版本 0.14.0 (2014年5月31日)#
这是从 0.13.1 版本以来的一个重大发布,包括少量 API 更改、几个新功能、增强功能和性能改进,以及大量错误修复。我们建议所有用户升级到此版本。
亮点包括:
警告
在0.14.0版本中,所有基于 NDFrame 的容器都经历了重大的内部重构。在此之前,每个同质数据块都有自己的标签,并且需要特别小心以保持这些标签与父容器的标签同步。这应该不会有任何可见的用户/API行为变化 (GH 6745)
API 变化#
read_excel使用 0 作为默认工作表 (GH 6573)iloc现在接受超出范围的索引器用于切片,例如,一个超过被索引对象长度的值。这些将被排除。这将使 pandas 更符合 python/numpy 对超出范围值的索引方式。一个超出范围且会降低对象维度的单个索引器仍将引发IndexError(GH 6296, GH 6299)。这可能导致一个空轴(例如,返回一个空 DataFrame)In [1]: dfl = pd.DataFrame(np.random.randn(5, 2), columns=list('AB')) In [2]: dfl Out[2]: A B 0 0.469112 -0.282863 1 -1.509059 -1.135632 2 1.212112 -0.173215 3 0.119209 -1.044236 4 -0.861849 -2.104569 [5 rows x 2 columns] In [3]: dfl.iloc[:, 2:3] Out[3]: Empty DataFrame Columns: [] Index: [0, 1, 2, 3, 4] [5 rows x 0 columns] In [4]: dfl.iloc[:, 1:3] Out[4]: B 0 -0.282863 1 -1.135632 2 -0.173215 3 -1.044236 4 -2.104569 [5 rows x 1 columns] In [5]: dfl.iloc[4:6] Out[5]: A B 4 -0.861849 -2.104569 [1 rows x 2 columns]
这些是越界选择
>>> dfl.iloc[[4, 5, 6]] IndexError: positional indexers are out-of-bounds >>> dfl.iloc[:, 4] IndexError: single positional indexer is out-of-bounds
使用负的开始、停止和步长值进行切片能更好地处理边界情况(GH 6531):
df.iloc[:-len(df)]现在是空的df.iloc[len(df)::-1]现在枚举所有元素的逆序
DataFrame.interpolate()关键字downcast的默认值已从infer更改为None。这是为了保留原始数据类型,除非明确要求其他方式 (GH 6290)。当将数据框转换为HTML时,它曾经返回
Empty DataFrame。这个特殊情况已被移除,取而代之的是返回带有列名的标题 (GH 6062)。Series和Index现在内部共享更多的通用操作,例如factorize(),nunique(),value_counts()现在也支持在Index类型上。Series.weekday属性已从 Series 中移除以保持 API 一致性。在 Series 上使用DatetimeIndex/PeriodIndex方法现在会引发TypeError。(GH 4551, GH 4056, GH 5519, GH 6380, GH 7206)。为
DateTimeIndex/Timestamp添加is_month_start、is_month_end、is_quarter_start、is_quarter_end、is_year_start、is_year_end访问器,这些访问器返回一个布尔数组,表示时间戳是否在DateTimeIndex/Timestamp定义的频率的月份/季度/年份的开始/结束 (GH 4565, GH 6998)本地变量用法在
pandas.eval()/DataFrame.eval()/DataFrame.query()中有所改变 (GH 5987)。对于DataFrame方法,有两点变化列名现在优先于局部变量
局部变量必须明确引用。这意味着即使你有一个*不是*列的局部变量,你仍然必须使用 `` ‘@’ `` 前缀来引用它。
你可以有一个像
df.query('@a < a')这样的表达式,而pandas不会对名称a的歧义有任何抱怨。顶级
pandas.eval()函数不允许你使用'@'前缀,并会提供一个错误信息告诉你这一点。NameResolutionError已被移除,因为它不再需要了。
定义和记录查询/评估中列与索引名称的顺序 (GH 6676)
concat现在将使用 Series 名称或根据需要编号列来连接混合的 Series 和 DataFrame (GH 2385)。请参阅 文档对
Index类的切片和高级/布尔索引操作,以及Index.delete()和Index.drop()方法将不再改变结果索引的类型 (GH 6440, GH 7040)In [6]: i = pd.Index([1, 2, 3, 'a', 'b', 'c']) In [7]: i[[0, 1, 2]] Out[7]: Index([1, 2, 3], dtype='object') In [8]: i.drop(['a', 'b', 'c']) Out[8]: Index([1, 2, 3], dtype='object')
之前,上述操作会返回
Int64Index。如果你想手动执行此操作,请使用Index.astype()In [9]: i[[0, 1, 2]].astype(np.int_) Out[9]: Index([1, 2, 3], dtype='int64')
set_index不再将 MultiIndexes 转换为元组的 Index。例如,旧的行为在这种情况下返回一个 Index (GH 6459):# Old behavior, casted MultiIndex to an Index In [10]: tuple_ind Out[10]: Index([('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd')], dtype='object') In [11]: df_multi.set_index(tuple_ind) Out[11]: 0 1 (a, c) 0.471435 -1.190976 (a, d) 1.432707 -0.312652 (b, c) -0.720589 0.887163 (b, d) 0.859588 -0.636524 [4 rows x 2 columns] # New behavior In [12]: mi Out[12]: MultiIndex([('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd')], ) In [13]: df_multi.set_index(mi) Out[13]: 0 1 a c 0.471435 -1.190976 d 1.432707 -0.312652 b c -0.720589 0.887163 d 0.859588 -0.636524 [4 rows x 2 columns]
当向
set_index传递多个索引时,这也适用:# Old output, 2-level MultiIndex of tuples In [14]: df_multi.set_index([df_multi.index, df_multi.index]) Out[14]: 0 1 (a, c) (a, c) 0.471435 -1.190976 (a, d) (a, d) 1.432707 -0.312652 (b, c) (b, c) -0.720589 0.887163 (b, d) (b, d) 0.859588 -0.636524 [4 rows x 2 columns] # New output, 4-level MultiIndex In [15]: df_multi.set_index([df_multi.index, df_multi.index]) Out[15]: 0 1 a c a c 0.471435 -1.190976 d a d 1.432707 -0.312652 b c b c -0.720589 0.887163 d b d 0.859588 -0.636524 [4 rows x 2 columns]
pairwise关键字被添加到统计矩函数rolling_cov、rolling_corr、ewmcov、ewmcorr、expanding_cov、expanding_corr中,以允许计算移动窗口协方差和相关矩阵 (GH 4950)。请参阅文档中的 计算滚动成对协方差和相关性。In [1]: df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD')) In [4]: covs = pd.rolling_cov(df[['A', 'B', 'C']], ....: df[['B', 'C', 'D']], ....: 5, ....: pairwise=True) In [5]: covs[df.index[-1]] Out[5]: B C D A 0.035310 0.326593 -0.505430 B 0.137748 -0.006888 -0.005383 C -0.006888 0.861040 0.020762
Series.iteritems()现在变得懒惰(返回一个迭代器而不是一个列表)。这是在0.14版本之前的文档行为。(GH 6760)在
Index中添加了nunique和value_counts函数,用于计算唯一元素的数量。(GH 6734)stack和unstack现在在level关键字引用Index中的非唯一项时会引发ValueError``(之前引发 ``KeyError)。(GH 6738)从
Series.sort中删除未使用的 order 参数;现在参数的顺序与Series.order相同;添加na_position参数以符合Series.order(GH 6847)Series.order的默认排序算法现在是quicksort,以符合 ``Series.sort``(和 numpy 默认值)在
Series.order/sort中添加inplace关键字,使它们成为逆操作 (GH 6859)DataFrame.sort现在根据na_position参数将 NaN 放在排序的开头或结尾。(GH 3917)在
concat中接受TextFileReader,这影响了常见的用户习惯用法(GH 6583),这是从 0.13.1 版本以来的一个退步。在
Index和Series中添加了factorize函数,以获取索引器和唯一值 (GH 7090)在包含混合 Timestamp 和字符串对象的 DataFrame 上使用
describe会返回不同的 Index (GH 7088)。之前,索引无意中被排序了。仅使用 仅
bool数据类型的算术运算现在会给出一个警告,指示它们在 Python 空间中进行+,-, 和*运算,并在所有其他运算中引发 (GH 7011, GH 6762, GH 7015, GH 7210)>>> x = pd.Series(np.random.rand(10) > 0.5) >>> y = True >>> x + y # warning generated: should do x | y instead UserWarning: evaluating in Python space because the '+' operator is not supported by numexpr for the bool dtype, use '|' instead >>> x / y # this raises because it doesn't make sense NotImplementedError: operator '/' not implemented for bool dtypes
在
HDFStore中,当键或选择器未找到时,select_as_multiple将始终引发KeyError(GH 6177)df['col'] = value和df.loc[:,'col'] = value现在完全等价;之前.loc不一定会强制转换结果系列的 dtype (GH 6149)dtypes和ftypes现在在空容器上返回一个dtype=object的系列 (GH 5740)df.to_csv如果未提供目标路径或缓冲区,现在将返回CSV数据的字符串 (GH 6061)pd.infer_freq()如果给定无效的Series/Index类型,现在会引发TypeError(GH 6407, GH 6463)传递给
DataFame.sort_index的元组将被解释为索引的级别,而不是需要一个元组列表 (GH 4370)所有偏移操作现在返回
Timestamp类型(而不是 datetime),Business/Week 频率不正确 (GH 4069)to_excel现在将np.inf转换为字符串表示形式,可以通过inf_rep关键字参数自定义(Excel 没有本机的 inf 表示形式)(GH 6782)将
pandas.compat.scipy.scoreatpercentile替换为numpy.percentile(GH 6810)在
datetime[ns]系列上的.quantile现在返回Timestamp而不是np.datetime64对象 (GH 6810)将
concat传递的无效类型从AssertionError改为TypeError(GH 6583)当
DataFrame的data参数传递一个迭代器时,引发TypeError(GH 5357)
显示更改#
默认的大数据框打印方式已经改变。超过
max_rows和/或max_columns的数据框现在以中央截断视图显示,与pandas.Series的打印方式一致 (GH 5603)。在以前的版本中,一旦达到维度约束,DataFrame 就会被截断,省略号 (…) 表示部分数据被截断。
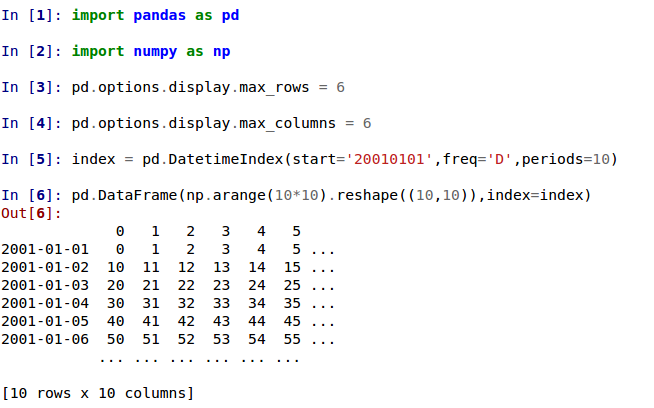
在当前版本中,大型 DataFrame 会中心截断,显示两维度的头尾预览。
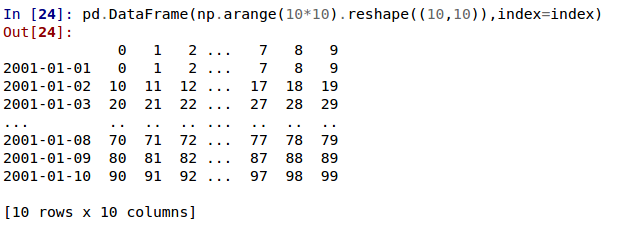
为
display.show_dimensions添加'truncate'选项,仅在数据框被截断时显示其尺寸 (GH 6547)。display.show_dimensions的默认值现在将是truncate。这与 Series 显示长度的方法一致。In [16]: dfd = pd.DataFrame(np.arange(25).reshape(-1, 5), ....: index=[0, 1, 2, 3, 4], ....: columns=[0, 1, 2, 3, 4]) ....: # show dimensions since this is truncated In [17]: with pd.option_context('display.max_rows', 2, 'display.max_columns', 2, ....: 'display.show_dimensions', 'truncate'): ....: print(dfd) ....: 0 ... 4 0 0 ... 4 .. .. ... .. 4 20 ... 24 [5 rows x 5 columns] # will not show dimensions since it is not truncated In [18]: with pd.option_context('display.max_rows', 10, 'display.max_columns', 40, ....: 'display.show_dimensions', 'truncate'): ....: print(dfd) ....: 0 1 2 3 4 0 0 1 2 3 4 1 5 6 7 8 9 2 10 11 12 13 14 3 15 16 17 18 19 4 20 21 22 23 24
当
display.max_rows小于 MultiIndexed Series 的长度时,显示中的回归 (GH 7101)修复了一个在
large_repr设置为 ‘info’ 时,截断的 Series 或 DataFrame 的 HTML 表示不显示类名称的错误 (GH 7105)在
DataFrame.info()中的verbose关键字,控制是否缩短info表示,现在默认是None。这将遵循display.max_info_columns中的全局设置。全局设置可以通过verbose=True或verbose=False覆盖。修复了
inforepr 不遵守display.max_info_columns设置的错误 (GH 6939)偏移/频率信息现在在 Timestamp __repr__ 中 (GH 4553)
文本解析 API 变更#
read_csv()/read_table() 现在会对无效选项发出更多噪音,而不是回退到 PythonParser。
在
read_csv()/read_table()中指定sep时,如果delim_whitespace=True,则引发ValueError(GH 6607)当在
read_csv()/read_table()中指定engine='c'与不支持的选项时,引发ValueError(GH 6607)当回退到python解析器导致选项被忽略时引发
ValueError(GH 6607)在没有忽略选项时,当回退到python解析器时生成
ParserWarning(GH 6607)在
read_csv()/read_table()中将sep='\s+'翻译为delim_whitespace=True,如果没有指定其他不支持的C选项 (GH 6607)
GroupBy API 变更#
某些 groupby 方法的更一致行为:
groupby
head和tail现在更像filter而不是聚合:In [1]: df = pd.DataFrame([[1, 2], [1, 4], [5, 6]], columns=['A', 'B']) In [2]: g = df.groupby('A') In [3]: g.head(1) # filters DataFrame Out[3]: A B 0 1 2 2 5 6 In [4]: g.apply(lambda x: x.head(1)) # used to simply fall-through Out[4]: A B A 1 0 1 2 5 2 5 6
按头和尾分组尊重列选择:
In [19]: g[['B']].head(1) Out[19]: B 0 2 2 6 [2 rows x 1 columns]
groupby
nth现在默认减少;可以通过传递as_index=False来实现过滤。通过一个可选的dropna参数来忽略 NaN。请参见 文档。减少
In [19]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], columns=['A', 'B']) In [20]: g = df.groupby('A') In [21]: g.nth(0) Out[21]: A B 0 1 NaN 2 5 6.0 [2 rows x 2 columns] # this is equivalent to g.first() In [22]: g.nth(0, dropna='any') Out[22]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns] # this is equivalent to g.last() In [23]: g.nth(-1, dropna='any') Out[23]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns]
过滤
In [24]: gf = df.groupby('A', as_index=False) In [25]: gf.nth(0) Out[25]: A B 0 1 NaN 2 5 6.0 [2 rows x 2 columns] In [26]: gf.nth(0, dropna='any') Out[26]: A B 1 1 4.0 2 5 6.0 [2 rows x 2 columns]
groupby 现在不会为非cython函数返回分组列(GH 5610, GH 5614, GH 6732),因为它已经是索引
In [27]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6], [5, 8]], columns=['A', 'B']) In [28]: g = df.groupby('A') In [29]: g.count() Out[29]: B A 1 1 5 2 [2 rows x 1 columns] In [30]: g.describe() Out[30]: B count mean std min 25% 50% 75% max A 1 1.0 4.0 NaN 4.0 4.0 4.0 4.0 4.0 5 2.0 7.0 1.414214 6.0 6.5 7.0 7.5 8.0 [2 rows x 8 columns]
传递
as_index将保留分组的列在原位(这在 0.14.0 版本中没有变化)In [31]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6], [5, 8]], columns=['A', 'B']) In [32]: g = df.groupby('A', as_index=False) In [33]: g.count() Out[33]: A B 0 1 1 1 5 2 [2 rows x 2 columns] In [34]: g.describe() Out[34]: A B count mean std min 25% 50% 75% max 0 1 1.0 4.0 NaN 4.0 4.0 4.0 4.0 4.0 1 5 2.0 7.0 1.414214 6.0 6.5 7.0 7.5 8.0 [2 rows x 9 columns]
允许通过
pd.Grouper指定更复杂的 groupby,例如同时按时间和字符串字段分组。请参阅 文档。 (GH 3794)在进行 groupby 操作时,更好地传播/保留 Series 名称:
SQL#
SQL 读写功能现在通过 SQLAlchemy 支持更多数据库类型(GH 2717, GH 4163, GH 5950, GH 6292)。所有 SQLAlchemy 支持的数据库都可以使用,例如 PostgreSQL、MySQL、Oracle、Microsoft SQL 服务器(参见 SQLAlchemy 文档中的 包含的方言)。
提供 DBAPI 连接对象的功能在未来将仅支持 sqlite3。'mysql' 风格已被弃用。
引入了新函数 read_sql_query() 和 read_sql_table()。函数 read_sql() 作为其他两个函数的便捷包装器保留,并将根据提供的输入(数据库表名或sql查询)委托给特定函数。
在实践中,你必须为sql函数提供一个SQLAlchemy engine。要与SQLAlchemy连接,你可以使用 create_engine() 函数从数据库URI创建一个引擎对象。你只需要为每个连接的数据库创建一次引擎。对于内存中的sqlite数据库:
In [35]: from sqlalchemy import create_engine
# Create your connection.
In [36]: engine = create_engine('sqlite:///:memory:')
这个 engine 可以用来向该数据库写入或读取数据:
In [37]: df = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
In [38]: df.to_sql(name='db_table', con=engine, index=False)
Out[38]: 3
你可以通过指定表名从数据库中读取数据:
In [39]: pd.read_sql_table('db_table', engine)
Out[39]:
A B
0 1 a
1 2 b
2 3 c
[3 rows x 2 columns]
或者通过指定一个 SQL 查询:
In [40]: pd.read_sql_query('SELECT * FROM db_table', engine)
Out[40]:
A B
0 1 a
1 2 b
2 3 c
[3 rows x 2 columns]
对sql函数的其他增强包括:
支持编写索引。这可以通过
index关键字来控制(默认是 True)。使用
index_label指定写入索引时使用的列标签。使用
parse_dates关键字在read_sql_query()和read_sql_table()中指定要解析为日期时间的字符串列。
警告
一些现有的函数或函数别名已被弃用,并将在未来的版本中移除。这包括:tquery、uquery、read_frame、frame_query、write_frame。
警告
在使用 DBAPI 连接对象时对 ‘mysql’ 风格的支持已被弃用。MySQL 将进一步支持 SQLAlchemy 引擎 (GH 6900)。
使用切片器进行多索引#
在 0.14.0 版本中,我们添加了一种新的方法来切片 MultiIndexed 对象。您可以通过提供多个索引来对 MultiIndex 进行切片。
你可以提供任何选择器,就像你按标签索引一样,参见 按标签选择 ,包括切片、标签列表、标签和布尔索引器。
你可以使用 slice(None) 来选择 该 级别的所有内容。你不需要指定所有 更深 的级别,它们将被隐含为 slice(None)。
像往常一样,切片器的两侧 都包括在内,因为这是标签索引。
参见 文档 另见问题 (GH 6134, GH 4036, GH 3057, GH 2598, GH 5641, GH 7106)
警告
你应该在
.loc指定符中指定所有轴,这意味着对 索引 和 列 的索引器。在某些情况下,传递的索引器可能会被误解为索引 两个 轴,而不是例如对行进行多索引。你应该这样做:
>>> df.loc[(slice('A1', 'A3'), ...), :] # noqa: E901
rather than this:
>>> df.loc[(slice('A1', 'A3'), ...)] # noqa: E901
警告
你需要确保选择轴是完全词法排序的!
In [41]: def mklbl(prefix, n):
....: return ["%s%s" % (prefix, i) for i in range(n)]
....:
In [42]: index = pd.MultiIndex.from_product([mklbl('A', 4),
....: mklbl('B', 2),
....: mklbl('C', 4),
....: mklbl('D', 2)])
....:
In [43]: columns = pd.MultiIndex.from_tuples([('a', 'foo'), ('a', 'bar'),
....: ('b', 'foo'), ('b', 'bah')],
....: names=['lvl0', 'lvl1'])
....:
In [44]: df = pd.DataFrame(np.arange(len(index) * len(columns)).reshape((len(index),
....: len(columns))),
....: index=index,
....: columns=columns).sort_index().sort_index(axis=1)
....:
In [45]: df
Out[45]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9 8 11 10
D1 13 12 15 14
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 237 236 239 238
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 249 248 251 250
D1 253 252 255 254
[64 rows x 4 columns]
使用切片、列表和标签进行基本的多索引切片。
In [46]: df.loc[(slice('A1', 'A3'), slice(None), ['C1', 'C3']), :]
Out[46]:
lvl0 a b
lvl1 bar foo bah foo
A1 B0 C1 D0 73 72 75 74
D1 77 76 79 78
C3 D0 89 88 91 90
D1 93 92 95 94
B1 C1 D0 105 104 107 106
... ... ... ... ...
A3 B0 C3 D1 221 220 223 222
B1 C1 D0 233 232 235 234
D1 237 236 239 238
C3 D0 249 248 251 250
D1 253 252 255 254
[24 rows x 4 columns]
你可以使用 pd.IndexSlice 来简化这些切片的创建
In [47]: idx = pd.IndexSlice
In [48]: df.loc[idx[:, :, ['C1', 'C3']], idx[:, 'foo']]
Out[48]:
lvl0 a b
lvl1 foo foo
A0 B0 C1 D0 8 10
D1 12 14
C3 D0 24 26
D1 28 30
B1 C1 D0 40 42
... ... ...
A3 B0 C3 D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[32 rows x 2 columns]
通过这种方法,可以在多个轴上同时执行相当复杂的选择。
In [49]: df.loc['A1', (slice(None), 'foo')]
Out[49]:
lvl0 a b
lvl1 foo foo
B0 C0 D0 64 66
D1 68 70
C1 D0 72 74
D1 76 78
C2 D0 80 82
... ... ...
B1 C1 D1 108 110
C2 D0 112 114
D1 116 118
C3 D0 120 122
D1 124 126
[16 rows x 2 columns]
In [50]: df.loc[idx[:, :, ['C1', 'C3']], idx[:, 'foo']]
Out[50]:
lvl0 a b
lvl1 foo foo
A0 B0 C1 D0 8 10
D1 12 14
C3 D0 24 26
D1 28 30
B1 C1 D0 40 42
... ... ...
A3 B0 C3 D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[32 rows x 2 columns]
使用布尔索引器,您可以提供与*值*相关的选择。
In [51]: mask = df[('a', 'foo')] > 200
In [52]: df.loc[idx[mask, :, ['C1', 'C3']], idx[:, 'foo']]
Out[52]:
lvl0 a b
lvl1 foo foo
A3 B0 C1 D1 204 206
C3 D0 216 218
D1 220 222
B1 C1 D0 232 234
D1 236 238
C3 D0 248 250
D1 252 254
[7 rows x 2 columns]
你也可以为 .loc 指定 axis 参数,以便在单个轴上解释传递的分片器。
In [53]: df.loc(axis=0)[:, :, ['C1', 'C3']]
Out[53]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C1 D0 9 8 11 10
D1 13 12 15 14
C3 D0 25 24 27 26
D1 29 28 31 30
B1 C1 D0 41 40 43 42
... ... ... ... ...
A3 B0 C3 D1 221 220 223 222
B1 C1 D0 233 232 235 234
D1 237 236 239 238
C3 D0 249 248 251 250
D1 253 252 255 254
[32 rows x 4 columns]
此外,您可以使用这些方法 设置 值
In [54]: df2 = df.copy()
In [55]: df2.loc(axis=0)[:, :, ['C1', 'C3']] = -10
In [56]: df2
Out[56]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 -10 -10 -10 -10
D1 -10 -10 -10 -10
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 -10 -10 -10 -10
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 -10 -10 -10 -10
D1 -10 -10 -10 -10
[64 rows x 4 columns]
你也可以使用一个可对齐对象的右侧。
In [57]: df2 = df.copy()
In [58]: df2.loc[idx[:, :, ['C1', 'C3']], :] = df2 * 1000
In [59]: df2
Out[59]:
lvl0 a b
lvl1 bar foo bah foo
A0 B0 C0 D0 1 0 3 2
D1 5 4 7 6
C1 D0 9000 8000 11000 10000
D1 13000 12000 15000 14000
C2 D0 17 16 19 18
... ... ... ... ...
A3 B1 C1 D1 237000 236000 239000 238000
C2 D0 241 240 243 242
D1 245 244 247 246
C3 D0 249000 248000 251000 250000
D1 253000 252000 255000 254000
[64 rows x 4 columns]
绘图#
从
DataFrame.plot使用kind='hexbin'生成的六边形分箱图 (GH 5478),请参见 文档。DataFrame.plot和Series.plot现在支持通过指定kind='area'来绘制面积图 (GH 6656),请参阅 文档来自
Series.plot和DataFrame.plot的饼图,使用kind='pie'(GH 6976),参见 文档。带有误差线的绘图现在在
DataFrame和Series对象的.plot方法中得到支持 (GH 3796, GH 6834),请参见 文档。DataFrame.plot和Series.plot现在支持table关键字用于绘制matplotlib.Table,请参见 文档。table关键字可以接收以下值。False: 不执行任何操作(默认)。True: 使用名为plot方法的DataFrame或Series绘制表格。数据将被转置以适应 matplotlib 的默认布局。DataFrame或Series: 使用传递的数据绘制 matplotlib.table。数据将按照打印方法中显示的方式绘制(不会自动转置)。此外,辅助函数pandas.tools.plotting.table被添加用于从DataFrame和Series创建表格,并将其添加到matplotlib.Axes中。
plot(legend='reverse')现在将反转大多数图表类型的图例标签顺序。(GH 6014)线图和面积图可以通过
stacked=True进行堆叠 (GH 6656)以下关键字现在可以用于
DataFrame.plot()与kind='bar'和kind='barh':width: 指定条形宽度。在之前的版本中,静态值 0.5 被传递给 matplotlib,并且无法覆盖。(GH 6604)align: 指定条形对齐方式。默认是center``(与 matplotlib 不同)。在以前的版本中,pandas 将 ``align='edge'传递给 matplotlib 并自行调整位置到center,这导致align关键字没有按预期应用。(GH 4525)position: 指定条形图布局的相对对齐方式。从 0(左/底端)到 1(右/顶端)。默认值是 0.5(中心)。(GH 6604)
由于默认的
align值变化,条形图的坐标现在位于整数值(0.0, 1.0, 2.0 …)。这是为了让条形图与线形图位于相同的坐标上。然而,当你手动调整条形位置或绘图区域时,条形图可能会有意外的不同,例如使用set_xlim、set_ylim等。在这种情况下,请修改你的脚本以适应新的坐标。parallel_coordinates()函数现在接受参数color而不是colors。会引发一个FutureWarning以提醒旧的colors参数在未来版本中将不再支持。(GH 6956)parallel_coordinates()和andrews_curves()函数现在接受位置参数frame而不是data。如果按名称使用旧的data参数,则会引发FutureWarning。 (GH 6956)DataFrame.boxplot()现在支持layout关键字 (GH 6769)DataFrame.boxplot()有一个新的关键字参数return_type。它接受'dict'、'axes'或'both',在这种情况下,返回一个包含 matplotlib 轴和 matplotlib 线条字典的命名元组。
先前版本的弃用/更改#
从 0.14.0 版本开始,有一些先前版本的不推荐使用的功能正在生效。
移除
DateRange以支持DatetimeIndex(GH 6816)从
DataFrame.sort中移除column关键字 (GH 4370)从
set_eng_float_format()中移除precision关键字 (GH 395)从
DataFrame.to_string(),DataFrame.to_latex(), 和DataFrame.to_html()中移除force_unicode关键字;这些函数默认以 unicode 编码 (GH 2224, GH 2225)从
DataFrame.to_csv()和DataFrame.to_string()中移除nanRep关键字 (GH 275)从
HDFStore.select_column()中移除unique关键字 (GH 3256)从
Timestamp.offset()中移除inferTimeRule关键字 (GH 391)从
get_data_yahoo()和get_data_google()中移除name关键字( commit b921d1a )从
DatetimeIndex构造函数中移除offset关键字( commit 3136390 )从几个滚动矩统计函数中移除
time_rule,例如rolling_sum()(GH 1042)在 numpy 数组上移除了负
-布尔运算,改为使用 inv~,因为这将在 numpy 1.9 中被弃用 (GH 6960)
弃用#
pivot_table()/DataFrame.pivot_table()和crosstab()函数现在接受index和columns参数,而不是rows和cols。会引发一个FutureWarning以提醒旧的rows和cols参数在未来版本中将不被支持 (GH 5505)DataFrame.drop_duplicates()和DataFrame.duplicated()方法现在使用参数subset而不是cols以更好地与DataFrame.dropna()保持一致。会引发一个FutureWarning以提醒旧的cols参数在未来版本中将不被支持 (GH 6680)现在,
DataFrame.to_csv()和DataFrame.to_excel()函数使用参数columns而不是cols。会引发一个FutureWarning以提醒旧的cols参数在未来版本中将不再支持 (GH 6645)当使用标量索引器和非浮点型索引时,索引器会发出
FutureWarning警告 (GH 4892, GH 6960)# non-floating point indexes can only be indexed by integers / labels In [1]: pd.Series(1, np.arange(5))[3.0] pandas/core/index.py:469: FutureWarning: scalar indexers for index type Int64Index should be integers and not floating point Out[1]: 1 In [2]: pd.Series(1, np.arange(5)).iloc[3.0] pandas/core/index.py:469: FutureWarning: scalar indexers for index type Int64Index should be integers and not floating point Out[2]: 1 In [3]: pd.Series(1, np.arange(5)).iloc[3.0:4] pandas/core/index.py:527: FutureWarning: slice indexers when using iloc should be integers and not floating point Out[3]: 3 1 dtype: int64 # these are Float64Indexes, so integer or floating point is acceptable In [4]: pd.Series(1, np.arange(5.))[3] Out[4]: 1 In [5]: pd.Series(1, np.arange(5.))[3.0] Out[6]: 1
关于弃用警告的 Numpy 1.9 兼容性 (GH 6960)
Panel.shift()现在有一个与DataFrame.shift()匹配的函数签名。旧的位置参数lags已更改为关键字参数periods,默认值为 1。如果按名称使用旧参数lags,则会引发FutureWarning。 (GH 6910)order关键字参数factorize()将被移除。(GH 6926)。从
DataFrame.xs(),Panel.major_xs(),Panel.minor_xs()中移除copy关键字。如果可能,将返回一个视图,否则将创建一个副本。以前用户可能会认为copy=False总是会返回一个视图。(GH 6894)parallel_coordinates()函数现在接受参数color而不是colors。会引发一个FutureWarning以提醒旧的colors参数在未来版本中将不再支持。(GH 6956)parallel_coordinates()和andrews_curves()函数现在接受位置参数frame而不是data。如果按名称使用旧的data参数,则会引发FutureWarning。 (GH 6956)在使用 DBAPI 连接对象时对 ‘mysql’ 风格的支持已被弃用。MySQL 将进一步支持 SQLAlchemy 引擎 (GH 6900)。
以下
io.sql函数已被弃用:tquery、uquery、read_frame、frame_query、write_frame。在
describe()中的percentile_width关键字参数已被弃用。请改用percentiles关键字,该关键字接受一个显示百分位数的列表。默认输出保持不变。boxplot()的默认返回类型将在未来的版本中从字典更改为 matplotlib Axes。您现在可以通过传递return_type='axes'给 boxplot 来使用未来的行为。
已知问题#
OpenPyXL 2.0.0 破坏了向后兼容性 (GH 7169)
增强功能#
如果传递了一个元组字典,DataFrame 和 Series 将创建一个 MultiIndex 对象,请参见 文档 (GH 3323)
In [60]: pd.Series({('a', 'b'): 1, ('a', 'a'): 0, ....: ('a', 'c'): 2, ('b', 'a'): 3, ('b', 'b'): 4}) ....: Out[60]: a b 1 a 0 c 2 b a 3 b 4 Length: 5, dtype: int64 In [61]: pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2}, ....: ('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4}, ....: ('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6}, ....: ('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8}, ....: ('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}}) ....: Out[61]: a b b a c a b A B 1.0 4.0 5.0 8.0 10.0 C 2.0 3.0 6.0 7.0 NaN D NaN NaN NaN NaN 9.0 [3 rows x 5 columns]
在
Index中添加了sym_diff方法 (GH 5543)DataFrame.to_latex现在接受一个 longtable 关键字,如果为 True,将返回一个在 longtable 环境中的表格。(GH 6617)在
DataFrame.to_latex中添加选项以关闭转义 (GH 6472)pd.read_clipboard如果在关键字sep未指定的情况下,会尝试检测从电子表格复制的数据并相应地解析。 (GH 6223)将单索引的 DataFrame 与多索引的 DataFrame 合并 (GH 3662)
请参阅 文档 。目前尚不支持在左右两侧连接 MultiIndex DataFrame。
In [62]: household = pd.DataFrame({'household_id': [1, 2, 3], ....: 'male': [0, 1, 0], ....: 'wealth': [196087.3, 316478.7, 294750] ....: }, ....: columns=['household_id', 'male', 'wealth'] ....: ).set_index('household_id') ....: In [63]: household Out[63]: male wealth household_id 1 0 196087.3 2 1 316478.7 3 0 294750.0 [3 rows x 2 columns] In [64]: portfolio = pd.DataFrame({'household_id': [1, 2, 2, 3, 3, 3, 4], ....: 'asset_id': ["nl0000301109", ....: "nl0000289783", ....: "gb00b03mlx29", ....: "gb00b03mlx29", ....: "lu0197800237", ....: "nl0000289965", ....: np.nan], ....: 'name': ["ABN Amro", ....: "Robeco", ....: "Royal Dutch Shell", ....: "Royal Dutch Shell", ....: "AAB Eastern Europe Equity Fund", ....: "Postbank BioTech Fonds", ....: np.nan], ....: 'share': [1.0, 0.4, 0.6, 0.15, 0.6, 0.25, 1.0] ....: }, ....: columns=['household_id', 'asset_id', 'name', 'share'] ....: ).set_index(['household_id', 'asset_id']) ....: In [65]: portfolio Out[65]: name share household_id asset_id 1 nl0000301109 ABN Amro 1.00 2 nl0000289783 Robeco 0.40 gb00b03mlx29 Royal Dutch Shell 0.60 3 gb00b03mlx29 Royal Dutch Shell 0.15 lu0197800237 AAB Eastern Europe Equity Fund 0.60 nl0000289965 Postbank BioTech Fonds 0.25 4 NaN NaN 1.00 [7 rows x 2 columns] In [66]: household.join(portfolio, how='inner') Out[66]: male wealth name share household_id asset_id 1 nl0000301109 0 196087.3 ABN Amro 1.00 2 nl0000289783 1 316478.7 Robeco 0.40 gb00b03mlx29 1 316478.7 Royal Dutch Shell 0.60 3 gb00b03mlx29 0 294750.0 Royal Dutch Shell 0.15 lu0197800237 0 294750.0 AAB Eastern Europe Equity Fund 0.60 nl0000289965 0 294750.0 Postbank BioTech Fonds 0.25 [6 rows x 4 columns]
quotechar、doublequote和escapechar现在可以在使用DataFrame.to_csv时指定 (GH 5414, GH 4528)仅通过
sort_remaining布尔关键字参数对 MultiIndex 的指定级别进行部分排序。(GH 3984)在
TimeStamp和DatetimeIndex中添加了to_julian_date。儒略日主要用于天文学,表示从公元前4713年1月1日中午开始的天数。由于纳秒用于定义pandas中的时间,因此您可以使用的实际日期范围是1678年至2262年。(GH 4041)DataFrame.to_stata现在会检查数据与 Stata 数据类型的兼容性,并在需要时进行向上转换。当无法无损地进行向上转换时,会发出警告 (GH 6327)。DataFrame.to_stata和StataWriter将接受关键字参数 time_stamp 和 data_label,这些参数允许在创建文件时设置时间戳和数据集标签。(GH 6545)pandas.io.gbq现在可以正确处理读取unicode字符串。(GH 5940)Float64Index现在由一个float64dtype ndarray 支持,而不是一个objectdtype 数组 (GH 6471)。实现了
Panel.pct_change(GH 6904)为滚动矩函数添加了
how选项,以指示如何处理重采样;rolling_max()默认为最大值,rolling_min()默认为最小值,其他所有函数默认为均值 (GH 6297)CustomBusinessMonthBegin和CustomBusinessMonthEnd现在可用 (GH 6866)Series.quantile()和DataFrame.quantile()现在接受一个分位数数组。describe()现在接受一个百分位数数组,以包含在汇总统计数据中 (GH 4196)pivot_table现在可以通过index和columns关键字接受Grouper(GH 6913)In [67]: import datetime In [68]: df = pd.DataFrame({ ....: 'Branch': 'A A A A A B'.split(), ....: 'Buyer': 'Carl Mark Carl Carl Joe Joe'.split(), ....: 'Quantity': [1, 3, 5, 1, 8, 1], ....: 'Date': [datetime.datetime(2013, 11, 1, 13, 0), ....: datetime.datetime(2013, 9, 1, 13, 5), ....: datetime.datetime(2013, 10, 1, 20, 0), ....: datetime.datetime(2013, 10, 2, 10, 0), ....: datetime.datetime(2013, 11, 1, 20, 0), ....: datetime.datetime(2013, 10, 2, 10, 0)], ....: 'PayDay': [datetime.datetime(2013, 10, 4, 0, 0), ....: datetime.datetime(2013, 10, 15, 13, 5), ....: datetime.datetime(2013, 9, 5, 20, 0), ....: datetime.datetime(2013, 11, 2, 10, 0), ....: datetime.datetime(2013, 10, 7, 20, 0), ....: datetime.datetime(2013, 9, 5, 10, 0)]}) ....: In [69]: df Out[69]: Branch Buyer Quantity Date PayDay 0 A Carl 1 2013-11-01 13:00:00 2013-10-04 00:00:00 1 A Mark 3 2013-09-01 13:05:00 2013-10-15 13:05:00 2 A Carl 5 2013-10-01 20:00:00 2013-09-05 20:00:00 3 A Carl 1 2013-10-02 10:00:00 2013-11-02 10:00:00 4 A Joe 8 2013-11-01 20:00:00 2013-10-07 20:00:00 5 B Joe 1 2013-10-02 10:00:00 2013-09-05 10:00:00 [6 rows x 5 columns]
In [75]: df.pivot_table(values='Quantity', ....: index=pd.Grouper(freq='M', key='Date'), ....: columns=pd.Grouper(freq='M', key='PayDay'), ....: aggfunc="sum") Out[75]: PayDay 2013-09-30 2013-10-31 2013-11-30 Date 2013-09-30 NaN 3.0 NaN 2013-10-31 6.0 NaN 1.0 2013-11-30 NaN 9.0 NaN [3 rows x 3 columns]
字符串数组可以被包装到指定的宽度(
str.wrap)(GH 6999)将
nsmallest()和Series.nlargest()方法添加到 Series,请参阅 文档 (GH 3960)PeriodIndex完全支持像DatetimeIndex这样的部分字符串索引 (GH 7043)In [76]: prng = pd.period_range('2013-01-01 09:00', periods=100, freq='H') In [77]: ps = pd.Series(np.random.randn(len(prng)), index=prng) In [78]: ps Out[78]: 2013-01-01 09:00 0.015696 2013-01-01 10:00 -2.242685 2013-01-01 11:00 1.150036 2013-01-01 12:00 0.991946 2013-01-01 13:00 0.953324 ... 2013-01-05 08:00 0.285296 2013-01-05 09:00 0.484288 2013-01-05 10:00 1.363482 2013-01-05 11:00 -0.781105 2013-01-05 12:00 -0.468018 Freq: H, Length: 100, dtype: float64 In [79]: ps['2013-01-02'] Out[79]: 2013-01-02 00:00 0.553439 2013-01-02 01:00 1.318152 2013-01-02 02:00 -0.469305 2013-01-02 03:00 0.675554 2013-01-02 04:00 -1.817027 ... 2013-01-02 19:00 0.036142 2013-01-02 20:00 -2.074978 2013-01-02 21:00 0.247792 2013-01-02 22:00 -0.897157 2013-01-02 23:00 -0.136795 Freq: H, Length: 24, dtype: float64
read_excel现在可以在 Excel 日期和时间中读取毫秒,使用 xlrd >= 0.9.3。(GH 5945)pd.stats.moments.rolling_var现在使用 Welford 方法以提高数值稳定性 (GH 6817)pd.expanding_apply 和 pd.rolling_apply 现在接受传递给 func 的 args 和 kwargs (GH 6289)
DataFrame.rank()现在有一个百分比排名选项 (GH 5971)Series.rank()现在有一个百分比排名选项 (GH 5971)Series.rank()和DataFrame.rank()现在接受method='dense'以进行无间隙的排名 (GH 6514)支持通过
encoding与 xlwt 一起使用 (GH 3710)重构 Block 类,移除
Block.items属性以避免在处理项目时出现重复 (GH 6745, GH 6988)。测试语句更新为使用专门的断言 (GH 6175)
性能#
使用
DatetimeConverter将DatetimeIndex转换为浮点序数时的性能提升 (GH 6636)DataFrame.shift的性能改进 (GH 5609)在多索引系列中索引性能的提升 (GH 5567)
单类型索引中的性能改进 (GH 6484)
通过移除有问题的缓存(例如 MonthEnd、BusinessMonthEnd),提高了使用某些偏移量构建 DataFrame 的性能,(GH 6479)
提高
CustomBusinessDay的性能(GH 6584)当从可迭代对象中读取指定数量的行时,
DataFrame.from_records的性能改进 (GH 6700)对于整数数据类型的timedelta转换的性能改进 (GH 6754)
改进了兼容pickle的性能(GH 6899)
通过优化
take_2d在某些重新索引操作中提高性能 (GH 6749)GroupBy.count()现在在 Cython 中实现,对于大量组来说速度更快 (GH 7016)。
实验性#
在 0.14.0 版本中没有实验性更改
错误修复#
当索引与数据不匹配时,系列中的错误值 (GH 6532)
防止由于 HDFStore 表格式不支持 MultiIndex 导致的段错误 (GH 1848)
pd.DataFrame.sort_index中的一个错误,当ascending=False时,mergesort 不稳定 (GH 6399)当参数有前导零时,
pd.tseries.frequencies.to_offset中的错误 (GH 6391)开发版本中浅克隆/从压缩包安装的版本字符串生成错误 (GH 6127)
当前年份的
Timestamp/to_datetime不一致的 tz 解析 (GH 5958)eval中的一个错误,其中类型提升在大表达式中失败 (GH 6205)使用
inplace=True进行插值时的错误 (GH 6281)HDFStore.remove现在处理开始和停止 (GH 6177)HDFStore.select_as_multiple处理开始和停止的方式与select相同 (GH 6177)HDFStore.select_as_coordinates和select_column与一个where子句一起工作,该子句结果为过滤器 (GH 6177)非唯一索引连接中的回归 (GH 6329)
使用单个函数和混合类型帧的 groupby
agg问题 (GH 6337)当传递一个非
bool类型的to_replace参数时,DataFrame.replace()中的错误 (GH 6332)在尝试对 MultiIndex 赋值的不同级别进行对齐时引发 (GH 3738)
通过布尔索引设置复杂的数据类型时出现的错误 (GH 6345)
当遇到一个非单调的 DatetimeIndex 时,TimeGrouper/resample 中的错误会导致返回无效结果。(GH 4161)
TimeGrouper/resample 中索引名称传播的错误 (GH 4161)
TimeGrouper 具有与其它分组器(例如缺少
groups)更兼容的 API (GH 3881)在依赖于目标列顺序的 TimeGrouper 进行多重分组时出现错误 (GH 6764)
在解析包含可能的标记如
'&'的字符串时,pd.eval中的错误 (GH 6351)正确处理在整数0除法时面板中
-inf的位置 (GH 6178)DataFrame.shift使用axis=1时会引发 (GH 6371)禁用剪贴板测试直到发布时间(使用
nosetests -A disabled在本地运行) (GH 6048)。当传递一个包含不在要替换的值中的键的嵌套
dict时,DataFrame.replace()中的错误 (GH 6342)str.match忽略了 na 标志 (GH 6609)。在处理重复列时未合并的错误 (GH 6240)
插值中改变数据类型的错误 (GH 6290)
Series.get中的错误,使用了有问题的访问方法 (GH 6383)在
where=[('date', '>=', datetime(2013,1,1)), ('date', '<=', datetime(2014,1,1))]形式的 hdfstore 查询中的错误 (GH 6313)DataFrame.dropna中重复索引的错误 (GH 6355)在0.12版本中,带有嵌入式类列表的链式getitem索引回归 (GH 6394)
Float64Index带有不正确比较的 nan (GH 6401)包含
@字符的字符串eval/query表达式现在可以正常工作 (GH 6366)。在指定
method时,Series.reindex中的错误与某些 nan 值不一致(在重采样时注意到)(GH 6418)在
DataFrame.replace()中的一个错误,其中嵌套的字典错误地依赖于字典键和值的顺序 (GH 5338)。在连接空对象时的性能问题 (GH 3259)
澄清在包含
NaN值的Index对象上对sym_diff的排序 (GH 6444)在
MultiIndex.from_product中使用DatetimeIndex作为输入时的回归 (GH 6439)当传递一个非默认索引时,
str.extract中的错误 (GH 6348)当传递
pat=None和n=1时str.split中的错误 (GH 6466)当传递
"F-F_Momentum_Factor"和data_source="famafrench"时,io.data.DataReader中的错误 (GH 6460)timedelta64[ns]系列的sum中的错误 (GH 6462)resample中带有时区和某些偏移的错误 (GH 6397)在
iat/iloc中使用重复索引的 Series 存在 Bug (GH 6493)read_html中的一个错误,其中 nan 被错误地用于表示文本中缺失的值。为了与 pandas 的其他部分保持一致,应该使用空字符串 (GH 5129)。read_html测试中的错误,重定向无效 URL 会导致一个测试失败 (GH 6445)。在使用
.loc进行多轴索引时,非唯一索引中的错误 (GH 6504)当对DataFrame的列轴进行切片索引时导致_ref_locs损坏的错误 (GH 6525)
在创建 Series 时对 numpy
datetime64非 ns dtypes 的处理从 0.13 版本回归 (GH 6529)传递给
set_index的 MultiIndexes 的.names属性现在被保留 (GH 6459)。在具有重复索引和对齐右侧的 setitem 中的错误 (GH 6541)
使用
.loc在混合整数索引上的 Bug (GH 6546)pd.read_stata中的一个错误,会导致使用错误的数据类型和缺失值 (GH 6327)在
DataFrame.to_stata中的一个错误,在某些情况下会导致数据丢失,并且可能使用错误的数据类型和缺失值导出数据 (GH 6335)StataWriter在字符串列中用空字符串替换缺失值 (GH 6802)在
Timestamp加法/减法中的不一致类型 (GH 6543)在时间戳加减中保留频率的错误 (GH 4547)
Series.quantile在object类型上引发 (GH 6555)当丢弃时,
.xs中带有nan的级别存在错误 (GH 6574)使用
method='bfill/ffill'和datetime64[ns]数据类型时 fillna 中的 Bug (GH 6587)混合dtypes可能导致数据丢失的sql写入错误 (GH 6509)
Series.pop中的错误 (GH 6600)当位置索引器匹配相应轴的
Int64Index且未发生重新排序时,iloc索引存在错误 (GH 6612)在指定
limit和value的情况下fillna中的 Bug当列名不是字符串时,
DataFrame.to_stata中的错误 (GH 4558)与
np.compress的兼容性问题,出现在 (GH 6658)在右侧为 Series 的二进制操作中存在错误,未对齐 (GH 6681)
DataFrame.to_stata中的错误,错误处理 nan 值并忽略with_index关键字参数 (GH 6685)在使用可整除频率时,重采样中存在额外箱的错误 (GH 4076)
当传递自定义函数时,groupby 聚合的一致性问题 (GH 6715)
当
how=None重采样频率与轴频率相同时的重采样错误 (GH 5955)空数组向下转换推断中的错误 (GH 6733)
在稀疏容器中
obj.blocks的错误,导致相同 dtype 的项目只保留最后一个 (GH 6748)在解封
NaT (NaTType)中的错误 (GH 4606)DataFrame.replace()中的一个错误,其中正则表达式元字符即使在regex=False时也被视为正则表达式 (GH 6777)。32位平台上的timedelta操作中的错误 (GH 6808)
通过
.index直接设置一个 tz-aware 索引的错误 (GH 6785)在 expressions.py 中的一个错误,其中 numexpr 会尝试评估算术运算 (GH 6762)。
Makefile 中的一个错误,它在执行
make clean时没有删除由 Cython 生成的 C 文件 (GH 6768)读取
HDFStore中的长字符串时,numpy < 1.7.2 的错误 (GH 6166)在
DataFrame._reduce中的一个错误,其中非布尔型(0/1)整数被转换为布尔值。(GH 6806)从 0.13 版本回归,使用
fillna和日期时间类型的 Series (GH 6344)在具有时区的
DatetimeIndex中添加np.timedelta64时输出错误结果 (GH 6818)DataFrame.replace()中的一个错误,通过替换改变数据类型只会替换值的第一次出现 (GH 6689)在
Period构造中传递 ‘MS’ 频率时提供更好的错误信息 (GH5332)当
max_rows=None且 Series 行数超过 1000 行时,Series.__unicode__中的 Bug。(GH 6863)groupby.get_group中的一个错误,其中时间型数据并不总是被接受 (GH 5267)由
TimeGrouper创建的groupBy.get_group中的错误引发AttributeError(GH 6914)DatetimeIndex.tz_localize和DatetimeIndex.tz_convert在转换NaT时存在错误 (GH 5546)算术运算中的错误影响
NaT(GH 6873)Series.str.extract中的一个错误,其中单个组匹配的结果Series没有被重命名为组名在
DataFrame.to_csv中的一个错误,当设置index=False时忽略了header关键字参数 (GH 6186)DataFrame.plot和Series.plot中的错误,在重复绘制到同一轴时,图例行为不一致 (GH 6678)在
concat中接受TextFileReader,这影响了常见的用户习惯用法 (GH 6583)C 解析器中前导空格的错误 (GH 3374)
C 解析器中
delim_whitespace=True和 `` `` 分隔行存在错误Python 解析器中存在一个错误,即在列标题后的行中使用显式 MultiIndex (GH 6893)
Series.rank和DataFrame.rank中的一个错误,导致非常小的浮点数 (<1e-13) 都获得相同的排名 (GH 6886)在
DataFrame.apply中使用*args或**kwargs函数并返回空结果的错误 (GH 6952)32位平台上的求和/均值溢出问题 (GH 6915)
将
Panel.shift移动到NDFrame.slice_shift并修复以尊重多种数据类型。(GH 6959)在
DataFrame.plot中启用subplots=True时,只有单列会引发TypeError,而Series.plot会引发AttributeError(GH 6951)在
DataFrame.plot中的错误会在启用subplots和kind=scatter时绘制不必要的轴 (GH 6951)read_csv在非 utf-8 编码文件系统中的错误 (GH 6807)当设置 / 对齐时
iloc中的错误 (GH 6766)当使用带有前缀的unicode值调用get_dummies时,导致UnicodeEncodeError的错误 (GH 6885)
频率时间序列图光标显示中的错误 (GH 5453)
在使用
Float64Index时,groupby.plot中出现了错误 (GH 7025)如果无法从雅虎下载选项数据,则停止测试失败 (GH 7034)
parallel_coordinates和radviz中的错误,其中类别列的重排序导致可能的颜色/类别不匹配 (GH 6956)radviz和andrews_curves中的错误,其中多个 ‘color’ 值被传递给绘图方法 (GH 6956)Float64Index.isin()中的一个错误,包含nan会使索引声称它们包含所有内容 (GH 7066)。DataFrame.boxplot中的一个错误,它未能使用作为ax参数传递的轴 (GH 3578)在
XlsxWriter和XlwtWriter实现中的一个错误导致日期时间列在没有时间的情况下被格式化(GH 7075),这些列被传递给绘图方法read_fwf()将colspec中的None视为常规的 python 切片。当colspec包含一个None时,它现在从开始读取或直到行尾(之前会引发TypeError)缓存一致性中链式索引和切片的错误;在
NDFrame中添加_is_view属性以正确预测视图;仅在xs是实际副本(而不是视图)时标记is_copy(GH 7084)从带有
dayfirst=True的字符串 ndarray 创建 DatetimeIndex 时的错误 (GH 5917)在从
DatetimeIndex创建的MultiIndex.from_arrays中的错误不会保留freq和tz(GH 7090)当
MultiIndex包含PeriodIndex时,unstack中的错误会引发ValueError(GH 4342)boxplot和hist中的错误绘制了不必要的轴 (GH 6769)groupby.nth()中超出范围索引器的回归 (GH 6621)quantile中使用日期时间值的错误 (GH 6965)Dataframe.set_index、reindex和pivot中的错误不会保留DatetimeIndex和PeriodIndex属性 (GH 3950, GH 5878, GH 6631)MultiIndex.get_level_values中的错误不会保留DatetimeIndex和PeriodIndex属性 (GH 7092)Groupby中的错误不保留tz(GH 3950)PeriodIndex部分字符串切片中的错误 (GH 6716)在
large_repr设置为 ‘info’ 时,截断的 Series 或 DataFrame 的 HTML 表示中不显示类名的问题 (GH 7105)在
DatetimeIndex中指定freq时,当传递的值太短时会引发ValueError(GH 7098)修复了
inforepr 不遵守display.max_info_columns设置的错误 (GH 6939)错误
PeriodIndex字符串切片带有越界值 (GH 5407)修复了在调整大表大小时哈希表实现/因子化器中的内存错误 (GH 7157)
当应用于0维对象数组时
isnull的错误 (GH 7176)query/eval中的错误,全局常量未正确查找 (GH 7178)在使用
iloc和多轴元组索引器时,识别越界位置列表索引器的错误 (GH 7189)使用 > 2 ndim 和 MultiIndex 进行多轴索引时的错误 (GH 7199)
修复一个无效的 eval/query 操作会导致堆栈溢出的错误 (GH 5198)
贡献者#
共有 94 人为此版本贡献了补丁。名字后面带有“+”的人是第一次贡献补丁。
Acanthostega +
Adam Marcus +
Alex Gaudio
Alex Rothberg
AllenDowney +
Andrew Rosenfeld +
Andy Hayden
Antoine Mazières +
Benedikt Sauer
Brad Buran
Christopher Whelan
Clark Fitzgerald
DSM
Dale Jung
Dan Allan
Dan Birken
Daniel Waeber
David Jung +
David Stephens +
Douglas McNeil
Garrett Drapala
Gouthaman Balaraman +
Guillaume Poulin +
Jacob Howard +
Jacob Schaer
Jason Sexauer +
Jeff Reback
Jeff Tratner
Jeffrey Starr +
John David Reaver +
John McNamara
John W. O’Brien
Jonathan Chambers
Joris Van den Bossche
Julia Evans
Júlio +
K.-Michael Aye
Katie Atkinson +
Kelsey Jordahl
Kevin Sheppard +
Matt Wittmann +
Matthias Kuhn +
Max Grender-Jones +
Michael E. Gruen +
Mike Kelly
Nipun Batra +
Noah Spies +
PKEuS
Patrick O’Keeffe
Phillip Cloud
Pietro Battiston +
Randy Carnevale +
Robert Gibboni +
Skipper Seabold
SplashDance +
Stephan Hoyer +
Tim Cera +
Tobias Brandt
Todd Jennings +
Tom Augspurger
TomAugspurger
Yaroslav Halchenko
agijsberts +
akittredge
ankostis +
anomrake
anton-d +
bashtage +
benjamin +
bwignall
cgohlke +
chebee7i +
clham +
danielballan
hshimizu77 +
hugo +
immerrr
ischwabacher +
jaimefrio +
jreback
jsexauer +
kdiether +
michaelws +
mikebailey +
ojdo +
onesandzeroes +
phaebz +
ribonoous +
rockg
sinhrks +
unutbu
westurner
y-p
zach powers