不再必要。 (#4089)qml.pauli.are_identical_pauli_words现在将所有的恒等式视为相等。具有非标准线路顺序的哈密顿量上的恒等项不再被消除。 (#4161)qml.pauli_sentence()现在与空哈密顿量qml.Hamiltonian([], [])兼容。 (#4171)修复了 Jax 的一个错误,在执行多个带有
gradient_fn="device"的情况时会失败。 (#4190)当使用伴随微分进行广播时,会引发更有意义的错误消息,适用于
(#4203)DefaultQubit。qml.ops.qubit.attributes中的has_unitary_generator属性不再包含具有非单位生成元的算子。 (#4183)修复了一个错误,使用
convention="Wx""和qml.matrix(op)时op = qml.qsvt()在全局相位下不正确。 (#4214)修复了
xyx_decomposition中角度计算的bug,这导致它给出了不正确的分解。 一个if条件应该防止除以零的错误,但实际上是除以了参数的正弦值。因此,任何倍数的 $pi$ 应该触发该条件,但它只检查参数是否为0。示例:qml.Rot(2.3, 2.3, 2.3)(#4210)修复了一个错误,该错误导致
ShotAdaptiveOptimizer在优化过程中截断了参数分布的镜头维度。(#4240)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
Venkatakrishnan AnushKrishna,
Utkarsh Azad,
Thomas Bromley,
Isaac De Vlugt,
Lillian M. A. Frederiksen,
Emiliano Godinez Ramirez
Nikhil Harle
Soran Jahangiri,
Edward Jiang,
Korbinian Kottmann,
Christina Lee,
Vincent Michaud-Rioux,
Romain Moyard,
Tristan Nemoz,
Mudit Pandey,
Manul Patel,
Borja Requena,
Modjtaba Shokrian-Zini,
Mainak Roy,
Matthew Silverman,
Jay Soni,
Edward Thomas,
David Wierichs,
Frederik Wilde.
- orphan
发布 0.30.0¶
自上次发布以来的新特性
硬件上的脉冲编程 ⚛️🔬
Support for loading time-dependent Hamiltonians that are compatible with quantum hardware has been added, making it possible to load a Hamiltonian that describes an ensemble of Rydberg atoms or a collection of transmon qubits. (#3749) (#3911) (#3930) (#3936) (#3966) (#3987) (#4021) (#4040)
Rydberg atoms are the foundational unit for neutral atom quantum computing. A Rydberg-system Hamiltonian can be constructed from a drive term —
qml.pulse.rydberg_drive— and an interaction term —qml.pulse.rydberg_interaction:from jax import numpy as jnp atom_coordinates = [[0, 0], [0, 4], [4, 0], [4, 4]] wires = [0, 1, 2, 3] amplitude = lambda p, t: p * jnp.sin(jnp.pi * t) phase = jnp.pi / 2 detuning = 3 * jnp.pi / 4 H_d = qml.pulse.rydberg_drive(amplitude, phase, detuning, wires) H_i = qml.pulse.rydberg_interaction(atom_coordinates, wires) H = H_d + H_i
The time-dependent Hamiltonian
Hcan be used in a PennyLane pulse-level differentiable circuit:dev = qml.device("default.qubit.jax", wires=wires) @qml.qnode(dev, interface="jax") def circuit(params): qml.evolve(H)(params, t=[0, 10]) return qml.expval(qml.PauliZ(0))
>>> params = jnp.array([2.4]) >>> circuit(params) Array(0.6316659, dtype=float32) >>> import jax >>> jax.grad(circuit)(params) Array([1.3116529], dtype=float32)
The qml.pulse page contains additional details. Check out our release blog post for a demonstration of how to perform the execution on actual hardware!
A pulse-level circuit can now be differentiated using a stochastic parameter-shift method. (#3780) (#3900) (#4000) (#4004)
The new qml.gradient.stoch_pulse_grad differentiation method unlocks stochastic-parameter-shift differentiation for pulse-level circuits. The current version of this new method is restricted to Hamiltonians composed of parametrized Pauli words, but future updates to extend to parametrized Pauli sentences can allow this method to be compatible with hardware-based systems such as an ensemble of Rydberg atoms.
This method can be activated by setting
diff_methodto qml.gradient.stoch_pulse_grad:>>> dev = qml.device("default.qubit.jax", wires=2) >>> sin = lambda p, t: jax.numpy.sin(p * t) >>> ZZ = qml.PauliZ(0) @ qml.PauliZ(1) >>> H = 0.5 * qml.PauliX(0) + qml.pulse.constant * ZZ + sin * qml.PauliX(1) >>> @qml.qnode(dev, interface="jax", diff_method=qml.gradients.stoch_pulse_grad) >>> def ansatz(params): ... qml.evolve(H)(params, (0.2, 1.)) ... return qml.expval(qml.PauliY(1)) >>> params = [jax.numpy.array(0.4), jax.numpy.array(1.3)] >>> jax.grad(ansatz)(params) [Array(0.16921353, dtype=float32, weak_type=True), Array(-0.2537478, dtype=float32, weak_type=True)]
量子奇异值变换 🐛➡️🦋
PennyLane now supports the quantum singular value transformation (QSVT), which describes how a quantum circuit can be constructed to apply a polynomial transformation to the singular values of an input matrix. (#3756) (#3757) (#3758) (#3905) (#3909) (#3926) (#4023)
Consider a matrix
Aalong with a vectoranglesthat describes the target polynomial transformation. Theqml.qsvtfunction creates a corresponding circuit:dev = qml.device("default.qubit", wires=2) A = np.array([[0.1, 0.2], [0.3, 0.4]]) angles = np.array([0.1, 0.2, 0.3]) @qml.qnode(dev) def example_circuit(A): qml.qsvt(A, angles, wires=[0, 1]) return qml.expval(qml.PauliZ(wires=0))
This circuit is composed of
qml.BlockEncodeandqml.PCPhaseoperations.>>> example_circuit(A) tensor(0.97777078, requires_grad=True) >>> print(example_circuit.qtape.expand(depth=1).draw(decimals=2)) 0: ─╭∏_ϕ(0.30)─╭BlockEncode(M0)─╭∏_ϕ(0.20)─╭BlockEncode(M0)†─╭∏_ϕ(0.10)─┤ <Z> 1: ─╰∏_ϕ(0.30)─╰BlockEncode(M0)─╰∏_ϕ(0.20)─╰BlockEncode(M0)†─╰∏_ϕ(0.10)─┤
The qml.qsvt function creates a circuit that is targeted at simulators due to the use of matrix-based operations. For advanced users, you can use the operation-based
qml.QSVTtemplate to perform the transformation with a custom choice of unitary and projector operations, which may be hardware compatible if a decomposition is provided.The QSVT is a complex but powerful transformation capable of generalizing important algorithms like amplitude amplification. Stay tuned for a demo in the coming few weeks to learn more!
直观的 QNode 返回 ↩️
引入了更新的 QNode 返回系统。PennyLane QNodes 现在准确地返回您所告诉它们的内容! 🎉 (#3957) (#3969) (#3946) (#3913) (#3914) (#3934)
这是在 PennyLane 版本 0.25 中引入的一项实验性功能,通过
qml.enable_return()启用。现在,它是默认的返回系统。让我们看看它是如何工作的。考虑以下电路:
import pennylane as qml dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0)), qml.probs(0)
在 PennyLane 的版本 0.29 及之前,
circuit()将返回一个长度为 3 的数组:>>> circuit(0.5) tensor([0.87758256, 0.93879128, 0.06120872], requires_grad=True)
在版本 0.30 及以上,
circuit()返回一个包含期望值和概率的长度为 2 的元组:>>> circuit(0.5) (tensor(0.87758256, requires_grad=True), tensor([0.93879128, 0.06120872], requires_grad=True))
您可以找到 关于此更改的更多详细信息, 以及帮助和故障排除提示以解决任何问题。 如果您还有问题、意见或顾虑,我们鼓励您在 PennyLane 讨论论坛 上发帖。
一系列性能调整 🏃💨
具有多量子比特控制的单量子比特操作现在可以使用更少的CNOT门更有效地分解。 (#3851)
提供了来自 arXiv:2302.06377 的三种分解,与已可用的
qml.ops.ctrl_decomp_zyz相比表现良好:wires = [0, 1, 2, 3, 4, 5] control_wires = wires[1:] @qml.qnode(qml.device('default.qubit', wires=6)) def circuit(): with qml.QueuingManager.stop_recording(): # 分解不会解除目标的排队 target = qml.RX(np.pi/2, wires=0) qml.ops.ctrl_decomp_bisect(target, (1, 2, 3, 4, 5)) return qml.state() print(qml.draw(circuit, expansion_strategy="device")())
0: ──H─╭X──U(M0)─╭X──U(M0)†─╭X──U(M0)─╭X──U(M0)†──H─┤ 状态 1: ────├●────────│──────────├●────────│─────────────┤ 状态 2: ────├●────────│──────────├●────────│─────────────┤ 状态 3: ────╰●────────│──────────╰●────────│─────────────┤ 状态 4: ──────────────├●───────────────────├●────────────┤ 状态 5: ──────────────╰●───────────────────╰●────────────┤ 状态
新增了一种对
qml.SingleExcitation的分解,减少了一半所需的CNOT数量。 (3976)>>> qml.SingleExcitation.compute_decomposition(1.23, wires=(0,1)) [Adjoint(T(wires=[0])), Hadamard(wires=[0]), S(wires=[0]), Adjoint(T(wires=[1])), Adjoint(S(wires=[1])), Hadamard(wires=[1]), CNOT(wires=[1, 0]), RZ(-0.615, wires=[0]), RY(0.615, wires=[1]), CNOT(wires=[1, 0]), Adjoint(S(wires=[0])), Hadamard(wires=[0]), T(wires=[0]), Hadamard(wires=[1]), S(wires=[1]), T(wires=[1])]
The adjoint differentiation method can now be more efficient, avoiding the decomposition of operations that can be differentiated directly. Any operation that defines a
generator()can be differentiated with the adjoint method. (#3874)For example, in version 0.29 the
qml.CRYoperation would be decomposed when calculating the adjoint-method gradient. Executing the code below shows that this decomposition no longer takes place in version 0.30 andqml.CRYis differentiated directly:import jax from jax import numpy as jnp def compute_decomposition(self, phi, wires): print("A decomposition has been performed!") decomp_ops = [ qml.RY(phi / 2, wires=wires[1]), qml.CNOT(wires=wires), qml.RY(-phi / 2, wires=wires[1]), qml.CNOT(wires=wires), ] return decomp_ops qml.CRY.compute_decomposition = compute_decomposition dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, diff_method="adjoint") def circuit(phi): qml.Hadamard(wires=0) qml.CRY(phi, wires=[0, 1]) return qml.expval(qml.PauliZ(1)) phi = jnp.array(0.5) jax.grad(circuit)(phi)
使用
jax.jit和梯度变换计算导数时效率更高;可训练参数现在被正确设置,而不需要每个参数都设置为可训练。在下面的电路中,现在只计算相对于参数
b的导数:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, interface="jax-jit") def circuit(a, b): qml.RX(a, wires=0) qml.RY(b, wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)) a = jnp.array(0.4) b = jnp.array(0.5) jac = jax.jacobian(circuit, argnums=[1]) jac_jit = jax.jit(jac) jac_jit(a, b) assert len(circuit.tape.trainable_params) == 1
改进 🛠
下一代设备 API
在此次发布及未来版本中,我们将对我们的设备API进行更改,目的是让开发插件对开发者来说变得更容易,并解锁新的设备功能。用户在使用PennyLane时不应该感受到这些变化,但以下是此次发布的更改内容:
在
devices/qubit中添加或改进了几个函数:qml.devices.qubit.preprocess现在允许使用具有非交换性观测量的电路。 (#3857)qml.devices.qubit.measure现在以一种与反向传播兼容的方式计算Hamiltonian和Sum的期望值。 (#3862)
脉冲编程
以下是添加或改进的功能、类等,以便于模拟Rydberg原子的集合: (#3749) (#3911) (#3930) (#3936) (#3966) (#3987) (#3889) (#4021)
HardwareHamiltonian: 一个内部类,包含关于脉冲和设置的附加信息。rydberg_interaction: 一个用户接口函数,它返回一个HardwareHamiltonian,包含所有 Rydberg 原子的交互哈密顿量。transmon_interaction: 一个面向用户的函数,用于构建描述超导传输子系统电路量子电动力学相互作用哈密顿量的哈密顿量。drive: 一个面向用户的函数,返回一个ParametrizedHamiltonian(HardwareHamiltonian),该函数包含驱动电磁场与一组量子位之间相互作用的哈密顿量。rydberg_drive: 一个用户可用的函数,返回一个ParametrizedHamiltonian(HardwareHamiltonian),包含驱动激光场与一组铷跃迁原子之间相互作用的哈密顿量。max_distance:添加到qml.pulse.rydberg_interaction的关键字参数,允许去除相互距离超过max_distance的原子的微不足道的贡献。
ParametrizedEvolution现在接受两个新的布尔关键字参数:return_intermediate和complementary。它们允许计算中间时间演化矩阵。(#3900)激活
return_intermediate将返回中间时间演化步骤,例如操作的矩阵,或者在 QNode 中使用时量子电路的矩阵。激活complementary会使这些中间步骤成为与complementary=False的输出相补充的 剩余 时间演化。有关详细信息,请参阅 docstring。与
qml.gradient.stoch_pulse_grad兼容的硬件脉冲序列梯度现在可以更快地使用新的关键字参数use_broadcasting进行计算。执行返回中间演化的ParametrizedEvolution使用状态向量ODE求解器的性能也得到了提升。 (#4000) (#4004)
直观的 QNode 返回值
QNode的关键字参数
mode已被布尔值grad_on_execution替代。 (#3969)“
(#3946)"default.gaussian"”设备和参数偏移CV都支持新的返回系统,但仅适用于单次测量。DefaultQutrit现在支持新的返回系统。 (#3934)
性能改善
tapering()、tapering_hf()和clifford()的效率得到了提升。 (3942)当用于更大的可观察量时,
tapering()和tapering_hf()的峰值内存需求得到了改善。 (3977)泡利算术已被更新,以更高效地转换为哈密顿量。 (#3939)
Operator具有一个新的布尔属性has_generator。它返回Operator是否定义了generator。has_generator在qml.operation.has_gen中使用,提升了性能并扩展了微分支持。 (#3875)现在
CompositeOp的性能得到了显著提升,因为它重写了确定是否与一组参数一起使用的功能(请参见Operator._check_batching)。Hamiltonian现在也重写了这一点,但由于它不支持批处理,因此没有任何作用。现在,
Sum操作符的性能得到了显著提升,因为is_hermitian检查 如果操作符具有预先计算的 Pauli 表示式,则所有系数都是实数。现在,
coefficients函数和visualize子模块的qml.fourier模块允许为输入函数的不同参数分配不同的度数。(#3005)之前,
qml.fourier.coefficients的参数degree和filter_threshold预期为整数。现在,它们可以是整数序列,每个函数参数对应一个整数(即len(degree)==n_inputs),返回的数组形状为(2*degrees[0]+1,..., 2*degrees[-1]+1)。qml.fourier.visualize中的函数相应地接受这样的系数数组。
其他改进
一个
Shots类被添加到measurements模块中,用于保存与射击相关的数据。 (#3682)PennyLane中的自定义JVP规则现在也支持非标量和混合形状的电路参数,以及多维电路返回类型,例如广播的
(#3766)qml.probs。更新了
AdaptiveOptimizer以使用非默认的用户定义 QNode 参数。 (#3765)运算符现在使用
TensorLike类型的双下划线方法。 (#3749)qml.QubitStateVector.state_vector现在支持广播功能。 (#3852)qml.SparseHamiltonian现在可以应用于电路中的任意导线,而不再局限于电路中的所有导线。 (#3888)运算符现在可以通过标量进行除法,使用
/,并增加了Operation.__truediv__魔法方法。 (#3749)打印一个
MutualInfoMP的实例现在显示了两个子系统之间线路的分布。 (#3898)Operator.num_wires已从抽象值更改为AnyWires。 (#3919)qml.transforms.sum_expand不会在Device.batch_transform中运行,如果设备支持Sum可观测量。 (#3915)在
qml.qchem.Molecule中,n_electrons的类型已设置为int。 (#3885)如果测量了
classical_shadow或shadow_expval,则已向QutritDevice添加了显式错误。 (#3934)QubitDevice现在定义了私有_get_diagonalizing_gates(circuit)方法,并在执行电路时使用它。 这允许继承自QubitDevice的设备覆盖并自定义它们对对角化门的定义。 (#3938)retworkx已更名为rustworkx以适应包名称的变化。 (#3975)qml.transforms.convert_to_numpy_parameters已添加以将具有接口特定参数的电路转换为仅具有numpy参数的电路。此变换旨在替换qml.tape.Unwrap。 (#3899)qml.operation.WiresEnum.AllWires现在是 -2 而不是 0,以避免op.num_wires = 0和op.num_wires = AllWires之间的歧义。(#3978)执行代码已更新为使用新的
qml.transforms.convert_to_numpy_parameters代替qml.tape.Unwrap。 (#3989)一个
expand_tape的子例程已被转换为qml.tape.tape.rotations_and_diagonal_measurements, 这是一个辅助函数,用于计算具有重叠电线的测量带的旋转和对角测量。 (#3912)各种运算符和模板已被更新,以确保它们的分解只返回运算符的列表。 (#3243)
已经引入了
qml.operation.enable_new_opmath切换,以使 dunder 方法返回算术运算符,而不是Hamiltonian或Tensor。 (#4008)>>> type(qml.PauliX(0) @ qml.PauliZ(1))
>>> qml.operation.enable_new_opmath() >>> type(qml.PauliX(0) @ qml.PauliZ(1)) >>> qml.operation.disable_new_opmath() >>> type(qml.PauliX(0) @ qml.PauliZ(1)) 新增了一个数据类
Resources来存储量子电路中门的数量和电路深度等资源。 (#3981)一个名为
_count_resources()的新函数被添加,用于计算在给定数量的 shots 下执行QuantumTape所需的资源。 (#3996)QuantumScript.specs已被修改以使用新的Resources类。这也修改了qml.specs()的输出。 (#4015)添加了一个新的类
ResourcesOperation,允许用户使用自定义资源信息定义操作。 (#4026)例如,用户可以通过继承这个新类来定义一个自定义操作:
>>> class CustomOp(qml.resource.ResourcesOperation): ... def resources(self): ... return qml.resource.Resources(num_wires=1, num_gates=2, ... gate_types={"PauliX": 2}) ... >>> CustomOp(wires=1) CustomOp(wires=[1])
然后,我们可以使用
qml.specs()跟踪和显示工作流的资源:>>> dev = qml.device("default.qubit", wires=[0,1]) >>> @qml.qnode(dev) ... def circ(): ... qml.PauliZ(wires=0) ... CustomOp(wires=1) ... return qml.state() ... >>> print(qml.specs(circ)()['resources']) wires: 2 gates: 3 depth: 1 shots: 0 gate_types: {'PauliZ': 1, 'PauliX': 2}
MeasurementProcess.shape现在接受一个Shots对象作为其参数之一,以减少对不必要执行细节的暴露。 (#4012)
重大变更 💔
从
qml.classical_shadow和qml.shadow_expval中移除了seed_recipes参数。 (#4020)电路方法
get_operation已经更新了签名。 (#3998)这两个 JIT 接口不再与 JAX
>0.4.3兼容(对于这些版本我们会引发错误)。(#3877)一个实现自定义
generator方法的操作,但不总是返回有效生成器,还必须实现has_generator属性,以反映在哪些情况下将返回生成器。Jax接口的可训练参数是由设置
argnums定义的JVPTracer参数。之前,所有JAX跟踪器,包括用于JIT编译的那些,被解释为可训练的。 (#3697)关键字参数
argnums现在用于使用 Jax 的梯度变换,而不是argnum。argnum在使用 Jax 时会自动转换为argnums,并将在 PennyLane 的 v0.31 中不再支持。 (#3697) (#3847)qml.OrbitalRotation和,因而,qml.GateFabric现在与交错的乔丹-维格纳排序更为一致。之前,它们与顺序的乔丹-维格纳排序一致。(#3861)某些
MeasurementProcess类现在只能使用它们实际会使用的参数进行qml.tape.tape.expand_tape和因此,QuantumScript.expand不再用旋转和对角测量更新输入带。请注意,返回的新扩展带仍将具有旋转和对角测量。 (#3912)qml.Evolution现在使用-1j作为系数初始化因子,而不是1j。 (#4024)
弃用功能 👋
此版本没有内容!
文档 📝
关于操作参数的
QubitUnitary和DiagonalQubitUnitary的文档进行了澄清。文档中的拼写错误已在对
inspecting_circuits和chemistry的介绍中更正。 (#3844)用法 细节和理论部分在qml.qchem.taper_operation的文档中已被分开。 (3977)
修复错误 🐛
ctrl_decomp_bisect和ctrl_decomp_zyz在分解受控操作时不再默认使用,因为某些目标算子的zyz分解中存在全局相位差。 (#4065)修复了一个错误,
qml.math.dot返回了一个 numpy 数组而不是 autograd 数组,在某些情况下导致 autograd 导数中断。 (#4019)运算符现在将一个
tuple转换为np.ndarray以及list。(#4022)修复了一个错误,其中
qml.ctrl和参数门在GPU上的PyTorch张量不兼容。 (#4002)修复了一个错误,即在新的返回系统中,广播扩展结果沿错误的轴堆叠。(#3984)
在
qml.jacobian中引发了更具信息量的错误消息,以解释新返回类型规范可能出现的问题。 (#3997)修复了一个错误,即在调用
Evolution.generator时,如果coeff是一个复数 ArrayBox,会引发错误。 (#3796)MeasurementProcess.hash现在使用可观测量的哈希属性。该属性现在依赖于所有影响对象行为的属性,例如VnEntropyMP.log_base或两个子系统之间的导线分布在MutualInfoMP中。(#3898)枚举
measurements.Purity已被添加以便定义PurityMP.return_type。str和repr现在也为PurityMP定义。Sum.hash和Prod.hash已稍作更改,以便与非数值线缆标签一起使用。sum_expand现在应该返回正确的结果,而不会将某些产品视为相同操作。 (#3898)修复了一个错误,导致在与其他算符相加时,系数未正确排序
ParametrizedHamiltonian。 (#3749) (#3902)度量张量变换现在与Jax完全兼容,因此用户可以提供多个参数。 (#3847)
qml.math.ndim和qml.math.shape现在已注册为内置函数和自动求导,以适应 Autoray 0.6.1。 #3864确保
qml.data.load返回的数据集顺序稳定且符合预期。 (#3856)现在,
qml.equal函数可以处理ParametrizedEvolution运算符的比较。 (#3870)qml.devices.qubit.apply_operation捕获当PauliZ或CNOT门应用于一个大型 (>8 根) tensorflow 状态时发生的tf.errors.UnimplementedError。当发生这种情况时,逻辑回退到 tensordot 逻辑。(#3884)在大多数情况下,支持固定参数广播与
qml.counts,否则引入显式错误。 (#3876)如果使用 Jax-jit 的 QNode 返回
counts并且有可训练参数,则现在会引发错误 (#3892)对
test_dipole_of中的参考值进行了修正,以考虑由于新的PySCF 2.2.0版本而导致的计算偶极矩值的微小变化(~2e-8)。 (#3908)SampleMP.shape现在在仅对设备接线的一部分进行采样时是正确的。 (#3921)在
qchem.Molecule中修复了一个问题,允许使用其他基组,而不是硬编码的基组,来 用于Molecule类。 (#3955)修复了一个错误,所有继承自
DefaultQubit的设备声称支持ParametrizedEvolution。现在,只有DefaultQubitJax支持该运算符,符合预期。(#3964)确保并行
AnnotatedQueues不会相互排队内容。 (#3924)为
PauliWord和PauliSentence添加了一个map_wires方法,并确保运算符在其各自的map_wires方法中调用它,如果它们有一个 Pauli 表示。修复了当一个
Tensor与一个Hamiltonian相乘或反之时出现的错误。 (#4036)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
Komi Amiko,
Utkarsh Azad,
Thomas Bromley,
Isaac De Vlugt,
Olivia Di Matteo,
Lillian M. A. Frederiksen,
Diego Guala,
Soran Jahangiri,
Korbinian Kottmann,
Christina Lee,
Vincent Michaud-Rioux,
Albert Mitjans Coma,
Romain Moyard,
Lee J. O’Riordan,
Mudit Pandey,
Matthew Silverman,
Jay Soni,
David Wierichs。
- orphan
发布 0.29.0¶
自上次发布以来的新特性
脉冲编程 🔊
Support for creating pulse-based circuits that describe evolution under a time-dependent Hamiltonian has now been added, as well as the ability to execute and differentiate these pulse-based circuits on simulator. (#3586) (#3617) (#3645) (#3652) (#3665) (#3673) (#3706) (#3730)
A time-dependent Hamiltonian can be created using
qml.pulse.ParametrizedHamiltonian, which holds information representing a linear combination of operators with parametrized coefficents and can be constructed as follows:from jax import numpy as jnp f1 = lambda p, t: p * jnp.sin(t) * (t - 1) f2 = lambda p, t: p[0] * jnp.cos(p[1]* t ** 2) XX = qml.PauliX(0) @ qml.PauliX(1) YY = qml.PauliY(0) @ qml.PauliY(1) ZZ = qml.PauliZ(0) @ qml.PauliZ(1) H = 2 * ZZ + f1 * XX + f2 * YY
>>> H ParametrizedHamiltonian: terms=3 >>> p1 = jnp.array(1.2) >>> p2 = jnp.array([2.3, 3.4]) >>> H((p1, p2), t=0.5) (2*(PauliZ(wires=[0]) @ PauliZ(wires=[1]))) + ((-0.2876553231625218*(PauliX(wires=[0]) @ PauliX(wires=[1]))) + (1.517961235535459*(PauliY(wires=[0]) @ PauliY(wires=[1]))))
The time-dependent Hamiltonian can be used within a circuit with
qml.evolve:def pulse_circuit(params, time): qml.evolve(H)(params, time) return qml.expval(qml.PauliX(0) @ qml.PauliY(1))
Pulse-based circuits can be executed and differentiated on the
default.qubit.jaxsimulator using JAX as an interface:>>> dev = qml.device("default.qubit.jax", wires=2) >>> qnode = qml.QNode(pulse_circuit, dev, interface="jax") >>> params = (p1, p2) >>> qnode(params, time=0.5) Array(0.72153819, dtype=float64) >>> jax.grad(qnode)(params, time=0.5) (Array(-0.11324919, dtype=float64), Array([-0.64399616, 0.06326374], dtype=float64))
Check out the qml.pulse documentation page for more details!
特殊酉操作 🌞
A new operation
qml.SpecialUnitaryhas been added, providing access to an arbitrary unitary gate via a parametrization in the Pauli basis. (#3650) (#3651) (#3674)qml.SpecialUnitarycreates a unitary that exponentiates a linear combination of all possible Pauli words in lexicographical order — except for the identity operator — fornum_wireswires, of which there are4**num_wires - 1. As its first argument,qml.SpecialUnitarytakes a list of the4**num_wires - 1parameters that are the coefficients of the linear combination.To see all possible Pauli words for
num_wireswires, you can use theqml.ops.qubit.special_unitary.pauli_basis_stringsfunction:>>> qml.ops.qubit.special_unitary.pauli_basis_strings(1) # 4**1-1 = 3 Pauli words ['X', 'Y', 'Z'] >>> qml.ops.qubit.special_unitary.pauli_basis_strings(2) # 4**2-1 = 15 Pauli words ['IX', 'IY', 'IZ', 'XI', 'XX', 'XY', 'XZ', 'YI', 'YX', 'YY', 'YZ', 'ZI', 'ZX', 'ZY', 'ZZ']
To use
qml.SpecialUnitary, for example, on a single qubit, we may define>>> thetas = np.array([0.2, 0.1, -0.5]) >>> U = qml.SpecialUnitary(thetas, 0) >>> qml.matrix(U) array([[ 0.8537127 -0.47537233j, 0.09507447+0.19014893j], [-0.09507447+0.19014893j, 0.8537127 +0.47537233j]])
A single non-zero entry in the parameters will create a Pauli rotation:
>>> x = 0.412 >>> theta = x * np.array([1, 0, 0]) # The first entry belongs to the Pauli word "X" >>> su = qml.SpecialUnitary(theta, wires=0) >>> rx = qml.RX(-2 * x, 0) # RX introduces a prefactor -0.5 that has to be compensated >>> qml.math.allclose(qml.matrix(su), qml.matrix(rx)) True
This operation can be differentiated with hardware-compatible methods like parameter shifts and it supports parameter broadcasting/batching, but not both at the same time. Learn more by visiting the qml.SpecialUnitary documentation.
始终可微分 📈
The Hadamard test gradient transform is now available via
qml.gradients.hadamard_grad. This transform is also available as a differentiation method withinQNodes. (#3625) (#3736)qml.gradients.hadamard_gradis a hardware-compatible transform that calculates the gradient of a quantum circuit using the Hadamard test. Note that the device requires an auxiliary wire to calculate the gradient.>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) ... def circuit(params): ... qml.RX(params[0], wires=0) ... qml.RY(params[1], wires=0) ... qml.RX(params[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> params = np.array([0.1, 0.2, 0.3], requires_grad=True) >>> qml.gradients.hadamard_grad(circuit)(params) (tensor(-0.3875172, requires_grad=True), tensor(-0.18884787, requires_grad=True), tensor(-0.38355704, requires_grad=True))
This transform can be registered directly as the quantum gradient transform to use during autodifferentiation:
>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev, interface="jax", diff_method="hadamard") ... def circuit(params): ... qml.RX(params[0], wires=0) ... qml.RY(params[1], wires=0) ... qml.RX(params[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> params = jax.numpy.array([0.1, 0.2, 0.3]) >>> jax.jacobian(circuit)(params) Array([-0.3875172 , -0.18884787, -0.38355705], dtype=float32)
梯度变换
qml.gradients.spsa_grad现在已注册为 QNodes 的微分方法。 (#3440)现在可以通过将 QNode 标记为可微分来隐式使用 SPSA 梯度变换。可以通过以下方式选择它:
>>> dev = qml.device("default.qubit", wires=1) >>> @qml.qnode(dev, interface="jax", diff_method="spsa", h=0.05, num_directions=20) ... def circuit(x): ... qml.RX(x, 0) ... return qml.expval(qml.PauliZ(0)) >>> jax.jacobian(circuit)(jax.numpy.array(0.5)) Array(-0.4792258, dtype=float32, weak_type=True)
参数
num_directions决定用于同时扰动的方向数量,因此电路评估的数量,取决于一个前因子。有关详细信息,请参见 SPSA 梯度变换文档。 注意:完整的 SPSA 优化方法已作为qml.SPSAOptimizer提供。默认接口现在是
auto。不再需要指定接口;它会通过检查你的 QNode 参数自动确定。 (#3677) (#3752) (#3829)import jax import jax.numpy as jnp qml.enable_return() a = jnp.array(0.1) b = jnp.array(0.2) dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(a, b): qml.RY(a, wires=0) qml.RX(b, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliY(1))
>>> circuit(a, b) (Array(0.9950042, dtype=float32), Array(-0.19767681, dtype=float32)) >>> jac = jax.jacobian(circuit)(a, b) >>> jac (Array(-0.09983341, dtype=float32, weak_type=True), Array(0.01983384, dtype=float32, weak_type=True))
The JAX-JIT interface now supports higher-order gradient computation with the new return types system. (#3498)
Here is an example of using JAX-JIT to compute the Hessian of a circuit:
import pennylane as qml import jax from jax import numpy as jnp jax.config.update("jax_enable_x64", True) qml.enable_return() dev = qml.device("default.qubit", wires=2) @jax.jit @qml.qnode(dev, interface="jax-jit", diff_method="parameter-shift", max_diff=2) def circuit(a, b): qml.RY(a, wires=0) qml.RX(b, wires=1) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(1)) a, b = jnp.array(1.0), jnp.array(2.0)
>>> jax.hessian(circuit, argnums=[0, 1])(a, b) (((Array(-0.54030231, dtype=float64, weak_type=True), Array(0., dtype=float64, weak_type=True)), (Array(-1.76002563e-17, dtype=float64, weak_type=True), Array(0., dtype=float64, weak_type=True))), ((Array(0., dtype=float64, weak_type=True), Array(-1.00700085e-17, dtype=float64, weak_type=True)), (Array(0., dtype=float64, weak_type=True), Array(0.41614684, dtype=float64, weak_type=True))))
这个
qchem工作流已被修改以支持 Autograd 和 JAX 框架。 (#3458) (#3462) (#3495)当可微分参数是 JAX 对象时,自动使用 JAX 接口。以下是计算 Hartree-Fock 能量对原子坐标梯度的示例。
import pennylane as qml from pennylane import numpy as np import jax symbols = ["H", "H"] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) mol = qml.qchem.Molecule(symbols, geometry) args = [jax.numpy.array(mol.coordinates)]
>>> jax.grad(qml.qchem.hf_energy(mol))(*args) Array([[ 0. , 0. , 0.3650435], [ 0. , 0. , -0.3650435]], dtype=float64)
qml.kernels中的核矩阵实用函数现在支持自动微分。此外,它们支持批处理,例如用于带有射击向量的量子核执行。(#3742)这使得可以进行以下操作:
dev = qml.device('default.qubit', wires=2, shots=(100, 100)) @qml.qnode(dev) def circuit(x1, x2): qml.templates.AngleEmbedding(x1, wires=dev.wires) qml.adjoint(qml.templates.AngleEmbedding)(x2, wires=dev.wires) return qml.probs(wires=dev.wires) kernel = lambda x1, x2: circuit(x1, x2)
然后,我们可以在一组4个(随机)特征向量
X上计算核矩阵,但使用两组各100次的评价,如下所示:>>> X = np.random.random((4, 2)) >>> qml.kernels.square_kernel_matrix(X, kernel)[:, 0] tensor([[[1. , 0.86, 0.88, 0.92], [0.86, 1. , 0.75, 0.97], [0.88, 0.75, 1. , 0.91], [0.92, 0.97, 0.91, 1. ]], [[1. , 0.93, 0.91, 0.92], [0.93, 1. , 0.8 , 1. ], [0.91, 0.8 , 1. , 0.91], [0.92, 1. , 0.91, 1. ]]], requires_grad=True)
请注意,我们已经提取了每个100次评估的第一个概率向量条目。
智能分解哈密顿演化 💯
哈密顿演化使用
qml.evolve或qml.exp现在可以分解为操作。 (#3691) (#3777)如果时间演化的哈密顿与另一个 PennyLane 操作等效,那么该操作将作为分解返回:
>>> exp_op = qml.evolve(qml.PauliX(0) @ qml.PauliX(1)) >>> exp_op.decomposition() [IsingXX((2+0j), wires=[0, 1])]
如果哈密顿是一个保利字,那么分解将作为
qml.PauliRot操作提供:>>> qml.evolve(qml.PauliZ(0) @ qml.PauliX(1)).decomposition() [PauliRot((2+0j), ZX, wires=[0, 1])]
否则,哈密顿是算子的线性组合,并使用铃木-特罗特分解:
>>> qml.evolve(qml.sum(qml.PauliX(0), qml.PauliY(0), qml.PauliZ(0)), num_steps=2).decomposition() [RX((1+0j), wires=[0]), RY((1+0j), wires=[0]), RZ((1+0j), wires=[0]), RX((1+0j), wires=[0]), RY((1+0j), wires=[0]), RZ((1+0j), wires=[0])]
量子化学和其他应用的工具 🛠️
添加了一种名为
qml.qchem.givens_decomposition的新方法,能够将单位算符分解为一系列带相位移的Givens旋转门和一个对角相位矩阵。 (#3573)unitary = np.array([[ 0.73678+0.27511j, -0.5095 +0.10704j, -0.06847+0.32515j], [-0.21271+0.34938j, -0.38853+0.36497j, 0.61467-0.41317j], [ 0.41356-0.20765j, -0.00651-0.66689j, 0.32839-0.48293j]]) phase_mat, ordered_rotations = qml.qchem.givens_decomposition(unitary)
>>> phase_mat tensor([-0.20604358+0.9785369j , -0.82993272+0.55786114j, 0.56230612-0.82692833j], requires_grad=True) >>> ordered_rotations [(tensor([[-0.65087861-0.63937521j, -0.40933651-0.j ], [-0.29201359-0.28685265j, 0.91238348-0.j ]], requires_grad=True), (0, 1)), (tensor([[ 0.47970366-0.33308926j, -0.8117487 -0.j ], [ 0.66677093-0.46298215j, 0.5840069 -0.j ]], requires_grad=True), (1, 2)), (tensor([[ 0.36147547+0.73779454j, -0.57008306-0.j ], [ 0.2508207 +0.51194108j, 0.82158706-0.j ]], requires_grad=True), (0, 1))]
新增了一个名为
qml.BasisRotation的模板,它执行由一组费米子阶梯算符定义的基变换。 (#3573)import pennylane as qml from pennylane import numpy as np V = np.array([[ 0.53672126+0.j , -0.1126064 -2.41479668j], [-0.1126064 +2.41479668j, 1.48694623+0.j ]]) eigen_vals, eigen_vecs = np.linalg.eigh(V) umat = eigen_vecs.T wires = range(len(umat)) def circuit(): qml.adjoint(qml.BasisRotation(wires=wires, unitary_matrix=umat)) for idx, eigenval in enumerate(eigen_vals): qml.RZ(eigenval, wires=[idx]) qml.BasisRotation(wires=wires, unitary_matrix=umat)
>>> circ_unitary = qml.matrix(circuit)() >>> np.round(circ_unitary/circ_unitary[0][0], 3) tensor([[ 1. -0.j , -0. +0.j , -0. +0.j , -0. +0.j ], [-0. +0.j , -0.516-0.596j, -0.302-0.536j, -0. +0.j ], [-0. +0.j , 0.35 +0.506j, -0.311-0.724j, -0. +0.j ], [-0. +0.j , -0. +0.j , -0. +0.j , -0.438+0.899j]], requires_grad=True)
添加了一个新的函数
qml.qchem.load_basisset,用于从基础集交换库中提取qml.qchem基础集数据。 (#3363)添加了一个新的函数
qml.math.max_entropy用于计算量子态的最大熵。 (#3594)A new template called
qml.TwoLocalSwapNetworkhas been added that implements a canonical 2-complete linear (2-CCL) swap network described in arXiv:1905.05118. (#3447)dev = qml.device('default.qubit', wires=5) weights = np.random.random(size=qml.templates.TwoLocalSwapNetwork.shape(len(dev.wires))) acquaintances = lambda index, wires, param: (qml.CRY(param, wires=index) if np.abs(wires[0]-wires[1]) else qml.CRZ(param, wires=index)) @qml.qnode(dev) def swap_network_circuit(): qml.templates.TwoLocalSwapNetwork(dev.wires, acquaintances, weights, fermionic=False) return qml.state()
>>> print(weights) tensor([0.20308242, 0.91906199, 0.67988804, 0.81290256, 0.08708985, 0.81860084, 0.34448344, 0.05655892, 0.61781612, 0.51829044], requires_grad=True) >>> print(qml.draw(swap_network_circuit, expansion_strategy = 'device')()) 0: ─╭●────────╭SWAP─────────────────╭●────────╭SWAP─────────────────╭●────────╭SWAP─┤ State 1: ─╰RY(0.20)─╰SWAP─╭●────────╭SWAP─╰RY(0.09)─╰SWAP─╭●────────╭SWAP─╰RY(0.62)─╰SWAP─┤ State 2: ─╭●────────╭SWAP─╰RY(0.68)─╰SWAP─╭●────────╭SWAP─╰RY(0.34)─╰SWAP─╭●────────╭SWAP─┤ State 3: ─╰RY(0.92)─╰SWAP─╭●────────╭SWAP─╰RY(0.82)─╰SWAP─╭●────────╭SWAP─╰RY(0.52)─╰SWAP─┤ State 4: ─────────────────╰RY(0.81)─╰SWAP─────────────────╰RY(0.06)─╰SWAP─────────────────┤ State
改进 🛠
脉冲编程
一个名为
qml.pulse.pwc的新函数已被添加为定义qml.pulse.ParametrizedHamiltonian的便利函数。该函数可以通过设置函数非零的时间范围来创建一个可调用的系数。生成的可调用对象可以传入一组参数和一个时间。(#3645)>>> timespan = (2, 4) >>> f = qml.pulse.pwc(timespan) >>> f * qml.PauliX(0) ParametrizedHamiltonian: terms=1
params数组将用作在时间范围内均匀分布的箱值,而参数t将决定返回哪个箱。>>> f(params=[1.2, 2.3, 3.4, 4.5], t=3.9) DeviceArray(4.5, dtype=float32) >>> f(params=[1.2, 2.3, 3.4, 4.5], t=6) # 超出范围 (2, 4) 时为零 DeviceArray(0., dtype=float32)
一个名为
qml.pulse.pwc_from_function的新函数已被添加为定义qml.pulse.ParametrizedHamiltonian的装饰器。该函数可以用于装饰一个函数,并创建其分段常量的近似值。(#3645)>>> @qml.pulse.pwc_from_function((2, 4), num_bins=10) ... def f1(p, t): ... return p * t
结果函数在区间
t=(2, 4)中以10个区间近似p**2 * t的相同值,并在区间外返回零。# t=2和t=2.1在同一个区间内 >>> f1(3, 2), f1(3, 2.1) (DeviceArray(6., dtype=float32), DeviceArray(6., dtype=float32)) # 下一个区间 >>> f1(3, 2.2) DeviceArray(6.6666665, dtype=float32) # 在区间外 t=(2, 4) >>> f1(3, 5) DeviceArray(0., dtype=float32)
添加
ParametrizedHamiltonianPytree类,这是一种 pytree jax 对象,表示一个参数化的 哈密顿量,其中矩阵计算被延迟以提高性能。 (#3779)
操作和批处理
函数
qml.dot已更新,可以计算向量和操作符列表之间的点积。 (#3586)>>> coeffs = np.array([1.1, 2.2]) >>> ops = [qml.PauliX(0), qml.PauliY(0)] >>> qml.dot(coeffs, ops) (1.1*(PauliX(wires=[0]))) + (2.2*(PauliY(wires=[0]))) >>> qml.dot(coeffs, ops, pauli=True) 1.1 * X(0) + 2.2 * Y(0)
qml.evolve返回一个Operator或ParametrizedHamiltonian的演化。 (#3617) (#3706)qml.ControlledQubitUnitary现在从qml.ops.op_math.ControlledOp继承,该类定义了decomposition、expand和sparse_matrix而不是引发错误。(#3450)如果基础操作符支持广播,
qml.ops.op_math.Controlled类已添加参数广播支持。 (#3450)现在,
qml.generator函数检查生成器是否是厄米的,而不是检查它是否是Observable的子类。这使得它可以从SymbolicOp和CompositeOp类返回有效的生成器。 (#3485)已扩展
qml.equal函数以比较Prod和Sum运算符。 (#3516)qml.purity已被添加为纯度的测量过程 (#3551)为qutrit操作移除了就地反转,以准备移除就地反转。 (#3566)
函数
qml.utils.sparse_hamiltonian已被移至qml.Hamiltonian.sparse_matrix方法。 (#3585)该
qml.pauli.PauliSentence.operation()方法已被改进,以避免在系数等于 1 时实例化一个SProd操作符。 (#3595)现在允许在所有
SymbolicOp运算符中进行批处理,包括Exp、Pow和SProd。 (#3597)现在,
Sum和Prod操作具有广播操作数。 (#3611)已实现XYX单量子比特单位分解。 (#3628)
所有双下划线方法现在返回
NotImplemented,允许调用其他类的正确双下划线方法(例如__radd__)。 (#3631)qml.GellMann运算符现在在显示时包括它们的索引。 (#3641)qml.ops.ctrl_decomp_zyz已被添加,用于计算给定单量子比特操作和控制线的受控单量子比特操作的分解。 (#3681)
(#3692)qml.pauli.is_pauli_word现在支持Prod和SProd操作符,并且当Hamiltonian包含多个项时,返回False。qml.pauli.pauli_word_to_string现在支持Prod、SProd和Hamiltonian运算符。 (#3692)qml.ops.op_math.Controlled现在可以更有效地使用 ZYZ 分解分解单量子比特目标操作。 (#3726)qml.qchem.Molecule类在分子的电子数为奇数或自旋多重性不为 1 时会引发错误。 (#3748)
qml.qchem.basis_rotation现在考虑自旋,允许它对分子哈密顿进行基旋转分组。 (#3714) (#3774)梯度变换适用于具有非平凡经典雅可比的新的返回类型系统。 (#3776)
default.mixed设备在多量子比特操作方面得到了性能提升。 这也允许施加作用于超过七个量子比特的通道,以前是无法做到的。 (#3584)qml.dot现在将系数组合在一起。 (#3691)>>> qml.dot(coeffs=[2, 2, 2], ops=[qml.PauliX(0), qml.PauliY(1), qml.PauliZ(2)]) 2*(PauliX(wires=[0]) + PauliY(wires=[1]) + PauliZ(wires=[2]))
qml.generator现在支持带有Sum和Prod生成器的运算符。 (#3691)现在,
Sum._sort方法在排序时考虑了操作符的名称。 (#3691)新增了一种称为
(#2852)qml.transforms.sign_expand的磁带变换。它实现了一种快速可转发哈密顿量的最佳分解,最小化在单量子比特测量中其估计量的方差,来源于 arXiv:2207.09479。
可微性和接口
现在,
qml.math模块还包含一个用于快速傅里叶变换的子模块qml.math.fft。该子模块特别提供了以下函数的可微版本,适用于PennyLane的所有常用接口
请注意,这些函数的导数输出在使用复值输入时可能会有所不同,这是由于复值导数的不同约定所致。
在初始化 QNode 时,已经对梯度关键字参数添加了验证——如果传递了意外的关键字参数,将会引发一个
UserWarning。当前预期的梯度函数关键字参数列表可以通过qml.gradients.SUPPORTED_GRADIENT_KWARGS访问。 (#3526)该
numpy版本已限制为<1.24。 (#3563)支持使用 JAX-JIT 的两比特单位分解功能已被添加。(#3569)
qml.math.size现在支持 PyTorch 张量。 (#3606)现在大多数量子通道在所有接口上都是完全可微分的。 (#3612)
qml.math.matmul现在支持 PyTorch 和 Autograd 张量。 (#3613)添加
qml.math.detach,该函数将一个张量从其跟踪中分离。这停止了自动梯度计算。 (#3674)添加
typing.TensorLike类型。 (#3675)qml.QuantumMonteCarlo模板现在在传递jax.numpy数组给模板时兼容 JAX-JIT。 (#3734)DefaultQubitJax现在支持在执行qml.pulse.ParametrizedEvolution门时演化状态向量。 (#3743)SProd.sparse_matrix现在支持具有单个元素的接口特定变量作为scalar。 (#3770)添加了
argnum参数到metric_tensor。通过传递一个序列,引用可训练的 tape 参数,度量张量仅相对于这些参数进行计算。这减少了需要运行的 tape 数量。 (#3587)方差的参数偏移导数节省了冗余的评估对应的未偏移期望值磁带(如果可能的话)(#3744)
下一代设备 API
将
apply_operation单一分派函数添加到devices/qubit,该函数对一个状态应用一个操作并返回一个新状态。 (#3637)函数
preprocess被添加到devices/qubit,用于验证、扩展和转换一批QuantumTape对象,以将抽象预处理细节与设备分离。 (#3708)将
create_initial_state函数添加到devices/qubit,返回执行的初始状态。 (#3683)添加了
simulate函数到devices/qubit,将单个量子光带转化为测量结果。 该函数仅支持基于状态的测量,具有零个可观测量或具有对角化门的可观测量。 它支持对非对易可观测量的同时测量。 (#3700)已添加
ExecutionConfig数据类。 (#3649)已经添加了
StatePrep类作为状态准备操作符必须实现的接口。 (#3654)qml.QubitStateVector现在实现了StatePrep接口。 (#3685)qml.BasisState现在实现了StatePrep接口。 (#3693)为设备添加了新的抽象基类
Device到devices.experimental子模块。 此接口仍处于实验模式,并未与pennylane的其余部分集成。 (#3602)
其他改进
通过采用压缩写入格式,使用
qml.data模块将哈密顿量写入文件的功能得到了改进。(#3592)在
qml.data.Dataset.read()方法中,延迟加载得到了更广泛的支持。 (#3605)当分子具有奇数电子或自旋多重性不是1时,
qchem.Molecule类会引发错误。qml.draw和qml.draw_mpl已经更新,可以绘制任何量子函数,这允许仅可视化完整电路/QNode的一部分。(#3760)测量过程的字符串表示现在包括
_eigvals属性(如果已设置)。(#3820)
重大变更 💔
执行中的参数
mode已被新执行管道中的布尔值grad_on_execution替代。 (#3723)qml.VQECost已被移除。 (#3735)默认接口现在是
auto. (#3677) (#3752) (#3829)接口是在 QNode 调用期间确定的,而不是在初始化时。这意味着
gradient_fn和gradient_kwargs仅在调用开始时在 QNode 上定义。此外,如果您使用反向传播(例如default.qubit更改为default.qubit.jax),在调用期间不指定接口就无法保证设备不会发生变化,而之前是在初始化时发生的。磁带方法
get_operation现在也可以返回磁带中的操作索引,您可以通过将return_op_index设置为True来激活它:get_operation(idx, return_op_index=True)。它将在版本0.30中成为默认值。(#3667)Operation.inv()和Operation.inverse属性已被移除。请使用qml.adjoint或qml.pow代替。 (#3618)例如,代替
>>> qml.PauliX(0).inv()
使用
>>> qml.adjoint(qml.PauliX(0))
属性
Operation.inverse已被完全移除。 (#3725)qml.ControlledQubitUnitary的目标线不再通过op.hyperparameters["u_wires"]访问。 相反,可以通过op.base.wires或op.target_wires访问。 (#3450)由一个
QNode构造的磁带不再排队到周围的上下文中。 (#3509)像
Tensor、Hamiltonian和Adjoint这样的嵌套运算符现在从队列中移除它们拥有的运算符,而不是更新它们的元数据以拥有一个"owner"。 (#3282)qml.qchem.scf,qml.RandomLayers.compute_decomposition,和qml.Wires.select_random现在使用局部随机数生成器而不是全局随机数生成器。这可能导致随机数略有不同,并使结果与全局随机数生成状态无关。如果您想要可控的结果,请为每个单独的函数提供一个种子。(#3624)qml.transforms.measurement_grouping已被移除。用户应改用qml.transforms.hamiltonian_expand。(#3701)op.simplify()针对是保利字的线性组合的运算符将使用内置的保利表示法,以更高效地计算运算符的简化。 (#3481)所有
Operator的输入参数中是列表的部分被转换为普通的 numpy 数组。 (#3659)QubitDevice.expval不再在将可观察量传递给QubitDevice.probability之前排列它的线路顺序。与default.qubit相关的下游更改已经完成,但这仍可能影响继承自QubitDevice并重写probability(或任何其他接受线路顺序的辅助函数,如marginal_prob、estimate_probability或analytic_probability)的其他设备的期望值。 (#3753)
弃用功能 👋
qml.utils.sparse_hamiltonian函数已被弃用,使用该函数将会引发警告。 相反,应该使用qml.Hamiltonian.sparse_matrix方法。 (#3585)qml.op_sum已被淘汰。用户应使用qml.sum替代。 (#3686)直接使用
Evolution已被弃用。用户应使用qml.evolve代替。 这个新函数会改变给定参数的符号。 (#3706)使用
qml.dot与QNodeCollection已被弃用。 (#3586)
文档 📝
使关于NumPy的香草版本进行微分的警告更加显眼。 (#3838)
对
qml.operation的文档进行了改进。 (#3664)qml.SparseHamiltonian中的代码示例已更新为正确的线圈范围。 (#3643)文本中为
qml.qchem.mol_data文档字符串中的URL添加了超链接。 (#3644)文档中的一个拼写错误已被更正,针对
qml.math.vn_entropy。 (#3740)
修复错误 🐛
修复了一个错误,该错误在使用非对易测量在计算基础上测量
qml.probs时返回不正确的结果。现在会引发错误。 (#3811)修复了一个错误,该错误在测量
(#3811)qml.probs时使用非交换测量在计算基中返回了不正确的结果。现在会引发错误。修复了抽屉中的一个错误,在该错误中,嵌套的受控操作会输出被控制操作的标签,而不是控制值。 (#3745)
修复了一个在
qml.transforms.metric_tensor中的错误,其中操作生成器的前因被多次考虑,导致非标准操作的错误输出。(#3579)现在尽可能使用本地随机数生成器,以避免改变全局随机状态。 (#3624)
networkx版本更改导致的故障已经被修复,修复方法是选择性跳过qcutTensorFlow-JIT 测试。 (#3609) (#3619)修复了ZX演算变换中
Y分解的电线。 (#3598)qml.pauli.PauliWord现在可以被序列化为 pickle 格式了。 (#3588)QuantumScript的子类现在在使用SomeChildClass.from_queue时返回它们自己的类型。 (#3501)在
operation.py的计算和错误信息中已修复一个错别字(#3536)qml.data.Dataset.write()现在确保在写入文件之前,任何懒加载的值都会被加载。 (#3605)Tensor._batch_size现在在初始化、复制和map_wires期间设置为None。 (#3642) (#3661)Tensor.has_matrix现在设置为True. (#3647)修正了
qml.IsingZZ门分解示例中的错字。 (#3676)修复了一个错误,该错误导致使用
qml.Snapshot的 tapes/qnodes 与qml.drawer.tape_mpl不兼容。 (#3704)Tensor._pauli_rep在初始化时被设置为None,并且Tensor.data已被添加到它的 setter 中。 (#3722)qml.math.ndim在对jax张量使用时已重定向到jnp.ndim。 (#3730)marginal_prob的实现(以及随后,qml.probs)现在返回以预期的线序排列的概率。 (#3753)这个错误影响了大多数在测量线与设备线的顺序不一致并且测量了3条或更多线的设备上 继承自
QubitDevice的概率测量过程。假设 是以设备的状态和线序计算边际概率,然后根据测量过程的线序重新排序。相反,重新排序是向相反方向进行的(即,从 测量过程线序到设备线序)。这个问题现在已修复。请注意,这种情况仅发生在测量3条或更多线时,因为在其他情况下此映射是相同的。更多详细信息和关于此错误的讨论可以在 原始错误报告中找到。空的可迭代对象不再能够从 QNodes 返回。 (#3769)
现在,
qml.equal的关键字参数在比较测量过程的可观察量时使用。只有在两个可观察量都是None时,才会请求测量的特征值,从而节省计算资源。只有当输入是一个列表时,才将输入转换为
qml.Hermitian的numpy数组。 (#3820)
贡献者 ✍
此版本包含来自(按字母顺序排列)的贡献:
吉安-卢卡·安塞尔梅蒂, 吉列尔莫·阿隆索-利纳赫, 胡安·米格尔·阿拉佐拉, 伊科·阿希米内, 乌特卡什·阿扎德, 米里亚姆·贝迪格, 克里斯蒂安·博吉乌, 托马斯·布罗姆利, 阿斯特拉尔·蔡, 艾萨克·德·弗吕特, 奥利维亚·迪·马泰奥, 莉莉安·M·A·弗雷德里克森, 索兰·贾汉吉里, 科尔比安·科特曼, 克里斯蒂娜·李, 阿尔伯特·米特扬斯·科玛, 罗曼·莫亚尔, 穆迪特·潘德, 博尔哈·雷奎纳, 马修·西尔弗曼, 杰伊·索尼, 安塔尔·萨瓦, 弗雷德里克·维尔德, 大卫·维里希斯, 莫里茨·维尔曼。
- orphan
发布 0.28.0¶
自上次发布以来的新特性
自定义测量过程 📐
现在可以通过增加
qml.measurements模块来方便地进行自定义测量。 (#3286) (#3343) (#3288) (#3312) (#3287) (#3292) (#3287) (#3326) (#3327) (#3388) (#3439) (#3466)在
qml.measurements中有新的子类,允许创建 自定义 测量:SampleMeasurement: 表示基于样本的测量StateMeasurement: 表示基于状态的测量MeasurementTransform: 代表一个测量过程,该过程需要应用批处理变换
创建自定义测量涉及制作一个从上述类继承的类。下面给出了一个例子。在这里,测量计算给定状态下获得的样本数量:
from pennylane.measurements import SampleMeasurement class CountState(SampleMeasurement): def __init__(self, state: str): self.state = state # string identifying the state, e.g. "0101" wires = list(range(len(state))) super().__init__(wires=wires) def process_samples(self, samples, wire_order, shot_range, bin_size): counts_mp = qml.counts(wires=self._wires) counts = counts_mp.process_samples(samples, wire_order, shot_range, bin_size) return counts.get(self.state, 0) def __copy__(self): return CountState(state=self.state)
我们现在可以在QNode中执行新的测量,如下所示。
dev = qml.device("default.qubit", wires=1, shots=10000) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return CountState(state="1")
>>> circuit(1.23) tensor(3303., requires_grad=True)
可微分性也支持此新的测量过程:
>>> x = qml.numpy.array(1.23, requires_grad=True) >>> qml.grad(circuit)(x) 4715.000000000001
有关这些新功能的更多信息,请参阅``qml.measurements` <https://docs.pennylane.ai/en/stable/code/qml_measurements.html>`_的文档。
ZX演算 🧮
QNodes can now be converted into ZX diagrams via the PyZX framework. (#3446)
ZX diagrams are the medium for which we can envision a quantum circuit as a graph in the ZX-calculus language, showing properties of quantum protocols in a visually compact and logically complete fashion.
QNodes decorated with
@qml.transforms.to_zxwill return a PyZX graph that represents the computation in the ZX-calculus language.dev = qml.device("default.qubit", wires=2) @qml.transforms.to_zx @qml.qnode(device=dev) def circuit(p): qml.RZ(p[0], wires=1), qml.RZ(p[1], wires=1), qml.RX(p[2], wires=0), qml.PauliZ(wires=0), qml.RZ(p[3], wires=1), qml.PauliX(wires=1), qml.CNOT(wires=[0, 1]), qml.CNOT(wires=[1, 0]), qml.SWAP(wires=[0, 1]), return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
>>> params = [5 / 4 * np.pi, 3 / 4 * np.pi, 0.1, 0.3] >>> circuit(params) Graph(20 vertices, 23 edges)
Information about PyZX graphs can be found in the PyZX Graphs API.
QChem 数据库和基组 ⚛️
现在可以通过
qchem.mol_data()访问 PubChem 数据库中化合物的符号和几何形状。 (#3289) (#3378)>>> import pennylane as qml >>> from pennylane.qchem import mol_data >>> mol_data("BeH2") (['Be', 'H', 'H'], tensor([[ 4.79404621, 0.29290755, 0. ], [ 3.77945225, -0.29290755, 0. ], [ 5.80882913, -0.29290755, 0. ]], requires_grad=True)) >>> mol_data(223, "CID") (['N', 'H', 'H', 'H', 'H'], tensor([[ 0. , 0. , 0. ], [ 1.82264085, 0.52836742, 0.40402345], [ 0.01417295, -1.67429735, -0.98038991], [-0.98927163, -0.22714508, 1.65369933], [-0.84773114, 1.373075 , -1.07733286]], requires_grad=True))
使用两种新的基组进行量子化学计算:
6-311g和CC-PVDZ。 (#3279)>>> symbols = ["H", "He"] >>> geometry = np.array([[1.0, 0.0, 0.0], [0.0, 0.0, 0.0]], requires_grad=False) >>> charge = 1 >>> basis_names = ["6-311G", "CC-PVDZ"] >>> for basis_name in basis_names: ... mol = qml.qchem.Molecule(symbols, geometry, charge=charge, basis_name=basis_name) ... print(qml.qchem.hf_energy(mol)()) [-2.84429531] [-2.84061284]
一堆新的操作符 👀
受控CZ门和受控哈达玛门现在可以通过
qml.CCZ和qml.CH获得。 (#3408)>>> ccz = qml.CCZ(wires=[0, 1, 2]) >>> qml.matrix(ccz) [[ 1 0 0 0 0 0 0 0] [ 0 1 0 0 0 0 0 0] [ 0 0 1 0 0 0 0 0] [ 0 0 0 1 0 0 0 0] [ 0 0 0 0 1 0 0 0] [ 0 0 0 0 0 1 0 0] [ 0 0 0 0 0 0 1 0] [ 0 0 0 0 0 0 0 -1]] >>> ch = qml.CH(wires=[0, 1]) >>> qml.matrix(ch) [[ 1. 0. 0. 0. ] [ 0. 1. 0. 0. ] [ 0. 0. 0.70710678 0.70710678] [ 0. 0. 0.70710678 -0.70710678]]
现在可用三个新的参数算子,
qml.CPhaseShift00、qml.CPhaseShift01和qml.CPhaseShift10。每个算子执行的相位移类似于qml.ControlledPhaseShift,但作用于状态向量的不同位置。 (#2715)>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) >>> def circuit(): ... qml.PauliX(wires=1) ... qml.CPhaseShift01(phi=1.23, wires=[0,1]) ... return qml.state() ... >>> circuit() tensor([0. +0.j , 0.33423773+0.9424888j, 1. +0.j , 0. +0.j ], requires_grad=True)
一个新的门操作叫做
qml.FermionicSWAP被添加进来。这实现了表示费米子模式的自旋轨道的交换,同时保持正确的反对称性。 (#3380)dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(phi): qml.BasisState(np.array([0, 1]), wires=[0, 1]) qml.FermionicSWAP(phi, wires=[0, 1]) return qml.state()
>>> circuit(0.1) tensor([0. +0.j , 0.99750208+0.04991671j, 0.00249792-0.04991671j, 0. +0.j ], requires_grad=True)
通过
qml.ops.op_math.Evolution从生成器创建定义的算子。 (#3375)qml.ops.op_math.Evolution定义了算子 $hat{O}$ 的指数形式 $e^{ixhat{O}}$,具有一个可训练的参数 $x$。限制为单个可训练参数允许使用qml.gradients.param_shift来求得关于参数 $x$ 的梯度。dev = qml.device('default.qubit', wires=2) @qml.qnode(dev, diff_method=qml.gradients.param_shift) def circuit(phi): qml.ops.op_math.Evolution(qml.PauliX(0), -.5 * phi) return qml.expval(qml.PauliZ(0))
>>> phi = np.array(1.2) >>> circuit(phi) tensor(0.36235775, requires_grad=True) >>> qml.grad(circuit)(phi) -0.9320390495504149
三态Hadamard门,
qml.THadamard,现在可用。 (#3340)该操作接受一个
subspace关键字参数,用于确定使用哪种变体的三态Hadamard。>>> th = qml.THadamard(wires=0, subspace=[0, 1]) >>> qml.matrix(th) array([[ 0.70710678+0.j, 0.70710678+0.j, 0. +0.j], [ 0.70710678+0.j, -0.70710678+0.j, 0. +0.j], [ 0. +0.j, 0. +0.j, 1. +0.j]])
新的变换、函数等等 😯
现在支持计算任意量子态的纯度。(#3290)
可以通过类似于冯·诺依曼熵的方式来计算纯度:
qml.math.purity可以作为内联函数使用:>>> x = [1, 0, 0, 1] / np.sqrt(2) >>> qml.math.purity(x, [0, 1]) 1.0 >>> qml.math.purity(x, [0]) 0.5 >>> x = [[1 / 2, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 1 / 2]] >>> qml.math.purity(x, [0, 1]) 0.5
qml.qinfo.transforms.purity可以将返回状态的 QNode 转换为返回纯度的函数:dev = qml.device("default.mixed", wires=2) @qml.qnode(dev) def circuit(x): qml.IsingXX(x, wires=[0, 1]) return qml.state()
>>> qml.qinfo.transforms.purity(circuit, wires=[0])(np.pi / 2) 0.5 >>> qml.qinfo.transforms.purity(circuit, wires=[0, 1])(np.pi / 2) 1.0
与
qml.qinfo中的其他方法一样,纯度是完全可微分的:>>> param = np.array(np.pi / 4, requires_grad=True) >>> qml.grad(qml.qinfo.transforms.purity(circuit, wires=[0]))(param) -0.5
一个新的梯度变换,
qml.gradients.spsa_grad,基于SPSA的思想,现在可用。 (#3366)这个新的变换允许用户使用参数的同时扰动和随机逼近来计算量子梯度的单个估计。一个接受参数
x的 QNode,可以计算近似梯度,如下所示。>>> dev = qml.device("default.qubit", wires=2) >>> x = np.array(0.4, requires_grad=True) >>> @qml.qnode(dev) ... def circuit(x): ... qml.RX(x, 0) ... qml.RX(x, 1) ... return qml.expval(qml.PauliZ(0)) >>> grad_fn = qml.gradients.spsa_grad(circuit, h=0.1, num_directions=1) >>> grad_fn(x) array(-0.38876964)
参数
num_directions确定使用的同时扰动方向的数量,这与电路评估的数量成正比。有关详细信息,请参见 SPSA 梯度变换文档。请注意,完整的 SPSA 优化器已经作为qml.SPSAOptimizer可用。现在可以将多个中间电路测量在算术上结合,以创建新的条件。 (#3159)
dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.Hadamard(wires=1) m0 = qml.measure(wires=0) m1 = qml.measure(wires=1) combined = 2 * m1 + m0 qml.cond(combined == 2, qml.RX)(1.3, wires=2) return qml.probs(wires=2)
>>> circuit() [0.90843735 0.09156265]
一个名为
pauli_decompose()的新方法已被添加到qml.pauli模块,该方法接受一个厄米矩阵,将其分解为泡利基,并作为qml.Hamiltonian或qml.PauliSentence实例返回。 (#3384)Operation或Hamiltonian实例现在可以通过新的operation()和hamiltonian()方法从qml.PauliSentence或qml.PauliWord生成。(#3391)为tapes添加了一个
sum_expand函数,该函数将测量Sum期望的tape拆分为多个求和期望的tapes,并提供一个函数来重新组合结果。 (#3230)
(实验性)对多重测量和梯度输出类型的更多接口支持 🧪
The autograd and Tensorflow interfaces now support devices with shot vectors when
qml.enable_return()has been called. (#3374) (#3400)Here is an example using Tensorflow:
import tensorflow as tf qml.enable_return() dev = qml.device("default.qubit", wires=2, shots=[1000, 2000, 3000]) @qml.qnode(dev, diff_method="parameter-shift", interface="tf") def circuit(a): qml.RY(a, wires=0) qml.RX(0.2, wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)), qml.probs([0, 1])
>>> a = tf.Variable(0.4) >>> with tf.GradientTape() as tape: ... res = circuit(a) ... res = tf.stack([tf.experimental.numpy.hstack(r) for r in res]) ... >>> res <tf.Tensor: shape=(3, 5), dtype=float64, numpy= array([[0.902, 0.951, 0. , 0. , 0.049], [0.898, 0.949, 0. , 0. , 0.051], [0.892, 0.946, 0. , 0. , 0.054]])> >>> tape.jacobian(res, a) <tf.Tensor: shape=(3, 5), dtype=float64, numpy= array([[-0.345 , -0.1725 , 0. , 0. , 0.1725 ], [-0.383 , -0.1915 , 0. , 0. , 0.1915 ], [-0.38466667, -0.19233333, 0. , 0. , 0.19233333]])>
当调用
qml.enable_return()时,PyTorch 接口现在完全支持,可以使用自定义微分方法(例如参数移位、有限差分或伴随法)计算雅可比和海森矩阵。 (#3416)import torch qml.enable_return() dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, diff_method="parameter-shift", interface="torch") def circuit(a, b): qml.RY(a, wires=0) qml.RX(b, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)), qml.probs([0, 1])
>>> a = torch.tensor(0.1, requires_grad=True) >>> b = torch.tensor(0.2, requires_grad=True) >>> torch.autograd.functional.jacobian(circuit, (a, b)) ((tensor(-0.0998), tensor(0.)), (tensor([-0.0494, -0.0005, 0.0005, 0.0494]), tensor([-0.0991, 0.0991, 0.0002, -0.0002])))
JAX-JIT接口现在支持在调用
qml.enable_return()后进行一阶梯度计算。 (#3235) (#3445)import jax from jax import numpy as jnp jax.config.update("jax_enable_x64", True) qml.enable_return() dev = qml.device("lightning.qubit", wires=2) @jax.jit @qml.qnode(dev, interface="jax-jit", diff_method="parameter-shift") def circuit(a, b): qml.RY(a, wires=0) qml.RX(b, wires=0) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(1)) a, b = jnp.array(1.0), jnp.array(2.0)
>>> jax.jacobian(circuit, argnums=[0, 1])(a, b) ((Array(0.35017549, dtype=float64, weak_type=True), Array(-0.4912955, dtype=float64, weak_type=True)), (Array(5.55111512e-17, dtype=float64, weak_type=True), Array(0., dtype=float64, weak_type=True)))
改进 🛠
qml.pauli.is_pauli_word现在支持qml.Hamiltonian实例。 (#3389)当
qml.probs、qml.counts和qml.sample在没有参数的情况下被调用时,它们会测量所有的 电线。使用空电线列表调用上述任何测量(例如,qml.sample(wires=[]))会引发错误。 (#3299)使
(#3426)qml.gradients.finite_diff在使用自定义数据类型的可观察对象/设备时更为方便,通过减少需要在自定义数据类型中定义的魔法方法数量,以支持finite_diff。现在在
default.mixed上原生支持qml.ISWAP门,提升了其效率。 (#3284)对
qml.transforms.hamiltonian_expand添加了更多输入验证,以便没有项的哈密顿量对象会引发错误。 (#3339)现在对Python 3.11和Torch v1.13进行了持续集成检查。Python 3.7已被弃用。 (#3276)
qml.Tracker现在还会在tracker.history中记录电路执行的结果。 (#3306)通过避免数据类型转换并利用
itertools.chain,改善了Wires.all_wires的执行时间。 (#3302)打印一个
qml.qchem.Molecule的实例现在更加简洁和信息丰富。 (#3364)当
qml.transforms.insert无法对非量子比特的非可交换观测量进行对角化时,错误消息现在更加详细。 (#3381)扩展了
qml.equal函数到qml.Hamiltonian和Tensor对象。 (#3390)QuantumTape._process_queue已移动到qml.queuing.process_queue以解耦其功能与QuantumTape类。 (#3401)QPE 现在可以接受目标算子而不是矩阵和目标线对。(#3373)
qml.ops.op_math.Controlled.map_wires方法现在内部使用base.map_wires,而不是私有的_wires属性设置器。 (#3405)一个名为
qml.tape.make_qscript的新函数已被创建,用于将量子函数转换为量子脚本。这替代了qml.transforms.make_tape。 (#3429)向操作符添加一个
_pauli_rep属性,以将新的 Pauli 算术类与原生 PennyLane 对象集成。 (#3443)将
qml.matrix的功能扩展到三比特。 (#3508)位于
pennylane/transforms/的qcut.py文件已重新组织为多个文件,现在位于pennylane/transforms/qcut/。 (#3413)当创建一个具有重叠线的
Tensor对象时,现在会出现警告,提示这可能导致未定义行为。 (#3459)将
qml.equal函数扩展到qml.ops.op_math.Controlled和qml.ops.op_math.ControlledOp对象。 (#3463)几乎每个
with QuantumTape()的实例都被替换为QuantumScript构造。 (#3454)向
qml.Operator添加了validate_subspace静态方法,以检查某些三态操作的子空间的有效性。 (#3340)qml.equal现在支持通过qml.s_prod、qml.pow、qml.exp和qml.adjoint创建的运算符。 (#3471)设备现在可以通过可选的
use_grouping属性忽略哈密顿量中的可观察分组索引。 (#3456)将可选参数
lazy=True添加到函数qml.s_prod,qml.prod和qml.op_sum以允许简化。(#3483)更新了
qml.transforms.zyz_decomposition函数,使其现在支持广播算子。这意味着可以对从一批单元算子实例化的单量子比特qml.QubitUnitary算子进行分解。 (#3477)在
jax.vmap转换下执行电路的性能得到了提升,因为能够利用某些设备的批量执行能力。 (#3452)将openfermion哈密顿复杂系数转换为实数的容差已被修改,以防止转换错误。 (#3367)
OperationRecorder现在继承自AnnotatedQueue和QuantumScript而不是QuantumTape。 (#3496)更新了
qml.transforms.split_non_commuting以支持新的返回类型。 (#3414)更新了
qml.transforms.mitigate_with_zne以支持新的返回类型。 (#3415)更新了
qml.transforms.metric_tensor,qml.transforms.adjoint_metric_tensor,qml.qinfo.classical_fisher, 和qml.qinfo.quantum_fisher以支持新的返回类型。 (#3449)更新了
qml.transforms.batch_params和qml.transforms.batch_input以支持新的返回类型。 (#3431)更新了
qml.transforms.cut_circuit和qml.transforms.cut_circuit_mc以支持新的返回类型。 (#3346)将NumPy版本限制为
<1.24. (#3346)
重大变更 💔
不再维护对Python 3.7的支持。PennyLane将继续维护3.8及更高版本。 (#3276)
属性
log_base已从MeasurementProcess移动到新的VnEntropyMP和MutualInfoMP类,这些类继承自MeasurementProcess。 (#3326)qml.utils.decompose_hamiltonian()已被移除。请改用qml.pauli.pauli_decompose()。 (#3384)MeasurementProcess的return_type属性已在可能的情况下被移除。请改用isinstance检查。(#3399)现在,
AnnotatedQueue从OrderedDict继承,而不是拥有一个名为_queue的OrderedDict属性,并封装了队列。因此,这同样适用于从AnnotatedQueue继承的QuantumTape类。 (#3401)ShadowMeasurementProcess类已更名为ClassicalShadowMP。 (#3388)已删除
qml.Operation.get_parameter_shift方法。应使用gradients模块代替,一般用于参数位移规则。 (#3419)QubitDevice.statistics方法的签名已从def statistics(self, observables, shot_range=None, bin_size=None, circuit=None):
变更为
def statistics(self, circuit: QuantumTape, shot_range=None, bin_size=None):
现在,
MeasurementProcess类是一个抽象类,return_type现在是这个类的一个属性。 (#3434)
弃用功能 👋
弃用周期记录在 doc/developement/deprecations.rst。
以下方法已被弃用: (#3281)
qml.tape.get_active_tape: 请改用qml.QueuingManager.active_context()代替qml.transforms.qcut.remap_tape_wires: 请使用qml.map_wires替代qml.tape.QuantumTape.inv(): 请使用qml.tape.QuantumTape.adjoint()替代qml.tape.stop_recording(): 请改用qml.QueuingManager.stop_recording()qml.tape.QuantumTape.stop_recording(): 请改用qml.QueuingManager.stop_recording()qml.QueuingContext现在是qml.QueuingManagerQueuingManager.safe_update_info和AnnotatedQueue.safe_update_info: 使用update_info替代。
qml.transforms.measurement_grouping已经过时。请使用qml.transforms.hamiltonian_expand代替。 (#3417)QubitDevice.statistics中的observables参数已被弃用。请改用circuit。 (#3433)qml.classical_shadow和qml.shadow_expval中的seed_recipes参数已被弃用。已添加一个新参数seed,默认为 None,可以包含一个所需的整数种子。 (#3388)qml.transforms.make_tape已被弃用。请改用qml.tape.make_qscript。 (#3478)
文档 📝
添加了关于参数广播的使用和技术方面的文档。 (#3356)
电路的快速入门指南以及QNodes和Operators的文档现在包含了关于参数广播的介绍和详细信息。QNode文档主要包含使用细节,Operator文档则关注实现细节及支持自定义操作符广播的指南。
梯度和海森变换的返回类型声明以及一系列其他函数的
batch_transform已被修正。 (#3476)队列模块的开发文档已添加。 (#3268)
所有相关操作的对角化门的提及已被更正。 (#3409)
compute_eigvals的文档字符串曾说对角化门实现了 $U$,即使得 $O = U \Sigma U^{dagger}$ 的酉算子,其中 $O$ 是原始可观察量,$Sigma$ 是对角矩阵。然而,对角化门实际上实现的是 $U^{dagger}$,因为 $langle psi | O | psi rangle = langle psi | U \Sigma U^{dagger} | psi rangle$,这使得 $U^{dagger} | psi rangle$ 成为在 $Z$-基测量的实际状态。关于使用
dill对数据集进行序列化和反序列化的警告已被添加。 (#3505)
修复错误 🐛
修复了一个错误,该错误阻止了
(#3528)qml.gradients.param_shift用于广播录音。修复了一个错误,
qml.transforms.hamiltonian_expand在输出中未能保留输入结果的类型。 (#3339)修复了一个错误,该错误导致
qml.gradients.param_shift在仅使用未偏移项的自定义配方时抛出错误,以及在新的返回类型系统下完全使用任何未偏移项时抛出错误。 (#3177)原始的
_obs_sharing_wires属性在其扩展期间被更新。 (#3293)自适应优化器中的
drain=False问题已修复。在修复之前,当drain=False时,需要在优化池内部重建操作池。通过此修复,此重建不再需要。 (#3361)如果设备最初没有测量但动态指定了有限的测量,则现在会发生哈密顿量展开。 (#3369)
(#3386)qml.matrix(op)现在会失败,如果运算符确实没有矩阵(例如,qml.Barrier)来匹配op.matrix()。在
qml.AmplitudeEmbedding模板中的pad_with参数现在与所有接口兼容。 (#3392)Operator.pow现在默认将其组成部分排队。修复了一个错误,即当在使用shot向量定义的设备上运行返回
qml.sample的QNode时,会产生不正确的结果。 (#3422)现在
qml.data模块在Windows上正常工作。 (#3504)
贡献者 ✍️
此版本包含来自(按字母顺序排列)的贡献:
吉列尔莫·阿隆索,
胡安·米格尔·阿拉佐拉,
乌特卡什·阿扎德,
塞缪尔·班宁,
托马斯·布朗利,
阿斯特拉尔·蔡,
阿尔伯特·米特詹斯·科马,
艾哈迈德·达尔维什,
艾萨克·德·弗吕赫特,
奥利维亚·迪·马泰奥,
阿明托尔·杜斯科,
皮特·恩德巴克,
莉莉安·M·A·弗雷德里克森,
迭戈·瓜拉,
凯瑟琳·海厄特,
乔希·伊扎克,
索兰·贾汉吉里,
爱德华·姜,
科尔比尼安·科特曼,
克里斯蒂娜·李,
罗曼·莫亚尔,
李·詹姆斯·奥’瑞尔登,
穆迪特·潘德,
凯文·申,
马修·西尔弗曼,
杰伊·索尼,
安塔尔·萨瓦,
大卫·韦里希斯,
莫里茨·维尔曼,以及
菲利波·维琴蒂尼。
- orphan
发布 0.27.0¶
自上次发布以来的新特性
全新的数据模块 💾
现在可用
qml.data模块,允许用户下载、加载和创建量子数据集。(#3156)数据集托管在Xanadu Cloud上,可以通过使用
qml.data.load()下载:>>> H2_datasets = qml.data.load( ... data_name="qchem", molname="H2", basis="STO-3G", bondlength=1.1 ... ) >>> H2data = H2_datasets[0] >>> H2data <Dataset = description: qchem/H2/STO-3G/1.1, attributes: ['molecule', 'hamiltonian', ...]>
可以通过
qml.data.list_datasets()列出可下载的数据集。要下载或加载数据集中仅特定的属性,我们可以在
qml.data.load中使用attributes关键字参数指定所需的属性:>>> H2_hamiltonian = qml.data.load( ... data_name="qchem", molname="H2", basis="STO-3G", bondlength=1.1, ... attributes=["molecule", "hamiltonian"] ... )[0] >>> H2_hamiltonian.hamiltonian
可用的属性可以使用
qml.data.list_attributes()找到:要交互式地选择数据,我们可以使用
qml.data.load_interactive():>>> qml.data.load_interactive() 请选择数据名称: 1) qspin 2) qchem 选择 [1-2]: 1 请选择系统名称: ... 请选择周期性: ... 请选择晶格: ... 请选择布局: ... 请选择属性: ... 是否强制下载文件?(默认是否) [y/N]: N 下载到哪个文件夹?(默认是当前目录,将下载到/datasets子目录): 请确认您的选择: 数据集: qspin/Ising/open/rectangular/4x4 属性: ['parameters', 'ground_states'] 强制: False 目标文件夹: datasets 您想要继续吗?(默认是是) [Y/n]: <数据集 = 描述: qspin/Ising/open/rectangular/4x4, 属性: ['parameters', 'ground_states']>
数据集加载后,可以如下访问其属性:
>>> dev = qml.device("default.qubit",wires=4) >>> @qml.qnode(dev) ... def circuit(): ... qml.BasisState(H2data.hf_state, wires = [0, 1, 2, 3]) ... for op in H2data.vqe_gates: ... qml.apply(op) ... return qml.expval(H2data.hamiltonian) >>> print(circuit()) -1.0791430411076344
还可以使用
qml.data.Dataset创建自定义数据集:>>> example_hamiltonian = qml.Hamiltonian(coeffs=[1,0.5], observables=[qml.PauliZ(wires=0),qml.PauliX(wires=1)]) >>> example_energies, _ = np.linalg.eigh(qml.matrix(example_hamiltonian)) >>> example_dataset = qml.data.Dataset( ... data_name = 'Example', hamiltonian=example_hamiltonian, energies=example_energies ... ) >>> example_dataset.data_name 'Example' >>> example_dataset.hamiltonian (0.5) [X1] + (1) [Z0] >>> example_dataset.energies array([-1.5, -0.5, 0.5, 1.5])
自定义数据集可以通过
qml.data.Dataset.write()和qml.data.Dataset.read()方法进行保存和读取。>>> example_dataset.write('./path/to/dataset.dat') >>> read_dataset = qml.data.Dataset() >>> read_dataset.read('./path/to/dataset.dat') >>> read_dataset.data_name 'Example' >>> read_dataset.hamiltonian (0.5) [X1] + (1) [Z0] >>> read_dataset.energies array([-1.5, -0.5, 0.5, 1.5])
我们将继续在未来的版本中为
qml.data添加更多的数据集和功能。
自适应优化 🏃🏋️🏊
Optimizing quantum circuits can now be done adaptively with
qml.AdaptiveOptimizer. (#3192)The
qml.AdaptiveOptimizertakes an initial circuit and a collection of operators as input and adds a selected gate to the circuit at each optimization step. The process of growing the circuit can be repeated until the circuit gradients converge to zero within a given threshold. The adaptive optimizer can be used to implement algorithms such as ADAPT-VQE as shown in the following example.Firstly, we define some preliminary variables needed for VQE:
symbols = ["H", "H", "H"] geometry = np.array([[0.01076341, 0.04449877, 0.0], [0.98729513, 1.63059094, 0.0], [1.87262415, -0.00815842, 0.0]], requires_grad=False) H, qubits = qml.qchem.molecular_hamiltonian(symbols, geometry, charge = 1)
The collection of gates to grow the circuit is built to contain all single and double excitations:
n_electrons = 2 singles, doubles = qml.qchem.excitations(n_electrons, qubits) singles_excitations = [qml.SingleExcitation(0.0, x) for x in singles] doubles_excitations = [qml.DoubleExcitation(0.0, x) for x in doubles] operator_pool = doubles_excitations + singles_excitations
Next, an initial circuit that prepares a Hartree-Fock state and returns the expectation value of the Hamiltonian is defined:
hf_state = qml.qchem.hf_state(n_electrons, qubits) dev = qml.device("default.qubit", wires=qubits) @qml.qnode(dev) def circuit(): qml.BasisState(hf_state, wires=range(qubits)) return qml.expval(H)
Finally, the optimizer is instantiated and then the circuit is created and optimized adaptively:
opt = qml.optimize.AdaptiveOptimizer() for i in range(len(operator_pool)): circuit, energy, gradient = opt.step_and_cost(circuit, operator_pool, drain_pool=True) print('Energy:', energy) print(qml.draw(circuit)()) print('Largest Gradient:', gradient) print() if gradient < 1e-3: break
Energy: -1.246549938420637 0: ─╭BasisState(M0)─╭G²(0.20)─┤ ╭<𝓗> 1: ─├BasisState(M0)─├G²(0.20)─┤ ├<𝓗> 2: ─├BasisState(M0)─│─────────┤ ├<𝓗> 3: ─├BasisState(M0)─│─────────┤ ├<𝓗> 4: ─├BasisState(M0)─├G²(0.20)─┤ ├<𝓗> 5: ─╰BasisState(M0)─╰G²(0.20)─┤ ╰<𝓗> Largest Gradient: 0.14399872776755085 Energy: -1.2613740231529604 0: ─╭BasisState(M0)─╭G²(0.20)─╭G²(0.19)─┤ ╭<𝓗> 1: ─├BasisState(M0)─├G²(0.20)─├G²(0.19)─┤ ├<𝓗> 2: ─├BasisState(M0)─│─────────├G²(0.19)─┤ ├<𝓗> 3: ─├BasisState(M0)─│─────────╰G²(0.19)─┤ ├<𝓗> 4: ─├BasisState(M0)─├G²(0.20)───────────┤ ├<𝓗> 5: ─╰BasisState(M0)─╰G²(0.20)───────────┤ ╰<𝓗> Largest Gradient: 0.1349349562423238 Energy: -1.2743971719780331 0: ─╭BasisState(M0)─╭G²(0.20)─╭G²(0.19)──────────┤ ╭<𝓗> 1: ─├BasisState(M0)─├G²(0.20)─├G²(0.19)─╭G(0.00)─┤ ├<𝓗> 2: ─├BasisState(M0)─│─────────├G²(0.19)─│────────┤ ├<𝓗> 3: ─├BasisState(M0)─│─────────╰G²(0.19)─╰G(0.00)─┤ ├<𝓗> 4: ─├BasisState(M0)─├G²(0.20)────────────────────┤ ├<𝓗> 5: ─╰BasisState(M0)─╰G²(0.20)────────────────────┤ ╰<𝓗> Largest Gradient: 0.00040841755397108586
For a detailed breakdown of its implementation, check out the Adaptive circuits for quantum chemistry demo.
自动接口检测 🧩
QNodes now accept an
autointerface argument which automatically detects the machine learning library to use. (#3132)from pennylane import numpy as np import torch import tensorflow as tf from jax import numpy as jnp dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, interface="auto") def circuit(weight): qml.RX(weight[0], wires=0) qml.RY(weight[1], wires=1) return qml.expval(qml.PauliZ(0)) interface_tensors = [[0, 1], np.array([0, 1]), torch.Tensor([0, 1]), tf.Variable([0, 1], dtype=float), jnp.array([0, 1])] for tensor in interface_tensors: res = circuit(weight=tensor) print(f"Result value: {res:.2f}; Result type: {type(res)}")
Result value: 1.00; Result type: <class 'pennylane.numpy.tensor.tensor'> Result value: 1.00; Result type: <class 'pennylane.numpy.tensor.tensor'> Result value: 1.00; Result type: <class 'torch.Tensor'> Result value: 1.00; Result type: <class 'tensorflow.python.framework.ops.EagerTensor'> Result value: 1.00; Result type: <class 'jaxlib.xla_extension.Array'>
升级的 JAX-JIT 梯度支持 🏎
现在可以使用JAX-JIT支持计算返回单个概率向量或多个期望值的QNodes的梯度。 (#3244) (#3261)
import jax from jax import numpy as jnp from jax.config import config config.update("jax_enable_x64", True) dev = qml.device("lightning.qubit", wires=2) @jax.jit @qml.qnode(dev, diff_method="parameter-shift", interface="jax") def circuit(x, y): qml.RY(x, wires=0) qml.RY(y, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(1)) x = jnp.array(1.0) y = jnp.array(2.0)
>>> jax.jacobian(circuit, argnums=[0, 1])(x, y) (Array([-0.84147098, 0.35017549], dtype=float64, weak_type=True), Array([ 4.47445479e-18, -4.91295496e-01], dtype=float64, weak_type=True))
请注意,此更改依赖于
jax.pure_callback,该功能要求jax>=0.3.17。
构造保利词和句子 🔤
我们已将PennyLane中负责操作Pauli算子的所有内容重新组织并分组为一个
pauli模块。由于这个原因,grouping模块已被弃用,逻辑已从pennylane/grouping移动到pennylane/pauli/grouping。 (#3179)qml.pauli.PauliWord和qml.pauli.PauliSentence可用于分别表示泡利算子的张量积和线性组合。这些提供了一种更高效的方法来计算泡利算子的和与积。 (#3195)qml.pauli.PauliWord表示Pauli算子的张量积。我们可以使用这种表示法高效地相乘并提取这些算子的矩阵。>>> pw1 = qml.pauli.PauliWord({0:"X", 1:"Z"}) >>> pw2 = qml.pauli.PauliWord({0:"Y", 1:"Z"}) >>> pw1, pw2 (X(0) @ Z(1), Y(0) @ Z(1)) >>> pw1 * pw2 (Z(0), 1j) >>> pw1.to_mat(wire_order=[0,1]) array([[ 0, 0, 1, 0], [ 0, 0, 0, -1], [ 1, 0, 0, 0], [ 0, -1, 0, 0]])
qml.pauli.PauliSentence表示 Pauli 字词的线性组合。我们可以在这种表示法中高效地添加、乘法和提取这些算子的矩阵。>>> ps1 = qml.pauli.PauliSentence({pw1: 1.2, pw2: 0.5j}) >>> ps2 = qml.pauli.PauliSentence({pw1: -1.2}) >>> ps1 1.2 * X(0) @ Z(1) + 0.5j * Y(0) @ Z(1) >>> ps1 + ps2 0.0 * X(0) @ Z(1) + 0.5j * Y(0) @ Z(1) >>> ps1 * ps2 -1.44 * I + (-0.6+0j) * Z(0) >>> (ps1 + ps2).to_mat(wire_order=[0,1]) array([[ 0. +0.j, 0. +0.j, 0.5+0.j, 0. +0.j], [ 0. +0.j, 0. +0.j, 0. +0.j, -0.5+0.j], [-0.5+0.j, 0. +0.j, 0. +0.j, 0. +0.j], [ 0. +0.j, 0.5+0.j, 0. +0.j, 0. +0.j]])
(实验性) 更多对多测量和梯度输出类型的支持 🧪
qml.enable_return()现在支持 QNodes 返回多个测量结果,包括射击向量和梯度输出类型。 (#2886) (#3052) (#3041) (#3090) (#3069) (#3137) (#3127) (#3099) (#3098) (#3095) (#3091) (#3176) (#3170) (#3194) (#3267) (#3234) (#3232) (#3223) (#3222) (#3315)在 v0.25 中,我们引入了
qml.enable_return(),它将测量分离到它们自己的张量中。这个变化的动机是因为 NumPy 中的不规则ndarray创建的弃用。随着这一版本的发布,我们继续通过添加对以下内容的支持来提升此功能:
执行 (
qml.execute)雅可比向量积 (JVP) 计算
梯度变换 (
qml.gradients.param_shift,qml.gradients.finite_diff,qml.gradients.hessian_transform,qml.gradients.param_shift_hessian).接口(Autograd、TensorFlow和JAX,尽管没有JIT)
通过添加此支持,JAX 接口可以处理多个测量(测量向量)、测量和梯度输出类型,使用
qml.enable_return():import jax qml.enable_return() dev = qml.device("default.qubit", wires=2, shots=(1, 10000)) params = jax.numpy.array([0.1, 0.2]) @qml.qnode(dev, interface="jax", diff_method="parameter-shift", max_diff=2) def circuit(x): qml.RX(x[0], wires=[0]) qml.RY(x[1], wires=[1]) qml.CNOT(wires=[0, 1]) return qml.var(qml.PauliZ(0) @ qml.PauliX(1)), qml.probs(wires=[0])
>>> jax.hessian(circuit)(params) ((Array([[ 0., 0.], [ 2., -3.]], dtype=float32), Array([[[-0.5, 0. ], [ 0. , 0. ]], [[ 0.5, 0. ], [ 0. , 0. ]]], dtype=float32)), (Array([[ 0.07677898, 0.0563341 ], [ 0.07238522, -1.830669 ]], dtype=float32), Array([[[-4.9707499e-01, 2.9999996e-04], [-6.2500127e-04, 1.2500001e-04]], [[ 4.9707499e-01, -2.9999996e-04], [ 6.2500127e-04, -1.2500001e-04]]], dtype=float32)))
有关更多详细信息,请 参阅文档。
qml.qchem中的新基旋转和锥度特性 🤓
现在可以通过
qml.qchem.basis_rotation()计算构建分子轨道旋转基中的量子比特哈密顿量所需的分组系数、可观测量和基础旋转变换矩阵。(#3011)>>> symbols = ['H', 'H'] >>> geometry = np.array([[0.0, 0.0, 0.0], [1.398397361, 0.0, 0.0]], requires_grad = False) >>> mol = qml.qchem.Molecule(symbols, geometry) >>> core, one, two = qml.qchem.electron_integrals(mol)() >>> coeffs, ops, unitaries = qml.qchem.basis_rotation(one, two, tol_factor=1.0e-5) >>> unitaries [tensor([[-1.00000000e+00, -5.46483514e-13], [ 5.46483514e-13, -1.00000000e+00]], requires_grad=True), tensor([[-1.00000000e+00, 3.17585063e-14], [-3.17585063e-14, -1.00000000e+00]], requires_grad=True), tensor([[-0.70710678, -0.70710678], [-0.70710678, 0.70710678]], requires_grad=True), tensor([[ 2.58789009e-11, 1.00000000e+00], [-1.00000000e+00, 2.58789009e-11]], requires_grad=True)]
Any gate operation can now be tapered according to \(\mathbb{Z}_2\) symmetries of the Hamiltonian via
qml.qchem.taper_operation. (#3002) (#3121)>>> symbols = ['He', 'H'] >>> geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.4589]]) >>> mol = qml.qchem.Molecule(symbols, geometry, charge=1) >>> H, n_qubits = qml.qchem.molecular_hamiltonian(symbols, geometry) >>> generators = qml.qchem.symmetry_generators(H) >>> paulixops = qml.qchem.paulix_ops(generators, n_qubits) >>> paulix_sector = qml.qchem.optimal_sector(H, generators, mol.n_electrons) >>> tap_op = qml.qchem.taper_operation(qml.SingleExcitation, generators, paulixops, ... paulix_sector, wire_order=H.wires, op_wires=[0, 2]) >>> tap_op(3.14159) [Exp(1.5707949999999993j PauliY)]
Moreover, the obtained tapered operation can be used directly within a QNode.
>>> dev = qml.device('default.qubit', wires=[0, 1]) >>> @qml.qnode(dev) ... def circuit(params): ... tap_op(params[0]) ... return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) >>> drawer = qml.draw(circuit, show_all_wires=True) >>> print(drawer(params=[3.14159])) 0: ──Exp(0.00+1.57j Y)─┤ ╭<Z@Z> 1: ────────────────────┤ ╰<Z@Z>
新增功能以估计计算期望值所需的测量次数,以达到目标误差,并估计在给定测量次数下计算期望值的误差。
(#3000)
新函数、操作和可观测量 🤩
操作符或整个 QNode 现在可以通过
qml.map_wires()映射到其他线路上。 (#3143) (#3145)该
qml.map_wires()函数需要一个表示导线映射的字典。与之一起使用任意操作符:
>>> op = qml.RX(0.54, wires=0) + qml.PauliX(1) + (qml.PauliZ(2) @ qml.RY(1.23, wires=3)) >>> op (RX(0.54, wires=[0]) + PauliX(wires=[1])) + (PauliZ(wires=[2]) @ RY(1.23, wires=[3])) >>> wire_map = {0: 10, 1: 11, 2: 12, 3: 13} >>> qml.map_wires(op, wire_map) (RX(0.54, wires=[10]) + PauliX(wires=[11])) + (PauliZ(wires=[12]) @ RY(1.23, wires=[13]))
已向操作符添加了一个
map_wires方法,该方法返回一个副本 根据给定的线路映射更改其线路的操作符。所有 QNodes:
dev = qml.device("default.qubit", wires=["A", "B", "C", "D"]) wire_map = {0: "A", 1: "B", 2: "C", 3: "D"} @qml.qnode(dev) def circuit(): qml.RX(0.54, wires=0) qml.PauliX(1) qml.PauliZ(2) qml.RY(1.23, wires=3) return qml.probs(wires=0)
>>> mapped_circuit = qml.map_wires(circuit, wire_map) >>> mapped_circuit() tensor([0.92885434, 0.07114566], requires_grad=True) >>> print(qml.draw(mapped_circuit)()) A: ──RX(0.54)─┤ 概率 B: ──X────────┤ C: ──Z────────┤ D: ──RY(1.23)─┤
现在可以使用
qml.IntegerComparator算术操作。 (#3113)给定一个基态\(\vert n \rangle\),其中\(n\)是一个正整数,以及一个固定的正整数\(L\),
qml.IntegerComparator在\(n \geq L\)时翻转目标量子比特。或者,翻转条件可以是\(n < L\),如下所示:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(): qml.BasisState(np.array([0, 1]), wires=range(2)) qml.broadcast(qml.Hadamard, wires=range(2), pattern='single') qml.IntegerComparator(2, geq=False, wires=[0, 1]) return qml.state()
>>> circuit() [-0.5+0.j 0.5+0.j -0.5+0.j 0.5+0.j]
现在可以使用
qml.GellMannqutrit 可观测量,它是 Pauli 可观测量的三元推广。 (#3035)使用
qml.GellMann时,index关键字参数决定了使用哪个 8 个 Gell-Mann 矩阵。dev = qml.device("default.qutrit", wires=2) @qml.qnode(dev) def circuit(): qml.TClock(wires=0) qml.TShift(wires=1) qml.TAdd(wires=[0, 1]) return qml.expval(qml.GellMann(wires=0, index=8) + qml.GellMann(wires=1, index=3))
>>> circuit() -0.42264973081037416
现在可以使用
qml.ControlledQutritUnitary执行受控的三能级操作。 (#2844)定义操作的控制线和控制值与量子比特操作类似。
dev = qml.device("default.qutrit", wires=3) @qml.qnode(dev) def circuit(U): qml.TShift(wires=0) qml.TAdd(wires=[0, 1]) qml.ControlledQutritUnitary(U, control_wires=[0, 1], control_values='12', wires=2) return qml.state()
>>> U = np.array([[1, 1, 0], [1, -1, 0], [0, 0, np.sqrt(2)]]) / np.sqrt(2) >>> circuit(U) tensor([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], requires_grad=True)
改进
PennyLane 现在支持 Python 3.11! (#3297)
qml.sample和qml.counts工作效率更高,并且在调用时不指定可观察量时能跟踪是否生成了计算基样本。(#3207)现在,更容易区分包含不同数量高斯函数的基组的参数。(#3213)
打印一个
qml.MultiControlledX操作符现在显示control_values关键字参数。 (#3113)qml.simplify和像qml.matrix、batch_transform、hamiltonian_expand和split_non_commuting这样的变换现在可以与QuantumScript以及QuantumTape一起使用。(#3209)已移除UCCSD和kUpCCGSD模板中初始状态的多余翻转。 (#3148)
qml.adjoint现在支持批处理,如果基础操作支持批处理的话。 (#3168)qml.OrbitalRotation现在被分解为两个qml.SingleExcitation操作,以便在本地支持qml.SingleExcitation的设备上实现更快的执行和更高效的参数移位梯度计算。 (#3171)如果系数是虚数且基操作符是保利字,
Exp类会分解为PauliRot类。(#3249)添加了运算符属性
has_decomposition和has_adjoint,用于指示是否有对应的decomposition或adjoint方法可用。(#2986)对
QueuingManager(以前称为QueuingContext)和AnnotatedQueue进行结构改进。 (#2794) (#3061) (#3085)QueuingContext被重命名为QueuingManager。QueuingManager现在应该是将可排队对象放入活动队列的全球通信点。QueuingManager不再是一个抽象基类。AnnotatedQueue及其子类不再从QueuingManager继承。QueuingManager不再是上下文管理器。录制队列应该通过
QueuingManager.add_active_queue和QueuingContext.remove_active_queue类方法开始和停止录制,而不是直接操作_active_contexts属性。AnnotatedQueue及其子类不再提供关于正在录音的队列的全局信息。这些信息现在仅通过QueuingManager可用。AnnotatedQueue及其子类不再拥有私有的_append、_remove、_update_info、_safe_update_info和_get_info方法。应使用公共的类似方法。QueuingManager.safe_update_info和AnnotatedQueue.safe_update_info已被弃用。它们的功能已移至update_info。
qml.Identity现在接受多个线。
>>> id_op = qml.Identity([0, 1]) >>> id_op.matrix() array([[1., 0., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.], [0., 0., 0., 1.]]) >>> id_op.sparse_matrix() <4x4 稀疏矩阵类型 '
' 在压缩稀疏行格式中存储了 4 个元素> >>> id_op.eigvals() array([1., 1., 1., 1.])添加了
unitary_check关键字参数到QubitUnitary类的构造函数中,表示用户是否希望检查输入矩阵的单位性。其默认值是false。 (#3063)通过使用
qml.draw_mpl修改了WireCut的表示。 (#3067)增加了对任意接口的标量张量的算子类的和与积的支持(NumPy、JAX、Tensorflow、PyTorch…)。 (#3149)
>>> s_prod = torch.tensor(4) * qml.RX(1.23, 0) >>> s_prod 4*(RX(1.23, wires=[0])) >>> s_prod.scalar tensor(4)
向
Composite类添加了overlapping_ops属性,以提高eigvals、diagonalizing_gates和Prod.matrix方法的性能。 (#3084)向操作符添加了
map_wires方法,该方法返回一个修改后的操作符副本,其电线根据给定的电线映射进行更改。 (#3143)>>> op = qml.Toffoli([0, 1, 2]) >>> wire_map = {0: 2, 2: 0} >>> op.map_wires(wire_map=wire_map) Toffoli(wires=[2, 1, 0])
调用
compute_matrix和compute_sparse_matrix的简单非参数操作现在更快,内存效率更高,因为增加了缓存。 (#3134)添加了
Exp.label()输出的详细信息。 (#3126)qml.math.unwrap不再创建不规则数组。列表仍然是列表。 (#3163)新的
null.qubit设备。null.qubit不执行任何操作或内存分配。 (#2589)default.qubit优先使用分解方法,避免在更大数量的量子位上为QFT和GroverOperator构造矩阵。 (#3193)qml.ControlledQubitUnitary现在有一个control_values属性。 (#3206)添加了一个新的
qml.tape.QuantumScript类,该类包含了所有非排队行为的QuantumTape。现在,QuantumTape继承自QuantumScript以及AnnotatedQueue。 (#3097)将
qml.equal函数扩展到测量过程 (#3189)qml.drawer.draw.draw_mpl现在接受一个style关键字参数来选择绘图样式,而不是在绘图之前调用qml.drawer.use_style(style)。为draw_mpl设置样式不会更改 matplotlib 绘图的全局配置。如果没有传入style,函数默认使用black_white样式进行绘图。(#3247)
重大变更
QuantumTape._par_info现在是一个字典列表,而不是一个以零开始的整数为键的字典。 (#3185)QueuingContext已更名为QueuingManager。 (#3061)返回类型枚举的位置的弃用补丁和
qml.utils.expand已被移除。 (#3092)_multi_dispatch功能已经移入get_interface函数内部。现在可以用一个或多个张量作为参数调用此函数。 (#3136)>>> torch_scalar = torch.tensor(1) >>> torch_tensor = torch.Tensor([2, 3, 4]) >>> numpy_tensor = np.array([5, 6, 7]) >>> qml.math.get_interface(torch_scalar) 'torch' >>> qml.math.get_interface(numpy_tensor) 'numpy'
_multi_dispatch之前只有一个参数,该参数包含要调度的张量列表:>>> qml.math._multi_dispatch([torch_scalar, torch_tensor, numpy_tensor]) 'torch'
为了区分用户是希望获取单个张量的接口还是多个张量的接口,
get_interface现在接受每个要调度的张量不同的参数:>>> qml.math.get_interface(*[torch_scalar, torch_tensor, numpy_tensor]) 'torch' >>> qml.math.get_interface(torch_scalar, torch_tensor, numpy_tensor) 'torch'
Operator.compute_terms已移除。在运算符的特定实例中,可以使用op.terms()代替。此方法不再是静态方法。 (#3215)
不推荐使用的功能
QueuingManager.safe_update_info和AnnotatedQueue.safe_update_info已被弃用。相反,update_info如果对象不在队列中,将不再引发错误。(#3085)qml.tape.stop_recording和QuantumTape.stop_recording已经迁移到qml.QueuingManager.stop_recording。旧函数将在 v0.29 之前仍然可用。 (#3068)qml.tape.get_active_tape已被弃用。请改用qml.QueuingManager.active_context()。 (#3068)Operator.compute_terms已被移除。在操作符的特定实例上,使用op.terms()。不再提供这个静态方法。 (#3215)qml.tape.QuantumTape.inv()已被弃用。请改用qml.tape.QuantumTape.adjoint。 (#3237)qml.transforms.qcut.remap_tape_wires已被弃用。请改用qml.map_wires。 (#3186)分组模块
qml.grouping已被弃用。请改用qml.pauli或qml.pauli.grouping。该模块将在 v0.28 之前仍可用。 (#3262)
文档
错误修复
qml.SparseHamiltonian现在验证输入矩阵的大小。 (#3278)用户在输入序列到
qml.Hermitian时不再看到不直观的错误。 (#3181)返回
vn_entropy或mutual_info的QNodes的评估在使用定义了shots向量的设备时会引发一条信息丰富的错误消息。(#3180)修复了一个导致
qml.AmplitudeEmbedding与 JITting 不兼容的错误。 (#3166)修复了
qml.transforms.transpile转换以正确处理所有的两比特操作。 (#3104)修复了受控版本的
ControlledQubitUnitary控制值的一个错误。 (#3119)修复了一个错误:
qml.math.fidelity(non_trainable_state, trainable_state)意外失败。 (#3160)修复了一个错误:
(#3182)qml.QueuingManager.stop_recording在代码执行时抛出异常时未能清理。返回
qml.sample()或qml.counts()与非对易观测量的其他测量现在会引发 QuantumFunctionError(例如,return qml.expval(PauliX(wires=0)), qml.sample()现在会引发错误)。(#2924)修复了一个错误,当
op.eigvals()的操作数是非厄米复合算子时,会返回不正确的结果。 (#3204)修复了一个错误,即
(#3239)qml.BasisStatePreparation和qml.BasisEmbedding在使用 JAX 时无法进行即时编译。修复了一个bug,
qml.MottonenStatePreparation在JAX中无法进行jit编译。 (#3260)修复了一个错误,其中
qml.expval(qml.Hamiltonian())在涉及一些设备上不存在的线的哈密顿量时不会引发错误。 (#3266)修复了一个 bug,
qml.tape.QuantumTape.shape()没有考虑到 tape 的批量维度 (#3269)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Kamal Mohamed Ali, Guillermo Alonso-Linaje, Juan Miguel Arrazola, Utkarsh Azad, Thomas Bromley, Albert Mitjans Coma, Isaac De Vlugt, Olivia Di Matteo, Amintor Dusko, Lillian M. A. Frederiksen, Diego Guala, Josh Izaac, Soran Jahangiri, Edward Jiang, Korbinian Kottmann, Christina Lee, Romain Moyard, Lee J. O’Riordan, Mudit Pandey, Matthew Silverman, Jay Soni, Antal Száva, David Wierichs,
- orphan
发布 0.26.0¶
自上次发布以来的新特性
经典阴影 👤
PennyLane 现在提供对实施经典阴影测量协议的内置支持。 (#2820) (#2821) (#2871) (#2968) (#2959) (#2968)
经典阴影测量协议在论文中详细描述 从极少的测量预测量子系统的许多属性。 作为本次发布对经典阴影的支持,提供了两种新的有限-shot 和完全可微分的测量:
返回新测量的QNodes
qml.classical_shadow()将返回两个实体;bits(如果采样到1或-1特征值,分别为0或1)和recipes(为每个量子比特执行的随机Pauli测量,用整数标记):dev = qml.device("default.qubit", wires=2, shots=3) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) return qml.classical_shadow(wires=[0, 1])
>>> bits, recipes = circuit() >>> bits tensor([[0, 0], [1, 0], [0, 1]], dtype=uint8, requires_grad=True) >>> recipes tensor([[2, 2], [0, 2], [0, 2]], dtype=uint8, requires_grad=True)
返回
qml.shadow_expval()的 QNodes 使用经典阴影进行期望值估计:dev = qml.device("default.qubit", wires=range(2), shots=10000) @qml.qnode(dev) def circuit(x, H): qml.Hadamard(0) qml.CNOT((0,1)) qml.RX(x, wires=0) return qml.shadow_expval(H) x = np.array(0.5, requires_grad=True) H = qml.Hamiltonian( [1., 1.], [qml.PauliZ(0) @ qml.PauliZ(1), qml.PauliX(0) @ qml.PauliX(1)] )
>>> circuit(x, H) tensor(1.8486, requires_grad=True) >>> qml.grad(circuit)(x, H) -0.4797000000000001
完全可微分的 QNode 变换用于新的经典阴影测量也可以通过
qml.shadows.shadow_state和qml.shadows.shadow_expval获得。为了方便后处理,我们还添加了通过
ClassicalShadow类的entropy方法计算一般Renyi熵的能力,该方法需要感兴趣的子系统的线路和Renyi熵的阶数:>>> shadow = qml.ClassicalShadow(bits, recipes) >>> vN_entropy = shadow.entropy(wires=[0, 1], alpha=1)
Qutrits: 量子电路用于三级自由度 ☘️
现在可以通过添加三态功能来模拟一个全新的量子计算框架。 (#2699) (#2781) (#2782) (#2783) (#2784) (#2841) (#2843)
Qutrits 类似于量子比特,但它们存在于一个三维希尔伯特空间中;它们不是二元自由度,而是三元自由度。Qutrits 的出现使得各种有趣的理论、实践和算法能力得以实现,这些能力还有待于进一步探索。
要实现三态电路,需要一个新设备:
default.qutrit。default.qutrit设备是一个基于Python的模拟器,类似于default.qubit,并按通常方式定义:>>> dev = qml.device("default.qutrit", wires=1)
以下操作在
default.qutrit设备上支持:该 qutrit 移位算符
qml.TShift和三元时钟算符qml.TClock,如Yeh et al. (2022)所定义,分别是 Pauli X 和 Pauli Z 操作的 qutrit 类比。qml.TAdd和qml.TSWAP操作是 CNOT 和 SWAP 操作的三比特类比。通过
qml.QutritUnitary自定义单元操作。qml.state和qml.probs测量。通过
qml.THermitian测量用户指定的厄米矩阵可观测量。
下面给出了这些功能的综合示例:
dev = qml.device("default.qutrit", wires=1) U = np.array([ [1, 1, 1], [1, 1, 1], [1, 1, 1] ] ) / np.sqrt(3) obs = np.array([ [1, 1, 0], [1, -1, 0], [0, 0, np.sqrt(2)] ] ) / np.sqrt(2) @qml.qnode(dev) def qutrit_state(U, obs): qml.TShift(0) qml.TClock(0) qml.QutritUnitary(U, wires=0) return qml.state() @qml.qnode(dev) def qutrit_expval(U, obs): qml.TShift(0) qml.TClock(0) qml.QutritUnitary(U, wires=0) return qml.expval(qml.THermitian(obs, wires=0))
>>> qutrit_state(U, obs) tensor([-0.28867513+0.5j, -0.28867513+0.5j, -0.28867513+0.5j], requires_grad=True) >>> qutrit_expval(U, obs) tensor(0.80473785, requires_grad=True)
我们将在未来的版本中继续增加对三元比特的支持。
简化变得... 更简单 😌
此版本的
qml.simplify()函数有几个直观的改进。 (#2978) (#2982) (#2922) (#3012)qml.simplify现在可以执行以下操作:简化参数化操作
简化特定算子的共轭和幂
对一个求和中的类似项进行分组
解析保利算子的积
组合相同旋转门的旋转角度
这是一个名为
qml.simplify的示例,使用了参数化旋转门。在这种情况下,旋转角度被简化为模\(4\pi\)。>>> op1 = qml.RX(30.0, wires=0) >>> qml.simplify(op1) RX(4.867258771281655, wires=[0]) >>> op2 = qml.RX(4 * np.pi, wires=0) >>> qml.simplify(op2) Identity(wires=[0])
所有这些简化功能都可以通过使用
@qml.simplify直接应用于量子函数、QNodes 和磁带:dev = qml.device("default.qubit", wires=2) @qml.simplify @qml.qnode(dev) def circuit(): qml.adjoint(qml.prod(qml.RX(1, 0) ** 1, qml.RY(1, 0), qml.RZ(1, 0))) return qml.probs(wires=0)
>>> circuit() >>> list(circuit.tape) [RZ(11.566370614359172, wires=[0]) @ RY(11.566370614359172, wires=[0]) @ RX(11.566370614359172, wires=[0]), probs(wires=[0])]
QNSPSA 优化器 💪
一个名为
qml.QNSPSAOptimizer的新优化器可用,它实现了基于 量子费舍尔信息的同时扰动随机逼近 的量子自然同时扰动随机逼近(QNSPSA)方法。(#2818)qml.QNSPSAOptimizer是一种二阶 SPSA 算法,它结合了量子感知的量子自然梯度(QNG)优化方法的收敛能力和 SPSA 方法的减少量子评估。虽然 QNSPSA 优化器相比于标准 SPSA 优化(每步 3 次执行)需要额外的电路执行(每步 10 次执行),但这些额外的评估用于提供二阶度量张量的随机估计,这通常帮助优化器实现更快速的收敛。
像使用任何其他优化器一样使用
qml.QNSPSAOptimizer:max_iterations = 50 opt = qml.QNSPSAOptimizer() for _ in range(max_iterations): params, cost = opt.step_and_cost(cost, params)
查看 我们的演示 以获取有关 QNSPSA 优化器的更多信息。
运算符和参数广播补充 📈
已添加用于指数运算和幂运算的操作符方法。 (#2799) (#3029)
可以使用
qml.exp函数来创建可观测量或通用旋转门:>>> x = 1.234 >>> t = qml.PauliX(0) @ qml.PauliX(1) + qml.PauliY(0) @ qml.PauliY(1) >>> isingxy = qml.exp(t, 0.25j * x) >>> isingxy.matrix() array([[1. +0.j , 0. +0.j , 1. +0.j , 0. +0.j ], [0. +0.j , 0.8156179+0.j , 1. +0.57859091j, 0. +0.j ], [0. +0.j , 0. +0.57859091j, 0.8156179+0.j , 0. +0.j ], [0. +0.j , 0. +0.j , 1. +0.j , 1. +0.j ]])
qml.pow函数将给定的算子提升到一个幂:>>> op = qml.pow(qml.PauliX(0), 2) >>> op.matrix() array([[1, 0], [0, 1]])
现在可以使用一个名为
qml.PSWAP的运算符。 (#2667)qml.PSWAP门 – 或相位-SWAP 门 – 之前仅在 PennyLane-Braket 插件中可用。现在在 PennyLane v0.26 中原生使用它。检查一个算子是否是厄米的或单位的,使用
qml.is_hermitian和qml.is_unitary。 (#2960)>>> op1 = qml.PauliX(wires=0) >>> qml.is_hermitian(op1) True >>> op2 = qml.PauliX(0) + qml.RX(np.pi/3, 0) >>> qml.is_unitary(op2) False
嵌入模板现在支持参数广播。 (#2810)
嵌入模板例如
AmplitudeEmbedding或IQPEmbedding现在支持在其变分参数中具有前导广播维度的参数广播。AmplitudeEmbedding,例如,通常会使用一维输入特征向量。通过广播,我们现在可以计算>>> features = np.array([ ... [0.5, 0.5, 0., 0., 0.5, 0., 0.5, 0.], ... [1., 0., 0., 0., 0., 0., 0., 0.], ... [0.5, 0.5, 0., 0., 0., 0., 0.5, 0.5], ... ]) >>> op = qml.AmplitudeEmbedding(features, wires=[1, 5, 2]) >>> op.batch_size 3
一个例外是
BasisEmbedding,它是不可广播的。
改进
现在,
qml.math.expand_matrix()方法允许将算子的稀疏矩阵表示扩展到更大的希尔伯特空间。 (#2998)>>> from scipy import sparse >>> mat = sparse.csr_matrix([[0, 1], [1, 0]]) >>> qml.math.expand_matrix(mat, wires=[1], wire_order=[0,1]).toarray() array([[0., 1., 0., 0.], [1., 0., 0., 0.], [0., 0., 0., 1.], [0., 0., 1., 0.]])
qml.ctrl现在使用Controlled代替ControlledOperation。新的Controlled类封装了单独的Operator而不是一个电路。它提供了改进的表示和集成。 (#2990)qml.matrix现在可以计算包含多个广播操作或在广播操作之后的非广播操作的电路和 QNodes 的矩阵。(#3025)这种情况常见于广播操作的分解:分解一般将包含一个或多个广播操作,以及没有参数或固定参数的非广播操作。
运算符的列表现在根据它们各自的导线内部排序,同时考虑到它们的交换性属性。 (#2995)
QuantumTape类的一些方法已被简化和重新排序,以提高可读性和性能。 (#2963)qml.qchem.molecular_hamiltonian函数已被修改以支持可观测量分组。 (#2997)qml.ops.op_math.Controlled现在具有基本的分解功能。 (#2938)通过改进分区不平衡推导,自动电路切割得到了提升。 现在更有可能为较大电路生成最佳切割。 (#2517)
默认情况下,
qml.counts仅返回在采样中观察到的结果。可选地,指定qml.counts(all_outcomes=True)将返回一个包含所有可能结果的字典。 (#2889)>>> dev = qml.device("default.qubit", wires=2, shots=1000) >>> >>> @qml.qnode(dev) >>> def circuit(): ... qml.Hadamard(wires=0) ... qml.CNOT(wires=[0, 1]) ... return qml.counts(all_outcomes=True) >>> result = circuit() >>> result {'00': 495, '01': 0, '10': 0, '11': 505}
为其弃用做准备,内部使用就地反演的情况已被消除。 (#2965)
受控运算符现在与qml.is_commuting一起工作。 (#2994)qml.prod和qml.op_sum现在支持sparse_matrix()方法。 (#3006)>>> xy = qml.prod(qml.PauliX(1), qml.PauliY(1)) >>> op = qml.op_sum(xy, qml.Identity(0)) >>> >>> sparse_mat = op.sparse_matrix(wire_order=[0,1]) >>> type(sparse_mat)
>>> sparse_mat.toarray() [[1.+1.j 0.+0.j 0.+0.j 0.+0.j] [0.+0.j 1.-1.j 0.+0.j 0.+0.j] [0.+0.j 0.+0.j 1.+1.j 0.+0.j] [0.+0.j 0.+0.j 0.+0.j 1.-1.j]] 提供了
sparse_matrix()对单量子比特可观测量的支持。 (#2964)qml.Barrier设置为only_visual=True现在通过op.simplify()简化为单位算符或单位算符的乘积。 (#3016)增加了更准确和直观的输出用于打印一些运算符。 (#3013)
算子的和或积的矩阵结果以更高效的方式存储。 (#3022)
现在算子和算子乘积的(稀疏)矩阵计算更高效了。 (#3030)
当
qml.prod的因子没有共享任何连接时,为了提高效率,矩阵和稀疏矩阵是使用克罗内克积计算的。 (#3040)qml.grouping.is_pauli_word现在对于不继承自qml.Observable的算子返回False,而不是引发错误。(#3039)增加了对从
qml.op_sum和qml.prod创建的算子的迭代功能。 (#3028)>>> op = qml.op_sum(qml.PauliX(0), qml.PauliY(1), qml.PauliZ(2)) >>> len(op) 3 >>> op[1] PauliY(wires=[1]) >>> [o.name for o in op] ['PauliX', 'PauliY', 'PauliZ']
不推荐使用的功能
原地取反现在已被弃用。这包括
op.inv()和op.inverse=value。请使用qml.adjoint或qml.pow代替。这些方法的支持将持续到 v0.28。 (#2988)不要使用:
>>> v1 = qml.PauliX(0).inv() >>> v2 = qml.PauliX(0) >>> v2.inverse = True
而是使用:
>>> qml.adjoint(qml.PauliX(0)) Adjoint(PauliX(wires=[0])) >>> qml.pow(qml.PauliX(0), -1) PauliX(wires=[0])**-1 >>> qml.pow(qml.PauliX(0), -1, lazy=False) PauliX(wires=[0]) >>> qml.PauliX(0) ** -1 PauliX(wires=[0])**-1
qml.adjoint取运算符的共轭转置,而qml.pow(op, -1)表示矩阵取反。对于酉运算符,adjoint将比qml.pow(op, -1)更有效,尽管它们表示相同的事物。该
supports_reversible_diff设备功能未被使用,已被移除。 (#2993)
重大变更
现在测量可能不是厄米算符的操作会引发警告而不是错误。要确定一个算符是否是厄米的,请使用
qml.is_hermitian。(#2960)ControlledOperation类已被移除。该类仅供开发者使用,因此这一变化对任何用户都不应该明显。它被Controlled替代。 (#2990)默认的
execute方法对于QubitDevice基类现在调用self.statistics并新增一个关键字参数circuit,它代表正在执行的量子电路。 任何重写statistics的设备应更新该方法的签名,以包含新的circuit关键字参数。 (#2820)expand_matrix()已从pennylane.operation移动到pennylane.math.matrix_manipulation(#3008)qml.grouping.utils.is_commuting已被移除,其泡利词逻辑现在是qml.is_commuting的一部分。 (#3033)qml.is_commuting已从pennylane.transforms.commutation_dag移动到pennylane.ops.functions。 (#2991)
文档
更新了傅里叶变换文档,使用
circuit_spectrum代替已弃用的spectrum。 (#3018)修正了所有相关操作的对角化门的文档字符串。文档字符串曾经表示对角化门实现了 \(U\),即使得 \(O = U \Sigma U^{\dagger}\),其中 \(O\) 是原始可观测量,\(\Sigma\) 是对角矩阵。然而,对角化门实际上实现了 \(U^{\dagger}\),因为 \(\langle \psi | O | \psi \rangle = \langle \psi | U \Sigma U^{\dagger} | \psi \rangle\),使得 \(U^{\dagger} | \psi \rangle\) 是在 Z-basis 中实际被测量的状态。 (#2981)
错误修复
修复了当系数为autograd但对角化门不作用于所有线路时,
qml.ops.Exp运算符的一个错误。 (#3057)修复了一个错误, tape 变换
single_qubit_fusion在特定的旋转组合下计算错误的旋转角度。(#3024)现在,当量子函数通过
qml.simplify转换时,Jax 梯度可以在 QNode 中使用。 (#3017)在用
wires=[]实例化时,具有num_wires = AnyWires或num_wires = AnyWires的运算符现在会引发错误,某些例外情况除外。 (#2979)修复了一个错误,在某些情况下,打印
qml.Hamiltonian具有复数系数时会引发TypeError。 (#3004)在电路结束时测量不可交换观测量时,添加了更具描述性的错误信息,包含了
probs、samples、counts和allcounts。 (#3065)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
胡安·米格尔·阿拉佐拉,乌特卡什·阿扎德,汤姆·布罗姆利,奥利维亚·迪·马泰奥,艾萨克·德·弗卢赫,狄扬·余,利莉安·玛丽·奥斯丁·弗雷德里克森,乔希·伊扎克,索兰·贾汉吉里,爱德华·江,安基特·坎德尔瓦尔,科尔比安·科特曼,梅努·库马里,克里斯蒂娜·李,阿尔伯特·米特扬斯·科马,罗曼·莫亚尔德,拉希德·N·H·M,泽越·牛,穆迪特·潘迪,马修·西尔弗曼,杰伊·索尼,安塔尔·萨瓦,科迪·王,大卫·维里希斯。
- orphan
版本 0.25.1¶
错误修复
通过更新
qml.math.array和qml.math.eye来修复某些参数化操作的 Torch 设备差异,以保持所使用的 Torch 设备。 (#2967)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
罗曼·莫亚尔德,拉希德·N·H·M,李·詹姆斯·奥里奥丹,安塔尔·萨瓦
- orphan
发布 0.25.0¶
自上次发布以来的新特性
估计计算资源需求 🧠
已添加用于估算分子模拟计算的功能,使用了
qml.resource。 (#2646) (#2653) (#2665) (#2694) (#2720) (#2723) (#2746) (#2796) (#2797) (#2874) (#2944) (#2644)新的 resource 模块允许您估算实现 量子相位估计 算法所需的非 Clifford gates 和逻辑量子位的数量,以模拟材料和分子。这包括对使用特定基的 第一 和 第二 量子化的量子算法的支持:
首次量子化 使用平面波基底通过
FirstQuantization类:>>> n = 100000 # 平面波的数量 >>> eta = 156 # 电子的数量 >>> omega = 1145.166 # 原子单位下的单位胞体积 >>> algo = FirstQuantization(n, eta, omega) >>> print(algo.gates, algo.qubits) 1.10e+13, 4416
第二量子化 通过
DoubleFactorization类的双重因子化哈密顿量:symbols = ["O", "H", "H"] geometry = np.array( [ [0.00000000, 0.00000000, 0.28377432], [0.00000000, 1.45278171, -1.00662237], [0.00000000, -1.45278171, -1.00662237], ], requires_grad=False, ) mol = qml.qchem.Molecule(symbols, geometry, basis_name="sto-3g") core, one, two = qml.qchem.electron_integrals(mol)() algo = DoubleFactorization(one, two)
>>> print(algo.gates, algo.qubits) 103969925, 290
FirstQuantization和DoubleFactorization类的方法,例如qubit_cost(逻辑量子比特的数量)和gate_cost(非Clifford门的数量),也可以作为静态方法访问:>>> qml.resource.FirstQuantization.qubit_cost(100000, 156, 169.69608, 0.01) 4377 >>> qml.resource.FirstQuantization.gate_cost(100000, 156, 169.69608, 0.01) 3676557345574
可微分错误缓解 ⚙️
可微分的零噪声外推(ZNE)误差缓解现已可用。 (#2757)
提升任何变分量子算法为缓解算法,以在嘈杂硬件上获得更好的结果,同时保持可微分性。
为此,请在您的 QNode 上使用
qml.transforms.mitigate_with_zne转换,并提供 PennyLane 独有的qml.transforms.fold_global折叠函数和qml.transforms.poly_extrapolate外推函数。 以下是一个关于嘈杂模拟设备的示例,我们对 QNode 进行缓解,并且仍然能够计算梯度:# 描述噪声 noise_gate = qml.DepolarizingChannel noise_strength = 0.1 # 加载设备 dev_ideal = qml.device("default.mixed", wires=1) dev_noisy = qml.transforms.insert(noise_gate, noise_strength)(dev_ideal) scale_factors = [1, 2, 3] @mitigate_with_zne( scale_factors, qml.transforms.fold_global, qml.transforms.poly_extrapolate, extrapolate_kwargs={'order': 2} ) @qml.qnode(dev_noisy) def qnode_mitigated(theta): qml.RY(theta, wires=0) return qml.expval(qml.PauliX(0))
>>> theta = np.array(0.5, requires_grad=True) >>> qml.grad(qnode_mitigated)(theta) 0.5712737447327619
对参数广播的更多原生支持 📡
default.qubit现在本地支持参数广播,在执行相同电路时,相比手动循环参数或直接使用qml.transforms.broadcast_expand转换,提供了更高的性能。(#2627)dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0))
>>> circuit(np.array([0.1, 0.3, 0.2])) tensor([0.99500417, 0.95533649, 0.98006658], requires_grad=True)
目前,并非所有模板都已更新以支持广播。
Parameter-shift gradients now allow for parameter broadcasting internally, which can result in a significant speedup when computing gradients of circuits with many parameters. (#2749)
The gradient transform
qml.gradients.param_shiftnow accepts the keyword argumentbroadcast. If set toTrue, broadcasting is used to compute the derivative:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x, y): qml.RX(x, wires=0) qml.RY(y, wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
>>> x = np.array([np.pi/3, np.pi/2], requires_grad=True) >>> y = np.array([np.pi/6, np.pi/5], requires_grad=True) >>> qml.gradients.param_shift(circuit, broadcast=True)(x, y) (tensor([[-0.7795085, 0. ], [ 0. , -0.7795085]], requires_grad=True), tensor([[-0.125, 0. ], [0. , -0.125]], requires_grad=True))
The following example highlights how to make use of broadcasting gradients at the QNode level. Internally, broadcasting is used to compute the parameter-shift rule when required, which may result in performance improvements.
@qml.qnode(dev, diff_method="parameter-shift", broadcast=True) def circuit(x, y): qml.RX(x, wires=0) qml.RY(y, wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
>>> x = np.array(0.1, requires_grad=True) >>> y = np.array(0.4, requires_grad=True) >>> qml.grad(circuit)(x, y) (array(-0.09195267), array(-0.38747287))
Here, only 2 circuits are created internally, rather than 4 with
broadcast=False.To illustrate the speedup, for a constant-depth circuit with Pauli rotations and controlled Pauli rotations, the time required to compute
qml.gradients.param_shift(circuit, broadcast=False)(params)(“No broadcasting”) andqml.gradients.param_shift(circuit, broadcast=True)(params)(“Broadcasting”) as a function of the number of qubits is given here.量子化学的操作现在支持参数广播。 (#2726)
>>> op = qml.SingleExcitation(np.array([0.3, 1.2, -0.7]), wires=[0, 1]) >>> op.matrix().shape (3, 4, 4)
{kind=link}
直观的运算符算术 🧮
现在可以表示运算符的和、积和标量积的新功能可用。
为了方便创建新的算子,添加了以下功能,这些算子的矩阵、项和特征值可以像往常一样访问,同时保持可微性。通过这些新特性创建的算子可以在 QNodes 中作为操作或可观测量(在物理上适用)使用。
通过
qml.op_sum汇总任何数量的算符会得到一个“汇总”的算符:>>> ops_to_sum = [qml.PauliX(0), qml.PauliY(1), qml.PauliZ(0)] >>> summed_ops = qml.op_sum(*ops_to_sum) >>> summed_ops PauliX(wires=[0]) + PauliY(wires=[1]) + PauliZ(wires=[0]) >>> qml.matrix(summed_ops) array([[ 1.+0.j, 0.-1.j, 1.+0.j, 0.+0.j], [ 0.+1.j, 1.+0.j, 0.+0.j, 1.+0.j], [ 1.+0.j, 0.+0.j, -1.+0.j, 0.-1.j], [ 0.+0.j, 1.+0.j, 0.+1.j, -1.+0.j]]) >>> summed_ops.terms() ([1.0, 1.0, 1.0], (PauliX(wires=[0]), PauliY(wires=[1]), PauliZ(wires=[0])))
通过
qml.prod乘以任意数量的算符将产生一个“乘积”算符,其中相应地使用矩阵乘积或张量乘积:>>> theta = 1.23 >>> prod_op = qml.prod(qml.PauliZ(0), qml.RX(theta, 1)) >>> prod_op PauliZ(wires=[0]) @ RX(1.23, wires=[1]) >>> qml.eigvals(prod_op) [-1.39373197 -0.23981492 0.23981492 1.39373197]
通过
qml.s_prod获取一个系数和一个算子的乘积会产生一个“标量积”算子:>>> sprod_op = qml.s_prod(2.0, qml.PauliX(0)) >>> sprod_op 2.0*(PauliX(wires=[0])) >>> sprod_op.matrix() array([[ 0., 2.], [ 2., 0.]]) >>> sprod_op.terms() ([2.0], [PauliX(wires=[0])])
这些新功能可以在QNodes中作为操作符或可观测量使用(如适用),同时保持可微性。例如:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(angles): qml.prod(qml.PauliZ(0), qml.RY(angles[0], 1)) qml.op_sum(qml.PauliX(1), qml.RY(angles[1], 0)) return qml.expval(qml.op_sum(qml.PauliX(0), qml.PauliZ(1)))
>>> angles = np.array([1.23, 4.56], requires_grad=True) >>> circuit(angles) tensor(0.33423773, requires_grad=True) >>> qml.grad(circuit)(angles) array([-0.9424888, 0. ])
所有的 PennyLane 运算符现在可以使用
+、-、@、*、**进行相加、相减、相乘、缩放和提升幂次。 (#2849) (#2825) (#2891)您现在可以将标量添加到算子中,解释为标量是一个适当大小的单位矩阵;
>>> sum_op = 5 + qml.PauliX(0) >>> sum_op.matrix() array([[5., 1.], [1., 5.]])
可以使用
+和-运算符组合所有Pennylane运算符:>>> sum_op = qml.RX(phi=1.23, wires=0) + qml.RZ(phi=3.14, wires=0) - qml.RY(phi=0.12, wires=0) >>> sum_op RX(1.23, wires=[0]) + RZ(3.14, wires=[0]) + -1*(RY(0.12, wires=[0])) >>> qml.matrix(sum_op) array([[-0.18063077-0.99999968j, 0.05996401-0.57695852j], [-0.05996401-0.57695852j, -0.18063077+0.99999968j]])
请注意,
+和-与可观测量的行为是不同的;它仍然会生成一个哈密顿量。*和@运算符可以用于缩放和组合所有 PennyLane 运算符。>>> prod_op = 2*qml.RX(1, wires=0) @ qml.RY(2, wires=0) >>> prod_op 2*(RX(1, wires=[0])) @ RY(2, wires=[0]) >>> qml.matrix(prod_op) array([[ 0.94831976-0.80684536j, -1.47692053-0.51806945j], [ 1.47692053-0.51806945j, 0.94831976+0.80684536j]])
**运算符可以用于将 PennyLane 运算符提升到一个幂。>>> exp_op = qml.RZ(1.0, wires=0) ** 2 >>> exp_op RZ**2(1.0, wires=[0]) >>> qml.matrix(exp_op) array([[0.54030231-0.84147098j, 0. +0.j ], [0. +0.j , 0.54030231+0.84147098j]])
一个新的类叫做
Controlled可用于qml.ops.op_math来表示任何算子的受控版本。这最终将集成到qml.ctrl中,以提供性能提升和更多特性覆盖。 (#2634)算术运算现在可以使用
qml.simplify来简化。 (#2835) (#2854)>>> op = qml.adjoint(qml.adjoint(qml.RX(x, wires=0))) >>> op Adjoint(Adjoint(RX))(tensor([1.04719755, 1.57079633], requires_grad=True), wires=[0]) >>> qml.simplify(op) RX(tensor([1.04719755, 1.57079633], requires_grad=True), wires=[0])
一个新的函数叫做
qml.equal可以用来比较参数算子的相等性。 (#2651)>>> qml.equal(qml.RX(1.23, 0), qml.RX(1.23, 0)) True >>> qml.equal(qml.RY(4.56, 0), qml.RY(7.89, 0)) False
奇妙的混合态特性 🙌
现在
default.mixed设备支持通过 反向传播 使用"jax"接口,这可以带来显著的速度提升。 (#2754) (#2776)dev = qml.device("default.mixed", wires=2) @qml.qnode(dev, diff_method="backprop", interface="jax") def circuit(angles): qml.RX(angles[0], wires=0) qml.RY(angles[1], wires=1) return qml.expval(qml.PauliZ(0) + qml.PauliZ(1))
>>> angles = np.array([np.pi/6, np.pi/5], requires_grad=True) >>> qml.grad(circuit)(angles) array([-0.8660254 , -0.25881905])
此外,量子通道现在支持 Jax 和 TensorFlow 张量。 这允许量子通道在被
tf.function、jax.jit或jax.vmap装饰的 QNodes 中使用。default.mixed设备现在支持读出误差。 (#2786)在创建
default.mixed设备时,可以指定一个新的关键字参数readout_prob。任何在具有有限readout_prob(上限为1)的default.mixed设备上运行的电路,都会在电路结束时改变执行的测量,类似于qml.BitFlip通道对电路测量的影响:>>> dev = qml.device("default.mixed", wires=2, readout_prob=0.1) >>> @qml.qnode(dev) ... def circuit(): ... return qml.expval(qml.PauliZ(0)) >>> circuit() array(0.8)
相对熵现在在qml.qinfo中可用 💥
-
我们已启用两种计算相对熵的情况:
通过
qml.qinfo.relative_entropy的 QNode 变换:dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(param): qml.RY(param, wires=0) qml.CNOT(wires=[0, 1]) return qml.state()
>>> relative_entropy_circuit = qml.qinfo.relative_entropy(circuit, circuit, wires0=[0], wires1=[0]) >>> x, y = np.array(0.4), np.array(0.6) >>> relative_entropy_circuit((x,), (y,)) 0.017750012490703237
在
qml.math中支持灵活的后处理:>>> rho = np.array([[0.3, 0], [0, 0.7]]) >>> sigma = np.array([[0.5, 0], [0, 0.5]]) >>> qml.math.relative_entropy(rho, sigma) tensor(0.08228288, requires_grad=True)
新的测量、操作符等!✨
一个新的测量称为
qml.counts可用。 (#2686) (#2839) (#2876)具有
shots != None的 QNodes 返回qml.counts将产出一个字典, 其键是表示测量的计算基态的位串, 其值是对应的计数(即,该计算基态被测量的次数):dev = qml.device("default.qubit", wires=2, shots=1000) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) return qml.counts()
>>> circuit() {'00': 495, '11': 505}
qml.counts还可以接受算子,其结果字典按算子的特征值排序。dev = qml.device("default.qubit", wires=2, shots=1000) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) return qml.counts(qml.PauliZ(0)), qml.counts(qml.PauliZ(1))
>>> circuit() ({-1: 470, 1: 530}, {-1: 470, 1: 530})
为具有多个测量的QNodes添加了一种新的实验性返回类型。 (#2814) (#2815) (#2860)
返回不同测量列表或元组的QNodes通过
qml.enable_return()返回一种直观的数据结构,其中各个测量被分隔到它们自己的张量中:qml.enable_return() dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.Hadamard(wires=[0]) qml.CRX(x, wires=[0, 1]) return (qml.probs(wires=[0]), qml.vn_entropy(wires=[0]), qml.probs(wires=0), qml.expval(wires=1))
>>> circuit(0.5) (tensor([0.5, 0.5], requires_grad=True), tensor(0.08014815, requires_grad=True), tensor([0.5, 0.5], requires_grad=True), tensor(0.93879128, requires_grad=True))
此外,利用这种新返回类型的QNodes支持反向传播。 此新返回类型可以通过
qml.disable_return()进行禁用。现在可以使用一个叫
qml.FlipSign的算子。 (#2780)在数学上,
qml.FlipSign的函数如下: \(\text{FlipSign}(n) \vert m \rangle = (-1)^\delta_{n,m} \vert m \rangle\),其中 \(\vert m \rangle\) 是一个任意的量子比特状态,而 $n$ 是一个量子比特配置:basis_state = [0, 1] dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(): for wire in list(range(2)): qml.Hadamard(wires = wire) qml.FlipSign(basis_state, wires = list(range(2))) return qml.state()
>>> circuit() tensor([ 0.5+0.j -0.5+0.j 0.5+0.j 0.5+0.j], requires_grad=True)
同时扰动随机逼近 (SPSA) 优化器可通过
qml.SPSAOptimizer获取。(#2661)SPSA 优化器适用于可能涉及噪声的成本函数。使用 SPSA 优化器就像使用任何其他优化器一样:
max_iterations = 50 opt = qml.SPSAOptimizer(maxiter=max_iterations) for _ in range(max_iterations): params, cost = opt.step_and_cost(cost, params)
更多绘图样式 🎨
现在可以使用新的受PennyLane启发的
sketch和sketch_dark样式来绘制电路图形。(#2709)
改进 📈
default.qubit现在本地执行任何定义矩阵的操作,除了可训练的Pow操作。 (#2836)将
expm添加到qml.math模块用于矩阵指数运算。 (#2890)当请求伴随微分时,电路现在被分解,以便所有可训练操作都有一个生成器。 (#2836)
现在在使用具有有限拍摄次数或拍摄列表的设备时,对于
qml.state、qml.density_matrix、qml.vn_entropy和qml.mutual_info会发出警告,因为这些测量总是解析的。(#2918)通过去除重复的步骤,Hartree-Fock工作流的效率得到了提高。 (#2850)
使用openfermion生成的不可微分分子哈密顿量的系数现在默认具有
(#2865)requires_grad = False。升级了可广播的参数操作的
compute_matrix方法的性能。 (#2759)雅可比矩阵现在在使用参数移位规则时通过自动求导接口进行缓存。 (#2645)
现在
qml.state和qml.density_matrix测量支持自定义线路标签。 (#2779)为
qml.operation.expand_matrix添加微不足道的行为逻辑。 (#2785)添加了一个
are_pauli_words_qwc函数,该函数检查某些 保利词是否是成对量子位的可交换。这个新函数提高了测量具有许多可交换项的哈密顿量的性能。 (#2789)伴随微分现在使用伴随符号包装器而不是就地反演。 (#2855)
重大变更 💔
已删除的
qml.hf模块被移除。调用qml.hf的用户可以简单地在大多数情况下将qml.hf替换为qml.qchem,或者参考 qchem 文档 和 demos 获取更多信息。 (#2795)default.qubit现在使用stopping_condition来指定对任何具有矩阵的支持。 要在继承设备中覆盖此行为,并仅支持特定子集的操作, 开发人员需要覆盖stopping_condition。 (#2836)继承自
DefaultQubit或QubitDevice的自定义设备可能会因为引入参数广播而发生故障。(#2627)自定义设备只有在以下三个条件同时成立时才应中断:
自定义设备继承自
DefaultQubit,而不是QubitDevice。该设备在模拟流水线中实现了与广播不兼容的自定义方法(例如
expval,apply_operation或analytic_probability)。自定义设备在其
capabilities字典中维护标志"supports_broadcasting": True或者 它覆盖Device.batch_transform而不应用broadcast_expand(或两者都如此)。
该
capabilities["supports_broadcasting"]被设置为True对于DefaultQubit。通常,最简单的解决方法是将capabilities["supports_broadcasting"]标志更改为False对于子设备 和/或在CustomDevice.batch_transform中包含对broadcast_expand的调用, 类似于Device.batch_transform是如何调用它的。除了以上内容,继承自
QubitDevice的自定义设备并实现自定义_gather方法需要允许将关键字参数axis传递给该_gather方法。The argument
argnumof the functionqml.batch_inputhas been redefined: now it indicates the indices of the batched parameters, which need to be non-trainable, in the quantum tape. Consequently, its default value (set to 0) has been removed. (#2873)Before this breaking change, one could call
qml.batch_inputwithout any arguments when using batched inputs as the first argument of the quantum circuit.dev = qml.device("default.qubit", wires=2, shots=None) @qml.batch_input() # argnum = 0 @qml.qnode(dev, diff_method="parameter-shift", interface="tf") def circuit(inputs, weights): # argument `inputs` is batched qml.RY(weights[0], wires=0) qml.AngleEmbedding(inputs, wires=range(2), rotation="Y") qml.RY(weights[1], wires=1) return qml.expval(qml.PauliZ(1))
With this breaking change, users must set a value to
argnumspecifying the index of the batched inputs with respect to all quantum tape parameters. In this example the quantum tape parameters are[ weights[0], inputs, weights[1] ], thusargnumshould be set to 1, specifying thatinputsis batched:dev = qml.device("default.qubit", wires=2, shots=None) @qml.batch_input(argnum=1) @qml.qnode(dev, diff_method="parameter-shift", interface="tf") def circuit(inputs, weights): qml.RY(weights[0], wires=0) qml.AngleEmbedding(inputs, wires=range(2), rotation="Y") qml.RY(weights[1], wires=1) return qml.expval(qml.PauliZ(1))
PennyLane 现在依赖于更新版本(>=2.7)的
semantic_version包,该包提供了与 2.7 之前版本不兼容的更新 API。如果你遇到与这个包相关的问题,请重新安装 PennyLane。 (#2744) (#2767)
文档 📕
为
QubitDevice.sample方法添加了专门的文档字符串。 (#2812)添加了使用 JAXopt 和 Optax 与 JAX 接口的优化示例。 (#2769)
更新了IsingXY门的文档字符串。 (#2858)
bug修复 🐞
修复了
qml.equal以便具有不同逆性质的运算符不相等。 (#2947)通过测试支持的情况并在不支持批处理时添加错误,清理操作符算术和批处理之间的交互。
(#2900)修复了一个错误,该错误导致
qml.kUpCCGSD没有定义参数位移规则。 (#2913)通过使用
qml.math调用重新处理了qml.Hermitian中的厄米性检查,因为在 TensorFlow 的EagerTensor上调用.conj()引发了错误。(#2895)修复了一个错误,参数移位梯度在使用包含未移位项的自定义
grad_recipe和不包含任何未移位项的食谱时会出错。 (#2834)修复了Torch接口的混合CPU-GPU数据局部性问题。 (#2830)
修复了一个错误:在参数无法训练的电路中,参数移位Hessian可能会针对错误的参数进行计算或引发错误。
(#2822)修复了一个错误,即未使用
states_to_binary设备方法的自定义实现。 (#2809)qml.grouping.group_observables现在可以在单独的线标签可迭代时工作。 (#2752)现在一个伴随的伴随具有正确的
expand结果。 (#2766)修复了通过Autograd接口返回自定义对象作为QNode期望值的能力。 (#2808)
WireCut 操作符在用空列表实例化时现在会引发错误。 (#2826)
现在允许在使用
qml.transform.insert()转换的设备上测量具有分组可测量项的哈密顿量。 (#2857)修复了一个错误,即在使用不位于电路开头的批量算子时,
qml.batch_input会引发错误。此外,现在在使用可训练的批量输入时,qml.batch_input会引发错误,从而避免了重复参数导致的不良行为。 (#2873)调用
qml.equal以及嵌套操作符现在会引发NotImplementedError。 (#2877)修复了使用
qml.counts和shots=False时出现不合理错误信息的bug。 (#2928)修复了一个错误,当使用
qml.counts与另一个非对易观测时没有引发错误并返回了错误的值。 (#2928)算子算术现在允许使用
Hamiltonian对象,并生成正确的矩阵。 (#2957)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
胡安·米格尔·阿拉佐拉,乌特卡什·阿扎德,塞缪尔·班宁,普拉贾瓦尔·博卡尔,艾萨克·德·弗吕特,奥利维亚·迪·马泰奥,克里斯蒂安·迪洛夫, 大卫·伊塔,乔希·伊扎克,索兰·贾汉基里,爱德华·姜,安基特·坎德尔瓦尔,科尔比尼安·科特曼,梅努·库马里,克里斯蒂娜·李,塞尔吉奥·马丁内斯-洛萨,阿尔贝特·米特贾斯·科马,伊赫切尔·梅萨·查韦斯,罗曼·莫亚尔,李·詹姆斯·奥'里奥丹,穆迪特·潘代,博格丹·雷兹尼琴科,舒莉·舒,杰伊·索尼,莫贾巴·肖克里安-齐尼,安塔尔·沙瓦,大卫·维里希斯,莫里茨·维尔曼
- orphan
发行 0.24.0¶
自上次发布以来的新特性
所有新的量子信息量 📏
已添加用于计算QNodes量子信息量的功能。 (#2554) (#2569) (#2598) (#2617) (#2631) (#2640) (#2663) (#2684) (#2688) (#2695) (#2710) (#2712)
这包括两个新的QNode测量:
通过 Von Neumann 熵 使用
qml.vn_entropy:>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) ... def circuit_entropy(x): ... qml.IsingXX(x, wires=[0,1]) ... return qml.vn_entropy(wires=[0], log_base=2) >>> circuit_entropy(np.pi/2) 1.0
通过
qml.mutual_info计算的 互信息:>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) ... def circuit(x): ... qml.IsingXX(x, wires=[0,1]) ... return qml.mutual_info(wires0=[0], wires1=[1], log_base=2) >>> circuit(np.pi/2) 2.0
新的可微分变换也可以在
qml.qinfo模块中找到:The classical and quantum Fisher information via
qml.qinfo.classical_fisher,qml.qinfo.quantum_fisher, respectively:dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circ(params): qml.RY(params[0], wires=1) qml.CNOT(wires=(1,0)) qml.RY(params[1], wires=1) qml.RZ(params[2], wires=1) return qml.expval(qml.PauliX(0) @ qml.PauliX(1) - 0.5 * qml.PauliZ(1)) params = np.array([0.5, 1., 0.2], requires_grad=True) cfim = qml.qinfo.classical_fisher(circ)(params) qfim = qml.qinfo.quantum_fisher(circ)(params)
These quantities are typically employed in variational optimization schemes to tilt the gradient in a more favourable direction — producing what is known as the natural gradient. For example:
>>> grad = qml.grad(circ)(params) >>> cfim @ grad # natural gradient [ 5.94225615e-01 -2.61509542e-02 -1.18674655e-18] >>> qfim @ grad # quantum natural gradient [ 0.59422561 -0.02615095 -0.03989212]
通过
qml.qinfo.fidelity计算两个任意状态之间的保真度:dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def circuit_rx(x): qml.RX(x[0], wires=0) qml.RZ(x[1], wires=0) return qml.state() @qml.qnode(dev) def circuit_ry(y): qml.RY(y, wires=0) return qml.state()
>>> x = np.array([0.1, 0.3], requires_grad=True) >>> y = np.array(0.2, requires_grad=True) >>> fid_func = qml.qinfo.fidelity(circuit_rx, circuit_ry, wires0=[0], wires1=[0]) >>> fid_func(x, y) 0.9905158135644924 >>> df = qml.grad(fid_func) >>> df(x, y) (array([-0.04768725, -0.29183666]), array(-0.09489803))
任意状态的约简密度矩阵 通过
qml.qinfo.reduced_dm:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.IsingXX(x, wires=[0,1]) return qml.state()
>>> qml.qinfo.reduced_dm(circuit, wires=[0])(np.pi/2) [[0.5+0.j 0.+0.j] [0.+0.j 0.5+0.j]]
类似的变换,
qml.qinfo.vn_entropy和qml.qinfo.mutual_info存在用于转换 QNodes。
目前,所有量子信息测量和变换都是可微分的,但仅支持状态向量设备,硬件支持将在未来版本中提供(
qml.qinfo.classical_fisher和qml.qinfo.quantum_fisher是两者都兼容硬件的例外)。有关更多信息,请查看新的 qinfo module 和 measurements page。
除了上面的QNode变换和测量外,已经将用于计算和微分量子信息度量的函数添加到
qml.math模块,支持灵活的自定义后处理。新增的函数包括:
qml.math.reduced_dmqml.math.vn_entropyqml.math.mutual_infoqml.math.fidelity
例如:
>>> x = torch.tensor([1.0, 0.0, 0.0, 1.0], requires_grad=True) >>> en = qml.math.vn_entropy(x / np.sqrt(2.), indices=[0]) >>> en tensor(0.6931, dtype=torch.float64, grad_fn=<DivBackward0>) >>> en.backward() >>> x.grad tensor([-0.3069, 0.0000, 0.0000, -0.3069])
使用反向传播进行更快的混合状态训练 📉
现在,
default.mixed设备通过Autograd、TensorFlow和PyTorch(CPU)接口支持反向传播的微分,从而显著提高了优化和训练的性能。 (#2615) (#2670) (#2680)因此,该设备的默认微分方法现在是
"backprop"。要继续使用旧的默认"parameter-shift",请在QNode中明确指定此微分方法:dev = qml.device("default.mixed", wires=2) @qml.qnode(dev, interface="autograd", diff_method="backprop") def circuit(x): qml.RY(x, wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(wires=1))
>>> x = np.array(0.5, requires_grad=True) >>> circuit(x) array(0.87758256) >>> qml.grad(circuit)(x) -0.479425538604203
对量子参数广播的支持 📡
Quantum operators, functions, and tapes now support broadcasting across parameter dimensions, making it more convenient for developers to execute their PennyLane programs with multiple sets of parameters. (#2575) (#2609)
Parameter broadcasting refers to passing tensor parameters with additional leading dimensions to quantum operators; additional dimensions will flow through the computation, and produce additional dimensions at the output.
For example, instantiating a rotation gate with a one-dimensional array leads to a broadcasted
Operation:>>> x = np.array([0.1, 0.2, 0.3], requires_grad=True) >>> op = qml.RX(x, 0) >>> op.batch_size 3
Its matrix correspondingly is augmented by a leading dimension of size
batch_size:>>> np.round(qml.matrix(op), 4) tensor([[[0.9988+0.j , 0. -0.05j ], [0. -0.05j , 0.9988+0.j ]], [[0.995 +0.j , 0. -0.0998j], [0. -0.0998j, 0.995 +0.j ]], [[0.9888+0.j , 0. -0.1494j], [0. -0.1494j, 0.9888+0.j ]]], requires_grad=True) >>> qml.matrix(op).shape (3, 2, 2)
This can be extended to quantum functions, where we may mix-and-match operations with batched parameters and those without. However, the
batch_sizeof each batchedOperatorwithin the quantum function must be the same:>>> dev = qml.device('default.qubit', wires=1) >>> @qml.qnode(dev) ... def circuit_rx(x, z): ... qml.RX(x, wires=0) ... qml.RZ(z, wires=0) ... qml.RY(0.3, wires=0) ... return qml.probs(wires=0) >>> circuit_rx([0.1, 0.2], [0.3, 0.4]) tensor([[0.97092256, 0.02907744], [0.95671515, 0.04328485]], requires_grad=True)
Parameter broadcasting is supported on all devices, hardware and simulator. Note that if not natively supported by the underlying device, parameter broadcasting may result in additional quantum device evaluations.
一个新的变换,
qml.transforms.broadcast_expand,已经被添加,自动化了将量子函数(和电路)转换为多个量子评估而不进行参数广播的过程。 (#2590)>>> dev = qml.device('default.qubit', wires=1) >>> @qml.transforms.broadcast_expand() >>> @qml.qnode(dev) ... def circuit_rx(x, z): ... qml.RX(x, wires=0) ... qml.RZ(z, wires=0) ... qml.RY(0.3, wires=0) ... return qml.probs(wires=0) >>> print(qml.draw(circuit_rx)([0.1, 0.2], [0.3, 0.4])) 0: ──RX(0.10)──RZ(0.30)──RY(0.30)─┤ Probs \ 0: ──RX(0.20)──RZ(0.40)──RY(0.30)─┤ Probs
在后台,这个变换用于不原生支持参数广播的设备。
要指定设备原生支持广播的磁带,新的标志
Device.capabilities()["supports_broadcasting"]应该设置为True。为了支持新操作或自定义操作的参数广播,必须指定以下新的
Operator类属性:Operator.ndim_params指定每个参数预期的维度数量
一旦设置,
Operator.batch_size和QuantumTape.batch_size将动态计算参数广播轴维度(如果存在)。
改进的 JAX JIT 支持 🏎
JAX即时编译(JIT)现在支持向量值QNode,支持新的工作流类型并显著提升性能。(#2034)
向量值QNodes包括以下内容:
qml.probs;qml.state;qml.sample或者多个
qml.expval/qml.var测量。
考虑一个返回基础态概率的 QNode:
dev = qml.device('default.qubit', wires=2) x = jnp.array(0.543) y = jnp.array(-0.654) @jax.jit @qml.qnode(dev, diff_method="parameter-shift", interface="jax") def circuit(x, y): qml.RX(x, wires=[0]) qml.RY(y, wires=[1]) qml.CNOT(wires=[0, 1]) return qml.probs(wires=[1])
>>> circuit(x, y) Array([0.8397495 , 0.16025047], dtype=float32)
请注意,使用JAX JIT不支持计算向量值QNode的雅可比。向量值QNode的输出可以用于标量值成本函数的定义,其梯度可以计算。
例如,可以定义一个成本函数,该函数输出概率向量的第一个元素:
def cost(x, y): return circuit(x, y)[0]
>>> jax.grad(cost, argnums=[0])(x, y) (Array(-0.2050439, dtype=float32),)
更多绘图样式 🎨
新的
solarized_light和solarized_dark风格可用于绘制电路图形。 (#2662)
新操作和变换 🤖
现在可以使用
qml.IsingXY门(见1912.04424)。(#2649)现在可以使用
qml.ECR(回声交叉共振)操作(见 2105.01063)。该门是一个最大纠缠门,相当于在单量子比特预旋转下的CNOT门。 (#2613)伴随变换
adjoint现在可以接受一个实例化的操作符或一个量子函数。它返回与给定内容相同类型/调用签名的实体: (#2222) (#2672)>>> qml.adjoint(qml.PauliX(0)) Adjoint(PauliX)(wires=[0]) >>> qml.adjoint(qml.RX)(1.23, wires=0) Adjoint(RX)(1.23, wires=[0])
现在,
adjoint将操作符包装在一个符号操作符类qml.ops.op_math.Adjoint中。该类 不应直接构造;应始终使用adjoint构造函数。该类的行为与任何其他Operator一样:>>> op = qml.adjoint(qml.S(0)) >>> qml.matrix(op) array([[1.-0.j, 0.-0.j], [0.-0.j, 0.-1.j]]) >>> qml.eigvals(op) array([1.-0.j, 0.-1.j])
一个新的符号运算符类
qml.ops.op_math.Pow代表一个提升到某个幂的运算符。当decomposition()被调用时,将返回一个新的运算符列表,它们等于这个运算符提升到给定的幂:(#2621)>>> op = qml.ops.op_math.Pow(qml.PauliX(0), 0.5) >>> op.decomposition() [SX(wires=[0])] >>> qml.matrix(op) array([[0.5+0.5j, 0.5-0.5j], [0.5-0.5j, 0.5+0.5j]])
一个新的变换
qml.batch_partial可用,该变换类似于functools.partial,但支持未评估参数中的批处理。 (#2585)这对于在某些参数中执行具有批处理维度的电路非常有用:
dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x, y): qml.RX(x, wires=0) qml.RY(y, wires=0) return qml.expval(qml.PauliZ(wires=0))
>>> batched_partial_circuit = qml.batch_partial(circuit, x=np.array(np.pi / 4)) >>> y = np.array([0.2, 0.3, 0.4]) >>> batched_partial_circuit(y=y) tensor([0.69301172, 0.67552491, 0.65128847], requires_grad=True)
一个新的变换
qml.split_non_commuting可用,能够将一个量子函数或量子线路根据交换可观测量的组划分成多个函数/线路: (#2587)dev = qml.device("default.qubit", wires=1) @qml.transforms.split_non_commuting @qml.qnode(dev) def circuit(x): qml.RX(x,wires=0) return [qml.expval(qml.PauliX(0)), qml.expval(qml.PauliZ(0))]
>>> print(qml.draw(circuit)(0.5)) 0: ──RX(0.50)─┤
\ 0: ──RX(0.50)─┤
改进
现在支持从单个 QNode 中获取多个不对易观测量的期望值: (#2587)
>>> dev = qml.device('default.qubit', wires=1) >>> @qml.qnode(dev) ... def circuit_rx(x, z): ... qml.RX(x, wires=0) ... qml.RZ(z, wires=0) ... return qml.expval(qml.PauliX(0)), qml.expval(qml.PauliY(0)) >>> circuit_rx(0.1, 0.3) tensor([ 0.02950279, -0.09537451], requires_grad=True)
现在可以选择计算参数平移海森矩阵的哪些部分。(#2538)
对于
qml.gradients.param_shift_hessian,argnum关键字参数现在允许为二维布尔array_like。只有指定的海森矩阵条目将被计算。一个特别有用的例子是计算海森矩阵的对角线:
dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): qml.RX(x[0], wires=0) qml.RY(x[1], wires=0) qml.RX(x[2], wires=0) return qml.expval(qml.PauliZ(0)) argnum = qml.math.eye(3, dtype=bool) x = np.array([0.2, -0.9, 1.1], requires_grad=True)
>>> qml.gradients.param_shift_hessian(circuit, argnum=argnum)(x) tensor([[-0.09928388, 0. , 0. ], [ 0. , -0.27633945, 0. ], [ 0. , 0. , -0.09928388]], requires_grad=True)
现在,通勤泡利算子测量得更快了。 (#2425)
检查量子比特间通勤(QWC)可观察量的逻辑已得到改善,从而带来了性能提升,当测量许多相同类型的通勤泡利算子时,这种提升尤为明显。
现在可以将
Observable对象添加到整数0,例如qml.PauliX(wires=[0]) + 0. (#2603)现在可以将电路作为最后一个参数传递给一个
Operator,而不需要通过关键字wires明确指定电路。这个功能已经在Observable中存在,但现在扩展到所有Operator: (#2432)>>> qml.S(0) S(wires=[0]) >>> qml.CNOT((0,1)) CNOT(wires=[0, 1])
现在可以使用
qml.taper函数一致性地缩减任何额外的可观测量,例如偶极矩、粒子数和自旋算符,使用从哈密顿量获得的对称性。(#2510)稀疏哈密顿量的表示形式已经从坐标(COO)更改为压缩稀疏行(CSR)格式。 (#2561)
CSR表示在算术运算和矩阵-向量乘法中表现更佳。此变更减少了
expval()在qml.SparseHamiltonian中的计算时间,特别是在大型工作流程中。此外,CSR格式在qml.SparseHamiltonian存储时消耗更少的内存。IPython 现在显示
str表示的Hamiltonian,而不是repr。这会显示更多有关该对象的信息。 (#2648)已重新结构化
qml.qchem测试。 (#2593) (#2545)与OpenFermion相关的测试现在已本地化并集中在
tests.qchem.of_tests中。新的模块test_structure被创建以将qchem.structure模块的测试集中在一个地方,并消除它们对OpenFermion的依赖。已经创建了测试类来分组积分和矩阵单元测试。
在
tape.get_parameters方法中引入了operations_only参数。 (#2543)现在,
gradients模块使用更快的子程序和统一的梯度规则格式。 (#2452)现在,基于新的
_queue_category属性,物体在QuantumTape中的处理不再检查类型。这是一个临时修复,将在未来消失。 (#2408)QNode类现在包含一个新方法best_method_str,该方法以人类可读的格式返回为提供的设备和接口选择的最佳微分方法。(#2533)在排队环境中使用
Operation.inv()不再更新队列的元数据,而只是就地更新操作。 (#2596)新增了一种方法
safe_update_info到qml.QueuingContext。此方法在多个地方替代了qml.QueuingContext.update_info。 (#2612) (#2675)BasisEmbedding可以接受一个整数作为参数,而不是比特列表。(#2601)例如,
qml.BasisEmbedding(4, wires = range(4))现在等同于qml.BasisEmbedding([0,1,0,0], wires = range(4))(因为4==0b100)。引入了一个新的
is_hermitian属性到Operator,用于确定一个算子是否可以在测量过程中使用。 (#2629)添加了单独的
requirements_dev.txt文件,以区分代码开发和仅使用 PennyLane 的需求。 (#2635)通过在临时存储中积累稀疏系数-算符对的稀疏表示,并消除对单位矩阵的多余
kron操作,稀疏哈密顿量构建的性能得到了提升。 (#2630)控制值现在在文本和电路的matplotlib绘图中清晰地显示出来。(#2668)
现在
TorchLayerinit_method参数可以接受一个torch.nn.init函数或一个字典,该字典应为每个不同的权重指定一个torch.nn.init/torch.Tensor。 (#2678)未使用的关键字参数
do_queue已经在Operation.adjoint中完全移除。 (#2583)几个不可分解的
Adjoint算子被添加到设备测试套件中。 (#2658)面向开发者的
pow方法已添加到Operator中,并为许多类提供了具体实现。 (#2225)ctrl变换和ControlledOperation已经移到新的qml.ops.op_math子模块。面向开发者的ControlledOperation类不再被顶层导入。 (#2656)
不推荐使用的功能
qml.ExpvalCost已被弃用,使用它将会引发警告。 (#2571)相反,建议直接将哈密顿量传递给 QNodes 内的
qml.expval函数:@qml.qnode(dev) def ansatz(params): some_qfunc(params) return qml.expval(Hamiltonian)
重大变更
当使用
qml.TorchLayer时,具有负形状的权重现在将引发错误,而具有size = 0的权重将创建空的张量对象。(#2678)PennyLane不再支持TensorFlow
(#2683)<=2.3。已经移除了
qml.queuing.Queue类。 (#2599)现在已删除
qml.utils.expand函数;应使用qml.operation.expand_matrix代替。 (#2654)模块
qml.gradients.param_shift_hessian已重命名为qml.gradients.parameter_shift_hessian以便与同名函数区分。请注意,param_shift_hessian函数不受此更改影响,可以像以前一样通过qml.gradients模块调用。 (#2528)来自
(#2498)Operator类的属性eigval和matrix被替换为方法eigval()和matrix(wire_order=None)。Operator.decomposition()现在是一个实例方法,不再接受参数。 (#2498)添加测试,添加无覆盖指令,并移除无法访问的逻辑以提高代码覆盖率。 (#2537)
基础类
QubitDevice和DefaultQubit现在接受状态向量的数据类型。这 使得插件中的派生类(设备)可以选择正确的数据类型: (#2448)>>> dev = qml.device("default.qubit", wires=4, r_dtype=np.float32, c_dtype=np.complex64) >>> dev.R_DTYPE
>>> dev.C_DTYPE
错误修复
修复了一个错误,其中使用PyTorch接口返回
qml.density_matrix时,会返回形状错误的密度矩阵。 (#2643)修复了一个错误,使得
param_shift_hessian可以在标记为可训练的门对 QNode 输出没有任何影响的 QNode 中正常工作。 (#2584)QNodes 现在可以解析接口名称的变体,比如
"tensorflow"或"jax-jit",在请求反向传播时。(#2591)修复了一处错误,针对
diff_method="adjoint",该错误导致对具有参数化可观察量的QNodes(例如,qml.Hermitian)计算了不正确的梯度。 (#2543)修复了一个错误,
QNGOptimizer在生成器为哈密顿量的算子上无法工作。(#2524)修复了
qml.CommutingEvolution分解的一个错误。 (#2542)修复了一个错误,使PennyLane能够与最新版本的Autoray兼容。 (#2549)
修复了一个导致
Hamiltonian @ Observable和Observable @ Hamiltonian行为不同的错误。 (#2570)修复了一个在
DiagonalQubitUnitary._controlled中的错误,该错误使得无效操作被排队,而不是对角单元算子的受控版本。 (#2525)更新了梯度修复,只适用于
strawberryfields.gbs设备,因为原来的逻辑破坏了一些设备。 (#2485) (#2595)修复了一个在
qml.transforms.insert中的错误,该错误导致操作未在模板中的门之后插入。 (#2704)Hamiltonian.wires现在在原地操作后已正确更新。 (#2738)
文档
集中式 Xanadu Sphinx主题 现在用于样式化 Sphinx 文档。(#2450)
在
qml.SparseHamiltonian中添加了对qml.utils.sparse_hamiltonian的引用,以澄清如何在 PennyLane 中构造稀疏哈密顿量。 (2572)在梯度和训练页面中添加了一个新部分,总结了支持的设备配置并提供了理由。此外,为某些选定的配置添加了代码示例。(#2540)
快速开始文档已得到改进。 (#2530) (#2534) (#2564 (#2565 (#2566) (#2607) (#2608)
量子化学快速入门文档已得到改进。 (#2500)
测试文档已得到改进。 (#2536)
已添加
pre-commit包的文档。 (#2567)控制线路绘制的文档已更新。 (#2682)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Guillermo Alonso-Linaje, Mikhail Andrenkov, Juan Miguel Arrazola, Ali Asadi, Utkarsh Azad, Samuel Banning, Avani Bhardwaj, Thomas Bromley, Albert Mitjans Coma, Isaac De Vlugt, Amintor Dusko, Trent Fridey, Christian Gogolin, Qi Hu, Katharine Hyatt, David Ittah, Josh Izaac, Soran Jahangiri, Edward Jiang, Nathan Killoran, Korbinian Kottmann, Ankit Khandelwal, Christina Lee, Chae-Yeun Park, Mason Moreland, Romain Moyard, Maria Schuld, Jay Soni, Antal Száva, tal66, David Wierichs, Roeland Wiersema, WingCode。
- orphan
发行版本 0.23.1¶
错误修复
修复了一个错误,使PennyLane能够与最新版本的Autoray兼容。 (#2548)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
乔希·艾扎克
- orphan
发布 0.23.0¶
自上次发布以来的新特性
更强大的电路切割 ✂️
Quantum circuit cutting (running
N-wire circuits on devices with fewer thanNwires) is now supported for QNodes of finite-shots using the new@qml.cut_circuit_mctransform. (#2313) (#2321) (#2332) (#2358) (#2382) (#2399) (#2407) (#2444)With these new additions, samples from the original circuit can be simulated using a Monte Carlo method, using fewer qubits at the expense of more device executions. Additionally, this transform can take an optional classical processing function as an argument and return an expectation value.
The following
3-qubit circuit contains aWireCutoperation and asamplemeasurement. When decorated with@qml.cut_circuit_mc, we can cut the circuit into two2-qubit fragments:dev = qml.device("default.qubit", wires=2, shots=1000) @qml.cut_circuit_mc @qml.qnode(dev) def circuit(x): qml.RX(0.89, wires=0) qml.RY(0.5, wires=1) qml.RX(1.3, wires=2) qml.CNOT(wires=[0, 1]) qml.WireCut(wires=1) qml.CNOT(wires=[1, 2]) qml.RX(x, wires=0) qml.RY(0.7, wires=1) qml.RX(2.3, wires=2) return qml.sample(wires=[0, 2])
we can then execute the circuit as usual by calling the QNode:
>>> x = 0.3 >>> circuit(x) tensor([[1, 1], [0, 1], [0, 1], ..., [0, 1], [0, 1], [0, 1]], requires_grad=True)
Furthermore, the number of shots can be temporarily altered when calling the QNode:
>>> results = circuit(x, shots=123) >>> results.shape (123, 2)
The
cut_circuit_mctransform also supports returning sample-based expectation values of observables using theclassical_processing_fnargument. Refer to theUsageDetailssection of the transform documentation for an example.现在,
cut_circuit转换支持通过指定auto_cutter=True来自动图划分,以切割任意 tape 转换的图形,使用通用的图划分框架 KaHyPar。请注意,
KaHyPar需要单独安装,并使用auto_cutter=True选项。有关与现有低级手动切割管道的集成,请参考 文档。
@qml.cut_circuit(auto_cutter=True) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) qml.RY(0.9, wires=1) qml.RX(0.3, wires=2) qml.CZ(wires=[0, 1]) qml.RY(-0.4, wires=0) qml.CZ(wires=[1, 2]) return qml.expval(qml.grouping.string_to_pauli_word("ZZZ"))
>>> x = np.array(0.531, requires_grad=True) >>> circuit(x) 0.47165198882111165 >>> qml.grad(circuit)(x) -0.276982865449393
伟大的QChem统一 ⚛️ 🏰
量子化学功能——之前分散在一个外部
pennylane-qchem包和内部qml.hf可微分的哈特里-福克求解器之间——现在统一成一个包含的qml.qchem模块。 (#2164) (#2385) (#2352) (#2420) (#2454)
(#2199) (#2371) (#2272) (#2230) (#2415) (#2426) (#2465)qml.qchem模块提供了一个可微分的哈特里-福克求解器和构建完全可微分分子哈密顿量的功能。例如,可以继续使用
qml.qchem.molecular_hamiltonian生成分子哈密顿量:symbols = ["H", "H"] geometry = np.array([[0., 0., -0.66140414], [0., 0., 0.66140414]]) hamiltonian, qubits = qml.qchem.molecular_hamiltonian(symbols, geometry, method="dhf")
默认情况下,将使用可微分的哈特里-福克求解器;然而,只需设置
method="pyscf"继续使用 PySCF 进行哈特里-福克计算。添加了用于构建可微分偶极矩可观察量的函数。还添加了计算多极矩分子积分的函数,这些函数是构建偶极矩可观察量所需的。 (#2173) (#2166)
偶极矩可观察量可以使用
qml.qchem.dipole_moment构建:symbols = ['H', 'H'] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) mol = qml.qchem.Molecule(symbols, geometry) args = [geometry] D = qml.qchem.dipole_moment(mol)(*args)
计算分子积分和哈密顿量的效率得到了提升。这是通过添加用于构建费米子和量子比特可观测量的优化函数,以及优化用于计算电子斥力积分的函数来实现的。
6-31G基组被添加到 qchem 基组库中。这个添加允许执行可微的哈特里-福克计算,使用超出最小sto-3g基组的基组,对原子号为 1-10 的原子进行计算。 (#2372)6-31G基组可以用于构建哈密顿量,如下所示symbols = ["H", "H"] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]]) H, qubits = qml.qchem.molecular_hamiltonian(symbols, geometry, basis="6-31g")
模式匹配优化 🔎 💎
Added an optimization transform that matches pieces of user-provided identity templates in a circuit and replaces them with an equivalent component. (#2032)
For example, consider the following circuit where we want to replace sequence of two
pennylane.Sgates with apennylane.PauliZgate.def circuit(): qml.S(wires=0) qml.PauliZ(wires=0) qml.S(wires=1) qml.CZ(wires=[0, 1]) qml.S(wires=1) qml.S(wires=2) qml.CZ(wires=[1, 2]) qml.S(wires=2) return qml.expval(qml.PauliX(wires=0))
We specify use the following pattern that implements the identity:
with qml.tape.QuantumTape() as pattern: qml.S(wires=0) qml.S(wires=0) qml.PauliZ(wires=0)
To optimize the circuit with this identity pattern, we apply the
qml.transforms.pattern_matchingtransform.>>> dev = qml.device('default.qubit', wires=5) >>> qnode = qml.QNode(circuit, dev) >>> optimized_qfunc = qml.transforms.pattern_matching_optimization(pattern_tapes=[pattern])(circuit) >>> optimized_qnode = qml.QNode(optimized_qfunc, dev) >>> print(qml.draw(qnode)()) 0: ──S──Z─╭C──────────┤ <X> 1: ──S────╰Z──S─╭C────┤ 2: ──S──────────╰Z──S─┤ >>> print(qml.draw(optimized_qnode)()) 0: ──S⁻¹─╭C────┤ <X> 1: ──Z───╰Z─╭C─┤ 2: ──Z──────╰Z─┤
For more details on using pattern matching optimization you can check the corresponding documentation and also the following paper.
测量两个单位之间的距离📏
Added the
HilbertSchmidtand theLocalHilbertSchmidttemplates to be used for computing distance measures between unitaries. (#2364)Given a unitary
U,qml.HilberSchmidtcan be used to measure the distance between unitaries and to define a cost function (cost_hst) used for learning a unitaryVthat is equivalent toUup to a global phase:# Represents unitary U with qml.tape.QuantumTape(do_queue=False) as u_tape: qml.Hadamard(wires=0) # Represents unitary V def v_function(params): qml.RZ(params[0], wires=1) @qml.qnode(dev) def hilbert_test(v_params, v_function, v_wires, u_tape): qml.HilbertSchmidt(v_params, v_function=v_function, v_wires=v_wires, u_tape=u_tape) return qml.probs(u_tape.wires + v_wires) def cost_hst(parameters, v_function, v_wires, u_tape): return (1 - hilbert_test(v_params=parameters, v_function=v_function, v_wires=v_wires, u_tape=u_tape)[0])
>>> cost_hst(parameters=[0.1], v_function=v_function, v_wires=[1], u_tape=u_tape) tensor(0.999, requires_grad=True)
For more information refer to the documentation of qml.HilbertSchmidt.
更多的张量网络支持 🕸️
Adds the
qml.MERAtemplate for implementing quantum circuits with the shape of a multi-scale entanglement renormalization ansatz (MERA). (#2418)MERA follows the style of previous tensor network templates and is similar to quantum convolutional neural networks.
def block(weights, wires): qml.CNOT(wires=[wires[0],wires[1]]) qml.RY(weights[0], wires=wires[0]) qml.RY(weights[1], wires=wires[1]) n_wires = 4 n_block_wires = 2 n_params_block = 2 n_blocks = qml.MERA.get_n_blocks(range(n_wires),n_block_wires) template_weights = [[0.1,-0.3]]*n_blocks dev= qml.device('default.qubit',wires=range(n_wires)) @qml.qnode(dev) def circuit(template_weights): qml.MERA(range(n_wires),n_block_wires,block, n_params_block, template_weights) return qml.expval(qml.PauliZ(wires=1))
It may be necessary to reorder the wires to see the MERA architecture clearly:
>>> print(qml.draw(circuit,expansion_strategy='device',wire_order=[2,0,1,3])(template_weights)) 2: ───────────────╭C──RY(0.10)──╭X──RY(-0.30)───────────────┤ 0: ─╭X──RY(-0.30)─│─────────────╰C──RY(0.10)──╭C──RY(0.10)──┤ 1: ─╰C──RY(0.10)──│─────────────╭X──RY(-0.30)─╰X──RY(-0.30)─┤ <Z> 3: ───────────────╰X──RY(-0.30)─╰C──RY(0.10)────────────────┤
用于转换的新转换 ⚙️
添加了一个基于交换的转译器变换。 (#2118)
转译函数接受一个量子函数和一个耦合图作为输入,并编译电路以确保可以在相应的硬件上执行。该变换可以按如下方式用作装饰器:
dev = qml.device('default.qubit', wires=4) @qml.qnode(dev) @qml.transforms.transpile(coupling_map=[(0, 1), (1, 2), (2, 3)]) def circuit(param): qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[0, 2]) qml.CNOT(wires=[0, 3]) qml.PhaseShift(param, wires=0) return qml.probs(wires=[0, 1, 2, 3])
>>> print(qml.draw(circuit)(0.3)) 0: ─╭C───────╭C──────────╭C──Rϕ(0.30)─┤ ╭Probs 1: ─╰X─╭SWAP─╰X────╭SWAP─╰X───────────┤ ├Probs 2: ────╰SWAP─╭SWAP─╰SWAP──────────────┤ ├Probs 3: ──────────╰SWAP────────────────────┤ ╰Probs
改进
QuantumTape对象现在是可迭代的,允许遍历包含的操作和测量。 (#2342)使用 qml.tape.QuantumTape() 作为 tape: qml.RX(0.432, wires=0) qml.RY(0.543, wires=0) qml.CNOT(wires=[0, 'a']) qml.RX(0.133, wires='a') qml.expval(qml.PauliZ(wires=[0]))
给定一个
QuantumTape对象,可以使用for循环遍历底层量子电路:>>> 对于 op 在 tape: ... 打印(op) RX(0.432, wires=[0]) RY(0.543, wires=[0]) CNOT(wires=[0, 'a']) RX(0.133, wires=['a']) expval(PauliZ(wires=[0]))
通过
tape[i]也可以对电路进行索引:>>> tape[0] RX(0.432, wires=[0])
一个 tape 对象也可以被转换为操作和测量的序列(例如,转换为
list):>>> list(tape) [RX(0.432, wires=[0]), RY(0.543, wires=[0]), CNOT(wires=[0, 'a']), RX(0.133, wires=['a']), expval(PauliZ(wires=[0]))]
添加了
QuantumTape.shape方法和QuantumTape.numeric_type属性,以允许提取量子电路执行后返回的输出的形状和数值类型的信息。 (#2044)dev = qml.device("default.qubit", wires=2) a = np.array([0.1, 0.2, 0.3]) def func(a): qml.RY(a[0], wires=0) qml.RX(a[1], wires=0) qml.RY(a[2], wires=0) with qml.tape.QuantumTape() as tape: func(a) qml.state()
>>> tape.shape(dev) (1, 4) >>> tape.numeric_type 复数
定义了一个
MeasurementProcess.shape方法和一个MeasurementProcess.numeric_type属性,以允许提取有关结果的形状和数值类型的信息,这些结果是在使用特定测量过程评估 QNodes 时获得的。 (#2044)现在可以为支持一般参数位移规则的任意操作计算参数位移Hessian,使用
qml.gradients.param_shift_hessian(#2319)支持多种获取梯度配方的方法,按以下优先顺序:
一个自定义
grad_recipe。它被迭代以获取海森矩阵对角项中二阶导数的平移规则。自定义
parameter_frequencies。可以直接使用它们计算二阶偏移规则。一个算子的
generator。它的特征值将被用于获取parameter_frequencies,如果没有为操作显式给出。
现在可以使用
qml.specs变换指定扩展电路的策略,例如计算设备实际将执行的电路的规格(expansion_strategy="device")。(#2395)现在,
default.qubit和default.mixed设备跳过单位算符,而不是执行与单位相乘的矩阵运算。 (#2356) (#2365)函数
qml.eigvals已修改为使用高效的scipy.sparse.linalg.eigsh方法来获得SparseHamiltonian的特征值。此scipy方法被调用 以计算 \(k\) 个稀疏 \(N \times N\) 矩阵的特征值,如果k小于 \(N-1\)。如果请求更大的 \(k\),则构建哈密顿量的稠密矩阵表示,并应用常规的qml.math.linalg.eigvalsh。 (#2333)函数
qml.ctrl被赋予了可选参数control_values=None。 如果被覆盖,control_values采用一个整数或一个整数列表,表示每个控制值应该取的二进制值。相同的更改也反映在ControlledOperation中。控制值0是通过在受控操作之前和之后应用qml.PauliX来实现的 (#2288)电路切割现在执行扩展以搜索包含操作或带中的电线切割。
(#2340)qml.draw和qml.draw_mpl变换现在位于drawer模块中。它们仍然可以通过顶层的qml命名空间访问。(#2396)当缓存产生在有限射击下执行结果相同的射击噪声时,发出警告。 (#2478)
不推荐使用的功能
可观察返回类型
ObservableReturnTypesSample,Variance,Expectation,Probability,State, 和MidMeasure已从operation移动到measurements。 (#2329) (#2481)
重大变更
设备的缓存功能已被移除。推荐的替代方案是在 QNode 级别使用缓存。 (#2443)
复制移除的
QubitDevice缓存行为的一种方法是 创建一个cache对象(例如,一个字典),并将其传递给QNode:n_wires = 4 wires = range(n_wires) dev = qml.device('default.qubit', wires=n_wires) cache = {} @qml.qnode(dev, diff_method='parameter-shift', cache=cache) def expval_circuit(params): qml.templates.BasicEntanglerLayers(params, wires=wires, rotation=qml.RX) return qml.expval(qml.PauliZ(0) @ qml.PauliY(1) @ qml.PauliX(2) @ qml.PauliZ(3)) shape = qml.templates.BasicEntanglerLayers.shape(5, n_wires) params = np.random.random(shape)
>>> expval_circuit(params) tensor(0.20598436, requires_grad=True) >>> dev.num_executions 1 >>> expval_circuit(params) tensor(0.20598436, requires_grad=True) >>> dev.num_executions 1
已移除
qml.finite_diff函数。请使用qml.gradients.finite_diff来计算QNodes的电路的梯度。否则,需要手动实现。 (#2464)已移除
get_unitary_matrix变换,请使用qml.matrix代替。 (#2457)update_stepsize方法已从GradientDescentOptimizer及其子优化器中移除。可以直接与stepsize属性进行交互。 (#2370)大多数优化器在计算过程中不再展平和反展平参数。由于这一变化,用户提供的梯度函数 必须 返回与
qml.grad相同的形状。 (#2381)旧的电路文本绘制基础设施已被移除。 (#2310)
RepresentationResolver被Operator.label方法替代。qml.drawer.CircuitDrawer被qml.drawer.tape_text替代。qml.drawer.CHARSETS被移除,因为假设可以访问unicode。Grid和qml.drawer.drawable_grid被移除因为自定义数据类被操作符或测量的集合列表所替代。qml.transforms.draw_old被qml.draw替换。qml.CircuitGraph.greedy_layers被删除了,因为它已经不再被电路画图工具所需要,并且在其他情况下似乎也没有用途。qml.CircuitGraph.draw已被删除,因为我们改为绘制带子。这个带状方法
qml.tape.QuantumTape.draw现在简单地调用qml.drawer.tape_text。在新的路径中,
charset关键字被删除,max_length关键字默认为100,并且添加了decimals和show_matrices关键字。
已删除不推荐使用的 QNode,原通过
qml.qnode_old.QNode获取。请 过渡到使用标准的qml.QNode。 (#2336) (#2337) (#2338)此外,一些推动已弃用的QNode的其他组件已被移除:
已删除不推荐使用的、与批处理不兼容的接口。
已删除不推荐使用的 tape 子类
QubitParamShiftTape,JacobianTape,CVParamShiftTape和ReversibleTape。
已弃用的磁带执行方法
tape.execute(device)已被删除。请改用qml.execute([tape], device)。 (#2339)
错误修复
修复了在
(#2466)qml.PauliRot操作中一个错误,该错误在计算生成元时没有考虑到操作的线。修复了一个错误,在参数列表中如果一个可训练参数在非可训练参数之后,
NesterovMomentumOptimizer中的非可训练参数会被移位。 (#2466)修复了在
@jax.jit中,当diff_method="adjoint"和mode="backward"时的一个错误。 (#2460)修复了一个错误,
(#2445)qml.DiagonalQubitUnitary不支持@jax.jit和@tf.function。修复了
(#2442)qml.PauliRot操作中的一个错误,计算生成器时未考虑操作线。修复了
AmplitudeEmbedding在输入位于GPU时的填充功能的一个错误。 (#2431)通过添加一个可理解的错误信息来修复一个错误,针对调用
qml.probs时没有传递导线或可观察量的情况。(#2438)qml.about()的行为已被修改,以避免因pip的遗留行为而发出警告。 (#2422)修复了一个错误,该错误在为拍摄次数较少的统计数据计算时出现 (例如,
shots=10),由于使用Array进行数组索引而导致错误。 (#2427)PennyLane Lightning版本在Docker容器中是从最新的wheel构建中获取的。 (#2416)
优化器仅在变量的
requires_grad = True时,才会将其视为可训练的。(#2381)修复了一个关于
qml.expval,qml.var,qml.state和qml.probs(当qml.probs是唯一的测量)的问题,其中设备上指定的dtype与 QNode 输出的dtype不匹配。 (#2367)修复了一个错误,批处理转换的输出形状与QNode输出形状不一致。 (#2215)
修复了由于压缩引起的一个错误,位于
qml.gradients.param_shift_hessian。 (#2215)修复了一个错误,即一个
Tensor(Observable)的expval/var取决于可观测量定义的顺序: (#2276)>>> @qml.qnode(dev) ... def circ(op): ... qml.RX(0.12, wires=0) ... qml.RX(1.34, wires=1) ... qml.RX(3.67, wires=2) ... return qml.expval(op) >>> op1 = qml.Identity(wires=0) @ qml.Identity(wires=1) @ qml.PauliZ(wires=2) >>> op2 = qml.PauliZ(wires=2) @ qml.Identity(wires=0) @ qml.Identity(wires=1) >>> print(circ(op1), circ(op2)) -0.8636111153905662 -0.8636111153905662
修复了一个错误,导致
qml.hf.transform_hf()由于缺少用于收敛HF状态的量子比特操作符中的线而失败。 (#2441)修复了自定义设备定义的雅可比矩阵未正确返回的错误。 (#2485)
文档
贡献者
此版本包含来自(按字母顺序排列)的贡献:
卡里姆·阿拉·埃尔-迪恩,吉列尔莫·阿隆索-林哈赫,胡安·米格尔·阿拉佐拉,阿里·阿萨迪,乌特卡斯·阿扎德,萨姆·班宁,托马斯·布罗姆利,阿兰·德尔加多,艾萨克·德·弗卢赫,奥利维亚·迪·马泰奥,阿敏托尔·杜斯科,安东尼·海斯,大卫·伊塔赫,乔希·伊扎克,索兰·贾汉吉里,内森·基洛兰,克里斯蒂娜·李,安格斯·洛,罗曼·莫亚尔,泽月·牛,马修·西尔弗曼,李·詹姆斯·奥'里奥丹,玛利亚·舒尔德,杰伊·索尼,安塔尔·萨瓦,莫里斯·韦伯,大卫·维里赫斯。
- orphan
发行版 0.22.2¶
错误修复
大多数编译转换和相关子程序已经更新,以支持使用 jax.jit 的即刻编译。这个修复原本计划包含在
v0.22.0中,但由于一个错误而不完整。(#2397)
文档
文档运行已更新,要求
jinja2==3.0.3,这是由于与jinja2v3.1.0和sphinxv3.5.3相关的问题。(#2378)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
奥利维亚·迪·马泰奥,克里斯蒂娜·李,罗曼·莫亚尔德,安塔尔·萨瓦。
- orphan
发布 0.22.1¶
错误修复
修复了
qml.measure的情况,其中意外的操作被添加到电路中。 (#2328)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
吉列尔莫·阿隆索-利纳赫,安塔尔·萨瓦。
- orphan
发布 0.22.0¶
自上次发布以来的新特性
量子电路切割 ✂️
You can now run
N-wire circuits on devices with fewer thanNwires, by strategically placingWireCutoperations that allow their circuit to be partitioned into smaller fragments, at a cost of needing to perform a greater number of device executions. Circuit cutting is enabled by decorating a QNode with the@qml.cut_circuittransform. (#2107) (#2124) (#2153) (#2165) (#2158) (#2169) (#2192) (#2216) (#2168) (#2223) (#2231) (#2234) (#2244) (#2251) (#2265) (#2254) (#2260) (#2257) (#2279)The example below shows how a three-wire circuit can be run on a two-wire device:
dev = qml.device("default.qubit", wires=2) @qml.cut_circuit @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) qml.RY(0.9, wires=1) qml.RX(0.3, wires=2) qml.CZ(wires=[0, 1]) qml.RY(-0.4, wires=0) qml.WireCut(wires=1) qml.CZ(wires=[1, 2]) return qml.expval(qml.grouping.string_to_pauli_word("ZZZ"))
Instead of executing the circuit directly, it will be partitioned into smaller fragments according to the
WireCutlocations, and each fragment executed multiple times. Combining the results of the fragment executions will recover the expected output of the original uncut circuit.>>> x = np.array(0.531, requires_grad=True) >>> circuit(0.531) 0.47165198882111165
Circuit cutting support is also differentiable:
>>> qml.grad(circuit)(x) -0.276982865449393
For more details on circuit cutting, check out the qml.cut_circuit documentation page or Peng et. al.
条件操作:量子隐形传态解锁 🔓🌀
增加了对中途测量和条件操作的支持,以实现量子传送、量子错误修正和量子错误缓解等用例。 (#2211) (#2236) (#2275)
为了支持这个功能,添加了两个新函数:
qml.measure()在量子函数的中间放置中途测量。qml.cond()允许对先前测量结果进行条件化操作和量子函数。
例如,下面的代码展示了如何将一个量子比特从导线0传送到导线2:
dev = qml.device("default.qubit", wires=3) input_state = np.array([1, -1], requires_grad=False) / np.sqrt(2) @qml.qnode(dev) def teleport(state): # Prepare input state qml.QubitStateVector(state, wires=0) # Prepare Bell state qml.Hadamard(wires=1) qml.CNOT(wires=[1, 2]) # Apply gates qml.CNOT(wires=[0, 1]) qml.Hadamard(wires=0) # Measure first two wires m1 = qml.measure(0) m2 = qml.measure(1) # Condition final wire on results qml.cond(m2 == 1, qml.PauliX)(wires=2) qml.cond(m1 == 1, qml.PauliZ)(wires=2) # Return state on final wire return qml.density_matrix(wires=2)
我们可以通过计算输入态和第2条线上结果态之间的重叠来再次确认量子比特已被传送:
>>> output_state = teleport(input_state) >>> output_state tensor([[ 0.5+0.j, -0.5+0.j], [-0.5+0.j, 0.5+0.j]], requires_grad=True) >>> input_state.conj() @ output_state @ input_state tensor(1.+0.j, requires_grad=True)
有关新功能的完整描述,请参阅文档中的 中间电路测量和条件操作 部分。
Train mid-circuit measurements by deferring them, via the new
@qml.defer_measurementstransform. (#2211) (#2236) (#2275)If a device doesn’t natively support mid-circuit measurements, the
@qml.defer_measurementstransform can be applied to the QNode to transform the QNode into one with terminal measurements and controlled operations:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) @qml.defer_measurements def circuit(x): qml.Hadamard(wires=0) m = qml.measure(0) def op_if_true(): return qml.RX(x**2, wires=1) def op_if_false(): return qml.RY(x, wires=1) qml.cond(m==1, op_if_true, op_if_false)() return qml.expval(qml.PauliZ(1))
>>> x = np.array(0.7, requires_grad=True) >>> print(qml.draw(circuit, expansion_strategy="device")(x)) 0: ──H─╭C─────────X─╭C─────────X─┤ 1: ────╰RX(0.49)────╰RY(0.70)────┤ <Z> >>> circuit(x) tensor(0.82358752, requires_grad=True)
Deferring mid-circuit measurements also enables differentiation:
>>> qml.grad(circuit)(x) -0.651546965338656
使用中间电路量子快照进行调试 📷
新增了一个操作
qml.Snapshot以帮助调试量子函数。 (#2233) (#2289) (#2291) (#2315)qml.Snapshot在执行的任意时刻保存设备的内部状态。当前支持的设备包括:
default.qubit: 每个快照保存量子状态向量default.mixed: 每个快照保存密度矩阵default.gaussian: 每个快照保存协方差矩阵和均值向量
在正常执行期间,快照被忽略:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, interface=None) def circuit(): qml.Snapshot() qml.Hadamard(wires=0) qml.Snapshot("very_important_state") qml.CNOT(wires=[0, 1]) qml.Snapshot() return qml.expval(qml.PauliX(0))
然而,当使用
qml.snapshots变换时,中间设备状态将被存储并与结果一同返回。>>> qml.snapshots(circuit)() {0: array([1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j]), 'very_important_state': array([0.70710678+0.j, 0. +0.j, 0.70710678+0.j, 0. +0.j]), 2: array([0.70710678+0.j, 0. +0.j, 0. +0.j, 0.70710678+0.j]), 'execution_results': array(0.)}
批量嵌入和状态准备数据 📦
添加了
@qml.batch_input转换,以支持批处理不可训练的门参数。 此外,qml.qnn.KerasLayer类已经更新,以原生支持 批处理训练数据。 (#2069)与其他转换一样,
@qml.batch_input可以用来装饰 QNodes:dev = qml.device("default.qubit", wires=2, shots=None) @qml.batch_input(argnum=0) @qml.qnode(dev, diff_method="parameter-shift", interface="tf") def circuit(inputs, weights): # 为嵌入数据添加一个批处理维度 qml.AngleEmbedding(inputs, wires=range(2), rotation="Y") qml.RY(weights[0], wires=0) qml.RY(weights[1], wires=1) return qml.expval(qml.PauliZ(1))
然后,可以在 QNode 评估期间传入批处理输入参数:
>>> x = tf.random.uniform((10, 2), 0, 1) >>> w = tf.random.uniform((2,), 0, 1) >>> circuit(x, w)
更强大的量子变换 🐛➡🦋
已添加新函数和算子的变换:
qml.matrix()用于计算一个或多个酉算子的矩阵表示。 (#2241)qml.eigvals()用于计算一个或多个算子的特征值。 (#2248)qml.generator()用于计算单参数单位操作的生成元。 (#2256)
所有运算符转换可以用于实例化的运算符,
>>> op = qml.RX(0.54, wires=0) >>> qml.matrix(op) [[0.9637709+0.j 0. -0.26673144j] [0. -0.26673144j 0.9637709+0.j ]]
算子变换也可以以函数形式使用:
>>> x = torch.tensor(0.6, requires_grad=True) >>> matrix_fn = qml.matrix(qml.RX) >>> matrix_fn(x, wires=[0]) tensor([[0.9553+0.0000j, 0.0000-0.2955j], [0.0000-0.2955j, 0.9553+0.0000j]], grad_fn=<AddBackward0>)
在其函数形式中,它对门参数是完全可微分的:
>>> loss = torch.real(torch.trace(matrix_fn(x, wires=0))) >>> loss.backward() >>> x.grad tensor(-0.2955)
一些运算符变换还可以作用于多个操作,通过传递量子函数或磁带:
>>> def circuit(theta): ... qml.RX(theta, wires=1) ... qml.PauliZ(wires=0) >>> qml.matrix(circuit)(np.pi / 4) array([[ 0.92387953+0.j, 0.+0.j , 0.-0.38268343j, 0.+0.j], [ 0.+0.j, -0.92387953+0.j, 0.+0.j, 0. +0.38268343j], [ 0. -0.38268343j, 0.+0.j, 0.92387953+0.j, 0.+0.j], [ 0.+0.j, 0.+0.38268343j, 0.+0.j, -0.92387953+0.j]])
A new transform has been added to construct the pairwise-commutation directed acyclic graph (DAG) representation of a quantum circuit. (#1712)
In the DAG, each node represents a quantum operation, and edges represent non-commutation between two operations.
This transform takes into account that not all operations can be moved next to each other by pairwise commutation:
>>> def circuit(x, y, z): ... qml.RX(x, wires=0) ... qml.RX(y, wires=0) ... qml.CNOT(wires=[1, 2]) ... qml.RY(y, wires=1) ... qml.Hadamard(wires=2) ... qml.CRZ(z, wires=[2, 0]) ... qml.RY(-y, wires=1) ... return qml.expval(qml.PauliZ(0)) >>> dag_fn = qml.commutation_dag(circuit) >>> dag = dag_fn(np.pi / 4, np.pi / 3, np.pi / 2)
Nodes in the commutation DAG can be accessed via the
get_nodes()method, returning a list of the form(ID, CommutationDAGNode):>>> nodes = dag.get_nodes() >>> nodes NodeDataView({0: <pennylane.transforms.commutation_dag.CommutationDAGNode object at 0x7f461c4bb580>, ...}, data='node')
Specific nodes in the commutation DAG can be accessed via the
get_node()method:>>> second_node = dag.get_node(2) >>> second_node <pennylane.transforms.commutation_dag.CommutationDAGNode object at 0x136f8c4c0> >>> second_node.op CNOT(wires=[1, 2]) >>> second_node.successors [3, 4, 5, 6] >>> second_node.predecessors []
改进
通过
qml.draw()访问的基于文本的抽屉已经过优化和改进。 (#2128) (#2198)新抽屉包含:
a
decimals关键字用于控制参数四舍五入a
show_matrices关键字,用于控制矩阵的显示一种不同的算法用于确定位置
对
charset关键字的弃用其他小的外观调整
@qml.qnode(qml.device('lightning.qubit', wires=2)) def circuit(a, w): qml.Hadamard(0) qml.CRX(a, wires=[0, 1]) qml.Rot(*w, wires=[1]) qml.CRX(-a, wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
>>> print(qml.draw(circuit, decimals=2)(a=2.3, w=[1.2, 3.2, 0.7])) 0: ──H─╭C─────────────────────────────╭C─────────┤ ╭<Z@Z> 1: ────╰RX(2.30)──Rot(1.20,3.20,0.70)─╰RX(-2.30)─┤ ╰<Z@Z>
门参数的频率现在可以作为操作属性访问,并可用于电路分析、通过
RotosolveOptimizer进行优化以及使用参数位移规则进行微分(包括一般位移规则)。(#2180)(#2182)(#2227)>>> op = qml.CRot(0.4, 0.1, 0.3, wires=[0, 1]) >>> op.parameter_frequencies [(0.5, 1.0), (0.5, 1.0), (0.5, 1.0)]
当使用
qml.gradients.param_shift时,使用自定义grad_recipe或参数频率来获得操作的位移规则,按照这个优先顺序。请参见Vidal and Theis (2018)和Wierichs et al. (2021)以获取一般参数位移规则的理论背景信息。
默认情况下不再假定两个项的参数移动规则。 (#2227)
之前,标记为解析微分的操作如果未提供一个
generator、parameter_frequencies或自定义grad_recipe,则被假定满足两个项移动规则。对于自定义操作,现在必须通过添加上述任何属性来明确这一点。大多数编译转换和相关子程序已更新,以支持使用
jax.jit的即时编译。 (#1894)该
qml.draw_mpl变换支持一个expansion_strategy关键字参数。 (#2271)qml.gradients模块已被简化,并将特殊用途函数与其使用案例更紧密地结合,同时保持现有行为。(#2200)在
grouping模块中添加了一个新的partition_pauli_group函数,用于有效测量N量子位的 Pauli 群,具有3 ** N量子位逐项对易的项。 (#2185)操作符类经过了重大的重构,以下是变化:
矩阵:静态方法
Operator.compute_matrices()定义了算子的矩阵表示,函数qml.matrix(op)计算给定实例的矩阵。 (#1996)特征值: 静态方法
Operator.compute_eigvals()定义了算子的矩阵表示,函数qml.eigvals(op)为给定实例计算此值。(#2048)分解: 静态方法
Operator.compute_decomposition()定义了算子的矩阵表示,方法op.decomposition()计算给定实例的分解。 (#2024) (#2053)稀疏矩阵:静态方法
Operator.compute_sparse_matrix()定义了操作符的稀疏矩阵表示,方法op.sparse_matrix()为给定实例计算这个表示。 (#2050)算子的线性组合: 静态方法
compute_terms()被添加,用于表示 表示算子的系数和算子的线性组合。该方法op.terms()为给定实例计算这一点。 目前,只有Hamiltonian类重写了compute_terms()来存储 系数和算子。于是Hamiltonian.terms属性变成了 通过Hamiltonian.terms()调用的正确方法。 (#2036)对角化:
diagonalizing_gates()表示已被移至最高级的Operator类,因此对所有子类可用。已添加一个条件qml.operation.defines_diagonalizing_gates,可在不排队的胶带上下文中使用。此外,还添加了一个静态compute_diagonalizing_gates方法,该方法在diagonalizing_gates()中默认调用。 (#1985) (#1993)操作符表示的错误处理得到了改善。如果未定义表示,将引发自定义错误,继承自
OperatorPropertyUndefined。这替代了NotImplementedError,并允许开发人员进行更细粒度的控制。 (#2064) (#2287)已在运算符类中添加了
Operator.hyperparameters属性,用于存储永远 不可训练的操作参数。 (#2017)属性
string_for_inverse被移除。 (#2021)
不推荐使用的功能
在创建自定义操作时有几个重要的变化:
(#2214) (#2227) (#2030) (#2061)方法
Operator.matrix已被弃用,应该改为定义Operator.compute_matrix。操作符矩阵应使用qml.matrix(op)访问。如果您之前定义了类方法Operator._matrix(),这是一个 重大变化 — 请更新您的操作,以便改为重写Operator.compute_matrix。Operator.decomposition方法已被弃用,应该改为定义Operator.compute_decomposition。操作符分解应使用Operator.decomposition()进行访问。该
Operator.eigvals方法已被弃用,应该改用Operator.compute_eigvals。运算符特征值应通过qml.eigvals(op)访问。现在,
Operator.generator属性是一个方法,应返回一个 运算符实例 表示生成器。请注意,与上面的其他表示不同,这是一个 重大变更。运算符生成器应使用qml.generator(op)访问。方法
Operation.get_parameter_shift已被弃用,且在未来的版本中将被移除。相应地,应使用
qml.gradients模块中的通用参数变化规则功能,以及操作属性parameter_frequencies或grad_recipe。
使用
tape.execute(dev)执行带子程序已被弃用。 请改用qml.execute([tape], dev)函数。 (#2306)量子磁带的子类,包括
JacobianTape,QubitParamShiftTape,CVParamShiftTape, 和ReversibleTape已被弃用。请不要调用JacobianTape.jacobian()和JacobianTape.hessian(), 请使用标准的QuantumTape,并使用qml.gradients模块应用梯度变换。 (#2306)qml.transforms.get_unitary_matrix()已被弃用,将在未来的版本中移除。要提取操作和量子函数的矩阵,请使用qml.matrix()。 (#2248)函数
qml.finite_diff()已被弃用,并将在即将发布的版本中移除。 取而代之的是,可以使用qml.gradients.finite_diff()来计算纯量子梯度 (即,操作或 QNode 的梯度)。 (#2212)现在,
MultiControlledX操作接受一个单一的wires关键字参数,用于control_wires和wires。 这个单一的wires关键字应该是所有的控制线路,后面跟着一个目标线路。 (#2121) (#2278)
重大变更
作为矩阵的算子表示已被彻底改进。 (#1996)
现在,“标准矩阵”被定义在静态方法
compute_matrix()中,而不是_matrix,它与线路无关。 默认情况下,该方法假定接受定义操作的所有参数和非可训练的超参数。>>> qml.RX.compute_matrix(0.5) [[0.96891242+0.j 0. -0.24740396j] [0. -0.24740396j 0.96891242+0.j ]]
如果没有为门指定标准矩阵,
compute_matrix()将会引发一个MatrixUndefinedError。生成器属性已更新为实例方法,
Operator.generator()。它现在返回一个实例化的操作, 表示实例化运算符的生成器。 (#2030) (#2061)各种运算符已更新,以指定生成器可以是
Observable、Tensor、Hamiltonian、SparseHamiltonian或Hermitian运算符。此外,
qml.generator(operation)已添加以帮助检索 运算符的生成器表示。在
heisenberg_obs、heisenberg_expand和heisenberg_tr中,参数wires被重命名为wire_order,以与其他矩阵表示保持一致。属性
kraus_matrices已被更改为一个方法,_kraus_matrices被重命名为compute_kraus_matrices,现在是一个静态方法。 (#2055)模块
pennylane.measure已重命名为pennylane.measurements。 (#2236)
错误修复
在
(#2287)qml.SWAP的basis属性被设置为"X", 这是不正确的; 现在已设置为None。当权重是一个列表的列表时,
qml.RandomLayers模板现在可以进行分解。现在,
qml.QubitUnitary操作支持使用 JAX 的即时编译。(#2249)修复了JAX接口中的一个错误,其中
Array对象在执行外部设备之前没有被转换为NumPy数组。 (#2255)现在,
qml.ctrl变换可以正确地与梯度变换一起使用,例如参数偏移规则。(#2238)修复了一个错误,该错误在将必需参数作为关键字参数传递给操作时,会因为文档中的调用签名与函数定义不匹配而抛出错误。(#1976)
之前操作
OrbitalRotation错误地注册以满足四项参数移位规则。现在使用参数移位规则时将采用正确的八项规则。 (#2180)修复了一个错误,即当海森矩阵的所有元素预先已知为0时,
qml.gradients.param_shift_hessian会产生错误。 (#2299)
文档
关于添加模板的开发者指南和架构概述已被重写,以反映操作符重构的过去和计划中的更改。 (#2066)
有关CV模型的信息,请参阅Strawberry Fields文档的链接。 (#2259)
修复了
qml.QFT的文档示例。 (#2232)修复了使用
qml.sample与jax.jit的文档示例。 (#2196)现在在PennyLane API文档中包含了
qml.numpy子包。 (#2179)改善了
RotosolveOptimizer的文档,关于传递的substep_optimizer及其关键字参数的使用。(#2160)确保
@qml.qfunc_transform装饰的函数的签名在文档中正确显示。 (#2286)文档字符串示例现在使用更新的基于文本的电路绘图工具显示。 (#2252)
为
OrbitalRotation.grad_recipe添加文档字符串。 (#2193)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Catalina Albornoz, Jack Y. Araz, Juan Miguel Arrazola, Ali Asadi, Utkarsh Azad, Sam Banning, Thomas Bromley, Olivia Di Matteo, Christian Gogolin, Diego Guala, Anthony Hayes, David Ittah, Josh Izaac, Soran Jahangiri, Nathan Killoran, Christina Lee, Angus Lowe, Maria Fernanda Morris, Romain Moyard, Zeyue Niu, Lee James O’Riordan, Chae-Yeun Park, Maria Schuld, Jay Soni, Antal Száva, David Wierichs.
- orphan
发布 0.21.0¶
自上次发布以来的新特性
减少模拟哈密顿量的量子比特需求 ⚛️
Functions for tapering qubits based on molecular symmetries have been added, following results from Setia et al. (#1966) (#1974) (#2041) (#2042)
With this functionality, a molecular Hamiltonian and the corresponding Hartree-Fock (HF) state can be transformed to a new Hamiltonian and HF state that acts on a reduced number of qubits, respectively.
# molecular geometry symbols = ["He", "H"] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.4588684632]]) mol = qml.hf.Molecule(symbols, geometry, charge=1) # generate the qubit Hamiltonian H = qml.hf.generate_hamiltonian(mol)(geometry) # determine Hamiltonian symmetries generators, paulix_ops = qml.hf.generate_symmetries(H, len(H.wires)) opt_sector = qml.hf.optimal_sector(H, generators, mol.n_electrons) # taper the Hamiltonian H_tapered = qml.hf.transform_hamiltonian(H, generators, paulix_ops, opt_sector)
We can compare the number of qubits required by the original Hamiltonian and the tapered Hamiltonian:
>>> len(H.wires) 4 >>> len(H_tapered.wires) 2
For quantum chemistry algorithms, the Hartree-Fock state can also be tapered:
n_elec = mol.n_electrons n_qubits = mol.n_orbitals * 2 hf_tapered = qml.hf.transform_hf( generators, paulix_ops, opt_sector, n_elec, n_qubits )
>>> hf_tapered tensor([1, 1], requires_grad=True)
新的张量网络模板 🪢
Quantum circuits with the shape of a matrix product state tensor network can now be easily implemented using the new
qml.MPStemplate, based on the work arXiv:1803.11537. (#1871)def block(weights, wires): qml.CNOT(wires=[wires[0], wires[1]]) qml.RY(weights[0], wires=wires[0]) qml.RY(weights[1], wires=wires[1]) n_wires = 4 n_block_wires = 2 n_params_block = 2 template_weights = np.array([[0.1, -0.3], [0.4, 0.2], [-0.15, 0.5]], requires_grad=True) dev = qml.device("default.qubit", wires=range(n_wires)) @qml.qnode(dev) def circuit(weights): qml.MPS(range(n_wires), n_block_wires, block, n_params_block, weights) return qml.expval(qml.PauliZ(wires=n_wires - 1))
The resulting circuit is:
>>> print(qml.draw(circuit, expansion_strategy="device")(template_weights)) 0: ──╭C──RY(0.1)───────────────────────────────┤ 1: ──╰X──RY(-0.3)──╭C──RY(0.4)─────────────────┤ 2: ────────────────╰X──RY(0.2)──╭C──RY(-0.15)──┤ 3: ─────────────────────────────╰X──RY(0.5)────┤ ⟨Z⟩
添加了树张量网络的模板,
qml.TTN. (#2043)def block(weights, wires): qml.CNOT(wires=[wires[0], wires[1]]) qml.RY(weights[0], wires=wires[0]) qml.RY(weights[1], wires=wires[1]) n_wires = 4 n_block_wires = 2 n_params_block = 2 n_blocks = qml.MPS.get_n_blocks(range(n_wires), n_block_wires) template_weights = [[0.1, -0.3]] * n_blocks dev = qml.device("default.qubit", wires=range(n_wires)) @qml.qnode(dev) def circuit(template_weights): qml.TTN(range(n_wires), n_block_wires, block, n_params_block, template_weights) return qml.expval(qml.PauliZ(wires=n_wires - 1))
生成的电路是:
>>> print(qml.draw(circuit, expansion_strategy="device")(template_weights)) 0: ──╭C──RY(0.1)─────────────────┤ 1: ──╰X──RY(-0.3)──╭C──RY(0.1)───┤ 2: ──╭C──RY(0.1)───│─────────────┤ 3: ──╰X──RY(-0.3)──╰X──RY(-0.3)──┤ ⟨Z⟩
广义旋转求解优化器 📉
The
RotosolveOptimizerhas been generalized to arbitrary frequency spectra in the cost function. Also note the changes in behaviour listed under Breaking changes. (#2081)Previously, the RotosolveOptimizer only supported variational circuits using special gates such as single-qubit Pauli rotations. Now, circuits with arbitrary gates are supported natively without decomposition, as long as the frequencies of the gate parameters are known. This new generalization extends the Rotosolve optimization method to a larger class of circuits, and can reduce the cost of the optimization compared to decomposing all gates to single-qubit rotations.
Consider the QNode
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def qnode(x, Y): qml.RX(2.5 * x, wires=0) qml.CNOT(wires=[0, 1]) qml.RZ(0.3 * Y[0], wires=0) qml.CRY(1.1 * Y[1], wires=[1, 0]) return qml.expval(qml.PauliX(0) @ qml.PauliZ(1)) x = np.array(0.8, requires_grad=True) Y = np.array([-0.2, 1.5], requires_grad=True)
Its frequency spectra can be easily obtained via
qml.fourier.qnode_spectrum:>>> spectra = qml.fourier.qnode_spectrum(qnode)(x, Y) >>> spectra {'x': {(): [-2.5, 0.0, 2.5]}, 'Y': {(0,): [-0.3, 0.0, 0.3], (1,): [-1.1, -0.55, 0.0, 0.55, 1.1]}}
We may then initialize the
RotosolveOptimizerand minimize the QNode cost function by providing this information about the frequency spectra. We also compare the cost at each step to the initial cost.>>> cost_init = qnode(x, Y) >>> opt = qml.RotosolveOptimizer() >>> for _ in range(2): ... x, Y = opt.step(qnode, x, Y, spectra=spectra) ... print(f"New cost: {np.round(qnode(x, Y), 3)}; Initial cost: {np.round(cost_init, 3)}") New cost: 0.0; Initial cost: 0.706 New cost: -1.0; Initial cost: 0.706
The optimization with
RotosolveOptimizeris performed in substeps. The minimal cost of these substeps can be retrieved by settingfull_output=True.>>> x = np.array(0.8, requires_grad=True) >>> Y = np.array([-0.2, 1.5], requires_grad=True) >>> opt = qml.RotosolveOptimizer() >>> for _ in range(2): ... (x, Y), history = opt.step(qnode, x, Y, spectra=spectra, full_output=True) ... print(f"New cost: {np.round(qnode(x, Y), 3)} reached via substeps {np.round(history, 3)}") New cost: 0.0 reached via substeps [-0. 0. 0.] New cost: -1.0 reached via substeps [-1. -1. -1.]
However, note that these intermediate minimal values are evaluations of the reconstructions that Rotosolve creates and uses internally for the optimization, and not of the original objective function. For noisy cost functions, these intermediate evaluations may differ significantly from evaluations of the original cost function.
改进的JAX支持 💻
JAX接口现在支持评估向量值QNodes。
向量值QNodes包括以下内容:
qml.probs;qml.state;qml.sample或者多个
qml.expval/qml.var测量。
考虑一个返回基础态概率的 QNode:
dev = qml.device('default.qubit', wires=2) x = jnp.array(0.543) y = jnp.array(-0.654) @qml.qnode(dev, diff_method="parameter-shift", interface="jax") def circuit(x, y): qml.RX(x, wires=[0]) qml.RY(y, wires=[1]) qml.CNOT(wires=[0, 1]) return qml.probs(wires=[1])
QNode可以被评估,并且其雅可比矩阵可以被计算:
>>> circuit(x, y) Array([0.8397495 , 0.16025047], dtype=float32) >>> jax.jacobian(circuit, argnums=[0, 1])(x, y) (Array([-0.2050439, 0.2050439], dtype=float32, weak_type=True), Array([ 0.26043, -0.26043], dtype=float32, weak_type=True))
请注意,
jax.jit尚不支持矢量值 QNodes。
更快的量子自然梯度 ⚡
A new function for computing the metric tensor on simulators,
qml.adjoint_metric_tensor, has been added, that uses classically efficient methods to massively improve performance. (#1992)This method, detailed in Jones (2020), computes the metric tensor using four copies of the state vector and a number of operations that scales quadratically in the number of trainable parameters.
Note that as it makes use of state cloning, it is inherently classical and can only be used with statevector simulators and
shots=None.It is particularly useful for larger circuits for which backpropagation requires inconvenient or even unfeasible amounts of storage, but is slower. Furthermore, the adjoint method is only available for analytic computation, not for measurements simulation with
shots!=None.dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circuit(x, y): qml.Rot(*x[0], wires=0) qml.Rot(*x[1], wires=1) qml.Rot(*x[2], wires=2) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[1, 2]) qml.CNOT(wires=[2, 0]) qml.RY(y[0], wires=0) qml.RY(y[1], wires=1) qml.RY(y[0], wires=2) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)), qml.expval(qml.PauliY(1)) x = np.array([[0.2, 0.4, -0.1], [-2.1, 0.5, -0.2], [0.1, 0.7, -0.6]], requires_grad=False) y = np.array([1.3, 0.2], requires_grad=True)
>>> qml.adjoint_metric_tensor(circuit)(x, y) tensor([[ 0.25495723, -0.07086695], [-0.07086695, 0.24945606]], requires_grad=True)
Computational cost
The adjoint method uses \(2P^2+4P+1\) gates and state cloning operations if the circuit is composed only of trainable gates, where \(P\) is the number of trainable operations. If non-trainable gates are included, each of them is applied about \(n^2-n\) times, where \(n\) is the number of trainable operations that follow after the respective non-trainable operation in the circuit. This means that non-trainable gates later in the circuit are executed less often, making the adjoint method a bit cheaper if such gates appear later. The adjoint method requires memory for 4 independent state vectors, which corresponds roughly to storing a state vector of a system with 2 additional qubits.
在硬件上计算Hessian ⬆️
新增的梯度变换
qml.gradients.param_shift_hessian可直接计算设备上的 QNodes 的海森矩阵(二阶偏导数矩阵)。 (#1884)该函数生成参数移位的电路,允许在硬件和软件设备上分析性地计算海森矩阵。与使用自动微分框架通过参数移位计算海森矩阵相比,该函数将使用更少的设备调用,并且可以直接检查参数移位的“海森电路”。该函数在所有支持的 PennyLane 接口上仍然是完全可微分的。
此外,参数移位海森矩阵配备了一个新的批量变换装饰器
@qml.gradients.hessian_transform,可以用于创建自定义海森函数。以下代码演示了如何使用参数移位海森矩阵:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.RX(x[0], wires=0) qml.RY(x[1], wires=0) return qml.expval(qml.PauliZ(0)) x = np.array([0.1, 0.2], requires_grad=True) hessian = qml.gradients.param_shift_hessian(circuit)(x)
>>> hessian tensor([[-0.97517033, 0.01983384], [ 0.01983384, -0.97517033]], requires_grad=True)
改进
现在,
qml.transforms.insert转换支持在某些特定门之后或之前添加操作。向
hf模块添加了一个修改版的simplify函数。 (#2103)该函数将哈密顿量中的冗余项合并,并消除系数小于截止值的项。新函数使得构建分子哈密顿量更加高效。以LiH为例,构建哈密顿量的时间大约减少了20倍。
QAOA模块现在接受NetworkX和RetworkX图作为函数输入。
(#1791)用于通过有向无环图表示电路的
CircuitGraph现在使用 RetworkX 作为其内部表示。这为依赖于有向无环图表示的算法带来了显著的速度提升。(#1791)对于
Operator的子类,其中参数的数量在实例化之前已知,num_params被还原为静态属性。这允许在不改变用户接口的情况下,程序上知道实例化操作符之前的参数数量。添加了一个测试以确保以不同方式定义num_params的效果符合预期。(#2101)(#2135)一个
WireCut运算符已被添加用于在构建 QNode 时手动放置电线切割。 (#2093)新函数
qml.drawer.tape_text生成一个带状图形的字符串。该函数在实现和一些细微的风格细节上与旧的字符串电路绘制基础设施有所不同。 (#1885)如果未检测到可训练参数,
RotosolveOptimizer现在会引发错误,而不是默默跳过所有参数的更新步骤。(#2109)函数
(#2080)qml.math.safe_squeeze被引入,gradient_transform允许 QNode 参数轴的大小为1。qml.math.safe_squeeze包装了qml.math.squeeze,稍作修改:当提供
axis关键字参数时,大小不为1的轴将被忽略,而不是引发错误。关键字参数
exclude_axis允许显式地排除轴以进行压缩。
现在,当应用于不可调用的对象时,
adjoint转换会引发错误。 (#2060)一个示例是可以应用
qml.adjoint的操作列表:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit_wrong(params): # 注意差异: v v qml.adjoint(qml.templates.AngleEmbedding(params, wires=dev.wires)) return qml.state() @qml.qnode(dev) def circuit_correct(params): # 注意差异: v v qml.adjoint(qml.templates.AngleEmbedding)(params, wires=dev.wires) return qml.state() params = list(range(1, 3))
现在评估
circuit_wrong(params)会引发ValueError,如果我们正确应用qml.adjoint,我们得到:>>> circuit_correct(params) [ 0.47415988+0.j 0. 0.73846026j 0. 0.25903472j -0.40342268+0.j ]
在 tape 的
to_openqasm函数中添加了一个精度参数,以控制参数的精度。 (#2071)干涉仪现在有了一个
shape方法。 (#1946)qml.BasisStatePreparation现在支持batch_params装饰器。 (#2091)新增了一个
multi_dispatch装饰器,有助于在 PennyLane 内部定义新函数。此装饰器在数学模块中得到应用,展示了用例。 (#2082) (#2096)我们可以装饰一个函数,指明接口处理的参数是张量:
>>> @qml.math.multi_dispatch(argnum=[0, 1]) ... def some_function(tensor1, tensor2, option, like): ... # 接口字符串存储在 ``like`` 中。 ... ...
之前,这是使用私有实用函数
_multi_dispatch完成的。>>> def some_function(tensor1, tensor2, option): ... interface = qml.math._multi_dispatch([tensor1, tensor2]) ... ...
将
IsingZZ门添加到diagonal_in_z_basis属性中。为此,添加了一个显式的_eigvals方法。 (#2113)添加了
IsingXX、IsingYY和IsingZZ门到composable_rotations属性中。 (#2113)
重大变更
使用Autograd接口时,QNode参数默认不再被视为可训练。为了获得相对于参数的导数,它应通过PennyLane的NumPy包装器使用
requires_grad=True属性进行实例化。之前的行为在PennyLane的版本v0.19.0中被弃用。 (#2116) (#2125) (#2139) (#2148) (#2156)from pennylane import numpy as np @qml.qnode(qml.device("default.qubit", wires=2)) def circuit(x): ... x = np.array([0.1, 0.2], requires_grad=True) qml.grad(circuit)(x)
对于
qml.grad和qml.jacobian函数,可通过argnum关键字替代性地指示可训练性:import numpy as np @qml.qnode(qml.device("default.qubit", wires=2)) def circuit(hyperparam, param): ... x = np.array([0.1, 0.2]) qml.grad(circuit, argnum=1)(0.5, x)
qml.jacobian现在遵循不同的输出形状约定。 (#2059)以前,
qml.jacobian尝试堆叠多个 QNode 参数的雅可比矩阵,当参数具有相同形状时,这会成功。在这种情况下,堆叠的雅可比矩阵也会被转置,从而导致输出形状(*reverse_QNode_args_shape, *reverse_output_shape, num_QNode_args)如果没有进行堆叠和转置,则输出形状将是一个
tuple,其中每个条目对应一个 QNode 参数,并具有形状(*output_shape, *QNode_arg_shape)。这一重大更改改变了第一种情况的行为,并删除了堆叠和转置的尝试,从而使输出始终具有第二种类型的形状。
请注意,当
argnum=None且只有一个 QNode 参数与之相关时,行为保持不变 — 即雅可比元组被解包为单个雅可比矩阵 — 或者当提供一个整数作为argnum时。一个允许
qml.jacobian区分多个 QNode 参数的解决方案将不再支持高阶导数。在这种情况下,建议将多个参数组合成一个数组。qml.metric_tensor,qml.adjoint_metric_tensor和qml.transforms.classical_jacobian现在在使用 Autograd 接口时,其输出形状遵循不同的约定 (#2059)有关详细信息,请参见之前的条目。这个破坏性变化紧随
qml.jacobian的更改,特别是在上面的方法中使用hybrid=True时。RotosolveOptimizer的行为已针对其关键字参数进行了更改。 (#2081)关键字参数
optimizer和optimizer_kwargs被重命名为substep_optimizer和substep_kwargs,分别。此外,它们已从step和step_and_cost移动到初始化__init__。关键字参数
num_freqs被重命名为nums_frequency并且现在预计采用不同的结构: 以前,它被期望为一个int或一个条目的列表,其中每个条目又是一个int或一个int条目的list。 现在预期的结构是一个嵌套字典,匹配 qml.fourier.reconstruct 所期望的格式。这也匹配新关键字参数spectra和shifts的期望格式。有关更多详细信息,请参见 RotosolveOptimizer documentation。
不推荐使用的功能
废弃了
QubitDevice提供的缓存能力。 (#2154)今后,推荐的方式是使用 QNode 的缓存能力:
dev = qml.device("default.qubit", wires=2) cache = {} @qml.qnode(dev, diff_method='parameter-shift', cache=cache) def circuit(): qml.RY(0.345, wires=0) return qml.expval(qml.PauliZ(0))
>>> for _ in range(10): ... circuit() >>> dev.num_executions 1
错误修复
修复了一个错误,即使用自定义缓存的QNode记录了不正确的执行次数,使用的
(#2171)diff_method="backprop"。修复了一个错误,即
default.qubit.jax设备无法与diff_method=None和 jitting 一起使用。 (#2136)修复了一个错误,Torch 接口在设备上执行梯度录制之前没有正确地将 Torch 张量解包为 NumPy 数组。 (#2117)
修复了TensorFlow接口的一个错误,其中输入张量的dtype未被转换。 (#2120)
修复了一个错误,该错误导致批量转换的 QNodes 无法应用底层设备提供的批量转换。 (#2111)
如果在指定有限次数的设备上请求反向传播,则在创建QNode时现在会引发错误。 (#2114)
Pytest 现在忽略在 autograd 的
numpy_wrapper模块中引发的任何DeprecationWarning。其他一些小的测试警告已修复。(#2007)修复了一个错误,该错误导致QNode未正确对可交换的量子比特观察量进行对角化。 (#2097)
修复了一个在
gradient_transform中的错误,该错误导致了具有单个参数化门的电路的混合微分失败,同时大小为1的QNode参数轴被移除了输出梯度。 (#2080)可用的
diff_method选项已在错误信息和文档中进行了修正。 (#2078)修复了一个在
DefaultQubit中的错误,该错误涉及到对应于消失状态矢量幅度的位置的 QNodes 的二阶导数不正确。 (#2057)修复了一个错误,之前PennyLane不需要v0.20.0版本的PennyLane-Lightning,但由于新的批处理执行管道,导致早于v0.20.0版本的Lightning发生错误。 (#2033)
修复了在与Torch一起使用时
(#2020)classical_jacobian中的一个错误,在这种情况下,预处理的雅可比也计算了不可训练参数的雅可比。修复了在队列中
two_qubit_decomposition方法的一个错误,该错误最初导致在通过unitary_to_rot优化转换时,超过3个双量子单位的电路失败。(#2015)修复了一个 bug,允许使用
jax.jit与返回qml.probs的电路兼容,当default.qubit.jax提供自定义射击 向量时。 (#2028)更新了
adjoint()方法以用于非参数量子比特操作,修复了一个错误,即重复调用adjoint()时不会返回正确的操作符。 (#2133)修复了在
insert()中的一个错误,该错误阻止了来自多个类的操作被插入。 (#2172)
文档
贡献者
此版本包含来自(按字母顺序排列)的贡献:
胡安·米格尔·阿拉佐拉,阿里·阿萨迪,乌特卡什·阿扎德,山姆·班宁,托马斯·布隆利,埃斯特·克鲁兹,奥利维亚·迪·马泰奥,克里斯蒂安·戈戈林,迭戈·瓜拉,安东尼·海斯,大卫·伊塔,乔希·伊扎克,索兰·贾汉吉里,爱德华·姜,安基特·坎德尔瓦尔,内森·基洛兰,科尔比安·科特曼,克里斯蒂娜·李,罗曼·莫亚德,李·詹姆斯·奥'里奥丹,玛丽亚·施尔德,杰·索尼,安塔尔·萨瓦,大卫·维里希斯,邵明·张。
- orphan
发布 0.20.0¶
自上次发布以来的新特性
崭新的电路绘图工具!🎨🖌️
PennyLane 现在支持使用 matplotlib 绘制 QNode! (#1803) (#1811) (#1931) (#1954)
dev = qml.device("default.qubit", wires=4) @qml.qnode(dev) def circuit(x, z): qml.QFT(wires=(0,1,2,3)) qml.Toffoli(wires=(0,1,2)) qml.CSWAP(wires=(0,2,3)) qml.RX(x, wires=0) qml.CRZ(z, wires=(3,0)) return qml.expval(qml.PauliZ(0)) fig, ax = qml.draw_mpl(circuit)(1.2345, 1.2345) fig.show()

新且改进的量子感知优化器
添加了
qml.LieAlgebraOptimizer,一个新的量子感知的李代数优化器, 允许在特殊酉群上执行梯度下降。 (#1911)dev = qml.device("default.qubit", wires=2) H = -1.0 * qml.PauliX(0) - qml.PauliZ(1) - qml.PauliY(0) @ qml.PauliX(1) @qml.qnode(dev) def circuit(): qml.RX(0.1, wires=[0]) qml.RY(0.5, wires=[1]) qml.CNOT(wires=[0,1]) qml.RY(0.6, wires=[0]) return qml.expval(H) opt = qml.LieAlgebraOptimizer(circuit=circuit, stepsize=0.1)
请注意,与其他优化器不同,
LieAlgebraOptimizer接受一个 没有 参数的 QNode,而是通过在优化期间附加操作来扩展电路:>>> circuit() tensor(-1.3351865, requires_grad=True) >>> circuit1, cost = opt.step_and_cost() >>> circuit1() tensor(-1.99378872, requires_grad=True)
有关更多详细信息,请参见 LieAlgebraOptimizer 文档。
The
qml.metric_tensortransform can now be used to compute the full tensor, beyond the block diagonal approximation. (#1725)This is performed using Hadamard tests, and requires an additional wire on the device to execute the circuits produced by the transform, as compared to the number of wires required by the original circuit. The transform defaults to computing the full tensor, which can be controlled by the
approxkeyword argument.As an example, consider the QNode
dev = qml.device("default.qubit", wires=3) @qml.qnode(dev) def circuit(weights): qml.RX(weights[0], wires=0) qml.RY(weights[1], wires=0) qml.CNOT(wires=[0, 1]) qml.RZ(weights[2], wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) weights = np.array([0.2, 1.2, -0.9], requires_grad=True)
Then we can compute the (block) diagonal metric tensor as before, now using the
approx="block-diag"keyword:>>> qml.metric_tensor(circuit, approx="block-diag")(weights) [[0.25 0. 0. ] [0. 0.24013262 0. ] [0. 0. 0.21846983]]
Instead, we now can also compute the full metric tensor, using Hadamard tests on the additional wire of the device:
>>> qml.metric_tensor(circuit)(weights) [[ 0.25 0. -0.23300977] [ 0. 0.24013262 0.01763859] [-0.23300977 0.01763859 0.21846983]]
See the metric tensor documentation. for more information and usage details.
通过优化的量子工作流程实现更快的性能
QNode已经被重写以支持全面的批量执行、自定义梯度、更好的分解策略和高阶导数。 (#1807) (#1969)
内部而言,如果为同时执行生成多个电路,它们将被打包成一个单一的作业在设备上执行。这在远程量子硬件或具有并行化能力的模拟器设备上执行QNode时,可以带来显著的性能提升。
可以将自定义梯度变换指定为微分方法:
@qml.gradients.gradient_transform def my_gradient_transform(tape): ... return tapes, processing_fn @qml.qnode(dev, diff_method=my_gradient_transform) def circuit():
有关使用新 QNode 的重大更改,请参阅 重大更改 部分。
请注意,旧的 QNode 可以通过
@qml.qnode_old.qnode访问,但这将在下一个版本中被移除。Custom decompositions can now be applied to operations at the device level. (#1900)
For example, suppose we would like to implement the following QNode:
def circuit(weights): qml.BasicEntanglerLayers(weights, wires=[0, 1, 2]) return qml.expval(qml.PauliZ(0)) original_dev = qml.device("default.qubit", wires=3) original_qnode = qml.QNode(circuit, original_dev)
>>> weights = np.array([[0.4, 0.5, 0.6]]) >>> print(qml.draw(original_qnode, expansion_strategy="device")(weights)) 0: ──RX(0.4)──╭C──────╭X──┤ ⟨Z⟩ 1: ──RX(0.5)──╰X──╭C──│───┤ 2: ──RX(0.6)──────╰X──╰C──┤
Now, let’s swap out the decomposition of the
CNOTgate intoCZandHadamard, and furthermore the decomposition ofHadamardintoRZandRYrather than the decomposition already available in PennyLane. We define the two decompositions like so, and pass them to a device:def custom_cnot(wires): return [ qml.Hadamard(wires=wires[1]), qml.CZ(wires=[wires[0], wires[1]]), qml.Hadamard(wires=wires[1]) ] def custom_hadamard(wires): return [ qml.RZ(np.pi, wires=wires), qml.RY(np.pi / 2, wires=wires) ] # Can pass the operation itself, or a string custom_decomps = {qml.CNOT : custom_cnot, "Hadamard" : custom_hadamard} decomp_dev = qml.device("default.qubit", wires=3, custom_decomps=custom_decomps) decomp_qnode = qml.QNode(circuit, decomp_dev)
Now when we draw or run a QNode on this device, the gates will be expanded according to our specifications:
>>> print(qml.draw(decomp_qnode, expansion_strategy="device")(weights)) 0: ──RX(0.4)──────────────────────╭C──RZ(3.14)──RY(1.57)──────────────────────────╭Z──RZ(3.14)──RY(1.57)──┤ ⟨Z⟩ 1: ──RX(0.5)──RZ(3.14)──RY(1.57)──╰Z──RZ(3.14)──RY(1.57)──╭C──────────────────────│───────────────────────┤ 2: ──RX(0.6)──RZ(3.14)──RY(1.57)──────────────────────────╰Z──RZ(3.14)──RY(1.57)──╰C──────────────────────┤
A separate context manager,
set_decomposition, has also been implemented to enable application of custom decompositions on devices that have already been created.>>> with qml.transforms.set_decomposition(custom_decomps, original_dev): ... print(qml.draw(original_qnode, expansion_strategy="device")(weights)) 0: ──RX(0.4)──────────────────────╭C──RZ(3.14)──RY(1.57)──────────────────────────╭Z──RZ(3.14)──RY(1.57)──┤ ⟨Z⟩ 1: ──RX(0.5)──RZ(3.14)──RY(1.57)──╰Z──RZ(3.14)──RY(1.57)──╭C──────────────────────│───────────────────────┤ 2: ──RX(0.6)──RZ(3.14)──RY(1.57)──────────────────────────╰Z──RZ(3.14)──RY(1.57)──╰C──────────────────────┤
给定形式为 \(U=e^{iHt}\) 的算子,其中 \(H\) 具有可交换的项和已知的特征值,
qml.gradients.generate_shift_rule计算用于确定在硬件上期望值 \(f(t) = \langle 0|U(t)^\dagger \hat{O} U(t)|0\rangle\) 的梯度的广义参数偏移规则。 (#1788) (#1932)给定
\[H = \sum_i a_i h_i,\]其中 \(H\) 的特征值已知且所有 \(h_i\) 是可交换的,我们可以使用
qml.gradients.eigvals_to_frequencies计算 频率(任意两个特征值的唯一正差异)。qml.gradients.generate_shift_rule然后可以用来计算参数偏移规则,以使用2R偏移的成本函数评估计算 \(f'(t)\)。当R小于生成器中的泡利词的数量时,这比标准的链式法则应用和二项偏移规则更便宜。例如,考虑 \(H\) 具有特征谱
(-1, 0, 1)的情况:>>> frequencies = qml.gradients.eigvals_to_frequencies((-1, 0, 1)) >>> frequencies (1, 2) >>> coeffs, shifts = qml.gradients.generate_shift_rule(frequencies) >>> coeffs array([ 0.85355339, -0.85355339, -0.14644661, 0.14644661]) >>> shifts array([ 0.78539816, -0.78539816, 2.35619449, -2.35619449])
正如我们所看到的,
generate_shift_rule返回了四个系数 \(c_i\) 和对应于四项参数偏移规则的 \(s_i\)。然后可以通过以下方式重构梯度:\[\frac{\partial}{\partial\phi}f = \sum_{i} c_i f(\phi + s_i),\]其中 \(f(\phi) = \langle 0|U(\phi)^\dagger \hat{O} U(\phi)|0\rangle\) 对于某些可观察量 \(\hat{O}\),单位算子 \(U(\phi)=e^{iH\phi}\)。
对具有量子硬件的TensorFlow AutoGraph模式的支持
It is now possible to use TensorFlow’s AutoGraph mode with QNodes on all devices and with arbitrary differentiation methods. Previously, AutoGraph mode only support
diff_method="backprop". This will result in significantly more performant model execution, at the cost of a more expensive initial compilation. (#1866)Use AutoGraph to convert your QNodes or cost functions into TensorFlow graphs by decorating them with
@tf.function:dev = qml.device("lightning.qubit", wires=2) @qml.qnode(dev, diff_method="adjoint", interface="tf", max_diff=1) def circuit(x): qml.RX(x[0], wires=0) qml.RY(x[1], wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)), qml.expval(qml.PauliZ(0)) @tf.function def cost(x): return tf.reduce_sum(circuit(x)) x = tf.Variable([0.5, 0.7], dtype=tf.float64) with tf.GradientTape() as tape: loss = cost(x) grad = tape.gradient(loss, x)
The initial execution may take slightly longer than when executing the circuit in eager mode; this is because TensorFlow is tracing the function to create the graph. Subsequent executions will be much more performant.
Note that using AutoGraph with backprop-enabled devices, such as
default.qubit, will yield the best performance.For more details, please see the TensorFlow AutoGraph documentation.
使用经典QNode重构来表征您的量子模型
The
qml.fourier.reconstructfunction is added. It can be used to reconstruct QNodes outputting expectation values along a specified parameter dimension, with a minimal number of calls to the original QNode. The returned reconstruction is exact and purely classical, and can be evaluated without any quantum executions. (#1864)The reconstruction technique differs for functions with equidistant frequencies that are reconstructed using the function value at equidistant sampling points, and for functions with arbitrary frequencies reconstructed using arbitrary sampling points.
As an example, consider the following QNode:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x, Y, f=1.0): qml.RX(f * x, wires=0) qml.RY(Y[0], wires=0) qml.RY(Y[1], wires=1) qml.CNOT(wires=[0, 1]) qml.RY(3 * Y[1], wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
It has three variational parameters overall: A scalar input
xand an array-valued inputYwith two entries. Additionally, we can tune the dependence onxwith the frequencyf. We then can reconstruct the QNode output function with respect toxvia>>> x = 0.3 >>> Y = np.array([0.1, -0.9]) >>> rec = qml.fourier.reconstruct(circuit, ids="x", nums_frequency={"x": {0: 1}})(x, Y) >>> rec {'x': {0: <function pennylane.fourier.reconstruct._reconstruct_equ.<locals>._reconstruction(x)>}}
As we can see, we get a nested dictionary in the format of the input
nums_frequencywith functions as values. These functions are simple float-to-float callables:>>> univariate = rec["x"][0] >>> univariate(x) -0.880208251507
For more details on usage, reconstruction cost and differentiability support, please see the fourier.reconstruct docstring.
最先进的操作和模板
一个用于在可交换的哈密顿量下进行时间演化的电路模板,使用通用的参数平移规则来计算成本函数梯度,可以通过
qml.CommutingEvolution获得。 (#1788)如果在其实例化过程中模板提供了频谱,那么
generate_shift_rule会被内部调用,以获取有关CommutingEvolution的\(t\)参数的一般参数平移规则,否则将使用CommutingEvolution的分解的平移规则。该模板可以在QNode中初始化,如下所示:
import pennylane as qml n_wires = 2 dev = qml.device('default.qubit', wires=n_wires) coeffs = [1, -1] obs = [qml.PauliX(0) @ qml.PauliY(1), qml.PauliY(0) @ qml.PauliX(1)] hamiltonian = qml.Hamiltonian(coeffs, obs) frequencies = (2,4) @qml.qnode(dev) def circuit(time): qml.PauliX(0) qml.CommutingEvolution(hamiltonian, time, frequencies) return qml.expval(qml.PauliZ(0))
请注意,没有内部验证 1) 输入的
qml.Hamiltonian是否完全可交换 和 2) 特征值频谱是否正确,因为这些检查在大型哈密顿量中变得代价昂贵。新增了
qml.Barrier()运算符。通过它我们可以在编译中分隔块或者将其用作视觉工具。 (#1844)添加了作为算子的单位可观测量。现在我们可以在我们的量子电路上明确调用单位操作,适用于量子比特和连续变量设备。(#1829)
新增了
qml.QubitDensityMatrix初始化门用于混合态模拟。 (#1850)一个热弛豫通道被添加到噪声通道中。通道描述可以在量子分类器与定制量子核的补充信息中找到。(#1766)
添加了一个新的
(#1781)qml.PauliError通道,允许在任意数量的导线上应用任意数量的保罗算子。
使用新的转换来操纵 QNodes 以满足您的 ❤️s 内容
变换
merge_amplitude_embedding已创建用于 自动将此类型的所有门合并为一个。 (#1933)from pennylane.transforms import merge_amplitude_embedding dev = qml.device("default.qubit", wires = 3) @qml.qnode(dev) @merge_amplitude_embedding def qfunc(): qml.AmplitudeEmbedding([0,1,0,0], wires = [0,1]) qml.AmplitudeEmbedding([0,1], wires = 2) return qml.expval(qml.PauliZ(wires = 0))
>>> print(qml.draw(qnode)()) 0: ──╭AmplitudeEmbedding(M0)──┤ ⟨Z⟩ 1: ──├AmplitudeEmbedding(M0)──┤ 2: ──╰AmplitudeEmbedding(M0)──┤ M0 = [0.+0.j 0.+0.j 0.+0.j 1.+0.j 0.+0.j 0.+0.j 0.+0.j 0.+0.j]
自
undo_swaps变换已创建,以自动移除电路中的所有交换。 (#1960)dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) @qml.transforms.undo_swaps def qfunc(): qml.Hadamard(wires=0) qml.PauliX(wires=1) qml.SWAP(wires=[0,1]) qml.SWAP(wires=[0,2]) qml.PauliY(wires=0) return qml.expval(qml.PauliZ(0))
>>> print(qml.draw(qfunc)()) 0: ──Y──┤ ⟨Z⟩ 1: ──H──┤ 2: ──X──┤
改进
添加了在给定位置计算原子和分子轨道值的函数。 (#1867)
可以使用函数
atomic_orbital和molecular_orbital,如以下代码块所示,来评估轨道。通过在不同位置生成轨道的值,可以绘制所需轨道的空间形状。symbols = ['H', 'H'] geometry = np.array([[0.0, 0.0, 0.0], [0.0, 0.0, 1.0]], requires_grad = False) mol = hf.Molecule(symbols, geometry) hf.generate_scf(mol)() ao = mol.atomic_orbital(0) mo = mol.molecular_orbital(1)
>>> print(ao(0.0, 0.0, 0.0)) >>> print(mo(0.0, 0.0, 0.0)) 0.6282468778183719 0.018251285973461928
添加对 Python 3.10 的支持。 (#1964)
具有执行的 QNodes
多返回类型;
除了方差和期望以外的返回类型
现在在使用JAX接口时会抛出描述性错误信息。 (#2011)
PennyLane
qchem包现在是懒加载的;它只在第一次访问时被导入。 (#1962)qml.math.scatter_element_add现在支持通过一次函数调用在多个索引处添加多个值,适用于所有接口 (#1864)例如,我们可以以下述方式设置三维张量的五个值:
>>> X = tf.zeros((3, 2, 9), dtype=tf.float64) >>> indices = [(0, 0, 1, 2, 2), (0, 0, 0, 0, 1), (1, 3, 8, 6, 7)] >>> values = [1 * i for i in range(1,6)] >>> qml.math.scatter_element_add(X, indices, values)
所有的
str.format实例已被 f-strings 替换。 (#1970)测试不再自动循环遍历导入和实例化的操作,这以前是不透明的,并且创建了不必要的许多测试。 (#1895)
一个
decompose()方法已被添加到Operator类中,以便我们可以直接从操作的实例中获取(并排队)分解。 (#1873)>>> op = qml.PhaseShift(0.3, wires=0) >>> op.decompose() [RZ(0.3, wires=[0])]
qml.circuit_drawer.tape_mpl生成一个 matplotlib 图形和坐标轴,给定一个磁带。 (#1787)现在,
AngleEmbedding、BasicEntanglerLayers和MottonenStatePreparation模板在使用@qml.batch_params装饰器时支持带有批维度的参数。qml.draw现在支持max_length参数,以防止在打印电路时文本溢出。 (#1892)Identity操作现在是ops.qubit和ops.cv模块的一部分。 (#1956)
重大变更
QNode已经被重写以支持全面的批量执行、自定义梯度、更好的分解策略和高阶导数。 (#1807) (#1969)
硬件上支持任意\(n\)阶导数,使用如参数偏移规则等梯度变换。要指定将计算QNode的\(n\)阶导数,应该设置
max_diff参数。默认情况下,该参数设置为1(仅一阶导数)。增加此值允许提取更高阶的导数,但会增加在反向传播期间的额外(经典)计算开销。在分解电路时,默认的分解策略
expansion_strategy="gradient"会优先考虑导致满足微分方法所需的参数化操作数量最少的分解。虽然这可能会导致经典处理的略微增加,但它显著减少了计算复杂单位的梯度所需的电路评估数量。要返回旧的行为,可以指定
expansion_strategy="device"。
请注意,旧的 QNode 可以通过
@qml.qnode_old.qnode访问,但这将在下一个版本中被移除。在
v0.19.0中弃用的某些功能已被移除: (#1981) (#1963)这个
qml.template装饰器 (使用一个 ` QuantumTape <https://pennylane.readthedocs.io/en/stable/code/api/pennylane.tape.QuantumTape.html>`_ 作为上下文管理器来记录操作以及其operations属性来返回它们,见链接页面以获取示例);实验设备
default.tensor和default.tensor.tf;这个
qml.fourier.spectrum函数(请使用qml.fourier.circuit_spectrum或qml.fourier.qnode_spectrum函数替代);diag_approx是qml.metric_tensor和qml.QNGOptimizer的关键字参数(使用approx='diag'代替)。
默认的
qml.metric_tensor变换行为已被修改。默认情况下,计算完整的度量张量,这比之前仅计算块对角线的默认值成本更高。同时,完整度量张量的哈达玛德测试需要设备上的额外线,因此>>> qml.metric_tensor(some_qnode)(weights)
将恢复到块对角线限制,并且如果所使用的设备没有额外的线,则会引发警告。(#1725)
circuit_drawer模块已重命名为drawer。(#1949)操作符类中的
par_domain属性已被移除。 (#1907)由于底层存在会导致不可变 QNode 返回错误结果的漏洞,
mutable关键字参数已从 QNode 中移除。此功能将在即将发布的版本中恢复。可逆的QNode微分方法已经被移除; 推荐使用伴随微分方法 (
diff_method='adjoint')。(#1807)QuantumTape.trainable_params现在是一个列表,而不是一个集合。这意味着tape.trainable_params将返回一个列表,和以前不同,但使用集合设置trainable_params的方式和以前完全一样。(#1904)操作符类中的
num_params属性现在是动态的。这使得定义具有灵活参数数量的操作符子类变得更加容易。 (#1898) (#1909)静态方法
decomposition(),以前在Operation类中,现在已移到基础Operator类中。 (#1873)DiagonalOperation不再是一个单独的子类。 (#1889)相反,设备可以使用属性检查对角特性:
from pennylane.ops.qubit.attributes import diagonal_in_z_basis if op in diagonal_in_z_basis: # 做一些事情
可以通过在运行时将自定义操作添加到此属性来扩展
diagonal_in_z_basis.add("MyCustomOp")。
错误修复
修复了使用
default.qubit.jax时qml.probs的一个错误。 (#1998)修复了一个错误,QNode的输出张量总是放在默认GPU上,使用
(#1982)default.qubit.torch。设备测试套件不使用空电路,以便它也可以测试IonQ插件,并检查操作在更多地方是否受支持。 (#1979)
修复了一个bug,在使用带有
gate.inverse=True的门时度量张量计算不正确的问题。 (#1987)修正了
qml.transforms.classical_jacobian在Autograd接口的文档(并提高了测试覆盖率)。(#1978)修复了一个错误:在使用JAX接口对QNode进行求导时,使用
qml.state会引发错误。 (#1906)修复了与
qml.QFT的伴随有关的一个错误。 (#1955)修复了一个错误,即
ApproxTimeEvolution模板未正确计算输入哈密顿量的操作线路。虽然这并未影响使用ApproxTimeEvolution模板的计算,但导致电路图绘制失败。 (#1952)修复了一个错误,即使用
(#1948)qml.transforms.classical_jacobian和 JAX 计算的经典预处理雅可比矩阵返回了雅可比矩阵的一个缩减子矩阵。修复了一个错误,该错误导致在
qml.fourier.qnode_spectrum中操作未按正确顺序访问,从而导致输出错误。 (#1935)修复了几个 Pylint 错误。 (#1951)
修复了一个错误,设备测试套件未测试某些操作。 (#1943)
修复了一个错误,该错误会导致批处理转换改变QNodes的执行选项。 (#1934)
qml.draw现在支持具有矩阵参数的任意模板。 (#1917)QuantumTape.trainable_params现在是一个列表而不是一个集合,这使得它在非常少见的边缘情况下更稳定。 (#1904)ExpvalCost现在在optimize=True时返回正确的结果形状,当进行镜头批处理时。(#1897)qml.circuit_drawer.MPLDrawer被稍微修改以支持 matplotlib 版本 3.5。 (#1899)qml.CSWAP和qml.CRot现在定义了control_wires,而qml.SWAP返回默认的空线对象。 (#1830)qml.numpy.tensor对象的requires_grad属性现在在对对象进行序列化/反序列化时得以保留。 (#1856)设备测试不再对变分参数的
requires_grad属性发出警告。 (#1913)AdamOptimizer和AdagradOptimizer在它们的优化步骤更新中进行了小修复。 (#1929)修复了一个错误,即通过
qml.gradients.param_shift对具有多个数组参数的 QNode 进行微分时会抛出错误。(#1989)AmplitudeEmbedding模板不再在features参数被批处理并作为二维数组提供时产生ComplexWarning。 (#1990)qml.circuit_drawer.CircuitDrawer不再在尝试在电路内部绘制磁带时产生错误(例如,从操作的分解或手动放置)。(#1994)修复了一个错误,使用SciPy稀疏矩阵与新的QNode时可能会引发关于优先考虑TensorFlow和PyTorch接口的警告。 (#2001)
修复了一个在首次导入PennyLane时
QueueContext不为空的错误。 (#1957)修复了带有
Interferometer和CVNeuralNet的电路绘制问题。 (#1953)
文档
为一些操作在文档中添加了示例。 (#1902)
改进了开发者指南测试文档。 (#1896)
为
AngleEmbedding,BasisEmbedding,StronglyEntanglingLayers,SqueezingEmbedding,DisplacementEmbedding,MottonenStatePreparation和Interferometer添加了文档示例。 (#1910) (#1908) (#1912) (#1920) (#1936) (#1937)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Catalina Albornoz, Guillermo Alonso-Linaje, Juan Miguel Arrazola, Ali Asadi, Utkarsh Azad, Samuel Banning, Benjamin Cordier, Alain Delgado, Olivia Di Matteo, Anthony Hayes, David Ittah, Josh Izaac, Soran Jahangiri, Jalani Kanem, Ankit Khandelwal, Nathan Killoran, Shumpei Kobayashi, Robert Lang, Christina Lee, Cedric Lin, Alejandro Montanez, Romain Moyard, Lee James O’Riordan, Chae-Yeun Park, Isidor Schoch, Maria Schuld, Jay Soni, Antal Száva, Rodrigo Vargas, David Wierichs, Roeland Wiersema, Moritz Willmann.
- orphan
发布 0.19.1¶
错误修复
修复了在GPU上使用
default.qubit.tensor设备进行参数化操作时的多个错误。该设备再次接受torch_device参数,以允许在GPU上运行非参数化的QNodes。(#1927)修复了一个错误,该错误在某些包含
qml.QubitStateVector操作的 QNodes 上使用 JAX 的 jit 函数时,会在早期的 JAX 版本中引发错误(例如jax==0.2.10和jaxlib==0.1.64)。(#1924)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
乔什·艾扎克,克里斯蒂娜·李,罗曼·莫亚尔,李·詹姆斯·奥'里奥丹,安塔尔·萨瓦。
- orphan
发布 0.19.0¶
自上次发布以来的新特性
可微分哈特里-福克求解器
A differentiable Hartree-Fock (HF) solver has been added. It can be used to construct molecular Hamiltonians that can be differentiated with respect to nuclear coordinates and basis-set parameters. (#1610)
The HF solver computes the integrals over basis functions, constructs the relevant matrices, and performs self-consistent-field iterations to obtain a set of optimized molecular orbital coefficients. These coefficients and the computed integrals over basis functions are used to construct the one- and two-body electron integrals in the molecular orbital basis which can be used to generate a differentiable second-quantized Hamiltonian in the fermionic and qubit basis.
The following code shows the construction of the Hamiltonian for the hydrogen molecule where the geometry of the molecule is differentiable.
symbols = ["H", "H"] geometry = np.array([[0.0000000000, 0.0000000000, -0.6943528941], [0.0000000000, 0.0000000000, 0.6943528941]], requires_grad=True) mol = qml.hf.Molecule(symbols, geometry) args_mol = [geometry] hamiltonian = qml.hf.generate_hamiltonian(mol)(*args_mol)
>>> hamiltonian.coeffs tensor([-0.09041082+0.j, 0.17220382+0.j, 0.17220382+0.j, 0.16893367+0.j, 0.04523101+0.j, -0.04523101+0.j, -0.04523101+0.j, 0.04523101+0.j, -0.22581352+0.j, 0.12092003+0.j, -0.22581352+0.j, 0.16615103+0.j, 0.16615103+0.j, 0.12092003+0.j, 0.17464937+0.j], requires_grad=True)
The generated Hamiltonian can be used in a circuit where the atomic coordinates and circuit parameters are optimized simultaneously.
symbols = ["H", "H"] geometry = np.array([[0.0000000000, 0.0000000000, 0.0], [0.0000000000, 0.0000000000, 2.0]], requires_grad=True) mol = qml.hf.Molecule(symbols, geometry) dev = qml.device("default.qubit", wires=4) params = [np.array([0.0], requires_grad=True)] def generate_circuit(mol): @qml.qnode(dev) def circuit(*args): qml.BasisState(np.array([1, 1, 0, 0]), wires=[0, 1, 2, 3]) qml.DoubleExcitation(*args[0][0], wires=[0, 1, 2, 3]) return qml.expval(qml.hf.generate_hamiltonian(mol)(*args[1:])) return circuit for n in range(25): mol = qml.hf.Molecule(symbols, geometry) args = [params, geometry] # initial values of the differentiable parameters g_params = qml.grad(generate_circuit(mol), argnum = 0)(*args) params = params - 0.5 * g_params[0] forces = qml.grad(generate_circuit(mol), argnum = 1)(*args) geometry = geometry - 0.5 * forces print(f'Step: {n}, Energy: {generate_circuit(mol)(*args)}, Maximum Force: {forces.max()}')
In addition, the new Hartree-Fock solver can further be used to optimize the basis set parameters. For details, please refer to the differentiable Hartree-Fock solver documentation.
与Mitiq的集成
Error mitigation using the zero-noise extrapolation method is now available through the
transforms.mitigate_with_znetransform. This transform can integrate with the Mitiq package for unitary folding and extrapolation functionality. (#1813)Consider the following noisy device:
noise_strength = 0.05 dev = qml.device("default.mixed", wires=2) dev = qml.transforms.insert(qml.AmplitudeDamping, noise_strength)(dev)
We can mitigate the effects of this noise for circuits run on this device by using the added transform:
from mitiq.zne.scaling import fold_global from mitiq.zne.inference import RichardsonFactory n_wires = 2 n_layers = 2 shapes = qml.SimplifiedTwoDesign.shape(n_wires, n_layers) np.random.seed(0) w1, w2 = [np.random.random(s) for s in shapes] @qml.transforms.mitigate_with_zne([1, 2, 3], fold_global, RichardsonFactory.extrapolate) @qml.beta.qnode(dev) def circuit(w1, w2): qml.SimplifiedTwoDesign(w1, w2, wires=range(2)) return qml.expval(qml.PauliZ(0))
Now, when we execute
circuit, errors will be automatically mitigated:>>> circuit(w1, w2) 0.19113067083636542
强大的新变换
与量子电路对应的幺正矩阵现在可以使用新的
get_unitary_matrix()变换生成。 (#1609) (#1786)该变换在所有支持的 PennyLane 自动微分框架中是完全可微分的。
def circuit(theta): qml.RX(theta, wires=1) qml.PauliZ(wires=0) qml.CNOT(wires=[0, 1])
>>> theta = torch.tensor(0.3, requires_grad=True) >>> matrix = qml.transforms.get_unitary_matrix(circuit)(theta) >>> print(matrix) tensor([[ 0.9888+0.0000j, 0.0000+0.0000j, 0.0000-0.1494j, 0.0000+0.0000j], [ 0.0000+0.0000j, 0.0000+0.1494j, 0.0000+0.0000j, -0.9888+0.0000j], [ 0.0000-0.1494j, 0.0000+0.0000j, 0.9888+0.0000j, 0.0000+0.0000j], [ 0.0000+0.0000j, -0.9888+0.0000j, 0.0000+0.0000j, 0.0000+0.1494j]], grad_fn=
) >>> loss = torch.real(torch.trace(matrix)) >>> loss.backward() >>> theta.grad tensor(-0.1494)Arbitrary two-qubit unitaries can now be decomposed into elementary gates. This functionality has been incorporated into the
qml.transforms.unitary_to_rottransform, and is available separately asqml.transforms.two_qubit_decomposition. (#1552)As an example, consider the following randomly-generated matrix and circuit that uses it:
U = np.array([ [-0.03053706-0.03662692j, 0.01313778+0.38162226j, 0.4101526 -0.81893687j, -0.03864617+0.10743148j], [-0.17171136-0.24851809j, 0.06046239+0.1929145j, -0.04813084-0.01748555j, -0.29544883-0.88202604j], [ 0.39634931-0.78959795j, -0.25521689-0.17045233j, -0.1391033 -0.09670952j, -0.25043606+0.18393466j], [ 0.29599198-0.19573188j, 0.55605806+0.64025769j, 0.06140516+0.35499559j, 0.02674726+0.1563311j ] ]) dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) @qml.transforms.unitary_to_rot def circuit(x, y): qml.QubitUnitary(U, wires=[0, 1]) return qml.expval(qml.PauliZ(wires=0))
If we run the circuit, we can see the new decomposition:
>>> circuit(0.3, 0.4) tensor(-0.81295986, requires_grad=True) >>> print(qml.draw(circuit)(0.3, 0.4)) 0: ──Rot(2.78, 0.242, -2.28)──╭X──RZ(0.176)───╭C─────────────╭X──Rot(-3.87, 0.321, -2.09)──┤ ⟨Z⟩ 1: ──Rot(4.64, 2.69, -1.56)───╰C──RY(-0.883)──╰X──RY(-1.47)──╰C──Rot(1.68, 0.337, 0.587)───┤
添加了一个新的变换,
@qml.batch_params,使得QNode能够处理可训练参数中的批量维度。 (#1710) (#1761)这个变换将创建多个电路,每个批量维度一个。 因此,它兼容模拟器和硬件。
@qml.batch_params @qml.beta.qnode(dev) def circuit(x, weights): qml.RX(x, wires=0) qml.RY(0.2, wires=1) qml.templates.StronglyEntanglingLayers(weights, wires=[0, 1, 2]) return qml.expval(qml.Hadamard(0))
qml.batch_params装饰器允许我们传递具有批量维度的参数x和weights。 例如,>>> batch_size = 3 >>> x = np.linspace(0.1, 0.5, batch_size) >>> weights = np.random.random((batch_size, 10, 3, 3))
如果我们用这些输入来评估QNode,我们将得到形状为
(batch_size,)的输出:>>> circuit(x, weights) tensor([0.08569816, 0.12619101, 0.21122004], requires_grad=True)
现在添加了
insert变换,提供了一种将单量子比特操作插入量子电路的方法。该变换可以应用于量子函数、录音带和设备。 (#1795)以下QNode可以被转换以在电路中添加噪声:
dev = qml.device("default.mixed", wires=2) @qml.qnode(dev) @qml.transforms.insert(qml.AmplitudeDamping, 0.2, position="end") def f(w, x, y, z): qml.RX(w, wires=0) qml.RY(x, wires=1) qml.CNOT(wires=[0, 1]) qml.RY(y, wires=0) qml.RX(z, wires=1) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
该电路的执行结果将与无噪声值不同:
>>> f(0.9, 0.4, 0.5, 0.6) tensor(0.754847, requires_grad=True) >>> print(qml.draw(f)(0.9, 0.4, 0.5, 0.6)) 0: ──RX(0.9)──╭C──RY(0.5)──AmplitudeDamping(0.2)──╭┤ ⟨Z ⊗ Z⟩ 1: ──RY(0.4)──╰X──RX(0.6)──AmplitudeDamping(0.2)──╰┤ ⟨Z ⊗ Z⟩
常见的磁带扩展函数现在可以在
qml.transforms中找到,同时还提供了一个新的create_expand_fn函数,用于根据停止标准轻松创建扩展函数。 (#1734) (#1760)create_expand_fn接受扩展函数应扩展磁带的默认深度、一个停止标准、一个可选的设备以及要设置给创建函数的文档字符串。 停止标准必须接受一个可排队的对象并返回一个布尔值。例如,创建一个分解所有可训练的多参数操作的扩展函数:
>>> stop_at = ~(qml.operation.has_multipar & qml.operation.is_trainable) >>> expand_fn = qml.transforms.create_expand_fn(depth=5, stop_at=stop_at)
创建的扩展函数可以在自定义变换中使用。 还可以提供设备,生成将磁带分解以支持设备的本机门集的扩展函数。
电路的批量执行
添加了一个新的实验性QNode,它支持电路的批量执行、自定义量子梯度支持和任意阶导数。该QNode可以通过
qml.beta.QNode和@qml.beta.qnode获取。(#1642)(#1646)(#1651)(#1804)它在几个方面不同于标准QNode:
可以将自定义梯度变换指定为微分方法:
@qml.gradients.gradient_transform def my_gradient_transform(tape): ... return tapes, processing_fn @qml.beta.qnode(dev, diff_method=my_gradient_transform) def circuit():
支持在硬件上使用梯度变换(例如参数偏移规则)进行任意\(n\)阶导数的计算。要指定计算QNode的\(n\)阶导数,应该设置
max_diff参数。默认情况下,这个值设为1(仅计算一阶导数)。在内部,如果同时生成多个电路进行执行,它们将被打包成一个单独的作业在设备上执行。这在远程量子硬件上执行QNode时,可以显著提高性能。
在分解电路时,默认的分解策略将优先考虑那些导致满足微分方法所需的参数化操作数量最少的分解。为了满足量子设备的本地门集,所需的额外分解将在执行时由设备进行。虽然这可能导致经典处理的轻微增加,但它显著减少了计算复杂酉操作梯度所需的电路评估数量。
在即将发布的版本中,这个QNode将替代现有的。如果您在使用这个QNode时遇到任何错误,请通过错误报告在我们的GitHub错误跟踪器上告知我们。
目前,此beta QNode不支持以下功能:
通过
mutable关键字参数实现不可变性可逆的
reversibleQNode 微分方法在使用 PyTorch 和 TensorFlow 时指定
dtype的能力。
它也没有与
qml.qnn模块进行测试。
新操作和模板
新增了一种操作
OrbitalRotation,实现了自旋适应的空间轨道旋转门。 (#1665)一个使用
OrbitalRotation操作的示例电路是:dev = qml.device('default.qubit', wires=4) @qml.qnode(dev) def circuit(phi): qml.BasisState(np.array([1, 1, 0, 0]), wires=[0, 1, 2, 3]) qml.OrbitalRotation(phi, wires=[0, 1, 2, 3]) return qml.state()
如果我们运行这个电路,我们将得到以下输出
>>> circuit(0.1) array([ 0. +0.j, 0. +0.j, 0. +0.j, 0.00249792+0.j, 0. +0.j, 0. +0.j, -0.04991671+0.j, 0. +0.j, 0. +0.j, -0.04991671+0.j, 0. +0.j, 0. +0.j, 0.99750208+0.j, 0. +0.j, 0. +0.j, 0. +0.j])
添加了一个新的模板
GateFabric,它实现了Anselmetti 等 在 arXiv:2104.05692 中提出的局部、表达性、量子数保持的 ansatz。 (#1687)使用
GateFabric模板的电路示例为:coordinates = np.array([0.0, 0.0, -0.6614, 0.0, 0.0, 0.6614]) H, qubits = qml.qchem.molecular_hamiltonian(["H", "H"], coordinates) ref_state = qml.qchem.hf_state(electrons=2, orbitals=qubits) dev = qml.device('default.qubit', wires=qubits) @qml.qnode(dev) def ansatz(weights): qml.templates.GateFabric(weights, wires=[0,1,2,3], init_state=ref_state, include_pi=True) return qml.expval(H)
有关更多详细信息,请参见 GateFabric 文档。
添加了一个新的模板
kUpCCGSD,它实现了一种具有广义单体和成对双体激发算子的单位耦合簇 ansatz,由 Joonho Lee 等人 在 arXiv:1810.02327 提出。(#1743)使用
kUpCCGSD模板的电路示例为:coordinates = np.array([0.0, 0.0, -0.6614, 0.0, 0.0, 0.6614]) H, qubits = qml.qchem.molecular_hamiltonian(["H", "H"], coordinates) ref_state = qml.qchem.hf_state(electrons=2, orbitals=qubits) dev = qml.device('default.qubit', wires=qubits) @qml.qnode(dev) def ansatz(weights): qml.templates.kUpCCGSD(weights, wires=[0,1,2,3], k=0, delta_sz=0, init_state=ref_state) return qml.expval(H)
改进的量子编译和特征化工具
The new
qml.fourier.qnode_spectrumfunction extends the formerqml.fourier.spectrumfunction and takes classical processing of QNode arguments into account. The frequencies are computed per (requested) QNode argument instead of per gateid. The gateids are ignored. (#1681) (#1720)Consider the following example, which uses non-trainable inputs
x,yandzas well as trainable parameterswas arguments to the QNode.import pennylane as qml import numpy as np n_qubits = 3 dev = qml.device("default.qubit", wires=n_qubits) @qml.qnode(dev) def circuit(x, y, z, w): for i in range(n_qubits): qml.RX(0.5*x[i], wires=i) qml.Rot(w[0,i,0], w[0,i,1], w[0,i,2], wires=i) qml.RY(2.3*y[i], wires=i) qml.Rot(w[1,i,0], w[1,i,1], w[1,i,2], wires=i) qml.RX(z, wires=i) return qml.expval(qml.PauliZ(wires=0)) x = np.array([1., 2., 3.]) y = np.array([0.1, 0.3, 0.5]) z = -1.8 w = np.random.random((2, n_qubits, 3))
This circuit looks as follows:
>>> print(qml.draw(circuit)(x, y, z, w)) 0: ──RX(0.5)──Rot(0.598, 0.949, 0.346)───RY(0.23)──Rot(0.693, 0.0738, 0.246)──RX(-1.8)──┤ ⟨Z⟩ 1: ──RX(1)────Rot(0.0711, 0.701, 0.445)──RY(0.69)──Rot(0.32, 0.0482, 0.437)───RX(-1.8)──┤ 2: ──RX(1.5)──Rot(0.401, 0.0795, 0.731)──RY(1.15)──Rot(0.756, 0.38, 0.38)─────RX(-1.8)──┤
Applying the
qml.fourier.qnode_spectrumfunction to the circuit for the non-trainable parameters, we obtain:>>> spec = qml.fourier.qnode_spectrum(circuit, encoding_args={"x", "y", "z"})(x, y, z, w) >>> for inp, freqs in spec.items(): ... print(f"{inp}: {freqs}") "x": {(0,): [-0.5, 0.0, 0.5], (1,): [-0.5, 0.0, 0.5], (2,): [-0.5, 0.0, 0.5]} "y": {(0,): [-2.3, 0.0, 2.3], (1,): [-2.3, 0.0, 2.3], (2,): [-2.3, 0.0, 2.3]} "z": {(): [-3.0, -2.0, -1.0, 0.0, 1.0, 2.0, 3.0]}
We can see that all three parameters in the QNode arguments
xandycontribute the spectrum of a Pauli rotation[-1.0, 0.0, 1.0], rescaled with the prefactor of the respective parameter in the circuit. The threeRXrotations using the parameterzaccumulate, yielding a more complex frequency spectrum.For details on how to control for which parameters the spectrum is computed, a comparison to
qml.fourier.circuit_spectrum, and other usage details, please see the fourier.qnode_spectrum docstring.在设备 API 中添加了两个新方法,使得 PennyLane 设备对电路分解有了更大的控制。
Device.expand_fn(tape) -> tape:扩展一个磁带,以便设备可以支持它。 默认情况下,在默认 QNode 中执行标准的设备特定门集合分解。 设备可以重写此方法,以定义它们自己的分解逻辑。请注意,应用此方法后的数值结果应保持不变; PennyLane 会假设扩展后的磁带在执行时返回与原始磁带完全相同的值。
Device.batch_transform(tape) -> (tapes, processing_fn): 在需要从输入电路生成多个电路以执行的情况下,对磁带进行预处理。 后处理函数的要求使其与上述expand_fn方法不同。默认情况下,此方法应用变换
\[\left\langle \sum_i c_i h_i\right\rangle → \sum_i c_i \left\langle h_i \right\rangle\]如果
expval(H)在不支持具有不对易项的哈密顿量的设备上存在。
新增了一个类,用于存储运算符属性,例如
self_inverses和composable_rotation,作为操作名称的列表。(#1763)为了编译变换的目的,可以在
ops/qubit/attributes.py中找到许多这样的属性,但该类也可以用来创建你自己的属性。例如,我们可以这样创建一个新的属性pauli_ops:>>> from pennylane.ops.qubit.attributes import Attribute >>> pauli_ops = Attribute(["PauliX", "PauliY", "PauliZ"])
我们可以检查字符串或操作是否包含在这个集合中:
>>> qml.PauliX(0) in pauli_ops True >>> "Hadamard" in pauli_ops False
我们还可以在运行时动态地向集合中添加运算符。这对于将自定义操作添加到编译变换中使用的属性,如
composable_rotations和self_inverses是非常有用的。例如,假设你创建了一个新的操作MyGate,你知道它是它自己的逆。将其添加到集合中,如下所示:>>> from pennylane.ops.qubit.attributes import self_inverses >>> self_inverses.add("MyGate")
将使得在电路中如果两个这样的门是相邻的,则此门将被
cancel_inverses编译变换考虑。
改进
该
qml.metric_tensor变换在功能和性能方面都有所改进。 (#1638) (#1721)如果底层设备支持电路的批量执行,则计算度量张量元素所需的量子电路将自动作为批处理作业提交。这可以为具有非平凡作业提交开销的设备带来显著的性能提升。
之前,变换只会返回与门参数相关的度量张量,并忽略QNode内部的任何经典处理,即使是非常简单的经典处理,例如参数的排列。现在,度量张量考虑了经典处理,并返回与QNode参数相关的度量张量,而不仅仅是与门参数相关的:
>>> @qml.qnode(dev) ... def circuit(x): ... qml.Hadamard(wires=1) ... qml.RX(x[0], wires=0) ... qml.CNOT(wires=[0, 1]) ... qml.RY(x[1] ** 2, wires=1) ... qml.RY(x[1], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> x = np.array([0.1, 0.2], requires_grad=True) >>> qml.metric_tensor(circuit)(x) array([[0.25 , 0. ], [0. , 0.28750832]])
要恢复之前返回与门参数相关的度量张量的行为,可以传递
qml.metric_tensor(qnode, hybrid=False)。>>> qml.metric_tensor(circuit, hybrid=False)(x) array([[0.25 , 0. , 0. ], [0. , 0.25 , 0. ], [0. , 0. , 0.24750832]])
度量张量变换现在支持更大范围的操作。特别是,所有具有单一变分参数并定义生成器的操作现在都被支持。除了减少分解开销之外,这一变化还导致电路评估的数量减少。
在
qml.metric_tensor转换中的扩展规则已被更改。 (#1721)如果
hybrid=False,更改后的扩展规则可能会导致输出发生变化。现在可以将
ApproxTimeEvolution模板与具有可训练系数的哈密顿量一起使用。 (#1789)生成的QNodes可以对时间参数和哈密顿系数进行微分。
dev = qml.device('default.qubit', wires=2) obs = [qml.PauliX(0) @ qml.PauliY(1), qml.PauliY(0) @ qml.PauliX(1)] @qml.qnode(dev) def circuit(coeffs, t): H = qml.Hamiltonian(coeffs, obs) qml.templates.ApproxTimeEvolution(H, t, 2) return qml.expval(qml.PauliZ(0))
>>> t = np.array(0.54, requires_grad=True) >>> coeffs = np.array([-0.6, 2.0], requires_grad=True) >>> qml.grad(circuit)(coeffs, t) (array([-1.07813375, -1.07813375]), array(-2.79516158))
所有微分方法,包括反向传播和参数迁移规则,均得到支持。
量子函数变换和批量变换现在可以应用于设备。一旦应用于设备,在修改后的设备上执行的任何量子函数都将在执行之前被转换。 (#1809) (#1810)
dev = qml.device("default.mixed", wires=1) dev = qml.transforms.merge_rotations()(dev) @qml.beta.qnode(dev) def f(w, x, y, z): qml.RX(w, wires=0) qml.RX(x, wires=0) qml.RX(y, wires=0) qml.RX(z, wires=0) return qml.expval(qml.PauliZ(0))
>>> print(f(0.9, 0.4, 0.5, 0.6)) -0.7373937155412453 >>> print(qml.draw(f, expansion_strategy="device")(0.9, 0.4, 0.5, 0.6)) 0: ──RX(2.4)──┤ ⟨Z⟩
现在可以绘制通过“批量变换”转换的QNodes;也就是说,一个将单个QNode映射到多个电路的变换。批量变换的示例包括
@qml.metric_tensor和@qml.gradients。(#1762)例如,考虑参数移位规则,它为每个参数生成两个电路;一个电路将参数向前移动,另一个电路将参数向后移动:
dev = qml.device("default.qubit", wires=2) @qml.gradients.param_shift @qml.beta.qnode(dev) def circuit(x): qml.RX(x, wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(wires=0))
>>> print(qml.draw(circuit)(0.6)) 0: ──RX(2.17)──╭C──┤ ⟨Z⟩ 1: ────────────╰X──┤ 0: ──RX(-0.971)──╭C──┤ ⟨Z⟩ 1: ──────────────╰X──┤
Support for differentiable execution of batches of circuits has been extended to the JAX interface for scalar functions, via the beta
pennylane.interfaces.batchmodule. (#1634) (#1685)For example using the
executefunction from thepennylane.interfaces.batchmodule:from pennylane.interfaces.batch import execute def cost_fn(x): with qml.tape.JacobianTape() as tape1: qml.RX(x[0], wires=[0]) qml.RY(x[1], wires=[1]) qml.CNOT(wires=[0, 1]) qml.var(qml.PauliZ(0) @ qml.PauliX(1)) with qml.tape.JacobianTape() as tape2: qml.RX(x[0], wires=0) qml.RY(x[0], wires=1) qml.CNOT(wires=[0, 1]) qml.probs(wires=1) result = execute( [tape1, tape2], dev, gradient_fn=qml.gradients.param_shift, interface="autograd" ) return (result[0] + result[1][0, 0])[0] res = jax.grad(cost_fn)(params)
所有量子比特操作都已重写为使用
qml.math框架进行内部经典处理和生成它们的矩阵表示。 因此,这些表示现在是完全可微分的,并且框架特定的设备类不再需要维护这些矩阵的框架特定版本。 (#1749) (#1802)使用
expval(H),其中H是由qaoa模块生成的成本哈密顿量,已加速。这是通过使PennyLane将具有expval(H)测量的电路分解为子电路来实现的,如果Hamiltonian.grouping_indices属性已设置,并在相关的qaoa模块函数中设置此属性。 (#1718)操作现在可以具有依赖于操作状态的梯度配方。 (#1674)
例如,这允许根据参数的梯度配方:
class RX(qml.RX): @property def grad_recipe(self): # 梯度由 [f(2x) - f(0)] / (2 sin(x)) 给出,通过替换 # shift = x 到两个项的参数移位规则中。 x = self.data[0] c = 0.5 / np.sin(x) return ([[c, 0.0, 2 * x], [-c, 0.0, 0.0]],)
现在可以将shots作为运行时参数传递给批量执行电路的变换,类似于QNodes。 (#1707)
此类变换的一个例子是
qml.gradients模块中的梯度变换。因此,我们现在可以调用梯度变换(例如qml.gradients.param_shift)并在运行时设置shots的数量。>>> dev = qml.device("default.qubit", wires=1, shots=1000) >>> @qml.beta.qnode(dev) ... def circuit(x): ... qml.RX(x, wires=0) ... return qml.expval(qml.PauliZ(0)) >>> grad_fn = qml.gradients.param_shift(circuit) >>> param = np.array(0.564, requires_grad=True) >>> grad_fn(param, shots=[(1, 10)]).T array([[-1., -1., -1., -1., -1., 0., -1., 0., -1., 0.]]) >>> param2 = np.array(0.1233, requires_grad=True) >>> grad_fn(param2, shots=None) array([[-0.12298782]])
模板现在是顶级导入的,可以直接使用,例如
qml.QFT(wires=0). (#1779)qml.probs现在接受一个属性op,可以旋转计算基,并获取旋转基中的概率。(#1692)重构了设备类中的
expand_fn功能,以避免导致插件失败的边缘情况。 (#1838)更新了
qml.QNGOptimizer.step_and_cost方法,以避免使用已弃用的功能。(#1834)添加了一个自定义
torch.to_numpy实现到pennylane/math/single_dispatch.py以确保与 PyTorch 1.10 的兼容性。 (#1824) (#1825)现在,
(#1821)Operation的control_wires属性的默认值是一个空的Wires对象,而不是属性引发NonImplementedError。qml.circuit_drawer.MPLDrawer现在会自动旋转和调整文本大小,以适应由box_gate方法创建的矩形。 (#1764)操作符现在有一个
label方法来确定它们的绘制方式。 这将最终覆盖RepresentationResolver类。 (#1678)现在操作
label方法支持字符串变量。 (#1815)引入了一个新的实用类
qml.BooleanFn。它封装了一个接受单个参数并返回布尔值的函数。 (#1734)在封装后,
qml.BooleanFn可以像被包装的函数一样调用,多个实例可以使用按位运算符&、|和~进行操作和组合。有一个新的实用函数
qml.math.is_independent用于检查一个可调用对象是否独立于其参数。 (#1700)此函数是实验性的,可能表现得与预期不同。
请注意,该测试依赖于数值和解析检查,除非使用 PyTorch 接口,该接口只执行数值检查。 已知此测试在某些边缘情况下会产生错误结果,尤其是非光滑函数可能会有问题。 有关详细信息,请参阅 is_indpendent docstring。
现在
qml.beta.QNode支持qml.qnn模块。 (#1748)@qml.beta.QNode现在支持qml.specs转换。 (#1739)qml.circuit_drawer.drawable_layers和qml.circuit_drawer.drawable_grid处理操作列表以进行绘图的图层定位。 (#1639)qml.transforms.batch_transform现在接受带有额外参数和关键字参数的expand_fn。实际上,expand_fn和transform_fn现在必须具有相同的签名。(#1721)现在在Sphinx构建期间忽略
(#1733)qml.batch_transform装饰器,从而允许正确的签名在生成的文档中显示。量子比特操作的测试分为多个文件。 (#1661)
QNode内经典预处理的雅可比变换,
qml.transforms.classical_jacobian,现在接受一个关键字参数argnum来指定雅可比矩阵计算时的QNode参数索引。 (#1645)使用
argnum的示例是@qml.qnode(dev) def circuit(x, y, z): qml.RX(qml.math.sin(x), wires=0) qml.CNOT(wires=[0, 1]) qml.RY(y ** 2, wires=1) qml.RZ(1 / z, wires=1) return qml.expval(qml.PauliZ(0)) jac_fn = qml.transforms.classical_jacobian(circuit, argnum=[1, 2])
然后可以在指定参数处计算雅可比矩阵。
>>> x, y, z = np.array([0.1, -2.5, 0.71]) >>> jac_fn(x, y, z) (array([-0., -5., -0.]), array([-0. , -0. , -1.98373339]))
返回的数组分别是电路中三个参数化门关于
y和z的导数。现在也对
classical_jacobian进行了明确的测试,而之前是通过其在metric_tensor变换中的使用进行隐含测试。有关更多使用细节,请参见 经典雅可比文档字符串。
添加了一个新的实用函数
qml.math.is_abstract(tensor)。该函数 如果张量是 抽象的,则返回True;也就是说,它没有值或形状。 这可能发生在一个刚刚进行即时编译的函数中。 (#1845)qml.circuit_drawer.CircuitDrawer可以接受一个字符串作为charset关键字,而不是一个CharSet对象。 (#1640)qml.math.sort现在只会返回排序后的 torch 张量,而不返回相应的索引,使得排序在不同接口之间保持一致。(#1691)特定的 QNode 执行选项现在被批处理转换重用,用于执行转换后的 QNodes。(#1708)
为了在所有优化器中实现标准化,
qml.optimize.AdamOptimizer现在也使用accumulation(以collections.namedtuple的形式)来跟踪运行量。之前使用了三个 变量fm、sm和t。 (#1757)
重大变更
操作符属性
has_unitary_generator,is_composable_rotation,is_self_inverse,is_symmetric_over_all_wires, 和is_symmetric_over_control_wires已从基类中移除作为属性。它们已被替换为存储在ops/qubit/attributes.py中具有相似属性的操作名称的集合。 (#1763)已删除
qml.inv函数,应使用qml.adjoint代替。 (#1778)在
batch_transform中使用的expand_fn的输入签名现在 必须 与提供的transform_fn有相同的签名,反之亦然。 (#1721)default.qubit.torch设备会自动判断计算是否应该在 CPU 或 GPU 上运行,并且不再接受torch_device参数。 (#1705)当使用Autograd时,实用函数
(#1638)qml.math.requires_grad现在仅在NumPy数组上设置了requires_grad=True属性时返回True。之前,除非明确设置了requires_grad=False,此函数会对所有 NumPy数组和Python浮点数返回True。操作
qml.Interferometer已被重命名为qml.InterferometerUnitary以便于与模板qml.templates.Interferometer区分。 (#1714)已将
qml.transforms.invisible装饰器替换为qml.tape.stop_recording,它既可以作为上下文管理器,也可以作为装饰器,以确保在 QNode 或量子带上下文中包含的逻辑是不可记录或不可排队的。模板
SingleExcitationUnitary和DoubleExcitationUnitary分别已被重命名为FermionicSingleExcitation和FermionicDoubleExcitation。(#1822)
不推荐使用的功能
Allowing cost functions to be differentiated using
qml.gradorqml.jacobianwithout explicitly marking parameters as trainable is being deprecated, and will be removed in an upcoming release. Please specify therequires_gradattribute for every argument, or specifyargnumwhen usingqml.gradorqml.jacobian. (#1773)The following raises a warning in v0.19.0 and will raise an error in an upcoming release:
import pennylane as qml dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def test(x): qml.RY(x, wires=[0]) return qml.expval(qml.PauliZ(0)) par = 0.3 qml.grad(test)(par)
Preferred approaches include specifying the
requires_gradattribute:import pennylane as qml from pennylane import numpy as np dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def test(x): qml.RY(x, wires=[0]) return qml.expval(qml.PauliZ(0)) par = np.array(0.3, requires_grad=True) qml.grad(test)(par)
Or specifying the
argnumargument when usingqml.gradorqml.jacobian:import pennylane as qml dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def test(x): qml.RY(x, wires=[0]) return qml.expval(qml.PauliZ(0)) par = 0.3 qml.grad(test, argnum=0)(par)

来自 beta 文件夹的
default.tensor设备不再维护,已被弃用。它将在未来的版本中移除。 (#1851)关键字参数
qml.metric_tensor和qml.QNGOptimizerdiag_approx已被弃用。 可以使用更细粒度的approx关键字来控制近似,approx="block-diag"(默认值)恢复旧的行为。 (#1721) (#1834)现在
template装饰器已被弃用,并将发出警告信息,在v0.20.0版本中移除。它已从不同的PennyLane函数中移除。 (#1794) (#1808)函数
qml.fourier.spectrum已被重命名为qml.fourier.circuit_spectrum,以清楚地区分新的qnode_spectrum函数和这个函数。qml.fourier.spectrum现在是circuit_spectrum的别名,但标记为将被弃用,并将在不久后移除。 (#1681)包含用于生成模板随机参数张量的函数的
init模块被标记为不推荐使用,并将在下一个版本周期中移除。相反,模板的shape方法可以用来获取所需的张量形状,然后可以手动生成。(#1689)要生成参数张量,可以使用
np.random.normal和np.random.uniform函数(就像在init模块中一样)。考虑到 NumPy v1.21 版本这些函数的默认参数,init模块使用了一些非默认选项:所有生成正态分布参数的函数都使用
np.random.normal,并传递scale=0.1;生成均匀分布参数的大多数函数(某些 CVQNN 初始化器除外)使用了
np.random.uniform,通过传递high=2*math.pi;使用的
cvqnn_layers_r_uniform,cvqnn_layers_a_uniform,cvqnn_layers_kappa_uniform函数通过传递np.random.uniformhigh=0.1。
这个
(#1746)QNode.draw方法已被弃用,并将在即将发布的版本中移除。请改用qml.draw转换。该
QNode.metric_tensor方法已被弃用,将在即将发布的版本中移除。请改用qml.metric_tensor变换。 (#1638)这个
qml.AmplitudeEmbedding模板的pad参数已被移除。 它已被重命名为pad_with参数。 (#1805)
错误修复
修复了一个错误,该错误导致
qml.math.dot在@tf.function自动生成模式下无法工作。 (#1842)修复了一个错误,在某些罕见情况下,
Tape.get_parameters返回的参数未排序。 (#1836)修复了
qml.circuit_drawer.MPLDrawer中measure的箭头宽度的一个错误。 (#1823)辅助函数
qml.math.block_diag和qml.math.scatter_element_add现在在使用 Autograd 时完全可微分。之前只有块对角线的索引条目可以被微分,而相对于qml.math.scatter_element_add的第二个参数的导数 被分发到 NumPy,而不是 Autograd。 (#1816) (#1818)修复了一个错误,使得设备的原始拍摄向量信息得以保存,这样在上下文管理器之外设备保持不变。(#1792)
修改
qml.math.take以兼容 JAX 0.2.24 中发布的破坏性更改,并确保 PennyLane 支持此 JAX 版本。 (#1769)修复了一个错误,导致GPU无法与
qml.qnn.TorchLayer一起使用。 (#1705)修复一个错误,设备对不同的可观察返回类型缓存相同的结果。 (#1719)
修复了默认电路绘图程序的一个错误,即在任何线路上的测量数量少于测量数量时会引发一个
KeyError。 (#1702)修复了一个 bug,之前在使用
QubitStateVector时无法在QNode上使用jax.jit。 (#1683)如果没有给定拍摄配置变量,设备套件测试现在可以成功执行。(#1641)
修复了一个 bug,在尝试计算具有不规则输出的 QNode 的方差时,
qml.gradients.param_shift转换会引发错误。(#1646)修复了
default.mixed中的一个错误,以确保返回的概率始终非负。 (#1680)修复了一个错误,梯度变换无法应用于包含经典处理的 QNodes。 (#1699)
修复了一个错误,在该错误中,当所有电路参数都需要回退时,参数移位方法未正确使用回退梯度函数。
(#1782)
文档
在导航栏中添加一个链接到 https://pennylane.ai/qml/demonstrations。 (#1624)
通过将
wires添加到ansatz参数的签名中,纠正了ExpvalCost的文档字符串。 (#1715)使用
qchem.molecular_hamiltonian函数更新了文档字符串示例。 (#1724)更新“梯度和训练”快速入门指南,以提供关于梯度变换的信息。 (#1751)
所有的
(#1750)qnode.draw()实例已更新为使用变换qml.draw(qnode)。在QNode文档中添加
jax接口。 (#1755)将所有与量子化学相关的模板重新组织在一个公共标题下
Quantum Chemistry templates。 (#1822)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Catalina Albornoz, Juan Miguel Arrazola, Utkarsh Azad, Akash Narayanan B, Sam Banning, Thomas Bromley, Jack Ceroni, Alain Delgado, Olivia Di Matteo, Andrew Gardhouse, Anthony Hayes, Theodor Isacsson, David Ittah, Josh Izaac, Soran Jahangiri, Nathan Killoran, Christina Lee, Guillermo Alonso-Linaje, Romain Moyard, Lee James O’Riordan, Carrie-Anne Rubidge, Maria Schuld, Rishabh Singh, Jay Soni, Ingrid Strandberg, Antal Száva, Teresa Tamayo-Mendoza, Rodrigo Vargas, Cody Wang, David Wierichs, Moritz Willmann.
- orphan
版本 0.18.0¶
自上次发布以来的新特性
PennyLane 现在配备了 lightning.qubit
The C++-based lightning.qubit device is now included with installations of PennyLane. (#1663)
The
lightning.qubitdevice is a fast state-vector simulator equipped with the efficient adjoint method for differentiating quantum circuits, check out the plugin release notes for more details! The device can be accessed in the following way:import pennylane as qml wires = 3 layers = 2 dev = qml.device("lightning.qubit", wires=wires) @qml.qnode(dev, diff_method="adjoint") def circuit(weights): qml.templates.StronglyEntanglingLayers(weights, wires=range(wires)) return qml.expval(qml.PauliZ(0)) weights = qml.init.strong_ent_layers_normal(layers, wires, seed=1967)
Evaluating circuits and their gradients on the device can be achieved using the standard approach:
>>> print(f"Circuit evaluated: {circuit(weights)}") Circuit evaluated: 0.9801286266677633 >>> print(f"Circuit gradient:\n{qml.grad(circuit)(weights)}") Circuit gradient: [[[-9.35301749e-17 -1.63051504e-01 -4.14810501e-04] [-7.88816484e-17 -1.50136528e-04 -1.77922957e-04] [-5.20670796e-17 -3.92874550e-02 8.14523075e-05]] [[-1.14472273e-04 3.85963953e-02 -9.39190132e-18] [-5.76791765e-05 -9.78478343e-02 0.00000000e+00] [ 0.00000000e+00 0.00000000e+00 0.00000000e+00]]]
The adjoint method operates after a forward pass by iteratively applying inverse gates to scan backwards through the circuit. The method is already available in PennyLane’s
default.qubitdevice, but the version provided bylightning.qubitintegrates with the C++ backend and is more performant, as shown in the plot below:
使用PyTorch支持原生反向传播
The built-in PennyLane simulator
default.qubitnow supports backpropogation with PyTorch. (#1360) (#1598)As a result,
default.qubitcan now use end-to-end classical backpropagation as a means to compute gradients. End-to-end backpropagation can be faster than the parameter-shift rule for computing quantum gradients when the number of parameters to be optimized is large. This is now the default differentiation method when usingdefault.qubitwith PyTorch.Using this method, the created QNode is a ‘white-box’ that is tightly integrated with your PyTorch computation, including TorchScript and GPU support.
x = torch.tensor(0.43316321, dtype=torch.float64, requires_grad=True) y = torch.tensor(0.2162158, dtype=torch.float64, requires_grad=True) z = torch.tensor(0.75110998, dtype=torch.float64, requires_grad=True) p = torch.tensor([x, y, z], requires_grad=True) dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, interface="torch", diff_method="backprop") def circuit(x): qml.Rot(x[0], x[1], x[2], wires=0) return qml.expval(qml.PauliZ(0)) res = circuit(p) res.backward()
>>> res = circuit(p) >>> res.backward() >>> print(p.grad) tensor([-9.1798e-17, -2.1454e-01, -1.0511e-16], dtype=torch.float64)
改进的量子优化方法
现在
RotosolveOptimizer可以处理一般的参数化电路,不再局限于单量子比特Pauli旋转。 (#1489)这包括:
由相同参数控制的门层,
参数化门的受控变体,以及
哈密顿时间演化。
请注意,门生成器的特征值谱需要被了解,以使用
RotosolveOptimizer进行一般门操作,并且这是产生等间隔频率所必需的。有关详细信息,请参见 Vidal and Theis, 2018 和 Wierichs, Izaac, Wang, Lin 2021。考虑一个包含保利旋转门、受控保利旋转和单参数保利旋转层的电路:
dev = qml.device('default.qubit', wires=3, shots=None) @qml.qnode(dev) def cost_function(rot_param, layer_par, crot_param): for i, par in enumerate(rot_param): qml.RX(par, wires=i) for w in dev.wires: qml.RX(layer_par, wires=w) for i, par in enumerate(crot_param): qml.CRY(par, wires=[i, (i+1) % 3]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1) @ qml.PauliZ(2))
这个代价函数对于前
RX旋转角度有一个频率, 对于依赖于layer_par的RX门层有三个频率,以及对于每个CRY门参数有两个频率。然后可以使用Rotosolve来最小化cost_function:# Initial parameters init_param = [ np.array([0.3, 0.2, 0.67], requires_grad=True), np.array(1.1, requires_grad=True), np.array([-0.2, 0.1, -2.5], requires_grad=True), ] # Numbers of frequencies per parameter num_freqs = [[1, 1, 1], 3, [2, 2, 2]] opt = qml.RotosolveOptimizer() param = init_param.copy()
此外,Rotosolve 子步骤的优化技术可以通过
optimizer和optimizer_kwargs关键字参数选择,最小化的中间一元重构的成本可以通过full_output读取,包括在完整的 Rotosolve 步骤 之后 的成本:for step in range(3): param, cost, sub_cost = opt.step_and_cost( cost_function, *param, num_freqs=num_freqs, full_output=True, optimizer="brute", ) print(f"Cost before step: {cost}") print(f"Minimization substeps: {np.round(sub_cost, 6)}")
Cost before step: 0.042008210392535605 Minimization substeps: [-0.230905 -0.863336 -0.980072 -0.980072 -1. -1. -1. ] Cost before step: -0.999999999068121 Minimization substeps: [-1. -1. -1. -1. -1. -1. -1.] Cost before step: -1.0 Minimization substeps: [-1. -1. -1. -1. -1. -1. -1.]
有关用法的详细信息,请参阅优化器的文档字符串。
更快、可训练的哈密顿模拟
哈密顿量现在可以根据其系数进行训练。 (#1483)
from pennylane import numpy as np dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(coeffs, param): qml.RX(param, wires=0) qml.RY(param, wires=0) return qml.expval( qml.Hamiltonian(coeffs, [qml.PauliX(0), qml.PauliZ(0)], simplify=True) ) coeffs = np.array([-0.05, 0.17]) param = np.array(1.7) grad_fn = qml.grad(circuit)
>>> grad_fn(coeffs, param) (array([-0.12777055, 0.0166009 ]), array(0.0917819))
此外,已添加哈密顿量系数的梯度公式。这使得在本地支持哈密顿量的设备上计算这些系数的参数位移梯度成为可能。 (#1551)
哈密顿量现在在
default.qubit设备上原生支持如果shots=None。这使得某些情况下VQE工作流程更快。 (#1551) (#1596)
哈密顿量现在可以存储分组信息,这些信息可以被设备访问,以加速哈密顿量期望值的计算。 (#1515)
obs = [qml.PauliX(0), qml.PauliX(1), qml.PauliZ(0)] coeffs = np.array([1., 2., 3.]) H = qml.Hamiltonian(coeffs, obs, grouping_type='qwc')
使用其他的
grouping_type进行初始化,而不是None会存储制作可交换可观测量及其系数所需的索引。>>> H.grouping_indices [[0, 1], [2]]
创建多电路量子变换和自定义梯度规则
现在可以使用新的
@qml.gradients.gradient_transform装饰器在批量电路变换上创建自定义梯度变换。 (#1589)量子梯度变换是
qml.batch_transform的特例。支持的梯度变换必须具有以下形式:
@qml.gradients.gradient_transform def my_custom_gradient(tape, argnum=None, **kwargs): ... return gradient_tapes, processing_fn
在
qml.gradients模块中提供了各种内置量子梯度变换,包括qml.gradients.param_shift。 一旦定义,量子梯度变换可以直接应用于QNodes:>>> @qml.qnode(dev) ... def circuit(x): ... qml.RX(x, wires=0) ... qml.CNOT(wires=[0, 1]) ... return qml.expval(qml.PauliZ(0)) >>> circuit(0.3) tensor(0.95533649, requires_grad=True) >>> qml.gradients.param_shift(circuit)(0.5) array([[-0.47942554]])
量子梯度变换是完全可微分的,允许访问高阶导数:
>>> qml.grad(qml.gradients.param_shift(circuit))(0.5) tensor(-0.87758256, requires_grad=True)
有关更多细节,请参阅量子梯度变换页面。
The ability to define batch transforms has been added via the new
@qml.batch_transformdecorator. (#1493)A batch transform is a transform that takes a single tape or QNode as input, and executes multiple tapes or QNodes independently. The results may then be post-processed before being returned.
For example, consider the following batch transform:
@qml.batch_transform def my_transform(tape, a, b): """Generates two tapes, one with all RX replaced with RY, and the other with all RX replaced with RZ.""" tape1 = qml.tape.JacobianTape() tape2 = qml.tape.JacobianTape() # loop through all operations on the input tape for op in tape.operations + tape.measurements: if op.name == "RX": with tape1: qml.RY(a * qml.math.abs(op.parameters[0]), wires=op.wires) with tape2: qml.RZ(b * qml.math.abs(op.parameters[0]), wires=op.wires) else: for t in [tape1, tape2]: with t: qml.apply(op) def processing_fn(results): return qml.math.sum(qml.math.stack(results)) return [tape1, tape2], processing_fn
We can transform a QNode directly using decorator syntax:
>>> @my_transform(0.65, 2.5) ... @qml.qnode(dev) ... def circuit(x): ... qml.Hadamard(wires=0) ... qml.RX(x, wires=0) ... return qml.expval(qml.PauliX(0)) >>> print(circuit(-0.5)) 1.2629730888100839
Batch tape transforms are fully differentiable:
>>> gradient = qml.grad(circuit)(-0.5) >>> print(gradient) 2.5800122591960153
Batch transforms can also be applied to existing QNodes,
>>> new_qnode = my_transform(existing_qnode, *transform_weights) >>> new_qnode(weights)
or to tapes (in which case, the processed tapes and classical post-processing functions are returned):
>>> tapes, fn = my_transform(tape, 0.65, 2.5) >>> from pennylane.interfaces.batch import execute >>> dev = qml.device("default.qubit", wires=1) >>> res = execute(tapes, dev, interface="autograd", gradient_fn=qml.gradients.param_shift) 1.2629730888100839
向
qml.gradients包添加了向量-雅可比乘积变换。 (#1494)新变换包括:
qml.gradients.vjpqml.gradients.batch_vjp
Support for differentiable execution of batches of circuits has been added, via the beta
pennylane.interfaces.batchmodule. (#1501) (#1508) (#1542) (#1549) (#1608) (#1618) (#1637)For now, this is a low-level feature, and will be integrated into the QNode in a future release. For example:
from pennylane.interfaces.batch import execute def cost_fn(x): with qml.tape.JacobianTape() as tape1: qml.RX(x[0], wires=[0]) qml.RY(x[1], wires=[1]) qml.CNOT(wires=[0, 1]) qml.var(qml.PauliZ(0) @ qml.PauliX(1)) with qml.tape.JacobianTape() as tape2: qml.RX(x[0], wires=0) qml.RY(x[0], wires=1) qml.CNOT(wires=[0, 1]) qml.probs(wires=1) result = execute( [tape1, tape2], dev, gradient_fn=qml.gradients.param_shift, interface="autograd" ) return result[0] + result[1][0, 0] res = qml.grad(cost_fn)(params)
改进
新增了一个操作
qml.SISWAP,是qml.ISWAP操作的平方根。 (#1563)函数
frobenius_inner_product已被移至qml.math模块,并且现在可以使用所有自动微分框架进行微分。警告通知用户,仅支持为
QubitDevice基础设备指定镜头列表。 (#1659)该
qml.circuit_drawer.MPLDrawer类提供了使用Matplotlib进行手动电路绘图的功能。虽然尚未与自动电路绘图集成,但该类提供了自定义和控制的能力。 (#1484)from pennylane.circuit_drawer import MPLDrawer drawer = MPLDrawer(n_wires=3, n_layers=3) drawer.label([r"$|\Psi\rangle$", r"$|\theta\rangle$", "aux"]) drawer.box_gate(layer=0, wires=[0, 1, 2], text="Entangling Layers", text_options={'rotation': 'vertical'}) drawer.box_gate(layer=1, wires=[0, 1], text="U(θ)") drawer.CNOT(layer=2, wires=[1, 2]) drawer.measure(layer=3, wires=2) drawer.fig.suptitle('My Circuit', fontsize='xx-large')

最慢的测试,超过1.5秒,现在标记为
slow,可以在本地执行测试时选择或取消选择。 (#1633)设备测试套件已扩展以覆盖更多的量子比特操作和可观察量。
(#1510)现在,
MultiControlledX类继承自Operation而不是ControlledQubitUnitary,这使得MultiControlledX门成为一个非参数化门。 (#1557)现在,
utils.sparse_hamiltonian函数可以处理非整数的线材标签,并且它会对从多量子比特操作创建的可观察量的边缘情况抛出错误。(#1550)为
qml.templates.subroutines.GroverOperator添加了矩阵属性(#1553)现在,
tape.to_openqasm()方法有一个measure_all参数,用于指定序列化的 OpenQASM 脚本是否包含对所有量子比特的计算基测量,还是仅包含胶卷中指定的量子比特。(#1559)当没有参数传递给可观察对象时,现在会引发错误,以提醒未提供线圈。
(#1547)现在
group_observables变换是可微分的。 (#1483)例如:
import jax from jax import numpy as jnp coeffs = jnp.array([1., 2., 3.]) obs = [PauliX(wires=0), PauliX(wires=1), PauliZ(wires=1)] def group(coeffs, select=None): _, grouped_coeffs = qml.grouping.group_observables(obs, coeffs) # 在这个例子中,grouped_coeffs 是一个包含两个 jax 张量的列表 # [Array([1., 2.], dtype=float32), Array([3.], dtype=float32)] return grouped_coeffs[select] jac_fn = jax.jacobian(group)
>>> jac_fn(coeffs, select=0) [[1. 0. 0.] [0. 1. 0.]] >>> jac_fn(coeffs, select=1) [[0., 0., 1.]]
该磁带不再验证所有可观测量在注释队列中是否有所有者。 (#1505)
这允许在磁带上下文中操作可观测量。一个例子是
expval(Tensor(qml.PauliX(0), qml.Identity(1)).prune()),它使得expval成为修剪后张量及其组成可观测量的所有者,但将原始张量留在队列中而没有所有者。现在支持在
default.mixed设备上使用qml.ResetError。 (#1541)QNode.diff_method现在将反映从diff_method="best"中选择的方法。 (#1568)QNodes 现在支持
(#1585)diff_method=None。其工作原理与interface=None相同。这些 QNodes 接受浮点数、整数、列表和 NumPy 数组,并返回 NumPy 输出,但无法进行微分。QNodes 现在包括验证功能,以警告用户如果提供的关键字参数不是已识别的参数之一。(#1591)
重大变更
QFT操作已被移动,现在可以通过pennylane.templates.QFT访问。 (#1548)在之前的版本中,使用
shots=None结合qml.sample已被弃用。 从此版本开始,当采样时设置shots=None也会对default.qubit.jax引发错误。 (#1629)当用户在有限拍次的设备上请求反向传播时,会在QNode创建过程中引发错误。 (#1588)
类
qml.Interferometer已弃用,将在发布周期后重命名为qml.InterferometerUnitary。 (#1546)除了Rotosolve和Rotoselect之外,所有优化器现在都有一个公共属性
stepsize。临时向后兼容已添加,以支持在一个版本周期内使用_stepsize。update_stepsize方法已被弃用。 (#1625)
错误修复
修复了与射击向量和
Device基类相关的错误。 (#1666)修复了一个错误,即
@jax.jit在使用qml.QubitStateVector的QNode上会失败。 (#1649)修复了与单量子比特
zyz_decomposition边界情况相关的一个错误,当仅存在非对角元素时。(#1643)MottonenStatepreparation现在可以使用单个线缆标签运行,而不是在列表中。 (#1620)修正了CY门的电路表示,以便在调用电路绘制器时与CNOT和CZ门对齐。 (#1504)
如果没有安装Dask和CVXPY依赖的包,则跳过相应的测试。 (#1617)
现在
qml.layer模板可以与 tensorflow 变量一起使用。 (#1615)从可能的操作中移除
(#1600)QFT在default.qubit和default.mixed中。修复了在使用TensorFlow计算哈密顿量期望值时的一个 bug。 (#1586)
修复了计算具有哈密顿算子的电路规范时的一个错误。 (#1533)
文档
操作
qml.Identity被放置在量子比特可观察量和连续变量可观察量部分。 (#1576)更新了
qml.grouping、qml.kernels和qml.qaoa模块的文档,首先展示函数列表,然后是模块的技术细节。(#1581)将量子比特操作重新分类为新类别和现有类别,以便更容易找到每个操作的代码。 (#1566)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Vishnu Ajith, Akash Narayanan B, Thomas Bromley, Olivia Di Matteo, Sahaj Dhamija, Tanya Garg, Anthony Hayes, Theodor Isacsson, Josh Izaac, Prateek Jain, Ankit Khandelwal, Nathan Killoran, Christina Lee, Ian McLean, Johannes Jakob Meyer, Romain Moyard, Lee James O’Riordan, Esteban Payares, Pratul Saini, Maria Schuld, Arshpreet Singh, Jay Soni, Ingrid Strandberg, Antal Száva, Slimane Thabet, David Wierichs, Vincent Wong。
- orphan
版本 0.17.0¶
自上次发布以来的新特性
电路优化
PennyLane 现在可以使用顶级变换
qml.compile进行量子电路优化。compile变换允许你将一系列的带和量子函数变换链接在一起,形成自定义的电路优化管道。(#1475)例如,考虑以下装饰的量子函数:
dev = qml.device('default.qubit', wires=[0, 1, 2]) @qml.qnode(dev) @qml.compile() def qfunc(x, y, z): qml.Hadamard(wires=0) qml.Hadamard(wires=1) qml.Hadamard(wires=2) qml.RZ(z, wires=2) qml.CNOT(wires=[2, 1]) qml.RX(z, wires=0) qml.CNOT(wires=[1, 0]) qml.RX(x, wires=0) qml.CNOT(wires=[1, 0]) qml.RZ(-z, wires=2) qml.RX(y, wires=2) qml.PauliY(wires=2) qml.CZ(wires=[1, 2]) return qml.expval(qml.PauliZ(wires=0))
qml.compile的默认行为是应用一系列三个变换:commute_controlled、cancel_inverses,然后是merge_rotations。>>> print(qml.draw(qfunc)(0.2, 0.3, 0.4)) 0: ──H───RX(0.6)──────────────────┤ ⟨Z⟩ 1: ──H──╭X────────────────────╭C──┤ 2: ──H──╰C────────RX(0.3)──Y──╰Z──┤
qml.compile变换是灵活的,并接受自定义的管道、量子函数变换(您甚至可以编写自己的!)。例如,如果我们只想将单量子比特门推过受控门并取消相邻的逆操作,我们可以这样做:from pennylane.transforms import commute_controlled, cancel_inverses pipeline = [commute_controlled, cancel_inverses] @qml.qnode(dev) @qml.compile(pipeline=pipeline) def qfunc(x, y, z): qml.Hadamard(wires=0) qml.Hadamard(wires=1) qml.Hadamard(wires=2) qml.RZ(z, wires=2) qml.CNOT(wires=[2, 1]) qml.RX(z, wires=0) qml.CNOT(wires=[1, 0]) qml.RX(x, wires=0) qml.CNOT(wires=[1, 0]) qml.RZ(-z, wires=2) qml.RX(y, wires=2) qml.PauliY(wires=2) qml.CZ(wires=[1, 2]) return qml.expval(qml.PauliZ(wires=0))
>>> print(qml.draw(qfunc)(0.2, 0.3, 0.4)) 0: ──H───RX(0.4)──RX(0.2)────────────────────────────┤ ⟨Z⟩ 1: ──H──╭X───────────────────────────────────────╭C──┤ 2: ──H──╰C────────RZ(0.4)──RZ(-0.4)──RX(0.3)──Y──╰Z──┤
以下编译转换已被添加,并且可用于独立使用或在一个
qml.compile管道中使用:commute_controlled: 通过受控操作推动通勤单量子比特门。 (#1464)cancel_inverses: 移除相邻的相消操作对。 (#1455)merge_rotations: 将相邻的同类型旋转门合并为单个门,包括受控旋转。 (#1455)single_qubit_fusion:作用于量子函数中的所有单量子位操作序列,并将每个序列转换为一个单一的Rot门。 (#1458)
有关
qml.compile和可用的编译转换的更多详细信息,请参见 编译文档。
QNodes 更加强大
现在可以通过
qml.sample()直接从 QNodes 返回来自底层设备的计算基样本。 (#1441)dev = qml.device("default.qubit", wires=3, shots=5) @qml.qnode(dev) def circuit_1(): qml.Hadamard(wires=0) qml.Hadamard(wires=1) return qml.sample() @qml.qnode(dev) def circuit_2(): qml.Hadamard(wires=0) qml.Hadamard(wires=1) return qml.sample(wires=[0,2]) # 未提供可观测量并指定了电线
>>> print(circuit_1()) [[1, 0, 0], [1, 1, 0], [1, 0, 0], [0, 0, 0], [0, 1, 0]] >>> print(circuit_2()) [[1, 0], [1, 0], [1, 0], [0, 0], [0, 0]] >>> print(qml.draw(circuit_2)()) 0: ──H──╭┤ 样本[基] 1: ──H──│┤ 2: ─────╰┤ 样本[基]
新的
qml.apply函数可以用于将可能已经在其他地方实例化的操作添加到 QNode 和其他排队上下文中: (#1433)op = qml.RX(0.4, wires=0) dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.RY(x, wires=0) qml.apply(op) return qml.expval(qml.PauliZ(0))
>>> print(qml.draw(circuit)(0.6)) 0: ──RY(0.6)──RX(0.4)──┤ ⟨Z⟩
之前实例化的测量值也可以应用于 QNodes。
设备资源跟踪器
The new Device Tracker capabilities allows for flexible and versatile tracking of executions, even inside parameter-shift gradients. This functionality will improve the ease of monitoring large batches and remote jobs. (#1355)
dev = qml.device('default.qubit', wires=1, shots=100) @qml.qnode(dev, diff_method="parameter-shift") def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0)) x = np.array(0.1) with qml.Tracker(circuit.device) as tracker: qml.grad(circuit)(x)
>>> tracker.totals {'executions': 3, 'shots': 300, 'batches': 1, 'batch_len': 2} >>> tracker.history {'executions': [1, 1, 1], 'shots': [100, 100, 100], 'batches': [1], 'batch_len': [2]} >>> tracker.latest {'batches': 1, 'batch_len': 2}
Users can also provide a custom function to the
callbackkeyword that gets called each time the information is updated. This functionality allows users to monitor remote jobs or large parameter-shift batches.>>> def shots_info(totals, history, latest): ... print("Total shots: ", totals['shots']) >>> with qml.Tracker(circuit.device, callback=shots_info) as tracker: ... qml.grad(circuit)(0.1) Total shots: 100 Total shots: 200 Total shots: 300 Total shots: 300
容器化支持
增加了对使用Docker构建PennyLane的支持,包括所有接口(TensorFlow、Torch和Jax),以及设备插件和QChem,支持GPU和CPU。
(#1391)使用Docker和
make的构建过程要求从GitHub克隆或下载仓库源代码。请访问详细描述以获取扩展选项列表。
改进的哈密顿模拟
添加了稀疏哈密顿算子的功能,并支持使用
default.qubit计算其期望值。 (#1398)例如,下面的 QNode 返回稀疏哈密顿的期望值:
dev = qml.device("default.qubit", wires=2) @qml.qnode(dev, diff_method="parameter-shift") def circuit(param, H): qml.PauliX(0) qml.SingleExcitation(param, wires=[0, 1]) return qml.expval(qml.SparseHamiltonian(H, [0, 1]))
我们可以执行这个 QNode,传入一个稀疏单位矩阵:
>>> print(circuit([0.5], scipy.sparse.eye(4).tocoo())) 0.9999999999999999
稀疏哈密顿的期望值是直接计算的,这导致执行速度提高了几个数量级。请注意,当可观察量是稀疏哈密顿时,“parameter-shift”是当前支持的唯一微分方法。
现在可以通过将哈密顿量作为可观测量直观地设置VQE问题。 (#1474)
dev = qml.device("default.qubit", wires=2) H = qml.Hamiltonian([1., 2., 3.], [qml.PauliZ(0), qml.PauliY(0), qml.PauliZ(1)]) w = qml.init.strong_ent_layers_uniform(1, 2, seed=1967) @qml.qnode(dev) def circuit(w): qml.templates.StronglyEntanglingLayers(w, wires=range(2)) return qml.expval(H)
>>> print(circuit(w)) -1.5133943637878295 >>> print(qml.grad(circuit)(w)) [[[-8.32667268e-17 1.39122955e+00 -9.12462052e-02] [ 1.02348685e-16 -7.77143238e-01 -1.74708049e-01]]]
请注意,其他测量类型如
var(H)或sample(H),以及多个期望值如expval(H1), expval(H2)不支持。新增功能以计算
qml.Hamiltonian对象的稀疏矩阵表示。 (#1394)
新的梯度模块
新增了一个梯度模块
qml.gradients,提供可微分的量子梯度变换。 (#1476) (#1479) (#1486)可用的量子梯度变换包括:
qml.gradients.finite_diffqml.gradients.param_shiftqml.gradients.param_shift_cv
例如,
>>> params = np.array([0.3,0.4,0.5], requires_grad=True) >>> with qml.tape.JacobianTape() as tape: ... qml.RX(params[0], wires=0) ... qml.RY(params[1], wires=0) ... qml.RX(params[2], wires=0) ... qml.expval(qml.PauliZ(0)) ... qml.var(qml.PauliZ(0)) >>> tape.trainable_params = {0, 1, 2} >>> gradient_tapes, fn = qml.gradients.finite_diff(tape) >>> res = dev.batch_execute(gradient_tapes) >>> fn(res) array([[-0.69688381, -0.32648317, -0.68120105], [ 0.8788057 , 0.41171179, 0.85902895]])
还有更多新的操作和模板
添加了 Grover 扩散算子模板。 (#1442)
例如,如果我们有一个将“全为1”状态标记为负号的oracle:
n_wires = 3 wires = list(range(n_wires)) def oracle(): qml.Hadamard(wires[-1]) qml.Toffoli(wires=wires) qml.Hadamard(wires[-1])
我们可以执行 Grover’s Search Algorithm:
dev = qml.device('default.qubit', wires=wires) @qml.qnode(dev) def GroverSearch(num_iterations=1): for wire in wires: qml.Hadamard(wire) for _ in range(num_iterations): oracle() qml.templates.GroverOperator(wires=wires) return qml.probs(wires)
我们可以看到这个电路以较高的概率产生标记状态:
>>> GroverSearch(num_iterations=1) tensor([0.03125, 0.03125, 0.03125, 0.03125, 0.03125, 0.03125, 0.03125, 0.78125], requires_grad=True) >>> GroverSearch(num_iterations=2) tensor([0.0078125, 0.0078125, 0.0078125, 0.0078125, 0.0078125, 0.0078125, 0.0078125, 0.9453125], requires_grad=True)
A decomposition has been added to
QubitUnitarythat makes the single-qubit case fully differentiable in all interfaces. Furthermore, a quantum function transform,unitary_to_rot(), has been added to decompose all single-qubit instances ofQubitUnitaryin a quantum circuit. (#1427)Instances of
QubitUnitarymay now be decomposed directly toRotoperations, orRZoperations if the input matrix is diagonal. For example, let>>> U = np.array([ [-0.28829348-0.78829734j, 0.30364367+0.45085995j], [ 0.53396245-0.10177564j, 0.76279558-0.35024096j] ])
Then, we can compute the decomposition as:
>>> qml.QubitUnitary.decomposition(U, wires=0) [Rot(-0.24209530281458358, 1.1493817777199102, 1.733058145303424, wires=[0])]
We can also apply the transform directly to a quantum function, and compute the gradients of parameters used to construct the unitary matrices.
def qfunc_with_qubit_unitary(angles): z, x = angles[0], angles[1] Z_mat = np.array([[np.exp(-1j * z / 2), 0.0], [0.0, np.exp(1j * z / 2)]]) c = np.cos(x / 2) s = np.sin(x / 2) * 1j X_mat = np.array([[c, -s], [-s, c]]) qml.Hadamard(wires="a") qml.QubitUnitary(Z_mat, wires="a") qml.QubitUnitary(X_mat, wires="b") qml.CNOT(wires=["b", "a"]) return qml.expval(qml.PauliX(wires="a"))
>>> dev = qml.device("default.qubit", wires=["a", "b"]) >>> transformed_qfunc = qml.transforms.unitary_to_rot(qfunc_with_qubit_unitary) >>> transformed_qnode = qml.QNode(transformed_qfunc, dev) >>> input = np.array([0.3, 0.4], requires_grad=True) >>> transformed_qnode(input) tensor(0.95533649, requires_grad=True) >>> qml.grad(transformed_qnode)(input) array([-0.29552021, 0. ])
已添加 Ising YY 门功能。 (#1358)
改进
该带不再验证所有可观测量在注释队列中是否有所有者。 (#1505)
这允许在带上下文中操作可观测量。一个示例是
expval(Tensor(qml.PauliX(0), qml.Identity(1)).prune()),这使得expval成为修剪后的张量及其组成可观测量的所有者,但将原始张量留在队列中而没有所有者。QNGOptimizer的step和step_and_cost方法现在接受一个自定义的grad_fn关键字参数,用于梯度计算。(#1487)default.qubit.jax使用的精度现在与由下述代码指示的浮点精度相匹配来自 jax.config 导入 config config.读取('jax_enable_x64')
其中
True代表float64/complex128,而False代表float32/complex64。 (#1485)该
./pennylane/ops/qubit.py文件分为六个独立文件的文件夹。 (#1467)已更改为在
qml.Hamiltonian对象的字符串表示中使用逗号作为多量子比特项的分隔符。 (#1465)根据NumPy从1.20版本开始的弃用,改为使用
np.object_而不是np.object。 (#1466)在
default.gaussian内部更改协方差矩阵和均值向量的顺序。 (#1331)为模板添加了
id属性。 (#1438)用于与框架无关的张量操作的
qml.math模块,现在有两个新函数可用: (#1490)qml.math.get_trainable_indices(sequence_of_tensors): 返回输入序列中可训练张量的索引。qml.math.unwrap(sequence_of_tensors): 将张量样式对象的序列展开为NumPy数组。
此外,
qml.math.requires_grad的行为得到了改善,以便在Autograd和JAX反向传递期间正确确定可训练性。添加了一种新的录音带方法,
tape.unwrap()。该方法是一个上下文管理器;在上下文内部,录音带的参数被解包为NumPy数组和浮点数,并设置可训练参数的索引。 (#1491)这些更改是临时的,在退出上下文时会恢复。
>>> with tf.GradientTape(): ... with qml.tape.QuantumTape() as tape: ... qml.RX(tf.Variable(0.1), wires=0) ... qml.RY(tf.constant(0.2), wires=0) ... qml.RZ(tf.Variable(0.3), wires=0) ... with tape.unwrap(): ... print("可训练参数:", tape.trainable_params) ... print("解包参数:", tape.get_parameters()) 可训练参数: {0, 2} 解包参数: [0.1, 0.3] >>> print("原始参数:", tape.get_parameters()) 原始参数: [
, ] 此外,
qml.tape.Unwrap是一个上下文管理器,可以解包多个录音带:>>> with qml.tape.Unwrap(tape1, tape2):
重大变更
移除了已弃用的 tape 方法
get_resources和get_depth,因为它们已被specstape 属性取代。 (#1522)指定
shots=None与qml.sample之前已被弃用。 从这一版本开始,当采样时设置shots=None将 引发错误。 (#1522)现有的
pennylane.collections.apply函数不再通过qml.apply访问,需要直接从collections包中导入。 (#1358)
错误修复
修复了一个在
qml.adjoint和qml.ctrl中的错误,即在QNode或QuantumTape外部的操作的伴随无法获得。(#1532)修复了一个在
GradientDescentOptimizer和NesterovMomentumOptimizer中的错误,其中一个具有可训练参数和非可训练参数的成本函数引发了错误。(#1495)修复了一个错误,即在使用
qml.adjoint函数时,qml.QFT的伴随没有正确计算。 (#1451)修复了操作
IsingYY在Autograd、Jax和Tensorflow中的可微性。 (#1425)修复了在
torch接口中一个阻止在GPU上计算梯度的错误。 (#1426)量子函数变换现在保留测量结果的格式,因此单次测量返回单个值,而不是一个只有单个元素的数组。(#1434)
修复了参数偏移Hessian实现中的一个错误,这导致对执行后处理的向量值QNode的成本函数返回了不正确的Hessian。
(#1436)修复了
QubitUnitary初始化中的一个错误,其中矩阵的大小没有与导线的数量进行检查。 (#1439)
文档
贡献者
此版本包含来自(按字母顺序排列)的贡献:
胡安·米格尔·阿拉佐拉,奥莉维亚·迪·马特奥,安东尼·海斯,西奥多尔·伊萨克森,乔希·伊扎克,索兰·贾汉吉里,内森·基洛兰,阿尔什普里特·辛格·康古拉,莱昂哈德·昆齐克,克里斯蒂娜·李,罗曼·莫亚尔,李·詹姆斯·奥里尔丹,阿希什·帕尼格拉希,纳胡姆·萨,玛丽亚·施尔德,杰伊·索尼,安塔尔·萨瓦,大卫·维里希斯。
- orphan
版本 0.16.0¶
对量子核的一级支持
新的
qml.kernels模块提供了 处理量子核 的基本功能,以及减轻采样误差和设备噪声的后处理方法:(#1102)num_wires = 6 wires = range(num_wires) dev = qml.device('default.qubit', wires=wires) @qml.qnode(dev) def kernel_circuit(x1, x2): qml.templates.AngleEmbedding(x1, wires=wires) qml.adjoint(qml.templates.AngleEmbedding)(x2, wires=wires) return qml.probs(wires) kernel = lambda x1, x2: kernel_circuit(x1, x2)[0] X_train = np.random.random((10, 6)) X_test = np.random.random((5, 6)) # 创建对称的平方核矩阵(用于训练) K = qml.kernels.square_kernel_matrix(X_train, kernel) # 计算测试数据和训练数据之间的核。 K_test = qml.kernels.kernel_matrix(X_train, X_test, kernel) K1 = qml.kernels.mitigate_depolarizing_noise(K, num_wires, method='single')
提取量子电路的傅里叶表示
PennyLane 现在有一个
fourier模块,里面有一个 不断增长的方法库,帮助研究由量子电路实现的函数的傅里叶表示。傅里叶表示可以用于检查和表征量子电路的表达能力。(#1160) (#1378)例如,可以绘制傅里叶级数系数的分布,如下所示:

与保利群无缝协作的支持
Added functionality for constructing and manipulating the Pauli group (#1181).
The function
qml.grouping.pauli_groupprovides a generator to easily loop over the group, or construct and store it in its entirety. For example, we can construct the single-qubit Pauli group like so:>>> from pennylane.grouping import pauli_group >>> pauli_group_1_qubit = list(pauli_group(1)) >>> pauli_group_1_qubit [Identity(wires=[0]), PauliZ(wires=[0]), PauliX(wires=[0]), PauliY(wires=[0])]
We can multiply together its members at the level of Pauli words using the
pauli_multandpauli_multi_with_phasefunctions. This can be done on arbitrarily-labeled wires as well, by defining a wire map.>>> from pennylane.grouping import pauli_group, pauli_mult >>> wire_map = {'a' : 0, 'b' : 1, 'c' : 2} >>> pg = list(pauli_group(3, wire_map=wire_map)) >>> pg[3] PauliZ(wires=['b']) @ PauliZ(wires=['c']) >>> pg[55] PauliY(wires=['a']) @ PauliY(wires=['b']) @ PauliZ(wires=['c']) >>> pauli_mult(pg[3], pg[55], wire_map=wire_map) PauliY(wires=['a']) @ PauliX(wires=['b'])
Functions for conversion of Pauli observables to strings (and back), are included.
>>> from pennylane.grouping import pauli_word_to_string, string_to_pauli_word >>> pauli_word_to_string(pg[55], wire_map=wire_map) 'YYZ' >>> string_to_pauli_word('ZXY', wire_map=wire_map) PauliZ(wires=['a']) @ PauliX(wires=['b']) @ PauliY(wires=['c'])
Calculation of the matrix representation for arbitrary Paulis and wire maps is now also supported.
>>> from pennylane.grouping import pauli_word_to_matrix >>> wire_map = {'a' : 0, 'b' : 1} >>> pauli_word = qml.PauliZ('b') # corresponds to Pauli 'IZ' >>> pauli_word_to_matrix(pauli_word, wire_map=wire_map) array([[ 1., 0., 0., 0.], [ 0., -1., 0., -0.], [ 0., 0., 1., 0.], [ 0., -0., 0., -1.]])
新的变换
The
qml.specsQNode transform creates a function that returns specifications or details about the QNode, including depth, number of gates, and number of gradient executions required. (#1245)For example:
dev = qml.device('default.qubit', wires=4) @qml.qnode(dev, diff_method='parameter-shift') def circuit(x, y): qml.RX(x[0], wires=0) qml.Toffoli(wires=(0, 1, 2)) qml.CRY(x[1], wires=(0, 1)) qml.Rot(x[2], x[3], y, wires=0) return qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliX(1))
We can now use the
qml.specstransform to generate a function that returns details and resource information:>>> x = np.array([0.05, 0.1, 0.2, 0.3], requires_grad=True) >>> y = np.array(0.4, requires_grad=False) >>> specs_func = qml.specs(circuit) >>> specs_func(x, y) {'gate_sizes': defaultdict(int, {1: 2, 3: 1, 2: 1}), 'gate_types': defaultdict(int, {'RX': 1, 'Toffoli': 1, 'CRY': 1, 'Rot': 1}), 'num_operations': 4, 'num_observables': 2, 'num_diagonalizing_gates': 1, 'num_used_wires': 3, 'depth': 4, 'num_trainable_params': 4, 'num_parameter_shift_executions': 11, 'num_device_wires': 4, 'device_name': 'default.qubit', 'diff_method': 'parameter-shift'}
The tape methods
get_resourcesandget_depthare superseded byspecsand will be deprecated after one release cycle.Adds a decorator
@qml.qfunc_transformto easily create a transformation that modifies the behaviour of a quantum function. (#1315)For example, consider the following transform, which scales the parameter of all
RXgates by \(x \rightarrow \sin(a) \sqrt{x}\), and the parameters of allRYgates by \(y \rightarrow \cos(a * b) y\):@qml.qfunc_transform def my_transform(tape, a, b): for op in tape.operations + tape.measurements: if op.name == "RX": x = op.parameters[0] qml.RX(qml.math.sin(a) * qml.math.sqrt(x), wires=op.wires) elif op.name == "RY": y = op.parameters[0] qml.RX(qml.math.cos(a * b) * y, wires=op.wires) else: op.queue()
We can now apply this transform to any quantum function:
dev = qml.device("default.qubit", wires=2) def ansatz(x): qml.Hadamard(wires=0) qml.RX(x[0], wires=0) qml.RY(x[1], wires=1) qml.CNOT(wires=[0, 1]) @qml.qnode(dev) def circuit(params, transform_weights): qml.RX(0.1, wires=0) # apply the transform to the ansatz my_transform(*transform_weights)(ansatz)(params) return qml.expval(qml.PauliZ(1))
We can print this QNode to show that the qfunc transform is taking place:
>>> x = np.array([0.5, 0.3], requires_grad=True) >>> transform_weights = np.array([0.1, 0.6], requires_grad=True) >>> print(qml.draw(circuit)(x, transform_weights)) 0: ──RX(0.1)────H──RX(0.0706)──╭C──┤ 1: ──RX(0.299)─────────────────╰X──┤ ⟨Z⟩
Evaluating the QNode, as well as the derivative, with respect to the gate parameter and the transform weights:
>>> circuit(x, transform_weights) tensor(0.00672829, requires_grad=True) >>> qml.grad(circuit)(x, transform_weights) (array([ 0.00671711, -0.00207359]), array([6.69695008e-02, 3.73694364e-06]))
添加一个
hamiltonian_expand录音带变换。这需要一个以qml.expval(H)结束的录音带,其中H是一个哈密顿量,然后将其映射到一组可以执行并传递给后处理函数以获得期望值的录音带。 (#1142)示例用法:
H = qml.PauliZ(0) + 3 * qml.PauliZ(0) @ qml.PauliX(1) with qml.tape.QuantumTape() as tape: qml.Hadamard(wires=1) qml.expval(H) tapes, fn = qml.transforms.hamiltonian_expand(tape)
我们现在可以评估变换后的录音带,并应用后处理函数:
>>> dev = qml.device("default.qubit", wires=3) >>> res = dev.batch_execute(tapes) >>> fn(res) 3.999999999999999
The
quantum_monte_carlotransform has been added, allowing an input circuit to be transformed into the full quantum Monte Carlo algorithm. (#1316)Suppose we want to measure the expectation value of the sine squared function according to a standard normal distribution. We can calculate the expectation value analytically as
0.432332, but we can also estimate using the quantum Monte Carlo algorithm. The first step is to discretize the problem:from scipy.stats import norm m = 5 M = 2 ** m xmax = np.pi # bound to region [-pi, pi] xs = np.linspace(-xmax, xmax, M) probs = np.array([norm().pdf(x) for x in xs]) probs /= np.sum(probs) func = lambda i: np.sin(xs[i]) ** 2 r_rotations = np.array([2 * np.arcsin(np.sqrt(func(i))) for i in range(M)])
The
quantum_monte_carlotransform can then be used:from pennylane.templates.state_preparations.mottonen import ( _uniform_rotation_dagger as r_unitary, ) n = 6 N = 2 ** n a_wires = range(m) wires = range(m + 1) target_wire = m estimation_wires = range(m + 1, n + m + 1) dev = qml.device("default.qubit", wires=(n + m + 1)) def fn(): qml.templates.MottonenStatePreparation(np.sqrt(probs), wires=a_wires) r_unitary(qml.RY, r_rotations, control_wires=a_wires[::-1], target_wire=target_wire) @qml.qnode(dev) def qmc(): qml.quantum_monte_carlo(fn, wires, target_wire, estimation_wires)() return qml.probs(estimation_wires) phase_estimated = np.argmax(qmc()[:int(N / 2)]) / N
The estimated value can be retrieved using:
>>> (1 - np.cos(np.pi * phase_estimated)) / 2 0.42663476277231915
The resources required to perform the quantum Monte Carlo algorithm can also be inspected using the
specstransform.
扩展QAOA模块
已添加支持解决最大权重循环问题的功能到
qaoa模块。 (#1207) (#1209) (#1251) (#1213) (#1220) (#1214) (#1283) (#1297) (#1396) (#1403)该
max_weight_cycle函数返回适当的成本和混合哈密顿量:>>> a = np.random.random((3, 3)) >>> np.fill_diagonal(a, 0) >>> g = nx.DiGraph(a) # 创建一个随机有向图 >>> cost, mixer, mapping = qml.qaoa.max_weight_cycle(g) >>> print(cost) (-0.9775906842165344) [Z2] + (-0.9027248603361988) [Z3] + (-0.8722207409852838) [Z0] + (-0.6426184210832898) [Z5] + (-0.2832594164291379) [Z1] + (-0.0778133996933755) [Z4] >>> print(mapping) {0: (0, 1), 1: (0, 2), 2: (1, 0), 3: (1, 2), 4: (2, 0), 5: (2, 1)}
额外的功能可以在 qml.qaoa.cycle 模块中找到。
扩展操作和模板
添加了计算
qml.Hamiltonian对象稀疏矩阵表示的功能。 (#1394)coeffs = [1, -0.45] obs = [qml.PauliZ(0) @ qml.PauliZ(1), qml.PauliY(0) @ qml.PauliZ(1)] H = qml.Hamiltonian(coeffs, obs) H_sparse = qml.utils.sparse_hamiltonian(H)
结果矩阵是以scipy坐标列表(COO)格式表示的稀疏矩阵:
>>> H_sparse <4x4 sparse matrix of type '
' with 8 stored elements in COOrdinate format>稀疏矩阵可以转换为数组如下:
>>> H_sparse.toarray() array([[ 1.+0.j , 0.+0.j , 0.+0.45j, 0.+0.j ], [ 0.+0.j , -1.+0.j , 0.+0.j , 0.-0.45j], [ 0.-0.45j, 0.+0.j , -1.+0.j , 0.+0.j ], [ 0.+0.j , 0.+0.45j, 0.+0.j , 1.+0.j ]])
Adds the new template
AllSinglesDoublesto prepare quantum states of molecules using theSingleExcitationandDoubleExcitationoperations. The new template reduces significantly the number of operations and the depth of the quantum circuit with respect to the traditional UCCSD unitary. (#1383)For example, consider the case of two particles and four qubits. First, we define the Hartree-Fock initial state and generate all possible single and double excitations.
import pennylane as qml from pennylane import numpy as np electrons = 2 qubits = 4 hf_state = qml.qchem.hf_state(electrons, qubits) singles, doubles = qml.qchem.excitations(electrons, qubits)
Now we can use the template
AllSinglesDoublesto define the quantum circuit,from pennylane.templates import AllSinglesDoubles wires = range(qubits) dev = qml.device('default.qubit', wires=wires) @qml.qnode(dev) def circuit(weights, hf_state, singles, doubles): AllSinglesDoubles(weights, wires, hf_state, singles, doubles) return qml.expval(qml.PauliZ(0)) params = np.random.normal(0, np.pi, len(singles) + len(doubles))
and execute it:
>>> circuit(params, hf_state, singles=singles, doubles=doubles) tensor(-0.73772194, requires_grad=True)
为基础算术添加
QubitCarry和QubitSum操作。 (#1169)以下示例添加两个1位数字,返回一个2位答案:
dev = qml.device('default.qubit', wires = 4) a = 0 b = 1 @qml.qnode(dev) def circuit(): qml.BasisState(np.array([a, b]), wires=[1, 2]) qml.QubitCarry(wires=[0, 1, 2, 3]) qml.CNOT(wires=[1, 2]) qml.QubitSum(wires=[0, 1, 2]) return qml.probs(wires=[3, 2]) probs = circuit() bitstrings = tuple(itertools.product([0, 1], repeat = 2)) indx = np.argwhere(probs == 1).flatten()[0] output = bitstrings[indx]
>>> print(output) (0, 1)
添加了
qml.Projector可观察量,该可观察量在所有继承自QubitDevice类的设备上均可用。 (#1356) (#1368)使用
qml.Projector,我们可以定义在计算期望值时使用的基态投影算符。例如,考虑一个准备贝尔态的电路:dev = qml.device("default.qubit", wires=2) @qml.qnode(dev) def circuit(basis_state): qml.Hadamard(wires=[0]) qml.CNOT(wires=[0, 1]) return qml.expval(qml.Projector(basis_state, wires=[0, 1]))
然后我们可以指定
|00>基态来构造|00><00|投影算符并计算期望值:>>> basis_state = [0, 0] >>> circuit(basis_state) tensor(0.5, requires_grad=True)
正如预期,当指定
|11>基态时,我们得到了类似的结果:>>> basis_state = [1, 1] >>> circuit(basis_state) tensor(0.5, requires_grad=True)
以下新的操作已被添加:
改进
The
argnumkeyword argument can now be specified for a QNode to define a subset of trainable parameters used to estimate the Jacobian. (#1371)For example, consider two trainable parameters and a quantum function:
dev = qml.device("default.qubit", wires=2) x = np.array(0.543, requires_grad=True) y = np.array(-0.654, requires_grad=True) def circuit(x,y): qml.RX(x, wires=[0]) qml.RY(y, wires=[1]) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliX(1))
When computing the gradient of the QNode, we can specify the trainable parameters to consider by passing the
argnumkeyword argument:>>> qnode1 = qml.QNode(circuit, dev, diff_method="parameter-shift", argnum=[0,1]) >>> print(qml.grad(qnode1)(x,y)) (array(0.31434679), array(0.67949903))
Specifying a proper subset of the trainable parameters will estimate the Jacobian:
>>> qnode2 = qml.QNode(circuit, dev, diff_method="parameter-shift", argnum=[0]) >>> print(qml.grad(qnode2)(x,y)) (array(0.31434679), array(0.))
Allows creating differentiable observables that return custom objects such that the observable is supported by devices. (1291)
As an example, first we define
NewObservableclass:from pennylane.devices import DefaultQubit class NewObservable(qml.operation.Observable): """NewObservable""" num_wires = qml.operation.AnyWires num_params = 0 par_domain = None def diagonalizing_gates(self): """Diagonalizing gates""" return []
Once we have this new observable class, we define a
SpecialObjectclass that can be used to encode data in an observable and a new device that supports our new observable and returns aSpecialObjectas the expectation value (the code is shortened for brevity, the extended example can be found as a test in the previously referenced pull request):class SpecialObject: def __init__(self, val): self.val = val def __mul__(self, other): new = SpecialObject(self.val) new *= other return new ... class DeviceSupportingNewObservable(DefaultQubit): name = "Device supporting NewObservable" short_name = "default.qubit.newobservable" observables = DefaultQubit.observables.union({"NewObservable"}) def expval(self, observable, **kwargs): if self.shots is None and isinstance(observable, NewObservable): val = super().expval(qml.PauliZ(wires=0), **kwargs) return SpecialObject(val) return super().expval(observable, **kwargs)
At this point, we can create a device that will support the differentiation of a
NewObservableobject:dev = DeviceSupportingNewObservable(wires=1, shots=None) @qml.qnode(dev, diff_method="parameter-shift") def qnode(x): qml.RY(x, wires=0) return qml.expval(NewObservable(wires=0))
We can then compute the jacobian of this object:
>>> result = qml.jacobian(qnode)(0.2) >>> print(result) <__main__.SpecialObject object at 0x7fd2c54721f0> >>> print(result.item().val) -0.19866933079506116
PennyLane NumPy 现在包括了 random 模块的
Generator对象,这是生成随机数的推荐方式。这允许使用本地种子而非全局种子进行随机数生成。 (#1267)from pennylane import numpy as np rng = np.random.default_rng() random_mat1 = rng.random((3,2)) random_mat2 = rng.standard_normal(3, requires_grad=False)
伴随雅可比微分的性能显著提高,因为该方法现在重用了在正向传播中计算的状态。通过在QNode创建时传递
adjoint_cache=False可以关闭此功能以节省内存,适用于Torch和TensorFlow接口。(#1341)该
Operator(以及通过继承而来的Operation和Observable类及其子类)现在拥有一个id属性,可以在电路中标记一个算符,例如通过磁带变换在磁带上识别它。 (#1377)已添加关于基本门的分解:
qml.CSWAP(#1306)qml.SWAP(#1329)qml.SingleExcitation(#1303)qml.SingleExcitationPlus和qml.SingleExcitationMinus(#1278)qml.DoubleExcitation(#1303)qml.Toffoli(#1320)qml.MultiControlledX. (#1287) 当在三个或更多线路上控制时,需要一个辅助 工作线的寄存器来支持分解。ctrl_wires = [f"c{i}" for i in range(5)] work_wires = [f"w{i}" for i in range(3)] target_wires = ["t0"] all_wires = ctrl_wires + work_wires + target_wires dev = qml.device("default.qubit", wires=all_wires) with qml.tape.QuantumTape() as tape: qml.MultiControlledX(control_wires=ctrl_wires, wires=target_wires, work_wires=work_wires)
>>> tape = tape.expand(depth=1) >>> print(tape.draw(wire_order=qml.wires.Wires(all_wires))) c0: ──────────────╭C──────────────────────╭C──────────┤ c1: ──────────────├C──────────────────────├C──────────┤ c2: ──────────╭C──│───╭C──────────────╭C──│───╭C──────┤ c3: ──────╭C──│───│───│───╭C──────╭C──│───│───│───╭C──┤ c4: ──╭C──│───│───│───│───│───╭C──│───│───│───│───│───┤ w0: ──│───│───├C──╰X──├C──│───│───│───├C──╰X──├C──│───┤ w1: ──│───├C──╰X──────╰X──├C──│───├C──╰X──────╰X──├C──┤ w2: ──├C──╰X──────────────╰X──├C──╰X──────────────╰X──┤ t0: ──╰X──────────────────────╰X──────────────────────┤
添加了
qml.CPhase作为现有qml.ControlledPhaseShift操作的别名。 (#1319).现在,
Device类在映射导线时使用缓存。 (#1270)
(#1270)Wires类现在使用缓存来计算其hash。为Toffoli添加了自定义门应用于
default.qubit。 (#1249)为噪声通道参数增加了验证。无效的噪声参数现在会引发一个
ValueError。 (#1357)设备测试套件现在提供了测试用例,通过比较期望值来检查门。(#1212)
PennyLane的测试用例现在使用
black -l 100进行代码格式化。 (#1222)PennyLane的
qchem包和测试现在使用black -l 100进行了代码格式化。 (#1311)
重大变更
函数
qml.inv()现在已被弃用,建议使用更通用的qml.adjoint()。 (#1325)移除对Python 3.6的支持,并增加对Python 3.9的支持。 (#1228)
录制方法
get_resources和get_depth被specs取代,并将在一个发布周期后被弃用。 (#1245)在使用
qml.sample()测量的设备上,shots=None继续引发警告,因为该功能已完全弃用,并将在一个发布周期后引发错误。 (#1079) (#1196)
错误修复
QNodes 现在在交互式环境中或打印时显示可读信息。 (#1359).
修复了一个与
qml.math.cast相关的错误,其中MottonenStatePreparation操作期待的是浮点类型而不是双精度类型。 (#1400)修复了一个错误,其中
qml.ControlledQubitUnitary的副本无法正常工作,因为它没有所有必要的信息。 (#1411)当在有限试验的设备上指定或调用伴随或可逆微分时发出警告。 (#1406)
修正了
IsingXX和IsingZZ的可微性,以支持Autograd、Jax和Tensorflow。 (#1390)修复了一个错误,多个相同的哈密顿项在使用
optimize=True和ExpvalCost时会产生不同的结果。 (#1405)修复了一个错误,之前在 QNode 调用中临时更改 shots 时
shots=None未被重置,例如在circuit(0.1, shots=3)中。(#1392)修复了在参数为
float32时使用diff_method="finite-diff"和order=1引发的浮点错误。(#1381)修复了一个错误,在该错误中
qml.ctrl无法转换没有定义控制和没有定义分解的门。 (#1376)复制
JacobianTape现在也正确地复制jacobian_options属性。这修复了一个错误,使得 JAX 接口支持伴随微分。 (#1349)修复在单个导线上绘制包含多个测量的QNode的问题。 (#1353)
修复绘制没有操作的 QNodes 问题。 (#1354)
修复了
ControlledPhaseShift操作分解中不正确的线圈。 (#1338)修复了使用 QNode 的
Permute操作的测试,因此由于 QNode 膜扩展和显式膜扩展调用,膏体被扩展了两次而不是一次。 (#1318)。防止共享线路的哈密顿量相乘。 (#1273)
修复了一个错误,导致自定义范围序列无法传递给
StronglyEntanglingLayers模板。(#1332)修复了一个错误,
qml.sum()和qml.dot()不支持 JAX 接口。 (#1380)
文档
现在
QubitParamShiftTape类的文档字符串中的数学内容正确呈现。 (#1402)修正了
qml.StronglyEntanglingLayers文档中的拼写错误。 (#1367)修正了TensorFlow接口文档中的拼写错误 (#1312)
修正了
qml.DoubleExcitation文档中数学表达式的拼写错误。 (#1278)从
qml.QNode文档字符串中移除不支持的None选项。 (#1271)更新了
qml.PolyXP的文档字符串,以引用内部使用的新位置。 (#1262)从文档中删除已弃用的设备参数
analytic的出现。 (#1261)更新了 PyTorch 和 TensorFlow 接口介绍。 (#1333)
更新量子化学快速入门,以反映对
qchem模块的最新更改。 (#1227)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Marius Aglitoiu, Vishnu Ajith, Juan Miguel Arrazola, Thomas Bromley, Jack Ceroni, Alaric Cheng, Miruna Daian, Olivia Di Matteo, Tanya Garg, Christian Gogolin, Alain Delgado Gran, Diego Guala, Anthony Hayes, Ryan Hill, Theodor Isacsson, Josh Izaac, Soran Jahangiri, Pavan Jayasinha, Nathan Killoran, Christina Lee, Ryan Levy, Alberto Maldonado, Johannes Jakob Meyer, Romain Moyard, Ashish Panigrahi, Nahum Sá, Maria Schuld, Brian Shi, Antal Száva, David Wierichs, Vincent Wong.
- orphan
版本 0.15.1¶
错误修复
修复了参数移位海森矩阵中的两个错误。 (#1260)
修复了一个错误:在Autograd接口中存在未使用的参数会导致反向传播时出现索引错误。
参数位移Hessian目前只支持双项参数位移规则,因此如果要求对任何不支持的门(如受控旋转门)进行微分,则会引发错误。
一个导致
qml.adjoint()和qml.inv()无法与模板一起使用的错误已被修复。 (#1243)PennyLane中的弃用警告实例已更改为
UserWarning,以考虑最近对Python警告过滤方式的更改在PEP565中。(#1211)
文档
更新了
GaussianState操作的参数顺序,以匹配PennyLane-SF插件使用的方式。 (#1255)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
托马斯·布朗利,奥利维亚·迪·马泰奥,迭戈·古阿拉,安东尼·海斯,瑞安·希尔,乔什·艾扎克,克里斯蒂娜·李,玛丽亚·舒尔德,安塔尔·萨瓦。
- orphan
发布 0.15.0¶
自上次发布以来的新特性
更好且更灵活的拍摄控制
Adds a new optimizer
qml.ShotAdaptiveOptimizer, a gradient-descent optimizer where the shot rate is adaptively calculated using the variances of the parameter-shift gradient. (#1139)By keeping a running average of the parameter-shift gradient and the variance of the parameter-shift gradient, this optimizer frugally distributes a shot budget across the partial derivatives of each parameter.
In addition, if computing the expectation value of a Hamiltonian, weighted random sampling can be used to further distribute the shot budget across the local terms from which the Hamiltonian is constructed.
This optimizer is based on both the iCANS1 and Rosalin shot-adaptive optimizers.
Once constructed, the cost function can be passed directly to the optimizer’s
stepmethod. The attributeopt.total_shots_usedcan be used to track the number of shots per iteration.>>> coeffs = [2, 4, -1, 5, 2] >>> obs = [ ... qml.PauliX(1), ... qml.PauliZ(1), ... qml.PauliX(0) @ qml.PauliX(1), ... qml.PauliY(0) @ qml.PauliY(1), ... qml.PauliZ(0) @ qml.PauliZ(1) ... ] >>> H = qml.Hamiltonian(coeffs, obs) >>> dev = qml.device("default.qubit", wires=2, shots=100) >>> cost = qml.ExpvalCost(qml.templates.StronglyEntanglingLayers, H, dev) >>> params = qml.init.strong_ent_layers_uniform(n_layers=2, n_wires=2) >>> opt = qml.ShotAdaptiveOptimizer(min_shots=10) >>> for i in range(5): ... params = opt.step(cost, params) ... print(f"Step {i}: cost = {cost(params):.2f}, shots_used = {opt.total_shots_used}") Step 0: cost = -5.68, shots_used = 240 Step 1: cost = -2.98, shots_used = 336 Step 2: cost = -4.97, shots_used = 624 Step 3: cost = -5.53, shots_used = 1054 Step 4: cost = -6.50, shots_used = 1798
现在可以将拍摄批次指定为一个列表,从而允许通过一次 QNode 评估来粗粒度地进行测量统计。 (#1103)
>>> shots_list = [5, 10, 1000] >>> dev = qml.device("default.qubit", wires=2, shots=shots_list)
当 QNodes 在此设备上执行时,将提交 1015 次拍摄的单次执行。 然而,将返回三组测量统计;分别使用前 5 次拍摄、第二组 10 次拍摄和最后 1000 次拍摄。
例如,执行一个有两个输出的电路将导致形状为
(3, 2)的结果:>>> @qml.qnode(dev) ... def circuit(x): ... qml.RX(x, wires=0) ... qml.CNOT(wires=[0, 1]) ... return qml.expval(qml.PauliZ(0) @ qml.PauliX(1)), qml.expval(qml.PauliZ(0)) >>> circuit(0.5) [[0.33333333 1. ] [0.2 1. ] [0.012 0.868 ]]
该输出保持完全可微分。
现在可以在评估 QNode 时按每次调用指定射击次数。 (#1075).
为此,qnode 应该使用额外的
shots关键字参数进行调用:>>> dev = qml.device('default.qubit', wires=1, shots=10) # 默认值为 10 >>> @qml.qnode(dev) ... def circuit(a): ... qml.RX(a, wires=0) ... return qml.sample(qml.PauliZ(wires=0)) >>> circuit(0.8) [ 1 1 1 -1 -1 1 1 1 1 1] >>> circuit(0.8, shots=3) [ 1 1 1] >>> circuit(0.8) [ 1 1 1 -1 -1 1 1 1 1 1]
新的可微分量子变换
一个新模块可用, qml.transforms, 它包含可微分量子变换。这些函数作用于QNodes、量子函数、设备和磁带,能够在保持完全可微分的同时进行变换。
-
这个新方法允许用户应用任意序列操作的伴随。
def subroutine(wire): qml.RX(0.123, wires=wire) qml.RY(0.456, wires=wire) dev = qml.device('default.qubit', wires=1) @qml.qnode(dev) def circuit(): subroutine(0) qml.adjoint(subroutine)(0) return qml.expval(qml.PauliZ(0))
这将创建以下电路:
>>> print(qml.draw(circuit)()) 0: --RX(0.123)--RY(0.456)--RY(-0.456)--RX(-0.123)--|
直接应用于门也能按预期工作。
qml.adjoint(qml.RX)(0.123, wires=0) # 应用 RX(-0.123)
现在可以使用一个新的变换
qml.ctrl,它向子程序添加控制线。 (#1157)def my_ansatz(params): qml.RX(params[0], wires=0) qml.RZ(params[1], wires=1) # 创建一个新的操作,应用 `my_ansatz` # 由 "2" 号控制线控制。 my_ansatz2 = qml.ctrl(my_ansatz, control=2) @qml.qnode(dev) def circuit(params): my_ansatz2(params) return qml.state()
这相当于:
@qml.qnode(...) def circuit(params): qml.CRX(params[0], wires=[2, 0]) qml.CRZ(params[1], wires=[2, 1]) return qml.state()
已添加
qml.transforms.classical_jacobian变换。(#1186)此变换返回一个函数,用于提取 QNode 的经典部分的雅可比矩阵,从而允许提取 QNode 参数与量子门参数之间的经典依赖。
例如,给定以下 QNode:
>>> @qml.qnode(dev) ... def circuit(weights): ... qml.RX(weights[0], wires=0) ... qml.RY(weights[0], wires=1) ... qml.RZ(weights[2] ** 2, wires=1) ... return qml.expval(qml.PauliZ(0))
我们可以使用此变换提取输入 QNode 参数 \(w\) 与门参数 \(g\) 之间的关系\(f: \mathbb{R}^n \rightarrow\mathbb{R}^m\),对于给定的 QNode 参数值:
>>> cjac_fn = qml.transforms.classical_jacobian(circuit) >>> weights = np.array([1., 1., 1.], requires_grad=True) >>> cjac = cjac_fn(weights) >>> print(cjac) [[1. 0. 0.] [1. 0. 0.] [0. 0. 2.]]
返回的雅可比矩阵的行对应于门参数,列对应于 QNode 参数;也就是说,\(J_{ij} = \frac{\partial}{\partial g_i} f(w_j)\)。
更多操作和模板
添加了
SingleExcitation两量子比特操作,适用于量子化学应用。 (#1121)它可以用于在由状态 \(|01\rangle\) 和 \(|10\rangle\) 展开的子空间中执行 SO(2) 旋转。 例如,以下电路执行转换 \(|10\rangle \rightarrow \cos(\phi/2)|10\rangle - \sin(\phi/2)|01\rangle\):
dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(phi): qml.PauliX(wires=0) qml.SingleExcitation(phi, wires=[0, 1])
SingleExcitation操作在硬件上支持解析梯度,仅使用四个期望值计算,遵循来自 Kottmann et al. 的结果。添加了
DoubleExcitation四比特操作,它对于量子化学应用非常有用。 (#1123)它可以用于在由状态 \(|1100\rangle\) 和 \(|0011\rangle\) 生成的子空间中执行 SO(2) 旋转。 例如,以下电路执行转换 \(|1100\rangle\rightarrow \cos(\phi/2)|1100\rangle - \sin(\phi/2)|0011\rangle\):
dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(phi): qml.PauliX(wires=0) qml.PauliX(wires=1) qml.DoubleExcitation(phi, wires=[0, 1, 2, 3])
DoubleExcitation操作支持在硬件上使用仅四个期望值计算的解析梯度,遵循 Kottmann et al. 的结果。Added the
QuantumMonteCarlotemplate for performing quantum Monte Carlo estimation of an expectation value on simulator. (#1130)The following example shows how the expectation value of sine squared over a standard normal distribution can be approximated:
from scipy.stats import norm m = 5 M = 2 ** m n = 10 N = 2 ** n target_wires = range(m + 1) estimation_wires = range(m + 1, n + m + 1) xmax = np.pi # bound to region [-pi, pi] xs = np.linspace(-xmax, xmax, M) probs = np.array([norm().pdf(x) for x in xs]) probs /= np.sum(probs) func = lambda i: np.sin(xs[i]) ** 2 dev = qml.device("default.qubit", wires=(n + m + 1)) @qml.qnode(dev) def circuit(): qml.templates.QuantumMonteCarlo( probs, func, target_wires=target_wires, estimation_wires=estimation_wires, ) return qml.probs(estimation_wires) phase_estimated = np.argmax(circuit()[:int(N / 2)]) / N expectation_estimated = (1 - np.cos(np.pi * phase_estimated)) / 2
添加了
QuantumPhaseEstimation模板,用于对输入的单元矩阵进行量子相位估计。 (#1095)考虑对应于从
RX门的旋转的矩阵:>>> phase = 5 >>> target_wires = [0] >>> unitary = qml.RX(phase, wires=0).matrix
phase参数可以使用QuantumPhaseEstimation进行估计。例如,使用五个相位估计量子比特:n_estimation_wires = 5 estimation_wires = range(1, n_estimation_wires + 1) dev = qml.device("default.qubit", wires=n_estimation_wires + 1) @qml.qnode(dev) def circuit(): # 在单元矩阵的 |+> 本征态下开始 qml.Hadamard(wires=target_wires) QuantumPhaseEstimation( unitary, target_wires=target_wires, estimation_wires=estimation_wires, ) return qml.probs(estimation_wires) phase_estimated = np.argmax(circuit()) / 2 ** n_estimation_wires # 由于 RX 门的约定,需要重新缩放相位 phase_estimated = 4 * np.pi * (1 - phase)
添加了
ControlledPhaseShift门以及QFT操作用于应用量子傅里叶变换。 (#1064)@qml.qnode(dev) def circuit_qft(basis_state): qml.BasisState(basis_state, wires=range(3)) qml.templates.QFT(wires=range(3)) return qml.state()
添加了
ControlledQubitUnitary操作。这个操作 使得可以实现具有可变数量控制量子位的多量子位门。还可以使用control_values参数指定不同的控制量子位状态(也称为混合极性多控制操作)。 (#1069) (#1104)例如,我们可以使用以下代码创建一个多控制 T 门:
T = qml.T._matrix() qml.ControlledQubitUnitary(T, control_wires=[0, 1, 3], wires=2, control_values="110")
在这里,如果控制线
0和1处于状态1,并且控制线3处于状态0,则 T 门将应用于线2。如果没有传递值给control_values,则当所有控制线处于1状态时,该门将被应用。添加了
MultiControlledX用于多控制NOT门。 这是ControlledQubitUnitary的一个特例,它根据任意数量控制量子位的状态施加 Pauli X 门。 (#1104)
对硬件上高阶导数的支持
现在支持使用参数偏移微分法计算QNodes的二阶导数和Hessian,适用于所有机器学习接口。 (#1130) (#1129) (#1110)
Hessian是使用参数偏移规则计算的,可以在硬件和模拟器设备上进行评估。
dev = qml.device('default.qubit', wires=1) @qml.qnode(dev, diff_method="parameter-shift") def circuit(p): qml.RY(p[0], wires=0) qml.RX(p[1], wires=0) return qml.expval(qml.PauliZ(0)) x = np.array([1.0, 2.0], requires_grad=True)
>>> hessian_fn = qml.jacobian(qml.grad(circuit)) >>> hessian_fn(x) [[0.2248451 0.7651474] [0.7651474 0.2248451]]
添加了函数
finite_diff()用于计算有限差分 近似于任意可调用函数的梯度和二阶导数。 (#1090)这对于计算参数化的
pennylane.Hamiltonian可观测量对其参数的导数非常有用。例如,在量子化学模拟中,它可以用于评估 电子哈密顿量对核坐标的导数:
>>> def H(x): ... return qml.qchem.molecular_hamiltonian(['H', 'H'], x)[0] >>> x = np.array([0., 0., -0.66140414, 0., 0., 0.66140414]) >>> grad_fn = qml.finite_diff(H, N=1) >>> grad = grad_fn(x) >>> deriv2_fn = qml.finite_diff(H, N=2, idx=[0, 1]) >>> deriv2_fn(x)
JAX接口现在支持所有设备,包括硬件设备,通过参数移位微分方法。
例如,使用JAX接口与Cirq:
dev = qml.device('cirq.simulator', wires=1) @qml.qnode(dev, interface="jax", diff_method="parameter-shift") def circuit(x): qml.RX(x[1], wires=0) qml.Rot(x[0], x[1], x[2], wires=0) return qml.expval(qml.PauliZ(0)) weights = jnp.array([0.2, 0.5, 0.1]) print(circuit(weights))
目前,当使用参数移位微分方法时,仅支持返回单个期望值或方差。不允许返回多个期望值/方差,以及概率和状态。
改进
dev = qml.device("default.qubit", wires=2)
inputstate = [np.sqrt(0.2), np.sqrt(0.3), np.sqrt(0.4), np.sqrt(0.1)]
@qml.qnode(dev)
def circuit():
mottonen.MottonenStatePreparation(inputstate,wires=[0, 1])
return qml.expval(qml.PauliZ(0))
Previously returned:
>>> print(qml.draw(circuit)())
0: ──RY(1.57)──╭C─────────────╭C──╭C──╭C──┤ ⟨Z⟩
1: ──RY(1.35)──╰X──RY(0.422)──╰X──╰X──╰X──┤
In this release, it now returns:
>>> print(qml.draw(circuit)())
0: ──RY(1.57)──╭C─────────────╭C──┤ ⟨Z⟩
1: ──RY(1.35)──╰X──RY(0.422)──╰X──┤
模板现在是从
Operation继承的类,并在它们的expand()方法中定义 ansatz。这个变化不会影响用户界面。 (#1138) (#1156) (#1163) (#1192)为了方便,一些模板有一个新方法,可以返回可训练参数张量的预期形状,能够用于创建随机张量。
shape = qml.templates.BasicEntanglerLayers.shape(n_layers=2, n_wires=4) weights = np.random.random(shape) qml.templates.BasicEntanglerLayers(weights, wires=range(4))
QubitUnitary现在验证以确保输入矩阵是二维的。 (#1128)Pytorch 或 Keras 中的大多数层接受任意维度的输入,其中除了最后一维之外的每个维度(在层的实际权重函数作用于一维向量的情况下)都被广播。这现在也得到了 KerasLayer 和 TorchLayer 的支持。 (#1062).
示例用法:
dev = qml.device("default.qubit", wires=4) x = tf.ones((5, 4, 4)) @qml.qnode(dev) def layer(weights, inputs): qml.templates.AngleEmbedding(inputs, wires=range(4)) qml.templates.StronglyEntanglingLayers(weights, wires=range(4)) return [qml.expval(qml.PauliZ(i)) for i in range(4)] qlayer = qml.qnn.KerasLayer(layer, {"weights": (4, 4, 3)}, output_dim=4) out = qlayer(x)
输出张量具有以下形状:
>>> out.shape (5, 4, 4)
如果函数
(#1067)(#1081)qml.grad只有一个参数具有requires_grad属性设置为 True,则返回的梯度将是一个 NumPy 数组,而不是长度为 1 的元组。对如何
QubitDevice生成和后处理样本进行了改进,允许 QNode 测量统计在超过 32 个量子比特的设备上工作。(#1088)由于在QNode中添加了
density_matrix()作为返回类型,元组现在被output_dim参数在qnn.KerasLayer中支持。(#1070)提供了两个新的实用方法,用于处理量子磁带。(#1175)
qml.tape.get_active_tape()获取当前正在录制的 tape。tape.stop_recording()是一个上下文管理器,它临时停止当前正在记录的磁带录制额外的磁带或量子操作。
例如:
>>> with qml.tape.QuantumTape(): ... qml.RX(0, wires=0) ... current_tape = qml.tape.get_active_tape() ... with current_tape.stop_recording(): ... qml.RY(1.0, wires=1) ... qml.RZ(2, wires=1) >>> current_tape.operations [RX(0, wires=[0]), RZ(2, wires=[1])]
打印
qml.Hamiltonian对象时,项按导线数量排序,后跟系数。 (#981)将
qml.math.conj添加到 PennyLane 数学模块。 (#1143)这个新方法将对给定的张量-like 对象进行逐元素共轭, 正确地分派到所需的张量操作框架 以保持可微性。
>>> a = np.array([1.0 + 2.0j]) >>> qml.math.conj(a) array([1.0 - 2.0j])
四项参数偏移规则,在受控旋转操作中使用,已更新为使用根据 https://arxiv.org/abs/2104.05695 最小化方差的系数。 (#1206)
新增了一个变换
qml.transforms.invisible,使得转换 QNodes 更加容易。 (#1175)
重大变更
设备不再具有
analytic参数或属性。相反,shots是判断模拟器是否从有限数量的 shot 中估计返回值的真实来源,或者它是否返回解析结果 (shots=None)。(#1079) (#1196)dev_analytic = qml.device('default.qubit', wires=1, shots=None) dev_finite_shots = qml.device('default.qubit', wires=1, shots=1000) def circuit(): qml.Hadamard(wires=0) return qml.expval(qml.PauliZ(wires=0)) circuit_analytic = qml.QNode(circuit, dev_analytic) circuit_finite_shots = qml.QNode(circuit, dev_finite_shots)
具有
shots=None的设备返回确定性、精确的结果:>>> circuit_analytic() 0.0 >>> circuit_analytic() 0.0
具有
shots > 0的设备返回基于每次运行中的样本估计的随机结果:>>> circuit_finite_shots() -0.062 >>> circuit_finite_shots() 0.034
qml.sample()测量只能在明确设置 shot 数量的设备上使用。如果从一个名为
shots的量子函数创建 QNode,将会引发UserWarning, 警告用户这是一个保留的参数,用于在每次调用时更改抽样次数。 (#1075)对于继承自
QubitDevice的设备,方法expval、var、sample接受两个新的关键字参数 —shot_range和bin_size。(#1103)这些新参数允许仅对一部分设备样本进行统计。通过用一批试拍实例化设备,可以从主界面获得这种更细粒度的控制。
例如,考虑以下设备:
>>> dev = qml.device("my_device", shots=[5, (10, 3), 100])
该设备将使用135次实验执行QNodes,但测量统计将会在这135次实验中粗粒度处理:
所有测量统计数据将首先使用前5次实验进行计算——即
shots_range=[0, 5],bin_size=5。接下来,元组
(10, 3)表示 10 次射击,重复 3 次。这将使用shot_range=[5, 35],在大小为 10 的箱子中执行期望值 (bin_size=10)。最后,我们重复最后100次测量的统计数据,
shot_range=[35, 135],bin_size=100.
旧的PennyLane核心已被移除,包括以下模块: (#1100)
pennylane.variablespennylane.qnodes
作为此次变更的一部分,新的核心在Python模块中的位置已被移动:
移动
pennylane.tape.interfaces→pennylane.interfaces合并
pennylane.CircuitGraph和pennylane.TapeCircuitGraph→pennylane.CircuitGraph合并
pennylane.OperationRecorder和pennylane.TapeOperationRecorder→pennylane.tape.operation_recorder合并
pennylane.measure和pennylane.tape.measure→pennylane.measure合并
pennylane.operation和pennylane.tape.operation→pennylane.operation合并
pennylane._queuing和pennylane.tape.queuing→pennylane.queuing
这对导入位置没有影响。
此外,
所有带录音带模式的功能已被移除 (
qml.enable_tape(),qml.tape_mode_active()),所有胶带夹具已被删除,
专门针对非磁带模式的测试已被删除。
设备测试套件不再接受
analytic关键字。 (#1216)
错误修复
修复了一个错误,使用电路绘图工具与一个
ControlledQubitUnitary操作时会引发错误。 (#1174)修复了一个错误和一个测试,其中
QuantumTape.is_sampled属性没有被更新。 (#1126)修复了一个错误,
BasisEmbedding不接受所有位都是1或所有位都是0的输入。(#1114)如果使用非期望测量统计实例化
ExpvalCost类,将引发错误。 (#1106)修复了一个错误,该错误会重置QNode的微分方法 (#1117)
修复了一个错误,在尝试计算具有多个二阶可观察量的QNode的梯度时,二阶CV参数转换规则会出错。
修复了一个错误,即在扩展后重复使用Torch接口导致错误。
(#1223)采样在指定为列表的多个拍摄批次中正常工作。 (#1232)
文档
更新了开发指南的架构概述页面中使用的图表,使其不再提及变量。 (#1235)
修正了模板文档中的拼写错误。 (#1094)
升级了文档,使用 Sphinx 3.5.3 和新的 m2r2 包。(#1186)
添加了
flaky作为文档中运行测试的依赖项。 (#1113)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Shahnawaz Ahmed, Juan Miguel Arrazola, Thomas Bromley, Olivia Di Matteo, Alain Delgado Gran, Kyle Godbey, Diego Guala, Theodor Isacsson, Josh Izaac, Soran Jahangiri, Nathan Killoran, Christina Lee, Daniel Polatajko, Chase Roberts, Sankalp Sanand, Pritish Sehzpaul, Maria Schuld, Antal Száva, David Wierichs。
- orphan
发布 0.14.1¶
错误修复
修复了一个测试错误,之前如果没有安装JAX,则需要JAX的测试会失败。现在,如果无法导入JAX,则测试将被跳过。
(#1066)修复了一个错误,该错误使得在
default.qubit上无法使用反向传播对逆操作进行微分。 (#1072)QNode 增加了一个新的关键字参数,
max_expansion,用于确定当在设备上执行时内部电路应扩展的最大次数。此外,最大扩展次数的默认值已从 2 增加到 10,从而支持需要超过两个运算符分解的设备。修复了一个错误:使用非列表参数创建的
Hamiltonian对象在进行算术操作时会引发错误。 (#1082)修复了一个错误,即当没有系数或操作的
Hamiltonian对象与ExpvalCost一起使用时会返回错误结果。(#1082)
文档
将
ExpvalCost和Hamiltonian类的文档字符串中对generate_hamiltonian的提及更新为molecular_hamiltonian。 (#1077)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
托马斯·布罗姆利, 乔希·伊扎克, 安塔尔·萨瓦.
- orphan
发布 0.14.0¶
自上次发布以来的新特性
使用JAX进行量子机器学习
使用
default.qubit创建的 QNodes 现在支持 JAX 接口,允许使用 JAX 创建、微分和优化混合量子-经典模型。 (#947)这通过一个新的
default.qubit.jax设备在内部得到支持。该设备在 JAX 中端到端运行,这意味着它支持所有出色的 JAX 转换 (jax.vmap,jax.jit,jax.hessian等).下面是如何使用新的 JAX 接口的示例:
dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, interface="jax", diff_method="backprop") def circuit(x): qml.RX(x[1], wires=0) qml.Rot(x[0], x[1], x[2], wires=0) return qml.expval(qml.PauliZ(0)) weights = jnp.array([0.2, 0.5, 0.1]) grad_fn = jax.grad(circuit) print(grad_fn(weights))
目前,仅支持
diff_method="backprop",未来计划支持更多方法。
新的,更快的量子梯度方法
新增了一种用于模拟器的微分方法。
"adjoint"方法在前向传递后,通过迭代应用逆门来反向扫描电路。 (#1032)该方法类似于可逆方法,但时间开销较低,而内存开销相似。它遵循Jones and Gacon提供的方法。此方法仅与某些基于状态向量的设备兼容,例如
default.qubit。示例用法:
import pennylane as qml wires = 1 device = qml.device("default.qubit", wires=wires) @qml.qnode(device, diff_method="adjoint") def f(params): qml.RX(0.1, wires=0) qml.Rot(*params, wires=0) qml.RX(-0.3, wires=0) return qml.expval(qml.PauliZ(0)) params = [0.1, 0.2, 0.3] qml.grad(f)(params)
选择“最佳”微分方法的默认逻辑已被更改,以提高性能。(#1008)
如果量子设备提供自己的梯度,这现在是首选的微分方法。
如果量子设备本地支持经典反向传播,那么这现在是首选,而不是参数移位规则。
这将在使用
default.qubit时,在优化过程中显著提高速度,但在前向传递评估中会有轻微的惩罚。
对于插件开发者,下面的“改进”部分提供了更多细节。
PennyLane 现在支持噪声通道的解析量子梯度,除了它对幺正操作的现有支持。噪声通道
BitFlip、PhaseFlip和DepolarizingChannel都支持开箱即用的解析梯度。(#968)已经添加了一种使用二阶参数位移公式计算量子电路的Hessian的方法。 (#961)
以下示例展示了Hessian的计算:
n_wires = 5 weights = [2.73943676, 0.16289932, 3.4536312, 2.73521126, 2.6412488] dev = qml.device("default.qubit", wires=n_wires) with qml.tape.QubitParamShiftTape() as tape: for i in range(n_wires): qml.RX(weights[i], wires=i) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[2, 1]) qml.CNOT(wires=[3, 1]) qml.CNOT(wires=[4, 3]) qml.expval(qml.PauliZ(1)) print(tape.hessian(dev))
Hessian尚不支持通过经典机器学习接口,但将在未来的版本中添加。
更多操作和模板
新增了两个错误通道,
BitFlip和PhaseFlip。 (#954)它们可以与现有的错误通道以相同的方式使用:
dev = qml.device("default.mixed", wires=2) @qml.qnode(dev) def circuit(): qml.RX(0.3, wires=0) qml.RY(0.5, wires=1) qml.BitFlip(0.01, wires=0) qml.PhaseFlip(0.01, wires=1) return qml.expval(qml.PauliZ(0))
使用
Permute子例程对线路应用置换。 (#952)import pennylane as qml dev = qml.device('default.qubit', wires=5) @qml.qnode(dev) def apply_perm(): # 将线路 4 的内容发送到线路 0,将线路 2 的内容发送到线路 1,等等。 qml.templates.Permute([4, 2, 0, 1, 3], wires=dev.wires) return qml.expval(qml.PauliZ(0))
QNode 转换
The
qml.metric_tensorfunction transforms a QNode to produce the Fubini-Study metric tensor with full autodifferentiation support—even on hardware. (#1014)Consider the following QNode:
dev = qml.device("default.qubit", wires=3) @qml.qnode(dev, interface="autograd") def circuit(weights): # layer 1 qml.RX(weights[0, 0], wires=0) qml.RX(weights[0, 1], wires=1) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[1, 2]) # layer 2 qml.RZ(weights[1, 0], wires=0) qml.RZ(weights[1, 1], wires=2) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[1, 2]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)), qml.expval(qml.PauliY(2))
We can use the
metric_tensorfunction to generate a new function, that returns the metric tensor of this QNode:>>> met_fn = qml.metric_tensor(circuit) >>> weights = np.array([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]], requires_grad=True) >>> met_fn(weights) tensor([[0.25 , 0. , 0. , 0. ], [0. , 0.25 , 0. , 0. ], [0. , 0. , 0.0025, 0.0024], [0. , 0. , 0.0024, 0.0123]], requires_grad=True)
The returned metric tensor is also fully differentiable, in all interfaces. For example, differentiating the
(3, 2)element:>>> grad_fn = qml.grad(lambda x: met_fn(x)[3, 2]) >>> grad_fn(weights) array([[ 0.04867729, -0.00049502, 0. ], [ 0. , 0. , 0. ]])
Differentiation is also supported using Torch, Jax, and TensorFlow.
Adds the new function
qml.math.cov_matrix(). This function accepts a list of commuting observables, and the probability distribution in the shared observable eigenbasis after the application of an ansatz. It uses these to construct the covariance matrix in a framework independent manner, such that the output covariance matrix is autodifferentiable. (#1012)For example, consider the following ansatz and observable list:
obs_list = [qml.PauliX(0) @ qml.PauliZ(1), qml.PauliY(2)] ansatz = qml.templates.StronglyEntanglingLayers
We can construct a QNode to output the probability distribution in the shared eigenbasis of the observables:
dev = qml.device("default.qubit", wires=3) @qml.qnode(dev, interface="autograd") def circuit(weights): ansatz(weights, wires=[0, 1, 2]) # rotate into the basis of the observables for o in obs_list: o.diagonalizing_gates() return qml.probs(wires=[0, 1, 2])
We can now compute the covariance matrix:
>>> weights = qml.init.strong_ent_layers_normal(n_layers=2, n_wires=3) >>> cov = qml.math.cov_matrix(circuit(weights), obs_list) >>> cov array([[0.98707611, 0.03665537], [0.03665537, 0.99998377]])
Autodifferentiation is fully supported using all interfaces:
>>> cost_fn = lambda weights: qml.math.cov_matrix(circuit(weights), obs_list)[0, 1] >>> qml.grad(cost_fn)(weights)[0] array([[[ 4.94240914e-17, -2.33786398e-01, -1.54193959e-01], [-3.05414996e-17, 8.40072236e-04, 5.57884080e-04], [ 3.01859411e-17, 8.60411436e-03, 6.15745204e-04]], [[ 6.80309533e-04, -1.23162742e-03, 1.08729813e-03], [-1.53863193e-01, -1.38700657e-02, -1.36243323e-01], [-1.54665054e-01, -1.89018172e-02, -1.56415558e-01]]])
一个新的
qml.draw函数可用,允许QNode在提供示例输入的情况下轻松绘制而无需执行。 (#962)@qml.qnode(dev) def circuit(a, w): qml.Hadamard(0) qml.CRX(a, wires=[0, 1]) qml.Rot(*w, wires=[1]) qml.CRX(-a, wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
QNode电路结构可能依赖于输入参数; 通过将示例QNode参数传递给
qml.draw()绘制函数来考虑这一点:>>> drawer = qml.draw(circuit) >>> result = drawer(a=2.3, w=[1.2, 3.2, 0.7]) >>> print(result) 0: ──H──╭C────────────────────────────╭C─────────╭┤ ⟨Z ⊗ Z⟩ 1: ─────╰RX(2.3)──Rot(1.2, 3.2, 0.7)──╰RX(-2.3)──╰┤ ⟨Z ⊗ Z⟩
更快、更精简、更加灵活的核心
PennyLane的新核心,完全重写并在过去几个版本周期中开发,实现了功能上的平衡,并已成为PennyLane v0.14的新默认设置。旧核心已被标记为不推荐使用,并将在即将发布的版本中移除。
虽然高层次的PennyLane代码和教程保持不变,但新的核心提供了几个优势和改进:
更快且更优化: 新的核心提供了各种性能优化,减少了前处理和后处理的开销,并在某些情况下减少了量子评估的次数。
支持在 QNode 中的经典处理: 这允许在 QNode 内进行可微分的经典处理。
dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, interface="tf") def circuit(p): qml.RX(tf.sin(p[0])**2 + p[1], wires=0) return qml.expval(qml.PauliZ(0))
在 QNode 中使用的经典处理函数必须与 QNode 接口匹配。这里,我们使用 TensorFlow:
>>> params = tf.Variable([0.5, 0.1], dtype=tf.float64) >>> with tf.GradientTape() as tape: ... res = circuit(params) >>> grad = tape.gradient(res, params) >>> print(res) tf.Tensor(0.9460913127754935, shape=(), dtype=float64) >>> print(grad) tf.Tensor([-0.27255248 -0.32390003], shape=(2,), dtype=float64)
由于这一变化,要求经典处理的量子分解得到了完全支持,并在 tape 模式下是端到端可微分的。
不再需要变量包装: QNode 参数不再成为
Variable对象。dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(x): print("参数值:", x) qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0))
内部 QNode 参数可以很容易地检查、打印和操作:
>>> circuit(0.5) 参数值: 0.5 tensor(0.87758256, requires_grad=True)
Less restrictive QNode signatures: There is no longer any restriction on the QNode signature; the QNode can be defined and called following the same rules as standard Python functions.
For example, the following QNode uses positional, named, and variable keyword arguments:
x = torch.tensor(0.1, requires_grad=True) y = torch.tensor([0.2, 0.3], requires_grad=True) z = torch.tensor(0.4, requires_grad=True) @qml.qnode(dev, interface="torch") def circuit(p1, p2=y, **kwargs): qml.RX(p1, wires=0) qml.RY(p2[0] * p2[1], wires=0) qml.RX(kwargs["p3"], wires=0) return qml.var(qml.PauliZ(0))
When we call the QNode, we may pass the arguments by name even if defined positionally; any argument not provided will use the default value.
>>> res = circuit(p1=x, p3=z) >>> print(res) tensor(0.2327, dtype=torch.float64, grad_fn=<SelectBackward>) >>> res.backward() >>> print(x.grad, y.grad, z.grad) tensor(0.8396) tensor([0.0289, 0.0193]) tensor(0.8387)
This extends to the
qnnmodule, whereKerasLayerandTorchLayermodules can be created from QNodes with unrestricted signatures.更智能的测量: QNodes 现在可以对线路进行多次测量,只要所有观察量是可交换的:
@qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return [ qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) ]
进一步地,
qml.ExpvalCost()函数允许优化测量,以减少所需的量子评估次数。
使用新的PennyLane核心,有一些小的破坏性更改,详细信息在下面的“破坏性更改”部分中。
改进
内置的 PennyLane 优化器允许更灵活的成本函数。传递给大多数优化器的成本函数可以接受任何组合的可训练参数、不可训练参数和关键字参数。 (#959) (#1053)
完整的更改适用于:
AdagradOptimizerAdamOptimizerGradientDescentOptimizerMomentumOptimizerNesterovMomentumOptimizerRMSPropOptimizerRotosolveOptimizer
属性
requires_grad=False必须标记任何不可训练的常量参数。
RotoselectOptimizer只允许传递关键字参数。示例用法:
def cost(x, y, data, scale=1.0): return scale * (x[0]-data)**2 + scale * (y-data)**2 x = np.array([1.], requires_grad=True) y = np.array([1.0]) data = np.array([2.], requires_grad=False) opt = qml.GradientDescentOptimizer() # the optimizer step and step_and_cost methods can # now update multiple parameters at once x_new, y_new, data = opt.step(cost, x, y, data, scale=0.5) (x_new, y_new, data), value = opt.step_and_cost(cost, x, y, data, scale=0.5) # list and tuple unpacking is also supported params = (x, y, data) params = opt.step(cost, *params)
电路绘图工具已更新,以支持通过传递
show_all_wires参数来包含未使用或不活跃的线。(#1033)dev = qml.device('default.qubit', wires=[-1, "a", "q2", 0]) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=-1) qml.CNOT(wires=[-1, "q2"]) return qml.expval(qml.PauliX(wires="q2"))
>>> print(qml.draw(circuit, show_all_wires=True)()) >>> -1: ──H──╭C──┤ a: ─────│───┤ q2: ─────╰X──┤ ⟨X⟩ 0: ─────────┤
选择“最佳”微分方法的逻辑已被更改以提高性能。(#1008)
如果设备提供自己的梯度,那么这现在是首选的微分方法。
如果一个设备提供额外的特定于接口的版本,能够原生支持经典的反向传播,那么现在优先使用这个,而不是参数移位规则。
设备通过它们的
capabilities()字典定义额外的特定于接口的设备。 例如,default.qubit支持 TensorFlow、Autograd 和 JAX 的补充设备:{ "passthru_devices": { "tf": "default.qubit.tf", "autograd": "default.qubit.autograd", "jax": "default.qubit.jax", }, }
由于这一变化,如果未明确提供 QNode
diff_method,那么 QNode 可能会在提供的设备的 补充设备 上运行:dev = qml.device("default.qubit", wires=2) qml.QNode(dev) # will default to backprop on default.qubit.autograd qml.QNode(dev, interface="tf") # will default to backprop on default.qubit.tf qml.QNode(dev, interface="jax") # will default to backprop on default.qubit.jax
default.qubit设备已被更新,因此内部以更具功能性的方式应用操作,即接受输入状态并返回一个演变后的状态。(#1025)新增了一组测试系列,
pennylane/devices/tests/test_compare_default_qubit.py,允许测试所选设备是否与default.qubit给出相同的结果。(#897)添加了三个测试:
test_hermitian_expectation,test_pauliz_expectation_analytic,以及test_random_circuit。
将以下无关的张量操作函数添加到
qml.math模块:abs,angle,arcsin,concatenate,dot,squeeze,sqrt,sum,take,where。这些函数是完全支持端到端可微分的 Mottonen 和幅度嵌入所必需的。 (#922) (#1011)现在
qml.math模块支持JAX。 (#985)对
Wires类进行了几项改进,以减少开销并简化线标签的解释逻辑: (#1019) (#1010) (#1005) (#983) (#967)如果输入的
wires到一个 wires 类实例化Wires(wires)可以被迭代, 其元素被解释为电线标签。否则,wires被解释为一个单一的电线标签。 唯一的例外是字符串,它们总是被解释为一个单一的 电线标签,因此用户可以使用像"ancilla"的标签来访问电线。现在任何类型都可以作为线的标签,只要它是可哈希的。哈希用于确定两个标签的唯一性。
索引电线对象现在返回一个标签,而不是一个新的
Wires对象。例如:>>> w = Wires([0, 1, 2]) >>> w[1] >>> 1
对导线唯一性的检查已从
Wires实例化移至qml.wires._process函数,以减少重复创建Wires实例的开销。对
Wires类的调用大幅减少,例如通过避免在Operation实例化时调用Wires,并通过在默认的量子比特设备中使用标签来代替Wires对象。
将
PauliRot生成器添加到qml.operation模块。这个生成器是构造度量张量所必需的。 (#963)这些模板经过修改,以利用新的
qml.math模块,适用于与框架无关的张量操作。这使得模板库在反向传播模式下可微分 (diff_method="backprop")。电路绘制工具现在允许(可选地)修改导线顺序: (#992)
>>> dev = qml.device('default.qubit', wires=["a", -1, "q2"]) >>> @qml.qnode(dev) ... def circuit(): ... qml.Hadamard(wires=-1) ... qml.CNOT(wires=["a", "q2"]) ... qml.RX(0.2, wires="a") ... return qml.expval(qml.PauliX(wires="q2"))
使用设备的默认导线顺序打印:
>>> print(circuit.draw()) a: ─────╭C──RX(0.2)──┤ -1: ──H──│────────────┤ q2: ─────╰X───────────┤ ⟨X⟩
改变导线顺序:
>>> print(circuit.draw(wire_order=["q2", "a", -1])) q2: ──╭X───────────┤ ⟨X⟩ a: ──╰C──RX(0.2)──┤ -1: ───H───────────┤
重大变更
使用新的PennyLane核心的QNodes将不再接受不规则数组作为输入。
在使用新的 PennyLane 核心和 Autograd 接口时,作为 QNode 参数或门传递的非可微分数据必须将
requires_grad属性设置为False:@qml.qnode(dev) def circuit(weights, data): basis_state = np.array([1, 0, 1, 1], requires_grad=False) qml.BasisState(basis_state, wires=[0, 1, 2, 3]) qml.templates.AmplitudeEmbedding(data, wires=[0, 1, 2, 3]) qml.templates.BasicEntanglerLayers(weights, wires=[0, 1, 2, 3]) return qml.probs(wires=0) data = np.array(data, requires_grad=False) weights = np.array(weights, requires_grad=True) circuit(weights, data)
错误修复
修复了一个问题,即如果张量积的组成可观测值不在队列中,则会引发错误。通过此修复,它们在注释发生之前会首先被排入队列。
(#1038)修复了与磁带扩展有关的问题,其中关于采样的信息(特别是
is_sampled磁带属性)未被保存。 (#1027)Tape扩展没有正确考虑支持逆操作的设备,导致逆操作不必要地被分解。QNode tape扩展逻辑以及
Operation.expand()方法已经被修改以修复此问题。 (#956)修复了一个问题,即Autograd接口未能展开不可微分的PennyLane张量,这可能在某些设备上导致问题。(#941)
qml.vqe.Hamiltonian打印任何可观察量和任意数量的字符串。 (#987)修复了一个错误,参数偏移微分在QNode包含单个概率输出时会失败。 (#1007)
修复了使用可训练参数时,参数为列表/数组时在
tape.vjp上出现的问题。 (#1042)更新了
TensorN可观察量,以支持在不传递任何参数或电线的情况下进行复制。 (#1047)修复了在从
collections导入Sequence时,而不是从collections.abc导入时出现的弃用警告,位于vqe/vqe.py中。 (#1051)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
胡安·米格尔·阿拉索拉,托马斯·布朗利,奥利维亚·迪·马泰奥,西奥多尔·伊萨克森,乔希·伊萨克,克里斯蒂娜·李,阿莱汉德罗·蒙塔涅斯,史蒂文·奥德,蔡斯·罗伯茨,桑卡尔普·萨南德,玛丽亚·舒尔德,安塔尔·萨瓦,大卫·维里希斯,贾浩·姚。
- orphan
发布 0.13.0¶
自上次发布以来的新特性
自动优化测量次数
当前在带状模式下的 QNodes 现在支持在相同的线路上返回可观察量,前提是这些可观察量是量子比特逐项对易的保利字。量子比特逐项对易的可观察量可以通过共享一组单量子比特旋转在同一基底中以 单个 设备运行进行评估。(#882)
以下示例展示了一个单 QNode 返回量子比特逐项对易的保利字
XX和XI的期望值:qml.enable_tape() @qml.qnode(dev) def f(x): qml.Hadamard(wires=0) qml.Hadamard(wires=1) qml.CRot(0.1, 0.2, 0.3, wires=[1, 0]) qml.RZ(x, wires=1) return qml.expval(qml.PauliX(0) @ qml.PauliX(1)), qml.expval(qml.PauliX(0))
>>> f(0.4) tensor([0.89431013, 0.9510565 ], requires_grad=True)
The
ExpvalCostclass (previouslyVQECost) now provides observable optimization using theoptimizeargument, resulting in potentially fewer device executions. (#902)This is achieved by separating the observables composing the Hamiltonian into qubit-wise commuting groups and evaluating those groups on a single QNode using functionality from the
qml.groupingmodule:qml.enable_tape() commuting_obs = [qml.PauliX(0), qml.PauliX(0) @ qml.PauliZ(1)] H = qml.vqe.Hamiltonian([1, 1], commuting_obs) dev = qml.device("default.qubit", wires=2) ansatz = qml.templates.StronglyEntanglingLayers cost_opt = qml.ExpvalCost(ansatz, H, dev, optimize=True) cost_no_opt = qml.ExpvalCost(ansatz, H, dev, optimize=False) params = qml.init.strong_ent_layers_uniform(3, 2)
Grouping these commuting observables leads to fewer device executions:
>>> cost_opt(params) >>> ex_opt = dev.num_executions >>> cost_no_opt(params) >>> ex_no_opt = dev.num_executions - ex_opt >>> print("Number of executions:", ex_no_opt) Number of executions: 2 >>> print("Number of executions (optimized):", ex_opt) Number of executions (optimized): 1
新的量子梯度特性
在支持的设备上并行计算量子电路的解析梯度。 (#840)
此版本引入了通过新的设备 API 方法支持电路的批量执行
Device.batch_execute()。实现此新 API 的设备支持同时提交一批电路进行并行评估,这可以显著减少计算时间。此外,如果在带式模式下使用并且设备兼容,梯度计算将会自动利用新的批量 API——在优化过程中提供加速。
梯度配方现在更强大,可以通过电路评估的任意线性组合来定义它们的梯度。 (#909) (#915)
随着这一变化,梯度配方现在可以是以下形式 \(\frac{\partial}{\partial\phi_k}f(\phi_k) = \sum_{i} c_i f(a_i \phi_k + s_i )\), 不再限制于具有相同(但符号相反)移位值的两项移位。
因此,PennyLane 现在支持受控旋转操作的原生解析量子梯度
CRX、CRY、CRZ和CRot。这允许在硬件上进行参数移位解析梯度,而无需分解。请注意,这对开发人员来说是一个重大变更;有关更多细节,请参阅 重大变更 部分。
现在,
qnn.KerasLayer类支持通过经典反向传播在录音带模式下对 QNode 进行微分。 (#869)qml.enable_tape() dev = qml.device("default.qubit.tf", wires=2) @qml.qnode(dev, interface="tf", diff_method="backprop") def f(inputs, weights): qml.templates.AngleEmbedding(inputs, wires=range(2)) qml.templates.StronglyEntanglingLayers(weights, wires=range(2)) return [qml.expval(qml.PauliZ(i)) for i in range(2)] weight_shapes = {"weights": (3, 2, 3)} qlayer = qml.qnn.KerasLayer(f, weight_shapes, output_dim=2) inputs = tf.constant(np.random.random((4, 2)), dtype=tf.float32) with tf.GradientTape() as tape: out = qlayer(inputs) tape.jacobian(out, qlayer.trainable_weights)
新操作、模板和测量
添加具有部分迹运算能力的
qml.density_matrixQNode 返回。 (#878)返回所提供导线上的密度矩阵,所有其他子系统被迹运算。
qml.density_matrix目前适用于default.qubit和default.mixed设备。qml.enable_tape() dev = qml.device("default.qubit", wires=2) def circuit(x): qml.PauliY(wires=0) qml.Hadamard(wires=1) return qml.density_matrix(wires=[1]) # 导线 0 被迹运算
添加平方根 X 门
SX. (#871)dev = qml.device("default.qubit", wires=1) @qml.qnode(dev) def circuit(): qml.SX(wires=[0]) return qml.expval(qml.PauliZ(wires=[0]))
已实现两个新的硬件高效的粒子守恒模板,以执行基于VQE的量子化学模拟。新的模板应用了Barkoutsos 等人 在图2a和2b中提出的几层粒子守恒纠缠器,arXiv:1805.04340 (#875) (#876)
估算和跟踪资源
QuantumTape类现在包含基本的资源估算功能。方法tape.get_resources()返回一个字典,包含电路中各组成操作及其出现次数的列表。同样,tape.get_depth()计算电路深度。(#862)>>> with qml.tape.QuantumTape() as tape: ... qml.Hadamard(wires=0) ... qml.RZ(0.26, wires=1) ... qml.CNOT(wires=[1, 0]) ... qml.Rot(1.8, -2.7, 0.2, wires=0) ... qml.Hadamard(wires=1) ... qml.CNOT(wires=[0, 1]) ... qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) >>> tape.get_resources() {'Hadamard': 2, 'RZ': 1, 'CNOT': 2, 'Rot': 1} >>> tape.get_depth() 4
现在可以使用
num_executions返回 QNode 生命周期内的设备执行次数。 (#853)>>> dev = qml.device("default.qubit", wires=2) >>> @qml.qnode(dev) ... def circuit(x, y): ... qml.RX(x, wires=[0]) ... qml.RY(y, wires=[1]) ... qml.CNOT(wires=[0, 1]) ... return qml.expval(qml.PauliZ(0) @ qml.PauliX(1)) >>> for _ in range(10): ... circuit(0.432, 0.12) >>> print(dev.num_executions) 10
改进
对pennylane的带模式支持得到了改善。以下功能现在可以在带模式下工作:
新增了一个函数,
qml.refresh_devices(),允许PennyLane重新扫描已安装的PennyLane插件并刷新设备列表。此外,qml.device加载器将尝试刷新设备,如果找不到所需的插件设备。这将改善在运行Python会话中安装PennyLane和插件的体验(例如,在Google Colab上),并避免需要重启内核/运行环境。 (#907)当使用
grad_fn = qml.grad(cost)通过 Autograd 接口计算成本函数的梯度时,当前向传递的中间值现在可以通过grad_fn.forward属性获得 (#914):def cost_fn(x, y): return 2 * np.sin(x[0]) * np.exp(-x[1]) + x[0] ** 3 + np.cos(y) params = np.array([0.1, 0.5], requires_grad=True) data = np.array(0.65, requires_grad=False) grad_fn = qml.grad(cost_fn) grad_fn(params, data) # 执行反向传播并评估梯度 grad_fn.forward # 成本函数值
基于梯度的优化器现在有一个
step_and_cost方法,返回 下一个步骤以及目标(成本)函数输出。 (#916)>>> opt = qml.GradientDescentOptimizer() >>> params, cost = opt.step_and_cost(cost_fn, params)
PennyLane 提供了一个新的实验模块
qml.proc,该模块提供了与框架无关的数组和张量操作函数。 (#886)给定输入的张量类对象,该调用被调度到相应的数组操作框架,从而保留端到端的微分。
>>> x = torch.tensor([1., 2.]) >>> qml.proc.ones_like(x) tensor([1, 1]) >>> y = tf.Variable([[0], [5]]) >>> qml.proc.ones_like(y, dtype=np.complex128)
请注意,这些函数是实验性的,仅支持常见功能的子集。此外,这些函数的名称和行为可能与常见框架中的类似函数有所不同;有关更多细节,请参考函数文档字符串。
现在,带有记忆模式的梯度方法完全分离了量子和经典处理。它们不再直接返回评估的梯度,而是返回一个包含所需量子和经典处理步骤的元组。 (#840)
def gradient_method(idx, param, **options): # 生成必须计算的量子带,以确定量子梯度 tapes = quantum_gradient_tapes(self) def processing_fn(results): # 对评估后的带进行经典处理 # 返回评估的量子梯度 return classical_processing(results) return tapes, processing_fn
JacobianTape.jacobian()方法也进行了类似的修改,以积累所有梯度量子带和经典处理函数,同时评估所有量子带,然后将后处理函数应用于评估的带结果。MultiRZ门现在有了一个定义的生成器,使其能够用于量子自然梯度优化。 (#912)
CRot门现在有一个
decomposition方法,它将该门分解为旋转和CNOT门。这允许CRot在不原生支持它的设备上使用。 (#908)在
MottonenStatePreparation模板中的经典处理大部分已经被重写,以尽可能使用密集矩阵和张量操作。这是为将来支持通过该模板进行微分的准备。(#864)基于设备的缓存已取代QNode缓存。现在通过将一个
cache参数传递给设备来访问缓存。 (#851)该
cache参数应为一个整数,指定缓存的大小。例如,使用以下代码创建一个大小为10的缓存:>>> dev = qml.device("default.qubit", wires=2, cache=10)
现在
Operation、Tensor和MeasurementProcess类具有定义的__copy__特殊方法。 (#840)这使我们能够确保在对操作进行浅拷贝时,存储操作参数的可变列表也会被浅拷贝。旧操作和拷贝的操作将继续共享相同的参数数据。
>>> import copy >>> op = qml.RX(0.2, wires=0) >>> op2 = copy.copy(op) >>> op.data[0] is op2.data[0] True
然而 列表容器 不是引用:
>>> op.data is op2.data False
这允许拷贝的操作的参数被修改,而不会改变原操作的参数。
该
QuantumTape.copy方法已被调整,以便(#840):可选地,通过传递
copy_operations=True布尔标志,带子的操作也会被浅复制。这允许复制的带子的参数被修改,而不影响原始带子的参数。(注意:这两个带子将共享参数数据直到其中一个带子的参数列表被修改。)复制的磁带可以通过传递
tape_cls关键字参数来转换为另一个QuantumTape子类。
重大变更
更新了参数偏移梯度公式的定义,允许以任意数量的项来指定梯度公式。(#909)
之前,
Operation.grad_recipe限制为两项参数偏移公式。通过此更改,梯度公式现在包含形式为\([c_i, a_i, s_i]\)的元素,从而得到的梯度公式为\(\frac{\partial}{\partial\phi_k}f(\phi_k) = \sum_{i} c_i f(a_i \phi_k + s_i )\)。由于这是一个破坏性更改,因此所有具有已定义梯度公式的自定义操作必须更新才能继续与PennyLane 0.13一起使用。请注意,如果
grad_recipe = None,默认梯度公式保持不变,并对应于每个参数的两项\([c_0, a_0, s_0]=[1/2, 1, \pi/2]\)和\([c_1, a_1, s_1]=[-1/2, 1, -\pi/2]\)。类
VQECost已更名为ExpvalCost以反映其在 VQE 之外的一般适用性。 仍然可以使用VQECost,但会导致弃用警告。 (#913)
错误修复
该
default.qubit.tf设备已更新,以正确处理 TensorFlow 对象(例如,tf.Variable)作为使用MultiRZ和CRot操作的门参数。 (#921)PennyLane张量对象在作为关键字参数传递给量子函数时,现在在BaseQNode中被解包。 (#903) (#893)
新的磁带模式现在防止在同一导线上评估多个可观察量,前提是这些可观察量不是逐位对易的保利字。
修复了
default.qubit中的一个错误,该错误导致常见门的逆未通过高效的特定门方法应用,而是回落到矩阵-向量乘法。 受影响的门包括:PauliX,PauliY,PauliZ,Hadamard,SWAP,S,T,CNOT,CZ。 (#872)PauliRot操作现在能够优雅地处理单量子比特的Pauli算子,以及全为单位算子的Pauli算子 (#860)。修复了一个错误,该错误导致二进制 Python 运算符未能正确地将
requires_grad属性传播到输出张量。 (#889)修复了一个在启用CUDA时导致
TorchLayer无法执行backward的错误。 (#899)修复了一个错误,在多线程执行
QNodeCollection时,由于同时排队,有时会失败。通过在排队期间添加线程锁定来修复此问题。 (#910)修复了
QuantumTape.set_parameters()中的一个错误。之前的实现假设self.trainable_parms集合将始终以递增的整数顺序进行迭代。然而,这并不是保证的行为,如果情况并非如此,可能会导致错误的磁带参数被设置。 (#923)修复了如果一个QNode被实例化时出现未知异常的错误信息错误。
贡献者
此版本包含来自(按字母顺序排列)的贡献:
胡安·米格尔·阿拉佐拉,托马斯·布罗姆利,克里斯蒂娜·李,阿兰·德尔加多·格兰,奥利维亚·迪·马泰奥,安东尼·海斯,西奥多·伊萨克森,乔希·伊扎克,索兰·贾汉吉里,内森·基洛兰,春平·小林,罗曼·莫亚尔,牛泽越,玛利亚·舒尔德,安塔尔·萨瓦。
- orphan
发布 0.12.0¶
自上次发布以来的新特性
新改进的模拟器
PennyLane 现在支持一个新的设备,
default.mixed,旨在模拟混合态量子计算。这使得在电路中原生支持实现有噪声通道,这通常将纯态映射到混合态。 (#794) (#807) (#819)该设备可以初始化为
>>> dev = qml.device("default.mixed", wires=1)
这允许构建包含非单位操作的 QNodes,例如有噪声通道:
>>> @qml.qnode(dev) ... def circuit(params): ... qml.RX(params[0], wires=0) ... qml.RY(params[1], wires=0) ... qml.AmplitudeDamping(0.5, wires=0) ... return qml.expval(qml.PauliZ(0)) >>> print(circuit([0.54, 0.12])) 0.9257702929524184 >>> print(circuit([0, np.pi])) 0.0
优化测量的新工具
新的
grouping模块提供功能,用于分组同时可测量的保利字观察量。 (#761) (#850) (#852)函数
optimize_measurements将以一组 Pauli 单词可观察量及其对应的系数(如果有的话)作为输入,并返回在测量基中对角化的分区 Pauli 项及其对应的对角化电路。from pennylane.grouping import optimize_measurements h, nr_qubits = qml.qchem.molecular_hamiltonian("h2", "h2.xyz") rotations, grouped_ops, grouped_coeffs = optimize_measurements(h.ops, h.coeffs, grouping="qwc")
rotations的对角化电路对应于grouped_ops的对角化 Pauli 单词分组。泡利字的分区实用工具由类
PauliGroupingStrategy执行。输入的泡利字列表可以分区为互相对易的、量子比特wise-对易的或反对易的分组。例如,通过递归最大优先(RLF)图着色启发式将泡利字分区为反对易分组:
from pennylane import PauliX, PauliY, PauliZ, Identity from pennylane.grouping import group_observables pauli_words = [ Identity('a') @ Identity('b'), Identity('a') @ PauliX('b'), Identity('a') @ PauliY('b'), PauliZ('a') @ PauliX('b'), PauliZ('a') @ PauliY('b'), PauliZ('a') @ PauliZ('b') ] groupings = group_observables(pauli_words, grouping_type='anticommuting', method='rlf')
包含各种实用功能,用于获取和操作二元辛向量空间表示中的保利字。
例如,可以将两个保利字转换为它们的二元向量表示:
>>> from pennylane.grouping import pauli_to_binary >>> from pennylane.wires import Wires >>> wire_map = {Wires('a'): 0, Wires('b'): 1} >>> pauli_vec_1 = pauli_to_binary(qml.PauliX('a') @ qml.PauliY('b')) >>> pauli_vec_2 = pauli_to_binary(qml.PauliZ('a') @ qml.PauliZ('b')) >>> pauli_vec_1 [1. 1. 0. 1.] >>> pauli_vec_2 [0. 0. 1. 1.]
它们的乘积可以通过对它们的二元向量表示求和来计算,并以算符表示返回。
>>> from pennylane.grouping import binary_to_pauli >>> binary_to_pauli((pauli_vec_1 + pauli_vec_2) % 2, wire_map) 张量积 ['PauliY', 'PauliX']: 0 参数, 连接线 ['a', 'b']
有关分组模块的更多详细信息,请参阅分组模块文档
从模拟器返回量子态
现在可以使用
qml.state()返回函数返回 QNode 的量子状态。 (#818)import pennylane as qml dev = qml.device("default.qubit", wires=3) qml.enable_tape() @qml.qnode(dev) def qfunc(x, y): qml.RZ(x, wires=0) qml.CNOT(wires=[0, 1]) qml.RY(y, wires=1) qml.CNOT(wires=[0, 2]) return qml.state() >>> qfunc(0.56, 0.1) array([0.95985437-0.27601028j, 0. +0.j , 0.04803275-0.01381203j, 0. +0.j , 0. +0.j , 0. +0.j , 0. +0.j , 0. +0.j ])
当使用与兼容设备的经典反向传播微分方法 (
diff_method="backprop") 以及使用新型带模式时,当前可以区分状态。
新操作和通道
PennyLane 现在包括标准通道,如幅度耗散通道、相位耗散通道和去极化通道,以及制作自定义量子比特通道的能力。 (#760) (#766) (#778)
受控-Y操作现在可以通过
qml.CY使用。对于不原生支持受控-Y操作的设备,它将被分解为qml.RY、qml.CNOT和qml.S操作。(#806)
预览下一代 PennyLane QNode
新的PennyLane
tape模块提供了一个重新设计的QNode类,从头开始重写,使用新的QuantumTape对象来表示QNode的量子电路。Tape模式相比标准的PennyLane QNode提供了几个优势。对 in-QNode 经典处理的支持:Tape 模式允许在 QNode 内进行可微分的经典处理。
不再需要变量包装:在磁带模式下,QNode 参数不再成为
Variable对象。QNode签名的限制减少:不再对QNode签名有任何限制;QNode可以按照标准Python函数的相同规则定义和调用。
统一所有QNode:带子模式的QNode将所有QNode(包括
JacobianQNode和PassthruQNode)合并为一个统一的QNode,具有相同的行为,无论微分类型如何。优化:Tape模式提供了各种性能优化,减少了预处理和后处理的开销,并在某些情况下减少了量子评估的数量。
请注意,带状模式是实验性的,目前与现有的QNode没有功能对等。反馈和错误报告是受到鼓励的,并将有助于改善新的带状模式。
可以通过
qml.enable_tape函数全局启用 tape 模式,而无需更改您的 PennyLane 代码:qml.enable_tape() dev = qml.device("default.qubit", wires=1) @qml.qnode(dev, interface="tf") def circuit(p): print("Parameter value:", p) qml.RX(tf.sin(p[0])**2 + p[1], wires=0) return qml.expval(qml.PauliZ(0))
有关更多详细信息,请参见磁带模式文档。
改进
引入了QNode缓存,允许QNode跟踪先前设备执行的结果,并在后续调用中重用这些结果。注意,QNode缓存仅在新的实验性胶带模式中受支持。(#817)
通过向QNode传递一个
caching参数可以使用缓存:dev = qml.device("default.qubit", wires=2) qml.enable_tape() @qml.qnode(dev, caching=10) # 缓存最多10个评估 def qfunc(x): qml.RX(x, wires=0) qml.RX(0.3, wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(1)) qfunc(0.1) # 第一次评估在设备上执行 qfunc(0.1) # 第二次评估访问缓存结果
通过使用数组/张量操作技巧,加速了某些门在
default.qubit中的应用。受影响的门包括:PauliX、PauliY、PauliZ、Hadamard、SWAP、S、T、CNOT、CZ。(#772)对于拥有大量导线的设备,边际概率的计算效率得到了提升,在某些情况下实现了5倍的速度提升。
在
Hamiltonian、Tensor和Observable对象之间添加算术操作(加法、张量积、减法和标量乘法),以及在哈密顿量和其他可观测量之间进行内联算术操作。(#765)哈密顿量现在可以很容易地定义为可观测量的和:
>>> H = 3 * qml.PauliZ(0) - (qml.PauliX(0) @ qml.PauliX(1)) + qml.Hamiltonian([4], [qml.PauliZ(0)]) >>> print(H) (7.0) [Z0] + (-1.0) [X0 X1]
将
compare()方法添加到Observable和Hamiltonian类中,允许 比较可观察量。 (#765)>>> H = qml.Hamiltonian([1], [qml.PauliZ(0)]) >>> obs = qml.PauliZ(0) @ qml.Identity(1) >>> print(H.compare(obs)) True
>>> H = qml.Hamiltonian([2], [qml.PauliZ(0)]) >>> obs = qml.PauliZ(1) @ qml.Identity(0) >>> print(H.compare(obs)) False
为
Hamiltonian类添加simplify()方法。 (#765)>>> H = qml.Hamiltonian([1, 2], [qml.PauliZ(0), qml.PauliZ(0) @ qml.Identity(1)]) >>> H.simplify() >>> print(H) (3.0) [Z0]
在
qml.qaoa模块中添加了一个新的比特翻转混合器。 (#774)现在支持两个
Wires对象的求和,并将返回一个包含求和中定义的所有电线的Wires对象。 (#812)
重大变更
PennyLane NumPy 模块现在返回标量(零维)数组,而以前返回的是 Python 标量。 (#820) (#833)
例如,这影响数组元素索引和求和:
>>> x = np.array([1, 2, 3], requires_grad=False) >>> x[0] tensor(1, requires_grad=False) >>> np.sum(x) tensor(6, requires_grad=True)
这可能需要对用户代码进行小的更新。添加了一个便利方法,
np.tensor.unwrap(),以帮助简化过渡。这将PennyLane NumPy 张量转换为标准 NumPy 数组和 Python 标量:>>> x = np.array(1.543, requires_grad=False) >>> x.unwrap() 1.543
但是,请注意,关于数组可微性的相关信息将会丢失。
设备能力字典已进行了重新设计,以提高清晰度和稳健性。特别是,能力字典现在从父类继承,多个键具有更具表现力的名称,并且所有键现在都在基础设备类中定义。有关更多详情,请 参考开发者文档。 (#781)
错误修复
更改为使用列表来存储
(#773)BaseQNode内部的变量值,允许将复杂矩阵传递给QubitUnitary。修复了在
default.qubit中的一个错误,从而在将状态向量应用于设备上的所有线路时提高了效率。 (#849)
文档
已在
qml.sample和qml.probs的文档字符串中添加了方程,以澄清所执行测量的数学基础。 (#843)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Aroosa Ijaz, Juan Miguel Arrazola, Thomas Bromley, Jack Ceroni, Alain Delgado Gran, Josh Izaac, Soran Jahangiri, Nathan Killoran, Robert Lang, Cedric Lin, Olivia Di Matteo, Nicolás Quesada, Maria Schuld, Antal Száva.
- orphan
版本 0.11.0¶
自上次发布以来的新特性
新改进的模拟器
添加了一个新设备,
default.qubit.autograd,这是一个使用Autograd编写的纯态量子比特模拟器。 该设备支持经典反向传播(diff_method="backprop");当要优化的参数数量较大时,这可能比参数位移规则计算量子梯度更快。 (#721)>>> dev = qml.device("default.qubit.autograd", wires=1) >>> @qml.qnode(dev, diff_method="backprop") ... def circuit(x): ... qml.RX(x[1], wires=0) ... qml.Rot(x[0], x[1], x[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> weights = np.array([0.2, 0.5, 0.1]) >>> grad_fn = qml.grad(circuit) >>> print(grad_fn(weights)) array([-2.25267173e-01, -1.00864546e+00, 6.93889390e-18])
请参阅设备文档以获取更多详细信息。
现在可以使用一个新的实验性C++状态向量模拟器设备,
lightning.qubit。它使用C++ Eigen库进行快速线性代数计算,以模拟量子状态向量的演化。lightning.qubit目前处于测试阶段;可以通过pip安装:$ pip install pennylane-lightning
安装后,可以作为PennyLane设备使用:
>>> dev = qml.device("lightning.qubit", wires=2)
更多细节,请参见 lightning qubit documentation。
新算法和模板
通过新的
qml.qaoa模块添加了内置的QAOA功能。 (#712) (#718) (#741) (#720)这包括以下功能:
新的
qml.qaoa.x_mixer和qml.qaoa.xy_mixer函数用于定义 Pauli-X 和 XY 混合哈密顿量。MaxCut:
qml.qaoa.maxcut函数允许轻松构建用于解决给定图的 MaxCut 问题的成本哈密顿量和推荐混合哈密顿量。层:
qml.qaoa.cost_layer和qml.qaoa.mixer_layer分别接受成本和混合哈密顿量,并将相应的 QAOA 成本层和混合层应用于量子电路
例如,使用 PennyLane 来构建和解决一个 MaxCut 问题,采用 QAOA:
wires = range(3) graph = Graph([(0, 1), (1, 2), (2, 0)]) cost_h, mixer_h = qaoa.maxcut(graph) def qaoa_layer(gamma, alpha): qaoa.cost_layer(gamma, cost_h) qaoa.mixer_layer(alpha, mixer_h) def antatz(params, **kwargs): for w in wires: qml.Hadamard(wires=w) # repeat the QAOA layer two times qml.layer(qaoa_layer, 2, params[0], params[1]) dev = qml.device('default.qubit', wires=len(wires)) cost_function = qml.VQECost(ansatz, cost_h, dev)
向PennyLane模板模块添加了一个
ApproxTimeEvolution模板,可以用于实现哈密顿量下的切罗特化时间演化。(#710)
新增了一个
qml.layer模板构造函数,该函数接受一个单位操作,并在一组线圈上反复应用,直到给定的深度。 (#723)def subroutine(): qml.Hadamard(wires=[0]) qml.CNOT(wires=[0, 1]) qml.PauliX(wires=[1]) dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) def circuit(): qml.layer(subroutine, 3) return [qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(1))]
这创建了如下电路:
>>> circuit() >>> print(circuit.draw()) 0: ──H──╭C──X──H──╭C──X──H──╭C──X──┤ ⟨Z⟩ 1: ─────╰X────────╰X────────╰X─────┤ ⟨Z⟩
添加了
qml.utils.decompose_hamiltonian函数。这个函数可以用来将哈密顿量分解为保利算子的线性组合。(#671)>>> A = np.array( ... [[-2, -2+1j, -2, -2], ... [-2-1j, 0, 0, -1], ... [-2, 0, -2, -1], ... [-2, -1, -1, 0]]) >>> coeffs, obs_list = decompose_hamiltonian(A)
新设备功能
现在可以指定自定义线路标签,例如
['anc1', 'anc2', 0, 1, 3],其中标签可以是字符串或数字。 (#666)通过在创建设备时将一个列表传递给
wires参数来定义自定义线路标签:>>> dev = qml.device("default.qubit", wires=['anc1', 'anc2', 0, 1, 3])
量子操作应该使用这些自定义线路标签进行调用:
>>> @qml.qnode(dev) >>> def circuit(): ... qml.Hadamard(wires='anc2') ... qml.CNOT(wires=['anc1', 3]) ... ...
在设备初始化时指定线路数量的现有行为仍然照常工作。这提供了一种默认行为,其中线路由连续整数标记。
>>> dev = qml.device("default.qubit", wires=5)
添加了一个集成设备测试套件,可以用于对核心或外部设备进行基本的集成测试。 (#695) (#724) (#733)
通过调用
pl-device-test命令行程序,可以针对特定设备进行测试:$ pl-device-test --device=default.qubit --shots=1234 --analytic=False
如果在外部设备上运行测试,则必须在本地安装该设备及其依赖项。有关更多详细信息,请参见 插件测试文档。
改进
实现量子电路的函数构建了单位耦合簇 (UCCSD) VQE 预设已经得到了改进,采用了更一致的命名约定和 改进的文档字符串。 (#748)
更改包括:
术语 1粒子-1孔 (ph) 和 2粒子-2孔 (pphh) 激发被分别替换为 单一 和 双重 激发。
在
UCCSD模板中,不可微分的参数已被相应地重命名:ph→s_wires,pphh→d_wires术语 virtual,以前用于指代 unoccupied 轨道,已被弃用。
使用详情部分已更新和改进。
新增对 TensorFlow 2.3 和 PyTorch 1.6 的支持。 (#725)
现在支持从光子 QNodes 返回概率。与量子位 QNodes 一样,返回概率的光子 QNodes 是端到端可微分的。(#699)
>>> dev = qml.device("strawberryfields.fock", wires=2, cutoff_dim=5) >>> @qml.qnode(dev) ... def circuit(a): ... qml.Displacement(a, 0, wires=0) ... return qml.probs(wires=0) >>> print(circuit(0.5)) [7.78800783e-01 1.94700196e-01 2.43375245e-02 2.02812704e-03 1.26757940e-04]
重大变更
已将
pennylane.plugins和pennylane.beta.plugins文件夹重命名为pennylane.devices和pennylane.beta.devices,以更好地反映它们的内容。(#726)
错误修复
PennyLane接口转换函数现在可以转换具有预先存在接口的QNodes。 (#707)
文档
文档的接口部分已更名为“接口和训练”,并更新了最新的变量处理细节。 (#753)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
胡安·米格尔·阿拉佐拉, 托马斯·布朗利, 杰克·切罗尼, 阿兰·德尔加多·格兰, 沙达布·侯赛因, 西奥多·伊萨克森, 乔希·伊扎克, 内森·基洛兰, 玛利亚·舍尔德, 安塔尔·萨瓦, 尼科拉·维图奇。
- orphan
发布 0.10.0¶
自上次发布以来的新特性
新改进的模拟器
新增了一种设备,
default.qubit.tf,这是一个使用TensorFlow编写的纯态量子比特模拟器。因此,它支持经典反向传播作为计算雅可比矩阵的一种方法。当需要优化的参数数量较大时,这可能比用于计算量子梯度的参数移动规则更快。设计
default.qubit.tf时,考虑了与TensorFlow接口的端到端经典反向传播(diff_method="backprop")的使用。这是使用该设备创建QNode时的默认微分方法。使用这种方法,创建的QNode是一个“白箱”,与您的TensorFlow计算紧密集成,包括AutoGraph支持:
>>> dev = qml.device("default.qubit.tf", wires=1) >>> @tf.function ... @qml.qnode(dev, interface="tf", diff_method="backprop") ... def circuit(x): ... qml.RX(x[1], wires=0) ... qml.Rot(x[0], x[1], x[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> weights = tf.Variable([0.2, 0.5, 0.1]) >>> with tf.GradientTape() as tape: ... res = circuit(weights) >>> print(tape.gradient(res, weights)) tf.Tensor([-2.2526717e-01 -1.0086454e+00 1.3877788e-17], shape=(3,), dtype=float32)
查看
default.qubit.tf文档 以获取更多详细信息。默认的tensor插件已经显著升级。现在允许使用两种不同的张量网络表示:
"exact"和"mps"。前者使用量子态的精确分解表示,而后者使用矩阵乘积态表示。 (#572) (#599)
新的机器学习功能和集成
PennyLane QNodes 现在可以转换为 Torch 层,这样可以使用
torch.nnAPI 创建量子和混合模型。 (#588)A PennyLane QNode 可以使用
qml.qnn.TorchLayer类转换为torch.nn层:>>> @qml.qnode(dev) ... def qnode(inputs, weights_0, weight_1): ... # 定义电路 ... # ... >>> weight_shapes = {"weights_0": 3, "weight_1": 1} >>> qlayer = qml.qnn.TorchLayer(qnode, weight_shapes)
然后可以轻松构建混合模型:
>>> model = torch.nn.Sequential(qlayer, torch.nn.Linear(2, 2))
添加了一种新的“可逆”微分方法,可以在模拟器中使用,但不能在硬件中使用。
可逆的方法类似于反向传播,但以额外的计算换取更高的内存效率。在模拟演化过程中,反向传播在每一步缓存状态张量,而可逆方法仅缓存最终的测量前状态。
与参数偏移法相比,可逆方法可以更快或更慢,具体取决于电路中参数化门的密度和位置(电路中靠近末端的参数化门密度较高的电路将受益)。(#670)
>>> dev = qml.device("default.qubit", wires=2) ... @qml.qnode(dev, diff_method="reversible") ... def circuit(x): ... qml.RX(x, wires=0) ... qml.RX(x, wires=0) ... qml.CNOT(wires=[0,1]) ... return qml.expval(qml.PauliZ(0)) >>> qml.grad(circuit)(0.5) (array(-0.47942554),)
新模板和成本函数
添加了新的模板
UCCSD,SingleExcitationUnitary, 和DoubleExcitationUnitary, 它们一起实现了单位耦合簇单激发和双激发 (UCCSD) 参数化方法 以使用 PennyLane-QChem 执行基于 VQE 的量子化学模拟。 (#622) (#638) (#654) (#659) (#622)添加了模块
pennylane.qnn.cost,其中包含类SquaredErrorLoss。该模块包含用于计算具有可训练参数的电路的损失和成本函数的类。 (#642)
改进
通过将
Operator.wires属性变为一个wires对象来改善电线管理。 (#666)在使用Autograd时,QNodes和接口如何标记量子函数参数为可微分的方面有了显著改进,旨在提高性能并使QNodes更加直观。
特别地,已经做出了以下更改:
一个新的
ndarray子类pennylane.numpy.tensor,它通过关键字参数和属性requires_grad扩展了 NumPy 数组。具有requires_grad=False的张量被 Autograd 接口视为不可微分。一个新的子包
pennylane.numpy,它封装了autograd.numpy,使得 NumPy 函数接受requires_grad关键字参数,并允许 Autograd 对pennylane.numpy.tensor对象进行微分。argnum参数现在是可选的;如果未提供,则显式标记为requires_grad=False的参数将被排除在可微分参数列表之外。 为了向后兼容,保留了传递argnum的能力,如果存在,旧的行为将继续保留。
QNode Torch接口现在检查QNode的位置参数。 如果任何参数没有属性
requires_grad=True,它 将自动排除在量子梯度计算之外。 (#652) (#660)现在QNode TF接口检查QNode的位置参数。 如果任何参数没有被
tf.GradientTape()监视, 它将自动从量子梯度计算中排除。 (#655) (#660)QNode 现在有两个新的公共方法:
QNode.set_trainable_args()和QNode.get_trainable_args()。 这些方法旨在被接口调用,以指定给 QNode 哪些输入参数是可微分的。那些不可微分的参数将不会在 QNode 内被转换为 PennyLane Variable 对象。 (#660)为PauliX、PauliY、PauliZ、S、T、Hadamard和PhaseShift门添加了
decomposition方法,该方法将这些门分解为旋转门。 (#668)CircuitGraph类现在支持将包含的电路操作和测量基旋转序列化为 OpenQASM2.0 脚本,通过新的CircuitGraph.to_openqasm()方法。 (#623)
重大变更
移除对 Python 3.5 的支持。 (#639)
文档
修复了多处小错误。
贡献者
此版本包含来自(按字母顺序排列)的贡献:
托马斯·布罗姆利,杰克·塞罗尼,阿兰·德尔加多·格兰,西奥多·伊萨克森,乔什·伊扎克,内森·基洛兰,玛利亚·舒尔德,安塔尔·萨瓦,尼科拉·维图奇。
- orphan
发布 0.9.0¶
自上次发布以来的新特性
新的机器学习集成
PennyLane QNodes 现在可以转换为 Keras 层,从而允许使用 Keras API 创建量子和混合模型。 (#529)
可以使用
KerasLayer类将 PennyLane QNode 转换为 Keras 层:from pennylane.qnn import KerasLayer @qml.qnode(dev) def circuit(inputs, weights_0, weight_1): # 定义电路 # ... weight_shapes = {"weights_0": 3, "weight_1": 1} qlayer = qml.qnn.KerasLayer(circuit, weight_shapes, output_dim=2)
然后可以轻松构建混合模型:
model = tf.keras.models.Sequential([qlayer, tf.keras.layers.Dense(2)])
添加了一种新的 QNode 类型,
qml.qnodes.PassthruQNode。对于使用外部库编码的仿真器,该库支持自动微分,PennyLane 将 PassthruQNode 视为“黑箱”,并依赖外部库通过反向传播直接提供梯度。这在参数数量较多时可能比使用参数移位规则更高效。(#488)目前,PennyLane 的这个行为得到了支持,
default.tensor.tf设备后端兼容使用 TensorFlow 2 的'tf'接口:dev = qml.device('default.tensor.tf', wires=2) @qml.qnode(dev, diff_method="backprop") def circuit(params): qml.RX(params[0], wires=0) qml.RX(params[1], wires=1) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliZ(0)) qnode = PassthruQNode(circuit, dev) params = tf.Variable([0.3, 0.1]) with tf.GradientTape() as tape: tape.watch(params) res = qnode(params) grad = tape.gradient(res, params)
新的优化器
添加了
qml.RotosolveOptimizer,这是一个无梯度优化器,通过保持其他参数不变,逐个更新每个参数,使用封闭形式表达式来最小化量子函数。 (#636) (#539)新增了
qml.RotoselectOptimizer,该工具使用 Rotosolve 最小化量子函数,针对应用的旋转操作和旋转参数。 (#636) (#539)例如,给定一个接受参数
x的量子函数f和相应的旋转操作列表generators,Rotoselect 优化器将在每一步更新参数值和旋转门列表,以最小化损失:>>> opt = qml.optimize.RotoselectOptimizer() >>> x = [0.3, 0.7] >>> generators = [qml.RX, qml.RY] >>> for _ in range(100): ... x, generators = opt.step(f, x, generators)
新操作
Added the
PauliRotgate, which performs an arbitrary Pauli rotation on multiple qubits, and theMultiRZgate, which performs a rotation generated by a tensor product of Pauli Z operators. (#559)dev = qml.device('default.qubit', wires=4) @qml.qnode(dev) def circuit(angle): qml.PauliRot(angle, "IXYZ", wires=[0, 1, 2, 3]) return [qml.expval(qml.PauliZ(wire)) for wire in [0, 1, 2, 3]]
>>> circuit(0.4) [1. 0.92106099 0.92106099 1. ] >>> print(circuit.draw()) 0: ──╭RI(0.4)──┤ ⟨Z⟩ 1: ──├RX(0.4)──┤ ⟨Z⟩ 2: ──├RY(0.4)──┤ ⟨Z⟩ 3: ──╰RZ(0.4)──┤ ⟨Z⟩
If the
PauliRotgate is not supported on the target device, it will be decomposed intoHadamard,RXandMultiRZgates. Note that identity gates in the Pauli word result in untouched wires:>>> print(circuit.draw()) 0: ───────────────────────────────────┤ ⟨Z⟩ 1: ──H──────────╭RZ(0.4)──H───────────┤ ⟨Z⟩ 2: ──RX(1.571)──├RZ(0.4)──RX(-1.571)──┤ ⟨Z⟩ 3: ─────────────╰RZ(0.4)──────────────┤ ⟨Z⟩
If the
MultiRZgate is not supported, it will be decomposed intoCNOTandRZgates:>>> print(circuit.draw()) 0: ──────────────────────────────────────────────────┤ ⟨Z⟩ 1: ──H──────────────╭X──RZ(0.4)──╭X──────H───────────┤ ⟨Z⟩ 2: ──RX(1.571)──╭X──╰C───────────╰C──╭X──RX(-1.571)──┤ ⟨Z⟩ 3: ─────────────╰C───────────────────╰C──────────────┤ ⟨Z⟩
PennyLane 现在提供
DiagonalQubitUnitary用于对角门,例如在 IQP 电路中遇到的这些类型的门可以在模拟器设备上更快地评估。 (#567)该门可以用于高效地模拟神谕:
dev = qml.device('default.qubit', wires=3) # 作为比特串的函数 f = np.array([1, 0, 0, 1, 1, 0, 1, 0]) @qml.qnode(dev) def circuit(weights1, weights2): qml.templates.StronglyEntanglingLayers(weights1, wires=[0, 1, 2]) # 将函数实现为相位反冲神谕 qml.DiagonalQubitUnitary((-1)**f, wires=[0, 1, 2]) qml.templates.StronglyEntanglingLayers(weights2, wires=[0, 1, 2]) return [qml.expval(qml.PauliZ(w)) for w in range(3)]
新增了
TensorNCVObservable,可以表示光子后端的NumberOperator的张量积。 (#608)
新模板
增加了
ArbitraryUnitary和ArbitraryStatePreparation模板,它们使用PauliRot门执行任意酉变换并准备具有最少参数的任意基态。 (#590)dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) def circuit(weights1, weights2): qml.templates.ArbitraryStatePreparation(weights1, wires=[0, 1, 2]) qml.templates.ArbitraryUnitary(weights2, wires=[0, 1, 2]) return qml.probs(wires=[0, 1, 2])
添加了
IQPEmbedding模板,该模板将输入编码到IQP电路的对角门中。 (#605)
添加了
SimplifiedTwoDesign模板,它实现了 Cerezo et al. (2020) 的电路设计。(#556)
添加了
BasicEntanglerLayers模板,这是一个简单的旋转和最近邻 CNOT 纠缠器的层架构。
PennyLane 现在提供广播功能以便于构建模板:
qml.broadcast()接受单量子操作或其他模板,并将它们应用于特定模式的线路上。 (#515) (#522) (#526) (#603)例如,我们可以使用广播在多个线路上重复自定义模板:
from pennylane.templates import template @template def mytemplate(pars, wires): qml.Hadamard(wires=wires) qml.RY(pars, wires=wires) dev = qml.device('default.qubit', wires=3) @qml.qnode(dev) def circuit(pars): qml.broadcast(mytemplate, pattern="single", wires=[0,1,2], parameters=pars) return qml.expval(qml.PauliZ(0))
>>> circuit([1, 1, 0.1]) -0.841470984807896 >>> print(circuit.draw()) 0: ──H──RY(1.0)──┤ ⟨Z⟩ 1: ──H──RY(1.0)──┤ 2: ──H──RY(0.1)──┤
有关其他可用模式,请参见 广播函数文档。
重大变更
现在的
QAOAEmbedding使用新的MultiRZ门作为ZZ纠缠器,这改变了约定。之前,嵌入中的ZZ门的实现为CNOT(wires=[wires[0], wires[1]]) RZ(2 * parameter, wires=wires[0]) CNOT(wires=[wires[0], wires[1]])
MultiRZ对应于CNOT(wires=[wires[1], wires[0]]) RZ(parameter, wires=wires[0]) CNOT(wires=[wires[1], wires[0]])
这在
2的因子上有所不同,并修复了施加CNOT的线的一个错误。(#609)概率方法由
QubitDevice处理,设备方法的要求被修改以简化插件开发。 (#573)内部变量
All和Any用于标记一个Operation是作用于所有或任意线路,已经改名为AllWires和AnyWires。
改进
引入了一个新的
Wires类用于内部记录线索的索引。 (#615)将
"backprop"和"device"微分方法添加到qnode装饰器中。 (#552)"backprop": 使用传统的反向传播。在经典端到端可微分的模拟器设备上默认启用。 返回的QNode只能与相同的机器学习框架一起使用(例如,default.tensor.tf模拟器与tensorflow接口)。"device": 直接查询设备以获取梯度。
使用
"backprop"微分方法和default.tensor.tf设备创建的 QNode 是一个“白盒”,并且与整体 TensorFlow 计算紧密集成:>>> dev = qml.device("default.tensor.tf", wires=1) >>> @qml.qnode(dev, interface="tf", diff_method="backprop") >>> def circuit(x): ... qml.RX(x[1], wires=0) ... qml.Rot(x[0], x[1], x[2], wires=0) ... return qml.expval(qml.PauliZ(0)) >>> vars = tf.Variable([0.2, 0.5, 0.1]) >>> with tf.GradientTape() as tape: ... res = circuit(vars) >>> tape.gradient(res, vars) <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-2.2526717e-01, -1.0086454e+00, 1.3877788e-17], dtype=float32)>
电路绘制器现在显示了反转操作,以及从设备返回概率的线路: (#540)
>>> @qml.qnode(dev) ... def circuit(theta): ... qml.RX(theta, wires=0) ... qml.CNOT(wires=[0, 1]) ... qml.S(wires=1).inv() ... return qml.probs(wires=[0, 1]) >>> circuit(0.2) array([0.99003329, 0. , 0. , 0.00996671]) >>> print(circuit.draw()) 0: ──RX(0.2)──╭C───────╭┤ Probs 1: ───────────╰X──S⁻¹──╰┤ Probs
您现在可以通过新的
VQECost.metric_tensor方法评估 VQE 哈密顿量的度量张量。这允许VQECost对象被量子自然梯度优化器 (qml.QNGOptimizer) 直接优化。(#618)现在在
pennylane.templates.utils中的输入检查函数是公开的,并在API文档中可见。 (#566)为
qnode装饰器、QNode和JacobianQNode类添加了步长和阶数的关键字参数。这使用户能够在使用有限差分方法时设置步长和阶数。这些选项在创建QNode集合时也会被暴露。 (#530) (#585) (#587)CRY门的分解现在使用更简单的形式RY @ CNOT @ RY @ CNOT(#547)底层队列系统进行了重构,移除了持有当前活动的
QNode或OperationRecorder的qml._current_context属性。现在,所有公开操作队列的对象都继承自QueuingContext并全局注册它们的队列。 (#548)PennyLane 仓库有一个新的基准测试工具,支持不同 git 修订版之间的比较。 (#568) (#560) (#516)
文档
错误修复
tf.GradientTape().jacobian()现在可以使用 TensorFlow 接口在 QNodes 上进行评估。 (#626)RandomLayers()现在兼容 qiskit 设备。(#597)DefaultQubit.probability()现在在调用device.analytic=False时返回正确的概率。 (#563)修复了
StronglyEntanglingLayers模板中的一个错误,使其在应用于单根线时能够正确工作。 (544)修复了在使用分解时反转操作的错误;标记为反转的操作在调用后备分解时现在会正确反转。(#543)
现在,
QNode.print_applied()方法正确显示返回qml.prob()的线路。 #542
贡献者
此版本包含来自(按字母顺序排列)的贡献:
维尔·贝尔霍尔姆, 拉娜·博扎尼克, 托马斯·布罗姆利, 西奥多·伊萨克森, 乔希·伊扎克, 纳森·基洛兰, 玛吉·李, 约翰内斯·雅各布·梅耶, 玛丽亚·舒尔德, 苏金·西姆, 安塔尔·萨瓦。
- orphan
发行版 0.8.0¶
自上次发布以来的新特性
添加了一个量子化学包,
pennylane.qchem,支持与OpenFermion、Psi4、PySCF和OpenBabel的集成。 (#453)功能包括:
直接从分子的原子结构生成量子比特哈密顿量。
计算分子 的平均场(哈特里-福克)电子结构。
允许根据活跃电子和活跃轨道的数量定义一个活跃空间。
使用OpenFermion中实现的不同函数执行电子哈密顿量的费米子到量子比特的转换。
将OpenFermion的QubitOperator转换为Pennylane
Hamiltonian类。使用这个哈密顿量在PennyLane中执行变分量子特征求解器(VQE)计算。
查看量子化学快速入门以及量子化学和变分量子特征值求解(VQE)教程。
PennyLane 现在有一些用于创建和解决 VQE 问题的函数和类。 (#467)
qml.Hamiltonian: 一个轻量级的类,用于表示量子比特哈密顿量qml.VQECost: 一个类,用于快速构造给定电路假设、哈密顿量和一个或多个设备的可微成本函数>>> H = qml.vqe.Hamiltonian(coeffs, obs) >>> cost = qml.VQECost(ansatz, hamiltonian, dev, interface="torch") >>> params = torch.rand([4, 3]) >>> cost(params) tensor(0.0245, dtype=torch.float64)
添加了一个电路绘制功能,提供了 QNode 实例的文本表示。可以通过
qnode.draw()调用。用户可以指定显示变量名称而不是变量值,并选择 ASCII 或 Unicode 字符集。 (#446)以下电路作为示例:
@qml.qnode(dev) def qfunc(a, w): qml.Hadamard(0) qml.CRX(a, wires=[0, 1]) qml.Rot(w[0], w[1], w[2], wires=[1]) qml.CRX(-a, wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
我们可以在执行后绘制电路:
>>> result = qfunc(2.3, [1.2, 3.2, 0.7]) >>> print(qfunc.draw()) 0: ──H──╭C────────────────────────────╭C─────────╭┤ ⟨Z ⊗ Z⟩ 1: ─────╰RX(2.3)──Rot(1.2, 3.2, 0.7)──╰RX(-2.3)──╰┤ ⟨Z ⊗ Z⟩ >>> print(qfunc.draw(charset="ascii")) 0: --H--+C----------------------------+C---------+|
1: -----+RX(2.3)--Rot(1.2, 3.2, 0.7)--+RX(-2.3)--+| >>> print(qfunc.draw(show_variable_names=True)) 0: ──H──╭C─────────────────────────────╭C─────────╭┤ ⟨Z ⊗ Z⟩ 1: ─────╰RX(a)──Rot(w[0], w[1], w[2])──╰RX(-1*a)──╰┤ ⟨Z ⊗ Z⟩ 添加了
QAOAEmbedding及其参数初始化作为一个新的可训练模板。 (#442)
添加了
qml.probs()测量函数,允许 QNodes 在模拟器和硬件上区分变分电路概率。 (#432)@qml.qnode(dev) def circuit(x): qml.Hadamard(wires=0) qml.RY(x, wires=0) qml.RX(x, wires=1) qml.CNOT(wires=[0, 1]) return qml.probs(wires=[0])
执行此电路将给出线 1 的边际概率:
>>> circuit(0.2) [0.40066533 0.59933467]
返回概率的 QNodes 完全支持自动微分。
添加了方便的加载函数
qml.from_pyquil,qml.from_quil和qml.from_quil_file,它们将 pyQuil 对象和 Quil 代码转换为 PennyLane 模板。此功能需要 PennyLane-Forest 插件的 0.8 版本或更高版本。 (#459)新增了一个
qml.inv方法,用于反转模板和操作序列。新增了一个@qml.template装饰器,使模板返回排队的操作。(#462)例如,使用此函数在 QNode 中反转一个模板:
@qml.template def ansatz(weights, wires): for idx, wire in enumerate(wires): qml.RX(weights[idx], wires=[wire]) for idx in range(len(wires) - 1): qml.CNOT(wires=[wires[idx], wires[idx + 1]]) dev = qml.device('default.qubit', wires=2) @qml.qnode(dev) def circuit(weights): qml.inv(ansatz(weights, wires=[0, 1])) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1))
添加了
QNodeCollection容器类,允许独立的 QNodes 被同时存储和评估。提供了对包含的 QNodes 的异步评估的实验性支持,使用parallel=True关键词参数。 (#466)添加了一个高级
qml.map函数,它将一个量子电路模板映射到一组观测值或设备上,并返回一个QNodeCollection。 (#466)例如:
>>> def my_template(params, wires, **kwargs): >>> qml.RX(params[0], wires=wires[0]) >>> qml.RX(params[1], wires=wires[1]) >>> qml.CNOT(wires=wires) >>> obs_list = [qml.PauliX(0) @ qml.PauliZ(1), qml.PauliZ(0) @ qml.PauliX(1)] >>> dev = qml.device("default.qubit", wires=2) >>> qnodes = qml.map(my_template, obs_list, dev, measure="expval") >>> qnodes([0.54, 0.12]) array([-0.06154835 0.99280864])
添加了高层次的
qml.sum,qml.dot,qml.apply函数 它们作用于 QNode 集合。 (#466)qml.apply允许向量化函数作用于整个 QNode 集合:>>> qnodes = qml.map(my_template, obs_list, dev, measure="expval") >>> cost = qml.apply(np.sin, qnodes) >>> cost([0.54, 0.12]) array([-0.0615095 0.83756375])
qml.sum和qml.dot分别对 QNode 集合求和和对张量/数组/QNode 集合进行点积。
重大变更
弃用旧式
QNode,现在只能使用新式QNode及其语法, 所有相关文件已从pennylane/beta文件夹移动到pennylane。
改进
添加了
Tensor.prune()方法和Tensor.non_identity_obs属性,用于提取构成Tensor实例的非单位观察量实例。(#498)将
expt.tensornet和expt.tensornet.tf设备重命名为default.tensor和default.tensor.tf。 (#495)向
CircuitGraph类添加了一个序列化方法,该方法用于为每个量子电路图创建唯一的哈希值。 (#470)新增了
Observable.eigvals方法以返回可观测量的特征值。 (#449)添加了
Observable.diagonalizing_gates方法,以返回在计算基中对可观察量进行对角化的门。 (#454)添加了
Operator.matrix方法来返回算子的计算基中的矩阵表示。 (#454)新增了一个
QubitDevice类,该类实现了插件设备的常见功能,因此插件设备可以依赖这些实现。新的QubitDevice还包含一个新的execute方法,使插件设计更加方便。此外,QubitDevice还统一了基于量子位设备生成样本的方式。 (#452) (#473)文档中的代码块现在有一个“复制”按钮,方便复制示例。 (#437)
文档
更新开发者插件指南以使用 QubitDevice。 (#483)
错误修复
修复了在
CVQNode._pd_analytic中的一个错误,在使用二阶参数移位方法评估偏导数时,非后代可观测量未经过海森堡变换,从而导致某些电路的雅可比矩阵错误。(#433)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
胡安·米格尔·阿拉佐拉,维尔·贝尔霍尔姆,阿兰·德尔加多·格兰,奥利维亚·迪·马泰奥, 西奥多·伊萨克森,乔什·伊扎克,索兰·贾汉吉里,纳森·基洛兰,约翰内斯·雅各布·迈耶, 泽越·牛,玛利亚·舒尔德,安塔尔·萨瓦。
- orphan
发布 0.7.0¶
自上次发布以来的新特性
在
AmplitudeEmbedding中支持自定义填充常数(见‘破坏性变更’。)(#419)StronglyEntanglingLayer和RandomLayer现在可以在单个线缆上工作。 (#409) (#413)添加了在电路中应用
Operation的逆操作的支持。 (#377)添加了一个
OperationRecorder()上下文管理器,允许在记录事件的同时执行模板和量子函数。记录器可以作为调试工具在有或没有 QNodes 的情况下使用。操作现在可以指定在目标设备上不支持所需操作时使用的分解。 (#396)
通过新的
qml.load()函数,增加了从外部框架加载电路作为模板的能力。此功能需要插件支持 — 此初始版本提供对 Qiskit 电路和 QASM 文件的支持,当pennylane-qiskit安装时,通过函数qml.from_qiskit和qml.from_qasm实现。(#418)已添加一个使用TensorFlow进行反向传播的实验性张量网络设备(#427)
在
AmplitudeEmbedding中支持自定义填充常数(见‘破坏性变更’。)(#419)
重大变更
在
AmplitudeEmbedding()中的pad参数现在可以是None(不进行自动填充),或者是一个用作填充值的数字。 (#419)初始化函数现在返回每个函数的单一权重数组。提供了多权重模板的工具
Interferometer()和CVNeuralNetLayers()。 (#412)单层模板
RandomLayer(),CVNeuralNetLayer()和StronglyEntanglingLayer()已被转换为私有函数_random_layer(),_cv_neural_net_layer()和_strongly_entangling_layer()。推荐的使用方式现在是通过相应的Layers()模板。 (#413)
改进
在模板中添加了广泛的输入检查。 (#419)
在
(#346)default.qubit插件中,状态向量准备操作现在可以应用于线路的子集,并且被限制为电路中的第一个操作。添加了门 U1、U2 和 U3,这些门对 1、2 和 3 量子比特上的任意单元进行参数化,并将 Toffoli 门添加到量子比特操作集。
已进行更改以适应将主函数移动到
(#404)pytest._internal到pytest._internal.main在 pip 19.3 中。添加了模板
BasisStatePreparation和MottonenStatePreparation,分别使用门电路准备基态和任意态。 (#336)基于状态准备模板,为
BasisState和QubitStateVector添加了分解。 (#414)在量子自然梯度优化器中将伪逆替换为
np.linalg.solve(这可能在数值上不稳定)。(#428)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
维尔·贝尔洪姆,乔什·伊扎克,内森·基洛兰,安格斯·洛,约翰内斯·雅各布·梅耶,奥卢瓦托比·奥古恩巴约,玛丽亚·舒尔德,安塔尔·沙瓦。
- orphan
发布 0.6.0¶
自上次发布以来的新特性
设备
default.qubit和default.gaussian具有一个新的初始化参数analytic,它指示期望值和方差是否应该通过解析计算,而不是从数据中估计。 (#317)将C-SWAP门添加到量子比特操作集 (#330)
TensorFlow接口已从
"tfe"重命名为"tf",并且现在支持TensorFlow 2.0。 (#337)将S和T门添加到量子位操作集合中。 (#343)
现在在
expval,var和sample函数中支持张量可观察量,使用@运算符。
重大变更
参数
n指定的方法Device.sample中的样本数量已被移除。 相反,该方法将始终返回Device.shots个样本。 (#317)
改进
用于估计期望值和方差的射击次数/随机样本数量,
Device.shots,现在可以在设备创建后进行更改。 (#317)统一的导入快捷方式应该在 qnode.py 和 test_operation.py 中 (#329)
量子自然梯度现在使用
scipy.linalg.pinvh,对于对称矩阵来说比之前使用的scipy.linalg.pinv更高效。(#331)已移除弃用的
qml.expval.Observable语法。 (#267)剩余的unittest风格的测试被移植到pytest中。 (#310)
对于操作,
(#359)do_queue参数现在仅在 QNodes 内有效。在 QNodes 之外,操作现在可以实例化而无需指定do_queue。
文档
文档已重写和重组,包含代码介绍部分以及API部分。 (#314)
已将伊辛模型示例添加到教程中 (#319)
为MaxCut问题添加了QAOA教程 (#328)
在其教程中添加了QGAN流程图 (#333)
为状态准备和QGAN教程的画廊缩略图添加了缺失的图形 (#326)
修正了状态准备教程中的拼写错误 (#321)
修复了VQE教程中的3D图表bug (#327)
错误修复
修正了qnode.py中测量类型错误消息的拼写错误 (#341)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
Shahnawaz Ahmed, Ville Bergholm, Aroosa Ijaz, Josh Izaac, Nathan Killoran, Angus Lowe, Johannes Jakob Meyer, Maria Schuld, Antal Száva, Roeland Wiersema。
- orphan
版本 0.5.0¶
自上次发布以来的新特性
添加一个新的优化器,
qml.QNGOptimizer,它使用量子自然梯度下降优化QNodes。详情请参见https://arxiv.org/abs/1909.02108。 (#295) (#311)添加一个新的 QNode 方法,
(#295)QNode.metric_tensor(),它返回附加设备上计算的 Fubini-Study 测度张量的块对角近似。采样支持:QNodes 现在可以通过顶层
pennylane.sample()函数从给定的可观测量返回指定数量的样本。为了在插件设备上支持这一功能,增加了新的Device.sample方法。涉及采样的 QNodes 的梯度计算是不可行的。
(#256)default.qubit已更新以支持采样。 (#256)为PennyLane操作和
default.qubit插件添加了受控旋转门。 (#251)
重大变更
方法
Device.supported被移除,并被方法Device.supports_observable和Device.supports_operation取代。 这两个方法可以接受字符串参数 (dev.supports_observable('PauliX')) 和 类参数 (dev.supports_observable(qml.PauliX))。 (#276)以下CV可观察量已更名以符合新的操作/可观察量方案:
MeanPhoton更名为NumberOperator,Homodyne更名为QuadOperator,以及NumberState更名为FockStateProjector。 (#254)
改进
现在,
AmplitudeEmbedding函数提供了规范化和填充特征的选项,以确保准备一个有效的状态向量。(#275)操作现在可以选择性地指定生成器,既可以是现有的PennyLane操作,也可以提供一个NumPy数组。 (#295) (#313)
添加一个
Device.parameters属性,以便设备可以查看自由参数与操作参数的字典映射。这将允许插件设备利用参数化编译。 (#283)引入了两个枚举:
Any和All,分别表示系统中的任意数量的线路和所有线路。它们可以从pennylane.operation导入,并可以在定义操作的Operation.num_wires类属性时使用。 (#277)作为此次更改的一部分:
所有等价于整数 0,以便与现有的测试套件向后兼容Any等价于整数 -1,以允许数值比较运算符继续工作现在在
Operation类中添加了额外的验证, 这将提醒用户一个num_wires = All的操作正在被错误地执行。
在
pennylane.plugins.default_qubit中,一量子比特旋转不再依赖于 Scipy 的expm。相反,它们是通过欧拉公式计算的。 (#292)创建一个
(#290)ObservableReturnTypes枚举类,包含Sample、Variance和Expectation。这些新值可以被赋值给return_type属性的Observable。将
RandomLayer和RandomLayers模板的签名更改为默认具有固定种子。 (#258)setup.py已经过清理,移除了无效的 shebang,并删除了未使用的导入。 (#262)
文档
一个文档重构,以简化教程并包含 Sphinx-Gallery。(#291)
以前分散在
examples/和doc/tutorials/目录中的示例和教程,用混合的 ReST 和 Jupyter 笔记本,已经被重写为在一个位置的 Python 脚本,并带有 ReST 注释,位于examples/文件夹中。Sphinx-Gallery用于自动构建和运行教程。渲染的输出显示在Sphinx文档中。
每个教程页面顶部提供了链接,以下载教程作为可执行的 python 脚本,下载教程作为 Jupyter notebook,或者在 GitHub 上查看该 notebook。
教程目录已移动到一个快速入门页面。
修正了
QubitStateVector中的一个拼写错误。 (#296)修复了
default_gaussian.gaussian_state函数中的一个拼写错误。 (#293)修正了
RX,RY,RZ操作文档字符串中的拼写错误。 (#248)修复了教程文档中的一个损坏链接,作为
qml.expval.Observable弃用的结果。(#246)
错误修复
修复了一个错误,即当将
PolyXP可观察量应用于default.gaussian的电线子集时会失败。 (#277)
贡献者
此版本包含来自(按字母顺序排列)的贡献:
西蒙·克罗斯,阿鲁萨·伊贾兹,乔什·伊扎克,纳森·基洛兰,约翰内斯·雅各布·迈耶,罗希特·米达,尼古拉斯·凯萨达,玛利亚·舒尔德,安塔尔·萨瓦,罗兰·维尔塞马。
- orphan
版本 0.4.0¶
自上次发布以来的新特性
pennylane.expval()现在是一个顶级 函数,不再是一个类的包。目前,现有的pennylane.expval.Observable接口仍然有效,但会引发弃用警告。 (#232)方差支持:QNodes 现在可以通过顶级
pennylane.var()函数返回可观察量的方差。为了在插件设备上支持这一点,增加了一个新的Device.var方法。以下可观测量支持方差的解析梯度:
所有量子比特可观察量(对自反可观察量,例如
Identity,X,Y,Z需要 3 次电路评估;对非自反可观察量,目前仅qml.Hermitian需要 5 次电路评估)一阶 CV 可观测量(需要 5 次电路评估)
二阶CV可观察量支持数值方差梯度。
pennylane.about()函数已添加,提供当前PennyLane版本、已安装插件、Python、平台和NumPy版本的详细信息 (#186)移除了允许在量子操作中将
wires作为位置参数传递的逻辑。这使我们能够在使用不正确的语法时为用户提供更有用的错误信息。 (#188)为
pennylane.Hermitian()可观测量的多量子比特期望值添加支持 (#192)为
default.qubit添加对多量子比特期望值的支持。 (#202)将模板组织为子模块 (#195)。这包括以下改进:
区分嵌入模板和层模板。
新的随机初始化函数支持在新的子模块
pennylane.init中可用的模板。新增了一个随机电路模板 (
RandomLayers()), 在其中旋转和2量子比特门随机分布在导线上添加各种嵌入策略
重大变更
(#232)Device方法expectations,pre_expval, 和post_expval已被重命名为observables,pre_measure, 和post_measure分别。
改进
default.qubit插件现在在应用量子操作和评估期望时使用np.tensordot,这导致了显著的速度提升 (#239),(#241)PennyLane 现在允许将量子操作参数除以一个常数 (#179)
测试套件的部分正在移植到pytest中。 注意:这仍然是一个正在进行中的工作。
移植的测试包括:
test_ops.pytest_about.pytest_classical_gradients.pytest_observables.pytest_measure.pytest_init.pytest_templates*.pytest_ops.pytest_variable.pytest_qnode.py(部分)
错误修复
修复了
Device.supported中的一个错误,该错误会错误地将一个操作标记为支持,如果它与一个可观察的对象共享名称 (#203)修复了
Operation.wires中的一个错误,通过显式地将每个导线的类型转换为整数 (#206)删除了在PennyLane中配置日志记录器的代码,因为这会与用户的配置冲突 (#208)
修复了在
default.qubit中的一个错误,其中QubitStateVector操作 错误地被转换为np.float而不是np.complex。 (#211)
贡献者
本次发布包含以下贡献者:
Shahnawaz Ahmed, riveSunder, Aroosa Ijaz, Josh Izaac, Nathan Killoran, Maria Schuld.
- orphan
发布 0.3.0¶
自上次发布以来的新特性
PennyLane 现在包括一个新的
interfaces子模块,允许 QNode 与其他机器学习库的集成。为QNodes添加对实验性PyTorch接口的支持
为QNodes添加对实验性TensorFlow即时执行接口的支持
在文档中添加一个 PyTorch+GPU+QPU 教程
文档现在包括链接和教程,包括新的 PennyLane-Forest 插件。
改进
通过
print(qnode)或在交互式终端中打印 QNode 对象,现在显示关于 QNode 的更多有用信息,包括它运行的设备、导线数量、接口以及它使用的量子函数:>>> print(qnode)
贡献者
本次发布包含以下贡献者:
乔什·伊扎克和内森·基洛兰。
- orphan
发布 0.2.0¶
自上次发布以来的新特性
新增了
Identity期望值,适用于CV和量子比特模型 (#135)添加了
templates.py子模块,包含一些常用的 QML 模型,可用作 QNodes 中的 Ansatz (#133)添加了
qml.InterferometerCV 操作 (#152)现在支持将线路作为自由 QNode 参数 (#151)
添加了更新优化器步长的能力 (#159)
改进
创建了新的
PlaceholderExpectation,当CV和qubit expval模块包含相同名称的期望时使用提供了一种让插件在应用操作之前查看操作队列的方法。这允许对队列进行即时修改,使基于硬件的插件能够支持所有量子比特期望值的范围。 (#143)
QNode 返回值现在支持 任何 形式的序列,例如列表、集合等。 (#144)
CV分析梯度计算现在更加稳健,允许进行可能无法被微分的操作,但具有明确的
_heisenberg_rep方法,因此可能成功执行解析上可微分的操作 (#152)
错误修复
贡献者
本次发布包含以下贡献者:
克里斯蒂安·戈戈林,乔希·伊扎克,内森·基洛兰和玛丽亚·舒尔德。
- orphan
发布 0.1.0¶
初始公开发布。
贡献者
本版本包含来自以下人员的贡献:
Ville Bergholm, Josh Izaac, Maria Schuld, Christian Gogolin和Nathan Killoran。