可视化统计关系#
统计分析是一个理解数据集中变量之间如何相互关联以及这些关系如何依赖于其他变量的过程。可视化可以是这一过程的核心组成部分,因为当数据被正确可视化时,人类的视觉系统能够看到表明关系的趋势和模式。
在本教程中,我们将讨论三个 seaborn 函数。我们最常使用的是 relplot()。这是一个用于使用两种常见方法(散点图和线图)可视化统计关系的 图级函数。relplot() 结合了 FacetGrid 和两个轴级函数之一:
散点图()(使用kind="scatter";默认)lineplot`(使用 ``kind="line"`())
正如我们将看到的,这些函数可以非常具有启发性,因为它们使用简单且易于理解的数据显示方式,尽管如此,它们仍然能够表示复杂的数据集结构。它们之所以能够做到这一点,是因为它们绘制了二维图形,这些图形可以通过使用色调、大小和样式的语义映射多达三个额外的变量来增强。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="darkgrid")
用散点图关联变量#
散点图是统计可视化的主要工具。它使用点的云图来描绘两个变量的联合分布,其中每个点代表数据集中的一个观测值。这种描绘方式使眼睛能够推断出它们之间是否存在任何有意义的关系。
在seaborn中,有几种方法可以绘制散点图。最基本的方法是使用 scatterplot() 函数,适用于两个变量均为数值型的情况。在 分类可视化教程 中,我们将看到使用散点图来可视化分类数据的专用工具。scatterplot() 是 relplot() 的默认 kind``(也可以通过设置 ``kind="scatter" 来强制使用):
tips = sns.load_dataset("tips")
sns.relplot(data=tips, x="total_bill", y="tip")
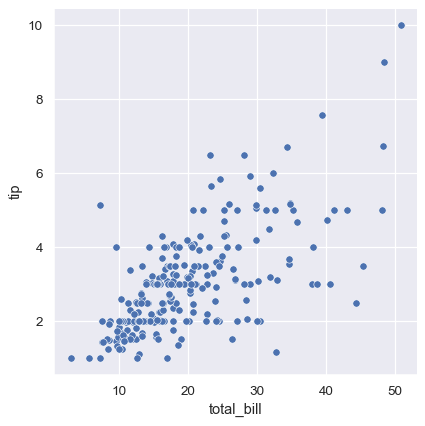
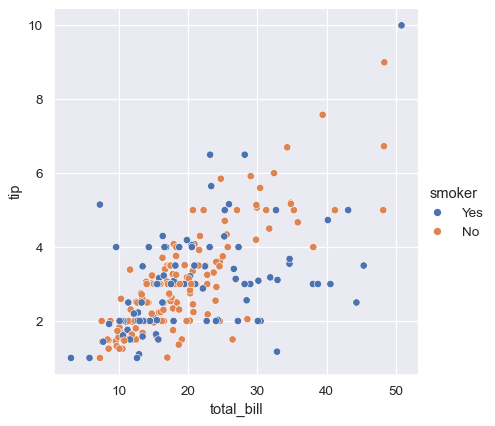
虽然这些点是在二维平面上绘制的,但可以通过根据第三个变量对点进行着色来为图表添加另一个维度。在 seaborn 中,这被称为使用“色调语义”,因为点的颜色获得了意义:
sns.relplot(data=tips, x="total_bill", y="tip", hue="smoker")
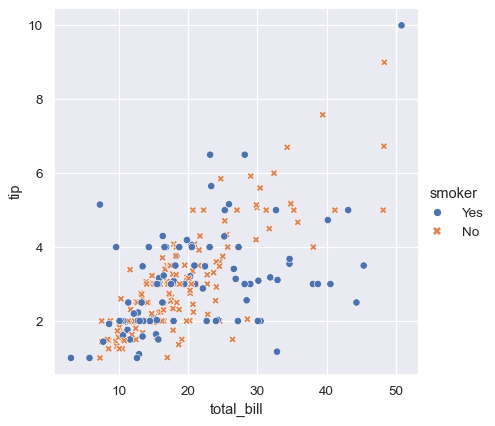
为了强调不同类之间的区别,并提高可访问性,您可以为每个类使用不同的标记样式:
sns.relplot(
data=tips,
x="total_bill", y="tip", hue="smoker", style="smoker"
)
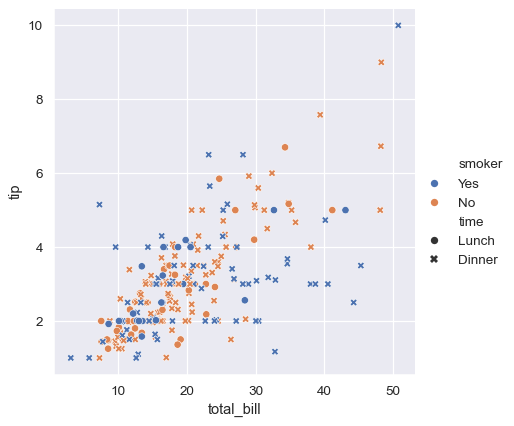
也可以通过改变每个点的色调和样式来表示四个变量。但这一点应谨慎处理,因为眼睛对形状的敏感度远低于对颜色的敏感度:
sns.relplot(
data=tips,
x="total_bill", y="tip", hue="smoker", style="time",
)
在上面的例子中,色调语义是分类的,因此应用了默认的 定性调色板 。如果色调语义是数值的(特别是,如果它可以转换为浮点数),默认的着色会切换到顺序调色板:
sns.relplot(
data=tips, x="total_bill", y="tip", hue="size",
)
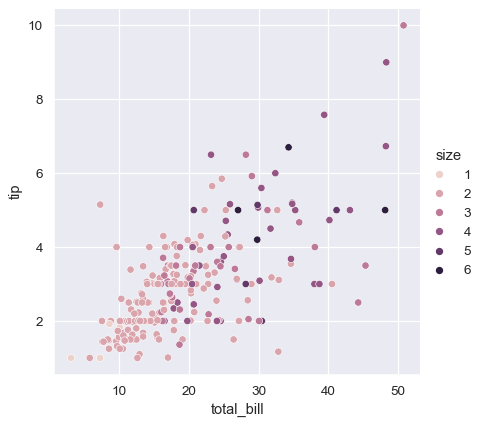
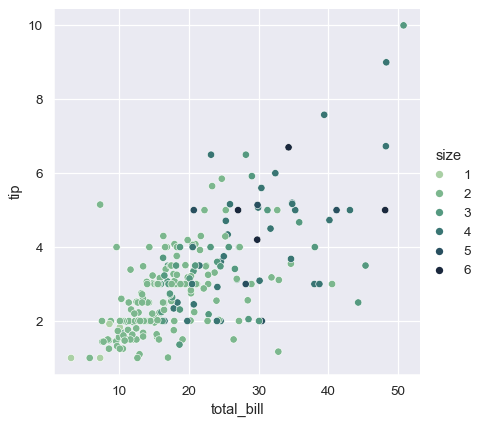
在这两种情况下,您都可以自定义调色板。有很多选项可以做到这一点。在这里,我们使用字符串接口自定义一个顺序调色板,使用 cubehelix_palette() 函数:
sns.relplot(
data=tips,
x="total_bill", y="tip",
hue="size", palette="ch:r=-.5,l=.75"
)
第三种语义变量改变了每个点的大小:
sns.relplot(data=tips, x="total_bill", y="tip", size="size")
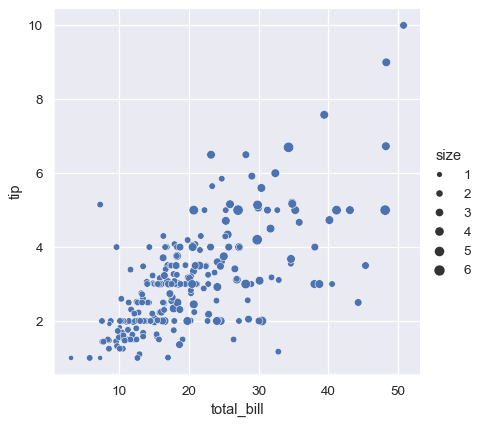
与 matplotlib.pyplot.scatter() 不同,变量的字面值不用于选择点的面积。相反,数据单位中的值范围被归一化为面积单位中的范围。这个范围可以自定义:
sns.relplot(
data=tips, x="total_bill", y="tip",
size="size", sizes=(15, 200)
)

在 scatterplot() API 示例中展示了更多关于如何自定义使用不同语义来展示统计关系的示例。
强调线图的连续性#
散点图非常有效,但没有一种普遍最优的可视化类型。相反,可视化表示应根据数据集的具体情况以及你试图通过图表回答的问题进行调整。
对于某些数据集,您可能希望了解一个变量随时间或其他类似连续变量的变化情况。在这种情况下,绘制折线图是一个不错的选择。在seaborn中,这可以通过 lineplot() 函数直接实现,或者通过设置 kind="line" 使用 relplot() 实现:
dowjones = sns.load_dataset("dowjones")
sns.relplot(data=dowjones, x="Date", y="Price", kind="line")
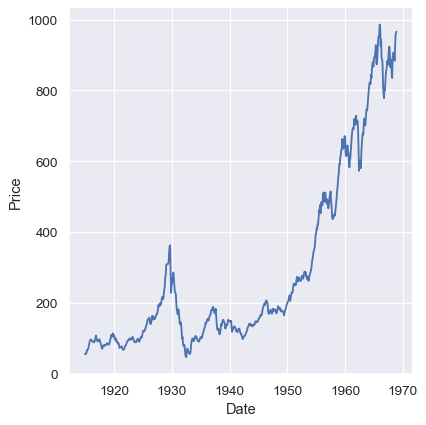
聚合与表示不确定性#
更复杂的数据集将对同一个 x 变量有多个测量值。seaborn 的默认行为是通过绘制均值和均值周围的 95% 置信区间来聚合每个 x 值的多个测量值:
fmri = sns.load_dataset("fmri")
sns.relplot(data=fmri, x="timepoint", y="signal", kind="line")
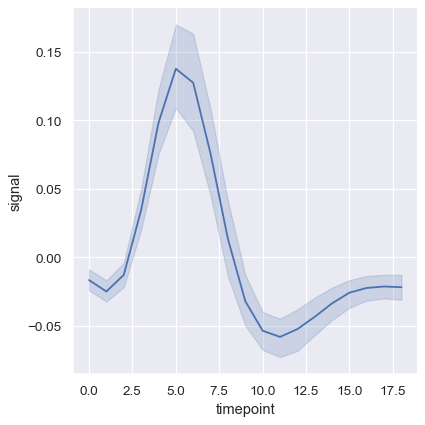
置信区间是使用自助法计算的,这对于较大的数据集来说可能是时间密集型的。因此,可以禁用它们:
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", errorbar=None,
)
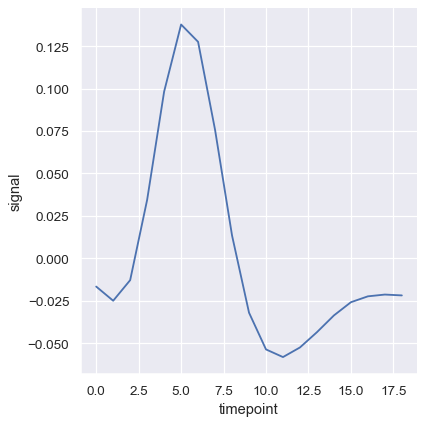
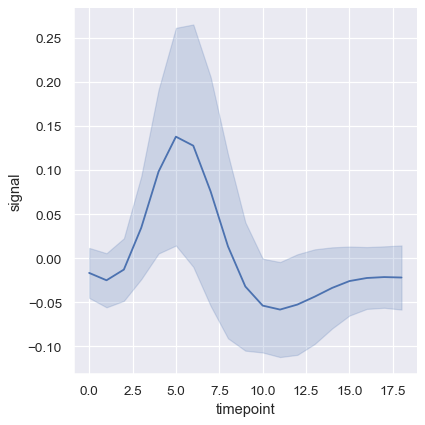
另一个好选项,特别是在处理大量数据时,是通过绘制标准差而不是置信区间来表示每个时间点的分布扩散:
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", errorbar="sd",
)
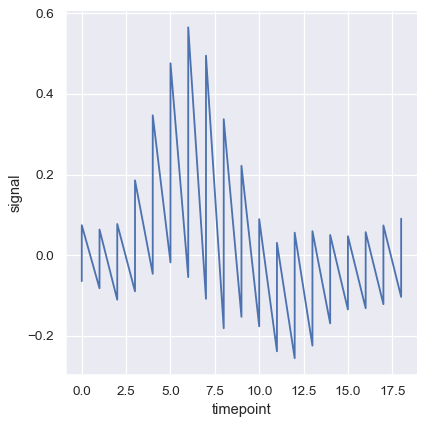
要完全关闭聚合,请将 estimator 参数设置为 None。当数据在每个点有多个观测值时,这可能会产生奇怪的效果。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal",
estimator=None,
)
使用语义映射绘制数据子集#
The lineplot() function has the same flexibility as scatterplot(): it can show up to three additional variables by modifying the hue, size, and style of the plot elements. It does so using the same API as scatterplot(), meaning that we don’t need to stop and think about the parameters that control the look of lines vs. points in matplotlib.
在 lineplot() 中使用语义也会决定数据如何被聚合。例如,添加一个有两个级别的色调语义会将图表分割成两条线和误差带,每条线的颜色表示它们对应的数据子集。
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", hue="event",
)

为折线图添加样式语义会默认改变线条中的虚线模式:
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal",
hue="region", style="event",
)

但你可以通过每个观测点使用的标记来识别子集,这些标记可以与破折号一起使用,或者代替破折号:
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", hue="region", style="event",
dashes=False, markers=True,
)
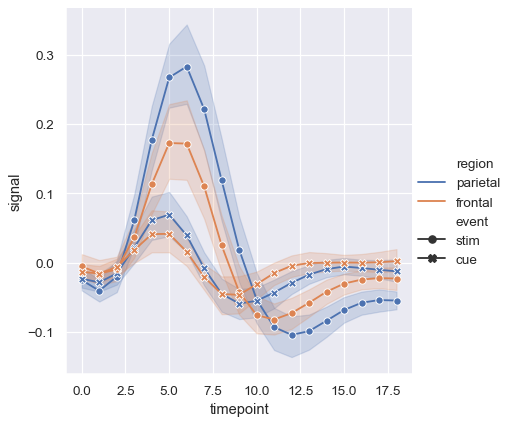
与散点图一样,在使用多种语义制作折线图时要谨慎。虽然有时信息丰富,但它们也可能难以解析和解释。但即使你只是在检查一个额外变量的变化,改变线条的颜色和样式也是有用的。这可以使图表在打印成黑白或被色盲人士查看时更具可读性:
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", hue="event", style="event",
)
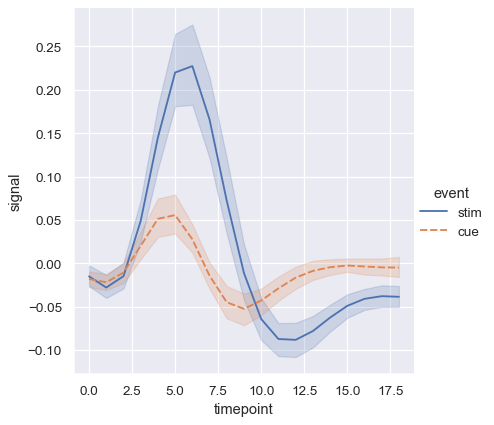
当你处理重复测量数据时(即你有多个被多次采样的单位),你也可以单独绘制每个采样单位,而不通过语义区分它们。这样可以避免图例混乱:
sns.relplot(
data=fmri.query("event == 'stim'"), kind="line",
x="timepoint", y="signal", hue="region",
units="subject", estimator=None,
)
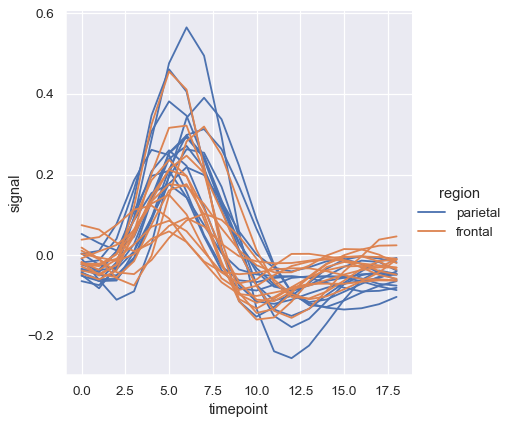
在 lineplot() 中,默认的颜色映射和图例的处理也取决于色调语义是分类的还是数值的:
dots = sns.load_dataset("dots").query("align == 'dots'")
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate",
hue="coherence", style="choice",
)

即使 hue 变量是数值型的,它也可能不适合用线性色标来表示。这里的情况就是如此,hue 变量的级别是按对数比例缩放的。你可以通过传递一个列表或字典来为每条线提供特定的颜色值:
palette = sns.cubehelix_palette(light=.8, n_colors=6)
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate",
hue="coherence", style="choice", palette=palette,
)

或者你可以改变颜色映射的归一化方式:
from matplotlib.colors import LogNorm
palette = sns.cubehelix_palette(light=.7, n_colors=6)
sns.relplot(
data=dots.query("coherence > 0"), kind="line",
x="time", y="firing_rate",
hue="coherence", style="choice",
hue_norm=LogNorm(),
)
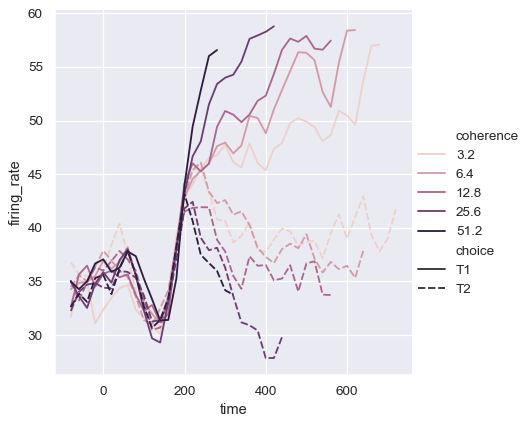
第三个语义,大小,改变了线的宽度:
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate",
size="coherence", style="choice",
)
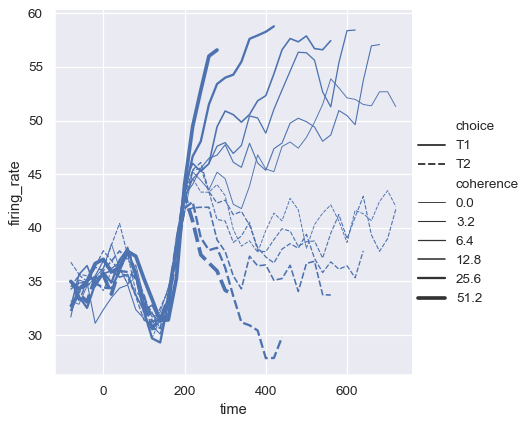
虽然 size 变量通常是数值型的,但也可以用线条的宽度来映射一个分类变量。这样做时要小心,因为很难区分出比“粗”和“细”更多的线条。然而,当线条具有高频变异性时,虚线可能难以察觉,因此在这种情况下使用不同的宽度可能更为有效:
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate",
hue="coherence", size="choice", palette=palette,
)
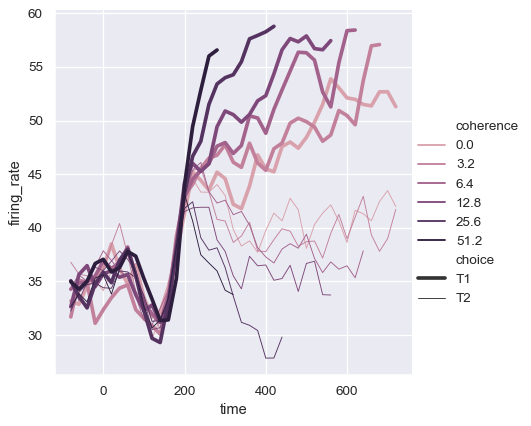
控制排序和方向#
因为 lineplot() 假设你通常试图将 y 作为 x 的函数来绘制,默认行为是在绘图前按 x 值对数据进行排序。然而,这可以被禁用:
healthexp = sns.load_dataset("healthexp").sort_values("Year")
sns.relplot(
data=healthexp, kind="line",
x="Spending_USD", y="Life_Expectancy", hue="Country",
sort=False
)
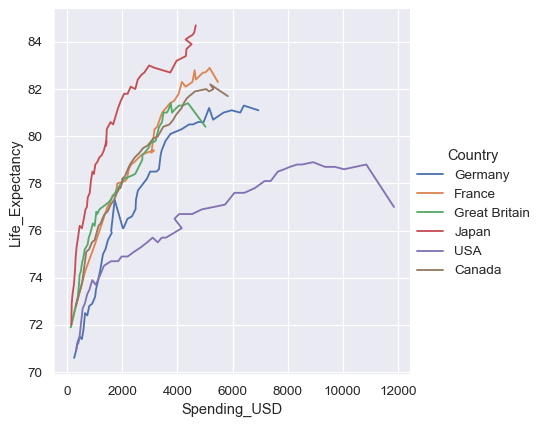
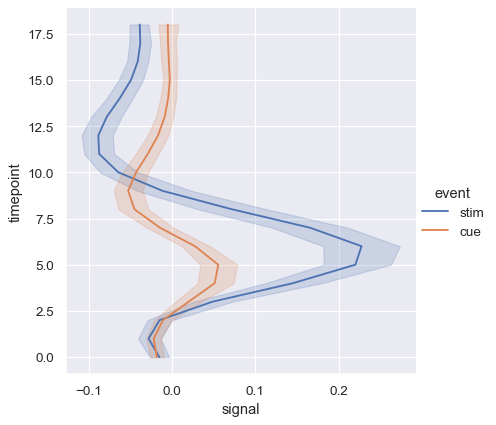
也可以沿 y 轴进行排序(和聚合):
sns.relplot(
data=fmri, kind="line",
x="signal", y="timepoint", hue="event",
orient="y",
)
通过分面展示多种关系#
在本教程中,我们强调了,虽然这些函数 可以 同时显示多个语义变量,但这样做并不总是有效的。但如果你想了解两个变量之间的关系如何依赖于多个其他变量时,该怎么办呢?
最好的方法可能是制作多个图。因为 relplot() 基于 FacetGrid,这很容易做到。要展示额外变量的影响,不是将其分配给图中的一个语义角色,而是用它来“分面”可视化。这意味着你制作多个轴并在每个轴上绘制数据的子集:
sns.relplot(
data=tips,
x="total_bill", y="tip", hue="smoker", col="time",
)

你也可以通过这种方式展示两个变量的影响:一个通过列分面,另一个通过行分面。当你开始向网格中添加更多变量时,你可能希望减小图形的大小。记住,FacetGrid 的大小是由 每个分面 的高度和宽高比参数化的:
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", hue="subject",
col="region", row="event", height=3,
estimator=None
)
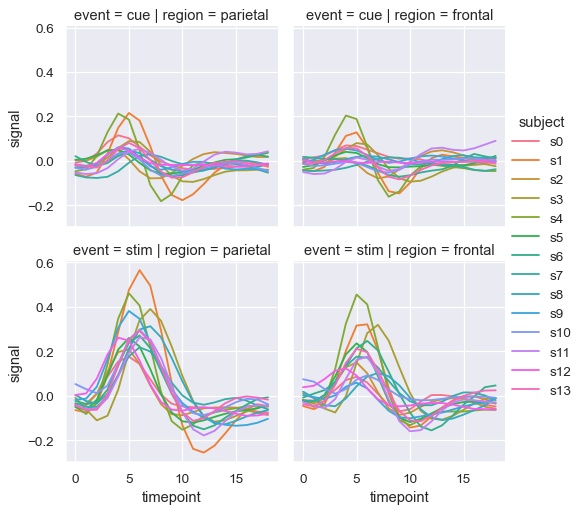
当你想在变量的多个层级上检查效果时,将该变量分面到列上,然后将分面“包裹”到行中可能是个好主意:
sns.relplot(
data=fmri.query("region == 'frontal'"), kind="line",
x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5,
height=3, aspect=.75, linewidth=2.5,
)
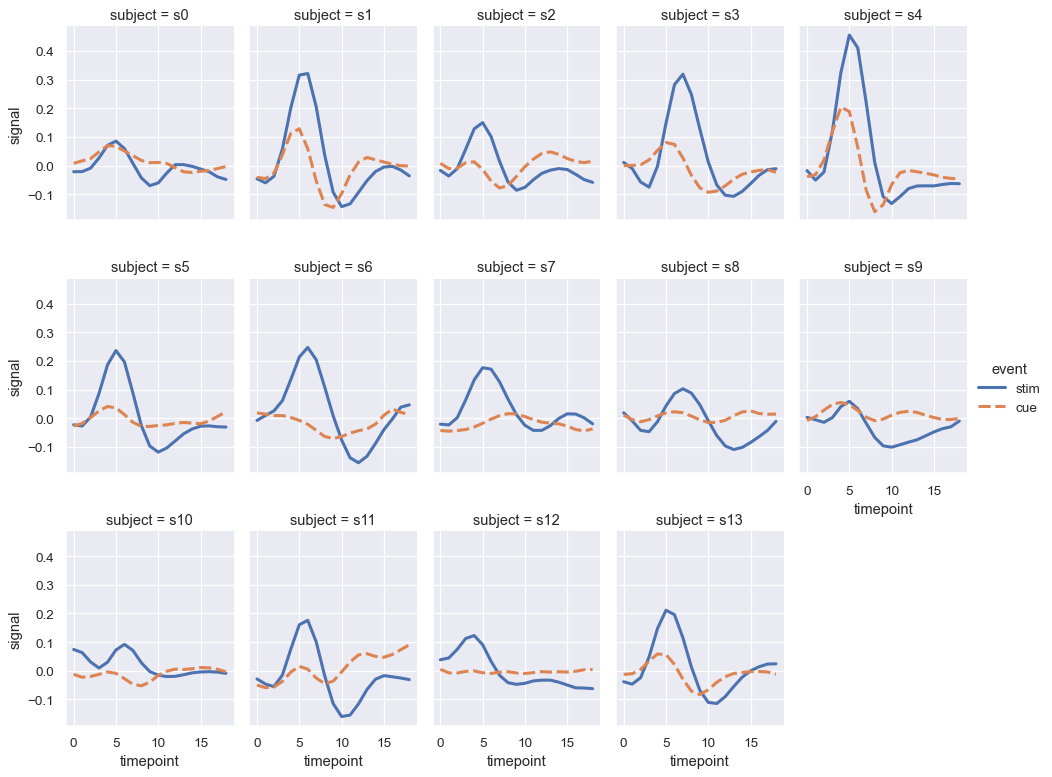
这些可视化图表,有时被称为“网格”图或“小倍数”图,非常有效,因为它们以一种易于眼睛检测总体模式及其偏差的形式呈现数据。虽然你应该利用 scatterplot() 和 relplot() 提供的灵活性,但始终要记住,几个简单的图表通常比一个复杂的图表更有效。