快速开始
开始创建一个写后管道
本指南将引导您创建一个写后管道。
概念
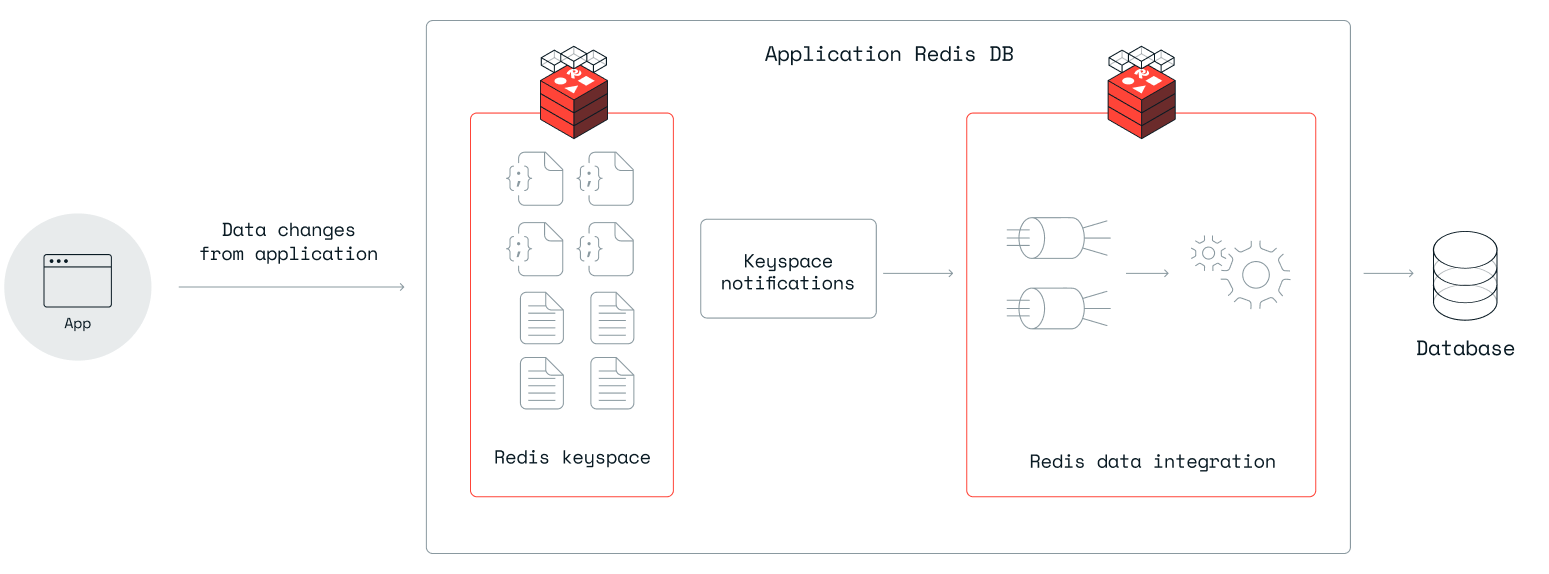
Write-behind 是一种处理管道,用于将 Redis 数据库中的数据与下游数据存储同步。 你可以将其视为一个管道,该管道从 Redis 数据库的变更数据捕获(CDC)事件开始,然后过滤、转换并将数据映射到目标数据存储的数据结构。
target 数据存储是写后管道连接并写入数据的目标。
写后管道由一个或多个作业组成。每个作业负责捕获Redis中一个键模式的变化,并将其映射到下游数据存储中的一个或多个表。每个作业在一个YAML文件中定义。
支持的数据存储
写后缓存目前支持这些目标数据存储:
| 数据存储 |
|---|
| Cassandra |
| MariaDB |
| MySQL |
| Oracle |
| PostgreSQL |
| Redis 企业版 |
| SQL Server |
先决条件
运行Write-behind的唯一前提条件是在Redis企业集群上安装并启用了Redis Gears Python >= 1.2.6,并且为您想要镜像到下游数据存储的数据库启用了该功能。 有关更多信息,请参阅 RedisGears installation。
准备写后管道
-
在连接到您的Redis Enterprise Cluster的Linux主机上安装Write-behind CLI。
-
运行
configure命令以在您的Redis数据库上安装Write-behind引擎,如果您之前没有将此Redis数据库与Write-behind一起使用过。 -
运行
scaffold命令,并指定你想要使用的数据存储类型,例如:redis-di scaffold --strategy write_behind --dir . --db-type mysql这将在当前目录下创建一个模板
config.yaml文件和一个名为jobs的文件夹。 你可以使用--dir指定任何文件夹名称,或者如果你的Write-behind CLI部署在Kubernetes (K8s) pod内,可以使用--preview config.yaml选项,将config.yaml模板输出到终端。 -
Add the connections required for downstream targets in the
connectionssection ofconfig.yaml, for example:connections: my-postgres: type: postgresql host: 172.17.0.3 port: 5432 database: postgres user: postgres password: postgres #query_args: # sslmode: verify-ca # sslrootcert: /opt/work/ssl/ca.crt # sslkey: /opt/work/ssl/client.key # sslcert: /opt/work/ssl/client.crt my-mysql: type: mysql host: 172.17.0.4 port: 3306 database: test user: test password: test #connect_args: # ssl_ca: /opt/ssl/ca.crt # ssl_cert: /opt/ssl/client.crt # ssl_key: /opt/ssl/client.keyThis is the first section of the
config.yamlfile and typically the only one you'll need to edit. Theconnectionssection is designed to have many target connections. In the previous example, there are two downstream connections namedmy-postgresandmy-mysql.To obtain a secured connection using TLS, you can add more
connect_argsorquery_args, depending on the specific target database terminology, to the connection definition.The name can be any arbitrary name as long as it is:
- Unique for this Write-behind engine
- Referenced correctly by the jobs in the respective YAML files
为了准备管道,请为目标数据存储填写正确的信息。可以通过引用密钥(见下文)或指定路径来提供密钥。
applier 部分包含有关用于将数据写入目标的批处理大小和频率的信息。
一些applier属性,如target_data_type、wait_enabled和retry_on_replica_failure,是专门用于Write-behind摄取管道的,可以忽略。
写后任务
写后作业是写后管道配置的强制性部分。
在jobs目录下(与config.yaml平行),你应该为每个你想写入下游数据库表的键模式在YAML文件中有一个作业定义。
YAML 文件可以使用目标表名或其他命名约定来命名,但它必须具有唯一的名称。
作业定义具有以下结构:
source:
redis:
key_pattern: emp:*
trigger: write-behind
exclude_commands: ["json.del"]
transform:
- uses: rename_field
with:
from_field: after.country
to_field: after.my_country
output:
- uses: relational.write
with:
connection: my-connection
schema: my-schema
table: my-table
keys:
- first_name
- last_name
mapping:
- first_name
- last_name
- address
- gender
源部分
source 部分描述了管道中数据的来源。
redis 部分对于由 Redis 中的事件(例如对数据应用更改)启动的每个管道都是通用的。在写回的情况下,它具有激活处理数据更改的管道所需的信息。它包括以下属性:
-
key_pattern属性指定了要监听的 Redis 键的模式。该模式必须对应于 Hash 或 JSON 类型的键。 -
exclude_commands属性指定要忽略的命令。例如,如果您监听带有哈希值的键模式,可以排除HDEL命令,这样就不会有数据删除传播到下游数据库。如果您不指定此属性,Write-behind 将对所有相关命令生效。 -
trigger属性是必需的,必须设置为write-behind。 -
row_format属性可以与值full一起使用,以接收有效载荷的before和after部分。请注意,对于写后事件,永远不会提供键的before值。
注意:Write-behind 不支持
expired事件。因此,在 Redis 中过期的键不会自动从目标数据库中删除。 注意:redis属性是一个重大变更,替换了keyspace属性。key_pattern属性替换了pattern属性。exclude_commands属性替换了exclude-commands属性。如果您升级到 0.105 及更高版本,必须编辑现有的作业并重新部署它们。
输出部分
output 部分至关重要。它指定了对 config.yaml 文件中 connections 部分的连接的引用:
-
uses属性指定了 writer Write-behind 将用于准备并将数据写入目标的类型。 在这个例子中,它是relational.write,一个将数据转换为具有下游关系数据库特定方言的 SQL 语句的写入器。 有关支持的写入器的完整列表,请参见 数据转换块类型。 -
schema属性指定要使用的模式/数据库(不同的数据库在对象层次结构中对模式有不同的名称)。 -
table属性指定要使用的下游表。 -
keys部分指定了表中作为唯一约束的字段。 -
mapping部分用于将数据库列映射到具有不同名称的 Redis 字段或表达式。映射可以是所有 Redis 数据字段,也可以是其中的一部分。
注意:在
keys中使用的列将自动包含,因此无需在mapping部分重复它们。
应用过滤器和转换到写回
写后作业可以在数据写入目标之前应用过滤器和转换。在transform部分下指定过滤器和转换。
过滤器
使用过滤器来跳过部分数据,不将其应用于目标。 过滤器可以应用简单或复杂的表达式,这些表达式以Redis条目键、字段甚至更改操作代码(创建、删除、更新等)作为参数。 有关更多信息,请参见Filter。
转换
转换操作以以下方式之一处理数据:
- 重命名字段
- 添加字段
- 删除字段
- 映射源字段以在输出中使用
要了解更多关于转换的信息,请参阅 data transformation pipeline。
提供目标的秘密
目标对象的秘密(如TLS证书)可以从Redis节点文件系统上的路径读取。这允许使用从秘密存储注入的秘密。
部署写后管道
要启动管道,请运行
deploy 命令:
redis-di deploy
您可以使用status命令检查管道是否正在运行、接收和写入数据:
redis-di status
监控写后管道
写后管道收集以下指标:
| 指标描述 | Prometheus中的指标 |
|---|---|
| 按流的总传入事件 | 计算为Prometheus DB查询:sum(pending, rejected, filtered, inserted, updated, deleted) |
| 按流创建的传入事件 | rdi_metrics_incoming_entries{data_source:"…",operation="inserted"} |
| 按流更新的传入事件 | rdi_metrics_incoming_entries{data_source:"…",operation="updated"} |
| 按流删除的传入事件 | rdi_metrics_incoming_entries{data_source:"…",operation="deleted"} |
| 按流过滤的传入事件 | rdi_metrics_incoming_entries{data_source:"…",operation="filtered"} |
| 按流处理的格式错误传入事件 | rdi_metrics_incoming_entries{data_source:"…",operation="rejected"} |
| 每个流的总事件数(快照) | rdi_metrics_stream_size{data_source:""} |
| 流中的时间(快照) | rdi_metrics_stream_last_latency_ms{data_source:"…"} |
要使用这些指标,您可以:
-
运行
status命令:redis-di status -
使用Write-behind的Prometheus导出器抓取指标
升级
如果您需要升级Write-behind,您应该使用upgrade命令,该命令支持零停机升级:
redis-di upgrade ...