注意
转到末尾 以下载完整的示例代码。
创建一个不平衡的数据集#
一个关于make_imbalance函数的示例,用于从平衡数据集中创建不平衡数据集。我们展示了make_imbalance处理Pandas DataFrame的能力。
# Authors: Dayvid Oliveira
# Christos Aridas
# Guillaume Lemaitre <g.lemaitre58@gmail.com>
# License: MIT
print(__doc__)
import seaborn as sns
sns.set_context("poster")
生成数据集#
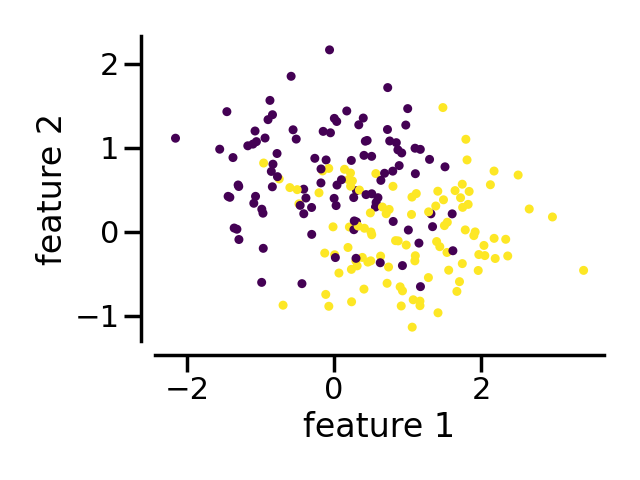
首先,我们将生成一个数据集并将其转换为具有任意列名的DataFrame。我们将绘制原始数据集。
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=200, shuffle=True, noise=0.5, random_state=10)
X = pd.DataFrame(X, columns=["feature 1", "feature 2"])
ax = X.plot.scatter(
x="feature 1",
y="feature 2",
c=y,
colormap="viridis",
colorbar=False,
)
sns.despine(ax=ax, offset=10)
plt.tight_layout()
使数据集不平衡#
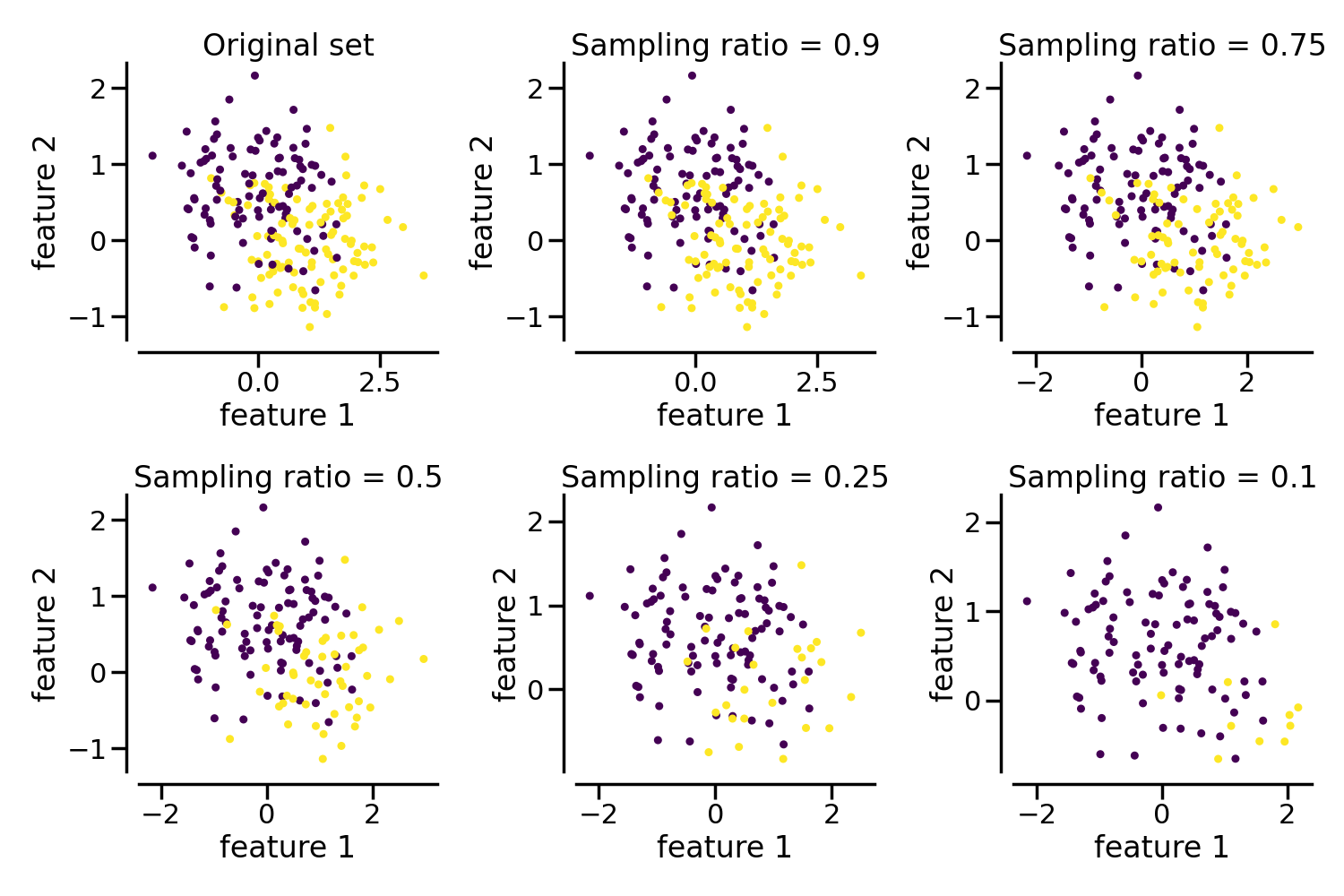
现在,我们将展示助手 make_imbalance,它对于随机选择样本子集非常有用。它将根据指定的参数影响类别分布。
from collections import Counter
def ratio_func(y, multiplier, minority_class):
target_stats = Counter(y)
return {minority_class: int(multiplier * target_stats[minority_class])}
from imblearn.datasets import make_imbalance
fig, axs = plt.subplots(nrows=2, ncols=3, figsize=(15, 10))
X.plot.scatter(
x="feature 1",
y="feature 2",
c=y,
ax=axs[0, 0],
colormap="viridis",
colorbar=False,
)
axs[0, 0].set_title("Original set")
sns.despine(ax=axs[0, 0], offset=10)
multipliers = [0.9, 0.75, 0.5, 0.25, 0.1]
for ax, multiplier in zip(axs.ravel()[1:], multipliers):
X_resampled, y_resampled = make_imbalance(
X,
y,
sampling_strategy=ratio_func,
**{"multiplier": multiplier, "minority_class": 1},
)
X_resampled.plot.scatter(
x="feature 1",
y="feature 2",
c=y_resampled,
ax=ax,
colormap="viridis",
colorbar=False,
)
ax.set_title(f"Sampling ratio = {multiplier}")
sns.despine(ax=ax, offset=10)
plt.tight_layout()
plt.show()
脚本的总运行时间: (0 分钟 1.816 秒)
预计内存使用量: 199 MB