预测
预测工作流程。
训练后,交互模型(例如,TransE, ConvE, RotatE)可以为任意三元组分配一个分数,无论它是否在训练或测试期间出现过。在PyKEEN中,每个模型的实现都是分数越高(或分数越不负面),三元组为真的可能性越大。
然而,对于大多数模型,这些分数没有明显的统计解释。这有两个主要后果:
一个模型中的三元组得分不能与另一个模型中的该三元组得分进行比较
没有先验的最低分数来标记三元组为真,因此必须通过按各自分数对一组三元组进行排序来给出预测的优先级。
在本部分文档的其余部分中,我们假设我们已经训练了一个模型,例如通过
>>> from pykeen.pipeline import pipeline
>>> result = pipeline(dataset="nations", model="pairre", training_kwargs=dict(num_epochs=0))
高级
预测工作流程提供了三种高级方法来进行预测
pykeen.predict.predict_triples()可以用于计算给定三元组的分数。pykeen.predict.predict_target()可以用于为给定的预测目标评分选择,即在给定其他两个的情况下计算头部实体、关系或尾部实体的分数。pykeen.predict.predict_all()可以用于计算所有可能三元组的分数。 从科学角度来看,pykeen.predict.predict_all()在可以实验性测试和验证预测的场景中最为有趣。
警告
请注意,并非所有模型都自动具有可解释的分数,其校准可能较差。因此,在解释结果时要谨慎。
三重评分
当使用pykeen.predict.predict_triples()对三元组进行评分时,我们会为每个给定的三元组获得一个分数。例如,我们将计算模型训练数据集中的所有验证三元组的分数。
>>> from pykeen.datasets import get_dataset
>>> from pykeen.predict import predict_triples
>>> dataset = get_dataset(dataset="nations")
>>> pack = predict_triples(model=result.model, triples=dataset.validation)
变量 pack 现在包含一个 pykeen.predict.ScorePack,它本质上是一对基于ID的三元组及其预测分数。为了解释,添加它们对应的标签可能会有所帮助,“nations” 数据集提供了这些标签,并将它们转换为 pandas 数据框:
>>> df = pack.process(factory=result.training).df
既然我们现在有了一个数据框,我们可以利用pandas的全部功能进行后续分析,例如,显示获得最高分数的三元组
>>> df.nlargest(n=5, columns="score")
或调查某些实体是否通常获得较大的分数
>>> df.groupby(by=["head_id", "head_label"]).agg({"score": ["mean", "std", "count"]})
目标评分
pykeen.predict.predict_target() 的主要用途是链接预测或关系预测。
例如,我们可以使用我们的模型来为查询 (“uk”, “conferences”, ?) 的所有可能尾部实体打分,通过
>>> from pykeen.datasets import get_dataset
>>> from pykeen.predict import predict_target
>>> dataset = get_dataset(dataset="nations")
>>> pred = predict_target(
... model=result.model,
... head="uk",
... relation="conferences",
... triples_factory=result.training,
... )
请注意,存储在pred中的结果是一个pykeen.predict.Predictions对象,它提供了一些后处理选项。例如,我们可以移除训练集中已经知道的所有目标。
>>> pred_filtered = pred.filter_triples(dataset.training)
或者向数据框添加额外的列,以证明目标是否包含在另一个集合中,例如验证集或测试集。
>>> pred_annotated = pred_filtered.add_membership_columns(validation=dataset.validation, testing=dataset.testing)
预测对象还通过其df属性公开了过滤/注释的数据框
>>> pred_annotated.df
完整评分
最后,我们可以使用pykeen.predict.predict()来计算所有可能三元组的分数。请注意,对于合理大小的知识图谱,此操作可能会非常昂贵,并且模型可能会为在训练期间从未见过的实体/关系组合产生额外的未校准分数。下一行计算并存储所有三元组和分数。
>>> from pykeen.predict import predict_all
>>> pack = predict_all(model=result.model)
除了昂贵的计算之外,这还要求我们有足够的内存来存储所有分数。一个计算上同样昂贵但内存需求减少且固定的选项是仅存储具有最高\(k\)分数的三元组。这可以通过可选参数k来实现。
>>> pack = predict_all(model=result.model, k=10)
我们可以再次将分数包转换为预测对象以进行进一步过滤,例如,添加一列指示该三元组是否在训练期间被看到
>>> pred = pack.process(factory=result.training)
>>> pred_annotated = pred.add_membership_columns(training=result.training)
>>> pred_annotated.df
低级
以下部分概述了关于需要为所有三元组计算分数的操作实现的一些细节。该算法的工作原理如下:
for batch in DataLoader(dataset, batch_size=batch_size):
scores = model.predict(batch)
for consumer in consumers:
consumer(batch, scores)
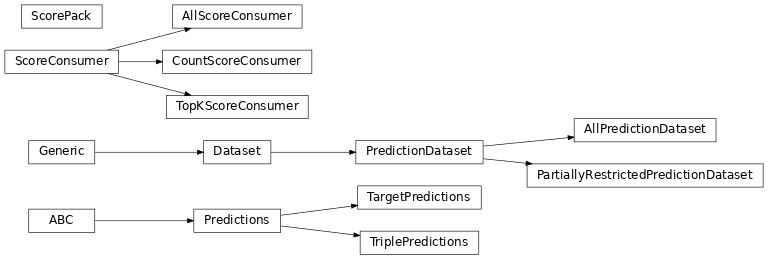
在这里,dataset 是一个 pykeen.predict.PredictionDataset,它将
得分计算分解为单个目标预测(例如,尾部预测)。
实现包括 pykeen.predict.AllPredictionDataset 和
pykeen.predict.PartiallyRestrictedPredictionDataset。请注意,
预测任务是延迟构建的,即仅在访问时实例化预测任务。此外,torch_max_mem 包用于自动调整
批量大小,以最大化当前硬件的内存利用率。
对于每个批次,预测任务的分数计算一次。之后,多个消费者可以处理这些分数。一个消费者扩展了pykeen.predict.ScoreConsumer并接收批次,即预测方法的输入,以及预测分数的张量。示例包括
pykeen.predict.CountScoreConsumer: 一个简单的消费者,仅计算它看到的分数数量。主要用于调试或测试目的pykeen.predict.AllScoreConsumer: 将所有分数累积到一个巨大的张量中。 对于合理大小的数据集,这会导致巨大的内存需求,通常可以通过将分数的处理与单个批次的计算交错进行来避免。pykeen.predict.TopKScoreConsumer: 仅保留前 \(k\) 个分数以及导致这些分数的输入。这是首先累积所有分数,然后按分数排序并仅保留顶部条目的内存高效变体。
潜在的注意事项
该模型是在特定的链接预测任务上训练的,例如预测给定头/关系对的适当尾部。这意味着虽然模型在技术上也可以预测其他链接,例如给定头/尾对之间的关系,但必须注意它并未为此任务进行训练,因此其得分可能会表现得不尽如人意。
迁移指南
直到版本1.9,模型本身提供了包装器,这些包装器会委托给pykeen.models.predict中的相应方法
model.get_all_prediction_df
model.get_prediction_df
model.get_head_prediction_df
model.get_relation_prediction_df
model.get_tail_prediction_df
这些方法已经被弃用,可以通过将模型作为显式参数提供给预测模块中的独立函数来替换。因此,我们将重点放在迁移独立函数上。
在pykeen.models.predict模块中,预测方法的组织方式有所不同。其中包括
get_prediction_df
get_head_prediction_df
get_relation_prediction_df
get_tail_prediction_df
get_all_prediction_df
predict_triples_df
其中get_head_prediction_df、get_relation_prediction_df和get_tail_prediction_df已被弃用,转而直接使用get_prediction_df,除了预测目标外,所有内容都已提供,例如,
>>> from pykeen.models import predict
>>> prediction.get_tail_prediction_df(
... model=model,
... head_label="belgium",
... relation_label="locatedin",
... triples_factory=result.training,
... )
已被弃用,转而支持
>>> from pykeen.models import predict
>>> predict.get_prediction_df(
... model=model,
... head_label="brazil",
... relation_label="intergovorgs",
... triples_factory=result.training,
... )
get_prediction_df
旧的使用方式
>>> from pykeen.models import predict
>>> predict.get_prediction_df(
... model=model,
... head_label="brazil",
... relation_label="intergovorgs",
... triples_factory=result.training,
... )
可以被替换为
>>> from pykeen import predict
>>> predict.predict_target(
... model=model,
... head="brazil",
... relation="intergovorgs",
... triples_factory=result.training,
... ).df
注意尾随的.df。
get_all_prediction_df
旧的使用方式
>>> from pykeen.models import predict
>>> predictions_df = predict.get_all_prediction_df(model, triples_factory=result.training)
可以被替换为
>>> from pykeen import predict
>>> predict.predict_all(model=model).process(factory=result.training).df
predict_triples_df
旧的使用
>>> from pykeen.models import predict
>>> score_df = predict.predict_triples_df(
... model=model,
... triples=[("brazil", "conferences", "uk"), ("brazil", "intergovorgs", "uk")],
... triples_factory=result.training,
... )
可以被替换为
>>> from pykeen import predict
>>> score_df = predict.predict_triples(
... model=model,
... triples=[("brazil", "conferences", "uk"), ("brazil", "intergovorgs", "uk")],
... triples_factory=result.training,
... )
函数
|
计算所有三元组的分数,并保留所有三元组或仅保留前k个三元组。 |
|
对标记或映射的三元组进行预测。 |
|
获取头部、关系和/或尾部组合的预测。 |
|
批量计算所有三元组分数和消耗。 |
类
访问者模式得分的消费者。 |
|
一个简单的消费者,用于计算批次和分数的数量。 |
|
|
收集前k个三元组和分数。 |
|
收集所有三元组的分数。 |
|
一对结果三元组和分数。 |
|
预测的基类。 |
|
带有预测分数的三元组。 |
|
目标及其预测得分。 |
|
预测数据集的基类。 |
|
用于预测所有可能三元组的数据集。 |
|
用于评分一些链接的数据集。 |
类继承图