教程:动态评估
动态评估功能让您能够评估结合了多个推理调用与任意应用逻辑的复杂工作流。 这里,我们将通过一个风格化的RAG工作流示例,演示如何设置和运行动态评估,但相同流程可应用于任何复杂工作流。
假设我们有以下基于LLM的工作流程,用于响应用户的自然语言问题:
- 推理:调用
generate_database_queryTensorZero函数,根据用户问题生成数据库查询。 - 自定义逻辑:对数据库执行查询并获取结果(
my_blackbox_search_function)。 - 推理:调用
generate_final_answerTensorZero函数,根据检索结果生成答案。 - 自定义逻辑:使用自定义评分函数(
my_blackbox_scoring_function)对答案进行评分 - 反馈:使用
task_success指标发送反馈。
单独评估generate_database_query和generate_final_answer(即使用静态评估)也可能有所帮助,但最终我们需要端到端地评估整个工作流程。这时就需要动态评估了。
复杂的LLM应用可能需要执行多次LLM调用并运行任意代码才能得出最终结果。在智能体应用中,工作流甚至可能根据用户输入、LLM调用结果或其他因素在运行时动态定义。TensorZero中的动态评估提供了完全的灵活性,使您能够联合评估整个工作流程。您可以将其视为LLM应用的集成测试。
启动动态评估运行
评估上述工作流涉及处理并评估一系列任务(例如用户查询)。 每个独立任务对应一个场景片段,这些场景片段的集合构成一次动态评估运行。
首先,让我们初始化TensorZero客户端(就像您处理常规推理请求时那样):
from tensorzero import TensorZeroGateway
# Initialize the client with `build_http` or `build_embedded`with TensorZeroGateway.build_http( gateway_url="http://localhost:3000",) as t0: # ...现在你可以启动一个动态评估运行。
在动态评估运行期间,您可以指定要在运行过程中固定的变体(即您想要评估的变体集合)。 这使您能够观察不同变体组合对端到端系统性能的影响。
您还可以选择为运行指定project_name和display_name。
如果指定了project_name,您将能够在TensorZero界面中将该运行与同一项目的其他运行进行比较。
display_name是一个人类可读的标识符,可用于在TensorZero界面中识别该运行。
run_info = t0.dynamic_evaluation_run( # Assume we have these variants defined in our `tensorzero.toml` configuration file variants={ "generate_database_query": "o4_mini_prompt_baseline", "generate_final_answer": "gpt_4o_updated_prompt", }, project_name="simple_rag_project", display_name="generate_database_query::o4_mini_prompt_baseline;generate_final_answer::gpt_4o_updated_prompt",)首先,让我们初始化TensorZero客户端(就像您处理常规推理请求时那样):
from tensorzero import AsyncTensorZeroGateway
# Initialize the client with `build_http` or `build_embedded`async with await AsyncTensorZeroGateway.build_http( gateway_url="http://localhost:3000",) as t0: # ...现在您可以启动动态评估运行。
在动态评估运行期间,您可以指定要在运行过程中固定的变体(即您想要评估的变体集合)。 这使您能够观察不同变体组合对端到端系统性能的影响。
您还可以选择为运行指定project_name和display_name。
如果指定了project_name,您将能够通过TensorZero UI将该运行与该项目下的其他运行进行比较。
display_name是一个人类可读的运行标识符,可用于在TensorZero UI中识别该运行。
run_info = await t0.dynamic_evaluation_run( # Assume we have these variants defined in our `tensorzero.toml` configuration file variants={ "generate_database_query": "o4_mini_prompt_baseline", "generate_final_answer": "gpt_4o_updated_prompt", }, project_name="simple_rag_project", display_name="generate_database_query::o4_mini_prompt_baseline;generate_final_answer::gpt_4o_updated_prompt",)在动态评估运行期间,您可以指定要在运行过程中固定的变体(即您想要评估的变体集合)。 这使您能够观察不同变体组合对端到端系统性能的影响。
您还可以选择为运行指定project_name和display_name。
如果指定了project_name,您将能够在TensorZero界面中将该运行与同一项目的其他运行进行比较。
display_name是一个人类可读的运行标识符,可用于在TensorZero界面中识别该运行。
curl -X POST http://localhost:3000/dynamic_evaluation_run \ -H "Content-Type: application/json" \ -d '{ "variants": { "generate_database_query": "o4_mini_prompt_baseline", "generate_final_answer": "gpt_4o_updated_prompt" }, "project_name": "simple_rag_project", "display_name": "generate_database_query::o4_mini_prompt_baseline;generate_final_answer::gpt_4o_updated_prompt" }'在动态评估运行中启动一个回合
对于我们希望纳入动态评估运行的每个任务(例如数据点),都需要启动一个智能体会话。例如,在我们的智能RAG项目中,每个会话将对应数据集中的一个用户查询;每个用户查询需要多次推理调用和应用程序逻辑来执行。
要初始化一个回合(episode),您需要提供想要包含该回合的动态评估运行的run_id。
您还可以选择性地为回合指定一个task_name。
如果指定了task_name,您将能够通过TensorZero UI将该回合与其他运行中相同任务的回合进行比较。
我们建议您使用task_name为该回合处理的任务提供一个有意义的标识符。
episode_info = t0.dynamic_evaluation_run_episode( run_id=run_info.run_id, task_name="user_query_123",)现在我们可以使用episode_info.episode_id来进行推理和反馈调用。
要初始化一个情节(episode),您需要提供想要包含该情节的动态评估运行的run_id。
您还可以选择性地为情节指定一个task_name。
如果指定了task_name,您将能够通过TensorZero UI将该情节与其他运行中相同任务的多个情节进行比较。
episode_info = await t0.dynamic_evaluation_run_episode( run_id=run_info.run_id, task_name="user_query_123",)现在我们可以使用episode_info.episode_id来进行推理和反馈调用。
要初始化一个情节(episode),您需要提供想要包含该情节的动态评估运行的run_id。
您还可以选择性地为情节指定一个task_name。
如果指定了task_name,您将能够通过TensorZero UI将该情节与其他运行中相同任务的剧情进行比较。
curl -X POST http://localhost:3000/dynamic_evaluation_run/{run_id}/episode \ -H "Content-Type: application/json" \ -d '{ "task_name": "user_query_123" }'现在我们可以使用episode_info.episode_id来进行推理和反馈调用。
在动态评估运行期间进行推理和反馈调用
generate_database_query_response = t0.inference( function_name="generate_database_query", episode_id=episode_info.episode_id, input={ ... },)
search_result = my_blackbox_search_function(generate_database_query_response)
generate_final_answer_response = t0.inference( function_name="generate_final_answer", episode_id=episode_info.episode_id, input={ ... },)
task_success_score = my_blackbox_scoring_function(generate_final_answer_response)
t0.feedback( metric_name="task_success", episode_id=episode_info.episode_id, value=task_success_score,)generate_database_query_response = await t0.inference( function_name="generate_database_query", episode_id=episode_info.episode_id, input={ ... },)
search_result = my_blackbox_search_function(generate_database_query_response)
generate_final_answer_response = await t0.inference( function_name="generate_final_answer", episode_id=episode_info.episode_id, input={ ... },)
task_success_score = my_blackbox_scoring_function(generate_final_answer_response)
await t0.feedback( metric_name="task_success", episode_id=episode_info.episode_id, value=task_success_score,)# First inference callcurl -X POST http://localhost:3000/inference \ -H "Content-Type: application/json" \ -d '{ "function_name": "generate_database_query", "episode_id": "00000000-0000-0000-0000-000000000000", "input": { ... } }'
# Run your custom search function with the result...my_blackbox_search_function(...)
# Second inference callcurl -X POST http://localhost:3000/inference \ -H "Content-Type: application/json" \ -d '{ "function_name": "generate_final_answer", "episode_id": "00000000-0000-0000-0000-000000000000", "input": { ... } }'
# Run your custom scoring function with the result...my_blackbox_scoring_function(...)
# Feedback callcurl -X POST http://localhost:3000/feedback \ -H "Content-Type: application/json" \ -d '{ "metric_name": "task_success", "episode_id": "00000000-0000-0000-0000-000000000000", "value": 0.85 }'在TensorZero界面中可视化评估结果
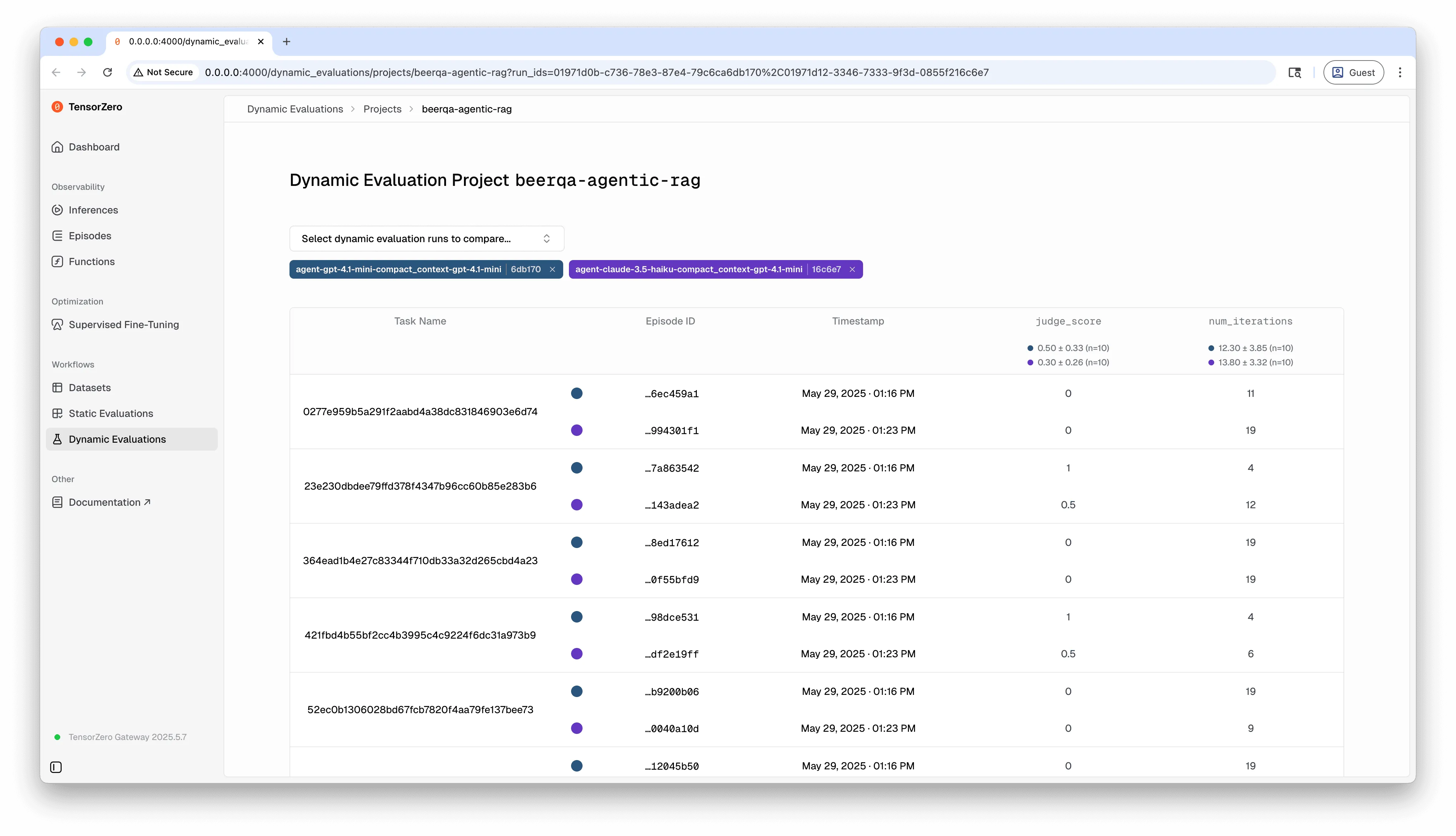
完成动态评估运行的所有相关片段后,您可以在TensorZero界面中可视化结果。
在用户界面中,您可以对比不同评估运行的指标,检查单个事件和推理过程等。