通过远程后端扩展GNNs
PyG(2.2 及以上版本)包含了许多原语,可以轻松与可扩展图机器学习的简单范式集成,使用户能够在远大于其机器可用内存大小的图上训练 GNN。它通过引入简单、易用且可扩展的 torch_geometric.data.FeatureStore 和 torch_geometric.data.GraphStore 抽象来实现这一点,这些抽象直接插入到现有的熟悉的 PyG 接口中。定义 FeatureStore 允许用户利用远程存储的节点(以及即将支持的边)特征,定义 GraphStore 允许用户利用远程存储的图结构信息。它们共同为 GNN 提供了强大的可扩展性,同时降低了开发者的负担。
警告
这里讨论的远程后端API可能会在未来发生变化,因为我们不断努力提高它们的易用性和通用性。
注意
目前,FeatureStore 和 GraphStore 仅支持异构图,并且不支持边特征。
同构图和边特征的支持即将推出。
背景
一个实例化的图神经网络由两种类型的数据组成:
节点和/或边特征信息: 对应于图中节点和边属性的密集向量
图结构信息: 图中的节点以及连接它们的边
对GNNs的一个直接观察是,扩展到比所选加速器可用内存更大的数据需要在采样子图(形成小批量)上进行训练,而不是一次性在整个图上进行训练(全批量训练)。 虽然这种方法在学习过程中增加了随机性,但它将加速器的内存需求降低到采样子图的需求。

图 1: 经典的 mini-batch GNN 训练范式。
然而,尽管小批量训练减少了所选加速器的内存需求,但它并不是解决所有图学习可扩展性问题的万能药。 特别是,由于必须在学习过程的每次迭代中采样子图以传递给加速器,传统上需要将图和特征存储在用户机器的CPU DRAM中。 在大规模情况下,这一要求可能会变得相当繁重:
获取具有足够CPU DRAM来存储图和特征的实例是具有挑战性的
使用数据并行进行训练需要在每个计算节点上复制图和特征
图形和特征很容易比单台机器的内存大得多
为了扩展到非常大的图和特征,超出了单台机器的内存需求,因此需要将这些数据结构移到外部存储,并且只在执行计算的节点上处理采样的子图。
为了实现这一目标,PyG 依赖于两个主要抽象来存储特征信息和图结构:
特征存储在键值对FeatureStore中,它必须支持高效的随机访问。
图信息存储在GraphStore中,它必须支持为定义在GraphStore实例上操作的采样器进行高效采样。

图2: 远程存储和训练实例之间的图数据存储布局。
在 PyG(2.2 及更高版本)中,图数据分为其特征和结构信息,这些信息存储在可能远离实际训练节点的位置,以及这些组件之间的交互,所有这些都对最终用户完全抽象。只要 FeatureStore 和 GraphStore 被正确定义(考虑到上述性能要求),PyG 会处理其余的事情!
特征存储
一个 torch_geometric.data.FeatureStore 保存了图的节点和边的特征。
在图学习应用中,特征存储通常是主要的存储瓶颈,因为存储图的布局信息(即 edge_index)相对便宜(每条边约32字节)。
PyG 提供了各种 FeatureStore 实现的通用接口,以便与其核心学习API进行交互。
FeatureStore 的实现细节通过类似 CRUD 的接口从 PyG 中抽象出来。
特别是,FeatureStore 抽象的实现者主要需要重写 put_tensor()、get_tensor() 和 remove_tensor() 功能。
这样做既使 PyG 能够利用实现中存储的特性,也允许用户使用 Python 接口来检查和修改 FeatureStore 元素:
feature_store = CustomFeatureStore()
paper_features = ... # [num_papers, num_paper_features]
author_features = ... # [num_authors, num_author_features]
# Add features:
feature_store['paper', 'x', None] = paper_features
feature_store['author', 'x', None] = author_features
# Access features:
assert torch.equal(feature_store['paper', 'x'], paper_features)
assert torch.equal(feature_store['paper'].x, paper_features)
assert torch.equal(feature_store['author', 'x', 0:20], author_features[0:20])
FeatureStore 抽象的常见实现是键值存储,例如,像 memcached、LevelDB、RocksDB 这样的后端都是可行的性能选项。
图存储和采样器
一个 torch_geometric.data.GraphStore 保存了定义图中节点之间关系的边索引。
GraphStore 的目标是以一种允许根据开发者选择的采样算法从根节点高效采样的方式存储图信息。
类似于FeatureStore,PyG为各种GraphStore实现提供了一个通用接口,以便与其核心学习API进行交互。
然而,与FeatureStore不同,GraphStore不需要为其所有元素提供高效的随机访问;相反,它需要定义一个提供高效子图采样的表示。
下面展示了该接口的一个示例用法:
graph_store = CustomGraphStore()
edge_index = torch.tensor([[0, 1, 1, 2], [1, 0, 2, 1]])
# Put edges:
graph_store['edge', 'coo'] = coo
# Access edges:
row, col = graph_store['edge', 'coo']
assert torch.equal(row, edge_index[0])
assert torch.equal(col, edge_index[1])
GraphStore 的常见实现是图数据库,例如,Neo4j、TigerGraph、ArangoDB、Kùzu 都是可行的性能选项。
我们提供了一个使用 PyG 结合 Kùzu 数据库的示例 这里。
图采样器与给定的GraphStore紧密耦合,并在GraphStore上操作以从输入节点生成采样子图。
不同的采样算法在torch_geometric.sampler.BaseSampler接口背后实现。
默认情况下,PyG的默认内存采样器将所有边索引从GraphStore拉入训练节点内存,将其转换为压缩稀疏列(CSC)格式,并利用预构建的内存采样例程。
然而,自定义采样器实现可以选择通过实现sample_from_nodes()和/或sample_from_edges()来调用专门的GraphStore方法,以提高效率(例如,直接在远程GraphStore上执行采样):
# `CustomGraphSampler` knows how to sample on `CustomGraphStore`:
node_sampler = CustomGraphSampler(
graph_store=graph_store,
num_neighbors=[10, 20],
...
)
数据加载器
PyG 没有定义一个必须由 GraphStore 实现的特定领域语言来进行采样;相反,采样器和 GraphStore 通过数据加载器紧密耦合在一起。
PyG 提供了两种现成的数据加载器:一个 torch_geometric.loader.NodeLoader,用于从输入节点中采样子图以用于节点分类任务,以及一个 torch_geometric.loader.LinkLoader,用于从边的两侧采样子图以用于链接预测任务。
这些数据加载器需要一个 FeatureStore、一个 GraphStore 和一个图采样器作为输入,并在内部调用采样器的 sample_from_nodes() 或 sample_from_edges() 方法来执行子图采样:
# Instead of passing PyG data objects, we now pass a tuple
# of the `FeatureStore` and `GraphStore as input data:
loader = NodeLoader(
data=(feature_store, graph_store),
node_sampler=node_sampler,
batch_size=20,
input_nodes='paper',
)
for batch in loader:
pass
将所有内容整合在一起
在高层次上,上述列出的组件共同协作,为在PyG中扩展GNN提供支持。
数据加载器(确切地说,每个工作器)利用一个
BaseSampler向GraphStore发出采样请求。在收到响应后,数据加载器随后查询
FeatureStore以获取与采样子图的节点和边相关联的特征。数据加载器随后从图结构和特征信息中构建最终的小批量数据,以发送到加速器进行前向/后向传递。
重复直到收敛。
所有概述的类都通过通用接口进行通信,使它们具有可扩展性、通用性,并且易于与您今天使用的PyG集成:
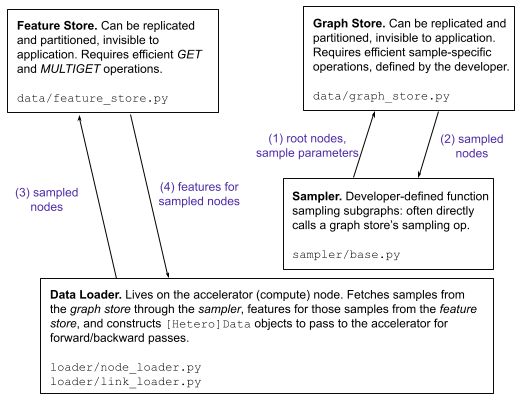
图3: 连接 :class:~torch_geometric.data.`FeatureStore`, GraphStore, 图采样器和数据加载器的通用接口(和数据流)。
要开始扩展性,我们建议检查上面列出的接口,并定义您自己的FeatureStore、GraphStore和BaseSampler实现。
一旦FeatureStore、GraphStore和BaseSampler正确实现,只需将它们作为参数传递给NodeLoader或LinkLoader,其余的PyG将无缝工作,类似于任何纯内存应用程序。