RedisOM 用于 Python
学习如何使用Redis Stack和Python进行构建
Redis OM Python 是一个 Redis 客户端,提供了用于管理 Redis 中文档数据的高级抽象。本教程将向您展示如何使用 Redis OM Python、Redis Stack 和 Flask 微框架快速入门。
我们很乐意看到您使用Redis Stack和Redis OM构建的内容。加入Redis社区的Discord,与我们讨论关于Redis OM和Redis Stack的所有事情。了解更多关于Redis OM Python的信息,请阅读我们的公告博客文章。
概述
这个应用程序,一个用Flask构建的API和一个简单的领域模型,展示了使用Redis OM的常见数据操作模式。
我们的实体是一个Person,具有以下JSON表示:
{
"first_name": "A string, the person's first or given name",
"last_name": "A string, the person's last or surname",
"age": 36,
"address": {
"street_number": 56,
"unit": "A string, optional unit number e.g. B or 1",
"street_name": "A string, name of the street they live on",
"city": "A string, name of the city they live in",
"state": "A string, state, province or county that they live in",
"postal_code": "A string, their zip or postal code",
"country": "A string, country that they live in."
},
"personal_statement": "A string, free text personal statement",
"skills": [
"A string: a skill the person has",
"A string: another still that the person has"
]
}
我们将让Redis OM处理唯一ID的生成,它使用ULIDs来实现。Redis OM还将为我们处理唯一Redis键名的创建,以及从存储在Redis Stack数据库中的JSON文档中保存和检索实体。
入门指南
需求
要运行此应用程序,您需要:
- git - 将仓库克隆到您的机器上。
- Python 3.9 或更高版本.
- 一个Redis Stack数据库,或者安装了Search and Query和JSON功能的Redis。我们为此提供了一个
docker-compose.yml。你也可以注册一个免费的30Mb Redis Cloud数据库 - 在创建云数据库时,请确保选择Redis Stack选项。 - curl,或Postman - 用于向应用程序发送HTTP请求。我们将在本文档中提供使用curl的示例。
- 可选:Redis Insight,一个用于Redis的免费数据可视化和数据库管理工具。下载Redis Insight时,请确保选择2.x版本或使用Redis Stack附带的版本。
获取源代码
从GitHub克隆仓库:
$ git clone https://github.com/redis-developer/redis-om-python-flask-skeleton-app.git
$ cd redis-om-python-flask-skeleton-app
启动一个Redis Stack数据库,或配置您的Redis云凭证
接下来,我们将启动并运行一个Redis Stack数据库。如果你正在使用Docker:
$ docker-compose up -d
Creating network "redis-om-python-flask-skeleton-app_default" with the default driver
Creating redis_om_python_flask_starter ... done
如果您使用的是 Redis Cloud,您将需要数据库的主机名、端口号和密码。使用这些信息来设置 REDIS_OM_URL 环境变量,如下所示:
$ export REDIS_OM_URL=redis://default:<password>@<host>:<port>
(在使用Docker时,此步骤不是必需的,因为Docker容器在localhost端口6379上运行Redis,没有密码,这是Redis OM使用的默认连接。)
例如,如果你的Redis Cloud数据库位于主机enterprise.redis.com上的端口9139,并且你的密码是5uper53cret,那么你应该如下设置REDIS_OM_URL:
$ export REDIS_OM_URL=redis://default:5uper53cret@enterprise.redis.com:9139
创建一个Python虚拟环境并安装依赖项
创建一个Python虚拟环境,并安装项目依赖项,这些依赖项包括Flask、Requests(仅在数据加载脚本中使用)和Redis OM:
$ python3 -m venv venv
$ . ./venv/bin/activate
$ pip install -r requirements.txt
启动Flask应用程序
让我们以开发模式启动Flask应用程序,这样每次你在app.py中保存代码更改时,Flask都会为你重新启动服务器:
$ export FLASK_ENV=development
$ flask run
如果一切顺利,你应该会看到类似这样的输出:
$ flask run
* Environment: development
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: XXX-XXX-XXX
您现在已启动并运行,准备使用Redis、搜索和查询、JSON以及Redis OM for Python对数据执行CRUD操作!为了确保服务器正在运行,请将浏览器指向http://127.0.0.1:5000/,在那里您将看到应用程序的基本主页:
加载示例数据
我们提供了一小部分示例数据(位于data/people.json中)。Python脚本dataloader.py通过将数据发布到应用程序的创建新人员端点,将每个人加载到Redis中。像这样运行它:
$ python dataloader.py
Created person Robert McDonald with ID 01FX8RMR7NRS45PBT3XP9KNAZH
Created person Kareem Khan with ID 01FX8RMR7T60ANQTS4P9NKPKX8
Created person Fernando Ortega with ID 01FX8RMR7YB283BPZ88HAG066P
Created person Noor Vasan with ID 01FX8RMR82D091TC37B45RCWY3
Created person Dan Harris with ID 01FX8RMR8545RWW4DYCE5MSZA1
请确保复制数据加载器的输出,因为您的ID将与教程中使用的ID不同。为了跟随教程,请将您的ID替换为上面显示的ID。例如,每当我们处理Kareem Khan时,将01FX8RMR7T60ANQTS4P9NKPKX8更改为您的数据加载器在Redis数据库中分配给Kareem的ID。
遇到问题?
如果Flask服务器启动失败,请查看其输出。如果你看到类似以下的日志条目:
raise ConnectionError(self._error_message(e))
redis.exceptions.ConnectionError: Error 61 connecting to localhost:6379. Connection refused.
然后,如果使用Docker,你需要启动Redis Docker容器,或者如果使用Redis Cloud,设置REDIS_OM_URL环境变量。
如果您已经设置了REDIS_OM_URL环境变量,并且代码在启动时出现类似这样的错误:
raise ConnectionError(self._error_message(e))
redis.exceptions.ConnectionError: Error 8 connecting to enterprise.redis.com:9139. nodename nor servname provided, or not known.
那么你需要检查在设置REDIS_OM_URL时是否使用了正确的主机名、端口、密码和格式。
如果数据加载器无法将样本数据发布到应用程序中,请确保在运行数据加载器之前Flask应用程序正在运行。
创建、读取、更新和删除数据
让我们在Redis中创建并操作一些数据模型的实例。这里我们将看看如何使用curl调用Flask API(你也可以使用Postman),代码是如何工作的,以及数据是如何存储在Redis中的。
使用Redis OM构建人员模型
Redis OM 允许我们使用 Python 类和 Pydantic 框架来建模实体。我们的人员模型包含在文件 person.py 中。以下是一些关于其工作原理的说明:
- 我们声明了一个类
Person,它继承了一个 Redis OM 类JsonModel。这告诉 Redis OM 我们希望将这些实体以 JSON 文档的形式存储在 Redis 中。 - 然后我们在模型中声明每个字段,指定数据类型以及我们是否希望在该字段上建立索引。例如,这里是
age字段,我们将其声明为一个我们希望建立索引的正整数:
age: PositiveInt = Field(index=True)
skills字段是一个字符串列表,声明如下:
skills: List[str] = Field(index=True)
- 对于
personal_statement字段,我们不希望对该字段的值进行索引,因为它是一个自由文本句子,而不是单个单词或数字。为此,我们将告诉Redis OM,我们希望能够在这些值上执行全文搜索:
personal_statement: str = Field(index=True, full_text_search=True)
address的工作方式与其他字段不同。请注意,在我们的模型JSON表示中,address 是一个对象,而不是字符串或数字字段。在 Redis OM 中,这被建模为一个扩展了 Redis OMEmbeddedJsonModel类的第二个类:
class Address(EmbeddedJsonModel):
# field definitions...
-
EmbeddedJsonModel中的字段以相同的方式定义,因此我们的类包含地址中每个数据项的字段定义。 -
并非我们JSON中的每个字段都存在于每个地址中,Redis OM允许我们将字段声明为可选的,只要我们不索引它:
unit: Optional[str] = Field(index=False)
- 我们还可以为字段设置默认值... 比如说,除非另有指定,否则国家应该是“英国”:
country: str = Field(index=True, default="United Kingdom")
- 最后,为了将嵌入的地址对象添加到我们的Person模型中,我们在Person类中声明了一个类型为
Address的字段:
address: Address
添加新人员
函数 create_person 在 app.py 中处理在 Redis 中创建新人的操作。它期望一个符合我们 Person 模型模式的 JSON 对象。然后使用该数据创建新的 Person 对象并将其保存在 Redis 中的代码很简单:
new_person = Person(**request.json)
new_person.save()
return new_person.pk
当创建一个新的 Person 实例时,Redis OM 会为其分配一个唯一的 ULID 主键,我们可以通过 .pk 访问它。我们将其返回给调用者,以便他们知道刚刚创建的对象的 ID。
将对象持久化到Redis中,只需在其上调用.save()即可。
试试看... 在服务器运行的情况下,使用curl添加一个新的人员:
curl --location --request POST 'http://127.0.0.1:5000/person/new' \
--header 'Content-Type: application/json' \
--data-raw '{
"first_name": "Joanne",
"last_name": "Peel",
"age": 36,
"personal_statement": "Music is my life, I love gigging and playing with my band.",
"address": {
"street_number": 56,
"unit": "4A",
"street_name": "The Rushes",
"city": "Birmingham",
"state": "West Midlands",
"postal_code": "B91 6HG",
"country": "United Kingdom"
},
"skills": [
"synths",
"vocals",
"guitar"
]
}'
运行上述curl命令将返回分配给新创建人员的唯一ULID ID。例如01FX8SSSDN7PT9T3N0JZZA758G。
检查Redis中的数据
让我们看看我们刚刚在Redis中保存了什么。使用Redis Insight或redis-cli,连接到数据库并查看存储在键:person.Person:01FX8SSSDN7PT9T3N0JZZA758G的值。这是以JSON文档的形式存储在Redis中的,所以如果使用redis-cli,你需要以下命令:
$ redis-cli
127.0.0.1:6379> json.get :person.Person:01FX8SSSDN7PT9T3N0JZZA758G
如果您正在使用Redis Insight,当您点击键名时,浏览器将为您呈现键值:
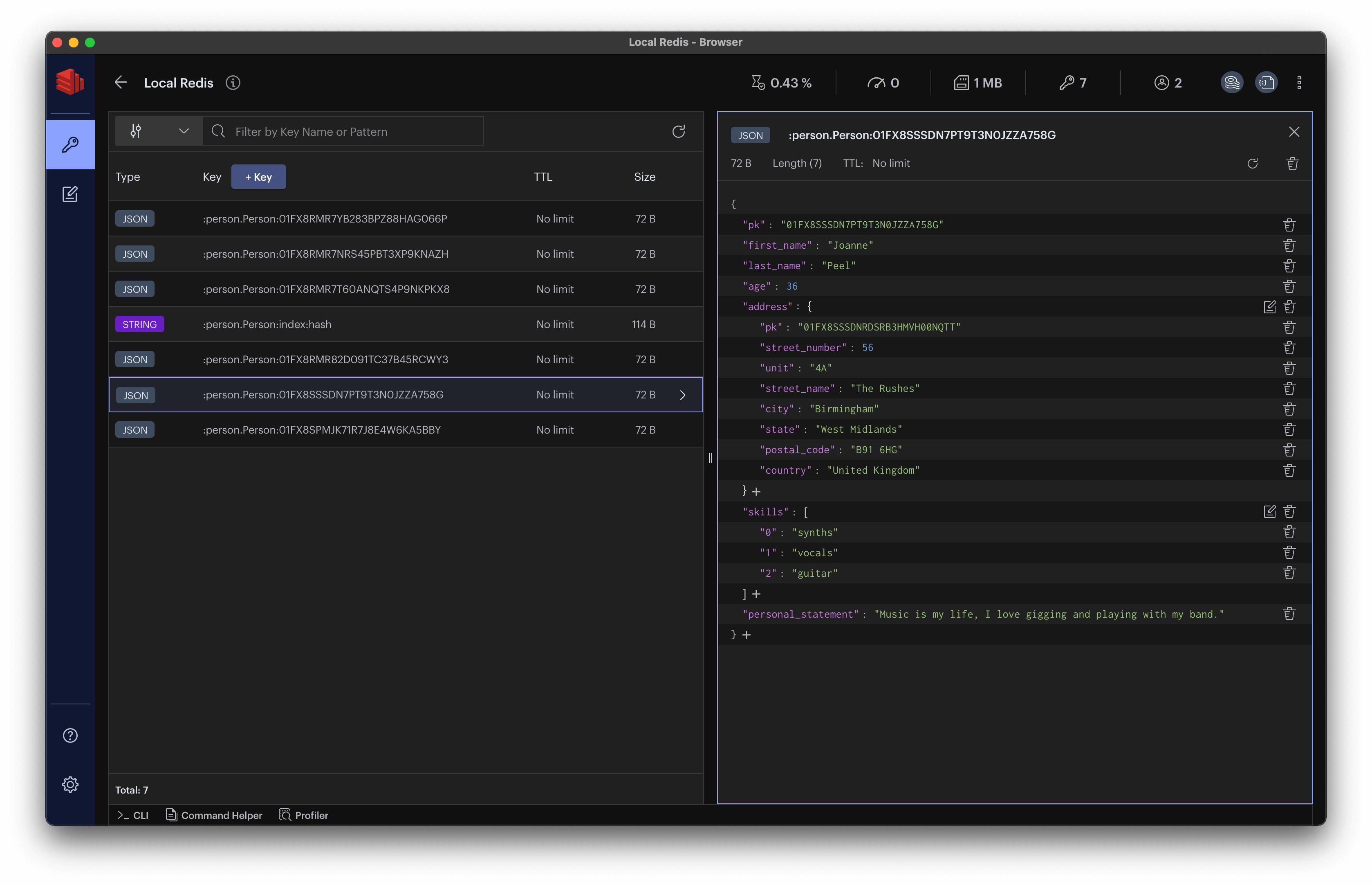
当在Redis中以JSON格式存储数据时,我们可以更新和检索整个文档,或者只是其中的一部分。例如,要仅检索人员的地址和第一项技能,请使用以下命令(Redis Insight用户应使用内置的redis-cli来执行此操作):
$ redis-cli
127.0.0.1:6379> json.get :person.Person:01FX8SSSDN7PT9T3N0JZZA758G $.address $.skills[0]
"{\"$.skills[0]\":[\"synths\"],\"$.address\":[{\"pk\":\"01FX8SSSDNRDSRB3HMVH00NQTT\",\"street_number\":56,\"unit\":\"4A\",\"street_name\":\"The Rushes\",\"city\":\"Birmingham\",\"state\":\"West Midlands\",\"postal_code\":\"B91 6HG\",\"country\":\"United Kingdom\"}]}"
有关用于在Redis中查询JSON文档的JSON Path语法的更多信息,请参阅文档。
通过ID查找人员
如果我们知道一个人的ID,我们可以检索他们的数据。app.py中的函数find_by_id接收一个ID作为其参数,并要求Redis OM使用该ID和Person的.get类方法来检索并填充一个Person对象:
try:
person = Person.get(id)
return person.dict()
except NotFoundError:
return {}
.dict() 方法将我们的 Person 对象转换为 Flask 随后返回给调用者的 Python 字典。
请注意,如果在 Redis 中没有找到提供的 ID 对应的 Person,get 将会抛出一个 NotFoundError。
尝试使用curl进行测试,将01FX8SSSDN7PT9T3N0JZZA758G替换为您刚刚在数据库中创建的人员的ID:
curl --location --request GET 'http://localhost:5000/person/byid/01FX8SSSDN7PT9T3N0JZZA758G'
服务器响应包含用户数据的JSON对象:
{
"address": {
"city": "Birmingham",
"country": "United Kingdom",
"pk": "01FX8SSSDNRDSRB3HMVH00NQTT",
"postal_code": "B91 6HG",
"state": "West Midlands",
"street_name": "The Rushes",
"street_number": 56,
"unit": null
},
"age": 36,
"first_name": "Joanne",
"last_name": "Peel",
"personal_statement": "Music is my life, I love gigging and playing with my band.",
"pk": "01FX8SSSDN7PT9T3N0JZZA758G",
"skills": [
"synths",
"vocals",
"guitar"
]
}
查找名字和姓氏匹配的人
让我们找到所有具有给定名字和姓氏的人... 这是由app.py中的find_by_name函数处理的。
在这里,我们使用由Redis OM提供的Person的find类方法。我们传递一个搜索查询给它,指定我们想要找到那些first_name字段包含传递给find_by_name的first_name参数值,并且last_name字段包含last_name参数值的人:
people = Person.find(
(Person.first_name == first_name) &
(Person.last_name == last_name)
).all()
.all() 告诉 Redis OM 我们想要检索所有匹配的人员。
尝试使用curl如下操作:
curl --location --request GET 'http://127.0.0.1:5000/people/byname/Kareem/Khan'
注意: 名字和姓氏是区分大小写的。
服务器响应一个包含results的对象,这是一个匹配数组:
{
"results": [
{
"address": {
"city": "Sheffield",
"country": "United Kingdom",
"pk": "01FX8RMR7THMGA84RH8ZRQRRP9",
"postal_code": "S1 5RE",
"state": "South Yorkshire",
"street_name": "The Beltway",
"street_number": 1,
"unit": "A"
},
"age": 27,
"first_name": "Kareem",
"last_name": "Khan",
"personal_statement":"I'm Kareem, a multi-instrumentalist and singer looking to join a new rock band.",
"pk":"01FX8RMR7T60ANQTS4P9NKPKX8",
"skills": [
"drums",
"guitar",
"synths"
]
}
]
}
查找给定年龄范围内的人员
能够找到属于特定年龄范围的人很有用... app.py 中的函数 find_in_age_range 处理如下...
我们将再次使用Person的find类方法,这次传递最小和最大年龄,指定我们希望结果中的age字段仅在这些值之间:
people = Person.find(
(Person.age >= min_age) &
(Person.age <= max_age)
).sort_by("age").all()
请注意,我们也可以使用 .sort_by 来指定我们希望结果按哪个字段排序。
让我们找出所有年龄在30到47岁之间的人,并按年龄排序:
curl --location --request GET 'http://127.0.0.1:5000/people/byage/30/47'
这将返回一个包含匹配数组的results对象:
{
"results": [
{
"address": {
"city": "Sheffield",
"country": "United Kingdom",
"pk": "01FX8RMR7NW221STN6NVRDPEDT",
"postal_code": "S12 2MX",
"state": "South Yorkshire",
"street_name": "Main Street",
"street_number": 9,
"unit": null
},
"age": 35,
"first_name": "Robert",
"last_name": "McDonald",
"personal_statement": "My name is Robert, I love meeting new people and enjoy music, coding and walking my dog.",
"pk": "01FX8RMR7NRS45PBT3XP9KNAZH",
"skills": [
"guitar",
"piano",
"trombone"
]
},
{
"address": {
"city": "Birmingham",
"country": "United Kingdom",
"pk": "01FX8SSSDNRDSRB3HMVH00NQTT",
"postal_code": "B91 6HG",
"state": "West Midlands",
"street_name": "The Rushes",
"street_number": 56,
"unit": null
},
"age": 36,
"first_name": "Joanne",
"last_name": "Peel",
"personal_statement": "Music is my life, I love gigging and playing with my band.",
"pk": "01FX8SSSDN7PT9T3N0JZZA758G",
"skills": [
"synths",
"vocals",
"guitar"
]
},
{
"address": {
"city": "Nottingham",
"country": "United Kingdom",
"pk": "01FX8RMR82DDJ90CW8D1GM68YZ",
"postal_code": "NG1 1AA",
"state": "Nottinghamshire",
"street_name": "Broadway",
"street_number": 12,
"unit": "A-1"
},
"age": 37,
"first_name": "Noor",
"last_name": "Vasan",
"personal_statement": "I sing and play the guitar, I enjoy touring and meeting new people on the road.",
"pk": "01FX8RMR82D091TC37B45RCWY3",
"skills": [
"vocals",
"guitar"
]
},
{
"address": {
"city": "San Diego",
"country": "United States",
"pk": "01FX8RMR7YCDAVSWBMWCH2B07G",
"postal_code": "92102",
"state": "California",
"street_name": "C Street",
"street_number": 1299,
"unit": null
},
"age": 43,
"first_name": "Fernando",
"last_name": "Ortega",
"personal_statement": "I'm in a really cool band that plays a lot of cover songs. I'm the drummer!",
"pk": "01FX8RMR7YB283BPZ88HAG066P",
"skills": [
"clarinet",
"oboe",
"drums"
]
}
]
}
在特定城市中寻找具备特定技能的人
现在,我们将尝试一种稍微不同的查询类型。我们想要找到所有居住在特定城市并且拥有特定技能的人。这需要对city字段(这是一个字符串)和skills字段(这是一个字符串数组)进行搜索。
本质上,我们想说“找到所有城市是city并且技能数组包含desired_skill的人”,其中city和desired_skill是app.py中find_matching_skill函数的参数。以下是该代码:
people = Person.find(
(Person.skills << desired_skill) &
(Person.address.city == city)
).all()
这里的<<操作符用于表示“在”或“包含”。
让我们找出谢菲尔德所有的吉他手:
curl --location --request GET 'http://127.0.0.1:5000/people/byskill/guitar/Sheffield'
注意: Sheffield 是区分大小写的。
服务器返回一个包含匹配人员的results数组:
{
"results": [
{
"address": {
"city": "Sheffield",
"country": "United Kingdom",
"pk": "01FX8RMR7THMGA84RH8ZRQRRP9",
"postal_code": "S1 5RE",
"state": "South Yorkshire",
"street_name": "The Beltway",
"street_number": 1,
"unit": "A"
},
"age": 28,
"first_name": "Kareem",
"last_name": "Khan",
"personal_statement": "I'm Kareem, a multi-instrumentalist and singer looking to join a new rock band.",
"pk": "01FX8RMR7T60ANQTS4P9NKPKX8",
"skills": [
"drums",
"guitar",
"synths"
]
},
{
"address": {
"city": "Sheffield",
"country": "United Kingdom",
"pk": "01FX8RMR7NW221STN6NVRDPEDT",
"postal_code": "S12 2MX",
"state": "South Yorkshire",
"street_name": "Main Street",
"street_number": 9,
"unit": null
},
"age": 35,
"first_name": "Robert",
"last_name": "McDonald",
"personal_statement": "My name is Robert, I love meeting new people and enjoy music, coding and walking my dog.",
"pk": "01FX8RMR7NRS45PBT3XP9KNAZH",
"skills": [
"guitar",
"piano",
"trombone"
]
}
]
}
使用全文搜索查找个人陈述中的人员
每个人都有一个人personal_statement字段,这是一个自由文本字符串,包含关于他们的几句话。我们选择以一种使其可全文搜索的方式索引此字段,所以让我们看看现在如何使用它。此代码位于app.py中的find_matching_statements函数中。
要搜索在其personal_statement字段中具有参数search_term值的人员,我们使用%运算符:
Person.find(Person.personal_statement % search_term).all()
让我们找到所有在个人陈述中提到“play”的人。
curl --location --request GET 'http://127.0.0.1:5000/people/bystatement/play'
服务器响应一个匹配人员的results数组:
{
"results": [
{
"address": {
"city": "San Diego",
"country": "United States",
"pk": "01FX8RMR7YCDAVSWBMWCH2B07G",
"postal_code": "92102",
"state": "California",
"street_name": "C Street",
"street_number": 1299,
"unit": null
},
"age": 43,
"first_name": "Fernando",
"last_name": "Ortega",
"personal_statement": "I'm in a really cool band that plays a lot of cover songs. I'm the drummer!",
"pk": "01FX8RMR7YB283BPZ88HAG066P",
"skills": [
"clarinet",
"oboe",
"drums"
]
}, {
"address": {
"city": "Nottingham",
"country": "United Kingdom",
"pk": "01FX8RMR82DDJ90CW8D1GM68YZ",
"postal_code": "NG1 1AA",
"state": "Nottinghamshire",
"street_name": "Broadway",
"street_number": 12,
"unit": "A-1"
},
"age": 37,
"first_name": "Noor",
"last_name": "Vasan",
"personal_statement": "I sing and play the guitar, I enjoy touring and meeting new people on the road.",
"pk": "01FX8RMR82D091TC37B45RCWY3",
"skills": [
"vocals",
"guitar"
]
},
{
"address": {
"city": "Birmingham",
"country": "United Kingdom",
"pk": "01FX8SSSDNRDSRB3HMVH00NQTT",
"postal_code": "B91 6HG",
"state": "West Midlands",
"street_name": "The Rushes",
"street_number": 56,
"unit": null
},
"age": 36,
"first_name": "Joanne",
"last_name": "Peel",
"personal_statement": "Music is my life, I love gigging and playing with my band.",
"pk": "01FX8SSSDN7PT9T3N0JZZA758G",
"skills": [
"synths",
"vocals",
"guitar"
]
}
]
}
请注意,我们得到的结果包括匹配“play”、“plays”和“playing”。
更新一个人的年龄
除了从Redis中检索信息外,我们还需要不时更新一个人的数据。让我们看看如何使用Redis OM for Python来实现这一点。
函数 update_age 在 app.py 中接受两个参数:id 和 new_age。使用这些参数,我们首先从 Redis 中检索该人的数据,并用它创建一个新对象:
try:
person = Person.get(id)
except NotFoundError:
return "Bad request", 400
假设我们找到了这个人,让我们更新他们的年龄并将数据保存回Redis:
person.age = new_age
person.save()
让我们将Kareem Khan的年龄从27岁改为28岁:
curl --location --request POST 'http://127.0.0.1:5000/person/01FX8RMR7T60ANQTS4P9NKPKX8/age/28'
服务器响应为ok。
删除一个人
如果我们知道一个人的ID,我们可以直接从Redis中删除他们,而不需要先将他们的数据加载到Person对象中。在app.py中的delete_person函数中,我们调用Person类上的delete类方法来实现这一点:
Person.delete(id)
让我们删除ID为01FX8RMR8545RWW4DYCE5MSZA1的Dan Harris:
curl --location --request POST 'http://127.0.0.1:5000/person/01FX8RMR8545RWW4DYCE5MSZA1/delete'
服务器会返回一个ok响应,无论提供的ID是否存在于Redis中。
设置人员的过期时间
这是一个示例,展示了如何对保存在Redis中的模型实例运行任意Redis命令。让我们看看如何为一个人设置生存时间(TTL),以便Redis在经过可配置的秒数后使JSON文档过期。
函数 expire_by_id 在 app.py 中处理如下。它接受两个参数:id - 要过期的人的ID,和 seconds - 在未来多少秒后使该人过期。这要求我们对这个人的键运行 Redis EXPIRE 命令。为此,我们需要从 Person 模型中访问 Redis 连接,如下所示:
person_to_expire = Person.get(id)
Person.db().expire(person_to_expire.key(), seconds)
让我们将ID为01FX8RMR82D091TC37B45RCWY3的人员设置为600秒后过期:
curl --location --request POST 'http://localhost:5000/person/01FX8RMR82D091TC37B45RCWY3/expire/600'
使用 redis-cli,你可以检查这个人现在是否有一个通过 Redis expire 命令设置的 TTL:
127.0.0.1:6379> ttl :person.Person:01FX8RMR82D091TC37B45RCWY3
(integer) 584
这表明Redis将在584秒后使该键过期。
你可以在模型类上使用.db()函数来获取底层的redis-py连接,以便随时运行更低级别的Redis命令。更多详情,请参阅redis-py文档。
关闭 Redis (Docker)
如果您正在使用Docker,并且希望在完成应用程序后关闭Redis容器,请使用docker-compose down:
$ docker-compose down
Stopping redis_om_python_flask_starter ... done
Removing redis_om_python_flask_starter ... done
Removing network redis-om-python-flask-skeleton-app_default