数据分布的可视化#
在任何分析或建模数据的尝试中,早期步骤之一应该是理解变量的分布情况。分布可视化技术可以快速回答许多重要问题。观察值覆盖的范围是什么?它们的集中趋势是什么?它们是否在某个方向上严重偏斜?是否有双峰性的证据?是否存在显著的异常值?这些问题的答案是否会因其他变量定义的子集而异?
The distributions module 包含几个函数,旨在回答此类问题。轴级函数包括 histplot()、kdeplot()、ecdfplot() 和 rugplot()。它们在图级函数 displot()、jointplot() 和 pairplot() 中被组合在一起。
有几种不同的方法来可视化一个分布,每种方法都有其相对的优点和缺点。理解这些因素很重要,这样你才能为你的特定目标选择最佳方法。
绘制单变量直方图#
也许最常见的分布可视化方法是 直方图。这是 displot() 中的默认方法,它使用与 histplot() 相同的底层代码。直方图是一种条形图,其中表示数据变量的轴被划分为一组离散的区间,每个区间内观察值的计数通过相应条形的高度来显示:
penguins = sns.load_dataset("penguins")
sns.displot(penguins, x="flipper_length_mm")
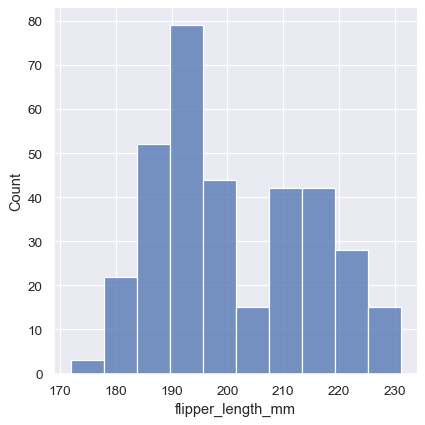
这个图表立即提供了关于 flipper_length_mm 变量的一些见解。例如,我们可以看到最常见的鳍状肢长度大约是 195 毫米,但分布呈现双峰,因此这个单一数字并不能很好地代表数据。
选择箱子大小#
箱子的大小是一个重要的参数,使用错误的箱子大小可能会通过掩盖数据的重要特征或通过随机变异性创造出明显的特征来误导。默认情况下,displot()/histplot() 根据数据的方差和观察次数选择一个默认的箱子大小。但你不应该过度依赖这种自动方法,因为它们依赖于关于数据结构的特定假设。始终建议检查你对分布的印象在不同箱子大小下是否一致。要直接选择大小,请设置 binwidth 参数:
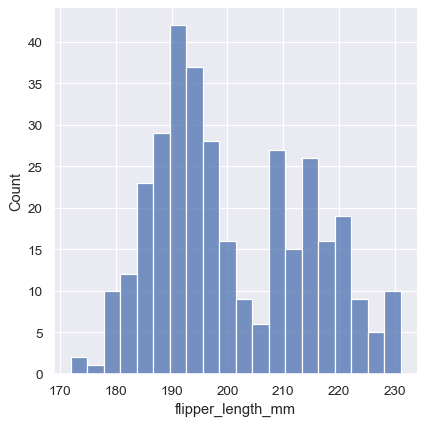
sns.displot(penguins, x="flipper_length_mm", binwidth=3)

在其他情况下,指定 数量 的箱子可能比指定它们的大小更有意义:
sns.displot(penguins, x="flipper_length_mm", bins=20)
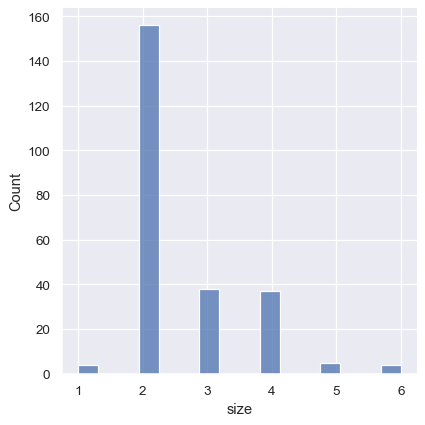
默认设置失效的一个例子是当变量取相对较少的整数值时。在这种情况下,默认的箱宽可能太小,导致分布中出现不自然的间隙:
tips = sns.load_dataset("tips")
sns.displot(tips, x="size")
一种方法是通过向 bins 传递一个数组来指定精确的箱子边界:
sns.displot(tips, x="size", bins=[1, 2, 3, 4, 5, 6, 7])
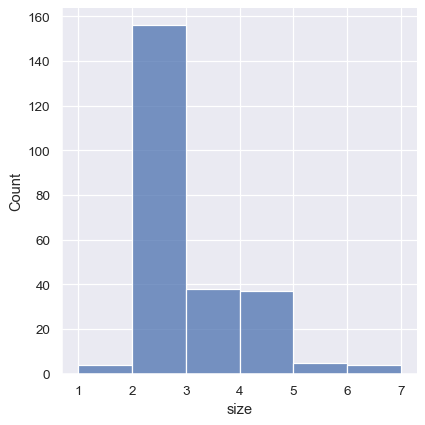
这也可以通过设置 discrete=True 来实现,该设置会选择代表数据集中唯一值的箱子断点,并且条形图会以其对应值为中心。
sns.displot(tips, x="size", discrete=True)
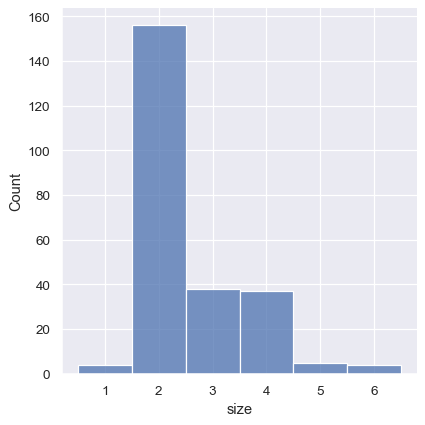
也可以使用直方图的逻辑来可视化分类变量的分布。分类变量的离散区间是自动设置的,但稍微“缩小”条形图可能有助于强调轴的分类性质:
sns.displot(tips, x="day", shrink=.8)
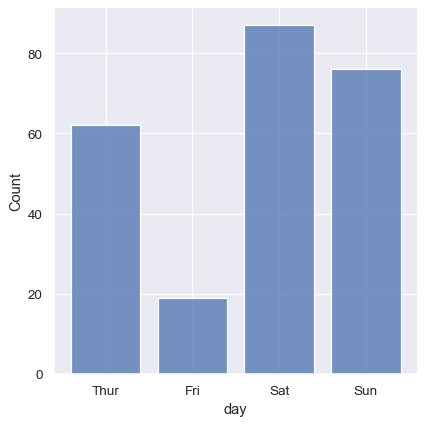
基于其他变量进行条件化#
一旦你理解了变量的分布,下一步通常是询问该分布的特征是否在数据集中的其他变量之间有所不同。例如,是什么导致了我们上面看到的蹼长度的双峰分布?displot() 和 histplot() 通过 hue 语义提供了对条件子集的支持。将一个变量分配给 hue 将为每个唯一值绘制一个单独的直方图,并通过颜色区分它们:
sns.displot(penguins, x="flipper_length_mm", hue="species")
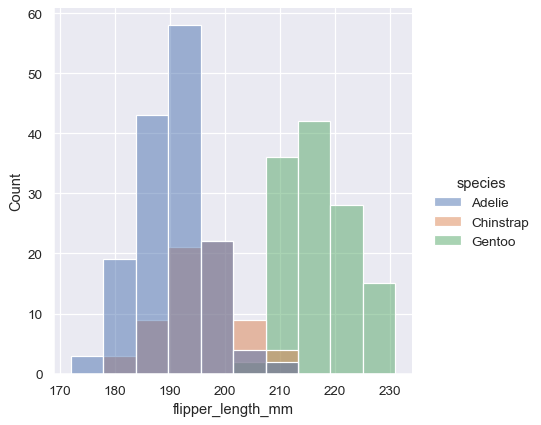
默认情况下,不同的直方图是“分层”叠加在一起的,在某些情况下,它们可能难以区分。一个选项是将直方图的视觉表示从条形图更改为“阶梯”图:
sns.displot(penguins, x="flipper_length_mm", hue="species", element="step")
或者,不逐层叠加每个条形,它们可以“堆叠”,或垂直移动。在这个图中,完整直方图的轮廓将与仅包含单个变量的图相匹配:
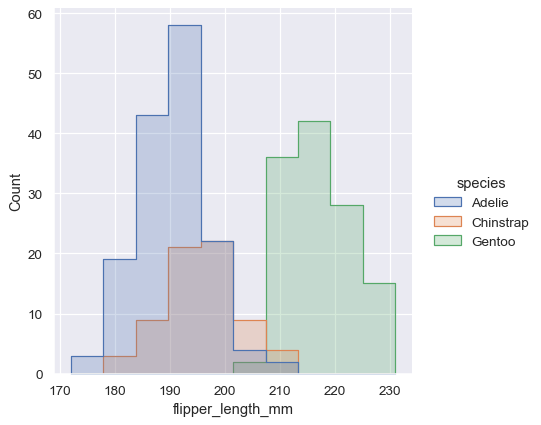
sns.displot(penguins, x="flipper_length_mm", hue="species", multiple="stack")
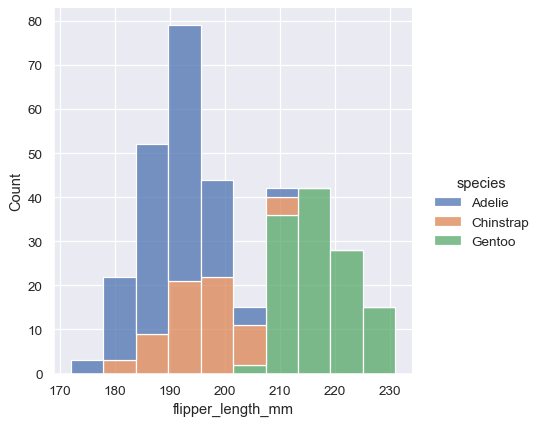
堆积直方图强调了变量之间的部分-整体关系,但它可能会掩盖其他特征(例如,很难确定Adelie分布的模式。另一个选项是“躲避”条形图,这会使它们水平移动并减少宽度。这样可以确保没有重叠,并且条形图在高度上保持可比性。但这只适用于分类变量具有少量水平的情况:
sns.displot(penguins, x="flipper_length_mm", hue="sex", multiple="dodge")
因为 displot() 是一个图级别的函数,并且是绘制在 FacetGrid 上的,所以也可以通过将第二个变量分配给 col 或 row 而不是(或除了) hue 来在单独的子图中绘制每个单独的分布。这很好地表示了每个子集的分布,但它使得直接比较变得更加困难:
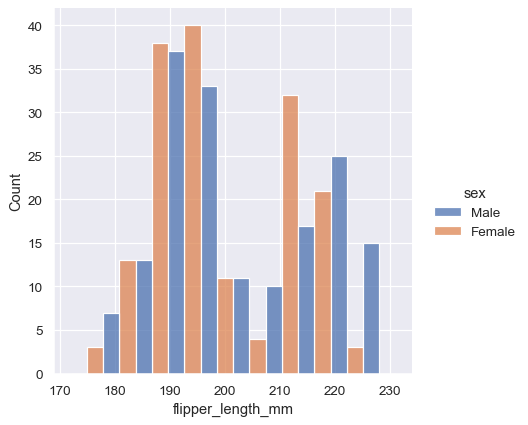
sns.displot(penguins, x="flipper_length_mm", col="sex")

这些方法都不完美,我们很快就会看到一些比直方图更适合比较任务的替代方法。
归一化直方图统计#
在我们开始之前,另一个需要注意的点是,当子集的观察数量不均等时,以计数的方式比较它们的分布可能并不理想。一种解决方案是使用 stat 参数对计数进行 归一化:
sns.displot(penguins, x="flipper_length_mm", hue="species", stat="density")
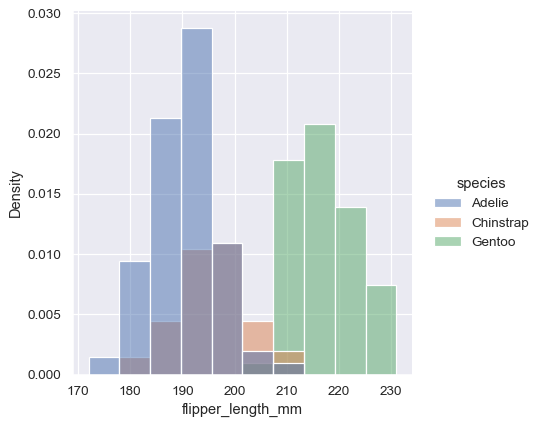
然而,默认情况下,归一化应用于整个分布,因此这只是重新调整了条形的高度。通过设置 common_norm=False,每个子集将独立进行归一化:
sns.displot(penguins, x="flipper_length_mm", hue="species", stat="density", common_norm=False)

密度归一化调整柱状图,使得它们的 面积 总和为1。因此,密度轴不能直接解释。另一个选项是归一化柱状图,使得它们的 高度 总和为1。当变量是离散时,这最有意义,但它适用于所有直方图:
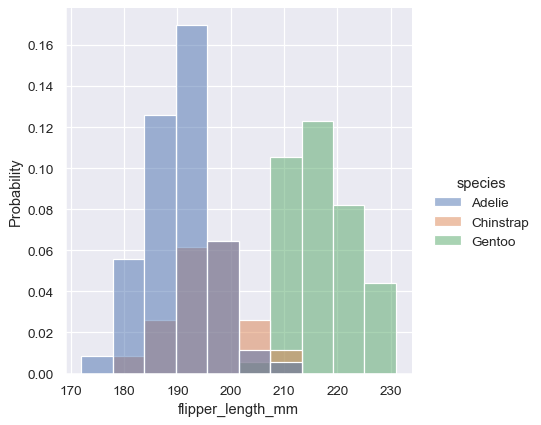
sns.displot(penguins, x="flipper_length_mm", hue="species", stat="probability")
核密度估计#
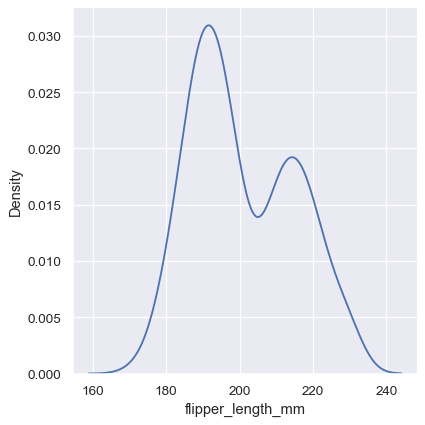
直方图旨在通过分箱和计数观测值来近似生成数据的底层概率密度函数。核密度估计(KDE)为同一问题提供了不同的解决方案。与使用离散箱不同,KDE 图使用高斯核平滑观测值,生成连续的密度估计:
sns.displot(penguins, x="flipper_length_mm", kind="kde")
选择平滑带宽#
与直方图中的箱子大小类似,KDE 准确表示数据的能力取决于平滑带宽的选择。过度平滑的估计可能会抹去有意义的特征,但平滑不足的估计可能会掩盖随机噪声中的真实形状。检查估计稳健性的最简单方法是调整默认带宽:
sns.displot(penguins, x="flipper_length_mm", kind="kde", bw_adjust=.25)
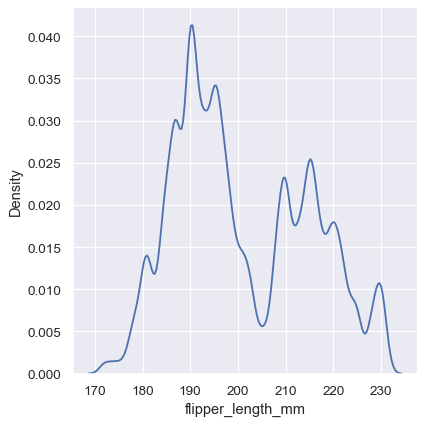
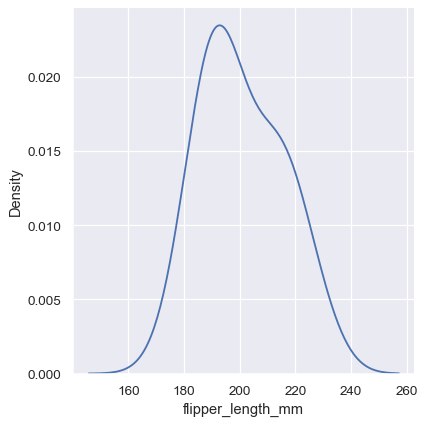
注意窄带宽如何使双峰性更加明显,但曲线变得不那么平滑。相比之下,较大的带宽几乎完全掩盖了双峰性:
sns.displot(penguins, x="flipper_length_mm", kind="kde", bw_adjust=2)
基于其他变量进行条件化#
与直方图一样,如果你分配一个 hue 变量,将为该变量的每个级别计算单独的密度估计:
sns.displot(penguins, x="flipper_length_mm", hue="species", kind="kde")
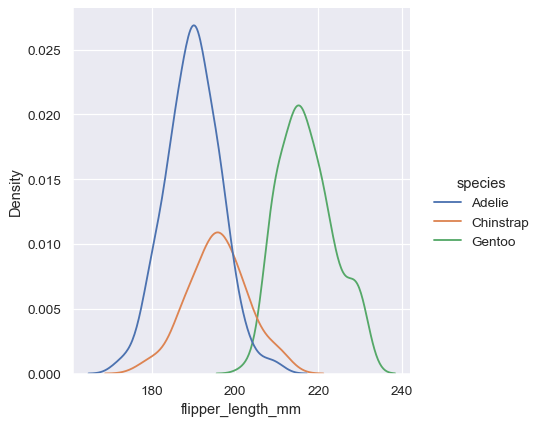
在许多情况下,分层的 KDE 比分层的直方图更容易解释,因此它通常是对比任务的一个好选择。然而,解决多个分布的许多相同选项也适用于 KDE:
sns.displot(penguins, x="flipper_length_mm", hue="species", kind="kde", multiple="stack")
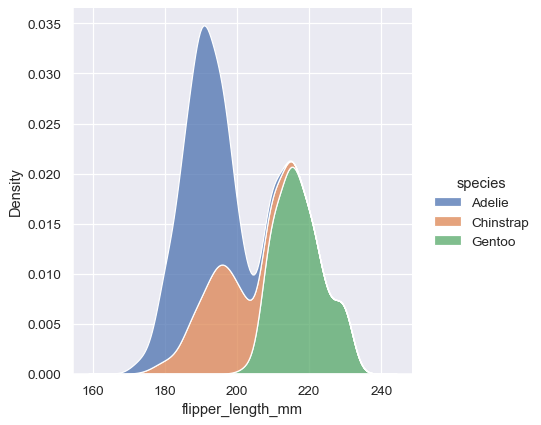
注意默认情况下堆叠图如何填充每条曲线之间的区域。也可以填充单个或分层密度的曲线,尽管默认的alpha值(不透明度)会有所不同,以便更容易分辨各个密度。
sns.displot(penguins, x="flipper_length_mm", hue="species", kind="kde", fill=True)
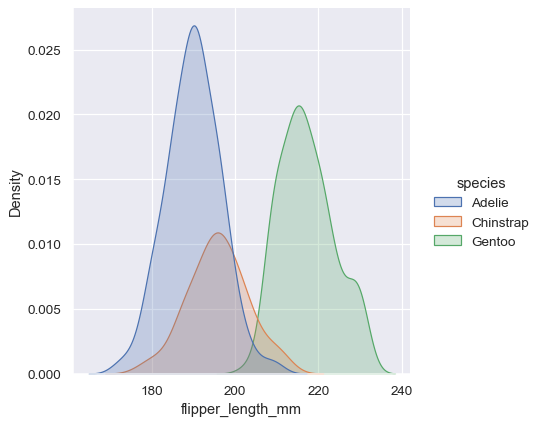
核密度估计的陷阱#
KDE 图有很多优点。数据的重要特征(如中心趋势、双峰性、偏斜)易于辨别,并且它们便于子集之间的比较。但也有一些情况下,KDE 不能很好地代表基础数据。这是因为 KDE 的逻辑假设基础分布是平滑且无界的。这种假设可能失败的一种情况是,当一个变量反映的是自然有界的数量时。如果有观测值接近边界(例如,一个不能为负的变量的较小值),KDE 曲线可能会延伸到不现实的值:
sns.displot(tips, x="total_bill", kind="kde")
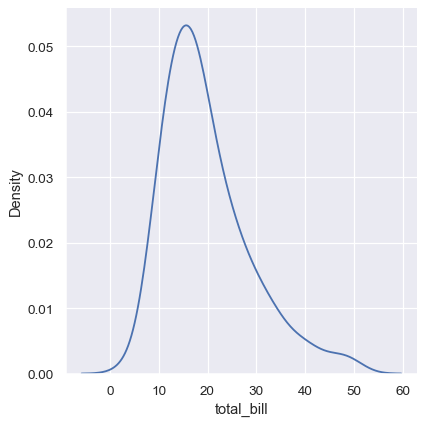
这可以通过 cut 参数部分避免,该参数指定曲线应在极端数据点之外延伸多远。但这仅影响曲线的绘制位置;密度估计仍会在没有数据存在的范围内进行平滑处理,导致分布的极端处密度估计人为地偏低:
sns.displot(tips, x="total_bill", kind="kde", cut=0)
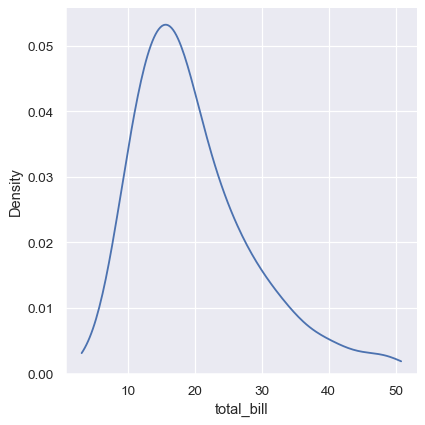
KDE 方法在处理离散数据或数据本身是连续的但某些特定值过度表示时也会失效。需要记住的重要一点是,KDE 将 总是展示一条平滑的曲线,即使数据本身并不平滑。例如,考虑这种钻石重量的分布:
diamonds = sns.load_dataset("diamonds")
sns.displot(diamonds, x="carat", kind="kde")
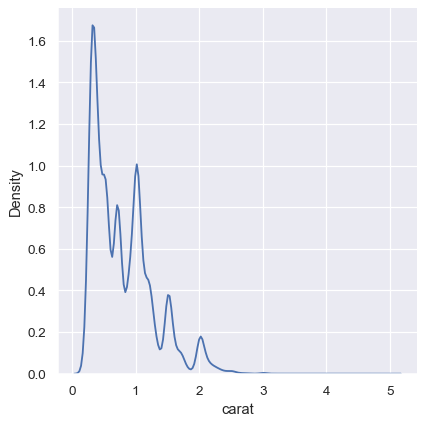
虽然KDE建议在特定值附近有峰值,但直方图显示了一个更加参差不齐的分布:
sns.displot(diamonds, x="carat")
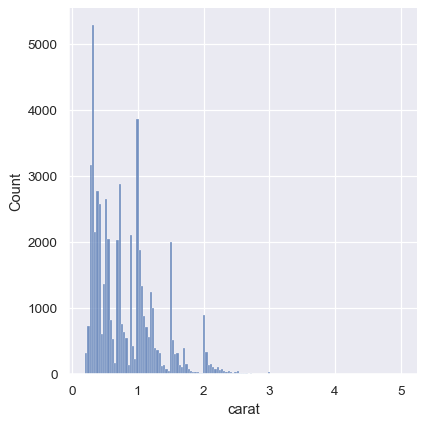
作为一种折中方案,可以将这两种方法结合起来。在直方图模式下,displot`(与:func:`histplot() 类似)可以选择包含平滑的 KDE 曲线(注意 kde=True,而不是 kind="kde"):
sns.displot(diamonds, x="carat", kde=True)
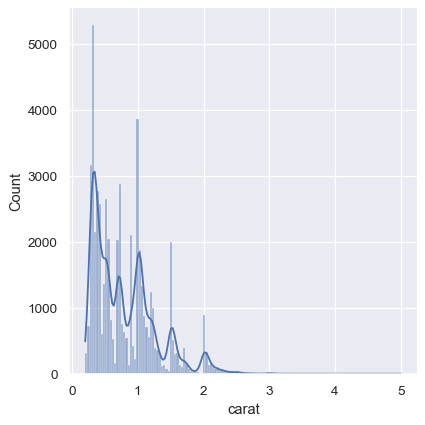
经验累积分布#
可视化分布的第三个选项是计算“经验累积分布函数”(ECDF)。这个图通过每个数据点绘制一条单调递增的曲线,使得曲线的高度反映了较小值的观测比例:
sns.displot(penguins, x="flipper_length_mm", kind="ecdf")
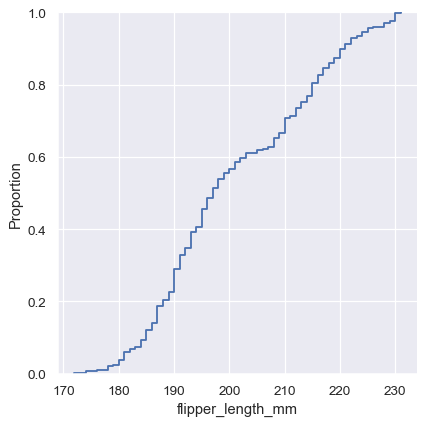
ECDF 图有两个主要优势。与直方图或 KDE 不同,它直接表示每个数据点。这意味着不需要考虑分箱大小或平滑参数。此外,由于曲线是单调递增的,因此非常适合比较多个分布:
sns.displot(penguins, x="flipper_length_mm", hue="species", kind="ecdf")
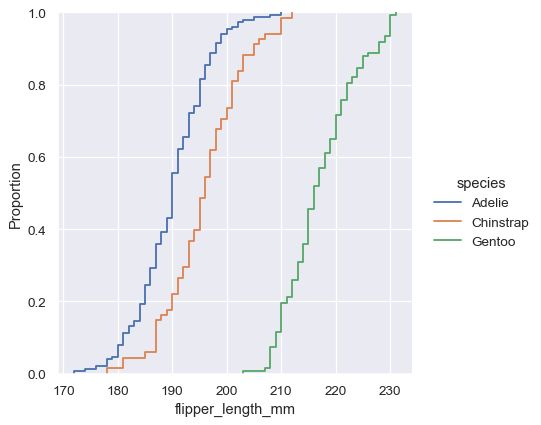
ECDF 图的主要缺点是它比直方图或密度曲线更不直观地表示分布的形状。考虑一下,在直方图中,鳍状肢长度的双峰性立即显现出来,但在 ECDF 图中,你必须寻找不同的斜率才能看到它。尽管如此,通过练习,你可以学会通过检查 ECDF 来回答关于分布的所有重要问题,这样做可能是一种强大的方法。
可视化双变量分布#
到目前为止,所有示例都考虑了 单变量 分布:单个变量的分布,可能是基于分配给 hue 的第二个变量的条件分布。然而,将第二个变量分配给 y 将绘制一个 双变量 分布:
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm")

双变量直方图将数据分箱到平铺图形的矩形中,然后使用填充颜色显示每个矩形内的观察计数(类似于 热图())。类似地,双变量 KDE 图使用二维高斯平滑 (x, y) 观测值。默认表示法随后显示二维密度的 等高线:
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", kind="kde")
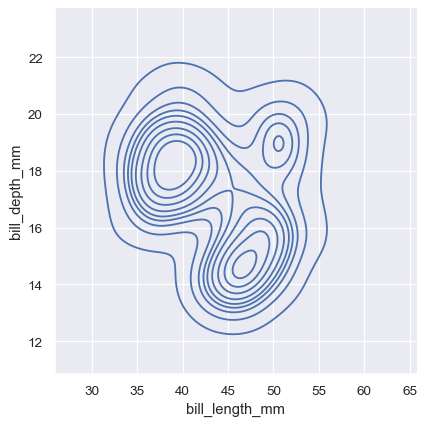
分配一个 hue 变量将使用不同的颜色绘制多个热图或等高线集。对于双变量直方图,只有在条件分布之间重叠最小的情况下,这种方法才能很好地工作:
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", hue="species")
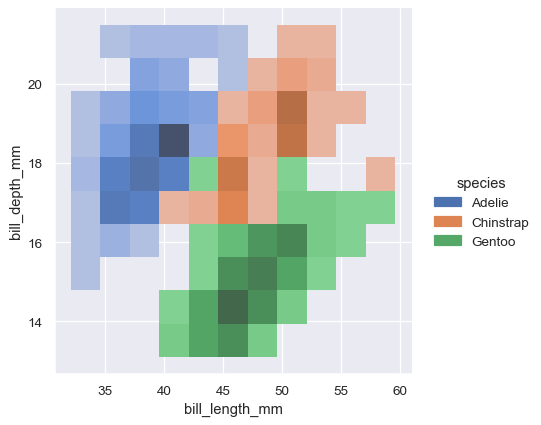
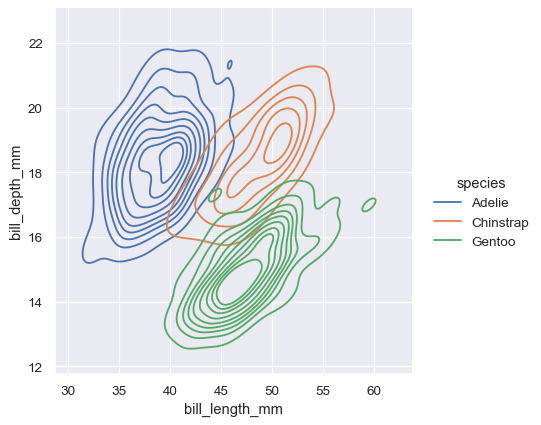
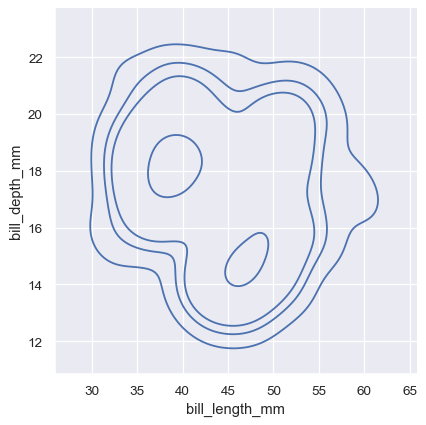
双变量KDE图的等高线方法更适合于评估重叠,尽管等高线过多的图可能会显得杂乱:
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", hue="species", kind="kde")
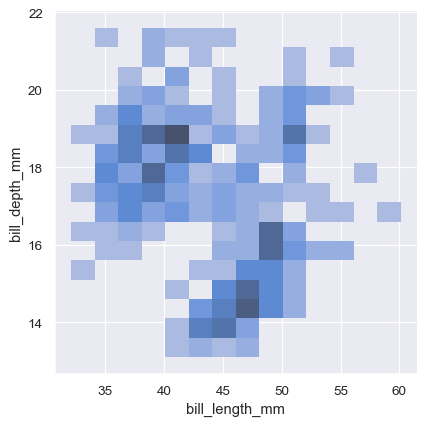
与单变量图一样,分箱大小或平滑带宽的选择将决定图表对基础二元分布的表示效果。相同的参数适用,但可以通过传递一对值来为每个变量进行调整:
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", binwidth=(2, .5))
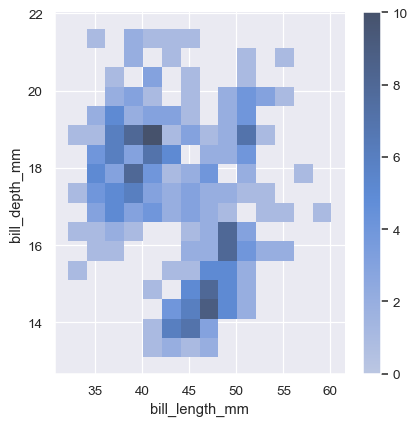
为了帮助解读热图,添加一个颜色条以显示计数与颜色强度之间的映射:
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", binwidth=(2, .5), cbar=True)
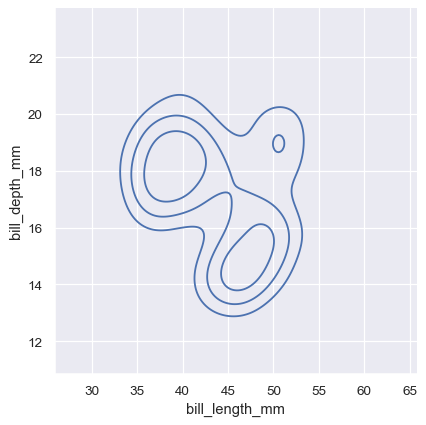
二元密度等高线的含义不那么直接。由于密度本身不易解释,等高线是根据 等比例 的密度绘制的,这意味着每条曲线显示了一个水平集,使得密度中某个比例 p 位于其下方。p 值均匀分布,最低水平由 thresh 参数控制,数量由 levels 控制:
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", kind="kde", thresh=.2, levels=4)
levels 参数也接受一个值列表,以实现更多控制:
sns.displot(penguins, x="bill_length_mm", y="bill_depth_mm", kind="kde", levels=[.01, .05, .1, .8])
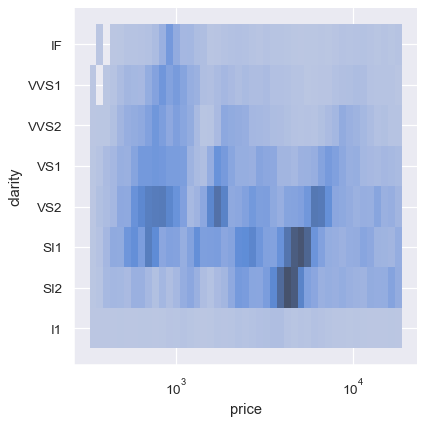
二元直方图允许一个或两个变量是离散的。绘制一个离散变量和一个连续变量提供了另一种比较条件单变量分布的方法:
sns.displot(diamonds, x="price", y="clarity", log_scale=(True, False))
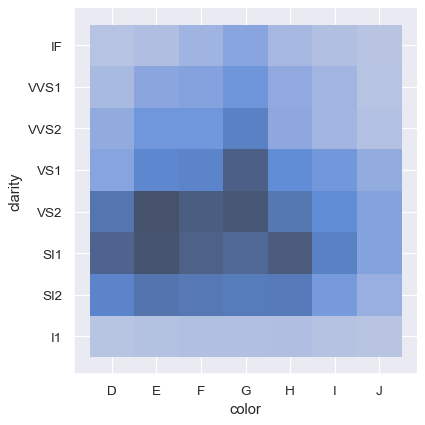
相比之下,绘制两个离散变量是一种简单的方式来展示观察值的交叉表:
sns.displot(diamonds, x="color", y="clarity")
其他环境中的分布可视化#
seaborn 中的其他几个图形级绘图函数使用了 histplot() 和 kdeplot() 函数。
绘制联合分布和边缘分布#
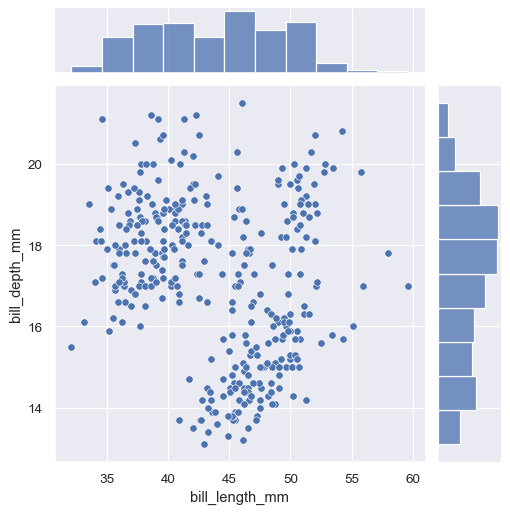
第一个是 jointplot(),它通过两个变量的边际分布来增强双变量关系或分布图。默认情况下,jointplot() 使用 scatterplot() 表示双变量分布,使用 histplot() 表示边际分布:
sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm")
与 displot() 类似,在 jointplot() 中设置不同的 kind="kde" 将改变联合图和边缘图,使其使用 kdeplot():
sns.jointplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="species",
kind="kde"
)
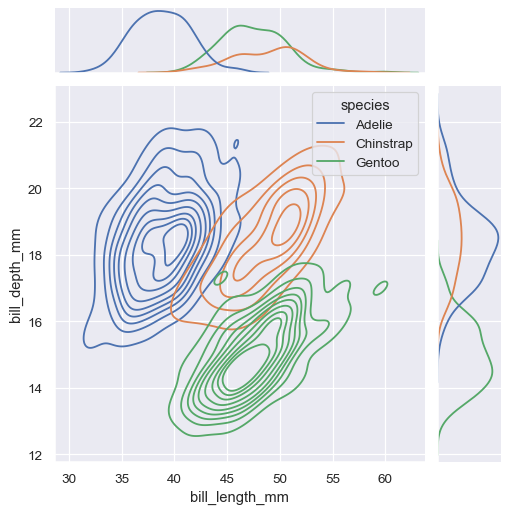
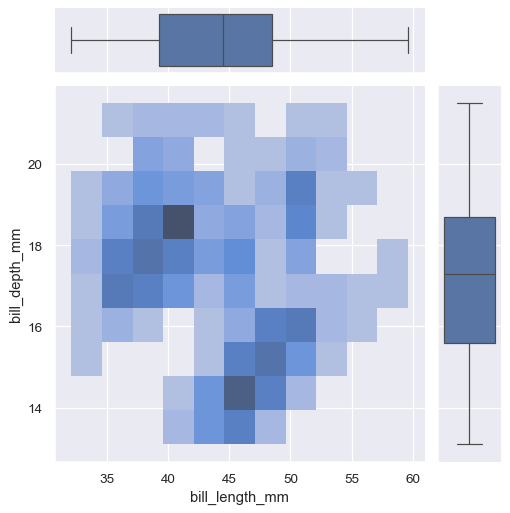
jointplot() 是 JointGrid 类的一个便捷接口,直接使用时提供了更多的灵活性:
g = sns.JointGrid(data=penguins, x="bill_length_mm", y="bill_depth_mm")
g.plot_joint(sns.histplot)
g.plot_marginals(sns.boxplot)
一种不那么显眼的方式来展示边缘分布是使用“rug”图,它在图的边缘添加一个小刻度来表示每个单独的观察结果。这内置于 displot() 中:
sns.displot(
penguins, x="bill_length_mm", y="bill_depth_mm",
kind="kde", rug=True
)
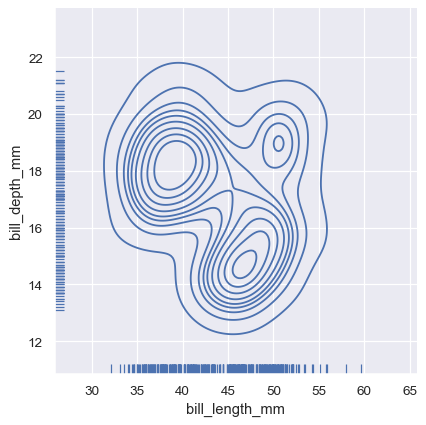
而轴级别的 rugplot() 函数可以用来在任何其他类型的图表旁边添加地毯图:
sns.relplot(data=penguins, x="bill_length_mm", y="bill_depth_mm")
sns.rugplot(data=penguins, x="bill_length_mm", y="bill_depth_mm")
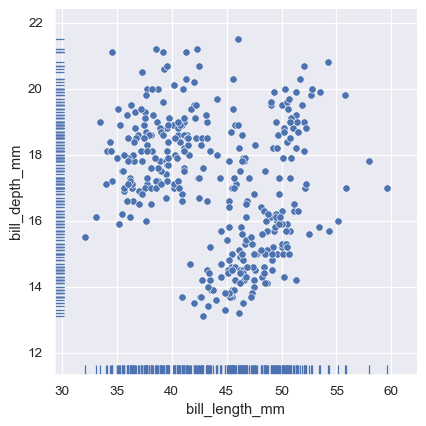
绘制多个分布#
函数 pairplot() 提供了类似的联合和边缘分布的混合。然而,与专注于单一关系不同,pairplot() 使用“小倍数”方法来可视化数据集中所有变量的单变量分布以及它们之间的所有成对关系:
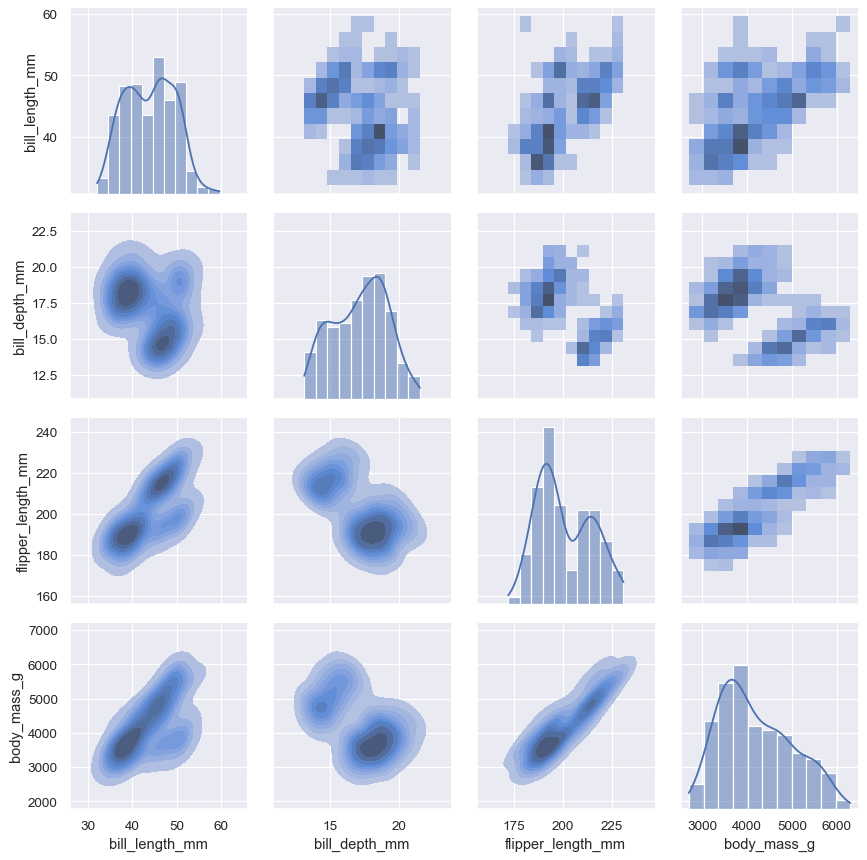
sns.pairplot(penguins)
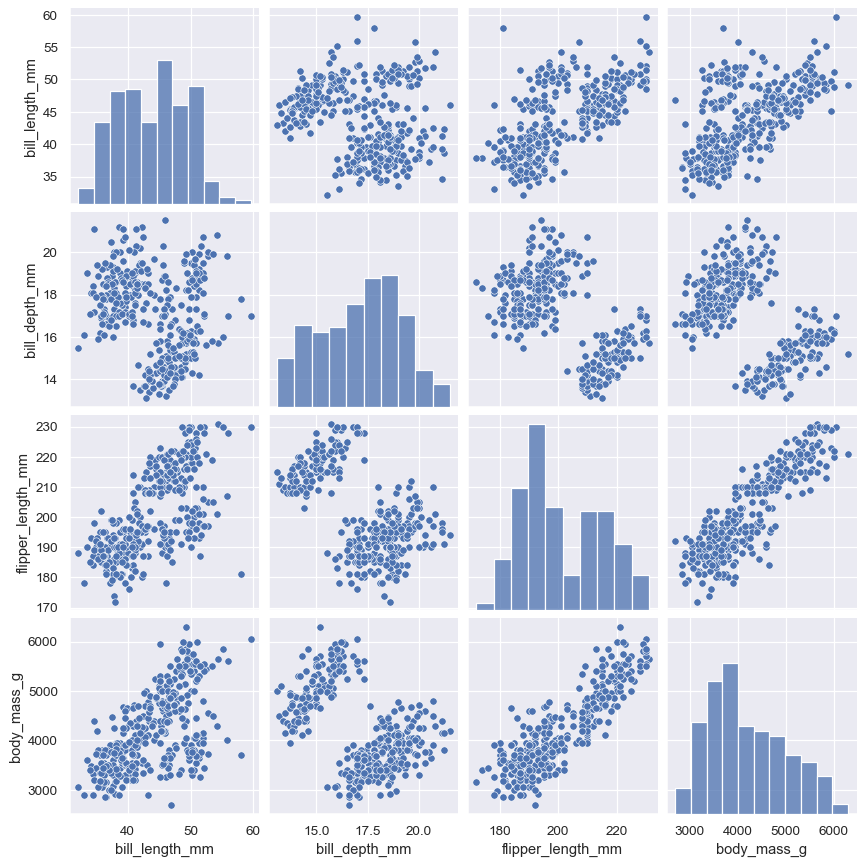
与 jointplot()/JointGrid 类似,直接使用底层的 PairGrid 将提供更多的灵活性,只需多打几个字:
g = sns.PairGrid(penguins)
g.map_upper(sns.histplot)
g.map_lower(sns.kdeplot, fill=True)
g.map_diag(sns.histplot, kde=True)