CountVectorizer#
- class sklearn.feature_extraction.text.CountVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern='(?u)\\b\\w\\w+\\b', ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=<class 'numpy.int64'>)#
将一组文本文档转换为标记计数矩阵。
该实现使用scipy.sparse.csr_matrix生成计数的稀疏表示。
如果您不提供先验字典,并且不使用进行某种特征选择的分析器,那么特征数量将等于通过分析数据发现的词汇量大小。
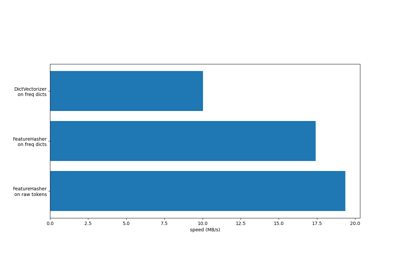
有关不同特征提取器的效率比较,请参见 特征哈希器和字典向量化器比较 。
更多信息请参见 用户指南 。
- Parameters:
- input{‘filename’, ‘file’, ‘content’}, 默认=’content’
如果
'filename',作为参数传递给fit的序列应为需要读取的文件名列表,以获取要分析的原始内容。如果
'file',序列项必须具有 ‘read’ 方法(类文件对象),该方法被调用以获取内存中的字节。如果
'content',输入应为项序列,项可以是字符串或字节类型。
- encodingstr, 默认=’utf-8’
如果给定要分析的字节或文件,则使用此编码进行解码。
- decode_error{‘strict’, ‘ignore’, ‘replace’}, 默认=’strict’
如果给定要分析的字节序列包含不属于给定
encoding的字符,则指示如何处理。默认情况下,它是 ‘strict’,意味着将引发 UnicodeDecodeError。其他值是 ‘ignore’ 和 ‘replace’。- strip_accents{‘ascii’, ‘unicode’} 或 callable, 默认=None
在预处理步骤中去除重音并执行其他字符规范化。 ‘ascii’ 是一种快速方法,仅适用于具有直接 ASCII 映射的字符。 ‘unicode’ 是一种稍慢的方法,适用于任何字符。 None(默认)表示不执行字符规范化。
‘ascii’ 和 ‘unicode’ 都使用来自
unicodedata.normalize的 NFKD 规范化。- lowercasebool, 默认=True
在分词之前将所有字符转换为小写。
- preprocessorcallable, 默认=None
覆盖预处理(去除重音和小写)阶段,同时保留分词和 n-grams 生成步骤。 仅在
analyzer不可调用时适用。- tokenizercallable, 默认=None
覆盖字符串分词步骤,同时保留预处理和 n-grams 生成步骤。 仅在
analyzer == 'word'时适用。- stop_words{‘english’}, list, 默认=None
如果 ‘english’,则使用内置的英语停用词列表。 ‘english’ 存在几个已知问题,您应考虑使用其他替代方案(参见 使用停用词 )。
如果是列表,则假定该列表包含停用词,所有这些词都将从生成的标记中删除。 仅在
analyzer == 'word'时适用。如果为 None,则不使用停用词。在这种情况下,设置
max_df为较高值,例如在范围 (0.7, 1.0) 内,可以自动检测并过滤基于语料库内文档频率的停用词。- token_patternstr 或 None, 默认=r”(?u)\b\w\w+\b”
表示 “标记” 的正则表达式,仅在
analyzer == 'word'时使用。默认正则表达式选择 2 个或更多字母数字字符的标记(标点符号完全忽略,始终被视为标记分隔符)。如果 token_pattern 中有捕获组,则捕获组内容(而不是整个匹配)成为标记。最多允许一个捕获组。
- ngram_rangetuple (min_n, max_n), 默认=(1, 1)
要提取的不同词 n-gram 或字符 n-gram 的 n 值范围的下限和上限。所有 n 值,使得 min_n <= n <= max_n 将被使用。例如,
ngram_range为(1, 1)表示仅使用 unigrams,(1, 2)表示使用 unigrams 和 bigrams,(2, 2)表示仅使用 bigrams。 仅在analyzer不可调用时适用。- analyzer{‘word’, ‘char’, ‘char_wb’} 或 callable, 默认=’word’
特征应由词 n-gram 还是字符 n-gram 组成。 选项 ‘char_wb’ 仅从词边界内的文本创建字符 n-gram;词边缘的 n-gram 用空格填充。
如果传递了可调用对象,则用于从原始未处理输入中提取特征序列。
Changed in version 0.21.
自 v0.21 起,如果
input为filename或file,数据首先从文件中读取,然后传递给给定的可调用分析器。- max_dffloat 在范围 [0.0, 1.0] 或 int, 默认=1.0
构建词汇表时忽略文档频率严格高于给定阈值的术语(特定于语料库的停用词)。 如果为浮点数,该参数表示文档的比例,整数表示绝对计数。 如果 vocabulary 不为 None,则忽略此参数。
- min_dffloat 在范围 [0.0, 1.0] 或 int, 默认=1
构建词汇表时忽略文档频率严格低于给定阈值的术语。该值在文献中也称为截断。 如果为浮点数,该参数表示文档的比例,整数表示绝对计数。 如果 vocabulary 不为 None,则忽略此参数。
- max_featuresint, 默认=None
如果不为 None,则仅考虑语料库中按词频排序的前
max_features个术语构建词汇表。 否则,所有特征都被使用。如果 vocabulary 不为 None,则忽略此参数。
- vocabularyMapping 或 iterable, 默认=None
要么是一个 Mapping(例如,字典),其中键是术语,值是特征矩阵中的索引,要么是一个术语的 iterable。如果不给定,则从输入文档中确定词汇表。映射中的索引不应重复,并且不应在 0 和最大索引之间有任何间隙。
- binarybool, 默认=False
如果为 True,所有非零计数都设置为 1。这对于建模二元事件而不是整数计数的离散概率模型很有用。
- dtypedtype, 默认=np.int64
fit_transform() 或 transform() 返回的矩阵类型。
- Attributes:
- vocabulary_dict
术语到特征索引的映射。
- fixed_vocabulary_bool
如果用户提供了术语到索引的固定词汇表映射,则为 True。
See also
HashingVectorizer将一组文本文档转换为标记计数矩阵。
TfidfVectorizer将一组原始文档转换为 TF-IDF 特征矩阵。
Examples
>>> from sklearn.feature_extraction.text import CountVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = CountVectorizer() >>> X = vectorizer.fit_transform(corpus) >>> vectorizer.get_feature_names_out() array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'], ...) >>> print(X.toarray()) [[0 1 1 1 0 0 1 0 1] [0 2 0 1 0 1 1 0 1] [1 0 0 1 1 0 1 1 1] [0 1 1 1 0 0 1 0 1]] >>> vectorizer2 = CountVectorizer(analyzer='word', ngram_range=(2, 2)) >>> X2 = vectorizer2.fit_transform(corpus) >>> vectorizer2.get_feature_names_out() array(['and this', 'document is', 'first document', 'is the', 'is this', 'second document', 'the first', 'the second', 'the third', 'third one', 'this document', 'this is', 'this the'], ...) >>> print(X2.toarray()) [[0 0 1 1 0 0 1 0 0 0 0 1 0] [0 1 0 1 0 1 0 1 0 0 1 0 0] [1 0 0 1 0 0 0 0 1 1 0 1 0] [0 0 1 0 1 0 1 0 0 0 0 0 1]]
- build_analyzer()#
返回一个可调用对象来处理输入数据。
该可调用对象处理预处理、标记化和n-grams生成。
- Returns:
- analyzer: callable
一个处理预处理、标记化和n-grams生成的函数。
- build_preprocessor()#
返回一个在分词前预处理文本的函数。
- Returns:
- preprocessor: callable
一个在分词前预处理文本的函数。
- build_tokenizer()#
返回一个将字符串拆分为一系列标记的函数。
- Returns:
- tokenizer: callable
一个将字符串拆分为一系列标记的函数。
- decode(doc)#
解码输入为一个unicode符号字符串。
解码策略取决于向量化器的参数。
- Parameters:
- docbytes 或 str
要解码的字符串。
- Returns:
- doc: str
一个unicode符号字符串。
- fit(raw_documents, y=None)#
学习所有原始文档中标记的词汇字典。
- Parameters:
- raw_documentsiterable
生成str、unicode或文件对象的可迭代对象。
- yNone
此参数被忽略。
- Returns:
- selfobject
拟合的向量化器。
- fit_transform(raw_documents, y=None)#
学习词汇字典并返回文档-词矩阵。
这等效于先拟合再转换,但实现更高效。
- Parameters:
- raw_documentsiterable
生成str、unicode或文件对象的可迭代对象。
- yNone
此参数被忽略。
- Returns:
- Xarray of shape (n_samples, n_features)
文档-词矩阵。
- get_feature_names_out(input_features=None)#
获取变换后的输出特征名称。
- Parameters:
- input_features字符串的数组或None,默认=None
未使用,此处仅为保持API一致性而存在。
- Returns:
- feature_names_out字符串对象的ndarray
变换后的特征名称。
- get_metadata_routing()#
获取此对象的元数据路由。
请查看 用户指南 以了解路由机制的工作原理。
- Returns:
- routingMetadataRequest
MetadataRequest封装的 路由信息。
- get_params(deep=True)#
获取此估计器的参数。
- Parameters:
- deepbool, 默认=True
如果为True,将返回此估计器和包含的子对象(也是估计器)的参数。
- Returns:
- paramsdict
参数名称映射到它们的值。
- get_stop_words()#
构建或获取有效的停用词列表。
- Returns:
- stop_words: list 或 None
一个停用词列表。
- inverse_transform(X)#
返回每个文档在X中具有非零条目的术语。
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
文档-术语矩阵。
- Returns:
- X_invlist of arrays of shape (n_samples,)
术语数组的列表。
- set_fit_request(*, raw_documents: bool | None | str = '$UNCHANGED$') CountVectorizer#
Request metadata passed to the
fitmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- raw_documentsstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
raw_documentsparameter infit.
- Returns:
- selfobject
The updated object.
- set_params(**params)#
设置此估计器的参数。
该方法适用于简单估计器以及嵌套对象(例如
Pipeline)。后者具有形式为<component>__<parameter>的参数,以便可以更新嵌套对象的每个组件。- Parameters:
- **paramsdict
估计器参数。
- Returns:
- selfestimator instance
估计器实例。
- set_transform_request(*, raw_documents: bool | None | str = '$UNCHANGED$') CountVectorizer#
Request metadata passed to the
transformmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed totransformif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it totransform.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- raw_documentsstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
raw_documentsparameter intransform.
- Returns:
- selfobject
The updated object.
- transform(raw_documents)#
将文档转换为文档-词条矩阵。
使用通过fit拟合的词汇表或提供给构造函数的词汇表,从原始文本文档中提取标记计数。
- Parameters:
- raw_documentsiterable
一个可迭代对象,可以生成str、unicode或文件对象。
- Returns:
- Xsparse matrix of shape (n_samples, n_features)
文档-词条矩阵。