聚合
分组、投影和聚合函数
聚合是一种处理搜索查询结果的方式。聚合允许你对结果数据进行分组、排序和转换,并从中提取分析见解。与其他数据库和搜索引擎中的聚合查询类似,它们可以用于创建分析报告,或执行分面搜索风格的查询。
例如,索引一个网络服务器的日志,你可以按小时、国家或任何其他分类创建唯一用户的报告。或者你可以为错误、警告等创建不同的报告。
核心概念
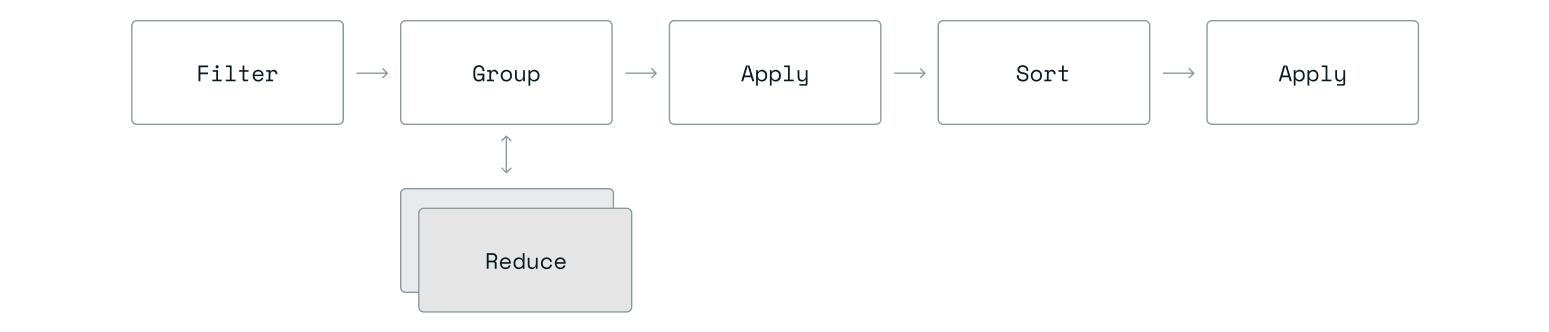
聚合查询的基本思想是这样的:
- 执行搜索查询,筛选出您希望处理的记录。
- 构建一个操作管道,通过零个或多个序列转换结果:
- 分组和归约:根据结果中的字段进行分组,并对每个组应用归约函数。
- 排序:根据一个或多个字段对结果进行排序。
- 应用转换:在管道中对字段应用数学和字符串函数,可以选择创建新字段或替换现有字段。
- 限制:限制结果,无论结果如何排序。
- 过滤:根据与其值相关的谓词过滤结果(查询后)。
管道是动态且可重入的,每个操作都可以重复。例如,您可以按属性X分组,按组大小对前100个结果进行排序,然后按属性Y分组并按其他属性对结果进行排序,最后对输出应用转换。
图1:聚合管道示例
聚合请求格式
聚合请求的语法定义如下:
FT.AGGREGATE
{index_name:string}
{query_string:string}
[VERBATIM]
[LOAD {nargs:integer} {property:string} ...]
[GROUPBY
{nargs:integer} {property:string} ...
REDUCE
{FUNC:string}
{nargs:integer} {arg:string} ...
[AS {name:string}]
...
] ...
[SORTBY
{nargs:integer} {string} ...
[MAX {num:integer}] ...
] ...
[APPLY
{EXPR:string}
AS {name:string}
] ...
[FILTER {EXPR:string}] ...
[LIMIT {offset:integer} {num:integer} ] ...
[PARAMS {nargs} {name} {value} ... ]
参数详情
可以接受可变数量参数的参数以param {nargs} {property_1... property_N}的形式表示。参数的第一个参数是跟随该参数的参数数量。这允许Redis Stack在您的一个参数具有另一个参数的名称时避免解析歧义。例如,要按名字、姓氏和国家排序,可以指定SORTBY 6 firstName ASC lastName DESC country ASC。
-
index_name: 查询所针对的索引。
-
query_string: 用于检索文档的基础过滤查询。它遵循与搜索查询完全相同的语法,包括过滤器、联合、非、可选等。
-
LOAD {nargs} {property} ... : 从文档HASH对象中加载文档字段。作为一般规则,应避免这样做。用于聚合的字段应存储为SORTABLE(并且可以选择UNF以避免任何规范化),这样它们在聚合管道中以非常低的延迟可用。LOAD会显著降低聚合查询的性能,因为每个处理的记录都需要对Redis键执行相当于HMGET的操作,当在数百万个键上执行时,会导致非常高的处理时间。 可以使用
@__key加载文档ID。 -
GROUPBY {nargs} {property} ... : 根据一个或多个属性对管道中的结果进行分组。每个组应至少有一个归约器(见下文),这是一个处理组条目的函数,可以计数或执行多个聚合操作(见下文)。
-
REDUCE {func} {nargs} {arg} ... [AS {name}]: 使用归约函数将每个组中的匹配结果减少为单个记录。例如,COUNT 将计算组中的记录数。有关可用归约器的更多详细信息,请参阅下面的归约器部分。
归约器可以使用
AS {name}可选参数拥有自己的属性名称。如果未给出名称,结果名称将是归约函数和组属性的名称。例如,如果未通过属性@foo给 COUNT_DISTINCT 指定名称,结果名称将为count_distinct(@foo)。 -
SORTBY {nargs} {property} {ASC|DESC} [MAX {num}]: 使用属性列表对管道进行排序,直到SORTBY的位置。默认情况下,排序是升序的,但可以为每个属性添加
ASC或DESC。nargs是排序参数的数量,包括ASC和DESC。例如:SORTBY 4 @foo ASC @bar DESC。MAX用于优化排序,仅对前n个最大元素进行排序。虽然它与LIMIT无关,但在常见查询中通常只需要SORTBY … MAX。 -
APPLY {expr} AS {name}: 对一个或多个属性应用一对一的转换,并将结果作为新属性存储在管道中,或使用此转换替换任何属性。
expr是一个表达式,可用于对数值属性执行算术运算,或根据属性类型应用的函数(见下文),或它们的任意组合。例如:APPLY "sqrt(@foo)/log(@bar) + 5" AS baz将为管道中的每条记录动态评估此表达式,并将结果存储为名为 baz 的新属性,该属性可以在管道中的后续 APPLY / SORTBY / GROUPBY / REDUCE 操作中引用。 -
LIMIT {offset} {num}. 限制返回结果的数量,只返回从索引
offset(从零开始)开始的num个结果。如上所述,如果你只对限制排序操作的输出感兴趣,使用SORTBY … MAX会更高效。然而,limit可以用于在不排序的情况下限制结果,或者用于分页显示由
SORTBY MAX确定的前n个最大结果。例如,获取前100个结果中的第50-100个结果,最有效的表达方式是SORTBY 1 @foo MAX 100 LIMIT 50 50。如果从SORTBY中移除MAX,将会导致管道对所有记录进行排序,然后对第50-100个结果进行分页。 -
FILTER {expr}. 使用与每个结果中的值相关的谓词表达式过滤结果。这些表达式在查询后应用,并与管道的当前状态相关。有关完整详细信息,请参见下面的FILTER表达式。
-
PARAMS {nargs} {name} {value}. 定义一个或多个值参数。每个参数都有一个名称和一个值。参数可以在查询字符串中通过
$后跟参数名称来引用,例如$user,并且在搜索查询中对参数名称的每个此类引用都将替换为相应的参数值。例如,使用参数定义PARAMS 4 lon 29.69465 lat 34.95126,表达式@loc:[$lon $lat 10 km]将被评估为@loc:[29.69465 34.95126 10 km]。参数不能在查询字符串中引用,其中不允许具体值,例如在字段名称中,例如@loc
Example
访问网站的日志可能如下所示,每条记录具有以下字段/属性:
- url (文本, 可排序)
- timestamp (numeric, sortable) - 访问条目的Unix时间戳。
- 国家 (标签, 可排序)
- user_id (文本, 可排序, 未索引)
示例1:按小时统计的唯一用户数,按时间顺序排序。
第一步是确定索引名称和过滤查询。过滤查询为 * 表示“获取所有记录”:
FT.AGGREGATE myIndex "*"
接下来,按小时对结果进行分组。数据包含以秒为单位的Unix时间戳的访问时间,因此您需要提取时间戳的小时部分。为此,添加一个APPLY步骤,从时间戳中去除小时以下的信息,并将其存储为一个新属性,hour:
FT.AGGREGATE myIndex "*"
APPLY "@timestamp - (@timestamp % 3600)" AS hour
接下来,按小时对结果进行分组,并计算每小时的不同用户ID数量。这是通过GROUPBY/REDUCE步骤完成的:
FT.AGGREGATE myIndex "*"
APPLY "@timestamp - (@timestamp % 3600)" AS hour
GROUPBY 1 @hour
REDUCE COUNT_DISTINCT 1 @user_id AS num_users
接下来,按小时升序排序结果:
FT.AGGREGATE myIndex "*"
APPLY "@timestamp - (@timestamp % 3600)" AS hour
GROUPBY 1 @hour
REDUCE COUNT_DISTINCT 1 @user_id AS num_users
SORTBY 2 @hour ASC
最后一步,将小时格式化为人类可读的时间戳。这是通过调用转换函数timefmt来完成的,该函数用于格式化Unix时间戳。您可以指定一个格式传递给系统的strftime函数(参见文档),但如果不指定,则等同于将%FT%TZ传递给strftime。
FT.AGGREGATE myIndex "*"
APPLY "@timestamp - (@timestamp % 3600)" AS hour
GROUPBY 1 @hour
REDUCE COUNT_DISTINCT 1 @user_id AS num_users
SORTBY 2 @hour ASC
APPLY timefmt(@hour) AS hour
示例2:按天和国家对特定URL的访问进行排序:
下一个示例通过URL进行过滤,将时间戳转换为其日期部分,并按日期和国家/地区进行分组,计算每组的访问次数,按日期升序和国家/地区降序排序。
FT.AGGREGATE myIndex "@url:\"about.html\""
APPLY "@timestamp - (@timestamp % 86400)" AS day
GROUPBY 2 @day @country
REDUCE count 0 AS num_visits
SORTBY 4 @day ASC @country DESC
GROUPBY 归约器
GROUPBY 的工作方式类似于 SQL 的 GROUP BY 子句,并根据每条记录中的一个或多个属性创建结果组。对于每个组,Redis 返回组键,即组中所有记录共有的值,以及零个或多个 REDUCE 子句的结果。
管道中的每个GROUPBY步骤可能伴随零个或多个REDUCE子句。Reducer对组中的每条记录应用累积函数,并将它们减少为代表组的单个记录。当处理完成后,GROUPBY步骤上游的所有记录都会发出它们的减少记录。
例如,最简单的 reducer 是 COUNT,它只是简单地计算每个组中的记录数。
如果单个GROUPBY步骤存在多个REDUCE子句,每个reducer独立处理每个结果并一次性写入其最终输出。每个reducer可以使用AS可选参数确定自己的别名。如果未指定AS,则别名为reduce函数及其参数,例如count_distinct(foo,bar)。
支持的GROUPBY归约器
计数
格式
REDUCE COUNT 0
描述
计算每组中的记录数量
COUNT_DISTINCT
格式
REDUCE COUNT_DISTINCT 1 {property}
描述
计算property的不同值的数量。
COUNT_DISTINCTISH
格式
REDUCE COUNT_DISTINCTISH 1 {property}
描述
与COUNT_DISTINCT相同,提供近似值而非精确计数,对于大数据组消耗更少的内存和CPU。
求和
格式
REDUCE SUM 1 {property}
描述
返回组中给定属性的所有数值的总和。组中的非数值被视为0。
最小值
格式
REDUCE MIN 1 {property}
描述
返回属性的最小值,无论它是字符串、数字还是NULL。
最大值
格式
REDUCE MAX 1 {property}
描述
返回属性的最大值,无论它是字符串、数字还是NULL。
平均值
格式
REDUCE AVG 1 {property}
描述
返回数值属性的平均值。这相当于通过求和和计数进行归约,然后应用它们的比率作为APPLY步骤。
标准差
格式
REDUCE STDDEV 1 {property}
描述
返回组中数值属性的标准差。
分位数
格式
REDUCE QUANTILE 2 {property} {quantile}
描述
返回结果在给定分位数处的数值属性的值。分位数表示为0到1之间的数字。例如,中位数可以表示为0.5处的分位数,例如REDUCE QUANTILE 2 @foo 0.5 AS median。
如果需要多个分位数,只需为每个分位数重复QUANTILE reducer。例如,REDUCE QUANTILE 2 @foo 0.5 AS median REDUCE QUANTILE 2 @foo 0.99 AS p99。
转换为列表
格式
REDUCE TOLIST 1 {property}
描述
将给定属性的所有不同值合并到一个数组中。
FIRST_VALUE
格式
REDUCE FIRST_VALUE {nargs} {property} [BY {property} [ASC|DESC]]
描述
返回组中给定属性的第一个或顶部值,可以选择将其与另一个属性进行比较。例如,您可以提取组中最年长用户的名称:
REDUCE FIRST_VALUE 4 @name BY @age DESC
如果没有指定BY,则返回组中遇到的第一个值。
如果您希望获取按相同值排序的组中的最高或最低值,最好使用MIN/MAX归约器,但通过执行REDUCE FIRST_VALUE 4 @foo BY @foo DESC也可以达到相同的效果。
随机样本
格式
REDUCE RANDOM_SAMPLE {nargs} {property} {sample_size}
描述
对组元素进行给定大小的水库采样,并返回一个均匀分布的采样项数组。
应用表达式
APPLY 对每条记录中的一个或多个属性执行一对一的转换。它可以将结果作为新属性存储在管道中,或者使用此转换替换任何属性。
转换被表示为算术表达式和内置函数的组合。评估函数和表达式是递归嵌套的,并且可以无限组合。例如:sqrt(log(foo) * floor(@bar/baz)) + (3^@qaz % 6) 或简单地 @foo/@bar。
如果表达式或函数应用于与预期类型不匹配的值,则不会发出错误,并将NULL值设置为结果。
APPLY 步骤必须有一个由 AS 参数确定的显式别名。
表达式中的字面量
- 数字表示为整数或浮点数,例如
2,3.141, 和-34。inf和-inf也是可以接受的。 - 字符串可以用单引号或双引号括起来。在双引号括起来的字符串中可以使用单引号,反之亦然。标点符号可以用反斜杠转义。例如:
"foo's bar",'foo\'s bar',"foo \"bar\""。 - 任何字面量或子表达式都可以用括号括起来,以解决运算符优先级的歧义。
算术运算
对于数值表达式和属性,支持加法(+)、减法(-)、乘法(*)、除法(/)、取模(%)和幂运算(^)。不支持位逻辑运算符。
请注意,这些运算符仅适用于数值和数值子表达式。例如,任何尝试将字符串乘以数字的操作都将导致NULL输出。
字段应用函数列表
| 函数 | 描述 | 示例 |
|---|---|---|
| exists(s) | 检查文档中是否存在某个字段。 | exists(@field) |
数值应用函数列表
| 函数 | 描述 | 示例 |
|---|---|---|
| log(x) | 返回一个数字、属性或子表达式的对数 | log(@foo) |
| abs(x) | 返回数值表达式的绝对值 | abs(@foo-@bar) |
| ceil(x) | 四舍五入到不小于x的最小值 | ceil(@foo/3.14) |
| floor(x) | 四舍五入到不大于x的最大值 | floor(@foo/3.14) |
| log2(x) | 返回以2为底的x的对数 | log2(2^@foo) |
| exp(x) | 返回x的指数,例如,e^x |
exp(@foo) |
| sqrt(x) | 返回x的平方根 | sqrt(@foo) |
字符串应用函数列表
| 函数 | ||
|---|---|---|
| upper(s) | 返回s的大写转换 | upper('hello world') |
| lower(s) | 返回s的小写转换 | lower("HELLO WORLD") |
| startswith(s1,s2) | 如果s2是s1的前缀,则返回1,否则返回0。 |
startswith(@field, "company") |
| contains(s1,s2) | 返回s1中s2出现的次数,否则返回0。如果s2是空字符串,返回length(s1) + 1。 |
contains(@field, "pa") |
| strlen(s) | 返回 s 的长度 | strlen(@t) |
| substr(s, offset, count) | 返回字符串s的子串,从offset开始,包含count个字符。 如果offset为负数,它表示从字符串末尾的距离。 如果count为-1,表示“从offset开始的字符串的剩余部分”。 |
substr("hello", 0, 3) substr("hello", -2, -1) |
| format( fmt, ...) | 使用fmt后面的参数来格式化字符串。目前唯一支持的格式参数是 %s,它适用于所有类型的参数。 |
format("Hello, %s, you are %s years old", @name, @age) |
| matched_terms([max_terms=100]) | 返回每个记录匹配的查询术语(最多100个),作为列表。如果指定了限制,Redis将根据查询顺序返回找到的前N个匹配项。 | matched_terms() |
| split(s, [sep=","], [strip=" "]) | 通过字符串 sep 中的任何字符分割字符串,并去除 strip 中的任何字符。如果仅指定 s,则按逗号分割并去除空格。输出是一个数组。 | split("foo,bar") |
日期/时间应用函数列表
| 函数 | 描述 |
|---|---|
| timefmt(x, [fmt]) | 返回基于数字时间戳值x的格式化时间字符串。 有关格式化选项,请参见strftime。 未指定 fmt等同于%FT%TZ。 |
| parsetime(timesharing, [fmt]) | timefmt()的反函数 - 使用给定的格式字符串解析时间格式 |
| day(timestamp) | 将Unix时间戳舍入到当前日期的午夜(00:00)开始。 |
| hour(timestamp) | 将Unix时间戳舍入到当前小时的开始。 |
| minute(timestamp) | 将Unix时间戳舍入到当前分钟的开始。 |
| month(timestamp) | 将Unix时间戳舍入到当前月的开始。 |
| dayofweek(timestamp) | 将Unix时间戳转换为星期几的数字(星期日 = 0)。 |
| dayofmonth(timestamp) | 将Unix时间戳转换为月份中的天数(1 .. 31)。 |
| dayofyear(timestamp) | 将Unix时间戳转换为一年中的第几天(0 .. 365)。 |
| year(timestamp) | 将Unix时间戳转换为当前年份(例如2018年)。 |
| monthofyear(timestamp) | 将Unix时间戳转换为当前月份(0 .. 11)。 |
地理应用函数列表
| 函数 | 描述 | 示例 |
|---|---|---|
| geodistance(field,field) | 返回以米为单位的距离。 | geodistance(@field1,@field2) |
| geodistance(field,"lon,lat") | 返回以米为单位的距离。 | geodistance(@field,"1.2,-3.4") |
| geodistance(field,lon,lat) | 返回以米为单位的距离。 | geodistance(@field,1.2,-3.4) |
| geodistance("lon,lat",field) | 返回以米为单位的距离。 | geodistance("1.2,-3.4",@field) |
| geodistance("lon,lat","lon,lat") | 返回以米为单位的距离。 | geodistance("1.2,-3.4","5.6,-7.8") |
| geodistance("lon,lat",lon,lat) | 返回以米为单位的距离。 | geodistance("1.2,-3.4",5.6,-7.8) |
| geodistance(lon,lat,field) | 返回以米为单位的距离。 | geodistance(1.2,-3.4,@field) |
| geodistance(lon,lat,"lon,lat") | 返回以米为单位的距离。 | geodistance(1.2,-3.4,"5.6,-7.8") |
| geodistance(lon,lat,lon,lat) | 返回以米为单位的距离。 | geodistance(1.2,-3.4,5.6,-7.8) |
FT.AGGREGATE myIdx "*" LOAD 1 location APPLY "geodistance(@location,\"-1.1,2.2\")" AS dist
要检索距离:
FT.AGGREGATE myIdx "*" LOAD 1 location APPLY "geodistance(@location,\"-1.1,2.2\")" AS dist
注意:geo字段必须使用LOAD预先加载。
结果也可以按距离排序:
FT.AGGREGATE idx "*" LOAD 1 @location FILTER "exists(@location)" APPLY "geodistance(@location,-117.824722,33.68590)" AS dist SORTBY 2 @dist DESC
注意:确保没有遗漏任何位置,否则SORTBY将不会返回任何结果。 使用FILTER确保对所有有效位置进行排序。
FILTER 表达式
FILTER 表达式使用与结果集中值相关的谓词来过滤结果。
FILTER 表达式在查询后评估,并与管道的当前状态相关。因此,它们可以用于基于组计算来修剪结果。请注意,过滤器没有索引,不会加快处理速度。
过滤表达式遵循APPLY表达式的语法,增加了条件==、!=、<、<=、>、>=。两个或更多的谓词可以通过逻辑AND(&&)和OR(||)组合。单个谓词可以通过NOT前缀(!)进行否定。
例如,过滤所有用户名为'foo'且年龄小于20的结果表示为:
FT.AGGREGATE
...
FILTER "@name=='foo' && @age < 20"
...
可以添加多个过滤步骤,尽管在管道的同一阶段,将多个谓词组合成一个过滤步骤更为高效。
游标 API
FT.AGGREGATE ... WITHCURSOR [COUNT {read size} MAXIDLE {idle timeout}]
FT.CURSOR READ {idx} {cid} [COUNT {read size}]
FT.CURSOR DEL {idx} {cid}
你可以使用游标与FT.AGGREGATE一起,使用WITHCURSOR关键字。游标允许你只消耗部分响应,允许你根据需要获取额外的结果。这比使用带有偏移量的LIMIT要快得多,因为查询只执行一次,并且其状态存储在服务器上。
要使用游标,请在FT.AGGREGATE中指定WITHCURSOR关键字。例如:
FT.AGGREGATE idx * WITHCURSOR
这将返回一个包含两个元素的数组响应。第一个元素是实际的(部分)结果,第二个是游标ID。然后可以将游标ID重复传递给FT.CURSOR READ,直到游标ID为0,此时所有结果都已返回。
要从现有的游标中读取,请使用 FT.CURSOR READ。例如:
FT.CURSOR READ idx 342459320
假设 342459320 是从 FT.AGGREGATE 请求返回的游标 ID,以下是一个伪代码示例:
response, cursor = FT.AGGREGATE "idx" "redis" "WITHCURSOR";
while (1) {
processResponse(response)
if (!cursor) {
break;
}
response, cursor = FT.CURSOR read "idx" cursor
}
请注意,即使游标为0,仍可能返回部分结果。
光标设置
读取大小
您可以通过使用COUNT参数来控制每次游标读取的行数。此参数可以在FT.AGGREGATE(紧接在WITHCURSOR之后)或FT.CURSOR READ中指定。
以下示例将一次读取10行:
FT.AGGREGATE idx query WITHCURSOR COUNT 10
您可以通过在CURSOR READ中指定COUNT来覆盖此设置。以下示例将最多返回50个结果:
FT.CURSOR READ idx 342459320 COUNT 50
默认读取大小为1000。
超时和限制
因为游标是占用服务器内存的有状态资源,它们有一个有限的生命周期。为了防止孤立的/过时的游标,游标有一个空闲超时值。如果在空闲超时之前游标上没有活动发生,游标将被删除。每当使用CURSOR READ从游标读取时,空闲计时器会重置为0。
默认的空闲超时时间为300000毫秒(或300秒)。您可以在创建游标时使用MAXIDLE关键字修改空闲超时时间。请注意,该值不能超过默认的300秒。
例如,设置十秒的限制:
FT.AGGREGATE idx query WITHCURSOR MAXIDLE 10000
其他光标命令
可以使用CURSOR DEL命令显式删除游标。例如:
FT.CURSOR DEL idx 342459320
请注意,如果游标的所有结果都已返回,或者它们已经超时,游标将自动删除。
可以使用FT.CURSOR GC idx 0命令同时强制清除所有空闲游标。
默认情况下,Redis Stack使用一种懒惰的节流方法进行垃圾收集,该方法
每500次操作或每秒收集一次空闲游标,以较晚者为准。