PyG中的分布式训练

注意
我们很高兴地宣布,通过torch_geometric.distributed,我们推出了首个内部分布式训练解决方案,适用于PyG,从2.5版本开始可用。
开发者和研究人员现在可以充分利用分布式训练来处理无法同时完全加载到一台机器内存中的大规模数据集。
此实现不需要在默认的PyG堆栈之上安装任何额外的包。
在现实生活的应用中,图通常由数十亿个节点组成,这些节点无法放入单个系统的内存中。 这时,图神经网络的分布式训练就派上了用场。 通过将大图的多个分区分配到一组CPU集群中,可以利用PyTorch的 分布式数据并行(DDP)功能,一次性在整个数据集上部署同步模型训练。 这种架构通过远程过程调用(RPCs)无缝地将图神经网络的训练分布到多个节点上,以便高效地采样和检索非局部特征,同时使用传统的DDP进行模型训练。 PyG中的这项新技术是由英特尔和Kumo AI的工程师开发的。
主要优势
平衡图分区 通过 METIS 确保在跨计算节点采样子图时通信开销最小。
利用DDP进行模型训练,并结合RPC进行远程采样和特征获取例程(使用TCP/IP协议和gloo通信后端),可以在每个节点上实现具有不同数据分区的数据并行。
通过自定义的
GraphStore和FeatureStoreAPI实现,为分发大型图结构信息和特征存储提供了一个灵活且定制化的接口。分布式邻居采样能够通过RPC通信通道在本地和远程分区中进行采样。 单节点采样的所有高级功能也适用于分布式训练,例如,异构采样、链路级采样、时间采样,等。
分布式数据加载器 提供了一个高级抽象来管理采样器进程,确保与标准 PyG 数据加载器的简单性和无缝集成。
在基于PyTorch的RPC之上,结合Python asyncio库进行异步处理,进一步提升了系统的响应速度和整体性能。
架构组件
注意
本教程的目的是指导您完成在PyG中部署分布式训练应用程序的最重要步骤。 有关代码示例,请参阅examples/distributed/pyg。
总体而言,torch_geometric.distributed 分为以下几个组件:
Partitoner将图分割成多个部分,这样每个节点只需要在内存中加载其本地数据。LocalGraphStore和LocalFeatureStore分别存储每个分区的图拓扑和特征。 此外,它们维护本地ID和全局ID之间的映射,以便高效地分配节点和查找特征。DistNeighborSampler实现了分布式采样算法,该算法包括本地+远程采样以及基于PyTorch的 RPC机制的本地/远程采样结果的最终合并。DistNeighborLoader通过多个RPC工作器管理分布式邻居采样和特征获取过程。 最后,它将采样的节点、边及其特征整理成经典的 PyG 数据格式。

torch_geometric.distributed 主要组件的示意图分解。
图分区
分布式训练的第一步是将图分割成多个较小的部分,然后可以将这些部分加载到集群的节点中。
分区是建立在 pyg-lib的实现之上的,该实现使用了METIS算法,适合高效地执行图分区,即使在大规模图上也是如此。
请注意,METIS需要无向、同质的图作为输入。
Partitoner执行必要的处理步骤,以正确分布和索引的方式对异质数据对象进行分区。
默认情况下,METIS尝试在最小化分区之间边数的同时,平衡每个分区中每种类型的节点数量。 这确保了生成的分区提供最大的邻居本地访问,使得采样器能够在不需不同计算节点之间通信的情况下执行本地计算。 通过这种分区方法,每个节点都会获得一个独特的分配,而“光环节点”(落入不同分区的1跳邻居)会被复制。 光环节点确保单层中单个节点的邻居采样保持纯粹的本地性。
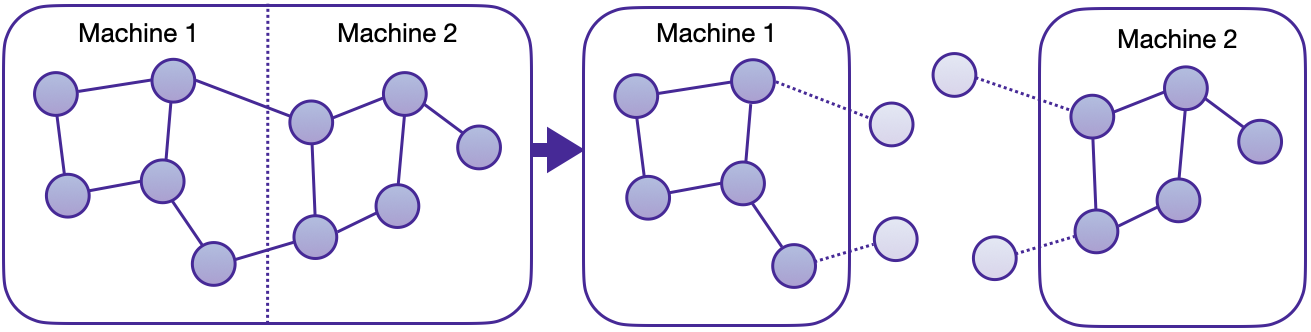
带有光环节点的图分区。
在我们的分布式训练示例中,我们准备了partition_graph.py脚本来演示如何在选定的同质图和异质图子集上应用分区。
Partitioner还可以在节点和边的级别上保留节点特征、边特征以及任何时间属性。
之后,集群中的每个节点将拥有该图的一个分区。
警告
通过METIS进行分区是非确定性的,因此在不同迭代之间可能会有所不同。 然而,所有计算节点应访问相同的分区数据。 因此,在一个节点上生成分区并将数据复制到集群的所有成员,或将文件夹放入共享位置。
在均匀的ogbn-products上进行两部分分割的分区结果结构如下所示:
partitions
└─ obgn-products
├─ ogbn-products-partitions
│ ├─ part_0
│ ├─ part_1
│ ├─ META.json
│ ├─ node_map.pt
│ └─ edge_map.pt
├─ ogbn-products-label
│ └─ label.pt
├─ ogbn-products-test-partitions
│ ├─ partition0.pt
│ └─ partition1.pt
└─ ogbn-products-train-partitions
├─ partition0.pt
└─ partition1.pt
分布式数据存储
为了维护分布式数据分区,我们利用了PyG’s的GraphStore和FeatureStore远程接口的实例化。
结合用于发送和接收RPC请求的集成API,它们为互连的分布式数据存储提供了强大的工具。
这两个存储可以通过多种方式填充数据,例如,从Data和HeteroData对象或直接从生成的分区文件初始化。
LocalGraphStore 是一个设计用于作为图拓扑信息的容器的类。
它保存了定义图中节点之间关系的边索引。
它提供了为节点和边提供映射信息到各个分区的方法,并支持同质和异质数据格式。
主要特点:
它只存储关于本地图连接及其在分区内的光环节点的信息。
远程连接:可以通过节点和边的“分区簿”检索单个节点和边到分区(本地和全局)的关联信息,即分区ID到全局节点/边ID的映射。
它为节点和边维护全局标识符,允许跨分区进行一致的映射。
LocalFeatureStore 是一个类,它既作为节点级别和边级别的特征存储。
它为本地和远程节点/边ID的属性检索提供了高效的put和get例程。
LocalFeatureStore 负责在训练过程中检索和更新不同分区和机器上的特征。
主要特点:
它提供了存储、检索和分发节点和边特征的功能。 在机器的管理分区内,节点和边特征被本地存储。
远程特征查找:它实现了在分布式训练过程中通过RPC请求在本地和远程节点上查找特征的机制。 该类设计用于在分布式训练场景中无缝工作,允许跨分区高效处理特征。
它为节点和边维护全局标识符,允许跨分区进行一致的映射。
以下是如何在内部使用 LocalFeatureStore 来检索本地和远程特征的示例:
import torch
from torch_geometric.distributed import LocalFeatureStore
from torch_geometric.distributed.event_loop import to_asyncio_future
feature_store = LocalFeatureStore(...)
async def get_node_features():
# Create a `LocalFeatureStore` instance:
# Retrieve node features for specific node IDs:
node_id = torch.tensor([1])
future = feature_store.lookup_features(node_id)
return await to_asyncio_future(future)
分布式邻居采样
DistNeighborSampler 是一个专为图神经网络的分布式训练设计的类。
它解决了在分布式环境中采样邻居的挑战,其中图数据被分割到多台机器或设备上。
该采样器确保图神经网络能够有效地从大规模图中学习,保持可扩展性和性能。
异步邻居采样和特征收集:
分布式邻居采样是通过异步的torch.distributed.rpc调用实现的。
它允许机器独立地采样邻居,而无需严格的同步。
每台机器从其本地图分区中自主选择邻居,而无需等待其他机器完成其采样过程。
这种方法增强了并行性,因为机器可以异步进行,从而加快训练速度。
除了异步采样外,分布式邻居采样还提供异步特征收集。
可定制的采样策略:
用户可以根据自己的特定需求自定义邻居采样策略。
DistNeighborSampler 类在定义采样技术方面提供了完全的灵活性,例如:
节点采样 vs. 边采样
同质与异质采样
时间采样与静态采样
分布式邻居采样工作流程:
在数据加载器使模型的forward()传递之前,一批种子节点需要经过三个主要步骤:
分布式节点采样: 虽然邻居采样的基本原理在分布式情况下也适用,但实现方式与单机采样略有不同。 在分布式训练中,种子节点可能属于不同的分区,导致在单个批次中在多个机器上同时进行采样。 因此,需要在机器之间同步采样结果,以获取后续层的种子节点,这需要对基本算法进行修改。 对于本地分区内的节点,采样在本地机器上进行。 相反,对于与远程分区相关的节点,邻居采样在负责存储相应分区的机器上进行。 采样是逐层进行的,其中采样的节点在后续层中充当种子节点。
分布式特征查找: 每个分区存储该分区内节点和边的特征数组。 因此,如果特定机器上的采样器输出包括不属于其分区的采样节点或边,则该机器会向这些节点(或边)所属的远程服务器发起RPC请求。
数据转换: 基于采样器输出和获取的节点(或边)特征,创建一个 PyG
Data或HeteroData对象。 该对象形成一个批次,用于模型的后续计算操作。

本地和远程邻居采样。
分布式数据加载
分布式数据加载器,如DistNeighborLoader和DistLinkNeighborLoader,为上述采样引擎提供了一个简单的API,因为它们完全在内部封装了采样器进程的初始化和清理。值得注意的是,分布式数据加载器继承自标准的PyG单节点NodeLoader和LinkLoader加载器,使得它们在训练脚本中的应用几乎完全相同。
批量生成与单节点情况略有不同,因为(本地+远程)特征获取的步骤发生在采样器内部,而不是封装成两个独立的步骤(采样->特征获取)。
这允许限制RPC的数量。
由于所有采样器子进程之间的异步处理,采样器随后将其输出返回到torch.multiprocessing.Queue。
使用DDP和RPC设置通信
在这个分布式训练实现中,使用了两种torch.distributed通信技术:
torch.distributed.rpc用于远程采样调用和分布式特征检索torch.distributed.ddp用于数据并行模型训练
我们的解决方案选择了torch.distributed.rpc而不是其他替代方案,如gRPC,因为PyTorch RPC天生理解张量类型的数据。
与其他需要将JSON或其他用户数据序列化或数字化为张量类型的RPC方法不同,使用此方法有助于避免额外的序列化和数字化开销。
DDP 组在主训练脚本中以标准方式初始化:
torch.distributed.init_process_group(
backend='gloo',
rank=current_ctx.rank,
world_size=current_ctx.world_size,
init_method=f'tcp://{master_addr}:{ddp_port}',
)
注意
对于基于CPU的采样,我们推荐使用gloo通信后端。
RPC组的初始化更为复杂,因为它发生在每个采样器子进程中,这是通过数据加载器的worker_init_fn()实现的,该函数由PyTorch在worker进程的初始化步骤中直接调用。
此函数首先为每个worker定义一个分布式上下文,并为其分配一个组和排名,随后初始化其自己的分布式邻居采样器,最后在RPC组中注册一个新成员。
只要子进程存在,这个RPC连接就会保持打开状态。
此外,我们选择了atexit模块来注册在进程终止时触发的额外清理行为。
结果与性能
我们收集了在PyTorch 2.1上的基准测试结果,使用了本博客底部的系统配置。
下表展示了在不同分区配置(1/2/4/8/16)下,ogbn-products数据集上GraphSAGE模型的扩展性能。
#分区 |
|
|
|
|---|---|---|---|
1 |
98秒 |
47秒 |
38秒 |
2 |
45秒 |
30秒 |
24秒 |
4 |
38秒 |
21秒 |
16秒 |
8 |
29秒 |
14秒 |
10秒 |
16 |
22秒 |
13秒 |
9秒 |
硬件: 2x Intel(R) Xeon(R) Platinum 8360Y CPU @ 2.40GHz, 36核心, HT开启, Turbo开启, NUMA 2, 集成加速器可用 [已使用]: DLB 0 [0], DSA 0 [0], IAA 0 [0], QAT 0 [0], 总内存 256GB (16x16GB DDR4 3200 MT/s [3200 MT/s]), BIOS SE5C620.86B.01.01.0003.2104260124, 微码 0xd000389, 2x 以太网控制器 X710 for 10GbE SFP+, 1x MT28908 系列 [ConnectX-6], 1x 894.3G INTEL SSDSC2KG96, Rocky Linux 8.8 (Green Obsidian), 4.18.0-477.21.1.el8_8.x86_64
软件: Python 3.9, PyTorch 2.1, PyG 2.5,
pyg-lib0.4.0