使用N-Beats进行可解释的预测#
[1]:
import warnings
warnings.filterwarnings("ignore")
[2]:
import lightning.pytorch as pl
from lightning.pytorch.callbacks import EarlyStopping
import pandas as pd
import torch
from pytorch_forecasting import Baseline, NBeats, TimeSeriesDataSet
from pytorch_forecasting.data import NaNLabelEncoder
from pytorch_forecasting.data.examples import generate_ar_data
from pytorch_forecasting.metrics import SMAPE
加载数据#
我们生成了一个合成数据集来展示网络的能力。数据包括一个二次趋势和一个季节性成分。
[3]:
data = generate_ar_data(seasonality=10.0, timesteps=400, n_series=100, seed=42)
data["static"] = 2
data["date"] = pd.Timestamp("2020-01-01") + pd.to_timedelta(data.time_idx, "D")
data.head()
[3]:
| 系列 | 时间索引 | 值 | 静态 | 日期 | |
|---|---|---|---|---|---|
| 0 | 0 | 0 | -0.000000 | 2 | 2020-01-01 |
| 1 | 0 | 1 | -0.046501 | 2 | 2020-01-02 |
| 2 | 0 | 2 | -0.097796 | 2 | 2020-01-03 |
| 3 | 0 | 3 | -0.144397 | 2 | 2020-01-04 |
| 4 | 0 | 4 | -0.177954 | 2 | 2020-01-05 |
在开始训练之前,我们需要将数据集分割成训练和验证的TimeSeriesDataSet。
[4]:
# create dataset and dataloaders
max_encoder_length = 60
max_prediction_length = 20
training_cutoff = data["time_idx"].max() - max_prediction_length
context_length = max_encoder_length
prediction_length = max_prediction_length
training = TimeSeriesDataSet(
data[lambda x: x.time_idx <= training_cutoff],
time_idx="time_idx",
target="value",
categorical_encoders={"series": NaNLabelEncoder().fit(data.series)},
group_ids=["series"],
# only unknown variable is "value" - and N-Beats can also not take any additional variables
time_varying_unknown_reals=["value"],
max_encoder_length=context_length,
max_prediction_length=prediction_length,
)
validation = TimeSeriesDataSet.from_dataset(training, data, min_prediction_idx=training_cutoff + 1)
batch_size = 128
train_dataloader = training.to_dataloader(train=True, batch_size=batch_size, num_workers=0)
val_dataloader = validation.to_dataloader(train=False, batch_size=batch_size, num_workers=0)
计算基线误差#
我们的基线模型通过重复最后一个已知值来预测未来值。结果得到的SMAPE令人失望,应该不容易被超越。
[5]:
# calculate baseline absolute error
baseline_predictions = Baseline().predict(val_dataloader, return_y=True)
SMAPE()(baseline_predictions.output, baseline_predictions.y)
[5]:
tensor(0.5462)
训练网络#
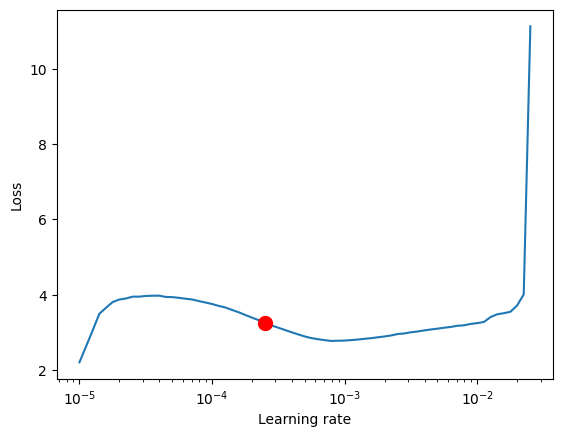
使用[PyTorch Lightning](https://pytorch-lightning.readthedocs.io/)找到最佳学习率很容易。NBeats模型的关键超参数是宽度。每个宽度表示每个预测块的宽度。默认情况下,第一个预测趋势,而第二个预测季节性。
[6]:
pl.seed_everything(42)
trainer = pl.Trainer(accelerator="auto", gradient_clip_val=0.01)
net = NBeats.from_dataset(training, learning_rate=3e-2, weight_decay=1e-2, widths=[32, 512], backcast_loss_ratio=0.1)
Global seed set to 42
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
[7]:
# find optimal learning rate
from lightning.pytorch.tuner import Tuner
res = Tuner(trainer).lr_find(net, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader, min_lr=1e-5)
print(f"suggested learning rate: {res.suggestion()}")
fig = res.plot(show=True, suggest=True)
fig.show()
net.hparams.learning_rate = res.suggestion()
LR finder stopped early after 68 steps due to diverging loss.
Learning rate set to 0.0002511886431509581
Restoring states from the checkpoint path at /Users/JanBeitner/Documents/code/pytorch-forecasting/.lr_find_6cdd9176-ee7a-4759-9728-172aaed215f7.ckpt
Restored all states from the checkpoint at /Users/JanBeitner/Documents/code/pytorch-forecasting/.lr_find_6cdd9176-ee7a-4759-9728-172aaed215f7.ckpt
suggested learning rate: 0.0002511886431509581
拟合模型
[14]:
early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=False, mode="min")
trainer = pl.Trainer(
max_epochs=3,
accelerator="auto",
enable_model_summary=True,
gradient_clip_val=0.01,
callbacks=[early_stop_callback],
limit_train_batches=150,
)
net = NBeats.from_dataset(
training,
learning_rate=1e-3,
log_interval=10,
log_val_interval=1,
weight_decay=1e-2,
widths=[32, 512],
backcast_loss_ratio=1.0,
)
trainer.fit(
net,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader,
)
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
-----------------------------------------------
0 | loss | MASE | 0
1 | logging_metrics | ModuleList | 0
2 | net_blocks | ModuleList | 1.7 M
-----------------------------------------------
1.7 M Trainable params
0 Non-trainable params
1.7 M Total params
6.851 Total estimated model params size (MB)
`Trainer.fit` stopped: `max_epochs=3` reached.
评估结果#
[15]:
best_model_path = trainer.checkpoint_callback.best_model_path
best_model = NBeats.load_from_checkpoint(best_model_path)
我们在验证数据集上使用predict()进行预测,并计算误差,该误差远低于基线误差
[16]:
actuals = torch.cat([y[0] for x, y in iter(val_dataloader)]).to("cpu")
predictions = best_model.predict(val_dataloader, trainer_kwargs=dict(accelerator="cpu"))
(actuals - predictions).abs().mean()
[16]:
tensor(0.1825)
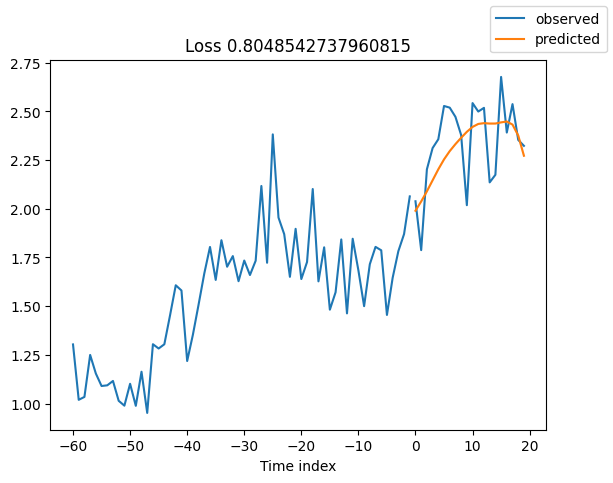
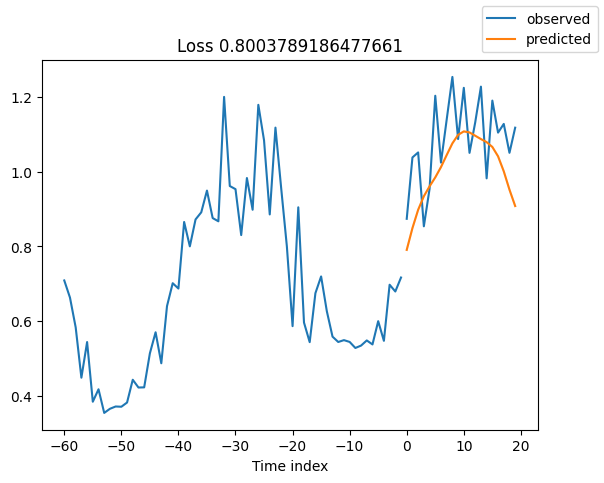
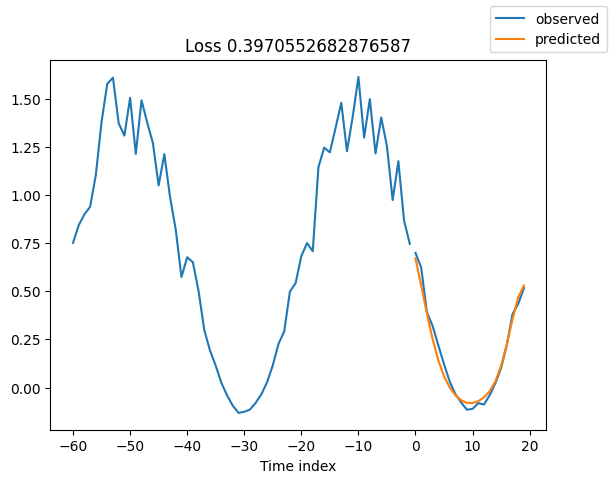
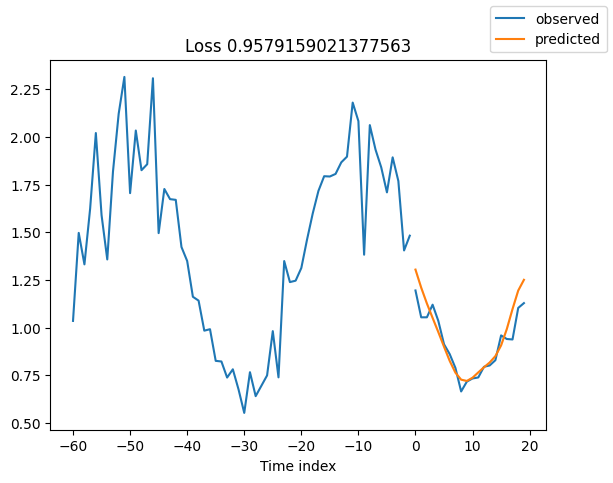
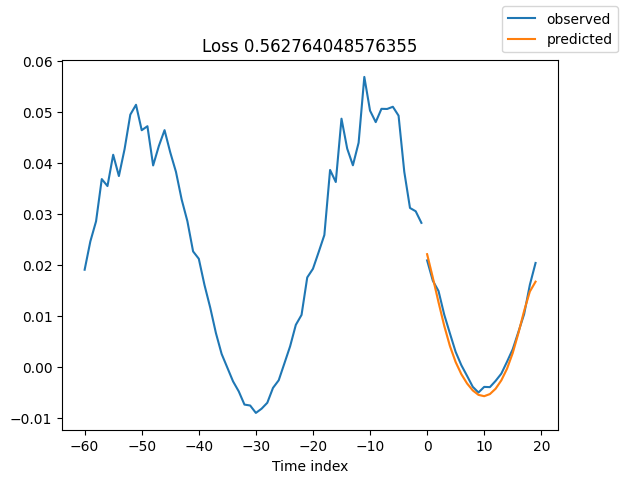
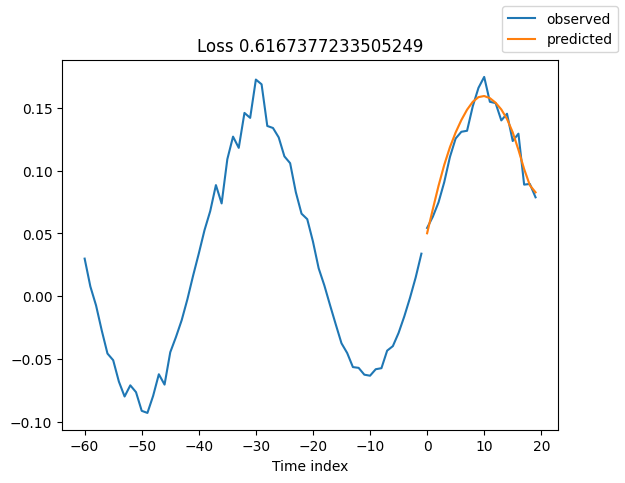
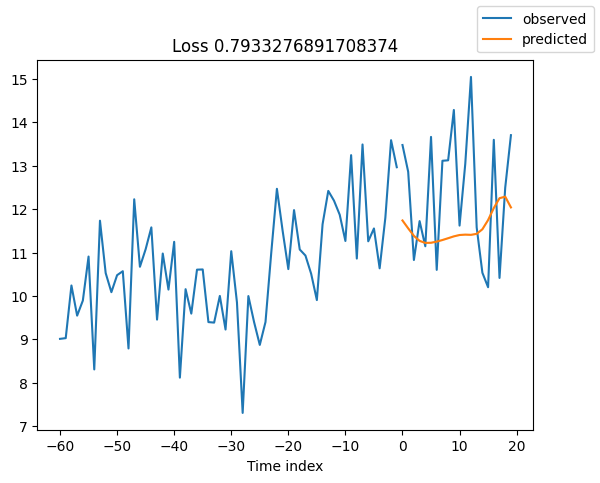
查看验证集中的随机样本总是了解预测是否合理的好方法 - 确实如此!
[17]:
raw_predictions = best_model.predict(val_dataloader, mode="raw", return_x=True)
[18]:
for idx in range(10): # plot 10 examples
best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True)
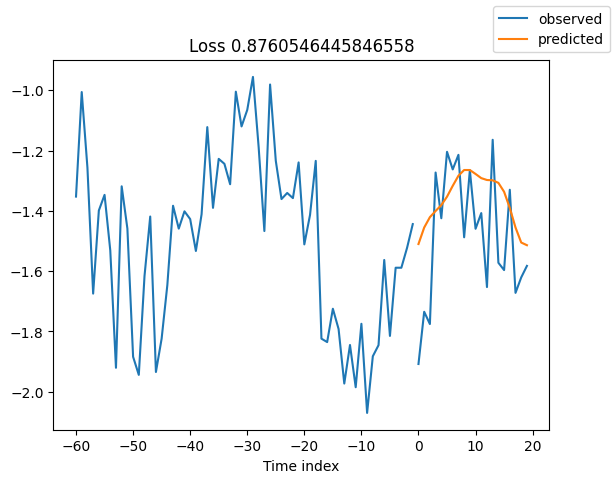
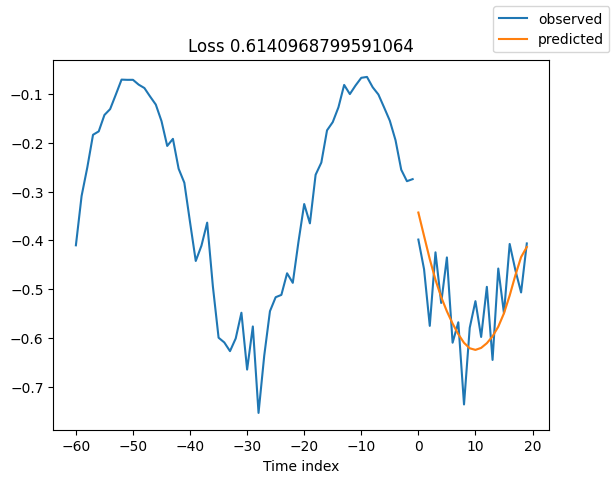
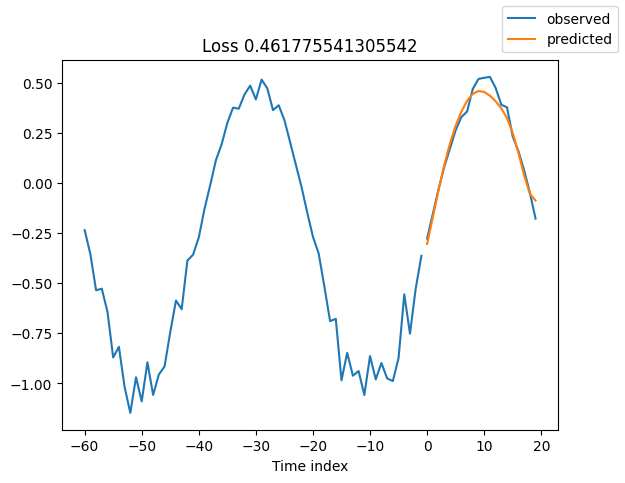
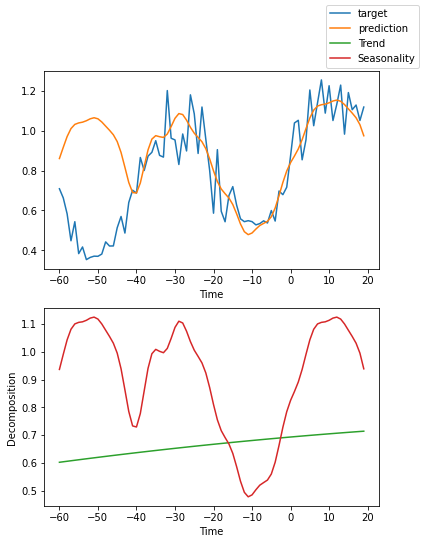
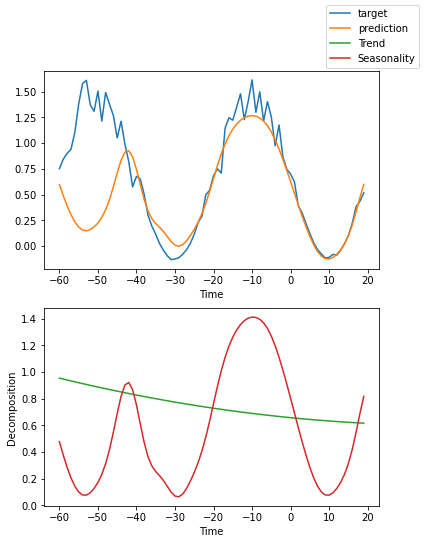
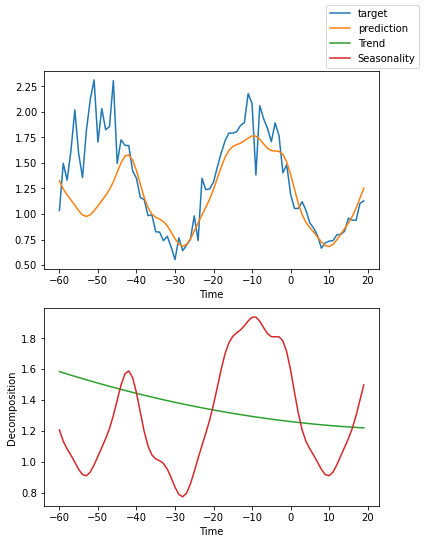
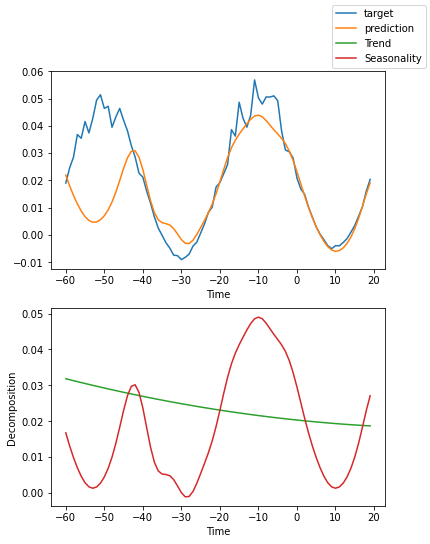
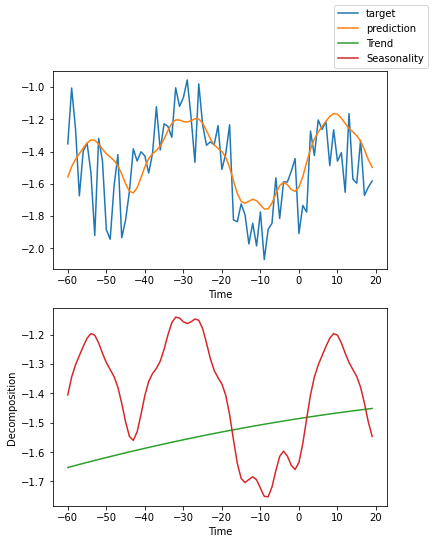
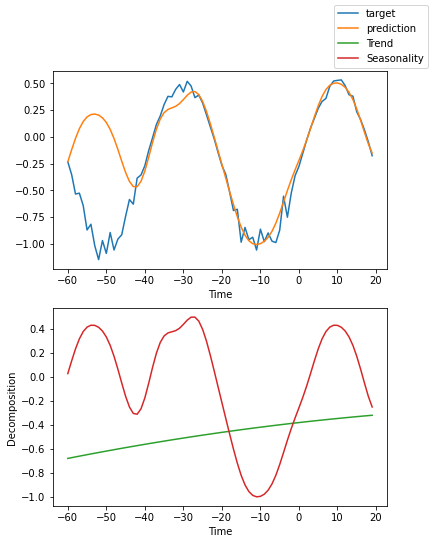
解释模型#
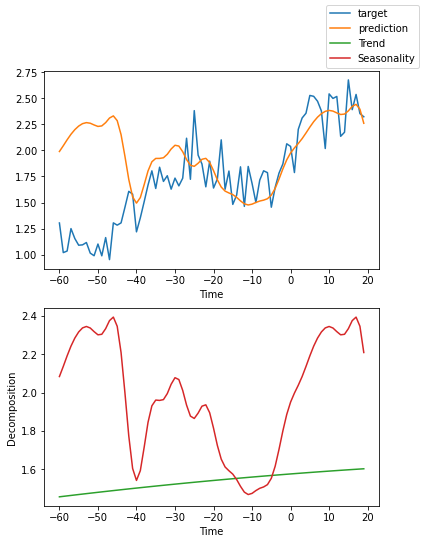
我们可以要求PyTorch Forecasting使用plot_interpretation()将预测分解为季节性和趋势。这是NBeats模型的一个特殊功能,只有其独特的架构才能实现。结果显示,似乎有很多方法可以解释数据,而算法并不总是选择直观上有意义的方法。这部分是因为我们训练的时间序列数量较少(100个)。但也是因为我们的预测期没有覆盖多个季节性。
[13]:
for idx in range(10): # plot 10 examples
best_model.plot_interpretation(raw_predictions.x, raw_predictions.output, idx=idx)



[ ]: