注意
Go to the end 下载完整的示例代码。
如何在imbalanced-learn中使用sampling_strategy#
此示例展示了参数 sampling_strategy 在不同采样器家族(即过采样、欠采样或清理方法)中的不同用法。
# Authors: Guillaume Lemaitre <g.lemaitre58@gmail.com>
# License: MIT
print(__doc__)
import seaborn as sns
sns.set_context("poster")
创建一个不平衡的数据集#
首先,我们将从鸢尾花数据集中创建一个不平衡的数据集。
from sklearn.datasets import load_iris
from imblearn.datasets import make_imbalance
iris = load_iris(as_frame=True)
sampling_strategy = {0: 10, 1: 20, 2: 47}
X, y = make_imbalance(iris.data, iris.target, sampling_strategy=sampling_strategy)
import matplotlib.pyplot as plt
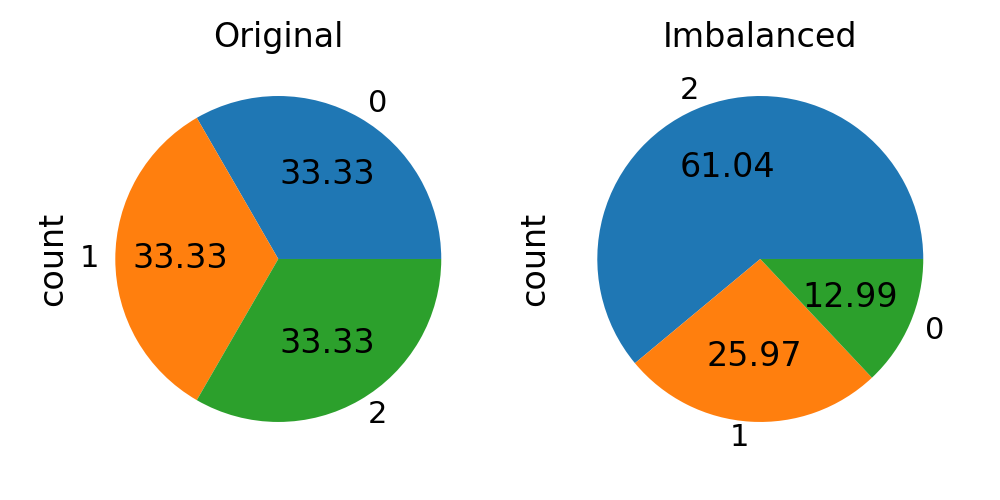
fig, axs = plt.subplots(ncols=2, figsize=(10, 5))
autopct = "%.2f"
iris.target.value_counts().plot.pie(autopct=autopct, ax=axs[0])
axs[0].set_title("Original")
y.value_counts().plot.pie(autopct=autopct, ax=axs[1])
axs[1].set_title("Imbalanced")
fig.tight_layout()
在重采样算法中使用sampling_strategy#
sampling_strategy 作为 float#
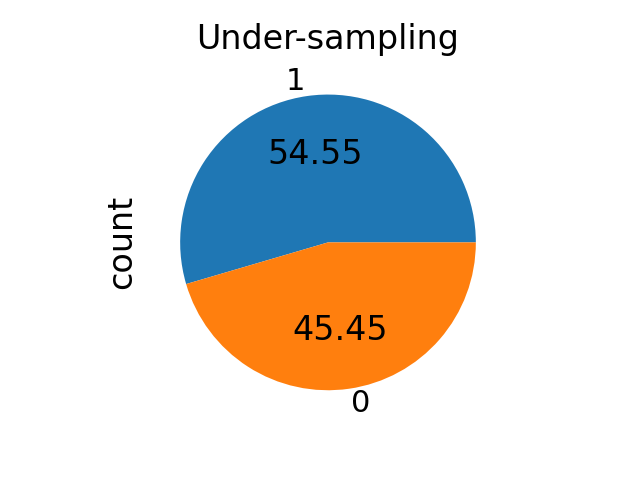
sampling_strategy 可以给定一个 float。对于欠采样方法,它对应于由 \(\alpha_{us}\) 定义的比率,其中 \(N_{rM} = \alpha_{us} \times N_{m}\),\(N_{rM}\) 和 \(N_{m}\) 分别是重采样后多数类中的样本数量和少数类中的样本数量。
# select only 2 classes since the ratio make sense in this case
binary_mask = y.isin([0, 1])
binary_y = y[binary_mask]
binary_X = X[binary_mask]
from imblearn.under_sampling import RandomUnderSampler
sampling_strategy = 0.8
rus = RandomUnderSampler(sampling_strategy=sampling_strategy)
X_res, y_res = rus.fit_resample(binary_X, binary_y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
_ = ax.set_title("Under-sampling")
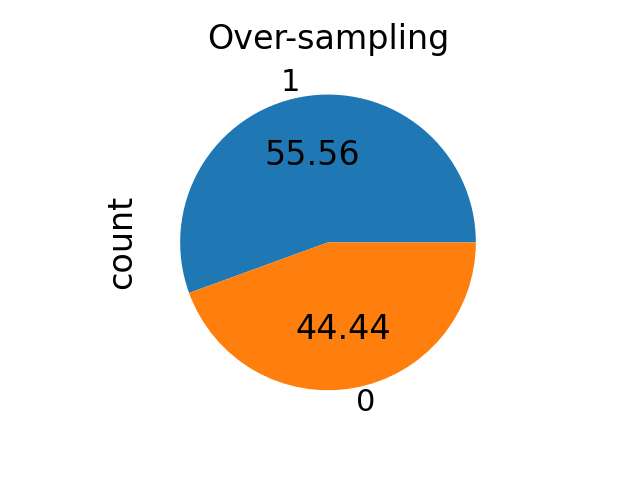
对于过采样方法,它对应于由\(N_{rm} = \alpha_{os} \times N_{M}\)定义的比率\(\alpha_{os}\),其中\(N_{rm}\)和\(N_{M}\)分别是重采样后少数类中的样本数量和多数类中的样本数量。
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(sampling_strategy=sampling_strategy)
X_res, y_res = ros.fit_resample(binary_X, binary_y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
_ = ax.set_title("Over-sampling")
sampling_strategy 作为 str#
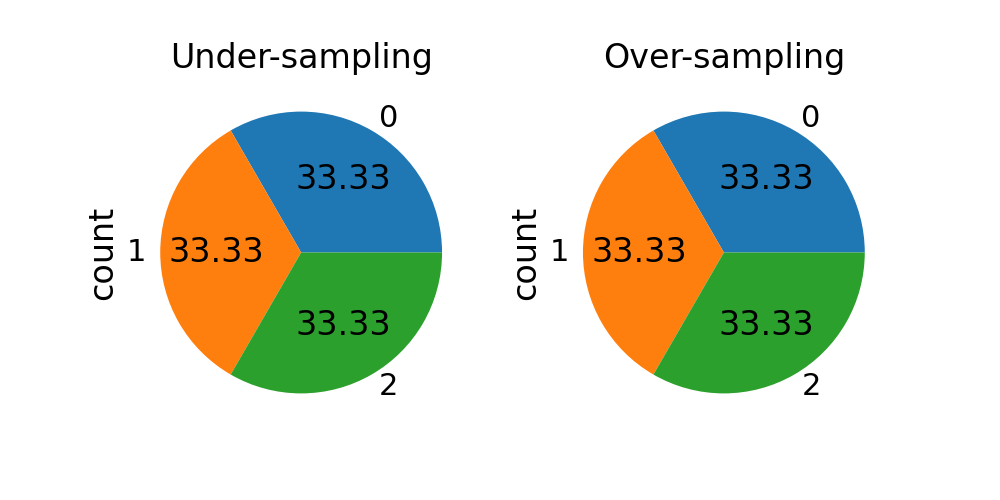
sampling_strategy 可以作为一个字符串给出,指定重采样所针对的类别。在欠采样和过采样中,样本数量将被均衡。
请注意,从现在开始我们将使用多个类。
sampling_strategy = "not minority"
fig, axs = plt.subplots(ncols=2, figsize=(10, 5))
rus = RandomUnderSampler(sampling_strategy=sampling_strategy)
X_res, y_res = rus.fit_resample(X, y)
y_res.value_counts().plot.pie(autopct=autopct, ax=axs[0])
axs[0].set_title("Under-sampling")
sampling_strategy = "not majority"
ros = RandomOverSampler(sampling_strategy=sampling_strategy)
X_res, y_res = ros.fit_resample(X, y)
y_res.value_counts().plot.pie(autopct=autopct, ax=axs[1])
_ = axs[1].set_title("Over-sampling")
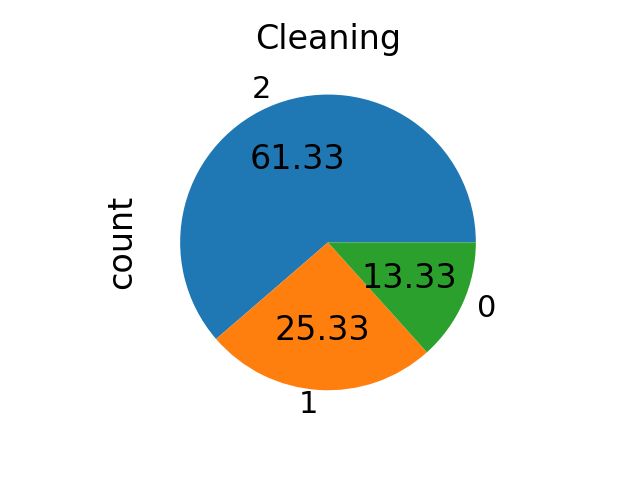
使用清理方法时,即使针对性地处理,每个类别中的样本数量也不会被均衡化。
from imblearn.under_sampling import TomekLinks
sampling_strategy = "not minority"
tl = TomekLinks(sampling_strategy=sampling_strategy)
X_res, y_res = tl.fit_resample(X, y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
_ = ax.set_title("Cleaning")
sampling_strategy 作为 dict#
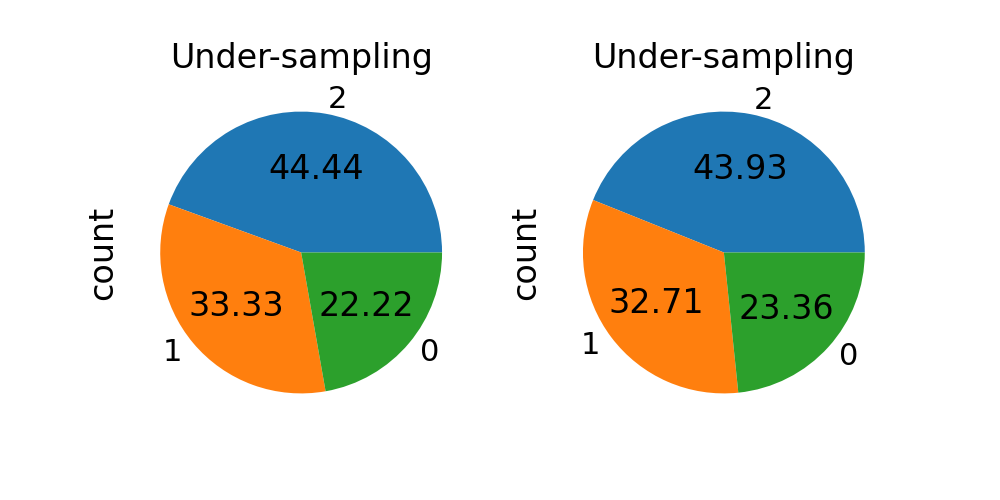
当sampling_strategy是一个dict时,键对应于目标类别。值对应于每个目标类别所需的样本数量。这适用于欠采样和过采样算法,但不适用于清理算法。请改用list。
fig, axs = plt.subplots(ncols=2, figsize=(10, 5))
sampling_strategy = {0: 10, 1: 15, 2: 20}
rus = RandomUnderSampler(sampling_strategy=sampling_strategy)
X_res, y_res = rus.fit_resample(X, y)
y_res.value_counts().plot.pie(autopct=autopct, ax=axs[0])
axs[0].set_title("Under-sampling")
sampling_strategy = {0: 25, 1: 35, 2: 47}
ros = RandomOverSampler(sampling_strategy=sampling_strategy)
X_res, y_res = ros.fit_resample(X, y)
y_res.value_counts().plot.pie(autopct=autopct, ax=axs[1])
_ = axs[1].set_title("Under-sampling")
sampling_strategy 作为 list#
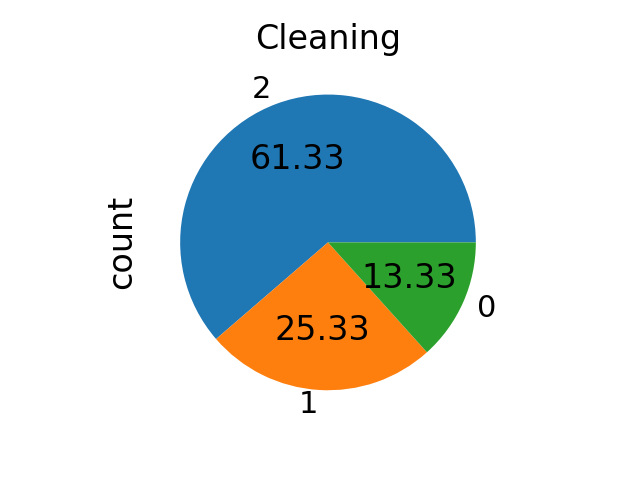
当 sampling_strategy 是一个 list 时,该列表包含目标类别。它仅用于 清理方法,否则会引发错误。
sampling_strategy = [0, 1, 2]
tl = TomekLinks(sampling_strategy=sampling_strategy)
X_res, y_res = tl.fit_resample(X, y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
_ = ax.set_title("Cleaning")
sampling_strategy 作为可调用对象#
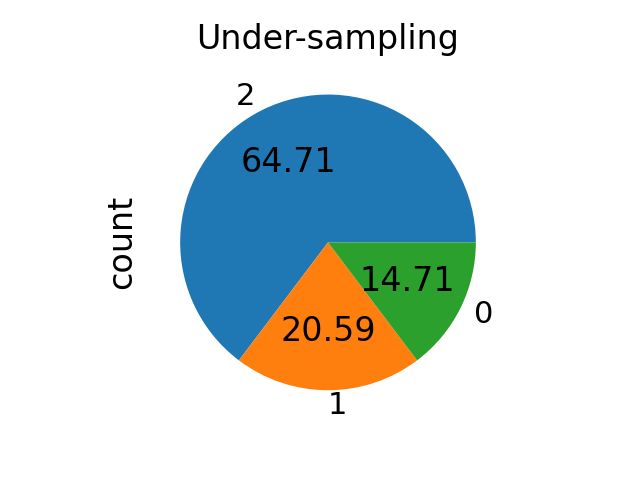
当可调用时,函数接受 y 并返回一个 dict。键对应于目标类别。值对应于每个类别所需的样本数量。
def ratio_multiplier(y):
from collections import Counter
multiplier = {1: 0.7, 2: 0.95}
target_stats = Counter(y)
for key, value in target_stats.items():
if key in multiplier:
target_stats[key] = int(value * multiplier[key])
return target_stats
X_res, y_res = RandomUnderSampler(sampling_strategy=ratio_multiplier).fit_resample(X, y)
ax = y_res.value_counts().plot.pie(autopct=autopct)
ax.set_title("Under-sampling")
plt.show()
脚本的总运行时间: (0 分钟 2.516 秒)
预计内存使用量: 205 MB