数据集
pykeen.datasets 包
PyKEEN的内置数据集。
新的数据集(继承自 pykeen.datasets.Dataset)可以通过在您自己的 setup.py、setup.cfg、pyproject.toml 或其他包配置中的 Python entrypoints 使用 pykeen.datasets 组来注册到 PyKEEN 中。它们通过 importlib.metadata.entry_points() 自动加载,并通过 class_resolver 进行解析。
函数
|
获取一个数据集,基于给定的kwargs进行缓存。 |
|
返回数据集是否在PyKEEN中注册。 |
类
|
基础数据集类。 |
|
来自[chen2021]的Aristo-v4数据集。 |
|
来自[himmelstein2017]的Hetionet数据集。 |
|
亲属关系数据集。 |
|
国家数据集。 |
|
OpenBioLink 数据集。 |
|
OpenBioLink数据集的低质量变体。 |
|
CoDEx小型数据集。 |
|
CoDEx 中型数据集。 |
|
CoDEx大型数据集。 |
|
CN3l 数据集家族。 |
|
OGB BioKG 数据集。 |
|
OGB WikiKG2 数据集。 |
|
UMLS数据集。 |
|
FB15k数据集。 |
|
FB15k-237 数据集。 |
|
WK3l-15k 数据集家族。 |
|
WK3l-120k 数据集家族。 |
|
WN18数据集。 |
|
WN18-RR数据集。 |
|
YAGO3-10数据集是YAGO3的一个子集,仅包含至少具有10个关系的实体。 |
|
DRKG数据集。 |
|
BioKG数据集来自[walsh2020]。 |
|
来自[speer2017]的ConceptNet数据集。 |
|
来自[santos2020]的临床知识图谱(CKG)数据集。 |
|
CSKG数据集。 |
|
DBpedia50数据集。 |
|
来自[ding2018]的DB100K数据集。 |
|
OpenEA 数据集家族。 |
|
国家数据集。 |
|
WD50K的三元组版本。 |
|
来自[wang2019]的Wikidata5M数据集。 |
|
来自[zheng2020]的PharmKG8k数据集。 |
|
来自[zheng2020]的PharmKGFull数据集。 |
|
来自[chandak2022]的精准医学知识图谱(PrimeKG)数据集。 |
|
全球生物相互作用(GloBI)数据集。 |
|
来自[koenigs2022]的PharMeBINet数据集。 |
变量
数据集解析器 |
类继承图

pykeen.datasets.base 模块
用于构建数据集的实用类。
函数
|
计算两个数据集之间的相似度。 |
类
|
基础数据集类。 |
|
一个数据集,其训练、测试和可选的验证工厂已预先加载。 |
一个数据集,其训练、测试和可选的验证工厂是延迟加载的。 |
|
|
包含对训练、测试和验证数据集的惰性引用。 |
|
包含对远程数据集的惰性引用,仅在需要时加载。 |
|
一个包含训练、测试和验证集作为URL的数据集。 |
|
一个以tar文件形式存储的远程数据集。 |
|
包含对远程数据集的惰性引用,仅在需要时加载。 |
|
加载一个位于存档内的单个文件的数据集。 |
|
加载一个位于tar.gz压缩包内的单个文件的数据集。 |
|
加载一个位于zip存档内的单个文件的数据集。 |
|
这个类适用于当你有一个单一的TSV边缘文件并希望它们自动分割时。 |
|
这个类适用于当你有一个单独的TSV边缘文件并希望它们自动分割时。 |
类继承图

pykeen.datasets.analysis 模块
数据集分析工具。
函数
|
创建一个包含关系计数的数据框。 |
|
创建一个包含实体计数的数据框。 |
|
创建一个实体/关系共现的数据框。 |
|
计算每个关系的功能性和逆功能性得分。 |
|
基于RotatE的模式对关系进行分类[sun2019]。 |
|
确定关系基数类型。 |
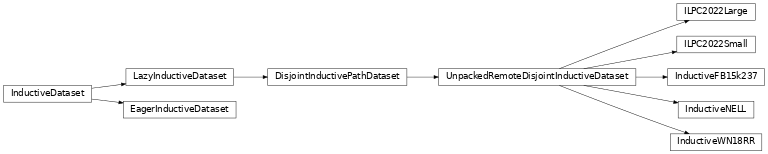
归纳数据集
pykeen.datasets.inductive 包
PyKEEN中的归纳模型。
类
包含转导训练和归纳推理/验证/测试数据集。 |
|
|
一个热切的归纳数据集。 |
一个具有延迟加载的归纳数据集。 |
|
|
由路径指定的不相交归纳数据集。 |
一个包含训练集、归纳推理集、归纳测试集和归纳验证集四个部分的数据集,这些数据集以URL形式提供。 |
|
|
归纳的FB15k-237数据集有4个版本。 |
|
归纳的WN18RR数据集有4个版本。 |
|
归纳NELL数据集的4个版本。 |
|
ILPC 2022挑战赛的归纳链接预测数据集。 |
|
ILPC 2022挑战赛的归纳链接预测数据集。 |
类继承图
实体对齐
pykeen.datasets.ea.combination 模块
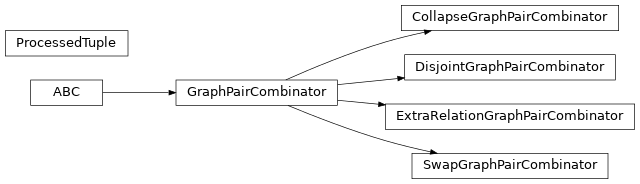
实体对齐数据集的组合策略。
类
将图对组合成单个图的基类。 |
|
这个组合器将两个图保持为不连接的组件。 |
|
通过交换对齐的实体来添加额外的三元组。 |
|
这个组合器保留了所有实体,但引入了一种新的对齐关系。 |
|
这个组合器将所有匹配的实体对合并为一个单一的ID。 |
|
|
处理一对三元组工厂的结果。 |
类继承图