文本页面#
该类表示在文档页面上显示的文本和图像。所有 MuPDF 文档类型 都受到支持。
创建文本页面的常用方法是 DisplayList.get_textpage() 和 Page.get_textpage()。由于这个类中的方法数量有限,因此在 Page 中存在更方便使用的封装。此表格的最后一列显示了这些对应的 Page 方法。
有关此类的描述,请参见附录2。
方法 |
描述 |
页面获取文本或搜索方法 |
|---|---|---|
提取纯文本 |
“text” |
|
前一个的同义词 |
“文本” |
|
以块为单位分组的纯文本 |
“blocks” |
|
所有单词及其边界框 |
“words” |
|
页面内容以HTML格式显示 |
“html” |
|
页面内容以XHTML格式 |
“xhtml” |
|
以XML格式的页面文本 |
“xml” |
|
以 dict 格式的页面内容 |
“dict” | |
以 JSON 格式显示的页面内容 |
“json” |
|
以 dict 格式的页面内容 |
“rawdict” |
|
以JSON格式呈现的页面内容 |
“rawjson” |
|
在页面中搜索字符串 |
类 API
- class TextPage#
- extractText(sort=False)#
- extractTEXT(sort=False)#
返回页面完整文本的字符串。文本为UTF-8 Unicode,并且与文档创建时指定的顺序相同。
None- Parameters:
sort (bool) – (新功能在 v1.19.1)按垂直,然后按水平坐标排序输出。在许多情况下,这应该足以生成“自然”的阅读顺序。
None- Return type:
字符串
- extractBLOCKS()#
文本页面内容作为按块分组的文本行列表。每个列表项看起来像这样:
None(x0, y0, x1, y1, "lines in the block", block_no, block_type)
前四个条目是块的边界框坐标,block_type 为 1 表示图像块,0 表示文本。block_no 是块的序列号。多行文本通过换行符连接。
None对于图像块,它的边界框和一条带有一些图像元信息的文本行被包含在内 - 不包括图像内容。
None这是一个高速方法,提供了足够的信息以按所需的阅读顺序输出纯文本。
None- Return type:
列表
- extractWORDS(delimiters=None)#
在v1.23.5中更改:添加了
delimiters参数
文本页面内容以单词列表和边界框信息呈现。该列表中的一项看起来像这样:
None(x0, y0, x1, y1, "word", block_no, line_no, word_no)
- Parameters:
分隔符 (str) – (在v1.23.5中新增加) 使用这些字符作为附加单词分隔符。默认情况下,所有空格(包括不换行空格
None0xA0)表示一个单词的开始和结束。现在你可以指定更多导致这种情况的字符。例如,默认将返回"john.doe@outlook.com"作为一个单词。如果你指定delimiters="@.",那么将返回四个单词"john"、"doe"、"outlook"、"com"。其他可能的用法包括忽略标点字符delimiters=string.punctuation。这些“单词”字符串将不包含任何分隔字符。
这是一个高速方法,例如允许从给定区域中提取文本或恢复文本阅读顺序。
None- Return type:
列表
- extractHTML()#
文本页面内容作为HTML格式的字符串。此版本包含完整的格式和定位信息。图像包含在内(编码为base64字符串)。您需要一个HTML包才能在Python中解释输出。您的互联网浏览器应该能够充分显示这些信息,但请参见控制HTML输出质量。
None- Return type:
字符串
- extractDICT(sort=False)#
文本页面内容作为一个Python字典。提供与HTML相同的信息细节。请参见下面的结构。
None- Parameters:
sort (bool) – (新功能在 v1.19.1)按垂直,然后按水平坐标排序输出。在许多情况下,这应该足以生成“自然”的阅读顺序。
None- Return type:
字典
- extractJSON(sort=False)#
文本页面内容作为一个 JSON 字符串。由
Nonejson.dumps(TextPage.extractDICT())创建。包含此内容是为了向后兼容。您可能只会使用此方法将结果输出到某个文件。该方法检测二进制图像数据并将其转换为 base64 编码的字符串。- Parameters:
sort (bool) – (新功能在 v1.19.1)按垂直,然后按水平坐标排序输出。在许多情况下,这应该足以生成“自然”的阅读顺序。
None- Return type:
字符串
- extractXHTML()#
以XHTML格式呈现的文本页面内容。文本信息详细内容可以与
NoneextractTEXT()相比,但也包含图像(base64编码)。此方法并不尝试重新创建原始视觉外观。- Return type:
字符串
- extractXML()#
文本页面内容作为XML格式的字符串。这包含关于页面上每个字符的完整格式信息:字体、大小、行、段落、位置、颜色等。不包含图像。您需要一个XML包来在Python中解释输出。
None- Return type:
字符串
- extractRAWDICT(sort=False)#
文本页面内容作为一个Python字典 - 在技术上类似于
NoneextractDICT(),并且它将该信息作为一个子集(包括任何图片)包含在内。它提供了每个字符的额外细节,这使得在许多情况下使用XML变得过时。请参见下面的结构。- Parameters:
sort (bool) – (新功能在 v1.19.1)按垂直,然后按水平坐标排序输出。在许多情况下,这应该足以生成“自然”的阅读顺序。
None- Return type:
字典
- extractRAWJSON(sort=False)#
将文本页面内容作为JSON字符串。由
Nonejson.dumps(TextPage.extractRAWDICT())创建。您可能只会将此方法用于将结果输出到某些文件。该方法检测二进制图像数据并将其转换为base64编码字符串。- Parameters:
sort (bool) – (新功能在 v1.19.1)按垂直,然后按水平坐标排序输出。在许多情况下,这应该足以生成“自然”的阅读顺序。
None- Return type:
字符串
- search(needle, quads=False)#
在 v1.18.2 中更改
None
搜索 string 并返回找到的位置列表。
None- Parameters:
needle (str) – 要搜索的字符串。如果needle仅由ASCII字母组成,则大小写都将匹配——尚不支持“Ä”与“ä”等的比较。
Nonequads (bool) – 返回四边形而不是矩形。
None
- Return type:
列表
- Returns:
一个Rect或Quad对象的列表,每个对象都围绕着找到的needle出现。由于搜索字符串可能包含空格,它的部分可能会出现在不同的行中。在这种情况下,将返回多个矩形(或四边形)。(在v1.18.2中更改) 该方法现在支持去连字符,因此它将找到例如“method”,即使它在两行之间被连字符拆分为“meth-”和“od”。返回的两个矩形将包含“meth”(没有连字符)和“od”。
None
注意
v1.18.2版本的变更概述:
None参数
Nonehit_max已被移除:所有的点击都将始终返回。现在尊重TextPage的Rect参数:仅在该区域内的文本会被检查。只有完全包含在边界框内的字符才会被考虑。包装方法
NonePage.search_for()相应地支持clip参数。带连字符的单词 现在被发现了。
None重叠的矩形现在会自动连接在同一行中。我们假设这种分隔是由多个标记内容组创建的伪影,这些内容组包含同一搜索针的部分。
示例四边形与矩形:当搜索针“pymupdf”时,相应的条目将是蓝色矩形,或者,如果指定了quads,则为四边形Quad(ul, ur, ll, lr)。

- rect#
与文本页面关联的矩形。这要么等于创建页面的矩形,要么等于
Noneclip参数的Page.get_textpage()和文本提取/搜索方法。注意
文本搜索和大多数文本提取的输出 限制在这个矩形内。但是,(X)HTML和XML输出将始终提取整个页面。
字典输出的结构#
方法 TextPage.extractDICT()、 TextPage.extractJSON()、 TextPage.extractRAWDICT() 和 TextPage.extractRAWJSON() 返回字典,包含页面的文本和图像内容。这四种方法的字典结构几乎相同。它们努力尽可能精确地映射文本页面的信息层级,包括块、行、跨度和字符,每个元素用自己的子字典表示:
一个 页面 由一系列 块字典 组成。
A (text) 块 consists of a list of 行字典.
A line consists of a list of span dictionaries.一行由一系列
组成。 A span 要么由文本本身组成,要么对于 RAW 变体,由一组 字符字典 组成。
RAW 变体:一个 字符 是其来源、边界框和unicode的字典。
这里所有的 PyMuPDF 几何对象(点、矩形、矩阵)都通过它们的 “类似于” 格式表示:使用 rect_like 元组 来代替 Rect,等等。这样做的原因是为了性能和内存的考虑:
这段代码是用C语言编写的,其中Python元组可以轻松生成。另一方面,几何对象仅在Python源代码中定义。将每个Python元组转换为其相应的几何对象将会增加显著的——且在很大程度上是不必要的——执行时间。
一个4元组大约需要168字节,相应的Rect占用472字节——几乎是其大小的三倍。一个针对文本密集型页面的“dict”字典包含300多个bbox对象——因此作为4元组大约需要50 KB存储,而作为Rect对象则需要140 KB。然而,对于这样的页面,“rawdict”的输出将包含4到5千个bboxes,因此在这种情况下,我们讨论的是750 KB与2 MB。
请注意,只有 bboxes (= rect_like 4元组) 被返回,而 TextPage 实际上具有 完整的位置信息 – 采用 Quad 格式。这一决定的原因再次是出于内存考虑:一个 quad_like 需要 488 字节(是 rect_like 的三倍)。考虑到生成的 bboxes 的数量,返回 quad_like 信息将产生显著的影响。
在绝大多数情况下,我们处理的都是仅水平文本,在这种情况下,边界框提供了完全足够的信息。
此外,完整的四元信息不会丢失:可以根据需要通过使用以下列表中的适当函数来恢复行、跨度和字符:
recover_quad()– 完整跨度的四元组recover_span_quad()– 字符子集的跨度的四元组recover_line_quad()– 线的四元组recover_char_quad()– 一个字符的四元组
如前所述,只有在文本不是水平书写时才需要使用这些函数 – line["dir"] != (1, 0) – 并且您需要四元组用于文本标记注释 (Page.add_highlight_annot() 和相关函数)。
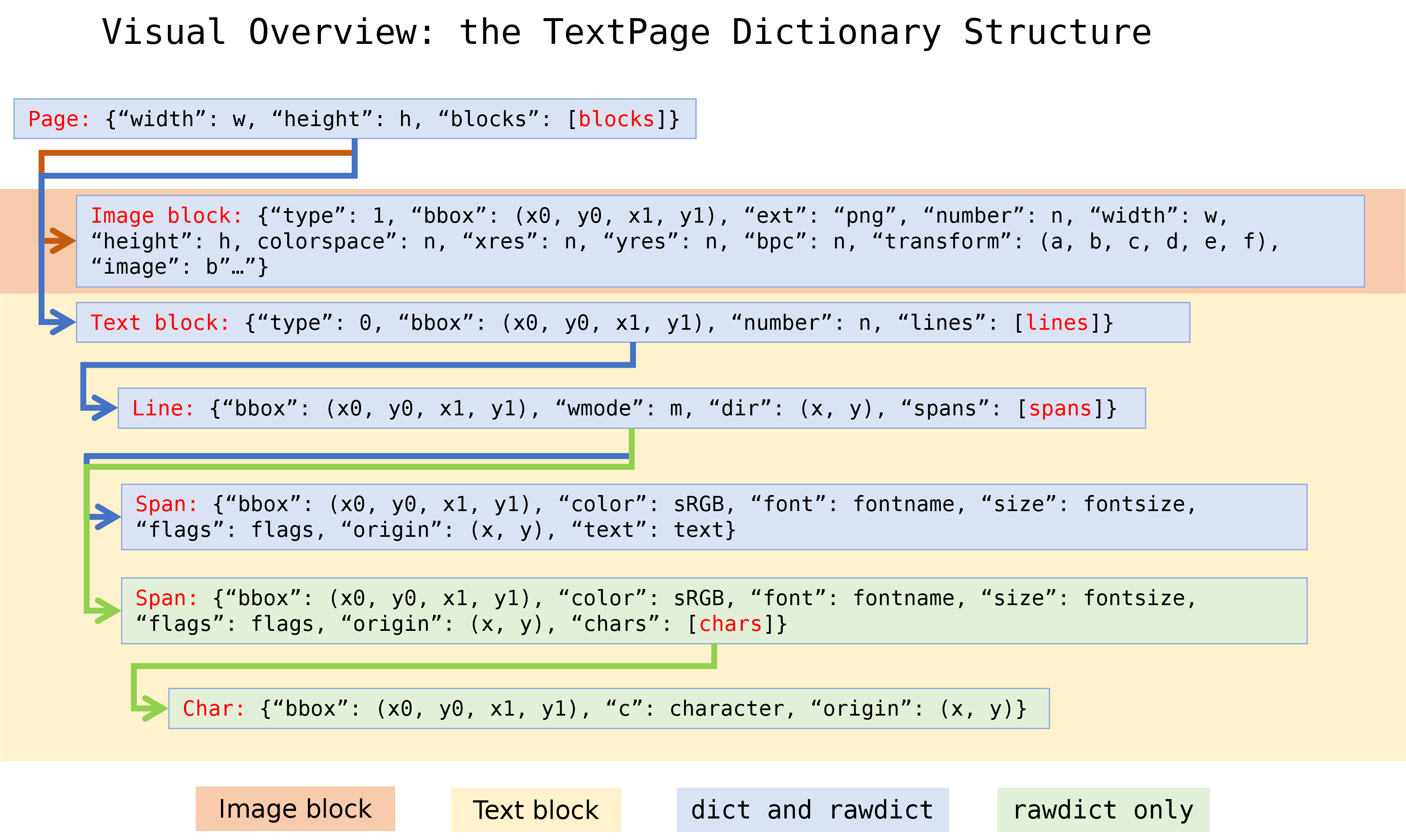
页面字典#
键 |
值 |
|---|---|
宽度 |
|
高度 |
|
区块 |
区块字典 的列表 |
块字典#
区块字典有两种不同的格式,一种用于图像块,另一种用于文本块。
图像块:
键 |
值 |
|---|---|
类型 |
1 = 图片 ( |
边界框 |
页面上的图像边界框 ( |
编号 |
区块数量 ( |
扩展名 |
图像类型 ( |
宽度 |
原始图像宽度 ( |
高度 |
原始图像高度 ( |
颜色空间 |
颜色空间组件数量 ( |
xres |
x方向的分辨率 ( |
yres |
y方向上的分辨率 ( |
bpc |
每个组件的位数 ( |
变换 |
矩阵将图像框变换为边界框 ( |
大小 |
图像的大小(以字节为单位)( |
图片 |
图像内容 ( |
掩码 |
透明图像的图像掩码内容 ( |
“ext”键的可能值有“bmp”、“gif”、“jpeg”、“jpx”(JPEG 2000)、“jxr”(JPEG XR)、“png”、“pnm”和“tiff”。
注意
为页面上的所有每个图像出现生成一个图像块。因此,如果图像在不同的位置显示,则可能会有重复。
文本页面 和相应的方法
Page.get_text()对于 所有文档类型均可用。只有对于 PDF 文档,方法Document.get_page_images()/Page.get_images()在图片列表方面提供了一些重叠的功能。但这两个列表 可能包含相同的项目,也可能不包含。任何差异最可能是由于以下原因之一造成的:PDF 页面中的“内联”图像(见 Adobe PDF References 第 214 页)包含在文本页面中,但 不出现 在
Page.get_images()中。注释也可以包含图片 - 这些将不会出现在
Page.get_images()中。文本页面中的图像块为每个图像位置生成,无论是否存在重复。这与
Page.get_images()形成对比,该方法每个参照名称只列出一次每个图像。页面的
object定义中提到的图像将始终出现在Page.get_images()[1]中。但有可能页面的contents中没有“display”命令(错误地或故意地)。在这种情况下,图像将不会出现在文本页面中。
图像的“变换矩阵”被定义为矩阵,对于这个表达式
bbox / transform == pymupdf.Rect(0, 0, 1, 1)为真,在这里查找详细信息: 图像变换矩阵。透明图像可能会伴随一个蒙版图像。这个图像存储在键
"mask"下,格式为DeviceGrayPNG 图像。否则,此键的值为None。如果存在,你可能能够恢复(相当于)原始图像 – 即具有透明度 – 通过从“图像”和“蒙版”值创建 Pixmap 对象并将其叠加。这并不能保证总是有效,因为蒙版图像有多种格式,并不是所有格式都符合叠加 Pixmap 支持的条件。以下是一个代码片段:
>>> base = pymupdf.Pixmap(block["image"])
>>> mask = pymupdf.Pixmap(block["mask"])
>>> result = pymupdf.Pixmap(base, mask)
文本块:
键 |
值 |
|---|---|
类型 |
0 = 文本 (int) |
边界框 |
块矩形, |
数字 |
区块数 (int) |
行 |
文本行字典的列表 |
行字典#
键 |
值 |
|---|---|
边界框 |
线矩形, |
wmode |
书写模式 (int): 0 = 水平, 1 = 垂直 |
dir |
书写方向, |
跨度 |
跨度 字典的列表 |
键 “dir” 的值是角度的 单位向量 dir = (cosine, -sine),该角度相对于 x 轴 [2]。请参阅以下图片:每个象限中的单词(从右上角开始逆时针方向到右下角)分别旋转了 30、120、210 和 300 度。

跨度字典#
跨度包含实际文本。如果一行包含具有不同字体属性的文本,则该行 仅包含一个以上的跨度。
在版本 1.14.17 中更改 现在跨度也有一个 bbox 键(再次)。
在版本 1.17.6 中更改,现在 Spans 也有一个 origin 键。
键 |
值 |
|---|---|
边界框 |
跨度矩形, |
起源 |
第一个字符的起源, |
字体 |
字体名称 (str) |
上升线 |
字体的上升线 (浮点数) |
下行符 |
字体的下行符 (float) |
大小 |
字体大小 (float) |
标志 |
字体特征 (int) |
字符标志 |
字符特征 (int) |
颜色 |
以 sRGB 格式表示的文本颜色 (int) |
文本 |
(仅适用于 |
字符 |
(仅适用于 |
(版本 1.16.0 中新增): “color” 是以 sRGB (int) 格式编码的文本颜色,例如 0xFF0000 表示红色。 有将这个整数转换回格式 (r, g, b) (PDF 中的浮点值范围从 0 到 1) sRGB_to_pdf() 的函数,或者 (R, G, B), sRGB_to_rgb() (整数值范围从 0 到 255)。
(在 v1.18.5 中新增): “ascender” 和 “descender” 是字体属性,相对于 fontsize 1 提供。请注意,descender 是一个负值。下图显示了与其他值和属性的关系。

这些数字可以用来计算字符(或跨度)的最小高度 - 与“bbox”值中提供的标准高度相对(实际上代表了行高)。以下代码重新计算跨度的 bbox,以使其高度为fontsize,正好适合内部的文本:
>>> a = span["ascender"]
>>> d = span["descender"]
>>> r = pymupdf.Rect(span["bbox"])
>>> o = pymupdf.Point(span["origin"]) # its y-value is the baseline
>>> r.y1 = o.y - span["size"] * d / (a - d)
>>> r.y0 = r.y1 - span["size"]
>>> # r now is a rectangle of height 'fontsize'
注意
上述计算可能会产生一个 更大的 高度!这可能发生在 OCR 处理的文档中,那里各种文本伪影的风险很高。MuPDF 试图提出一个合理的边界框高度,与在 PDF 中找到的 fontsize 无关。因此,请确保 span["bbox"] 的高度大于 更大 的 span["size"]。
注意
您可以通过执行 pymupdf.TOOLS.set_small_glyph_heights(True) 请求 PyMuPDF 自动执行上述所有操作。这设置了一个全局参数,以便所有后续的文本搜索和文本提取都基于缩小的字形高度(在有意义的情况下)。
下图显示了原始的红色矩形和重新计算高度后的蓝色矩形。

“flags” 是一个整数,表示字体属性,除了第一个位 0。它们的解释如下:
位 0: 上标 (20) – 不是字体属性,由 MuPDF 代码检测。
位 1: 斜体 (21)
位 2: 带衬线的 (22)
位 3: 等宽字体 (23)
bit 4: 粗体 (24)
像这样测试这些特征:
>>> if flags & 2**1: print("italic")
>>> # etc.
位1到4是字体属性,即编码在字体程序中。请注意,这些信息不一定是正确或完整的:字体中往往包含错误的数据。
“char_flags” 是一个整数,表示额外的字符属性:
位 0: 划掉。
位 1:下划线。
位 2:合成。
位 3:已填充。
位 4:已描边。
位 5: 被截断。
例如,如果没有填充且没有边框 (if not (char_flags & 2**3 & 2**4):
...) 那么文本将不可见。
(char_flags 在 v1.25.2 中是新的。)
提取原始字典的字符字典 extractRAWDICT()#
键 |
值 |
|---|---|
原点 |
角色的左基线点, |
边界框 |
字符矩形, |
c |
字符(unicode) |
此图显示了字符的边界框与其四边形之间的关系: 
脚注