用户指南
在将开源库PyPop7应用于PyPI中的实际黑箱优化(BBO)问题之前,应依次阅读以下四项基本信息:
问题定义
首先,需要以函数的形式定义一个目标函数(在进化计算中也被称为适应度函数,在机器学习中被称为损失函数)。然后,使用数据结构dict作为一种简单而有效的方式来存储与当前优化问题相关的所有设置,例如:
fitness_function: 需要最小化的目标/成本函数(func),
ndim_problem: 维度数 (int),
upper_boundary: 搜索范围的上边界(array_like),
lower_boundary: 搜索范围的下边界(array_like)。
不失一般性,本库仅考虑最小化过程,因为通过简单地否定其目标函数,最大化可以轻松转换为最小化。
下面是一个定义优化领域中著名的测试函数Rosenbrock的简单示例:
1>>> import numpy as np # engine for numerical computing 2>>> def rosenbrock(x): # to define the fitness function to be minimized 3... return 100.0*np.sum(np.square(x[1:] - np.square(x[:-1]))) + np.sum(np.square(x[:-1] - 1.0)) 4>>> ndim_problem = 1000 # to define its settings 5>>> problem = {'fitness_function': rosenbrock, # cost function to be minimized 6... 'ndim_problem': ndim_problem, # dimension of cost function 7... 'lower_boundary': -10.0*np.ones((ndim_problem,)), # lower search boundary 8... 'upper_boundary': 10.0*np.ones((ndim_problem,))} # upper search boundary
当适应度函数本身涉及除了采样点x之外的其他输入参数时(这里我们区分输入参数和上述问题设置),有两种简单的方法来支持这种更复杂的场景:
1) 创建一个类包装器,例如:
1>>> import numpy as np # engine for numerical computing 2>>> def rosenbrock(x, arg): # to define the fitness function to be minimized 3... return arg*np.sum(np.square(x[1:] - np.square(x[:-1]))) + np.sum(np.square(x[:-1] - 1.0)) 4>>> class Rosenbrock(object): # to build a class wrapper 5... def __init__(self, arg): # arg is an extra input argument 6... self.arg = arg 7... def __call__(self, x): # for fitness evaluations 8... return rosenbrock(x, self.arg) 9>>> ndim_problem = 1000 # to define its settings 10>>> problem = {'fitness_function': Rosenbrock(100.0), # cost function to be minimized 11... 'ndim_problem': ndim_problem, # dimension of cost function 12... 'lower_boundary': -10.0*np.ones((ndim_problem,)), # lower search boundary 13... 'upper_boundary': 10.0*np.ones((ndim_problem,))} # upper search boundary
利用本库为所有BBO提供的易于使用的统一 (API) 接口,例如:
1>>> import numpy as np # engine for numerical computing 2>>> def rosenbrock(x, args): 3... return args*np.sum(np.square(x[1:] - np.square(x[:-1]))) + np.sum(np.square(x[:-1] - 1.0)) 4>>> ndim_problem = 10 5>>> problem = {'fitness_function': rosenbrock, # cost function to be minimized 6... 'ndim_problem': ndim_problem, # dimension of cost function 7... 'lower_boundary': -5.0*np.ones((ndim_problem,)), # lower search boundary 8... 'upper_boundary': 5.0*np.ones((ndim_problem,))} # upper search boundary 9>>> from pypop7.optimizers.es.maes import MAES # replaced by any other BBO in this library 10>>> options = {'fitness_threshold': 1e-10, # to terminate when the best-so-far fitness is lower than 1e-10 11... 'max_function_evaluations': ndim_problem*10000, # maximum of function evaluations 12... 'seed_rng': 0, # seed of random number generation (which should be set for repeatability) 13... 'sigma': 3.0, # initial global step-size of Gaussian search distribution 14... 'verbose': 500} # to print verbose information every 500 generations 15>>> maes = MAES(problem, options) # to initialize the black-box optimizer 16>>> results = maes.optimize(args=100.0) # args as input arguments of fitness function 17>>> print(results['best_so_far_y'], results['n_function_evaluations']) 187.57e-11 15537
当除了采样点x之外有多个(>=2)输入参数时,所有参数都应通过function或class包装器以dict或tuple的形式组织。
高级用法
通常,两个问题定义 upper_boundary 和 lower_boundary 足以让大多数最终用户控制初始搜索范围。然而,有时出于优化器基准测试的目的(例如,为了避免利用对称性和原点可能导致的搜索偏差),我们添加了两个额外的定义来控制种群/个体的初始化:
initial_upper_boundary: 仅用于初始化的上边界 (array_like),
initial_lower_boundary: 仅用于初始化的下边界 (array_like).
如果没有明确给出,initial_upper_boundary和initial_lower_boundary将分别设置为upper_boundary和lower_boundary。当明确给出initial_upper_boundary和initial_lower_boundary时,种群/个体的初始化将从[initial_lower_boundary, initial_upper_boundary]中采样,而不是从[lower_boundary, upper_boundary]中采样。
优化器设置
该库为所有BBO的统一 API提供了超参数设置。以下算法选项(全部存储为dict格式)对所有BBO都非常常见:
max_function_evaluations: 函数评估的最大次数 (int, 默认值: np.inf),
max_runtime: 允许的最大运行时间 (float, 默认: np.inf),
seed_rng: 用于随机数生成(TNG)的种子需要明确设置(int)。
根据可用的计算资源或可接受的运行时间(即问题依赖),应至少设置两个算法选项之一(max_function_evaluations和max_runtime)。为了可重复性,seed_rng应明确设置为随机数生成(RNG)。请注意,由于不同的NumPy版本可能使用不同的RNG实现,可重复性主要在同一NumPy版本内得到保证。
请注意,对于任何优化器,其特定选项/设置(详见其API文档)可以自然地添加到dict数据结构中。以著名的交叉熵方法(CEM)为例。其高斯采样分布的均值和标准差设置通常对收敛速度有显著影响(有关其超参数的更多详情,请参阅其API):
1>>> import numpy as np 2>>> from pypop7.benchmarks.base_functions import rosenbrock # function to be minimized 3>>> from pypop7.optimizers.cem.scem import SCEM 4>>> problem = {'fitness_function': rosenbrock, # define problem arguments 5... 'ndim_problem': 10, 6... 'lower_boundary': -5.0*np.ones((10,)), 7... 'upper_boundary': 5.0*np.ones((10,))} 8>>> options = {'max_function_evaluations': 1000000, # set optimizer options 9... 'seed_rng': 2022, 10... 'mean': 4.0*np.ones((10,)), # initial mean of Gaussian search distribution 11... 'sigma': 3.0} # initial std (aka global step-size) of Gaussian search distribution 12>>> scem = SCEM(problem, options) # initialize the optimizer class 13>>> results = scem.optimize() # run the optimization process 14>>> # return the number of function evaluations and best-so-far fitness 15>>> print(f"SCEM: {results['n_function_evaluations']}, {results['best_so_far_y']}") 16SCEM: 1000000, 10.328016143160333
结果分析
在优化阶段结束后,所有黑箱优化器至少会以统一的方式返回以下常见结果(收集到dict数据结构中):
best_so_far_x: 在优化过程中找到的最佳解决方案,
best_so_far_y: 在优化过程中找到的最佳适应度(即目标值),
n_function_evaluations: 优化过程中使用的函数评估总数(永远不会超过max_function_evaluations),
runtime: 整个优化阶段使用的总运行时间(不超过max_runtime),
termination_signal: 来自三个常见候选者的终止信号(MAX_FUNCTION_EVALUATIONS、MAX_RUNTIME 和 FITNESS_THRESHOLD),
time_function_evaluations: 仅在函数评估中花费的总运行时间,
fitness: 在整个优化阶段生成的适应度(即目标值)列表。
当优化器选项saving_fitness设置为False时,fitness将为None。当优化器选项saving_fitness设置为整数n(> 0)时,fitness将是一个列表,其中包含每n次函数评估生成的适应度值。请注意,第一个和最后一个适应度值总是作为优化的开始和结束被保存。在实践中,正确设置saving_fitness可以为最终优化结果生成一个低内存的数据存储。
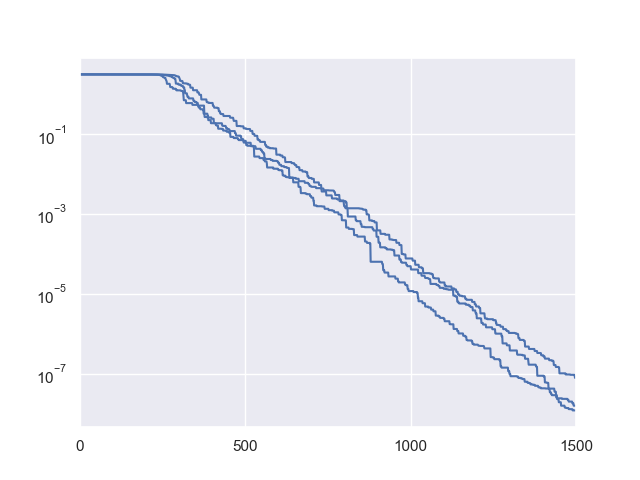
下面是一个简单的例子,用于可视化Rechenberg的(1+1)-进化策略在经典sphere函数(最简单的测试函数之一)上的适应度收敛过程:
1>>> import numpy as np # https://link.springer.com/chapter/10.1007%2F978-3-662-43505-2_44 2>>> import seaborn as sns 3>>> import matplotlib.pyplot as plt 4>>> from pypop7.benchmarks.base_functions import sphere 5>>> from pypop7.optimizers.es.res import RES 6>>> sns.set_theme(style='darkgrid') 7>>> plt.figure() 8>>> for i in range(3): 9>>> problem = {'fitness_function': sphere, 10... 'ndim_problem': 10} 11... options = {'max_function_evaluations': 1500, 12... 'seed_rng': i, 13... 'saving_fitness': 1, 14... 'x': np.ones((10,)), 15... 'sigma': 1e-9, 16... 'lr_sigma': 1.0/(1.0 + 10.0/3.0), 17... 'is_restart': False} 18... res = RES(problem, options) 19... fitness = res.optimize()['fitness'] 20... plt.plot(fitness[:, 0], np.sqrt(fitness[:, 1]), 'b') # sqrt for distance 21... plt.xticks([0, 500, 1000, 1500]) 22... plt.xlim([0, 1500]) 23... plt.yticks([1e-9, 1e-6, 1e-3, 1e0]) 24... plt.yscale('log') 25>>> plt.show()
高级用法
根据最近一位最终用户的建议,我们添加了EARLY_STOPPING作为第四个终止信号。详情请参阅#issues/175。
算法选择与配置
对于大多数现实世界中的黑箱优化问题,通常很少有先验知识可以作为算法选择的基础。也许最简单的算法选择方法是试错法。然而,我们仍然希望提供一个经验法则,根据算法分类来指导算法选择。有关三种不同分类家族(仅基于维度)的详细信息,请参阅我们的GitHub主页。值得注意的是,这种分类对于算法选择来说只是一个非常粗略的估计。在实践中,算法选择应主要取决于要关注的性能标准(例如,收敛速度和最终解的质量)以及可用的最大运行时间。
在未来,我们期望将自动化算法选择与配置技术加入这个开源的Python库中,如下所示(仅举几例):
Lindauer, M., Eggensperger, K., Feurer, M., Biedenkapp, A., Deng, D., Benjamins, C., Ruhkopf, T., Sass, R. 和 Hutter, F., 2022. SMAC3: 一个用于超参数优化的多功能贝叶斯优化包. JMLR, 23(54), pp.1-9.
Schede, E., Brandt, J., Tornede, A., Wever, M., Bengs, V., Hüllermeier, E. 和 Tierney, K., 2022. 自动化算法配置方法的调查. JAIR, 75, pp.425-487.
Kerschke, P., Hoos, H.H., Neumann, F. 和 Trautmann, H., 2019. 自动化算法选择:调查与展望. ECJ, 27(1), pp.3-45.
Probst, P., Boulesteix, A.L. 和 Bischl, B., 2019. 可调性:机器学习算法超参数的重要性. JMLR, 20(1), pp.1934-1965.
Hoos, H.H., Neumann, F. 和 Trautmann, H., 2017. 自动化算法选择和配置(Dagstuhl研讨会16412). Dagstuhl报告, 6(10), 第33-74页.
Rice, J.R., 1976. 算法选择问题. 在《计算机进展》(第15卷,第65-118页)中。Elsevier.