PyG工作负载的CPU亲和性
通过设置适当的亲和性掩码,可以显著提高使用CPU的PyG工作负载的性能。 处理器亲和性,或核心绑定,是对本机操作系统队列调度算法的修改,使应用程序能够为其在CPU上执行期间启动的进程或线程分配一组特定的核心。 因此,它通过最小化核心停顿和内存限制来提高整体有效的硬件利用率。 即使在系统负载较重的情况下,它也能确保关键进程或线程的CPU资源。
CPU亲和性针对两个主要的性能关键区域:
执行绑定: 指示进程/线程将运行的核心。
内存绑定: 表示内存页面将被绑定的首选内存区域(NUMA机器中的本地区域)。
以下文章讨论了可用的工具和环境设置,这些工具和设置可以用来最大化Intel CPU与PyG的性能。
注意
总的来说,CPU亲和性可以是提高某些类型应用程序性能和可预测性的有用工具,但一种配置并不一定适合所有情况:重要的是要仔细考虑CPU亲和性是否适合您的使用场景,并测试和衡量您所做的任何更改的影响。
使用CPU亲和性
每个PyG工作负载都可以使用PyTorch迭代器类MultiProcessingDataLoaderIter进行并行化,如果在torch.utils.data.DataLoader中传递了num_workers > 0,则会自动启用。
在底层,它会创建num_workers多个子进程,这些子进程将与主进程并行运行。
为数据加载进程设置CPU亲和性掩码会将DataLoader工作线程放置在特定的CPU核心上。
实际上,它通过将预取的数据批次分配到本地内存中,从而更高效地准备数据批次。
每次进程或线程从一个核心移动到另一个核心时,寄存器和缓存都需要刷新并重新加载。
如果这种情况经常发生,代价可能会非常高,线程也可能不再靠近它们的数据,或者无法在缓存中共享数据。
自 PyG(2.3 及更高版本)起,NodeLoader 和 LinkLoader 类正式支持使用 torch_geometric.loader.AffinityMixin 上下文管理器的原生 CPU 亲和性解决方案。
可以通过 enable_cpu_affinity() 方法为 num_workers > 0 的用例启用 CPU 亲和性,
并确保在初始化时为每个工作线程分配一个独立的核心。
可以使用 loader_cores 参数分配用户定义的核心 ID 列表。
否则,核心将从核心 ID 0 开始自动分配。
截至目前,每个工作线程只能分配一个核心,因此默认情况下在工作线程的进程中禁用了多线程。
建议的初始工作线程数量在 [2, 4] 之间,最佳数量可能因工作负载特性而异:
loader = NeigborLoader(
data,
num_workers=3,
...,
)
with loader.enable_cpu_affinity(loader_cores=[0, 1, 2]):
for batch in loader:
pass
通常建议在任何多进程CPU工作负载中使用filter_per_worker=True(默认情况下为True)。
然后,工作进程准备每个小批量:首先使用预定义的采样器采样节点索引,其次根据采样的节点和边过滤节点和边特征。
过滤函数从加载到DRAM中的完整输入Data张量中选择节点特征向量。
当filter_per_worker设置为True时,每个工作进程的子进程在其CPU资源内执行过滤。
因此,主进程资源得到释放,可以仅用于GNN计算。
将进程绑定到物理核心
遵循一般的性能调优原则,建议仅使用物理核心进行深度学习工作负载。
例如,当两个逻辑线程同时运行GEMM时,它们将共享相同的核心资源,导致前端受限,这样从前端受限产生的开销大于同时运行两个逻辑线程带来的增益。
这是因为OpenMP线程将争夺相同的GEMM执行单元,参见这里。
绑定可以通过多种方式完成,然而最常见的工具是:
numactl(仅在Linux上):--physcpubind=<cpus>, -C <cpus> or --cpunodebind=<nodes>, -N <nodes>Intel OMP
libiomp:export KMP_AFFINITY=granularity=fine,proclist=[0-<physical_cores_num-1>],explicitGNU
libgomp:export GOMP_CPU_AFFINITY="0-<physical_cores_num-1>"
隔离DataLoader进程
为了获得最佳性能,需要使用上述工具结合主进程亲和性设置与多进程DataLoader的亲和性设置。
在每个并行化的PyG工作负载执行中,主进程负责在GNN层上进行消息传递更新,而DataLoader工作进程子进程负责获取和预处理数据以传递给GNN模型。
建议隔离分配给这两个进程的CPU资源以获得最佳结果。
为此,分配给每个亲和性掩码的CPU应该是互斥的。
例如,如果四个DataLoader工作进程被分配给CPU [0, 1, 2, 3],主进程应使用其余可用的核心,即通过调用:
numactl -C 4-(N-1) --localalloc python …
其中 N 是物理核心的总数,最后一个 CPU 的核心 ID 为 N-1。
添加 --localalloc 可以改善本地内存分配,并使缓存更接近活跃的核心。
双插槽CPU分离
使用双插槽CPU时,进一步隔离插槽之间的进程可能是有益的。
这可以减少主进程的远程内存调用频率。
目标是利用本地内存上的高速缓存,并减少由于在NUMA节点之间迁移缓存数据而导致的内存限制。
这可以通过使用DataLoader亲和性,并在第二个插槽的核心上启动主进程来实现,即:
numactl -C M-(N-1) -m 1 python …
其中 M 是第二个 CPU 插槽的第一个核心的 cpuid。
添加一个补充的内存分配标志 -m 1 优先在同一 NUMA 节点上分配缓存,主进程正在该节点上运行(或者对于不太严格的内存分配,使用 --preferred 1)。
这使得数据在计算发生的同一插槽上立即可用。
使用此设置非常依赖于工作负载,可能需要一些微调,因为需要在增加 OMP 线程数量与限制远程内存调用次数之间进行权衡。
改进内存限制
遵循PyTorch的CPU性能优化指南,也建议PyG使用jemalloc或TCMalloc。
这些通常可以达到比默认的PyTorch 内存分配器 PTMalloc更好的内存使用效果。
可以在脚本执行前使用LD_PRELOAD指定非默认内存分配器。
快速入门指南
实现最佳性能的CPU亲和性的一般指南可以总结为以下步骤:
测试您的数据集是否受益于使用并行数据加载器。 对于某些数据集,使用普通的串行数据加载器可能更有益,特别是当输入
Data的维度相对较小时。通过设置
num_workers > 0来启用多进程数据加载器。num_workers的一个良好估计值在[2, 4]范围内。 然而,对于更复杂的数据集,您可能需要尝试使用更多的worker。 使用enable_cpu_affinity()功能来绑定DataLoader核心。将执行绑定到物理核心。 或者,可以在系统级别完全禁用超线程。
通过使用
numactl、libiomp5库的KMP_AFFINITY或libgomp库的GOMP_CPU_AFFINITY,将用于主进程的核心与数据加载器工作进程的核心分开。为你的工作负载找到最佳的OMP线程数。 一个好的起点是
N - num_workers。 通常,良好并行化的模型会从多个OMP线程中受益。 然而,如果你的模型计算流程中有交替的并行和串行区域,由于在并行区域之间生成和维护线程所需的资源分配,性能将会下降。在使用双插槽CPU时,您可能希望尝试将数据加载分配到一个插槽,而将主进程分配到另一个插槽,并在执行主进程的同一插槽上进行内存分配(
numactl -m)。 这通常会导致最佳的缓存分配,并且往往超过使用更多OMP线程的好处。通过使用非默认的内存分配器,如
jemalloc或TCMalloc,可以获得额外的性能提升。为CPU亲和性掩码找到最佳设置是一个管理每次迭代中用于加载和准备数据的CPU时间与GNN执行期间花费的时间比例的问题。 通过更改模型超参数(如批量大小、采样邻居数量和层数)可能会获得不同的结果。 一般来说,需要采样复杂图的工作负载可能会从为数据准备步骤保留一些CPU资源中获益更多。
示例结果
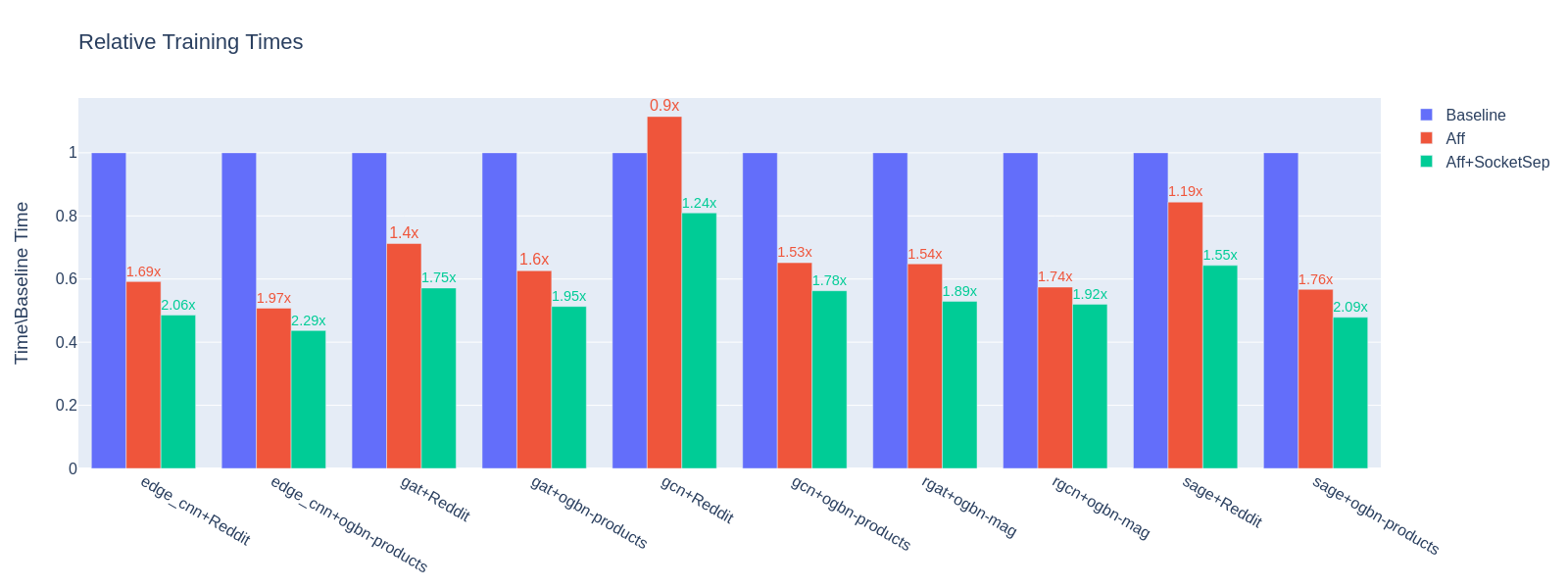
下图展示了将CPU亲和性掩码应用于benchmark/training/training_benchmark.py的结果。
测量是针对不同数量的工作线程进行的,而每个基准测试的其他超参数保持不变:--warmup 0 --use-sparse-tensor --num-layers 3 --num-hidden-channels 128 --batch-sizes 2048。
展示了三种不同的亲和性配置:
基线 - 仅更改
OMP_NUM_THREADS:
OMP_NUM_THREADS=(N-num_workers) python training_benchmark.py --num-workers …
Aff - 第一个套接字上的数据加载器进程,第一个和第二个套接字上的主进程,98-110个线程:
LD_PRELOAD=(path)/libjemalloc.so (path)/libiomp5.so MALLOC_CONF=oversize_threshold:1,background_thread:true,metadata_thp:auto OMP_NUM_THREADS=(N-num_workers) KMP_AFFINITY=granularity=fine,compact,1,0 KMP_BLOCKTIME=0 numactl -C <num_workers-(N-1)> --localalloc python training_benchmark.py --cpu-affinity --num-workers …
Aff+SocketSep - 第一个套接字上的数据加载器进程,第二个套接字上的主进程,60个线程:
LD_PRELOAD=(path)/libjemalloc.so (path)/libiomp5.so MALLOC_CONF=oversize_threshold:1,background_thread:true,metadata_thp:auto OMP_NUM_THREADS=(N-M) KMP_AFFINITY=granularity=fine,compact,1,0 KMP_BLOCKTIME=0 numactl -C <M-(N-1)> -m 1 python training_benchmark.py --cpu-affinity --num-workers ...
每个模型/数据集组合的训练时间是通过在不同数量的数据加载器工作线程上取结果的平均值获得的:基线为[0, 2, 4, 8, 16],每个亲和性配置为[2, 4, 8, 16]工作线程。
然后,亲和性平均值相对于基线测量平均值进行了归一化。
该值在\(y\)轴上表示。
每个结果上方的标签表示使用讨论的配置所带来的端到端性能增益。
在所有模型/数据集样本中,普通亲和性的平均训练时间减少了1.53倍,而带有套接字分离的亲和性减少了1.85倍。
预生产双插槽 Intel(R) Xeon(R) Platinum 8481C @ 2.0Ghz (2 x 56) 核心 CPU。