将Label Studio集成到您的机器学习流程中
您可以使用ML后端将模型开发流程与数据标注工作流集成。主要应用场景包括:
- 预标注/自动标记数据:让机器学习/人工智能模型自主预测标签,然后由人工标注员进行审核。
- 交互式标注: 将机器学习模型集成到平台中,帮助人类更高效、更准确地标注或注释大型数据集。
- 模型评估与微调:标注人员审查和分析模型输出,以评估模型准确性并优化性能。
企业
Label Studio Enterprise 提供了一套开箱即用的解决方案,用于LLM辅助的自动标注和模型评估。基于准确性和成本比较不同LLM。更多信息请参阅Prompts。
例如,在图像分类任务中,模型会预先选择一个图像类别供数据标注人员验证。对于音频转录任务,模型会显示一个转录文本供数据标注人员修改。
一旦模型连接成功,其工作方式如下:
- 用户打开任务。
- Label Studio 将请求发送至 ML 后端。
- ML后端返回其预测结果。
- 预测结果会加载到Label Studio界面中并展示给标注人员。
如果您只需要将静态预标注数据加载到Label Studio中,运行机器学习后端可能有些大材小用。相反,您可以导入预标注数据。
提示
您可以使用Label Studio Enterprise构建一个带有机器学习模型后端的自动化主动学习循环。如果您使用Label Studio的开源社区版,可以手动排序任务并获取预测结果来模拟主动学习过程。
设置一个示例ML后端
Label Studio ML后端是一个SDK,它将您的机器学习代码封装并转化为一个Web服务器。该Web服务器可以连接到正在运行的Label Studio实例,以实现标注任务的自动化。我们提供了示例模型库,您可以在自己的工作流中使用,或根据需要扩展和定制。
如果你想自己编写模型,请参阅编写自己的机器学习后端。
前提条件
启动模型
首先,确定您想使用的模型并检查所需参数(点击每个模型的链接查看完整参数列表)。
在模型目录下的
docker-compose.yml文件中设置您的参数。然后将下方命令中的
{MODEL_NAME}替换为对应的目录。例如,如果您使用SAM后端配合SegmentAnything模型,模型名称应为
segment_anything_model,这与代码库中的目录名相匹配:git clone https://github.com/HumanSignal/label-studio-ml-backend.git cd label-studio-ml-backend/label_studio_ml/examples/segment_anything_model docker-compose up
模型将在 http://localhost:9090 开始运行(如果您使用的是Docker容器,请参阅下面的说明)。您可以通过点击模型旁边溢出菜单中的发送测试请求或使用以下命令来验证:
> curl http://localhost:9090
{"model_class":"SamMLBackend","status":"UP"}本地主机与Docker容器
localhost 是一个特殊的域名,可直接回环指向您的本地环境。
如果您在Docker容器中运行Label Studio,localhost会回环到容器本身,而非托管容器的主机。Docker提供了一个特殊域名作为解决方案:docker.host.internal。如果您在Docker内部署Label Studio和ML后端服务,请尝试使用该域名替代localhost(http://host.docker.internal:9090)或内部IP地址。
将模型连接到Label Studio
点击连接模型并填写以下字段:
| 字段 | 描述 |
|---|---|
| 名称 | 输入模型的名称。 |
| Backend URL | Enter a URL for the model. If you are following the steps above, this would be http://localhost:9090. If you are running Label Studio in a Docker container, see the note above. |
| 选择认证方式 | 如果需要用户名和密码才能访问模型,可以选择基本认证并在此处输入。 |
| 额外参数 | 输入您想要传递给模型的任何额外参数。 |
| 交互式预标注 | 启用此选项后,模型将通过实时提供预测或建议来辅助标注过程,当标注人员处理任务时。 换句话说,当您与数据交互时(例如在图像上绘制区域、高亮文本或向LLM提问),机器学习后端会接收此输入并返回基于此的预测。更多信息请参阅下方的交互式预标注。 |
提示
您也可以通过API添加机器学习后端。您需要提供项目ID和机器学习后端的URL。
示例模型
ML后端代码库包含多种示例模型,您可以进行实验并适配到自己的工作流程中。
其中一些无需额外配置即可工作。请查看必填参数列以确认是否需要设置任何额外参数。如果模型有必填参数,您可以在模型目录内的docker-compose.yml文件中设置这些参数。
- 预标注 列表示该模型是否可用于Label Studio中的预标注功能:
当您打开标注页面或对一批数据运行预测后,可以看到预标注的数据。 - 交互模式列显示该模型是否可用于Label Studio中的交互式标注:在标注页面执行操作时查看交互式预测结果。
- 训练列表示该模型是否可用于Label Studio中的训练:根据提交的标注更新模型状态。
| 模型名称 | 描述 | 预标注 | 交互模式 | 训练 | 必填参数 |
|---|---|---|---|---|---|
| segment_anything_model | 由Meta提供的图像分割模型 | ❌ | ✅ | ❌ | None |
| llm_interactive | 使用OpenAI、Azure LLMs进行提示工程。 | ✅ | ✅ | ✅ | OPENAI_API_KEY |
| grounding_dino | 通过提示进行目标检测。Details | ❌ | ✅ | ❌ | None |
| tesseract | 交互式OCR。Details | ❌ | ✅ | ❌ | None |
| easyocr | 自动化OCR识别。EasyOCR | ✅ | ❌ | ❌ | None |
| spacy | 使用SpaCy进行命名实体识别 | ✅ | ❌ | ❌ | None |
| flair | 使用flair进行命名实体识别 | ✅ | ❌ | ❌ | 无 |
| bert_classifier | 使用Huggingface进行文本分类 | ✅ | ❌ | ✅ | None |
| huggingface_llm | 使用Hugging Face进行LLM推理 | ✅ | ❌ | ❌ | None |
| huggingface_ner | 使用Hugging Face进行命名实体识别 | ✅ | ❌ | ✅ | None |
| nemo_asr | 语音自动识别由NVIDIA NeMo提供 | ✅ | ❌ | ❌ | None |
| mmdetection | 使用OpenMMLab进行目标检测 | ✅ | ❌ | ❌ | None |
| sklearn_text_classifier | 使用scikit-learn进行文本分类 | ✅ | ❌ | ✅ | None |
| interactive_substring_matching | 简单关键词搜索 | ❌ | ✅ | ❌ | None |
| langchain_search_agent | 使用Google搜索和Langchain构建的RAG流程 | ✅ | ✅ | ✅ | OPENAI_API_KEY, GOOGLE_CSE_ID, GOOGLE_API_KEY |
允许机器学习后端访问Label Studio数据
在大多数情况下,您需要设置环境变量以允许机器学习后端访问Label Studio中的数据。
Label Studio任务可以拥有多个资源文件的来源:
直接使用
http和https链接。
示例:task['data'] = {"image": "http://example.com/photo_1.jpg"}已通过导入操作上传至Label Studio的文件。
示例:task['data'] = {"image": "https://ls-instance/data/upload/42/photo_1.jpg"}通过本地存储连接添加的文件。
示例:task['data'] = {"image": "https://ls-instance/data/local-files/?d=folder/photo_1.jpg"}通过云存储(S3、GCS、Azure)连接添加的文件。
示例:task['data'] = {"image": "s3://bucket/prefix/photo_1.jpg"}
当Label Studio在机器学习后端调用predict(tasks)方法时,它会发送包含数据子字典的任务,这些子字典带有资源文件的链接。
从直接的http和https链接下载文件(如上第一个示例)非常简单。然而,其他三种类型(导入的文件、本地存储文件和云存储文件)则更为复杂。
为了解决这个问题,ML后端使用了label_studio_tools包中的get_local_path(url, task_id)函数(该包已预装在label-studio-ml-backend中):
from label_studio_tools.core.utils.io import get_local_path
class MLBackend(LabelStudioMLBase)
def predict(tasks):
task = tasks[0]
local_path = get_local_path(task['data']['image'], task_id=task['id'])
with open(local_path, 'r') as f:
f.read()get_local_path() 函数将URI解析为URL,然后下载并缓存文件。
要使此功能正常工作,您必须在使用get_local_path之前为您的ML后端指定LABEL_STUDIO_URL和LABEL_STUDIO_API_KEY环境变量。如果您使用的是docker-compose.yml,这些变量需要添加到环境部分。例如:
services:
ml-backend-1:
container_name: ml-backend-1
...
environment:
# Specify the Label Studio URL and API key to access
# uploaded, local storage and cloud storage files.
# Do not use 'localhost' as it does not work within Docker containers.
# Use prefix 'http://' or 'https://' for the URL always.
# Determine the actual IP using 'ifconfig' (Linux/Mac) or 'ipconfig' (Windows).
- LABEL_STUDIO_URL=http://192.168.42.42:8080/ # replace with your IP!
- LABEL_STUDIO_API_KEY=<your-label-studio-api-key>请注意以下事项:
LABEL_STUDIO_URL必须能够从ML后端实例访问。如果您在Docker中运行ML后端,
LABEL_STUDIO_URL不能包含localhost或0.0.0.0。请使用完整的IP地址,例如192.168.42.42。您可以通过ifconfig(Unix系统)或ipconfig(Windows系统)命令获取该地址。LABEL_STUDIO_URL必须以http://或https://开头。
要查找您的LABEL_STUDIO_API_KEY,请打开Label Studio并转到您的用户账户页面。
模型训练
训练模型使其能够从提交的标注中学习,并可能提升其对后续任务的预测能力。
将模型连接到Label Studio作为机器学习后端并至少标注一个任务后,您就可以开始训练模型了。您可以选择自动或手动训练方式。
在项目设置的模型页面中,从已连接模型旁边的溢出菜单中选择开始训练。这将手动启动训练。如果您想控制模型训练的时机(例如在收集到特定数量的标注后或按特定间隔),请使用此操作。
您也可以通过编程方式使用以下代码启动训练:
- 通过API指定机器学习后端的ID,并运行以下命令:
详情请参阅训练API文档。curl -X POST http://localhost:8080/api/ml/{id}/train
训练日志会显示在标准输出和控制台中。
要查看更详细的日志,请使用--debug选项启动ML后端服务器。
预标注/预测
备注
术语"predictions"和"pre-annotations"可以互换使用。
从模型获取预测结果
将模型连接到Label Studio后,如果模型是预训练的,或者刚完成训练,您就可以在标注界面中看到模型预测结果。
- 要手动添加预测结果,请前往数据管理器,选择需要获取预测的任务,然后选择操作 > 获取预测。
- 要使用预测自动预标注数据,请进入项目设置并启用标注 > 使用预测进行任务预标注,同时确保您已从选择要使用的预测或模型下拉菜单中选择了合适的模型。
备注
对于大型数据集,检索预测的HTTP请求可能会因超时而中断。如果您希望从连接的机器学习后端获取所有任务的所有预测,请为每个任务向Label Studio API的预测端点发起POST调用,以促使机器学习后端为这些任务生成预测。
如果您想仅使用机器学习后端手动获取任务列表的预测结果,请向您的机器学习后端的/predict URL发送POST请求,并附带您想要获取预测的任务负载,格式如下例所示:
{
"tasks": [
{"data": {"text":"some text"}}
]
}交互式预标注
ML-assisted labeling with interactive pre-annotations works with image segmentation and object detection tasks using rectangles, ellipses, polygons, brush masks, and keypoints, as well as with HTML and text named entity recognition tasks. Your ML backend must support the type of labeling that you’re performing, recognize the input that you create, and be able to respond with the relevant output for a prediction.
在添加模型时启用交互式预标注选项,或者从项目设置页面使用编辑操作来启用/禁用此选项。
智能工具
智能工具会复制您通过标注配置设置的工具(例如矩形),以便与ML后端进行交互。目前智能工具可用于Rectangle、Ellipse、Polygon、KeyPoint和Brush标签。
智能工具是动态的,能够基于上下文利用机器学习预测来改变行为或外观。例如,智能工具可以自动检测并建议图像中对象的标注,标注人员随后可以审查和完善这些建议。这能显著加快标注流程,尤其是在处理大型数据集时。
智能工具利用context根据标注环境的当前状态和手头任务的具体需求来调整其行为。例如,它们可能会根据正在标注的数据类型或任务中特定关注区域来改变功能。当为标注任务启用智能工具时,它们可以通过向/predict端点发送数据与ML后端交互以获取预测结果。这些预测结果随后用于在标注界面中提供交互式预标注。更多信息请参阅Support interactive pre-annotations in your ML backend。
例如,当标注员开始标注一张图像时,智能工具可以将该图像发送至机器学习后端进行处理,并返回建议的标注结果(如边界框或分割掩码),标注员可以选择接受、拒绝或优化这些建议。这一流程通过基于模型当前对数据的理解提供标注起点,有助于简化标注工作流程。
要使用智能工具:
- 如果在标注界面启用了自动标注功能,智能工具将默认显示。
- 您还可以更新标注配置,为您正在执行的标注类型添加
smart="true"选项。 - 如果仅希望显示智能选项而完全不想进行手动标注,请使用
smartOnly="true"。
例如:
开始标注后,启用自动标注功能即可查看并使用智能选项来绘制形状、遮罩或分配关键点。
对于图像标注任务,在启用自动标注功能后,您可以选择是否自动接受标注建议。若开启自动接受功能,标注区域将自动显示并立即创建;若不开启自动接受,标注区域仍会显示但需要手动逐条或批量确认或拒绝这些建议。
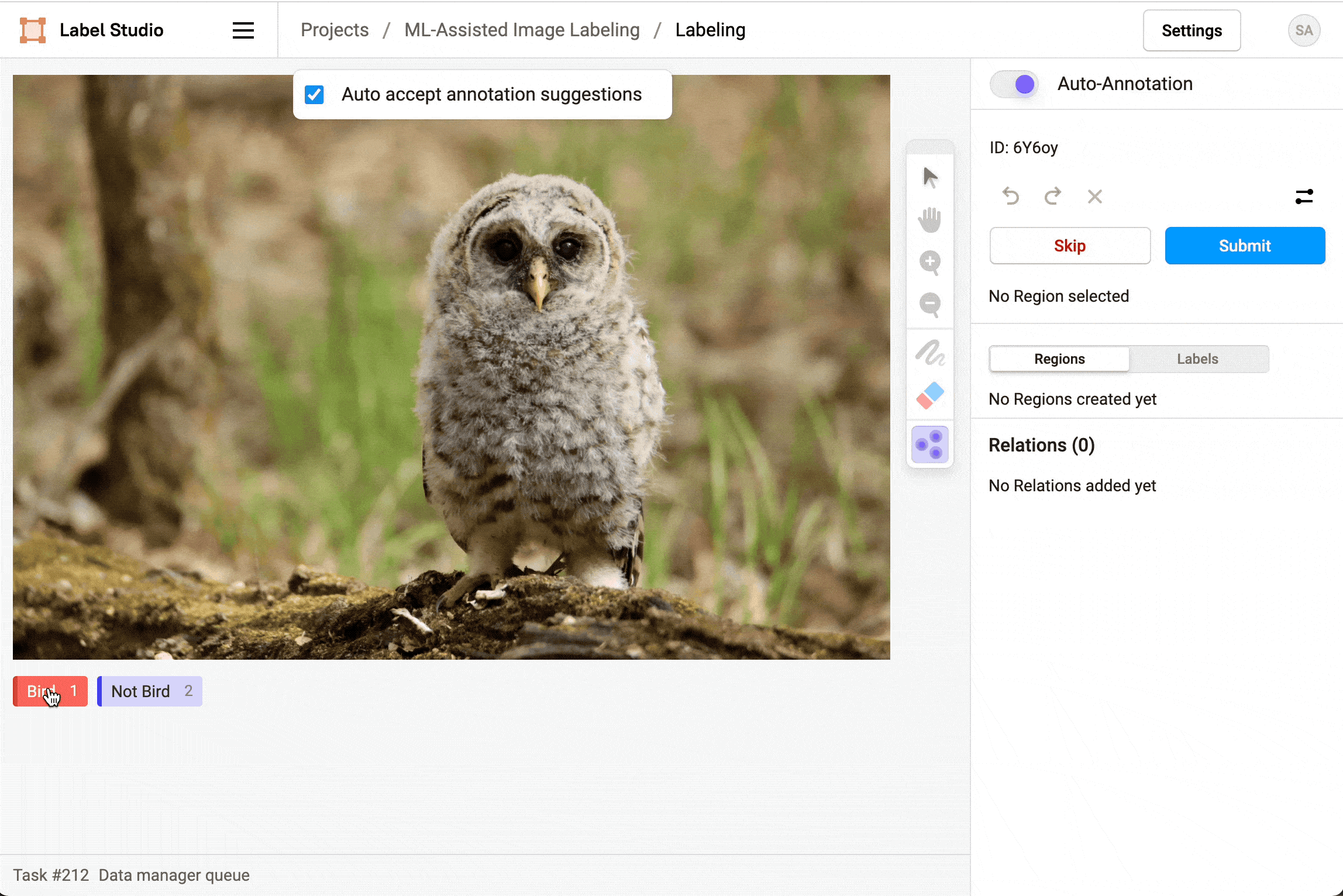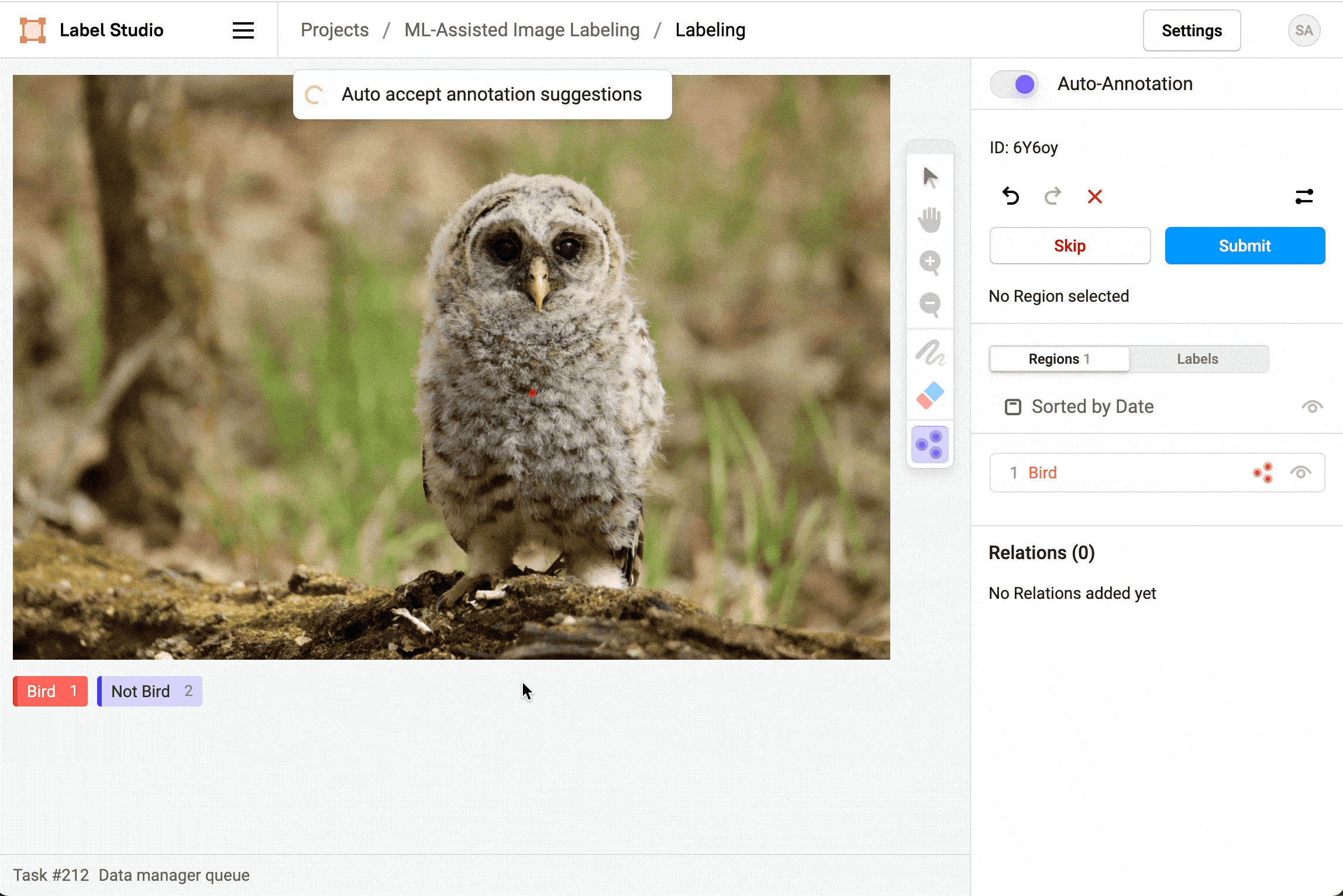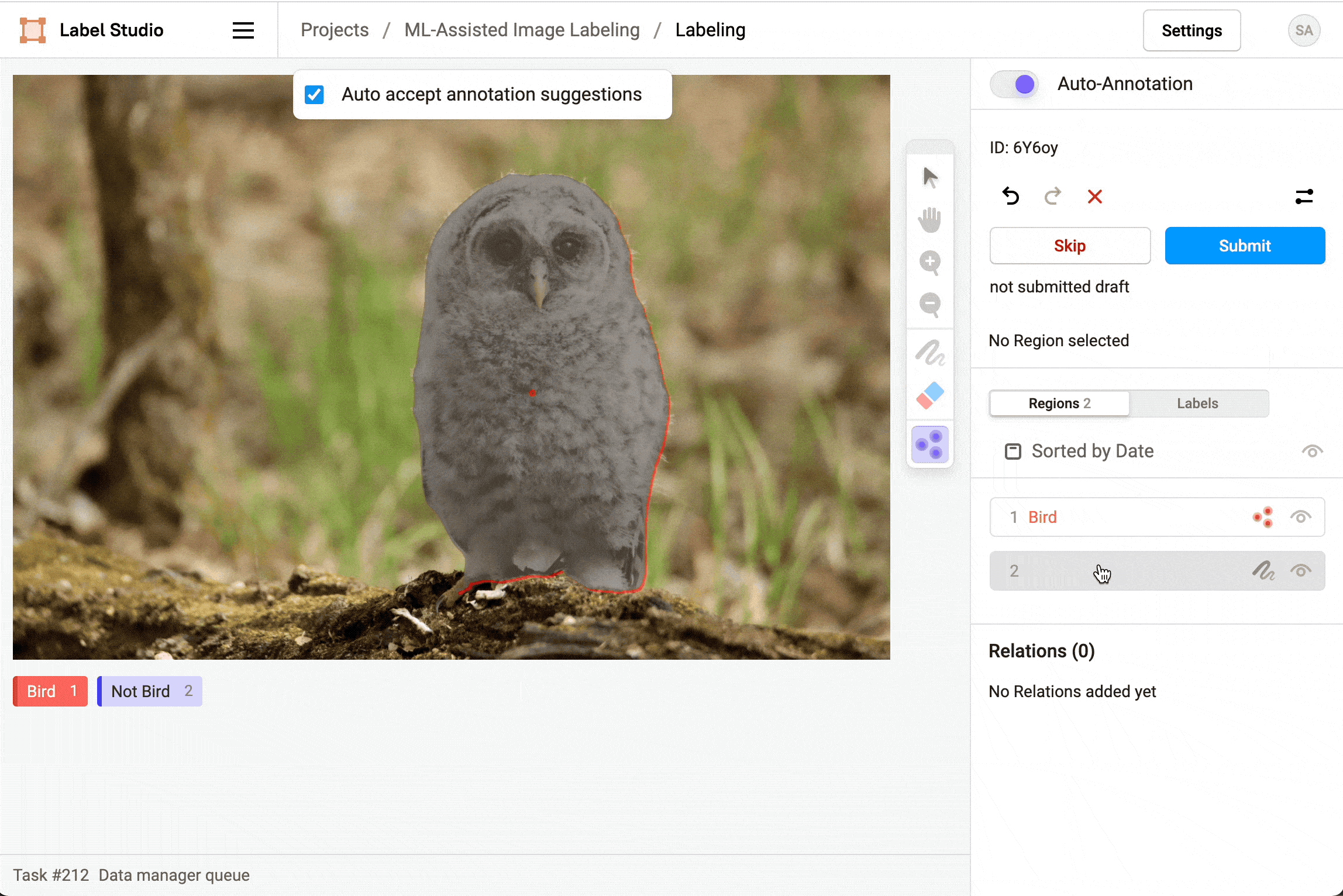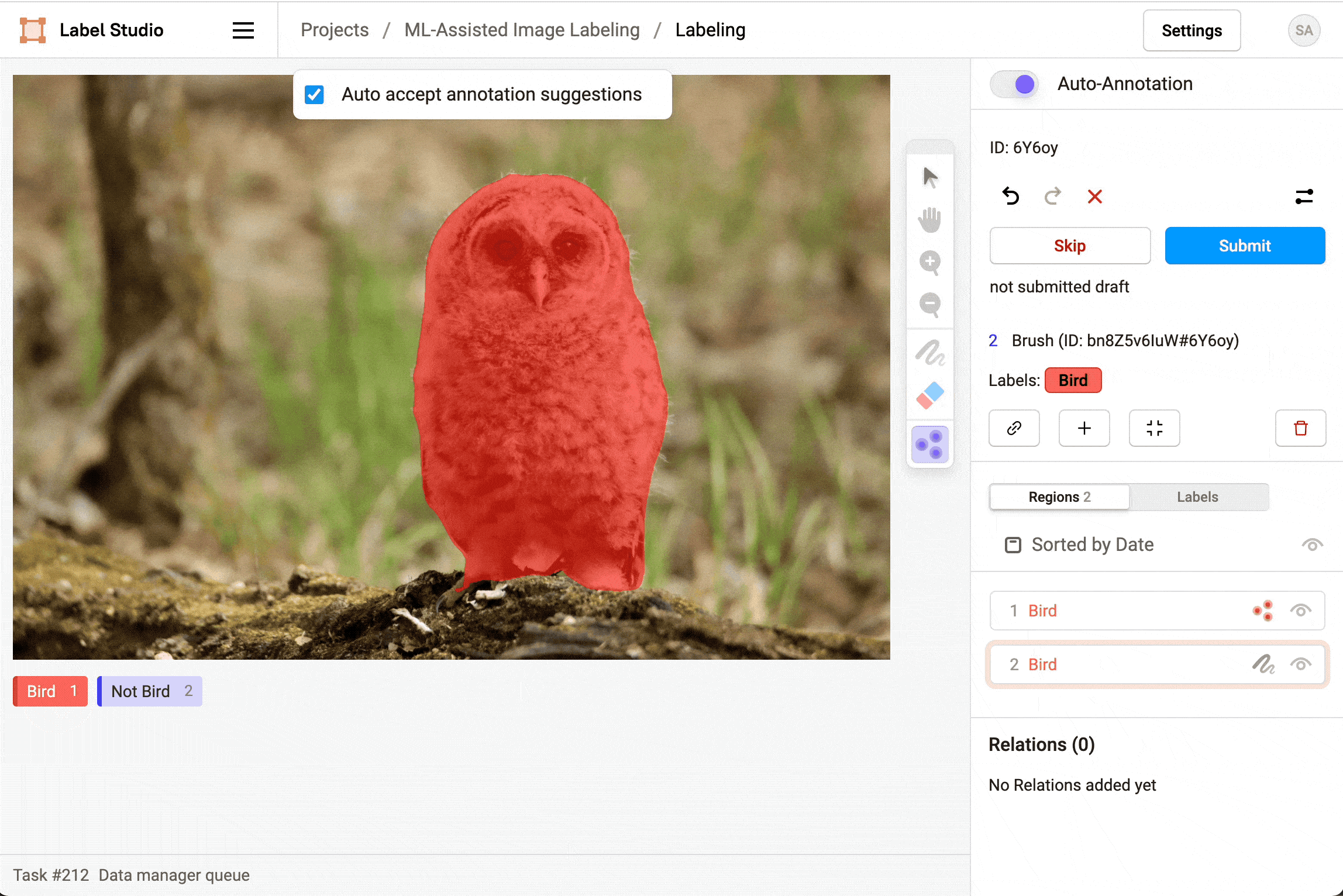
删除预测
如果你想从Label Studio中删除所有预测结果,可以通过数据管理器或API实现:
- 对于特定项目,选择您想要删除预测的任务,然后从下拉菜单中选择删除预测。
- 通过API,在命令行中运行以下命令以删除特定项目ID的预测:
curl -H 'Authorization: Token' -X POST \ " /api/dm/actions?id=delete_tasks_predictions&project= "
选择要向标注者显示的预测结果
您可以选择默认向标注者显示哪个模型或预测集。此选项位于项目设置中的标注 > 实时预测下。
使用下拉菜单选择在标注工作流中要使用的模型或预测结果。