使用GraphGym管理实验
GraphGym 是一个用于设计和评估图神经网络(GNNs)的平台,最初在“图神经网络的设计空间”论文中提出。我们现在正式支持 GraphGym 作为PyG的一部分。
警告
GraphGym API 可能会在未来发生变化,因为我们正在不断努力实现与 PyG 更好和更深入的集成。
亮点
高度模块化的GNN管道:
数据: 数据加载和数据分割
模型: 模块化的GNN实现
任务: 节点级别、边级别和图级别的任务
评估: 准确率, ROC AUC, …
可重复的实验配置:
每个实验都由一个配置文件完全描述
可扩展的实验管理:
轻松启动数千个GNN实验并行
自动生成跨随机种子和实验的实验分析和图表
灵活的用户定制:
轻松注册您自己的模块,例如数据加载器、GNN层、损失函数等
为什么选择GraphGym?
TL;DR: GraphGym 非常适合 GNN 初学者、领域专家和 GNN 研究人员。
场景 1: 你是图表示学习的初学者,想要了解GNNs的工作原理:
你可能已经阅读了许多关于GNN的激动人心的论文,并尝试编写自己的GNN实现。 即使使用原始的PyG,你仍然需要自己编写基本的管道。 GraphGym 是你开始学习标准化的GNN实现和评估的完美地方。
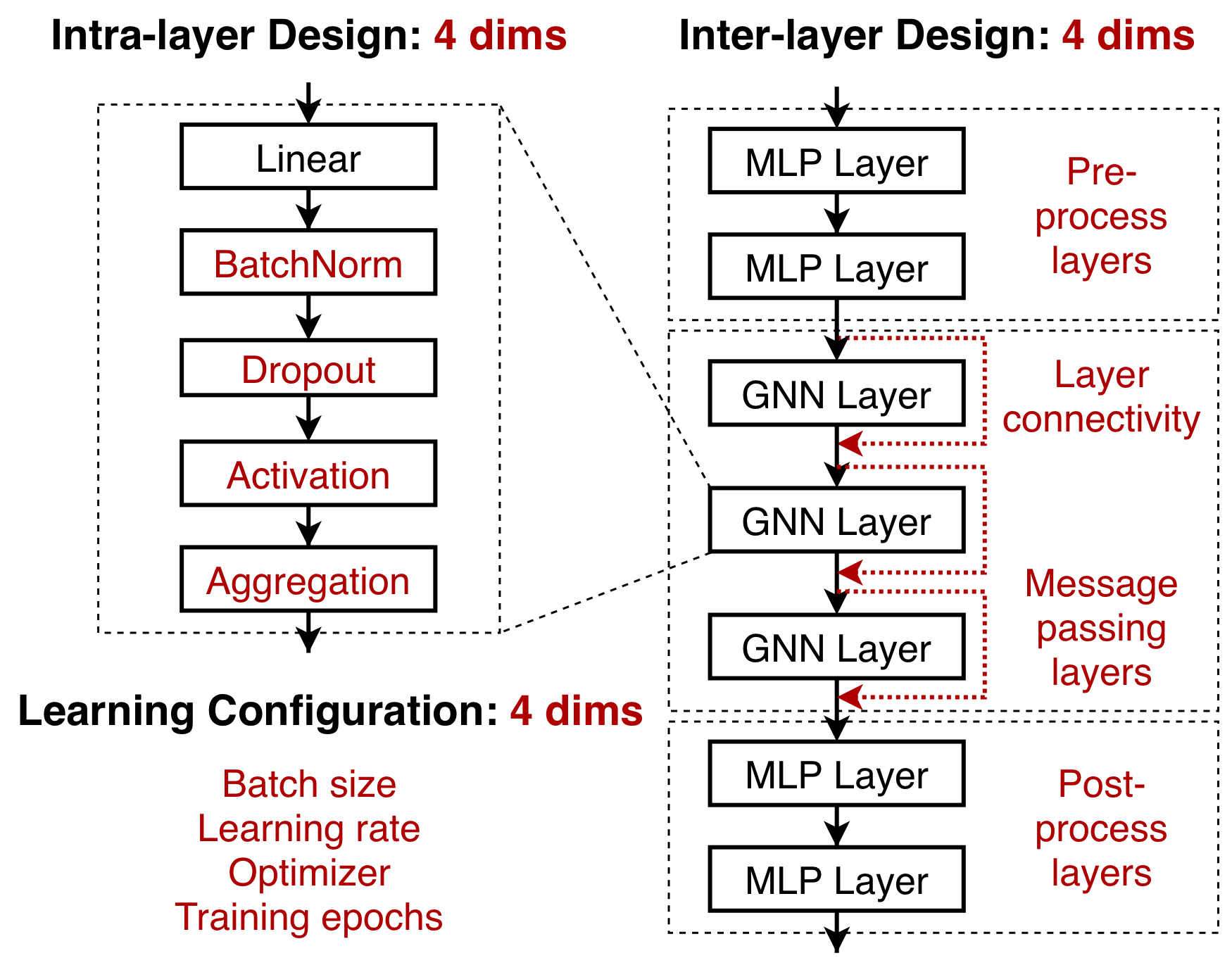
图1: 模块化的GNN实现。
场景2: 您希望将GNNs应用于您令人兴奋的应用程序:
你可能知道有数百种可能的GNN模型,选择最佳模型是出了名的困难。 更糟糕的是,GraphGym论文显示,不同任务的最佳GNN设计差异巨大。 GraphGym提供了一个简单的界面,可以并行尝试数千种GNN,并了解针对你特定任务的最佳设计。 在调查了1000万种GNN模型-任务组合后,GraphGym还推荐了一个“首选”GNN设计空间。
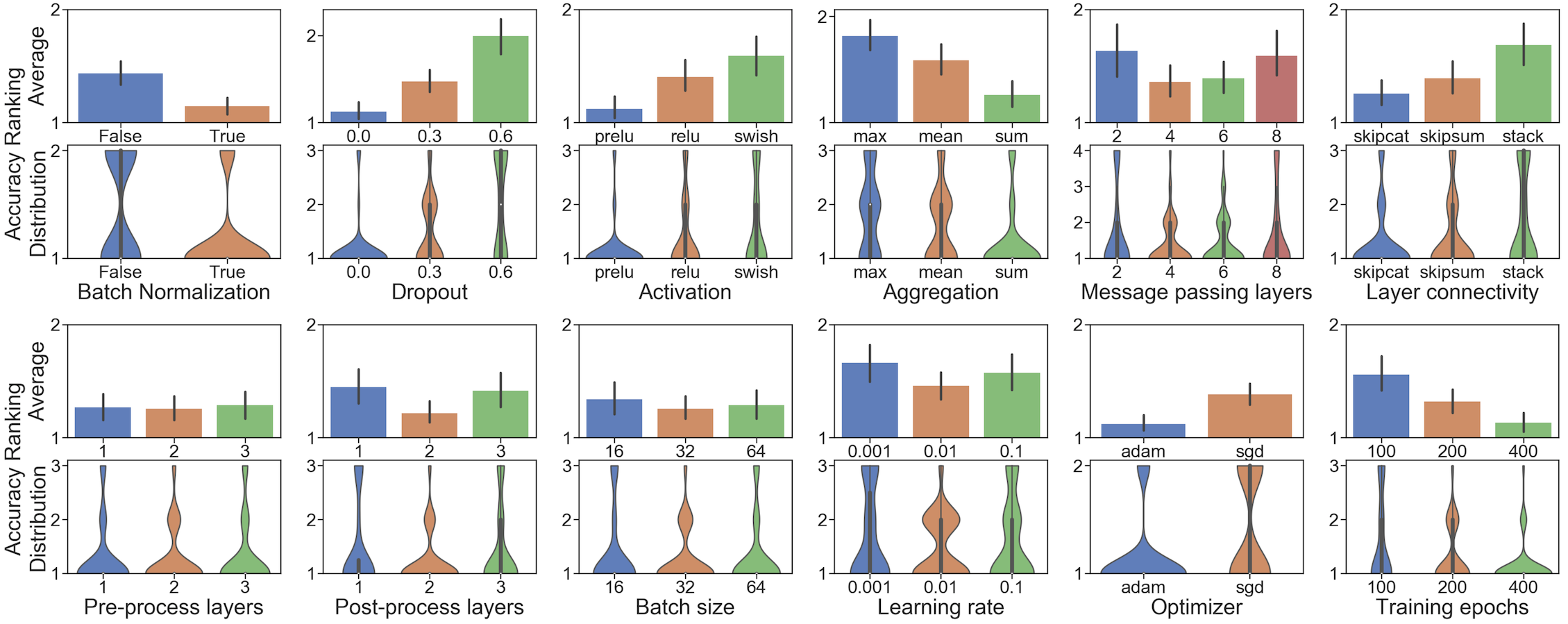
图2: 理想的GNN设计选择的指南。
场景3: 你是一名GNN研究员,希望创新新的GNN模型或提出新的GNN任务:
假设你提出了一个新的GNN层 ExampleConv。
GraphGym 可以帮助你有力地证明 ExampleConv 比,例如,GCNConv 更好:
当从1000万个可能的模型-任务组合中随机抽样时,ExampleConv 在一切其他条件固定(包括计算成本)的情况下,会比 GCNConv 表现更好的频率是多少?
此外,GraphGym 可以帮助你轻松进行超参数搜索,并可视化哪些设计选择更好。
总之,GraphGym 可以极大地促进你的GNN研究。

图3: 评估给定的GNN设计维度,例如,BatchNorm。
Basic Usage
注意
要使用GraphGym,PyG需要额外的依赖项。
您可以通过运行pip install torch-geometric[graphgym]来安装这些依赖项。
要使用GraphGym,你需要从GitHub克隆PyG,然后切换到graphgym/目录。
git clone https://github.com/pyg-team/pytorch_geometric.git
cd pytorch_geometric/graphgym
运行单个实验: 通过
run_single.sh使用GraphGym运行实验。 配置在configs/pyg/example_node.yaml中指定。 默认实验是关于在Planetoid数据集上进行节点分类(使用随机的80/20训练/验证分割)。bash run_single.sh # run a single experiment
运行一批实验: 使用GraphGym通过
run_batch.sh运行一批实验。 配置在configs/pyg/example_node.yaml(控制基本架构)和grids/example.txt(控制如何进行网格搜索)中指定。 该实验在推荐的GNN设计空间中检查了96个模型,使用了2个图分类数据集。 每个实验重复3次,我们设置了可以同时运行8个任务。 根据你的基础设施,完成所有实验可能需要很长时间; 你可以通过Ctrl-C退出实验(GraphGym会正确终止所有进程)。bash run_batch.sh # run a batch of experiments
使用CPU后端运行GraphGym: GraphGym也支持CPU后端——你只需要在
*.yaml文件中添加一行accelerator: cpu。
深入使用
要使用GraphGym,你需要从GitHub克隆PyG,然后切换到graphgym/目录。
git clone https://github.com/pyg-team/pytorch_geometric.git
cd pytorch_geometric/graphgym
运行单个实验: 一个完整的示例在
run_single.sh中指定。指定配置文件: 在GraphGym中,实验完全由
*.yaml文件指定。*.yaml文件中未指定的配置将由torch_geometric.graphgym.set_cfg()中的默认值填充。 例如,在configs/pyg/example_node.yaml中,有关于数据集、训练过程、模型等的配置。 每个配置的具体描述在set_cfg()中有描述。启动一个实验: 例如,在
run_single.sh中:python main.py --cfg configs/pyg/example_node.yaml --repeat 3
您可以通过
--repeat指定要重复的不同随机种子的数量。理解结果: 实验结果将自动保存在
results/${CONFIG_NAME}/。 在上面的例子中,这相当于results/pyg/example_node/。 不同随机种子的结果将保存在不同的子目录中,例如,results/pyg/example_node/2。 所有随机种子的聚合结果将自动生成到results/example/agg,包括每个指标的均值和标准差_std。 训练/验证/测试结果进一步保存在子目录中,例如results/example/agg/val。 在这里,stats.json存储了每个 epoch 后跨随机种子聚合的结果,而best.json存储了验证准确率最高的 epoch 的结果。
运行一批实验: 一个完整的示例在
run_batch.sh中指定。指定一个基础文件: GraphGym 支持运行一批实验。 首先,用户需要通过
--config选择一个基础架构。 通过扰动基础架构的某些配置,将创建一批实验。(可选)指定计算预算的基础文件: 此外,GraphGym 允许用户通过
--config_budget选择一个基础架构来控制网格搜索的计算预算。 当前,计算预算通过可训练参数的数量来衡量,控制是通过自动调整底层 GNN 的隐藏维度来实现的。 如果没有提供--config_budget,GraphGym 将不会控制计算预算。指定一个网格文件: 网格文件描述了如何扰动基础文件,以生成一批实验。 例如,基础文件可以指定一个在
Planetoid数据集上进行节点分类的3层GCN实验。 然后,网格文件指定了如何沿不同维度扰动实验,例如层数、模型架构、数据集、任务级别等。根据上述信息生成实验批次的配置文件: 例如,在
run_batch.sh中:python configs_gen.py --config configs/${DIR}/${CONFIG}.yaml \ --config_budget configs/${DIR}/${CONFIG}.yaml \ --grid grids/${DIR}/${GRID}.txt \ --out_dir configs
启动实验批次: 例如,在
run_batch.sh中:bash parallel.sh configs/${CONFIG}_grid_${GRID} $REPEAT $MAX_JOBS $SLEEP
每个实验将重复
$REPEAT次。 我们实现了一个队列系统来顺序启动所有作业,同时运行$MAX_JOBS个并发作业。 在实践中,我们的系统在处理数千个作业时表现良好。理解结果: 实验结果将自动保存在目录
results/${CONFIG_NAME}_grid_${GRID_NAME}/中。 在上面的示例中,这相当于results/pyg/example_grid_example/。 在运行每个实验后,GraphGym 还会自动对不同模型进行平均,并保存在results/pyg/example_grid_example/agg中。 在那里,val.csv表示每个模型配置在最终 epoch 的验证准确率,val_best.csv表示在具有最高平均验证准确率的 epoch 的结果,val_best_epoch.csv表示在不同随机种子平均验证准确率最高的 epoch 的结果。 当提供测试集分割时,test.csv表示每个模型配置在最终 epoch 的测试准确率,test_best.csv表示在具有最高平均验证准确率的 epoch 的测试集结果,test_best_epoch.csv表示在不同随机种子平均验证准确率最高的 epoch 的测试集结果。
自定义GraphGym
GraphGym 的一个亮点是它允许您轻松注册自定义模块。 对于每个项目,您可以拥有一个独特的 GraphGym 副本,其中包含不同的自定义模块。 例如,“Design Space for Graph Neural Networks” 和 “Identity-aware Graph Neural Networks” 论文代表了两个使用自定义 GraphGym 的成功项目,您可以在此处找到有关它们的更多详细信息 here。 最终,每个由 GraphGym 支持的项目都将是独一无二的。
有两种自定义GraphGym的方法:
使用位于PyG包外部的
graphgym/custom_graphgym目录: 您可以在此处注册您的自定义模块,而无需修改PyG。这种使用场景非常适合您自己的自定义项目。使用 PyG 包中的
torch_geometric/graphgym/contrib目录: 如果您想出了一个很好的自定义模块,您可以直接将您的文件复制到torch_geometric/graphgym/contrib中,并向 PyG 创建一个拉取请求。 这样,您的想法可以随 PyG 安装一起发布,并且将具有更高的可见性和影响力。
具体来说,支持的定制模块包括
激活函数:
custom_graphgym/act/自定义配置:
custom_graphgym/config/特征增强:
custom_graphgym/feature_augment/特征编码器:
custom_graphgym/feature_encoder/GNN 头:
custom_graphgym/head/GNN层:
custom_graphgym/layer/数据加载器:
custom_graphgym/loader/损失函数:
custom_graphgym/loss/GNN网络架构:
custom_graphgym/network/优化器:
custom_graphgym/optimizer/GNN全局池化层(仅用于图分类):
custom_graphgym/pooling/GNN 阶段:
custom_graphgym/stage/GNN 训练管道:
custom_graphgym/train/数据转换:
custom_graphgym/transform/
在每个目录中,至少提供了一个示例,展示如何通过torch_geometric.graphgym.register()注册自定义模块。
请注意,新的自定义模块可能会导致新的配置。
在这些情况下,可以通过custom_graphgym/config/注册新的配置字段。